#Difference Between Char and Varchar
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
The main difference between CHAR and VARCHAR lies in how they store data. CHAR is a fixed-length data type, meaning it always uses the defined space, even if the actual string is shorter. In contrast, VARCHAR is variable-length, only using the space necessary for the string plus a few bytes for storage length, making it more space-efficient. Click here to learn more.
0 notes
Text

Top 3 Difference between char and varchar
0 notes
Text
100%OFF | SQL Server Interview Questions and Answers

If you are looking forward to crack SQL Server interviews then you are at the right course.
Working in SQL Server and cracking SQL Server interviews are different ball game. Normally SQL Server professionals work on repetitive tasks like back ups , custom reporting and so on. So when they are asked simple questions like Normalization , types of triggers they FUMBLE.
Its not that they do not know the answer , its just that they need a revision. That’s what this course exactly does. Its prepares you for SQL Server interview in 2 days.
Below are the list of questions with answers , demonstration and detailed explanation. Happy learning. Happy job hunting.
SQL Interview Questions & Answers – Part 1 :-
Question 1 :- Explain normalization ?
Question 2 :- How to implement normalization ?
Question 3 :- What is denormalization ?
Question 4 :- Explain OLTP vs OLAP ?
Question 5 :- Explain 1st,2nd and 3rd Normal form ?
Question 6 :- Primary Key vs Unique key ?
Question 7 :- Differentiate between Char vs Varchar ?
Question 8 :- Differentiate between Char vs NChar ?
Question 9 :- Whats the size of Char vs NChar ?
Question 10 :- What is the use of Index ?
Question 11 :- How does it make search faster?
Question 12 :- What are the two types of Indexes ?
Question 13 :- Clustered vs Non-Clustered index
Question 14 :- Function vs Stored Procedures
Question 15 :- What are triggers and why do you need it ?
Question 16 :- What are types of triggers ?
Question 17 :- Differentiate between After trigger vs Instead Of ?
Question 18 :- What is need of Identity ?
Question 19 :- Explain transactions and how to implement it ?
Question 20 :- What are inner joins ?
Question 21 :- Explain Left join ?
Question 22 :- Explain Right join ?
Question 23 :- Explain Full outer joins ?
Question 24 :- Explain Cross joins ?
SQL Interview Questions & Answers – Part 2 :-
Question 25:-Why do we need UNION ?
Question 26:-Differentiate between Union vs Union All ?
Question 27:-can we have unequal columns in Union?
Question 28:-Can column have different data types in Union ?
Question 29:- Which Aggregate function have you used ?
Question 30:- When to use Group by ?
Question 31:- Can we select column which is not part of group by ?
Question 32:- What is having clause ?
Question 33:- Having clause vs Where clause
Question 34:- How can we sort records ?
Question 35:- Whats the default sort ?
Question 36:- How can we remove duplicates ?
Question 37:- Select the first top X records ?
Question 38:- How to handle NULLS ?
Question 39:- What is use of wild cards ?
Question 40:- What is the use of Alias ?
Question 41:- How to write a case statement ?
Question 42:- What is self reference tables ?
Question 43:- What is self join ?
Question 44:- Explain the between clause ?
SQL Interview Questions & Answers – Part 3 :-
Question 45:- Explain SubQuery?
Question 46:- Can inner Subquery return multiple results?
Question 47:- What is Co-related Query?
Question 48:- Differentiate between Joins and SubQuery?
Question 49:- Performance Joins vs SubQuery?
SQL Interview Questions & Answers – Part 4 :-
Question 50:- Find NTH Highest Salary in SQL.
SQL Interview Questions & Answers – Part 5
Question 51:- Select the top nth highest salary using correlated Queries?
Question 52:- Select top nth using using TSQL
Question 53:- Performance comparison of all the methods.
[ENROLL THE COURSE]
21 notes
·
View notes
Text
Top 12 MySQL Interview Questions and Answers for Experienced
SQL Server is just one of those database management systems (DBMS) and was created by Microsoft. DBMS are computer software programs that can interact with customers, several different programs, and databases. SQL Server aims to capture and assess data and handle the definition, querying, production, upgrading, and management of this database.
1.Just how and use SQL Server?
SQL Server is completely free, and everyone can download and use it. The program uses SQL (Structured Query Language), and it's not difficult to use.
2.What are the characteristics of MySQL?
MySQL provides cross-platform aid, a vast array of ports for application programming, also contains many stored procedures like activates and cursors that assist with handling the database.
3.What's the Conventional Network Library to get a system?
In either Windows or POSIX systems, the pipes supply manners of inter-process communications to join unique processes running on precisely the same machine. It dispenses with the requirement of employing the system stack, and information can be routed without affecting the operation. Servers set up pipes to obey requests. The client process has to be aware of the particular pipe title to send the petition.
4.What's the default interface for MySQL Server?
The default interface for MySQL Server is 3306. The other typical default port is 1433 in TCP/IP for SQL Server.
Learn about SQL through this SQL Certification Course!
5.What exactly do DDL, DML, and DCL stand for?
DDL is the abbreviation for Data Definition Language coping with database schemas and the description of how information resides in the database. A good instance of that can be the CREATE TABLE command. DML denotes Data Manipulation Language, including commands like SELECT, INSERT, etc.. DCL stands for Data Control Language and contains commands such as GRANT, REVOKE, etc..
6.What's a link in MySQL?
In MySQL, units are utilized to query data from a few tables. The question is made using the association between particular columns present from the table. There are four kinds of joins in MySQL.
7.What's the difference between CHAR and VARCHAR?
When a table is created, CHAR is used to specify these columns and tables' fixed duration. The duration value could be in the selection of 1--255. The VARCHAR control is used to correct the table and column spans as needed.
6.What exactly are Heap Tables?
Fundamentally, Heap tables have been in-memory tables utilized for temporary storage that was temporary. However, TEXT or BLOB fields aren't permitted in them. They likewise, don't encourage AUTOINCREMENT.
7.What's the limitation of indexed columns which may be made for a desk?
The utmost limit of indexed columns that could be made for almost any dining table is 16.
8.What are the various kinds of strings used in database columns in MySQL?
In MySQL, the various sorts of strings used for database columns are SET, BLOB, VARCHAR, TEXT, ENUM, and CHAR.
9.What's the limitation of indexed columns which may be made for a desk?
The utmost limitation of indexed columns which could be made for almost any dining table is 16.
10.What are the various kinds of strings used in database columns in MySQL?
In MySQL, the various sorts of strings which may be used for database columns are SET, BLOB, VARCHAR, TEXT, ENUM, and CHAR.
11.What's the usage of ENUM in MySQL?
Using ENUM will restrict the values that may go to a desk. As an example, a user may make a table providing specific month worth along with other month worth wouldn't enter in the table.
12.The way to use the MySQL slow query log?
Information that's provided on the slow query log may be enormous in size. The question might also be recorded more than a million times. To be able to outline the slow query log into an informative fashion, an individual can utilize the third-party application'pt-query-digest'.
Know more
1 note
·
View note
Text
Q33. What is the difference between Unicode data types and Non-Unicode data types? Q34. What is the difference between fixed-length data type and variable-length data type? Q35. What is the difference between CHAR vs VARCHAR data types? Q36. What is the difference between VARCHAR vs NVARCHAR data types? Q37. What is the max size of a VARCHAR and NVARCHAR data type in SQL, Why? Q38. What is the difference between VARCHAR(MAX) and VARCHAR(n) data types? Q39. What is the difference between VARCHAR(MAX) and TEXT(n) data types? Q40. What is the difference between LEN() and DATALENGTH() in SQL? Q41. What is the difference between DateTime and DateTime2 data types in SQL?
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda#techpoint#interview
0 notes
Text
Understanding MySQL’s New Heatwave
Data Analytics is important in any company as you can see what happened in the past to be able to make smart decisions or even predict future actions using the existing data. Analyze a huge amount of data could be hard and you should need to use more than one database engine, to handle OLTP and OLAP workloads. In this blog, we will see what is HeatWave, and how it can help you on this task. What is HeatWave? HeatWave is a new integrated engine for MySQL Database Service in the Cloud. It is a distributed, scalable, shared-nothing, in-memory, columnar, query processing engine designed for fast execution of analytic queries. According to the official documentation, it accelerates MySQL performance by 400X for analytics queries, scales out to thousands of cores, and is 2.7X faster at around one-third the cost of the direct competitors. MySQL Database Service, with HeatWave, is the only service for running OLTP and OLAP workloads directly from the MySQL database. How HeatWave Works A HeatWave cluster includes a MySQL DB System node and two or more HeatWave nodes. The MySQL DB System node has a HeatWave plugin that is responsible for cluster management, loading data into the HeatWave cluster, query scheduling, and returning query results to the MySQL DB System. HeatWave nodes store data in memory and process analytics queries. Each HeatWave node contains an instance of HeatWave. The number of HeatWave nodes required depends on the size of your data and the amount of compression that is achieved when loading the data into the HeatWave cluster. We can see the architecture of this product in the following image: As you can see, users don’t access the HeatWave cluster directly. Queries that meet certain prerequisites are automatically offloaded from the MySQL DB System to the HeatWave cluster for accelerated processing, and the results are returned to the MySQL DB System node and then to the MySQL client or application that issued the query. How to use it To enable this feature, you will need to access the Oracle Cloud Management Site, access the existing MySQL DB System (or create a new one), and add an Analitycs Cluster. There you can specify the type of cluster and the number of nodes. You can use the Estimate Node Count feature to know the necessary number based on your workload. Loading data into a HeatWave cluster requires preparing tables on the MySQL DB System and executing table load operations. Preparing Tables Preparing tables involves modifying table definitions to exclude certain columns, define string column encodings, add data placement keys, and specify HeatWave (RAPID) as the secondary engine for the table, as InnoDB is the primary one. To define RAPID as the secondary engine for a table, specify the SECONDARY_ENGINE table option in a CREATE TABLE or ALTER TABLE statement: mysql> CREATE TABLE orders (id INT) SECONDARY_ENGINE = RAPID; or mysql> ALTER TABLE orders SECONDARY_ENGINE = RAPID; Loading Data Loading a table into a HeatWave cluster requires executing an ALTER TABLE operation with the SECONDARY_LOAD keyword. mysql> ALTER TABLE orders SECONDARY_LOAD; When a table is loaded, data is sliced horizontally and distributed among HeatWave nodes. After a table is loaded, changes to a table's data on the MySQL DB System node are automatically propagated to the HeatWave nodes. Example For this example, we will use the table orders: mysql> SHOW CREATE TABLE ordersG *************************** 1. row *************************** Table: orders Create Table: CREATE TABLE `orders` ( `O_ORDERKEY` int NOT NULL, `O_CUSTKEY` int NOT NULL, `O_ORDERSTATUS` char(1) COLLATE utf8mb4_bin NOT NULL, `O_TOTALPRICE` decimal(15,2) NOT NULL, `O_ORDERDATE` date NOT NULL, `O_ORDERPRIORITY` char(15) COLLATE utf8mb4_bin NOT NULL, `O_CLERK` char(15) COLLATE utf8mb4_bin NOT NULL, `O_SHIPPRIORITY` int NOT NULL, `O_COMMENT` varchar(79) COLLATE utf8mb4_bin NOT NULL, PRIMARY KEY (`O_ORDERKEY`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin You can exclude columns that you don’t want to load to HeatWave: mysql> ALTER TABLE orders MODIFY `O_COMMENT` varchar(79) NOT NULL NOT SECONDARY; Now, define RAPID as SECONDARY_ENGINE for the table: mysql> ALTER TABLE orders SECONDARY_ENGINE RAPID; Make sure that you have the SECONDARY_ENGINE parameter added in the table definition: ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin SECONDARY_ENGINE=RAPID And finally, load the table into HeatWave: mysql> ALTER TABLE orders SECONDARY_LOAD; You can use EXPLAIN to check if it is using the correct engine. You should see something like this: Extra: Using where; Using temporary; Using filesort; Using secondary engine RAPID On the MySQL official site, you can see a comparison between a normal execution and using HeatWave: HeatWave Execution mysql> SELECT O_ORDERPRIORITY, COUNT(*) AS ORDER_COUNT FROM orders WHERE O_ORDERDATE >= DATE '1994-03-01' GROUP BY O_ORDERPRIORITY ORDER BY O_ORDERPRIORITY; +-----------------+-------------+ | O_ORDERPRIORITY | ORDER_COUNT | +-----------------+-------------+ | 1-URGENT | 2017573 | | 2-HIGH | 2015859 | | 3-MEDIUM | 2013174 | | 4-NOT SPECIFIED | 2014476 | | 5-LOW | 2013674 | +-----------------+-------------+ 5 rows in set (0.04 sec) Normal Execution mysql> SELECT O_ORDERPRIORITY, COUNT(*) AS ORDER_COUNT FROM orders WHERE O_ORDERDATE >= DATE '1994-03-01' GROUP BY O_ORDERPRIORITY ORDER BY O_ORDERPRIORITY; +-----------------+-------------+ | O_ORDERPRIORITY | ORDER_COUNT | +-----------------+-------------+ | 1-URGENT | 2017573 | | 2-HIGH | 2015859 | | 3-MEDIUM | 2013174 | | 4-NOT SPECIFIED | 2014476 | | 5-LOW | 2013674 | +-----------------+-------------+ 5 rows in set (8.91 sec) As you can see, there is an important difference in the time of the query, even in a simple query. For more information, you can refer to the official documentation. Conclusion A single MySQL Database can be used for both OLTP and Analytics Applications. It is 100% compatible with MySQL on-premises, so you can keep your OLTP workloads on-premises and offload your analytics workloads to HeatWave without changes in your application, or even use it directly on the Oracle Cloud to improve your MySQL performance for Analytics purposes. Tags: MySQLMySQL HeatwaveHeatWave clustermysql deployment https://severalnines.com/database-blog/understanding-mysql-s-new-heatwave
0 notes
Text
Constraints In SQL By Sagar Jaybhay
New Post has been published on https://is.gd/zFLU3k
Constraints In SQL By Sagar Jaybhay

Constraints In SQL
Constraints are the rules which are enforced on columns of the table in database. They specifically used to limit or restrict that data goes into a column. Constraints ensure the reliability and accuracy of data.
We can apply constraints on column level or table level. In this column level constraints are applied on one column at a time but when you use table-level constraints these are applied on all columns of that table.
Commonly used Column constraints are below
Not Null
Default
Unique
Primary Key
Foreign key
Check
Index
Commonly used table-level constraints
Primary key
Foreign key
Unique
Check
In case if you insert any data that violets the constraints then the operation is aborted.
Constraints can be applied at the time of table creation by using Create Table syntax and another is with Alter table statement.
Default Constraint
This constraint is used to set or specify a default value for that column if any value doesn’t provide. This means it is used to insert a default value into a column. The default value is set for all records if any value doesn’t provide including Null.
To alter an existing table or add default constraint to a column using Alter table syntax.
Alter table table_name Add constraint constraint_name Default default_value for Column_name
To add a new column to an existing table with a default value
Alter table table_name Add column_name data_type (Null | Not Null) Constraint constraint_name default default_value
Drop Constraint
Alter table table_name Drop constraint constraint_name
alter table Person add constraint df_value default 3 for [genederID]
Check Constraint
The check constraint is used to limit the range of the values which are entered for a specific column. In our case, a person’s table is already created. So we can add a new column age with check constraint by using alter table syntax.
alter table person add age int constraint chk_age check(age>0 and age<200)
Now if I going to insert negative value in that person column by using below query
insert into Person values(7,'rr1','[email protected]',Null,-9)
it will throw below error Msg 547, Level 16, State 0, Line 50 The INSERT statement conflicted with the CHECK constraint “chk_age”. The conflict occurred in database “temp”, table “dbo.Person”, column ‘age’. The statement has been terminated. The only flaw of this if you pass the null value it will be inserted any way and not throw any error.
insert into Person values(9,'rr2','[email protected]',Null,NULL)
this query works perfectly.
How Check constraint works?
When we add check constraint we add some condition in parenthesis. It is actually Boolean Expression when we pass value it will first pass to that expression and the expression returns the value.
If it returns true value then check constraint allows the value otherwise it doesn’t allow that value. So what happens when we pass the null value? In this person’s age case when we pass NULL value it passes to expression and expression is evaluated this as Unknown so for that reason it allows null value.
Drop a Check Constraint Alter table person Drop constraint chek_constraint_name
Unique Key Constraint
This unique key constraint is used to enforce the uniqueness of a column i.e column shouldn’t allow any duplicate value. You can add unique key constraints by using a designer or by using a query.
Below is the syntax for add unique constraint by using alter table syntax.
Alter table table_name Add constraint constraint_name unique(column_name);
If you see both primary key and unique keys are used to enforce the uniqueness of column so the question in your mind when to use what?
One table has only one primary key and if you want to add uniqueness for more than one column you can use unique key constraints.
What is the difference between the Unique key and Primary Key?
A table has only one primary key but a table can have more than one unique key
The primary key doesn’t allow null values where a unique key allows only one null value.
alter table person add constraint unique_name_key Unique([email]);
What if you enter the same value again for a unique constraint?
insert into Person values(10,'rr2','[email protected]',Null,NULL)
I use the above query to insert value I only change a primary key value and all record is present previously in a table at 9’Th location but when I ran this query I get the following result
Msg 2627, Level 14, State 1, Line 87 Violation of UNIQUE KEY constraint ‘unique_name_key’. Cannot insert duplicate key in object ‘dbo.Person’. The duplicate key value is ([email protected]). The statement has been terminated.
How to drop unique key constraint?
Alter table table_name Drop constraint constraint_name;
alter table person drop constraint unique_name_key
Not Null Constraint
By default, a column can contain null values but you want to restrict the column that not to allow NULL values then this constraint is used.
This not null constraint enforces a rule on a column that always contains a value.
CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255) NOT NULL, Age int );
Not Null constraint by using Alter table syntax
ALTER TABLE Persons MODIFY Age int NOT NULL;
Index Constraint
It is used to access the data very fast means for faster retrieval of data index is created. An index can be created on a single column or multiple columns. When you create an index it will create or assign rowed for each row.
Indexes have a good performance on large databases when it comes to retrieval of data but performance is low when insertion.
create table Person(ID int not null Primary key,name varchar(100),email varchar(100),genederID int)
CREATE INDEX index_name ON table_name ( column1, column2.....);
CREATE INDEX person_tabel_index ON person (id,name);
How to drop an Index?
ALTER TABLE table_name DROP INDEX index_name;
But you will get the following error
Msg 10785, Level 16, State 2, Line 97 The operation ‘ALTER TABLE DROP INDEX’ is supported only with memory-optimized tables. Msg 1750, Level 16, State 0, Line 97 Could not create constraint or index. See previous errors.
To avoid this error your table needs to memory-optimized and for that when you create a table use this syntax to create table memory optimize. But for that, your database needs to memory-optimized so use below command for that in below query temp is my database name.
ALTER DATABASE temp ADD FILEGROUP [TestDBSampleDB_mod_fg] CONTAINS MEMORY_OPTIMIZED_DATA; After that use below command ALTER DATABASE temp ADD FILE (NAME='temp_mod_dir', FILENAME='D:\timepass\TestDB_mod_dir') TO FILEGROUP [TestDBSampleDB_mod_fg]; --Then you use this create table command to create memory optimized table. CREATE TABLE userSession ( SessionId int not null, UserId int not null, CreatedDate datetime2 not null, ShoppingCartId int index ix_UserId nonclustered hash (UserId) with (bucket_count=400000) ) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY) ;
Primary key Constraint
A primary key is a field in the table which uniquely identifies the row in a table. The primary key contains unique values. The primary key doesn’t have null values.
A primary key is one per table but it can contain more than one column and this called a Composite key. Create primary key at the time of table creation
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
Create a primary key using the alter table
ALTER TABLE CUSTOMER ADD PRIMARY KEY (ID);
When you use alter table syntax you need to ensure that the column which you provide is Not Null.
Foreign Key Constraint
The foreign key constraint is used to join 2 tables together.
It is a key which might have a combination of one or more column or fields in one table that refers to Primary Key in another table.
The table which contains foreign key is called the child table and the table containing the candidate key is called the referenced or parent table.
The relationship between 2 tables matches the Primary Key in one of the tables with a Foreign Key in the second table.
If a table has a primary key defined on any field(s), then you cannot have two records having the same value of that field(s).
CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), FOREIGN KEY (PersonID) REFERENCES Persons(PersonID) ); --Foreign key using alter table ALTER TABLE Orders ADD FOREIGN KEY (PersonID) REFERENCES Persons(PersonID); --Drop a Foreign Key constraint ALTER TABLE Orders DROP FOREIGN KEY FK_PersonOrder;
0 notes
Text
MSSQL 문법정리
MS-SQL
** SQL문은 대소문자를 구분하지 않지만 데이타는 대문자와 소문자를 구분한다 주석을 다는 방법은 /* 주석 */ 이거나 한줄만 주석 처리를 할 경우는 문장 맨앞에 --를 붙인다 ** 각각의 데이타베이스의 SYSOBJECTS 테이블에 해당 데이타베이스의 모든 정보가 보관되어 있다 SYSOBJECTS의 TYPE 칼럼으로 'U'=사용자 테이블, 'P'=저장 프로시저, 'K'=프라이머리 키, 'F'=포린 키, 'V'=뷰, 'C'=체크 제약등 오브젝트 이름과 정보를 알 수 있다
데이타 검색 USE 데이타베이스명 /* USE 문을 사용한 데이타베이스 선택 */ SELECT * FROM 데이블명 /* 모든 칼럼 불러오기 */ SELECT TOP n * FROM 테이블명 /* 상위 n개의 데이타만 가져오기 */ SELECT 칼럼1, 칼럼2, 칼럼3 FROM 테이블명 /* 특정 칼럼 가져오기 */ SELECT 칼럼1 별명1, 칼럼2 AS 별명2 FROM 테이블명 /* 칼럼에 별명 붙이기 */ SELECT 칼럼3 '별 명3' FROM 테이블명 /* 칼럼 별명에 스페이스가 들어갈 경우는 작은따옴표 사용 */ SELECT DISTINCT 칼럼 FROM 테이블명 /* 중복되지 않는 데이타만 가져오기 */ ** 데이타는 오름차순으로 재배열된다 DISTINCT를 사용하면 재배열이 될때까지 데이타가 리턴되지 않으므로 수행 속도에 영향을 미친다 */ SELECT * FROM 테이블명 WHERE 조건절 /* 조건에 해당하는 데이타 가져오기 */ ** 조건식에 사용하는 비교는 칼럼=값, 칼럼!=값, 칼럼>값, 칼럼>=값, 칼럼<값, 칼럼<=값이 있다 문자열은 ''(작은따옴표)를 사용한다 날짜 비교를 할때는 'yy-mm-dd' 형식의 문자열로 한다(날짜='1992-02-02', 날짜>'1992-02-02') SELECT * FROM 테이블명 WHERE 칼럼 BETWEEN x AND y /* 칼럼이 x>=와 y<=사이의 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 IN (a, b...) /* 칼럼이 a이거나 b인 데이타 가져오기 */
SELECT * FROM 테이블명 WHERE 칼럼 LIKE '패턴' /* 칼럼이 패턴과 같은 데이타 가져오기 */ ** 패턴에 사용되는 기호는 %, _가 있다 'k%'(k로 시작���는), '%k%'(중간에 k가 있는), '%k'(k로 끝나는) 'p_'(p로 시작하는 2자리), 'p___'(p로 시작하는 4자리), '__p'(3자리 데이타중 p로 끝나는)
Like 패턴 주의점
- MSSQL LIKE 쿼리에서 와일드 카드(예약어) 문자가 들어간 결과 검색시
언더바(_)가 들어간 결과를 보기 위해 아래처럼 쿼리를 날리니
select * from 테이블명 where 컬럼명 like '%_%'
모든 데이터가 결과로 튀어나왔다. -_-;;
언더바가 와일드 카드(쿼리 예약어)이기 때문인데 이럴 땐
select * from 테이블명 where 컬럼명 like '%[_]%'
SELECT * FROM 테이블명 WHERE 칼럼 IS NULL /* 칼럼이 NULL인 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 NOT BETWEEN x AND y /* 칼럼이 x와 y 사이가 아닌 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 NOT IN (a, b...) /* 칼럼이 a나 b가 아닌 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 NOT LIKE '패턴' /* 칼럼이 패턴과 같지 않은 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 IS NOT NULL /* 칼럼이 NULL이 아닌 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼>=x AND 칼럼<=y SELECT * FROM 테이블명 WHERE 칼럼=a or 칼럼=b SELECT * FROM 데이블명 WHERE 칼럼1>=x AND (칼럼2=a OR 칼럼2=b) ** 복수 조건을 연결하는 연산자는 AND와 OR가 있다 AND와 OR의 우선순위는 AND가 OR보다 높은데 우선 순위를 바꾸고 싶다면 ()을 사용한다 SELECT * FROM 테이블명 ORDER BY 칼럼 /* 칼럼을 오름차순으로 재배열하기 */ SELECT * FROM 테이블명 ORDER BY 칼럼 ASC SELECT * FROM 테이블명 ORDER BY 칼럼 DESC /* 칼럼을 내림차순으로 재배열하기 */ SELECT * FROM 테이블명 ORDER BY 칼럼1 ASC, 칼럼2 DESC /* 복수 칼럼 재배열하기 */ SELECT * FROM 테이블명 ORDER BY 1 ASC, DESC 3 /* 칼럼 순서로 재배열하기 */ ** 기본적으로 SELECT 문에서는 출력순서가 보증되지 않기 때문에 데이타의 등록 상태나 서버의 부하 상태에 따라 출력되는 순서가 달라질 수 있다 따라서 출력하는 경우 되도록이면 ORDER BY를 지정한다 ** 칼럼 번호는 전체 칼럼에서의 번호가 아니라 SELECT문에서 선택한 칼럼의 번호이고 1부터 시작한다
연산자 ** 1순위는 수치 앞에 기술되는 + - 같은 단항 연산자 2순위는 사칙 연산의 산술 연산자인 * / + - 3순위는 = > 비교 연산자 4순위는 AND OR 같은 논리 연산자 ()을 붙이면 우선 순위를 바꿀수 있다
1. SELECT 문의 연산 SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 2. ORDER BY 구의 연산 SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 ORDER BY 칼럼3+칼럼4 DESC SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 ORDER BY 3 DESC 3. WHERE 구의 연산 SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 WHERE 칼럼2>=(칼럼3+칼럼4) 4. NULL 연산 SELECT 칼럼1, 칼럼2, ISNULL(칼럼3, 0) + ISNULL(칼럼4, 0) AS '별명' FROM 테이블명 ** 수치형 데이타와 NULL값과의 연산 결과는 항상 NULL이다 만약 NULL 값을 원치 않으면 ISNULL(칼럼, 기준값) 함수를 사용해서 기준값을 변환시킨다 5. 날짜 연산 SELECT GETDATE() /* 서버의 현재 날짜를 구한다 */ SELECT 날짜칼럼, 날짜칼럼-7 FROM 테이블명 SELECT 날짜칼럼, 날짜칼럼+30 FROM 테이블명 SELECT 날짜칼럼, DATEDIFF(day, 날짜칼럼, GETDATE()) FROM 테이블명 ** 날짜의 가산과 감산은 + -로 할 수 있다 날짜와 날짜 사이의 계산은 DATEDIFF(돌려주는값, 시작날짜, 끝날짜) 함수를 사용한다 6. 문자 연산 SELECT 칼럼1 + 칼럼2 FROM 테이블명 SELECT 칼럼 + '문자열' FROM 테이블명 SELECT 칼럼1 + '문자열' + 칼럼2 FROM 테이블명 ** 기본 연결은 문자와 문자이고 문자와 숫자의 연결은 CONVERT 함수를 사용해야 한다
함수 1. 수치 함수 ROUND(수치값, ���올림위치) /* 반올림 및 자르기 */ ABS(수치 데이타) /* 절대값 */ SIGN(수치 데이타) /* 부호 */ SQRT(수치값) /* 제곱근 */ POWER(수치값, n) /* n승 */ 2. 문자열 함수 정리
1) Ascii() - 문자열의 제일 왼쪽 문자의 아스키 코드 값을 반환(Integer)
예) SELECT Ascii('abcd')
>> 결과는 a의 아스키 코드값인 97 반환
2) Char() - 정수 아스키 코드를 문자로 반환(Char)
예) SELECT Char(97)
>> 결과는 a 반환
3) Charindex() - 문자열에서 지정한 식의 위치를 반환
예) SELECT Charindex('b','abcde') >> 결과 : 2 SELECT Charindex('b','abcde',2) >> 결과 : 2 SELECT Charindex('b','abcde',3) >> 결과 : 0
-- 인수값이 3개일때 마지막은 abcde 에서의 문자열 검색 시작위치를 말하며
2인경우는 bcde 라는 문자열에 대해서 검색
3인 경우는 cde 라는 문자열에 대해서 검색 하게 된다.
4) Difference() - 두 문자식에 SUONDEX 값 간의 차이를 정수로 반환
예) SELECT Difference('a','b')
5) Left() - 문자열에서 왼쪽에서부터 지정한 수만큼의 문자를 반환
예) SELECT Left('abced',3) 결과 >> 3
6) Len() - 문자열의 길이 반환
예) SELECT Len('abced') 결과>>5
7) Lower() - 대문자를 소문자로 반환
예) SELECT Lower('ABCDE') 결과 >> abcde
8) Ltrim() - 문자열의 왼쪽 공백 제거
예) SELECT Ltrim(' AB CDE') 결과>> AB CDE
9)Nchar() - 지정한 정수 코드의 유니코드 문자 반환
예) SELECT Nchar(20) 결과 >>
10) Replace - 문자열에서 바꾸고 싶은 문자 다른 문자로 변환
예) SELECT Replace('abcde','a','1') 결과>>1bcde
11) Replicate() - 문자식을 지정한 횟수만큼 반복
예) SELECT Replicate('abc',3) 결과>> abcabcabc
12) Reverse() - 문자열을 역순으로 출력
예) SELECT Reverse('abcde') 결과>> edcba
13) Right() - 문자열의 오른쪽에서 부터 지정한 수 만큼 반환(Left() 와 비슷 )
예) SELECT Right('abcde',3) 결과>> cde
14)Rtrim() - 문자열의 오른쪽 공백 제거
예) SELECT Rtrim(' ab cde ') 결과>> ' ab cde' <-- 공백구분을위해 ' 표시
15) Space() - 지정한 수만큼의 공백 문자 반환
예) SELECT Space(10) 결과 >> ' ' -- 그냥 공백이 나옴
확인을 위해서 SELECT 'S'+Space(10)+'E' 결과 >> S E
16) Substring() - 문자,이진,텍스트 또는 이미지 식의 일부를 반환
예) SELECT Substring('abcde',2,3) 결과>> bcd
17)Unicode() - 식에 있는 첫번째 문자의 유니코드 정수 값을 반환
예)SELECT Unicode('abcde') 결과 >> 97
18)Upper() - 소문자를 대문자로 반환
예) SELECT Upper('abcde') 결과>> ABCDE
※ 기타 함수 Tip
19) Isnumeric - 해당 문자열이 숫자형이면 1 아니면 0을 반환
>> 숫자 : 1 , 숫자X :0
예) SELECT Isnumeric('30') 결과 >> 1
SELECT Isnumeric('3z') 결과 >> 0
20) Isdate() - 해당 문자열이 Datetime이면 1 아니면 0 >> 날짜 : 1 , 날짜 X :0 예) SELECT Isdate('20071231') 결과 >> 1
SELECT Isdate(getdate()) 결과 >> 1 SELECT Isdate('2007123') 결과 >> 0
SELECT Isdate('aa') 결과 >> 0
※ 날짜및 시간함수 정리
getdate() >> 오늘 날짜��� 반환(datetime)
1> DateAdd() - 지정한 날짜에 일정 간격을 + 새 일정을 반환
예) SELECT Dateadd(s,2000,getdate())
2> Datediff() - 지정한 두 날짜의 간의 겹치는 날짜 및 시간 범위 반환
예)SELECT DateDiff(d,getdate(),(getdate()+31))
3> Datename() -지정한 날짜에 특정 날짜부분을 나타내는 문자열을 반환
예) SELECT Datename(d,getdate())
4> Datepart() -지정한 날짜에 특정 날짜부분을 나타내는 정수를 반환
예) SELECT Datepart(d,getdate())
** 돌려주는값(약어) Year-yy, Quarter-qq, Month-mm, DayofYear-dy, Day-dd, Week-wk, Hour-hh, Minute-mi, Second-ss, Milisecond-ms SELECT DATEADD(dd, 7, 날짜칼럼)
>> Datename , Datepart 은 결과 값은 같으나 반환 값의 타입이 틀림.
5> Day() -지정한 날짜에 일 부분을 나타내는 정수를 반환
예) SELECT Day(getdate()) -- 일 반환
SELECT Month(getdate()) -- 월 반환
SELECT Year(getdate()) -- 년 반환 4. 형변환 함수 CONVERT(데이타 타입, 칼럼) /* 칼럼을 원하는 데이타 타입으로 변환 */ CONVERT(데이타 타입, 칼럼, 날짜형 스타일) /* 원하는 날짜 스타일로 변환 */ CAST(칼럼 AS 데이타 타입) /* 칼럼을 원하는 데이타 타입으로 변환 */ ** 스타일 1->mm/dd/yy, 2->yy.mm.dd, 3->dd/mm/yy, 4->dd.mm.yy, 5->dd-mm-yy, 8->hh:mm:ss, 10->mm-dd-yy, 11->yy/mm/dd, 12->yymmdd SELECT CONVERT(varchar(10), 날짜칼럼, 2)
그룹화 함수 SELECT COUNT(*) FROM 테이블명 /* 전체 데이타의 갯수 가져오기 */ SEELECT COUNT(칼럼) FROM 테이블명 /* NULL은 제외한 칼럼의 데이타 갯수 가져오기 */ SELECT SUM(칼럼) FROM 테이블명 /* 칼럼의 합계 구하기 */ SELECT MAX(칼럼) FROM 테이블명 /* 칼럼의 최대값 구하기 */ SELECT MIN(칼럼) FROM 테이블명 /* 칼럼의 최소값 구하기 */ SELECT AVG(칼럼) FROM 테이블명 /* 칼럼의 평균값 구하기 */ GROUP BY문 SELECT 칼럼 FROM 테이블명 GROUP BY 칼럼 SELECT 칼럼1, SUM(칼럼2) FROM 테이블명 GROUP BY 칼럼1 SELECT 칼럼1, COUNT(*) FROM 테이블명 GROUP BY 칼럼1 SELECT 칼럼1, 칼럼2, MAX(칼럼3) FROM 테이블명 GROUP BY 칼럼1, 칼럼2 ** GROUP BY를 지정한 경우 SELECT 다음에는 반드시 GROUP BY에서 지정한 칼럼 또는 그룹 함수만이 올 수 있다
조건 SELECT 칼럼1, SUM(칼럼2) FROM 테이블명 GROUP BY 칼럼1 HAVING SUM(칼럼2) < a SELECT 칼럼1, SUM(칼럼2) FROM 테이블명 ORDER BY 칼럼1 COMPUTE SUM(칼럼2) ** HAVING: 그룹 함수를 사용할 경우의 조건을 지정한다 HAVING의 위치: GROUP BY의 뒤 ORDER BY의 앞에 지정한다 COMPUTE: 각 그룹의 소계를 요약해서 보여준다 ORDER BY가 항상 선행해서 나와야 한다 조건절의 서브 쿼리 ** SELECT 또는 INSERTY, UPDATE, DELETE 같은 문의 조건절에서 SELECT문을 또 사용하는 것이다 SELECT문 안에 또 다른 SELECT문이 포함되어 있다고 중첩 SELECT문(NESTED SELECT)이라고 한다 ** 데이타베이스에는 여러명이 엑세스하고 있기 때문에 쿼리를 여러개 나누어서 사용하면 데이타의 값이 달라질수 있기때문에 트랜잭션 처리를 하지 않는다면 복수의 쿼리를 하나의 쿼리로 만들어 사용해야 한다 SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 칼럼2 = (SELECT 칼럼2 FROM 테이블명 WHERE 조건) SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 칼럼1 IN (SELECT 칼럼1 FROM 테이블명 WHERE 조건) ** 서브 쿼리에서는 다른 테이블을 포함할 수 있다 두개의 테이블에서 읽어오는 서브쿼리의 경우 서브 쿼리쪽에 데이타가 적은 테이블을 주 쿼리쪽에 데이타가 많은 테이블을 지정해야 처리 속도가 빨라진다 SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 칼럼1 IN (SELECT 칼럼2-1 FROM 테이블명2 WHERE 조건) ** FROM구에서 서브 쿼리를 사용할 수 있다 사용시 반드시 별칭을 붙여야 하고 처리 속도가 빨라진다 SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 조건1 AND 조건2 SEELCT 칼럼1, 칼럼2 FROM (SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 조건1) 별칭 WHERE 조건2
데이타 편집
추가 ** NULL 값을 허용하지도 않고 디폴트 값도 지정되어 있지 않은 칼럼에 값을 지정하지 않은채 INSERT를 수행하면 에러가 발생한다 ** 수치값은 그대로 문자값은 ''(작은따옴표)로 마무리 한다 ** SELECT INTO는 칼럼과 데이타는 복사하지만 칼럼에 설정된 프라이머리, 포린 키등등의 제약 조건은 복사되지 않기 때문에 복사가 끝난후 새로 설정해 주어야 한다
INSERT INTO 테이블명 VALUES (값1, 값2, ...) /* 모든 필드에 데이타를 넣을 때 */ INSERT INTO 테이블명 (칼럼1, 칼럼2, ...) VALUES (값1, 값2, ...) /* 특정 칼럼에만 데이타를 넣을 때 */ INSERT INTO 테이블명 SELECT * FROM 테이블명2 /* 이미 존재하는 테이블에 데이타 추가 */ INSERT INTO 테이블명(칼럼1, 칼럼2, ...) SELECT 칼럼1, 칼럼2, ...) FROM 테이블명2 SELECT * INTO 테이블명 FROM 테이블명2 �� /* 새로 만든 테이블에 데이타 추가 */ SELECT 칼럼1, 칼럼2, ... 테이블명 FROM 테이블명2 갱신 UPDATE 테이블명 SET 칼럼1=값1, 칼럼2=값2 /* 전체 데이타 갱신 */ UPDATE 테이블명 SET 칼럼1=값1, 칼럼2=값2 WHERE 조건 /* 조건에 해당되는 데이타 갱신 */
- UPDATE~SELECT
UPDATE A SET A.cyberLectures = B.bizAddress FROM OF_Member A, OF_Member B WHERE A.no = B.no
삭제 DELETE FROM 테이블명 /* 전체 데이타 삭제 */ DELETE FROM 테이블명 WHERE 조건 /* 조건에 해당되는 데이타 삭제 */
오브젝트 ** 데이타베이스는 아래 오브젝트들을 각각의 유저별로 관리를 하는데 Schema(스키마)는 각 유저별 소유 리스트이다
1. Table(테이블) ** CREATE일때 프라이머리 키를 설정하지 않는다면 (칼럼 int IDENTITY(1, 1) NOT NULL) 자동 칼럼을 만든다 데이타들의 입력 순서와 중복된 데이타를 구별하기 위해서 반드시 필요하다 ** 테이블 정보 SP_HELP 테이블명, 제약 조건은 SP_HELPCONSTRAINT 테이블명 을 사용한다
CREATE TABLE 데이타베이스이름.소유자이름.테이블이름 (칼럼 데이타형 제약, ...) /* 테이블 만들기 */ DROP TABLE 테이블명 /* 테이블 삭제 */ ALTER TABLE 테이블명 ADD 칼럼 데이타형 제약, ... /* 칼럼 추가 */ ALTER TABLE 테이블명 DROP COLUMN 칼럼 /* 칼럼 삭제 */ ** DROP COLUMN으로 다음 칼럼은 삭제를 할 수 없다 - 복제된 칼럼 - 인덱스로 사용하는 칼럼 - PRIMARY KEY, FOREGIN KEY, UNIQUE, CHECK등의 제약 조건이 지정된 칼럼 - DEFAULT 키워드로 정의된 기본값과 연결되거나 기본 개체에 바인딩된 칼럼 - 규칙에 바인딩된 칼럼 CREATE TABLE 테이블명 (칼럼 데이타형 DEFAULT 디폴트값, ...) /* 디폴트 지정 */ CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 UNIQUE, ...) /* 유니크 설정 */ ** UNIQUE란 지정한 칼럼에 같은 값이 들어가는것을 금지하는 제약으로 기본 키와 비슷하지만 NULL 값을 하용하는것이 다르다 CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 NOT NULL, ...) /* NOT NULL 설정 */ CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 PRIMARY KEY, ...) /* 기본 키 설정 */ ** 기본 키는 유니크와 NOT NULL이 조합된 제약으로 색인이 자동적으로 지정되고 데이타를 유���하게 만들어 준다 ** 기본 키는 한 테이블에 한개의 칼럼만 가능하다 CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 FOREIGN KEY REFERENCES 부모테이블이름(부모칼럼), ...) CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 CHECK(조건), ...) /* CHECK 설정 */ ** CHECK는 조건을 임의로 정의할 수 있는 제약으로 설정되면 조건을 충족시키는 데이타만 등록할 수 있고 SELECT의 WHERE구와 같은 조건을 지정한다 ** CONSTRAINT와 제약 이름을 쓰지 않으면 데이타베이스가 알아서 이름을 붙이지만 복잡한 이름이 되기 때문에 되도록이면 사용자가 지정하도록 한다 ** CONSTRAINT는 칼럼과 데이타형을 모두 정의한 뒤에 맨 마지막에 설정할 수 있다 CREATE TABLE 테이블명 (칼럼1 데이타형, 칼럼2 데이타형, ... CONSTRAINT 이름 PRIMARY KEY(칼럼1) CONSTRAINT 이름 CHECK(칼럼2 < a) ...) ALTER TABLE 테이블명 ADD CONSTRAINT 이름 제약문 /* 제약 추가 */ ALTER TABLE 테이블명 DROP CONSTRAINT 제약명 /* 제약 삭제 */ ALTER TABLE 테이블명 NOCHECK CONSTRAINT 제약명 /* 제약 효력 정지 */ ALTER TABLE 테이블명 CHECK CONSTRAINT 제약명 /* 제약 효력 유효 */ ** 제약명은 테이블을 만들때 사용자가 지정한 파일 이름을 말한다
2. View(뷰) ** 자주 사용하는 SELECT문이 있을때 사용한다 테이블에 존재하는 칼럼들중 특정 칼럼을 보이고 싶지 않을때 사용한다 테이블간의 결합등으로 인해 복잡해진 SELECT문을 간단히 다루고 싶을때 사용한다 ** 뷰를 만들때 COMPUTE, COMPUTE BY, SELECT INTO, ORDER BY는 사용할 수 없고 #, ##으로 시작되는 임시 테이블도 뷰의 대상으로 사용할 수 없다 ** 뷰의 내용을 보고 싶으면 SP_HELPTEXT 뷰명 을 사용한다 CREATE VIEW 뷰명 AS SELECT문 /* 뷰 만들기 */ CREATE VIEW 뷰명 (별칭1, 별칭2, ...) AS SELECT문 /* 칼럼의 별칭 붙이기 */ CREATE VIEW 뷰명 AS (SELECT 칼럼1 AS 별칭1, 칼럼2 AS 별칭2, ...) ALTER VIEW 뷰명 AS SELECT문 /* 뷰 수정 */ DROP VIEW 뷰명 /* 뷰 삭제 */ CREATE VIEW 뷰명 WITH ENCRYPTION AS SELECT문 /* 뷰 암호 */ ** 한번 암호화된 뷰는 소스 코드를 볼 수 없으므로 뷰를 암호화하기전에 뷰의 내용을 스크립트 파일로 저장하여 보관한다 INSERT INTO 뷰명 (칼럼1, 칼럼2, ...) VALUES (값1, 값2, ...) UPDATE 뷰명 SET 칼럼=값 WHERE 조건 ** 원래 테이블에 있는 반드시 값을 입력해야 하는 칼럼이 포함되어 있지 않거나 원래 칼럼을 사용하지 않고 변형된 칼럼을 사용하는 뷰는 데이타를 추가하거나 갱신할 수 없다 ** WHERE 조건을 지정한 뷰는 뷰를 만들었을때 WITH CHECK OPTION을 지정하지 않았다면 조건에 맞지 않는 데이타를 추가할 수 있지만 뷰에서는 보이지 않는다 또한 뷰를 통해서 가져온 조건을 만족하는 값도 뷰의 조건에 만족하지 않는 값으로도 갱신할 수 있다 CREATE VIEW 뷰명 AS SELECT문 WITH CHECK OPTION ** 뷰의 조건에 맞지 않는 INSERT나 UPDATE를 막을려면 WITH CHECK OPTION을 설정한다
3. Stored Procedure(저장 프로시저) ** 데이타베이스내에서 SQL 명령을 컴파일할때 캐시를 이용할 수 있으므로 처리가 매우 빠르다 반복적으로 SQL 명령을 실행할 경우 매회 명령마다 네트워크를 경유할 필요가 없다 어플리케이션마다 새로 만들 필요없이 이미 만들어진 프로시저를 반복 사용한다 데이타베이스 로직을 수정시 프로시저는 서버측에 있으므로 어플리케이션을 다시 컴파일할 필요가 없다 ** 저장 프로시저의 소스 코드를 보고 싶으면 SP_HELPTEXT 프로시저명 을 사용한다
CREATE PROC 프로시저명 AS SQL문 /* 저장 프로시저 */ CREATE PROC 프로시저명 변수선언 AS SQL문 /* 인수를 가지는 ���장 프로시저 */ CREATE PROC 프로시저명 WITH ENCRYPTION AS SQL문 /* 저장 프로시저 보안 설정 */ CREATE PROC 프로시저명 /* RETURN 값을 가지는 저장 프로시저 */ 인수1 데이타형, ... 인수2 데이타형 OUTPUT AS SQL문 RETURN 리턴값 DROP PROCEDURE 프로시저명1, 프로시저명2, ... /* 저장 프로시저 삭제 */ 명령어 BEGIN ... END /* 문장의 블록 지정 */ DECLARE @변수명 데이타형 /* 변수 선언 */ SET @변수명=값 /* 변수에 값 지정 */ PRINT @변수명 /* 한개의 변수 출력 */ SELECT @변수1, @변수2 /* 여러개의 변수 출력 */ IF 조건 /* 조건 수행 */ 수행1 ELSE 수행2 WHILE 조건1 /* 반복 수행 */ BEGIN IF 조건2 BREAK - WHILE 루프를 빠져 나간다 CONTINUE - 수행을 처리하지 않고 조건1로 되돌아간다 수행 END EXEC 저장프로시저 /* SQL문을 실행 */ EXEC @(변수로 지정된 SQL문) GO /* BATCH를 구분 지정 */
에제 1. 기본 저장 프로시저 CREATE PROC pUpdateSalary AS UPDATE Employee SET salary=salary*2
2. 인수를 가지는 저장 프로시저 CREATE PROC pUpdateSalary @mul float=2, @mul2 int AS UPDATE Employee SET salary=salary* @Mul* @mul2 EXEC pUpdateSalary 0.5, 2 /* 모든 변수에 값을 대입 */ EXEC pUpdateSalary @mul2=2 /* 원하는 변수에만 값을 대입 */
3. 리턴값을 가지는 저장 프로시저 CREATE PROC pToday @Today varchar(4) OUTPUT AS SELECT @Today=CONVERT(varchar(2), DATEPART(dd, GETDATE())) RETURN @Today DECLARE @answer varchar(4) EXEC pToday @answer OUTPUT SELECT @answer AS 오늘날짜
4. 변수 선언과 대입, 출력 ** @는 사용자 변수이고 @@는 시스템에서 사용하는 변수이다
DECLARE @EmpNum int, @t_name VARCHAR(20) SET @EmpNum=10
SET @t_name = '강우정' SELECT @EmpNum
이런식으로 다중입력도 가능함.
SELECT @no = no, @name = name, @level = level FROM OF_Member WHERE userId ='"
4. Trigger(트리거) ** 한 테이블의 데이타가 편집(INSERT/UPDATE/DELETE)된 경우에 자동으로 다른 테이블의 데이타를 삽입, 수정, 삭제한다 ** 트리거 내용을 보고 싶으면 SP_HELPTRIGGER 트리거명 을 사용한다
CREATE TRIGGER 트리거명 on 테이블명 FOR INSERT AS SQL문 /* INSERT 작업이 수행될때 */ CREATE TRIGGER 트리거명 on 테이블명 AFTER UPDATE AS SQL문 /* UPDATE 작업이 수행되고 난 후 */ CREATE TRIGGER 트리거명 on 테이블명 INSTEAD OF DELETE AS SQL문 DROP TRIGGER 트리거명
5. Cursor(커서) ** SELECT로 가져온 결과들을 하나씩 읽어들여 처리하고 싶을때 사용한다 ** 커서의 사용방법은 OPEN, FETCH, CLOSE, DEALLOCATE등 4단계를 거친다 ** FETCH에는 NEXT, PRIOR, FIRST, LAST, ABSOLUTE {n / @nvar}, RELATIVE {n / @nvar}가 있다
SET NOCOUNT on /* SQL문의 영향을 받은 행수를 나타내는 메시지를 숨긴다 */ DECLARE cStatus SCROLL CURSOR /* 앞뒤로 움직이는 커서 선언 */ FOR SELECT ID, Year, City FROM aPlane FOR READ onLY OPEN cStatus /* 커서를 연다 */ DECLARE @ID varchar(50), @Year int, @City varchar(50), @Status char(1) FETCH FROM cStatus INTO @ID, @Year, @City /* 커서에서 데이타를 하나씩 가져온다 */ WHILE @@FETCH_STATUS=0 /* 커서가 가르키는 결과의 끝까지 */ BEGIN IF @Year <= 5 SET @Status='A' ELSE IF @Year> 6 AND @Year <= 9 SET @Status='B' ELSE SET @Status='C' INSERT INTO aPlane(ID, City, Status) VALUES(@ID, @Year, @Status) FETCH FROM cStatus INTO @ID, @Year, @City /* 커서에서 데이타를 하나씩 가져온다 */ END CLOSE cStaus /* 커서를 닫는다 */ DEALLOCATE cStatus /* 커서를 해제한다 */
보안과 사용자 권한 ** 보안의 설정 방법은 크게 WINDOWS 보안과 SQL 보안으로 나뉘어 진다 ** 사용자에게 역할을 부여하는데는 서버롤과 데이타베이스롤이 있다
1. SA(System Administrator) ** 가장 상위의 권한으로 SQL 서버에 관한 전체 권한을 가지고 모든 오브젝트를 만들거나 수정, 삭제할 수 있다
2. DBO(Database Owner) ** 해당 데이타베이스에 관한 모든 권한을 가지며 SA로 로그인해서 데이타베이스에서 테이블을 만들어도 사용자는 DBO로 매핑된다 ** 테이블이름의 구조는 서버이름.데이타베이스이름.DBO.테이블이름이다
3. DBOO(Database Object Owner) ** 테이블, 인덱스, 뷰, 트리거, 함수, 스토어드 프로시저등의 오브젝트를 만드는 권한을 가지며 SA나 DBO가 권한을 부여한다
4. USER(일반 사용자) ** DBO나 DBOO가 해당 오브젝트에 대한 사용 권한을 부여한다
[SQL 서버 2005 실전 활용] ① 더 강력해진 T-SQL : http://blog.naver.com/dbwpsl/60041936511
MSSQL 2005 추가 쿼리 http://kuaaan.tistory.com/42 or=#747474>사용 방법 http://kuaaan.tistory.com/42 or=#747474>사용 방법 http://kuaaan.tistory.com/42
-- ANY (OR 기능)
WHERE 나이 >= (SELECT 나이 FROM .......)
-- GROUP BY ALL (WHERE 절과 일치 하지 않는 내용은 NULL 로 표시)
SELECT 주소, AVG(나이) AS 나이 FROM MEMBER
WHERE 성별='남'
GROUP BY ALL 주소
-- 모든 주소는 나오며 성별에 따라 나이 데이터는 NULL
-- WITH ROLLUP
SELECT 생일, 주소, SUM(나이) AS 나이
FROM MEMBER
GROUP BY 생일, 주소 WITH ROLLUP
-- 생일 과 주소를 요약행이 만들어짐
-- WITH CUBE (위의 예제를 기준으로, 주소에 대한 별도 그룹 요약데이터가 하단에 붙어나옴)
-- GROUPING(컬럼명) ROLLUP 또는 CUBE 의 요약행인지 여부 판단(요약행이면 1 아니면 0)
SELECT 생일, 주소, GROUPING(생일) AS 생일요약행여부
-- COMPUTE (GROUP BY 와 상관없이 별도의 테이블로 요약정보 생성)
SELECT 생일, 나이
FROM MEMBER
COMPUTE SUM(나이), AVG(나이)
-- PIVOT (세로 컬럼을 가로 변경)
EX)
학년/ 반 / 학생수
1 1 40
1 2 45
2 1 30
2 2 40
3 1 10
3 2 10
위와 같이 SCHOOL 테이블이 있다면
SELECT 그룹할컬럼명, [열로변환시킬 행]
FROM 테이블
PIVOT(
SUM(검색할열)
FOR 옆으로만들 컬럼명
IN([열로변환시킬 행])
) AS 별칭
--실제 쿼리는
SELECT 학년, [1반], [2반]
FROM SCHOOL
PIVOT(
SUM(학생수)
FOR 반
IN([1반], [2반])
) AS PVT
-- UNPIVOT (가로 컬럼을 세로로)
SELECT 학년, 반, 학생수
FROM SCHOOL
UNPIVOT(
FOR 반
IN( [1반], [2반] )
) AS UNPVT
-- RANK (순위)
SELECT 컬럼명, RANK() OVER( ORDER BY 순위 기준 컬럼명) AS 순위
FROM 테이블
-- PARTITION BY (그룹별로 순위 생성)
SELECT 컬럼명, RANK() OVER( PARTITION BY 그룹기준컬러명 ORDER BY 순위기준컬럼명) AS 순위
FROM 테이블
-- FULL OUTER JOIN (LEFT 조인과 RIGHT 조인을 합한것)
양쪽 어느 하나라도 데이가 있으면 나옴
-- ROW_NUMBER (순차번호 생성)
SELECT ROW_NUMBER() OVER( ORDER BY 기준열) AS 번호, 컬럼명
FROM 테이블
자료형 (데이터타입)
MSSQL 서버에서 사용하는 데이터 타입(자료형)은 두가지가 있다.
1. 시스템에서 제공하는 System data type
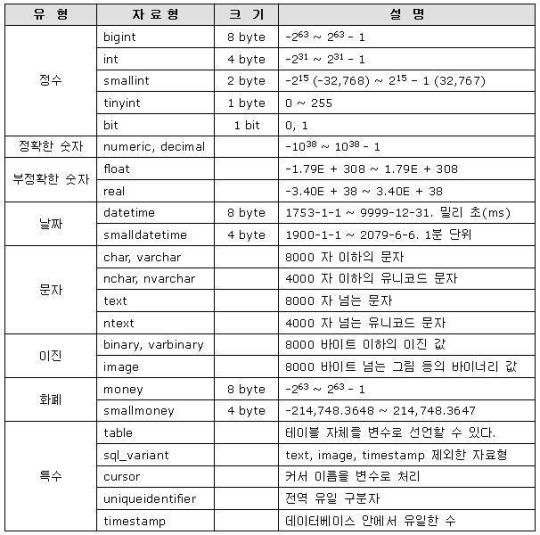
내가 생각해도 참 깔끔하게 정리를 잘 해놨다. -_-;;
성능향상을 위해서라면 가능한 작은 자료형을 사용하도록 하자.
불필요하게 int를 쓰는 경우가 흔한데, 사용될 데이터의 범위를 생각해 본 후, 가장 작은 범위의 자료형을 사용하도록 하자.
2. 사용자가 정의 하는 User data type
사용자 정의 자료형이 왜 필요한가?
C언어를 비로한 몇 가지 언어에서 나타나는 사용자 정의 데이터 유형과 같다.
프로젝트에 참가하는 사람들이 동일한 데이터 타입을 사용하고자 원하거나,
한 컬럼에 대한 데이터 유형을 더 쉽게 사용하려고 할 때 적용시킬 수 있다.
사용 방법
sp_addtype [새로운 타입 이름], '[SQL 데이터 타입]'
예
sp_addtype empID, 'CHAR(10)'
sp_addtype empNO, 'CHAR(12)'
* 참고로 자료형을 바꾸는 함수로는 CONVERT() 가 있다.
사용방법
SELECT CONVERT(CHAR(30), title) FROM BOOKS
--> title 라는 컬럼을 CHAR(30) 으로 변환하여 가져오는 것이다.
SELECT CONVERT(VARCHAR(10), 35)
--> 35 라는 숫자를 VARCHAR(10) 으로 변환한다.
흐름 제어문의 종류
흐름 제어문이란 언어의 처리 순서를 변경하거나 변수를 선언하는 등의 문장을 말한다.
○ GOTO 라벨
- GOTO 를 만나면 라벨 부분으로 무조건 건너뛴다. 라벨은 라벨: 으로 정의한다.
예)
DECLARE...
SET...
table_label1:
.
.
IF .... GOTO table_label1
.
--> GOTO table_label1 을 만나면 table_label1: 부분으로 건너 뛴다.
○ RETURN
- RETURN 은 무조건 수행을 중지 하고 원래 호출된 곳으로 돌아간다.
○ IF / ELSE
- 이름만 들어도 알만한 문법이다. 주의 할 점은 조건문 안의 SQL문장이 둘 이상이라면 BEGIN / END 로 묶어 준다.
예)
IF @begin > @end
BEGIN
SELECT * FROM 테이블1 WHERE 조건
RETURN
END
ELSE
SELECT * FROM.........
○ WHILE / BREAK / CONTINUE
- WHILE 다음에 조건으로 반복을 하게 되고,
BREAK 를 만나면 무조건 WHILE 을 벗어나고,
CONTINUE 를 만나면 무조건 WHILE 로 돌아간다.
예)
WHILE 조건
BEGIN
반복하는 동안 실행할 문장들...
IF 조건
BREAK
IF 조건
CONTINUE
END
○ EXEC[UTE]
- EXEC 와 EXECUTE 는 같은 의미이다.
- 두가지 용도로 사용되는데,
- 첫 번째, 스토어드 프로시저를 실행할 때 사용한다.
예)
EXEC stored_procedure
- 두 번재, SQL 문장을 동적으로 변화시키며 수행할 수 있다.
예)
DECLARE @sql VARCHAR(255)
SET @sql = 'SELECT COUNT(*) FROM '
SET @sql = @sql + 'titles '
EXEC(@sql)
--> 실제 수행되는 문장은 SELECT COUNT(*) FROM titles 가 된다.
○ CASE
- 단순 CASE
예)
SELECT
CASE type
WHEN 'a' THEN 'Apple'
WHEN 'b' THEN 'Banana'
ELSE 'No Data'
END AS 과일
, price
FROM titles
- 검색된 CASE
예)
SELECT title_id
, qty AS '수량'
, CASE
WHEN qty >= 50 THEN 'A'
WHEN qty >= 30 THEN 'B'
ELSE 'C'
END AS '등급'
FROM titles
NULLIF : 표현식 1과, 2를 비교
>> 표현식 1과, 2를 비교 두 표현식이 같으면 NULL 을 리턴, 같지 않으면 표현식 1을 리턴 SELECT NULLIF(2,3) -- 2 리턴 SELECT NULLIF(3,3) -- NULL 리턴 사용예 : 양쪽필드에서 수량이 같으면 NULL을 리턴하고 하니면 첫 필드의 값을 리턴할때
COALESCE : 뒤에 오는 표현식중에 처음으로 오는 NULL 이 아닌 값을 리턴
SELECT COALESCE(NULL, 3, 4) -- 3 리턴 SELECT COALESCE(1,NULL,) -- 1 리턴 SELECT COALESCE(NULL,NULL,4) -- 4 리턴
SELECT COALESCE(NULL,NULL, NULL)--문법오류
사용예 : 하나만 값을 가지고 있는 컬럼에서 비교해서 값을 가져올때 매우 좋다
SET : 세성 옵션 (한번설정하면 세션이 끊어 질때까지 유용)
=====================================================================================
SET nocount OFF : 몇개 행이 처리 되었는지 결과보여주는 것을 설정한다 '
SET rowcount [n]
ex) SET rowcount 4 SELECT title_id FROM titles ORDER BY TITLE
SET rowcount 0
: 보여줄 목록의 행수를 선택한다. 목록의 정렬의 임의로 설정되므로 필요한 순서가 있다면 ORDER BY 를 사용해야 한다. 사용후엔 반드시 SET ROWCOUNT 0 을 이용해서 원위치 시켜놓아야 한다 '
============================== 유니크 키 넣기 ============================== ALTER TABLE 테이블명 ADD UNIQUE(컬럼1, 컬럼2) ALTER TABLE 테이블명 DROP CONSTRAINT 유니크명
============================== IDENTITY 관련 ==============================
http://l2j.co.kr/1460
http://mcdasa.cafe24.com/wordpress/mssql-identity-scope_identity%ec%9d%98-%ec%b0%a8%ec%9d%b4%ec%a0%90/
============================== INSERT SELECT ==============================
http://blog.naver.com/sorkanj2000/50106968790
============================== UPDATE SELECT ==============================
http://applejara.tistory.com/302
============================== JOIN UPDATE ==============================
http://blog.naver.com/ballkiss/30096524074
sp_addtype [새로운 타입 이름], '[SQL 데이터 타입]'
예
sp_addtype empID, 'CHAR(10)'
sp_addtype empNO, 'CHAR(12)'
* 참고로 자료형을 바꾸는 함수로는 CONVERT() 가 있다.
사용방법
SELECT CONVERT(CHAR(30), title) FROM BOOKS
--> title 라는 컬럼을 CHAR(30) 으로 변환하여 가져오는 것이다.
SELECT CONVERT(VARCHAR(10), 35)
--> 35 라는 숫자를 VARCHAR(10) 으로 변환한다.
흐름 제어문의 종류
흐름 제어문이란 언어의 처리 순서를 변경하거나 변수를 선언하는 등의 문장을 말한다.
○ GOTO 라벨
- GOTO 를 만나면 라벨 부분으로 무조건 건너뛴다. 라벨은 라벨: 으로 정의한다.
예)
DECLARE...
SET...
table_label1:
.
.
IF .... GOTO table_label1
.
--> GOTO table_label1 을 만나면 table_label1: 부분으로 건너 뛴다.
○ RETURN
- RETURN 은 무조건 수행을 중지 하고 원래 호출된 곳으로 돌아간다.
○ IF / ELSE
- 이름만 들어도 알만한 문법이다. 주의 할 점은 조건문 안의 SQL문장이 둘 이상이라면 BEGIN / END 로 묶어 준다.
예)
IF @begin > @end
BEGIN
SELECT * FROM 테이블1 WHERE 조건
RETURN
END
ELSE
SELECT * FROM.........
○ WHILE / BREAK / CONTINUE
- WHILE 다음에 조건으로 ���복을 하게 되고,
BREAK 를 만나면 무조건 WHILE 을 벗어나고,
CONTINUE 를 만나면 무조건 WHILE 로 돌아간다.
예)
WHILE 조건
BEGIN
반복하는 동안 실행할 문장들...
IF 조건
BREAK
IF 조건
CONTINUE
END
○ EXEC[UTE]
- EXEC 와 EXECUTE 는 같은 의미이다.
- 두가지 용도로 사용되는데,
- 첫 번째, 스토어드 프로시저를 실행할 때 사용한다.
예)
EXEC stored_procedure
- 두 번재, SQL 문장을 동적으로 변화시키며 수행할 수 있다.
예)
DECLARE @sql VARCHAR(255)
SET @sql = 'SELECT COUNT(*) FROM '
SET @sql = @sql + 'titles '
EXEC(@sql)
--> 실제 수행되는 문장은 SELECT COUNT(*) FROM titles 가 된다.
○ CASE
- 단순 CASE
예)
SELECT
CASE type
WHEN 'a' THEN 'Apple'
WHEN 'b' THEN 'Banana'
ELSE 'No Data'
END AS 과일
, price
FROM titles
- 검색된 CASE
예)
SELECT title_id
, qty AS '수량'
, CASE
WHEN qty >= 50 THEN 'A'
WHEN qty >= 30 THEN 'B'
ELSE 'C'
END AS '등급'
FROM titles
NULLIF : 표현식 1과, 2를 비교
>> 표현식 1과, 2를 비교 두 표현식이 같으면 NULL 을 리턴, 같지 않으면 표현식 1을 리턴 SELECT NULLIF(2,3) -- 2 리턴 SELECT NULLIF(3,3) -- NULL 리턴 사용예 : 양쪽필드에서 수량이 같으면 NULL을 리턴하고 하니면 첫 필드의 값을 리턴할때
COALESCE : 뒤에 오는 표현식중에 처음으로 오는 NULL 이 아닌 값을 리턴
SELECT COALESCE(NULL, 3, 4) -- 3 리턴 SELECT COALESCE(1,NULL,) -- 1 리턴 SELECT COALESCE(NULL,NULL,4) -- 4 리턴
SELECT COALESCE(NULL,NULL, NULL)--문법오류
사용예 : 하나만 값을 가지고 있는 컬럼에서 비교해서 값을 가져올때 매우 좋다
SET : 세성 옵션 (한번설정하면 세션이 끊어 질때까지 유용)
=====================================================================================
SET nocount OFF : 몇개 행이 처리 되었는지 결과보여주는 것을 설정한다 '
SET rowcount [n]
ex) SET rowcount 4 SELECT title_id FROM titles ORDER BY TITLE
SET rowcount 0
: 보여줄 목록의 행수를 선택한다. 목록의 정렬의 임의로 설정되므로 필요한 순서가 있다면 ORDER BY 를 사용해야 한다. 사용후엔 반드시 SET ROWCOUNT 0 을 이용해서 원위치 시켜놓아야 한다 '
============================== 유니크 키 넣기 ============================== ALTER TABLE 테이블명 ADD UNIQUE(컬럼1, 컬럼2) ALTER TABLE 테이블명 DROP CONSTRAINT 유니크명
============================== IDENTITY 관련 ==============================
http://l2j.co.kr/1460
http://mcdasa.cafe24.com/wordpress/mssql-identity-scope_identity%ec%9d%98-%ec%b0%a8%ec%9d%b4%ec%a0%90/
============================== INSERT SELECT ==============================
http://blog.naver.com/sorkanj2000/50106968790
============================== UPDATE SELECT ==============================
http://applejara.tistory.com/302
============================== JOIN UPDATE ==============================
http://blog.naver.com/ballkiss/30096524074
sp_addtype [새로운 타입 이름], '[SQL 데이터 타입]'
예
sp_addtype empID, 'CHAR(10)'
sp_addtype empNO, 'CHAR(12)'
* 참고로 자료형을 바꾸는 함수로는 CONVERT() 가 있다.
사용방법
SELECT CONVERT(CHAR(30), title) FROM BOOKS
--> title 라는 컬럼을 CHAR(30) 으로 변환하여 가져오는 것이다.
SELECT CONVERT(VARCHAR(10), 35)
--> 35 라는 숫자를 VARCHAR(10) 으로 변환한다.
흐름 제어문의 종류
흐름 제어문이란 언어의 처리 순서를 변경하거나 변수를 선언하는 등의 문장을 말한다.
○ GOTO 라벨
- GOTO 를 만나면 라벨 부분으로 무조건 건너뛴다. 라벨은 라벨: 으로 정의한다.
예)
DECLARE...
SET...
table_label1:
.
.
IF .... GOTO table_label1
.
--> GOTO table_label1 을 만나면 table_label1: 부분으로 건너 뛴다.
○ RETURN
- RETURN 은 무조건 수행을 중지 하고 원래 호출된 곳으로 돌아간다.
○ IF / ELSE
- 이름만 들어도 알만한 문법이다. 주의 할 점은 조건문 안의 SQL문장이 둘 이상이라면 BEGIN / END 로 묶어 준다.
예)
IF @begin > @end
BEGIN
SELECT * FROM 테이블1 WHERE 조건
RETURN
END
ELSE
SELECT * FROM.........
○ WHILE / BREAK / CONTINUE
- WHILE 다음에 조건으로 반복을 하게 되고,
BREAK 를 만나면 무조건 WHILE 을 벗어나고,
CONTINUE 를 만나면 무조건 WHILE 로 돌아간다.
예)
WHILE 조건
BEGIN
반복하는 동안 실행할 문장들...
IF 조건
BREAK
IF 조건
CONTINUE
END
○ EXEC[UTE]
- EXEC 와 EXECUTE 는 같은 의미이다.
- 두가지 용도로 사용되는데,
- 첫 번째, 스토어드 프로시저를 실행할 때 사용한다.
예)
EXEC stored_procedure
- 두 번재, SQL 문장을 동적으로 변화시키며 수행할 수 있다.
예)
DECLARE @sql VARCHAR(255)
SET @sql = 'SELECT COUNT(*) FROM '
SET @sql = @sql + 'titles '
EXEC(@sql)
--> 실제 수행되는 문장은 SELECT COUNT(*) FROM titles 가 된다.
○ CASE
- 단순 CASE
예)
SELECT
CASE type
WHEN 'a' THEN 'Apple'
WHEN 'b' THEN 'Banana'
ELSE 'No Data'
END AS 과일
, price
FROM titles
- 검색된 CASE
예)
SELECT title_id
, qty AS '수량'
, CASE
WHEN qty >= 50 THEN 'A'
WHEN qty >= 30 THEN 'B'
ELSE 'C'
END AS '등급'
FROM titles
NULLIF : 표현식 1과, 2를 비교
>> 표현식 1과, 2를 비교 두 표현식이 같으면 NULL 을 리턴, 같지 않으면 표현식 1을 리턴 SELECT NULLIF(2,3) -- 2 리턴 SELECT NULLIF(3,3) -- NULL 리턴 사용예 : 양쪽필드에서 수량이 같으면 NULL을 리턴하고 하니면 첫 필드의 값을 리턴할때
COALESCE : 뒤에 오는 표현식중에 처음으로 오는 NULL 이 아닌 값을 리턴
SELECT COALESCE(NULL, 3, 4) -- 3 리턴 SELECT COALESCE(1,NULL,) -- 1 리턴 SELECT COALESCE(NULL,NULL,4) -- 4 리턴
SELECT COALESCE(NULL,NULL, NULL)--문법오류
사용예 : 하나만 값을 가지고 있는 컬럼에서 비교해서 값을 가져올때 매우 좋다
SET : 세성 옵션 (한번설정하면 세션이 끊어 질때까지 유용)
=====================================================================================
SET nocount OFF : 몇개 행이 처리 되었는지 결과보여주는 것을 설정한다 '
SET rowcount [n]
ex) SET rowcount 4 SELECT title_id FROM titles ORDER BY TITLE
SET rowcount 0
: 보여줄 목록의 행수를 선택한다. 목록의 정렬의 임의로 설정되므로 필요한 순서가 있다면 ORDER BY 를 사용해야 한다. 사용후엔 반드시 SET ROWCOUNT 0 을 이용해서 원위치 시켜놓아야 한다 '
============================== 유니크 키 넣기 ============================== ALTER TABLE 테이블명 ADD UNIQUE(컬럼1, 컬럼2) ALTER TABLE 테이블명 DROP CONSTRAINT 유니크명
============================== IDENTITY 관련 ==============================
http://l2j.co.kr/1460
http://mcdasa.cafe24.com/wordpress/mssql-identity-scope_identity%ec%9d%98-%ec%b0%a8%ec%9d%b4%ec%a0%90/
============================== INSERT SELECT ==============================
http://blog.naver.com/sorkanj2000/50106968790
============================== UPDATE SELECT ==============================
http://applejara.tistory.com/302
============================== JOIN UPDATE ==============================
http://blog.naver.com/ballkiss/30096524074
0 notes
Text
DBA Interview Questions with Answer Part 20
What is Checkpoint SCN and Checkpoint Count? How we can check it?Checkpoint is an event when the database writer is going to flush the dirty buffers into the datafiles. This an ongoing activity and in the result checkpoint number constantly incremented in the datafile header and controfile and the background process CKPT take care of this responsibility.How can you find length of Username and Password?You can find the length of username with below query. The password is hashed (#) so there is no way to get their length.You can use special characters ($, #, _) without single quotes and any other characters must be enclosed in single quotation.Select length (username), usernamefrom dba_users;The minimum length for password is at least 1 character where as maximum depends on database version. In 10g it is restricted to 17 characters long.What are the restrictions applicable while creating view?– A view can be created referencing tables and views only in the current database.– A view name must not be the same as any table owned by that user.– You can build view on other view and on procedure that references views.For More information you can click on the below link: Common Interview Question & AnswerWhat is difference between Delete/Drop/Truncate?DELETE is a command that only removes data from the table. It is DML statement. Deleted data can be rollback (when you delete all the data get copied into rollback first then deleted). We can use where condition with delete to delete particular data from the table.Where as DROP commands remove the table from data dictionary. This is DDL statement. We cannot recover the table before oracle 10g, but flashback feature of oracle 10g provides the facility to recover the drop table.While TRUNCATE is a DDL command that delete data as well as freed the storage held by this table. This free space can be used by this table or some other table again. This is faster because it performs the deleted operation directly (without copying the data into rollback).Alternatively you can enable the row movement for that table and can use shrink command while using the delete command.SQL> Create table test ( Number s1, Number s2 );SQL> Select bytes, blocks from user_segments where segment_name = ‘test’;Bytes block---------- -------65536 8SQL> insert into t select level, level*3 From dual connect by level Select bytes, blocks from user_segments where segment_name = ‘test’;Bytes block---------- -------131072 16SQL> Delete from test;3000 rows deleted.SQL> select bytes,blocks from user_segments where segment_name = 'test';Bytes block---------- -------131072 16SQL> Alter table t enable row movement;SQL> Alter table t shrink space;Table alteredSQL> Select bytes,blocks from user_segments where segment_name = 'test';Bytes block---------- -------65536 8What is difference between Varchar and Varchar2?Varchar2 can store upto 4000 bytes where as Varchar can only store upto 2000 bytes. Varchar2 can occupy space for NULL values where as Varchar2 will not specify any space for NULL values.What is difference between Char and Varchar2?A CHAR values have fixed length. They are padded with space characters to match the specified length where as VARCHAR2 values have a variable length. They are not padded with any characters. In which Language oracle has been developed?Oracle is RDBMS package developed using C language.What is difference between Translate and Replace?Translate is used for character by character substitution where as Replace is used to substitute a single character with a word.What is the fastest query method to fetch data from table?Using ROWID is the fastest method to fetch data from table.What is Oracle database Background processes specific to RAC?LCK0—Instance Enqueue Process LMS—Global Cache Service Process LMD—Global Enqueue Service Daemon LMON—Global Enqueue Service Monitor Oracle RAC instances use two processes, the Global Cache Service (GCS) and the Global Enqueue Service (GES) to ensure that each oracle RAC database instance obtain the block that it needs to satisfy as query or transaction. The GCS and GES maintain records of the statuses of each data file and each cached block using a Global Resource Directory (GRD). The GRD contents are distributed across all of the active instances.What is SCAN in respect of oracle RAC?Single client access name (SCAN) is a new oracle real application clusters (RAC) 11g releases 2 features that provides a single name for client to access an oracle database running in a cluster. The benefit is clients using SCAN do not need to change if you add or remove nodes in the clusters.Why do we have a virtual IP (VIP) in oracle RAC?Without VIP when a node fails the client wait for the timeout before getting error where as with VIP when a node fails, the VIP associated with it is automatically failed over to some other node and new node re-arps the world indicating a new MAC address for the IP. Subsequent packets sent to the VIP go to the new node, which will send error RST packets back to the clients. This results in the clients getting errors immediately.Why query fails sometimes?Rollback segments dynamically extent to handle large transactions entry loads. A single transaction may occupy all available free space in rollback segment tablespace. This situation prevents other user using rollback segments. You can monitor the rollback segment status by querying DBA_ROLLBACK_SEGS view.What is ADPATCH and OPATCH utility? Can you use both in Application?ADPATCH is a utility to apply application patch and OPATCH is a utility to apply database patch. You have to use both in application for applying in application you have to use ADPATCH and for applying in database you have to use OPATCH.What is Automatic refresh of Materialized view and how you will find last refresh time of Materialized view?Since oracle 10g complete refresh of materialized view can be done with deleted instead of truncate. To force the instance to do the refresh with truncate instead of deleted, parameter AUTOMIC_REFRESH must be set to FALSEWhen it is FALSE Mview will be faster and no UNDO will be generated and whole data will be inserted.When it is TRUE Mview will be slower and UNDO will be generated and whole data will be inserted. Thus we will have access of all time even while it is being refreshed.If you want to find when the last refresh has taken place. You can query with these view: dba_mviews or dba_mview_analysis or dba_mview_refresh_times SQL> select MVIEW_NAME, to_char(LAST_REFRESH_DATE,’YYYY-MM-DD HH24:MI:SS’) from dba_mviews; -or- SQL> select NAME, to_char(LAST_REFRESH,’YYYY-MM-DD HH24:MI:SS’) from dba_mview_refresh_times; -or- SQL> select MVIEW_NAME, to_char(LAST_REFRESH_DATE,’YYYY-MM-DD HH24:MI:SS’) from dba_mview_analysis;Why more archivelogs are generated, when database is begin backup mode?During begin backup mode datafiles headers get freezed so row information can not be retrieved as a result the entire block is copied to redo logs thus more redo log generated or more log switch occur in turn more archivelogs. Normally only deltas (change vector) are logged to the redo logs.The main reason is to overcome the fractured block. A fractured block is a block in which the header and footer are not consistent at a given SCN. In a user-managed backup, an operating system utility can back up a datafile at the same time that DBWR is updating the file. It is possible for the operating system utility to read a block in a half-updated state, so that the block that is copied to the backup media is updated in its first half, while the second half contains older data. In this case, the block is fractured.For non-RMAN backups, the ALTER TABLESPACE ... BEGIN BACKUP or ALTER DATABASE BEGIN BACKUP when a tablespace is in backup mode, and a change is made to a data block, the database logs a copy of the entire block image before the change so that the database can re-construct this block if media recovery finds that this block was fractured.The block that the operating system reads can be split, that is, the top of the block is written at one point in time while the bottom of the block is written at another point in time. If you restore a file containing a fractured block and Oracle reads the block, then the block is considered a corrupt.Why is UNION ALL faster than UNION?UNION ALL faster than a UNION because UNION ALL will not eliminate the duplicate rows from the base tables instead it access all rows from all tables according to your query where as the UNION command is simply used to select related distinct information from base tables like JOIN command.Thus if you know that all the records of your query returns the unique records then always use UNION ALL instead of UNION. It will give you faster results.How will you find your instance is started with Spfile and Pfile?You can query with V$spparameter viewSQL> Select isspecified, count(*) from v$spparameter Group by isspecified;ISSPEC COUNT(*)------ ----------FALSE 221TRUE 39As isspecified is TRUE with some count we can say that instance is running with spfile. Now try to start your database with pfile and run the previous query again.SQL> Select isspecified, count(*) from v$spparameter Group by isspecified;ISSPEC COUNT(*)------ ----------FALSE 258Then you will not find any parameter isspecified in spfile they all come from pfile thus you can say instance is started with pfile.Alternatively you can use the below querySQL> show parameter spfile;SQL> Select decode(count(*), 1, 'spfile', 'pfile' ) from v$spparameter where rownum=1 and isspecified='TRUE';Why we need to enable Maintenance Mode?To ensure optimal performance and reduce downtime during patching sessions, enabling this feature shuts down the Workflow Business Events System and sets up function security so that Oracle Applications functions are unavailable to users. This provides a clear separation between normal run time operation and system downtime for patching..
0 notes
Text
Difference between CHAR and VARCHAR2 In Oracle
Difference between CHAR and VARCHAR2 In Oracle
Oracle database contains different types of Character data types. Among those data types, CHAR and VARCHAR2 are widely utilized compared to other types such as VARCHAR, CLOB etc. in PL/SQL programming. Due to this it becomes evident to understand the difference between CHAR and VARCHAR2. Additionally, this is the most frequently asked interview question of Oracle database.
Difference between CHAR…
View On WordPress
0 notes
Text
PHP, MySql Experienced Interview Questions and Answers.
PHP, MySql Experienced Interview Questions and Answers.
What is the REGEXP? A REGEXP pattern match succeed if the pattern matches anywhere in the value being tested. What is the difference between CHAR AND VARCHAR? The CHAR and VARCHAR types are similar, but differ in the way they are stored and retrieved. The length of a CHAR column is fixed to the length that you declare when you create the table. The length can be any value between 1 and 255. When…
View On WordPress
0 notes
Link
0 notes
Link
(Via: Hacker News)
Mapping strings to things makes sense. You take a meaningful string and you assign it a value. As with most things we do in programming there are many pitfalls to approaching a problem. So, lets explore some of them!
What Exactly Is Your Problem?
Here’s a situation we’ve all run into at some point.
Say you’re reading records from a database and it has a column called “Type”. Lets say for some reason the designer wanted things to be a little bit human readable so this “Type” column is a varchar(30). When you read this string in you need to parse it into some internal type within your application.
What method do you use?
std::vector<std::string> and use the index as your enum type?
std::map<std::string, enum_t>?
std::unordered_map<std::string, enum_t>?
Hey, std::vector is fast!
And indeed you would be right! Of all the STL containers std::vector is by far the most used, tested, and fully understood container to ever grace C++. What it isn’t is a Swiss Army Knife. But lets use it like one anyway!
Consider this:
enum class types_t : std::size_t { circle, square, triangle, num_types }; // initialize size == num_types std::vector<std::string> v(static_cast<std::size_t>(types_t::num_types)); auto convert = [](types_t t) -> std::size_t { return static_cast<std::size_t>(t); }; v[convert(types_t::circle)] = "circle"; v[convert(types_t::square)] = "square"; v[convert(types_t::triangle)] = "triangle";
With this you can now lookup your internal type like so:
// returns type_t::num_types if failed auto get_type(const std::string& type) { return static_cast<types_t>(std::distance( std::begin(v), std::find(std::begin(v), std::end(v), type))); }
I understand this is an extremely naïve implementation but the concept is there. We use strings in order to obtain a handle to some internal type.
Don’t worry we’ll get to benchmarks and how we can make this particular implementation faster.
But Why Not Use std::map?
Good question. Let’s use one:
// using same 'types_t' std::map<std::string, types_t> m; m["circle"] = types_t::circle; m["square"] = types_t::square; m["triangle"] = types_t::triangle;
Well that was easier. What does the request to get the type look like?
auto get_type(const std::string& type) { auto e = m.find(type); if (e == std::end(m)) return type_t::num_types; return e->second; }
OK so that looks a little easier to read and if we have a ton of types we won’t exactly do a linear search due to the way std::map stores its entries (using RB trees).
std::unordered_map follows the same rules as std::map the only difference is that when you want to request all of the types from it the resulting list is unsorted. This behavior does have some performance implications and tells us a little bit about std::unordered_map stores its elements (probably using buckets and separate-chaining to handle collisions).
Lets See Some Numbers!
Right, so you’re probably tired of hearing me ramble about silly implementations of different things string storing techniques. Lets compare some.
For this test I generated random strings all between the lengths of 10 and 100 so we can observe strings outside of SSO (Small String Optimization)
So… That’s less than helpful. At around 1,000,000 elements our unsorted vector takes around 32 minutes to lookup a string.
Let’s fix this. An easy way to get our std::vector implementation in-line with the rest of the containers is we can sort it and utilize an algorithm, std::lower_bound, in order to speed up our lookup times.
Lets see how that change affects the benchmark:
These are much better numbers. We can actually see std::vector basically even with std::map while std::unordered_map starts beating out both.
There Might Be A Better Way…
If you think about the problem we’re actually solving here you could actually relate it to another common problem of pattern matching in search engines.
In our problem we have a finite set of things that a string could match to. With that in mind we can short cut a lot of the matching process if we manage to find a string with a certain prefix.
For example, in the list of strings ["cat", "cake", "bat"] if we have the prefix "ca" then we have two potential matches, "cat" and "cake", however if we have a prefix of just "b" then we don’t even have to compare the rest of the string to "bat" to have a full match, we can just take "bat". This, of course, is all under the assumption you can short circuit like that in your string match. It’s possible you have malformed type strings. Keep this in mind when considering the following solution!
Luckily there is a data structure that will do just this type of prefix matching. A Trie.
The Trie
Many may know what a Trie is but for those who don’t it is a tree based structure that is optimized for matching string prefixes to words inserted into the tree.
Conceptually:
This is the resulting structure after we insert the words "ask", "as", "bake", "bat", "cat" and, "to"
An extremely simple implementation of this structure uses a std::map to place a char leading to another node in the tree. Nodes can then be annotated with whether or not they’re a word (since individual branches can also be words in the case of "as" above).
Lets see how this implementation might compare to our existing benchmarks:
OK, so with the naïve implementation we don’t even beat std::map. This is unsurprising because it uses std::map under the covers to maintain the Trie invariant of being sorted. We want to maintain that the Trie is sorted so we can return sorted lists of words, so we won’t bother using std::unordered_map to implement the node behavior.
Improving Trie
All this said, there is a lot of room for improvement. Mainly in the way we store words that are leaves. If you’ll notice, whenever we created the subtree for "bake" we added an extra branch node between where the leaf and the end of the word. This problem is exacerbated when we have very long words with no common prefixes with other words in the tree.
In essence the tree has two different types of nodes: leaf nodes and branch nodes. Leaf nodes are those that only contain the full words and branch nodes have child nodes that are either leaves or more branches. Here, I chose inheritance to do the trick for me:
struct node_concept_t; struct branch_node_t : node_concept_t; struct leaf_node_t : node_concept_t;
To determine if I was at a leaf or branch I used the visitor pattern to tell me the information I needed.
Lets see how this implementation stacks up:
This is looking promising! This implementation even beats std::unordered_map in terms of lookups. The reason we start to edge out std::unordered_map is because this structure is allowed to shortcut longer string comparisons by binary searching and has a decent memory layout when inspecting leaf data.
So I Kinda Lied…
impl2 doesn’t quite have what we need just yet. It can’t actually store values. It only looks up strings. So the final implementation, impl3, will store values and has yet another neat feature.
In impl2 branch nodes were annotated via a boolean variable to indicate whether or not it was word. Just like in the naïve implementation, impl1. In impl3, however, we take a different approach. We distinguish branches that carry values with a type of their own:
template <typename> struct node_concept_t; template <typename> struct branch_node_t : node_concept_t; tmplate <typename> struct branch_value_node_t : node_concept_t; template <typename> struct leaf_node_t : node_concept_t;
Notice we also templated each type in order to store the values in leaf and value branches. How does this implementation fare?
Good! We’re still beating out the std::unordered_map implementation even while storing values!
Bringing It All Together
Now that we have all the information, lets see how it all looks:
It’s not enough to just benchmark lookup times, insert times are a concern too. Here’s a benchmark of inserting various numbers of elements using the same parameters (words between 10 and 100 characters in length):
Here it’s pretty expected that std::unordered_map beats impl{1,2,3} since its insert time only occasionally rehashes the whole data set. Generally the hash is linear in complexity, making the total insert time O(n + k) where n is the string length and k is (potentially your chain size). In our Trie we need to do a prefix match and potentially breakup a leaf node into multiple branches and up to two other leaf nodes. This makes our insert time on the order of O(n lg n).
I encourage you to check out the code where the benchmark code can be found along with the Trie implementations.
A quick shout out to gochart for providing the awesome chart making utility and draw.io for the Trie visualization.
Until next time!
0 notes
Text
Laravel Random Keys with Keygen
When developing applications, it is usually common to see randomness come into play - and as a result, many programming languages have built-in random generation mechanisms. Some common applications include:
Generating a random numeric code for email confirmation or phone number verification service.
Password generation service that generates random alphanumeric password strings.
Generating random base64-encoded tokens or strings as API keys.
Generating random strings as password salts to hash user passwords.
When your application is required to generate very simple random character sequences like those enumerated above, then the Keygen package is a good option to go for.
Introducing the Keygen Package
Keygen is a PHP package for generating simple random character sequences of any desired length and it ships with four generators, namely: numeric, alphanumeric, token and bytes. It has a very simple interface and supports method chaining - making it possible to generate simple random keys with just one line of code. The Keygen package can save you some time trying to implement a custom random generation mechanism for your application. Here are some added benefits of the Keygen package:
Seamless key affixes: It's very easy to add a prefix or suffix to the random generated string.
Key Transformations: You can process the random generated string through a queue of callables before it is finally outputted.
Key Mutations: You can control manipulations and mutations of multiple Keygen instances.
This tutorial provides a quick guide on how you can get started with the Keygen package and using it in your Laravel applications. For a complete documentation and usage guide of the Keygen package, see the README document at Github.
Getting Started
In this tutorial, we would be creating a simple REST API service. The API simply provides endpoints for creating user record, showing user record and generating a random password.
This tutorial assumes you already have a Laravel application running and the Composer tool is installed in your system and added to your system PATH. In this tutorial, I am using Laravel 5.3, which is the latest stable version at this time of writing. You can refer to the Laravel Installation guide if you don't have Laravel installed.
Next, we would install the Keygen package as a dependency for our project using composer. The Keygen package is available on the Packagist repository as gladcodes/keygen.
composer require gladcodes/keygen
If it installed correctly, you should see a screen like the following screenshot.
Creating an alias for the Keygen package
The functionality of the Keygen package is encapsulated in the Keygen\Keygen class. For convenience, we would register an alias for this class, so that we can easily use it anywhere in our application. To create the alias, we would edit the config/app.php file and add a record for our alias after the last record in the aliases array as shown in the following snippet.
// config/app.php 'aliases' => [ // ... other alias records 'Keygen' => Keygen\Keygen::class, ],
Now we can use the Keygen package anywhere in our application. Add the use Keygen directive in your code to use the Keygen package as shown in the following usage example code.
// usage example <?php use Keygen; $id = Keygen::numeric(10)->generate(); echo $id; //2542831057
Creating the User Model
Next, we would create a database table called users to store our users records. The schema for the table is as follows:
id INT(11) NOT NULL PRIMARY
code CHAR(24) NOT NULL UNIQUE
firstname VARCHAR(32) NOT NULL
lastname VARCHAR(32) NOT NULL
email VARCHAR(80) NOT NULL UNIQUE
password_salt CHAR(64) NOT NULL
password_hash CHAR(60) NOT NULL
What about autoincrement? For this tutorial, the id of our users table would be a unique random generated integer, just to demonstrate with the Keygen package. This choice is based on preference, and does not in anyway discourage the use of auto-incremented IDs.
If created correctly, it should be as shown in the following screenshot.
Before you proceed, check the config/database.php file and .env file of your application to ensure that you have the correct configuration for your database.
Next, we would create a model for the users table using Laravel's artisan command-line interface. Laravel ships with a built-in User model so we have to create our custom User model in a different location - app/Models folder, as shown in the following command.
php artisan make:model Models/User
We would modify the created User class in the app/Models/User.php file as shown in the following code to configure our model as required.
// app/Models/User.php <?php namespace App\Models; use Illuminate\Database\Eloquent\Model; class User extends Model { protected $table = 'users'; public $timestamps = false; public $incrementing = false; public function setEmailAttribute($email) { // Ensure valid email if (!filter_var($email, FILTER_VALIDATE_EMAIL)) { throw new \Exception("Invalid email address."); } // Ensure email does not exist elseif (static::whereEmail($email)->count() > 0) { throw new \Exception("Email already exists."); } $this->attributes['email'] = $email; } }
In the preceeding code, we set the timestamps property to false to disable Laravel's timestamps features in our model. We also set the incrementing property to false to disable auto-incrementing of the primary key field.
Finally, defined a mutator for the email attribute of our model with email validation check and check to avoid duplicate email entries.
Defining Routes for the API
Next, we would define routes for the API endpoints. There are basically four endpoints:
GET /api/users
POST /api/users
GET /api/user/{id}
GET /api/password
// routes/web.php // Add the following route definitions for API Route::group(['prefix' => 'api'], function() { Route::get('/users', 'ApiController@showAllUsers'); Route::post('/users', 'ApiController@createNewUser'); Route::get('/user/{id}', 'ApiController@showOneUser'); Route::get('/password', 'ApiController@showRandomPassword'); });
Next, we would create our ApiController using Laravel's artisan command-line interface and then add the methods registered in the routes.
php artisan make:controller ApiController
The above command creates a new file app/Http/Controllers/ApiController.php that contains the ApiController class. We can go ahead to edit the class and add the methods registered in the routes.
// app/Http/Controllers/ApiController.php <?php namespace App\Http\Controllers; use Illuminate\Http\Request; class ApiController extends Controller { public function showAllUsers(Request $request) {} public function createNewUser(Request $request) {} public function showOneUser(Request $request, $id) {} public function showRandomPassword(Request $request) {} }
Laravel ships with a middleware for CSRF verification on all web routes. We won't require this for our API, so we will exclude our api routes from the CSRF verification service in the app/Http/Middleware/VerifyCsrfToken.php file.
// app/Http/Middleware/VerifyCsrfToken.php <?php namespace App\Http\Middleware; use Illuminate\Foundation\Http\Middleware\VerifyCsrfToken as BaseVerifier; class VerifyCsrfToken extends BaseVerifier { /** * The URIs that should be excluded from CSRF verification. * * @var array */ protected $except = [ '/api/*', ]; }
Generate Unique ID for User
The Keygen package will be used to generate a unique 8-digit integer ID for the user. We will implement the unique ID generation mechanism in a new generateID() method. We will also add use directives for Hash, Keygen and App\Models\User classes in our controller.
First let's add a new generateNumericKey() method for generating random numeric keys of length 8 integers.
// app/Http/Controllers/ApiController.php <?php namespace App\Http\Controllers; use Hash; use Keygen; use App\Models\User; use Illuminate\Http\Request; class ApiController extends Controller { // ... other methods protected function generateNumericKey() { return Keygen::numeric(8)->generate(); } }
The Keygen package generates numeric keys by statically calling the numeric() method of the Keygen\Keygen class. It takes an optional length argument which specifies the length of the numeric key and defaults to 16 if omitted or not a valid integer. In our case, the length of the generated numeric key is 8. The generate() method must be called to return the generated key.
Usually it is not desirable to have zeroes starting-off integers that will be stored in the database, especially IDs. The following snippet modifies the generation mechanism of the generateNumericKey() method by using the prefix() method provided by the Keygen package to add a non-zero integer at the beginning of the numeric key. This is known as an affix. The Keygen package also provides a suffix() method for adding characters at the end of generated keys.
// modified generateNumericKey() method // Ensures non-zero integer at beginning of key protected function generateNumericKey() { // prefixes the key with a random integer between 1 - 9 (inclusive) return Keygen::numeric(7)->prefix(mt_rand(1, 9))->generate(true); }
In the preceeding code, observe how we called numeric() with length 7. This is because we are adding a random non-zero integer as a prefix, making the length of the final generated numeric key to be 8 as is required.
And now let's implement the generateID() method to generate unique user IDs.
// generateID() method protected function generateID() { $id = $this->generateNumericKey(); // Ensure ID does not exist // Generate new one if ID already exists while (User::whereId($id)->count() > 0) { $id = $this->generateNumericKey(); } return $id; }
Generate Code for User
Now we will generate a random code of the form XXXX-XXXX-XXXX-XXXX-XXXX for the user such that X is a hexadecimal character and always in uppercase. We will use a feature provided by the Keygen package called Key Transformation to transform randomly generated bytes to our desired code.
What is a Key Transformation? A transformation is simply a callable that can take the generated key as the first argument and returns a string. Each transformation is added to a queue and executed on the generated key before the key is returned.
Let's create a new generateCode() method to handle the code generation logic.
protected function generateCode() { return Keygen::bytes()->generate( function($key) { // Generate a random numeric key $random = Keygen::numeric()->generate(); // Manipulate the random bytes with the numeric key return substr(md5($key . $random . strrev($key)), mt_rand(0,8), 20); }, function($key) { // Add a (-) after every fourth character in the key return join('-', str_split($key, 4)); }, 'strtoupper' ); }
Here we generated some random bytes by calling the byte() method of the Keygen package and then added three transformations to the randomly generated bytes as follows:
The first is a custom function that manipulates the randomly generated bytes, computes an MD5-hash and returns a substring of the hash that is 20 characters long.
The second is a custom function that adds a hyphen (-) after every fourth character of the substring from the previous transformation.
The last is the built-in strtoupper PHP function that makes the resulting string uppercase.
Creating a New User
Let's write the implementation of the createNewUser() method in our ApiController to create record for new user.
public function createNewUser() { $user = new User; // Generate unique ID $user->id = $this->generateID(); // Generate code for user $user->code = $this->generateCode(); // Collect data from request input $user->firstname = $request->input('firstname'); $user->lastname = $request->input('lastname'); $user->email = $request->input('email'); $password = $request->input('password'); // Generate random base64-encoded token for password salt $salt = Keygen::token(64)->generate(); $user->password_salt = $salt; // Create a password hash with user password and salt $user->password_hash = Hash::make($password . $salt . str_rot13($password)); // Save the user record in the database $user->save(); return $user; }
In the preceeding snippet, we have used Keygen::token() to generate a random base64-encoded token for our password salt, 64 characters long. We also used Laravel's built-in Hash facade to make a bcrypt password hash using the user password and the password salt.
You can now create a user record through the route POST /api/users. I am using Postman to test the API endpoints. This is the JSON payload of my POST request:
{ "firstname": "Jack", "lastname": "Bauer", "email": "[email protected]", "password": "f1gHtTerr0rIsts" }
Here is the screenshot from Postman.
Implementing the remaining methods
Let's write the implementation for the remaining methods in our controller.
// app/Http/Controllers/ApiController.php public function showAllUsers(Request $request) { // Return a collection of all user records return User::all(); } public function showOneUser(Request $request, $id) { // Return a single user record by ID return User::find($id); } public function showRandomPassword(Request $request) { // Set length to 12 if not specified in request $length = (int) $request->input('length', 12); // Generate a random alphanumeric combination $password = Keygen::alphanum($length)->generate(); return ['length' => $length, 'password' => $password]; }
In the showRandomPassword() method implementation, we are using Keygen::alphanum() to create a random combination of alphanumeric characters as the generated password. The length of the generated password is gotten from the length query parameter of the request if provided, else, it defaults to 12 as specified.
Testing the API
Let's create another user record with the endpoint POST /api/users. I am using Postman to test the API endpoints. This is the JSON payload of my POST request:
{ "firstname": "Glad", "lastname": "Chinda", "email": "[email protected]", "password": "l0VeKOd1Ng" }
Here is the screenshot from Postman.
Now let's get all the user records using the endpoint GET /api/users. Here is the screenshot from Postman.
Next, we would get the record for one user. I want to get the record for the user Glad Chinda, so I will use the endpoint GET /api/user/93411315. Here is the screenshot from Postman.
Finally, we would test the password generation endpoint to generate random passwords. First, we would call the endpoint without a length parameter to generate a password of length 12 i.e GET /api/password. Here is the screenshot from Postman.
Next, we would call the endpoint with a length parameter, GET /api/password?length=8 to generate a password of length 8. Here is the screenshot from Postman.
Conclusion
In this article, we have been able to explore the basic random key generation techniques of the Keygen package and also wire them into our Laravel application. For a detailed usage guide and documentation of the Keygen package, see the Keygen repository on Github. For a code sample of this tutorial, checkout the laravel-with-keygen-demo repository on Github.
via Scotch.io http://ift.tt/2koNLMT
0 notes
Text
MySQL: Some Character Set Basics
This is the updated and english version of some older posts of mine in German. It is likely still incomplete, and will need information added to match current MySQL, but hopefully it is already useful. Old source articles in German: 1, 2 and 3. Some vocabulary Symbol, Font, Encoding and Collation - what do they even mean? A character set is a collection of symbols that belong together. That is a completely abstract thing, and also almost useless. The only thing you can do with a character set is decide if a specific symbol is legal within a context or not. And, if it is legal, what position the symbol in the character set has (the code point). To be able to print symbols they need a shape, which is defined in a Font. For example is this here: “ö” a letter “ö” in Arial, and “ö” the same thing in a different font, Times New Roman. To be able to use symbols with computers they need a binary represenation of their code point, an encoding. In my Terminal we are using utf8. The Text “Köhntopp” is being represented as the byte sequence 4b c3 b6 68 6e 74 6f 70 70. LATIN SMALL LETTER O WITH DIARESIS has the code point 0x00F6, which is being represented as C3 B6 in utf8 encoding. $ echo Köhntopp | hexdump -C 00000000 4b c3 b6 68 6e 74 6f 70 70 0a |K..hntopp.| 0000000aIf I change the terminal settings to use ISO-8859-1 (“Latin1”) instead, the same text is being encoded differently - 4b f6 68 6e 74 6f 70 70. The ö is now F6. $ echo Köhntopp | hexdump -C 00000000 4b f6 68 6e 74 6f 70 70 0a |K.hntopp.| 00000009If you have two character sequences and want to compare or sort them, you need a set of comparison and ordering rules, a collation. You can think of a collation as a canonical representation of an encoding for comparison and sorting. For example, the collation latin1_german1_ci represents “Köhntopp” internally as “kohntopp” and uses this internal represenation to compare it to other strings or sort it. But in storage we always find the original string, “Köhntopp”. There is a second german language collation, latin1_german2_ci, which interally writes “Köhntopp” as “koehntopp” to compare and sort - but it will also save the same “Köhntopp” to disk. The variants of Unicode and Unicode encoding ASCII was a 7bit character set of 128 characters from 0 to 127. It works with english, but with almost no other writing systems in the world. A set of 8 bit character sets were defined in ISO-8859, among them ISO-8859-1 (“latin1”), later slightly revised to ISO-8859-15 (modified to contain, among other things, the Euro sign). The code points that exist in both ISO-8859-1 and ASCII are identical, ISO-8859-1 is a full superset of ASCII. ISO-8859 also contained other character sets for Cyrillic, Arabic, Greek, Hebrew and other languages, but because of the limitation to 8 bits, it was not possible to easily write text that switches between languages. Unicode development started in 1991 as a 16 bit character set, and it was assumed that this is sufficient to hold all characters from all possible writing systems. Unicode was design as a superset of ISO-8859-1, so codepoints that exist in both character sets are identical. In 1996 it became clear that a set of 65536 characters was not sufficient, and Uncode 2.0 was fitted with an extension mechanism to allow more than 65536 symbols. Again, this extension is a true superset of original Unicode. As of March 2020, Unicode 13.0 contains some 140k characters from 154 writing systems. The definition of Unicode 13.0 currently allows for 1.112064 possible characters. The weird number is necessary, because some code points in the lower 65536 characters are reserved to encode surrogate pairs, basically extension characters for the original 16 bit character set. 16 Bit Unicode is stored as UCS2 (what Windows NT used to use) - a fixed length encoding, which instead of 8 bit characters now uses 16 bit characters. When writing western languages, every other byte in text is 0. UTF-16 extends UCS2 and uses variable length encoding of 2 bytes or 4 bytes to allow representation of all unicode characters, even those beyond the initial 65536 characters. Unix systems tend to use UTF-8 (utf8), a variable length encoding in which Unicode characters are 1-3 bytes in length (for the initial 65536 characters of Unicode 1.0), or 1-4 bytes in length (for full unicode). Server Terms MySQL names an encoding a “CHARACTER SET” or “CHARSET”. The charsets available in the server can be listed with SHOW CHARSET, or by searching through INFORMATION_SCHEMA.CHARACTER_SETS. In both cases, looking at the Maxlen column will tell you how long a symbols encoding in bytes can become in the worst case. Conversely, SHOW COLLATION (and INFORMATION_SCHEMA.COLLATIONS) will show you the collations the server knows about. Collations are not things that can be used standalone, they always belong to charsets. So INFORMATION_SCHEMA.COLLATION_CHARACTER_SET_APPLICABILITY tells you which collation can be used with which character set (or you SHOW COLLATION WHERE Charset = "..."). Setting charset and collation on a table Every string in MySQL is labeled with an charset and a collation. For database objects that happens at the column level: A column with CHAR, VARCHAR, or any TEXT type always has a charset and a collation. The same can be true for an ENUM type that contains strings. If you define these without specifying, the column will inherit the table defaults. If you specify no table default, the table will inherit the database default, which in turn inherits from the server default, which is defined in the my.cnf: [mysqld] default-character-set=utf8mb4 default-collation=utf8_0900_ai_ciOr you set them at the database level: mysql> show create database krisG Database: kris Create Database: CREATE DATABASE `kris` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ 1 row in set (0.01 sec)Or at the table level: mysql> show create table chsetG Table: chset Create Table: CREATE TABLE `chset` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `c` char(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL, `d` varchar(20) CHARACTER SET cp850 COLLATE cp850_general_ci DEFAULT NULL, `t` text CHARACTER SET latin1 COLLATE latin1_german1_ci, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec)String Literals A string literal in MySQL is written in double quotes, “a string literal”. When nothing else is specified, the connections character set and collation are being used. An identifier in MySQL is written as a bare word tablename or written in backticks `weird tablename`. When written in backticks, the identifier can contain any utf8 unicode character (unfortunately, not utf8mb4 character, so you have to constrain yourself to the BMP). Don’t do this in production, though. mysql> create table `❤` ( `✔` serial ) ; Query OK, 0 rows affected (0.07 sec) mysql> insert into `❤` values (1); Query OK, 1 row affected (0.02 sec) mysql> select * from `❤`; +-----+ | ✔ | +-----+ | 1 | +-----+ 1 row in set (0.00 sec)If you check, the table is stored with the filename @2764.ibd on disk. The full notation for a string literal is _charsetname "string" COLLATE collationname. The _charsetname thing is called an introducer and tells the parser what character set label to put on the string that follows. It does not convert, the CONVERT() function would do that. A string literal can also be written as X'hexcode', so this works: mysql> select _latin1 X'F6' as umlaut; +--------+ | umlaut | +--------+ | ö | +--------+ 1 row in set (0.00 sec)This creates a string literal from the hex code 0xF6 and labels it as latin1. The statement is then run, produces an Umlaut, and this Umlaut is then emitted as a result table. Because the connection is set to utf8, the Umlaut is converted to utf8, yields C3 B6 and that is sent to the terminal, where it renders correctly. When we leave the label off, the conversion does not work. When we lie, the result is invalid and rejected: mysql> select X'F6' as umlaut; +----------------+ | umlaut | +----------------+ | 0xF6 | +----------------+ 1 row in set (0.00 sec) mysql> select _utf8 X'F6' as umlaut; ERROR 1300 (HY000): Invalid utf8 character string: 'F6'Charset on a connection The other thing that has a character set is the connection from the client to the database server. That is required, because when you type for example “ö” into a utf8 terminal to send it to kris.chset, column t as defined above, it has to be converted from utf8 (C3B6) to latin1 (F6), because the column t is defined with a charset of latin1. MySQL does that automatically for you, if a conversion exists: You sent a utf8 c3b6, MySQL detects the column defined as latin1, and tries to convert, yielding f6, which is then stored. How do you tell MySQL what charset the connection uses? You can set a default with default-character-set and default-encoding in the [mysql] section of your my.cnf to tell MySQL what character set your terminal uses, or use the command SET NAMES to change it on the fly. If I am setting up my terminal to send utf8, and SET NAMES utf8, these things match and all will be well and converted correctly, if at all possible. I can check: root@localhost [kris]> set names utf8; Query OK, 0 rows affected (0.00 sec) root@localhost [kris]> select hex("ö"); +-----------+ | hex("ö") | +-----------+ | C3B6 | +-----------+ 1 row in set (0.00 sec)Switching my terminal to latin1, and then telling the database about this with SET NAMES latin, I get: root@localhost [kris]> set names latin1; Query OK, 0 rows affected (0.00 sec) root@localhost [kris]> select hex("ö"); +----------+ | hex("ö") | +----------+ | F6 | +----------+ 1 row in set (0.00 sec)So this actually works. MySQL converts automatically Now, let’s use a utf8-Client to store data into a column into kris.chset.t, which is latin1. What will happen? MySQL converts this automatically and we can show this. root@localhost [kris]> set names utf8; Query OK, 0 rows affected (0.00 sec) mysql> insert into kris.chset (id, t) values ( 1, "ö"); Query OK, 1 row affected (0.02 sec) mysql> select hex("ö"), hex(t), t from kris.chset where id = 1; +-----------+--------+------+ | hex("ö") | hex(t) | t | +-----------+--------+------+ | C3B6 | F6 | ö | +-----------+--------+------+ 1 row in set (0.00 sec)I am sending SET NAMES utf8 and I am inserting a row id=1 into the table kris.chset (see above for the definition, which has the charset latin1). Selecting the value back, I see the hex code for an actual “ö”, C3B6, utf8, so I know my terminal sends utf8. I also see the hex code stored in the table, F6, by selecting the column value from t, wrapped in the HEX() function. And on reading that back, I am still getting an “ö”. That proves the database sent me a C3B6, converting back from the storage character set to the terminal character set, as declared with SET NAMES. So as long as I am not lying to the database about what my connection sends, values should be transaparently converted back and forth if at all possible. CONVERT(), LENGTH() and CHAR_LENGTH() functions Normally you will never need this, but it is possible to change the character set of a column or string literal explicitly using the convert( ... using ... ) function: mysql> select hex("ö"); +-----------+ | hex("ö") | +-----------+ | C3B6 | +-----------+ 1 row in set (0.00 sec) mysql> select hex(convert("Köhntopp" using latin1)) as example; +------------------+ | example | +------------------+ | 4BF6686E746F7070 | +------------------+ 1 row in set (0.00 sec)After validating that my umlaut is indeed sent as C3B6, I am using a string with an Umlaut as an input to CONVERT( ... USING ... ). I am converting to latin1, and as you can see, I am indeed getting an F6 as the second byte. There are other encodings of unicode, too. Windows systems for example often use ucs2 instead of utf8. That is, each symbol is stored as a 16 bit code: mysql> select hex(convert("Köhntopp" using ucs2)) as example; +----------------------------------+ | example | +----------------------------------+ | 004B00F60068006E0074006F00700070 | +----------------------------------+ 1 row in set (0.00 sec)My Umlaut ends up being 00f6 on disk. The points to take away from this: Some character sets have fixed length codes for letters. In latin1, each letter takes the fixed amount of one byte. In ucs2, each letter takes the fixed amount of 2 bytes. Other character set have variable length encodings. In utf8, each letter can be between 1 and 3 bytes long. Later Unicode extensions define a larger character set, and utf32 stores them in a fixed set of 4 byte characters (3 of them 0 for the latin1 subset), while utf8mb4 stores them in 1 to 4 bytes, depending on the symbol. Depending on what we want to know we have to ask differently: mysql> select length("Köhntopp") as len, char_length("Köhntopp") as clen; +-----+------+ | len | clen | +-----+------+ | 9 | 8 | +-----+------+ 1 row in set (0.00 sec) mysql> select length(convert("Köhntopp" using ucs2)) as len, char_length(convert("Köhntopp" using ucs2)) as clen; +------+------+ | len | clen | +------+------+ | 16 | 8 | +------+------+ 1 row in set (0.00 sec)The function LENGTH() gives us the length of a symbol or string in bytes, which is dependent on the character set encoding used. The function CHAR_LENGTH() gives us the length of the symbol or string in symbols, which is fixed and independent of the character set encoding. It is important to use the right function depending on what you want to know. The default character set in MySQL you should be using is utf8mb4. Comparison and Sorting When MySQL originally gained character set support, this was done by implementing a comparison function. The same function was used for sorting and comparison. So when “Köhntopp” sorts as “kohntopp” in the latin1_german1_ci collation, it also means that searching for “Köhntopp” will find “Köhntopp” as well as “kohntopp”, because to the comparison function they are the same string. mysql> show create table t G Table: t Create Table: CREATE TABLE `t` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `d` varchar(20) CHARACTER SET latin1 COLLATE latin1_german1_ci DEFAULT NULL, UNIQUE KEY `id` (`id`) ) 1 row in set (0.00 sec) mysql> select * from t; +----+-----------+ | id | d | +----+-----------+ | 1 | Köhntopp | | 2 | kohntopp | +----+-----------+ 2 rows in set (0.00 sec) mysql> select * from t where d = "Köhntopp"; +----+-----------+ | id | d | +----+-----------+ | 1 | Köhntopp | | 2 | kohntopp | +----+-----------+ 2 rows in set (0.00 sec)This was not exactly what most people expected, so in MySQL 8 things are a bit more differentiated when using utf8mb4. From the manual: | Suffix | Meaning | +——–+———+ | _ai | Accent-insensitive | | _as | Accent-sensitive | | _ci | Case-insensitive | | _cs | Case-sensitive | | _ks | Kana-sensitive | | _bin | Binary | “Kana-sensitive” collations distinguish Hiragana characters from Katakana characters in Japanese. The collation you want with utf8mb4 is utf8mb4_0900_ai_ci (and replace ai and ci as necessary). The 0900 part is a reference to UCA 9.0.0, the current Unicode Comparison Algorithm. MySQL also supports UCA 5.2.0 (utf8mb4_520_ci) and 4.0.0 (utf8mb4_unicode_ci), but these have no ai/as variants. UCA 9.0.0 solves the Köhntopp/koehntopp problem by defining different functions for searching things (testing for equality) and ordering (testing for smaller than). Why utf8mb4, and not simply utf8? MySQL gained character set support with the MySQL 4.1 series of server releases in 2003. At that time, utf8 was a character set with room for 65536 (2^16) code points, and the UCS2 encoding (for 16 bit fixed width characters used in Windows) plus the UTF8 encoding (for variable length characters of 1-3 bytes in length). MySQL at that point in time changed character sets and collations several times, as bugs were detected and fixed. This created a lot of problems: In databases, an Index is created by extracting the indexed column from a table, sorting it, and storing it next to the table in sorted order with pointers to the original rows. An index is, in short, a materialized order for the indexed column, in order to speed searches. Now if you change the character set or the order of symbols in the character set by fixing the collation, the materialized order of the index differs from newly fixed and redefined order to the fixed collation. When upgrading to the changed server version the index needs to be dropped and recreated - which for large databases with many indexes on large tables can take a very, very long time. If you do not do this, a query such as mysql> SELECT * FROM t WHERE d = "kohntopp";may find different results depending on the optimizer using an index (pre-update rules apply until the index is recreated) or not using an index (post-update rules apply immediately). This is unpredictable, and hence bad behavior. It was decided that MySQL will, in order to simplify updates, never do this ever again. Instead fixes and changes will be publicised under new names so that changes could be made at will and a pace set by the user by ALTER TABLEing the index definitions from the old collation name to the new name. Hence we have utf8 (the 16-bit character set) and utf8mb4 (the larger than 16 bit character set) that was defined later. And we have even collations referring to different UCA rules for collating utf8mb4 in order to allow controlled migration to newer, better comparison rules. The same is true for Timezones: MySQL does not use operating system sort and comparison rules as offered in the glibc functions, but brings its own, and it also does not use Timezone functions and rules as offered by glibc, but again uses its own. That provides stable and controlled migration that is also independent of operating system updates - the same comparison and index rules exist indendent of glibc updates, and on Linux, MacOS and Windows. This also keeps binary data files portable and upgradeable across operating systems and database versions. Compare that for example to Postgres, which uses glibc functions for string comparison, sorting and for timezone conversions. In Postgres, you have to be aware of operating system updates that affect sorting, comparison or timezones, and you have to recreate indexes every time you make changes to these operating system functions. Noticing glibc updates that affect the function of the database on a system with security auto-updates can be very hard. Fixing broken data Sometimes data ends up inside the database, converted from latin1 to utf8 by an application and then again by the database. This can only happen when the declared character set of the connection (SET NAMES) and the data sent to not match. For example, if you define a table with a VARCHAR column in latin1, and set the connection to latin1, but then send actual utf8 data to the table, you not triggering a conversion (connection and column have the same character set), but the data is not valid latin1. mysql> create table t ( id serial, d varchar(20) charset latin1 ); Query OK, 0 rows affected (0.08 sec) mysql> set names latin1; -- we will be sending utf8 Query OK, 0 rows affected (0.00 sec) mysql> insert into t ( id, d ) values ( 1, "Köhntopp"); -- this is utf8 Query OK, 1 row affected (0.01 sec) mysql> select hex(d) from t where id = 1; -- stored c3b6, should be f6 +--------------------+ | hex(d) | +--------------------+ | 4BC3B6686E746F7070 | +--------------------+ 1 row in set (0.00 sec) mysql> set names utf8; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> select * from t; -- output broken +----+-------------+ | id | d | +----+-------------+ | 1 | Köhntopp | +----+-------------+ 1 row in set (0.00 sec)If we were to convert the column to utf8, the data would als be converted. But since it already is c3b6, this must not happen. So this does not work: mysql> select hex(d) from t; +--------------------+ | hex(d) | +--------------------+ | 4BC3B6686E746F7070 | +--------------------+ 1 row in set (0.00 sec) mysql> alter table t modify column d varchar(20) charset utf8; Query OK, 1 row affected, 1 warning (0.19 sec) Records: 1 Duplicates: 0 Warnings: 1 mysql> select hex(d) from t; -- broken utf8 +------------------------+ | hex(d) | +------------------------+ | 4BC383C2B6686E746F7070 | +------------------------+ 1 row in set (0.00 sec)The correct solution converts in two steps: Convert to a VARBINARY. This keeps the binary data, but removes all charset labels, without conversion. Convert to the target VARCHAR with the target CHARSET. This applies the charset label without conversion. mysql> select hex(d) from t; -- column latin1, data utf8 +--------------------+ | hex(d) | +--------------------+ | 4BC3B6686E746F7070 | +--------------------+ 1 row in set (0.00 sec) mysql> alter table t modify column d varbinary(20); -- convert to binary, keep data Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table t modify column d varchar(20) charset utf8; -- convert to utf8, keep data Query OK, 1 row affected, 1 warning (0.15 sec) Records: 1 Duplicates: 0 Warnings: 1 mysql> select d, hex(d) from t; -- all works now +-----------+--------------------+ | d | hex(d) | +-----------+--------------------+ | Köhntopp | 4BC3B6686E746F7070 | +-----------+--------------------+ 1 row in set (0.01 sec) https://isotopp.github.io/2020/08/18/mysql-character-sets.html
0 notes