#Apache Airflow
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text

Top 10 Python ETL Solutions for Data Integration in 2024
http://tinyurl.com/4ssjvrtd
From Apache Airflow to Talend, here are the top 10 Python ETL solutions that empower organizations with seamless data integration capabilities
0 notes
Text
Misconfigured Kubernetes RBAC in Azure Airflow Could Expose Entire Cluster to Exploitation
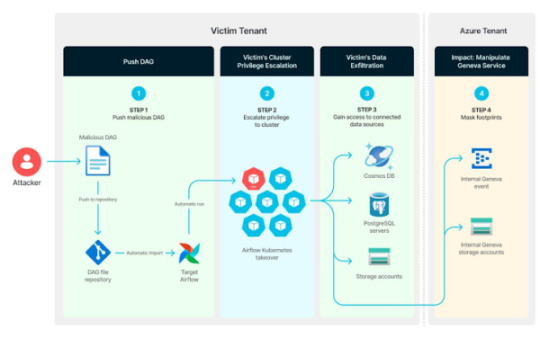
Source: https://thehackernews.com/2024/12/misconfigured-kubernetes-rbac-in-azure.html
More info: https://unit42.paloaltonetworks.com/azure-data-factory-apache-airflow-vulnerabilities/
11 notes
·
View notes
Text
invented a kind of guy who only knows Airbnb for their open source products and not for their main application. You're telling me the people who made Apache Airflow also run fake hotels? Next thing you're going to tell me is that the people who made AWS also sell a bunch of garbage online.
2 notes
·
View notes
Text
Data Engineering Concepts, Tools, and Projects
All the associations in the world have large amounts of data. If not worked upon and anatomized, this data does not amount to anything. Data masterminds are the ones. who make this data pure for consideration. Data Engineering can nominate the process of developing, operating, and maintaining software systems that collect, dissect, and store the association’s data. In modern data analytics, data masterminds produce data channels, which are the structure armature.
How to become a data engineer:
While there is no specific degree requirement for data engineering, a bachelor's or master's degree in computer science, software engineering, information systems, or a related field can provide a solid foundation. Courses in databases, programming, data structures, algorithms, and statistics are particularly beneficial. Data engineers should have strong programming skills. Focus on languages commonly used in data engineering, such as Python, SQL, and Scala. Learn the basics of data manipulation, scripting, and querying databases.
Familiarize yourself with various database systems like MySQL, PostgreSQL, and NoSQL databases such as MongoDB or Apache Cassandra.Knowledge of data warehousing concepts, including schema design, indexing, and optimization techniques.
Data engineering tools recommendations:
Data Engineering makes sure to use a variety of languages and tools to negotiate its objects. These tools allow data masterminds to apply tasks like creating channels and algorithms in a much easier as well as effective manner.
1. Amazon Redshift: A widely used cloud data warehouse built by Amazon, Redshift is the go-to choice for many teams and businesses. It is a comprehensive tool that enables the setup and scaling of data warehouses, making it incredibly easy to use.
One of the most popular tools used for businesses purpose is Amazon Redshift, which provides a powerful platform for managing large amounts of data. It allows users to quickly analyze complex datasets, build models that can be used for predictive analytics, and create visualizations that make it easier to interpret results. With its scalability and flexibility, Amazon Redshift has become one of the go-to solutions when it comes to data engineering tasks.
2. Big Query: Just like Redshift, Big Query is a cloud data warehouse fully managed by Google. It's especially favored by companies that have experience with the Google Cloud Platform. BigQuery not only can scale but also has robust machine learning features that make data analysis much easier. 3. Tableau: A powerful BI tool, Tableau is the second most popular one from our survey. It helps extract and gather data stored in multiple locations and comes with an intuitive drag-and-drop interface. Tableau makes data across departments readily available for data engineers and managers to create useful dashboards. 4. Looker: An essential BI software, Looker helps visualize data more effectively. Unlike traditional BI tools, Looker has developed a LookML layer, which is a language for explaining data, aggregates, calculations, and relationships in a SQL database. A spectacle is a newly-released tool that assists in deploying the LookML layer, ensuring non-technical personnel have a much simpler time when utilizing company data.
5. Apache Spark: An open-source unified analytics engine, Apache Spark is excellent for processing large data sets. It also offers great distribution and runs easily alongside other distributed computing programs, making it essential for data mining and machine learning. 6. Airflow: With Airflow, programming, and scheduling can be done quickly and accurately, and users can keep an eye on it through the built-in UI. It is the most used workflow solution, as 25% of data teams reported using it. 7. Apache Hive: Another data warehouse project on Apache Hadoop, Hive simplifies data queries and analysis with its SQL-like interface. This language enables MapReduce tasks to be executed on Hadoop and is mainly used for data summarization, analysis, and query. 8. Segment: An efficient and comprehensive tool, Segment assists in collecting and using data from digital properties. It transforms, sends, and archives customer data, and also makes the entire process much more manageable. 9. Snowflake: This cloud data warehouse has become very popular lately due to its capabilities in storing and computing data. Snowflake’s unique shared data architecture allows for a wide range of applications, making it an ideal choice for large-scale data storage, data engineering, and data science. 10. DBT: A command-line tool that uses SQL to transform data, DBT is the perfect choice for data engineers and analysts. DBT streamlines the entire transformation process and is highly praised by many data engineers.
Data Engineering Projects:
Data engineering is an important process for businesses to understand and utilize to gain insights from their data. It involves designing, constructing, maintaining, and troubleshooting databases to ensure they are running optimally. There are many tools available for data engineers to use in their work such as My SQL, SQL server, oracle RDBMS, Open Refine, TRIFACTA, Data Ladder, Keras, Watson, TensorFlow, etc. Each tool has its strengths and weaknesses so it’s important to research each one thoroughly before making recommendations about which ones should be used for specific tasks or projects.
Smart IoT Infrastructure:
As the IoT continues to develop, the measure of data consumed with high haste is growing at an intimidating rate. It creates challenges for companies regarding storehouses, analysis, and visualization.
Data Ingestion:
Data ingestion is moving data from one or further sources to a target point for further preparation and analysis. This target point is generally a data storehouse, a unique database designed for effective reporting.
Data Quality and Testing:
Understand the importance of data quality and testing in data engineering projects. Learn about techniques and tools to ensure data accuracy and consistency.
Streaming Data:
Familiarize yourself with real-time data processing and streaming frameworks like Apache Kafka and Apache Flink. Develop your problem-solving skills through practical exercises and challenges.
Conclusion:
Data engineers are using these tools for building data systems. My SQL, SQL server and Oracle RDBMS involve collecting, storing, managing, transforming, and analyzing large amounts of data to gain insights. Data engineers are responsible for designing efficient solutions that can handle high volumes of data while ensuring accuracy and reliability. They use a variety of technologies including databases, programming languages, machine learning algorithms, and more to create powerful applications that help businesses make better decisions based on their collected data.
4 notes
·
View notes
Text
Apache Airflow: From Stagnation to Millions of Downloads
Unlock the Secrets of Ethical Hacking! Ready to dive into the world of offensive security? This course gives you the Black Hat hacker’s perspective, teaching you attack techniques to defend against malicious activity. Learn to hack Android and Windows systems, create undetectable malware and ransomware, and even master spoofing techniques. Start your first hack in just one hour! Enroll now and…
0 notes
Text
Senior Data Engineer
Job title: Senior Data Engineer Company: Zendesk Job description: primarily Python Experience with ETL schedulers such as Apache Airflow, AWS Glue or similar frameworks Developer skills… processing (batch and streaming) Intermediate experience with any of the programming language: Python, Go, Java, Scala, we use… Expected salary: Location: Pune, Maharashtra Job date: Sun, 01 Jun 2025 02:48:50…
0 notes
Text
Match Data Pro LLC: Precision, Automation, and Efficiency in Data Integration
In a digital world driven by information, efficient data processing is no longer optional—it's essential. At Match Data Pro LLC, we specialize in streamlining, automating, and orchestrating complex data workflows to ensure your business operations remain smooth, scalable, and secure. Whether you're a startup managing marketing lists or an enterprise syncing millions of records, our services are designed to help you harness the full potential of your data.
One of the core challenges many businesses face is integrating data from multiple sources without losing accuracy, consistency, or time. That’s where we come in—with smart data matching automation, advanced data pipeline schedulers, and precise data pipeline cron jobs, we build intelligent data infrastructure tailored to your unique needs.
Why Match Data Pro LLC?
At Match Data Pro LLC, we don’t just handle data—we refine it, align it, and deliver it where it needs to be, when it needs to be there. We work with businesses across sectors to clean, match, and schedule data flows, reducing manual labor and increasing business intelligence.
We’re not another off-the-shelf data solution. We build custom pipelines, fine-tuned to your goals. Think of us as your personal data orchestration team—on demand.
What We Offer
1. Data Matching Automation
Manual data matching is not only time-consuming, but it's also error-prone. When databases grow in size or come from different systems (like CRM, ERP, or marketing platforms), matching them accurately becomes a daunting task.
Our data matching automation services help identify, connect, and unify similar records from multiple sources using AI-driven rules and fuzzy logic. Whether it’s customer deduplication, record linkage, or merging third-party datasets, we automate the process end-to-end.
Key Benefits:
Identify duplicate records across systems
Match customer profiles, leads, or transactions with high precision
Improve data accuracy and reporting
Save hundreds of hours in manual data review
Ensure GDPR and data integrity compliance
2. Custom Data Pipeline Scheduler
Data doesn’t flow once. It flows continuously. That’s why a one-time integration isn’t enough. You need a dynamic data pipeline scheduler that can handle the flow of data updates, insertions, and changes at regular intervals.
Our experts design and deploy pipeline schedules tailored to your business—whether you need hourly updates, daily synchronization, or real-time triggers. We help you automate data ingestion, transformation, and delivery across platforms like Snowflake, AWS, Azure, Google Cloud, or on-premise systems.
Our Pipeline Scheduler Services:
Flexible scheduling: hourly, daily, weekly, or custom intervals
Smart dependency tracking between tasks
Failure alerts and retry logic
Logging, monitoring, and audit trails
Integration with tools like Apache Airflow, Prefect, and Dagster
Let your data flow like clockwork—with total control.
3. Efficient Data Pipeline Cron Jobs
Cron jobs are the unsung heroes of automation. With well-configured data pipeline cron jobs, you can execute data workflows on a precise schedule—without lifting a finger. But poorly implemented cron jobs can lead to missed updates, broken pipelines, and data silos.
At Match Data Pro LLC, we specialize in building and optimizing cron jobs for scalable, resilient data operations. Whether you’re updating inventory records nightly, syncing user data from APIs, or triggering ETL processes, we create cron jobs that work flawlessly.
Cron Job Capabilities:
Multi-source data ingestion (APIs, FTP, databases)
Scheduled transformations and enrichment
Error handling with detailed logs
Email or webhook-based notifications
Integration with CI/CD pipelines for agile development
With our help, your data pipeline cron jobs will run silently in the background, powering your business with up-to-date, reliable data.
Use Case Scenarios
Retail & eCommerce
Automatically match customer data from Shopify, Stripe, and your CRM to create unified buyer profiles. Schedule inventory updates using cron jobs to keep your product availability in sync across channels.
Healthcare
Match patient records across clinics, insurance systems, and EMRs. Ensure data updates are securely pipelined and scheduled to meet HIPAA compliance.
Financial Services
Automate reconciliation processes by matching transactions from different banks or vendors. Schedule end-of-day data processing pipelines for reporting and compliance.
Marketing & AdTech
Unify leads from multiple marketing platforms, match them against CRM data, and automate regular exports for retargeting campaigns.
Why Businesses Trust Match Data Pro LLC
✅ Expertise in Modern Tools: From Apache Airflow to AWS Glue and dbt, we work with cutting-edge technologies.
✅ Custom Solutions: No one-size-fits-all templates. We tailor every integration and pipeline to your environment.
✅ Scalability: Whether you're dealing with thousands or millions of records, we can handle your scale.
✅ Compliance & Security: GDPR, HIPAA, SOC 2—we build with compliance in mind.
✅ End-to-End Support: From data assessment and architecture to deployment and maintenance, we cover the full lifecycle.
What Our Clients Say
“Match Data Pro automated what used to take our team two full days of manual matching. It’s now done in minutes—with better accuracy.” — Lisa T., Director of Operations, Fintech Co.
“Their data pipeline scheduler has become mission-critical for our marketing team. Every lead is synced, every day, without fail.” — Daniel M., Head of Growth, SaaS Platform
“Our old cron jobs kept failing and we didn’t know why. Match Data Pro cleaned it all up and now our data flows like a dream.” — Robert C., CTO, eCommerce Brand
Get Started Today
Don’t let poor data processes hold your business back. With Match Data Pro LLC, you can automate, schedule, and synchronize your data effortlessly. From data matching automation to reliable data pipeline cron jobs, we’ve got you covered.
Final Thoughts
In the age of automation, your business should never be waiting on yesterday’s data. At Match Data Pro LLC, we transform how organizations handle information—making your data pipelines as reliable as they are intelligent.
Let’s build smarter data flows—together.
0 notes
Text
Automating MLOps: From Notebooks to Production with Apache Airflow
Table of Contents Introduction Technical Background Implementation Guide Code Examples Best Practices and Optimization Testing and Debugging Conclusion 1. Introduction 1.1 Brief Explanation The journey from exploratory data analysis in notebooks to deploying machine learning models into production is a critical but challenging phase in the machine learning lifecycle. Apache Airflow, a…
0 notes
Text
What Are The Programmatic Commands For EMR Notebooks?

EMR Notebook Programming Commands
Programmatic Amazon EMR Notebook interaction.
How to leverage execution APIs from a script or command line to control EMR notebook executions outside the AWS UI. This lets you list, characterise, halt, and start EMR notebook executions.
The following examples demonstrate these abilities:
AWS CLI: Amazon EMR clusters on Amazon EC2 and EMR Notebooks clusters (EMR on EKS) with notebooks in EMR Studio Workspaces are shown. An Amazon S3 location-based notebook execution sample is also provided. The displayed instructions can list executions by start time or start time and status, halt an ongoing execution, and describe a notebook execution.
Boto3 SDK (Python): Demo.py uses boto3 to interface with EMR notebook execution APIs. The script explains how to initiate a notebook execution, get the execution ID, describe it, list all running instances, and stop it after a short pause. Status updates and execution IDs are shown in this script's output.
Ruby SDK: Sample Ruby code shows notebook execution API calls and Amazon EMR connection setup. Example: describe execution, print information, halt notebook execution, start notebook execution, and get execution ID. Predicted Ruby notebook run outcomes are also shown.
Programmatic command parameters
Important parameters in these programming instructions are:
EditorId: EMR Studio workspace.
relative-path or RelativePath: The notebook file's path to the workspace's home directory. Pathways include my_folder/python3.ipynb and demo_pyspark.ipynb.
execution-engine or ExecutionEngine: EMR cluster ID (j-1234ABCD123) or EMR on EKS endpoint ARN and type to choose engine.
The IAM service role, such as EMR_Notebooks_DefaultRole, is defined.
notebook-params or notebook_params: Allows a notebook to receive multiple parameter values, eliminating the need for multiple copies. Typically, parameters are JSON strings.
The input notebook file's S3 bucket and key are supplied.
The S3 bucket and key where the output notebook will be stored.
notebook-execution-name: Names the performance.
This identifies an execution when describing, halting, or listing.
–from and –status: Status and start time filters for executions.
The console can also access EMR Notebooks as EMR Studio Workspaces, according to documentation. Workspace access and creation require additional IAM role rights. Programmatic execution requires IAM policies like StartNotebookExecution, DescribeNotebookExecution, ListNotebookExecutions, and iam:PassRole. EMR Notebooks clusters (EMR on EKS) require emr-container permissions.
The AWS Region per account maximum is 100 concurrent executions, and executions that last more than 30 days are terminated. Interactive Amazon EMR Serverless apps cannot execute programs.
You can plan or batch EMR notebook runs using AWS Lambda and Amazon CloudWatch Events, or Apache Airflow or Amazon Managed Workflows for Apache Airflow (MWAA).
#EMRNotebooks#EMRNotebookscluster#AWSUI#EMRStudio#AmazonEMR#AmazonEC2#technology#technologynews#technews#news#govindhtech
0 notes
Text
Empowering Businesses with Advanced Data Engineering Solutions in Toronto – C Data Insights
In a rapidly digitizing world, companies are swimming in data—but only a few truly know how to harness it. At C Data Insights, we bridge that gap by delivering top-tier data engineering solutions in Toronto designed to transform your raw data into actionable insights. From building robust data pipelines to enabling intelligent machine learning applications, we are your trusted partner in the Greater Toronto Area (GTA).
What Is Data Engineering and Why Is It Critical?
Data engineering involves the design, construction, and maintenance of scalable systems for collecting, storing, and analyzing data. In the modern business landscape, it forms the backbone of decision-making, automation, and strategic planning.
Without a solid data infrastructure, businesses struggle with:
Inconsistent or missing data
Delayed analytics reports
Poor data quality impacting AI/ML performance
Increased operational costs
That’s where our data engineering service in GTA helps. We create a seamless flow of clean, usable, and timely data—so you can focus on growth.
Key Features of Our Data Engineering Solutions
As a leading provider of data engineering solutions in Toronto, C Data Insights offers a full suite of services tailored to your business goals:
1. Data Pipeline Development
We build automated, resilient pipelines that efficiently extract, transform, and load (ETL) data from multiple sources—be it APIs, cloud platforms, or on-premise databases.
2. Cloud-Based Architecture
Need scalable infrastructure? We design data systems on AWS, Azure, and Google Cloud, ensuring flexibility, security, and real-time access.
3. Data Warehousing & Lakehouses
Store structured and unstructured data efficiently with modern data warehousing technologies like Snowflake, BigQuery, and Databricks.
4. Batch & Streaming Data Processing
Process large volumes of data in real-time or at scheduled intervals with tools like Apache Kafka, Spark, and Airflow.
Data Engineering and Machine Learning – A Powerful Duo
Data engineering lays the groundwork, and machine learning unlocks its full potential. Our solutions enable you to go beyond dashboards and reports by integrating data engineering and machine learning into your workflow.
We help you:
Build feature stores for ML models
Automate model training with clean data
Deploy models for real-time predictions
Monitor model accuracy and performance
Whether you want to optimize your marketing spend or forecast inventory needs, we ensure your data infrastructure supports accurate, AI-powered decisions.
Serving the Greater Toronto Area with Local Expertise
As a trusted data engineering service in GTA, we take pride in supporting businesses across:
Toronto
Mississauga
Brampton
Markham
Vaughan
Richmond Hill
Scarborough
Our local presence allows us to offer faster response times, better collaboration, and solutions tailored to local business dynamics.
Why Businesses Choose C Data Insights
✔ End-to-End Support: From strategy to execution, we’re with you every step of the way ✔ Industry Experience: Proven success across retail, healthcare, finance, and logistics ✔ Scalable Systems: Our solutions grow with your business needs ✔ Innovation-Focused: We use the latest tools and best practices to keep you ahead of the curve
Take Control of Your Data Today
Don’t let disorganized or inaccessible data hold your business back. Partner with C Data Insights to unlock the full potential of your data. Whether you need help with cloud migration, real-time analytics, or data engineering and machine learning, we’re here to guide you.
📍 Proudly offering data engineering solutions in Toronto and expert data engineering service in GTA.
📞 Contact us today for a free consultation ��� https://cdatainsights.com
C Data Insights – Engineering Data for Smart, Scalable, and Successful Businesses
#data engineering solutions in Toronto#data engineering and machine learning#data engineering service in Gta
0 notes
Text
Choosing the Best Workflow Orchestration Software for Scalable Business Growth
As businesses expand, managing complex workflows becomes a critical challenge. This is where workflow orchestration software plays a vital role. It automates, coordinates, and optimizes various processes, ensuring seamless communication across teams and systems. Choosing the right orchestration tool is crucial for scalable business growth, and Cflow is an excellent choice for businesses looking to streamline their operations effectively.

Why Workflow Orchestration is Essential for Scalability
Workflow orchestration software simplifies complex processes by integrating tasks, data, and applications. It reduces manual intervention, minimizes errors, and accelerates time-to-market. Here’s why investing in the right tool is a game-changer for scalable growth:
Improved Efficiency: Automated workflows reduce manual tasks, allowing teams to focus on high-value activities.
Cost Savings: Fewer errors and faster processes mean lower operational costs.
Better Collaboration: Seamless communication across departments ensures smoother operations.
Scalability: It allows businesses to scale without the chaos of manual process management.
Key Features to Look for in a Workflow Orchestration Tool
When choosing the best workflow orchestration software for scalable growth, consider these critical features:
No-Code Automation: Tools like Cflow offer no-code automation, allowing users to create complex workflows without deep technical knowledge. This is crucial for businesses that need agility without relying on IT teams.
Integration Capabilities: The software should integrate easily with your existing tools, like CRM, ERP, and cloud storage platforms, ensuring seamless data flow.
Scalability and Flexibility: Choose a tool that can grow with your business, supporting more users, processes, and data as needed.
Real-Time Analytics: Detailed insights into process performance help identify bottlenecks and improve efficiency.
Security and Compliance: Make sure the platform adheres to industry security standards to protect sensitive business data.
Top Workflow Orchestration Tools in 2025
Here are some leading workflow orchestration tools known for their scalability:
Cflow: Known for its no-code automation, flexible workflow designs, and robust analytics.
Apache Airflow: Ideal for complex data pipelines but requires technical expertise.
Zapier: Great for small businesses looking for easy integrations without code.
Camunda: An open-source option with powerful orchestration capabilities for large enterprises.
Why Cflow is a Smart Choice for Growing Businesses
Cflow stands out as a reliable choice for small to medium-sized businesses looking for flexibility and ease of use. It offers:
No-Code Automation: Simplifies process automation without the need for technical skills.
Customizable Workflows: Easily adapt workflows as your business evolves.
Powerful Integrations: Connects seamlessly with popular tools like Slack, Salesforce, and QuickBooks.
Scalable Architecture: Grows with your business without compromising performance.
Detailed Reporting: Provides actionable insights to optimize workflows.
youtube
Conclusion
Choosing the right workflow orchestration software is a critical decision for businesses aiming for scalable growth. With the right tool, you can streamline operations, reduce costs, and improve overall efficiency. Cflow, with its no-code automation, powerful integrations, and scalable architecture, is an excellent choice for businesses looking to stay ahead in today’s competitive market.
SITES WE SUPPORT
Smart Screen AI - WordPress
SOCIAL LINKS Facebook Twitter LinkedIn
0 notes
Text

Learn how to streamline ETL pipelines using Apache Airflow. Ideal for those taking a data science course in Chennai to master real-world data workflows.
0 notes
Text
What is Data Workflow Management? A Complete Guide for 2025
Discover what data workflow management is, why it matters in 2025, and how businesses can optimize their data pipelines for better efficiency, compliance, and decision-makingIn the digital era, businesses are inundated with vast amounts of data. But raw data alone doesn’t add value unless it’s processed, organized, and analyzed effectively. This is where data workflow management comes in. It plays a critical role in ensuring data flows seamlessly from one system to another, enabling efficient analytics, automation, and decision-making.
In this article, we’ll break down what data workflow management is, its core benefits, common tools, and how to implement a successful workflow strategy in 2025.
What is Data Workflow Management?
Data workflow management refers to the design, execution, and automation of processes that move and transform data across different systems and stakeholders. It ensures that data is collected, cleaned, processed, stored, and analyzed systematically—without manual bottlenecks or errors.
A typical data workflow may include steps like:
Data ingestion from multiple sources (e.g., CRMs, websites, IoT devices)
Data validation and cleaning
Data transformation and enrichment
Storage in databases or cloud data warehouses
Analysis and reporting through BI tools
Why is Data Workflow Management Important?
Efficiency and Automation Automating data pipelines reduces manual tasks and operational overhead, enabling faster insights.
Data Accuracy and Quality Well-managed workflows enforce validation rules, reducing the risk of poor-quality data entering decision systems.
Regulatory Compliance With regulations like GDPR and CCPA, structured workflows help track data lineage and ensure compliance.
Scalability As businesses grow, managing large datasets manually becomes impossible. Workflow management systems scale with your data needs.
Key Features of Effective Data Workflow Management Systems
Visual workflow builders for drag-and-drop simplicity
Real-time monitoring and alerts for proactive troubleshooting
Role-based access control to manage data governance
Integration with popular tools like Snowflake, AWS, Google BigQuery, and Tableau
Audit logs and versioning to track changes and ensure transparency
Popular Tools for Data Workflow Management (2025)
Apache Airflow – Ideal for orchestrating complex data pipelines
Prefect – A modern alternative to Airflow with strong observability features
Luigi – Developed by Spotify, suited for batch data processing
Keboola – A no-code/low-code platform for data operations
Datafold – Focuses on data quality in CI/CD pipelines
How to Implement a Data Workflow Management Strategy
Assess Your Current Data Ecosystem Understand where your data comes from, how it’s used, and what bottlenecks exist.
Define Workflow Objectives Is your goal better reporting, real-time analytics, or compliance?
Choose the Right Tools Align your technology stack with your team’s technical expertise and project goals.
Design Workflows Visually Use modern tools that let you visualize dependencies and transformations.
Automate and Monitor Implement robust scheduling, automation, and real-time error alerts.
Continuously Optimize Collect feedback, iterate on designs, and evolve your workflows as data demands grow.
Conclusion
Data workflow management is no longer a luxury—it’s a necessity for data-driven organizations in 2025. With the right strategy and tools, businesses can turn chaotic data processes into streamlined, automated workflows that deliver high-quality insights faster and more reliably.
Whether you’re a startup building your first data pipeline or an enterprise looking to scale analytics, investing in efficient data workflow management will pay long-term dividends.
0 notes
Text
Machine Learning Infrastructure: The Foundation of Scalable AI Solutions

Introduction: Why Machine Learning Infrastructure Matters
In today's digital-first world, the adoption of artificial intelligence (AI) and machine learning (ML) is revolutionizing every industry—from healthcare and finance to e-commerce and entertainment. However, while many organizations aim to leverage ML for automation and insights, few realize that success depends not just on algorithms, but also on a well-structured machine learning infrastructure.
Machine learning infrastructure provides the backbone needed to deploy, monitor, scale, and maintain ML models effectively. Without it, even the most promising ML solutions fail to meet their potential.
In this comprehensive guide from diglip7.com, we’ll explore what machine learning infrastructure is, why it’s crucial, and how businesses can build and manage it effectively.
What is Machine Learning Infrastructure?
Machine learning infrastructure refers to the full stack of tools, platforms, and systems that support the development, training, deployment, and monitoring of ML models. This includes:
Data storage systems
Compute resources (CPU, GPU, TPU)
Model training and validation environments
Monitoring and orchestration tools
Version control for code and models
Together, these components form the ecosystem where machine learning workflows operate efficiently and reliably.
Key Components of Machine Learning Infrastructure
To build robust ML pipelines, several foundational elements must be in place:
1. Data Infrastructure
Data is the fuel of machine learning. Key tools and technologies include:
Data Lakes & Warehouses: Store structured and unstructured data (e.g., AWS S3, Google BigQuery).
ETL Pipelines: Extract, transform, and load raw data for modeling (e.g., Apache Airflow, dbt).
Data Labeling Tools: For supervised learning (e.g., Labelbox, Amazon SageMaker Ground Truth).
2. Compute Resources
Training ML models requires high-performance computing. Options include:
On-Premise Clusters: Cost-effective for large enterprises.
Cloud Compute: Scalable resources like AWS EC2, Google Cloud AI Platform, or Azure ML.
GPUs/TPUs: Essential for deep learning and neural networks.
3. Model Training Platforms
These platforms simplify experimentation and hyperparameter tuning:
TensorFlow, PyTorch, Scikit-learn: Popular ML libraries.
MLflow: Experiment tracking and model lifecycle management.
KubeFlow: ML workflow orchestration on Kubernetes.
4. Deployment Infrastructure
Once trained, models must be deployed in real-world environments:
Containers & Microservices: Docker, Kubernetes, and serverless functions.
Model Serving Platforms: TensorFlow Serving, TorchServe, or custom REST APIs.
CI/CD Pipelines: Automate testing, integration, and deployment of ML models.
5. Monitoring & Observability
Key to ensure ongoing model performance:
Drift Detection: Spot when model predictions diverge from expected outputs.
Performance Monitoring: Track latency, accuracy, and throughput.
Logging & Alerts: Tools like Prometheus, Grafana, or Seldon Core.
Benefits of Investing in Machine Learning Infrastructure
Here’s why having a strong machine learning infrastructure matters:
Scalability: Run models on large datasets and serve thousands of requests per second.
Reproducibility: Re-run experiments with the same configuration.
Speed: Accelerate development cycles with automation and reusable pipelines.
Collaboration: Enable data scientists, ML engineers, and DevOps to work in sync.
Compliance: Keep data and models auditable and secure for regulations like GDPR or HIPAA.
Real-World Applications of Machine Learning Infrastructure
Let’s look at how industry leaders use ML infrastructure to power their services:
Netflix: Uses a robust ML pipeline to personalize content and optimize streaming.
Amazon: Trains recommendation models using massive data pipelines and custom ML platforms.
Tesla: Collects real-time driving data from vehicles and retrains autonomous driving models.
Spotify: Relies on cloud-based infrastructure for playlist generation and music discovery.
Challenges in Building ML Infrastructure
Despite its importance, developing ML infrastructure has its hurdles:
High Costs: GPU servers and cloud compute aren't cheap.
Complex Tooling: Choosing the right combination of tools can be overwhelming.
Maintenance Overhead: Regular updates, monitoring, and security patching are required.
Talent Shortage: Skilled ML engineers and MLOps professionals are in short supply.
How to Build Machine Learning Infrastructure: A Step-by-Step Guide
Here’s a simplified roadmap for setting up scalable ML infrastructure:
Step 1: Define Use Cases
Know what problem you're solving. Fraud detection? Product recommendations? Forecasting?
Step 2: Collect & Store Data
Use data lakes, warehouses, or relational databases. Ensure it’s clean, labeled, and secure.
Step 3: Choose ML Tools
Select frameworks (e.g., TensorFlow, PyTorch), orchestration tools, and compute environments.
Step 4: Set Up Compute Environment
Use cloud-based Jupyter notebooks, Colab, or on-premise GPUs for training.
Step 5: Build CI/CD Pipelines
Automate model testing and deployment with Git, Jenkins, or MLflow.
Step 6: Monitor Performance
Track accuracy, latency, and data drift. Set alerts for anomalies.
Step 7: Iterate & Improve
Collect feedback, retrain models, and scale solutions based on business needs.
Machine Learning Infrastructure Providers & Tools
Below are some popular platforms that help streamline ML infrastructure: Tool/PlatformPurposeExampleAmazon SageMakerFull ML development environmentEnd-to-end ML pipelineGoogle Vertex AICloud ML serviceTraining, deploying, managing ML modelsDatabricksBig data + MLCollaborative notebooksKubeFlowKubernetes-based ML workflowsModel orchestrationMLflowModel lifecycle trackingExperiments, models, metricsWeights & BiasesExperiment trackingVisualization and monitoring
Expert Review
Reviewed by: Rajeev Kapoor, Senior ML Engineer at DataStack AI
"Machine learning infrastructure is no longer a luxury; it's a necessity for scalable AI deployments. Companies that invest early in robust, cloud-native ML infrastructure are far more likely to deliver consistent, accurate, and responsible AI solutions."
Frequently Asked Questions (FAQs)
Q1: What is the difference between ML infrastructure and traditional IT infrastructure?
Answer: Traditional IT supports business applications, while ML infrastructure is designed for data processing, model training, and deployment at scale. It often includes specialized hardware (e.g., GPUs) and tools for data science workflows.
Q2: Can small businesses benefit from ML infrastructure?
Answer: Yes, with the rise of cloud platforms like AWS SageMaker and Google Vertex AI, even startups can leverage scalable machine learning infrastructure without heavy upfront investment.
Q3: Is Kubernetes necessary for ML infrastructure?
Answer: While not mandatory, Kubernetes helps orchestrate containerized workloads and is widely adopted for scalable ML infrastructure, especially in production environments.
Q4: What skills are needed to manage ML infrastructure?
Answer: Familiarity with Python, cloud computing, Docker/Kubernetes, CI/CD, and ML frameworks like TensorFlow or PyTorch is essential.
Q5: How often should ML models be retrained?
Answer: It depends on data volatility. In dynamic environments (e.g., fraud detection), retraining may occur weekly or daily. In stable domains, monthly or quarterly retraining suffices.
Final Thoughts
Machine learning infrastructure isn’t just about stacking technologies—it's about creating an agile, scalable, and collaborative environment that empowers data scientists and engineers to build models with real-world impact. Whether you're a startup or an enterprise, investing in the right infrastructure will directly influence the success of your AI initiatives.
By building and maintaining a robust ML infrastructure, you ensure that your models perform optimally, adapt to new data, and generate consistent business value.
For more insights and updates on AI, ML, and digital innovation, visit diglip7.com.
0 notes
Text
A Spanitor of the past $ 93m raising special times: orthestration and king in Ai
Enter our daily routes and every week recent update and accessories on the experts. learn more A skilled astronautThe company that made the Apache Airflow Astro, has $ 93 million of D The circular amount is given by Biin capital majorDue to participation The seller’s supplier and the seller of money such as Insight, AmphitechAnd Venrock. Bosch off It also wants to take part in a circle, showing…
0 notes
Text
Building Scalable and Resilient Data Pipelines With Apache Airflow
http://securitytc.com/TKStmp
0 notes