#Different Types of Functions in R Programming
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
Learning About Different Types of Functions in R Programming
Summary: Learn about the different types of functions in R programming, including built-in, user-defined, anonymous, recursive, S3, S4 methods, and higher-order functions. Understand their roles and best practices for efficient coding.
Introduction
Functions in R programming are fundamental building blocks that streamline code and enhance efficiency. They allow you to encapsulate code into reusable chunks, making your scripts more organised and manageable.
Understanding the various types of functions in R programming is crucial for leveraging their full potential, whether you're using built-in, user-defined, or advanced methods like recursive or higher-order functions.
This article aims to provide a comprehensive overview of these different types, their uses, and best practices for implementing them effectively. By the end, you'll have a solid grasp of how to utilise these functions to optimise your R programming projects.
What is a Function in R?
In R programming, a function is a reusable block of code designed to perform a specific task. Functions help organise and modularise code, making it more efficient and easier to manage.
By encapsulating a sequence of operations into a function, you can avoid redundancy, improve readability, and facilitate code maintenance. Functions take inputs, process them, and return outputs, allowing for complex operations to be performed with a simple call.
Basic Structure of a Function in R
The basic structure of a function in R includes several key components:
Function Name: A unique identifier for the function.
Parameters: Variables listed in the function definition that act as placeholders for the values (arguments) the function will receive.
Body: The block of code that executes when the function is called. It contains the operations and logic to process the inputs.
Return Statement: Specifies the output value of the function. If omitted, R returns the result of the last evaluated expression by default.
Here's the general syntax for defining a function in R:

Syntax and Example of a Simple Function
Consider a simple function that calculates the square of a number. This function takes one argument, processes it, and returns the squared value.

In this example:
square_number is the function name.
x is the parameter, representing the input value.
The body of the function calculates x^2 and stores it in the variable result.
The return(result) statement provides the output of the function.
You can call this function with an argument, like so:

This function is a simple yet effective example of how you can leverage functions in R to perform specific tasks efficiently.
Must Read: R Programming vs. Python: A Comparison for Data Science.
Types of Functions in R
In R programming, functions are essential building blocks that allow users to perform operations efficiently and effectively. Understanding the various types of functions available in R helps in leveraging the full power of the language.
This section explores different types of functions in R, including built-in functions, user-defined functions, anonymous functions, recursive functions, S3 and S4 methods, and higher-order functions.
Built-in Functions
R provides a rich set of built-in functions that cater to a wide range of tasks. These functions are pre-defined and come with R, eliminating the need for users to write code for common operations.
Examples include mathematical functions like mean(), median(), and sum(), which perform statistical calculations. For instance, mean(x) calculates the average of numeric values in vector x, while sum(x) returns the total sum of the elements in x.
These functions are highly optimised and offer a quick way to perform standard operations. Users can rely on built-in functions for tasks such as data manipulation, statistical analysis, and basic operations without having to reinvent the wheel. The extensive library of built-in functions streamlines coding and enhances productivity.
User-Defined Functions
User-defined functions are custom functions created by users to address specific needs that built-in functions may not cover. Creating user-defined functions allows for flexibility and reusability in code. To define a function, use the function() keyword. The syntax for creating a user-defined function is as follows:

In this example, my_function takes two arguments, arg1 and arg2, adds them, and returns the result. User-defined functions are particularly useful for encapsulating repetitive tasks or complex operations that require custom logic. They help in making code modular, easier to maintain, and more readable.
Anonymous Functions
Anonymous functions, also known as lambda functions, are functions without a name. They are often used for short, throwaway tasks where defining a full function might be unnecessary. In R, anonymous functions are created using the function() keyword without assigning them to a variable. Here is an example:

In this example, sapply() applies the anonymous function function(x) x^2 to each element in the vector 1:5. The result is a vector containing the squares of the numbers from 1 to 5.
Anonymous functions are useful for concise operations and can be utilised in functions like apply(), lapply(), and sapply() where temporary, one-off computations are needed.
Recursive Functions
Recursive functions are functions that call themselves in order to solve a problem. They are particularly useful for tasks that can be divided into smaller, similar sub-tasks. For example, calculating the factorial of a number can be accomplished using recursion. The following code demonstrates a recursive function for computing factorial:

Here, the factorial() function calls itself with n - 1 until it reaches the base case where n equals 1. Recursive functions can simplify complex problems but may also lead to performance issues if not implemented carefully. They require a clear base case to prevent infinite recursion and potential stack overflow errors.
S3 and S4 Methods
R supports object-oriented programming through the S3 and S4 systems, each offering different approaches to object-oriented design.
S3 Methods: S3 is a more informal and flexible system. Functions in S3 are used to define methods for different classes of objects. For instance:

In this example, print.my_class is a method that prints a custom message for objects of class my_class. S3 methods provide a simple way to extend functionality for different object types.
S4 Methods: S4 is a more formal and rigorous system with strict class definitions and method dispatch. It allows for detailed control over method behaviors. For example:

Here, setClass() defines a class with a numeric slot, and setMethod() defines a method for displaying objects of this class. S4 methods offer enhanced functionality and robustness, making them suitable for complex applications requiring precise object-oriented programming.
Higher-Order Functions
Higher-order functions are functions that take other functions as arguments or return functions as results. These functions enable functional programming techniques and can lead to concise and expressive code. Examples include apply(), lapply(), and sapply().
apply(): Used to apply a function to the rows or columns of a matrix.
lapply(): Applies a function to each element of a list and returns a list.
sapply(): Similar to lapply(), but returns a simplified result.
Higher-order functions enhance code readability and efficiency by abstracting repetitive tasks and leveraging functional programming paradigms.
Best Practices for Writing Functions in R
Writing efficient and readable functions in R is crucial for maintaining clean and effective code. By following best practices, you can ensure that your functions are not only functional but also easy to understand and maintain. Here are some key tips and common pitfalls to avoid.
Tips for Writing Efficient and Readable Functions
Keep Functions Focused: Design functions to perform a single task or operation. This makes your code more modular and easier to test. For example, instead of creating a function that processes data and generates a report, split it into separate functions for processing and reporting.
Use Descriptive Names: Choose function names that clearly indicate their purpose. For instance, use calculate_mean() rather than calc() to convey the function’s role more explicitly.
Avoid Hardcoding Values: Use parameters instead of hardcoded values within functions. This makes your functions more flexible and reusable. For example, instead of using a fixed threshold value within a function, pass it as a parameter.
Common Mistakes to Avoid
Overcomplicating Functions: Avoid writing overly complex functions. If a function becomes too long or convoluted, break it down into smaller, more manageable pieces. Complex functions can be harder to debug and understand.
Neglecting Error Handling: Failing to include error handling can lead to unexpected issues during function execution. Implement checks to handle invalid inputs or edge cases gracefully.
Ignoring Code Consistency: Consistency in coding style helps maintain readability. Follow a consistent format for indentation, naming conventions, and comment style.
Best Practices for Function Documentation
Document Function Purpose: Clearly describe what each function does, its parameters, and its return values. Use comments and documentation strings to provide context and usage examples.
Specify Parameter Types: Indicate the expected data types for each parameter. This helps users understand how to call the function correctly and prevents type-related errors.
Update Documentation Regularly: Keep function documentation up-to-date with any changes made to the function’s logic or parameters. Accurate documentation enhances the usability of your code.
By adhering to these practices, you’ll improve the quality and usability of your R functions, making your codebase more reliable and easier to maintain.
Read Blogs:
Pattern Programming in Python: A Beginner’s Guide.
Understanding the Functional Programming Paradigm.
Frequently Asked Questions
What are the main types of functions in R programming?
In R programming, the main types of functions include built-in functions, user-defined functions, anonymous functions, recursive functions, S3 methods, S4 methods, and higher-order functions. Each serves a specific purpose, from performing basic tasks to handling complex operations.
How do user-defined functions differ from built-in functions in R?
User-defined functions are custom functions created by users to address specific needs, whereas built-in functions come pre-defined with R and handle common tasks. User-defined functions offer flexibility, while built-in functions provide efficiency and convenience for standard operations.
What is a recursive function in R programming?
A recursive function in R calls itself to solve a problem by breaking it down into smaller, similar sub-tasks. It's useful for problems like calculating factorials but requires careful implementation to avoid infinite recursion and performance issues.
Conclusion
Understanding the types of functions in R programming is crucial for optimising your code. From built-in functions that simplify tasks to user-defined functions that offer customisation, each type plays a unique role.
Mastering recursive, anonymous, and higher-order functions further enhances your programming capabilities. Implementing best practices ensures efficient and maintainable code, leveraging R’s full potential for data analysis and complex problem-solving.
#Different Types of Functions in R Programming#Types of Functions in R Programming#r programming#data science
4 notes
·
View notes
Note
What are some of the coolest computer chips ever, in your opinion?
Hmm. There are a lot of chips, and a lot of different things you could call a Computer Chip. Here's a few that come to mind as "interesting" or "important", or, if I can figure out what that means, "cool".
If your favourite chip is not on here honestly it probably deserves to be and I either forgot or I classified it more under "general IC's" instead of "computer chips" (e.g. 555, LM, 4000, 7000 series chips, those last three each capable of filling a book on their own). The 6502 is not here because I do not know much about the 6502, I was neither an Apple nor a BBC Micro type of kid. I am also not 70 years old so as much as I love the DEC Alphas, I have never so much as breathed on one.
Disclaimer for writing this mostly out of my head and/or ass at one in the morning, do not use any of this as a source in an argument without checking.
Intel 3101
So I mean, obvious shout, the Intel 3101, a 64-bit chip from 1969, and Intel's first ever product. You may look at that, and go, "wow, 64-bit computing in 1969? That's really early" and I will laugh heartily and say no, that's not 64-bit computing, that is 64 bits of SRAM memory.


This one is cool because it's cute. Look at that. This thing was completely hand-designed by engineers drawing the shapes of transistor gates on sheets of overhead transparency and exposing pieces of crudely spun silicon to light in a """"cleanroom"""" that would cause most modern fab equipment to swoon like a delicate Victorian lady. Semiconductor manufacturing was maturing at this point but a fab still had more in common with a darkroom for film development than with the mega expensive building sized machines we use today.
As that link above notes, these things were really rough and tumble, and designs were being updated on the scale of weeks as Intel learned, well, how to make chips at an industrial scale. They weren't the first company to do this, in the 60's you could run a chip fab out of a sufficiently well sealed garage, but they were busy building the background that would lead to the next sixty years.
Lisp Chips
This is a family of utterly bullshit prototype processors that failed to be born in the whirlwind days of AI research in the 70's and 80's.
Lisps, a very old but exceedingly clever family of functional programming languages, were the language of choice for AI research at the time. Lisp compilers and interpreters had all sorts of tricks for compiling Lisp down to instructions, and also the hardware was frequently being built by the AI researchers themselves with explicit aims to run Lisp better.
The illogical conclusion of this was attempts to implement Lisp right in silicon, no translation layer.

Yeah, that is Sussman himself on this paper.
These never left labs, there have since been dozens of abortive attempts to make Lisp Chips happen because the idea is so extremely attractive to a certain kind of programmer, the most recent big one being a pile of weird designd aimed to run OpenGenera. I bet you there are no less than four members of r/lisp who have bought an Icestick FPGA in the past year with the explicit goal of writing their own Lisp Chip. It will fail, because this is a terrible idea, but damn if it isn't cool.
There were many more chips that bridged this gap, stuff designed by or for Symbolics (like the Ivory series of chips or the 3600) to go into their Lisp machines that exploited the up and coming fields of microcode optimization to improve Lisp performance, but sadly there are no known working true Lisp Chips in the wild.
Zilog Z80
Perhaps the most important chip that ever just kinda hung out. The Z80 was almost, almost the basis of The Future. The Z80 is bizzare. It is a software compatible clone of the Intel 8080, which is to say that it has the same instructions implemented in a completely different way.
This is, a strange choice, but it was the right one somehow because through the 80's and 90's practically every single piece of technology made in Japan contained at least one, maybe two Z80's even if there was no readily apparent reason why it should have one (or two). I will defer to Cathode Ray Dude here: What follows is a joke, but only barely

The Z80 is the basis of the MSX, the IBM PC of Japan, which was produced through a system of hardware and software licensing to third party manufacturers by Microsoft of Japan which was exactly as confusing as it sounds. The result is that the Z80, originally intended for embedded applications, ended up forming the basis of an entire alternate branch of the PC family tree.
It is important to note that the Z80 is boring. It is a normal-ass chip but it just so happens that it ended up being the focal point of like a dozen different industries all looking for a cheap, easy to program chip they could shove into Appliances.
Effectively everything that happened to the Intel 8080 happened to the Z80 and then some. Black market clones, reverse engineered Soviet compatibles, licensed second party manufacturers, hundreds of semi-compatible bastard half-sisters made by anyone with a fab, used in everything from toys to industrial machinery, still persisting to this day as an embedded processor that is probably powering something near you quietly and without much fuss. If you have one of those old TI-86 calculators, that's a Z80. Oh also a horrible hybrid Z80/8080 from Sharp powered the original Game Boy.
I was going to try and find a picture of a Z80 by just searching for it and look at this mess! There's so many of these things.

I mean the C/PM computers. The ZX Spectrum, I almost forgot that one! I can keep making this list go! So many bits of the Tech Explosion of the 80's and 90's are powered by the Z80. I was not joking when I said that you sometimes found more than one Z80 in a single computer because you might use one Z80 to run the computer and another Z80 to run a specialty peripheral like a video toaster or music synthesizer. Everyone imaginable has had their hand on the Z80 ball at some point in time or another. Z80 based devices probably launched several dozen hardware companies that persist to this day and I have no idea which ones because there were so goddamn many.
The Z80 eventually got super efficient due to process shrinks so it turns up in weird laptops and handhelds! Zilog and the Z80 persist to this day like some kind of crocodile beast, you can go to RS components and buy a brand new piece of Z80 silicon clocked at 20MHz. There's probably a couple in a car somewhere near you.
Pentium (P6 microarchitecture)
Yeah I am going to bring up the Hackers chip. The Pentium P6 series is currently remembered for being the chip that Acidburn geeks out over in Hackers (1995) instead of making out with her boyfriend, but it is actually noteworthy IMO for being one of the first mainstream chips to start pulling serious tricks on the system running it.

The P6 microarchitecture comes out swinging with like four or five tricks to get around the numerous problems with x86 and deploys them all at once. It has superscalar pipelining, it has a RISC microcode, it has branch prediction, it has a bunch of zany mathematical optimizations, none of these are new per se but this is the first time you're really seeing them all at once on a chip that was going into PC's.
Without these improvements it's possible Intel would have been beaten out by one of its competitors, maybe Power or SPARC or whatever you call the thing that runs on the Motorola 68k. Hell even MIPS could have beaten the ageing cancerous mistake that was x86. But by discovering the power of lying to the computer, Intel managed to speed up x86 by implementing it in a sensible instruction set in the background, allowing them to do all the same clever pipelining and optimization that was happening with RISC without having to give up their stranglehold on the desktop market. Without the P5 we live in a very, very different world from a computer hardware perspective.
From this falls many of the bizzare microcode execution bugs that plague modern computers, because when you're doing your optimization on the fly in chip with a second, smaller unix hidden inside your processor eventually you're not going to be cryptographically secure.
RISC is very clearly better for, most things. You can find papers stating this as far back as the 70's, when they start doing pipelining for the first time and are like "you know pipelining is a lot easier if you have a few small instructions instead of ten thousand massive ones.
x86 only persists to this day because Intel cemented their lead and they happened to use x86. True RISC cuts out the middleman of hyperoptimizing microcode on the chip, but if you can't do that because you've girlbossed too close to the sun as Intel had in the late 80's you have to do something.
The Future
This gets us to like the year 2000. I have more chips I find interesting or cool, although from here it's mostly microcontrollers in part because from here it gets pretty monotonous because Intel basically wins for a while. I might pick that up later. Also if this post gets any longer it'll be annoying to scroll past. Here is a sample from a post I have in my drafts since May:

I have some notes on the weirdo PowerPC stuff that shows up here it's mostly interesting because of where it goes, not what it is. A lot of it ends up in games consoles. Some of it goes into mainframes. There is some of it in space. Really got around, PowerPC did.
237 notes
·
View notes
Text

astrobots really went lets have a cynical thoughtful determined robot catgirl sword mom protagonist and we are here for that:
anyone else on the edge of their seats w/ patient anticipation of what's going to go down in Astrobots #6? We are. the story so far lays out a complex world where mass produced bots r stratified by hardlined code thanks to humanity, hierarchy therein inherited from them too...
reading that in issues #1 and #2 alone for both atlas city & the persephone ship gave the impression that something was deeply wrong that would be the source of conflict (see: atlas being a jerk). also was nice 2 be able 2 see the overlaps between athenia & arcee, & references to transformers such as solus, scylla, and xaaron
#5 ends on such a massive cliffhanger. the conflict is laid out sure, but how is artimis going 2 be psychologically throughout the series? r her clashes with athenia going to have some level of homoeroticism, and can the latter help her? will atlas's bioessentialism end him?
his whole shtick of trying to make a genetically improved humanity without hate he learned from them & attempting to coerce a specific line of bots to do it may not seem like him being a misogynist at a first glance but when you account for humans making that line that way, well. a greek goddess-named line of bots who r sword wielding curvy bipeds w/ cat ears & hardlined coding to nurture with skills to raise humans no other line got (it is unclear at present if multiple genders exist per bot line or not, we genuinely hope for the former) sure does feel like humans had a particular idea about what kind of fierce parental figure they wanted to mass-produce that raise even more questions. one that leaves one realizing humans made the bots of all lines without thinking about programming modularity. frames too. they all have heels, no body type variety, gave us a feeling of the humans in charge not quite having humanity's or robotkind's interests in mind so much as perpetuating a specific kind of society especially since the one body type only thing is true of every other bot line because of adherence to an alienated concept of function (its still unclear whether the remaining humans in the sol system are capitalists or collectivists or what but we have a feeling which one it is). and atlas making the threats he does thus does come off as him having recreated a form of discrimination a few times removed from human context.
the other thing we like is that astrobots doesnt simply do humans vs robots. it is instead robots vs robots who are both custodians of different kinds of humanity, following up on conflict of genocidal reactionary humans vs robots and humans living in harmony responded to w/ dirty nukes, after exodus from earth.
we do genuinely think this very easily some of Furman's best writing. there's an earnest revisiting of older ideas with new ones in a new setting that carries a great deal of nuance and delicacy. Athenia and Apollo's insightul valiant outlooks are entwined, minor characters r fun
#astrobots#athenia#artimis#atlas#ab athenia#ab artimis#ab atlas#scifi#robot stories#arcee#transformers#its not transformers but there is a unique appreciation to be had for it if familiar with transformers
23 notes
·
View notes
Text
My Cheatsheet
Information Elements
Irrational elements (because they perceive, not reason):
Se - extroverted sensing: Force (F)
Accumulation of external involvements
Force: strength or energy as an attribute of physical action or movement. In physics, understood as an influence tending to change the motion of a body or produce motion or stress in a stationary body.
Si - introverted sensing: Senses (S)
Integration of external involvements
Senses: faculties by which the body perceives external stimuli.
Ne - extroverted intuition: Ideas (I)
Accumulation of internal abstractions
Ideas: thoughts as to possible courses of action or outcomes.
Ni - introverted intuition: Telos (T)
Integration of internal abstractions
Telos: ancient Greek term for an end, fulfillment, completion, aim or goal. Ethymologic source for the word 'teleology', the explanation of phenomena in terms of the purpose they serve rather than of cause by which they arise.
Rational elements (because they reason, not perceive):
Te - extroverted thinking: Pragmatism (P)
Accumulation of external abstractions
Pragmatism: an approach that evaluates theories or beliefs in terms of the success of their practical application.
Ti - introverted thinking: Laws (L)
Integration of external abstractions
Laws: the system of rules which a particular country or community recognizes as regulating the actions of its members and which it may enforce by the imposition of penalties.
Fe - extroverted feeling: Emotions (E)
Accumulation of internal involvements
Emotions: strong feelings deriving from one's circumstances, mood, or relationships with others.
Fi - introverted feeling: Relations (R)
Integration of internal involvements
Relations: the ways in which two or more people or things are connected; a thing's effect on or relevance to another. Also the way in which two or more people or groups feel about and behave towards each other.
Each of the eight information elements fit into and fill one of the eight cognitive functions that make up a person's personality type. The different assortments result in the 16 different types.
Cognitive Functions

1. Leading - most capable (4D), valued, public, and stubborn. Automatic, confident, and comfortable first approach that sets and programs the base objectives of the personality. Also called Base, Dominant, or sometimes Program function
2. Creative - highly capable (3D), valued, public, and flexible. Complements the leading function's set program and takes it into actions, brings it into the world. Also called Auxiliary function.
3. Role - less capable (2D), unvalued, public, and flexible. Conscious adaptation to respond to outside expectations. Sometimes called Reluctant function.
4. Vulnerable - least capable (1D), unvalued, public, and stubborn. Source of insecurity, least resistance to external pressure, and inflexible lack of comprehension of its given information element. Sometimes called Exposed function or Path/Point of Least Resistance (PoLR).
5. Suggestive - least capable (1D), valued, private, and flexible. Search for intimate reassurance and/or influence of others, appreciation and enthralling of the presence of the element in them, feels calmed by it. Also called Accepting or Seeking function.
6. Mobilizing - less capable (2D), valued, private, and stubborn. Highly personal need for being independently capable in this element, but is overconfident. Consistently clumsy in its effectiveness or overcompensating in its expression. Its usage energizes the person. Also called Activating function or Hidden Agenda.
7. Observing - highly capable (3D), unvalued, private, and stubborn. Non-participation in the usage of its given element outside of scrutizing from the sidelines and sometimes consistently critizicing or questioning its validity. Traditionally called Ignoring function.
8. Demonstrative - most capable (4D), unvalued, private, and flexible. Unconscious and persistent leading utilization of the element, even when it would rather not be used. Willingly let go of when asked of by overwhelmed people due to its unvalued and flexible nature, yet it still assists in the achieving of the type's goals.
Each of the eight functions fit into one of four Blocks within the model, creating Rings of information metabolism:
Blocks

Public and conscious blockings: the Mental Ring
Ego Block: valued and "strong" functions
Super-Ego Block: unvalued and "weak" functions
Private and unconscious blockings: the Vital Ring
Super-Id Block: valued but "weak" functions
Id Block: unvalued but "strong" functions
Inert functions: stubborn, intransigent, bold, assertive, and energetic functions
Contact functions: flexible, collaborative, subtle, and reluctant functions
The "strength" or "weakness" of a given function is explained through the qualitative parameters with which they are able to process information to elaborate conclusions and internalize lessons. Each set of which are called Dimensionality of a function:
Dimensionality
Each function processes information and grows by taking into account the parameters of:
1-Dimensional (1D): experience. Referred to as least capable, "weakest".
2-Dimensional (2D): norms and experience. Referred to as less capable, "weak".
3-Dimensional (3D): situational, norms, and experience. Referred to as highly capable, "strong".
4-Dimensional (4D): time, situational, norms, and experience. Referred to as most capable, "strongest.
Commonalities can be discerned between types depending on strengths and values, called small groups or quaternions:
Small Groups
Quadras: according to valued elements
Alpha: value Ti, Fe, Si, Ne - Acceptance and Togetherness
Beta: value Ti, Fe, Se, Ni - Calling and Order
Gamma: value Te, Fi, Se, Ni - Aptitude and Independence
Delta: value Te, Fi, Si, Ne - Growth and Hope
Clubs: according to dominant primary information
Researchers: intuitive and logical (NT)
Socials: sensing and ethical (SF)
Pragmatists: sensing and logical (ST)
Humanitarians: intuitive and ethical (NF)
Temperaments: according to primary extroversion (E or I) and rationality (P or J)
Flexible-maneuvering: extroverted and perceiving (EP)
Linear-assertive: extroverted and rational (EJ)
Receptive-adaptive: introverted and perceiving (IP)
Balanced-stable: introverted and rational (IJ)
Communication styles: according to primary extroversion (E or I) and rational preferrence (F or T)
Bussinesslike: extroverted and logical (ET)
Passionate: extroverted and ethical (EF)
Cold-blooded: introverted and logical (IT)
Sincere/Soulful: introverted and ethical (IF)
I will make separate in-depth entries for each of the points in every section, the 16 Socionics types and more.
16 notes
·
View notes
Text
Balatro-Inspired Spinning Card Tweetcart Breakdown
I recently made a tweetcart of a spinning playing card inspired by finally playing Balatro, the poker roguelike everybody is talking about.
If you don't know what a tweetcart is, it's a type of size-coding where people write programs for the Pico-8 fantasy console where the source code is 280 characters of less, the length of a tweet.
I'm actually not on twitter any more, but I still like 280 characters as a limitation. I posted it on my mastodon and my tumblr.
Here's the tweetcart I'm writing about today:

And here is the full 279 byte source code for this animation:
a=abs::_::cls()e=t()for r=0,46do for p=0,1,.025do j=sin(e)*20k=cos(e)*5f=1-p h=a(17-p*34)v=a(23-r)c=1+min(23-v,17-h)%5/3\1*6u=(r-1)/80z=a(p-.2)if(e%1<.5)c=a(r-5)<5and z<u+.03and(r==5or z>u)and 8or 8-sgn(h+v-9)/2 g=r+39pset((64+j)*p+(64-j)*f,(g+k)*p+(g-k)*f,c)end end flip()goto _
This post is available with much nicer formatting on the EMMA blog. You can read it here.
You can copy/paste that code into a blank Pico-8 file to try it yourself. I wrote it on Pico-8 version 0.2.6b.
I'm very pleased with this cart! From a strictly technical perspective I think it's my favorite that I've ever made. There is quite a bit going on to make the fake 3D as well as the design on the front and back of the card. In this post I'll be making the source code more readable as well as explaining some tools that are useful if you are making your own tweetcarts or just want some tricks for game dev and algorithmic art.
Expanding the Code
Tweetcarts tend to look completely impenetrable, but they are often less complex than they seem. The first thing to do when breaking down a tweetcart (which I highly recommend doing!) is to just add carriage returns after each command.
Removing these line breaks is a classic tweetcart method to save characters. Lua, the language used in Pico-8, often does not need a new line if a command does not end in a letter, so we can just remove them. Great for saving space, bad for readability. Here's that same code with some line breaks, spaces and indentation added:
a=abs ::_:: cls() e=t() for r=0,46 do for p=0,1,.025 do j=sin(e)*20 k=cos(e)*5 f=1-p h=a(17-p*34) v=a(23-r) c=1+min(23-v,17-h)%5/3\1*6 u=(r-1)/80 z=a(p-.2) if(e%1<.5) c= a(r-5) < 5 and z < u+.03 and (r==5 or z>u) and 8 or 8-sgn(h+v-9)/2 g=r+39 pset((64+j)*p+(64-j)*f,(g+k)*p+(g-k)*f,c) end end flip()goto _
Note: the card is 40 pixels wide and 46 pixels tall. Those number will come up a lot. As will 20 (half of 40) and 23 (half of 46).
Full Code with Variables and Comments
Finally, before I get into what each section is doing, here is an annotated version of the same code. In this code, variables have real names and I added comments:
[editor's note. this one came out terribly on tumblr. Please read the post on my other blog to see it]
This may be all you need to get a sense of how I made this animation, but the rest of this post will be looking at how each section of the code contributes to the final effect. Part of why I wanted to write this post is because I was happy with how many different tools I managed to use in such a small space.
flip() goto_
This pattern shows up in nearly every tweetcart:
::_:: MOST OF THE CODE flip()goto _
This has been written about in Pixienop's Tweetcart Basics which I highly recommend for anybody curious about the medium! The quick version is that using goto is shorter than declaring the full draw function that Pico-8 carts usually use.
Two Spinning Points
The card is drawn in rows starting from the top and going to the bottom. Each of these lines is defined by two points that move around a center point in an elliptical orbit.
The center of the top of the card is x=64 (dead center) and y=39 (a sort of arbitrary number that looked nice).
Then I get the distance away from that center that my two points will be using trigonometry.
x_dist = sin(time)*20 y_dist = cos(time)*5
Here are those points:

P1 adds x_dist and y_dist to the center point and P2 subtracts those same values.
Those are just the points for the very top row. The outer for loop is the vertical rows. The center x position will be the same each time, but the y position increases with each row like this: y_pos = row+39
Here's how it looks when I draw every 3rd row going down:

It is worth noting that Pico-8 handles sin() and cos() differently than most languages. Usually the input values for these functions are in radians (0 to two pi), but in Pico-8 it goes from 0 to 1. More info on that here. It takes a little getting used to but it is actually very handy. More info in a minute on why I like values between 0 and 1.
Time
In the shorter code, e is my time variable. I tend to use e for this. In my mind it stands for "elapsed time". In Pico-8 time() returns the current elapsed time in seconds. However, there is a shorter version, t(), which obviously is better for tweetcarts. But because I use the time value a lot, even the 3 characters for t() is often too much, so I store it in the single-letter variable e.
Because it is being used in sine and cosine for this tweetcart, every time e reaches 1, we've reached the end of a cycle. I would have liked to use t()/2 to slow this cart down to be a 2 second animation, but after a lot of fiddling I wound up being one character short. So it goes.
e is used in several places in the code, both to control the angle of the points and to determine which side of the card is facing the camera.
Here you can see how the sine value of e controls the rotation and how we go from showing the front of the card to showing the back when e%1 crosses the threshold of 0.5.
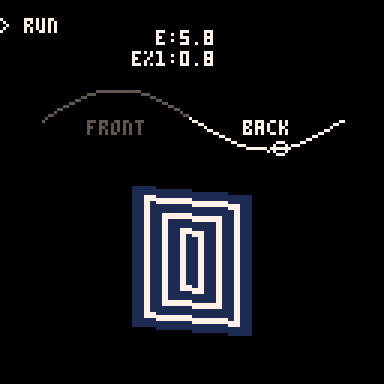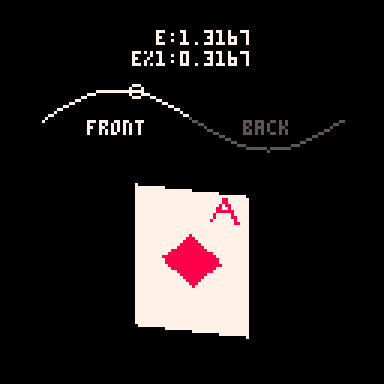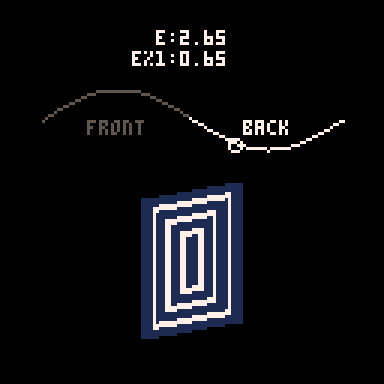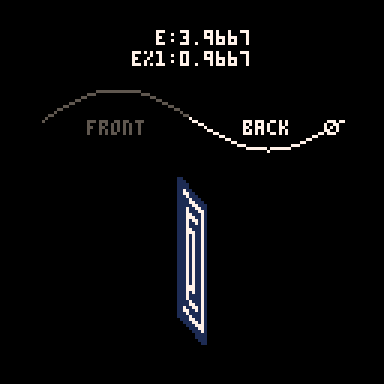
Drawing and Distorting the Lines
Near the top and bottom of the loop we'll find the code that determines the shape of the card and draws the horizontal lines that make up the card. Here is the loop for drawing a single individual line using the code with expanded variable names:
for prc = 0,1,.025 do x_dist = sin(time)*20 y_dist = cos(time)*5 ... y_pos = row+39 pset( (64+x_dist)*prc + (64-x_dist)*(1-prc), (y_pos+y_dist)*prc + (y_pos-y_dist)*(1-prc), color) end
You might notice that I don't use Pico-8's line function! That's because each line is drawn pixel by pixel.
This tweetcart simulates a 3D object by treating each vertical row of the card as a line of pixels. I generate the points on either side of the card(p1 and p2 in this gif), and then interpolate between those two points. That's why the inner for loop creates a percentage from 0 to 1 instead of pixel positions. The entire card is drawn as individual pixels. I draw them in a line, but the color may change with each one, so they each get their own pset() call.
Here's a gif where I slow down this process to give you a peek at how these lines are being drawn every frame. For each row, I draw many pixels moving across the card between the two endpoints in the row.
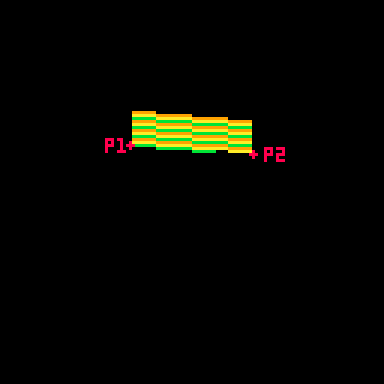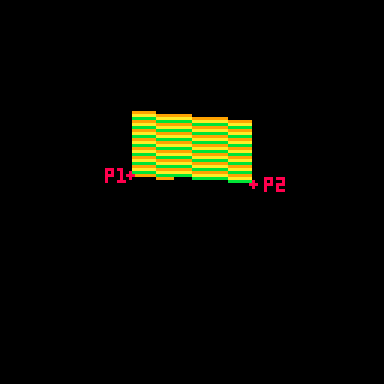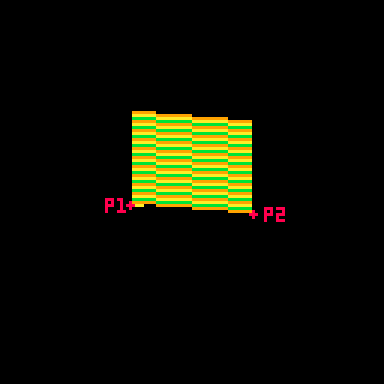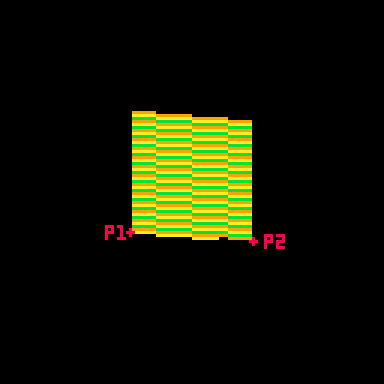
Here's the loop condition again: for prc = 0,1,.025 do
A step of 0.025 means there are 40 steps (0.025 * 40 = 1.0). That's the exact width of the card! When the card is completely facing the camera head-on, I will need 40 steps to make it across without leaving a gap in the pixels. When the card is skinnier, I'm still drawing all 40 pixels, but many of them will be in the same place. That's fine. The most recently drawn one will take priority.
Getting the actual X and Y position
I said that the position of each pixel is interpolated between the two points, but this line of code may be confusing:
y_pos = row+39 pset( (64+x_dist)*prc + (64-x_dist)*(1-prc), (y_pos+y_dist)*prc + (y_pos-y_dist)*(1-prc), color)
So let's unpack it a little bit. If you've ever used a Lerp() function in something like Unity you've used this sort of math. The idea is that we get two values (P1 and P2 in the above example), and we move between them such that a value of 0.0 gives us P1 and 1.0 gives us P2.
Here's a full cart that breaks down exactly what this math is doing:

::_:: cls() time = t()/8 for row = 0,46 do for prc = 0,1,.025 do x_dist = sin(time)*20 y_dist = cos(time)*5 color = 9 + row % 3 p1x = 64 + x_dist p1y = row+39 + y_dist p2x = 64 - x_dist p2y = row+39 - y_dist x = p2x*prc + p1x*(1-prc) y = p2y*prc + p1y*(1-prc) pset( x, y, color) end end flip()goto _
I'm defining P1 and P2 very explicitly (getting an x and y for both), then I get the actual x and y position that I use by multiplying P2 by prc and P1 by (1-prc) and adding the results together.
This is easiest to understand when prc is 0.5, because then we're just taking an average. In school we learn that to average a set of numbers you add them up and then divide by how many you had. We can think of that as (p1+p2) / 2. This is the same as saying p1*0.5 + p2*0.5.
But the second way of writing it lets us take a weighted average if we want. We could say p1*0.75 + p2*0.25. Now the resulting value will be 75% of p1 and 25% of p2. If you laid the two values out on a number line, the result would be just 25% of the way to p2. As long as the two values being multiplied add up to exactly 1.0 you will get a weighted average between P1 and P2.
I can count on prc being a value between 0 and 1, so the inverse is 1.0 - prc. If prc is 0.8 then 1.0-prc is 0.2. Together they add up to 1!
I use this math everywhere in my work. It's a really easy way to move smoothly between values that might otherwise be tricky to work with.
Compressing
I'm using a little over 400 characters in the above example. But in the real cart, the relevant code inside the loops is this:
j=sin(e)*20 k=cos(e)*5 g=r+39 pset((64+j)*p+(64-j)*f,(g+k)*p+(g-k)*f,c)
which can be further condensed by removing the line breaks:
j=sin(e)*20k=cos(e)*5g=r+39pset((64+j)*p+(64-j)*f,(g+k)*p+(g-k)*f,c)
Because P1, P2 and the resulting interpolated positions x and y are never used again, there is no reason to waste chars by storing them in variables. So all of the interpolation is done in the call to pset().
There are a few parts of the calculation that are used more than once and are four characters or more. Those are stored as variables (j, k & g in this code). These variables tend to have the least helpful names because I usually do them right at the end to save a few chars so they wind up with whatever letters I have not used elsewhere.
Spinning & Drawing
Here's that same example, but with a checker pattern and the card spinning. (Keep in mind, in the real tweetcart the card is fully draw every frame and would not spin mid-draw)
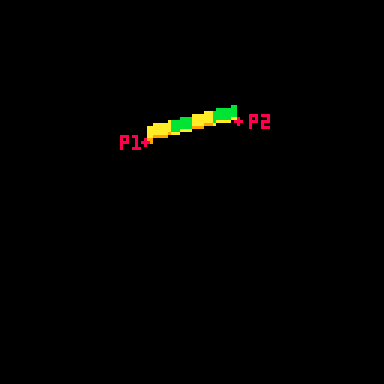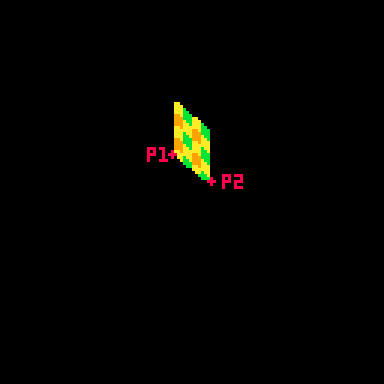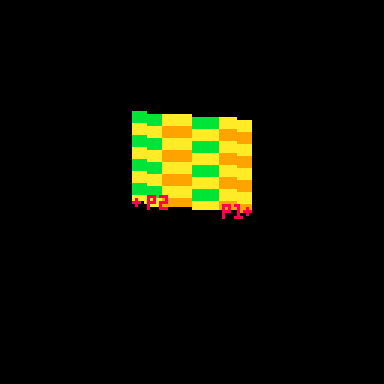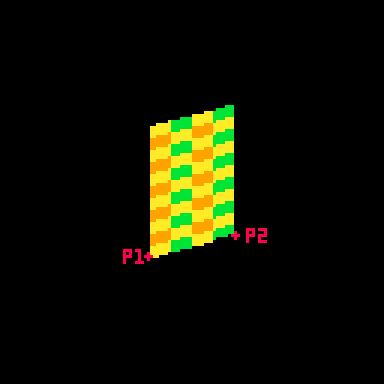
This technique allows me to distort the lines because I can specify two points and draw my lines between them. Great for fake 3D! Kind of annoying for actually drawing shapes, because now instead of using the normal Pico-8 drawing tools, I have to calculate the color I want based on the row (a whole number between0 and 46) and the x-prc (a float between 0 and 1).
Drawing the Back
Here's the code that handles drawing the back of the card:
h=a(17-p*34) v=a(23-r) c=1+min(23-v,17-h)%5/3\1*6
This is inside the nested for loops, so r is the row and p is a percentage of the way across the horizontal line.
c is the color that we will eventually draw in pset().
h and v are the approximate distance from the center of the card. a was previously assigned as a shorthand for abs() so you can think of those lines like this:
h=abs(17-p*34) v=abs(23-r)
v is the vertical distance. The card is 46 pixels tall so taking the absolute value of 23-r will give us the distance from the vertical center of the card. (ex: if r is 25, abs(23-r) = 2. and if r is 21, abs(23-r) still equals 2 )
As you can probably guess, h is the horizontal distance from the center. The card is 40 pixels wide, but I opted to shrink it a bit by multiplying p by 34 and subtracting that from half of 34 (17). The cardback just looks better with these lower values, and the diamond looks fine.
The next line, where I define c, is where things get confusing. It's a long line doing some clunky math. The critical thing is that when this line is done, I need c to equal 1 (dark blue) or 7 (white) on the Pico-8 color pallette.
Here's the whole thing: c=1+min(23-v,17-h)%5/3\1*6
Here is that line broken down into much more discrete steps.
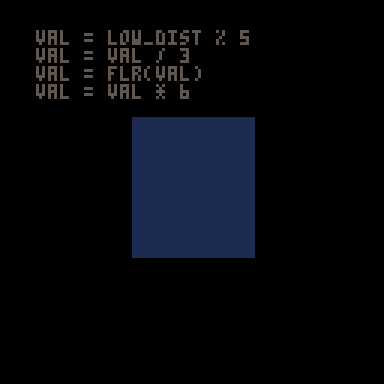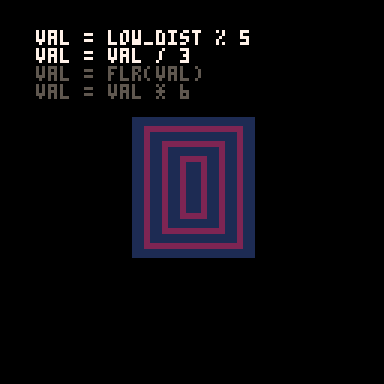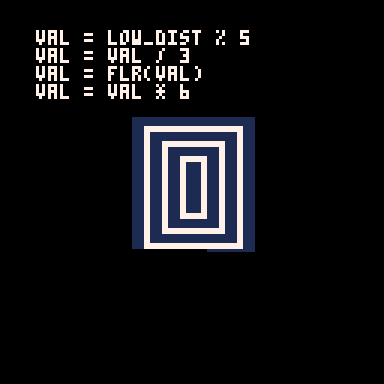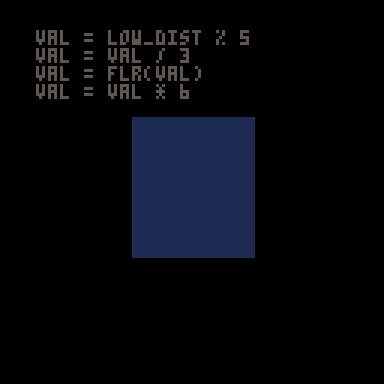
c = 1 --start with a color of 1 low_dist = min(23-v,17-h) --get the lower inverted distance from center val = low_dist % 5 --mod 5 to bring it to a repeating range of 0 to 5 val = val / 3 --divide by 3. value is now 0 to 1.66 val = flr(val) --round it down. value is now 0 or 1 val = val * 6 --multiply by 6. value is now 0 or 6 c += val --add value to c, making it 1 or 7
The first thing I do is c=1. That means the entire rest of the line will either add 0 or 6 (bumping the value up to 7). No other outcome is acceptable. min(23-v,17-h)%5/3\1*6 will always evaluate to 0 or 6.
I only want the lower value of h and v. This is what will give it the nice box shape. If you color the points inside a rectangle so that ones that are closer to the center on their X are one color and ones that are closer to the center on their Y are a different color you'll get a pattern with clean diagonal lines running from the center towards the corners like this:

You might think I would just use min(v,h) instead of the longer min(23-v,17-h) in the actual code. I would love to do that, but it results in a pattern that is cool, but doesn't really look like a card back.

I take the inverted value. Instead of having a v that runs from 0 to 23, I flip it so it runs from 23 to 0. I do the same for h. I take the lower of those two values using min().
Then I use modulo (%) to bring the value to a repeating range of 0 to 5. Then I divide that result by 3 so it is 0 to ~1.66. The exact value doens't matter too much because I am going round it down anyway. What is critical is that it will become 0 or 1 after rounding because then I can multiply it by a specific number without getting any values in between.
Wait? If I'm rounding down, where is flr() in this line: c=1+min(23-v,17-h)%5/3\1*6?
It's not there! That's because there is a sneaky tool in Pico-8. You can use \1 to do the same thing as flr(). This is integer division and it generally saves a 3 characters.
Finally, I multiply the result by 6. If it is 0, we get 0. If it is 1 we get 6. Add it to 1 and we get the color we want!
Here's how it looks with each step in that process turned on or off:
A Note About Parentheses
When I write tweetcarts I would typically start by writing this type of line like this: c=1+ (((min(23-v,17-h)%5)/3) \1) *6
This way I can figure out if my math makes sense by using parentheses to ensure that my order of operations works. But then I just start deleting them willy nilly to see what I can get away with. Sometimes I'm surprised and I'm able to shave off 2 characters by removing a set of parentheses.
The Face Side
The face side with the diamond and the "A" is a little more complex, but basically works the same way as the back. Each pixel needs to either be white (7) or red (8). When the card is on this side, I'll be overwriting the c value that got defined earlier.

Here's the code that does it (with added white space). This uses the h and v values defined earlier as well as the r and p values from the nested loops.
u=(r-1)/80 z=a(p-.2) if(e%1<.5) c= a(r-5) < 5 and z < u+.03 and (r==5 or z>u) and 8 or 8-sgn(h+v-9)/2
Before we piece out what this is doing, we need to talk about the structure for conditional logic in tweetcarts.
The Problem with If Statements
The lone line with the if statement is doing a lot of conditional logic in a very cumbersome way designed to avoid writing out a full if statement.
One of the tricky things with Pico-8 tweetcarts is that the loop and conditional logic of Lua is very character intensive. While most programming language might write an if statement like this:
if (SOMETHING){ CODE }
Lua does it like this:
if SOMETHING then CODE end
Using "then" and "end" instead of brackets means we often want to bend over backwards to avoid them when we're trying to save characters.
Luckily, Lua lets you drop "then" and "end" if there is a single command being executed inside the if.
This means we can write
if(e%1 < 0.5) c=5
instead of
if e%1 < 0.5 then c=5 end
This is a huge savings! To take advantage of this, it is often worth doing something in a slightly (or massively) convoluted way if it means we can reduce it to a single line inside the if. This brings us to:
Lua's Weird Ternary Operator
In most programming language there is an inline syntax to return one of two values based on a conditional. It's called the Ternary Operator and in most languages I use it looks like this:
myVar = a>b ? 5 : 10
The value of myVar will be 5 if a is greater than b. Otherwise is will be 10.
Lua has a ternary operator... sort of. You can read more about it here but it looks something like this:
myVar = a>b and 5 or 10
Frankly, I don't understand why this works, but I can confirm that it does.
In this specific instance, I am essentially using it to put another conditional inside my if statement, but by doing it as a single line ternary operation, I'm keeping the whole thing to a single line and saving precious chars.
The Face Broken Out
The conditional for the diamond and the A is a mess to look at. The weird syntax for the ternary operator doesn't help. Neither does the fact that I took out any parentheses that could make sense of it.
Here is the same code rewritten with a cleaner logic flow.
--check time to see if we're on the front half if e%1 < .5 then --this if checks if we're in the A u=(r-1)/80 z=a(p-.2) if a(r-5) < 5 and z < u+.03 and (r==5 or z>u) then c = 8 --if we're not in the A, set c based on if we're in the diamond else c = 8-sgn(h+v-9)/2 end end
The first thing being checked is the time. As I explained further up, because the input value for sin() in Pico-8 goes from 0 to 1, the midpoint is 0.5. We only draw the front of the card if e%1 is less than 0.5.
After that, we check if this pixel is inside the A on the corner of the card or the diamond. Either way, our color value c gets set to either 7 (white) or 8 (red).
Let's start with diamond because it is easier.
The Diamond
This uses the same h and v values from the back of the card. The reason I chose diamonds for my suit is that they are very easy to calculate if you know the vertical and horizontal distance from a point! In fact, I sometimes use this diamond shape instead of proper circular hit detection in size-coded games.
Let's look at the line: c = 8-sgn(h+v-9)/2
This starts with 8, the red color. Since the only other acceptable color is 7 (white), tha means that sgn(h+v-9)/2 has to evaluate to either 1 or 0.
sgn() returns the sign of a number, meaning -1 if the number is negative or 1 if the number is positive. This is often a convenient way to cut large values down to easy-to-work-with values based on a threshold. That's exactly what I'm doing here!
h+v-9 takes the height from the center plus the horizontal distance from the center and checks if the sum is greater than 9. If it is, sgn(h+v-9) will return 1, otherwise -1. In this formula, 9 is the size of the diamond. A smaller number would result in a smaller diamond since that's the threshold for the distance being used. (note: h+v is NOT the actual distance. It's an approximation that happens to make a nice diamond shape.)
OK, but adding -1 or 1 to 8 gives us 7 or 9 and I need 7 or 8.
That's where /2 comes in. Pico-8 defaults to floating point math, so dividing by 2 will turn my -1 or 1 into -0.5 or 0.5. So this line c = 8-sgn(h+v-9)/2 actually sets c to 7.5 or 8.5. Pico-8 always rounds down when setting colors so a value of 7.5 becomes 7 and 8.5 becomes 8. And now we have white for most of the card, and red in the space inside the diamond!
The A
The A on the top corner of the card was the last thing I added. I finished the spinning card with the card back and the diamond and realized that when I condensed the whole thing, I actually had about 50 characters to spare. Putting a letter on the ace seemed like an obvious choice. I struggled for an evening trying to make it happen before deciding that I just couldn't do it. The next day I took another crack at it and managed to get it in, although a lot of it is pretty ugly! Luckily, in the final version the card is spinning pretty fast and it is harder to notice how lopsided it is.
I mentioned earlier that my method of placing pixels in a line between points is great for deforming planes, but makes a lot of drawing harder. Here's a great example. Instead of just being able to call print("a") or even using 3 calls to line() I had to make a convoluted conditional to check if each pixel is "inside" the A and set it to red if it is.
I'll do my best to explain this code, but it was hammered together with a lot of trial and error. I kept messing with it until I found an acceptable balance between how it looked and how many character it ate up.
Here are the relevant bits again:
u=(r-1)/80 z=a(p-.2) if a(r-5) < 5 and z < u+.03 and (r==5 or z>u) then c = 8
The two variables above the if are just values that get used multiple times. Let's give them slightly better names. While I'm making edits, I'll expand a too since that was just a replacement for abs().
slope = (r-1)/80 dist_from_center = abs(p-.2) if abs(r-5) < 5 and dist_from_center < slope+.03 and (r==5 or dist_from_center>slope) then c = 8
Remember that r is the current row and p is the percentage of the way between the two sides where this pixel falls.
u/slope here is basically how far from the center line of the A the legs are at this row. As r increases, so does slope (but at a much smaller rate). The top of the A is very close to the center, the bottom is further out. I'm subtracting 1 so that when r is 0, slope is negative and will not be drawn. Without this, the A starts on the very topmost line of the card and looks bad.
z/dist_from_center is how far this particular p value is from the center of the A (not the center of the card), measured in percentage (not pixels). The center of the A is 20% of the way across the card. This side of the card starts on the right (0% is all the way right, 100% is all the way left), which is why you see the A 20% away from the right side of the card.
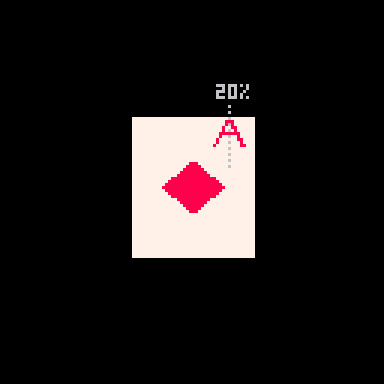
These values are important because the two legs of the A are basically tiny distance checks where the slope for a given r is compared against the dist_from_center. There are 3 checks used to determine if the pixel is part of the A.
if a(r-5) < 5 and z < u+.03 and (r==5 or z>u) then
The first is abs(r-5) < 5. This checks if r is between 1 and 9, the height of my A.
The second is dist_from_center < slope+.03. This is checking if this pixel's x distance from the center of the A is no more than .03 bigger than the current slope value. This is the maximum distance that will be considered "inside" the A. All of this is a percentage, so the center of the A is 0.20 and the slope value will be larger the further down the A we get.
Because I am checking the distance from the center point (the grey line in the image above), this works on either leg of the A. On either side, the pixel can be less than slope+.03 away.
Finally, it checks (r==5 or dist_from_center>slope). If the row is exactly 5, that is the crossbar across the A and should be red. Otherwise, the distance value must be greater than slope (this is the minimum value it can have to be "inside" the A). This also works on both sides thanks to using distance.
Although I am trying to capture 1-pixel-wide lines to draw the shape of the A, I could not think of a cleaner way than doing this bounding check. Ignoring the crossbar on row 5, you can think about the 2nd and 3rd parts of the if statement essentially making sure that dist_from_center fits between slope and a number slightly larger than slope. Something like this:
slope < dist_from_center < slope+0.03
Putting it Together
All of this logic needed to be on a single line to get away with using the short form of the if statement so it got slammed into a single ternary operator. Then I tried removing parentheses one at a time to see what was structurally significant. I wish I could say I was more thoughtful than that but I wasn't. The end result is this beefy line of code:
if(e%1<.5)c=a(r-5)<5and z<u+.03and(r==5or z>u)and 8or 8-sgn(h+v-9)/2
Once we've checked that e (our time value) is in the phase where we show the face, the ternary operator checks if the pixel is inside the A. If it is, c is set to 8 (red). If it isn't, then we set c = 8-sgn(h+v-9)/2, which is the diamond shape described above.
That's It!
Once we've set c the tweetcart uses pset to draw the pixel as described in the section on drawing the lines.
Here's the full code and what it looks like when it runs again. Hopefully now you can pick out more of what's going on!
a=abs::_::cls()e=t()for r=0,46do for p=0,1,.025do j=sin(e)*20k=cos(e)*5f=1-p h=a(17-p*34)v=a(23-r)c=1+min(23-v,17-h)%5/3\1*6u=(r-1)/80z=a(p-.2)if(e%1<.5)c=a(r-5)<5and z<u+.03and(r==5or z>u)and 8or 8-sgn(h+v-9)/2 g=r+39pset((64+j)*p+(64-j)*f,(g+k)*p+(g-k)*f,c)end end flip()goto _
I hope this was helpful! I had a lot of fun writing this cart and it was fun to break it down. Maybe you can shave off the one additional character needed to slow it down by using e=t()/2 a bit. If you do, please drop me a line on my mastodon or tumblr!
And if you want to try your hand at something like this, consider submitting something to TweetTweetJam which just started! You'll get a luxurious 500 characters to work with!
Links and Resources
There are some very useful posts of tools and tricks for getting into tweetcarts. I'm sure I'm missing many but here are a few that I refer to regularly.
Pixienop's tweetcart basics and tweetcart studies are probably the single best thing to read if you want to learn more.
Trasevol_Dog's Doodle Insights are fascinating, and some of them demonstrate very cool tweetcart techniques.
Optimizing Character Count for Tweetcarts by Eli Piilonen / @2DArray
Guide for Making Tweetcarts by PrincessChooChoo
The official documentation for the hidden P8SCII Control Codes is worth a read. It will let you do wild things like play sound using the print() command.
I have released several size-coded Pico-8 games that have links to heavily annotated code:
Pico-Mace
Cold Sun Surf
1k Jump
Hand Cram
And if you want to read more Pico-8 weirdness from me, I wrote a whole post on creating a networked Pico-8 tribute to Frog Chorus.
18 notes
·
View notes
Text
Hydrogen Electrolysers: Powering the Green Revolution, One Molecule at a Time
Imagine a world where our energy doesn't come from the depths of the Earth but from the splitting of a simple, abundant molecule—water. This isn't the future. It’s happening now. At the heart of this clean-energy transformation is an often-overlooked yet vital component: the Hydrogen Electrolyser.
Yes, batteries are booming. Solar panels are spreading across rooftops. But behind the scenes, for industries that demand large-scale, continuous, and reliable clean fuel, Hydrogen Electrolysers are emerging as the quiet champions.
What Is a Hydrogen Electrolyser?
Let’s start with the basics — but not too basic. A Hydrogen Electrolyser is a device that splits water (H₂O) into hydrogen (H₂) and oxygen (O₂) using electricity through a process called electrolysis.
If the electricity comes from renewable sources (like wind or solar), the hydrogen produced is known as green hydrogen — clean, emission-free, and a true zero-carbon fuel. This hydrogen can be used in:
Fuel cells (to power electric vehicles or backup systems)
Industrial processes (steelmaking, ammonia production)
Power generation and grid storage
Even in heating applications
In essence, hydrogen electrolysis enables renewable electricity to be stored as a versatile fuel.
Different Types of Hydrogen Electrolysers
All electrolysers perform the same function — splitting water — but the way they do it varies based on their design and use case. The three primary types are:
1. Alkaline Electrolysers (AEL)
These are the most mature and widely used. They use a liquid electrolyte (typically potassium hydroxide) and are known for their reliability and lower cost. However, they respond slowly to variable power inputs, making them less ideal for pairing with renewables.
2. Proton Exchange Membrane (PEM) Electrolysers
These are more compact and respond quickly to changes in electrical input. That makes them perfect partners for solar or wind power. They use a solid polymer membrane as the electrolyte. While more expensive than AEL, their efficiency and flexibility make them increasingly popular.
3. Solid Oxide Electrolysers (SOEC)
The new kids on the block. They operate at high temperatures (~700–1000°C), allowing for very high efficiency. They are still in R&D and pilot phases but show great promise for large-scale industrial hydrogen production, especially when integrated with waste heat from industrial processes.
Why Are Hydrogen Electrolysers Gaining Traction?
The answer lies in a powerful mix of global urgency and technological maturity.
Climate Commitments: Countries and corporations are pledging to reach net-zero emissions. Hydrogen plays a key role, especially in sectors that are hard to electrify directly (like aviation, shipping, and steel).
Energy Security: As global geopolitics continue to affect fossil fuel markets, green hydrogen offers energy independence.
Technology Costs Are Dropping: Like solar panels a decade ago, the cost of electrolysers is falling rapidly as production scales up.
Government Incentives: Programs like the U.S. Hydrogen Hub initiative, Europe’s Green Deal, and India’s National Green Hydrogen Mission are injecting billions into hydrogen infrastructure.
So yes, the hydrogen economy is coming — and Hydrogen Electrolysers are leading the charge.
Real-World Applications (That Might Surprise You)
It’s easy to think of hydrogen as something only giant corporations or governments deal with. But its reach is growing fast.
Refineries & Fertilizer Plants: These have traditionally used hydrogen derived from natural gas (grey hydrogen). Electrolysers allow them to switch to green hydrogen with existing infrastructure.
Public Transit: Cities in Germany, Japan, and South Korea are already running hydrogen-powered buses and trains.
Remote Power Systems: Hydrogen electrolysers are being paired with solar arrays in remote locations to store excess energy and provide electricity even at night or during bad weather.
Data Centers: Companies like Microsoft are experimenting with hydrogen fuel cells as a clean backup power source for massive cloud server farms.
Challenges Still Remain
No energy transition is ever smooth. Here’s where electrolysers still face roadblocks:
Cost of Green Hydrogen: It's still 2–3 times more expensive than grey hydrogen (from fossil fuels). That gap is shrinking, but slowly.
Electrolyser Longevity: Especially for PEM and SOEC systems, degradation over time is a concern and needs advanced materials research.
Water Access: Electrolysis requires ultra-pure water. In arid regions, this can be a limiting factor.
Energy Source Reliability: When paired with renewables, fluctuating electricity input can reduce efficiency unless buffered with battery systems or smart grids.
But like all early technologies — from the first cell phones to early solar panels — what starts expensive and clunky often evolves into cheap and ubiquitous.
The Human Side: Meet the People Behind the Machines
Let’s take a detour from the tech and meet the people.
Sonal works as a process engineer at a startup in Pune designing scalable hydrogen electrolyser stacks. “It’s not just about splitting water,” she says. “It’s about redesigning an entire energy infrastructure. We’re building systems that could power a clean planet — it gives you goosebumps.”
Or Anand, an operations manager at a steel plant in Gujarat, where an electrolyser pilot replaced natural gas-derived hydrogen. “We cut emissions by 20% in one quarter,” he says. “Our clients care. Our investors care. And frankly, so do my kids.”
These stories aren’t rare anymore. They’re multiplying.
The Future Is Electrifying — and Electrolyzing
Here’s the thing: hydrogen isn’t a silver bullet. It won’t replace every fossil fuel overnight. But it is a crucial piece of the puzzle — especially for sectors where batteries won’t work, and direct electrification hits a wall.
And the Hydrogen Electrolyser? It’s the engine of that transition.
It connects green electricity with industrial decarbonization. It converts solar energy into fuel that can fly planes. It turns excess wind into backup power. It even helps stabilize electrical grids when used with storage.
And as we scale up — gigawatt-scale factories are already being built — the cost per unit will fall. The reliability will rise. And one day, hydrogen might flow as freely as diesel does today.
Final Thoughts
We often glamorize the flashy aspects of green tech — EVs, futuristic buildings, smart cities. But sometimes, real change happens behind the scenes. In labs. On factory floors. In devices like Hydrogen Electrolysers, quietly making clean fuel out of thin air and water.
They may not be sexy. But they are essential.
If the 20th century belonged to oil and gas, the 21st might belong to molecules split by renewable electrons. And in that world, the Hydrogen Electrolyser stands tall — small in size, huge in impact.
0 notes
Text
How to Choose the Right Analytical Instruments for Your Laboratory
Choosing the right analytical instruments is essential for any modern laboratory striving to deliver accurate, consistent, and high-quality results. Whether you work in pharmaceuticals, environmental science, food testing, or industrial R&D, your lab’s performance heavily depends on selecting equipment tailored to your needs. From spectrometers to chromatographs, the right tools ensure data precision, streamline workflows, and help meet industry standards.
This guide walks you through the essential factors to consider when investing in analytical instrumentation for your lab.
Why Selecting the Right Analytical Instruments Matters
Poor equipment choices can lead to inefficiencies, flawed data, costly recalibrations, and excessive downtime. Conversely, well-matched instruments enhance productivity, reduce operational costs, and help your lab stay competitive. A strategic investment ensures accurate testing, regulatory alignment, and long-term efficiency—outcomes that ultimately define your lab’s success.
1. Assess Your Laboratory's Specific Needs
Before selecting any instruments, evaluate your lab’s specific workflows and testing focus:
What types of samples do you analyze—solids, liquids, gases, or biological materials?
Are your primary tests qualitative, quantitative, elemental, or structural?
What precision and throughput levels are essential?
Analytical instruments such as Ultra High-Performance Liquid Chromatographs (UHPLC) are crucial in pharmaceutical labs for separating and quantifying compounds. In contrast, portable XRF analyzers are ideal for environmental and mining labs due to their field readiness. Calorimeters are indispensable in food and energy testing labs for determining energy values.
2. Consider Accuracy and Performance Specifications
Different instruments offer different performance thresholds. Be sure to evaluate:
Sensitivity
Detection limits
Resolution
Measurement speed
For trace metal detection, atomic absorption spectrometers or high-resolution FTIR systems offer exceptional accuracy. The better the alignment with your analysis goals, the more reliable your outcomes will be.
3. Understand the Analytical Techniques You Use Most
Every lab has preferred methods, and choosing tools that support them ensures consistent results. Examples include:
Spectroscopy: UV-Vis, FTIR, AAS
Chromatography: HPLC, GC
Mass Spectrometry
X-ray Fluorescence (XRF)
Calorimetry
Select analytical instruments based on the techniques your team uses regularly. Compatibility between instrument and method is essential for accurate and reproducible data.
4. Think About Flexibility and Versatility
A versatile tool can address various testing needs and save on long-term investments. A UV-Vis spectrophotometer, for example, applies to environmental testing, pharmaceutical quality control, and biochemical research. Look for:
Multi-application functionality
Modular or upgradable components
Broad measurement capabilities
Choosing flexible analytical instruments equips your lab to adapt as demands shift or new projects arise.
5. Review Ease of Use and Training Requirements
Instruments with user-friendly interfaces minimize training time and speed up onboarding. Evaluate:
Software simplicity and automation options
Setup and calibration procedures
Availability of pre-programmed methods
The easier it is for staff to learn and operate, the faster your lab can reach full productivity.
6. Consider Maintenance and Calibration Needs
Reliable performance requires consistent upkeep. When investing in analytical instruments, assess:
Frequency of maintenance
Cost and ease of calibration
Availability of service documentation and support
Instruments with automated calibration or minimal manual maintenance—such as the TT-BC1.5A Bomb Calorimeter—can reduce downtime and extend equipment lifespan.
7. Evaluate Connectivity and Integration
Today’s labs thrive on data integration and automation. Your equipment should offer:
LIMS and ERP compatibility
Remote access and real-time monitoring
USB, Wi-Fi, or Ethernet connectivity
These features improve workflow efficiency and ensure fast, secure data handling across systems.
8. Consider After-Sales Support and Warranty
Support is often the deciding factor between two similar instruments. When choosing a supplier, look for:
Installation assistance and user training
Fast, reliable technical support
Comprehensive warranties and service contracts
Companies like Rose Scientific provide ongoing support and ensure minimal disruption to your operations, from installation through daily use.
9. Ensure Compliance with Industry Standards
In regulated fields, compliance is not optional. Your analytical instruments must meet standards such as:
FDA (for pharmaceuticals and clinical testing)
ISO (international quality systems)
ASTM (industrial testing and materials)
Final Thoughts: Making the Right Choice for Your Laboratory
Choosing the right analytical instruments doesn’t need to be overwhelming. Start with a clear understanding of your lab's applications and techniques. Factor in ease of use, flexibility, and support. Prioritize long-term reliability and regulatory compliance. The right decisions now will ensure your lab operates efficiently, adapts easily, and produces reliable results for years to come.
Ready to Equip Your Lab with Advanced Analytical Instrumentation?
Explore high-performance solutions from Rose Scientific, including portable XRF analyzers, UHPLC systems, atomic absorption units, and more. Each product is engineered for precision, reliability, and ease of use across diverse scientific disciplines.
👉 Contact us today for a tailored consultation and see how our analytical instruments can elevate your lab’s performance.
0 notes
Text
10 Must Ask Questions For Every Artificial Intelligence Developer
Introduction: Properly Evaluating AI Talent
It is possible to make or break your AI efforts with the appropriate artificial intelligence developer. As artificial intelligence is revolutionizing companies at warp speed, businesses require talented individuals to handle difficult technical issues while enabling business value. However, it takes more than reviewing resumes or asking simple technical questions to gauge AI talent.
The problem is finding candidates with not only theoretical understanding but practical expertise in designing, implementing, and managing AI systems in actual application environments. The below ten key questions form an exhaustive framework to evaluate any Artificial Intelligence Developer candidate so that you end up hiring experts who will make your AI endeavors a success.
Technical Expertise
Programming Language Proficiency
In assessing an Artificial Intelligence Developer, their coding skills are the starting point for assessment. Most critically, how proficient they are with Python, R, Java, and C++ are questions that need to be resolved. These are the foundation programming languages of AI development, with Python leading the charge because of the abundance of machine learning libraries and frameworks available to it.
A career Artificial Intelligence Developer would, at the minimum, know a variety of programming languages as each project requires a different technical approach. Their answer would not show just familiarity but detailed understanding of which language to use and when to get the best result.
Machine Learning Framework Experience
The second important question is whether or not they are experienced in working with them hands-on using the mainstream ML libraries. TensorFlow, PyTorch, Scikit-learn, and Keras are industry standards which any qualified Artificial Intelligence Developer must be skilled in. Their exposure to these libraries directly influences project efficiency and solution quality.
Problem-Solving Approach
Data Preprocessing Methodology
Its success with an AI model relies on data quality, and thus it should have data preprocessing skills. An Artificial Intelligence Developer needs to clarify its strategy on dealing with missing data, outliers, feature scaling, and data transformation. Its strategy is an illustration of how raw data is converted into actionable intelligence.
Model Selection Strategy
Understanding how an Artificial Intelligence Developer makes his/her choice of model enables one to understand how he/she analytically thinks. They have to explain how they choose between supervised, unsupervised, and reinforcement learning techniques based on project requirements and data types.
Real-World Application Experience
The fifth question needs to assess their experience in various industries. Healthcare AI differs dramatically from financial technology or self-driving car development. A generic Artificial Intelligence Developer shows adaptability in deploying AI solutions in various industries.
Practice in the utilization of theoretical knowledge. An Artificial Intelligence Developer has to describe their experience with cloud platforms, containerization, and the scaling of AI models for use in the real world. Their answer varies from describing their understanding of the end-to-end AI development lifecycle.
Cross-Functional Team Experience
Collaboration and Communication
Current AI development demands harmonious collaboration between technical and non-technical stakeholders. The seventh question must examine the extent to which an Artificial Intelligence Developer conveys intricate technical information to business executives in a way that technical competence serves business goals.
Documentation and Knowledge Transfer
AI development is based on robust documentation and knowledge transfer. A seasoned Artificial Intelligence Developer possesses detailed documentation to facilitate team members to comprehend, administer, and extend existing systems.
Continuous Learning and Innovation
Staying Abreast of AI Trends
The AI environment is extremely dynamic with new technologies and methodologies emerging on a daily basis. The ninth question should test to what degree an Artificial Intelligence Developer stays abreast of trends in industry innovations, research studies, and emerging best practices.
Research and Development Contributions
Lastly, knowing their work on AI or community projects indicates that they are interested and dedicated to the job. A keen Artificial Intelligence Developer will attend conferences, write papers, or help with community projects, showing their enthusiasm more than required by immediate work.
The answers to these ten questions form a thorough assessment framework to determine any Artificial Intelligence Developer candidate such that businesses may hire specialists who can provide innovative, scalable AI solutions.
Conclusion: Informed Decision Making in Hiring
Hiring the correct artificial intelligence developer demands systematic assessment on multiple axes. These questions constitute a comprehensive framework of assessment that extends beyond mere technical skills to challenge problem-solving style, team work ability, and commitment to a lifetime of learning.
Keep in mind that top AI practitioners bridge technical expertise with robust communications and business sense. They recognize that effective AI deployment is more than providing accurate models,it is making sustainable, scalable solutions delivering quantifiable business value.
Use these questions as a basis for your evaluation process and tailor them to your own industry needs and organizational culture. Investing money in serious candidate evaluation pays back manyfold in the success of your AI project and team performance in the long term.
0 notes
Text
Understanding the Different Types of Functions in R Programming
Explore the various types of functions in R programming, including built-in, user-defined, and anonymous functions. This comprehensive guide covers their definitions, applications, and examples to help you harness the full power of R for your data analysis and statistical needs. Perfect for beginners and advanced users looking to deepen their knowledge of R's functional programming capabilities.
0 notes
Text
Unlock the Power of Code: 2025 Rust Programming for Beginners

In 2025, the world of programming continues to evolve rapidly—and if you're searching for a powerful, fast, and reliable language that’s growing in popularity, Rust should be on your radar. Whether you're just starting out or transitioning from another language, Rust Programming for Beginners is the perfect place to begin your journey into systems-level programming, the safe way.
Rust isn’t just another programming language—it’s a revolution. Built with safety, concurrency, and performance at its core, Rust is used by developers at Google, Microsoft, Dropbox, Amazon, and many top-tier companies. If you want a future-proof skill that employers are actively hiring for, learning Rust in 2025 is a smart move.
Why Rust? What Makes It So Special?
Rust was designed to solve real-world programming problems that other languages struggle with. It combines the speed and control of C and C++ with memory safety—without the need for a garbage collector. This makes it ideal for system-level development, embedded systems, and even web development using tools like WebAssembly.
Here’s why Rust is getting the spotlight in 2025:
Memory Safety Without Garbage Collection: Rust’s ownership model ensures that you don’t deal with memory leaks or dangling pointers.
Blazing Fast Performance: Rust code is compiled directly to machine code and optimized for speed.
Concurrency Made Safe: Rust’s approach to multithreading ensures thread safety without sacrificing performance.
Backed by Industry Leaders: Companies like Mozilla, Meta, and AWS use Rust in production.
Growing Community & Ecosystem: Rust’s tooling (Cargo, Clippy, Rustfmt) is modern and developer-friendly.
Who Should Learn Rust in 2025?
If you're wondering whether Rust is right for you, the answer is yes—especially if:
You're a complete beginner with an interest in programming.
You’re a software developer wanting to explore systems programming.
You come from Python, JavaScript, or Java and want a high-performance language.
You’re interested in game development, embedded systems, or WebAssembly.
You want to level up your coding interview game with low-level problem-solving.
No matter your background, you can learn Rust from scratch with the right guidance. That’s where this top-rated beginner course comes in.
Introducing the Best Course: Rust Programming for Beginners
If you're serious about mastering Rust, don’t waste hours jumping from blog to blog or piecing together fragmented tutorials. The Rust Programming for Beginners course offers structured, beginner-friendly training that walks you through everything from basics to hands-on projects.
📌 Course Highlights:
Absolute Beginner-Friendly: No prior programming experience needed.
Step-by-Step Lessons: From variables to control flow, functions to ownership.
Real Projects: Build actual applications to solidify your knowledge.
Lifetime Access: Learn at your own pace, and revisit whenever needed.
Quizzes and Practice Exercises: Test your knowledge as you go.
Certificate of Completion: Showcase your skills on your resume or LinkedIn.
Whether you’re just dabbling or fully committing to Rust, this course makes sure you're not just learning—but actually understanding.
What You'll Learn: From "Hello, World!" to Building Real Projects
This course truly covers everything you need to become productive with Rust. Here’s a quick peek at the modules:
1. Introduction to Rust
History of Rust
Setting up your environment
Understanding Cargo (Rust’s package manager)
2. Basic Programming Concepts
Variables and data types
Functions and control flow
Loops and conditionals
3. Ownership, Borrowing, and Lifetimes
The heart of Rust’s memory safety
Avoiding bugs at compile time
How Rust manages memory differently than other languages
4. Structs and Enums
Data structures in Rust
When to use structs vs. enums
Pattern matching with match
5. Collections and Error Handling
Vectors, HashMaps, and Strings
Option and Result types
Handling errors the Rust way
6. Working with Modules and Crates
Organizing your code
Using external libraries from crates.io
7. Project-Based Learning
Build your own command-line tools
Create a mini web scraper
Start a simple API with Rocket or Actix-web
What Makes This Course Different?
With hundreds of Rust tutorials online, why should you choose this course? Here’s the difference:
✅ Hands-On Approach – You won’t just watch videos; you’ll build real things. ✅ Beginner-Focused – Complex topics are explained simply, with clear visuals. ✅ Updated for 2025 – Content is fresh, aligned with the latest Rust updates. ✅ Trusted Platform – Hosted on Udemy, promoted by Korshub, and trusted by thousands.
Plus, the instructor is known for teaching with clarity, warmth, and energy—making learning Rust genuinely fun.
Real-World Applications of Rust
Wondering what you can actually do with Rust after completing this course?
Here are just a few career paths and domains where Rust is making waves:
🛠️ System-Level Development
Rust is excellent for writing OS-level code, drivers, and performance-critical tools.
🌐 Web Development with WebAssembly
Rust compiles to WebAssembly (WASM), letting you build blazing-fast web apps.
🎮 Game Development
Rust’s performance and safety features make it a great fit for modern game engines.
🔐 Cybersecurity Tools
Rust’s memory safety makes it ideal for building secure applications like firewalls or scanning tools.
🚀 Embedded Systems and IoT
Rust runs on small devices, allowing you to build firmware and IoT projects with confidence.
Testimonials from Learners Like You
“I was completely new to programming, and this course helped me grasp core concepts fast. Rust seemed intimidating until now!” – Ankit, Student
“After taking this course, I landed an internship where they use Rust in production. Couldn’t have done it without this course!” – Priya, Junior Developer
“The project sections made everything click. I finally feel confident with a low-level language like Rust.” – Kevin, Freelance Dev
What’s Next After You Complete the Course?
Learning Rust is a journey—and this course is your foundation. After completing Rust Programming for Beginners, you can:
Dive into intermediate topics like async programming and concurrency.
Contribute to open-source Rust projects on GitHub.
Build performance-critical applications from scratch.
Start freelancing or apply for Rust developer jobs.
And guess what? Rust developers are in high demand in 2025—with salaries averaging $100,000+ globally. So, this isn’t just a learning investment—it’s a career move.
Final Thoughts: Is Rust the Right Choice for You?
If you're looking for a language that combines power, performance, and safety, then Rust is the future. Whether you're planning to become a professional developer or you’re just a curious learner, starting with Rust in 2025 puts you ahead of the curve.
The best part? You don’t have to figure it all out alone.
The Rust Programming for Beginners course provides everything you need to build your skills step-by-step, gain confidence, and start building exciting projects from day one.
So, don’t wait. Learn Rust now and be future-ready.
0 notes
Text
Get Started Coding for non-programmers

How to Get Started with Coding: A Guide for Non-Techies
If you ever considered learning how to Get Started Coding for non-programmers but were intimidated by technical terms or daunted by the prospect, you're in good company. The good news is that coding isn't for "techies" alone. Anyone can learn to code, no matter their background or experience. In this guide, we'll take you through the fundamentals of how to get started coding, whether you're looking to create a website, work with data, or simply learn how the technology that surrounds you operates. Why Learn to Code? Before diving into the "how," it's worth knowing the "why." Coding can unlock new doors, both personally and professionally. Some of the reasons why learning to code is worth it include: Problem-solving abilities: Programming allows you to dissect difficult problems and identify solutions. Career adaptability: More and more careers, from marketing to medicine, are turning to coding as a requirement. Empowerment: Code knowledge enables you to have a better understanding of the technology you're using daily and enables you to own your own project development. Creativity: Coding isn't purely logical—it's also about making new things and creating your own ideas. Step 1: Choose Your Learning Path Before you start, consider what you are most interested in. The route you take will depend on what you want to do. These are some of the most popular routes: Web Development: Creating websites and web apps (learn HTML, CSS, JavaScript). Data Science: Examining data, visualizing patterns, and making informed decisions based on data (learn Python, R, or SQL). App Development: Creating mobile apps for iOS or Android (learn Swift or Kotlin). Game Development: Building video games (learn Unity or Unreal Engine using C# or C++). Take a moment to determine which area speaks to you. Don't stress about choosing the "perfect" path—coding skills are interchangeable, and you can always make a change later. Step 2: Begin with the Basics After you've decided on your route, it's time to begin learning. As a novice, you'll want to begin with the fundamentals of coding. Here are some fundamental concepts to familiarize yourself with: Variables: A means of storing data (such as numbers or text). Data Types: Familiarity with various types of data, including integers, strings (text), and booleans (true/false). Loops: Doing things over and over again without writing the same code over and over. Conditionals: Deciding things in code using if-else statements. Functions: These are the Building blocks of code that can be reused to accomplish particular tasks. For instance, when you're learning Python, you could begin with a basic program such as: Step 3: Select the Proper Learning Material There's plenty of learning material out there for beginners, and the correct resource can mean a big difference in how rapidly you learn to code. Some of the most popular methods include: Online Courses: Websites such as Coursera, Udemy, edX, and freeCodeCamp provide sequential courses, and some of these are available free of charge. Interactive Platforms: Sites such as Codecademy, Khan Academy, or LeetCode offer in-the-code lessons that walk you through problems sequentially. Books: There are a lot of code books for beginners, such as "Python Crash Course" or "Automate the Boring Stuff with Python." YouTube Tutorials: YouTube contains a plethora of coding tutorials for beginners where you can work through actual projects. For complete beginners, sites such as freeCodeCamp and Codecademy are excellent as they enable you to code in the browser itself, so you don't have to install anything. Step 4: Practice, Practice, Practice The secret to mastering coding is regular practice. Similar to learning a musical instrument or a foreign language, you'll have to develop muscle memory and confidence. Practice Coding Challenges: Sites such as HackerRank or Codewars offer exercises that allow you to practice what you've learned. Build Small Projects: Begin with small projects, like a to-do list, a basic calculator, or a personal blog. This reinforces your learning and makes coding more rewarding. Join Coding Communities: Sites like GitHub, Stack Overflow, or Reddit's /r/learnprogramming are excellent for asking questions, sharing your work, and receiving feedback. Step 5: Don't Be Afraid to Make Mistakes Keep in mind that errors are all part of learning. While you're coding, you'll get errors, and that's completely fine. Debugging is a skill that takes time to master. The more you code, the more accustomed you'll get to spotting and resolving errors in your code. Here's a useful approach when faced with errors: Read the error message: It usually indicates precisely what's wrong. Search online: Chances are, someone else has faced the same issue. Platforms like Stack Overflow are full of solutions. Break the problem down: If something’s not working, try to isolate the issue and test each part of your code step by step. Step 6: Stay Motivated Get Started Coding for Non-Programmers. Learning to code can be challenging, especially in the beginning. Here are a few tips to stay motivated: Break goals into bite-sized pieces: Don't try to learn it all at once; set mini goals such as "Complete this course" or "Finish this project." Pat yourself on the back: Celebrate every time you complete a project or figure out a problem. Get a learning buddy: It's always more fun and engaging with someone learning alongside you. Don't do it in one sitting: It takes time to learn to code. Relax, be good to yourself, and enjoy the process. Conclusion Learning to Get Started Coding for non-programmers might seem daunting, but it’s possible with the right mindset and resources. Start small, be consistent, and remember that every coder, no matter how experienced, was once a beginner. By following these steps—choosing the right learning path, mastering the basics, practicing regularly, and staying motivated—you’ll soon gain the skills and confidence you need to code like a pro. Read the full article
0 notes
Text
Testing vs Debugging: A Comprehensive Guide

In the ever-evolving landscape of software development, two critical processes ensure the delivery of reliable and efficient software: testing and debugging. While they often go hand-in-hand, each plays a distinct role in the Software Development Life Cycle (SDLC). Understanding their differences, objectives, and applications can lead to smoother development and higher-quality outcomes.
Testing Definition
Testing is the systematic process of evaluating a software application to identify discrepancies between expected and actual behavior. It aims to uncover defects, ensure functionality, verify requirements, and confirm that the product meets user expectations before it is released.
Testing can be done at various stages of development and involves checking inputs, outputs, usability, and performance against pre-defined conditions.
Debugging Definition
Debugging is the process of identifying, analyzing, and fixing defects or issues found during testing or actual usage. It begins when a fault is detected and ends when the issue is resolved and the program behaves as intended.
Debugging often requires developers to trace the source of the problem, understand the cause, and apply changes to the codebase without introducing new errors.

The Role in Software Development Life Cycle
In the SDLC, both testing and debugging are integral:
Testing is present in nearly every phase, from unit testing in development to user acceptance testing before release. It validates the correctness and completeness of the software.
Debugging typically follows testing. When test cases fail or users report issues, developers enter the debugging phase to resolve them.
Their combined contribution ensures not only the detection of issues but also their resolution before deployment.
Types of Testing
There are several types of software testing, each targeting a different aspect of the application:
Unit Testing — Verifies individual code components or functions.
Integration Testing — Ensures multiple components work together correctly.
System Testing — Examines the entire system’s functionality.
Acceptance Testing — Validates that software meets business requirements.
Regression Testing — Checks that new changes haven’t disrupted existing features.
Performance Testing — Assesses how well the software performs under stress.
Each type is crucial in building confidence in the software’s reliability and performance.
Types of Debugging
Debugging techniques vary depending on the nature of the issue and the system environment:
Print Debugging — Using logs or print statements to trace code execution.
Step-by-step Debugging — Walking through the code using a debugger.
Post-mortem Debugging — Investigating logs or crash reports after failure.
Remote Debugging — Debugging an application running on another machine.
Automated Debugging — Utilizing smart platforms that assist in root cause analysis.
Effective debugging requires a good understanding of both the application and the underlying platform.
Best Testing and Debugging Tools
While there are many tools available for software quality assurance, one standout solution that integrates both testing and debugging workflows is genqe.ai.
Genqe.ai offers intelligent automation, real-time analytics, and collaborative capabilities to streamline both testing and debugging. It enhances code reliability by identifying patterns and offering actionable insights throughout the development cycle, making it a valuable asset for any development team focused on efficiency and precision.
Conclusion
Testing and debugging are not optional — they are essential. While testing ensures the quality of a product, debugging ensures that flaws are resolved efficiently. Both contribute uniquely to a robust, maintainable, and user-friendly software system.
By incorporating smart platforms like genqe.ai, teams can enhance these practices, reduce time-to-market, and deliver software that performs flawlessly in real-world conditions.
0 notes
Text
youtube
Welcome to Imarticus Learning! In this video, we dive into Logistic Regression, a foundational classification algorithm in machine learning that plays a vital role in both binary and multi-class predictions. As part of the best machine learning course offerings, this session explores what Logistic Regression is, how it differs from Linear Regression, and its critical applications in real-world decision-making. Whether you're a beginner or a data enthusiast, this video simplifies core concepts to help you effectively apply logistic regression models.
You’ll learn about the mathematical intuition behind Logistic Regression, key differences between Logistic and Linear Regression, and how the sigmoid function helps convert probabilities into predictions. We’ll also cover essential evaluation metrics such as Accuracy, Precision, Recall, F1-Score, and ROC-AUC. Timestamps are included for easy navigation through topics like the Logistic Regression equation and its various types.
Learning with Imarticus offers numerous benefits, including expert guidance from seasoned professionals, flexible and structured learning options, access to mock tests, expert mentorship, and comprehensive study materials—all geared towards driving your career success. The Postgraduate Program in Data Science and Analytics (PGA) by Imarticus is a 6-month course tailored for graduates and professionals with less than three years of experience. As part of the best machine learning course suite, it ensures 100% job assurance through 2,000+ hiring partners, 300+ learning hours, 25+ hands-on projects, and training in tools like Python, Power BI, and Tableau. With a highest salary of 22.5 LPA and average salary hikes of 52%, this course is a gateway to success in data science and analytics.
Explore additional learning with recommended books like An Introduction to Statistical Learning, Logistic Regression Using R, and Hands-On Machine Learning with Scikit-Learn & TensorFlow. For real-world context, we also suggest watching Moneyball, The Great Hack, and Coded Bias—films that illustrate the power and ethical implications of data-driven decisions and classification systems.
Transform your career from Data to AI with the best machine learning course at Imarticus Learning.
0 notes
Text
Optima CNC Press Brake by Energy Mission: Precision Metal Bending by a Trusted Manufacturer and Supplier
In today’s advanced industrial landscape, precision, reliability, and automation are critical drivers of productivity. The Optima CNC Press Brake from Energy Mission, a leading CNC press brake manufacturer and supplier, stands at the forefront of these innovations. Engineered with state-of-the-art components and intelligent systems, this press brake is designed to meet the most demanding fabrication tasks with ease.
Energy Mission has earned a solid reputation as a quality-driven manufacturer, offering high-performance CNC bending machines tailored for a range of industries including automotive, aerospace, construction, and general manufacturing. The Optima Series embodies their commitment to innovation, accuracy, and long-term performance.
Engineered for Efficiency and Precision
The Optima CNC Press Brake combines heavy-duty structural design with advanced motion technology. Designed with servo motor integration and high-speed hydraulic systems, the machine ensures consistent beam movement and precise bend angles even under continuous operation. Its robust frame and precision-machined components enable higher throughput while maintaining tight tolerances, making it ideal for complex, high-volume projects.
With a bending capacity ranging from 25 to 325 metric tons and a length range between 1250 mm and 8000 mm, the Optima series supports a broad spectrum of sheet metal processing needs. This level of flexibility makes it a highly sought-after solution for fabricators who need to switch between different job types without sacrificing performance.
CNC Controls That Empower Operators
A key feature of the Optima CNC Press Brake is its user-friendly interface, powered by the CybTouch 8PS CNC controller from CYBELEC Switzerland. This control unit allows operators to manage bending programs, angles, and sequences with intuitive touchscreen functionality. It reduces the learning curve for new users and enhances operational efficiency on the shop floor.
The system supports automatic crowning adjustments, back gauge positioning, and beam synchronization, all essential for ensuring repeatability and eliminating rework. These features empower fabricators to take on complex bending tasks while reducing material waste and energy consumption.
Energy-Efficient, Maintenance-Friendly Design
Energy Mission has incorporated intelligent energy-saving systems into the Optima series. The use of servo drives with hydraulic pumps results in significant energy savings—up to 50% in some cases—compared to traditional press brake systems. Furthermore, stable oil temperature management ensures consistent bending quality and longer service life for hydraulic components.
Maintenance is also made simple with accessible service points and diagnostics available directly through the CNC interface. This ease of maintenance reduces downtime and keeps production running smoothly.
Tailored Tooling and Back Gauge Options
Understanding the unique needs of fabricators, Energy Mission offers a variety of tooling and back gauge configurations:
Tooling Options: Available with self-centering, hardened and ground single-V, 2-V, and 4-V dies, as well as customized punches to suit diverse materials and thicknesses.
Back Gauge Configurations: Choose from X+R, X+R+Z1-Z2, or advanced multi-axis gauges for more complex part geometries.
Crowning Systems: Manual, automatic, and hydraulic crowning systems available to ensure consistent angle accuracy across the length of the bend.
Each machine is customizable, enabling buyers to select components that align with their production goals and job requirements.
Applications Across Industries
The Optima CNC Press Brake is widely used in:
Automotive manufacturing: Producing high-precision body panels and frame components.
Aerospace fabrication: Creating lightweight, complex parts requiring strict tolerances.
Construction and architecture: Forming structural metal sheets, brackets, and profiles.
General fabrication: Supporting custom production of machine parts, enclosures, and sheet assemblies.
As a leading CNC press brake supplier, Energy Mission ensures its machines can adapt to the fast-changing needs of these industries with ease.
Why Choose Energy Mission?
With decades of experience in metalworking technologies, Energy Mission is not just a manufacturer—it is a partner to businesses seeking industrial excellence. Their dedication to R&D, responsive customer support, and quality assurance makes them a preferred supplier of CNC press brakes in India and abroad.
Their production standards meet global benchmarks, and all equipment is backed by strong technical support and comprehensive after-sales service. Whether you are upgrading your bending capabilities or setting up a new fabrication line, the Optima CNC Press Brake is a smart, future-proof investment.
Conclusion
The Optima Series CNC Press Brake is a testament to Energy Mission’s engineering prowess and customer-focused innovation. As a reliable CNC press brake manufacturer and supplier, Energy Mission delivers more than a machine—it delivers a promise of precision, productivity, and partnership. Whether for light-duty tasks or heavy fabrication, the Optima series offers unmatched value and performance.
0 notes
Text
Top Theatre Chairs for Auditoriums in Delhi

As the entertainment and education sectors continue to expand in Delhi, the demand for comfortable and durable theatre chairs in auditoriums has grown significantly. Whether it's a school auditorium, a public performance venue, or a cinema hall, audience seating plays a crucial role in enhancing the overall experience. A well-designed theatre chair ensures not just comfort, but also adds to the aesthetic and functional value of the space. In this fast-evolving landscape, Perfect Furniture emerges as a trusted theatre chair supplier in Delhi, offering top-tier products customized to meet varying venue requirements.
Why Quality Theatre Chairs Matter
The seating experience in a theatre or auditorium can either elevate or diminish the audience’s engagement. High-quality theatre chairs are engineered for ergonomic support, ensuring that viewers can comfortably sit through long sessions without strain. Durable construction also translates to lower maintenance and repair costs in the long run, making them a smart investment for institutions and venues.
Quality theatre seating is essential for:
Schools and colleges conducting lectures, events, and seminars.
Auditoriums and conference halls hosting cultural programs and business functions.
Cinema halls that require plush, premium seating to attract patrons.
Multipurpose venues that demand flexible, foldable, or stackable seating options.
Top Theatre Chair Options in Delhi
Delhi’s market offers a diverse range of theatre chair designs, but Perfect Furniture stands out for its blend of style, functionality, and affordability. Here are the top types of theatre chairs available:
Recliner Theatre Chairs: Ideal for premium auditoriums and cinemas, these chairs offer maximum comfort with motorized or manual reclining features. Perfect for luxury experiences.
Fixed Push-Back Chairs: A popular choice for school auditoriums and conference halls, these chairs come with soft upholstery and push-back functionality for ease and durability.
Foldable and Space-Saving Designs: Especially suited for multi-use halls and event spaces, these theatre chairs can be easily stowed away to optimize room usage.
Perfect Furniture offers all the above with custom upholstery, branding options, and multiple color choices, ensuring that each venue gets seating tailored to its specific vibe and needs.
How to Choose the Right Theatre Chair Supplier
Choosing the right supplier can be the difference between a successful seating upgrade and a frustrating investment. Here's what to look for:
Supplier Credibility: Always verify customer reviews, past projects, and client testimonials.
Product Quality and Warranty: Ensure the chairs are made with robust materials and come with warranty coverage for peace of mind.
Timely Delivery and Service: Especially important for large-scale projects or renovations with tight deadlines.
Perfect Furniture shines in all these areas, with years of experience, skilled craftsmanship, and the ability to handle bulk orders efficiently. Our commitment to excellence and professionalism makes us a preferred choice in Delhi.
Benefits of Buying from Perfect Furniture
Choosing Perfect Furniture means choosing reliability and value. Here’s what you can expect:
Local Manufacturing Edge: Being based in Delhi allows us to offer faster delivery times and cost-effective solutions.
Tailor-Made Designs: We work closely with clients to develop seating layouts and finishes that complement each venue’s theme.
Client-Centric Approach: We prioritize on-time project completion and provide dedicated support throughout the installation process.
Trusted Supplier Network: With a growing list of satisfied customers, we’ve established ourselves as a leading theatre chair supplier in Delhi.
Conclusion
Investing in top-quality theatre chairs isn’t just about looks—it’s about offering your audience the best experience while ensuring long-term durability and savings. From premium recliners to space-saving auditorium seating, Perfect Furniture delivers it all with precision and passion.
Ready to upgrade your auditorium with the best theatre chairs in Delhi? Contact Perfect Furniture today and let’s bring your vision to life!
Want more tailored solutions or have a specific query? Reach out now and get expert consultation from the leading theatre chair manufacturer in Delhi—Perfect Furniture!
0 notes
Text
The Complete R Programming Tutorial for Aspiring Data Scientists

In the world of data science, the right programming language can make all the difference. Among the top contenders, R programming stands out for its powerful statistical capabilities, robust data analysis tools, and a rich ecosystem of packages. If you're an aspiring data scientist, mastering R can open the door to a wide range of opportunities in research, business intelligence, machine learning, and online R compiler.
In this complete R programming tutorial, we’ll walk you through the essentials you need to start coding with R—from installation to basic syntax, data manipulation, and even simple visualizations.
Why Learn R for Data Science?
R is a language built specifically for statistical computing and data analysis. It is widely used in academia, finance, healthcare, and tech industries. Some key reasons to learn R include:
Open Source & Free: R is completely free to use and has a vast community contributing packages and resources.
Built for Data: Unlike general-purpose languages, R was designed with statistics in mind.
Visualization Power: With packages like ggplot2, R makes data visualization intuitive and beautiful.
Data Analysis-Friendly: Data frames, tidyverse, and built-in functions make data wrangling a breeze.
Step 1: Installing R and RStudio
Before you can dive into coding, you’ll need two essential tools:
R: Download and install R from CRAN.
RStudio: A user-friendly IDE (Integrated Development Environment) that makes writing R code easier. Download it from rstudio.com.
Once installed, open RStudio. You'll see a scripting window, console, environment panel, and files/plots/packages/help panel—everything you need to code efficiently.
Step 2: Writing Your First R Script
Let’s start with a simple script.# This is a comment print("Hello, Data Science World!")
Hit Ctrl + Enter (Windows) or Cmd + Enter (Mac) to run the line. You’ll see the output in the console.
Step 3: Understanding Data Types and Variables
R has several basic data types:# Numeric num <- 42 # Character name <- "Data Scientist" # Logical is_learning <- TRUE # Vector scores <- c(90, 85, 88, 92) # Data Frame students <- data.frame(Name = c("John", "Sara"), Score = c(90, 85))
Use the str() function to explore objects:str(students)
Step 4: Importing and Exploring Data
R can read multiple file formats like CSV, Excel, and JSON. To read a CSV:data <- read.csv("yourfile.csv") head(data) summary(data)
If you're working with large datasets, packages like data.table or readr can offer better performance.
Step 5: Data Manipulation with dplyr
Part of the tidyverse, dplyr is essential for transforming data.library(dplyr) # Select columns data %>% select(Name, Score) # Filter rows data %>% filter(Score > 85) # Add new column data %>% mutate(Grade = ifelse(Score > 90, "A", "B"))
Step 6: Data Visualization with ggplot2
ggplot2 is one of the most powerful visualization tools in R.library(ggplot2) ggplot(data, aes(x = Name, y = Score)) + geom_bar(stat = "identity") + theme_minimal()
You can customize charts with titles, colors, and themes to make your data presentation-ready.
Step 7: Writing Functions
Functions help you reuse code and keep things clean.calculate_grade <- function(score) { if(score > 90) { return("A") } else { return("B") } } calculate_grade(95)
Step 8: Exploring Machine Learning Basics
R offers packages like caret, randomForest, and e1071 for machine learning.
Example using linear regression:model <- lm(Score ~ Age + StudyHours, data = students) summary(model)
This builds a model to predict score based on age and study hours.
Final Thoughts
Learning R is a valuable skill for anyone diving into data science. With its statistical power, ease of use, and strong community support, R continues to be a go-to tool for data scientists around the globe.
Key Takeaways:
Start by installing R and RStudio.
Understand basic syntax, variables, and data structures.
Learn data manipulation with dplyr and visualizations with ggplot2.
Begin exploring models using built-in functions and machine learning packages.
Whether you're analyzing research data, building reports, or preparing for a data science career, this R programming tutorial gives you the solid foundation you need.
For Interview Related Q&A :
Happy coding!
0 notes