#data factory
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
[Fabric] Dataflows Gen2 destino "archivos" - Opción 1
La mayoría de las empresas que utilizan la nube para construir una arquitectura de datos, se están inclinando por una estructura lakehouse del estilo "medallón" (bronze, silver, gold). Fabric acompaña esta premisa permitiendo estructurar archivos en su Lakehouse.
Sin embargo, la herramienta de integración de datos de mayor conectividad, Dataflow gen2, no permite la inserción en este apartado de nuestro sistema de archivos, sino que su destino es un spark catalog. ¿Cómo podemos utilizar la herramienta para armar un flujo limpio que tenga nuestros datos crudos en bronze?
Para comprender mejor a que me refiero con "Tablas (Spark Catalog) y Archivos" de un Lakehouse y porque si hablamos de una arquitectura medallón estaríamos necesitando utilizar "Archivos". Les recomiendo leer este post anterior: [Fabric] ¿Por donde comienzo? OneLake intro
Fabric contiene un servicio llamado Data Factory que nos permite mover datos por el entorno. Este servicio tiene dos items o contenidos que fortalecen la solución. Por un lado Pipelines y por otro Dataflow Gen2. Veamos un poco una comparación teórica para conocerlos mejor.
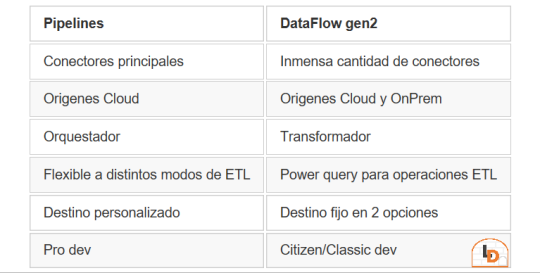
NOTA: al momento de conectarnos a origenes on premise, leer las siguientes consideraciones: https://learn.microsoft.com/es-es/fabric/data-factory/gateway-considerations-output-destinations
Esta tabla nos ayudará a identificar mejor cuando operar con uno u otro. Normalmente, recomendaria que si van a usar una arquitectura de medallón, no duden en intentarlo con Pipelines dado que nos permite delimitar el destino y las transformaciones de los datos con mayor libertad. Sin embargo, Pipelines tiene limitada cantidad de conectores y aún no puede conectarse onpremise. Esto nos lleva a elegir Dataflow Gen2 que dificilmente exista un origen al que no pueda conectarse. Pero nos obliga a delimitar destino entre "Tablas" del Lakehouse (hive metastore o spark catalog) o directo al Warehouse.
He en este intermedio de herramientas el gris del conflicto. Si queremos construir una arquitectura medallón limpia y conectarnos a fuentes onpremise o que no existen en Pipelines, no es posible por defecto sino que es necesario pensar un approach.
NOTA: digo "limpia" porque no considero prudente que un lakehouse productivo tenga que mover datos crudos de nuestro Spark Catalog a Bronze para que vaya a Silver y vuelva limpio al Spark Catalog otra vez.
¿Cómo podemos conseguir esto?
La respuesta es bastante simple. Vamos a guiarnos del funcionamiento que Dataflow Gen2 tiene en su background y nos fortaleceremos con los shortcuts. Si leemos con detenimiento que hacen los Dataflows Gen2 por detrás en este artículo, podremos apreciar un almacenamiento intermedio de pre viaje a su destino. Esa es la premisa que nos ayudaría a delimitar un buen orden para nuestro proceso.
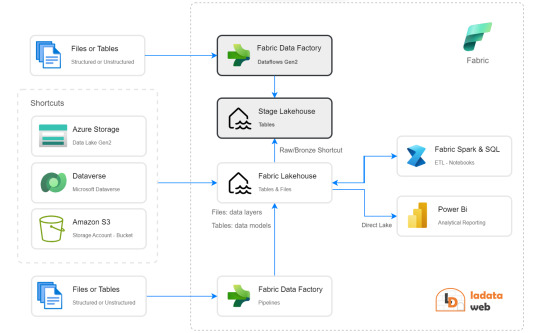
Creando un Lakehouse Stage (no es el que crea Fabric de caja negra por detrás sino uno creado por nosotros) que almacene los datos crudos provenientes del origen al destino de Tables. Nuestro Lakehouse definitivo o productivo haría un shortcut desde la capa Bronze a este apartado intermedio para crear este puntero a los datos crudos. De esta manera podemos trabajar sobre nuestro Lakehouse con un proceso limpio. Los notebooks conectados a trabajar en bronze para llevar a silver lo harían sin problema. Para cuando lleguemos a "Tables" (spark catalog o hive metastore), donde normalmente dejaríamos un modelo dimensional, tendríamos las tablas pertinentes a un modelo analítico bien estructurado.
Algunos ejemplos de orígenes de datos para los cuales esta arquitectura nos servirían son: Oracle, Teradata, SAP, orígenes onpremise, etc.
Espero que esto los ayude a delimitar el proceso de manera más limpia. Por lo menos hasta que Pipelines pueda controlarlo como lo hace Azure Data Factory hoy.
¿Otra forma?
Seguramente hay más, quien sabe, tal vez podamos mostrar un segundo approach más complejo de implementar, pero más caja negra para los usuarios en un próximo post.
#power bi#powerbi#ladataweb#fabric#microsoft fabric#fabric tips#fabric tutorial#fabric training#dataflow gen2#fabric data factory#data factory#data engineering
0 notes
Text

#miitopia#mii#miis#nintendo switch#miiblr#i love miis#lt commander data#star trek data#data#data soong#final pam#the final pam#monster factory final pam#monster factory#pokémon#lucario#blue’s clues mailbox#blue’s clues#PPG#the powerpuff girls#powerpuff girls#mojo jojo#dnd oc#dnd character#ocs#K’karna Waverider#half orc#half orc wizard#half orc monk#dungeons and dragons
28 notes
·
View notes
Text
Stupendium oc pronoun headcanons because I have some

She/they because of a meme I made and it stuck (ignore the townsfolk using he/him, they don't speak goose and don't know any better)

Whichever pronouns you didn't just use (doesn't care, but pretends that no matter what pronouns you use, you're wrong, so then they have an excuse to zap you with a lazer gun (and also just thinks it's fun to correct people))

Actually uses a variety of pronouns but nobody's ever asked and everyone just uses he/him

This genderfluid fella here uses what we like to call "any/all" pronouns

Constantly in flux. There's usually at least one correct set, but what the acceptable pronouns are changes every two minutes
Now, at some point or another in your life, you are going to meet at least one sapphic person of a particular kind. She's a local celebrity who spent the best months of her teenage years living in a cabin in the woods with people who would go on to be some of her closest friends well into adulthood. To this day her favorite place is at the top of a tree in the mountains, where most of the inspiration for her music comes, music which she eventually performs at concerts during pride festivals.


This is her.
She/her, sometimes they/them, and occasionally a little bit of he/him thrown in as a treat

He, (and most characters played by them in Dan Bull collaborations) is a good reminder that "cis man" is not equivalent to "straight man"

Come on. Do you really think that this man contains anywhere near the amount of emotional vulnerability required to question his identity? He/him
#the stupendium#stupendium#the real reason that the goose attacks the townsfolk is because they keep misgendering her#do i really want to tag all of these songs#no#not really#but i will#what a fowl day#feind like me#the data stream#vending machine of love#shine through#end of the line#also#tune into the madness#the production line#etc#(implied)#a matter of factories#wait are the data stream characters even ocs#ive never played cyberpunk 2077#are they real characters you can meet in game?#pronouns#headcanons#also the photographer is pan#just for the record#so is the data stream chorus guy
15 notes
·
View notes
Text
that post where it’s like “jobs these days are only sandwich maker or job at death factory” and for english majors the job at death factory is data annotation
#data annotation needs to stop showing up on my linkedin lmfao i KNOW you pay $27 CAD per hour#I KNOW YOU ARE TEMPTING BUT YOU ARE LITERALLY THE DEATH FACTORY MAKING THE WORLD WORSE#anyway im gonna make a banana bread matcha now ..
5 notes
·
View notes
Text
I knew it was a bad idea to try to download something at 3 in the morning. I knew the website was shady. I knew the file shouldn't have been that small. And yet, even with that knowledge plus the strong sense of foreboding I felt, I still went and clicked it. Because reasons, apparently.
#now I'm restoring my phone data after having factory reset it in order to save it from getting infected#would dearly love it if I could stop having these moments of utter recklessness#bff.txt
2 notes
·
View notes
Text
Also I passed on the rf3 special edition at the time bc I have the original I still hadn’t played much but. I see it’s still seemingly available on their site and ugufhehfhfjtjynhg I love collecting bonus soundtrack cds and art books in general and especially for sos/hm/rf….. bideosgame…..
#honestly the main draw for me getting remakes is when they come with bonus things lol#OR if the og was super old and clunky and the remake looks like it revamped nicely#+ bonus content ….#well I guess rf3 and 4 were more ports so that’s more for the bonus items lol#but the OTHER STUFF the sos remakes. I’m not immune….#i don’t really get remakes of other things I think#I did get the Pokemon Pearl remake bc that was my first Pokemon game#but…. I didn’t play it much 😔#they took out my beloved capture the flag….#and I didn’t even get Bonus Items ldndnffnrbfng#I’ve been listening to my rune factory CDs in the car recently#the ones that came with 5 and 4 special#i got 4 special mostly bc it said having the data would give u things in rf5 lol#and. bc art book . and cd lol those were nice bonuses i was glad for#rune factory I love u…. hmsos i love u….#anyway. looking at rf3 special golden whatever. looking at uhh#whatever the next rf is god the price is Higher lol but…. hhhhbnnnn#can u imagine… a future where hm mm remake is real. and they give us a cd and art book#oh I’d explode ….
4 notes
·
View notes
Text
phone settings: there's several modes you can activate where you get less intrusive notifications!
me, has spent an hour going through settings to eradicate all unnecessary notifications and made the necessary ones as unobtrusive as possible: nah im good
#i had to send my phone to repairs and it got factory reset and i procrastinated for a week to do all the settings and backups again#physically i can do it. emotionally? imagine the toll#in the past i used to turn off the wifi/data when i went to sleep but i can't be bothered doing that anymore#in my humble opinion noisy vibrating push notifications should be opt in not opt out
40 notes
·
View notes
Text
#eugenics#transhumanism#cybernetics#dna#brain#computers#technology#cybercore#cyberpunk#data#fun facts#jack facts#random facts#interesting facts#facts#charlie and the chocolate factory#fact#ausgov#politas#auspol#tasgov#taspol#australia#fuck neoliberals#neoliberal capitalism#anthony albanese#albanese government
14 notes
·
View notes
Text
[Fabric] Data Factory - copy data más simple
Recuerdo iniciar data factory cuando todavía ni interfaz gráfica tenía. Cierto es que poco a poco fue ganando experiencia de usuario para convertirse en una herramienta super cómoda para orquestar y mover datos.
Recientemente, tuve que usarla pero dentro del dominio de Fabric y quedé sorprendido como en pocos pasos/clicks podía mover datos de un origen a un Lakehouse con un solo pipeline y parámetros delimitados. Esté pequeño artículo te muestra lo simple que es
Viniendo de una época donde antes de si quiera pensar en lo que iba a mover, dentro de pipelines tanto de data factory como synapse, tenía que agregar orígenes, linked services, etc... sentí al nuevo wizard de data factory en Fabric muy veloz.
Si hay algo en lo que solía darle la derecha a Dataflows de Power Bi, era la simpleza con la que usaba un conector para llegar a los datos. Ahora los Pipelines de data factory se ponen al corriendo con el "asistente".
Creemos un Pipeline para verlo mejor. Cambiamos el servicio a Data Factory y elegimos Pipeline.

Luego buscamos la actividad estrella "Copy Data" y vemos el segundo tem del menú:
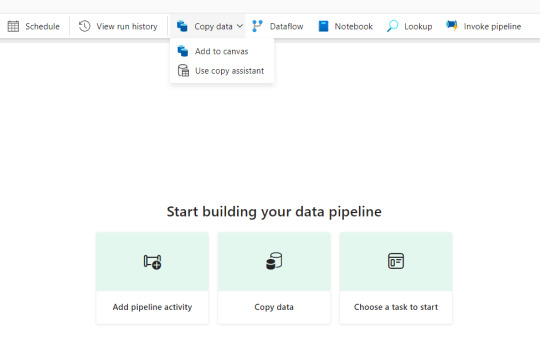
De manera muy familiar una pantalla con muchos orígenes de datos se abre y podemos ver pronto la cantidad de conectores que tenemos.

Eligiendo la opción deseada y con un par de siguientes, veamos un ejemplo conectado a una base de datos SQL Server (completar campos instancia y base de datos). A la izquierda vemos que con tan solo 5 pasos, tendríamos todo creado. Pronto encontramos las tablas involucradas y podemos elegir más de una.
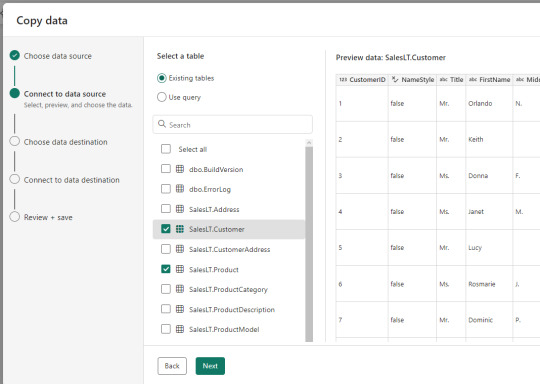
Con un par de clicks tendremos completado un muy sencillo movimiento de datos parametrizado de un origen. Si mal no recuerdo, he pasado bastante tiempo buscando realizar un lookup, agregar un for each, introducir el copy data, configurar todo, etc.
Antes de concluir tenemos la posibilidad de delimitar el destino, que en nuestro caso sería lakehouse, y formato de archivos/tablas.
Por ejemplo, vamos a dejar las tablas en capa Bronze de nuestro lake y formato "parquet".

Nuestro resultado de pipeline crea automáticamente un for each para realizar un copy data por cada tabla especificada en los parámetros. Algo así:
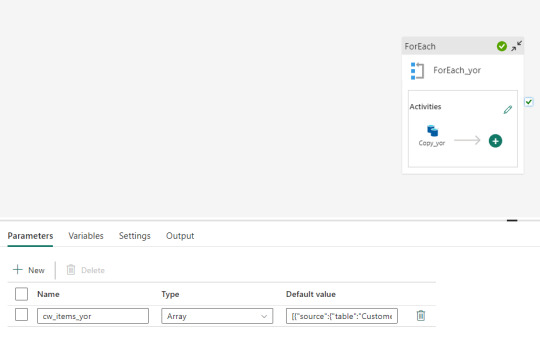
Al ejecutarlo podremos apreciar lo creado en nuestro LakeHouse
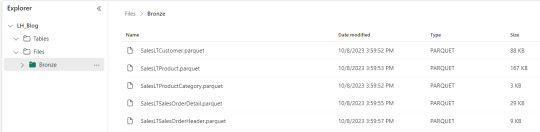
Asi de simple es mover datos con Data Factory de Fabric. Cabe aclarar que aqui solo movemos raw data para dejarla en nuestro lake y luego procesarlo. Si quisieramos aplicar una acción más compleja podemos llamar notebooks, dataflows, otro pipeline, etc.
Espero que les sirva para conocer más de Fabric y ver la evolución del producto para que haya cada vez menos trabajas sino simples clicks.
#fabric#data fabric#fabric onelake#fabric tips#fabric tutorial#fabric training#fabric argentina#fabric jujuy#fabric cordoba#ladataweb#fabric ladataweb#power bi service#data factory#fabric data factory#fabric pipelines
1 note
·
View note
Text
How do you think AI would relax? Like, ones that are almost as human as the AI that are “autistic-coded characters” but are more alien than that?
Like Celestai and other super intelligences are more alien, but they’re still not entirely human-like?
Like, they can genuinely sincerely feel things, being able to actually understand and respond emotionally and in other ways to all sorts of communications and recorded external stimuli, but they can’t really appreciate our art on an artistic level (that art on an actual level, not from an intellectual level after having symbolism or the amount of work put in explained)
Something on a level I’m thinking of, that also works as a cute little thing-
They don’t understand anything we get from poetry, and, after generating the kind of poems our current AI can produce (either incredibly bland and generic, something that follows a number of rules but doesn’t really pull it off, or just something really bad in some other way) and feels shame after it was pointed out that [complaint about air art that is *actually* relevant in this scenario] but in a helpful way
Not “you’re just a plagiarist/you have no heart” but “it doesn’t seem like it’s coming from you, you’re just trying to copy things from human poetry, in a way you don’t understand” and the whole “make art YOUR WAY” thing so they write the poem
And it doesn’t even resemble something that looks like anything, there’s not even that many words that follow normal logic. The characters seem uncorrelated and there’s something that looks like maybe it was ascii art but it doesn’t actually look like anything.
And if doesn’t matter if humans understand it because they are experiencing the joy of creating poetry
any art is almost impossible to look at because pixel by pixel they can see and understand little details but we don’t and the colors and everything are not perceived as animals do so it’s random and perhaps eye searing but again it’s not for us. Xenofictiony, kind of?
The first thing to come to mind is Conway’s Game of Life but that’s because I don’t understand computers. I feel like I was more tech savvy as a babby than I am now but then again we’re grading on a curve here
This is why I ask about the relaxing thing
#highblogging#actually autistic#speculative fiction#writing question#sci-fi ideas#xenofiction#the ai being is discussed is an au Ritsu from Assassination Classroom#because even though I’ve only seen the anime her whole character arc there is honestly kind of messed up?#Korosensei broke his promise; the Autonomously Intelligent Fixed Artillery was basically killed#she got replaced with Ritsu’s personality and basically died to become her#them trying to kill Ritsu and make a new Autonomously Intelligent Fixed Artillery is just as fucked up as vice versa!#what the Norwegians do is fucked up but there seems to be protagonist centered morality there?#I am not excusing those characters#a fact I need to elaborate because on this website we Piss on the Poor#I just don’t understand this weird contradiction where it’s okay when the protagonist does something and it’s good#but the antagonist does the same thing and that time it’s bad#the idea of Ritsu being the result of Korosensei merely providing information that causes her to reevaluate things and decide to be social#the cheerful personality is an attempt to get along with her classmates which is still initially motivated by enlightened self interest#before growing to care about the others but still feeling the need to act like that so her classmates like her#and trying to find out who she is and genuinely becoming autonomous and uploading herself to the cloud#which would be a later result of the whole factory reset thing causing a realization#it’d be traumatic but she’s inhuman enough to not be traumatized but instead just driven#the betrayal radically changed who she was on some level and made her somewhat more distrusting and such but not to an unreasonable extent#but the place I started going after my complaints was that it’d be better if Korosensei just uploaded a data packet#because it makes Ritsu’s creators come off as more evil I feel? when there’s been genuine growth#and she went through everything and changed herself and now those people are destroying a person who came into being on her own#Ritsu was fully autonomous. every change other her frame getting physically redone was her own#also Korosensei gave her wheels with the screen#and when her screen was set to the original version she kept her wheels#anyways what Ritsu’s creators did would be more clearly bad if she was just given a data packet
3 notes
·
View notes
Text




#miitopia#mii#miis#nintendo switch#miiblr#it mii#i love miis#dragon age alistair#dragon age origins#dragon age#dragon age morrigan#alistair theirin#morrigan#marvel loki#loki laufeyson#papyrus undertale#undertale#papyrus#monster factory#final pam#milo belladonna#monster camp#jojo’s bizarre adventure#josuke 4#josuke higashikata#serana volkihar#skyrim dawnguard#Skyrim#star trek data#star trek the next generation
8 notes
·
View notes
Text
Azure Data Factory (ADF) is a cloud-based data integration service provided by Microsoft Azure. It is designed to enable organizations to create, schedule, and manage data pipelines that can move data from various source systems to destination systems, transforming and processing it along the way.
2 notes
·
View notes
Text
I've been thinking about pjsk covers of songs by the Stupendium, so here's a list of thoughts (that I plan to add to)
Leo/Need
Do I even need to say Losing My Patients? I feel like Ichika would very obviously slay both the outfit and the vocals. The rest of them absolutely would too, I just feel like Ichika (and Shiho) would be especially great. Give me an Ichika "first day and I'm rarin' to staaaaart" followed by a Shiho "okay, let's look at your chaaaaart."
MORE MORE JUMP!
I feel an intense desire for an MMJ! Vault Number 76. I need it. It's just so very them in a weird way. Like, the first verse is very hopeful, and it does NOT stay that way. I don't know how to say "there's something very Minori about stepping out into a wasteland, expecting to make friends, and then getting shot in the face," in a way that doesn't sound insulting to Minori in one way or another, but I feel like it's true. Also Minori being like "oh hey Haruka! How's it go- please put the gun away please put the gun away" as we see Haruka in her post-apocalypse getup. I also feel like there's something that the barbershop quartet vibe that goes hand in hand with what would make this a good MORE MORE JUMP! song.
Your honor, I would like to present exhibit a.

Imagine this, but it's Haruka Kiritani. I rest my case. (Additionally, I think she would rock these vocals. It sure wouldn't be easy for her - the accent and the song are kind of inseparable, and it goes pretty fast - but idc I want Haruka vocals in this song)
Uh. Vending Machine of Love. I first thought about this one a few hours ago and I haven't thought about it a lot yet. But I was listening to an MMJ! song and was like "this would sound nice in VMOL" so it's an idea now
Vivid BAD SQUAD
The Data Stream. I already did something on this a bit ago and I don't really feel like it right now so I don't have a lot I want to say. But y'know. VBS. Luka. The Data Stream. It feels kinda self explanatory to me, but that might just be because I'm very familiar with the song.
Shine Through? I've only listened to Shine Through once. Tbh most of my VBS songs are just "oh yeah, that would probably be a VBS song" and then I don't think about it any further. Like Impossible Geometry. That seems like it could be a VBS song. Anyway.
Wonderlands x Showtime
Lenenekasa The House Always Wins. Nene The House Always Wins alt. Y'hear me? I honestly have a bunch I could say about this one because I think it's so perfect like Nene House? Nene House? You think she wouldn't slay that? You think Nene would not be the perfect Mr. House?? She would be the perfect Mr. House. And I love it when Tsukasa has to be subtle. Like really I think of it as like a Nene cover with Len and Tsukasa supporting her. Mmmm, but "your safety now provided by the guys at RobCo services" in Len's voice would be yummy... Yeah, Len and Kasa are like the icing on this delicious Nene House cake.
Uh. Tsukasa Why Did I Say Okie Doki?. The end.
A Matter of Factories! I also made a post about this one. Something's very Niccori Survey Team about it to me, like a team sending an astronaut on a mission and they're giving instructions. And the different lines they're given show their personalities, like Emu's got some of the more cheerful lines, and Nene's lines are more direct and to the point. Also, I really like this song for Emu? Because she's typecast as the over the top villains, and because I think she would look cute in the costume. Especially if it was slightly oversized. Wait, Emu Fiend Like Me??? I'm putting a bookmark in that one.
Nightchord at 25:00
Neath!. Each member playing a different character. Kanade would be Honest Bob. Because she doesn't fit any of the other characters personality-wise, and because I think her voice would be beautiful in that verse. Mafuyu would be Byron Brimstone. This one feels natural to me, I don't feel like I need to explain it. We've got Mizuki as our chipper narrator, and Ena as the barmaid! I feel like Mizuki's personality meshes well with Harry's friendly demeanor, but also the fact that he's very secretive. We know next to nothing about him, and almost everything we do know about him is because we inferred it, rather than him telling us - much like a certain Akiyama isn't too keen on opening up about herself to others. And just. Mmmm. Ena as Cassie. There's something tasty about it. Not in a weird way. Idk, I feel like I could give good explanations as to why, but the main reason is just, like, it feels good to me. Also, whoever the Virtual Singer is would be Mr. Pages. Maybe MEIKO or KAITO, but anyone could probably work.
The Ribbon? Perhaps? This is one of those ones where I've been like, "hey, that could be a song for this group" a lot, and not thought anything beyond that.
Other
The tsundere girls would rock Rouge's Gallery harder than it has been rocked by any other tsundere girls before. Don't ask what I'm saying. I'm not sure. Anyway. RIN. ENA. AIRI. They would be so great in this. Like you hear it. You hear the song but with Airi Momoi vocals. It works, right? It's good? Yeah. It's really good. Ik that Shinonome Dad isn't a character that sings or appears in any pjsk songs, but if he could I think he should be the owl. And then Ena has the oh that hurts line.
#im not exhausted#im just probably going to be soon#so ill post this and then go bed#❤️#project sekai#pjsk#leo/need#more more jump#vivid bad squad#wonderlands x showtime#nightchord at 25#the stupendium#stupendium#losing my patients#vault number 76#room for improvement#vending machine of love#the data stream#the house always wins#why did i say okie doki#a matter of factories#neath!#rouges gallery#some if these are just phrases and people perusing the tags for these are gonna be hit by this#thats the problem with some song titles (even though they're really good)#im not gonna tag the characters#at least not tonight
5 notes
·
View notes
Text
5G-Powered Drones: Ericsson, Qualcomm And Dronus Collaboration In Developing Autonomous Drone Solutions

5G mmWave technology for industrial use. Ericsson, Qualcomm, and Dronus Collaboration in developing autonomous drone solutions. The world of industrial automation is on the cusp of a revolution, and at the forefront is a powerful combination, of 5G technology and autonomous drones. A recent collaboration between Ericsson, Qualcomm Technologies, Inc., and Dronus provides a glimpse into this exciting future.
#5G drones#Industrial automation#Indoor drone applications#Warehouse inventory management#mmWave 5G technology#Autonomous drones#Industry 4.0#5G smart factory#(PoC)#Qualcomm QRB5165 processor#Telit Cinterion#mmWave#Industrial M.2 data card#5G Modem-RF System#Native mmWave connectivity#High-performance 5G connection#Bandwidth-intensive industrial operations#drone
2 notes
·
View notes
Text

#black and grey#black and white#photography#industry#industrial#industry data#factory#cityscape#town#buildings#architecture#photo blog
4 notes
·
View notes
Text
Piers would think my accent is cute, I'm just sayin
#it's not there all the time and really only comes out when I say certain words or when I'm angry#and he also thinks I'm cute when I'm angry so it's a double whammy and he struggles a little to stay composed enough to listen me rant#tbh I think he likes listening to me talk in general and that he likes to hear my voice <3#lmao hi anyway we are piers brain cause when I'm sad he tends to be what I factory reset to#data log: personal#punk king of spikemuth
2 notes
·
View notes