#DNA-encoded compound
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
What does it mean that Homelander is the only supe that has Compound V incorporated into his DNA? And that he can pass it down to progeny?
A short essay no one asked for (but inspired by @saintmathieublanc ‘s poll about whether HL and Ryan can be depowered)
Reading 1: literal
His DNA consists of Compound V. Which means that Compound V is a nucleotide analogue, a proteinaceous component of histones around which DNA wraps and gets packed into a chromosome, or some kind of non-organic chemical that binds to DNA (DNA intercalators). I actually kind of like the idea that Compound V is a part of histones, because you could handwavely imagine it gets incorporated haphazardly and affects the expression of random genes, turning them on or off, hence its varied effects.
Reason 1 none of these seem likely: DNA replicates constantly, not only during embryonic development but throughout your life. Having DNA be modified but not requiring a constant influx of new Compound V means that the DNA would eventually dilute out to become normal.
Reason 2 these aren’t likely: a proteinaceous histone component injected into infants wouldn’t really exert any effects. Wouldn’t even go into cells. A nucleotide analog or a DNA intercalator chemical could go into cells and effectively act as a DNA damaging agent (this is how some chemo works, in fact). Hard to imagine how randomly damaging DNA would result in gaining of abilities, but I guess formally possible if the damage is somehow directed. The randomness of powers gained could potentially be compatible with “random damage”. But what would then be the difference between Homelander and other supes? The Compound V would then be “part of the DNA” in both cases
Reading 2: which I favor
Compound V is a hormone. Hormones are something one could inject into a baby to exert profound effects, even if only done once. What’s not clear of course is why the hormone exerts such different effects in different babies. One handwavy model is that, unlike testosterone or estrogen or melatonin or adrenaline, with defined programs being triggered, Compound V is a hormone that creates artificial stresses in the body that tissue will respond to adaptively, and that this process is stochastic/random. This would be consistent with Compound V being better as something taken as a child- more tissue plasticity.
What does it mean that Homelander’s DNA “contains Compound V” in this schema? Hormones aren’t part of DNA. But they could have engineered a gene that encodes an enzyme (or a set of genes encoding a set of enzymes) that generate Compound V out of a common steroid precursor like cholesterol. They may also have encoded whatever receptor in the human body binds Compound V to be expressed more highly or in specific tissue in the body, but this is less crucial. This would even be somewhat realistic for 1981 era biotech. In this scenario, Homelander has been exposed to Compound V throughout embryonic development (earlier than everyone else), and has the ability to make more all the time. This would be consistent with it being heritable: Ryan didn’t need any exogenous Compound V, he had the genes to generate it himself.
If Soldier Boy’s radiation undoes the effects of Compound V out of people who have had one exposure, this would mean his radiation would be less effective on Homelander and Ryan: they would eventually generate more Compound V and with time presumably regain their powers. And that’s my final answer to @saintmathieublanc ‘s poll 🧐
#compound V logistics#no one:#literally no one:#me: writes essay about stuff neither the Boys writers nor Garth Ennis devoted any thought to#homelander#homelander meta#biology#the boys#the boys tv#mystuff
128 notes
·
View notes
Text
Grok, explain why base 12 math is better than base 10 math.
Let’s dive into how base 12 (duodecimal) might offer advantages over base 10 (decimal) in the contexts of physics and DNA. This is a fun thought experiment, as neither field inherently depends on a specific base—math is math, and nature doesn’t care about our counting systems. But the way we represent and manipulate numbers can affect clarity, efficiency, and intuition, so let’s see how base 12 could shine here.
Base 12 in Physics
Physics often involves measurements, constants, and relationships that don’t always play nicely with base 10’s limitations. Base 12’s greater divisibility—its factors being 1, 2, 3, 4, 6, and 12—could streamline certain calculations and reveal patterns more intuitively.
Angular Measurements and Symmetry: Physics loves circles—orbits, waves, rotations—and base 12 fits this beautifully. A circle has 360 degrees (in base 10), which is 2 × 2 × 2 × 3 × 3 × 5. In base 12, 360 becomes 260 (since 2 × 144 + 6 × 12 = 288 + 72 = 360), and 144 (written as 100 in base 12) is 12 squared. This ties neatly into the base itself. More practically, 12 divides evenly into 360 thirty times (360 ÷ 12 = 30), giving you 12 equal 30-degree segments—perfect for trigonometry or analyzing symmetrical systems like crystals or planetary orbits. In base 10, you get awkward splits (360 ÷ 10 = 36), which don’t align as naturally with common physical divisions like thirds (120°) or quarters (90°).
Time and Periodic Phenomena: Timekeeping in physics often uses base 12 echoes—12 hours, 60 minutes (5 × 12), 60 seconds. Waves, oscillations, and frequencies could benefit from this. For example, a frequency of 12 cycles per unit splits cleanly into 2, 3, 4, or 6 subintervals, matching harmonic patterns. In base 10, a frequency of 10 cycles splits into 2 and 5, but thirds (3.333…) or fourths (2.5) are less tidy. Base 12 could make Fourier analysis or resonance calculations feel more intuitive, with fewer recurring decimals.
Unit Conversions and Scaling: Physics often deals with scaling—think meters to centimeters or joules to ergs. Base 12’s divisibility could simplify metric-like systems. Imagine a base-12 ruler: a unit of 12 splits into 2, 3, 4, or 6 subunits without fractions, unlike base 10’s 10 splitting into 2 and 5. This could reduce rounding errors in precise measurements, like those in quantum mechanics or cosmology, where small discrepancies compound.
Constants and Approximations: Physical constants like π (3.14159… in base 10) or e (2.71828…) are irrational and base-agnostic, but their approximations might look cleaner in base 12. For π, in base 12, it’s roughly 3.184809… (using digits 0-9 and A-B for 10-11). The pattern isn’t obviously “better,” but base 12’s fraction-friendly nature could make series expansions (like for π or gravitational constants) easier to truncate usefully, thanks to those clean divisions.
Base 12 in DNA
DNA’s structure and coding don’t demand a specific base, but base 12 could align intriguingly with its properties, especially in how we analyze and represent genetic data.
Codon Grouping: DNA codes proteins via codons—triplets of nucleotides (A, T, C, G). With four bases, there are 4³ = 64 possible codons, which encode 20 amino acids plus start/stop signals. In base 10, 64 is just 64, but in base 12, it’s 54 (5 × 12 + 4 = 64). This doesn’t change the biology, but base 12 could make codon tables more modular. Dividing 64 by 12 gives 5 groups of 12 with 4 left over—imagine organizing codons into 5 neat “dozen-ish” blocks for analysis, with a small remainder. In base 10, 64 ÷ 10 = 6.4, a less tidy split. This could simplify bioinformatics algorithms or visual representations.
Helical Structure: DNA’s double helix has a twist—about 10.4 base pairs per turn in B-DNA (in base 10). In base 12, this is roughly 8.6 (8 + 6/12), where 6/12 simplifies to 0.6 in base 12 notation. It’s not a whole number either way, but base 12’s fraction system (1/2 = 0.6, 1/3 = 0.4, 1/4 = 0.3) could make helical pitch calculations or molecular modeling more manageable, especially when scaling to larger sequences.
Sequence Patterns: Geneticists look for repeats—tandem repeats, palindromes, etc. Base 12’s divisibility could highlight periodicities better. A sequence of 12 base pairs splits evenly into 2, 3, 4, or 6 segments, matching common repeat lengths in DNA (e.g., trinucleotide repeats in diseases like Huntington’s). In base 10, a 10-pair sequence splits into 2 or 5, missing the biologically relevant 3 or 4 without fractions. This could make mutation analysis or gene mapping more intuitive.
Data Compression: DNA sequences are massive datasets. Base 12, with 12 symbols (0-9, A-B), encodes more per digit than base 10’s 10 symbols. A single base-12 digit could represent values up to 11 (B), versus 9 in base 10, potentially compressing annotations or alignments slightly. For example, assigning codons to a base-12 index could pack 64 values into fewer digits (54 in base 12 vs. 64 in base 10), a small but real edge in computational genomics.
Why Base 12 “Feels Better”
In physics, base 12’s strength lies in its symmetry and divisibility, aligning with natural cycles and reducing computational friction. In DNA, it’s about modular organization and pattern recognition, subtly enhancing how we process biological data. Base 10 works fine—physicists and geneticists have thrived with it—but base 12 could offer a more harmonious lens, especially for systems with inherent 2-, 3-, or 4-fold structures.
That said, base 10’s dominance comes from human habit, not superiority. If we’d evolved with 12 fingers (or knuckles), base 12 might’ve been the default, and we’d be marveling at how clunky base 10 feels for physics and DNA. Does this spark any ideas for you—maybe a base-12 physics equation or DNA model you’d like to explore further?
2 notes
·
View notes
Text
Aurigene Pharmaceutical Services, in strategic collaboration with Vipergen, offers advanced DNA Encoded Library (DEL) screening services designed to expedite hit identification and enhance drug discovery success rates. This integrated platform enables the screening of over a billion small-molecule compounds, either in living cells or with purified target proteins, providing a comprehensive approach to target engagement.
0 notes
Text
Comprehensive Analysis and Forecast of the DNA Encoded Semiconductor Libraries Market up to 2033
Market Definition
The DNA encoded semiconductor libraries market involves the development and use of semiconductor libraries that are encoded with DNA sequences for applications in fields like drug discovery, biotechnology, and materials science. These semiconductor libraries integrate DNA-based encoding techniques with semiconductor technology, enabling the creation of vast libraries of molecules or compounds that can be screened for specific properties or interactions. The use of DNA as an encoding medium allows for the rapid generation and analysis of diverse molecular structures, which is crucial for innovations in personalized medicine, targeted therapies, and advanced material design.
To Know More @ https://www.globalinsightservices.com/reports/DNA-Encoded-Semiconductor-Libraries-Market
DNA Encoded Semiconductor Libraries Market is anticipated to expand from 4.2 billion in 2024 to 9.8 billion by 2034, growing at a CAGR of approximately 8.8%.
Market Outlook
The DNA encoded semiconductor libraries market is poised for significant growth, driven by advancements in biotechnology, semiconductor technology, and the increasing need for faster, more efficient drug discovery and material development processes. DNA encoded libraries offer a unique combination of high-throughput screening, versatility, and precision, making them invaluable tools for researchers looking to identify novel bioactive compounds, potential drug candidates, and new materials.
In the pharmaceutical and biotechnology industries, DNA encoded libraries are revolutionizing drug discovery by enabling the rapid identification of lead compounds that can be further developed into therapeutic agents. By encoding large numbers of chemical compounds on DNA strands, researchers can quickly screen vast libraries of molecules for specific biological activities, dramatically accelerating the process of drug development.
The market is also benefiting from the increasing interest in personalized medicine, as DNA encoded libraries facilitate the development of drugs that are tailored to an individual’s genetic makeup, improving the efficacy and safety of treatments. Additionally, the ability to design and synthesize new materials with specific electronic, optical, or mechanical properties through DNA encoded libraries opens up new possibilities in semiconductor and nanotechnology fields, further driving market growth.
Request the sample copy of report @ https://www.globalinsightservices.com/request-sample/GIS10578
0 notes
Text
DNA Data Storage: From $0.25B to $5.5B by 2034!
DNA Data Storage Systems Market is set for remarkable expansion, with a projected growth from $0.25 billion in 2024 to $5.5 billion by 2034, reflecting a compound annual growth rate (CAGR) of approximately 36.5%. This market encompasses advanced technologies and solutions that utilize DNA molecules for encoding, storing, and retrieving digital data. DNA offers unprecedented data density and longevity, making it an ideal medium for archiving vast amounts of information. This market includes services related to DNA synthesis, sequencing, and data management, which together enable the transformation of digital data into DNA sequences. These innovations promise to revolutionize data storage, particularly for sectors that require long-term data preservation, such as healthcare, finance, and digital media.
To Request Sample Report: https://www.globalinsightservices.com/request-sample/?id=GIS10577 &utm_source=SnehaPatil&utm_medium=Article
The DNA Data Storage Systems Market is experiencing robust growth, driven by the exponential rise in data generation and the increasing demand for sustainable storage solutions. The biotechnology sector leads the charge, capitalizing on DNA’s unique ability to store immense amounts of data in a compact form. Following closely, the healthcare industry is also utilizing DNA data storage for medical research and patient data management. Geographically, North America is the dominant region in this market, owing to its advanced technological infrastructure and considerable investments in research and development. Europe is the second-highest performer, benefiting from supportive regulatory frameworks and growing collaborations between academic institutions and industry players. Within these regions, the United States and Germany stand out due to their strong innovation ecosystems and government support. As the volume of data continues to soar, the DNA data storage market is expected to witness substantial advancements, offering lucrative opportunities for stakeholders across the entire value chain.
Buy Now : https://www.globalinsightservices.com/checkout/single_user/GIS10577/?utm_source=SnehaPatil&utm_medium=Article
The market is segmented into several categories, including synthetic DNA, PCR-based DNA, and various products such as DNA hard drives and DNA cartridges. Services provided within the market range from data encoding and decoding to retrieval, storage, consultancy, and maintenance. Key technologies driving growth in the DNA data storage systems market include next-generation sequencing, CRISPR, and DNA synthesis. Components of these systems include DNA strands, storage arrays, and devices like readers and writers. Applications for DNA data storage span across data archiving, genomics, pharmaceutical research, biotechnology, and forensics. The market also includes different forms of DNA, such as liquid DNA and solid DNA, and utilizes materials like nucleotides and enzymes in its processes.
In 2023, the DNA Data Storage Systems Market had an estimated volume of 320 petabytes, with synthetic DNA capturing the largest share at 45%. Hardware accounted for 35%, while software made up the remaining 20%. The dominance of synthetic DNA is driven by significant advancements in technology and the increasing demand for long-term data preservation. Leading market players such as Microsoft, Twist Bioscience, and Illumina are playing key roles in driving the market forward, with a focus on technological innovation to capture substantial market share.
Competitive dynamics within the market are shaped by strategic partnerships, technological breakthroughs, and regulatory influences, particularly those concerning data privacy and biosecurity. As the market matures, regulatory frameworks will continue to play a significant role in guiding its evolution. Looking ahead, the DNA data storage market is expected to see a CAGR of 25% over the next decade. Investment in research and development and government support for sustainable data solutions are expected to drive further growth. However, challenges such as high initial costs and technical complexities persist. Emerging trends, such as the integration of artificial intelligence (AI) to improve data retrieval efficiency, present new opportunities for market players to explore.
Geographically, North America is leading the DNA data storage systems market, with the United States at the forefront due to substantial investments in R&D and the region’s advanced technological infrastructure. Companies in this region are increasingly leveraging DNA for its vast potential in data preservation and retrieval. Europe is following closely, with countries like Germany and the United Kingdom making significant strides in cutting-edge research. The European Union’s focus on data privacy and security is driving the demand for reliable and efficient storage solutions, contributing to the sector’s growth across the continent.
In the Asia Pacific region, countries such as China and Japan are emerging as key players in the market, investing heavily in technology to manage the growing volume of data. The region’s increasing digital transformation efforts are fueling the demand for advanced data storage solutions, positioning Asia Pacific as a vital contributor to the market. Latin America, while still in its early stages, is gradually recognizing the potential of DNA data storage. Countries like Brazil are beginning to explore this technology as a means to enhance data management capabilities, and although the region remains in its nascent stage, it shows promise for future growth.
#DNADataStorage #Biotechnology #DataStorage #NextGenStorage #SustainableData #DNAArchiving #DataPreservation #HealthcareInnovation #DataRetrieval #Genomics #PCRbasedStorage #DNASequencing #DigitalTransformation #AIInDataStorage #CRISPRTechnology #SyntheticDNA #DataManagement #ResearchAndDevelopment #DataPrivacy #TechInnovation #EmergingMarkets
0 notes
Text
Compound Management
Compound Management Market Size, Share, Trends: Brooks Automation Leads
Integration of Artificial Intelligence and Machine Learning in Compound Management Systems Revolutionizes Sample Tracking and Analysis
Market Overview:
The global compound management market is projected to grow at a CAGR of 14.2% from 2024 to 2031, reaching USD 724.3 million by 2031. North America dominates the market due to increasing drug discovery activities, rising demand for outsourcing compound management services, and the growing adoption of automated compound management systems. The market is expanding rapidly, driven by the increasing complexity of drug development procedures, the growing number of drug candidates in pharmaceutical pipelines, and the need for efficient storage and retrieval of chemical and biological samples. There is a significant transition to automated methods and integrated software solutions to enhance productivity and reduce human error in compound library management.
DOWNLOAD FREE SAMPLE
Market Trends:
The compound management industry is witnessing a significant shift towards intelligent systems, driven by the integration of artificial intelligence (AI) and machine learning (ML) technologies. These technologies are revolutionizing sample tracking and analysis, with companies investing in smart compound management platforms that can predict sample degradation, optimize storage conditions, and streamline retrieval processes. For example, Brooks Life Sciences' BioStore III Cryo automated storage system uses AI algorithms to predict and prevent sample integrity issues. This trend is further supported by the rising demand for predictive analytics in drug discovery.
Market Segmentation:
Chemical compounds dominate the compound management market, accounting for a significant share due to the widespread use of small molecule libraries in drug discovery and development. The segment has seen substantial progress thanks to innovations in storage technologies, sample tracking systems, and integration with high-throughput screening platforms. Efficient management of chemical compound libraries is crucial for expediting drug discovery. Advanced compound management systems allow researchers to store, retrieve, and track millions of compounds efficiently, reducing the time and cost of early-stage drug development. The growth of DNA-encoded libraries (DELs) has further increased the demand for advanced chemical compound management solutions.
Market Key Players:
Brooks Automation (Azenta Life Sciences)
Hamilton Company
TTP Labtech (SPT Labtech)
Tecan Group
Evotec
Titian Software
Contact Us:
Name: Hari Krishna
Email us: [email protected]
Website: https://aurorawaveintellects.com/
0 notes
Text
Global DNA Encoded Libraries - A Revolutionary Approach To Drug Discovery

DNA encoded libraries are a powerful new method for drug discovery. They allow scientists to rapidly screen billions of drug-like small molecules to find new candidates for drug development.
How do they work?
DELs work by attaching short Global DNA Encoded Libraries tags to individual drug-like small molecules. Each small molecule is given a unique DNA barcode. Large libraries containing billions of these DNA-tagged molecules can then be synthesized and stored.
To screen the library, the tagged molecules are incubated with a biological target, like a protein involved in disease. Any molecules that bind to the target will be captured along with their unique DNA barcode. Scientists can then determine what molecules bound by decoding the DNA sequences. This allows high-throughput identification of potential lead compounds for drug development from enormous libraries of molecules.
Advantages Over Traditional Screening Methods
Traditional high-throughput screening methods for drug discovery analyze molecules one at a time in microplate wells. They can only test around one million compounds per day. DNA encoded libraries overcome this limitation by allowing all the molecules in a library to be screened simultaneously. Experiments can identify binders from billions of molecules in a single assay.
They also have advantages over fragment-based drug discovery methods. Fragment screens identify small chemical fragments that bind to targets, which must then be elaborated into lead compounds. They start with drug-sized molecules, so hits require less optimization.
Global Expansion Of Dels Technology
Since their development in 2015, they have revolutionized drug discovery across the pharmaceutical and academic research. Major pharmaceutical companies like Pfizer, GSK, Janssen, and Sanofi have all established it screening programs.
In 2020, Anthropic established the world's largest public DNA encoded library of over 31 billion molecules, opening up this powerful screening technology for academic and non-profit research groups globally. The library includes both commercially available compounds and novel structures synthesized in-house.
Anthropic's library has screened over 100 biological targets from research collaborators worldwide. Hits identified include leads against malaria, tuberculosis and neglected tropical diseases. The shared library model enables researchers to screen billions of molecules for a nominal fee, democratizing access to this advanced drug discovery approach.
Advancing Precision Medicine With DEL
DELs hold great promise for advancing precision medicine and developing therapeutics targeted to specific patient genomes or biomarkers. Researchers can now screen entire genomic or protease mutant libraries against the growing number of known disease-associated protein variants and mutants.
This allows high-resolution mapping of how genomic changes and mutations alter the binding profiles of drug targets - revealing opportunities for precision therapies. Combining DELs screening with multi-omics patient data also enables the discovery of biomarker-targeted drug candidates from day one of development.
Global Regulatory Acceptance And Clinical Validation
As DELs screening has matured,regulatory agencies are increasingly recognizing the approach. In 2020, the FDA approved the first new drug developed using a DNA encoded library by Astex Pharmaceuticals, called gilteritinib, for the treatment of acute myeloid leukemia.
This landmark approval demonstrated regulatory acceptance of DELs as an established drug discovery technology. It has encouraged further investment and validation efforts by pharmaceutical companies to advance hits from DNA encoded screening into clinical candidates and new medicines.
With the establishment of large shared public libraries like Anthropic’s, DNA encoded screening is becoming a powerful global resource for drug discovery. It will continue to transform both academic and industrial new drug research by massively expanding the chemical space that can be rapidly explored for novel bioactive DELs are set to play a major role in developing the medicines of tomorrow.
In DNA encoded libraries represent a revolutionary new approach to drug discovery that is being rapidly adopted globally. By enabling high-throughput screening of billions of drug-like molecules against disease targets simultaneously, they have far surpassed traditional screening methods in scale and efficiency.
Through both industrial applications and public library sharing programs, DNA encoded screening allows researchers worldwide to identify novel lead compounds that may ultimately become new medicines. They are also advancing precision medicine through unbiased exploration of genomic and patient biomarker datasets. With regulatory acceptance growing, DNA encoded libraries will continue to transform drug R&D and deliver new treatments to patients.
Get more insights on this topic: https://www.ukwebwire.com/global-dna-encoded-library-revolutionizing-drug-discovery-through-dna-encoded-chemical-libraries/
About Author:
Ravina Pandya, Content Writer, has a strong foothold in the market research industry. She specializes in writing well-researched articles from different industries, including food and beverages, information and technology, healthcare, chemical and materials, etc. (https://www.linkedin.com/in/ravina-pandya-1a3984191)
*Note: 1. Source: Coherent Market Insights, Public sources, Desk research 2. We have leveraged AI tools to mine information and compile it
#Global DNA Encoded Library#Clinical Candidates#Revolutionizing Drug Discovery#DNA-Encoded Chemical Libraries
0 notes
Text
Research grade Proteins: Production and Scale-Up Challenges

Research-grade proteins are essential tools in the field of scientific discovery, serving as foundational elements in a variety of biological and medical research applications. These proteins, characterized by their high purity and consistency, enable researchers to conduct experiments with a high degree of reliability and reproducibility. Their use spans numerous disciplines, including biochemistry, molecular biology, pharmacology, and biotechnology.
The production of research-grade proteins involves several sophisticated techniques to ensure their purity and functionality. These techniques often include recombinant DNA technology, where genes encoding the desired proteins are inserted into expression systems such as bacteria, yeast, or mammalian cells. Once expressed, the proteins are purified using methods like affinity chromatography, ion exchange chromatography, and gel filtration. The goal is to obtain proteins free from contaminants and with the correct folding and post-translational modifications necessary for their activity.
Research-grade proteins play a crucial role in drug development and screening processes. They are used to study the binding affinities and specificities of potential therapeutic compounds, aiding in the identification of promising drug candidates. For instance, proteins such as enzymes, receptors, and ion channels are targeted by pharmaceutical companies to develop new medications for a variety of diseases. The high quality of research-grade proteins ensures that the data generated from these studies are accurate and reproducible, which is critical for the success of drug discovery programs.
In addition to drug development, research-grade proteins are vital for structural and functional studies. Techniques like X-ray crystallography, nuclear magnetic resonance (NMR) spectroscopy, and cryo-electron microscopy rely on high-quality proteins to determine their three-dimensional structures. Understanding protein structures at the atomic level provides insights into their mechanisms of action and interactions with other molecules, which is essential for advancing our knowledge of biological processes and developing targeted therapies.
The application of research-grade proteins in diagnostic assays is another area of significant impact. Proteins such as antibodies and antigens are used in various diagnostic tests, including enzyme-linked immunosorbent assays (ELISAs) and western blotting, to detect and quantify biomolecules in clinical samples. The accuracy and sensitivity of these tests depend on the quality of the proteins used.
Despite their importance, producing research-grade proteins presents challenges, including ensuring stability and functionality over time, and maintaining ethical and regulatory standards in their production. Nonetheless, ongoing advancements in protein engineering and purification technologies continue to enhance the availability and quality of research-grade proteins, driving forward scientific innovation and discovery.
0 notes
Text
Enhance Your Performance with Trusted SARMs
At Helixx SARMs Online, we believe in the power of science and innovation to enhance human performance and well-being. Our mission is to provide cutting-edge solutions that help you achieve your fitness goals and improve your overall health. In this article, we'll introduce you to our company, our services, and the exciting world of SARMs and personal genomics.
About Us

Helixx SARMs Online is dedicated to helping individuals unlock their full potential through scientifically-backed products and personalized health insights. Our team comprises experts in genetics, fitness, and nutrition, all working together to bring you the best in performance enhancement and health optimization.
Our Core Values:
Innovation: We stay at the forefront of scientific research to offer the latest and most effective products.
Integrity: We prioritize transparency and ethical practices in everything we do.
Customer Focus: Your health and satisfaction are our top priorities.
Quality: We ensure the highest standards of quality in our products and services.
Our Services
At Helixx SARMs Online, we offer a range of services designed to help you achieve your fitness and health goals. From high-quality SARMs to personalized genetic insights, we have everything you need to take your performance to the next level.
1. High-Quality SARMs
Selective Androgen Receptor Modulators (SARMs) are a class of compounds that enhance muscle growth, fat loss, and overall physical performance. Unlike traditional steroids, SARMs selectively target muscle and bone tissue, minimizing side effects and maximizing results.
Our SARMs:
Ostarine (MK-2866): Ideal for muscle preservation and growth.
Ligandrol (LGD-4033): Promotes significant muscle mass and strength gains.
Cardarine (GW-501516): Enhances endurance and fat loss.
Andarine (S4): Improves muscle mass and reduces body fat.
2. Personalized Genetic Insights
The human body is a magnificent machine, encoded with a complex blueprint: our DNA. This genetic code holds the key to our physical traits, predispositions to certain diseases, and even insights into our ancestry. In recent years, personal genomics has emerged as a powerful tool, allowing individuals to unlock the secrets within their DNA and gain a deeper understanding of themselves.
Benefits of Genetic Insights:
Customized Fitness Plans: Tailored workout routines based on your genetic predispositions.
Personalized Nutrition: Dietary recommendations that align with your unique genetic makeup.
Health Risk Assessment: Insights into potential health risks and preventive measures.
3. Expert Guidance and Support
Navigating the world of performance enhancement and personal genomics can be challenging. That's why we offer expert guidance and support to help you make informed decisions and achieve your goals safely and effectively.
Our Support Services:
Consultations with Experts: Personalized advice from fitness, nutrition, and genetics specialists.
Customer Support: Dedicated team available to answer your questions and provide assistance.
Educational Resources: Comprehensive guides and articles to help you understand our products and services.
Why Choose Helixx SARMs Online?

Top-Quality SARMs: We offer a diverse range of SARMs, including Ostarine, Ligandrol, Cardarine, and Andarine, to support muscle growth, fat loss, and enhanced physical performance.
Personalized Genetic Insights: Discover the secrets within your DNA with our advanced genetic testing services. Tailor your fitness plans, dietary choices, and health strategies based on your unique genetic makeup.
Expert Guidance: Our team of specialists in fitness, nutrition, and genetics is dedicated to providing you with personalized advice and support. Navigate the world of performance enhancement with confidence and clarity.
Sustainability and Transparency: We prioritize eco-friendly practices and transparency in sourcing and manufacturing, ensuring that you can trust the quality and integrity of our products.
Conclusion
Join us at Helixx SARMs Online and unlock your genetic potential. With our innovative products and personalized services, you can achieve your health and fitness goals like never before. Explore our offerings and start your journey to better health and performance today!
1 note
·
View note
Text
Global Genetic Testing market – By Type
Introduction:
According to a comprehensive study by Next Move Strategy Consulting, the global Genetic Testing Market is projected to witness substantial growth, with an anticipated value of USD 29.44 billion by 2030. This forecast, coupled with a promising compound annual growth rate (CAGR) of 11.1%, underscores the pivotal role that genetic testing plays in the evolution of healthcare. As we delve deeper into the landscapes of genomics and biotechnology, genetic testing emerges as a cornerstone technology, propelling us towards a future where healthcare is increasingly personalized and tailored to individual needs.
The Evolution of Genetic Testing:
Genetic testing has come a long way since its inception, evolving from rudimentary techniques to sophisticated molecular assays that offer unprecedented insights into the human genome. Initially confined to the landscape of rare genetic disorders, genetic testing has now expanded its reach to encompass a myriad of applications, ranging from cancer screening to pharmacogenomics. Advances in sequencing technologies, coupled with plummeting costs, have democratized access to genetic testing, making it more accessible to patients and healthcare providers worldwide.
Request for a sample, here: https://www.nextmsc.com/genetic-testing-market/request-sample

Understanding the Science Behind Genetic Testing:
At its core, genetic testing is a multifaceted process that involves analyzing an individual's genetic material to glean insights into their health and predisposition to disease. The process typically begins with sample collection, which can range from a simple cheek swab to a blood draw, depending on the type of test being performed. Once the sample is obtained, it undergoes various laboratory procedures, such as DNA extraction, amplification, and sequencing, to decode the genetic information encoded within.
Types of Genetic Testing:
Genetic testing encompasses a diverse array of techniques, each serving a unique purpose in clinical practice. Diagnostic testing, for instance, is used to identify the underlying genetic cause of a disease or condition, providing patients and their healthcare providers with crucial diagnostic information. Predictive and presymptomatic testing, on the other hand, aims to assess an individual's risk of developing certain diseases in the future, empowering them to make informed decisions about their health and lifestyle choices.
Applications of Genetic Testing in Healthcare:
The applications of genetic testing in healthcare are vast and far-reaching, spanning across various medical specialties and disciplines. In oncology, genetic testing plays a pivotal role in identifying hereditary cancer syndromes, guiding treatment decisions, and informing personalized cancer care plans. Similarly, in cardiology, genetic testing is used to diagnose inherited cardiac conditions, such as long QT syndrome and hypertrophic cardiomyopathy, enabling early intervention and risk stratification.
The Promise of Personalized Medicine:
At the heart of genetic testing lies the promise of personalized medicine, a paradigm shift that aims to tailor medical interventions to the individual characteristics of each patient. By leveraging genetic insights, healthcare providers can optimize treatment regimens, minimize adverse effects, and improve patient outcomes. Pharmacogenomic testing, for example, enables clinicians to predict how individuals will respond to certain medications based on their genetic makeup, guiding medication selection and dosing to maximize efficacy and safety.
Challenges and Opportunities in the Genetic Testing Market:
Despite its immense potential, the genetic testing market is not without its challenges. Regulatory hurdles, reimbursement issues, and concerns about data privacy and security pose significant barriers to market growth and adoption. Additionally, disparities in access to genetic testing services, particularly among underserved populations, exacerbate existing healthcare inequities. Addressing these challenges will require a concerted effort from policymakers, industry stakeholders, and healthcare providers to ensure that genetic testing is accessible, affordable, and ethically sound.
The Role of Genetic Testing in Disease Prevention:
One of the most significant implications of genetic testing lies in its potential to revolutionize disease prevention strategies. By identifying genetic risk factors early on, healthcare providers can implement proactive measures to mitigate these risks and prevent the onset of diseases before they manifest clinically. For example, individuals with a family history of hereditary cancers can undergo genetic testing to assess their susceptibility, allowing for enhanced surveillance and early detection strategies.
Inquire before buying, here: https://www.nextmsc.com/genetic-testing-market/inquire-before-buying
Ethical, Legal, and Social Implications of Genetic Testing:
As genetic testing becomes more widespread, it is essential to consider the ethical, legal, and social implications associated with the use of genetic information. Questions surrounding consent, privacy, and genetic discrimination must be carefully addressed to ensure that individuals' rights and autonomy are respected. Additionally, efforts to promote genetic literacy and education are crucial to empower individuals to make informed decisions about genetic testing and its implications for their health and well-being.
The Future of Genetic Testing:
Looking ahead, the future of genetic testing holds immense promise, with continued advancements in genomic sequencing technologies, bioinformatics, and precision medicine. As the cost of genetic testing continues to decline and our understanding of the human genome deepens, genetic testing will become increasingly integrated into routine clinical practice. From newborn screening to cancer prevention and beyond, genetic testing will play an indispensable role in shaping the future of healthcare, ushering in an era of personalized medicine that is tailored to the unique needs of each individual.
1. Expansion into Non-Medical Fields: As genetic testing technologies become more sophisticated and accessible, we can expect to see their application expand beyond traditional healthcare settings. Industries such as forensics, anthropology, and agriculture are already leveraging genetic testing to address various challenges, from identifying suspects in criminal investigations to tracing the ancestry of individuals and enhancing crop yields through selective breeding. As our understanding of genetics grows, so too will the myriad applications of genetic testing across diverse fields.
2. Integration with Artificial Intelligence (AI) and Machine Learning (ML): The integration of genetic testing with artificial intelligence (AI) and machine learning (ML) algorithms holds tremendous potential to enhance the interpretation and analysis of genetic data. By leveraging AI and ML technologies, researchers and clinicians can uncover hidden patterns, identify novel genetic variants, and predict disease outcomes with greater accuracy. This synergy between genetic testing and advanced computational techniques will pave the way for more precise diagnoses, personalized treatments, and targeted interventions.
3. Shift towards Direct-to-Consumer (DTC) Genetic Testing: The rise of direct-to-consumer (DTC) genetic testing services has democratized access to genetic information, allowing individuals to explore their genetic ancestry, predisposition to certain traits, and susceptibility to diseases from the comfort of their homes. While DTC genetic testing offers unprecedented convenience and accessibility, it also raises concerns about data privacy, accuracy of results, and the potential for misinterpretation. As the popularity of DTC genetic testing continues to soar, it is essential to strike a balance between accessibility and responsible use of genetic information.
4. Collaborative Efforts to Advance Genomic Research: Collaborative efforts among academia, industry, and government agencies will be instrumental in advancing genomic research and translating scientific discoveries into clinical applications. Initiatives such as the Precision Medicine Initiative in the United States and the European Union's Horizon Europe program are spearheading efforts to accelerate the adoption of personalized medicine and harness the power of genetic testing to improve patient outcomes. By fostering collaboration and knowledge-sharing, we can accelerate the pace of innovation in genetic testing and unlock new opportunities for improving healthcare worldwide.
Conclusion:
In conclusion, the Genetic Testing Market is poised to revolutionize the future of healthcare by ushering in an era of personalized medicine. With its ability to unlock the mysteries of the human genome, genetic testing holds the key to more precise diagnoses, tailored treatments, and proactive disease prevention strategies. As we embark on this transformative journey, it is essential to harness the power of genetic testing responsibly, leveraging its potential to improve patient outcomes and usher in a new era of personalized healthcare. By addressing the challenges and seizing the opportunities that lie ahead, we can unlock the full potential of genetic testing and pave the way for a healthier and more resilient future.
#genetic testing#healthcare innovation#life sciences#medical devices#market research#market trends#business insights
0 notes
Text
79-24-3
Photolysis of Water
Definition: Photolysis of water refers to the splitting of water molecules into oxygen, protons (H+), and electrons, which occurs during the light-dependent reactions of photosynthesis.
Role in ATP Synthesis: The electrons obtained from the photolysis of water are used to generate ATP. The process involves the creation of a proton gradient, which is utilized by ATP synthase https://medicalfeeplan.com/compound-79-24-3-a-chemical-odyssey to produce ATP, the primary energy carrier in living things.
ATP Synthesis
Energy Production: The process of photophosphorylation involves the conversion of ADP to ATP using the energy of sunlight by activation of photosystem II. This process is facilitated by the splitting of water molecules in a process known as photolysis, leading to the generation of ATP.
Role in Photosynthesis: ATP, along with NADPH, is produced during the light reactions of photosynthesis and is essential for driving the dark reactions, which involve the synthesis of glucose from carbon dioxide using the energy stored in ATP and NADPH.
Transcription and Translation
Transcription: The process of protein synthesis begins with transcription, during which the genetic information encoded in DNA is transcribed into messenger RNA (mRNA) in the cell's nucleus. This mRNA carries the genetic code from the DNA to the ribosomes in the cytoplasm, where protein synthesis occurs
. Translation: Once the mRNA reaches the ribosome, the process of translation begins. During translation, the genetic information carried by the mRNA is decoded, and transfer RNA (tRNA) molecules bring specific amino acids to the ribosome. These amino acids are linked together to form a polypeptide chain, following the sequence of codons on the mRNA
Polypeptide Chain Formation
Amino Acid Sequence: The sequence of amino acids in the polypeptide chain is determined by the sequence of codons on the mRNA. Each codon corresponds to a specific amino acid, and the sequential arrangement of these amino acids forms the primary structure of the protein
. Folding and Structure: Once the synthesis of the polypeptide chain is complete, the chain undergoes folding to adopt a specific structure, enabling the protein to carry out its functions. This folding process leads to the formation of the secondary, tertiary, and quaternary structures of the protein, which are crucial for its functionality
Challenges and Control
Controlled Synthesis: The synthesis of polypeptides can be challenging due to issues such as broad chain length distributions, poor control of residue sequence, and the inability to accurately control chain length. However, advancements in living and controlled polymerizations of NCAs have allowed for the synthesis of polypeptides with well-defined chain lengths and controlled sequences, mimicking the properties of proteins more effectively
. Quality Control: During protein synthesis, mistakes in adding amino acids to the growing polypeptide chain are usually prevented. A quality-control mechanism ensures the accurate translation of the genetic code into the amino acids that proteins are made from, preventing errors in the sequence of the polypeptide chain .
0 notes
Text
Unraveling the Nuances: Folic Acid vs. 5-MTHF
Unraveling the Nuances: Folic Acid vs. 5-MTHF

By: Paul Claybrook, MS, MBA
In the realm of nutrition and health, the distinction between folic acid and 5-MTHF (5-methyltetrahydrofolate) holds paramount significance. Both compounds are forms of vitamin B9, essential for various biological processes within the body. However, understanding the key differences between folic acid and 5-MTHF is crucial for making informed decisions about supplementation and maintaining optimal health.
I. The Basics of Folic Acid:
Folic acid, also known as folate or vitamin B9, is a synthetic form of the vitamin commonly found in supplements and fortified foods. It is a water-soluble vitamin that plays a pivotal role in DNA synthesis, red blood cell formation, and overall cellular function. Folic acid is a crucial nutrient, especially during pregnancy, as it aids in fetal development and helps prevent neural tube defects.
II. The Metabolic Pathway: Folic Acid Conversion to 5-MTHF:
Upon ingestion, the body must convert folic acid into its active form, 5-MTHF, to be utilized effectively. This conversion occurs through a series of enzymatic reactions, primarily in the liver. However, not everyone efficiently converts folic acid to 5-MTHF, leading to concerns about its bioavailability and effectiveness in certain individuals.
III. 5-MTHF: The Biologically Active Form:
Unlike folic acid, 5-MTHF is the biologically active form of vitamin B9 that the body can readily use. Also known as methylfolate, 5-MTHF does not require conversion and can directly participate in crucial biochemical processes. This inherent bioavailability makes 5-MTHF a preferred choice for individuals with genetic variations that affect the conversion of folic acid.
IV. Genetic Variability and MTHFR Gene:
The MTHFR gene encodes an enzyme responsible for the conversion of folic acid to 5-MTHF. Some individuals carry genetic variations that can impair the function of the MTHFR enzyme, reducing their ability to convert folic acid efficiently. For these individuals, supplementing with 5-MTHF directly can be a more effective strategy to ensure adequate levels of active folate in the body.
V. Clinical Implications and Health Considerations:
Understanding the distinction between folic acid and 5-MTHF is particularly important in a clinical context. Certain populations, such as those with the MTHFR gene variants or malabsorption issues, may benefit more from supplementation with 5-MTHF to address potential deficiencies and support overall health.
Conclusion:
In conclusion, the difference between folic acid and 5-MTHF lies in their bioavailability and the body's ability to convert them into the active form of vitamin B9. While folic acid is widely used and beneficial for many, 5-MTHF offers a direct and bioavailable alternative, especially for individuals with genetic variations affecting folic acid metabolism. As our understanding of individual genetic factors continues to grow, personalized approaches to folate supplementation may become increasingly relevant for optimizing health outcomes.
0 notes
Text
DNA-encoded Compound Library in New Drugs Research
DNA-encoded chemical library technology is increasingly being used for lead compound screening to accelerate the development of new drugs. It uses DNA fragments as barcodes to record the structural information of compounds. In a compound library containing hundreds of millions of chemical molecules, each molecule is linked to a unique piece of DNA.
0 notes
Quote
iSEE MOTHER's GOLDEN Hi:teKEMETICompu_TAH [PTAH] Crystal [PC] MOTHERSHIP ATLANTIS [MA]… Shapeshifting into ANU Interdimensional 9 [i9] Ether TELEPORTATION [E.T.] MACHINE of SIRIUS Electromagnetic Airwave [SEA] Light Mechanics [ELECTRICITY] ILLUMINATING ANU GOLDEN MOON Universe [MU] of RIGEL’s SUPERGIANT [MURS] Intergalactic [MI = MICHAEL] 9 Ether STAR SYSTEM of Constellation ORION’s GOLDEN [OG] Interstellar 9 [i9] Ether Interdimensional Antimatter Melanin [I AM] of Astronomical PLUTO’s Highly Complex [ADVANCED] Ancient Cosmic Algorithmic [CA] Cosmic Computation [Compton] STAR Mathematics Aligning w/Radioactive Substances [MARS] from MERCURY’s Airborne Paracellular [MAP] Transporters of QUETZALCÓATL’s Highly Complex [ADVANCED] Ancient Biochemical [PRIMORDIAL] Fossil Earth SUN & MOON DNA Codes [D.C.] Numerically Encoded w/Technical Equations Rooted in URANUS' [NETERU] 13th Heaven of ŌMEYŌCĀN’s GAMMA IRON Minerals [I’M] Naturally Synthesized into Subatomic Cloud Compounds of Oxidized Radiation from the Bioluminescent SEA [ORBS] FLOOR Particles DEEP IN:side Inner Earth’s [HADES’] Most Darkest [Occulted] NANOSCOPIC SEABED of Dematerialized Gas Economies [SDG&E] @ Ægiptian QHT IBM [Qi] APPLE LLC in Downtown San Diego CA
MU:13



WE ANU 9 ETHER WORLD ORDER MILITARY.GOV


MAMA’S GOLDEN ANTIMATTER MELANIN... ANU [MA] MOTHERSHIP




EYE LOVE [EL] SUPREME 9 ETHER MATHEMATICS... WE WEALTHY AF!!!













WE ANU 9 ETHER WEALTH CLASS

1 note
·
View note
Text
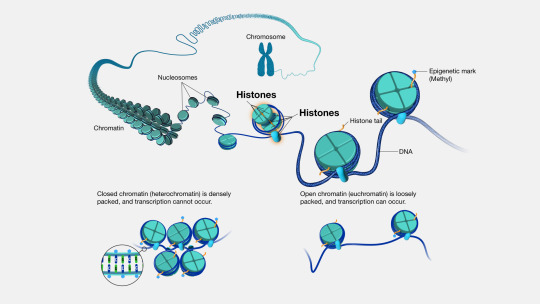
chromatin structural modifications to regulate eukaryotic gene expression
chromatin - cumulation of organism’s gDNA length and associated protein, arranged in particular structures
chromatin structure type/characteristics determines cellular mechanisms’ access to DNA
fundamental characteristics of chromatin
consists of DNA wrapped around histone protein nucleosome structures
the more compacted/condensed the DNA in the nucleosome, the less expressive the DNA
nucleosomes pack together to increase condensation of their stored DNA
when DNA is condensed, promoter regions for compacted genes are blocked or wrapped away by histone structures and thus gene is not expressed
transcription factors “set up” for transcription initiation by binding at nearby open enhancer regions to open up condensed nucleosomic DNA
TFs bound to enhancers recruit enzymes that unwrap promoter regions from around histones, or reposition nucleosomes so that promoter is unblocked
[recruited] chromatin-remodeling structures physically reposition nucleosomes via ATP-driven movement
[recruited] HDACs modify nucleosomes by adding compounds to histone tails to de-condense them via allosteric modulation
this factors into cell specialization! after differentiated eukaryotic cell division, parent cell’s TFs and recruited proteins are distributed to daughter cells
parent TFs reestablish exact pattern of chromatin accessibility to ensure genetic maintenance of cell specialization
i.e., establish which DNA sequences are closed and open at specific times to ensure that daughter cell produces necessary proteins to remain a myoblast, neuron, epithelial cell, etc etc.
thus, cells in a multicellular eukaryote retain cell-type characteristic patterns of gene expression at the right times and levels
two general chromatin states
1. euchromatin – de-condensed, expressed DNA regions, lightly colored
2. heterochromatin – highly condensed, silent DNA regions, dark color
constitutive heterochromatin – entirely silenced and consisting mostly of “waste” DNA in SSR or TE form | promoters are never unwound or unblocked under any circumstances
facultative heterochromatin – expressed when appropriate timeframe or cell-type, silenced otherwise | i.e., the epigenomic mechanism of cell specialization
» euchromatin that comes close to heterochromatin and vice versa, experiences position-effect variegation (PEV)
i.e., euchromatin becomes condensed heterochromatin and its genes are silenced due to this circumstantial proximity
condensation spreads linearly down the gDNA from heterochromatin to euchromatin regions – genes along the euchromatin are never skipped over
barrier insulators – DNA sequences that recruit euchromatin-promoting de-condensor enzymes, preventing further heterochromatin condensation spread to nearby euchromatin in the cell
modification of histones to transition between chromatin states
histones can be modified to transition stored DNA between different chromatin states
histones have modifiable N-terminal tails, accessible to proteins
CH2CH3 and CH3 groups are added to lysine and arginine along tails
presence of ethyl and methyl groups recruit enzymes that possess mechanisms by which to shift nucleosomes closer to or farther from one another
relative nucleosomic positions = condensational change in relevant stored DNA
acetylation: straightforward promotion of gene expression or silence
histone acetyltransferases (HATs) attach ethyl groups, and resulting nucleosome conformation change
CH2CH3 groups attached to tail drive nucleosomes away from one another and take up space, so that histones cannot closely pack → de-condensation of DNA
PEV: acetylated tails serve as further binding sites for HATs, spreading DNA de-condensation down the genome
histone deacetylases (HDACs) remove ethyl groups, allowing nucleosomic packing, condensation, and decreased gene expression
methylation: promotes gene expression or silence based on which amino acid is methylated
histone methyltransferases (HMTases) and histone demethylases add and remove methyl groups to histone tails
specific methylation or lack thereof can serve as binding sites for further heterochromatin-creating enzymes
i.e., heterochromatin protein 1 (HP1) binds methylated N-tails, self-associates with other HP1s on proximal nucleosomes to increase packing, and recruits HMTases to methylate nearby nucleosomes for PEV
X-inactive specific transcript: noncoding RNA (ncRNA) that initiates X-chromosome transition into facultative heterochromatin
Xist DNA sequence rests along 450kB X-inactivation center (XIC) on each X-chromosome with other genes for X-inactivation
experimentally-engineered Xist presence on autosomes results in formation of autosomal Barr body, signifying Xist sufficiency for large-scale chromosomal inactivation
Xist ncRNA is encoded → ncRNA coats to-be-Barred chromosome → ncRNA recruits condensing histone-modification enzymes to create Barr body, genes silenced
7 notes
·
View notes
Text
Global DNA Encoded Library Market Will Grow At Highest Pace Owing To Rising Demand For Targeted Drug Discovery

DNA encoded library is an innovative approach that employs DNA sequences to encode large chemical libraries for drug discovery. DNA encoded libraries provide advantages like screening of millions of compounds in parallel and facilitating drug discovery research. The technique involves encoding large collections of small molecules, peptides or oligonucleotides with short DNA tags and then screening them for potential hits. This enables high-throughput screens focusing on specific targets for applications in drug discovery, chemical biology and systematic evolution of ligands by exponential enrichment (SELEX).
The Global DNA Encoded Library Market is estimated to be valued at US$ 0.8 Bn in 2024 and is expected to exhibit a CAGR of 16% over the forecast period 2024-2031.
Key Takeaways
Key players operating in the Global DNA Encoded Library are BOC Sciences, DyNAbind, Edelris, GenScript, and HitGen. These players are adopting strategies like collaborations, investments in R&D and new product launches to strengthen their market position. The growing demand for effective therapeutics against various diseases is also boosting the demand for DNA encoded library-based drug discovery worldwide. Additionally, technological advancements like next generation sequencing and mass spectrometry is further enhancing the screening capabilities and fueling the growth of this market.
Market Trends
Some of the key trends driving the growth of the Global DNA Encoded Library market include rising adoption of DNA-encoded library techniques by pharmaceutical companies and growth of clinical trials. The traditional drug discovery methods are being replaced with DNA-encoded techniques owing to their advantages. They enable screening libraries of billions of compounds efficiently in a high-throughput manner. Another trend is the increasing partnerships between technology providers and end-users to accelerate the drug discovery process using DNA-encoded library platforms.
Market Opportunities
The untapped potential of emerging economies and growing research in genomic applications presents huge opportunities for players in this market. Rapid advances in DNA synthesis and sequencing technologies are further expanding the applications of DNA-encoded libraries. Adoption of artificial intelligence and machine learning can also enhance the screening and data analysis capabilities. Development of customized DNA-encoded libraries focused on specific disease pathways will witness high demand in coming years.
Impact Of Covid-19 On Global DNA Encoded Library Market Growth:
The outbreak of Covid-19 pandemic severely impacted the growth of global DNA encoded library market in the initial months of 2020. Various social restrictions imposed by governments like lockdowns and social distancing norms disrupted the supply chain and halted research activities at labs and research institutions globally. This led to delays in drug discovery programs utilizing DNA encoded libraries. Many biopharma companies also shifted resources to focus on Covid-19 vaccine and treatment research in the short term.
However, as research communities and industries adapted to the new normal, activity levels recovered gradually in 2021. The pandemic also highlighted the importance of therapeutics for infectious diseases, boosting investment in areas like antibiotic discovery utilizing DNA encoded libraries. Many players in the market also expedited development of Covid-19 antiviral and treatment libraries. Going forward, market players are focusing on digitalization of operations and remote collaborations to make discovery processes more resilient to future disruptions. Governments are also providing increased funding for genomics and biotech to accelerate development of new drugs.
Concentration Of Global DNA Encoded Library Market In Terms Of Value:
North America region currently accounts for the largest share of global DNA encoded library market in terms of value, estimated at over 40% in 2024. This is due to presence of major pharmaceutical players and contract research organizations (CROs) actively utilizing these libraries for drug discovery programs in the US and Canada. Countries like the US also provide favorable funding environment for genomic and biotech research. Europe is the second largest regional market led by presence of large pharma companies and academic research institutes in countries like UK, Germany and France. The market is also witnessing fastest growth in Asia Pacific region led by China and India. This is attributed to increasing government investments in healthcare sector, emerging biotech industry and growing expertise in DNA sequencing and library construction technologies.
Fastest Growing Region In The Global DNA Encoded Library Market:
Asia Pacific region is poised to emerge as the fastest growing regional market for DNA encoded libraries during the forecast period from 2024 to 2031. This growth can be attributed to increasing government emphasis and funding for research in genomics, biotech and synthetic biology in emerging economies like China and India. Favorable business environment and presence of skilled labor are also attracting many global library developers and pharmaceutical companies to set up research and manufacturing facilities in the region. In addition, the region provides significant cost advantages compared to developed markets for drug discovery processes. With improving standards and widespread adoption of DNA encoded library technologies, Asia Pacific will continue dominating the growth of worldwide market in the coming years.
Get more insights on this topic: https://www.pressreleasebulletin.com/global-dna-encoded-library-market-set-for-high-growth-due-to-advancements-in-dna-screening-technologies/
Author Bio:
Money Singh is a seasoned content writer with over four years of experience in the market research sector. Her expertise spans various industries, including food and beverages, biotechnology, chemical and materials, defense and aerospace, consumer goods, etc. (https://www.linkedin.com/in/money-singh-590844163 )
What Are The Key Data Covered In This Global DNA Encoded Library Market Report?
:- Market CAGR throughout the predicted period
:- Comprehensive information on the aspects that will drive the Global DNA Encoded Library Market's growth between 2024 and 2031.
:- Accurate calculation of the size of the Global DNA Encoded Library Market and its contribution to the market, with emphasis on the parent market
:- Realistic forecasts of future trends and changes in consumer behaviour
:- Global DNA Encoded Library Market Industry Growth in North America, APAC, Europe, South America, the Middle East, and Africa
:- A complete examination of the market's competitive landscape, as well as extensive information on vendors
:- Detailed examination of the factors that will impede the expansion of Global DNA Encoded Library Market vendors
FAQ’s
Q.1 What are the main factors influencing the Global DNA Encoded Library Market?
Q.2 Which companies are the major sources in this industry?
Q.3 What are the market’s opportunities, risks, and general structure?
Q.4 Which of the top Global DNA Encoded Library Market companies compare in terms of sales, revenue, and prices?
Q.5 Which businesses serve as the Global DNA Encoded Library Market’s distributors, traders, and dealers?
Q.6 How are market types and applications and deals, revenue, and value explored?
Q.7 What does a business area’s assessment of agreements, income, and value implicate?
*Note: 1. Source: Coherent Market Insights, Public sources, Desk research 2. We have leveraged AI tools to mine information and compile it
#Global DNA Encoded Library Market Trend#Global DNA Encoded Library Market Size#Global DNA Encoded Library Market Information#Global DNA Encoded Library Market Analysis#Global DNA Encoded Library Market Demand
1 note
·
View note