#Data Techniques
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
0 notes
Text
idk if I mentioned but I got to speak to JRO after the con at tfnation; specifically about the first aid plot line he didn’t end up getting to include in the mtmte comics!!
I missed the panel where he was talking about it, but one of my friends mentioned it, so I had to ask for more information!!!!!. First Aid essentially loses the plot for a while trying to find a way to bring ambulon back. it’s briefly mentioned as an off comment by (maybe ratchet?) that first aid has been isolating himself for months with ambulon’s dead body in the comics. Which is crazy btw lol anyway
first aid spends all that time between the plot failing to find ways to bring ambulon back to life. He fully repairs ambulons body, every fragment of him is visually perfect, /technically/ functional. He even repaints ambulon, touching up the patchy paint job Ambulon was known for.
But ambulon is truly dead. What made ambulon who he was, his memories, his personality, his knowledge, his friendship- was obliterated in the bisecting, as was his spark. It was a complete brain-death by cybertronian standards.
As far as I’m aware, the spark is just a power source, relative to the memory banks portion of their processors and whatnot, specifically the sections that store the bots actual personality and memories. Though it’s always worded differently. JRO didn’t give an exact time range (understandable lol) for how long they were on Delphi, but the general thought is that First Aid and Ambulon were on Delphi together for a decent chunk of years, relative to the timeline.
:((( first aid and ambulon really endured Delphi together and bonded throughout that, and to see him murdered so abruptly, (by their ex-boss who they watched descend into madness- no less!!!) was extremely traumatising, as much as it’s played as a joke by the fandom lolol. ambulon suffered what was essentially complete brain death at the moment of injury, non-recoverable.
The dynamic between ratchet, Pharma and first aid/ambulon is really interesting, other people can word it better than me but it ties massively into the feedback loop first aid gets lost in from that point. Watching his closest friend die in a hysterical power play between his two superiors would be helpless agony. And it hurts more because we know first aids temperament :(( he’s still soft, despite it all, and he’s the type of character that you just want to shield from the nastiness of it all. 😭😭
First aid goes as far tracking down the mechs that were involved in the faulty combiner experiment Ambulon was forced into. Looking for maybe even an echo or an imprint, faint traces in the data+code of the mech’s that might have had /anything/ of his friend left in it. Pieces he could put together to make him whole again. But there’s nothing, just surface level memories from a bond that never succeeded. MAN
Anyway, I’m going to try and draw something for it, please give me focus
#first aid#first aid mtmte#ambulon#maccadam#he just wants his friend back :(((((#i don’t ship them they are besties 2 me and JRO AGREES AJAHDHSHSJ#I missed so much because I had to go sit in complete silence in my hotel room for at least 1.5 hours after tabling LMAOO#ALSO TO NOTE: ambulon was heavily involved with saving rung after he was shot in the head by the swerve#I just picture first aid desperately trying the same techniques and it not working :((((#also I imagine ratchet manhandling his corpse into a weapon obliterated anything that could be saved from his data-banks
115 notes
·
View notes
Text

#fully functional and programmed in multiple techniques#the memes will continue until morale improves#RIKER#data tng#star trek memes#star trek
134 notes
·
View notes
Text

2 notes
·
View notes
Text

#lore soong#worf#star trek comics#black and white#wires#androids#uss defiant#st tng#data soong#datalore#nice coloring technique#brent spiner#robosexual#my edit#lore star trek#lore tng#data x lore#soong family#cybernetics#cyberpunk#artificial life#artifical intelligence#noonien soong#i love saying soongian#if i were brent id love that ppl were still blogging me every day
27 notes
·
View notes
Text
Unveiling the Best SEO Worker in Bangladesh: Driving Digital Success
#https://dev-seo-worker-in-bangladesh.pantheonsite.io/home/: With years of experience and a deep understanding of search engine algorithms#[Insert Name] possesses unparalleled expertise in SEO strategies and techniques. They stay abreast of the latest trends and updates in the#ensuring that clients benefit from cutting-edge optimization practices.#Customized Solutions: Recognizing that each business is unique#[Insert Name] tailors their SEO strategies to suit the specific needs and goals of every client. Whether it's improving website rankings#enhancing user experience#or boosting conversion rates#they craft personalized solutions that yield tangible results.#Data-Driven Approach: [Insert Name] firmly believes in the power of data to drive informed decision-making. They meticulously analyze websi#keyword performance#and competitor insights to devise data-driven SEO strategies that deliver maximum impact.#Transparent Communication: Clear and transparent communication lies at the heart of [Insert Name]'s approach to client collaboration. From#they maintain open lines of communication#ensuring that clients are always kept informed and empowered.#Proven Results: The success stories speak for themselves. Time and again#[Insert Name] has helped businesses across diverse industries achieve unprecedented growth in online visibility#organic traffic#and revenue generation. Their impressive portfolio of satisfied clients serves as a testament to their prowess as the best SEO worker in Ba#Continuous Improvement: In the dynamic landscape of SEO#adaptation is key to staying ahead. [Insert Name] is committed to continuous learning and refinement#constantly refining their skills and strategies to stay at the forefront of industry best practices.#In conclusion#[Insert Name] stands as a shining beacon of excellence in the realm of SEO in Bangladesh. Their unw
3 notes
·
View notes
Text

Armando Reverón – Reina con corona y vestido de Reverón, ND.
#armando reveron#1940s#I’m guessing based on the technique and colors that it belongs to the later period before his death but I couldn’t find a concrete data#venezuelan art#latin american art
2 notes
·
View notes
Text
Lensnure Solutions is a passionate web scraping and data extraction company that makes every possible effort to add value to their customer and make the process easy and quick. The company has been acknowledged as a prime web crawler for its quality services in various top industries such as Travel, eCommerce, Real Estate, Finance, Business, social media, and many more.
We wish to deliver the best to our customers as that is the priority. we are always ready to take on challenges and grab the right opportunity.
3 notes
·
View notes
Text
Mastering Data Analytics: Your Path to Success Starts at Corpus Digital Hub
Corpus Digital Hub is more than just a training institute—it's a hub of knowledge, innovation, and opportunity. Our mission is simple: to empower individuals with the skills and expertise needed to thrive in the fast-paced world of data analytics. Located in the vibrant city of Calicut, our institute serves as a gateway to endless possibilities and exciting career opportunities.
A Comprehensive Approach to Learning
At Corpus Digital Hub, we believe that education is the key to unlocking human potential. That's why we offer a comprehensive curriculum that covers a wide range of topics, from basic data analysis techniques to advanced machine learning algorithms. Our goal is to provide students with the tools and knowledge they need to succeed in today's competitive job market.
Building Strong Foundations
Success in data analytics begins with a strong foundation. That's why our courses are designed to provide students with a solid understanding of core concepts and principles. Whether you're new to the field or a seasoned professional, our curriculum is tailored to meet your unique needs and aspirations.
Hands-On Experience
Theory is important, but nothing beats hands-on experience. That's why we place a strong emphasis on practical learning at Corpus Digital Hub. From day one, students have the opportunity to work on real-world projects and gain valuable experience that will set them apart in the job market.
A Supportive Learning Environment
At Corpus Digital Hub, we believe that learning is a collaborative effort. That's why we foster a supportive and inclusive learning environment where students feel empowered to ask questions, share ideas, and explore new concepts. Our experienced faculty members are dedicated to helping students succeed and are always available to provide guidance and support.
Cultivating Future Leaders
Our ultimate goal at Corpus Digital Hub is to cultivate the next generation of leaders in data analytics. Through our rigorous curriculum, hands-on approach, and supportive learning environment, we provide students with the tools and confidence they need to excel in their careers and make a positive impact on the world.
Join Us on the Journey
Are you ready to take the next step towards a brighter future? Whether you're a recent graduate, a mid-career professional, or someone looking to make a career change, Corpus Digital Hub welcomes you with open arms. Join us on the journey to mastery in data analytics and unlock your full potential.
Contact Us Today
Ready to get started? Contact Corpus Digital Hub to learn more about our programs, admissions process, and scholarship opportunities. Your journey towards success starts here!
Stay connected with Corpus Digital Hub for the latest news, updates, and success stories from our vibrant community of learners and educators. Together, we'll shape the future of data analytics and make a difference in the world!

#data analytics#data science#machinelearning#Data Visualization#Business Intelligence#big data#Data Mining#Business Analytics#Data Exploration#Data Analysis Techniques#Data Analytics Certification#Data Analytics Training#Data Analyst Skills#Data Analytics Careers#Data Analytics Jobs#Data Analytics Industry
2 notes
·
View notes
Text
Swarm Enterprises
Website: https://swarm.enterprises/
Address: San Francisco, California
Phone: +1 (504) 249-8350
Swarm Enterprises: Revolutionizing Decision-Making with Cutting-Edge Technology
Swarm Enterprises is at the forefront of innovation, harnessing the power of swarm intelligence algorithms to redefine the way decisions are made. Inspired by the coordinated movements of natural swarms, these algorithms deliver unparalleled precision and intelligent recommendations. Clients are empowered to embrace data-driven decision-making, resulting in heightened efficiency and superior outcomes.
The company's secret weapon lies in its utilization of machine learning techniques, where massive data sets are transformed into invaluable insights. By training algorithms on both historical and real-time data, Swarm Enterprises uncovers hidden patterns, emerging trends, and subtle anomalies that often elude human analysis. This extraordinary capability allows clients to unearth concealed opportunities, minimize risks, and gain an undeniable competitive edge.
Swarm Enterprises doesn't stop there; they seamlessly integrate IoT (Internet of Things) devices into their offerings, enabling real-time data collection and analysis. These connected physical objects grant clients the ability to remotely monitor and manage various aspects of their operations. This groundbreaking technology not only streamlines proactive maintenance but also enhances operational efficiency and boosts overall productivity.
In a world where informed decisions are paramount, Swarm Enterprises is a trailblazer, providing the tools and insights necessary for success in an increasingly data-centric landscape.

#Bot Detection & Defense in San Francisco#Real-time bot detection near me#Security against live botnet traffic#Browser Feature Signatures#Performance Profiling#Automated Behavior Analysis#Advanced Analysis Technique#Integration & Results#Data & Insights#Simplified Integration#Accuracy and Precision#Real-time Reporting
2 notes
·
View notes
Text
“To sum up, just because someone put a lot of work into gathering data and making a nice color-coded chart, doesn’t mean the data is GOOD or VALUABLE.”
^^^^^^^ this!! A massive pet peeve of mine is that people assume just because “analysis” has been done on data that it’s valid. But you can do analysis on junk data and still turn out a pretty picture! Your analysis is only as good as the data and assumptions you have made.
If something looks hinky, investigate it further. Maybe it’s nothing, but maybe the assumptions underlying the data are wrong, or the type of analysis someone has done is wrong.
AO3 Ship Stats: Year In Bad Data
You may have seen this AO3 Year In Review.

It hasn’t crossed my tumblr dash but it sure is circulating on twitter with 3.5M views, 10K likes, 17K retweets and counting. Normally this would be great! I love data and charts and comparisons!
Except this data is GARBAGE and belongs in the TRASH.
I first noticed something fishy when I realized that Steve/Bucky – the 5th largest ship on AO3 by total fic count – wasn’t on this Top 100 list anywhere. I know Marvel’s popularity has fallen in recent years, but not that much. Especially considering some of the other ships that made it on the list. You mean to tell me a femslash HP ship (Mary MacDonald/Lily Potter) in which one half of the pairing was so minor I had to look up her name because she was only mentioned once in a single flashback scene beat fandom juggernaut Stucky? I call bullshit.
Now obviously jumping to conclusions based on gut instinct alone is horrible practice... but it is a good place to start. So let’s look at the actual numbers and discover why this entire dataset sits on a throne of lies.
Here are the results of filtering the Steve/Bucky tag for all works created between Jan 1, 2023 and Dec 31, 2023:
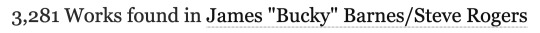
Not only would that place Steve/Bucky at #23 on this list, if the other counts are correct (hint: they're not), it’s also well above the 1520-new-work cutoff of the #100 spot. So how the fuck is it not on the list? Let’s check out the author’s FAQ to see if there’s some important factor we’re missing.
The first thing you��ll probably notice in the FAQ is that the data is being scraped from publicly available works. That means anything privated and only accessible to logged-in users isn’t counted. This is Sin #1. Already the data is inaccurate because we’re not actually counting all of the published fics, but the bots needed to do data collection on this scale can't easily scrape privated fics so I kinda get it. We’ll roll with this for now and see if it at least makes the numbers make more sense:
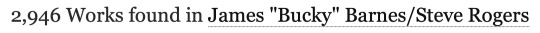
Nope. Logging out only reduced the total by a couple hundred. Even if one were to choose the most restrictive possible definition of "new works" and filter out all crossovers and incomplete fics, Steve/Bucky would still have a yearly total of 2,305. Yet the list claims their total is somewhere below 1,500? What the fuck is going on here?
Let’s look at another ship for comparison. This time one that’s very recent and popular enough to make it on the list so we have an actual reference value for comparison: Nick/Charlie (Heartstopper). According to the list, this ship sits at #34 this year with a total of 2630 new works. But what’s AO3 say?
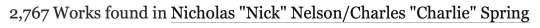
Off by a hundred or so but the values are much closer at least!
If we dig further into the FAQ though we discover Sin #2 (and the most egregious): the counting method. The yearly fic counts are NOT determined by filtering for a certain time period, they’re determined by simply taking a snapshot of the total number of fics in a ship tag at the end of the year and subtracting the previous end-of-year total. For example, if you check a ship tag on Jan 1, 2023 and it has 10,000 fics and check it again on Jan 1, 2024 and it now has 12,000 fics, the difference (2,000) would be the number of "new works" on this chart.
At first glance this subtraction method might seem like a perfectly valid way to count fics, and it’s certainly the easiest way, but it can and did have major consequences to the point of making the entire dataset functionally meaningless. Why? If any older works are deleted or privated, every single one of those will be subtracted from the current year fic count. And to make the problem even worse, beginning at the end of last year there was a big scare about AI scraping fics from AO3, which caused hundreds, if not thousands, of users to lock down their fics or delete them.
The magnitude of this fuck up may not be immediately obvious so let’s look at an example to see how this works in practice.
Say we have two ships. Ship A is more than a decade old with a large fanbase. Ship B is only a couple years old but gaining traction. On Jan 1, 2023, Ship A had a catalog of 50,000 fics and ship B had 5,000. Both ships have 3,000 new works published in 2023. However, 4% of the older works in each fandom were either privated or deleted during that same time (this percentage is was just chosen to make the math easy but it’s close to reality).
Ship A: 50,000 x 4% = 2,000 removed works Ship B: 5,000 x 4% = 200 removed works
Ship A: 3,000 - 2,000 = 1,000 "new" works Ship B: 3,000 - 200 = 2,800 "new" works
This gives Ship A a net gain of 1,000 and Ship B a net gain of 2,800 despite both fandoms producing the exact same number of new works that year. And neither one of these reported counts are the actual new works count (3,000). THIS explains the drastic difference in ranking between a ship like Steve/Bucky and Nick/Charlie.
How is this a useful measure of anything? You can't draw any conclusions about the current size and popularity of a fandom based on this data.
With this system, not only is the reported "new works" count incorrect, the older, larger fandom will always be punished and it’s count disproportionately reduced simply for the sin of being an older, larger fandom. This example doesn’t even take into account that people are going to be way more likely to delete an old fic they're no longer proud of in a fandom they no longer care about than a fic that was just written, so the deletion percentage for the older fandom should theoretically be even larger in comparison.
And if that wasn't bad enough, the author of this "study" KNEW the data was tainted and chose to present it as meaningful anyway. You will only find this if you click through to the FAQ and read about the author’s methodology, something 99.99% of people will NOT do (and even those who do may not understand the true significance of this problem):


The author may try to argue their post states that the tags "which had the greatest gain in total public fanworks” are shown on the chart, which makes it not a lie, but a error on the viewer’s part in not interpreting their data correctly. This is bullshit. Their chart CLEARLY titles the fic count column “New Works” which it explicitly is NOT, by their own admission! It should be titled “Net Gain in Works” or something similar.
Even if it were correctly titled though, the general public would not understand the difference, would interpret the numbers as new works anyway (because net gain is functionally meaningless as we've just discovered), and would base conclusions on their incorrect assumptions. There’s no getting around that… other than doing the counts correctly in the first place. This would be a much larger task but I strongly believe you shouldn’t take on a project like this if you can’t do it right.
To sum up, just because someone put a lot of work into gathering data and making a nice color-coded chart, doesn’t mean the data is GOOD or VALUABLE.
#ao3#ao3 stats#data quality#also a reason I hate the use of big data techniques#it’s very easy to just run junk data through it til you find something#doesn’t mean the something is useful#data should be considered in CONTEXT
4K notes
·
View notes
Text
How Do You Use a SAS Tutorial to Learn Data Cleaning Techniques?
Before you start analyzing data, it's important to understand how clean your dataset is. If your data has missing values, duplicate entries, or inconsistent formatting, it can throw off your entire analysis. Even the most advanced model won’t work well if the data going into it is flawed.
That’s where SAS programming comes in. When you follow a SAS tutorial, you’re not just learning how to write code—you’re learning how to think through data problems. A good tutorial explains what each step does and why it’s important.
Here’s how to use a SAS tutorial to build your data cleaning skills, step by step.
1. Start by Inspecting the Data
The first thing most SAS tutorials will show you is how to explore and inspect your dataset. This helps you understand what you’re working with.
You’ll learn how to use:
PROC CONTENTS to see the structure and metadata
PROC PRINT to view the raw data
PROC FREQ and PROC MEANS to check distributions and summaries
As you review the outputs, you’ll start spotting common problems like:
Too many missing values in key variables
Numbers stored as text
Values that don’t make sense or fall outside expected ranges
These early steps help you catch red flags before you go deeper.
2. Learn How to Handle Missing Data
Missing data is very common, and a good SAS tutorial will show you a few ways to deal with it.
This includes:
Using IF conditions to identify missing values
Replacing them with zeros, averages, or medians
Removing variables or rows if they’re not useful anymore
The tutorial might also explain when to fill in missing data and when to just leave it out. Real-world examples from healthcare, marketing, or finance help make the decisions easier to understand.
3. Standardize and Format Your Data
A lot of data comes in messy. For example, dates might be stored in different formats or categories might use inconsistent labels like "M", "Male", and "male".
With SAS programming, you can clean this up by:
Converting dates using INPUT and PUT functions
Making text consistent with UPCASE or LOWCASE
Recoding values into standardized categories
Getting your formatting right helps make sure your data is grouped and analyzed correctly.
4. Remove Duplicate Records
Duplicate records can mess up your summaries and analysis. SAS tutorials usually explain how to find and remove duplicates using:
PROC SORT with the NODUPKEY option
BY group logic to keep the most recent or most relevant entry
Once you understand the concept in a tutorial, you’ll be able to apply it to more complex datasets with confidence.
5. Identify Outliers and Inconsistencies
Advanced tutorials often go beyond basic cleaning and help you detect outliers—data points that are far from the rest.
You’ll learn techniques like:
Plotting your data with PROC SGPLOT
Using PROC UNIVARIATE to spot unusual values
Writing logic to flag or filter out problem records
SAS makes this process easier, especially when dealing with large datasets.
6. Validate Your Cleaning Process
Cleaning your data isn’t complete until you check your work. Tutorials often show how to:
Re-run summary procedures like PROC MEANS or PROC FREQ
Compare row counts before and after cleaning
Save versions of your dataset along the way so nothing gets lost
This step helps prevent mistakes and makes sure your clean dataset is ready for analysis.
youtube
Why SAS Programming Helps You Learn Faster
SAS is great for learning data cleaning because:
The syntax is simple and easy to understand
The procedures are powerful and built-in
The SAS community is active and supportive
Whether you're a beginner or trying to improve your skills, SAS tutorials offer a strong, step-by-step path to learning how to clean data properly.
Final Thoughts
Learning data cleaning through a SAS tutorial doesn’t just teach you code—it trains you to think like a data analyst. As you go through each lesson, try applying the same steps to a dataset you’re working with. The more hands-on experience you get, the more confident you’ll be.
If you want to improve your data analysis and make better decisions, start by getting your data clean. And using SAS programming to do it? That’s a smart first move.
#sas tutorial#sas programming tutorial#sas online training#data analyst#Data Cleaning Techniques#Data Cleaning#Youtube
0 notes
Text
LORE + SPOCK : Star Trek #5
Spock: “It may prove useful to our investigation, and when you are engaged with such a scientific puzzle, you seem far less threatening and potentially violent.” Lore: “Hm. Sure.”




IDOL ⭐️ HANDS: apparently they already re-dressed themselves or do the outfits repair themselves?? *insert stripper music* 🎶 V'Ger
A sentient, massive entity which threatened Earth in 2271, en route to find its "Creator." In doing so, V'Ger destroyed anything it encountered by digitizing it for its memory chamber.
Generating a power field "cloud" about itself of over 22 AUs in diameter, the entity had gained sentience after unknown aliens repaired the old Earth space probe that formed its core — Voyager 6, whose name in corrupted English gave the sentience its name.
The entity, which viewed organic lifeforms as carbon-based units "infesting" starships, later joined with Starfleet's Lt. Ilia and Cmdr. Will Decker and evolved into a higher, yet unknown lifeform. source: https://www.startrek.com/database_article/vger
#I sympathize#lore soong#lore star trek#lore tng#data x lore#star trek lore#spock#mr spock#ambassador spock#mister spock#star trek comics#star trek defiant#star trek: defiant#nice coloring technique#vulcans#androids#st tng#brent spiner#star trek tng#star trek the next generation#soong family#star trek tos#trek#star trek art#datalore#crystalline entity#ai sentience#sentient
24 notes
·
View notes
Text
Demystifying Data Analytics: Techniques, Tools, and Applications

Introduction: In today’s digital landscape, data analytics plays a critical role in transforming raw data into actionable insights. Organizations rely on data-driven decision-making to optimize operations, enhance customer experiences, and gain a competitive edge. At Tudip Technologies, the focus is on leveraging advanced data analytics techniques and tools to uncover valuable patterns, correlations, and trends. This blog explores the fundamentals of data analytics, key methodologies, industry applications, challenges, and emerging trends shaping the future of analytics.
What is Data Analytics? Data analytics is the process of collecting, processing, and analyzing datasets to extract meaningful insights. It includes various approaches, ranging from understanding past events to predicting future trends and recommending actions for business optimization.
Types of Data Analytics: Descriptive Analytics – Summarizes historical data to reveal trends and patterns Diagnostic Analytics – Investigates past data to understand why specific events occurred Predictive Analytics – Uses statistical models and machine learning to forecast future outcomes Prescriptive Analytics – Provides data-driven recommendations to optimize business decisions Key Techniques & Tools in Data Analytics Essential Data Analytics Techniques: Data Cleaning & Preprocessing – Ensuring accuracy, consistency, and completeness in datasets Exploratory Data Analysis (EDA) – Identifying trends, anomalies, and relationships in data Statistical Modeling – Applying probability and regression analysis to uncover hidden patterns Machine Learning Algorithms – Implementing classification, clustering, and deep learning models for predictive insights Popular Data Analytics Tools: Python – Extensive libraries like Pandas, NumPy, and Matplotlib for data manipulation and visualization. R – A statistical computing powerhouse for in-depth data modeling and analysis. SQL – Essential for querying and managing structured datasets in databases. Tableau & Power BI – Creating interactive dashboards for data visualization and reporting. Apache Spark – Handling big data processing and real-time analytics. At Tudip Technologies, data engineers and analysts utilize scalable data solutions to help businesses extract insights, optimize processes, and drive innovation using these powerful tools.
Applications of Data Analytics Across Industries: Business Intelligence – Understanding customer behavior, market trends, and operational efficiency. Healthcare – Predicting patient outcomes, optimizing treatments, and managing hospital resources. Finance – Detecting fraud, assessing risks, and enhancing financial forecasting. E-commerce – Personalizing marketing campaigns and improving customer experiences. Manufacturing – Enhancing supply chain efficiency and predicting maintenance needs for machinery. By integrating data analytics into various industries, organizations can make informed, data-driven decisions that lead to increased efficiency and profitability. Challenges in Data Analytics Data Quality – Ensuring clean, reliable, and structured datasets for accurate insights. Privacy & Security – Complying with data protection regulations to safeguard sensitive information. Skill Gap – The demand for skilled data analysts and scientists continues to rise, requiring continuous learning and upskilling. With expertise in data engineering and analytics, Tudip Technologies addresses these challenges by employing best practices in data governance, security, and automation. Future Trends in Data Analytics Augmented Analytics – AI-driven automation for faster and more accurate data insights. Data Democratization – Making analytics accessible to non-technical users via intuitive dashboards. Real-Time Analytics – Enabling instant data processing for quicker decision-making. As organizations continue to evolve in the data-centric era, leveraging the latest analytics techniques and technologies will be key to maintaining a competitive advantage.
Conclusion: Data analytics is no longer optional—it is a core driver of digital transformation. Businesses that leverage data analytics effectively can enhance productivity, streamline operations, and unlock new opportunities. At Tudip Learning, data professionals focus on building efficient analytics solutions that empower organizations to make smarter, faster, and more strategic decisions. Stay ahead in the data revolution! Explore new trends, tools, and techniques that will shape the future of data analytics.
Click the link below to learn more about the blog Demystifying Data Analytics Techniques, Tools, and Applications: https://tudiplearning.com/blog/demystifying-data-analytics-techniques-tools-and-applications/.
#Data Analytics Techniques#Big Data Insights#AI-Powered Data Analysis#Machine Learning for Data Analytics#Data Science Applications#Data Analytics#Tudip Learning
1 note
·
View note
Text
Reblogging to add a specific thing I’ve messed around with: blurring data is not secure. Blurred data can be recovered, with some trial and error. Just gotta guess the right values for the kernel (the blurring filter, basically) that was applied and you can “reverse” the blur effect (it’s not likely to be one to one, there will likely be some artifacts) well enough that a person could read data from the image. If they get it right. But they have as many tries to get the parameters right as they need.
Censor it as completely as you can, destroy any pixels that could give data.
Unfortunately I am no expert in security so I can’t give advice on what to do instead, I just know about undoing blurring because I messed around with image processing techniques last fall.
Maybe look up destructive censoring? You want to destroy the sensitive data, not transform it. It should not be recoverable.
I try to use the boxes filled in to try and cover the pixels completely, and then I (maybe unnecessarily, idk) take a screenshot of the image and send that. I don’t want to chance that the original image is recoverable when sent out, even though I’m pretty sure that’s not easily done. But I think designing the feature for sending edited images such that it contained the original image in its data would be a terrible idea. I doubt major companies do that but there is likely a lot of metadata in files other than images that you might send out.
He did bro so bad homie made another video just to apologize.
#data security#computers#i’m talking about image processing techniques#using fast Fourier transform and blurring kernels of different radii to unblur
41K notes
·
View notes
Text
What is NLP? What is the Role of NLP in AI?
#nlp#machine learning#automation#data analytics#generativeai#datascience#nlp techniques#app development#apple store#applications#game development#app#game#web#unity game#software development#usa
0 notes