#ModelTraining
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Battling Bakeries in an AI Arms Race! Inside the High-Tech Doughnut Feud

#AI#TechSavvy#commercialwar#AIAccelerated#EdgeAnalytic#CloudComputing#DeepLearning#NeuralNetwork#AICardUpgradeCycle#FutureProof#ComputerVision#ModelTraining#artificialintelligence#ai#Supergirl#Batman#DC Official#Home of DCU#Kara Zor-El#Superman#Lois Lane#Clark Kent#Jimmy Olsen#My Adventures With Superman
2 notes
·
View notes
Text


#PyTorch#DeepLearning#PyTorchBootcamp#MachineLearning#NeuralNetworks#ComputerVision#AITraining#LearnPyTorch#PyTorchTutorial#MLBootcamp#TensorOperations#AIProjects#ModelTraining#BISPTraining#OnlineCourses#DataScience#PythonForAI#Arti
0 notes
Text

Scaling AI Workloads with Auto Bot Solutions Distributed Training Module
As artificial intelligence models grow in complexity and size, the demand for scalable and efficient training infrastructures becomes paramount. Auto Bot Solutions addresses this need with its AI Distributed Training Module, a pivotal component of the Generalized Omni-dimensional Development (G.O.D.) Framework. This module empowers developers to train complex AI models efficiently across multiple compute nodes, ensuring high performance and optimal resource utilization.
Key Features
Scalable Model Training: Seamlessly distribute training workloads across multiple nodes for faster and more efficient results.
Resource Optimization: Effectively utilize computational resources by balancing workloads across nodes.
Operational Simplicity: Easy to use interface for simulating training scenarios and monitoring progress with intuitive logging.
Adaptability: Supports various data sizes and node configurations, suitable for small to large-scale workflows.
Robust Architecture: Implements a master-worker setup with support for frameworks like PyTorch and TensorFlow.
Dynamic Scaling: Allows on-demand scaling of nodes to match computational needs.
Checkpointing: Enables saving intermediate states for recovery in case of failures.
Integration with the G.O.D. Framework
The G.O.D. Framework, inspired by the Hindu Trimurti, comprises three core components: Generator, Operator, and Destroyer. The AI Distributed Training Module aligns with the Operator aspect, executing tasks efficiently and autonomously. This integration ensures a balanced approach to building autonomous AI systems, addressing challenges such as biases, ethical considerations, transparency, security, and control.
Explore the Module
Overview & Features
Module Documentation
Technical Wiki & Usage Examples
Source Code on GitHub
By integrating the AI Distributed Training Module into your machine learning workflows, you can achieve scalability, efficiency, and robustness, essential for developing cutting-edge AI solutions.
#AI#MachineLearning#DistributedTraining#ScalableAI#AutoBotSolutions#GODFramework#DeepLearning#AIInfrastructure#PyTorch#TensorFlow#ModelTraining#AIDevelopment#ArtificialIntelligence#EdgeComputing#DataScience#AIEngineering#TechInnovation#Automation
1 note
·
View note
Text
International Modeling Agency In Delhi Build Your Career with Rj Talents
RJ Talents Pvt. Ltd. is a leading international modeling agency in Delhi and Mumbai, helping aspiring models build successful careers in the glamour industry. From advertisements to films, TV, fashion, and events, we provide training, grooming, and opportunities to turn fresh faces into celebrities. Our expert guidance ensures models achieve success in their careers.
Visit Us: rjtalents.com/international-modeling-agency-in-delhi Contact Us : 90046 72311

#internationalmodelingagency#modelingagencydelhi#fashionmodles#modelingcareer#glamourindustry#advertisingmodels#tvandfilmmodels#celebritymanagement#modeltraining#fashionindustry
0 notes
Link
#wupples#wuppleshome#modeltrains#modeltrain#modeltraining#modeltrainer#modeltrainrailway#modeltrainphotograps#modeltrainstagram#modeltrainhobby#train
0 notes
Text
IBM Research Data Loader Helps Open-source AI Model Training

IBM Research data loader improves open-source community’s access to AI models for training.
Training AI models More quickly than ever
IBM showcased new advances in high-throughput AI model training at PyTorch 2024, along with a state-of-the-art data loader, all geared toward empowering the open-source AI community.
IBM Research experts are contributing to the open-source model training framework at this year’s PyTorch Conference. These contributions include major advances in large language model training throughput as well as a data loader that can handle enormous amounts of data with ease.
It must constantly enhance the effectiveness and resilience of the cloud infrastructure supporting LLMs’ training, tuning, and inference to supply their ever-increasing capabilities at a reasonable cost. The open-source PyTorch framework and ecosystem have greatly aided the AI revolution that is about to change its lives. IBM joined the PyTorch Foundation last year and is still bringing new tools and techniques to the AI community because it recognizes that it cannot happen alone.
In addition to IBM’s earlier contributions, these new tools are strengthening PyTorch’s capacity to satisfy the community’s ever-expanding demands, be they related to more cost-effective checkpointing, faster data loading, or more effective use of GPUs.
An exceptional data loader for foundation model training and tuning
Using a high-throughput data loader, PyTorch users can now easily distribute LLM training workloads among computers and even adjust their allocations in-between jobs. In order to prevent work duplication during model training, it also enables developers to save checkpoints more effectively. And all of it is attributable to a group of researchers who were only creating the instruments they required to complete a task.
When you wish to rerun your training run with a new blend of sub-datasets to alter model weights, or when you have all of your raw text data and want to use a different tokenizer or maximum sequence length, the resulting tool is well-suited for LLM training in research contexts. With the help of the data loader, you can tell your dataset what you want to do on the fly rather than having to reconstruct it each time you want to make modifications of this kind.
You can adjust the job even halfway through, for example, by increasing or decreasing the number of GPUs in response to changes in your resource quota. The data loader makes sure that data that has already been viewed won’t be viewed again.
Increasing the throughput of training
Bottlenecks occur because everything goes at the speed of the slowest item when it comes to model training at scale. The efficiency with which the GPU is being used is frequently the bottleneck in AI tasks.
Fully sharded data parallel (FSDP), which uniformly distributes big training datasets across numerous processors to prevent any one machine from becoming overburdened, is one component of this method. It has been demonstrated that this distribution greatly increases the speed and efficiency of model training and tuning while enabling faster AI training with fewer GPUs.
This development progresses concurrently with the data loader since the team discovered ways to use GPUs more effectively while they worked with FSDP and torch.compile to optimize GPU utilization. Consequently, data loaders rather than GPUs became the bottleneck.
Next up
Although FP8 isn’t yet generally accessible for developers to use, Ganti notes that the team is working on projects that will highlight its capabilities. In related work, they’re optimizing model tweaking and training on IBM’s artificial intelligence unit (AIU) with torch.compile.
Triton, Nvidia’s open-source platform for deploying and executing AI, will also be a topic of discussion for Ganti, Wertheimer, and other colleagues. Triton allows programmers to write Python code that is then translated into the native programming language of the hardware Intel or Nvidia, for example, to accelerate computation. Although Triton is currently ten to fifteen percent slower than CUDA, the standard software framework for using Nvidia GPUs, the researchers have just completed the first end-to-end CUDA-free inferencing with Triton. They believe Triton will close this gap and significantly optimize training when this initiative picks up steam.
The starting point of the study
IBM Research’s Davis Wertheimer outlines a few difficulties that may arise during extensive training: It’s possible to use an 80/20 rule to large-scale training. In the published research, algorithmic tradeoffs between GPU memory and compute and communication make up 80% of the work. However, because the pipeline moves at the pace of the narrowest bottleneck, you may expect a very long tail of all these other practical concerns when you really try to build something 80 percent of the time.
The IBM team was running into problems when they constructed their training platform. Wertheimer notes, “As we become more adept at using our GPUs, the data loader is increasingly often the bottleneck.”
Important characteristics of the data loader
Stateful and checkpointable: If your data loader state is saved whenever you save a model, and both the model state and data loader states need to be recovered at the same time whenever you recover from a checkpoint.”
Checkpoint auto-rescaling: During prolonged training sessions, the data loader automatically adapts to workload variations. There are a lot of reasons why you might have to rescale your workload in the middle. Training could easily take weeks or months.”
Effective data streaming: There is no build overhead for shuffling data because the system supports data streaming.
Asynchronous distributed operation: The data loader is non-blocking. The data loader states to be saved and then distributed in a way that requires no communication at all.”
Dynamic data mixing: This feature is helpful for changing training requirements since it allows the data loader to adjust to various data mixing ratios.
Effective global shuffling: As data accumulates, shuffling remains effective since the tool handles memory bottlenecks when working with huge datasets.
Native, modular, and feature-rich PyTorch: The data loader is built to be flexible and scalable, making it ready for future expansion. “What if we have to deal with thirty trillion, fifty trillion, or one hundred trillion tokens next year?” “it needs to build the data loader so it can survive not only today but also tomorrow because the world is changing quickly.”
Actual results
The IBM Research team ran hundreds of small and big workloads over several months to rigorously test their data loader. They saw code numbers that were steady and fluid. Furthermore, the data loader as a whole runs non-blocking and asynchronously.
Read more on govindhtech.com
#IBMResearch#DataLoaderHelp#OpensourceAI#ModelTraining#AImodel#IBM#dataloader#Triton#IBMartificialintelligence#startingpoint#ibm#technology#technews#news#govindhtech
0 notes
Text
🚀 Unlock the Power of AI with Parameter-efficient Fine-tuning (PEFT)! 🚀
PEFT is revolutionizing how we train models by refining only a subset of parameters, making the process more efficient and cost-effective. 🌟 With benefits like reduced computational resources, faster training times, and improved performance, it’s a game-changer for AI development. 🧠💡 Techniques like adapters, LoRA, and prompt tuning are leading the charge. Dive into this transformative approach and stay ahead in AI innovation!
🔗 Read more to explore how PEFT can elevate your projects!
0 notes
Text
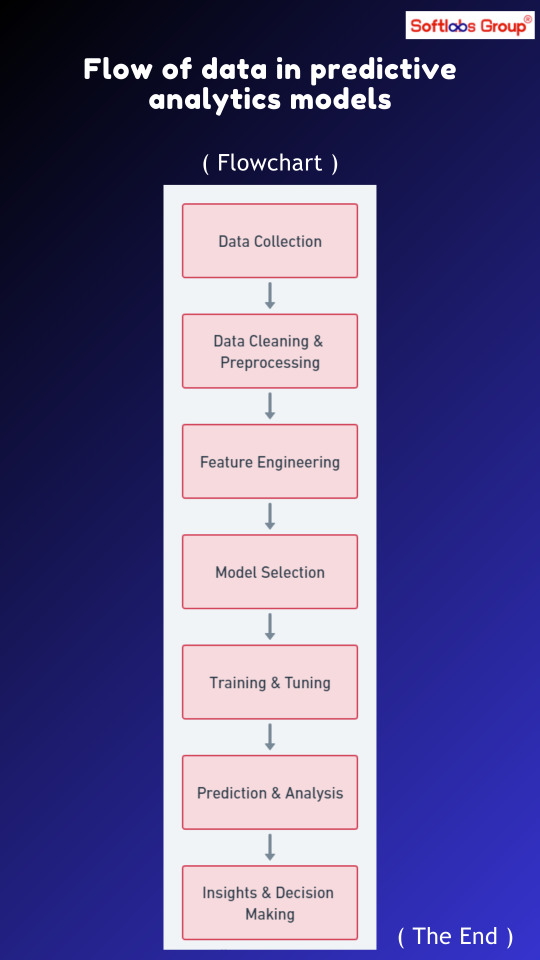
Visualize the flow of data in predictive analytics models with our comprehensive diagram. Follow steps including data collection, preprocessing, feature engineering, model training, validation, and prediction. Simplify the process of harnessing data for accurate predictions and decision-making. Ideal for data scientists, analysts, and professionals in predictive analytics. Stay updated with Softlabs Group for more insights into data-driven solutions!
0 notes
Text

Which of the following is a hyperparameter in a machine learning model?
a. Learning rate b. Feature importance c. Training data d. Prediction output
#MachineLearning#MachineLearningquiz#MachineLearningPoll#followme#followforfollow#instadaily#follow4follow#like4like#letsconnect#scriptzol#MachineLearningBasics#HyperparameterTuning#AIInnovation#DataScience101#MLAlgorithm#TechInsights#AlgorithmOptimization#ModelTraining#AIKnowledge#DataDrivenDecisions
0 notes
Text



Fulfilled my dream from when I was 10 and got a BR442 yippeee
#trains#railway#model trains#deutsche bahn#model railroad#model railway#miniature#h0scale#modellbahn#modeltrains
68 notes
·
View notes
Text










This is of a model train. This is located in Hudson Gardens in Littleton Colorado.
#Photography#Nature#Miniature#Garden#ModelRailroad#ModelTrain#RailroadPhotography#TrainSpotting#UrbanGardening#MissedMileMarkers
16 notes
·
View notes
Text
Custom Flight Case for Train Model | Safe & Secure Transport
We made a custom flight case for a client’s train model to keep it safe during transport. The size is 1040mm x 390mm x 375mm, designed to fit the model perfectly and client was highly satisfied with the final result. Watch the video to see how it turned out. Contact us if you need a custom flight case for your equipment!
Call to Action: Like, share, and comment to discover more of our innovative projects!
Connect With Us: 📞 Contact: +91 81491 86780 📧 Email: [email protected] 🌐 Website: www.flightscase.in
#equipmenttransport#customflightcase#trainmodel#modelequipment#safetransport#flightcasedesign#heavydutycase#modeltrain#custommade#heavyequipment#transportation#suitcase#travelgear#customcase#luggageprotection#travelaccessories
2 notes
·
View notes
Text

A Beginner’s Guide to Model Trains and Toy Trains
This beginner's guide breaks down the differences between toy trains and model trains. Toy trains are ideal for kids and imaginative play, while model trains offer a realistic, creative hobby for enthusiasts. Learn about scales, starter kits, and how to begin your train journey, whether for fun or a long-term passion.
#toytrains#modeltrains#trains#trainsets#railroad#trainlayout#traincollector#modelrailroad#hobbytrains#trainfans
2 notes
·
View notes
Text
Tiny Train Miniature Model, Big Details | Maadhu Creatives
We create high-quality, detailed miniature train models tailored to your specifications. Watch the short video to see the intricate details! If you like it, don't forget to like and share!
Connect with Us: 📞 Contact Number: +919664883746 📧 Email: [email protected] 🌐 Website: maadhucreatives.com
2 notes
·
View notes
Link
#wupples#wuppleshome#modeltrains#modeltrain#modeltraining#modeltrainer#modeltrainrailway#modeltrainphotograps#modeltrainstagram#modeltrainhobby#train
0 notes
Text
Shazam! Rides the Rails

OK, this may be silly, but... I am absolutely obsessed with the mere existence of this Shazam! HO scale model train. My son loves trains more than he loves his momma and Twix bars, and this one would look great on his track. Am I going to buy it and try to convince my wife it's for a kid who doesn't know anything at all about Billy Batson and the Marvel Family? I mean... Probably...? (This story comes from my newsletter, which goes out monthly. For more stuff like this, and to get it first, sign up here!) Read the full article
10 notes
·
View notes