#Option recompile sql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text
Option recompile sql

The difference between RECOMPILE and WITH RECOMPILE is that RECOMPILE can be added to the stored procedure as a query hint, and only that query within the stored procedure, not all of the queries in the stored procedure, will be recompiled. In SQL Server 2005, a new option if available: the RECOMPILE query hint. If the stored procedure has more than one query in it, as most do, it will recompile all of the queries in the stored procedure, even those that are not affected due to atypical parameters. This of course removes the benefits of query plan reuse, but it does ensure that each time the query is run, that the correct query plan is used. With this option added, a stored procedure will always recompile itself and create a new query plan each time it is run. In this case, what you can do is to ALTER the stored procedure and add the WITH RECOMPILE option to it. If you identify a stored procedure that usually runs fine, but sometimes runs slowly, it is very possible that you are seeing the problem described above. But, in some circumstances, it can cause a problem, assuming the parameters vary substantially from execution to execution of the query. Most of the time, you probably don’t need to worry about the above problem. But if the parameters are not typical, it is possible that the cached query plan that is being reused might not be optimal, resulting in the query running more slowly because it is using a query plan that is not really designed for the parameters used. If the values of the parameters of the stored procedure are similar from execution to execution, then the cached query plan will work fine and the query will perform optimally. But what if the same stored procedure is run, but the values of the parameters change? What happens depends on how typical the parameters are. If the query inside the stored procedure that runs each time has identical parameters in the WHERE clause, then reusing the same query plan for the stored procedure makes sense. So if you need to run the same stored procedure 1,000 times a day, a lot of time and hardware resources can be saved and SQL Server doesn’t have to work as hard. Each time the same stored procedure is run after it is cached, it will use the same query plan, eliminating the need for the same stored procedure from being optimized and compiled every time it is run. Whenever a stored procedure is run in SQL Server for the first time, it is optimized and a query plan is compiled and cached in SQL Server’s memory.
0 notes
Text
Sql server option recompile

#SQL SERVER OPTION RECOMPILE SERIAL#
#SQL SERVER OPTION RECOMPILE CODE#
Use of a temporary table within an SP also causes recompilation of that statement. Since we have auto-update statistics off, we have less recompilation of SP's to begin with. This plan reuse system works as long as objects are qualified with it owner and DatabaseName (for e.g. If all four tables have changed by about 20% since last statistics update, then the entire SP is recompiled. If say, you are accessing four tables in that SP and roughly 20% of the data for one table has been found to have changed since last statistics update, then that statement is recompiled. Recompilation happens only when about 20% of the data in the tables being called from within the SP is found to have changed since the last time statistics was updated for those tables and its indexes. So usage of different input parameters doesn't cause a recompilation. New input parameters in the current execution replace the previous input parameters from a previous execution plan in the execution context handle which is part of the overall execution plan.
#SQL SERVER OPTION RECOMPILE SERIAL#
The new plan is discarded imeediately after execution of the statement.Īssuming both of these options are not being used, an execution of an SP prompts a search for pre-existing plans (one serial plan and one parallel plan) in memory (plan cache). Any pre- existing plan even if it is exactly the same as the new plan, is not used. When used with a TSQL statement whether inside an SP or adhoc, Option 2 above creates a new execution plan for that particular statement. There is no caching of the execution plan for future reuse. Once the SP is executed, the plan is discarded immediately. Any existing plan is never reused even if the new plan is exactly the same as any pre-existing plan for that SP. It can not be used at a individual statement level.
#SQL SERVER OPTION RECOMPILE CODE#
When used in the code of a particular Stored procedure, Option 1compiles that SP everytime it is executed by any user. We should use RECOMPILE option only when the cost of generating a new execution plan is much less then the performance improvement which we got by using RECOMPILE option.WITH RECOMPILE This is because of the WITH RECOMPILE option, here each execution of stored procedure generates a new execution plan. Here you see the better execution plan and great improvement in Statistics IO. Now execute this stored procedure as: set statistics IO on Now again creating that stored procedure with RECOMPILE option. Here when we execute stored procedure again it uses the same execution plan with clustered index which is stored in procedure cache, while we know that if it uses non clustered index to retrieve the data here then performance will be fast. Now executing the same procedure with different parameter value: set statistics IO on The output of this execution generates below mention statistics and Execution plan: Select address,name from xtdetails where execute this stored procedure as: set statistics IO on Now create stored procedure as shown below: create procedure as varchar(50)) Set into xtdetails table xtdetails contains 10000 rows, where only 10 rows having name = asheesh and address=Moradabad. Now, I am inserting the data into this table: declare as int Ĭreate clustered index IX_xtdetails_id on xtdetails(id)Ĭreate Nonclustered index IX_xtdetails_address on xtdetails(address) In this case if we reuse the same plan for different values of parameters then performance may degrade.įor Example, create a table xtdetails and create indexes on them and insert some data as shown below: CREATE TABLE. But sometimes plans generation depends on parameter values of stored procedures. If plan found in cache then it reuse that plan that means we save our CPU cycles to generate a new plan. If we again execute the same procedure then before creating a new execution plan sql server search that plan in procedure cache. When we execute stored procedure then sql server create an execution plan for that procedure and stored that plan in procedure cache. Here i am focusing on why we use WITH RECOMPILE option. Some time, we also use WITH RECOMPILE option in stored procedures. We use stored procedures in sql server to get the benefit of reusability. Today here, I am explaining the Use of Recompile Clause in SQL Server Stored Procedures.
0 notes
Text
Sql server option recompile

SQL SERVER OPTION RECOMPILE SOFTWARE
SQL SERVER OPTION RECOMPILE CODE
SQL SERVER OPTION RECOMPILE FREE
I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly. I’m offering a 75% discount on to my blog readers if you click from here. If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m not mad.Īnd yeah, there’s advances in SQL Server 20 that start to address some issues here, but they’re still imperfect. Using a plan guide doesn’t interfere with that precious vendor IP that makes SQL Server unresponsive every 15 minutes.
Plan Guides: An often overlooked detail of plan guides is that you can attach hints to them, including recompile.
You can single out troublesome queries to remove specific plans.
DBCC FREEPROCCACHE: No, not the whole cache.
Sure, you might be able to sneak a recompile hint somewhere in the mix even if it’d make the vendor upset.
SQL SERVER OPTION RECOMPILE SOFTWARE
For third party vendors who have somehow developed software that uses SQL Server for decades without running into a single best practice even by accident, it’s often harder to get those changes through. And yeah, sometimes there’s a good tuning option for these, like changing or adding an index, moving parts of the query around, sticking part of the query in a temp table, etc.īut all that assumes that those options are immediately available. Those are very real problems that I see on client systems pretty frequently.
SQL SERVER OPTION RECOMPILE CODE
CPU spikes for high-frequency execution queries: Maybe time for caching some stuff, or getting away from the kind of code that executes like this (scalar functions, cursors, etc.)īut for everything in the middle: a little RECOMPILE probably won’t hurt that bad.Sucks less if you have a monitoring tool or Query Store. No plan history in the cache (only the most recent plan): Sucks if you’re looking at the plan cache.Long compile times: Admittedly pretty rare, and plan guides or forced plans are likely a better option.Not necessarily caused by recompile, but by not re-using plans. Here are some problems you can hit with recompile. But as I list them out, I’m kinda shrugging. Obviously, you can run into problems if you (“you” includes Entity Framework, AKA the Database Demolisher) author the kind of queries that take a very long time to compile. And if you put it up against the performance problems that you can hit with parameter sniffing, I’d have a hard time telling someone strapped for time and knowledge that it’s the worst idea for them. You can do it in SSMS as well, but Plan Explorer is much nicer.It’s been a while since SQL Server has had a real RECOMPILE problem. Look at details of each operator in the plan and you should see what is going on.
SQL SERVER OPTION RECOMPILE FREE
I would recommend to look at both actual execution plans in the free SQL Sentry Plan Explorer tool. Without OPTION(RECOMPILE) optimiser has to generate a plan that is valid (produces correct results) for any possible value of the parameter.Īs you have observed, this may lead to different plans. If there are a lot of values in the table that are equal to 1, it would choose a scan. If there is only one value in the table that is equal to 1, most likely it will choose a seek. Also, optimiser knows statistics of the table and usually can make a better decision. It does not have to be valid for any other value of the parameter. The generated plan has to be valid for this specific value of the parameter. With OPTION(RECOMPILE) optimiser knows the value of the variable and essentially generates the plan, as if you wrote: SELECT * And simple (7 rows) and actual statistics. With OPTION (RECOMPILE) it uses the key lookup for the D table, without it uses scan for D table. INSERT INTO D (idH, detail) VALUES 'nonononono') INSERT INTO H (header) VALUES ('nonononono') The script is: Create two tables: CREATE TABLE H (id INT PRIMARY KEY CLUSTERED IDENTITY(1,1), header CHAR(100))ĬREATE TABLE D (id INT PRIMARY KEY CLUSTERED IDENTITY(1,1), idH INT, detail CHAR(100)) I am lost why execution plan is different if I run query with option recompile to compare to same query (with clean proc cache) without option recompile.
0 notes
Link
Description of Software Engineer
A software engineer is a person who applies the principles of software engineering to the design, development, maintenance, testing, and evaluation of computer software.
Prior to the mid-1970s, software practitioners generally called themselves computer scientists, computer programmers or software developers, regardless of their actual jobs. Many people prefer to call themselves software developer and programmer, because most widely agree what these terms mean, while the exact meaning of software engineer is still being debated.
What Does a Software Engineer Do?
Computer software engineers apply engineering principles and systematic methods to develop programs and operating data for computers. If you have ever asked yourself, "What does a software engineer do?" note that daily tasks vary widely. Professionals confer with system programmers, analysts, and other engineers to extract pertinent information for designing systems, projecting capabilities, and determining performance interfaces. Computer software engineers also analyze user needs, provide consultation services to discuss design elements, and coordinate software installation. Designing software systems requires professionals to consider mathematical models and scientific analysis to project outcomes.
KEY HARD SKILLS
Hard skills refers to practical, teachable competencies that an employee must develop to qualify for a particular position. Examples of hard skills for software engineers include learning to code with programming languages such as Java, SQL, and Python.
Java: This programming language produces software on multiple platforms without the need for recompilation. The code runs on nearly all operating systems including Mac OS or Windows. Java uses syntax from C and C++ programming. Browser-operated programs facilitate GUI and object interaction from users.
JavaScript: This scripting programming language allows users to perform complex tasks and is incorporated in most webpages. This language allows users to update content, animate images, operate multimedia, and store variables. JavaScript represents one of the web's three major technologies.
SQL: Also known as Structured Query Language, SQL queries, updates, modifies, deletes, and inserts data. To achieve this, SQL uses a set number of commands. This computer language is standard for the manipulation of data and relational database management. Professionals use SQL to manage structured data where relationships between variables and entities exist.
C++: Regarded as an object-oriented, general purpose programming language, C++ uses both low and high-level language. Given that virtually all computers contain C++, computer software engineers must understand this language. C++ encompases most C programs without switching the source code line. C++ primarily manipulates text, numbers, and other computer-capable tasks.
C#: Initially developed for Microsoft, this highly expressive program language is more simple in comparison to other languages, yet it includes components of C++ and Java. Generic types and methods provide additional safety and increased performance. C# also allows professionals to define iteration behavior, while supporting encapsulation, polymorphism, and inheritance.
Python: This high-level programing language contains dynamic semantics, structures, typing, and binding that connect existing components; however, the Python syntax is easy to learn with no compilation stage involved, reducing program maintenance and enhancing productivity. Python also supports module and package use, which allows engineers to use the language for varying projects.
Programming languages comprise a software engineer's bread and butter, with nearly as many options to explore as there are job possibilities. Examples include Ruby, an object-oriented language that works in blocks; Rust, which integrates with other languages for application development; PHP, a web development script that integrates with HTML; and Swift, which can program apps for all Apple products. Learn more about programming languages here.
KEY SOFT SKILLS
While hard skills like knowledge of programming languages are essential, software engineers must also consider which soft skills they may need to qualify for the position they seek. Soft skills include individual preferences and personality traits that demonstrate how an employee performs their duties and fits into a team.
Communication: Whether reporting progress to a supervisor, explaining a product to a client, or coordinating with team members to work on the same product, software engineers must be adept at communicating via email, phone, and in-person meetings.
Multitasking: Software development can require engineers to split attention across different modules of the same project, or switch easily between projects when working on a deadline or meeting team needs.
Organization: To handle multiple projects through their various stages and keep track of details, software engineers must demonstrate a certain level of organization. Busy supervisors oversee entire teams and need to access information efficiently at a client's request.
Attention to Detail: Concentration plays a critical role for software engineers. They must troubleshoot coding issues and bugs as they arise, and keep track of a host of complex details surrounding multiple ongoing projects.
2 notes
·
View notes
Text
Best way to prepare for PHP interview
PHP is one among the programming languages that are developed with built-in web development functions. The new language capabilities contained in PHP 7 ensure it is simpler for developers to extensively increase the performance of their web application without the use of additional resources. interview questions and answers topics for PHP They can move to the latest version of the commonly used server-side scripting language to make improvements to webpage loading without spending extra time and effort. But, the Web app developers still really should be able to read and reuse PHP code quickly to maintain and update web apps in the future.
Helpful tips to write PHP code clean, reliable and even reusable
Take advantage of Native Functions. When ever writing PHP code, programmers may easily achieve the same goal utilizing both native or custom functions. However, programmers should make use of the built-in PHP functions to perform a number of different tasks without writing extra code or custom functions. The native functions should also help developers to clean as well as read the application code. By reference to the PHP user manual, it is possible to collect information about the native functions and their use.
Compare similar functions. To keep the PHP code readable and clean, programmers can utilize native functions. However they should understand that the speed at which every PHP function is executed differs. Some PHP functions also consume additional resources. Developers must therefore compare similar PHP functions and select the one which does not negatively affect the performance of the web application and consume additional resources. As an example, the length of a string must be determined using isset) (instead of strlen). In addition to being faster than strlen (), isset () is also valid irrespective of the existence of variables.
Cache Most PHP Scripts. The PHP developers needs keep in mind that the script execution time varies from one web server to another. For example, Apache web server provide a HTML page much quicker compared with PHP scripts. Also, it needs to recompile the PHP script whenever the page is requested for. The developers can easily eliminate the script recompilation process by caching most scripts. They also get option to minimize the script compilation time significantly by using a variety of PHP caching tools. For instance, the programmers are able to use memcache to cache a lot of scripts efficiently, along with reducing database interactions.
common asked php interview questions and answers for freshers
Execute Conditional Code with Ternary Operators. It is actually a regular practice among PHP developers to execute conditional code with If/Else statements. But the programmers want to write extra code to execute conditional code through If/Else statements. They could easily avoid writing additional code by executing conditional code through ternary operator instead of If/Else statements. The ternary operator allows programmers to keep the code clean and clutter-free by writing conditional code in a single line.
Use JSON instead of XML. When working with web services, the PHP programmers have option to utilize both XML and JSON. But they are able to take advantage of the native PHP functions like json_encode( ) and json_decode( ) to work with web services in a faster and more efficient way. They still have option to work with XML form of data. The developers are able to parse the XML data more efficiently using regular expression rather than DOM manipulation.
Replace Double Quotes with Single Quotes. When writing PHP code, developers are able to use either single quotes (') or double quotes ("). But the programmers can easily improve the functionality of the PHP application by using single quotes instead of double quotes. The singular code will speed up the execution speed of loops drastically. Similarly, the single quote will further enable programmers to print longer lines of information more effectively. However, the developers will have to make changes to the PHP code while using single quotes instead of double quotes.
Avoid Using Wildcards in SQL Queries. PHP developers typically use wildcards or * to keep the SQL queries lightweight and simple. However the use of wildcards will impact on the performance of the web application directly if the database has a higher number of columns. The developers must mention the needed columns in particular in the SQL query to maintain data secure and reduce resource consumption.
However, it is important for web developers to decide on the right PHP framework and development tool. Presently, each programmer has the option to decide on a wide range of open source PHP frameworks including Laravel, Symfony, CakePHP, Yii, CodeIgniter, and Zend. Therefore, it becomes necessary for developers to opt for a PHP that complements all the needs of a project. interview questions on PHP They also need to combine multiple PHP development tool to decrease the development time significantly and make the web app maintainable.
php interview questions for freshers
youtube
1 note
·
View note
Text
PHP is one amongst the programming languages that were developed with inbuilt net development capabilities. The new language options enclosed in PHP seven any makes it easier for programmers to boost the speed of their net application considerably while not deploying extra resources. They programmers will switch to the foremost recent version of the wide used server-side scripting language to enhance the load speed of internet sites while not swing beyond regular time and energy. however the net application developers still want target the readability and reusability of the PHP code to take care of and update the net applications quickly in future.
12 Tips to write down Clean, rectifiable, and Reusable PHP Code
1) benefit of Native Functions While writing PHP code, the programmers have choice to accomplish identical objective by victimisation either native functions or custom functions. however the developers should benefit of the inbuilt functions provided by PHP to accomplish a spread of tasks while not writing extra code or custom functions. The native functions can any facilitate the developers to stay the appliance code clean and decipherable. they'll simply gather info concerning the native functions and their usage by touching on the PHP user manual.
Another way to check phpstorm key shortcuts
2) Compare Similar Functions The developers will use native functions to stay the PHP code decipherable and clean. however they need to keep in mind that the speed of individual PHP functions differs. Also, bound PHP functions consume extra resources than others. Hence, the developers should compare similar PHP functions, and select the one that doesn't have an effect on the performance of the net application negatively and consume extra resources. as an example, they need to verify the length of a string by victimisation isset() rather than strlen(). additionally to being quicker than strlen(), isset() conjointly remains valid in spite of the existence of variables.
3) Cache Most PHP Scripts The PHP programmers should keep in mind that the script execution time differs from one net server to a different. as an example, Apache net server serve a HTML page abundant quicker than PHP scripts. Also, it has to recompile the PHP script on every occasion the page is requested for. The programmers will simply eliminate the script recompilation method by caching most scripts. They even have choice to scale back the script compilation time considerably by employing a style of PHP caching tools. as an example, the programmers will use memcache to cache an oversized variety of scripts expeditiously, at the side of reducing info interactions.
4) Execute Conditional Code with Ternary Operators It is a typical observe among PHP developers to execute conditional code with If/Else statements. however the developers got to writing extra code to execute conditional code through If/Else statements. they'll simply avoid writing extra code by corporal punishment conditional code through ternary operator rather than If/Else statements. The ternary operator helps programmers to stay the code clean and clutter-free by writing conditional code during a single line.
5) Keep the Code decipherable and rectifiable Often programmers notice it intimidating perceive and modify the code written by others. Hence, they have beyond regular time to take care of and update the PHP applications expeditiously. whereas writing PHP code, the programmers will simply build the appliance simple to take care of and update by describing the usage and significance of individual code snippets clearly. they'll simply build the code decipherable by adding comments to every code piece. The comments can build it easier for alternative developers to form changes to the present code in future while not swing beyond regular time and energy.
6) Use JSON rather than XML While operating with net services, the PHP programmers have choice to use each XML and JSON. however they'll continuously benefit of the native PHP functions like json_encode( ) and json_decode( ) to figure with net services during a quicker and a lot of economical manner. They still have choice to work with XML style of information. The programmers will break down the XML information a lot of expeditiously by victimisation regular expression rather than DOM manipulation.
7) Pass References rather than worth to Functions The intimate PHP programmers ne'er declare new categories and strategies only if they become essential. They conjointly explore ways in which to recycle the categories and strategies throughout the code. However, they conjointly perceive the actual fact that a perform may be manipulated quickly by passing references rather than values. they'll any avoid adding additional overheads by passing references to the perform rather than values. However, they still got to make sure that the logic remains unaffected whereas passing relevancy the functions.
8) flip Error coverage on in Development Mode The developers should establish and repair all errors or flaws within the PHP code throughout the event method. They even have to place overtime and energy to mend the writing errors and problems known throughout testing method. The programmers merely set the error coverage to E_ALL to spot each minor and major errors within the PHP code throughout the event method. However, they need to flip the error coverage choice off once the appliance moves from development mode to production mode.
9) Replace inverted comma with Single Quotes While writing PHP code, programmers have choice to use either single quotes (') or inverted comma ("). however the developers will simply enhance the performance of the PHP application by victimisation single quotes rather than inverted comma. the only code can increase the speed of loops drastically. Likewise, the only quote can any change programmers to print longer lines of data a lot of expeditiously. However, the developers got to build changes to the PHP code whereas victimisation single quotes rather than inverted comma.
10) Avoid victimisation Wildcards in SQL Queries PHP programmers typically use wildcards or * to stay the SQL queries compact and easy. however the employment of wildcards might have an effect on the performance of the net application directly if the info includes a higher variety of columns. The programmers should mention the desired columns specifically within the SQL question to stay information secure and scale back resource consumption.
11) Avoid corporal punishment info Queries in Loop The PHP programmers will simply enhance the net application's performance by not corporal punishment info queries in loop. They even have variety of choices to accomplish identical results while not corporal punishment info queries in loop. as an example, the developers will use a strong WordPress plug-in like question Monitor to look at the info queries at the side of the rows laid low with them. they'll even use the debugging plug-in to spot the slow, duplicate, and incorrect info queries.
12) ne'er Trust User Input The sensible PHP programmers keep the net application secure by ne'er trusting the input submitted by users. They continuously check, filter and sanitize all user info to guard the appliance from varied security threats. they'll any forestall users from submitting inappropriate or invalid information by victimisation inbuilt functions like filter_var(). The perform can check for applicable values whereas receiving or process user input.
However, it's conjointly necessary for the net developers to select the correct PHP framework and development tool. At present, every technologist has choice to choose between a large vary of open supply PHP frameworks as well as Laravel, Symfony, CakePHP, Yii, CodeIgniter and Iranian language. Hence, it becomes essential for programmers to select a PHP that enhances all wants of a project. They conjointly got to mix multiple PHP development tool to scale back the event time considerably and build the net application rectifiable.
1 note
·
View note
Text
SQL Interview Questions and Answers - Part 12:
Q100. How can you return value from a stored procedure? Q101. What is a temporary stored procedure? What is the use of a temp stored procedure? Q102. What is the difference between recursive vs nested stored procedures? Q103. What is the use of the WITH RECOMPILE option in the stored procedure? Why one should use it? Q104. How can you ENCRYPT and DECRYPT the stored procedure? Q105. How can you improve the performance of a stored procedure? Q106. What is SCHEMABINDING in stored procedure? If all the stored procedures are bounded to the schema by default, then why do we need to do it explicitly? Q107. How can you write a stored procedure which executes automatically when SQL Server restarts? Q108. Is stored procedure names case-sensitive? Q109. What is CLR stored procedure? What is the use of the CLR procedure? Q110. What is the use of EXECUTE AS clause in the stored procedure?
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda#techpoint
1 note
·
View note
Text
File Server Stress Test Tool

File Server Stress Test Tool Harbor Freight
Server Stress Tester
Server Stress Test Software
Web Server Stress Test
DTM DB Stress is a software for stress testing and load testing the server parts of information systems and database applications, as well as databases and servers themselves. It is suitable for solution scalability and performance testing, comparison and tuning. The stress tool supports all unified database interfaces: ODBC, IDAPI, OLE DB and Oracle Call Interface. The dynamic SQL statement support and built-in test data generator enable you to make test jobs more flexible. Value File allows users to emulate variations in the end-user activity. I’m working with my customer to perform a file server (Win2k8 R2) stress test exercise and I found the FSCT is a great tool that can help to simulate users workload. However I can’t find an option to define the file size using the tool. Whether you have a desktop PC or a server, Microsoft’s free Diskspd utility will stress test and benchmark your hard drives. NOTE: A previous version of this guide explained using Microsoft’s old “SQLIO” utility. The program says that the information passed to the server is anonymous. If you select a different stress level, the program cannot upload the results even if they are visible in the pane to the left. Most of the tests were completed quite fast, except for the Files Encrypt test which took 67 seconds to complete.
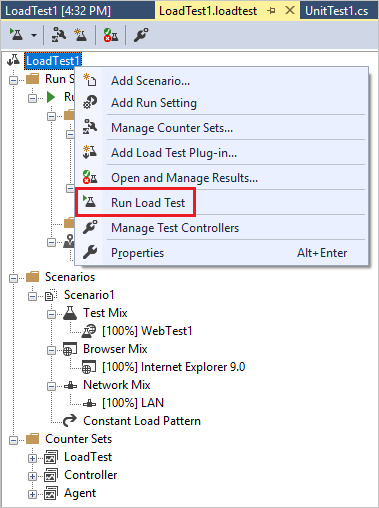
By: John Sterrett | Updated: 2012-07-18 | Comments (15) | Related: More >Testing
Problem
I have a stored procedure and I need to add additional stress and test thestored procedureusing a random set of parameters before it can be pushed to production. I don'thave a budget for stress testing tools. Can you show me how to accomplish thesegoals without buying a third party tool?
Solution
Yes, theSQLQueryStresstool provided byAdam Machaniccan be used to apply additional stress when testing your stored procedures. Thistool can also be used to apply a dataset as random parameter values when testingyour stored procedures. You can also read more about SQLStressTest on the toolsdocumentation page to find more details about how you can use the tool.
For the purpose of this tip we are going to use the uspGetEmployeeManagers storedprocedure in theAdventureWorks2008R2 database. You can exchange this with your stored procedureto walk through this tip in your own environment.
Step 1
Our first step is to test the following stored procedure with a test parameter.This is done in Management Studio using the query shown below.
Now that we know we have a working stored procedure and a valid parameter thatreturns data we can get started with theSQLStressTool.Once you downloaded and installed SQLQueryStress, fire the tool up and pastein the code that you used in Management Studio. Next, we need to click on the databasebutton to configure our database connection.
Step 2 - Configure Database Connectivity
Now that we clicked on the database button we will want to connect to our AdventureWorksdatabase. In this example I am using a instance named 'r2' on my localhost. We willconnect with windows authentication and our default database will be AdventureWorks2008R2.Once this is done we will click on Test Connection and click on the 'OK' box inthe popup window. We'll see the Connection Succeeded message to verify that ourconnection settings are connect.
Step 3 - Clear Proc Cache
Before we execute our stored procedure using SQLQueryStress we are going to clearout the procedure cache so we can track the total executions of our stored procedure.This shouldn't be done on a production system as this can causesignificant performance problems. You would have to recompile all user objects toget them back into the procedure cache. We are doing this in this walkthrough tipto show you how we can count the total executions of the stored procedure.
File Server Stress Test Tool Harbor Freight
NOTE: In SQL Server 2008 and up you can actually clear a specificplan from the buffer pool. In this example we are clearing out all plan's incaseyour using SQL 2005. Once again, this shouldn't be done on a productionsystem . Pleasesee BOL for a specific example on clearing out a single plan.
Step 4 - Execute Stored Procedure Using SQLQueryStress
Now that we have established our connection and specified a default databasewe are going to execute our stored procedure specified in step one. You can executethe stored procedure once by making sure the number of interations and number ofthreads both have the value of 'one.' We will go over these options in more detailsa little later in the tip. Once those values are set correctly you can execute thestored procedure once by clicking on the 'GO' button on the top right side of theSQLQueryStress tool.
Once the stored procedure execution completes you will see that statistics aregenerated to help give you valuable feedback towards your workload. You can seethe iterations that completed. In this case we only executed the stored procedureonce. You can also see valuable information for actual seconds, CPU, Logical readsand elapsed time as shown in the screen shot below.
Step 5 - View Total Executions via T-SQL
Now we will execute the following T-SQL script below, which will give us theexecution count for our stored procedure. We just cleared the procedure cache soyou will get an execution count of one as shown in the screen shot below.
Step 6 - Using SQLQueryStress to Add Additional Stress with Multiple Threads.
Now that we have gone over the basics of executing a stored procedure with SQLQueryStresswe will go over adding additional stress by changing the values for Number of Threadsand Number of Iterations. The number of Iterations means the query will be executedthis amount of times for each thread that is specified. The numbers of threads specifyhow many concurrent threads (SPIDS) will be used to execute the number of iterations.
Being that we changed the number of iterations to five and the number of threadsto five we will expect the total number of iterations completed to be twenty-five.The iterations completed is twenty-five because we used five threads and had fiveiterations that were executed for each thread. Below is a screen shot of thethe workload completed after we clicked on the 'GO' button with valuable averagestatistics during the workload.
If we rerun our T-SQL script from step 5, you will see that there is a totalof twenty-six executions for the uspGetEmployeeManagers stored procedure. This includesour initial execution from step 4 and the additional stress applied in step 6.
Server Stress Tester
Step 7 - Use Random Values for Parameters with SQLQueryStress
Next, we are going to cover using a dataset to randomly provide parameters toour stored procedure. Currently we use a hard coded value of eight as the valuefor the BusinessEntityID parameter. Now, we are going to click on the 'ParameterSubstitution' button to use a T-SQL script to create a pool of values that willbe used during our stress testing of the uspGetEmployeeManagers stored procedure.
Once the parameter substitution window opens we will want to copy our T-SQL statementprovided below that will generate the BusinessEntityID values we would want to passinto our stored procedure.
Once you added the T-SQL script, you would want to select the column you wouldlike to map to the parameter used for your stored procedure.
Finally, the last part of this step is to drop the hard coded value assignmentfor the stored procedure. This way the parameter substitution will be used for theparameter value.
Step 8 - Wrap-up Results
To wrap up this tip, we have gone over controlling a workload to provide additionalstress and randomly substituting parameters to be used for your workload replay.If you capture aSQL traceand replay the workload you should see a similar output as the one provided in thescreen shot below. Looking at the screen shot below you will notice that each thread(SPID) has five iterations. Also, you will notice that the values for the businessentityidprovided are randomly selected from our block of code provided for the parametersubstitution.
Next Steps
If you need to do some load testing, start usingSQLQueryStresstool.
Review severaltips on SQL Profiler and trace
Revew tips on working withStored Procedures
Last Updated: 2012-07-18
About the author
John Sterrett is a DBA and Software Developer with expertise in data modeling, database design, administration and development. View all my tips

One of the questions that often pops up in our forums is “how do I run a stress test on my game”?
There are several ways in which this can be done. A simple way to stress test your server side Extension is to build a client application that acts as a player, essentially a “bot”, which can be replicated several hundreds or thousands of times to simulate a large amount of clients.
» Building the client
For this example we will build a simple Java client using the standard SFS2X Java API which can be downloaded from here. The same could be done using C# or AS3 etc…
The simple client will connect to the server, login as guest, join a specific Room and start sending messages. This basic example can serve as a simple template to build more complex interactions for your tests.
» Replicating the load
Before we proceed with the creation of the client logic let’s see how the “Replicator” will work. With this name we mean the top-level application that will take a generic client implementation and will generate many copies at a constant interval, until all “test bots” are ready.
The class will startup by loading an external config.properties file which looks like this:
Server Stress Test Software
The properties are:
the name of the class to be used as the client logic (clientClassName)
the total number of clients for the test (totalCCU)
the interval between each generated client, expressed in milliseconds (generationSpeed)
Once these parameters are loaded the test will start by generating all the requested clients via a thread-pool based scheduled executor (ScheduledThreadPoolExecutor)
In order for the test class to be “neutral” to the Replicator we have created a base class called BaseStressClient which defines a couple of methods:
The startUp() method is where the client code gets initialized and it must be overridden in the child class. The onShutDown(…) method is invoked by the client implementation to signal the Replicator that the client has disconnected, so that they can be disposed.
» Building the client logic
Web Server Stress Test
This is the code for the client itself:
The class extends the BaseStressClient parent and instantiates the SmartFox API. We then proceed by setting up the event listeners and connection parameters. Finally we invoke the sfs.connect(…) method to get started.
Notice that we also declared a static ScheduledExecutorService at the top of the declarations. This is going to be used as the main scheduler for sending public messages at specific intervals, in this case one message every two second.
We chose to make it static so that we can share the same instance across all client objects, this way only one thread will take care of all our messages. If you plan to run thousands of clients or use faster message rates you will probably need to increase the number of threads in the constructor.
» Performance notes
When replicating many hundreds / thousands of clients we should keep in mind that every new instance of the SmartFox class (the main API class) will use a certain amount of resources, namely RAM and Java threads.
For this simple example each instance should take ~1MB of heap memory which means we can expect 1000 clients to take approximately 1GB of RAM. In this case you will probably need to adjust the heap settings of the JVM by adding the usual -Xmx switch to the startup script.
Similarly the number of threads in the JVM will increase by 2 units for each new client generated, so for 1000 clients we will end up with 2000 threads, which is a pretty high number.
Any relatively modern machine (e.g 2-4 cores, 4GB RAM) should be able to run at least 1000 clients, although the complexity of the client logic and the rate of network messages may reduce this value.
On more powerful hardware, such as a dedicated server, you should be able to run several thousands of CCU without much effort.
Before we start running the test let’s make sure we have all the necessary monitoring tool to watch the basic performance parameters:
Open the server’s AdminTool and select the Dashboard module. This will allow you to check all vital parameters of the server runtime.
Launch your OS resource monitor so that you can keep an eye on CPU and RAM usage.
Here are some important suggestions to make sure that a stress test is executed successfully:
Monitor the CPU and RAM usage after all clients have been generated and make sure you never pass the 90% CPU mark or 90% RAM used. This is of the highest importance to avoid creating a bottleneck between client and server. (NOTE: 90% is meant of the whole CPU, not just a single core)
Always run a stress test in a ethernet cabled LAN (local network) where you have access to at least a 100Mbit low latency connection. Even better if you have a 1Gbps or 10Gbps connection.
To reinforce the previous point: never run a stress test over a Wifi connection or worse, a remote server. The bandwidth and latency of a Wifi are horribly slow and bad for these kind of tests. Remember the point of these stress tests is assessing the performance of the server and custom Extension, not the network.
Before running a test make sure the ping time between client and server is less or equal to 1-5 milliseconds. More than that may suggest an inadequate network infrastructure.
Whenever possible make sure not to deliver the full list of Rooms to each client. This can be a major RAM eater if the test involves hundreds or thousands of Rooms. To do so simply remove all group references to the “Default groups” setting in your test Zone.
» Adding more client machines
What happens when the dreaded 90% of the machine resources are all used up but we need more CCU for our performance test?
It’s probably time to add another dedicated machine to run more clients. If you don’t have access to more hardware you may consider running the whole stress test in the cloud, so that you can choose the size and number of “stress clients” to employ.
The cloud is also convenient as it lets you clone one machine setup onto multiple servers, allowing a quick way for deploying more instances.
In order to choose the proper cloud provider for your tests make sure that they don’t charge you for internal bandwidth costs (i.e. data transfer between private IPs) and have a fast ping time between servers.
We have successfully run many performance tests using Jelastic and Rackspace Cloud. The former is economical and convenient for medium-size tests, while the latter is great for very large scale tests and also provides physical dedicated servers on demand.
Amazon EC2 should also work fine for these purposes and there are probably many other valid options as well. You can do a quick google research, if you want more options.
» Advanced testing
1) Login: in our simple example we have used an anonymous login request and we don’t employ a server side Extension to check the user credentials. Chances are that your system will probably use a database for login and you wish to test how the DB performs with a high traffic.
A simple solution is to pre-populate the user’s database with index-based names such as User-1, User-2 … User-N. This way you can build a simple client side logic that will generate these names with an auto-increment counter and perform the login. https://loadingiwant517.tumblr.com/post/661702399021481984/how-to-play-marvels-spider-man-on-pc. Passwords can be handled similarly using the same formula, e.g. Password-1, Password-2… Password-N
TIP: When testing a system with an integrated database always monitor the Queue status under the AdminTool > Dashboard. Slowness with DB transactions will show up in those queues.
2) Joining Rooms: another problem is how to distribute clients to multiple Rooms. Suppose we have a game for 4 players and we want to distribute a 1000 clients into Rooms for 4 users. A simple solution is to create this logic on the server side.
The Extension will take a generic “join” request and perform a bit of custom logic:
search for a game Room with free slots:
if found it will join the user there
otherwise it will create a new game Room and join the user
A similar logic has been discussed in details in this post in our support forum.
» Source files
The sources of the code discussed in this article are available for download as a zipped project for Eclipse. If you are using a different IDE you can unzip the archive and extract the source folder (src/), the dependencies (sfs2x-api/) and build a new project in your editor.
0 notes
Text
Diagnosing Slow-Running Stored Procedures
This week, I had a stored procedure taking 2 to 3 seconds to execute from a .NET application, where it previously took under 40ms. A few seconds doesn't seem that long, but the application was looping through a collection of items and calling the procedure around a hundred times. Meaning for the user, the time to complete the workflow had increased from around 4 seconds to over 4 minutes. Nothing had changed with the tables being used and index fragmentation was not an issue, thanks to fairly aggressive maintenance plans.
What was more baffling was the same process looping the same stored procedure used in the same application installed in a test environment took the expected four seconds or so. In SSMS, in both production and test environments, everything was well-behaved. Firing up the profiler, I could see that the sproc was reading around a thousand records when executed from SSMS (regardless of environment), but when the .NET application ran it, it was reading 250,000.
The culprit was the execution plan. Or rather plans. Plural. SSMS was getting one plan and the .NET application was getting another. To figure out why SQL was using two separate plans, you need to get the handles for the plans for the stored procedure:
SELECT sys.objects.object_id, sys.dm_exec_procedure_stats.plan_handle, [x].query_plan FROM sys.objects INNER JOIN sys.dm_exec_procedure_stats ON sys.objects.object_id = sys.dm_exec_procedure_stats.object_id CROSS APPLY sys.Dm_exec_query_plan(sys.dm_exec_procedure_stats.plan_handle) [x] WHERE sys.objects.object_id = Object_id('StoredProcName')
From there, consulting the SET options for the plans revealed something interesting: one plan had ARITHABORT ON, the other ARITHABORT OFF. SSMS, by default, has it set to on. Client applications have it set to off. The result was that SQL was using a horrifically bad execution plan for the .NET application and a reasonable one for SSMS. This is usually tied to issues with the parameter sniffing that SQL uses when compiling a plan. The solution I decided to go with was to queue the sproc for a plan recompile:
EXEC sp_recompile N'StoredProcName'
The next time the sproc was executed, SQL generated a new plan for it. The result was a drop from 250k reads and 3 seconds per execution to around a thousand reads and under 40ms. Exactly what it should be.
0 notes
Text
Programming Language Help
Programming Language Assignment Help
Can you do my assignment? Programming language assignment is an important service to help you. Programming language is a computing language engraved in the form of coding and decoding to instruct computers. The programming language is also called processed machine language by translators and interpreters to perform the work performed on the computer. We provide programming assignment writing services to students, helping them achieve the grade they are entitled to.
Programming language assignment help students in syntax and semantics, two common programming forms in which the language is subdivided. To be precise, both syntax and semantics are subclassified into the following:
context-free syntax
This gets the order in which the ordered characters i.e. symbols are divided into tokens. For more information on our programming support, get our Assignment Assistance Services.
syntax lexical
It is derived how ordered token phrases are clustered in. To help with programming language assignments, take advantage of our services.
context sensitive syntax
Also known as static semantics, it checks various constraints at compile time, type checking etc. For more information on programming language assignment help, select our services.
Dynamics Semantics
It plans the execution of verified programs. For more information about programming language assignment help, contact our experts.
History Of Programming Language
Authors who help with our online programming language assignment give you complete programming assignment writing services. In the year 1950, the programming language was first developed to instruct the computer. Since then, more than 500 qualified programming languages have developed significantly and it remains a continuous process for designing more advanced forms. The short language proposed by John Mauchli in the year 1951 was different from machine code in various aspects. The shortcode was designed with profound mathematical expressions but was not powerful enough to run as fast as machine code. Autocode is another important computer language developed in the mid-1950s that automatically converts code to machine language using the compiler. Experts who help with our programming language help assignment can highlight the history of the programming language.
Our programming language assignment help also provides knowledge in the stages of programming development. The main models of the programming language were developed between 1960 and 1970.
Array programming introduced by APL that plays a major role in influencing functional programming
The structural process of programming was refined by ALGOL
Object-oriented programming was supported by machine language simala
C is the most popular system programming language developed in 1970
The first language of logic programming is considered prolog which was developed in the year 1972.
Programming language assignment help provides full support on the programming language.
Sample Question & Answer Of Programming Language Assignment Help
question:
Since the development of Plancalukal in the 1940s, a large number of programming languages have been designed and implemented for their own specific problem domains and built with their own design decisions and compromises. For example, there are languages that:? is strongly typed and loosely typed,
Object Orientation / Object Orientation Provide support for abstraction of data types,
Use static or dynamic scoping rules,
Provide memory management (i.e. garbage collection) or give the developer precise control over pile-allocation and recycling,
Provide closures to allow passage around like variables,
Allow easy access to array slices and those that don't
Check the internal accuracy of the data and those that do not,
Provide diverse and comprehensive suites with built-in functionality and diverse limited features,
Use pre-processors and macros for select extension codes or option sources, etc.
north:
Introduction and clarification of language purpose
It is rare that programming language, one of many programming languages since the development of Plankalkul in 1940, has been clearly developed for the problem area of banking. COBOL (Common Business Oriented Language) was used in writing business software until the 1980s when it was replaced by C and C++ programming languages.
Objectives Of Programming Language
Helping language assignment helps students understand the purpose of programming languages:
It helps users communicate with computers by applying instructions through the programming language
To determine the design pattern of the programming language
To evaluate diversions and swaps between different programming language features
The benefits of recent machine languages are determined by comparing them with traditional languages
To observe the pattern of programming associated with different language features.
To study the efficiency of programming languages in the manufacture and development of software. For more information, take the help of our programming language assignments.
Types Of Programming Languages
Our programming language assignment helps experts explain a variety of programming languages. The description of the main programming languages is given below:
C Language
It is considered to be the most popular and general-purpose machine language, which aims to serve as building blocks for various popular programming languages such as JAA, C#, Python, JAVA scripts, etc. C is the effective application of the language to execute the operating. The system and various applications are built in it. For more information on C language, get our C Programming Assignment Assistance service.
Java
It is an object-oriented, concurrent and class-based system programming language that is used for general purpose. It once works on the principle of writing once and running anywhere', which implies that once developed code can run in any platform repeatedly without recompilation. Regardless of any architecture of the computer, the Java application can run in any Java virtual machine (JVM) due to its specific byte compilation. For more information on Java, take the help of programming language assignments
C++
It is a system programming language that has mandatory, general and object-oriented features of programming. C++ is used to design embedded and operating systems in kernels. It is a compiled version of the programming language that can be used across multiple platforms, including servers, desktops, and entertainment software applications. C++ ISO is standardized and its newest version is C#. For more information on C++, get our programming language assignment help.
C#
This object-oriented programming language is compatible with Microsoft.Net's platform. Compatibility of C# with Microsoft. Net enhances the development of portable applications and facilitates users with advanced web services. C# includes SOAP (Simple Object Access Protocol) and XML (Markup Language) to simplify programming without applying additional code in each step. In addition, C# plays an efficient role in introducing advanced services into the industry at relatively low cost. Big brands such as LEAD technologies, component sources, seagate software, apex software use ISO standardized C# applications. Our programming language assignment help explains more about this.
python
It is a high-level general-purpose programming language. The language is designed to simplify the overall application. Unlike Java and C++, the language encourages the implications of readable code and concepts to include fewer code lines. For more information, get our programming language assignment help.
Sql
It is an abbreviation for structured query language considered a language for special purpose programming. It is efficient to process a stream of relational data management systems and manipulate data into the relational database of the management system. In addition, SQL is specific as data definition and data manipulation language, due to relational calculus and in-built configuration of relational algebra. For more information, try our programming language assignment help.
Java Script
It is a scripting language based on prototypes displayed with dynamic and high-class functions. Being an important part of the web browser, the implementation of JavaScript helps to manipulate the browser, conduct asynchronous communication, allow the user to interact with client scripts and change the content of the documents displayed. JavaScript is renowned as a versatile language due to its functional, object-oriented and mandatory programming features. For more information on Java Script, get our programming language assignment help.
Different Levels Of Programming Languages
A programming language is broadly categorized according to its levels. Our programming language assignment help services explain this. The importance of each level is considered in detail below.
1. Micro-code
Each component of the CPU is directed to perform minute scale operation by this machine-specific code
Programmers develop instructions written in micro-code to execute micro-programs
Commonly used in CPU and other processing units such as microcontrollers, channels and disk controllers, processing unit of digital signal and graphics, controller of network interfaces, etc.
Microcode usually converts instructions into machine language and is a feature of high speed memory. For more on microcode, get our programming language assignment help.
2. Machine code
Machine code is a series of instructions executed directly by a computer's CPU
Machine code is relative to the architecture of the computer
Numeric machine code is considered as the hardware-based primitive language of programming that represents a computer program assembled at the lowest level
However, programs that are written directly into numerical machine code lead to problem-centered calculations. Our programming assignment authors can elaborate on this with the help of our programming language assignments.
3. Assembly Language
It usually represents the domain of the low-level programming language
Assembly language is assembled with computer code in computer code
This is different from the many utility systems of the high-level programming language
Instructions are given to low-level machine code or operations
Operations such as symbols, labels and expressions are essentially needed to execute a directive
For the purpose of offering macro instruction operations, macro assemblers represent code as extended
Adjustment of assembly process, creation of programs and debugging assistance are some of the important features that are provided by the assemblers. To help with assembly language, take the help of our programming language assignments.
4. Low-level programming language
It is a type of programming language that has negligible or no abstract with a set of instructions configured in the computer's architecture
Low-level language refers to both assembly language and machine code
However, there is no essence of language with machine language, but related to hardware
Language does not require the use of interpreter or compiler to translate it into machine code
Low-level language written programs are simple with negligible memory footprint and run very quickly
This includes detailed technical details. So, its usefulness is very difficult. For low-level programming language assistance, try our programming language assignment help.
5. High-level programming language
This programming language is strong abstraction with detailed instructions configured in the computer
It is a highly comprehensive and simple process of programming language
High-level language pseudocode as a compiler to translate the language into machine code
high level
Language data relates to item abstracts such as threads, arrays, objects, loops, locks, subroute, Boolean and complex arithmetic expressions, variables, functions, objects, etc.
Compared to low-level language, high-level language emphasizes the optimal efficiency of the program. For the high-level programming language assistant, get our programming language assignment assistant.
Difference Between High Level And Low Level Programming Language
translator
It refers to the translation or conversion of written instructions into machine language before it is executed. Our programming assignment writing services explain translators in more detail.
Translators are broadly classified as three important types.
Assembler
It converts programs written in assembly language to machine code before execution
eclectic
It converts programs written in high-level language to machine code before execution
Interpreters
It directly interprets high-level language instructions and sends them for execution.
Similarities between interpreters and compilers
High-level languages are translated into machine code by both interpreter and compiler
Both identify errors and print it in error messages
Both interpreters and compilers find memory addresses to store data and machine code. Contact us for more information about programming assignment writing services.
Why Writing Programming Language Assignments Are Difficult For Students?
It is clear that students should face problems writing their C programming language assignments if they are not knowledgeable about the basics of programming language. Writing programming language assignments seems difficult for students as they try to directly understand programs and skip the early learning modules of the computer language. Our programming assignment writers from our programming language assignments have to take care of these problems.
The basic but important drawback of students is that they do not focus on key areas of difference between high-level and low-level programming languages. This leads to serious mistakes in their assignments. Students are particularly suggested to seek professional assignment assistance, especially when preparing their programming language assignments. Students can get guidance on each stage of program execution so that it will be interesting and simple. Our programming language assignments help our programming language assignment help you get to such issues.
0 notes
Text
Option Recompile
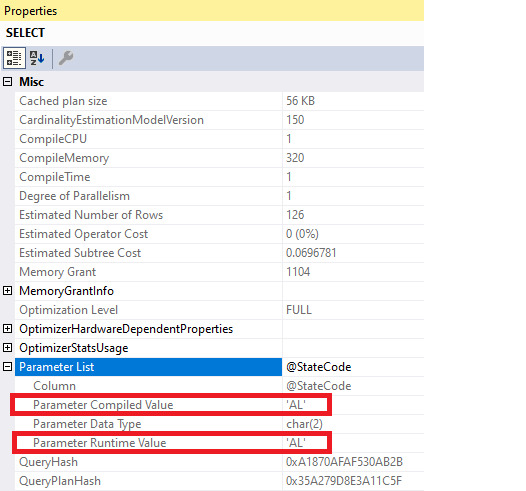
When doing query tuning, sometimes the answer can be that it’s just better to get SQL Server to recompile a plan based on the data passed in. You might have a batch process that runs every hour and sometimes it has only a few hundred rows, other times it has a few billion rows. The ideal query plan for each could be vastly different. We could try indexing for these plans, we could try rewriting…
View On WordPress
0 notes
Text
Amazon RDS for SQL Server now supports SQL Server 2019
Amazon RDS for SQL Server now supports Microsoft SQL Server 2019 for Express, Web, Standard, and Enterprise Editions. You can use SQL Server 2019 features such as Accelerated Database Recovery, Intelligent Query Processing, Intelligent Performance, Monitoring improvements, and Resumable Online Index creations. The purpose of this post is to: Summarize the new features in SQL Server 2019 that are supported in Amazon RDS for SQL Server Explain when and how the compatibility level of a database is set Describe changes to tempdb default configuration Review a few caveats with respect to some of the new features New Features Amazon RDS for SQL Server 2019 supports the following new features: Accelerated database recovery (ADR) improves database availability by reducing crash recovery time. ADR also allows for instantaneous transaction rollback and aggressive transaction log truncation, even in the presence of active long-running transactions. Intelligent query processing (IQP) features such as: Row mode memory grant feedback to automatically correct excessive memory grants based on real execution statistics. Row mode memory grant feedback is an extension to the batch mode memory grant feedback feature in previous version of SQL Server . This feature fine-tunes the memory grant sizes for both batch and row mode operator. Batch mode runs on rowstore, without requiring column store indexes. Scalar User Defined Functions (UDF) Inlining to automatically transform UDFs into scalar expressions or scalar subqueries. Table variable deferred compilation, to defer the compilation of a statement that references a table variable until the first actual use of the statement, resulting in actual cardinality use. Approximate counts with APPROX_COUNT_DISTINCT to return the approximate number of unique non-null values in a group without having to scan the entire table. Interleaved implementation for multi-statement table-valued functions to pause the optimization until the applicable subtree runs and accurate cardinality estimates are received. Memory-optimized tempdb metadata improves scalability of tempdb-heavy workloads by moving system tables managing temporary table metadata into latch-free, non-durable, memory-optimized tables. Intelligent Performance features such as: OPTIMIZE_FOR_SEQUENTIAL_KEY for index creation, which improves the throughput for high-concurrency inserts into an index. Forcing fast forward and static cursors provides Query Store plan forcing support for fast forward and static cursors. Indirect checkpoint scalability improvements to help DML-heavy workloads. Reduced recompilations for workloads running DML on temporary tables created by an outer scope batch. Concurrent Page Free Space (PFS) updates by using a shared latch instead of an exclusive latch. Scheduler worker migration enables the migration of long-running tasks across schedulers on the same NUMA node to provide balanced CPU usage. Monitoring improvements such as: A new wait type, WAIT_ON_SYNC_STATISTICS_REFRESH shows accumulated instance-level time spent on synchronous statistics refresh operations. LIGHTWEIGHT_QUERY_PROFILING to reduce the overhead of capturing performance data. COMMAND column of dm_exec_requests to show “SELECT (STATMAN)” for tasks waiting on a synchronous statistics update. Dynamic Management Function (DMF) dm_exec_query_plan_stats returns the last known actual query plan when LAST_QUERY_PLAN_STATS database configuration is enabled. DMF dm_db_page_info returns information about a database page. Mission-critical security features such as: Data Discovery & Classification to facilitate classifying and labeling columns basing on their data content. SQL Server Audit enhancements to view the new data_sensitivity_information column in the Audit Log. Transparent Data Encryption (TDE) is now also available on Standard Edition. The data truncation error message defaults to include table and column names, and the truncated value. Prior to SQL Server 2019, only resumable online index rebuild was supported. Resumable online index creations are also now supported. For more details, review the Guidelines for online index operations. Provisioning a SQL Server 2019 DB instance You can provision a SQL Server 2019 DB instance on Amazon RDS for SQL Server two different ways: Create a new RDS DB instance with the engine version = 15.00 Upgrade an existing DB instance to engine version = 15.00 Amazon RDS for SQL Server supports upgrading directly to SQL Server 2019 from all supported versions. The oldest supported engine version is SQL Server 2012 (engine version 11.00). We highly recommend testing database workloads on the new engine version prior to upgrading the DB instances. Amazon RDS for SQL Server makes this easy to do. Simply take a snapshot of the DB instance, restore the snapshot as a test DB instance, and upgrade the test DB instance to the new engine version. When the testing is complete, you can stop the test DB instance. For more information about testing and upgrading to new major versions, see Best practices for upgrading SQL Server 2008 R2 to SQL Server 2016 on Amazon RDS for SQL Server. You can provision a SQL Server 2019 DB instance on Amazon RDS for SQL Server by using the AWS Management Console, AWS Command Line Interface (AWS CLI), AWS SDK, or AWS CloudFormation. While provisioning the DB instance, the engine version needs to be set to 15.00. Compatibility level The compatibility level defines the Transact SQL (T-SQL) and query processing behavior in SQL Server. For more information, see ALTER DATABASE (Transact-SQL) Compatibility Level. The compatibility level is set at the database level and the native compatibility level of a newly created database on SQL Server 2019 is 150. Irrespective of the provisioning method (creating a new DB instance or upgrading an existing DB instance), a newly created database on an RDS SQL Server 2019 DB instance has a compatibility level of 150 by default. On an upgraded RDS SQL Server 2019 DB instance, existing databases that were created on older engine versions prior to the engine version upgrade remain on the older compatibility level. For example, if an RDS SQL Server 2017 DB instance was upgraded to SQL Server 2019, prior to the upgrade, databases created on SQL Server 2017 had a compatibility level of 140. These databases continue to have a compatibility level of 140 even after the upgrade. However, after the upgrade, you can change the compatibility level using the ALTER DATABASE T-SQL command: alter database set compatibility_level=150 SQL Server Management Studio (SSMS) provides an option to change the compatibility mode via the SSMS graphical user interface (GUI). This requires elevated privileges that aren’t available in Amazon RDS, so you can’t change the compatibility level using the SSMS GUI. Instead, use the T-SQL command to change the compatibility level. Changes to tempdb In Amazon RDS for SQL Server, starting with SQL Server 2019, the number of tempdb data files created by default has changed. Prior to SQL Server 2019, an RDS SQL Server instance had one tempdb data file across all editions and instance sizes. With SQL Server 2019, a newly created RDS SQL Server 2019 DB instance uses the following mapping for deciding how many tempdb data files get created. Edition Instance Class Size Number of TempDB Data Files Express All 1 Enterprise/Standard and Web db.*.xlarge and below Number of vCPUs Enterprise/Standard and Web db.*.2xlarge and above 8 The number of tempdb data files are decided during the creation of the DB instance. Post-creation, scaling a DB instance up or down doesn’t change the number of tempdb data files. For example, a newly created Standard Edition db.m5.xlarge DB instance has four tempdb datafiles. Scaling the instance to a db.m5.2xlarge doesn’t increase the number of tempdb files to eight. Using the new Amazon RDS for SQL Server features You can enable and use most of the new features as described in the SQL Server documentation, but there are a few exceptions. Multi-AZ deployments Multi-AZ deployments in Amazon RDS for SQL Server 2019 use one of two modes for synchronous replication: Always On or database mirroring, depending on the edition and upgrade path. Keep in mind the following: A newly created Multi-AZ RDS SQL Server 2019 Enterprise Edition (EE) DB instance uses Always On. Enabling Multi-AZ on a newly created Single-AZ RDS SQL Server 2019 EE DB instance uses Always On. Enabling Multi-AZ on a Single-AZ RDS SQL Server 2019 EE DB instance that was upgraded from any older engine version or edition uses Always On. A Multi-AZ DB instance upgraded from an older engine version to SQL Server 2019 uses the same mode it used on the older engine version. All Standard Edition DB instances use database mirroring. To check if a Multi-AZ DB instance is using Always On or database mirroring, on the Amazon RDS console, choose the database and navigate to its Configuration tab. On the Configuration tab, look for Multi AZ. For a Multi-AZ DB instance using Always On, the setting shows as Yes (Always On). For a DB Multi-AZ instance using database mirroring only, the setting shows as just Yes. To check using the AWS CLI or the AWS SDK, look for the ListenerEndpoint. Multi-AZ DB instances using database mirroring only have one endpoint. An additional ListenerEndpoint exists for Multi-AZ DB instances using Always On. You can change a Multi-AZ RDS SQL Server 2019 EE DB instance using database mirroring to use Always On by converting the DB instance to Single-AZ and then re-enabling Multi-AZ. Accelerated database recovery ADR is a SQL database engine feature that greatly improves database availability, especially in the presence of long running transactions, by redesigning the SQL database engine recovery. ADR achieves fast database recovery by versioning database modifications and only undoing logical operations, which are limited and can be undone almost instantly. Any transactions that were active at the time of a crash are marked as stopped and therefore concurrent user queries can ignore any versions generated by these transactions. For more information, see Accelerated database recovery. In Amazon RDS for SQL Server, ADR is fully supported on Single-AZ instances. On a Multi-AZ instances, ADR is supported on instances using Always On and is not supported on instances using database mirroring. As indicated in this bugfix, ADR is incompatible with database mirroring and trying to enable ADR on a mirrored database results in an error: Msg 1484, Level 16, State 1, Line LineNumber Database Mirroring cannot be set for database 'ADR_Mirroring' because the database has Accelerated Database Recovery enabled or there are still versions in the Persisted Version Store. If Accelerated Database Recovery is disabled, please run sys.sp_persistent_version_cleanup '' to clean up previous versions. On a Multi-AZ DB instance using database mirroring, enabling ADR on a newly created database results in Amazon RDS automation disabling ADR and enabling database mirroring. When enabling Multi-AZ on a DB instance wherein the mode is database mirroring, if ADR enabled databases are found, enabling Multi-AZ fails and the following notification appears: Unable to convert the DB instance to Multi-AZ: The database(s) ‘’ prevented the conversion because they have Accelerated Database Recovery (ADR) enabled. Disable ADR for these databases and try again. Intelligent query processing All IQP features in SQL Server 2019 are supported in Amazon RDS for SQL Server. Apart from the Approximate Count Distinct feature, you need to enable all the IQP features at the database level using the following command: alter database scoped configuration set =on You can also enable some of these features on tempdb, and the Amazon RDS primary user has the permissions to do so. On Multi-AZ DB instances, enabling these features on tempdb needs to be done on the primary and secondary. This can be achieved in two ways: Enable the feature on the primary, reboot the DB instance with failover, and enable the feature on the new primary Convert the Multi-AZ DB instance to Single-AZ, enable the feature, and convert the DB instance to Multi-AZ In-Memory database Amazon RDS for SQL Server doesn’t support persistent memory (PMEM) devices and SQL Server native database snapshots. So, the enhancement to Hybrid Buffer Pool to use PMEM devices and In-Memory OLTP support for SQL Server native database snapshots are not supported. The memory-optimized tempdb metadata feature is supported in Amazon RDS for SQL Server. You can enable this feature by running the alter server configuration command. However, the Amazon RDS primary user doesn’t have access to run this command on an RDS SQL Server DB instance. Instead, you can set the parameter “Memory optimized tempdb Metadata” in the Amazon RDS parameter group. After applying the parameter group with the modified parameter to the DB instance, the feature is enabled on the DB instance. Intelligent Performance As part of Intelligent Performance, SQL Server 2019 brings some enhancements to Resource Governance. Given that Amazon RDS for SQL Server doesn’t support SQL Server’s Resource Governor feature, these enhancements are not supported. All other Intelligent Performance features like concurrent PFS updates, scheduler worker migration, and more, are supported in Amazon RDS for SQL Server. Mission-critical security Data Discovery & Classification introduces a new tool built into SSMS for discovering, classifying, labeling, and reporting sensitive data in databases. For more information, see SQL Data Discovery and Classification. Using SSMS version 17.5 and above, Data Discovery & Classification is achievable on Amazon RDS for SQL Server. You can also add data sensitivity labeling using the ADD SENSITIVITY CLASSIFICATION clause, and the Amazon RDS primary user has the necessary permissions to run this command. The data sensitivity information has been added to the SQL Server Audit file record under the new field data_sensitivity_information. You can enable SQL Server auditing in Amazon RDS for SQL Server using options groups. After the SQL Server Audit is enabled on the DB instance and audit specifications are created, you can read the Audit files on the DB instance using the function msdb.dbo.rds_fn_get_audit_file. This function also returns the new field data_sensitivity_information. You can read the audit files as long as they are on the disk. To change how long the audit files should be persisted on the disk, you can configure the parameter RETENTION_TIME while setting up the SQL Server Audit option. Amazon RDS for SQL Server now supports TDE for SQL Server Standard Edition. TDE needs be enabled on the DB instance using option groups. For more information about enabling TDE, see Support for Transparent Data Encryption in SQL Server. Conclusion In this post, we listed some of the new and exciting features of SQL Server 2019 that are supported in Amazon RDS for SQL Server, along with brief descriptions of the features. We called out cases where the features differ slightly, provided instructions on how to enable the features, and advised on any prerequisites they might have. A major engine version release like SQL Server 2019 brings significant changes to the engine—some visible and others not. We highly recommend testing database workloads using the Amazon RDS easy clone mechanisms as described in this post before upgrading to this new engine version. About the Author Prashant Bondada is a Senior Database Engineer at Amazon Web Services. He works on the RDS team, focusing on commercial database engines, SQL Server and Oracle. Sudarshan Roy is a Senior Database Specialist Cloud Solution Architect with the AWS Database Services Organization (DBSO), Customer Advisory Team (CAT). He has led large scale Database Migration & Modernization engagements for Enterprise Customers to move their on-premises database environment to Multi Cloud based database solutions. https://aws.amazon.com/blogs/database/amazon-rds-for-sql-server-now-supports-sql-server-2019/
0 notes
Text
Oracle DBA interview Question with Answer (All in One Doc)
1. General DB Maintenance2. Backup and Recovery3. Flashback Technology4. Dataguard5. Upgration/Migration/Patches6. Performance Tuning7. ASM8. RAC (RAC (Cluster/ASM/Oracle Binaries) Installation Link 9. Linux Operating10. PL/SQLGeneral DB Maintenance Question/Answer:When we run a Trace and Tkprof on a query we see the timing information for three phase?Parse-> Execute-> FetchWhich parameter is used in TNS connect identifier to specify number of concurrent connection request?QUEUESIZEWhat does AFFIRM/NOFFIRM parameter specify?AFFIRM specify redo transport service acknowledgement after writing to standby (SYNC) where as NOFFIRM specify acknowledgement before writing to standby (ASYNC).After upgrade task which script is used to run recompile invalid object?utlrp.sql, utlprpDue to too many cursor presents in library cache caused wait what parameter need to increase?Open_cursor, shared_pool_sizeWhen using Recover database using backup control file?To synchronize datafile to controlfileWhat is the use of CONSISTENT=Y and DIRECT=Y parameter in export?It will take consistent values while taking export of a table. Setting direct=yes, to extract data by reading the data directly, bypasses the SGA, bypassing the SQL command-processing layer (evaluating buffer), so it should be faster. Default value N.What the parameter COMPRESS, SHOW, SQLFILE will do during export?If you are using COMPRESS during import, It will put entire data in a single extent. if you are using SHOW=Y during import, It will read entire dumpfile and confirm backup validity even if you don’t know the formuser of export can use this show=y option with import to check the fromuser.If you are using SQLFILE (which contains all the DDL commands which Import would have executed) parameter with import utility can get the information dumpfile is corrupted or not because this utility will read entire dumpfile export and report the status.Can we import 11g dumpfile into 10g using datapump? If so, is it also possible between 10g and 9i?Yes we can import from 11g to 10g using VERSION option. This is not possible between 10g and 9i as datapump is not there in 9iWhat does KEEP_MASTER and METRICS parameter of datapump?KEEP_MASTER and METRICS are undocumented parameter of EXPDP/IMPDP. METRICS provides the time it took for processing the objects and KEEP_MASTER prevents the Data Pump Master table from getting deleted after an Export/Import job completion.What happens when we fire SQL statement in Oracle?First it will check the syntax and semantics in library cache, after that it will create execution plan. If already data is in buffer cache it will directly return to the client (soft parse) otherwise it will fetch the data from datafiles and write to the database buffer cache (hard parse) after that it will send server and finally server send to the client.What are between latches and locks?1. A latch management is based on first in first grab whereas lock depends lock order is last come and grap. 2. Lock creating deadlock whereas latches never creating deadlock it is handle by oracle internally. Latches are only related with SGA internal buffer whereas lock related with transaction level. 3. Latches having on two states either WAIT or NOWAIT whereas locks having six different states: DML locks (Table and row level-DBA_DML_LOCKS ), DDL locks (Schema and Structure level –DBA_DDL_LOCKS), DBA_BLOCKERS further categorized many more.What are the differences between LMTS and DMTS? Tablespaces that record extent allocation in the dictionary are called dictionary managed tablespaces, the dictionary tables are created on SYSTEM tablespace and tablespaces that record extent allocation in the tablespace header are called locally managed tablespaces.Difference of Regular and Index organized table?The traditional or regular table is based on heap structure where data are stored in un-ordered format where as in IOT is based on Binary tree structure and data are stored in order format with the help of primary key. The IOT is useful in the situation where accessing is commonly with the primary key use of where clause statement. If IOT is used in select statement without primary key the query performance degrades.What are Table portioning and their use and benefits?Partitioning the big table into different named storage section to improve the performance of query, as the query is accessing only the particular partitioned instead of whole range of big tables. The partitioned is based on partition key. The three partition types are: Range/Hash/List Partition.Apart from table an index can also partitioned using the above partition method either LOCAL or GLOBAL.Range partition:How to deal online redo log file corruption?1. Recover when only one redo log file corrupted?If your database is open and you lost or corrupted your logfile then first try to shutdown your database normally does not shutdown abort. If you lose or corrupted only one redo log file then you need only to open the database with resetlog option. Opening with resetlog option will re-create your online redo log file.RECOVER DATABASE UNTIL CANCEL; then ALTER DATABASE OPEN RESETLOGS;2. Recover when all the online redo log file corrupted?When you lose all member of redo log group then the step of maintenance depends on group ‘STATUS’ and database status Archivelog/NoArchivelog.If the affected redo log group has a status of INACTIVE then it is no longer required crash recovery then issues either clear logfile or re-create the group manually.ALTER DATABASE CLEAR UNARCHIVED LOGFILE GROUP 3; -- you are in archive mode and group still not archivedALTER DATABASE CLEAR LOGFILE GROUP 3; noarchive mode or group already archivedIf the affected redo log group has a status ACTIVE then it is still required for crash recovery. Issue the command ALTER SYSTEM CHECKPOINT, if successful then follow the step inactive if fails then you need to perform incomplete recovery up to the previous log file and open the database with resetlog option.If the affected redo log group is CURRENT then lgwr stops writing and you have to perform incomplete recovery up to the last logfile and open the database with resetlog option and if your database in noarchive then perform the complete recovery with last cold backup.Note: When the online redolog is UNUSED/STALE means it is never written it is newly created logfile.What is the function of shared pool in SGA?The shared pool is most important area of SGA. It control almost all sub area of SGA. The shortage of shared pool may result high library cache reloads and shared pool latch contention error. The two major component of shared pool is library cache and dictionary cache.The library cache contains current SQL execution plan information. It also holds PL/SQL procedure and trigger.The dictionary cache holds environmental information which includes referential integrity, table definition, indexing information and other metadata information.Backup & Recovery Question/Answer:Is target database can be catalog database?No recovery catalog cannot be the same as target database because whenever target database having restore and recovery process it must be in mount stage in that period we cannot access catalog information as database is not open.What is the use of large pool, which case you need to set the large pool?You need to set large pool if you are using: MTS (Multi thread server) and RMAN Backups. Large pool prevents RMAN & MTS from competing with other sub system for the same memory (specific allotment for this job). RMAN uses the large pool for backup & restore when you set the DBWR_IO_SLAVES or BACKUP_TAPE_IO_SLAVES parameters to simulate asynchronous I/O. If neither of these parameters is enabled, then Oracle allocates backup buffers from local process memory rather than shared memory. Then there is no use of large pool.How to take User-managed backup in RMAN or How to make use of obsolete backup? By using catalog command: RMAN>CATALOG START WITH '/tmp/KEEP_UNTIL_30APRIL2010;It will search into all file matching the pattern on the destination asks for confirmation to catalog or you can directly change the backup set keep until time using rman command to make obsolete backup usable.RMAN> change backupset 3916 keep until time "to_date('01-MAY-2010','DD-MON-YYYY')" nologs;This is important in the situation where our backup become obsolete due to RMAN retention policy or we have already restored prior to that backup. What is difference between using recovery catalog and control file?When new incarnation happens, the old backup information in control file will be lost where as it will be preserved in recovery catalog .In recovery catalog, we can store scripts. Recovery catalog is central and can have information of many databases. This is the reason we must need to take a fresh backup after new incarnation of control file.What is the benefit of Block Media Recovery and How to do it?Without block media recovery if the single block is corrupted then you must take datafile offline and then restore all backup and archive log thus entire datafile is unavailable until the process is over but incase of block media recovery datafile will be online only the particular block will be unavailable which needs recovery. You can find the details of corrupted block in V$database_Block_Corruption view as well as in alert/trace file.Connect target database with RMAN in Mount phase:RMAN> Recover datafile 8 block 13;RMAN> Recover CORRUPTION_LIST; --to recover all the corrupted block at a time.In respect of oracle 11g Active Dataguard features (physical standby) where real time query is possible corruption can be performed automatically. The primary database searches for good copies of block on the standby and if they found repair the block with no impact to the query which encounter the corrupt block.By default RMAN first searches the good block in real time physical standby database then flashback logs then full and incremental rman backup.What is Advantage of Datapump over Traditional Export?1. Data pump support parallel concept. It can write multiple dumps instead of single sequential dump.2. Data can be exported from remote database by using database link.3. Consistent export with Flashback_SCN, Flashback_Time supported in datapump.4. Has ability to attach/detach from job and able to monitor the job remotely.5. ESTIMATE_ONLY option can be used to estimate disk space requirement before perform the job.6. Explicit DB version can be specified so only supported object can be exported.7. Data can be imported from one DB to another DB without writing into dump file using NETWORK_LINK.8. During impdp we change the target file name, schema, tablespace using: REMAP_Why datapump is faster than traditional Export. What to do to increase datapump performace?Data Pump is block mode, exp is byte mode.Data Pump will do parallel execution.Data Pump uses direct path API and Network link features.Data pump export/import/access file on server rather than client by providing directory structure grant.Data pump is having self-tuning utilities, the tuning parameter BUFFER and RECORDLENGTH no need now.Following initialization parameter must be set to increase data pump performance:· DISK_ASYNCH_IO=TRUE· DB_BLOCK_CHECKING=FALSE· DB_BLOCK_CHECKSUM=FALSEFollowing initialization must be set high to increase datapump parallelism:· PROCESSES· SESSIONS· PARALLEL_MAX_SERVERS· SHARED_POOL_SIZE and UNDO_TABLESPACENote: you must set the reasonable amount of STREAMS_POOL_SIZE as per database size if SGA_MAXSIZE parameter is not set. If SGA_MAXSIZE is set it automatically pickup reasonable amount of size.Flashback Question/AnswerFlashback Archive Features in oracle 11gThe flashback archiving provides extended features of undo based recovery over a year or lifetime as per the retention period and destination size.Limitation or Restriction on flashback Drop features?1. The recyclebin features is only for non-system and locally managed tablespace. 2. When you drop any table all the associated objects related with that table will go to recyclebin and generally same reverse with flashback but sometimes due to space pressure associated index will finished with recyclebin. Flashback cannot able to reverse the referential constraints and Mviews log.3. The table having fine grained auditing active can be protected by recyclebin and partitioned index table are not protected by recyclebin.Limitation or Restriction on flashback Database features?1. Flashback cannot use to repair corrupt or shrink datafiles. If you try to flashback database over the period when drop datafiles happened then it will records only datafile entry into controlfile.2. If controlfile is restored or re-created then you cannot use flashback over the point in time when it is restored or re-created.3. You cannot flashback NOLOGGING operation. If you try to flashback over the point in time when NOLOGGING operation happens results block corruption after the flashback database. Thus it is extremely recommended after NOLOGGING operation perform backup.What are Advantages of flashback database over flashback Table?1. Flashback Database works through all DDL operations, whereas Flashback Table does not work with structural change such as adding/dropping a column, adding/dropping constraints, truncating table. During flashback Table operation A DML exclusive lock associated with that particular table while flashback operation is going on these lock preventing any operation in this table during this period only row is replaced with old row here. 2. Flashback Database moves the entire database back in time; constraints are not an issue, whereas they are with Flashback Table. 3. Flashback Table cannot be used on a standby database.How should I set the database to improve Flashback performance? Use a fast file system (ASM) for your flash recovery area, configure enough disk space for the file system that will hold the flash recovery area can enable to set maximum retention target. If the storage system used to hold the flash recovery area does not have non-volatile RAM (ASM), try to configure the file system on top of striped storage volumes, with a relatively small stripe size such as 128K. This will allow each write to the flashback logs to be spread across multiple spindles, improving performance. For large production databases set LOG_BUFFER to be at least 8MB. This makes sure the database allocates maximum memory (typically 16MB) for writing flashback database logs.Performance Tuning Question/Answer:If you are getting complain that database is slow. What should be your first steps to check the DB performance issues?In case of performance related issues as a DBA our first step to check all the session connected to the database to know exactly what the session is doing because sometimes unexpected hits leads to create object locking which slow down the DB performance.The database performance directly related with Network load, Data volume and Running SQL profiling.1. So check the event which is waiting for long time. If you find object locking kill that session (DML locking only) will solve your issues.To check the user sessions and waiting events use the join query on views: V$session,v$session_wait2. After locking other major things which affect the database performance is Disk I/O contention (When a session retrieves information from datafiles (on disk) to buffer cache, it has to wait until the disk send the data). This waiting time we need to minimize.We can check these waiting events for the session in terms of db file sequential read (single block read P3=1 usually the result of using index scan) and db file scattered read (multi block read P3 >=2 usually the results of for full table scan) using join query on the view v$system_eventSQL> SELECT a.average_wait "SEQ READ", b.average_wait "SCAT READ" 2 FROM sys.v_$system_event a, sys.v_$system_event b 3 WHERE a.event = 'db file sequential read'AND b.event = 'db file scattered read'; SEQ READ SCAT READ---------- ---------- .74 1.6When you find the event is waiting for I/O to complete then you must need to reduce the waiting time to improve the DB performance. To reduce this waiting time you must need to perform SQL tuning to reduce the number of block retrieve by particular SQL statement.How to perform SQL Tuning?1. First of all you need to identify High load SQL statement. You can identify from AWR Report TOP 5 SQL statement (the query taking more CPU and having low execution ratio). Once you decided to tune the particular SQL statement then the first things you have to do to run the Tuning Optimizer. The Tuning optimize will decide: Accessing Method of query, Join Method of query and Join order.2. To examine the particular SQL statement you must need to check the particular query doing the full table scan (if index not applied use the proper index technique for the table) or if index already applied still doing full table scan then check may be table is having wrong indexing technique try to rebuild the index. It will solve your issues somehow…… otherwise use next step of performance tuning.3. Enable the trace file before running your queries, then check the trace file using tkprof created output file. According to explain_plan check the elapsed time for each query, and then tune them respectively.To see the output of plan table you first need to create the plan_table from and create a public synonym for plan_table @$ORACLE_HOME/rdbms/admin/utlxplan.sql)SQL> create public synonym plan_table for sys.plan_table;4. Run SQL Tuning Advisor (@$ORACLE_HOME/rdbms/admin/sqltrpt.sql) by providing SQL_ID as you find in V$session view. You can provide rights to the particular schema for the use of SQL Tuning Advisor: Grant Advisor to HR; Grant Administer SQL Tuning set to HR;SQL Tuning Advisor will check your SQL structure and statistics. SQL Tuning Advisor suggests indexes that might be very useful. SQL Tuning Advisor suggests query rewrites. SQL Tuning Advisor suggests SQL profile. (Automatic reported each time)5. Now in oracle 11g SQL Access Advisor is used to suggests new index for materialized views. 6. More: Run TOP command in Linux to check CPU usage information and Run VMSTAT, SAR, PRSTAT command to get more information on CPU, memory usage and possible blocking.7. Optimizer Statistics are used by the query optimizer to choose the best execution plan for each SQL statement. Up-to-date optimizer statistics can greatly improve the performance of SQL statements.8. A SQL Profile contains object level statistics (auxiliary statistics) that help the optimizer to select the optimal execution plan of a particular SQL statement. It contains object level statistics by correcting the statistics level and giving the Tuning Advisor option for most relevant SQL plan generation.DBMS_SQLTUNE.ACCEPT_SQL_PROFILE – to accept the correct plan from SQLplusDBMS_SQLTUNE.ALTER_SQL_PROFILE – to modify/replace existing plan from SQLplus.DBMS_SQLTUNE.DROP_SQL_PROFILE – to drop existing plan.Profile Type: REGULAR-PROFILE, PX-PROFILE (with change to parallel exec)SELECT NAME, SQL_TEXT, CATEGORY, STATUS FROM DBA_SQL_PROFILES; 9. SQL Plan Baselines are a new feature in Oracle Database 11g (previously used stored outlines, SQL Profiles) that helps to prevent repeatedly used SQL statements from regressing because a newly generated execution plan is less effective than what was originally in the library cache. Whenever optimizer generating a new plan it is going to the plan history table then after evolve or verified that plan and if the plan is better than previous plan then only that plan going to the plan table. You can manually check the plan history table and can accept the better plan manually using the ALTER_SQL_PLAN_BASELINE function of DBMS_SPM can be used to change the status of plans in the SQL History to Accepted, which in turn moves them into the SQL Baseline and the EVOLVE_SQL_PLAN_BASELINE function of the DBMS_SPM package can be used to see which plans have been evolved. Also there is a facility to fix a specific plan so that plan will not change automatically even if better execution plan is available. The plan base line view: DBA_SQL_PLAN_BASELINES.Why use SQL Plan Baseline, How to Generate new plan using Baseline 10. SQL Performance Analyzer allows you to test and to analyze the effects of changes on the execution performance of SQL contained in a SQL Tuning Set. Which factors are to be considered for creating index on Table? How to select column for index? 1. Creation of index on table depends on size of table, volume of data. If size of table is large and you need only few data < 15% of rows retrieving in report then you need to create index on that table. 2. Primary key and unique key automatically having index you might concentrate to create index on foreign key where indexing can improve performance on join on multiple table.3. The column is best suitable for indexing whose values are relatively unique in column (through which you can access complete table records. Wide range of value in column (good for regular index) whereas small range of values (good for bitmap index) or the column contains many nulls but queries can select all rows having a value. CREATE INDEX emp_ename ON emp_tab(ename);The column is not suitable for indexing which is having many nulls but cannot search non null value or LONG, LONG RAW column not suitable for indexing.CAUTION: The size of single index entry cannot exceed one-half of the available space on data block.The more indexes on table will create more overhead as with each DML operation on table all index must be updated. It is important to note that creation of so many indexes would affect the performance of DML on table because in single transaction should need to perform on various index segments and table simultaneously. What are Different Types of Index? Is creating index online possible? Function Based Index/Bitmap Index/Binary Tree Index/4. implicit or explicit index, 5. Domain Index You can create and rebuild indexes online. This enables you to update base tables at the same time you are building or rebuilding indexes on that table. You can perform DML operations while the index building is taking place, but DDL operations are not allowed. Parallel execution is not supported when creating or rebuilding an index online.An index can be considered for re-building under any of these circumstances:We must first get an idea of the current state of the index by using the ANALYZE INDEX VALIDATE STRUCTURE, ANALYZE INDEX COMPUTE STATISTICS command* The % of deleted rows exceeds 30% of the total rows (depending on table length). * If the ‘HEIGHT’ is greater than 4, as the height of level 3 we can insert millions of rows. * If the number of rows in the index (‘LF_ROWS’) is significantly smaller than ‘LF_BLKS’ this can indicate a large number of deletes, indicating that the index should be rebuilt.Differentiate the use of Bitmap index and Binary Tree index? Bitmap indexes are preferred in Data warehousing environment when cardinality is low or usually we have repeated or duplicate column. A bitmap index can index null value Binary-tree indexes are preferred in OLTP environment when cardinality is high usually we have too many distinct column. Binary tree index cannot index null value.If you are getting high “Busy Buffer waits”, how can you find the reason behind it? Buffer busy wait means that the queries are waiting for the blocks to be read into the db cache. There could be the reason when the block may be busy in the cache and session is waiting for it. It could be undo/data block or segment header wait. Run the below two query to find out the P1, P2 and P3 of a session causing buffer busy wait then after another query by putting the above P1, P2 and P3 values. SQL> Select p1 "File #",p2 "Block #",p3 "Reason Code" from v$session_wait Where event = 'buffer busy waits'; SQL> Select owner, segment_name, segment_type from dba_extents Where file_id = &P1 and &P2 between block_id and block_id + blocks -1;What is STATSPACK and AWR Report? Is there any difference? As a DBA what you should look into STATSPACK and AWR report?STATSPACK and AWR is a tools for performance tuning. AWR is a new feature for oracle 10g onwards where as STATSPACK reports are commonly used in earlier version but you can still use it in oracle 10g too. The basic difference is that STATSPACK snapshot purged must be scheduled manually but AWR snapshots are purged automatically by MMON BG process every night. AWR contains view dba_hist_active_sess_history to store ASH statistics where as STASPACK does not storing ASH statistics.You can run $ORACLE_HOME/rdbms/admin/spauto.sql to gather the STATSPACK report (note that Job_queue_processes must be set > 0 ) and awrpt to gather AWR report for standalone environment and awrgrpt for RAC environment.In general as a DBA following list of information you must check in STATSPACK/AWR report. ¦ Top 5 wait events (db file seq read, CPU Time, db file scattered read, log file sync, log buffer spac)¦ Load profile (DB CPU(per sec) < Core configuration and ratio of hard parse must be < parse)¦ Instance efficiency hit ratios (%Non-Parse CPU nearer to 100%)¦ Top 5 Time Foreground events (wait class is ‘concurrency’ then problem if User IO, System IO then OK)¦ Top 5 SQL (check query having low execution and high elapsed time or taking high CPU and low execution)¦ Instance activity¦ File I/O and segment statistics¦ Memory allocation¦ Buffer waits¦ Latch waits 1. After getting AWR Report initially crosscheck CPU time, db time and elapsed time. CPU time means total time taken by the CPU including wait time also. Db time include both CPU time and the user call time whereas elapsed time is the time taken to execute the statement.2. Look the Load profile Report: Here DB CPU (per sec) must be < Core in Host configuration. If it is not means there is a CPU bound need more CPU (check happening for fraction time or all the time) and then look on this report Parse and Hard Parse. If the ratio of hard parse is more than parse then look for cursor sharing and application level for bind variable etc.3. Look instance efficiency Report: In this statistics you have to look ‘%Non-Parse CPU’, if this value nearer to 100% means most of the CPU resource are used into operation other than parsing which is good for database health.4. Look TOP five Time foreground Event: Here we should look ‘wait class’ if the wait class is User I/O, system I/O then OK if it is ‘Concurrency’ then there is serious problem then look Time(s) and Avg Wait time(s) if the Time (s) is more and Avg Wait Time(s) is less then you can ignore if both are high then there is need to further investigate (may be log file switch or check point incomplete).5. Look Time Model Statistics Report: This is detailed report of system resource consumption order by Time(s) and % of DB Time.6. Operating system statistics Report7. SQL ordered by elapsed time: In this report look for the query having low execution and high elapsed time so you have to investigate this and also look for the query using highest CPU time but the lower the execution.What is the difference between DB file sequential read and DB File Scattered Read? DB file sequential read is associated with index read where as DB File Scattered Read has to do with full table scan. The DB file sequential read, reads block into contiguous (single block) memory and DB File scattered read gets from multiple block and scattered them into buffer cache. Dataguard Question/AnswerWhat are Benefits of Data Guard?Using Data guard feature in your environment following benefit:High availability, Data protection, Offloading backup operation to standby, Automatic gap detection and resolution in standby database, Automatic role transitions using data guard broker.Oracle Dataguard classified into two types:1. Physical standby (Redo apply technology)2. Logical Standby (SQL Apply Technology)Physical standby are created as exact copy (matching the schema) of the primary database and keeping always in recoverable mode (mount stage not open mode). In physical standby database transactions happens in primary database synchronized by using Redo Apply method by continually applying redo data on standby database received from primary database. Physical standby database can be opened for read only transitions only that time when redo apply is not going on. But from 11g onward using active data guard option (extra purchase) you can simultaneously open the physical standby database for read only access and can apply redo log received from primary in the meantime.Logical standby does not matching the same schema level and using the SQL Apply method to synchronize the logical standby database with primary database. The main advantage of logical standby database over physical standby is you can use logical standby database for reporting purpose while you are apply SQL.What are different services available in oracle data guard?1. Redo Transport Service: Transmit the redo from primary to standby (SYNC/ASYNC method). It responsible to manage the gap of redo log due to network failure. It detects if any corrupted archive log on standby system and automatically perform replacement from primary. 2. Log Apply Service: It applies the archive redo log to the standby. The MRP process doing this task.3. Role Transition service: it control the changing of database role from primary to standby includes: switchover, switchback, failover.4. DG broker: control the creation and monitoring of data guard through GUI and command line.What is different protection mode available in oracle data guard? How can check and change it?1. Maximum performance: (default): It provides the high level of data protection that is possible without affecting the performance of a primary database. It allowing transactions to commit as soon as all redo data generated by those transactions has been written to the online log.2. Maximum protection: This protection mode ensures that no data loss will occur if the primary database fails. In this mode the redo data needed to recover a transaction must be written to both the online redo log and to at least one standby database before the transaction commits. To ensure that data loss cannot occur, the primary database will shut down, rather than continue processing transactions.3. Maximum availability: This provides the highest level of data protection that is possible without compromising the availability of a primary database. Transactions do not commit until all redo data needed to recover those transactions has been written to the online redo log and to at least one standby database.Step to create physical standby database?On Primary site Modification:1. Enable force logging: Alter database force logging;2. Create redolog group for standby on primary server:Alter database add standby logfile (‘/u01/oradata/--/standby_redo01.log) size 100m;3. Setup the primary database pfile by changing required parameterLog_archive_dest_n – Primary database must be running in archive modeLog_archive_dest_state_nLog_archive_config -- enble or disable the redo stream to the standby site.Log_file_name_convert , DB_file_name_convert -- these parameter are used when you are using different directory structure in standby database. It is used for update the location of datafile in standby database.Standby_File_Management -- by setting this AUTO so that when oracle file added or dropped from primary automatically changes made to the standby. DB_Unique_Name, Fal_server, Fal_client4. Create password file for primary5. Create controlfile for standby database on primary site:alter database create standby controlfile as ‘STAN.ctl;6. Configure the listner and tnsname on primary database.On Standby Modification:1. Copy primary site pfile and modify these pfile as per standby name and location:2. Copy password from primary and modify the name.3. Startup standby database in nomount using modified pfile and create spfile from it4. Use the created controlfile to mount the database.5. Now enable DG Broker to activate the primary or standby connection.6. Finally start redo log apply.How to enable/disable log apply service for standby?Alter database recover managed standby database disconnect; apply in backgroundAlter database recover managed standby database using current logfile; apply in real time.Alter database start logical standby apply immediate; to start SQL apply for logical standby database.What are different ways to manage long gap of standby database?Due to network issue sometimes gap is created between primary and standby database but once the network issue is resolved standby automatically starts applying redolog to fill the gap but in case when the gap is too long we can fill through rman incremental backup in three ways.1. Check the actual gap and perform incremental backup and use this backup to recover standby site.2. Create controlfile for standby on primary and restore the standby using newly created controlfile.3. Register the missing archive log.Use the v$archived_log view to find the gap (archived not applied yet) then find the Current_SCN and try to take rman incremental backup from physical site till that SCN and apply on standby site with recover database noredo option. Use the controlfile creation method only when fail to apply with normal backup method. Create new controlfile for standby on primary site using backup current controlfile for standby; Copy this controlfile on standby site then startup the standby in nomount using pfile and restore with the standby using this controlfile: restore standby controlfile from ‘/location of file’; and start MRP to test.If still alert.log showing log are transferred to the standby but still not applied then need to register these log with standby database with Alter database register logfile ‘/backup/temp/arc10.rc’;What is Active DATAGUARD feature in oracle 11g?In physical standby database prior to 11g you are not able to query on standby database while redo apply is going on but in 11g solve this issue by quering current_scn from v$database view you are able to view the record while redo log applying. Thus active data guard feature s of 11g allows physical standby database to be open in read only mode while media recovery is going on through redo apply method and also you can open the logical standby in read/write mode while media recovery is going on through SQL apply method.How can you find out back log of standby?You can perform join query on v$archived_log, v$managed_standbyWhat is difference between normal Redo Apply and Real-time Apply?Normally once a log switch occurs on primary the archiver process transmit it to the standby destination and remote file server (RFS) on the standby writes these redo log data into archive. Finally MRP service, apply these archive to standby database. This is called Redo Apply service.In real time apply LGWR or Archiver on the primary directly writing redo data to standby there is no need to wait for current archive to be archived. Once a transaction is committed on primary the committed change will be available on the standby in real time even without switching the log.What are the Back ground processes for Data guard?On primary:Log Writer (LGWR): collects redo information and updates the online redolog . It can also create local archive redo log and transmit online redo log to standby.Archiver Process (ARCn): one or more archiver process makes copies of online redo log to standby locationFetch Archive Log (FAL_server): services request for archive log from the client running on different standby server.On standby:Fetch Archive Log (FAL_client): pulls archive from primary site and automatically initiates transfer of archive when it detects gap.Remote File Server (RFS): receives archives on standby redo log from primary database. Archiver (ARCn): archived the standby redo log applied by managed recovery process.Managed Recovery Process (MRP): applies archives redo log to the standby server.Logical Standby Process (LSP): applies SQL to the standby server.ASM/RAC Question/AnswerWhat is the use of ASM (or) Why ASM preferred over filesystem?ASM provides striping and mirroring. You must put oracle CRD files, spfile on ASM. In 12c you can put oracle password file also in ASM. It facilitates online storage change and also rman recommended to backed up ASM based database.What are different types of striping in ASM & their differences?Fine-grained striping is smaller in size always writes data to 128 kb for each disk, Coarse-grained striping is bigger in size and it can write data as per ASM allocation unit defined by default it is 1MB.Default Memory Allocation for ASM? How will backup ASM metadata?Default Memory allocation for ASM in oracle 10g in 1GB in Oracle 11g 256M in 12c it is set back again 1GB.You can backup ASM metadata (ASM disk group configuration) using Md_Backup.How to find out connected databases with ASM or not connected disks list?ASMCMD> lsctSQL> select DB_NAME from V$ASM_CLIENT;ASMCMD> lsdgselect NAME,ALLOCATION_UNIT_SIZE from v$asm_diskgroup;What are required parameters for ASM instance Creation?INSTANCE_TYPE = ASM by default it is RDBMSDB_UNIQUE_NAME = +ASM1 by default it is +ASM but you need to alter to run multiple ASM instance.ASM_POWER_LIMIT = 11 It defines maximum power for a rebalancing operation on ASM by default it is 1 can be increased up to 11. The higher the limit the more resources are allocated resulting in faster rebalancing. It is a dynamic parameter which will be useful for rebalancing the data across disks.ASM_DISKSTRING = ‘/u01/dev/sda1/c*’it specify a value that can be used to limit the disks considered for discovery. Altering the default value may improve the speed disk group mount time and the speed of adding a disk to disk group.ASM_DISKGROUPS = DG_DATA, DG_FRA: List of disk group that will be mounted at instance startup where DG_DATA holds all the datafiles and FRA holds fast recovery area including online redo log and control files. Typically FRA disk group size will be twice of DATA disk group as it is holding all the backups.How to Creating spfile for ASM database?SQL> CREATE SPFILE FROM PFILE = ‘/tmp/init+ASM1.ora’;Start the instance with NOMOUNT option: Once an ASM instance is present disk group can be used for following parameter in database instance to allow ASM file creation:DB_CREATE_FILE_DEST, DB_CREATE_ONLINE_LOG_DEST_n, DB_RECOVERY_FILE_DEST, CONTROL_FILESLOG_ARCHIVE_DEST_n,LOG_ARCHIVE_DEST,STANDBY_ARCHIVE_DESTWhat are DISKGROUP Redundancy Level?Normal Redundancy: Two ways mirroring with 2 FAILURE groups with 3 quorum (optionally to store vote files)High Redundancy: Three ways mirroring requiring three failure groupsExternal Redundancy: No mirroring for disk that are already protecting using RAID on OS level.CREATE DISKGROUP disk_group_1 NORMAL REDUNDANCY FAILGROUP failure_group_1 DISK '/devices/diska1' NAME diska1,'/devices/diska2' NAME diska2 FAILGROUP failure_group_2 DISK '/devices/diskb1' NAME diskb1,'/devices/diskb2' NAME diskb2;We are going to migrate new storage. How we will move my ASM database from storage A to storage B? First need to prepare OS level to disk so that both the new and old storage accessible to ASM then simply add the new disks to the ASM disk group and drop the old disks. ASM will perform automatic rebalance whenever storage will change. There is no need to manual i/o tuning. ASM_SQL> alter diskgroup DATA drop disk data_legacy1, data_legacy2, data_legacy3 add disk ‘/dev/sddb1’, ‘/dev/sddc1’, ‘/dev/sddd1’;What are required component of Oracle RAC installation?:1. Oracle ASM shared disk to store OCR and voting disk files.2. OCFS2 for Linux Clustered database3. Certified Network File system (NFS)4. Public IP: Configuration: TCP/IP (To manage database storage system)5. Private IP: To manager RAC cluster ware (cache fusion) internally.6. SCAN IP: (Listener): All connection to the oracle RAC database uses the SCAN in their client connection string with SCAN you do not have to change the client connection even if the configuration of cluster changes (node added or removed). Maximum 3 SCAN is running in oracle.7. Virtual IP: is alternate IP assigned to each node which is used to deliver the notification of node failure message to active node without being waiting for actual time out. Thus possibly switchover will happen automatically to another active node continue to process user request.Steps to configure RAC database:1. Install same OS level on each nodes or systems.2. Create required number of group and oracle user account.3. Create required directory structure or CRS and DB home.4. Configure kernel parameter (sysctl.config) as per installation doc set shell limit for oracle user account.5. Edit etc/host file and specify public/private/virtual ip for each node.6. Create required level of partition for OCR/Votdisk and ASM diskgroup.7. Install OCFSC2 and ASM RPM and configure with each node.8. Install clustware binaries then oracle binaries in first node.9. Invoke netca to configure listener. 10. Finally invoke DBCA to configure ASM to store database CRD files and create database.What is the structure change in oracle 11g r2?1. Grid and (ASM+Clustware) are on home. (oracle_binaries+ASM binaries in 10g)2. OCR and Voting disk on ASM.3. SAN listener4. By using srvctl can manage diskgroups, SAN listener, oracle home, ons, VIP, oc4g.5. GSDWhat are oracle RAC Services?Cache Fusion: Cache fusion is a technology that uses high speed Inter process communication (IPC) to provide cache to cache transfer of data block between different instances in cluster. This eliminates disk I/O which is very slow. For example instance A needs to access a data block which is being owned/locked by another instance B. In such case instance A request instance B for that data block and hence access the block through IPC this concept is known as Cache Fusion.Global Cache Service (GCS): This is the main heart of Cache fusion which maintains data integrity in RAC environment when more than one instances needed particular data block then GCS full fill this task:In respect of instance A request GCS track that information if it finds read/write contention (one instance is ready to read while other is busy with update the block) for that particular block with instance B then instance A creates a CR image for that block in its own buffer cache and ships this CR image to the requesting instance B via IPC but in case of write/write contention (when both the instance ready to update the particular block) then instance A creates a PI image for that block in its own buffer cache, and make the redo entries and ships the particular block to the requesting instance B. The dba_hist_seg_stats is used to check the latest object shipped.Global Enqueue Service (GES): The GES perform concurrency (more than one instance accessing the same resource) control on dictionary cache lock, library cache lock and transactions. It handles the different lock such as Transaction lock, Library cache lock, Dictionary cache lock, Table lock.Global Resource Directory (GRD): As we know to perform any operation on data block we need to know current state of the particular data block. The GCS (LMSN + LMD) + GES keep track of the resource s, location and their status of (each datafiles and each cache blocks ) and these information is recorded in Global resource directory (GRD). Each instance maintains their own GRD whenever a block transfer out of local cache its GRD is updated.Main Components of Oracle RAC Clusterware?OCR (Oracle Cluster Registry): OCR manages oracle clusterware (all node, CRS, CSD, GSD info) and oracle database configuration information (instance, services, database state info).OLR (Oracle Local Registry): OLR resides on every node in the cluster and manages oracle clusterware configuration information for each particular node. The purpose of OLR in presence of OCR is that to initiate the startup with the local node voting disk file as the OCR is available on GRID and ASM file can available only when the grid will start. The OLR make it possible to locate the voting disk having the information of other node also for communicate purpose.Voting disk: Voting disk manages information about node membership. Each voting disk must be accessible by all nodes in the cluster for node to be member of cluster. If incase a node fails or got separated from majority in forcibly rebooted and after rebooting it again added to the surviving node of cluster. Why voting disk place to the quorum disk or what is split-brain syndrome issue in database cluster?Voting disk placed to the quorum disk (optionally) to avoid the possibility of split-brain syndrome. Split-brain syndrome is a situation when one instance trying to update a block and at the same time another instance also trying to update the same block. In fact it can happen only when cache fusion is not working properly. Voting disk always configured with odd number of disk series this is because loss of more than half of your voting disk will cause the entire cluster fail. If it will be even number node eviction cannot decide which node need to remove due to failure. You must store OCR and voting disk on ASM. Thus if necessary you can dynamically add or replace voting disk after you complete the Cluster installation process without stopping the cluster.ASM Backup:You can use md_backup to restore ASM disk group configuration in case of ASM disk group storage loss.OCR and Votefile Backup: Oracle cluster automatically creates OCR backup (auto backup managed by crsd) every four hours and retaining at least 3 backup (backup00.ocr, day.ocr, week.ocr on the GRID) every times but you can take OCR backup manually at any time using: ocrconfig –manualbackup --To take manual backup of ocrocrconfig –showbackup -- To list the available backup.ocrdump –backupfile ‘bak-full-location’ -- To validate the backup before any restore.ocrconfig –backuploc --To change the OCR configured backup location.dd if=’vote disk name’ of=’bakup file name’; To take votefile backupTo check OCR and Vote disk Location:crsctl query css votedisk/etc/orcle/ocr.loc or use ocrcheckocrcheck --To check the OCR corruption status (if any).Crsctl check crs/cluster --To check crs status on local and remote nodeMoving OCR and Votedisk:Login with root user as the OCR store on root and for votedisk stops all crs first.Ocrconfig –replace ocrmirror/ocr -- Adding/removing OCR mirror and OCR file.Crsctl add/delete css votedisks --Adding and Removing Voting disk in Cluster.List to check all nodes in your cluster from root or to check public/private/vi pip info.olsnodes –n –p –I How can Restore the OCR in RAC environment?1. Stop clusterware all node and restart with one node in exclusive mode to restore. The nocrs ensure crsd process and OCR do not start with other node.# crsctl stop crs, # crsctl stop crs –f # crsctl start crs –excel –nocrs Check if crsd still open then stop it: # crsctl stop resource ora.crsd -init 2. If you want to restore OCR to and ASM disk group then you must check/activate/repair/create diskgroup with the same name and mount from local node. If you are not able to mount that diskgroup locally then drop that diskgroup and re-create it with the same name. Finally run the restore with current backup.# ocrconfig –restore file_name; 3. Verify the integrity of OCR and stop exclusive mode crs# ocrcheck # crsctl stop crs –f4. Run ocrconfig –repair –replace command all other node where you did not use the restore. For example you restore the node1 and have 4 node then run that rest of node 3,2,4.# ocrconfig –repair –replace 5. Finally start all the node and verify with CVU command# crsctl start crs# cluvfy comp ocr –n all –verboseNote: Using ocrconfig –export/ocrconfig –import also enables you to restore OCR Why oracle recommends to use OCR auto/manual backup to restore the OCR instead of Export/Import?1. An OCR auto/manual backup is consistent snapshot of OCR whereas export is not.2. Backup are created when the system is online but you must shutdown all node in clusterware to take consistent export.3. You can inspect a backup using OCRDUMP utility where as you cannot inspect the contents of export.4. You can list and see the backup by using ocrconfig –showbackup where as you must keep track of each export.How to Restore Votedisks?1. Shutdown the CRS on all node in clusterCrsctl stop crs2. Locate current location of the vote disk restore each of the votedisk using dd command from previous good backup taken using the same dd command.Crsctl query css votedisksDd if= of=3. Finally start crs of all node.Crsctl start crsHow to add node or instance in RAC environment?1. From the ORACLE_HOME/oui/bin location of node1 run the script addNode.sh$ ./addNode.sh -silent "CLUSTER_NEW_NODES={node3}"2. Run from ORACLE_HOME/root.sh script of node33. Run from existing node srvctl config db -d db_name then create a new mount point4. Mkdir –p ORACLE_HOME_NEW/”mount point name”;5. Finally run the cluster installer for new node and update the inventory of clusterwareIn another way you can start the dbca and from instance management page choose add instance and follow the next step.How to Identify master node in RAC ? # /u1/app/../crsd>grep MASTER crsd.log | tail -1 (or) cssd >grep -i "master node" ocssd.log | tail -1 OR You can also use V$GES_RESOURCE view to identify the master node.Difference crsctl and srvctl?Crsctl managing cluster related operation like starting/enabling clusters services where srcvctl manages oracle related operation like starting/stoping oracle instances. Also in oracle 11gr2 srvctl can be used to manage network,vip,disks etc.What are ONS/TAF/FAN/FCF in RAC?ONS is a part of clusterware and is used to transfer messages between node and application tiers.Fast Application Notification (FAN) allows the database to notify the client, of any changes either node UP/DOWN, Database UP/DOWN.Transport Application Failover (TAF) is a feature of oracle Net services which will move a session to the backup connection whenever a session fails.FCF is a feature of oracle client which receives notification from FAN and process accordingly. It clean up connection when down event receives and add new connection when up event is received from FAN.How OCCSD starts if voting disk & OCR resides on ASM?Without access to the voting disk there is no css to join or accelerate to start the CLUSTERWARE as the voting disk stored in ASM and as per the oracle order CSSD starts before ASM then how it become possible to start OCR as the CSSD starts before ASM. This is due to the ASM disk header in 11g r2 having new metadata kfdhbd.vfstart, kfdhbd.vfend (which tells the CSS where to find the voting files). This does not require to ASM instance up. Once css getting the voting files it can join the cluster easily.Note: Oracle Clusterware can access the OCR and the voting disks present in ASM even if the ASM instance is down. As a result CSS can continue to maintain the Oracle cluster even if the ASM instance has failed.Upgration/Migration/Patches Question/AnswerWhat are Database patches and How to apply?CPU (Critical Patch Update or one-off patch): security fixes each quarter. They are cumulative means fixes from previous oracle security alert. To Apply CPU you must use opatch utility.- Shutdown all instances and listener associated with the ORACLE_HOME that you are updating.- Setup your current directory to the directory where patch is located and then run the opatch utility.- After applying the patch startup all your services and listner and startup all your database with sysdba login and run the catcpu.sql script.- Finally run the utlrp.sql to validate invalid object.To rollback CPU Patch:- Shutdown all instances or listner.- Go to the patch location and run opatch rollback –id 677666- Start all the database and listner and use catcpu_rollback.sql script.- Bounce back the database use utlrp.sql script.PSU (Patch Set Update): Security fixes and priority fixes. Once a PSU patch is applied only a PSU can be applied in near future until the database is upgraded to the newer version.You must have two things two apply PSU patch: Latest version for Opatch, PSU patch that you want to apply1. Check and update Opatch version: Go to ORACLE_HOME/OPATCH/opatch versionNow to Update the latest opatch. Take the backup of opatch directory then remove the current opatch directory and finally unzip the downloaded patch into opatch directory. Now check again your opatch version.2. To Apply PSU patch:unzip p13923374_11203_.zipcd 13923374opatch apply -- in case of RAC optach utility will prompt for OCM (oracle configuration manager) response file. You have to provide complete path of OCM response if you have already created.3. Post Apply Steps: Startup database with sys as sysdbaSQL> @catbundle.sql psu applySQL> quitOpatch lsinventory --to check which psu patch is installed.Opatch rollback –id 13923374 --Rolling back a patch you have applied.Opatch nrollback –id 13923374, 13923384 –Rolling back multiple patch you have applied.SPU (Security Patch Update): SPU cannot be applied once PSU is applied until the database is upgraded to the new base version.Patchset: (eg. 10.2.0.1 to 10.2.0.3): Applying a patchset usually requires OUI.Shutdown all database services and listener then Apply the patchset to the oracle binaries. Finally Startup services and listner then apply post patch script.Bundle Patches: it is for windows and Exadata which include both quarterly security patch as well as recommended fixes.You have collection of patch nearly 100 patches. How can you apply only one of them?By napply itself by providing the specific patch id and you can apply one patch from collection of many patch by using opatch util napply - id9- skip_subset-skip_duplicate. This will apply only patch 9 within many extracted patches.What is rolling upgrade?It is new ASM feature in oracle 11g. This enables to patch ASM node in clustered environment without affecting database availability. During rolling upgrade we can maintain node while other node running different software.What happens when you use STARTUP UPGRADE?The startup upgrade enables you to open a database based on earlier version. It restrict sysdba logon and disable system trigger. After startup upgrade only specific view query can be used no other views can be used till catupgrd.sql is executed.
0 notes
Link
From manual coding to automation and from repeated work to innovation, developer tools have been evolving along with technologies. Alibaba Group and Alibaba Cloud have made its technologies available to public through open source release and cloud-based implementation. These technologies have been accumulated through years of development in various business scenarios. This article introduces some Alibaba developer tools in the hopes that they can help make your development process more efficient and graceful.
Given the vast diversity of technological branches that developers may engage in, this article introduces some tools that may be helpful for backend developers.
1. Arthas Java Online Diagnostic Tool
Arthas is an online diagnostic tool for Java applications open-sourced by Alibaba in September 2018.
Typical scenarios:
You do not know the specific JAR package from which a class was loaded. You want to figure out why your system throws various class-related exceptions.
You do not know why your modified code failed to be executed. You cannot remember whether you have committed the changes. You are not sure if you are using the right branch.
A problem occurs and you cannot debug online. You are wondering whether you have to add logs to your app and publish it again.
You have encountered a user data processing problem, but you cannot debug online or reproduce the problem offline.
You want to have a global view to monitor the running status of your system.
You want a solution to monitor the real-time running status of your JVM.
Arthas supports Java Development Kit (JDK) 6 and later versions, and it supports Linux, Mac, and Windows. Arthas uses the command line interaction mode, and allows you to use Tab to autocomplete commands in the command line, making problem locating and diagnosis much easier.
Basic tutorial: https://alibaba.github.io/arthas/arthas-tutorials?language=en&id=arthas-basics
Advanced tutorial: https://alibaba.github.io/arthas/arthas-tutorials?language=en&id=arthas-advanced
GitHub page: https://github.com/alibaba/arthas
2. Cloud Toolkit IDE Plug-in
Cloud Toolkit is an integrated development environment (IDE) plug-in that can be used to help developers more efficiently develop, test, diagnose, and deploy applications. Cloud Toolkit allows developers to conveniently deploy local applications to any machines (on-premises or cloud-based). Cloud Toolkit is built-in with the Arthas diagnostic tool, and supports efficiently executing terminal commands and SQL statements. Cloud Toolkit is available for different IDEs such as IntelliJ IDEA, Eclipse, PyCharm, and Maven.
Typical scenarios:
You are tired of repeatedly packaging your code every time you modify it.
You do not want to regularly switch back and forth between code management tools such as Maven and Git.
You use a secure copy (SCP) tool to upload files, and you use XShell or SecureCRT to log on to your server, replace deployment packages, or to restart your server.
You do not want to regularly switch back and forth between various FTP and SCP tools to upload files to the specified directories of your server.
Download link: https://plugins.jetbrains.com/plugin/11386-alibaba-cloud-toolkit
3. ChaosBlade Chaos Engineering Fault Injection Tool
ChaosBlade is a chaos engineering tool that follows principles of chaos engineering experiments, and provides extensive fault scenarios to help you improve the fault tolerance and recoverability of distributed systems. It can inject underlying faults, and provides various fault scenarios. These scenarios include delays, exceptions, returning specific values, modification of parameter values, repeated calls, and try-catch block exceptions.
Typical scenarios:
You find it difficult to measure the fault tolerance capacity of microservices.
You do not know how to verify the reasonableness of the container orchestration configuration.
You do not know how to implement the robustness testing of the PaaS layer.
GitHub page: https://github.com/chaosblade-io/chaosblade
(adsbygoogle = window.adsbygoogle || []).push({});
4. Alibaba Java Coding Guidelines
This plug-in detects coding problems in Java code, and gives you prompts. This plug-in was developed based on the Kotlin language.
IDEA plug-in usage instruction:
https://github.com/alibaba/p3c/tree/master/idea-plugin
Eclipse plug-in usage instruction: https://github.com/alibaba/p3c/tree/master/eclipse-plugin
GitHub page: https://github.com/alibaba/p3c
5. Application Real-Time Monitoring Service (ARMS)
ARMS is an application performance management (APM) tool. It offers three monitoring options: front-end monitoring, application monitoring, and custom monitoring to help you build up your own real-time application performance and business monitoring capability.
Typical scenarios:
You receive 37 alarming messages at 22:00, but you do not know where to start.
The customer or business team finds the problem earlier than you do.
You invest tens of thousands of dollars in servers each month, but you still cannot guarantee good user experience.
Application monitoring integration: https://www.alibabacloud.com/help/doc-detail/63796.htm
Custom monitoring: https://www.alibabacloud.com/help/doc-detail/47474.htm
Product page: https://www.alibabacloud.com/product/arms
6. Docsite Open-Source Static Website Generator
Docsite is an open-source static website generator that helps you build your own official website, document center, blog site, and community. It is easy to use and addictive. It supports react and static rendering, PC and mobile clients, internationalization, SEO, markdown documents, and many useful features such as global site search, site style customization, and page customization.
Tutorial: https://docsite.js.org/en-us/docs/installation.html
GitHub page: https://github.com/txd-team/docsite
7. Freeline - A Second-Level Compilation Solution for Android
Freeline caches reusable class files and resource indices, and compiles code updates and deploys them to your device in seconds. This effectively reduces large amounts of time for recompilation and installation during daily development. The most convenient way to use Freeline is to directly install the Android Studio plug-in.
Tutorial: https://github.com/alibaba/freeline/blob/master/README.md
GitHub page: https://github.com/alibaba/freeline
8. Alibaba Cloud Application High Availability Service (AHAS)
AHAS provides many powerful features, such as architecture visualization for container environments such as Kubernetes (K8s), fault-injection-based high-availability evaluation, and one-click throttling and downgrade. AHAS helps you quickly improve application availability at low costs.
Typical scenarios:
When you reconstruct your service, you want to visualize the architecture to precisely understand the resource-instance composition and interaction.
You want real fault scenarios and drill models.
You want to use the throttling and downgrade feature at low costs.
Tutorial: https://www.alibabacloud.com/help/doc-detail/90323.htm
Product page: https://www.alibabacloud.com/product/ahas
9. EasyExcel Data Processing Tool
EasyExcel is a framework that parses Java code and generates excel files. It rewrites the Apache POI SAX parser for Microsoft Excel 2007. To process a 3 MB Excel file, the Apache POI SAX parser needs about 100 MB memory, while EasyExcel needs about several KB. In addition, EasyExcel eliminates the out-of-memory (OOM) problem, no matter how large the excel file is. For Microsoft Excel 2003, EasyExcel still uses the Apache POI SAX parser. But it encapsulates the model converter at the upper layer to make it easier to use.
Tutorial: https://github.com/alibaba/easyexcel/blob/master/quickstart.md
GitHub Page: https://github.com/alibaba/easyexcel
(adsbygoogle = window.adsbygoogle || []).push({});
10. HandyJSON for iOS
HandyJSON is a json-object serialization/deserialization library written in Swift language.
Compared with other popular Swift JSON libraries, HandyJSON supports pure Swift classes and is easy to use. When you use HandyJSON in deserialization, which converts JSON to model, the model does not have to inherit from the NSObject, because HandyJSON is not KVC-based. You do not have to define a mapping function for the model either. After you define the model class and declare that it follows the HandyJSON protocol, HandyJSON automatically parses values from JSON strings by taking the property name as the key.
Tutorial: https://github.com/alibaba/HandyJSON/blob/master/README.md
GitHub page: https://github.com/alibaba/HandyJSON
BONUS
11. Druid Database Connection Pool
Druid is the best database connection pool in the Java language, and it provides powerful monitoring and expansion capabilities.
Tutorial: https://github.com/alibaba/druid/wiki/FAQ
GitHub page: https://github.com/alibaba/druid
12. Alibaba Dragonwell Java Development Kit
Alibaba Dragonwell is the open-source version of Alibaba/AlipayJDK (AJDK), the customized OpenJDK used internally by Alibaba. AJDK has made business-scenario-based optimizations for online-ecommerce, finance, and logistics applications. It has been running in super large Alibaba data centers that run more than 100,000 servers each. Alibaba Dragonwell is compatible with the Java SE standard. Currently, it only supports the Linux x86_64 platform.
Tutorial: https://github.com/alibaba/dragonwell8/wiki/Alibaba-Dragonwell8-User-Guide
GitHub page: https://github.com/alibaba/dragonwell8
0 notes
Text
IPS Community Suite 4.3.6
This is a maintenance release to fix reported issues.
Additional Information
Core - Members & Accounts
Added ability to use bulk mail subscription status as a filter for group promotions.
Fixed profanity filters applying to account usernames during registration.
Fixed following a member not updating the follow button correctly.
Fixed filters when creating a bulk mail or downloading a member list not working in certain combinations.
Fixed inability to manually set a member's reputation count less than 0.
Core - Search & Activity Streams:
Improved performance of indexing content when using Elasticsearch.
Improved the phrasing of the description on search results page when a custom date range has been chosen to sound more natural.
Fixed some Elasticsearch queries not working on very high traffic sites.
Fixed an issue where content that had been restored after being deleted would not be reindexed correctly.
Fixed an issue with Elasticsearch where content that had been hidden or moved would not be reindexed correctly.
Fixed filtering by specific members when using Elasticsearch.
Fixed various issues with activity streams not behaving correctly.
Core - Posting & Post Content:
Improved message when embedded content is not available to indicate if the content has been deleted or the user doesn't have permission to see it.
Fixed some Emojis rendering incorrectly.
Fixed broken TED Talks embeds.
Core - Clubs:
Fixed pagination of the list of members in a club not working.
Fixed some moderator permissions not applying correctly within clubs.
Fixed paid clubs being able to be created with $0 fee.
Fixed granting permission to create specific types of clubs via secondary groups not working properly.
Fixed content rebuild task not running on custom fields for clubs.
Core - Sitemap
Fixed some items not included in the sitemap.
Fixed error generating the sitemap when entering zero for the number of items to include.
Fixed sitemap not generating on some PHP versions.
Core - Redis:
Added ability to use Redis as a data storage method if is also being used as the caching method.
Fixed online users older than 30 minutes showing when using Redis.
Fixed uncaught exception that may occur when using Redis and clearing caches.
Core - Misc
Added a warning to the AdminCP dashboard, and when editing the login handler, if Facebook login is enabled but site is not using https. Also changed the Facebook login setup process to not allow new setups if site is not using https.
Added an option to use a different Facebook application for social promotion (opposed to the Facebook application used for login) so that Facebook login is not affected while your Facebook app is under review.
Added logging any time the support tool has been run.
Improved session handling performance.
Improved performance of viewupdates task.
Improved performance of queue task.
Fixed announcements being shown before the start date.
Fixed error when deleting the node being viewed in AdminCP node trees.
Fixed copying some node settings in the AdminCP not working.
Fixed replacement tags not working in bulk mails within URLs.
Fixed lost image style attributes in bulk emails.
Fixed Acronym Expansion page in AdminCP not line breaking correctly for very long values, breaking the page layout.
Fixed profile field management checking wrong AdminCP restriction.
Fixed CSS and JavaScript files not being deleted when recompiled on upgrade or when running the support tool.
Fixed false warnings from the database checker when using MySQL 8 and in certain other edge cases.
Fixed error after changing cache or datastore settings in certain PHP configurations.
Fixed link to the setting for allowed characters in usernames (which shows when setting up certain login handlers) not highlighting the setting.
Fixed possible error when creating the default English language when running the support tool.
Fixed AdminCP dashboard warning about failed tasks showing for disabled tasks.
Fixed browsers potentially keeping a cache of outdated JavaScript files.
Fixed JSON-LD data for ratings in several apps.
Fixed some widgets not limiting results correctly which could cause performance issues.
Fixed a possible technical error message (rather than a graceful error screen) showing if a very low-level error (such as database server offline) occurs in certain circumstances.
Fixed a missing warning when the hooks.php file was not writable before application and plugin installations and upgrades.
Fixed an issue when using profile complete and forum specific themes.
Fixed uncaught exception if manually going to a specific URL to try to promote something which cannot be promoted.
Fixed an unnecessary redirect in the applications upgrade process.
Fixed some minor language string inconsistencies.
Removed logging of notices that a template was requested to be rebuilt while already rebuilding.
Check to ensure that https is used before allowing Facebook to be used as a log in handler.
Fixes a read/write separation issue with unhiding
Forums
Fixed moderator permissions for posts.
Fixed an issue where moving archived topics from one forum to another did not update the forum counters.
Fixed an issue where posting a hidden post causes the forum to indicate a post pending approval is present.
Commerce
Added an option when refunding a transaction which was paid by a PayPal Billing Agreement to also cancel the Billing Agreement.
Added support for AUD, CZK, DKK, HKD, ILS, MXN, NZD, NOK, PHP, PLN, RUB, SGD, SEK, SEK, CHF, and THB for PayPal card payments.
Fixed automatic recurring payments for subscriptions not re-subscribing members correctly.
Fixed subscription upgrades/downgrades not being available at all to plans which are set to only be payable by particular gateways, or whose base price is modified by the chosen renewal term.
Fixed missing language strings in member history when upgrading subscriptions.
Fixed missing tax on purchase reactivation.
Fixed not being able to remove product discounts.
Fixed incoming emails being saved as blank replies.
Fixed incoming emails from certain email address formats, including emails using new domain extensions.
Fixed the link to print an invoice that gets sent in the email not working for guests.
Fixed missing language strings in the email advising a user their support request will automatically be marked resolved.
Fixed invalid referral banner image URL shown to users.
Fixed broken referrer tab in AdminCP customer profile.
Fixed broken images when viewing a purchase of an advertisement in the AdminCP.
Fixed advertisement purchases created by generating an invoice in the AdminCP.
Fixed possible text overflow when viewing shipping order in AdminCP.
Fixed support requests not showing assigned staff member in preview.
Pages
Fixed the page BBCode and editor button which allows content to be split over multiple pages.
Fixed incorrect sorting of number database fields.
Fixed search permissions when changing the "User can see records posted by other users" setting for a database.
Fixed an error occurring when editing a comment that is synced with a topic that has been hidden.
Fixed numeric database fields which use more than 2 decimal places in the value.
Fixed an issue where using a custom field validator with a unique field would mean the unique check is skipped.
Gallery
Fixed broken redirect after deleting an album and moving images in it to a category.
Fixed broken promote form for images within an album.
Fixed missing watermark when a file was inserted via the "Insert other media" feature.
Downloads
Fixed screenshots that have been imported from a URL missing from embeds.
Blog
Fixed blog cover photo being used when sharing entries on social media even when the entry has its own feature photo.
Fixed broken Blog Embeds.
Fixed link to the last Blog Entry inside the Blog Embed.
Calendar
Fixed cover photo offset not copying correctly when copying events.
Fixed venue not saving from ical upload.
REST & OAuth
Fixed OAuth setups refreshing refresh tokens more often than they should.
Fixed OAuth setups not properly supporting implicit grants.
Converters
Added support for redirecting direct post links for Vanilla.
Improved performance of conversions.
Improved description of minimum version for vBulletin 3 conversions.
Fixed error with login after conversion.
Fixed extraneous breaks in content converted from vBulletin.
Fixed personal conversations from Vanilla.
Fixed Gallery albums being converted with no default sort option.
Fixed issue with converting Calendar Event attachments.
Fixed issue where some code box content may be broken after conversion from phpBB.
Fixed vBulletin 3 redirects no longer working if you converted prior to upgrading to 4.x.
Upgrader
Added UConverter support to the UTF-8 Converter for sites with mixed character sets.
Fixed an issue where announcement widgets may not get removed when upgrading to 4.3.
Fixed possible SQL error when upgrading Calendar from 3.x.
Fixed how sharedmedia BBCode gets converted to embeds for Gallery albums when upgrading from 3.x.
Fixed an issue where converting to UTF-8 prior to upgrade can throw an error in some situations.
Fixed Gallery sitemap showing incorrect date for images upgraded from 3.x.
Third-Party / Developer / Designer Mode
Fixed album embeds when in developer mode.
Fixed errors adjusting sitemap configuration preferences when using developer mode
ips-v4.3.6-nulled.zip
source https://xenforoleaks.com/topic/302-ips-community-suite-436/
0 notes
Text
Java Training in Bangalore
Java is one of the most popular computer programming language in India. Most of the software companies in the IT industry in this country uses Java to develop desktop application and sometimes in web development too. In this post let’s talk about what Java is and followed by the best Java training in Bangalore.
What is Java?
Like I said before Java is a language that which developers use to create software application and core functionalities of websites in both end. Java was designed James Gosling in 1995 under Sun Microsystems. Java is available for everyone under GNU license and now owned by Oracle.
The main advantage of Java is its independency among multiple platforms. In simple English it means that it can be easily transported from one computer to another computer or one operating system to another. This feature of Java is called Write Once Run Anywhere or in short WORA. How Java achieves that is quit a trick.
It basically generates a bytecode when compiles. This bytecode can be carried to any other computer and it will run irrespective of what OS that device is running on. As long as that desktop has JVM or Java Virtual Machine installed, you’re good to go. The bytecode doesn’t need to be recompiled it can be easily run using the JVM.
Why use Java?
Java is truly one of the most powerful and most popular coding language in the world. It’s mainly used for client-server web applications. According to Wikipedia, over 10 million developers use Java for their development purposes.
One reason to use Java is that it is easy to learn and it is quite user friendly for first time coders. Besides that, it can be easily coded and debugged.
And the second reason is that it’s platform independent. Like I said earlier, since it generates a universal bytecode, a Java programme can be run in any computer which has JVM installed in it. Obviously, the JVM is different for each OS. But once the corresponding JVM is installed the user won’t have any issues running Java.
Third amazing feature of Java is its Object Orientation. This means a developer doesn’t have write the same chunk of code multiple times for a same program, he can type once and reuse it several times.
Along with all these, multithreading capability of Java takes it even higher. Being multithreaded allows a Java program to execute multiple tasks at the same time, similar to multitasking.
If we compare Java with another language, say, PHP, we’ll see that it is Java is more powerful than PHP and it has more customization options than PHP. For example, in PHP you don’t have to declare a datatype in PHP, whereas in Java you have to.
Training in Java
In India, the craze for Java is really high. Although, many start-ups are opting for other languages like Python for development purposes, a big chunk of IT industry is still trending to Java. Hence, you should surely do Java Training in Bangalore.
Bangalore is arguably one of the best tech cities in India. Therefore, you’ll find a lot of companies that provide cheap yet high quality Java training. Look for the one that fits your budget and go for it. Java is and will be the first choice of many software companies around the globe.
DataBytes; leading IT Training Institutes in Bangalore offers Software Testing Courses (Selenium, QTP [Quick Test Professional]), PHP, Tableau / Qlikeview, UI UX Web Development, Python, Adv Java, Android, Dot NET, SQL /PL SQL, ETL, Hadoop, BIG Data, Java, Informatica, AutoCAD etc.
#Java Training#java course in bangalore#java training in Bangalore#java course#Java training institutes in Bangalore
0 notes