#Free software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
abandonware should be public domain. force companies to actively support and provide products if they don't wanna lose the rights to them
128K notes
·
View notes
Text

join the praxis discord - sign up - github
#praxis#free software#foss#design#software#programming#leftist memes#leftblr#late stage capitalism#socialism
2K notes
·
View notes
Text
i have scraped culpepers compleat physician and made a database of the plants mentioned and their planetary associations as given in the text.
it is available as a single html page for offline reference in a browser:
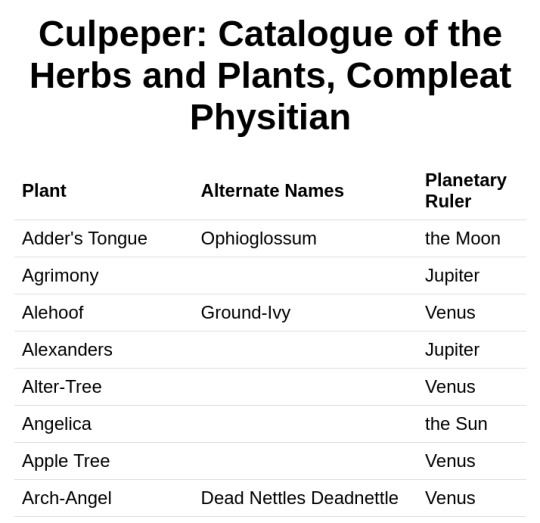
and JSON (more formats soon) on github:
199 notes
·
View notes
Text
Cleantech has an enshittification problem

On July 14, I'm giving the closing keynote for the fifteenth HACKERS ON PLANET EARTH, in QUEENS, NY. Happy Bastille Day! On July 20, I'm appearing in CHICAGO at Exile in Bookville.

EVs won't save the planet. Ultimately, the material bill for billions of individual vehicles and the unavoidable geometry of more cars-more traffic-more roads-greater distances-more cars dictate that the future of our cities and planet requires public transit – lots of it.
But no matter how much public transit we install, there's always going to be some personal vehicles on the road, and not just bikes, ebikes and scooters. Between deliveries, accessibility, and stubbornly low-density regions, there's going to be a lot of cars, vans and trucks on the road for the foreseeable future, and these should be electric.
Beyond that irreducible minimum of personal vehicles, there's the fact that individuals can't install their own public transit system; in places that lack the political will or means to create working transit, EVs are a way for people to significantly reduce their personal emissions.
In policy circles, EV adoption is treated as a logistical and financial issue, so governments have focused on making EVs affordable and increasing the density of charging stations. As an EV owner, I can affirm that affordability and logistics were important concerns when we were shopping for a car.
But there's a third EV problem that is almost entirely off policy radar: enshittification.
An EV is a rolling computer in a fancy case with a squishy person inside of it. While this can sound scary, there are lots of cool implications for this. For example, your EV could download your local power company's tariff schedule and preferentially charge itself when the rates are lowest; they could also coordinate with the utility to reduce charging when loads are peaking. You can start them with your phone. Your repair technician can run extensive remote diagnostics on them and help you solve many problems from the road. New features can be delivered over the air.
That's just for starters, but there's so much more in the future. After all, the signal virtue of a digital computer is its flexibility. The only computer we know how to make is the Turing complete, universal, Von Neumann machine, which can run every valid program. If a feature is computationally tractable – from automated parallel parking to advanced collision prevention – it can run on a car.
The problem is that this digital flexibility presents a moral hazard to EV manufacturers. EVs are designed to make any kind of unauthorized, owner-selected modification into an IP rights violation ("IP" in this case is "any law that lets me control the conduct of my customers or competitors"):
https://locusmag.com/2020/09/cory-doctorow-ip/
EVs are also designed so that the manufacturer can unilaterally exert control over them or alter their operation. EVs – even more than conventional vehicles – are designed to be remotely killswitched in order to help manufacturers and dealers pressure people into paying their car notes on time:
https://pluralistic.net/2023/07/24/rent-to-pwn/#kitt-is-a-demon
Manufacturers can reach into your car and change how much of your battery you can access:
https://pluralistic.net/2023/07/28/edison-not-tesla/#demon-haunted-world
They can lock your car and have it send its location to a repo man, then greet him by blinking its lights, honking its horn, and pulling out of its parking space:
https://tiremeetsroad.com/2021/03/18/tesla-allegedly-remotely-unlocks-model-3-owners-car-uses-smart-summon-to-help-repo-agent/
And of course, they can detect when you've asked independent mechanic to service your car and then punish you by degrading its functionality:
https://www.repairerdrivennews.com/2024/06/26/two-of-eight-claims-in-tesla-anti-trust-lawsuit-will-move-forward/
This is "twiddling" – unilaterally and irreversibly altering the functionality of a product or service, secure in the knowledge that IP law will prevent anyone from twiddling back by restoring the gadget to a preferred configuration:
https://pluralistic.net/2023/02/19/twiddler/
The thing is, for an EV, twiddling is the best case scenario. As bad as it is for the company that made your EV to change how it works whenever they feel like picking your pocket, that's infinitely preferable to the manufacturer going bankrupt and bricking your car.
That's what just happened to owners of Fisker EVs, cars that cost $40-70k. Cars are long-term purchases. An EV should last 12-20 years, or even longer if you pay to swap the battery pack. Fisker was founded in 2016 and shipped its first Ocean SUV in 2023. The company is now bankrupt:
https://insideevs.com/news/723669/fisker-inc-bankruptcy-chapter-11-official/
Fisker called its vehicles "software-based cars" and they weren't kidding. Without continuous software updates and server access, those Fisker Ocean SUVs are turning into bricks. What's more, the company designed the car from the ground up to make any kind of independent service and support into a felony, by wrapping the whole thing in overlapping layers of IP. That means that no one can step in with a module that jailbreaks the Fisker and drops in an alternative firmware that will keep the fleet rolling.
This is the third EV risk – not just finance, not just charger infrastructure, but the possibility that any whizzy, cool new EV company will go bust and brick your $70k cleantech investment, irreversibly transforming your car into 5,500 lb worth of e-waste.
This confers a huge advantage onto the big automakers like VW, Kia, Ford, etc. Tesla gets a pass, too, because it achieved critical mass before people started to wise up to the risk of twiddling and bricking. If you're making a serious investment in a product you expect to use for 20 years, are you really gonna buy it from a two-year old startup with six months' capital in the bank?
The incumbency advantage here means that the big automakers won't have any reason to sink a lot of money into R&D, because they won't have to worry about hungry startups with cool new ideas eating their lunches. They can maintain the cozy cartel that has seen cars stagnate for decades, with the majority of "innovation" taking the form of shitty, extractive and ill-starred ideas like touchscreen controls and an accelerator pedal that you have to rent by the month:
https://www.theverge.com/2022/11/23/23474969/mercedes-car-subscription-faster-acceleration-feature-price
Put that way, it's clear that this isn't an EV problem, it's a cleantech problem. Cleantech has all the problems of EVs: it requires a large capital expenditure, it will be "smart," and it is expected to last for decades. That's rooftop solar, heat-pumps, smart thermostat sensor arrays, and home storage batteries.
And just as with EVs, policymakers have focused on infrastructure and affordability without paying any attention to the enshittification risks. Your rooftop solar will likely be controlled via a Solaredge box – a terrible technology that stops working if it can't reach the internet for a protracted period (that's right, your home solar stops working if the grid fails!).
I found this out the hard way during the covid lockdowns, when Solaredge terminated its 3G cellular contract and notified me that I would have to replace the modem in my system or it would stop working. This was at the height of the supply-chain crisis and there was a long waiting list for any replacement modems, with wifi cards (that used your home internet rather than a cellular connection) completely sold out for most of a year.
There are good reasons to connect rooftop solar arrays to the internet – it's not just so that Solaredge can enshittify my service. Solar arrays that coordinate with the grid can make it much easier and safer to manage a grid that was designed for centralized power production and is being retrofitted for distributed generation, one roof at a time.
But when the imperatives of extraction and efficiency go to war, extraction always wins. After all, the Solaredge system is already in place and solar installers are largely ignorant of, and indifferent to, the reasons that a homeowner might want to directly control and monitor their system via local controls that don't roundtrip through the cloud.
Somewhere in the hindbrain of any prospective solar purchaser is the experience with bricked and enshittified "smart" gadgets, and the knowledge that anything they buy from a cool startup with lots of great ideas for improving production, monitoring, and/or costs poses the risk of having your 20 year investment bricked after just a few years – and, thanks to the extractive imperative, no one will be able to step in and restore your ex-solar array to good working order.
I make the majority of my living from books, which means that my pay is very "lumpy" – I get large sums when I publish a book and very little in between. For many years, I've used these payments to make big purchases, rather than financing them over long periods where I can't predict my income. We've used my book payments to put in solar, then an induction stove, then a battery. We used one to buy out the lease on our EV. And just a month ago, we used the money from my upcoming Enshittification book to put in a heat pump (with enough left over to pay for a pair of long-overdue cataract surgeries, scheduled for the fall).
When we started shopping for heat pumps, it was clear that this was a very exciting sector. First of all, heat pumps are kind of magic, so efficient and effective it's almost surreal. But beyond the basic tech – which has been around since the late 1940s – there is a vast ferment of cool digital features coming from exciting and innovative startups.
By nature, I'm the kid of person who likes these digital features. I started out as a computer programmer, and while I haven't written production code since the previous millennium, I've been in and around the tech industry for my whole adult life. But when it came time to buy a heat-pump – an investment that I expected to last for 20 years or more – there was no way I was going to buy one of these cool new digitally enhanced pumps, no matter how much the reviewers loved them. Sure, they'd work well, but it's precisely because I'm so knowledgeable about high tech that I could see that they would fail very, very badly.
You may think EVs are bullshit, and they are – though there will always be room for some personal vehicles, and it's better for people in transit deserts to drive EVs than gas-guzzlers. You may think rooftop solar is a dead-end and be all-in on utility scale solar (I think we need both, especially given the grid-disrupting extreme climate events on our horizon). But there's still a wide range of cleantech – induction tops, heat pumps, smart thermostats – that are capital intensive, have a long duty cycle, and have good reasons to be digitized and networked.
Take home storage batteries: your utility can push its rate card to your battery every time they change their prices, and your battery can use that information to decide when to let your house tap into the grid, and when to switch over to powering your home with the solar you've stored up during the day. This is a very old and proven pattern in tech: the old Fidonet BBS network used a version of this, with each BBS timing its calls to other nodes to coincide with the cheapest long-distance rates, so that messages for distant systems could be passed on:
https://en.wikipedia.org/wiki/FidoNet
Cleantech is a very dynamic sector, even if its triumphs are largely unheralded. There's a quiet revolution underway in generation, storage and transmission of renewable power, and a complimentary revolution in power-consumption in vehicles and homes:
https://pluralistic.net/2024/06/12/s-curve/#anything-that-cant-go-on-forever-eventually-stops
But cleantech is too important to leave to the incumbents, who are addicted to enshittification and planned obsolescence. These giant, financialized firms lack the discipline and culture to make products that have the features – and cost savings – to make them appealing to the very wide range of buyers who must transition as soon as possible, for the sake of the very planet.
It's not enough for our policymakers to focus on financing and infrastructure barriers to cleantech adoption. We also need a policy-level response to enshittification.
Ideally, every cleantech device would be designed so that it was impossible to enshittify – which would also make it impossible to brick:
Based on free software (best), or with source code escrowed with a trustee who must release the code if the company enters administration (distant second-best);
All patents in a royalty-free patent-pool (best); or in a trust that will release them into a royalty-free pool if the company enters administration (distant second-best);
No parts-pairing or other DRM permitted (best); or with parts-pairing utilities available to all parties on a reasonable and non-discriminatory basis (distant second-best);
All diagnostic and error codes in the public domain, with all codes in the clear within the device (best); or with decoding utilities available on demand to all comers on a reasonable and non-discriminatory basis (distant second-best).
There's an obvious business objection to this: it will reduce investment in innovative cleantech because investors will perceive these restrictions as limits on the expected profits of their portfolio companies. It's true: these measures are designed to prevent rent-extraction and other enshittificatory practices by cleantech companies, and to the extent that investors are counting on enshittification rents, this might prevent them from investing.
But that has to be balanced against the way that a general prohibition on enshittificatory practices will inspire consumer confidence in innovative and novel cleantech products, because buyers will know that their investments will be protected over the whole expected lifespan of the product, even if the startup goes bust (nearly every startup goes bust). These measures mean that a company with a cool product will have a much larger customer-base to sell to. Those additional sales more than offset the loss of expected revenue from cheating and screwing your customers by twiddling them to death.
There's also an obvious legal objection to this: creating these policies will require a huge amount of action from Congress and the executive branch, a whole whack of new rules and laws to make them happen, and each will attract court-challenges.
That's also true, though it shouldn't stop us from trying to get legal reforms. As a matter of public policy, it's terrible and fucked up that companies can enshittify the things we buy and leave us with no remedy.
However, we don't have to wait for legal reform to make this work. We can take a shortcut with procurement – the things governments buy with public money. The feds, the states and localities buy a lot of cleantech: for public facilities, for public housing, for public use. Prudent public policy dictates that governments should refuse to buy any tech unless it is designed to be enshittification-resistant.
This is an old and honorable tradition in policymaking. Lincoln insisted that the rifles he bought for the Union Army come with interoperable tooling and ammo, for obvious reasons. No one wants to be the Commander in Chief who shows up on the battlefield and says, "Sorry, boys, war's postponed, our sole supplier decided to stop making ammunition."
By creating a market for enshittification-proof cleantech, governments can ensure that the public always has the option of buying an EV that can't be bricked even if the maker goes bust, a heat-pump whose digital features can be replaced or maintained by a third party of your choosing, a solar controller that coordinates with the grid in ways that serve their owners – not the manufacturers' shareholders.
We're going to have to change a lot to survive the coming years. Sure, there's a lot of scary ways that things can go wrong, but there's plenty about our world that should change, and plenty of ways those changes could be for the better. It's not enough for policymakers to focus on ensuring that we can afford to buy whatever badly thought-through, extractive tech the biggest companies want to foist on us – we also need a focus on making cleantech fit for purpose, truly smart, reliable and resilient.
Support me this summer on the Clarion Write-A-Thon and help raise money for the Clarion Science Fiction and Fantasy Writers' Workshop!
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/06/26/unplanned-obsolescence/#better-micetraps
Image: 臺灣古寫真上色 (modified) https://commons.wikimedia.org/wiki/File:Raid_on_Kagi_City_1945.jpg
Grendelkhan (modified) https://commons.wikimedia.org/wiki/File:Ground_mounted_solar_panels.gk.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
#pluralistic#procurement#cleantech#evs#solar#solarpunk#policy#copyfight#copyright#felony contempt of business model#floss#free software#open source#oss#dmca 1201#interoperability#adversarial interoperability#solarization#electrification#enshittification#innovation#incumbency#climate#climate emergency
433 notes
·
View notes
Text
Tux Paint is 23 today!
29 notes
·
View notes
Text
the current status of FLOSS

108 notes
·
View notes
Text
Good news!

34 notes
·
View notes
Text
Did Winamp accidentally just provide proof that they were violating GPL for decades? Yes!
Have they potentially GPL poisoned their entire codebase as well as proprietary Dolby algorithms? Also yes!
Can you download this code today? You guessed it, yes!!!
Orphaned commits containing all of these issues after they tried to hide their crimes are waiting for you to download them!
#0954e03b3acbc11b6c90298598db6b6469568d72#gnuposting#retro tech#free software#winamp#gplposting#they also leaked the entire source to shoutcast server
86 notes
·
View notes
Text
I proudly present you : an in-development pixel art editor! Largely oriented at tilesets and charsets, Voidsprite supports custom-size grids alongside resize-canvas-by-grid-size and resize-canvas-by-grid-count, alongside numerous (and growing with future update) supported image formats. Please check it out, and leave any suggestions or feedback on the itch.io page! As it is a FOSS project, check it out on github also!
67 notes
·
View notes
Quote
Free software is an example of a Luddite technology: an innovation in the interest of the preservation of practitioners’ autonomy against the imposition of control over the labor process by capitalists. By “breaking” software copyright and challenging closed and proprietary business models connected to it, free and open-source software has helped preserve independent and craft-like working conditions for programmers for decades. In addition to launching important software projects, like the operating system Linux, the free software movement was instrumental in establishing nonproprietary coding languages as standard in the industry, which meant that skill development, rather than being controlled exclusively by large corporations, could be done through open community involvement.
Gavin Mueller, Breaking Things at Work
177 notes
·
View notes
Text
nobody asked but what i use for video editing is OpenShot Video Editor which is free and open source. i don't know how good it'd be for fancy stuff, but for my own level which is "cut clips from a TV show and rearrange them with a pop song over it all" it does the job and most importantly it is, as mentioned, free.
i'm using it with windows but it can also be got for mac and linux too.
48 notes
·
View notes
Text

join the praxis discord - sign up - github
#meme#memes#leftist memes#leftblr#open source#praxis#free software#typescript#nodejs#foss#reactjs#design#software#programming
2K notes
·
View notes
Text
/* Filename: Discipline.scala */ for (i <- 1 to 1000) { println( f"$i%4d: I will not use code to cheat." ); } // >:3
#computer programming#open source software#software#computer science#development#free software#software development#software developers#programming#scala#scala programming
50 notes
·
View notes
Text
"Open" "AI" isn’t

Tomorrow (19 Aug), I'm appearing at the San Diego Union-Tribune Festival of Books. I'm on a 2:30PM panel called "Return From Retirement," followed by a signing:
https://www.sandiegouniontribune.com/festivalofbooks

The crybabies who freak out about The Communist Manifesto appearing on university curriculum clearly never read it – chapter one is basically a long hymn to capitalism's flexibility and inventiveness, its ability to change form and adapt itself to everything the world throws at it and come out on top:
https://www.marxists.org/archive/marx/works/1848/communist-manifesto/ch01.htm#007
Today, leftists signal this protean capacity of capital with the -washing suffix: greenwashing, genderwashing, queerwashing, wokewashing – all the ways capital cloaks itself in liberatory, progressive values, while still serving as a force for extraction, exploitation, and political corruption.
A smart capitalist is someone who, sensing the outrage at a world run by 150 old white guys in boardrooms, proposes replacing half of them with women, queers, and people of color. This is a superficial maneuver, sure, but it's an incredibly effective one.
In "Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI," a new working paper, Meredith Whittaker, David Gray Widder and Sarah B Myers document a new kind of -washing: openwashing:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4543807
Openwashing is the trick that large "AI" companies use to evade regulation and neutralizing critics, by casting themselves as forces of ethical capitalism, committed to the virtue of openness. No one should be surprised to learn that the products of the "open" wing of an industry whose products are neither "artificial," nor "intelligent," are also not "open." Every word AI huxters say is a lie; including "and," and "the."
So what work does the "open" in "open AI" do? "Open" here is supposed to invoke the "open" in "open source," a movement that emphasizes a software development methodology that promotes code transparency, reusability and extensibility, which are three important virtues.
But "open source" itself is an offshoot of a more foundational movement, the Free Software movement, whose goal is to promote freedom, and whose method is openness. The point of software freedom was technological self-determination, the right of technology users to decide not just what their technology does, but who it does it to and who it does it for:
https://locusmag.com/2022/01/cory-doctorow-science-fiction-is-a-luddite-literature/
The open source split from free software was ostensibly driven by the need to reassure investors and businesspeople so they would join the movement. The "free" in free software is (deliberately) ambiguous, a bit of wordplay that sometimes misleads people into thinking it means "Free as in Beer" when really it means "Free as in Speech" (in Romance languages, these distinctions are captured by translating "free" as "libre" rather than "gratis").
The idea behind open source was to rebrand free software in a less ambiguous – and more instrumental – package that stressed cost-savings and software quality, as well as "ecosystem benefits" from a co-operative form of development that recruited tinkerers, independents, and rivals to contribute to a robust infrastructural commons.
But "open" doesn't merely resolve the linguistic ambiguity of libre vs gratis – it does so by removing the "liberty" from "libre," the "freedom" from "free." "Open" changes the pole-star that movement participants follow as they set their course. Rather than asking "Which course of action makes us more free?" they ask, "Which course of action makes our software better?"
Thus, by dribs and drabs, the freedom leeches out of openness. Today's tech giants have mobilized "open" to create a two-tier system: the largest tech firms enjoy broad freedom themselves – they alone get to decide how their software stack is configured. But for all of us who rely on that (increasingly unavoidable) software stack, all we have is "open": the ability to peer inside that software and see how it works, and perhaps suggest improvements to it:
https://www.youtube.com/watch?v=vBknF2yUZZ8
In the Big Tech internet, it's freedom for them, openness for us. "Openness" – transparency, reusability and extensibility – is valuable, but it shouldn't be mistaken for technological self-determination. As the tech sector becomes ever-more concentrated, the limits of openness become more apparent.
But even by those standards, the openness of "open AI" is thin gruel indeed (that goes triple for the company that calls itself "OpenAI," which is a particularly egregious openwasher).
The paper's authors start by suggesting that the "open" in "open AI" is meant to imply that an "open AI" can be scratch-built by competitors (or even hobbyists), but that this isn't true. Not only is the material that "open AI" companies publish insufficient for reproducing their products, even if those gaps were plugged, the resource burden required to do so is so intense that only the largest companies could do so.
Beyond this, the "open" parts of "open AI" are insufficient for achieving the other claimed benefits of "open AI": they don't promote auditing, or safety, or competition. Indeed, they often cut against these goals.
"Open AI" is a wordgame that exploits the malleability of "open," but also the ambiguity of the term "AI": "a grab bag of approaches, not… a technical term of art, but more … marketing and a signifier of aspirations." Hitching this vague term to "open" creates all kinds of bait-and-switch opportunities.
That's how you get Meta claiming that LLaMa2 is "open source," despite being licensed in a way that is absolutely incompatible with any widely accepted definition of the term:
https://blog.opensource.org/metas-llama-2-license-is-not-open-source/
LLaMa-2 is a particularly egregious openwashing example, but there are plenty of other ways that "open" is misleadingly applied to AI: sometimes it means you can see the source code, sometimes that you can see the training data, and sometimes that you can tune a model, all to different degrees, alone and in combination.
But even the most "open" systems can't be independently replicated, due to raw computing requirements. This isn't the fault of the AI industry – the computational intensity is a fact, not a choice – but when the AI industry claims that "open" will "democratize" AI, they are hiding the ball. People who hear these "democratization" claims (especially policymakers) are thinking about entrepreneurial kids in garages, but unless these kids have access to multi-billion-dollar data centers, they can't be "disruptors" who topple tech giants with cool new ideas. At best, they can hope to pay rent to those giants for access to their compute grids, in order to create products and services at the margin that rely on existing products, rather than displacing them.
The "open" story, with its claims of democratization, is an especially important one in the context of regulation. In Europe, where a variety of AI regulations have been proposed, the AI industry has co-opted the open source movement's hard-won narrative battles about the harms of ill-considered regulation.
For open source (and free software) advocates, many tech regulations aimed at taming large, abusive companies – such as requirements to surveil and control users to extinguish toxic behavior – wreak collateral damage on the free, open, user-centric systems that we see as superior alternatives to Big Tech. This leads to the paradoxical effect of passing regulation to "punish" Big Tech that end up simply shaving an infinitesimal percentage off the giants' profits, while destroying the small co-ops, nonprofits and startups before they can grow to be a viable alternative.
The years-long fight to get regulators to understand this risk has been waged by principled actors working for subsistence nonprofit wages or for free, and now the AI industry is capitalizing on lawmakers' hard-won consideration for collateral damage by claiming to be "open AI" and thus vulnerable to overbroad regulation.
But the "open" projects that lawmakers have been coached to value are precious because they deliver a level playing field, competition, innovation and democratization – all things that "open AI" fails to deliver. The regulations the AI industry is fighting also don't necessarily implicate the speech implications that are core to protecting free software:
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech
Just think about LLaMa-2. You can download it for free, along with the model weights it relies on – but not detailed specs for the data that was used in its training. And the source-code is licensed under a homebrewed license cooked up by Meta's lawyers, a license that only glancingly resembles anything from the Open Source Definition:
https://opensource.org/osd/
Core to Big Tech companies' "open AI" offerings are tools, like Meta's PyTorch and Google's TensorFlow. These tools are indeed "open source," licensed under real OSS terms. But they are designed and maintained by the companies that sponsor them, and optimize for the proprietary back-ends each company offers in its own cloud. When programmers train themselves to develop in these environments, they are gaining expertise in adding value to a monopolist's ecosystem, locking themselves in with their own expertise. This a classic example of software freedom for tech giants and open source for the rest of us.
One way to understand how "open" can produce a lock-in that "free" might prevent is to think of Android: Android is an open platform in the sense that its sourcecode is freely licensed, but the existence of Android doesn't make it any easier to challenge the mobile OS duopoly with a new mobile OS; nor does it make it easier to switch from Android to iOS and vice versa.
Another example: MongoDB, a free/open database tool that was adopted by Amazon, which subsequently forked the codebase and tuning it to work on their proprietary cloud infrastructure.
The value of open tooling as a stickytrap for creating a pool of developers who end up as sharecroppers who are glued to a specific company's closed infrastructure is well-understood and openly acknowledged by "open AI" companies. Zuckerberg boasts about how PyTorch ropes developers into Meta's stack, "when there are opportunities to make integrations with products, [so] it’s much easier to make sure that developers and other folks are compatible with the things that we need in the way that our systems work."
Tooling is a relatively obscure issue, primarily debated by developers. A much broader debate has raged over training data – how it is acquired, labeled, sorted and used. Many of the biggest "open AI" companies are totally opaque when it comes to training data. Google and OpenAI won't even say how many pieces of data went into their models' training – let alone which data they used.
Other "open AI" companies use publicly available datasets like the Pile and CommonCrawl. But you can't replicate their models by shoveling these datasets into an algorithm. Each one has to be groomed – labeled, sorted, de-duplicated, and otherwise filtered. Many "open" models merge these datasets with other, proprietary sets, in varying (and secret) proportions.
Quality filtering and labeling for training data is incredibly expensive and labor-intensive, and involves some of the most exploitative and traumatizing clickwork in the world, as poorly paid workers in the Global South make pennies for reviewing data that includes graphic violence, rape, and gore.
Not only is the product of this "data pipeline" kept a secret by "open" companies, the very nature of the pipeline is likewise cloaked in mystery, in order to obscure the exploitative labor relations it embodies (the joke that "AI" stands for "absent Indians" comes out of the South Asian clickwork industry).
The most common "open" in "open AI" is a model that arrives built and trained, which is "open" in the sense that end-users can "fine-tune" it – usually while running it on the manufacturer's own proprietary cloud hardware, under that company's supervision and surveillance. These tunable models are undocumented blobs, not the rigorously peer-reviewed transparent tools celebrated by the open source movement.
If "open" was a way to transform "free software" from an ethical proposition to an efficient methodology for developing high-quality software; then "open AI" is a way to transform "open source" into a rent-extracting black box.
Some "open AI" has slipped out of the corporate silo. Meta's LLaMa was leaked by early testers, republished on 4chan, and is now in the wild. Some exciting stuff has emerged from this, but despite this work happening outside of Meta's control, it is not without benefits to Meta. As an infamous leaked Google memo explains:
Paradoxically, the one clear winner in all of this is Meta. Because the leaked model was theirs, they have effectively garnered an entire planet's worth of free labor. Since most open source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.
https://www.searchenginejournal.com/leaked-google-memo-admits-defeat-by-open-source-ai/486290/
Thus, "open AI" is best understood as "as free product development" for large, well-capitalized AI companies, conducted by tinkerers who will not be able to escape these giants' proprietary compute silos and opaque training corpuses, and whose work product is guaranteed to be compatible with the giants' own systems.
The instrumental story about the virtues of "open" often invoke auditability: the fact that anyone can look at the source code makes it easier for bugs to be identified. But as open source projects have learned the hard way, the fact that anyone can audit your widely used, high-stakes code doesn't mean that anyone will.
The Heartbleed vulnerability in OpenSSL was a wake-up call for the open source movement – a bug that endangered every secure webserver connection in the world, which had hidden in plain sight for years. The result was an admirable and successful effort to build institutions whose job it is to actually make use of open source transparency to conduct regular, deep, systemic audits.
In other words, "open" is a necessary, but insufficient, precondition for auditing. But when the "open AI" movement touts its "safety" thanks to its "auditability," it fails to describe any steps it is taking to replicate these auditing institutions – how they'll be constituted, funded and directed. The story starts and ends with "transparency" and then makes the unjustifiable leap to "safety," without any intermediate steps about how the one will turn into the other.
It's a Magic Underpants Gnome story, in other words:
Step One: Transparency
Step Two: ??
Step Three: Safety
https://www.youtube.com/watch?v=a5ih_TQWqCA
Meanwhile, OpenAI itself has gone on record as objecting to "burdensome mechanisms like licenses or audits" as an impediment to "innovation" – all the while arguing that these "burdensome mechanisms" should be mandatory for rival offerings that are more advanced than its own. To call this a "transparent ruse" is to do violence to good, hardworking transparent ruses all the world over:
https://openai.com/blog/governance-of-superintelligence
Some "open AI" is much more open than the industry dominating offerings. There's EleutherAI, a donor-supported nonprofit whose model comes with documentation and code, licensed Apache 2.0. There are also some smaller academic offerings: Vicuna (UCSD/CMU/Berkeley); Koala (Berkeley) and Alpaca (Stanford).
These are indeed more open (though Alpaca – which ran on a laptop – had to be withdrawn because it "hallucinated" so profusely). But to the extent that the "open AI" movement invokes (or cares about) these projects, it is in order to brandish them before hostile policymakers and say, "Won't someone please think of the academics?" These are the poster children for proposals like exempting AI from antitrust enforcement, but they're not significant players in the "open AI" industry, nor are they likely to be for so long as the largest companies are running the show:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4493900

I'm kickstarting the audiobook for "The Internet Con: How To Seize the Means of Computation," a Big Tech disassembly manual to disenshittify the web and make a new, good internet to succeed the old, good internet. It's a DRM-free book, which means Audible won't carry it, so this crowdfunder is essential. Back now to get the audio, Verso hardcover and ebook:
http://seizethemeansofcomputation.org
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/08/18/openwashing/#you-keep-using-that-word-i-do-not-think-it-means-what-you-think-it-means
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#llama-2#meta#openwashing#floss#free software#open ai#open source#osi#open source initiative#osd#open source definition#code is speech
253 notes
·
View notes
Text
Some fractal-drawing Magic tools for Tux Paint.
32 notes
·
View notes