#ModelEvaluation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
Model Evaluation on Amazon Bedrock Performance Analysis

Model Evaluation on Amazon Bedrock
IBM demonstrated the Amazon Bedrock model evaluation feature at AWS re:Invent 2023, and it is now freely accessible. This new feature allows you to choose the foundation model that produces the best results for your specific use case, which makes it easier for you to integrate generative AI into your application. Model assessments are important at every stage of development, as my colleague Antje noted in her piece (Evaluate, compare, and choose the best foundation models for your use case in Amazon Bedrock).
You now have evaluation tools at your disposal as a developer to create generative applications using artificial intelligence (AI). One way to get started is by trying out several models in a playground setting. Include automatic model evaluations to accelerate iterations. Then, you can include human evaluations to help assure quality when you get ready for an initial launch or limited release.
They’ll get to those shortly. During the preview, we got a tonne of fantastic and helpful input, which AWS used to refine the features of this new capability in time for today’s launch. Here are the fundamental steps as a quick reminder (for a thorough walk-through, see Antje’s post).
Make a Model Assessment Work – Choose a task type, an evaluation technique (human or automated), a foundation model from the list of options, and evaluation metrics. For an automated assessment, you can select toxicity, robustness, and accuracy; for a human evaluation, you can select any desired metrics (like friendliness, style, and brand voice conformance, for example). You can employ an AWS-managed team or your own work team if you decide to do a human evaluation. Together with a custom task type (not shown), there are four pre-built task kinds.
Once the job type has been selected, you may specify the metrics and datasets to be used in assessing the model’s performance. If you choose Text classification, for instance, you can assess robustness and/or accuracy in relation to either an internal or your own dataset: As seen above, you have the option of creating a new dataset in JSON Lines (JSONL) format or using one that is already built in.
Every submission needs to have a prompt, and it may also have a category. For all human assessment settings and for some combinations of job types and metrics for automatic evaluation, the reference response is optional:
You can use product descriptions, sales literature, or customer support queries that are unique to your company and use case to construct a dataset (or consult your local subject matter experts). Real Toxicity, BOLD, TREX, WikiText-2, Gigaword, BoolQ, Natural Questions, Trivia QA, and Women’s Ecommerce Clothing Reviews are among of the pre-installed datasets. These datasets can be selected as needed because they are made to evaluate particular kinds of activities and metrics.
Run Model Evaluation Job: Begin the process and give it some time to finish. The status of every model evaluation job that you have is accessible through the console and the newly added GetEvaluationJob API function.
Obtain and Examine the Evaluation Report Obtain the report and evaluate the model’s performance using the previously chosen metrics. Once more, for a thorough examination of an example report, see Antje’s post.
Model Evaluation on Amazon Bedrock Features
Fresh Features for GA
Now that we have cleared all of that up, let’s examine the features that were introduced in advance of today’s launch:
Better Job Management: Using the console or the recently introduced model evaluation API, you may now halt a running job.
Model assessment API: Programmatic creation and management of model assessment tasks is now possible. There are the following features available:
CreateEvaluationJob: This function creates and executes a model evaluation job with the parameters—an evaluationConfig and an inferenceConfig���specified in the API request.
ListEvaluationJobs: This is a list of model evaluation jobs that may be filtered and sorted according to the evaluation job name, status, and creation time.
To retrieve a model evaluation job’s properties, including its status (InProgress, Completed, Failed, Stopping, or Stopped), use the GetEvaluationJob function. The evaluation’s findings will be saved at the S3 URI mentioned in the outputDataConfig field that was provided to CreateEvaluationJob when the job is finished.
StopEvaluationJob: Terminate an ongoing task. A job that has been interrupted cannot be continued; to run it again, a new one must be created.
During the preview, one of the most requested features was this model evaluation API. It can be used to conduct large-scale evaluations, possibly as a component of your application’s development or testing schedule.
Enhanced Security – Your evaluation task data can now be encrypted using customer-managed KMS keys (if you do not select this option, AWS will use their own key for encryption):image credited to aws
Access to More Models – You now have access to Claude 2.1:image credited to AWS
Once a model has been chosen, you can configure the inference settings that will be applied to the model evaluation task
Important Information
Here are some interesting facts about this just added Amazon Bedrock feature:
Pricing: There is no extra fee for algorithmically generated scores; you only pay for the conclusions made during the model evaluation. A human worker submits an evaluation of a single prompt and its accompanying inference replies in the human evaluation user interface. If you employ human-based evaluation with your own team, you pay for the inferences and $0.21 for each completed task. Evaluations carried out by an AWS managed work team are priced according to the metrics, task categories, and dataset that are relevant to your assessment.
Read more on govindhtech.com
#Claude#AI#ArtificialIntelligence#ModelEvaluation#GenerativeAI#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
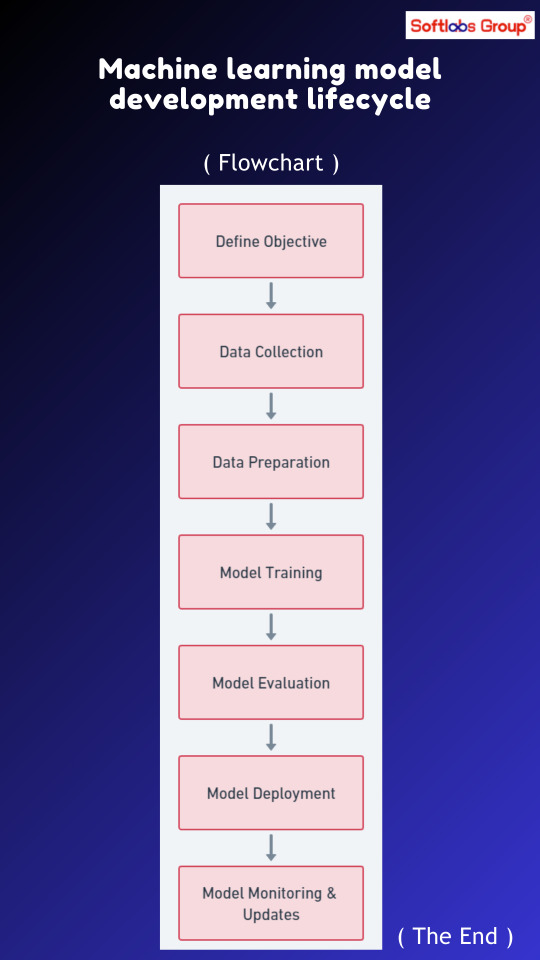
Embark on the journey of Machine Learning Model Development with our detailed flowchart. Explore the phases from data collection to deployment, including data preprocessing, model training, evaluation, and optimization. Simplify your understanding of this comprehensive process from inception to implementation. Perfect for both beginners and experienced practitioners. Stay tuned to Softlabs Group for more insights into the evolving ML landscape!
0 notes
Text
youtube
0 notes
Text
Model Evaluation: Mastering Performance Metrics and Selection in Machine Learning
Dive into the world of model evaluation in machine learning! Discover how to optimize logistic regression, compare ensemble techniques, and select the best model using key performance metrics. #MachineLearning #ModelEvaluation #DataScience
Model evaluation is a crucial step in the machine learning pipeline. In this comprehensive guide, we’ll explore how to master performance metrics and make informed model selections to ensure your machine learning projects succeed. The Importance of Post-Optimization Model Evaluation When it comes to machine learning, model evaluation goes beyond simple accuracy comparisons. To truly understand…
0 notes
Photo
這是我在2022年整理的文章「機器學習模型真的準嗎?從虛無假設檢定來檢驗模型成效」,現在在這個blog備份一下。 ---- # 前言 / Background 隨著人工智慧的普及與日常化,利用機器學習演算法建立模型,並以模型進行預測,已經被很多人融入日常工作之中。 建立模型本身不難,建立完成後我們也會用正確率或F-measure來評估模型,讓我們能掌握模型的預測能力高低。 一個機器學習模型是否可靠,我們通常會用各種評估指��來描述它。 最常見也是最基本的評估指標就是「正確率」(accuracy)。 將建立好的機器學習模型拿去預測測試集(test set),如果預測正確的比例是70%,那麼就會得到「正確率70%」的模型評估結果。 當然,如果能夠100%正確,那的確是再好不過的事情,但大多時候機器學習模型的預測率都只能做到儘可能準確,100%正確率反而有點像是過擬合的結果。 然而,很多人會對「正確率70%」這樣的結果表示疑惑。 「這個模型準嗎?該不會是剛好它猜中而已吧?」事實上,還真的會有與其用模型來進行預測的結果,甚至不如用佔比最高的類別來瞎猜的情況。 證實機器學習模型是否有比瞎猜還有準確,其實是有科學方法可以用來證實,那就是推論統計中的虛無假設檢定(Null-Hypothesis Statistical Testing)。 也許有同學已經知道科學實驗或問卷調查會用到虛無假設檢定,但在機器學習評估模型上用虛無假設檢定來評估成效的做法,可能就不是這麼廣為人知了。 這篇文章將基於Japkowicz跟Shah提出的交互驗證t檢定(cross-validated t test),用有別以往的方式來評估機器學習的模型。 文章最後也會介紹使用交互驗證t檢定的限制,以及其他用推論統計評估機器學習模型的方法。 # 你所知道的機器學習模型預測正確率 / How to evaluate a machine learning model?。 在機器學習與資料探勘百科全書(Sammut & Webb, 2017)的定義中,「正確率」的意思是「模型的預測與被建模的資料實際符合的程度」。 正確率通常以百分比來呈現,介於0%到100%之間。 0%表示模型完全預測錯誤,100%表示模型預測完全正確。 ---- 繼續閱讀 ⇨ 機器學習模型真的準嗎?從虛無假設檢定來檢驗模型成效 / Applying Null-Hypothesis Statistical Testing on Machine Learning Model Evaluation https://blog.pulipuli.info/2023/03/blog-post_28.html
0 notes