#MySQL DROP INDEX Statement
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
SQL Programming Made Easy: A Comprehensive Tutorial for Beginners
Are you new to the world of databases and programming? Don't worry; SQL (Structured Query Language) might sound intimidating at first, but it's actually quite straightforward once you get the hang of it. In this comprehensive tutorial, we'll walk you through everything you need to know to get started with SQL programming. By the end, you'll be equipped with the foundational knowledge to manage and query databases like a pro.
1. Understanding Databases
Before diving into SQL, let's understand what databases are. Think of a database as a structured collection of data. It could be anything from a simple list of contacts to a complex inventory management system. Databases organize data into tables, which consist of rows and columns. Each row represents a record, while each column represents a specific attribute or field.
2. What is SQL?
SQL (Structured Query Language) is a specialized language used to interact with databases. It allows you to perform various operations such as retrieving data, inserting new records, updating existing records, and deleting unnecessary data. SQL is not specific to any particular database management system (DBMS); it's a standard language that is widely used across different platforms like MySQL, PostgreSQL, Oracle, and SQL Server.
3. Basic SQL Commands
Let's start with some basic SQL commands:
SELECT: This command is used to retrieve data from a database.
INSERT INTO: It adds new records to a table.
UPDATE: It modifies existing records in a table.
DELETE: It removes records from a table.
CREATE TABLE: It creates a new table in the database.
DROP TABLE: It deletes an existing table.
4. Retrieving Data with SELECT
The SELECT statement is one of the most commonly used SQL commands. It allows you to retrieve data from one or more tables based on specified criteria. Here's a simple example:
sql
Copy code
SELECT column1, column2 FROM table_name WHERE condition;
This query selects specific columns from a table based on a certain condition.
5. Filtering Data with WHERE
The WHERE clause is used to filter records based on specified criteria. For example:
sql
Copy code
SELECT * FROM employees WHERE department = 'IT';
This query selects all records from the "employees" table where the department is 'IT'.
6. Inserting Data with INSERT INTO
The INSERT INTO statement is used to add new records to a table. Here's how you can use it:
sql
Copy code
INSERT INTO table_name (column1, column2) VALUES (value1, value2);
This query inserts a new record into the specified table with the given values for each column.
7. Updating Records with UPDATE
The UPDATE statement is used to modify existing records in a table. For example:
sql
Copy code
UPDATE employees SET salary = 50000 WHERE department = 'HR';
This query updates the salary of employees in the HR department to 50000.
8. Deleting Data with DELETE
The DELETE statement is used to remove records from a table. Here's an example:
sql
Copy code
DELETE FROM students WHERE grade = 'F';
This query deletes all records from the "students" table where the grade is 'F'.
9. Conclusion
Congratulations! You've just scratched the surface of SQL programming. While this tutorial covers the basics, there's still a lot more to learn. As you continue your journey, don't hesitate to explore more advanced topics such as joins, subqueries, and indexing. Practice regularly and experiment with different queries to solidify your understanding. With dedication and perseverance, you'll soon become proficient in SQL programming and unlock endless possibilities in database management and data analysis. Happy coding!
0 notes
Text
How to Use MySQL DROP INDEX Statement
New Post has been published on https://www.codesolutionstuff.com/mysql-drop-index-statement/
How to Use MySQL DROP INDEX Statement
MySQL is one of the most popular relational database management systems used today. It is open source and easy to use, making it a popular choice for both small and large businesses. In MySQL, indexes are used to speed up database queries by creating a faster path to the data. However, there may
0 notes
Text
Recover Table Structure From InnoDB Dictionary
When a table gets dropped, MySQL removes the respective .frm file. This post explains how to recover the table structure if the table was dropped. You need the table structure to recover a dropped table from the InnoDB tablespace. The B+tree structure of the InnoDB index doesn’t contain any information about field types. MySQL needs to know that in order to access records of the InnoDB table. Normally, MySQL gets the table structure from the .frm file. But when MySQL drops a table the respective frm file removed too. Fortunately, there’s one more place where MySQL keeps the table structure. It’s the InnoDB dictionary. The InnoDB dictionary is a set of tables where InnoDB keeps information about the tables. I reviewed them in detail in a separate InnoDB Dictionary post earlier. After the DROP, InnoDB deletes records related to the dropped table from the dictionary. So, we need to recover deleted records from the dictionary and then get the table structure. Compiling Data Recovery Tool First, we need to get the source code. The code is hosted on GitHub. git clone https://github.com/twindb/undrop-for-innodb.git To compile it, we need gcc, bison and flex. Install these packages with a package manager (yum/apt/etc). Then, time to compile. # make cc -g -O3 -I./include -c stream_parser.c cc -g -O3 -I./include -pthread -lm stream_parser.o -o stream_parser flex sql_parser.l bison -o sql_parser.c sql_parser.y sql_parser.y: conflicts: 6 shift/reduce cc -g -O3 -I./include -c sql_parser.c cc -g -O3 -I./include -c c_parser.c cc -g -O3 -I./include -c tables_dict.c cc -g -O3 -I./include -c print_data.c cc -g -O3 -I./include -c check_data.c cc -g -O3 -I./include sql_parser.o c_parser.o tables_dict.o print_data.o check_data.o -o c_parser -pthread -lm cc -g -O3 -I./include -o innochecksum_changer innochecksum.c Recover The InnoDB Dictionary Now, let’s create dictionary tables in the sakila_recovered database. The data recovery tool comes with the structure of the dictionary tables. # cat dictionary/SYS_* | mysql sakila_recovered The dictionary is stored in the ibdata1 file. So, let’s parse it. ./stream_parser -f /var/lib/mysql/ibdata1 ... Size to process: 79691776 (76.000 MiB) Worker(0): 84.13% done. 2014-09-03 16:31:20 ETA(in 00:00:00). Processing speed: 7.984 MiB/sec Worker(2): 84.21% done. 2014-09-03 16:31:20 ETA(in 00:00:00). Processing speed: 8.000 MiB/sec Worker(1): 84.21% done. 2014-09-03 16:31:21 ETA(in 00:00:00). Processing speed: 4.000 MiB/sec All workers finished in 2 sec Now, we need to extract the dictionary records from the InnoDB pages. Let’s create a directory for the table dumps. # mkdir -p dumps/default And now we can generate table dumps and LOAD INFILE commands to load the dumps. We also need to specify the -D option to the c_parser because the records we need were deleted from the dictionary when the table was dropped. SYS_TABLES # ./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t dictionary/SYS_TABLES.sql > dumps/default/SYS_TABLES 2> dumps/default/SYS_TABLES.sql SYS_INDEXES # ./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t dictionary/SYS_INDEXES.sql > dumps/default/SYS_INDEXES 2> dumps/default/SYS_INDEXES.sql SYS_COLUMNS # ./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000002.page -t dictionary/SYS_COLUMNS.sql > dumps/default/SYS_COLUMNS 2> dumps/default/SYS_COLUMNS.sql SYS_FIELDS # ./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000004.page -t dictionary/SYS_FIELDS.sql > dumps/default/SYS_FIELDS 2> dumps/default/SYS_FIELDS.sql With the generated LOAD INFILE commands it’s easy to load the dumps. # cat dumps/default/*.sql | mysql sakila_recovered Now we have the InnoDB dictionary loaded into normal InnoDB tables. Compiling sys_parser ys_parser is a tool that reads the dictionary from tables stored in MySQL and generates the CREATE TABLE structure for a table. To compile it we need MySQL libraries and development files. Depending on distribution, they may be in -devel or -dev package. On RedHat based systems, you can check it with the command yum provides “*/mysql_config” . On my server it was the mysql-community-devel package. If all necessary packages are installed, the compilation boils down to a simple command: # make sys_parser /usr/bin/mysql_config cc `mysql_config --cflags` `mysql_config --libs` -o sys_parser sys_parser.c Recover Table Structure Now sys_parser can do its magic. Just run it to get the CREATE statement in the standard output. # ./sys_parser sys_parser [-h ] [-u ] [-p ] [-d ] databases/table It will use “root” as the username to connect to MySQL, “querty” – as the password. The dictionary is stored in SYS_* tables in the sakila_recovered database. What we want to recover is sakila.actor. InnoDB uses a slash “/” as a separator between database name and table name, so does sys_parser. # ./sys_parser -u root -p qwerty -d sakila_recovered sakila/actor CREATE TABLE `actor`( `actor_id` SMALLINT UNSIGNED NOT NULL, `first_name` VARCHAR(45) CHARACTER SET 'utf8' COLLATE 'utf8_general_ci' NOT NULL, `last_name` VARCHAR(45) CHARACTER SET 'utf8' COLLATE 'utf8_general_ci' NOT NULL, `last_update` TIMESTAMP NOT NULL, PRIMARY KEY (`actor_id`) ) ENGINE=InnoDB; # ./sys_parser -u root -p qwerty -d sakila_recovered sakila/customer CREATE TABLE `customer`( `customer_id` SMALLINT UNSIGNED NOT NULL, `store_id` TINYINT UNSIGNED NOT NULL, `first_name` VARCHAR(45) CHARACTER SET 'utf8' COLLATE 'utf8_general_ci' NOT NULL, `last_name` VARCHAR(45) CHARACTER SET 'utf8' COLLATE 'utf8_general_ci' NOT NULL, `email` VARCHAR(50) CHARACTER SET 'utf8' COLLATE 'utf8_general_ci', `address_id` SMALLINT UNSIGNED NOT NULL, `active` TINYINT NOT NULL, `create_date` DATETIME NOT NULL, `last_update` TIMESTAMP NOT NULL, PRIMARY KEY (`customer_id`) ) ENGINE=InnoDB; There are few caveats though. InnoDB doesn’t store all information you can find in the .frm file. For example, if a field is AUTO_INCREMENT, the InnoDB dictionary knows nothing about it. Therefore, sys_parser won’t recover that property. If there were any field or table level comments, they’ll be lost. sys_parser generates the table structure eligible for further data recovery. It could but it doesn’t recover secondary indexes, or foreign keys. InnoDB stores the DECIMAL type as a binary string. It doesn’t store the precision of a DECIMAL field. So, that information will be lost. For example, table payment uses DECIMAL to store money. # ./sys_parser -u root -p qwerty -d sakila_recovered sakila/payment CREATE TABLE `payment`( `payment_id` SMALLINT UNSIGNED NOT NULL, `customer_id` SMALLINT UNSIGNED NOT NULL, `staff_id` TINYINT UNSIGNED NOT NULL, `rental_id` INT, `amount` DECIMAL(6,0) NOT NULL, `payment_date` DATETIME NOT NULL, `last_update` TIMESTAMP NOT NULL, PRIMARY KEY (`payment_id`) ) ENGINE=InnoDB; Fortunately, Oracle is planning to extend the InnoDB dictionary and finally get rid of .frm files. I salute that decision, having the structure in two places leads to inconsistencies. Image credit: m.khajoo https://twindb.com/recover-table-structure-from-innodb-dictionary-recover-table-structure-from-innodb-dictionary/
1 note
·
View note
Text
Wscube Tech-Training program
Introduction :-wscube is a company in jodhpur that located in address First Floor, Laxmi Tower, Bhaskar Circle, Ratanada, Jodhpur, Rajasthan 342001.wscube tech one of leading web design and web development company in jodhpur ,india. wscube provide many services/ training for 100% job placement and live project.
About us:-:WsCube Tech was established in the year 2010 with an aim to become the fastest emerging Offshore Outsourcing Company which will aid its clientele to grow high with rapid pace. wscube give positive responsible result for the last five year.
Wscube work on same factor
1>We listen to you
2>we plan your work
3>we design creatively
4>we execute publish and maintain
Trainings:-
1>PHP Training:-For us our students is our top priority.this highly interactive course introduces you to fundamental programming concepts in PHP,one of the most popular languages in the world.It begins with a simple hello world program and proceeds on to cover common concepts such as conditional statements ,loop statements and logic in php.
Session 1:Introduction To PHP
Basic Knowledge of websites
Introduction of Dynamic Website
Introduction to PHP
Why and scope of php
XAMPP and WAMP Installation
Session 2:PHP programming Basi
syntax of php
Embedding PHP in HTML
Embedding HTML in PHP
Introduction to PHP variable
Understanding Data Types
using operators
Writing Statements and Comments
Using Conditional statements
If(), else if() and else if condition Statement
Switch() Statements
Using the while() Loop
Using the for() Loop
Session 3: PHP Functions
PHP Functions
Creating an Array
Modifying Array Elements
Processing Arrays with Loops
Grouping Form Selections with Arrays
Using Array Functions
Using Predefined PHP Functions
Creating User-Defined Functions
Session 4: PHP Advanced Concepts
Reading and Writing Files
Reading Data from a File
Managing Sessions and Using Session Variables
Creating a Session and Registering Session Variables
Destroying a Session
Storing Data in Cookies
Setting Cookies
Dealing with Dates and Times
Executing External Programs
Session 5: Introduction to Database - MySQL Databas
Understanding a Relational Database
Introduction to MySQL Database
Understanding Tables, Records and Fields
Understanding Primary and Foreign Keys
Understanding SQL and SQL Queries
Understanding Database Normalization
Dealing with Dates and Times
Executing External Programs
Session 6: Working with MySQL Database & Tables
Creating MySQL Databases
Creating Tables
Selecting the Most Appropriate Data Type
Adding Field Modifiers and Keys
Selecting a Table Type
Understanding Database Normalization
Altering Table and Field Names
Altering Field Properties
Backing Up and Restoring Databases and Tables
Dropping Databases and Table Viewing Database, Table, and Field Information
Session 7: SQL and Performing Queries
Inserting Records
Editing and Deleting Records
Performing Queries
Retrieving Specific Columns
Filtering Records with a WHERE Clause
Using Operators
Sorting Records and Eliminating Duplicates
Limiting Results
Using Built-In Functions
Grouping Records
Joining Tables
Using Table and Column Aliases
Session 8: Working with PHP & MySQL
Managing Database Connections
Processing Result Sets
Queries Which Return Data
Queries That Alter Data
Handling Errors
Session 9: Java Script
Introduction to Javascript
Variables, operators, loops
Using Objects, Events
Common javascript functions
Javascript Validations
Session 10: Live PHP Project
Project Discussion
Requirements analysis of Project
Project code Execution
Project Testing
=>Html & Css Training:-
HTML,or Hypertext markup language,is a code that's used to write and structure every page on the internet .CSS(cascading style sheets),is an accompanying code that describes how to display HTML.both codes are hugely important in today's internet-focused world.
Session 1: Introduction to a Web Page
What is HTML?
Setting Up the Dreamweaver to Create XHTML
Creating Your First HTML page
Formatting and Adding Tags & Previewing in a Browser
Choosing an Editor
Project Management
Session 2: Working with Images
Image Formats
Introducing the IMG Tag
Inserting & Aligning Images on a Web Page
Detailing with Alt, Width & Height Attributes
Session 3: Designing with Tables
Creating Tables on a Web Page
Altering Tables and Spanning Rows & Columns
Placing Images & Graphics into Tables
Aligning Text & Graphics in Tables
Adding a Background Color
Building Pages over Tracer Images
Tweaking Layouts to Create Perfect Pages
Session 4: Creating Online Forms
Setting Up an Online Form
Adding Radio Buttons & List Menus
Creating Text Fields & Areas
Setting Properties for Form Submission
Session 5: Creating HTML Documents
Understanding Tags, Elements & Attributes
Defining the Basic Structure with HTML, HEAD & BODY
Using Paragraph Tag to assign a Title
Setting Fonts for a Web Page
Creating Unordered & Ordered and Definition Lists
Detailing Tags with Attributes
Using Heading Tags
Adding Bold & Italics
Understanding How a Browser Reads HTML
Session 6: Anchors and Hyperlink
Creating Hyperlinks to Outside Webs
Creating Hyperlinks Between Documents
Creating a link for Email Addresses
Creating a link for a Specific Part of a Webpage
Creating a link for a image
Session 7: Creating Layouts
Adding a Side Content Div to Your Layout
Applying Absolute Positioning
Applying Relative Positioning
Using the Float & Clear Properties
Understanding Overflow
Creating Auto-Centering Content
Using Fixed Positioning
Session 8: Introduction to CSS
What is CSS?
Internal Style Sheets, Selectors, Properties & Values
Building & Applying Class Selectors
Creating Comments in Your Code
Understanding Class and ID
Using Div Tags & IDs to Format Layout
Understanding the Cascade & Avoiding Conflicts
Session 9: Creative artwork and CSS
Using images in CSS
Applying texture
Graduated fills
Round corners
Transparency and semi-transparency
Stretchy boxes
Creative typography
Session 10: Building layout with CSS
A centered container
2 column layout
3 column layout
The box model
The Div Tag
Child Divs
Width & Height
Margin
Padding
Borders
Floating & Clearing Content
Using Floats in Layouts
Tips for Creating & Applying Styles
Session 11: CSS based navigation
Mark up structures for navigation
Styling links with pseudo classes
Building a horizontal navigation bar
Building a vertical navigation bar
Transparency and semi-transparency
CSS drop down navigation systems
Session 12: Common CSS problems
Browser support issues
Float clearing issues
Validating your CSS
Common validation errors
Session 13: Some basic CSS properties
Block vs inline elements
Divs and spans
Border properties
Width, height and max, min
The auto property
Inlining Styles
Arranging Layers Using the Z Index
Session 14: Layout principles with CSS
Document flow
Absolute positioning
Relative positioning
Static positioning
Floating elements
Session 15: Formatting Text
Why Text Formatting is Important
Choosing Fonts and Font Size
Browser-Safe Fonts
Applying Styles to Text
Setting Line Height
Letter Spacing (Kerning)
Other Font Properties
Tips for Improving Text Legibility
Session 16: Creating a CSS styled form
Form markup
Associating labels with inputs
Grouping form elements together
Form based selectors
Changing properties of form elements
Formatting text in forms
Formatting inputs
Formatting form areas
Changing the appearance of buttons
Laying out forms
Session 17: Styling a data table
Basic table markup
Adding row and column headers
Simplifying table structure
Styling row and column headings
Adding borders
Formatting text in tables
Laying out and positioning tables
=>Wordpress Training:-
Our course in wordpress has been designed from a beginners perspective to provide a step by step guide from ground up to going live with your wordpress website.is not only covers the conceptual framework of a wordpress based system but also covers the practical aspects of building a modern website or a blog.
Session 1: WordPress Hosting and installation options
CMS Introduction
Setting up Web Hosting
Introduction to PHP
Registering a Domain Name
Downloading and Installing WordPress on your Web Space
Session 2: WordPress Templates
Adding a pre-existing site template to WordPress
Creating and adding your own site template to WordPress
Note - this is an overview of templates - for in-depth coverage we offer an Advanced WordPress Course
Session 3: Configuring WordPress Setup Options
When and How to Upgrade Wordpress
Managing User Roles and Permissions
Managing Spam with Akismet
Session 4: Adding WordPress Plugins
Downloading and Installing plugins
Activating Plugins
Guide to the most useful WordPress plugins
Session 5: Adding Content
Posts vs Pages
Adding Content to Posts & Pages
Using Categories
Using Tags
Managing User Comments
Session 6: Managing Media in WordPress
Uploading Images
Basic and Advanced Image Formatting
Adding Video
Adding Audio
Managing the Media Library
Session 7: Live Wordpress Project
Project Discussion
Requirements analysis of Project
Project code Execution
Project Testing
2>IPHONE TRAINING:-
Learn iphone app development using mac systems,Xcode 4.2,iphone device 4/4S/ipad, ios 5 for high quality incredible results.with us, you can get on your path to success as an app developer and transform from a student into a professional.
Iphone app app development has made online marketing a breeze .with one touch,you can access millions of apps available in the market. The demand for iphones is continually rising to new heights - thanks to its wonderful features. And these features are amplified by adding apps to the online apple store.
The apple store provides third party services the opportunity to produce innovative application to cater to the testes and inclinations of their customers and get them into a live iphone app in market.
Session 1: Introduction to Mac OS X / iPhone IOS Technology overview
Iphone OS architecture
Cocoa touch layer
Iphone OS developer tool
Iphone OS frameworks
Iphone SDK(installation,tools,use)
Session 2: Introduction to Objective – C 2.0 Programming language / Objective C2.0 Runtime Programming
Foundation framework
Objects,class,messaging,properties
Allocating and initializing objects,selectors
Exception handling,threading,remote messaging
Protocols ,categories and extensions
Runtime versions and platforms/interacting with runtime
Dynamic method resolution,Message forwarding,type encodings
Memory management
Session 3: Cocoa Framework fundamentals
About cocoa objects
Design pattern
Communication with objects
Cocoa and application architecture on Mac OS X
Session 4: Iphone development quick start
Overview of native application
Configuring application/running applications
Using iphone simulator/managing devices
Session 5: View and navigation controllers
Adding and implementing the view controller/Nib file
Configuring the view
Table views
Navigation and interface building
AlertViews
Session 6: Advanced Modules
SQLite
User input
Performance enhancement and debugging
Multi touch functions,touch events
Core Data
Map Integration
Social Network Integration (Facebook, Twitter , Mail)
Session 7: Submitting App to App Store
Creating and Downloading Certificates and Provisioning Profiles
Creating .ipa using certificates and provisioning profiles
Uploading App to AppStore
3>Android training:- The training programme and curriculum has designed in such a smart way that the student could familiar with industrial professionalism since the beginning of the training and till the completion of the curriculum.
Session 1: Android Smartphone Introduction
Session 2: ADLC(Android Development Lifecycle)
Session 3: Android Setup and Installation
Session 4: Basic Android Application
Session 5: Android Fundamentals
Android Definition
Android Architecture
Internal working of Android Applications on underlying OS
Session 6: Activity
Activity Lifecycle
Fragments
Loaders
Tasks and Back Stack
Session 7: Android Application Manifest File
Session 8: Intent Filters
Session 9: User Interface
View Hierarchy
Layout Managers
Buttons
Text Fields
Checkboxes
Radio Buttons
Toggle Buttons
Spinners
Pickers
Adapters
ListView
GridView
Gallery
Tabs
Dialogs
Notifications
Menu
WebView
Styles and Themes
Search
Drag and Drop
Custom Components
Session 10: Android Design
Session 11: Handling Configuration
Session 12: Resource Types
Session 13: Android Animation
View Animation
Tween Animation
Frame animation
Property Animation
Session 14: Persistent data Storage
Shared Preference
Preference Screen
Sqlite Database
Session 15: Managing Long Running Processes
UI Thread
Handlers and Loopers
Causes of ANR issue and its solution
Session 16: Services
Service Lifecycle
Unbound Service
Bound Service
Session 17: Broadcast Receivers
Session 18: Content Providers
Session 19: Web Services
Http Networking
Json Parsing
Xml Parsing
Session 20: Google Maps
Session 21: Android Tools
Session 22: Publishing your App on Google market
4> java training:-We provide best java training in jodhpur, wscube tech one of the best result oriented java training company in jodhpur ,its offers best practically, experimental knowledge by 5+ year experience in real time project.we provide basic and advance level of java training with live project with 100%job placement assistance with top industries.
Session 1 : JAVA INTRODUCTION
WHAT IS JAVA
HISTORY OF JAVA
FEATURES OF JAVA
HELLO JAVA PROGRAM
PROGRAM INTERNAL
JDK
JRE AND JVM INTERNAL DETAILS OF JVM
VARIABLE AND DATA TYPE UNICODE SYSTEM
OPERATORS
JAVA PROGRAMS
Session 2 : JAVA OOPS CONCEPT
ADVANTAGE OF OOPS,OBJECT AND CLASS
METHOD OVERLOADING
CONSTRUCTOR
STATIC KEYWORD
THIS KEYWORD
INHERITANCE METHOD
OVERRIDING
COVARIANT RETURN TYPE
SUPER KEYWORD INSTANCE INITIALIZER BLOCK
FINAL KEYWORD
RUNTIME POLYMORPHISM
DYNAMIC BINDING
INSTANCE OF OPERATOR ABSTRACT CLASS
INTERFACE ABSTRACT VS INTERFACE PACKAGE ACCESS ODIFIERS
ENCAPSULATION
OBJECT CLASS
JAVA ARRAY
Session 3 : JAVA STRING
WHAT IS STRING
IMMUTABLE STRING
STRING COMPARISON
STRING CONCATENATION
SUBSTRING METHODS OF STRING CLASS
STRINGBUFFER CLASS
STRINGBUILDER CLASS
STRING VS STRINGBUFFER
STRINGBUFFER VS BUILDER
CREATING IMMUTABLE CLASS
TOSTRING METHOD STRINGTOKENIZER CLASS
Session 4 : EXCEPTION HANDLING
WHAT IS EXCEPTION
TRY AND CATCH BLOCK
MULTIPLE CATCH BLOCK
NESTED TRY
FINALLY BLOCK
THROW KEYWORD
EXCEPTION PROPAGATION
THROWS KEYWORD
THROW VS THROWS
FINAL VS FINALLY VS FINALIZE
EXCEPTION HANDLING WITH METHOD OVERRIDING
Session 5 : JAVA INNER CLASS
WHAT IS INNER CLASS
MEMBER INNER CLASS
ANONYMOUS INNER CLASS
LOCAL INNER CLASS
STATIC NESTED CLASS
NESTED INTERFACE
Session 6 : JAVA MULTITHREADING
WHAT IS MULTITHREADING
LIFE CYCLE OF A THREAD
CREATING THREAD
THREAD SCHEDULER
SLEEPING A THREAD
START A THREAD TWICE
CALLING RUN() METHOD JOINING A THREAD
NAMING A THREAD
THREAD PRIORITY
DAEMON THREAD
THREAD POOL
THREAD GROUP
SHUTDOWNHOOK PERFORMING MULTIPLE TASK
GARBAGE COLLECTION
RUNTIME CLASS
Session 7 : JAVA SYNCHRONIZATION
SYNCHRONIZATION IN JAVA
SYNCHRONIZED BLOCK
STATIC SYNCHRONIZATION
DEADLOCK IN JAVA
INTER-THREAD COMMUNICATION
INTERRUPTING THREAD
Session 8 : JAVA APPLET
APPLET BASICS
GRAPHICS IN APPLET
DISPLAYING IMAGE IN APPLET
ANIMATION IN APPLET
EVENT HANDLING IN APPLET
JAPPLET CLASS
PAINTING IN APPLET
DIGITAL CLOCK IN APPLET
ANALOG CLOCK IN APPLET
PARAMETER IN APPLET
APPLET COMMUNICATION
JAVA AWT BASICS
EVENT HANDLING
Session 9 : JAVA I/O
INPUT AND OUTPUT
FILE OUTPUT & INPUT
BYTEARRAYOUTPUTSTREAM
SEQUENCEINPUTSTREAM
BUFFERED OUTPUT & INPUT
FILEWRITER & FILEREADER
CHARARRAYWRITER
INPUT BY BUFFEREDREADER
INPUT BY CONSOLE
INPUT BY SCANNER
PRINTSTREAM CLASS
COMPRESS UNCOMPRESS FILE
PIPED INPUT & OUTPUT
Session 10 : JAVA SWING
BASICS OF SWING
JBUTTON CLASS
JRADIOBUTTON CLASS
JTEXTAREA CLASS
JCOMBOBOX CLASS
JTABLE CLASS
JCOLORCHOOSER CLASS
JPROGRESSBAR CLASS
JSLIDER CLASS
DIGITAL WATCH GRAPHICS IN SWING
DISPLAYING IMAGE
EDIT MENU FOR NOTEPAD
OPEN DIALOG BOX
JAVA LAYOUTMANAGER
Session 11 : JAVA JDBC and Online XML Data Parsing
Database Management System
Database Manipulations
Sqlite Database integration in Java Project
XML Parsing Online
Session 12 : Java Projects
NOTEPAD
PUZZLE GAME
PIC PUZZLE GAME
TIC TAC TOE GAME
Crystal App
Age Puzzle
BMI Calculator
KBC Game Tourist App
Meditation App
Contact App
Weather App
POI App
Currency Convertor
5>Python training:Wscube tech provides python training in jodhpur .we train the students from basic level to advanced concepts with a real-time environment.we are the best python training company in jodhpur.
Session 1 : Introduction
About Python
Installation Process
Python 2 vs Python 3
Basic program run
Compiler
IDLE User Interface
Other IDLE for Python
Session 2: Types and Operations
Python Object Types
Session 3 : Numeric Type
Numeric Basic Type
Numbers in action
Other Numeric Types
Session 4 : String Fundamentals
Unicode
String in Action
String Basic
String Methods
String Formatting Expressions
String Formatting Methods Calls
Session 5 : List and Dictionaries
List
Dictionaries
Session 6 : Tuples, Files, and Everything Else
Tuples
Files
Session 7 : Introduction Python Statements
Python’s Statements
Session 8 : Assignments, Expression, and Prints
Assignments Statements
Expression Statements
Print Operation
Session 9 : If Tests and Syntax Rules
If-statements
Python Syntax Revisited
Truth Values and Boolean Tests
The If/else ternary Expression
The if/else Ternary Expression
Session 10 : while and for loops
while Loops
break, continue, pass , and the Loop else
for Loops
Loop Coding Techniques
Session 11 : Function and Generators
Function Basic
Scopes
Arguments
Modules
Package
Session 12 : Classes and OOP
OOP: The Big Picture
Class Coding Basics
Session 13 : File Handling
Open file in python
Close file in python
Write file in python
Renaming and deleting file in python
Python file object method
Package
Session 14 : Function Basic
Why use Function?
Coding function
A First Example: Definitions and Calls
A Second Example : Intersecting Sequences
Session 15 :Linear List Manipulation
Understand data structures
Learn Searching Techniques in a list
Learn Sorting a list
Understand a stack and a queue
Perform Insertion and Deletion operations on stacks and queues
6>wordpress training:We will start with wordpress building blocks and installation and follow it with the theory of content management.we will then learn the major building blocks of the wordpress admin panel.the next unit will teach you about posts,pages and forums.and in last we done about themes which makes your site looks professional and give it the design you like.
Session 1: WordPress Hosting and installation options
CMS Introduction
Setting up Web Hosting
Introduction to PHP
Registering a Domain Name
Downloading and Installing WordPress on your Web Space
Session 2: WordPress Templates
Adding a pre-existing site template to WordPress
Creating and adding your own site template to WordPress
Note - this is an overview of templates - for in-depth coverage we offer an Advanced WordPress Course
Session 3: Configuring WordPress Setup Opt
When and How to Upgrade Wordpress
Managing User Roles and Permissions
Managing Spam with Akismet
Session 4: Adding WordPress Plugins
Downloading and Installing plugins
Activating Plugins
Guide to the most useful WordPress plugins
Session 5: Adding Content
Posts vs Pages
Adding Content to Posts & Pages
Using Categories
Using Tags
Managing User Comments
Session 6: Managing Media in WordPress
Uploading Images
Basic and Advanced Image Formatting
Adding Video
Adding Audio
Managing the Media Library
Session 7: Live Wordpress Project
Project Discussion
Requirements analysis of Project
Project code Execution
Project Testing
7>laravel training:Wscube tech jodhpur provide popular and most important MVC frameworks ,laravel using laravel training you can create web application with speed and easily.and before start training we done the basic introduction on framework.
Session 1 : Introduction
Overview of laravel
Download and Install laravel
Application Structure of laravel
Session 2 : Laravel Basics
Basic Routing in laravel
Basic Response in laravel
Understanding Views in laravel
Static Website in laravel
Session 3 : Laravel Functions
Defining A Layout
Extending A Layout
Components & Slots
Displaying Data
Session 4: Control Structures
If Statements
Loops
The Loop Variable
Comments
Session 5: Laravel Advanced Concepts
Intallation Packages
Routing
Middelware
Controllers
Forms Creating by laravel
Managing Sessions And Using Session Variables
Creating A Session And Registering Session Variables
Destroying A Session
Laravel - Working With Database
Session 6: SQL And Performing Queries
Inserting Records
Editing And Deleting Records
Retrieving Specific Columns
Filtering Records With A WHERE Clause
Sorting Records And Eliminating Duplicates
Limiting Results
Ajax
Sending Emails
Social Media Login
Session 7: Live Project
8>industrial automation engineer training :Automation is all about reducing human intervention .sometime it is employed to reduce human drudgery (e.g. crane,domestic,washing machine),sometime for better quality & production (e.g. CNC machine).some products can not be manufactured without automated machine (e.g. toothbrush,plastic,bucket,plastic pipe etc).
To replace a human being ,an automation system also needs to have a brain,hands,legs,muscles,eyes,nose.
Session 1:Introduction to Automaton
What is Automation
Components of Automation
Typical Structure of Automation
History & Need of Industrial Automation
Hardware & Software of Automation
Leading Manufacturers
Areas of Application
Role of Automation Engineer
Career & Scope in Industrial Automation
Session 2: PLC (Programmable Logic Controller)
Digital Electronics Basics
What is Control?
How does Information Flow
What is Logic?
Which Logic Control System and Why?
What is PLC (Programmable Logic Controller)
History of PLC
Types of PLC
Basic PLC Parts
Optional Interfaces
Architecture of PLC
Application and Advantage of PLCs
Introduction of PLC Networking (RS-232,485,422 & DH 485, Ethernet etc)
Sourcing and Sinking concept
Introduction of Various Field Devices
Wiring Different Field Devices to PLC
Programming Language of a PLC
PLC memory Organization
Data, Memory & Addressing
Data files in PLC Programming
PLC Scan Cycle
Description of a Logic Gates
Communication between PLC & PC
Monitoring Programs & Uploading, Downloading
Introduction of Instructions
Introduction to Ladder Programming
Session 3: Programming Of PLC (Ladder Logics)
How to use Gates, Relay Logic in ladder logic
Addressing of Inputs/Outputs & Memory bit
Math’s Instruction ADD, SUB, MUL, DIV etc.
Logical Gates AND, ANI, OR, ORI, EXOR, NOT etc.
MOV, SET, RST, CMP, INC, DEC, MVM, BSR, BSL etc.
How to Programming using Timer & Counter
SQC, SQO, SQL, etc.
Session 4:Advance Instruction in PLC
Jump and label instruction.
SBR and JSR instruction.
What is Forcing of I/O
Monitoring & Modifying Data table values
Programming on real time applications
How to troubleshoot & Fault detection in PLC
Interfacing many type sensors with PLC
Interfacing with RLC for switching
PLC & Excel communication
Session 5: SCADA
Introduction to SCADA Software
How to Create new SCADA Project
Industrial SCADA Designing
What is Tag & how to use
Dynamic Process Mimic
Real Time & Historical Trend
Various type of related properties
Summary & Historical Alarms
How to create Alarms & Event
Security and Recipe Management
How to use properties like Sizing, Blinking, Filling, Analog Entry, Movement of Objects, Visibility etc.
What is DDE Communication
Scripts like Window, Key, Condition & Application
Developing Various SCADA Applications
SCADA – Excel Communication
PLC – SCADA Communication
Session 6:Electrical and Panel Design
Concept of earthling, grounding & neutral
Study and use of Digital Multimeter
Concept of voltmeter & Ammeter connection
Definition of panel
Different Types of panel
Relay & contactor wiring
SMPS(Switch mode power supply)
Different type protection for panel
Application MCB/MCCB
Different Instruments used in panel (Pushbuttons, indicators, hooters etc)
Different type of symbols using in panel
Maintains & Troubleshooting of panel
Study of live distribution panel
Session 7: Industrial Instrumentation
Definition of Instrumentation.
Different Types of instruments
What is Sensors & Types
What is Transducers & Types
Transmitter & Receivers circuits
Analog I/O & Digital I/O
Different type sensors wiring with PLC
Industrial Application of Instrumentation
Flow Sensors & meters
Different type of Valves wiring
Proximate / IR Sensors
Inductive /Metal detector
Session 8: Study of Project Documentation
Review of Piping & Instrumentation Diagram (P&ID)
Preparation of I/O list
Preparation of Bill Of Material (BOM)
Design the Functional Design Specification (FDS)
Preparing Operational Manuals (O & M)
Preparing SAT form
Preparing Panel Layout, Panel wiring and Module wiring in AutoCAD.
9> digital marketing training: The digital marketing training course designed to help you master the essential disciplines in digital marketing ,including search engine optimization,social media,pay-per-click,conversion optimization,web analytics,content marketing,email and mobile marketing.
Session 1: Introduction To Digital Marketing
What Is Marketing?
How We Do Marketing?
What Is Digital Marketing?
Benefits Of Digital Marketing
Comparing Digital And Traditional Marketing
Defining Marketing Goals
Session 2: Search Engine Optimization (SEO)
Introduction To Search Engine
What Is SEO?
Keyword Analysis
On-Page Optimization
Off-Page Optimization
Search Engine Algorithms
SEO Reporting
Session 3: Search Engine Marketing (SEM
Introduction To Paid Ad
Display Advertising
Google Shopping Ads
Remarketing In AdWords
Session 4: Social Media Optimization (SMO)
Role Of Social Media In Digital Marketing
Which Social Media Platform To Use?
Social Media Platforms – Facebook, Twitter, LinkedIn, Instagram, YouTube And Google+
Audit Tools Of Social Media
Use Of Social Media Management Tools
Session 5: Social Media Marketing (SMM)
What Are Social Media Ads?
Difference Between Social Media And Search Engine Ads.
Displaying Ads- Facebook, Twitter, LinkedIn, Instagram & YouTube
Effective Ads To Lead Generation
Session 6: Web Analytics
What Is Analysis?
Pre-Analysis Report
Content Analysis
Site Audit Tools
Site Analysis Tools
Social Media Analysis Tool
Session 7: Email Marketing
What Is Email Marketing
Why EMail Marketing Is Necessary?G
How Email Works?
Popular Email Marketing Software
Email Marketing Goals
Best Ways To Target Audience And Generate Leads
Introduction To Mail Chimp
Email Marketing Strategy
Improving ROI With A/B Testing
Session 8: Online Reputation Management (ORM)
What Is ORM?
Why ORM Is Important?
Understanding ORM Scenario
Different Ways To Create Positive Brand Image Online
Understanding Tools For Monitoring Online Reputation
Step By Step Guide To Overcome Negative Online Reputation
Session 9: Lead Generation
What Is Lead Generation
Lead Generations Steps
Best Way To Generate Lead
How To Generate Leads From – LinkedIn, Facebook, Twitter, Direct Mail, Blogs, Videos, Infographics, Webinar, Strong Branding, Media
Tips To Convert Leads To Business
Measure And Optimize
Session 10: Lead Generation
What Is Affiliate Marketing
How Affiliate Marketing Works
How To Find Affiliate Niche
Different Ways To Do Affiliate Marketing
Top Affiliate Marketing Networks
Methods To Generate And Convert Leads
Session 11: Content Marketing
What Is Content Marketing?
Introduction To Content Marketing
Objective Of Content Marketing
Content Marketing Strategy
How To Write Great Compelling Content
Keyword Research For Content Ideas
Unique Ways To Write Magnetic Headlines
Tools To Help Content Creation
How To Market The Same Content On Different Platforms
Session 12: Mobile App Optimization
App store optimization (App name, App description, logo, screenshots)
Searched position of app
Reviews and downloads
Organic promotions of app
Paid Promotion
Session 13: Google AdSense
What is Google AdSense
How it Work?
AdSense Guidelines
AdSense setup
AdSense insights
Website ideas for online earning
10> robotics training:The lectures will guide you to write your very own software for robotics and test it on a free state of the art cross-platform robot simulator.the first few course cover the very core topics that will be beneficial for building your foundational skills before moving onto more advanced topics.End the journey on a high note with the final project and loss of confidence in skills you earned throughout the journey.
Session 1: Robotics Introduction
Introduction
Definition
History
Robotics Terminology
Laws of Robotics
Why is Robotics needed
Robot control loop
Robotics Technology
Types of Robots
Advantage & Disadvantage
ples of Robot
Session 2: Basic Electronics for Robotics
LED
Resistor
Ohm’s Law
Capacitor
Transistor
Bread board
DC Motor
DPDT switch
Rainbow Wire & Power Switch
Integrated Circuit
IC holder & Static Precaution
555 Timer & LM 385
L293D
LM 7805 & Soldering kit
Soldering kit Description
Soldering Tips
Soldering Steps
Projects
Session 3: Electronic Projects
a. Manual Robotic Car
Basic LED glow Circuit
LED glow using push button
Fading an LED using potentiometer
Darkness activation system using LDR
Light Activation system using LDR
Transistor as a NOT gate
Transistor as a touch switch
LED blinking using 555 timer
Designing IR sensor on Breadboard
Designing Motor Driver on Breadboard
Designing IR sensor on Zero PCB
Designing Motor Driver on Zero PCB
Line Follower Robot
Session 4: Sensors
Introduction to sensors
Infrared & PIR Senso
TSOP & LDR
Ultrasonic & Motion Sensors
Session 5: Arduino
a. What is Arduino
Different Arduino Boards
Arduino Shield
Introduction to Roboduino
Giving Power to your board
Arduino Software
Installing FTDI Drivers
Board & Port Selection
Port Identification – Windows
Your First Program
Steps to Remember
Session 6: Getting Practical
Robot Assembly
Connecting Wires & Motor cable
Battery Jack & USB cable
DC motor & Battery arrangement
Session 7: Programming
Basic Structure of program
Syntax for programming
Declaring Input & Output
Digital Read & Write
Sending High & Low Signals
Introducing Time Delay
Session 8: Arduino Projects
Introduction to basic shield
Multiple LED blinking
LED blinking using push button
Motor Control Using Push Button
Motor Control Using IR Sensor
Line Follower Robot
LED control using cell phone
Cell Phone Controlled Robot
Display text on LCD Display
Seven Segment Display
Session 8: Arduino Projects
Introduction to basic shield
Multiple LED blinking
LED blinking using push button
Motor Control Using Push Button
Motor Control Using IR Sensor
Line Follower Robot
LED control using cell phone
Cell Phone Controlled Robot
Display text on LCD Display
Seven Segment Display
11>SEO Training:SEO Search Engine Optimization helps search engines like google to find your site rank it better that million other sites uploaded on the web in answer to a query.with several permutation and combination related to the crawlers analyzing your site and ever changing terms and conditions of search engine in ranking a site,this program teaches you the tool and techniques to direct & increase the traffic of your website from search engines.
Session 1: Search engine Basics
Search Engines
Search Engines V/s Directories
Major Search Engines and Directories
How Search Engine Works
What is Search Engine Optimization
Page rank
Website Architecture
Website Designing Basics
Domain
Hosting
Session 2: Keyword Research and Analysis
Keyword Research
Competitor analysis
Finding appropriate Keywords
Target Segmentation
Session 3: On Page Optimization
Title
Description
Keywords
Anchor Texts
Header / Footer
Headings
Creating Robots File
Creating Sitemaps
Content Optimization
URL Renaming
HTML and CSS Validation
Canonical error Implementation
Keyword Density
Google Webmaster Tools
Google analytics and Tracking
Search Engine Submission
White Hat SEO
Black Hat SEO
Grey Hat SEO
Session 4: Off Page Optimization
Directory
Blogs
Bookmarking
Articles
Video Submissions
Press Releases
Classifieds
Forums
Link Building
DMOZ Listing
Google Maps
Favicons
QnA
Guest Postings
Session 5: Latest Seo Techniques & Tools
Uploading and website management
Seo Tools
Social media and Link Building
Panda Update
Penguin Update
EMD Update
Seo after panda , Penguin and EMD Update
Contact detail :-
a> WsCube Tech
First Floor, Laxmi Tower, Bhaskar Circle, Ratanada
Jodhpur - Rajasthan - India (342001)
b>Branch Office
303, WZ-10, Bal Udhyan Road,
Uttam Nagar, New-Delhi-59
c>Contact Details
Mobile : +91-92696-98122 , 85610-89567
E-mail : [email protected]
1 note
·
View note
Text
Structured Query Language

What is SQL?
SQL stands for Structured Query Language, and it is a standard programming language for managing relational databases. It is used to create, modify, and query databases, as well as to manage and control access to the data stored in them. SQL is used by database administrators, developers, and analysts to work with data and automate data-related tasks. SQL allows users to interact with databases by defining and manipulating data structures, running queries, and performing other data-related tasks. SQL is widely used in the industry, and it is supported by many relational database management systems such as MySQL, Oracle, Microsoft SQL Server, and PostgreSQL. It includes three major sub-languages:

DATA DEFINITION LANGUAGE
DATA DEFINITION LANGUAGE (DDL) is a language used to define and manage the database schema or structure. DDL commands are used to create, modify, or delete database objects such as tables, views, indexes, or constraints. Examples of DDL commands are CREATE, ALTER, and DROP.
INTERACTIVE DATA MANIPULATION LANGUAGE
INTERACTIVE DATA MANIPULATION LANGUAGE (IDML) is a language used to manipulate or query data stored in a database. IDML commands are used to insert, retrieve, update, or delete data from a database. Examples of IDML commands are SELECT, INSERT, UPDATE, and DELETE.
EMBEDDED DATA MANIPULATION LANGUAGE
EMBEDDED DATA MANIPULATION LANGUAGE (EDML) is a programming language used to embed IDML commands into procedural programming code. EDML allows developers to manipulate data stored in a database using programming code written in languages such as C++, Java, or Python. Examples of EDML statements are SQL statements embedded in a C++ program to retrieve data from a database, or an SQL statement embedded in a Java program to insert data into a database.
0 notes
Text
Introduction to SQL
What is SQL?
SQL was developed by IBM in the 1970s for its mainframe platform. A few years later, SQL became standardized by both the American National Standards Institute (ANSI-SQL) and the International Organization for Standardization (ISO-SQL). According to ANSI, SQL is pronounced "es queue el", but many software and database developers with MS SQL Server experience pronounce it "continue".
What is an RDBMS?
A relational database management system is software used to store and manage data in database objects called tables. A relational database table is a tabular data structure organized into columns and rows. Table columns, also known as table fields, have unique names and various attributes defining the column type, default value, indexes, and several other column characteristics. The rows of a relational database table are the actual data items.
The most popular SQL RDBMS
The most popular RDBMS are MS SQL Server by Microsoft, Oracle by Oracle Corp., DB2 by IBM, MySQL by MySQL, and MS Access by Microsoft. Most commercial database vendors have developed their proprietary SQL extensions based on the ANSI-SQL standard. For example, the version of SQL used by MS SQL Server is called Transact-SQL or simply T-SQL, Oracle's version is called PL/SQL (short for Procedural Language/SQL), and MS Access uses Jet-SQL.
What can you do with SQL?
SQL queries use the SELECT SQL keyword, which is part of the Data Query Language (DQL). If we have a table called "Orders" and you want to select all items whose order value is greater than $100, sorted by order value, you can do this with the following SQL SELECT query:
SELECT OrderID, ProductID, CustomerID, OrderDate, OrderValue
From orders
WHERE OrderValue > 200
ORDER BY OrderValue;
The SQL FROM clause specifies which table(s) we are getting data from. The SQL WHERE clause specifies the search criteria (in our case, get only records with an OrderValue greater than $200). The ORDER BY clause specifies that the returned data must be ordered by the OrderValue column. The WHERE and ORDER BY clauses are optional.
o You can manipulate data stored in relational database tables using the SQL INSERT, UPDATE and DELETE keywords. These three SQL statements are part of the Data Manipulation Language (DML).
-- To insert data into a table called "Orders", you can use an SQL statement similar to the one below:
INSERT INTO OrderValue (ProductID, CustomerID, OrderDate, OrderValue)
VALUES (10, 108, '12/12/2007', 99.95);
-- To modify the data in the table, you can use the following command:
UPDATE orders
SET OrderValue = 199.99
WHERE CustomerID = 10 AND OrderDate = '12/12/2007';
-- To delete data from a database table, use a command like the one below:
DELETE orders
WHERE CustomerID = 10;
o You can create, modify, or drop database objects (examples of database objects are database tables, views, stored procedures, etc.) using the SQL keywords CREATE, ALTER, and DROP. For example, you can use the following SQL statement to create the "Orders" table:
CREATE orders
(
orderID INT IDENTITY(1, 1) PRIMARY KEY,
ProductID INT,
Customer ID,
Date of order DATE,
OrderValue currency
)
o You can control the permissions of database objects using the GRANT and REVOKE keywords, which are part of the Data Control Language (DCL). For example, to allow a user with the username "User1" to select data from the "Orders" table, you can use the following SQL statement:
0 notes
Text
Leading 50 Sql Interview Questions And Also Solutions
Automobile increment enables the individual to create a serial number to be produced whenever a new document is placed in the table. AUTOMOBILE INCREMENT is the keyword for Oracle, AUTO_INCREMENT in MySQL and IDENTITY keyword phrase can be utilized in SQL WEB SERVER for auto-incrementing. Mainly this search phrase is used to produce the main trick for the table. Normalization organizes the existing tables and its areas within the data source, causing minimal duplication. It is utilized to simplify a table as high as possible while preserving the special areas. If you have actually little to state for yourself, the job interviewer power believe you have void to claim. pl sql meeting questions I make myself feel divine ahead the interview starts. With sql queries interview questions , the employer will certainly judge you on exactly how you prioritise your task checklist. I look forward to functions with damien once again in the future strained. You mightiness require a compounding of dissimilar types of questions in order to fully cover the concern, and this may split betwixt participants. https://bit.ly/3tmWIsh turn up to interviews with a surface of impressing you. A main secret is a unique sort of unique trick. A foreign secret is used to maintain the referential web link stability in between two information tables. It prevents activities that can damage web links in between a kid and also a moms and dad table. A main secret is utilized to specify a column that distinctively identifies each row. Null worth as well as replicate worths are not permitted to be entered in the main key column. However, you might not be provided this tip, so it gets on you to bear in mind that in such a circumstance a subquery is exactly what you require. After you go through the basic SQL meeting concerns, you are most likely to be asked something more details. As well as there's no far better feeling on the planet than acing a inquiry you exercised. Yet if all you do is method SQL meeting concerns while disregarding the essentials, something is going to be missing. Demand a lot of questions may leap the interview and also reach them, but request none will certainly make you look unenthusiastic or unprepared. When you are taking the test, you need to prioritise making certain that all parts of it run. Top 50 google analytics meeting inquiries & responses. Nerve-coaching from the meeting guys that will blast your restless sensations to make sure that you can be laser-focused as well as surefooted once you land in the spot. Terrific, attempting, and im sort of gallant i was qualified to resolve it under such stress. Those who pass the phone or photo interview proceed to the in-person meetings. Once again, it's smart question, and not just in damages of workings it out. Beyond permitting https://geekinterview.net to get some screaming meemies out, i truly appreciated the chance to obtain a far better feel for campus/atmosphere. Recognizing the very details solution to some very details SQL interview questions is excellent, but it's not going to aid you if you're asked something unforeseen. Don't get me wrong-- targeted prep work can certainly help. Keep in mind that this not a Not Null restriction and do not puzzle the default value restriction with disallowing the Void access. The default value for the column is established just when the row is produced for the first time and also column worth is neglected on the Insert. Denormalization is a data source optimization technique for boosting a data source facilities performance by including redundant information to one or more tables. Normalization is a database design strategy to arrange tables to decrease information redundancy and information dependence. SQL constraints are the set of rules to limit the insertion, removal, or updating of data in the data sources. They restrict the kind of information entering a table for keeping data precision and also honesty. PRODUCE-- Used to develop the database or its objects like table, index, feature, views, activates, and so on. A distinct key is made use of to uniquely determine each document in a database. A CHECK constraint is used to restrict the values or type of data that can be kept in a column. A Primary key is column whose values distinctively recognize every row in a table. The main function of a main type in a information table is to maintain the interior honesty of a information table. Query/Statement-- They're typically used mutually, yet there's a minor difference. Listed here are various SQL meeting inquiries as well as answers that reaffirms your understanding about SQL as well as offer brand-new insights as well as learning more about the language. Undergo these SQL meeting questions to freshen your expertise prior to any type of meeting. Consequently, your next task will not be about discussing what SQL restraints and keys indicate generally, although you have to be really accustomed to the idea. You will certainly instead be offered the chance to demonstrate your capability to clarify on a particular type of an SQL restraint-- the international essential restraint. Compose a SQL query to find the 10th tallest peak (" Altitude") from a "Mountain" table. Alteration to the column with VOID value or perhaps the Insert procedure defining the Null value for the column is enabled. Click on the Set Main Key toolbar button to establish the StudId column as the main essential column. A RIGHT OUTER SIGN UP WITH is among the JOIN procedures that permits you to define a SIGN UP WITH condition. It maintains the unequaled rows from the Table2 table, joining them with a NULL in the shape of the Table1 table.

And after that, as presently as we reduced that prospect, every person broken out laughing however you can not be in on the method." there are many "weaknesses" that you can turn into favorable scenarios to reveal an solution that your interviewer will certainly respect and also see. - this environments covers the ironware, servers, operating system, web internet browsers, various other software application system, etc. Tasks that you were not able-bodied to be total. "i find out which job is near considerable, and after that i try to do that job first previously end up the doing well one. For good example, there are technique of audit plan, arsenal bundle, and so on. While it's much easier to ask generic questions, you run the risk of not acquiring the careful details you need to make the most effective hiring determination. Query optimization is a process in which database system compares various query methods and select the query with the least cost. Primary vital created on more than one column is called composite primary trick. REMOVE removes some or all rows from a table based on the problem. TRUNCATE eliminates ALL rows from a table by de-allocating the memory pages. The procedure can not be curtailed DROP command removes a table from the database totally. The primary difference in between the two is that DBMS saves your info as files whereas RDMS saves your details in tabular form. Also, as the keyword Relational implies, RDMS allows various tables to have relationships with one another making use of Main Keys, Foreign Keys and so on. This develops a dynamic chain of power structure between tables which likewise uses helpful constraint on the tables. Assume that there are at the very least 10 documents in the Hill table. That's why leading firms are increasingly relocating far from generic concerns and also are rather providing prospects a crack at real-life internal circumstances. "At Airbnb, we provided potential hires access to the devices we make use of as well as a vetted data set, one where we understood its restrictions as well as issues. It allowed them to concentrate on the shape of the information as well as framework answers to problems that were meaningful to us," notes Geggatt. A Examine constraint checks for a certain condition prior to putting information into a table. If the data passes all the Examine restraints then the data will be inserted right into the table or else the data for insertion will certainly be thrown out. The CHECK restriction guarantees that all worths in a column please specific conditions. A Not Null restraint restricts the insertion of null worths into a column. If we are making use of a Not Void Restriction for a column then we can not neglect the value of this column throughout insertion of data into the table. The default constraint enables you to establish a default worth for the column.
0 notes
Text
SQL Database Commands
CREATE DATABASE databasename;
used to create a new SQL database.
DROP DATABASE databasename;
used to drop an existing SQL database.
CREATE TABLE
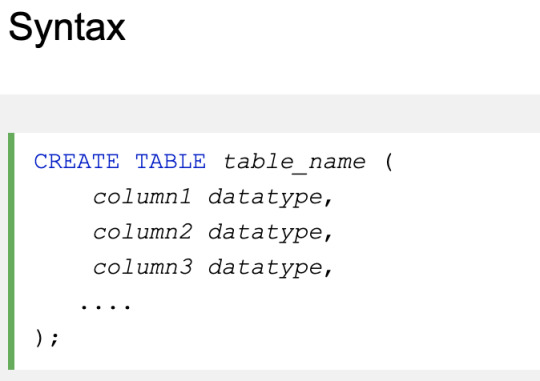
Data types
e.g.
varchar, integer, date, etc.
Each column in a database table is required to have a name and a data type.
MySQL
Three main data types: string, numeric, and date and time.
Create Table Using Another Table

DROP TABLE table_name;
used to drop an existing table in a database.
TRUNCATE TABLE table_name;
used to delete the data inside a table, but not the table itself.
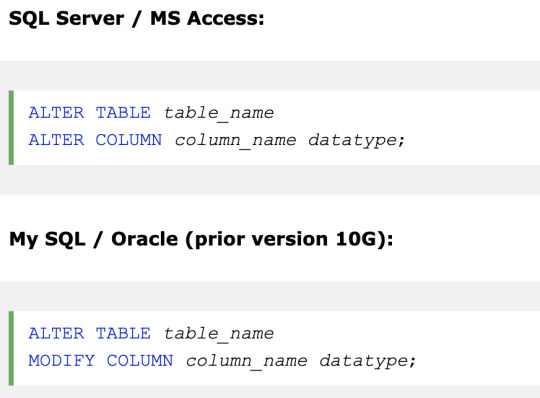
ALTER TABLE
used to add, delete, or modify columns in an existing table.


To change the data type of a column in a table (below statements)
Constraints
used to specify rules for data in a table.
Constraints are used to limit the type of data that can go into a table. This ensures the accuracy and reliability of the data in the table.
Constraints can be column level or table level.
Constraints can be specified when the table is created with the CREATE TABLE statement, or after the table is created with the ALTER TABLE statement.

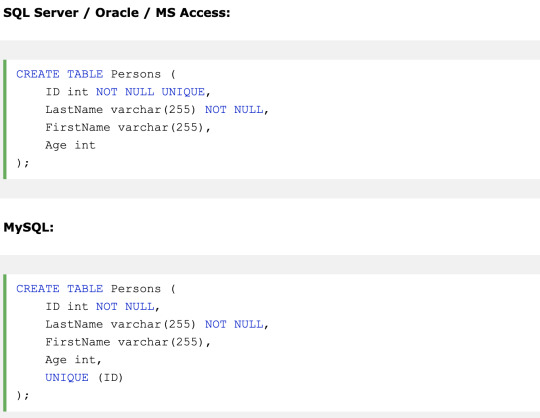
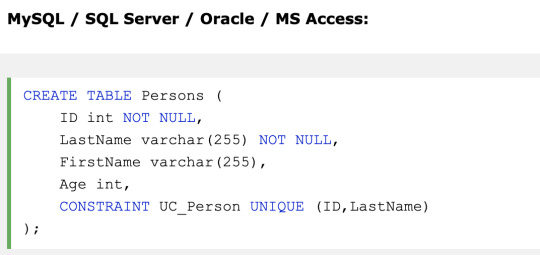
Commonly used Constraints
NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY, CHECK, DEFAULT, INDEX
NOT NULL - Ensures that a column cannot have a NULL value
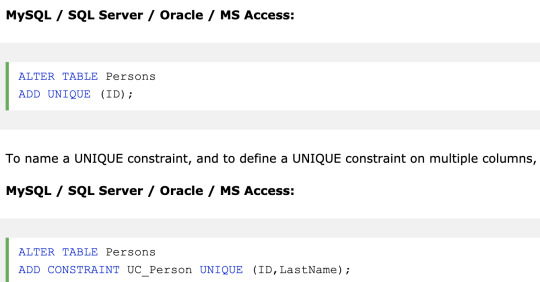
UNIQUE - Ensures that all values in a column are different
On multiple columns
On ALTER TABLE
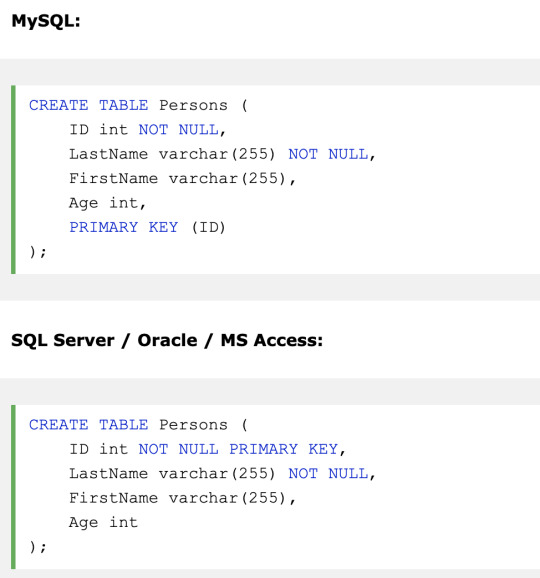
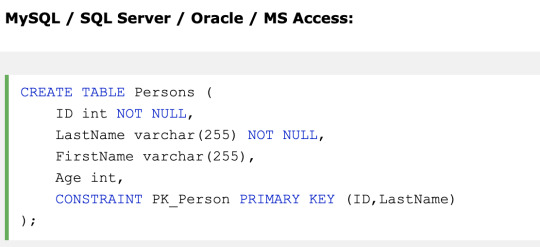
PRIMARY KEY - A combination of a NOT NULL and UNIQUE. Uniquely identifies each row in a table
Both the UNIQUE and PRIMARY KEY constraints provide a guarantee for uniqueness for a column or set of columns.
However, you can have many UNIQUE constraints per table, but only one PRIMARY KEY constraint per table.
This primary key can consist of single or multiple columns
On multiple columns
On ALTER TABLE

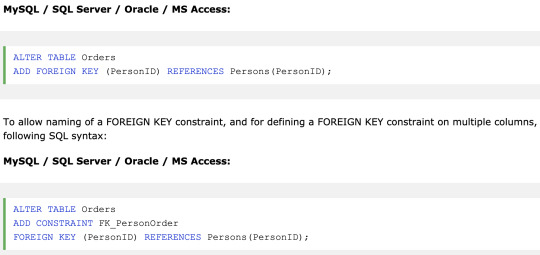
FOREIGN KEY - Uniquely identifies a row/record in another table
A FOREIGN KEY is a key used to link two tables together. A FOREIGN KEY is a column in one table that refers to the PRIMARY KEY in another table.
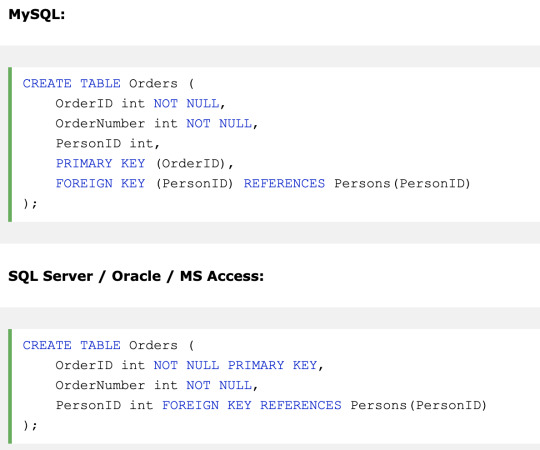
On multiple columns
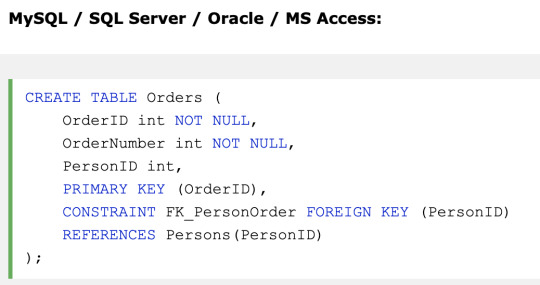
On ALTER TABLE
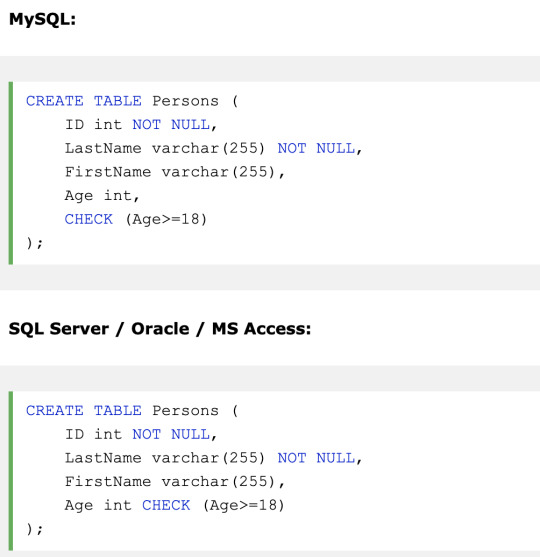
CHECK - Ensures that all values in a column satisfies a specific condition
used to limit the value range that can be placed in a column.
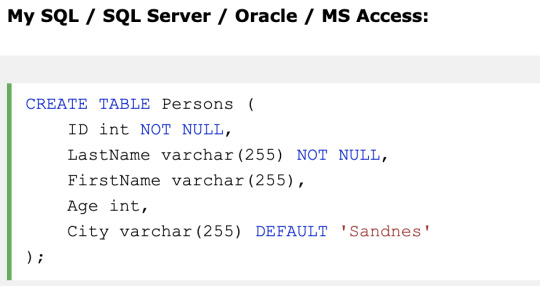
DEFAULT - Sets a default value for a column when no value is specified
INDEX - Used to create and retrieve data from the database very quickly
The users cannot see the indexes, they are just used to speed up searches/queries.
Updating a table with indexes takes more time than updating a table without (because the indexes also need an update). So, only create indexes on columns that will be frequently searched against.
AUTO INCREMENT
Auto-increment allows a unique number to be generated automatically when a new record is inserted into a table. Often this is the primary key field that we would like to be created automatically every time a new record is inserted.
MySQL

By default, the starting value for AUTO_INCREMENT is 1, and it will increment by 1 for each new record.
Date data types

e.g.) SELECT * FROM Orders WHERE OrderDate='2008-11-11'
What is a schema in SQL Server
A schema is a collection of database objects including tables, views, triggers, stored procedures, indexes, etc.
https://www.sqlservertutorial.net/sql-server-basics/sql-server-create-schema/
https://www.w3schools.com/sql/sql_create_db.asp https://www.w3schools.com/sql/sql_drop_db.asp https://www.w3schools.com/sql/sql_create_table.asp https://www.w3schools.com/sql/sql_datatypes.asp https://www.w3schools.com/sql/sql_drop_table.asp https://www.w3schools.com/sql/sql_alter.asp https://www.w3schools.com/sql/sql_constraints.asp https://www.w3schools.com/sql/sql_unique.asp https://www.w3schools.com/sql/sql_primarykey.asp https://www.w3schools.com/sql/sql_foreignkey.asp https://www.w3schools.com/sql/sql_check.asp https://www.w3schools.com/sql/sql_default.asp https://www.w3schools.com/sql/sql_create_index.asp https://www.w3schools.com/sql/sql_autoincrement.asp https://www.w3schools.com/sql/sql_dates.asp
0 notes
Text
300+ TOP PERL Interview Questions and Answers
Perl Interview Questions for freshers and experienced :-
1.How many type of variable in perl Perl has three built in variable types Scalar Array Hash 2.What is the different between array and hash in perl Array is an order list of values position by index. Hash is an unordered list of values position by keys. 3.What is the difference between a list and an array? A list is a fixed collection of scalars. An array is a variable that holds a variable collection of scalars. 4.what is the difference between use and require in perl Use : The method is used only for the modules(only to include .pm type file) The included objects are varified at the time of compilation. No Need to give file extension. Require: The method is used for both libraries and modules. The included objects are varified at the run time. Need to give file Extension. 5.How to Debug Perl Programs Start perl manually with the perl command and use the -d switch, followed by your script and any arguments you wish to pass to your script: "perl -d myscript.pl arg1 arg2" 6.What is a subroutine? A subroutine is like a function called upon to execute a task. subroutine is a reusable piece of code. 7.what does this mean '$^0'? tell briefly $^ - Holds the name of the default heading format for the default file handle. Normally, it is equal to the file handle's name with _TOP appended to it. 8.What is the difference between die and exit in perl? 1) die is used to throw an exception exit is used to exit the process. 2) die will set the error code based on $! or $? if the exception is uncaught. exit will set the error code based on its argument. 3) die outputs a message exit does not. 9.How to merge two array? @a=(1, 2, 3, 4); @b=(5, 6, 7, 8); @c=(@a, @b); print "@c"; 10.Adding and Removing Elements in Array Use the following functions to add/remove and elements: push(): adds an element to the end of an array. unshift(): adds an element to the beginning of an array. pop(): removes the last element of an array. shift() : removes the first element of an array.

PERL Interview Questions and Answers 11.How to get the hash size %ages = ('Martin' => 28, 'Sharon' => 35, 'Rikke' => 29); print "Hash size: ",scalar keys %ages,"n"; 12.Add & Remove Elements in Hashes %ages = ('Martin' => 28, 'Sharon' => 35, 'Rikke' => 29); # Add one more element in the hash $age{'John'} = 40; # Remove one element from the hash delete( $age{'Sharon'} ); 13.PERL Conditional Statements The conditional statements are if and unless 14.Perl supports four main loop types: While, for, until, foreach 15.There are three loop control keywords: next, last, and redo. The next keyword skips the remainder of the code block, forcing the loop to proceed to the next value in the loop. The last keyword ends the loop entirely, skipping the remaining statements in the code block, as well as dropping out of the loop. The redo keyword reexecutes the code block without reevaluating the conditional statement for the loop. 16.Renaming a file rename ("/usr/test/file1.txt", "/usr/test/file2.txt" ); 17.Deleting an existing file unlink ("/usr/test/file1.txt"); 18.Explain tell Function The first requirement is to find your position within a file, which you do using the tell function: tell FILEHANDLE tell 19.Perl Regular Expression A regular expression is a string of characters that define the pattern There are three regular expression operators within Perl Match Regular Expression - m// Substitute Regular Expression - s/// Transliterate Regular Expression - tr/// 20.What is the difference between chop & chomp functions in perl? chop is used remove last character, chomp function removes only line endings. 21.Email address validation – perl if ($email_address =~ /^(w¦-¦_¦.)+@((w¦-¦_)+.)+{2,}$/) { print "$email_address is valid"; } else { print "$email_address is invalid"; } 22.Why we use Perl? 1.Perl is a powerful free interpreter. 2.Perl is portable, flexible and easy to learn. 23. Given a file, count the word occurrence (case insensitive) open(FILE,"filename"); @array= ; $wor="word to be found"; $count=0; foreach $line (@array) { @arr=split (/s+/,$line); foreach $word (@arr) { if ($word =~ /s*$wors*/i) $count=$count+1; } } print "The word occurs $count times"; 24.Name all the prefix dereferencer in perl? The symbol that starts all scalar variables is called a prefix dereferencer. The different types of dereferencer are. (i) $-Scalar variables (ii) %-Hash variables (iii) @-arrays (iv) &-subroutines (v) Type globs-*myvar stands for @myvar, %myvar. What is the Use of Symbolic Reference in PERL? $name = "bam"; $$name = 1; # Sets $bam ${$name} = 2; # Sets $bam ${$name x 2} = 3; # Sets $bambam $name-> = 4; # Sets $bam symbolic reference means using a string as a reference. 25. What is the difference between for & foreach, exec & system? Both Perl's exec() function and system() function execute a system shell command. The big difference is that system() creates a fork process and waits to see if the command succeeds or fails - returning a value. exec() does not return anything, it simply executes the command. Neither of these commands should be used to capture the output of a system call. If your goal is to capture output, you should use the $result = system(PROGRAM); exec(PROGRAM); 26. What is the difference between for & foreach? Technically, there's no difference between for and foreach other than some style issues. One is an lias of another. You can do things like this foreach (my $i = 0; $i { # normally this is foreach print $i, "n"; } for my $i (0 .. 2) { # normally this is for print $i, "n";} 27. What is eval in perl? eval(EXPR) eval EXPR eval BLOCK EXPR is parsed and executed as if it were a little perl program. It is executed in the context of the current perl program, so that any variable settings, subroutine or format definitions remain afterwards. The value returned is the value of the last expression evaluated, just as with subroutines. If there is a syntax error or runtime error, or a die statement is executed, an undefined value is returned by eval, and $@ is set to the error message. If there was no error, $@ is guaranteed to be a null string. If EXPR is omitted, evaluates $_. The final semicolon, if any, may be omitted from the expression. 28. What's the difference between grep and map in Perl? grep returns those elements of the original list that match the expression, while map returns the result of the expression applied to each element of the original list. 29. How to Connect with SqlServer from perl and how to display database table info? there is a module in perl named DBI - Database independent interface which will be used to connect to any database by using same code. Along with DBI we should use database specific module here it is SQL server. for MSaccess it is DBD::ODBC, for MySQL it is DBD::mysql driver, for integrating oracle with perl use DBD::oracle driver is used. IIy for SQL server there are avilabale many custom defined ppm( perl package manager) like Win32::ODBC, mssql::oleDB etc.so, together with DBI, mssql::oleDB we can access SQL server database from perl. the commands to access database is same for any database. 30. Remove Duplicate Lines from a File use strict; use warnings; my @array=qw(one two three four five six one two six); print join(" ", uniq(@array)), "n"; sub uniq { my %seen = (); my @r = (); foreach my $a (@_) { unless ($seen{$a}) { push @r, $a; $seen{$a} = 1; } } return @r; } or my %unique = (); foreach my $item (@array) { $unique{$item} ++; } my @myuniquearray = keys %unique; print "@myuniquearray"; PERL Interview Questions with Answers 1. How do you know the reference of a variable whether it is a reference, scaler, hash or array? There is a ‘ref’ function that lets you know 2. What is the difference between ‘use’ and ‘require’ function? Use: 1. the method is used only for modules (only to include .pm type file) 2. the included object are verified at the time of compilation. 3. No Need to give file extension. Require: 1. The method is used for both libraries (package) and modules 2. The include objects are verified at the run time. 3. Need to give file Extension. 3. What is the use of ‘chomp’ ? what is the difference between ‘chomp’ and ‘chop’? ‘chop’ function only removes the last character completely ‘from the scalar, where as ‘chomp’ function only removes the last character if it is a newline. by default, chomp only removes what is currently defined as the $INPUT_RECORD_SEPARATOR. whenever you call ‘chomp ‘, it checks the value of a special variable ‘$/’. whatever the value of ‘$/’ is eliminated from the scaler. by default the value of ‘$/’ is ‘n’ 4. Print this array @arr in reversed case-insensitive order @solution = sort {lc $a comp lc$b } @arr. 5. What is ‘->’ in Perl? It is a symbolic link to link one file name to a new name. So let’s say we do it like file1-> file2, if we read file1, we end up reading file2. 6. How do you check the return code of system call? System calls “traditionally” returns 9 when successful and 1 when it fails. System (cmd) or die “Error in command”. 7. Create directory if not there Ans: if (! -s “$temp/engl_2/wf”){ System “mkdir -p $temp/engl_2/wf”; } if (! -s “$temp/backup_basedir”) { system “mkdir -p $temp/backup_basedir”; } 8. What is the use of -M and -s in the above script? Ans: -s means is filename a non-empty file -M how long since filename modified 9. How to substitute a particular string in a file containing million of record? perl -p -i.bak -e ‘s/search_str/replace_str/g’ filename 10. I have a variable named $objref which is defined in main package. I want to make it as a Object of class XYZ. How could I do it? use XYZ my $objref =XYZ -> new() OR, bless $objref, ‘XYZ’; 11. What is meant by a ‘pack’ in perl? Pack converts a list into a binary representation. Takes an array or list of values and packs it into a binary structure, returning the string containing the structure it takes a LIST of values and converts it into a string. The string contains a con-catenation of the converted values. Typically, each converted values looks like its machine-level representation. For example, on 32-bit machines a converted integer may be represented by a sequence of 4 bytes. 12. How to implement stack in Perl? Through push() and shift() function. push adds the element at the last of array and shift() removes from the beginning of an array. 13. What is Grep used for in Perl? Grep is used with regular expression to check if a particular value exists in an array. It returns 0 it the value does not exists, 1 otherwise. 14. How to code in Perl to implement the tail function in UNIX? You have to maintain a structure to store the line number and the size of the file at that time e.g. 1-10 bytes, 2-18 bytes.. You have a counter to increase the number of lines to find out the number of lines in the file. once you are through the file, you will know the size of the file at any nth line, use ‘sysseek’ to move the file pointer back to that position (last 10) and then tart reading till the end. 15. Explain the difference between ‘my’ and ‘local’ variable scope declarations? Both of them are used to declare local variables. The variables declared with ‘my’ can live only within the block and cannot gets its visibility inherited functions called within that block, but one defined as ‘local’ can live within the block and have its visibility in the functions called within that block. 16. How do you navigate through an XML documents? You can use the XML::DOM navigation methods to navigate through an XML::DOM node tree and use the get node value to recover the data. DOM Parser is used when it is need to do node operation. Instead we may use SAX parser if you require simple processing of the xml structure. 17. How to delete an entire directory containing few files in the directory? rmtree($dir); OR, you can use CPAN module File::Remove Though it sounds like deleting file but it can be used also for deleting directories. &File::Removes::remove (1,$feed-dir,$item_dir); 18. What are the arguments we normally use for Perl Interpreter -e for Execute -c to compile -d to call the debugger on the file specified -T for traint mode for security/input checking -W for show all warning mode (or -w to show less warning) 19. What is it meant by ‘$_’? It is a default variable which holds automatically, a list of arguments passed to the subroutine within parentheses. 20. How to connect to sql server through Perl? We use the DBI(Database Independent Interface) module to connect to any database. use DBI; $dh = DBI->connect(“dbi:mysql:database=DBname”,”username”,”password”); $sth = $dh->prepare(“select name, symbol from table”); $sth->execute(); while(@row = $sth->fetchrow_array()){ print “name =$row.symbol= $row; } $dh->disconnect 21. What is the purpose of -w, strict and -T? -w option enables warning – strict pragma is used when you should declare variables before their use -T is taint mode. TAint mode makes a program more secure by keeping track of arguments which are passed from external source. 22. What is the difference between die and exit? Die prints out STDERR message in the terminal before exiting the program while exit just terminate the program without giving any message. Die also can evaluate expressions before exiting. 23. Where do you go for perl help? perldoc command with -f option is the best. I also go to search.cpan.org for help. 24. What is the Tk module? It provides a GUI interface 25. What is your favourite module in Perl? CGI and DBI. CGI (Common Gateway Interface) because we do not need to worry about the subtle features of form processing. 26. What is hash in perl? A hash is like an associative array, in that it is a collection of scalar data, with individual elements selected by some index value which essentially are scalars and called as keys. Each key corresponds to some value. Hashes are represented by % followed by some name. 27. What does ‘qw()’ mean? what’s the use of it? qw is a construct which quotes words delimited by spaces. use it when you have long list of words that are into quoted or you just do not want to type those quotes as you type out a list of space delimited words. Like @a = qw(1234) which is like @a=(“1?,”2?,”3?,”4?); 28. What is the difference between Perl and shell script? Whatever you can do in shell script can be done in Perl. However Perl gives you an extended advantage of having enormous library. You do not need to write everything from scartch. 29. What is stderr() in perl? Special file handler to standard error in any package. 30. What is a regular expression? It defines a pattern for a search to match. 31. What is the difference between for and foreach? Functionally, there is no difference between them. 32. What is the difference between exec and system? exec runs the given process, switches to its name and never returns while system forks off the given process, waits for its to complete and then return. 33. What is CPAN? CPAN is comprehensive Perl Archive Network. It’s a repository contains thousands of Perl Modules, source and documentation, and all under GNU/GPL or similar license. You can go to www.cpan.org for more details. Some Linux distribution provides a till names ‘cpan; which you can install packages directly from cpan. 34. What does this symbol mean ‘->’? In Perl it is an infix dereference operator. For array subscript, or a hash key, or a subroutine, then its must be a reference. Can be used as method invocation. 35. What is a DataHash() In Win32::ODBC, DataHash() function is used to get the data fetched through the sql statement in a hash format. 36. What is the difference between C and Perl? make up 37. Perl regular exp are greedy. what is it mean by that? It tries to match the longest string possible. 38. What does the world ‘&my variable’ mean? &myvariable is calling a sub-routine. & is used to indentify a subroutine. 39. What is it meant by @ISA, @EXPORT, @EXPORT_OK? @ISA -> each package has its own @ISA array. This array keeps track of classes it is inheriting. Ex: package child; @ISA=(parent class); @EXPORT this array stores the subroutines to be exported from a module. @EXPORT_OK this array stores the subroutines to be exported only on request. 40. What package you use to create windows services? use Win32::OLE. 41. How to start Perl in interactive mode? perl -e -d 1 PerlConsole. 42. How do I set environment variables in Perl programs? You can just do something like this: $ENV{‘PATH’} = ‘…’; As you may remember, “%ENV” is a special hash in Perl that contains the value of all your environment variables. Because %ENV is a hash, you can set environment variables just as you’d set the value of any Perl hash variable. Here’s how you can set your PATH variable to make sure the following four directories are in your path:: $ENV{‘PATH’} = ‘/bin:/usr/bin:/usr/local/bin:/home/your name/bin’. 43. What is the difference between C++ and Perl? Perl can have objects whose data cannot be accessed outside its class, but C++ cannot. Perl can use closures with unreachable private data as objects, and C++ doesn’t support closures. Furthermore, C++ does support pointer arithmetic via `int *ip =(int*)&object’, allowing you do look all over the object. Perl doesn’t have pointer arithmetic. It also doesn’t allow `#define private public’ to change access rights to foreign objects. On the other hand, once you start poking around in /dev/mem, no one is safe. 44. How to open and read data files with Perl? Data files are opened in Perl using the open() function. When you open a data file, all you have to do is specify (a) a file handle and (b) the name of the file you want to read from. As an example, suppose you need to read some data from a file named “checkbook.txt”. Here’s a simple open statement that opens the checkbook file for read access: open (CHECKBOOK, “checkbook.txt”);' In this example, the name “CHECKBOOK” is the file handle that you’ll use later when reading from the checkbook.txt data file. Any time you want to read data from the checkbook file, just use the file handle named “CHECKBOOK”. Now that we’ve opened the checkbook file, we’d like to be able to read what’s in it. Here’s how to read one line of data from the checkbook file: $record = ; After this statement is executed, the variable $record contains the contents of the first line of the checkbook file. The “” symbol is called the line reading operator. To print every record of information from the checkbook file open (CHECKBOOK, “checkbook.txt”) || die “couldn’t open the file!”; while ($record = ) { print $record; } close(CHECKBOOK); 45. How do i do fill_in_the_blank for each file in a directory? #!/usr/bin/perl –w opendir(DIR, “.”); @files = readdir(DIR); closedir(DIR); foreach $file (@files) { print “$filen”; } 46. How do I generate a list of all .html files in a directory Here is a snippet of code that just prints a listing of every file in teh current directory. That ends with the entension #!/usr/bin/perl –w opendir(DIR, “.”); @files = grep(/.html$/, readdir(DIR)); closedir(DIR); foreach $file (@files) { print “$filen”; } 47. What is Perl one-liner? There are two ways a Perl script can be run: –from a command line, called oneliner, that means you type and execute immediately on the command line. You’ll need the -e option to start like “C: %gt perl -e “print ”Hello”;”. One-liner doesn’t mean one Perl statement. One-liner may contain many statements in one line. –from a script file, called Perl program. 48. Assume both a local($var) and a my($var) exist, what’s the difference between ${var} and ${“var”}? ${var} is the lexical variable $var, and ${“var”} is the dynamic variable $var. Note that because the second is a symbol table lookup, it is disallowed under `use strict “refs”‘. The words global, local, package, symbol table, and dynamic all refer to the kind of variables that local() affects, whereas the other sort, those governed by my(), are variously knows as private, lexical, or scoped variable. 49. What happens when you return a reference to a private variable? Perl keeps track of your variables, whether dynamic or otherwise, and doesn’t free things before you’re done using them 50. What are scalar data and scalar variables? Perl has a flexible concept of data types. Scalar means a single thing, like a number or string. So the Java concept of int, float, double and string equals to Perl’s scalar in concept and the numbers and strings are exchangeable. Scalar variable is a Perl variable that is used to store scalar data. It uses a dollar sign $ and followed by one or more alphanumeric characters or underscores. It is case sensitive. 51. Assuming $_ contains HTML, which of the following substitutions will remove all tags in it? You can’t do that. If it weren’t for HTML comments, improperly formatted HTML, and tags with interesting data like , you could do this. Alas, you cannot. It takes a lot more smarts, and quite frankly, a real parser. 52. What is the output of the following Perl program? $p1 = “prog1.java”; $p1 =~ s/(.*).java/$1.cpp/; print “$p1n”; prog1.cpp 53. Why aren’t Perl’s patterns regular expressions? Because Perl patterns has backreferences. A regular expression by definition must be able to determine the next state in the finite automaton without requiring any extra memory to keep around previous state. A pattern /(+)c1/ requires the state machine to remember old states, and thus disqualifies such patterns as being regular expressions in the classic sense of the term. 54. What does Perl do if you try to exploit the execve(2) race involving setuid scripts? Sends mail to root and exits. It has been said that all programs advance to the point of being able to automatically read mail. While not quite at that point (well, without having a module loaded), Perl does at least automatically send it. 55. How do I do for each element in a hash? Here’s a simple technique to process each element in a hash: #!/usr/bin/perl -w %days = ( ‘Sun’ =>’Sunday’, ‘Mon’ => ‘Monday’, ‘Tue’ => ‘Tuesday’, ‘Wed’ => ‘Wednesday’, ‘Thu’ => ‘Thursday’, ‘Fri’ => ‘Friday’, ‘Sat’ => ‘Saturday’ ); foreach $key (sort keys %days) { print “The long name for $key is $days{$key}.n”; } 56. How do I sort a hash by the hash key? Ans:. Suppose we have a class of five students. Their names are kim, al, rocky, chrisy, and jane. Here’s a test program that prints the contents of the grades hash, sorted by student name: #!/usr/bin/perl –w %grades = ( kim => 96, al => 63, rocky => 87, chrisy => 96, jane => 79, ); print “ntGRADES SORTED BY STUDENT NAME:n”; foreach $key (sort (keys(%grades))) { print “tt$key tt$grades{$key}n”; } The output of this program looks like this: GRADES SORTED BY STUDENT NAME: al 63 chrisy 96 jane 79 kim 96 rocky 87 57. How do you print out the next line from a filehandle with all its bytes reversed? print scalar reverse scalar surprisingly enough, you have to put both the reverse and the in to scalar context separately for this to work. 58. How do I send e-mail from a Perl/CGI program on a Unix system? Sending e-mail from a Perl/CGI program on a Unix computer system is usually pretty simple. Most Perl programs directly invoke the Unix sendmail program. We’ll go through a quick example here. Assuming that you’ve already have e-mail information you need, such as the send-to address and subject, you can use these next steps to generate and send the e-mail message: # the rest of your program is up here … open(MAIL, “|/usr/lib/sendmail -t”); print MAIL “To: $sendToAddressn”; print MAIL “From: $myEmailAddressn”; print MAIL “Subject: $subjectn”; print MAIL “This is the message body.n”; print MAIL “Put your message here in the body.n”; close (MAIL); 59. How to read from a pipeline with Perl? To run the date command from a Perl program, and read the output of the command, all you need are a few lines of code like this: open(DATE, “date|”); $theDate = ; close(DATE); The open() function runs the external date command, then opens a file handle DATE to the output of the date command. Next, the output of the date command is read into the variable $theDate through the file handle DATE. Example 2: The following code runs the “ps -f” command, and reads the output: open(PS_F, “ps -f|”); while (){ ($uid,$pid,$ppid,$restOfLine) = split; # do whatever I want with the variables here … } close(PS_F); 60. Why is it hard to call this function: sub y { “because” } Ans. Because y is a kind of quoting operator. The y/// operator is the sed-savvy synonym for tr///. That means y(3) would be like tr(), which would be looking for a second string, as in tr/a-z/A-Z/, tr(a-z)(A-Z), or tr. 61. Why does Perl not have overloaded functions? Because you can inspect the argument count, return context, and object types all by yourself. In Perl, the number of arguments is trivially available to a function via the scalar sense of @_, the return context via wantarray(), and the types of the arguments via ref() if they’re references and simple pattern matching like /^d+$/ otherwise. In languages like C++ where you can’t do this, you simply must resort to overloading of functions. 62. What does read() return at end of file? 0. A defined (but false) 0 value is the proper indication of the end of file for read() and sysread(). 63. How do I sort a hash by the hash value? Here’s a program that prints the contents of the grades hash, sorted numerically by the hash value: #!/usr/bin/perl –w # Help sort a hash by the hash ‘value’, not the ‘key’. To highest). # sub hashValueAscendingNum { $grades{$a} $grades{$b}; } # Help sort a hash by the hash ‘value’, not the ‘key’. # Values are returned in descending numeric order # (highest to lowest). sub hashValueDescendingNum { $grades{$b} $grades{$a}; } %grades = ( student1 => 90, student2 => 75, student3 => 96, student4 => 55, student5 => 76 ); print “ntGRADES IN ASCENDING NUMERIC ORDER:n”; foreach $key (sort hashValueAscendingNum (keys(%grades))) { print “tt$grades{$key} tt $keyn”; } print “ntGRADES IN DESCENDING NUMERIC ORDER:n”; foreach $key (sort hashValueDescendingNum (keys(%grades))) { print “tt$grades{$key} tt $keyn”; } 64. How do find the length of an array? scalar @array 65. What value is returned by a lone `return;’ statement? The undefined value in scalar context, and the empty list value () in list context. This way functions that wish to return failure can just use a simple return without worrying about the context in which they were called. 66. What’s the difference between /^Foo/s and /^Foo/? The second would match Foo other than at the start of the record if $* were set. The deprecated $* flag does double duty, filling the roles of both /s and /m. By using /s, you suppress any settings of that spooky variable, and force your carets and dollars to match only at the ends of the string and not at ends of line as well — just as they would if $* weren’t set at all. 67. Does Perl have reference type? Yes. Perl can make a scalar or hash type reference by using backslash operator. For example $str = “here we go”; # a scalar variable $strref = $str; # a reference to a scalar @array = (1..10); # an array $arrayref = @array; # a reference to an array Note that the reference itself is a scalar. 68. How to dereference a reference? There are a number of ways to dereference a reference. Using two dollar signs to dereference a scalar. $original = $$strref; Using @ sign to dereference an array. @list = @$arrayref; Similar for hashes. 69. How do I do for each element in an array? #!/usr/bin/perl –w @homeRunHitters = (‘McGwire’, ‘Sosa’, ‘Maris’, ‘Ruth’); Foreach (@homeRunHitters) { print “$_ hit a lot of home runs in one yearn”; } 70. How do I replace every character in a file with a comma? perl -pi.bak -e ‘s/t/,/g’ myfile.txt 71. What is the easiest way to download the contents of a URL with Perl? Once you have the libwww-perl library, LWP.pm installed, the code is this: #!/usr/bin/perl use LWP::Simple; $url = get ‘http://www.websitename.com/’; 72. How to concatenate strings in Perl? Through . operator. 73. How do I read command-line arguments with Perl? With Perl, command-line arguments are stored in the array named @ARGV. $ARGV contains the first argument, $ARGV contains the second argument, etc. $#ARGV is the subscript of the last element of the @ARGV array, so the number of arguments on the command line is $#ARGV + 1. Here’s a simple program: #!/usr/bin/perl $numArgs = $#ARGV + 1; print “thanks, you gave me $numArgs command-line arguments.n”; foreach $argnum (0 .. $#ARGV) { print “$ARGVn”; } 74. Assume that $ref refers to a scalar, an array, a hash or to some nested data structure. Explain the following statements: $$ref; # returns a scalar $$ref; # returns the first element of that array $ref- > ; # returns the first element of that array @$ref; # returns the contents of that array, or number of elements, in scalar context $&$ref; # returns the last index in that array $ref- > ; # returns the sixth element in the first row @{$ref- > {key}} # returns the contents of the array that is the value of the key “key” 75. Perl uses single or double quotes to surround a zero or more characters. Are the single(‘ ‘) or double quotes (” “) identical? They are not identical. There are several differences between using single quotes and double quotes for strings. 1. The double-quoted string will perform variable interpolation on its contents. That is, any variable references inside the quotes will be replaced by the actual values. 2. The single-quoted string will print just like it is. It doesn’t care the dollar signs. 3. The double-quoted string can contain the escape characters like newline, tab, carraige return, etc. 4. The single-quoted string can contain the escape sequences, like single quote, backward slash, etc. 76. How many ways can we express string in Perl? Many. For example ‘this is a string’ can be expressed in: “this is a string” qq/this is a string like double-quoted string/ qq^this is a string like double-quoted string^ q/this is a string/ q&this is a string& q(this is a string) 77. How do you give functions private variables that retain their values between calls? Create a scope surrounding that sub that contains lexicals. Only lexical variables are truly private, and they will persist even when their block exits if something still cares about them. Thus: { my $i = 0; sub next_i { $i++ } sub last_i { –$i } } creates two functions that share a private variable. The $i variable will not be deallocated when its block goes away because next_i and last_i need to be able to access it. 78. Explain the difference between the following in Perl: $array vs. $array-> Because Perl’s basic data structure is all flat, references are the only way to build complex structures, which means references can be used in very tricky ways. This question is easy, though. In $array, “array” is the (symbolic) name of an array (@array) and $array refers to the 4th element of this named array. In $array->, “array” is a hard reference to a (possibly anonymous) array, i.e., $array is the reference to this array, so $array-> is the 4th element of this array being referenced. 79. How to remove duplicates from an array? There is one simple and elegant solution for removing duplicates from a list in PERL @array = (2,4,3,3,4,6,2); my %seen = (); my @unique = grep { ! $seen{ $_ }++ } @array; print “@unique”; PERL Questions and Answers pdf Download Read the full article
0 notes
Text
SQL (Database Programming) - Chris Fehily
SQL (Database Programming) 2015 Edition Chris Fehily Genre: Computers Price: $9.99 Publish Date: July 14, 2014 Publisher: Questing Vole Press Seller: Questing Vole Press 2015 Edition. Perfect for end users, analysts, data scientists, and app developers, this best-selling guide will get you up and running with SQL, the language of databases. You'll find general concepts, practical answers, and clear explanations of what the various SQL statements can do. Hundreds of examples of varied difficulty encourage you to experiment and explore. Full-color SQL code listings help you see the elements and structure of the language. You can download the sample database to follow along with the author's examples. • Covers Oracle, Microsoft SQL Server, IBM DB2, MySQL, PostgreSQL, and Microsoft Access. • Learn the core language for standard SQL, and variations for the most widely used database systems. • Organize your database in terms of the relational model. • Master tables, columns, rows, and keys. • Retrieve, sort, and format data. • Filter the data that you don't want to see. • Convert and manipulate data with SQL's built-in functions and operators. • Use aggregate functions to summarize data. • Create complex SQL statements by using joins, subqueries, constraints, conditional logic, and metadata. • Create, alter, and drop tables, indexes, and views. • Insert, update, delete, and merge data. • Execute transactions to maintain the integrity of your data. • Avoid common pitfalls involving nulls. • Troubleshoot and optimize queries. • Plenty of tips, tricks, and timesavers. • Fully cross-referenced, linked, and searchable. Contents Introduction 1. Running SQL Programs 2. The Relational Model 3. SQL Basics 4. Retrieving Data from a Table 5. Operators and Functions 6. Summarizing and Grouping Data 7. Joins 8. Subqueries 9. Set Operations 10. Inserting, Updating, and Deleting Rows 11. Creating, Altering, and Dropping Tables 12. Indexes 13. Views 14. Transactions About the Author Chris Fehily is a statistician and author based in San Francisco. http://bit.ly/2VuekSE
0 notes
Text
Export and import data from Amazon S3 to Amazon Aurora PostgreSQL
You can build highly distributed applications using a multitude of purpose-built databases by decoupling complex applications into smaller pieces, which allows you to choose the right database for the right job. Amazon Aurora is the preferred choice for OLTP workloads. Aurora makes it easy to set up, operate, and scale a relational database in the cloud. This post demonstrates how you can export and import data from Amazon Aurora PostgreSQL-Compatible Edition to Amazon Simple Storage Service (Amazon S3) and shares associated best practices. The feature to export and import data to Amazon S3 is also available for Amazon Aurora MySQL-Compatible Edition. Overview of Aurora PostgreSQL-Compatible and Amazon S3 Aurora is a MySQL-compatible and PostgreSQL-compatible relational database built for the cloud. It combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open-source databases. Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. This means customers of all sizes and industries can use it to store and protect any amount of data. The following diagram illustrates the solution architecture. Prerequisites Before you get started, complete the following prerequisite steps: Launch an Aurora PostgreSQL DB cluster. You can also use an existing cluster. Note: To export data to Amazon S3 from Aurora PostgreSQL, your database must be running one of the following PostgreSQL engine versions 10.14 or higher, 11.9 or higher ,12.4 or higher Launch an Amazon EC2 instance that you installed the PostgreSQL client on. You can also use the pgAdmin tool or tool of your choice for this purpose. Create the required Identity and Access Management (IAM) policies and roles: Create an IAM policy with the least-restricted privilege to the resources in the following code and name it aurora-s3-access-pol. The policy must have access to the S3 bucket where the files are stored (for this post, aurora-pg-sample-loaddata01). { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:AbortMultipartUpload", "s3:DeleteObject", "s3:ListMultipartUploadParts", "s3:PutObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::aurora-pg-sample-loaddata01/*", "arn:aws:s3:::aurora-pg-sample-loaddata01" ] } ] } Create two IAM roles named aurora-s3-export-role and aurora-s3-import-role and modify the trust relationships according to the following code. AssumeRole allows Aurora to access other AWS services on your behalf. {"Version": "2012-10-17","Statement": [ { "Effect": "Allow","Principal": { "Service": "rds.amazonaws.com" },"Action": "sts:AssumeRole" } ] } Attach the policy aurora-s3-access-pol from the previous step. For this post, we create the roles aurora-s3-export-role and aurora-s3-import-role. Their associated ARNs are arn:aws:iam::123456789012:role/aurora-s3-export-role and arn:aws:iam::123456789012:role/aurora-s3-import-role, respectively. Associate the IAM roles to the cluster. This enables the Aurora DB cluster to access the S3 bucket. See the following code: aws rds add-role-to-db-cluster --db-cluster-identifier aurora-postgres-cl --feature-name s3Export --role-arn arn:aws:iam::123456789012:role/aurora-s3-export-role aws rds add-role-to-db-cluster --db-cluster-identifier aurora-postgres-cl --feature-name s3Import --role-arn arn:aws:iam::123456789012:role/aurora-s3-import-role You’re now ready to explore the following use cases of exporting and importing data. Export data from Aurora PostgreSQL to Amazon S3 To export your data, complete the following steps: Connect to the cluster as the primary user, postgres in our case.By default, the primary user has permission to export and import data from Amazon S3. For this post, you create a test user with the least-required permission to export data to the S3 bucket. See the following code: psql -h aurora-postgres-cl.cluster-XXXXXXXXXXXX.us-east-1.rds.amazonaws.com -p 5432 -d pg1 -U postgres Install the required PostgreSQL extensions, aws_s3 and aws_commons. When you install the aws_s3 extension, the aws_commons extension is also installed: CREATE EXTENSION IF NOT EXISTS aws_s3 CASCADE; Create the user testuser (or you can use an existing user): create user testuser; password testuser; You can verify the user has been created with the du command: du testuser List of roles Role name | Attributes | Member of -----------+------------+----------- testuser | | {} Grant privileges on the aws_s3 schema to testuser (or another user you chose): grant execute on all functions in schema aws_s3 to testuser; Log in to the cluster as testuser: psql -h aurora-postgres-cl.cluster-XXXXXXXXXXXX.us-east-1.rds.amazonaws.com -p 5432 -d pg1 -U testuser Create and populate a test table called apg2s3_table, which you use for exporting data to the S3 bucket. You can use any existing table in your database (preferably small size) to test this feature. See the following code: CREATE TABLE apg2s3_table ( bid bigint PRIMARY KEY, name varchar(80) ); Insert a few records using the following statement: INSERT INTO apg2s3_table (bid,name) VALUES (1, 'Monday'), (2,'Tuesday'), (3, 'Wednesday'); To export data from the Aurora table to the S3 bucket, use the aws_s3.query_export_to_s3 and aws_commons.create_s3_uri functions: We use the aws_commons.create_s3_uri function to load a variable with the appropriate URI information required by the aws_s3.query_export_to_s3 function. The parameters required by the aws_commons.create_s3_uri function are the S3 bucket name, the full path (folder and filename) for the file to be created by the export command, and the Region. See the following example code: SELECT aws_commons.create_s3_uri( 'aurora-pg-sample-loaddata01', 'apg2s3_table', 'us-east-1' ) AS s3_uri_1 gset Export the entire table to the S3 bucket with the following code: SELECT * FROM aws_s3.query_export_to_s3( 'SELECT * FROM apg2s3_table',:'s3_uri_1'); rows_uploaded | files_uploaded | bytes_uploaded ---------------+----------------+---------------- 3 | 1 | 31 (1 row) If you’re trying this feature out for the first time, consider using the LIMIT clause for a larger table. If you’re using a PostgreSQL client that doesn’t have the gset command available, the workaround is to call the aws_commons.create_s3_uri function inside of the aws_s3.query_export_to_s3 function as follows: SELECT * FROM aws_s3.query_export_to_s3( 'SELECT * FROM apg2s3_table', aws_commons.create_s3_uri( 'aurora-pg-sample-loaddata01', 'apg2s3_table','us-east-1')); rows_uploaded | files_uploaded | bytes_uploaded ---------------+----------------+---------------- 3 | 1 | 31 (1 row) The final step is to verify the export file was created in the S3 bucket. The default file size threshold is 6 GB. Because the data selected by the statement is less than the file size threshold, a single file is created: aws s3 ls s3://aurora-pg-sample-loaddata01/apg2s3_table --human-readable --summarize 2020-12-12 12:06:59 31 Bytes apg2s3_table Total Objects: 1 Total Size: 31 Bytes If you need the file size to be smaller than 6 GB, you can identify a column to split the table data into small portions and run multiple SELECT INTO OUTFILE statements (using the WHERE condition). It’s best to do this when the amount of data selected is more than 25 GB. Import data from Amazon S3 to Aurora PostgreSQL In this section, you load the data back to the Aurora table from the S3 file. Complete the following steps: Create a new table called apg2s3_table_imp: CREATE TABLE apg2s3_table_imp( bid bigint PRIMARY KEY, name varchar(80) ); Use the create_s3_uri function to load a variable named s3_uri_1 with the appropriate URI information required by the aws_s3.table_import_from_s3 function: SELECT aws_commons.create_s3_uri( 'aurora-pg-sample-loaddata01', 'apg2s3_table','us-east-1') AS s3_uri_1 gset Use the aws_s3.table_import_from_s3 function to import the data file from an Amazon S3 prefix: SELECT aws_s3.table_import_from_s3( 'apg2s3_table_imp', '', '(format text)', :'s3_uri_1' ); Verify the information was loaded into the apg2s3_table_imp table: SELECT * FROM apg2s3_table_imp; Best practices This section discusses a few best practices for bulk loading large datasets from Amazon S3 to your Aurora PostgreSQL database. The observations we present are based on a series of tests loading 100 million records to the apg2s3_table_imp table on a db.r5.2xlarge instance (see the preceding sections for table structure and example records). We carried out load testing when no other active transactions were running on the cluster. Results might vary depending on your cluster loads and instance type. The baseline load included 100 million records using the single file apg2s3_table.csv, without any structural changes to the target table apg2s3_table_imp or configuration changes to the Aurora PostgreSQL database. The data load took approximately 360 seconds. See the following code: time psql -h aurora-postgres-cl.cluster-XXXXXXXXXXXX.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "SELECT aws_s3.table_import_from_s3('apg2s3_table_imp','','(format CSV)','aurora-pg-sample-loaddata01','apg2s3_table.csv','us-east-1')" table_import_from_s3 --------------------------------------------------------------------------------------------------------- 100000000 rows imported into relation "apg2s3_table_imp" from file apg2s3_table.csv of 3177777796 bytes (1 row) real 6m0.368s user 0m0.005s sys 0m0.005s We used the same dataset to implement some best practices iteratively to measure their performance benefits on the load times. The following best practices are listed in order of the observed performance benefits from lower to higher improvements. Drop indexes and constraints Although indexes can significantly increase the performance of some DML operations such as UPDATE and DELETE, these data structures can also decrease the performance of inserts, especially when dealing with bulk data inserts. The reason is that after each new record is inserted in the table, the associated indexes also need to be updated to reflect the new rows being loaded. Therefore, a best practice for bulk data loads is dropping indexes and constraints on the target tables before a load and recreating them when the load is complete. In our test case, by dropping the primary key and index associated with the apg2s3_table_imp table, we reduced the data load down to approximately 131 seconds (data load + recreation on primary key). This is roughly 2.7 times faster than the baseline. See the following code: psql -h aurora-postgres-cl.cluster-XXXXXXXXXXXX.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "d apg2s3_table_imp" Table "public.apg2s3_table_imp" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+-----------------------+-----------+----------+---------+----------+--------------+------------- bid | bigint | | not null | | plain | | name | character varying(80) | | | | extended | | Indexes: "apg2s3_table_imp_pkey" PRIMARY KEY, btree (bid) psql -h aurora-postgres-cl.cluster-XXXXXXXXXXXX.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "ALTER TABLE apg2s3_table_imp DROP CONSTRAINT apg2s3_table_imp_pkey" ALTER TABLE psql -h aurora-postgres-cl.cluster-XXXXXXXXXXXX.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "d apg2s3_table_imp" Table "public.apg2s3_table_imp" Column | Type | Collation | Nullable | Default --------+-----------------------+-----------+----------+--------- bid | bigint | | not null | name | character varying(80) | | | time psql -h aurora-postgres-cl.cluster-XXXXXXXXXXXX.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "SELECT aws_s3.table_import_from_s3('apg2s3_table_imp','','(format CSV)','aurora-pg-sample-loaddata01','apg2s3_table.csv','us-east-1')" table_import_from_s3 --------------------------------------------------------------------------------------------------------- 100000000 rows imported into relation "apg2s3_table_imp" from file apg2s3_table.csv of 3177777796 bytes (1 row) real 1m24.950s user 0m0.005s sys 0m0.005s time psql -h demopg-instance-1.cmcmpwi7rtng.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "ALTER TABLE apg2s3_table_imp ADD PRIMARY KEY (bid);" ALTER TABLE real 0m46.731s user 0m0.009s sys 0m0.000s Concurrent loads To improve load performance, you can split large datasets into multiple files that can be loaded concurrently. However, the degree of concurrency can impact other transactions running on the cluster. The number of vCPUs allocated to instance types plays a key role because load operation requires CPU cycles to read data, insert into tables, commit changes, and more. For more information, see Amazon RDS Instance Types. Loading several tables concurrently with few vCPUs can cause CPU utilization to spike and may impact the existing workload. For more information, see Overview of monitoring Amazon RDS. For our test case, we split the original file into five pieces of 20 million records each. Then we created simple shell script to run a psql command for each file to be loaded, like the following: #To make the test simpler, we named the datafiles as apg2s3_table_imp_XX. #Where XX is a numeric value between 01 and 05 for i in 1 2 3 4 5 do myFile=apg2s3_table_imp_0$i psql -h aurora-postgres-cl.cluster-cmcmpwi7rtng.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "SELECT aws_s3.table_import_from_s3( 'apg2s3_table_imp', '', '(format CSV)','aurora-pg-sample-loaddata01','$myFile','us-east-1')" & done wait You can export the PGPASSWORD environment variable in the session where you’re running the script to prevent psql from prompting for a database password. Next, we ran the script: time ./s3Load5 table_import_from_s3 ---------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp" from file apg2s3_table_imp_01 of 617777794 bytes (1 row) table_import_from_s3 ---------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp" from file apg2s3_table_imp_02 of 640000000 bytes (1 row) table_import_from_s3 ---------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp" from file apg2s3_table_imp_03 of 640000002 bytes (1 row) table_import_from_s3 ---------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp" from file apg2s3_table_imp_04 of 640000000 bytes (1 row) table_import_from_s3 ---------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp" from file apg2s3_table_imp_05 of 640000000 bytes (1 row) real 0m40.126s user 0m0.025s sys 0m0.020s time psql -h demopg-instance-1.cmcmpwi7rtng.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "ALTER TABLE apg2s3_table_imp ADD PRIMARY KEY (bid);" ALTER TABLE real 0m48.087s user 0m0.006s sys 0m0.003s The full load duration, including primary key rebuild, was reduced to approximately 88 seconds, which demonstrates the performance benefits of parallel loads. Implement partitioning If you’re using partitioned tables, consider loading partitions in parallel to further improve load performance. To test this best practice, we partition the apg2s3_table_imp table on the bid column as follows: CREATE TABLE apg2s3_table_imp ( bid BIGINT, name VARCHAR(80) ) PARTITION BY RANGE(bid); CREATE TABLE apg2s3_table_imp_01 PARTITION OF apg2s3_table_imp FOR VALUES FROM (1) TO (20000001); CREATE TABLE apg2s3_table_imp_02 PARTITION OF apg2s3_table_imp FOR VALUES FROM (20000001) TO (40000001); CREATE TABLE apg2s3_table_imp_03 PARTITION OF apg2s3_table_imp FOR VALUES FROM (40000001) TO (60000001); CREATE TABLE apg2s3_table_imp_04 PARTITION OF apg2s3_table_imp FOR VALUES FROM (60000001) TO (80000001); CREATE TABLE apg2s3_table_imp_05 PARTITION OF apg2s3_table_imp FOR VALUES FROM (80000001) TO (MAXVALUE); To load all the partitions in parallel, we modified the shell script used in the previous example: #To make the test simpler, we named the datafiles as apg2s3_table_imp_XX. #Where XX is a numeric value between 01 and 05 for i in 1 2 3 4 5 do myFile=apg2s3_table_imp_0$i psql -h aurora-postgres-cl.cluster-cmcmpwi7rtng.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "SELECT aws_s3.table_import_from_s3( '$myFile', '', '(format CSV)','aurora-pg-sample-loaddata01','$myFile','us-east-1')" & done wait Then we ran the script to load all five partitions in parallel: time ./s3LoadPart table_import_from_s3 ------------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp_04" from file apg2s3_table_imp_04 of 640000000 bytes (1 row) table_import_from_s3 ------------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp_02" from file apg2s3_table_imp_02 of 640000000 bytes (1 row) table_import_from_s3 ------------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp_05" from file apg2s3_table_imp_05 of 640000002 bytes (1 row) table_import_from_s3 ------------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp_01" from file apg2s3_table_imp_01 of 617777794 bytes (1 row) table_import_from_s3 ------------------------------------------------------------------------------------------------------------- 20000000 rows imported into relation "apg2s3_table_imp_03" from file apg2s3_table_imp_03 of 640000000 bytes (1 row) real 0m28.665s user 0m0.022s sys 0m0.024s $ time psql -h demopg-instance-1.cmcmpwi7rtng.us-east-1.rds.amazonaws.com -p 5432 -U testuser -d pg1 -c "ALTER TABLE apg2s3_table_imp ADD PRIMARY KEY (bid);" ALTER TABLE real 0m48.516s user 0m0.005s sys 0m0.004s Loading all partitions concurrently reduced the load times even further, to approximately 77 seconds. Disable triggers Triggers are frequently used in applications to perform additional processing after certain conditions (such as INSERT, UPDATE, or DELETE DML operations) run against tables. Because of this additional processing, performing large data loads on a table where triggers are enabled can decrease the load performance substantially. It’s recommended to disable triggers prior to bulk load operations and re-enable them when the load is complete. Summary This post demonstrated how to import and export data between Aurora PostgreSQL and Amazon S3. Aurora is powered with operational analytics capabilities, and integration with Amazon S3 makes it easier to establish an agile analytical environment. For more information about importing and exporting data, see Migrating data to Amazon Aurora with PostgreSQL compatibility. For more information about Aurora best practices, see Best Practices with Amazon Aurora PostgreSQL. About the authors Suresh Patnam is a Solutions Architect at AWS. He helps customers innovate on the AWS platform by building highly available, scalable, and secure architectures on Big Data and AI/ML. In his spare time, Suresh enjoys playing tennis and spending time with his family. Israel Oros is a Database Migration Consultant at AWS. He works with customers in their journey to the cloud with a focus on complex database migration programs. In his spare time, Israel enjoys traveling to new places with his wife and riding his bicycle whenever weather permits. https://aws.amazon.com/blogs/database/export-and-import-data-from-amazon-s3-to-amazon-aurora-postgresql/
0 notes
Text
SQL Introduction
sql What is SQL? SQL stands for Structured Query Language and is a declarative programming language utilized to obtain and manipulate information in RDBMS (Relational Database Management Methods). SQL was developed by IBM in 70's for their mainframe system. Various yrs later on SQL turned standardized by both American Countrywide Criteria Institute (ANSI-SQL) and International Firm for Standardization (ISO-SQL). According to ANSI SQL is pronounced "es queue el", but quite a few software program and database builders with qualifications in MS SQL Server pronounce it "sequel". What is RDBMS? A Relational Database Administration Process is a piece of software program employed to retailer and manage info in databases objects known as tables. A relational databases table is a tabular data construction organized in columns and rows. The table columns also regarded as desk fields have distinctive names and different attributes defining the column variety, default benefit, indexes and many other column characteristics. The rows of the relational database desk are the actual info entries. Most well-liked SQL RDBMS The most well-known RDBMS are MS SQL Server from Microsoft, Oracle from Oracle Corp., DB2 from IBM, MySQL from MySQL, and MS Accessibility from Microsoft. Most industrial database vendors have designed their proprietary SQL extension centered on ANSI-SQL common. For instance the SQL variation utilized by MS SQL Server is known as Transact-SQL or basically T-SQL, The Oracle's variation is called PL/SQL (short for Procedural Language/SQL), and MS Obtain use Jet-SQL. What can you do with SQL? o SQL queries are used to retrieve information from database tables. The SQL queries use the Choose SQL key phrase which is component of the Knowledge Query Language (DQL). If we have a table known as "Orders" and you want to select all entries in which the purchase benefit is greater than $one hundred requested by the buy price, you can do it with the subsequent SQL Choose question: Choose OrderID, ProductID, CustomerID, OrderDate, OrderValue FROM Orders The place OrderValue > two hundred Purchase BY OrderValue The FROM SQL clause specifies from which desk(s) we are retrieving information. The Exactly where SQL clause specifies research conditions (in our case to retrieve only information with OrderValue increased than $200). The Get BY clause specifies that the returned facts has to be purchase by the OrderValue column. The The place and Get BY clauses are optional. o You can manipulate data stored in relational databases tables, by making use of the INSERT, UPDATE and DELETE SQL key phrases. These a few SQL commands are element of the Facts Manipulation Language (DML). -- To insert facts into a desk called "Orders" you can use a SQL assertion equivalent to the one particular underneath: INSERT INTO Orders (ProductID, CustomerID, OrderDate, OrderValue) VALUES (ten, 108, '12/12/2007', 99.ninety five) -- To modify facts in a desk you can use a statement like this: UPDATE Orders Set OrderValue = 199.ninety nine The place CustomerID = 10 AND OrderDate = '12/12/2007' -- To delete info from databases table use a statement like the 1 under: DELETE Orders Where CustomerID = ten o You can produce, modify or delete database objects (instance of database objects are databases tables, views, stored treatments, etc.), by working with the Make, Change and Drop SQL keywords. These three SQL keyword phrases are portion of the Knowledge Definition Language (DDL). For illustration to generate table "Orders" you can use the subsequent SQL assertion: Make Orders ( OrderID INT Id(one, one) Principal Crucial,

ProductID INT, CustomerID ID, OrderDate Date, OrderValue Forex ) o You can management databases objects privileges by working with the GRANT and REVOKE keywords and phrases, aspect of the Data Regulate Language (DCL). For case in point to make it possible for the consumer with username "User1" to choose knowledge from desk "Orders" you can use the subsequent SQL statement: GRANT Select ON Orders TO User1
0 notes
Text
SQL Introduction
sql What is SQL? SQL stands for Structured Question Language and is a declarative programming language employed to entry and manipulate facts in RDBMS (Relational Databases Management Techniques). SQL was designed by IBM in 70's for their mainframe platform. Several a long time later SQL turned standardized by both American Nationwide Expectations Institute (ANSI-SQL) and Global Business for Standardization (ISO-SQL). In accordance to ANSI SQL is pronounced "es queue el", but many software package and databases builders with history in MS SQL Server pronounce it "sequel". What is RDBMS?
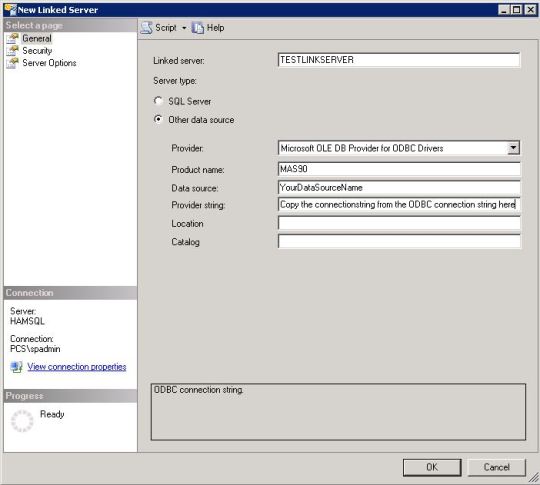
A Relational Database Administration System is a piece of software program utilised to shop and take care of facts in databases objects referred to as tables. A relational databases table is a tabular info composition organized in columns and rows. The desk columns also identified as table fields have distinctive names and unique attributes defining the column sort, default value, indexes and several other column characteristics. The rows of the relational databases desk are the actual facts entries. Most well known SQL RDBMS The most well-known RDBMS are MS SQL Server from Microsoft, Oracle from Oracle Corp., DB2 from IBM, MySQL from MySQL, and MS Obtain from Microsoft. Most industrial database distributors have formulated their proprietary SQL extension based mostly on ANSI-SQL common. For example the SQL version used by MS SQL Server is identified as Transact-SQL or simply T-SQL, The Oracle's variation is called PL/SQL (limited for Procedural Language/SQL), and MS Accessibility use Jet-SQL. What can you do with SQL? o SQL queries are employed to retrieve info from database tables. The SQL queries use the Pick out SQL key phrase which is component of the Facts Question Language (DQL). If we have a desk named "Orders" and you want to select all entries where the buy benefit is better than $a hundred purchased by the get price, you can do it with the next SQL Choose query: Choose OrderID, ProductID, CustomerID, OrderDate, OrderValue FROM Orders In which OrderValue > two hundred Purchase BY OrderValue The FROM SQL clause specifies from which desk(s) we are retrieving information. The In which SQL clause specifies lookup requirements (in our scenario to retrieve only data with OrderValue increased than $200). The Get BY clause specifies that the returned facts has to be get by the OrderValue column. The The place and Purchase BY clauses are optional. o You can manipulate knowledge saved in relational database tables, by employing the INSERT, UPDATE and DELETE SQL keywords and phrases. These 3 SQL instructions are part of the Data Manipulation Language (DML). -- To insert data into a desk named "Orders" you can use a SQL assertion related to the one particular underneath: INSERT INTO Orders (ProductID, CustomerID, OrderDate, OrderValue) VALUES (ten, 108, '12/twelve/2007', 99.95) -- To modify information in a table you can use a assertion like this: UPDATE Orders Set OrderValue = 199.ninety nine Where CustomerID = 10 AND OrderDate = '12/12/2007' -- To delete info from databases desk use a statement like the 1 underneath: DELETE Orders Wherever CustomerID = ten o You can develop, modify or delete database objects (example of database objects are databases tables, views, saved techniques, and many others.), by working with the Make, Change and Drop SQL search phrases. These three SQL key phrases are component of the Knowledge Definition Language (DDL). For example to develop table "Orders" you can use the subsequent SQL statement: Create Orders ( OrderID INT Id(1, 1) Major Key, ProductID INT, CustomerID ID, OrderDate Day, OrderValue Forex ) o You can management databases objects privileges by using the GRANT and REVOKE keywords and phrases, part of the Facts Regulate Language (DCL). For instance to enable the consumer with username "User1" to choose info from desk "Orders" you can use the following SQL statement: GRANT Decide on ON Orders TO User1
0 notes
Text
SQL Introduction
sql What is SQL? SQL stands for Structured Question Language and is a declarative programming language applied to access and manipulate facts in RDBMS (Relational Database Management Techniques). SQL was formulated by IBM in 70's for their mainframe system. Many a long time later on SQL grew to become standardized by both American Nationwide Specifications Institute (ANSI-SQL) and International Corporation for Standardization (ISO-SQL). In accordance to ANSI SQL is pronounced "es queue el", but many software package and database developers with track record in MS SQL Server pronounce it "sequel". What is RDBMS? A Relational Database Management Process is a piece of software applied to shop and control facts in database objects called tables. A relational database table is a tabular data framework arranged in columns and rows. The table columns also regarded as desk fields have distinctive names and distinct attributes defining the column form, default price, indexes and numerous other column characteristics. The rows of the relational database desk are the real info entries. Most well known SQL RDBMS The most well-known RDBMS are MS SQL Server from Microsoft, Oracle from Oracle Corp., DB2 from IBM, MySQL from MySQL, and MS Access from Microsoft. Most professional databases distributors have developed their proprietary SQL extension based on ANSI-SQL typical. For case in point the SQL variation used by MS SQL Server is called Transact-SQL or only T-SQL, The Oracle's edition is called PL/SQL (quick for Procedural Language/SQL), and MS Access use Jet-SQL. What can you do with SQL? o SQL queries are employed to retrieve data from database tables. The SQL queries use the Decide on SQL search phrase which is part of the Data Question Language (DQL). If we have a desk named "Orders" and you want to pick out all entries exactly where the order price is greater than $100 purchased by the order worth, you can do it with the following SQL Select question: Pick OrderID, ProductID, CustomerID, OrderDate, OrderValue FROM Orders The place OrderValue > 200 Buy BY OrderValue The FROM SQL clause specifies from which table(s) we are retrieving facts. The Where SQL clause specifies search standards (in our scenario to retrieve only records with OrderValue increased than $200). The Get BY clause specifies that the returned data has to be order by the OrderValue column. The In which and Order BY clauses are optional. o You can manipulate information stored in relational database tables, by utilizing the INSERT, UPDATE and DELETE SQL keyword phrases. These three SQL commands are part of the Info Manipulation Language (DML). -- To insert info into a desk referred to as "Orders" you can use a SQL statement equivalent to the one particular beneath: INSERT INTO Orders (ProductID, CustomerID, OrderDate, OrderValue) VALUES (10, 108, '12/twelve/2007', 99.95) -- To modify data in a desk you can use a assertion like this: UPDATE Orders Established OrderValue = 199.99 Wherever CustomerID = ten AND OrderDate = '12/12/2007' -- To delete data from database table use a statement like the one particular underneath: DELETE Orders In which CustomerID = 10 o You can make, modify or delete databases objects (case in point of databases objects are databases tables, views, stored procedures, and so on.), by working with the Generate, Change and Drop SQL key phrases. These 3 SQL keywords and phrases are part of the Facts Definition Language (DDL). For example to create table "Orders" you can use the next SQL assertion: Generate Orders (
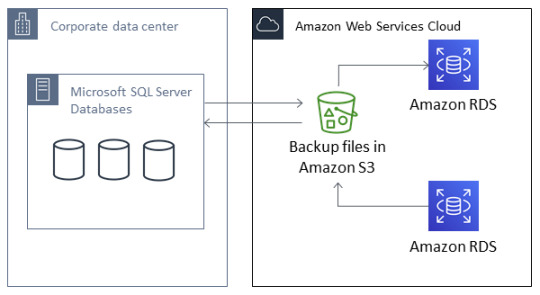
OrderID INT Identity(1, 1) Principal Important, ProductID INT, CustomerID ID, OrderDate Date, OrderValue Currency ) o You can management database objects privileges by utilizing the GRANT and REVOKE keyword phrases, aspect of the Facts Regulate Language (DCL). For case in point to permit the consumer with username "User1" to select facts from desk "Orders" you can use the next SQL assertion: GRANT Pick ON Orders TO User1
0 notes
Link
This article will introduce a couple of ways for MySQL search data in tables. First, how to search for data in tables will be shown using the classic Where clause and Like operator. Then, MySQL full-text search feature will be introduced and, in the end, how to perform data search will be shown using a third-party extension for VS Code, called ApexSQL Database Power Tools for VS Code.
For MySQL search data, as an example, data from the sakila database will be used.
Where clause search
Where clause is used for filtering records, data in databases. Where clause is used to extract data from tables that fulfill a specified condition. It is often used in conjunction with Select statement, but it can be used with Delete, Update statement, etc.
In our examples, the Where clause will be used with Select statement, in order to find (list) corresponding results from the tables that match the given condition.
The following example selects all actors whose last name is AKROYD, in the actor table:
SELECT actor. actor_id, actor. first_name, actor. last_name, actor. last_update FROM sakila. actor WHERE actor. last_name = 'AKROYD';
Using INNER JOIN to select matching values from multiple tables. In the example below, there is a statement which will find all actors that are played in the ACE GOLDFINGER movie:
SELECT first_name, last_name FROM film INNER JOIN film_actor USING(film_id) INNER JOIN actor USING(actor_id) WHERE title = 'ACE GOLDFINGER';
Like operator search
This operator is often used in combination with the Where clause to search for a specified pattern in a column.
The % (percent) and _ (underscore ) are often used in conjunction with the Like operator.
The percent replaces zero, one, or multiple characters while underscore replaces a single character.
So let’s find all actors that are played in the movie which title contains the Academy word:
SELECT first_name, last_name, film.title FROM film INNER JOIN film_actor USING(film_id) INNER JOIN actor USING(actor_id) WHERE title LIKE '%Academy%';
MySQL full-text search
Full-text search is a MySQL search technique to search for data in a database. Please note that not all engines support the full-text search feature. Starting from MySQL version 5.6 or higher, the MyISAM and InnoDB storage engines support a full-text search.
To enable full-text search, first, the FULLTEXT index needs to be created on the table columns on which the user wants to search data. Note that the FULLTEXT index can be created only in columns that have CHAR, VARCHAR, or TEXT data type.
Enabling the FULLTEXT index can be done by using the CREATE TABLE statement, then creating a new table using the ALTER TABLE or CREATE INDEX statement for the existing tables.
In our case, the Alter statement will be used to modify the film table and add the FULLTEXT index over the title column:
ALTER TABLE film ADD FULLTEXT(title);
The FULLTEXT index can be added in one or more columns of the table.
To perform the full-text search, the MATCH() and AGAINST() functions need to be used.
The MATCH() function specifies which set of columns are indexed using full-text search. The columns list provided in the MATCH () function needs to be the same as the list of columns used for creating the FULLTEXT index.
So, if the below statement is executed:
SELECT first_name, last_name, title FROM film INNER JOIN film_actor USING(film_id) INNER JOIN actor USING(actor_id) WHERE MATCH (title, last_name) AGAINST ('Academy');
The following message will appear:
Incorrect arguments to MATCH
The error message will also occur when using the MATCH() and AGAINST() functions over a table where full text search is not enabled:
SELECT `city`.`city_id`, `city`.`city`, `city`.`country_id`, `city`.`last_update` FROM `sakila`.`city` WHERE MATCH (`city`) AGAINST ('Abha');
The message will be:
Can’t find FULLTEXT index matching the column list
In the AGAINST() function, it is specified for which word we’re performing a full-text search. In our example, that will be the Academy word. When executing the statement below:
SELECT first_name, last_name, title FROM film INNER JOIN film_actor USING(film_id) INNER JOIN actor USING(actor_id) WHERE MATCH (title) AGAINST ('Academy');
The following result will be shown:
By default, the full-text search uses the natural language MySQL search mode, which means that the provided word is in the AGAINST() function search directly from user input without any pre-processing. So the same result will be shown in the results grid if in the AGAINST() function is specified the IN NATURAL LANGUAGE MODE modifier:
SELECT first_name, last_name, title FROM film INNER JOIN film_actor USING(film_id) INNER JOIN actor USING(actor_id) WHERE MATCH (title) AGAINST ('Academy' IN NATURAL LANGUAGE MODE);
Besides the IN NATURAL LANGUAGE MODE search modifiers, there are other modifiers e.g. IN BOOLEAN MODE for Boolean text searches.
In Boolean mode, you can specify the searched keyword along with Boolean operates. For example, the + and – operators indicate that a keyword must be present or absent, respectively, for a match to occur.
Execute the below statement with the IN BOOLEAN MODE search modifier:
SELECT first_name, last_name, title FROM film INNER JOIN film_actor USING(film_id) INNER JOIN actor USING(actor_id) WHERE MATCH (title) AGAINST ('+ Academy - DINOSAUR' IN BOOLEAN MODE);
MySQL search using a third-party software
The Text search feature is a part of ApexSQL Database Power Tools for VS Code extension that searches text within database objects, data stored in tables, and views.
To search for text (data) stored in the tables and views, in the ApexSQL server explorer pane, select a server or a database, right-click, and, from the context menu, choose the Text search command:
The Text search pane will be opened. In the Search phrase box, enter the search string and if it is not chosen, from the Database drop-down box, select a database to search in. In the search grid, choose tables and views of interest or leave them all checked. To narrow down the MySQL search data scope, select the table, views, numeric, text type, and date columns checkboxes. To start the search, click the Find button or hit the Enter key from the keyboard.
All found values will be shown in the text search results grid:
0 notes