#Apache Kafka 2.0 Ecosystem
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
Apache Kafka Series – Learn Apache Kafka for Beginners v2
START HERE: Learn Apache Kafka 2.0 Ecosystem, Core Concepts, Real World Java Producers/Consumers & Big Data Architecture
What you’ll learn
Understand Apache Kafka Ecosystem, Architecture, Core Concepts and Operations
Master Concepts such as Topics, Partitions, Brokers, Producers, Consumers
Start a personal Kafka development environment
Learn major CLIs: kafka-topics, kafka-console-producer,…
View On WordPress
#Apache Kafka 2.0 Ecosystem#Apache Kafka Series#Big Data Architecture#Core Concepts#Learn Apache Kafka#Real World Java Producers/Consumers
0 notes
Text
What is the Data Science Processing Tools
Now that I have introduced data storage, the next step involves processing tools to transform your data lakes into data vaults and then into data warehouses. These tools are the workhorses of the data science and engineering ecosystem. Following are the recommended foundations for the data tools I use.
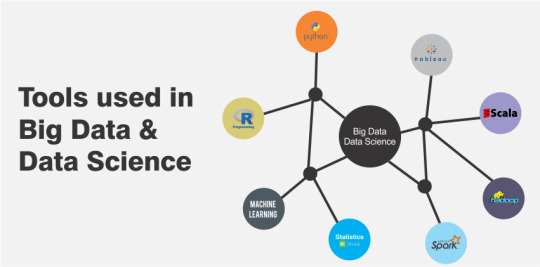
Spark
Apache Spark is an open-source cluster computing framework. Originally developed at the AMP Lab of the University of California, Berkeley, the Spark codebase was donated to the Apache Software Foundation, which now maintains it as an open-source project. This tool is evolving at an incredible rate.
IBM is committing more than 3,500 developers and researchers to work on Spark-related projects and formed a dedicated Spark technology center in San Francisco to pursue Spark-based innovations.
SAP, Tableau, and Talend now support Spark as part of their core software stack. Cloudera, Hortonworks, and MapR distributions support Spark as a native interface. To get more information to learn data science online training
Spark offers an interface for programming distributed clusters with implicit data parallelism and fault-tolerance. Spark is a technology that is becoming a de-facto standard for numerous enterprise-scale processing applications.
I discovered the following modules using this tool as part of my technology toolkit.
SPARK CORE
Spark Core is the foundation of the overall development. It provides distributed task dispatching, scheduling, and basic I/O functionalities.
This enables you to offload the comprehensive and complex running environment to the Spark Core. This safeguards that the tasks you submit are accomplished as anticipated. The distributed nature of the Spark ecosystem enables you to use the same processing request on a small Spark cluster, then on a cluster of thousands of nodes, without any code changes.
SPARK SQL
Spark SQL is a component on top of the Spark Core that presents a data abstraction called Data Frames. Spark SQL makes accessible a domain-specific language (DSL) to manipulate data frames. This feature of Spark enables ease of transition from your traditional SQL environments into the Spark environment. I have recognized its advantage when you want to enable legacy applications to offload the data from their traditional relational-only data storage to the data lake ecosystem.
SPARK STREAMING
Spark Streaming leverages Spark Core’s fast scheduling capability to perform streaming analytics. Spark Streaming has built-in support to consume from Kafka, Flume, Twitter, ZeroMQ, Kinesis, and TCP/IP sockets. The process of streaming is the primary technique for importing data from the data source to the data lake. Learn more info at data science online course
Streaming is becoming the leading technique to load from multiple data sources. I have found that there are connectors available for many data sources. There is a major drive to build even more improvements on connectors, and this will improve the ecosystem even further in the future.
MLLIB MACHINE LEARNING LIBRARY
Spark MLlib is a distributed machine learning framework used on top of the Spark Core using the distributed memory-based Spark architecture.
In Spark 2.0, a new library, spark.mk, was introduced to replace the RDD-based data processing with a DataFrame-based model. It is planned that by the introduction of Spark 3.0, only DataFrame-based models will exist.
Common machine learning and statistical algorithms have been implemented and are shipped with MLlib, which simplifies large-scale machine learning pipelines, including
Dimensionality reduction techniques, such as singular value decomposition (SVD) and principal component analysis (PCA)
Summary statistics, correlations, stratified sampling, hypothesis testing, and random data generation
Collaborative filtering techniques, including alternating least squares (ALS)
GRAPHX
GraphX is a powerful graph-processing application programming interface (API) for the Apache Spark analytics engine that can draw insights from large data sets. GraphX provides outstanding speed and capacity for running massively parallel and machine-learning algorithms.
Akka
The toolkit and runtime methods shorten the development of large-scale data-centric applications for processing. Akka is an actor-based message-driven runtime for running concurrency, elasticity, and resilience processes. The use of high-level abstractions such as actors, streams, and futures facilitates the data science and engineering granularity processing units.
The use of actors enables the data scientist to spawn a series of concurrent processes by using a simple processing model that employs a messaging technique and specific predefined actions/behaviors for each actor.
R
R is a programming language and software environment for statistical computing and graphics. The R language is widely used by data scientists, statisticians, data miners, and data engineers for developing statistical software and performing data analysis.
0 notes
Link
Apache Kafka Series - Learn Apache Kafka for Beginners v2, START HERE: Learn Apache Kafka 2.0 Ecosystem, Core Concepts, Real World Java P...
0 notes
Text
Apache Kafka Series – Learn Apache Kafka for Beginners v2 (2020 update)
Apache Kafka Series – Learn Apache Kafka for Beginners v2 (2020 update)
START HERE: Learn Apache Kafka 2.0 Ecosystem, Core Concepts, Real World Java Producers/Consumers & Big Data Architecture What you’ll learn
Understand Apache Kafka Ecosystem, Architecture, Core Concepts and Operations
Master Concepts such as Topics, Partitions, Brokers, Producers, Consumers
Start a personal Kafka development environment
Learn major CLIs: kafka-topics,…
View On WordPress
0 notes
Link
START HERE: Learn Apache Kafka 2.0 Ecosystem, Core Concepts, Real World Java Producers/Consumers & Big Data Architecture
What you’ll learn
Understand Apache Kafka Ecosystem, Architecture, Core Concepts and Operations
Master Concepts such as Topics, Partitions, Brokers, Producers, Consumers
Start a personal Kafka development environment
Learn major CLIs: kafka-topics, kafka-console-producer, kafka-console-consumer, kafka-consumer-groups, kafka-configs
Create your Producers and Consumers in Java to interact with Kafka
Program a Real World Twitter Producer & ElasticSearch Consumer
Extended APIs Overview (Kafka Connect, Kafka Streams), Case Studies and Big Data Architecture
Practice and Understand Log Compaction
Requirements
A recent Windows / Mac / Linux machine with minimum 4GB of RAM, 5 GB of disk space
Some understanding of Java Programming
Good to have knowledge about Linux command line
Desire to learn something awesome and new!
Description
UPDATE SEPTEMBER 2018: Course newly recorded with Kafka 2.0!
Welcome to the Apache Kafka Series! Join a community of 20,000+ students learning Kafka.
Apache Kafka has become the leading distributed data streaming enterprise big data technology. Kafka is used in production by over 33% of the Fortune 500 companies such as Netflix, Airbnb, Uber, Walmart and LinkedIn.
To learn Kafka easily, step-by-step, you have come to the right place! No prior Kafka knowledge is required
===============================
If you look at the documentation, you can see that Apache Kafka is not easy to learn…
Thanks to my several years of experience in Kafka and Big Data, I wanted to make learning Kafka accessible to everyone.
We’ll take a step-by-step approach to learn all the fundamentals of Apache Kafka. At the end of this course, you’ll be productive and you’ll know the following:
The Apache Kafka Ecosystem Architecture
The Kafka Core Concepts: Topics, Partitions, Brokers, Replicas, Producers, Consumers, and more!
Launch your own Kafka cluster in no time using native Kafka binaries – Windows / MacOS X / Linux
Learn and Practice using the Kafka Command Line Interface (CLI)
Code Producer and Consumers using the Java API
Real world project using Twitter as a source of data for a producer and ElasticSearch as a sink for our consumer
Overview of Advanced APIs (Kafka Connect, Kafka Streams)
Real World Case Studies and Big Use cases
Overview of Advanced Kafka for Administrators
Advanced Topic Configurations
Annexes (starting a Kafka cluster locally, using Docker, etc…)
Note: The hands-on section is based on Java, which is the native Kafka programming language. But, good news! Your learning in Java will be completely applicable to other programming languages, such as Python, C#, Node.js or Scala, and Big Data frameworks such as Spark, NiFi or Akka
===============================
The Kafka for Beginners course is the best place to start your Kafka learning journey… Ask other students!
★★★★★ “That’s one of the most high-quality on-line courses I ever took” – Paul L.
★★★★★ “This training was awesome and learnt many things about KAFKA though having 0 years of experience in this technology” – Puneet G.
★★★★★ “Outstanding on all fronts! I wish all courses were that well presented. I especially appreciate the hands-on sections. I was able to get everything up and running with ease. Highly recommend this course and this instructor!” – David G.
You can take this course risk-free and if you don’t like it, you can get a refund anytime in the first 30 days!
===============================
Instructor
Stephane Maarek is the instructor of this course. He is a Kafka Expert, guest author on the Confluent Blog and Speaker at the Kafka Summit SF 2018. He’s the author of the highly-rated Apache Kafka Series on Udemy, having taught already to 40,000+ students and received 12,000+ reviews.
He shares all his Kafka knowledge on the platform, taking the time to explain every concept and provide students with both theoretical and practical dimensions. You are in good hands!
===============================
This Course Also Comes With:
✔ Lifetime Access to All Future Updates
✔ A responsive instructor in the Q&A Section
✔ Links to interesting articles, and lots of good code to base your next applications onto
✔ Udemy Certificate of Completion Ready for Download
This is the course that could improve your career!
Apache Kafka is a skill in high demand and there are not enough people to fulfil all the open positions. You can boost your income, take on new roles and fun challenges. Many of my students are now the Kafka experts of their companies!
I hope to see you inside the course!
=======================
Note: Looking for more advanced Kafka concepts? There are many volumes in the Apache Kafka Series:
Learn Kafka for Beginners v2 (this course – great to start)
Kafka Connect Hands On Learning
Kafka Streams for Data Processing
Kafka Cluster Setup & Administration
Confluent Schema Registry & Kafka REST Proxy
Kafka Security (SSL SASL ACL)
Kafka Monitoring and Operations
Happy learning!
Who this course is for:
Developers who want to learn the Apache Kafka Fundamentals, start a cluster and write their first application
Architects who want to understand how Apache Kafka fits into their solution architecture
Anyone looking to learn the full theory of how Apache Kafka works as a distributed system
Created by Stephane Maarek | AWS Certified Solutions Architect & Developer Associate Last updated 5/2020 English English
Size: 4.25 GB
Download Now
https://ift.tt/38jUosO.
The post Apache Kafka Series – Learn Apache Kafka for Beginners v2 appeared first on Free Course Lab.
0 notes
Text
Pretty low level, pretty big deal: Apache Kafka and Confluent Open Source go mainstream
Featured stories
Apache Kafka, the open-source distributed messaging system, has steadily carved a foothold as the de facto real-time standard for brokering messages in scale-out environments. And if you think you have seen this opener before, it’s because you have.
Also: Pulsar graduates to being an Apache top-level project
Besides being fellow ZDNet’s Tony Baer opener for his piece commenting on Kafka usage survey in July, you’ve probably read something along these lines elsewhere, or had that feeling yourself. Yes, Kafka is in most whiteboards, but it’s mostly the whiteboards of early adopters, was the gist of Baer’s analysis.
With Kafka Summit kicking off today San Francisco, we took the opportunity for a chat with Jay Kreps, Kafka co-creator and Confluent CEO, on all things Kafka, as well as the broader landscape.
Going mainstream
Kreps indicated his belief that in the last year Kafka has actually gone mainstream. As evidence to back this claim, he cited use cases in four out of five biggest banks in the US, as well as the Bank of Canada: “These are 200 year-old organizations, and they don’t just jump at the first technology out of Silicon Valley. We are going mainstream in a big way,” Kreps asserted, while also mentioning big retail use cases.
While we have no reason to question these use cases, it’s hard to assess whether this translates to adoption in the majority of the market as well. Traditionally, big finance and retail are on the forefront of real-time use case adoption.
Also: We interrupt this revolution: Apache Spark changes the rules of the game
Still, it may take a while for this to spill over, so it depends on what one considers “mainstream.” Looking at Kafka Summit, however, we see a mix of Confluent staff and household names, which is the norm for events of this magnitude.
But what is driving this adoption? Something pretty low level, which is a pretty big deal, according to Kreps: The ability to integrate disparate systems via messaging, and to do this at scale and in real time. It’s not that this is a novel idea – messaging has been around for a while and it’s the key premise of Enterprise Service Bus (ESB) solutions for years.
Conceptually, Kafka is not all that different. The difference, Kreps said, is that older systems were not able to handle the scale that Kafka can: “We can scale to trillions of messages. New style, cloud data systems are just better at this, such techniques did not exist before. We benefited as we came around a bit later.”
Going cloud and real-time
The cloud is something Kreps emphasized, and the discussion around the latest developments in the field was centered around it. The recent Cloudera – Hortonworks merger, for example, touches upon this as well, according to Kreps.
“It was a smart move. These were two companies competing on the same product, which makes the competition more fierce, ironically. You’d think it’s people with different views that compete more fiercely, but it’s actually people with similar views. That really showed also in the business model,” Kreps said.
Also: Kafka: The story so far
Kreps believes that this competition slowed down progress in core Hadoop, as the need for differentiation resulted in more attention towards edge features. Case in point, he noted, the fact that HDFS, Hadoop’s file system, which historically has been a key component of its value proposition, is no longer the most economic way to store loads of data — cloud storage is now.
This could also be interpreted as a sign of moving away from batch processing that Hadoop started from and more toward real-time processing. Although Hadoop has been gradually grown to a full ecosystem, including streaming engines, the majority of its use cases are still batch-oriented, believes Kreps. How this will evolve, time will tell.
The cloud is gaining gravity in terms of data, and data-infrastructure platforms need to work both there and on premise. (Image: ktsimage, Getty Images/iStockphoto)
Despite Kreps pointing out the cloud as a gravitational point, and Hadoop actually moving toward it in the last couple of years, Confluent is not going to pursue a cloud-only policy. As opposed to data science workloads, which can be hosted either on premise or in the cloud, the kind of data infrastructure that Kafka provided must work on both, argued Kreps.
Since many organizations still have huge investments in software and infrastructure built over years in their data centers, any move to the cloud will be gradual. Confluent’s hosted version of Kafka plus proprietary extensions will continue to work seamlessly with on-premise Kafka or Confluent open source, said Kreps. He also emphasized Kafka support for Kubernetes, noting that any stateful data system has to put in some effort to make this work.
Streaming coopetition and real-time machine learning
In terms of differentiation with other streaming platforms, Kreps pointed out that these are mostly geared toward analytics, while Kafka is infrastructure on which operational systems can be, and are, built. When wondering whether Kafka could also be moving in the analytics direction, Kreps did not give any such indication, and questioned the applicability of real-time machine learning (ML):
Also: An inside look at Apache Kafka adoption TechRepublic
“What is the use of a real-time machine learning platform? When i was in school, ironically the focus of my advisors was real-time ML — ironically, because ML was not very popular back then, let alone real-time ML.
We were struggling to name a mainstream production system using real-time ML. And the idea of having a ML algorithm retrain itself in real-time is not necessarily positive. Most of the time, the effort is to have enough checks and balances in places to make sure ML really works even when working with batch data.
And if you look at ML algorithms built by people who build databases and infrastructure, they are never as good, which is normal. There is a separate ecosystem for data science, and the best stuff is separate from the big infrastructure projects.
The reality is that Spark machine learning is mostly used for offline ML. Streaming brings together all the data needed for this, and Kafka works with other streaming platforms, too.”
Kafka is a key element of the streaming landscape, but it also works complementary to other streaming platforms.
More often than not, Kafka seems to be mentioned in the same breath, or whiteboard, with a number of other systems, including streaming ones. Although some might say this means it will be hard for Kafka to come into its own, its position in those architectures also means it’s equally hard to take it out of the equation.
Although no big announcement is reserved for this Kafka Summit, Kafka and Confluent have had a few of those in the last year — KSQL and version 5.0 being the most prominent ones — and seems to be well on the way to the mainstream.
Previous and related coverage:
Confluent release adds enterprise, developer, IoT savvy to Apache Kafka
Confluent, the company founded by the creators of streaming data platform Apache Kafka, is announcing a new release today. Confluent Platform 5.0, based on yesterday’s release of open source Kafka 2.0, adds enterprise security, new disaster recovery capabilities, lots of developer features, and important IoT support.
Hortonworks ups its Kafka Game
Ahead of the Strata conference next month, Hortonworks is focusing on streaming data as it introduces a new Kafka management tool and adds some refinements to its DataFlow product.
Kafka is establishing its toehold
Data pipelines were the headline from the third annual survey of Apache Kafka use. Behind anecdotal evidence of a growing user base, Kafka is still at the early adopter stage and skills remain hard to find.
Confluent brings fully-managed Kafka to the Google Cloud Platform
The partnership between Confluent and Google extends the Kafka ecosystem, making it easier to consume with Google Cloud services for machine learning, analytics and more.
Source: https://bloghyped.com/pretty-low-level-pretty-big-deal-apache-kafka-and-confluent-open-source-go-mainstream/
0 notes
Text
JEEConf 2018: Highlights

photo source
The past month was rich in conferences for SciForce team. Among others, our colleagues visited one of the largest Java conferences in Eastern Europe, JEEConf, which took place in Kyiv, May 18–19th.
Let’s have a look at what they found to be the most exciting newest developments and trends.
15 Years of Spring: Evolving a Java Application Framework

The opening speech was given by Juergen Hoeller, the co-founder of Spring Framework.
Spring is the most widely used application framework for Java developers which celebrates its 15-year anniversary. Mr. Hoeler started with a brief overview of Spring history as it evolved from a small open-source project to a true development philosophy and a huge ecosystem which supports new Java-based languages such as Groovy and Kotlin. In his speech, Juergen Hoeller presented new features for Java and Kotlin, including Reactive Web Stack on Reactor and the support of JDK 11.
Juergen Hoeller on Twitter and GitHub.
Building Event-Driven Microservices with Event Sourcing and CQRS

Lidan Hifi, a Team Lead at Wix, shared his experience on designing and supporting systems with Event-Sourcing and CQRS patterns for an invoice service. Before describing these patterns, he sketched the drawbacks of the state-based model for high-scaled and complex regulation rules as well as the advantages of saving the whole event sequence in order to rebuild the actual state once needed. Such approach, on the one hand, allows generating an audit log and, therefore, debugging the process at no expense; yet it adds additional complexity to the system.
Slides and video. Lidan Hifi on Twitter and Medium.
Spring Framework 5: Feature Highlights & Hidden Gems

It was the second speech given by Juergen Hoeller, the co-founder of the Spring Framework. This time, he gave an overview of new features in Spring Framework 5, including the out-of-box first-class support for Kotlin and Java 8 and the functional-style API. He also presented a infrastructure-level reactive interaction model based on the publisher-subscriber pattern. This innovative model underlies new stream-based methods used in the framework. The presentation also touched upon a new stack named Spring WebFlux as a programming model for reactive microservices. Last, but not the least, Juergen Hoeller raised the curtain over the upcoming release 5.1.
Designing Fault Tolerant Microservices

Orkhan Gasimov, Senior Data Developer at AppsFlyer, gave in his speech an overview of popular approaches, patterns and complete solution cases in the field of microservices and distributed business applications.
First, he described the Service Discovery pattern which provides an means for service orchestration in network without preconfigured service locations and dynamic load-balancing.
The following approach described was an autoscaler-service, which balanced the infrastructure based on a range of metrics. This approach has a number of open-source solutions that make in potentially attractive for businesses.
The Circuit Breaker pattern helps identify an overloaded or corrupted path in the RPC services orchestration. The user is notified that his request can’t be processed, or another path will be chosen.
Afterwards, Mr. Gasimov discussed the advantages of N-module-redundancy both for fault-tolerance and for acceleration of processing. At the same time, he pointed out that we should always take into account a situation where more than one service will give a response at the same time.
The procedures of service recovery should not slow down the processing by default. The normal behavior should be processed as fast as possible. It is the pattern recovery blocks that realize this feature.
If a root (or parent) microservice fails, the whole job is compromised. These services are error kernels in the system. The instance healer service realizes event-sourcing and CQRS patterns (see the previous speech) for saving states of child services. This approach ensures that the jobs of executors will not be lost upon a failure of parent service.
Slides Orkhan Gasimov on Facebook.
Hexagonal Architecture with Spring Boot

“Have you seen the Domain Driven Design in the real world?” — was the first question Mikalai Alimenkou, Founder and Coach at Xp Injection, asked. He represented the Hexagonal Architecture as the new level of Application Design that came just in time in the era of Microservices Architecture. The idea it rests upon is rather simple: logic inside, ports outside. With Spring Boot, it is possible to implement the application ports for external communications without the temptation for moving a part of the business logic to application bounds. Spring Boot and other Spring projects isolate the business logic inside the microservice around the domain and save it in the use cases structure. If you want an API or an UI, use Spring MVC. Want to connect to the databases — use Spring Data. Listen to message queues — Spring Messaging is ready to help. The Hexagonal Architecture brings the Domain Driven Design described by Eric Evans into the real world.
Slides Mikalai Alimenkou Twitter and GitHub.
Bootiful Kotlin

The second conference day began with a speech by Josh Long, Spring Developer Advocate. It was a very exciting and funny morning. With his sense of humor Josh presented the Kotlin support provided by Spring Framework 5.0 and demonstrated how quick and easy it might be to build apps with Kotlin + Spring Boot 2.0. Just go to start.spring.io which configures everything for you and do your best while coding. The second part is a little bit harder as Kotlin looks of course less verbose than Java. Therefore, you should be ready to spend some time trying it on try.kotlinlang.org.
Josh Long on Twitter, GitHub and on his Blog.
Building event sourced systems with Kafka Streams

This year, there were multiple presentations on Event sourcing and CQRS, because these techniques are suitable for big applications with huge amount of data and, therefore, have become quite popular nowadays. They solve a lot of problems but, as it usually happens, also cause new problems. Amitay Horwitz (Software Engineer at WIX) shared his team’s experience of using the Event Sourcing and showed how Kafka & Kafka Stream became a rescue for them.
Kafka is a distributed streaming platform that enables exchanging messages between producers and consumers which are actually microservices. The topic is a basic structure that Kafka gives us. The producer can send messages to different partitions of the topic which is configured by a message key. Kafka Streams is the library provided by Apache Kafka that does amazing things with messages in partitions. You can write a small app that takes messages from partition into a stream, transforms it by mapping, filtering, joining separate streams and sends the resulting stream to another partition which can be read by a consumer. Besides, with this tool you can add or change your query views easily.
Slides and video Amitay Horwitz on Twitter, GitHub and Medium.
Dive into the Internet of Things with Java 9/10

Finally, we dived into the Internet of Things with Java 9/10. Alexander Belokrylov, CEO/Product Manager at BellSoft, shared his experience of using Embedded Java that has recently been included into OpenJDK 9. He presented a few features that simplify the usage of Java for hardware products: modularization, AppCDS, http/2, and Process API. Even for those who are not hardware developers, it was exciting to watch his demo cooling the beer bottle and notifying the user about the current and desired temperature in Telegram. Veronika Herasymenko, our Java developer, has admitted after the conference that she was so amused that the demo made her want to buy a Raspberry Pi 3 and try something similar just for fun.
Slides Alexander Belokrylov on Twitter and Facebook.
As a concluding remark, we can say that, as you could notice, the main trends in Java 9/10 world are Event Sourcing + CQRS, Spring Framework and its projects, Reactive, and Kotlin. Now, with new insights and ideas, we will be waiting for Java 11… and, of course, for JEEConf 2019!
0 notes
Link
START HERE: Learn Apache Kafka 2.0 Ecosystem, Core Concepts, Real World Java Producers/Consumers & Big Data Architecture
What you’ll learn
Understand Apache Kafka Ecosystem, Architecture, Core Concepts and Operations
Master Concepts such as Topics, Partitions, Brokers, Producers, Consumers
Start a personal Kafka development environment
Learn major CLIs: kafka-topics, kafka-console-producer, kafka-console-consumer, kafka-consumer-groups, kafka-configs
Create your Producers and Consumers in Java to interact with Kafka
Program a Real World Twitter Producer & ElasticSearch Consumer
Extended APIs Overview (Kafka Connect, Kafka Streams), Case Studies and Big Data Architecture
Practice and Understand Log Compaction
Requirements
A recent Windows / Mac / Linux machine with minimum 4GB of RAM, 5 GB of disk space
Some understanding of Java Programming
Good to have knowledge about Linux command line
Desire to learn something awesome and new!
Description
UPDATE SEPTEMBER 2018: Course newly recorded with Kafka 2.0!
Welcome to the Apache Kafka Series! Join a community of 20,000+ students learning Kafka.
Apache Kafka has become the leading distributed data streaming enterprise big data technology. Kafka is used in production by over 33% of the Fortune 500 companies such as Netflix, Airbnb, Uber, Walmart and LinkedIn.
To learn Kafka easily, step-by-step, you have come to the right place! No prior Kafka knowledge is required
===============================
If you look at the documentation, you can see that Apache Kafka is not easy to learn…
Thanks to my several years of experience in Kafka and Big Data, I wanted to make learning Kafka accessible to everyone.
We’ll take a step-by-step approach to learn all the fundamentals of Apache Kafka. At the end of this course, you’ll be productive and you’ll know the following:
The Apache Kafka Ecosystem Architecture
The Kafka Core Concepts: Topics, Partitions, Brokers, Replicas, Producers, Consumers, and more!
Launch your own Kafka cluster in no time using native Kafka binaries – Windows / MacOS X / Linux
Learn and Practice using the Kafka Command Line Interface (CLI)
Code Producer and Consumers using the Java API
Real world project using Twitter as a source of data for a producer and ElasticSearch as a sink for our consumer
Overview of Advanced APIs (Kafka Connect, Kafka Streams)
Real World Case Studies and Big Use cases
Overview of Advanced Kafka for Administrators
Advanced Topic Configurations
Annexes (starting a Kafka cluster locally, using Docker, etc…)
Note: The hands-on section is based on Java, which is the native Kafka programming language. But, good news! Your learning in Java will be completely applicable to other programming languages, such as Python, C#, Node.js or Scala, and Big Data frameworks such as Spark, NiFi or Akka
===============================
The Kafka for Beginners course is the best place to start your Kafka learning journey… Ask other students!
★★★★★ “That’s one of the most high-quality on-line courses I ever took” – Paul L.
★★★★★ “This training was awesome and learnt many things about KAFKA though having 0 years of experience in this technology” – Puneet G.
★★★★★ “Outstanding on all fronts! I wish all courses were that well presented. I especially appreciate the hands-on sections. I was able to get everything up and running with ease. Highly recommend this course and this instructor!” – David G.
You can take this course risk-free and if you don’t like it, you can get a refund anytime in the first 30 days!
===============================
Instructor
Stephane Maarek is the instructor of this course. He is a Kafka Expert, guest author on the Confluent Blog and Speaker at the Kafka Summit SF 2018. He’s the author of the highly-rated Apache Kafka Series on Udemy, having taught already to 40,000+ students and received 12,000+ reviews.
He shares all his Kafka knowledge on the platform, taking the time to explain every concept and provide students with both theoretical and practical dimensions. You are in good hands!
===============================
This Course Also Comes With:
✔ Lifetime Access to All Future Updates
✔ A responsive instructor in the Q&A Section
✔ Links to interesting articles, and lots of good code to base your next applications onto
✔ Udemy Certificate of Completion Ready for Download
This is the course that could improve your career!
Apache Kafka is a skill in high demand and there are not enough people to fulfil all the open positions. You can boost your income, take on new roles and fun challenges. Many of my students are now the Kafka experts of their companies!
I hope to see you inside the course!
=======================
Note: Looking for more advanced Kafka concepts? There are many volumes in the Apache Kafka Series:
Learn Kafka for Beginners v2 (this course – great to start)
Kafka Connect Hands On Learning
Kafka Streams for Data Processing
Kafka Cluster Setup & Administration
Confluent Schema Registry & Kafka REST Proxy
Kafka Security (SSL SASL ACL)
Kafka Monitoring and Operations
Happy learning!
Who this course is for:
Developers who want to learn the Apache Kafka Fundamentals, start a cluster and write their first application
Architects who want to understand how Apache Kafka fits into their solution architecture
Anyone looking to learn the full theory of how Apache Kafka works as a distributed system
Created by Stephane Maarek | AWS Certified Developer Last updated 1/2019 English English
Size: 3.16 GB
Download Now
https://ift.tt/38jUosO.
The post Apache Kafka Series – Learn Apache Kafka for Beginners v2 appeared first on Free Course Lab.
0 notes