#Apache Kafka Series
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Link
0 notes
Text
How AI Is Revolutionizing Contact Centers in 2025
As contact centers evolve from reactive customer service hubs to proactive experience engines, artificial intelligence (AI) has emerged as the cornerstone of this transformation. In 2025, modern contact center architectures are being redefined through AI-based technologies that streamline operations, enhance customer satisfaction, and drive measurable business outcomes.
This article takes a technical deep dive into the AI-powered components transforming contact centers—from natural language models and intelligent routing to real-time analytics and automation frameworks.
1. AI Architecture in Modern Contact Centers
At the core of today’s AI-based contact centers is a modular, cloud-native architecture. This typically consists of:
NLP and ASR engines (e.g., Google Dialogflow, AWS Lex, OpenAI Whisper)
Real-time data pipelines for event streaming (e.g., Apache Kafka, Amazon Kinesis)
Machine Learning Models for intent classification, sentiment analysis, and next-best-action
RPA (Robotic Process Automation) for back-office task automation
CDP/CRM Integration to access customer profiles and journey data
Omnichannel orchestration layer that ensures consistent CX across chat, voice, email, and social
These components are containerized (via Kubernetes) and deployed via CI/CD pipelines, enabling rapid iteration and scalability.
2. Conversational AI and Natural Language Understanding
The most visible face of AI in contact centers is the conversational interface—delivered via AI-powered voice bots and chatbots.
Key Technologies:
Automatic Speech Recognition (ASR): Converts spoken input to text in real time. Example: OpenAI Whisper, Deepgram, Google Cloud Speech-to-Text.
Natural Language Understanding (NLU): Determines intent and entities from user input. Typically fine-tuned BERT or LLaMA models power these layers.
Dialog Management: Manages context-aware conversations using finite state machines or transformer-based dialog engines.
Natural Language Generation (NLG): Generates dynamic responses based on context. GPT-based models (e.g., GPT-4) are increasingly embedded for open-ended interactions.
Architecture Snapshot:
plaintext
CopyEdit
Customer Input (Voice/Text)
↓
ASR Engine (if voice)
↓
NLU Engine → Intent Classification + Entity Recognition
↓
Dialog Manager → Context State
↓
NLG Engine → Response Generation
↓
Omnichannel Delivery Layer
These AI systems are often deployed on low-latency, edge-compute infrastructure to minimize delay and improve UX.
3. AI-Augmented Agent Assist
AI doesn’t only serve customers—it empowers human agents as well.
Features:
Real-Time Transcription: Streaming STT pipelines provide transcripts as the customer speaks.
Sentiment Analysis: Transformers and CNNs trained on customer service data flag negative sentiment or stress cues.
Contextual Suggestions: Based on historical data, ML models suggest actions or FAQ snippets.
Auto-Summarization: Post-call summaries are generated using abstractive summarization models (e.g., PEGASUS, BART).
Technical Workflow:
Voice input transcribed → parsed by NLP engine
Real-time context is compared with knowledge base (vector similarity via FAISS or Pinecone)
Agent UI receives predictive suggestions via API push
4. Intelligent Call Routing and Queuing
AI-based routing uses predictive analytics and reinforcement learning (RL) to dynamically assign incoming interactions.
Routing Criteria:
Customer intent + sentiment
Agent skill level and availability
Predicted handle time (via regression models)
Customer lifetime value (CLV)
Model Stack:
Intent Detection: Multi-label classifiers (e.g., fine-tuned RoBERTa)
Queue Prediction: Time-series forecasting (e.g., Prophet, LSTM)
RL-based Routing: Models trained via Q-learning or Proximal Policy Optimization (PPO) to optimize wait time vs. resolution rate
5. Knowledge Mining and Retrieval-Augmented Generation (RAG)
Large contact centers manage thousands of documents, SOPs, and product manuals. AI facilitates rapid knowledge access through:
Vector Embedding of documents (e.g., using OpenAI, Cohere, or Hugging Face models)
Retrieval-Augmented Generation (RAG): Combines dense retrieval with LLMs for grounded responses
Semantic Search: Replaces keyword-based search with intent-aware queries
This enables agents and bots to answer complex questions with dynamic, accurate information.
6. Customer Journey Analytics and Predictive Modeling
AI enables real-time customer journey mapping and predictive support.
Key ML Models:
Churn Prediction: Gradient Boosted Trees (XGBoost, LightGBM)
Propensity Modeling: Logistic regression and deep neural networks to predict upsell potential
Anomaly Detection: Autoencoders flag unusual user behavior or possible fraud
Streaming Frameworks:
Apache Kafka / Flink / Spark Streaming for ingesting and processing customer signals (page views, clicks, call events) in real time
These insights are visualized through BI dashboards or fed back into orchestration engines to trigger proactive interventions.
7. Automation & RPA Integration
Routine post-call processes like updating CRMs, issuing refunds, or sending emails are handled via AI + RPA integration.
Tools:
UiPath, Automation Anywhere, Microsoft Power Automate
Workflows triggered via APIs or event listeners (e.g., on call disposition)
AI models can determine intent, then trigger the appropriate bot to complete the action in backend systems (ERP, CRM, databases)
8. Security, Compliance, and Ethical AI
As AI handles more sensitive data, contact centers embed security at multiple levels:
Voice biometrics for authentication (e.g., Nuance, Pindrop)
PII Redaction via entity recognition models
Audit Trails of AI decisions for compliance (especially in finance/healthcare)
Bias Monitoring Pipelines to detect model drift or demographic skew
Data governance frameworks like ISO 27001, GDPR, and SOC 2 compliance are standard in enterprise AI deployments.
Final Thoughts
AI in 2025 has moved far beyond simple automation. It now orchestrates entire contact center ecosystems—powering conversational agents, augmenting human reps, automating back-office workflows, and delivering predictive intelligence in real time.
The technical stack is increasingly cloud-native, model-driven, and infused with real-time analytics. For engineering teams, the focus is now on building scalable, secure, and ethical AI infrastructures that deliver measurable impact across customer satisfaction, cost savings, and employee productivity.
As AI models continue to advance, contact centers will evolve into fully adaptive systems, capable of learning, optimizing, and personalizing in real time. The revolution is already here—and it's deeply technical.
#AI-based contact center#conversational AI in contact centers#natural language processing (NLP)#virtual agents for customer service#real-time sentiment analysis#AI agent assist tools#speech-to-text AI#AI-powered chatbots#contact center automation#AI in customer support#omnichannel AI solutions#AI for customer experience#predictive analytics contact center#retrieval-augmented generation (RAG)#voice biometrics security#AI-powered knowledge base#machine learning contact center#robotic process automation (RPA)#AI customer journey analytics
0 notes
Text
The Ultimate Roadmap to AIOps Platform Development: Tools, Frameworks, and Best Practices for 2025
In the ever-evolving world of IT operations, AIOps (Artificial Intelligence for IT Operations) has moved from buzzword to business-critical necessity. As companies face increasing complexity, hybrid cloud environments, and demand for real-time decision-making, AIOps platform development has become the cornerstone of modern enterprise IT strategy.

If you're planning to build, upgrade, or optimize an AIOps platform in 2025, this comprehensive guide will walk you through the tools, frameworks, and best practices you must know to succeed.
What Is an AIOps Platform?
An AIOps platform leverages artificial intelligence, machine learning (ML), and big data analytics to automate IT operations—from anomaly detection and event correlation to root cause analysis, predictive maintenance, and incident resolution. The goal? Proactively manage, optimize, and automate IT operations to minimize downtime, enhance performance, and improve the overall user experience.
Key Functions of AIOps Platforms:
Data Ingestion and Integration
Real-Time Monitoring and Analytics
Intelligent Event Correlation
Predictive Insights and Forecasting
Automated Remediation and Workflows
Root Cause Analysis (RCA)
Why AIOps Platform Development Is Critical in 2025
Here’s why 2025 is a tipping point for AIOps adoption:
Explosion of IT Data: Gartner predicts that IT operations data will grow 3x by 2025.
Hybrid and Multi-Cloud Dominance: Enterprises now manage assets across public clouds, private clouds, and on-premises.
Demand for Instant Resolution: User expectations for zero downtime and faster support have skyrocketed.
Skill Shortages: IT teams are overwhelmed, making automation non-negotiable.
Security and Compliance Pressures: Faster anomaly detection is crucial for risk management.
Step-by-Step Roadmap to AIOps Platform Development
1. Define Your Objectives
Problem areas to address: Slow incident response? Infrastructure monitoring? Resource optimization?
KPIs: MTTR (Mean Time to Resolution), uptime percentage, operational costs, user satisfaction rates.
2. Data Strategy: Collection, Integration, and Normalization
Sources: Application logs, server metrics, network traffic, cloud APIs, IoT sensors.
Data Pipeline: Use ETL (Extract, Transform, Load) tools to clean and unify data.
Real-Time Ingestion: Implement streaming technologies like Apache Kafka, AWS Kinesis, or Azure Event Hubs.
3. Select Core AIOps Tools and Frameworks
We'll explore these in detail below.
4. Build Modular, Scalable Architecture
Microservices-based design enables better updates and feature rollouts.
API-First development ensures seamless integration with other enterprise systems.
5. Integrate AI/ML Models
Anomaly Detection: Isolation Forest, LSTM models, autoencoders.
Predictive Analytics: Time-series forecasting, regression models.
Root Cause Analysis: Causal inference models, graph neural networks.
6. Implement Intelligent Automation
Use RPA (Robotic Process Automation) combined with AI to enable self-healing systems.
Playbooks and Runbooks: Define automated scripts for known issues.
7. Deploy Monitoring and Feedback Mechanisms
Track performance using dashboards.
Continuously retrain models to adapt to new patterns.
Top Tools and Technologies for AIOps Platform Development (2025)
Data Ingestion and Processing
Apache Kafka
Fluentd
Elastic Stack (ELK/EFK)
Snowflake (for big data warehousing)
Monitoring and Observability
Prometheus + Grafana
Datadog
Dynatrace
Splunk ITSI
Machine Learning and AI Frameworks
TensorFlow
PyTorch
scikit-learn
H2O.ai (automated ML)
Event Management and Correlation
Moogsoft
BigPanda
ServiceNow ITOM
Automation and Orchestration
Ansible
Puppet
Chef
SaltStack
Cloud and Infrastructure Platforms
AWS CloudWatch and DevOps Tools
Google Cloud Operations Suite (formerly Stackdriver)
Azure Monitor and Azure DevOps
Best Practices for AIOps Platform Development
1. Start Small, Then Scale
Begin with a few critical systems before scaling to full-stack observability.
2. Embrace a Unified Data Strategy
Ensure that your AIOps platform ingests structured and unstructured data across all environments.
3. Prioritize Explainability
Build AI models that offer clear reasoning for decisions, not black-box results.
4. Incorporate Feedback Loops
AIOps platforms must learn continuously. Implement mechanisms for humans to approve, reject, or improve suggestions.
5. Ensure Robust Security and Compliance
Encrypt data in transit and at rest.
Implement access controls and audit trails.
Stay compliant with standards like GDPR, HIPAA, and CCPA.
6. Choose Cloud-Native and Open-Source Where Possible
Future-proof your system by building on open standards and avoiding vendor lock-in.
Key Trends Shaping AIOps in 2025
Edge AIOps: Extending monitoring and analytics to edge devices and remote locations.
AI-Enhanced DevSecOps: Tight integration between AIOps and security operations (SecOps).
Hyperautomation: Combining AIOps with enterprise-wide RPA and low-code platforms.
Composable IT: Building modular AIOps capabilities that can be assembled dynamically.
Federated Learning: Training models across multiple environments without moving sensitive data.
Challenges to Watch Out For
Data Silos: Incomplete data pipelines can cripple AIOps effectiveness.
Over-Automation: Relying too much on automation without human validation can lead to errors.
Skill Gaps: Building an AIOps platform requires expertise in AI, data engineering, IT operations, and cloud architectures.
Invest in cross-functional teams and continuous training to overcome these hurdles.
Conclusion: Building the Future with AIOps
In 2025, the enterprises that invest in robust AIOps platform development will not just survive—they will thrive. By integrating the right tools, frameworks, and best practices, businesses can unlock proactive incident management, faster innovation cycles, and superior user experiences.
AIOps isn’t just about reducing tickets—it’s about creating a resilient, self-optimizing IT ecosystem that powers future growth.
0 notes
Text
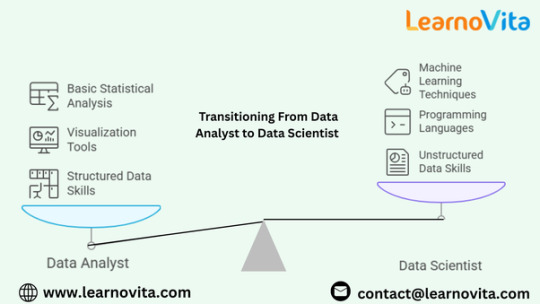
Key Skills You Need to Move from Data Analyst to Data Scientist
Transitioning from a data analyst to a data scientist requires expanding your skill set beyond basic data manipulation and visualization. While both roles revolve around extracting insights from data, data scientists rely heavily on machine learning, programming, and advanced statistical techniques to build predictive models. If you are a data analyst looking to move into data science, developing key technical and analytical skills is crucial. This blog outlines the essential skills you need to successfully transition into a data science role from the best Data Analytics Online Training.

Programming Proficiency: Python and R
A fundamental requirement for data science is strong programming skills. While data analysts often use SQL and Excel, data scientists must be proficient in Python or R. These languages are widely used in machine learning and statistical analysis. Python, in particular, is a preferred choice due to its vast ecosystem of libraries like Pandas, NumPy, Matplotlib, and Seaborn for data manipulation and visualization. Additionally, frameworks such as Scikit-learn, TensorFlow, and PyTorch enable machine learning model development. Mastering these tools is essential for handling large datasets and building predictive models.
Advanced Statistics and Probability
While data analysts use basic statistical techniques to summarize data and find patterns, data scientists require a deeper understanding of statistics and probability. Concepts such as hypothesis testing, Bayesian inference, A/B testing, regression analysis, and time series forecasting play a significant role in making data-driven decisions. Strong statistical knowledge helps in feature selection, model evaluation, and performance optimization. If you want to learn more about Data Analytics, consider enrolling in an Best Online Training & Placement programs . They often offer certifications, mentorship, and job placement opportunities to support your learning journey.
Machine Learning and Deep Learning
One of the biggest differences between data analysts and data scientists is the ability to build machine learning models. Data scientists use supervised learning techniques like classification and regression, as well as unsupervised methods like clustering and dimensionality reduction. Understanding model training, evaluation metrics, and hyperparameter tuning is crucial. Additionally, learning deep learning concepts such as neural networks, natural language processing (NLP), and computer vision can further expand career opportunities.
Data Wrangling and Preprocessing
Real-world data is often messy and unstructured, making data preprocessing a critical step in data science. Data scientists must be skilled in handling missing values, dealing with outliers, normalizing and transforming data, and feature engineering. Tools like Pandas, SQL, and OpenCV help in cleaning and structuring data for effective analysis. Efficient data preparation ensures that machine learning models perform accurately.
Big Data Technologies
As businesses generate vast amounts of data, working with big data technologies becomes essential. Data scientists often use distributed computing frameworks such as Hadoop, Spark, and Apache Kafka to process large datasets efficiently. Cloud computing platforms like AWS, Google Cloud, and Microsoft Azure also offer data science tools that facilitate large-scale analytics. Understanding these technologies allows data scientists to work with real-time and large-scale data environments.
Data Visualization and Storytelling
Even though data scientists build complex models, their findings must be communicated effectively. Data visualization is essential for interpreting and presenting insights. Proficiency in tools like Tableau, Power BI, and Python visualization libraries such as Matplotlib and Seaborn is necessary. Additionally, the ability to tell a compelling data-driven story helps stakeholders understand the impact of insights on business decisions.
SQL and Database Management
While programming and machine learning are important, SQL remains a fundamental skill for any data professional. Data scientists frequently work with structured databases, writing advanced queries to extract relevant data. Understanding indexing, joins, window functions, and stored procedures can enhance efficiency when dealing with relational databases like MySQL, PostgreSQL, or SQL Server.
Business Acumen and Problem-Solving
A successful data scientist must bridge the gap between technical expertise and business impact. Understanding industry-specific problems and applying data science techniques to solve them is key. Data scientists must be able to translate business problems into data-driven solutions, making business acumen an invaluable skill. Additionally, problem-solving skills help in selecting the right algorithms, optimizing models, and making data-driven recommendations.
Version Control and Deployment Skills
Data scientists not only build models but also deploy them into production. Learning version control systems like Git and GitHub helps in tracking code changes and collaborating with teams. Deploying machine learning models using tools like Flask, Docker, and Kubernetes ensures that models can be integrated into real-world applications. Understanding MLOps (Machine Learning Operations) can also enhance the ability to maintain and improve models post-deployment.
Continuous Learning and Experimentation
Data science is an evolving field, requiring continuous learning and adaptation to new technologies. Experimenting with new algorithms, participating in data science competitions like Kaggle, and keeping up with research papers can help stay ahead in the field. The ability to learn, experiment, and apply new techniques is crucial for long-term success.
Conclusion
The transition from data analyst to data scientist requires developing a robust skill set that includes programming, machine learning, statistical analysis, and business problem-solving. While data analysts already have experience working with data, advancing technical skills in Python, deep learning, and big data technologies is essential for stepping into data science. By continuously learning, working on real-world projects, and gaining hands-on experience, data analysts can successfully move into data science roles and contribute to solving complex business challenges with data-driven insights.
0 notes
Text
Data Pipeline Architecture for Amazon Redshift: An In-Depth Guide

In the era of big data and analytics, Amazon Redshift stands out as a popular choice for managing and analyzing vast amounts of structured and semi-structured data. To leverage its full potential, a well-designed data pipeline for Amazon Redshift is crucial. This article explores the architecture of a robust data pipeline tailored for Amazon Redshift, detailing its components, workflows, and best practices.
Understanding a Data Pipeline for Amazon Redshift
A data pipeline is a series of processes that extract, transform, and load (ETL) data from various sources into a destination system for analysis. In the case of Amazon Redshift, the pipeline ensures data flows seamlessly from source systems into this cloud-based data warehouse, where it can be queried and analyzed.
Key Components of a Data Pipeline Architecture
A comprehensive data pipeline for Amazon Redshift comprises several components, each playing a pivotal role:
Data Sources These include databases, APIs, file systems, IoT devices, and third-party services. The data sources generate raw data that must be ingested into the pipeline.
Ingestion Layer The ingestion layer captures data from multiple sources and transports it into a staging area. Tools like AWS DataSync, Amazon Kinesis, and Apache Kafka are commonly used for this purpose.
Staging Area Before data is loaded into Amazon Redshift, it is often stored in a temporary staging area, such as Amazon S3. This step allows preprocessing and ensures scalability when handling large data volumes.
ETL/ELT Processes The ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) layer prepares the data for Redshift. Tools like AWS Glue, Apache Airflow, and Matillion help clean, transform, and structure data efficiently.
Amazon Redshift The central data warehouse where transformed data is stored and optimized for querying. Amazon Redshift's columnar storage and MPP (Massively Parallel Processing) architecture make it ideal for analytics.
Data Visualization and Analytics Tools like Amazon QuickSight, Tableau, or Power BI connect to Redshift to visualize and analyze the data, providing actionable insights.
Data Pipeline Workflow
A well-designed pipeline operates in sequential or parallel workflows, depending on the complexity of the data and the business requirements:
Data Extraction: Data is extracted from source systems and moved into a staging area, often with minimal transformations.
Data Transformation: Raw data is cleaned, enriched, and structured to meet the schema and business logic requirements of Redshift.
Data Loading: Transformed data is loaded into Amazon Redshift tables using COPY commands or third-party tools.
Data Validation: Post-load checks ensure data accuracy, consistency, and completeness.
Automation and Monitoring: Scheduled jobs and monitoring systems ensure the pipeline runs smoothly and flags any issues.
Best Practices for Data Pipeline Architecture
To maximize the efficiency and reliability of a data pipeline for Amazon Redshift, follow these best practices:
Optimize Data Ingestion
Use Amazon S3 as an intermediary for large data transfers.
Compress and partition data to minimize storage and improve query performance.
Design for Scalability
Choose tools and services that can scale as data volume grows.
Leverage Redshift's spectrum feature to query data directly from S3.
Prioritize Data Quality
Implement rigorous data validation and cleansing routines.
Use AWS Glue DataBrew for visual data preparation.
Secure Your Pipeline
Use encryption for data at rest and in transit.
Configure IAM roles and permissions to restrict access to sensitive data.
Automate and Monitor
Schedule ETL jobs with AWS Step Functions or Apache Airflow.
Set up alerts and dashboards using Amazon CloudWatch to monitor pipeline health.
Tools for Building a Data Pipeline for Amazon Redshift
Several tools and services streamline the process of building and managing a data pipeline for Redshift:
AWS Glue: A serverless data integration service for ETL processes.
Apache Airflow: An open-source tool for workflow automation and orchestration.
Fivetran: A SaaS solution for automated data integration.
Matillion: A cloud-native ETL tool optimized for Redshift.
Amazon Kinesis: A service for real-time data streaming into Redshift.
Benefits of a Well-Architected Data Pipeline
A robust data pipeline for Amazon Redshift provides several advantages:
Efficiency: Automates complex workflows, saving time and resources.
Scalability: Handles growing data volumes seamlessly.
Reliability: Ensures consistent data quality and availability.
Actionable Insights: Prepares data for advanced analytics and visualization.
Conclusion
Designing an efficient data pipeline for Amazon Redshift is vital for unlocking the full potential of your data. By leveraging modern tools, adhering to best practices, and focusing on scalability and security, businesses can streamline their data workflows and gain valuable insights. Whether you’re a startup or an enterprise, a well-architected data pipeline ensures that your analytics capabilities remain robust and future-ready. With the right pipeline in place, Amazon Redshift can become the backbone of your data analytics strategy, helping you make data-driven decisions with confidence.
0 notes
Text
Data Analytics Strategy
Our Data Analytics Services are designed to help organizations extract valuable insights from their data, leveraging a combination of computer skills, mathematics, statistics, descriptive techniques, and predictive models. These insights are then used to recommend actions or guide decision-making processes within a business context. Data Analytics Strategy
Key Components and Execution
1. Advanced Analytics and Insights
Descriptive Analytics: We utilize descriptive techniques to summarize historical data and identify patterns. This provides a clear picture of what has happened in the past, helping businesses understand trends and behaviors.
Predictive Analytics: Implementing predictive models, we analyze current and historical data to make forecasts about future events. Techniques such as machine learning, regression analysis, and time series forecasting are used to predict outcomes and trends.
Prescriptive Analytics: We provide actionable recommendations based on data analysis. By using optimization and simulation algorithms, we help businesses determine the best course of action among various options.
2. Machine Learning and Artificial Intelligence (AI)
Machine Learning Models: Leveraging machine learning techniques, we build models that can learn from data and improve over time. These models are used for tasks such as classification, regression, clustering, and anomaly detection.
AI Integration: Implementing AI solutions to automate processes, enhance decision-making, and drive innovation. AI technologies are used for natural language processing (NLP), image recognition, and other advanced applications.
Large Language Models (LLM): Utilizing advanced NLP models like GPT-4 for tasks such as text generation, summarization, and sentiment analysis. These models help in understanding and generating human language, providing deeper insights from textual data.
3. Data Science
Statistical Analysis: Utilizing statistical methods to interpret complex data and uncover hidden patterns. Our data scientists apply techniques such as hypothesis testing, variance analysis, and multivariate analysis to gain deeper insights.
Data Visualization: Creating interactive and intuitive data visualizations to help stakeholders understand data insights quickly. Tools like Tableau, Power BI, and D3.js are used to build dashboards and visual reports.
4. Real-time Analytics
Stream Processing: Leveraging technologies such as Apache Kafka, Apache Flink, and Spark Streaming, we handle real-time data ingestion and processing. This enables immediate analysis and insights, crucial for time-sensitive decisions.
Event-driven Architectures: Implementing event-driven systems to process and analyze data in real-time. This supports the development of responsive applications and systems that can react to changes as they occur.
5. Big Data and Analytics Platforms
Big Data Technologies: Utilizing Hadoop ecosystems and Spark for big data processing and analytics. These technologies allow us to handle and analyze large volumes of data efficiently.
Analytics Platforms: Deploying platforms like Databricks, Snowflake, and Google BigQuery for advanced analytics and machine learning integration. These platforms provide robust environments for executing complex data analytics tasks.
6. Recent Techniques in Analytics
Retrieval-Augmented Generation (RAG): Integrating RAG models to improve information retrieval and provide accurate, context-aware responses. This technique combines large language models with document retrieval systems to enhance the quality and relevance of generated outputs.
Edge Analytics: Performing data processing at the edge of the network, near the data source, to reduce latency and bandwidth usage. This technique is especially useful for IoT applications and real-time decision-making.
AutoML: Leveraging automated machine learning tools to streamline the model development process, making it more accessible and efficient. AutoML helps in selecting the best algorithms and hyperparameters, reducing the time and expertise required for building machine learning models.
Execution Approach
Assessment and Planning: Conducting a thorough assessment of your current data analytics capabilities and identifying key areas for improvement. We develop a tailored analytics strategy that aligns with your business goals. Data Strategy and Analytics
Implementation and Integration: Implementing advanced analytics solutions and integrating them into your existing systems. This includes setting up data pipelines, building predictive models, and developing visualization tools.
Optimization and Monitoring: Continuously monitoring and optimizing analytics processes to ensure they deliver the expected value. We use performance metrics and feedback loops to refine models and techniques.
Training and Support: Providing training to your team on the new analytics tools and methodologies. We offer ongoing support to ensure the effective use and continuous improvement of your data analytics capabilities.
0 notes
Text
SNOWFLAKE OPEN SOURCE

Snowflake and Open Source: A Complex Relationship
Snowflake is a powerful cloud data warehouse platform known for its scalability, speed, and ease of use. But is Snowflake considered open source? The answer could be more precise.
Snowflake’s Approach to Open Source
Not a Core Open Source Product: Snowflake is a proprietary, closed-source software platform. Its code is not publicly available on platforms like GitHub.
Support for Open Source Projects: Snowflake actively engages with and supports the open-source community. For example, they offer connectors to open-source tools like Python, Spark, and Kafka. Additionally, they contribute to projects such as Apache Iceberg.
Open Source Tools: Snowflake has developed and released a few open-source tools related to their platform. Some examples include:
Snowflake SQLAlchemy: An open-source Python library for interacting with Snowflake.
Snowpark is a developer framework currently available for Scala, Java, and Python that offers functionality within its data warehouse.
Understanding the Nuances
It’s essential to understand why Snowflake isn’t considered a fully open-source product:
Business Model: Snowflake’s business model relies on providing a cloud-based, managed service. Offering a fully open-source solution might lead to the proliferation of competing self-hosted platforms, undermining their revenue source.
Complexity: Building, scaling, and maintaining a genuinely open-source data warehouse at Snowflake’s level of performance is a highly complex task that could potentially require considerable resources and investment.
Security and Control: Open-source models can introduce security vulnerabilities if not meticulously managed. Snowflake likely retains control over its core code to ensure robust security standards.
Open Source Alternatives to Snowflake
If you’re seeking robust open-source options for data warehousing, consider these highly regarded alternatives:
ClickHouse: A columnar database optimized for speed, ideal for large-scale analytics.
StarRocks: Another high-performance columnar database designed for real-time analytics scenarios.
Apache Druid: Great for real-time analytics and time-series data processing.
DuckDB: An embedded database focused on simplicity and ease of use.
Should I Choose Snowflake?
Snowflake’s decision to be closed-source while actively interacting with the open-source ecosystem is strategic. Here’s how you can decide if it’s the right fit for your needs:
Consider Snowflake if:
You prioritize ease of use, scalability, and a fully managed cloud solution.
Cost is less of a concern than getting the job done quickly.
Open-source licensing is a low priority for your internal tools.
Open-source alternatives might be better if:
You have a strong preference for fully open-source technologies.
It would help if you had flexibility and granular control over every aspect of the platform.
Cost efficiency is a significant factor.
Conclusion
Snowflake is an undisputed leader in the cloud data warehousing space, even though it’s not fully open source. Its commitment to supporting and engaging with the open-source community demonstrates its acknowledgment of open-source software’s benefits. Whether Snowflake or a completely open-source alternative is better depends on your organization’s specific needs and priorities.
youtube
You can find more information about Snowflake in this Snowflake
Conclusion:
Unogeeks is the No.1 IT Training Institute for SAP Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Snowflake here – Snowflake Blogs
You can check out our Best In Class Snowflake Details here – Snowflake Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Text
Mastering Big Data: Essential Skills You'll Learn in a Data Analytics Course

In today's digital age, the sheer volume and complexity of data generated by organizations present both challenges and opportunities. Big data analytics has emerged as a critical tool for extracting valuable insights from large and diverse datasets, driving informed decision-making and driving business success. If you're looking to master the intricacies of big data analytics, enrolling in a data analytics course is an excellent starting point. In this blog post, we'll explore some essential skills you'll learn in a data analytics course that will help you excel in the field of big data analytics.
Understanding the Fundamentals of Big Data
Before delving into advanced analytics techniques, it's essential to understand the fundamentals of big data. A data analytics course will introduce you to key concepts such as volume, velocity, variety, and veracity—the four V's of big data. You'll learn how to navigate large datasets, understand data storage and retrieval systems, and identify the unique challenges posed by big data analytics.
Data Wrangling and Preprocessing
Raw data is often messy, incomplete, and unstructured, making it challenging to analyze effectively. In a data analytics course, you'll learn essential data wrangling and preprocessing techniques to clean, transform, and prepare data for analysis. This includes handling missing values, removing duplicates, standardizing data formats, and merging datasets from different sources.
Statistical Analysis and Machine Learning
Statistical analysis forms the backbone of data analytics, providing valuable insights into relationships and patterns within data. In a data analytics course, you'll learn essential statistical techniques such as hypothesis testing, regression analysis, and time series analysis. Additionally, you'll explore machine learning algorithms and techniques for predictive modeling, clustering, classification, and anomaly detection—a cornerstone of big data analytics.
Data Visualization and Interpretation
Data visualization plays a crucial role in communicating insights and findings from big data analysis effectively. In a data analytics course, you'll learn how to create visually compelling and informative data visualizations using tools like Python libraries (e.g., Matplotlib, Seaborn) and data visualization platforms (e.g., Tableau, Power BI). You'll also develop skills in interpreting visualizations and effectively communicating insights to stakeholders.
Big Data Tools and Technologies
Mastering big data analytics requires familiarity with a range of tools and technologies designed to handle large datasets efficiently. In a data analytics course, you'll gain hands-on experience with popular big data platforms such as Hadoop, Spark, and Apache Kafka. You'll learn how to leverage these tools to store, process, and analyze vast amounts of data in distributed computing environments.
Real-World Applications and Case Studies
A data analytics course will provide you with opportunities to apply your skills to real-world data analytics projects and case studies. You'll work on practical assignments that simulate the challenges and scenarios encountered in professional data analytics settings. This hands-on experience will not only reinforce your learning but also prepare you for real-world applications of big data analytics.
Conclusion
Mastering big data analytics requires a combination of technical skills, analytical thinking, and practical experience. By enrolling in a data analytics course, you'll acquire the essential skills and knowledge needed to excel in the field of big data analytics. From understanding the fundamentals of big data to mastering advanced analytics techniques and tools, a well-designed course will equip you with the expertise needed to tackle the complexities of analyzing large and diverse datasets effectively.
Ready to Master Big Data Analytics?
If you're ready to take your big data analytics skills to the next level, consider enrolling in a data analytics course today. ineubytes offers comprehensive data analytics courses designed to equip you with the skills and knowledge needed to succeed in the fast-paced world of big data analytics. With expert instructors, hands-on projects, and flexible learning options, ineubytes is your partner in mastering big data analytics.
Embark on your journey to mastering big data analytics today and unlock a world of opportunities in this dynamic and rapidly growing field.
0 notes
Text
Best 10 Data Scientist Skills You Need in 2024

In the ever-evolving landscape of technology and data, the role of a data scientist remains as crucial as ever. As we step into 2024, the demand for skilled data scientists continues to soar, driven by the increasing reliance on data-driven decision-making across industries. However, the skills required to excel in this field are constantly evolving. Here, we delve into the best 10 data scientist skills you need in 2024.
Advanced Statistical Knowledge:
While statistical knowledge has always been fundamental for data scientists, in 2024, an advanced understanding of statistical methods is essential. This includes proficiency in regression analysis, hypothesis testing, Bayesian methods, and time series analysis, among others.
Machine Learning Mastery:
With the proliferation of machine learning applications, data scientists must possess a strong grasp of various machine learning algorithms and techniques. This includes supervised and unsupervised learning, deep learning, reinforcement learning, and ensemble methods.
Big Data Technologies:
In today's data landscape, dealing with large volumes of data is the norm. Proficiency in big data technologies such as Apache Hadoop, Spark, and Kafka is indispensable for data scientists to efficiently process, analyze, and derive insights from massive datasets.
Programming Proficiency:
Data scientists should be proficient in programming languages such as Python, R, and SQL. Python, in particular, continues to be the go-to language for data science due to its versatility, extensive libraries, and vibrant community support.
Data Visualization Skills:
Communicating insights effectively is a crucial aspect of a data scientist's role. Proficiency in data visualization tools and techniques such as Matplotlib, Seaborn, and Tableau is essential for creating compelling visualizations that convey complex findings simply and intuitively.
Domain Knowledge:
Understanding the domain in which one operates is paramount for effective data analysis. Data scientists should possess domain-specific knowledge, whether it's finance, healthcare, e-commerce, or any other industry, to contextualize their analyses and derive actionable insights.
Ethical Considerations:
As data science continues to impact various aspects of society, including privacy, bias, and fairness, ethical considerations are becoming increasingly important. Data scientists must be mindful of ethical implications in their work and adhere to ethical principles and guidelines.
Problem-Solving Skills:
Data science often involves tackling complex and ambiguous problems. Strong problem-solving skills, including critical thinking, creativity, and the ability to think analytically, are essential for data scientists to effectively address challenges and find innovative solutions.
Collaboration and Communication:
Data science is rarely a solitary endeavor. Data scientists must collaborate with cross-functional teams, including engineers, product managers, and business stakeholders. Effective communication skills, both verbal and written, are crucial for conveying findings, gaining buy-in, and driving decision-making.
Continuous Learning Mindset:
Given the rapid pace of technological advancements in data science, a willingness to learn and adapt is indispensable. Data scientists should embrace a continuous learning mindset, staying abreast of the latest developments, tools, and techniques in the field to remain competitive and relevant.
Conclusion
In conclusion, the field of data science continues to evolve rapidly, and data scientists must stay ahead of the curve by acquiring and honing the necessary skills. From advanced statistical knowledge to proficiency in machine learning, big data technologies, programming, and communication skills, the best 10 data scientist skills for 2024 encompass a broad spectrum of competencies. By cultivating these skills and embracing a mindset of lifelong learning, data scientists can thrive in an increasingly data-driven world and make meaningful contributions to their organizations and society at large.
0 notes
Text
This Week in Rust 504
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.71.0
Rustc Trait System Refactor Initiative Update
Project/Tooling Updates
rust-analyzer changelog #190
Generating terminal user interfaces with Ratatui + ChatGPT
Kani 0.32.0 has been released!
Bevy XPBD 0.2.0: Spatial queries, Bevy 0.11 support, and a lot more
bwrap : A fast, lightweight, embedded environment-friendly Rust library for wrapping text
We Just Released our Rust Teleconferencing System for Free | Repo
Observations/Thoughts
Mutex without lock, Queue without push: cancel safety in lilos
Why Rust is a great fit for embedded software - 2023 update
{n} times faster than C, where n = 128
I have written a JVM in Rust
On Maximizing Your Rust Code's Performance
How rustdoc achieves a genius design
ESP32 Standard Library Embedded Rust: GPIO Control
Rust vs Julia in scientific computing
Writing a toy DNS resolver in Rust
Rust Walkthroughs
[series] Rust multi crate monorepo microservices series with Kafka, Apache Avro, OpenTelemetry tracing
The easiest way to speed up Python with Rust
Writing an AI Chatbot in Rust and Solid.js
Simple Rust Function Macros
Updated fluvio SQL sink connector (repo) | Walkthrough of deduplication on write using upsert function
[video] Rust Releases! Rust 1.71.0
ratatui 0.22.0 is released! (community fork of tui-rs)
Asynchronous Rust on Cortex-M Microcontrollers
Research
RustSmith: Random Differential Compiler Testing for Rust
Miscellaneous
[video] How Functions Function
[video] Rust's iterators are more interesting than they look
[audio] Bootstrapping Rust with Albert Larsan
[release] A Decade of Rust, and Announcing Ferrocene
Crate of the Week
This week's crate is ratatui, a crate to build rich terminal user interfaces and dashboards.
Thanks to orhun for the (partial self-)suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Hyperswitch - Replacing the occurrences of gen_range with a safe alternative
Hyperswitch - Include Currency Conversion utility functions to Currency Trait implementation
Hyperswitch - Change Currency Enum to text string
Ockam - Tauri based Ockam App: Stop app from appearing in the macOS dock 1
Ockam - Tauri based Ockam App: Verify if a user is properly enrolled when starting the app 1
Ockam - Clap based Ockam Command: Irregular spacing in output when calling ockam node list 1
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
391 pull requests were merged in the last week
dynamically size sigaltstk in rustc
add #[rustc_confusables] attribute to allow targeted "no method" error suggestions on standard library types
add machine-applicable suggestion for unused_qualifications lint
add support for inherent projections in new solver
allow escaping bound vars during normalize_erasing_regions in new solver
avoid building proof trees in select
check entry type as part of item type checking
don't call predicate_must_hold-esque functions during fulfillment in intercrate
don't fail early if try_run returns an error
don't suggest impl Trait in path position
enable potential_query_instability lint in rustc_hir_typeck
enable coinduction support for Safe Transmute
generate safe stable code for derives on empty enums
implement "items do not inherit unsafety" note for THIR unsafeck
implement selection for Unsize for better coercion behavior
lint against misplaced where-clauses on associated types in traits
normalize lazy type aliases when probing for ADTs
structurally resolve in pattern matching when peeling refs in new solver
trait system refactor ping: also apply to nested modules of solve
uplift clippy::fn_null_check lint
while let suggestion will work for closure body
implement a few more rvalue translation to SMIR
add Adt to SMIR
add more ty conversions to SMIR
enable MIR reference propagation by default
miri: fail when calling a function that requires an unavailable target feature
miri: protect Move() function arguments during the call
miri: work around custom_mir span
rustc_target: Add alignment to indirectly-passed by-value types, correcting the alignment of byval on x86 in the process
add a cache for maybe_lint_level_root_bounded
rewrite UnDerefer, again
add support for allocators in Rc & Arc
std::io: add back BorrowedBuf::filled_mut
eliminate ZST allocations in Box and Vec
regex: improve literal extraction from certain repetitions
codegen_gcc: add support for pure function attribute
codegen_gcc: add support for returns_twice function attribute
cargo: Always generate valid package names
cargo: Error on intentionally unsupported commands
rustdoc: add jump to doc to sourceview
clippy: arithmetic_side_effect: allow different types on the right hand side for Wrapping<T>
clippy: panic_in_result_fn remove todo!, unimplemented!, unreachable!
clippy: semicolon_if_nothing_returned: add an autofix
clippy: tuple_array_conversions: move from complexity to nursery
clippy: unnecessary_literal_unwrap: also lint unwrap_(err_)unchecked
clippy: don't lint needless_return in fns across a macro boundary
clippy: new lint: format_collect
rust-analyzer: add write_bytes and ctlz intrinsics
rust-analyzer: enable cfg miri in analysis
rust-analyzer: fix eager token mapping panics
rust-analyzer: fix rust-analzyer ssr help message
rust-analyzer: give real discriminant_type to chalk
rust-analyzer: handle TyAlias in projected_ty
rust-analyzer: make fields of mir::Terminator public
rust-analyzer: normalize type alias in projected_ty
rust-analyzer: revert "Handle TyAlias in projected_ty"
Rust Compiler Performance Triage
A lot of spurious results in the regressions this week. However, we did see some real gains with PR #113609, with nearly 40 real-world benchmarks improving their check-build performance by >=1%.
Triage done by @pnkfelix. Revision range: 1d4f5aff..6b9236ed
5 Regressions, 5 Improvements, 5 Mixed; 2 of them in rollups 57 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Infer type in irrefutable slice patterns with fixed length as array
[disposition: merge] discard default auto trait impls if explicit ones exist (rebase of #85048)
[disposition: merge] Support interpolated block for try and async
[disposition: close] Uplift clippy::option_env_unwrap lint
[disposition: merge] Add documentation on v0 symbol mangling.
[disposition: merge] Check Cargo.lock in to version control for libraries
New and Updated RFCs
[new] Unsafe fields
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-07-19 - 2023-08-16 🦀
Virtual
2023-07-19 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-07-20 | Virtual (Tehran, IR) | Iran Rust Meetup
Iran Rust Meetup #12 - Ownership and Memory management
2023-07-24 | Virtual (Toronto, CA) | Programming Languages Virtual Meetup
Crafting Interpreters Chapter 18: Types of Values
2023-07-25 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2023-07-25 | Virtual (Dublin, IE) | Rust Dublin
Ruff. An extremely fast Python linter, written in Rust
2023-07-26 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
The unreasonable power of combinator APIs
2023-07-27 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-07-28 | Virtual (Tunis, TN) | Rust Meetup Tunisia
Rust Meetup Tunisia - Volume I, Number IV
2023-08-01 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn
2023-08-01 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-08-08 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-08-15 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn
2023-08-16 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
Asia
2023-07-27 | Seoul, KR | Rust Programming Meetup Seoul
Seoul Rust Meetup
Europe
2023-07-21 | Nuremberg, DE | Rust Nuremberg
Rust Nuremberg Get Together #2
North America
2023-07-27 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2023-08-10 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2023-08-15 | Seattle, WA, US | Seattle Rust User Group Meetup
Seattle Rust User Group - August Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
(...) complexity in programming is just like energy in physics: it cannot be created, nor destroyed, but only transformed. So, if a programming language is simple and can only express very simple concepts, the complexity is going to move from the language constructs to your source code and vice versa. One needs to find a balance here, it's a personal choice based on mindset and experience.
– u/inamestuff on r/rust
Thanks to Arthur Rodrigues for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
Apache Kafka: Energy and Utilities
Apache Kafka: Energy and Utilities
The public sector includes many different areas. Some groups leverage cutting-edge technology, like military leverage. Others like the public administration are years or even decades behind. This blog series explores how the public sector leverages data in motion powered by Apache Kafka to add value for innovative new applications and modernize legacy IT infrastructures. This is part 4: Use cases…

View On WordPress
#cybersecurity#Energy#industrial iot#internet of things#kafka#ransomware#Security#smart grid#Tesla#Utilities
1 note
·
View note
Text
Apache Spark Training and its Benefits in 2020
What is Apache Spark?
Apache Spark is today one of the most influential and important technologies in the world of Big Data. It is an open cluster computing system, ultra-fast, unified analysis engine for Big Data and Machine Learning.

Since its launch, Apache Spark has been quickly adopted by companies in a wide range of industries. It has quickly become the largest open source community in big data, with more than 1,000 collaborators from more than 250 technology organizations, making programming more accessible to data scientists. Prwatech is the leading Training institute for apache spark online training Offers apache sparks online courses with our Qualified Industry Certified Experts.
APACHE SPARK BENEFITS
Speed
Spark can be 100 times faster than Hadoop for large-scale data processing by exploiting in-memory computing and other optimizations. It is also fast when data is stored on disk, and currently holds the world record for large-scale disk classification.
Easy to use
Spark has easy-to-use APIs to operate on large data sets. This includes a collection of over 100 operators to transform data and familiar data frame APIs to manipulate semi-structured data. APIs such as Java, Scala, Phyton and R. It is also known for its ease of use when creating algorithms that acquire all the knowledge of very complex data.
A unified engine
Spark comes packaged with top-level libraries, including support for SQL queries, data transmission, machine learning, and graphics processing. These standard libraries increase developer productivity and can be seamlessly combined to create complex workflows.
Apache Spark consists of:
Spark SQL : Structured and semi-structured data processing module. With this you can transform and carry out operations on RDDs or dataframes. Special for data processing.
Spark Core : Core of the framework. It is the base of libraries where the rest of the modules are supported.
Spark MLLib : It is a very complete library that contains numerous Machine Learning algorithms, both clustering, classification, regression, etc. It allows us, in a friendly way, to be able to use Machine Learning algorithms.
Spark Streaming : It is the one that allows the ingestion of data in real time. If we have a source, for example Kafka or Twitter, with this module we can ingest the data from that source and dump it to a destination. Between data intake and its subsequent dumping, we can have a series of transformations.
4 notes
·
View notes
Text
Step-by-Step Guide to AIOps Platform Development for Enterprises
As IT infrastructures become more complex, enterprises are increasingly turning to AIOps (Artificial Intelligence for IT Operations) platforms to streamline operations, enhance efficiency, and proactively manage incidents. A well-developed AIOps platform can automate troubleshooting, reduce downtime, and optimize IT performance using AI and machine learning.

In this blog, we’ll take you through a step-by-step guide to AIOps platform development for enterprises, covering everything from planning and data integration to model deployment and continuous optimization.
Step 1: Define Business Goals and Requirements
Before starting AIOps platform development, enterprises must clearly define objectives and align them with business needs. Key considerations include:
What IT challenges need to be solved? (e.g., downtime reduction, anomaly detection, performance optimization)
What metrics will define success? (e.g., Mean Time to Resolution (MTTR), system uptime, cost savings)
What existing IT tools and processes need integration?
A collaborative approach involving IT teams, data scientists, and business stakeholders ensures alignment between AIOps capabilities and enterprise goals.
Step 2: Choose the Right AIOps Architecture
The AIOps platform should be designed with scalability, flexibility, and real-time processing in mind. A typical AIOps architecture consists of:
1. Data Collection Layer
Collects data from logs, metrics, traces, and event streams
Integrates with IT monitoring tools (e.g., Splunk, Datadog, Prometheus)
2. Data Processing & Normalization
Cleans and structures raw data to prepare it for analysis
Eliminates redundant, outdated, and irrelevant data
3. AI & Machine Learning Models
Uses anomaly detection, predictive analytics, and event correlation algorithms
Applies natural language processing (NLP) for automated log analysis
4. Automation & Remediation Layer
Implements self-healing capabilities through automation scripts
Provides recommendations or auto-remediation for IT incidents
5. Visualization & Reporting
Dashboards and reports for monitoring insights
Custom alerts for proactive issue resolution
By selecting the right cloud-based, on-premises, or hybrid architecture, enterprises ensure scalability and flexibility.
Step 3: Data Integration & Collection
AIOps thrives on real-time, high-quality data from multiple sources. The platform should ingest data from:
IT infrastructure monitoring tools (Nagios, Zabbix)
Application performance monitoring (APM) tools (New Relic, AppDynamics)
Network monitoring tools (SolarWinds, Cisco DNA)
Cloud services (AWS CloudWatch, Azure Monitor)
💡 Best Practice: Use streaming data pipelines (Kafka, Apache Flink) for real-time event processing.
Step 4: Implement AI/ML Models for Analysis
The core of an AIOps platform is its AI-driven analysis. Enterprises should develop and deploy models for:
1. Anomaly Detection
Identifies abnormal patterns in system behavior using unsupervised learning
Helps detect issues before they escalate
2. Event Correlation & Noise Reduction
Uses graph-based analysis to correlate alerts from different sources
Filters out noise and reduces alert fatigue
3. Predictive Analytics
Forecasts potential failures using time-series forecasting models
Helps IT teams take preventive action
4. Incident Root Cause Analysis (RCA)
Uses AI-based pattern recognition to identify root causes
Reduces mean time to detect (MTTD) and mean time to resolve (MTTR)
💡 Best Practice: Continuously train and refine models using historical and real-time data for higher accuracy.
Step 5: Implement Automation & Self-Healing Capabilities
The true power of AIOps comes from its ability to automate responses and remediation. Enterprises should:
Automate routine IT tasks like server restarts, patch updates, and log cleanup
Use AI-driven playbooks for common incident resolution
Implement closed-loop automation where AI detects issues and applies fixes automatically
💡 Example: If an AIOps system detects high memory usage on a server, it can automatically restart specific processes without human intervention.
Step 6: Develop Dashboards & Alerts for Monitoring
To provide IT teams with real-time insights, enterprises must develop intuitive dashboards and alerting systems:
Use Grafana, Kibana, or Power BI for visualization
Set up dynamic alert thresholds using AI to prevent false positives
Enable multi-channel notifications (Slack, Teams, email, SMS)
💡 Best Practice: Implement explainable AI (XAI) to provide transparent insights into why alerts are triggered.
Step 7: Test, Deploy, and Optimize
After development, the AIOps platform should be rigorously tested for:
Scalability: Can it handle large data volumes?
Accuracy: Are AI models correctly identifying anomalies?
Latency: Is the system responding in real-time?
After successful testing, deploy the platform in stages (pilot → phased rollout → full deployment) to minimize risks.
💡 Best Practice: Implement a feedback loop where IT teams validate AI recommendations and continuously improve models.
Step 8: Continuous Learning and Improvement
AIOps is not a one-time setup—it requires continuous monitoring and optimization:
Retrain AI models regularly with new datasets
Refine automation workflows based on performance feedback
Incorporate user feedback to improve accuracy and usability
💡 Best Practice: Schedule quarterly AIOps audits to ensure efficiency and alignment with business goals.
Conclusion
Developing an AIOps platform for enterprises requires a structured, step-by-step approach—from goal setting and data integration to AI model deployment and automation. When implemented correctly, AIOps can enhance IT efficiency, reduce downtime, and enable proactive incident management.
0 notes
Text
Apache Kafka Series – Learn Apache Kafka for Beginners v2
START HERE: Learn Apache Kafka 2.0 Ecosystem, Core Concepts, Real World Java Producers/Consumers & Big Data Architecture
What you’ll learn
Understand Apache Kafka Ecosystem, Architecture, Core Concepts and Operations
Master Concepts such as Topics, Partitions, Brokers, Producers, Consumers
Start a personal Kafka development environment
Learn major CLIs: kafka-topics, kafka-console-producer,…
View On WordPress
#Apache Kafka 2.0 Ecosystem#Apache Kafka Series#Big Data Architecture#Core Concepts#Learn Apache Kafka#Real World Java Producers/Consumers
0 notes
Photo

Apache Kafka Series - Learn Apache Kafka for Beginners v2 ☞ http://bit.ly/33pKWkg #bigdata #hadoop
2 notes
·
View notes