#Consultas SQL Automáticas
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Paradigmas de Base de Datos
Debido a una asignatura de la carrera, Bases de datos avanzadas, he tenido que investigar sobre bases de datos temporales. Pero, en verdad, existen muchos tipos de paradigmas y/o tendencias en las BD, muchas de ellas en verdad interrelacionadas entre sí. Voy a intentar hacer un resumen de todas ellas o, al menos, de las que considero más relevantes.
Relacionales, es la base de todo. El modelo más estudiado, comercializado y utilizado. No por ello el mejor, sino que ciertos aspectos (estar en el momento justo, en el lugar indicado) han hecho que así llegue a ser. En definitiva, actualmente hablar de BD es hablar de BD relacionales. Pero todo está cambiando, sino no escribiría este post realmente.

Orientadas a objeto, si todas nuestras aplicaciones son con objetos, es tontería querer mantener el modelo relacional por debajo. Existen diferentes ORM que permiten solventar ese inmenso puente entre un modelo de objetos y el modelo relacional. Hay ciertas cosas bastante llamativas en una BDOO, como que no es necesario tener claves primarias, o las claves ajenas en verdad ahora son referencias. Se podría hablar mucho sobre este tema, pero resumiendo una BDOO son simplemente nuestros objetos hechos persistentes.
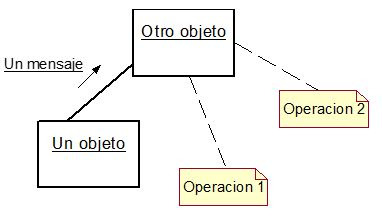
Activas, una SGBD activo es aquel, que bajo ciertas condiciones, y de manera automática ejecuta acciones anteriormente especificadas, todo ello sin intervención del usuario. Es decir una especie de BD + super-triggers (BD relacional con triggers no es una BD activa). Se puede subdividir en dos modelos que lo constituyen:

Deductivas, un SGBD deductivo es aquel que es capaz, a partir de un conjunto de axiomas deductivos y reglas de inferencias que ya posee, deducir hechos. Una especie de BD + lógica (BD + prolog, imagínate sql + prolog, dios que miedo!). Un esquema global podría ser que recibida una consulta concreta, el SGBD deductivo según unas determinadas reglas de inferencia consulta sus datos para obtener una respuesta. Este modelo está muy ligado a las BD Activas, y tienden a converger. Tanto las BD Activas y como las Deductivas podrían englobarse en el área de representación del conocimiento, quizá por ello tiendan a converger.

Temporales, ¡no existen los datos!, adiós datos; bienvenidos los datos temporales (dato + tiempo). Cada dato tendrá información de tiempo válido (cuando ese dato es, o ha sido, válido en el MundoReal) y de tiempo transaccional (cuando ese dato ha estado en la BD). Es decir, ahora no se guarda información, bueno si, pero se guarda junto con su evolución en el tiempo.
Difusas, casi toda la información que manejamos acerca del MundoReal es incompleta, imprecisa y vaga. Las BD Difusas se basan en la lógica difusa que a su vez se basa en álgebra de conjuntos difusa, que viene a ser mayormente que dado un conjunto de elementos se le da un valor a cada elemento, entre 0 y 1, que indica el grado de pertenencia que tiene dicho elemento en ese conjunto. Este modelo se una ampliación de las BD relaciones, y amplía los operadores del álgebra relacional para poder adaptarlos a los nuevos elementos que se definen. Emocionante.

Multimedia, actualmente estamos desbordados por audio, video, imagenes, texto, en definitiva documentos multimedia. Éstos por poder se pueden guardar en campos “Blobs” (binary large objets), pero ya que hacemos modelos de BD para todo lo que se nos ocurre, pues que mejor que una BD Multimedia?. El principal inconveniente está en que una BD tradicional carece de una interfaz de usuario para poder tratar con estos datos multimedia, sin mencionar el problema de la inclusión de metadatos (que se podría solventar, si. Pero serían todo soluciones muy “ad-hoc”, eso de ingieneril tiene poco). Las BD Multimedia proponen tres niveles: Un nivel monomedia que trataría con un solo tipo de datos (p.ej. audio), un nivel central que hablaría con todos los niveles inferiores y desde el cual se gestionarían las preguntas y se guardarían los metadatos de todos los elementos de la BD; y un último nivel con una interfaz de usuario para poder manejar cada formato multimedia. Todo esto quizá es muy ambicioso, hay BD actualmente usándose como las BD Documentales que serían un subconjunto de las Multimedia.

Modelo del conocimiento: especifica las reglas del sistema, en resumen serían tuplas (Evento, Condición, Acción).
Modelo de ejecución: se encarga de realizar un seguimiento de la situación y de gestionar el comportamiento. Vamos, el jefe que dice qué hacer y cómo.
0 notes
Text
Administrador de Base de Datos Salario Competitivo
New Post has been published on https://www.tuempleord.do/2020/11/10/administrador-de-base-de-datos-salario-competitivo/
Administrador de Base de Datos Salario Competitivo

Administrador para realizar el modelado y diseño de base de datos requeridas por la organización para el desempeño óptimo de los sistemas informáticos. Auditar los sistemas de base de datos validando el cumplimiento de normas y estándares comúnmente aceptados en la gestión de base de datos. Implementar y mantener la política de acceso a base de datos y uso adecuado de objetos. Proponer mejoras a los sistemas según nuevas tecnologías y tendencias en el mercado. Programar en lenguaje SQL consultas, funciones y procedimientos almacenados, así como también trabajos para la ejecución automática de paquetes de integración de datos. Asistir en tareas afines y complementarias a requerimiento del supervisor. Cumplir con los objetivos, normas y procedimientos de calidad, seguridad, salud y ambiente establecidos para el departamento.
Salario Competitivo
Interesados enviar si CV actualizado a [email protected] con el nombre de la vacante en el asunto
0 notes
Text
Data Factory ¿Que es? ¿Que NO es?
Hola a todos! En esta oportunidad quiero hablarles de mi servicio favorito (y probablemente de muchos otros Ingenieros de Datos) en Azure, que es Azure Data Factory. A modo de introducción, para hacer algo distinto se me ocurrió escribir sobre que es y que NO es Data Factory, ya que el servicio muchas veces es evaluado
Es un servicio que casi todo proyecto relacionado con analítica en Azure debería utilizar, salvando algunas muy raras excepciones. Provee muchísimas ventajas y simplifica un montón de aspectos clave para estos proyectos, como calendarización, orquestación, modularidad para procesos, entre otros. Pero también tiene (como todo servicio) sus limitaciones, que si bien son salvables de uno u otro modo, pueden llegar a dejar una mala impresión cuando recién nos iniciamos con la tecnología. El objetivo de este post es aclarar que ES Data Factory y que NO es, o que no hace por defecto (y posiblemente algún work-around para esas limitaciones).
¿Que es?
Empecemos por mencionar que es Data Factory, y porque es una herramienta casi imprescindible:
Pipelines!! Es simple agregar actividades (y dependencias entre ellas) como llevar datos de un storage a otro, buscar datos en bases de datos, condicionales, y todo tipo de estructuras de control.
Interfaz gráfica simple de entender, cualquiera que le dedique 10 minutos a ver la interfaz podrá entender y hacer algún pipeline básico para orquestar algún proceso.
Múltiples opciones de calendarización de pipelines gracias a los Triggers (disparadores), en función a eventos, ventanas de tiempo, según día, hora, numero de día. Por ej: el primer día de cada mes, todos los Miércoles, etc.
Parámetros: igual que en cualquier lenguaje de programación, podemos usar parámetros para alterar el funcionamiento de algunos componentes como Pipelines, Actividades, Datasets, etc. Pueden usarse básicamente en cualquier lugar donde haya un string, para evitar errores lo mejor es encapsular el llamado a parámetros en @{nombreParametro}. Nos permiten recorrer bases de datos enteras con 1 o 2 actividades.
Variables: podemos almacenar valores en variables para utilizarlos después, se asignan con la actividad de asignar variables y se llaman del mismo modo que los parámetros.
Modularidad en diseño: podemos "encapsular" ciertos procesos que vamos a repetir frecuentemente en un pipeline y después llamarlo desde otro pipe, mediante la actividad "Ejecutar pipeline", esto brinda mucha flexibilidad a la herramienta si agregamos el uso de parámetros y variables.
Serverless!! Nunca sabemos (ni nos importa) donde están los servidores que ejecutan los trabajos. Solo darle play al pipeline y Azure se encargara de manejar por nosotros la memoria, ancho de banda, procesador, etc. Hay algunas excepciones, como en el caso del Integration Runtime (que sera instalado en una pc/vm on premise) o los Mapping Dataflow (en los cuales elegimos el tamaño del cluster que sera provisto).
Alertas configurables para enterarnos inmediatamente cuando algo anda mal, con la opción de ser informados mediante Email, SMS, Push (notificación en el celular), o con un mensaje de voz. Esto se logra gracias a la integración con Azure Monitor.
Soporte para utilizar Polybase al mover datos entre un Data Lake o Blob Storage y Synapse, aprovechando la mejora en performance de esta tecnología.
Conexión con muchos servicios!! Mas de 80 conectores, literalmente se conecta a todo lo que este dentro de Azure, pero ademas puede interactuar con varios servicios de otras nubes como AWS (S3, Redshift, etc), recursos que se encuentren en redes on premise (requiere la instalación de un Integration Runtime) e incluso soporta Rest apis o conexiones ODBC, así que si un servicio no esta en el listado pero soporta esas formas de conexión, también sera posible conectarnos.
Múltiples tipos de archivos soportados: Json, Csv, Excel, ORC, Parquet, Avro, Binario (cualquier archivo, no sera interpretado el contenido).
Soporte para trabajar de forma cooperativa gracias a la integración con Git, se pueden usar repositorios en GitHub o Azure DevOps. Como todo su código son definiciones en Json, podemos enviar ese código a un repositorio y trabajarlo con una metodología similar a la de desarrollo convencional. Por ej: creamos nuestro propio branch, desarrollamos una feature, y una vez que esta todo testeado y funcionando, creamos un pull request a master.
Soporte para deploys automáticos, de modo que podemos tener entornos separados y asegurarnos que solo llegan a producción aquellas versiones de código que sabemos que funcionan bien.
Esas features mencionadas son excelentes! Ya podemos ver porque no imagino un proyecto de analítica ejecutado en Azure sin usar Data Factory.
¿Que NO es?
A pesar de todas las bondades del servicio, es notorio que cuando arrancamos a utilizarlo muchas personas esperan mas de el, y creo que es porque por todos lados lo muestran o publicitan como una "herramienta ETL", siendo que no lo es en un 100% (al menos en su versión básica). Por eso, para evitar malos entendidos y tener opciones para evaluar, acá va un listado de las cosas que NO es Data Factory (con sugerencias de solución):
NO es una herramienta de transformación de datos! Su principal objetivo es ser un orquestador, mantener servicios y procesos trabajando, moviendo los datos de un modo coordinado, con todas las ventajas nombradas anteriormente. Recientemente se añadió la posibilidad de hacer algunas transformaciones de datos gracias a sus dataflows (Wrangling y Mapping), pero aun así es una opción con mucho tiempo de startup, bastante costosa y mi recomendación es siempre utilizar algún servicio externo para hacer las transformaciones (puede ser Databricks, T-SQL en una base de datos o en Synapse, para algo sencillo Azure Functions o Automation).
NO maneja de forma automática las cargas incrementales! Esta es una consulta habitual que tengo entre los clientes. No es complicado de hacer, pero tampoco es tan straight-forward como muchos esperan (sobretodo si tienen experiencia previa con alguna herramienta ETL como StreamSets, Pentaho, Talend, NiFi, etc).
Por si solo NO prende o apaga servicios tales como Synapse, o Analysis Services. Para esto sera necesario escribir un pequeño script en PowerShell para ejecutar en Azure Automation o en uno de los múltiples lenguajes que soporta Azure Functions. Por supuesto que Data Factory si tiene capacidades para llamar a esos servicios y ejecutar el encendido o apagado de estos servicios. Cuando nos conectamos a Databricks, si tiene la capacidad de encender un job cluster, ejecutar un código y apagarlo.
Lo mismo sucede con el refresh de modelos en Azure Analysis Services, para estos sera necesario un script en alguno de los servicios mencionados previamente. Otra opción es disparar el refresco mediante la REST api del servicio.
Data Factory NO almacena datos (solo metadatos), de modo que si creamos un dataset para una tabla en una base de datos que tiene 1 millón de registros, ese dataset solo tendrá la forma de acceder a la base de datos (mediante su linked service), el nombre de la tabla, tipo de dato de cada columna, pero bajo ningún escenario contendrá todos los registros en Data Factory.
Entre actividades SOLO podemos intercambiar Metadata! Con la excepción de Lookup activity, que nos devolverá el resultado de una consulta como output de la actividad, que podremos consultar desde otras actividades o asignarlas a variables.
Seguro estoy olvidando algunas limitaciones o beneficios, pero a modo introductorio creo que estos son los puntos principales a tener en cuenta al momento de crearnos expectativas respecto a las capacidades del servicio.
Espero que les haya gustado, seguramente vendrán algunos artículos mas sobre el tema.
#azure#azure data factory#data factory#data engineering#azure argentina#azure cordoba#azure jujuy#azure tips
0 notes