#Pentaho Data Integration Architecture
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
Unravel the Potential of Pentaho Data Integration Architecture with Diligene
Discover the power of data integration with Pentaho data integration architecture by Diligene. Our experts leverage Pentaho's robust framework to streamline data workflows, ensuring efficiency and accuracy in your business processes. Revolutionize your data management strategy with Diligene's unparalleled expertise.
0 notes
Text
What is a Data Lake?
A data lake refers to a central storage repository used to store a vast amount of raw, granular data in its native format. It is a single store repository containing structured data, semi-structured data, and unstructured data.
A data lake is used where there is no fixed storage, no file type limitations, and emphasis is on flexible format storage for future use. Data lake architecture is flat and uses metadata tags and identifiers for quicker data retrieval in a data lake.
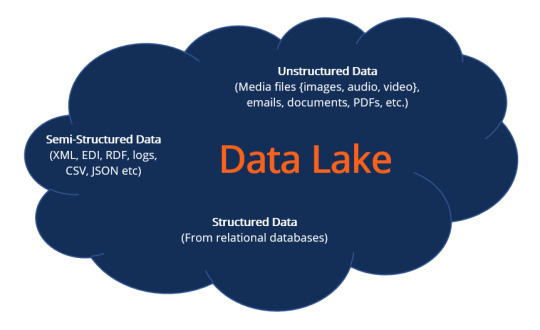
The term “data lake” was coined by the Chief Technology Officer of Pentaho, James Dixon, to contrast it with the more refined and processed data warehouse repository. The popularity of data lakes continues to grow, especially in organizations that prefer large, holistic data storage.
Data in a data lake is not filtered before storage, and accessing the data for analysis is ad hoc and varied. The data is not transformed until it is needed for analysis. However, data lakes need regular maintenance and some form of governance to ensure data usability and accessibility. If data lakes are not maintained well and become inaccessible, they are referred to as “data swamps.”
Data Lakes vs. Data Warehouse
Data lakes are often confused with data warehouses; hence, to understand data lakes, it is crucial to acknowledge the fundamental distinctions between the two data repositories.
As indicated, both are data repositories that serve the same universal purpose and objective of storing organizational data to support decision-making. Data lakes and data warehouses are alternatives and mainly differ in their architecture, which can be concisely broken down into the following points.
Structure
The schema for a data lake is not predetermined before data is applied to it, which means data is stored in its native format containing structured and unstructured data. Data is processed when it is being used. However, a data warehouse schema is predefined and predetermined before the application of data, a state known as schema on write. Data lakes are termed schema on read.
Flexibility
Data lakes are flexible and adaptable to changes in use and circumstances, while data warehouses take considerable time defining their schema, which cannot be modified hastily to changing requirements. Data lakes storage is easily expanded through the scaling of its servers.
User Interface
Accessibility of data in a data lake requires some skill to understand its data relationships due to its undefined schema. In comparison, data in a data warehouse is easily accessible due to its structured, defined schema. Many users can easily access warehouse data, while not all users in an organization can comprehend data lake accessibility.
Why Create a Data Lake?
Storing data in a data lake for later processing when the need arises is cost-effective and offers an unrefined view to data analysts. The other reasons for creating a data lake are as follows:
The diverse structure of data in a data lake means it offers a robust and richer quality of analysis for data analysts.
There is no requirement to model data into an enterprise-wide schema with a data lake.
Data lakes offer flexibility in data analysis with the ability to modify structured to unstructured data, which cannot be found in data warehouses.
Artificial intelligence and machine learning can be employed to make profitable forecasts.
Using data lakes can give an organization a competitive advantage.
Data Lake Architecture
A data lake architecture can accommodate unstructured data and different data structures from multiple sources across the organization. All data lakes have two components, storage and compute, and they can both be located on-premises or based in the cloud. The data lake architecture can use a combination of cloud and on-premises locations.
It is difficult to measure the volume of data that will need to be accommodated by a data lake. For this reason, data lake architecture provides expanded scalability, as high as an exabyte, a feat a conventional storage system is not capable of. Data should be tagged with metadata during its application into the data lake to ensure future accessibility.
Below is a concept diagram for a data lake structure:

Data lakes software such as Hadoop and Amazon Simple Storage Service (Amazon S3) vary in terms of structure and strategy. Data lake architecture software organizes data in a data lake and makes it easier to access and use. The following features should be incorporated in a data lake architecture to prevent the development of a data swamp and ensure data lake functionality.
Utilization of data profiling tools proffers insights into the classification of data objects and implementing data quality control
Taxonomy of data classification includes user scenarios and possible user groups, content, and data type
File hierarchy with naming conventions
Tracking mechanism on data lake user access together with a generated alert signal at the point and time of access
Data catalog search functionality
Data security that encompasses data encryption, access control, authentication, and other data security tools to prevent unauthorized access
Data lake usage training and awareness
Hadoop Data Lakes Architecture
We have singled out illustrating Hadoop data lake infrastructure as an example. Some data lake architecture providers use a Hadoop-based data management platform consisting of one or more Hadoop clusters. Hadoop uses a cluster of distributed servers for data storage. The Hadoop ecosystem comprises three main core elements:
Hadoop Distributed File System (HDFS) – The storage layer whose function is storing and replicating data across multiple servers.
Yet Another Resource Negotiator (YARN) – Resource management tool
MapReduce – The programming model for splitting data into smaller subsections before processing in servers
Hadoop supplementary tools include Pig, Hive, Sqoop, and Kafka. The tools assist in the processes of ingestion, preparation, and extraction. Hadoop can be combined with cloud enterprise platforms to offer a cloud-based data lake infrastructure.

Hadoop is an open-source technology that makes it less expensive to use. Several ETL tools are available for integration with Hadoop. It is easy to scale and provides faster computation due to its data locality, which has increased its popularity and familiarity among most technology users.
Data Lake Key Concepts
Below are some key data lake concepts to broaden and deepen the understanding of data lakes architecture.
Data ingestion – The process where data is gathered from multiple data sources and loaded into the data lake. The process supports all data structures, including unstructured data. It also supports batch and one-time ingestion.
Security – Implementing security protocols for the data lake is an important aspect. It means managing data security and the data lake flow from loading, search, storage, and accessibility. Other facets of data security such as data protection, authentication, accounting, and access control to prevent unauthorized access are also paramount to data lakes.
Data quality – Information in a data lake is used for decision making, which makes it important for the data to be of high quality. Poor quality data can lead to bad decisions, which can be catastrophic to the organization.
Data governance – Administering and managing data integrity, availability, usability, and security within an organization.
Data discovery – Discovering data is important before data preparation and analysis. It is the process of collecting data from multiple sources and consolidating it in the lake, making use of tagging techniques to detect patterns enabling better data understandability.
Data exploration – Data exploration starts just before the data analytics stage. It assists in identifying the right dataset for the analysis.
Data storage – Data storage should support multiple data formats, be scalable, accessible easily and swiftly, and be cost-effective.
Data auditing – Facilitates evaluation of risk and compliance and tracks any changes made to crucial data elements, including identifying who made the changes, how data was changed, and when the changes took place.
Data lineage – Concerned with the data flow from its source or origin and its path as it is moved within the data lake. Data lineage smoothens error corrections in a data analytics process from its source to its destination.
Benefits of a Data Lake
A data lake is an agile storage platform that can be easily configured for any given data model, structure, application, or query. Data lake agility enables multiple and advanced analytical methods to interpret the data.
Being a schema on read makes a data lake scalable and flexible.
Data lakes support queries that require a deep analysis by exploring information down to its source to queries that require a simple report with summary data. All user types are catered for.
Most data lakes software applications are open source and can be installed using low-cost hardware.
Schema development is deferred until an organization finds a business case for the data. Hence, no time and costs are wasted on schema development.
Data lakes offer centralization of different data sources.
They provide value for all data types as well as the long-term cost of ownership.
Cloud-based data lakes are easier and faster to implement, cost-effective with a pay-as-you-use model, and are easier to scale up as the need arises. It also saves on space and real estate costs.
Challenges and Criticism of Data Lakes
Data lakes are at risk of losing relevance and becoming data swamps over time if they are not properly governed.
It is difficult to ensure data security and access control as some data is dumped in the lake without proper oversight.
There is no trail of previous analytics on the data to assist new users.
Storage and processing costs may increase as more data is added to the lake.
On-premises data lakes face challenges such as space constraints, hardware and data center setup, storage scalability, cost, and resource budgeting.
Popular Data Lake Technology Vendors
Popular data lake technology providers include the following:
Amazon S3 – Offers unlimited scalability
Apache – Uses Hadoop open-source ecosystem
Google Cloud Platform (GCP) – Google cloud storage
Oracle Big Data Cloud
Microsoft Azure Data Lake and Azure Data Analytics
Snowflake – Processes structured and semi-structured datasets, notably JSON, XML, and Parquet
More Resources
To keep learning and developing your knowledge base, please explore the additional relevant resources below:
Business Intelligence
Data Mart
Scalability
Data Protection
1 note
·
View note
Text
Learn Pentaho Online with Expert Training

In today's digital world, staying on top of the latest technology can make a big difference when it comes to keeping your career and business competitive. Pentaho is one of the leading open-source business intelligence (BI) platforms, and taking a Pentaho online training course can provide you with the essential skills to stay ahead in this field. In this article, we'll take a closer look at Pentaho, the benefits of online learning, how to find the right course, and how to ensure success when taking an online Pentaho course.
What is Pentaho?
Pentaho is an open-source business intelligence platform that provides powerful data analysis and reporting capabilities, as well as ETL (Extract, Transform, Load) and data mining tools. It is used by a variety of organizations, from small businesses to large corporations, for analyzing and reporting on data from multiple sources. With its intuitive user interface and powerful capabilities, Pentaho is considered one of the most popular open-source BI platforms.
Pentaho is designed to be highly extensible, allowing users to customize the platform to meet their specific needs. It also offers a wide range of features, including data visualization, predictive analytics, and machine learning. Additionally, Pentaho integrates with a variety of other systems, such as Hadoop, MongoDB, and Spark, making it easy to access and analyze data from multiple sources.
Benefits of Learning Pentaho
Pentaho's flexible architecture and scalability make it an attractive choice for businesses of all sizes. It can be used for a variety of tasks, from simple reporting and data analysis to more advanced data mining projects. With Pentaho, you can identify new trends, create detailed reports, and gain valuable insights into your data. This can help you make better decisions and stay ahead in today's competitive market.
Pentaho also offers a wide range of features and tools that can be used to create custom solutions for your business. It is easy to use and can be integrated with other systems, such as databases and web services. Additionally, Pentaho is open source, meaning it is free to use and modify. This makes it an ideal choice for businesses looking to save money while still getting the most out of their data.
What You'll Learn in an Online Pentaho Course
A Pentaho online training course can provide you with the skills to use this powerful platform effectively. You'll learn how to set up Pentaho projects, design data models, create reports, query databases, and create dashboards. You'll also learn how to use Pentaho's ETL tools to extract and transform data from multiple sources. With an online course, you'll have access to comprehensive learning materials and on-demand support from expert instructors.
You'll also gain an understanding of the Pentaho architecture and how to integrate it with other systems. You'll learn how to use Pentaho's data integration tools to create data pipelines and automate data processing tasks. Additionally, you'll learn how to use Pentaho's analytics tools to analyze data and create visualizations. By the end of the course, you'll have the skills to use Pentaho to create powerful data-driven applications.
Finding the Right Online Training Course
When searching for an online Pentaho course, you should look for a program that is designed for your needs. Look for courses that offer comprehensive learning materials, such as video tutorials and quizzes. You should also make sure that the course is taught by experienced instructors who are available to answer any questions you may have. Finally, check if the course is accredited by a professional organization to ensure that it meets industry standards.
It is also important to consider the cost of the course. While some courses may be more expensive, they may also offer more comprehensive learning materials and support. Additionally, you should look for courses that offer flexible payment options, such as monthly or annual payments. This will help you budget for the course and ensure that you can complete it without any financial strain.
Tips for Successful Learning with an Online Course
When taking an online Pentaho course, it's important to set clear goals for yourself and plan out your learning schedule in advance. This will help you stay focused and motivated when learning. You should also break up your lessons into smaller tasks so that you don't get overwhelmed. Finally, practice your skills regularly and ask questions when you're stuck – this will help you master the material faster.
It's also important to take regular breaks while studying. Taking a few minutes to relax and clear your head can help you stay focused and productive. Additionally, it's important to stay organized and keep track of your progress. This will help you stay motivated and on track with your learning goals.
Taking Your Knowledge Further with Advanced Online Pentaho Training
Once you have mastered the basics of working with Pentaho, you can take your knowledge further with advanced online training. This type of training will provide you with more advanced skills, such as using predictive analytics and visualizing data. With advanced training, you'll be able to use more sophisticated techniques when analyzing data and creating reports.
Advanced Pentaho Online Training can also help you to develop a deeper understanding of the software and its capabilities. You'll learn how to use the software to its fullest potential, and you'll be able to create more complex reports and dashboards. Additionally, you'll gain a better understanding of the data structures and how to manipulate them to get the most out of your data.
The Future of Pentaho and its Applications
As technology advances, Pentaho will continue to grow in popularity and become even more powerful. With its powerful tools and user-friendly interface, Pentaho can be used for a wide range of applications, from simple data analysis to complex predictive analytics projects. With the right skills and knowledge, you'll be able to take advantage of the latest technology and stay ahead in today's digital world.
In the future, Pentaho will continue to develop new features and capabilities to make it even easier to use. For example, Pentaho could develop a more intuitive user interface, or add new features such as automated data cleansing and data visualization. Additionally, Pentaho could expand its capabilities to include machine learning and artificial intelligence, allowing users to create more sophisticated predictive models. With these new features, Pentaho will become an even more powerful tool for data analysis and predictive analytics.
Conclusion
Pentaho online training is a great way to learn the basics and advanced concepts of Pentaho data integration and analytics. It provides a comprehensive learning experience that can help you become a successful Pentaho user. With an array of online resources, tutorials, and support, you can gain the skills necessary to become a successful Pentaho user. With the right training, you can quickly become an expert in Pentaho and begin using it to its fullest potential.
1 note
·
View note
Link
Infometry INC providers of Data Architecture, Program Management, SAP-Business Objects, SAP-BW, Oracle OBIEE, Hyperion, MicroStrategy, MDM, Data Quality, Informatica, Pentaho, Talend, QlikView, Microsoft BI, Open Source BI, and InfoFiscus is a pre-built Cloud-based, highly scalable, self-service analytics solution developed using Snowflake, RedShift, Informatica Cloud, Tableau, Qlik, PowerBI..etc integrating across Salesforce, Microsoft Dynamics, NetSuite, Marketo, Oracle ERP, SAP. Contact Us :- [email protected]
#Informatica#InformaticaConnectors#InformaticaGoogleConnectors#InformaticaAdaptiveInsightsConnectors#InformaticaHubspotConnector
0 notes
Text
ETL Developer - Columbus, OH
Ad Id: 1154894 Posted by Nationwide Children's Hospital in Columbus The ETL Developer will design, develop, code, test, debug, maintain, support and document database ETL flows in support of the Biopathology Center within the Research Institute at Nationwide Children’s Hospital. The ETL Developer is expected to be detailed-oriented and able to create stable and robust data flows between and within our systems. As he/she will be called upon to document critical flows, the developer must possess excellent written communication skills and the ability to collaborate with an extended team. The design and implementation of proper ETL flows which are easy to troubleshoot and maintain is of particular importance. Demonstrated experience with ETL tooling and best practices—as well as strong data querying/profiling skills—are essential to success in this job. The ETL Developer must possess excellent verbal communication skills and ability to interact with data stakeholders at all levels within the organization.Nationwide Children’s Hospital. A Place to Be Proud: Work with the team architect(s) to help define and document the overall approach for ETL Ensure that developed ETL flows are robust in the face of changing technologies and business needs Strive to balance the needs for operational stability and business agility/flexibility Engage in the proper amount of documentation to allow for cross-coverage by other team members Develop and maintain strong proficiency in database tooling, SQL, ETL tools, and related/supporting technologies (e.g., scheduling, dependency management, version control, reporting, issue tracking) Consult with the team architect(s) on design issues and incorporate feedback from periodic ETL design/code reviews; Demonstrate meticulousness and a desire to learn and improve approaches Ensure developed ETL flows provide operational transparency via logging, performance metrics, notifications, data quality statistics, and documentation in the team wiki. Assist with a variety of analytic and data-related team activities, including query/report design, performance tuning, job scheduling/monitoring, analytic model design, database refactoring, data profiling, data quality remediation, data dictionary/documentation, etc. Identify, quantify, and track relevant data quality issues that impact the team Help maintain technical documentation related to the ETL stack, environments, and technical architecture Maintain appropriate mindfulness related to ETL flow/component reuse and consolidation (refactoring) Provide input to schedules via time estimates and high-level design/approach planning with architect(s) Learn; Share knowledge; Enable the team’s capabilities to grow; Have fun Qualifications: 3+ years of experience in ETL-related activities Strong working knowledge of SQL and data design best practices Strong ability to learn from colleagues, books, documentation, and hands-on exercises Possess an analytic, detail-oriented mentality in regard to key duties Possess creativity in technical problem identification/investigation/resolution Experience with SQL Server ideal Experience with an ETL toolset (e.g., Pentaho Spool/Kettle, SSIS, Data Integrator, etc.) ideal Experience with dimensional data modeling and ETL design ideal Exposure to source version control tools (e.g., Git, SVN, TFS) ideal Ability to balance multiple short term d Healthcare / Pharma / Bio-tech | Jobs in Columbus, OH Skills: ETL, ETL Testing, Git, MS SQL Server, SQL, SSIS, SVN, TFS ETLDeveloper-Columbus,OH from Job Portal https://www.jobisite.com/extrJobView.htm?id=150131
0 notes
Link
Recruitment in Al Futtaim Group Customer Insights Manager (Dubai, AE)
No two days are the same at Al-Futtaim, no matter what role you have. Our work is driven by the desire to make a difference and to have a meaningful impact with the goal of enriching everyday lives. Take our engaging and supportive work environment and couple it with a company culture that recognises and rewards quality performance, and what do you get? The chance to push the limits every single day.
As a humble family business that started on the banks of the Dubai Creek in the 1930s, Al-Futtaim has expanded to a presence in 31 countries, a portfolio of over 200 companies, and 42,000 employees. You’ll find us in industries ranging from automotive and retail, to finance and real estate, and connecting people with international names like Lexus, Ikea, Robinsons, and Adidas. Our team is proudly multicultural and multinational because that kind of diverse representation gives us the global mindset to grow and impact the people, markets, and trends around us.
Come join us to live well, work better, and be the best.
The objective of the role is to contribute to the Group’s CRM strategy, with a strong focus on delivering data analysis and actionable insights to support all Group Brand stakeholders.
This role will be based out of our corporate offices at Dubai Festival City and will directly report to the General Manager-Group CRM
Core Competencies:
Identify opportunities to drive customer value through CRM activities at Group level
Provide a detailed and complete understanding of customer bases across all Group Brands leveraging the new Group CRM Platform and the Single View of the Customer (Hybris Marketing Platform)
Provide Corporate Marketing and business units with models (both segmentation and propensity) to aid targeting and understanding of customer behavior across businesses and Brands.
Own the delivery of insight and business intelligence which are cross-divisional, making recommendations to divisions and brands, for them to implement
Review customer data for trends, patterns and casual analysis to assist Brand and Divisions in understanding customer behavior cross brand and divisions
Advise business units of appropriate marketing actions based on the relevant information to ensure maximum Return on digital campaign investment, in collaboration with division marketing team
Propose appropriate and common measurement methodologies across the Brand and Divisions to understand digital campaign performance and implement for corporate digital campaigns
Perform and support marketing campaigns analysis to determine business impacts and Design, enhance, and distribute marketing reports that clearly communicate campaign and/or business results, for corporate campaigns
Identify data quality issues in the CRM DB and address the data cleansing actions that will be managed and executed at Division/Brand level
Industry Experience (Must Have):
Previous experience from working as a data analyst with focus on CRM and Customer Analytics
Mathematics and/or Statistics Bachelor’s degree or higher with at least 3-5 years previous work experience within Insight CRM space and 3-5 years in a Consulting or Market Research Agency
Strong understanding of data mining techniques, statistical concepts and predictive modelling. (e.g., neural networks, multi-scalar dimensional models, logistic regression techniques, machine-based learning)
Experience with Big Data technologies (eg. Hadoop, Cassandra, Hive, Pig, Impala, Parquet, etc.) and large Data Warehouse implementation (Oracle, Teradata, GreenPlum, SAP Hana, Netezza TF) or Data Lakes implementation (Microsoft, Oracle, Teradata, Cloudera, Amazon, …)
Experience in Reporting architectures (eg. SAS, MicroStrategy, Oracle, SAP BO, Pentaho, Tableau and Cognos)
Experience with predictive analytics tools (eg. SAS, SPSS, MATLAB)
Experience in CRM Modelling, Analytics & Campaign Execution (eg. MS Dynamics, SAS, Unica, Teradata, Oracle
Expertise with the Microsoft Office suite (including advanced Excel skills with embedded Pivot Tables & Macros; advanced PowerPoint usage for storyboard design and presentation)
Familiarity with marketing disciplines and particularly CRM to aid understanding and delivery of business objectives.
Passion for Analytics
Understanding of business financials, ROI & profitability
Ability to present complex information in simple terms with clear recommendations based on data insight
Maintain a good knowledge of relevant analytical and statistical techniques
Maintain a good technical knowledge of SAS, SPSS and other analytical and modelling software.
Ability to work in a fast paced environment, adapt easily to changing situations and demonstrates flexibility in juggling priorities
Problem solver with a can do attitude
Strong customer focus mentality
Teamwork
REF: AW
We’re here to provide excellent service but a little help from you can ensure a five-star candidate experience from start to finish.
Before you click “apply”: Please read the job description carefully to ensure you can confidently demonstrate why this opportunity is right for you and take the time to put together a well-crafted and personalised CV to further boost your visibility. Our global Talent Acquisition team members are all assigned to specific businesses to ensure that we make the best matches between talent and opportunities. We not only consider the requisite compatibility of skills and behaviours, but also how candidates align with our Values of Respect, Integrity, Collaboration, and Excellence.
As part of our candidate experience promise, we also want to make ourselves available to you throughout the application process. We make every effort to review and respond to every application.
0 notes
Text
Unlocking Power with Pentaho Data Integration Architecture
Discover the core of data integration excellence with our in-depth coverage of Pentaho Data Integration Architecture. At Diligene, we delve into the intricacies of Pentaho's architecture, providing you with the knowledge to optimize your data workflows and achieve peak efficiency.
1 note
·
View note
Text
Pentaho Data Integration & Analytics: Expert Consulting by Helical IT Solutions
What Is Pentaho Data Integration (PDI)?
Pentaho Data Integration (PDI), also known as Kettle, is an open-source ETL (Extract, Transform, Load) tool designed to help organizations manage data workflows efficiently. Acquired by Pentaho in 2005, Kettle evolved into PDI, with both a freely available community edition and a more feature-rich enterprise version.
While the community version is suitable for basic ETL tasks, the enterprise edition of PDI offers enhanced features such as scalability, advanced security, real-time data processing, and integration with enterprise data platforms. This makes it the perfect option for settings with a lot of data and complexity.
Pentaho offers PDI as part of its Business Intelligence (BI) suite, enabling end-to-end data operations such as: Data cleaning and transformation, Data migration between databases or systems, Bulk data loading and processing, Data quality enforcement, Governance and compliance
Organizations looking to implement or scale these capabilities often rely on Pentaho data integration consulting services to ensure efficient architecture, optimized workflows, and successful deployment.
PDI consists of several core components that support various stages of the ETL process:
Spoon – A visual design tool for ETL developers to build data transformations (data flows) and jobs (execution workflows).
Pan – A command-line utility used to execute transformations created in Spoon.
Kitchen – Executes jobs designed in Spoon from the command line or automated scripts.
Carte – A lightweight web server for remotely executing and monitoring ETL jobs.
With its modular architecture and strong community support, PDI is a leading choice for businesses looking to build scalable and automated data pipelines. Helical IT Solutions offers expert Pentaho data integration consulting services to help organizations implement, customize, and optimize PDI for their specific data environments.
Why Choose Pentaho for Data Integration and Analytics?
Pentaho Data Integration (PDI) is a powerful and flexible ETL platform that helps organizations unify, transform, and analyse data from multiple sources. With support for cloud, big data, and traditional systems, Pentaho enables end-to-end data workflows—from ingestion to insightful dashboards.
Businesses choose Pentaho because it offers:
A user-friendly, visual interface for designing data pipelines
Tight integration with business intelligence and reporting tools
Scalable support for real-time and batch processing
Flexible deployment (on-premises, cloud, or hybrid)
Open-source extensibility with enterprise-grade features
Pentaho becomes a complete solution for building modern, efficient, and customized data architectures tailored to your business needs.
Common Data Challenges Businesses Face Without a Proper ETL Solution
Many businesses struggle with data chaos stemming from disparate sources, inconsistent formats, and a lack of proper data governance. Without a robust ETL (Extract, Transform, Load) solution, they face challenges like:
Inaccurate Reporting: Relying on manual processes or partial data leads to flawed insights and poor decision-making.
Operational Inefficiencies: Time is wasted on data reconciliation and cleaning, diverting resources from core business activities.
Limited Scalability: Growing data volumes overwhelm existing systems, hindering expansion and agility.
Data Silos: Critical information remains isolated, preventing a unified view of the business.
Compliance Risks: Difficulty in tracking and auditing data can lead to regulatory non-compliance.
These issues directly impact profitability and growth. This is where a powerful ETL tool like Pentaho Data Integration & Analytics becomes crucial.
How Helical IT Solutions Enhances Your Pentaho Implementation
While Pentaho Data Integration & Analytics is a powerful tool, maximizing its potential requires specialized expertise. Helical IT Solutions elevates your Pentaho implementation by offering:
Deep Pentaho Expertise: Our certified consultants possess extensive experience across the entire Pentaho suite (PDI, Analyzer, Report Designer, etc.), ensuring you leverage every feature.
Tailored Solutions: We don't just implement; we customize Pentaho to perfectly align with your unique business needs, data sources, and analytical goals.
End-to-End Services: From initial consultation and data strategy to development, integration, migration, support, and training, we cover the full project lifecycle.
Optimized Performance: We focus on building efficient data pipelines, optimizing performance, and ensuring data quality for accurate, timely insights.
Cost-Effective Implementation: As a Pentaho partner with a strong track record, we deliver high-quality solutions that maximize your ROI and minimize overhead.
What Helical IT Solutions Offers
Certified Pentaho consulting and development
Pentaho Data Integration (Kettle) services
Pentaho Report Designer (PRPT) and dashboard development
Embedding Pentaho analytics in web applications
SSO, high availability, and load balancing setup
OLAP schema modelling and advanced analytics
End-to-end implementation, training, and post-deployment support
Helical IT Solutions delivers expert Pentaho consulting and implementation services, enabling businesses to unlock the full potential of their data integration and analytics initiatives with tailored, scalable, and reliable solutions
Why Helical IT Solutions Is the Right Pentaho Partner for You
With years of hands-on experience in implementing Pentaho Data Integration across industries, Helical IT Solutions brings the technical expertise, flexibility, and client-first approach needed for successful data projects. We focus on delivering custom, scalable, and cost-effective solutions—whether you're starting from scratch or optimizing an existing setup.
Our deep understanding of both community and enterprise editions, combined with a strong track record in ETL, BI, and analytics, makes us a trusted partner for businesses looking to turn data into actionable insights.
Contact Us for Expert Pentaho Consulting Services
Contact Helical IT Solutions for a demo, client references, or to discuss your requirements:
Email: [email protected] | [email protected]
Phone: +91-7893947676
Experience the difference of working with a dedicated Pentaho partner focused on your success.
0 notes
Text
Data Engineer job at FLEXIROAM Malaysia
PROFILE
FLEXIROAM is the fastest growing budget international roaming provider in Asia Pacific with half a milliion subscribers and successfully offering its services to travellers from 8 countries to roam in over 200 countries worldwide.
To date, FLEXIROAM has access to 580 telecommunication networks worldwide and enabled global travelers to save over USD 3 million worth of roaming charges. FLEXIROAM currently operates within 4 international airports in Malaysia and is expanding its presence in major International airports within the region.
FLEXIROAM collaborates with strategic travel industry partners in the airlines industry, travel agencies, travel insurance companies and international events companies to bring the budget roaming experience to travelers on a global audience.
The roaming industry is currently valued at USD$67billion and it is expected to each USD$80billion by 2017. Being the world pioneer in the unlimited flat rate per day roaming calls concept, FLEXIROAM is well positioned to maximize its potential in this industry.
FLEXIROAM is revolutionizing the travel industry by offering ‘The Smartest Way to Roam’.
CAREERS WITH FLEXIROAM
Driven by VISION and PASSION
Career at FLEXIROAM is unlike any other you’ve had. Working here is FUN and challenging because we are constantly renewing our minds to make the impossible POSSIBLE!! Join us to experience a career driven by vision & passion and tell the difference for yourself!
Understand and combine data from a variety of disparate data sources to create meaningful analysis for organization leaders
Validate accuracy and cleanliness of data
Responsible for designing and creating the data warehouse and all related ETL of data functions
Create, modify and/or maintain Business Intelligence solutions, Data Stores and ETL
Work with Business Development team to integrate data warehouse with BI tools and provide insights on available data for analysis
Research and recommend targets for key metrics and performance indicators using external benchmarks and internal data
1-2 years of experience in related field
Knowledge and experience in MySQL or other databases
Knowledge and experience in Python or R and data science libraries
Knowledge and experience in data warehousing or ETL process design
Able to lead a team and also work independently
Plus point if you have:
Background in machine learning applications, big data architecture, and product analytics
Experience in using Business Intelligence tools like Looker, Tableau, GoodData, Pentaho, etc
Experience in AWS
Experience in PHP language
StartUp Jobs Asia - Startup Jobs in Singapore , Malaysia , HongKong ,Thailand from http://www.startupjobs.asia/job/40854-data-engineer-big-data-job-at-flexiroam-malaysia Startup Jobs Asia https://startupjobsasia.tumblr.com/post/178915160014
0 notes
Text
[Packt] Beginning DevOps with Docker [eLearning]
Automatically and easily deploy your environment with this toolchain of lightweight containers Video Description The course outlines the power of containerization and the influence this innovation has on development teams and general operations. You will understand what DevOps really is, the principles involved, and how the process contributes to product health, by implementing a Docker workflow. Docker is an open source containerization tool, that makes it easier to streamline product delivery and reduce the time it takes to get from a whiteboard sketch of the business to a money-back implementation. We will start by defining how Docker influences the DevOps process. Then we will design and build simple containers, with a clear outline of how applications are involved in the process. We will also learn to define the key highlights when setting up multiple containers, while setting up a number using docker-compose, Docker’s tool for running multi-container applications. By the end of the course, you will be able to build a real-business application and host it locally. Style and Approach This course is a seamless blend of videos, code examples, and assessments that will help you take learn efficiently as you progress through the course. The course has a perfect blend of theory and practical knowledge. It is also example-heavy so that it is easier to relate to. What You Will Learn Understand basics of Docker and DevOps, why and how they integrate Effectively design and build containers for different applications Set-up an environment for testing, avoiding environment mismatch Set-up and manage a multi-tier environment Run, debug, and experiment with applications in a container Build a production-ready application and host it locally Authors Stefan Bauer Stefan Bauer has worked in business intelligence and data warehousing since the late 1990s on a variety of platforms in a variety of industries. Stefan has worked with most major databases, including Oracle, Informix, SQL Server, and Amazon Redshift as well as other data storage models, such as Hadoop. Stefan provides insight into hardware architecture, database modeling, as well as developing in a variety of ETL and BI tools, including Integration Services, Informatica, Analysis Services, Reporting Services, Pentaho, and others. In addition to traditional development, Stefan enjoys teaching topics on architecture, database administration, and performance tuning. Redshift is a natural extension fit for Stefan’s broad understanding of database technologies and how they relate to building enterprise-class data warehouses. source https://ttorial.com/beginning-devops-docker-elearning
source https://ttorialcom.tumblr.com/post/177371084108
0 notes
Text
[Packt] Beginning DevOps with Docker [eLearning]
Automatically and easily deploy your environment with this toolchain of lightweight containers Video Description The course outlines the power of containerization and the influence this innovation has on development teams and general operations. You will understand what DevOps really is, the principles involved, and how the process contributes to product health, by implementing a Docker workflow. Docker is an open source containerization tool, that makes it easier to streamline product delivery and reduce the time it takes to get from a whiteboard sketch of the business to a money-back implementation. We will start by defining how Docker influences the DevOps process. Then we will design and build simple containers, with a clear outline of how applications are involved in the process. We will also learn to define the key highlights when setting up multiple containers, while setting up a number using docker-compose, Docker’s tool for running multi-container applications. By the end of the course, you will be able to build a real-business application and host it locally. Style and Approach This course is a seamless blend of videos, code examples, and assessments that will help you take learn efficiently as you progress through the course. The course has a perfect blend of theory and practical knowledge. It is also example-heavy so that it is easier to relate to. What You Will Learn Understand basics of Docker and DevOps, why and how they integrate Effectively design and build containers for different applications Set-up an environment for testing, avoiding environment mismatch Set-up and manage a multi-tier environment Run, debug, and experiment with applications in a container Build a production-ready application and host it locally Authors Stefan Bauer Stefan Bauer has worked in business intelligence and data warehousing since the late 1990s on a variety of platforms in a variety of industries. Stefan has worked with most major databases, including Oracle, Informix, SQL Server, and Amazon Redshift as well as other data storage models, such as Hadoop. Stefan provides insight into hardware architecture, database modeling, as well as developing in a variety of ETL and BI tools, including Integration Services, Informatica, Analysis Services, Reporting Services, Pentaho, and others. In addition to traditional development, Stefan enjoys teaching topics on architecture, database administration, and performance tuning. Redshift is a natural extension fit for Stefan's broad understanding of database technologies and how they relate to building enterprise-class data warehouses. source https://ttorial.com/beginning-devops-docker-elearning
0 notes
Text
Pentaho 8.0 Move Beyond Big Data to Transformation

This post was originally published on SPEC INDIA Blog
Sticking to the basic advantages of Pentaho BI Services, Pentaho 8.0 retains the original flavour, adding more sugar and spice to the newer version. It now showcases data integration as well as data mining, featuring the Pentaho Data Integration (PDI) component.
Major Highlights that are sure to Make Pentaho 8.0 a User’s Delight
Enhancement in connectivity to streaming data sources
Pentaho 8.0 showcases stream processing with Spark, connections to Kafka streams and big data security with Knox, when it comes to expanding in terms of velocity and volume.
Augmentation of processing resources
Pentaho 8.0 has come up with a provision to append worker nodes, whenever there is a requirement during peak times. It shall scale out enterprise workloads and provides native support to Apache Avro and Apache Parquet.
Increase in team efficiency
Attempting to overcome the weaknesses realized in Big Data, Pentaho 8.0 has added certain features that takes it a step further and surely will be a big booster in increasing the efficiency levels. Features like granular filters for data preparation, improvised usage of repository, simplistic audit of application are some of them.
“Pentaho Setting Trends among the Business Intelligence Analytics Tools in the recent years”
Bringing in cluster of worker nodes
Hitachi Vantara is set to append a scale out architecture, letting Kettle engine to be positioned to a cluster of worker nodes rather than a single server. With this, many jobs can be taken up in parallel, surely bringing a big amount of time and cost savings.
Addition of filtering facility in data explorer
In the earlier version, the data explorer component of PDI did not have the filtering functionality and now Pentaho 8.0 has proposed to offer the same, along with usage of the repository and simple audit features.
Read more @ Pentaho 8 and Big Data Transformation
0 notes
Text
[Full-time] Sr. Business Intelligence at dhar
Location: Wisconsin URL: http://www.jobisite.com Description:
Job Title : Sr. Business Intelligence Developer Project Duration : 6+ Months Location : Milwaukee, WI Positions : 1 Rate : Market Job Description: REQUIRED TECHNOLOGY STACK: Database Experience ? Oracle, DB2, MS, Netezza, GreenPlumb BI Tools ? Tableau, Qlik, Business Objects, Essbase, Microstrategy, Cognos, PowerBI, BOBJ Modeling Tools ? Erwin, Embarcadero ETL Tools ? Alteryx, Informatica, Talend, SSIS, DataStage, Pentaho In this role, the BI Engineer will be responsible for: Executing and facilitating 4-8 concurrent BI Projects, as well as ongoing pre-sales support. Maintaining a solid understanding of traditional enterprise data warehousing and next generation data platforms to meet use case specific requirements of multiple vertically aligned customers. Facilitating data platform discussions and working with data owners to define and understand business requirements of a future state Enterprise Data Platform. Understanding of disparate data sources and integrating them into a meaningful platform to support reporting and analytical needs of customers and audiences. Understanding of complex data relationships and business requirements that formulates new technologies to reduce overall cost and ROI for customers. Ability to present and communicate between all levels of an organization that would include C-Level Executives, Directors, Management, Analysts, Business Users, etc. Strict understanding of traditional Kimball / Inman architecture designs and Data Modeling efforts. Articulating data definitions, content domains, data classes, subject area classification, and conformed dimensions. Experience in collecting, maintaining, and publishing corporate data models related to database architectures. Enforcing data governance standards, policies, and procedures for the design and proper use and care of a customer?s data sets. Developing, managing, and updating data models, including physical and logical models of traditional data warehouse, data mart, staging area, and the operational data store and source system designs. Understanding a company’s transactional systems and data sources and identifying gaps in business processes and recommend solutions to close those gaps. Assisting in the design of a company’s data extraction, staging and loading to a data warehouse processes to ensure that data is as consistent, clean and accurate as possible. Acting as a key business partner to the company’s Data Management Team and developers, to design solutions to correct problems, increase efficiency and performance, as well as recommending best practices for a next generation data platform that supports and drives reporting and analytic needs. Developing technical documentation including requirements documents, process overviews, data models /data flows from source to target, and design specificationsQUALIFICATIONS: Bachelor’s degree in Computer Science, Engineering, or related field (MS Candidates Preferred) 5+ years of experience in Enterprise Data Warehousing, Architecture and Analytics 5+ years of data integration and architecture 5+years of data integration and non-traditional data platforms 5+years of design and implementation of enterprise-level data platforms that support a variety of business intelligence initiatives. Hands on experience with data modeling software tools Strong grasp of advanced SQL writing and query tuning / optimization Strong documentation skills Strong written / oral communication and organizational skills Excellent communication skills and ability to articulate modern data integration strategies Excellent problem solving skills Excellent relationship building skills Excellent white boarding skills Ability to educate and knowledge transfer Team player and collaborator Experience in code migration, database change management and data management through various stages of the development life cycle Understanding of architecture of next generation HA / DR Data Platforms EXPOSURE PREFFERRED: Hadoop ? IBM BigInsights, Cloudera, Horton Works, MapR Cloud ? IBM (DashDB), AWS (Amazon Web Services), Microsoft (Azure) Predictive Analytics ? Python, R, Jupiter Notebooks Statistical Modeling ? Linear Regression, Decision Tree, Neural Network, Logistic Regression Reference : Sr. Business Intelligence jobs
Apply to this job from Employment-USA.Net http://employment-usa.net/job/53550/sr-business-intelligence-at-dhar/
0 notes
Text
Top 7 Tools You Should use for Big Data Analytics
Big Data Analytics platform is helping an organisation to shorten the information processing stage for the various type of enterprise data. Many options for analytics emerge as organization attempt to turn data into information first and then into high-quality logical insights that can improve or empower a business scenario.
SAP Big Data Analytics
SAP HANA and SAP IQ are the part of Big Data platform. SAP IQ is parallel processing database. Apache Hadoop and SAP HANA platforms can also be clubbed together.
HP Big Data
HP HAVEn and HP Vertica are the flagships big data products. HAVEn has the hardware, software, and services. Structured and unstructured data can be analyzed by HAVEn to generate meaning. Vertica Dragline helps the enterprise in cost effective data storage and make it possible to skim it quickly using SQL function.
Microsoft Big Data
Launched in 2010, Azure is a cloud-ready-flexible platform by Microsoft. This tools aids in the conception, preparation, and governance of application on a worldwide center of Microsoft such as called data center. The strong point is that application can build on the basis of any programming language or IT framework and also be combined with other cloud application.
Pentaho Big Data Analytics
Pentaho provides the board solution that supports an end-to-end data cycle. Irrespective of the data source, an individual platform affords developers the ability to extract data using visual big data tools and prepare it.
Cisco Big Data
Cisco’s Common Platform Architecture (CPA) has storage, computing, and unified management feature. CPA’s main characteristics are simple manner through which is database integrated with an enterprise application ecosystem.
MongoDB
A leading NoSQL database, MongoDB enhances a business’s agility and scalability. A large number of big companies are using MongoDB to create a novel application, improve user experience and decrease costs.
Teradata BigData Analytics
Teradata has made a simple architecture called Unified Data Architecture in Big Data Analytics. Crucial business knowledge can be gained from the Teradata Aster Discovery platform using different data types.
In Conclusion, the list of above Big Data Analytics provides you an overview of the tools that you should use for Big Data Analytics. They are may be plenty of other tools and some of other popular big data analytics tools that have been used for data analytics and that may be suited to your business needs. But main while selecting the handy tool that fulfills your analytics needs depend upon your company requirements.
For More to know click the link :-http://www.raygain.com/top-7-tools-use-big-data-analytics/
0 notes
Text
Pentaho Ends Machine Learning Gridlock
Pentaho, a Hitachi Group Company, today announced orchestration capabilities that streamline the entire machine learning workflow and enable teams of data scientists, engineers and analysts to train, tune, test and deploy predictive models. Pentaho’s Data Integration and analytics platform ends the ‘gridlock’ associated with machine learning by enabling smooth team collaboration, maximizing limited data science resources and putting predictive models to work on big data faster — regardless of use case, industry, or language — whether models were built in R, Python, Scala or Weka.
Streamlining four areas of the machine learning workflow With Pentaho’s machine learning orchestration, the process of building and deploying advanced analytics models maximizes efficiency. Most enterprises struggle to put predictive models to work because data professionals often operate in silos and the workflow — from data preparation to updating models — create bottlenecks. Pentaho’s platform enables collaboration and removes bottlenecks in four key areas:
Data and feature engineering — Pentaho helps data scientists and engineers easily prepare and blend traditional sources like ERP, EAM and big data sources like sensors and social media. Pentaho also accelerates the notoriously difficult and costly task of feature engineering by automating data onboarding, data transformation and data validation in an easy-to-use drag and drop environment.
Model training, tuning and testing — Data scientists often apply trial and error to strike the right balance of complexity, performance and accuracy in their models. With integrations for languages like R and Python, and for machine learning packages like Spark MLlib and Weka, Pentaho allows data scientists to seamlessly train, tune, build and test models faster.
Model deployment and operationalization — a completely trained, tuned and tested machine learning model still needs to be deployed. Pentaho allows data professionals to easily embed models developed by the data scientist directly in a data workflow. They can leverage existing data and feature engineering efforts, significantly reducing time-to-deployment. With embeddable APIs, organizations can also include the full power of Pentaho within existing applications.
Update models regularly — According to Ventana Research, less than a third (31%) of organizations use an automated process to update their models. With Pentaho, data engineers and scientists can re-train existing models with new data sets or make feature updates using custom execution steps for R, Python, Spark MLlib and Weka. Pre-built workflows can automatically update models and archive existing ones.
Hitachi Rail uses Pentaho with Hitachi’s Hyper Scale-Out Platform to fulfil its pioneering “Trains-as-a-Service” concept, applying advanced IoT technology in three event horizons: real-time (monitoring, fault alerting), medium-term (predictive maintenance) and long-term (big data trend analysis). With each train carrying thousands of sensors generating huge amounts of data per day, the project’s data engineers and scientists face many challenges associated with big data and machine learning. Although the project is not yet operational, Pentaho is already helping to deliver productivity improvements across the business.
According to Philip Hewlett, Project Manager, “Hitachi Rail conservatively estimate that Pentaho’s orchestration capabilities for data preparation, engineering and machine learning have already delivered wide-reaching productivity improvements and specialized development ambitions which will translate into value-added services for our customers — and this is at a very early stage in the project.”
David Menninger, SVP & Research Director, Ventana Research, commented, “According to our research, 92 percent of organizations plan to deploy more predictive analytics, however, 50 percent of organizations have difficulty integrating predictive analytics into their information architecture. Pentaho offers a robust platform to help companies take advantage of machine learning algorithms throughout their organization, helping business units and IT to work together with the common goal of making predictive analytics deliver value to the enterprise.”
Wael Elrifai, Director of Worldwide Enterprise Data Science, Pentaho said, “In 2017 we’re working with early adopters looking to transform their businesses with machine learning. Fortunately our early foray into big data analytics gave us the insight to solve some of the toughest challenges in this area. As part of Hitachi, which has a large team of data science experts, we will continue growing our machine learning capabilities as this market matures.”
The machine learning orchestration capabilities are available in Pentaho 7.0.
Source: Nasdaq GlobeNewswire
Go to Source
The post Pentaho Ends Machine Learning Gridlock appeared first on Statii News.
from Statii News http://news.statii.co.uk/pentaho-ends-machine-learning-gridlock/ from Statii News https://statiicouk.tumblr.com/post/158430537047
0 notes
Link
Recruitment in Al Futtaim Group Customer Insights Manager | Group Marketing | Al Futtaim Group | Dubai (Dubai, AE)
No two days are the same at Al-Futtaim, no matter what role you have. Our work is driven by the desire to make a difference and to have a meaningful impact with the goal of enriching everyday lives. Take our engaging and supportive work environment and couple it with a company culture that recognises and rewards quality performance, and what do you get? The chance to push the limits every single day.
As a humble family business that started on the banks of the Dubai Creek in the 1930s, Al-Futtaim has expanded to a presence in 31 countries, a portfolio of over 200 companies, and 42,000 employees. You’ll find us in industries ranging from automotive and retail, to finance and real estate, and connecting people with international names like Lexus, Ikea, Robinsons, and Adidas. Our team is proudly multicultural and multinational because that kind of diverse representation gives us the global mindset to grow and impact the people, markets, and trends around us.
Come join us to live well, work better, and be the best.
The objective of the role is to contribute to the Group’s CRM strategy, with a strong focus on delivering data analysis and actionable insights to support all Group Brand stakeholders.
This role will be based out of our corporate offices at Dubai Festival City and will directly report to the General Manager-Group CRM
Core Competencies:
Identify opportunities to drive customer value through CRM activities at Group level
Provide a detailed and complete understanding of customer bases across all Group Brands leveraging the new Group CRM Platform and the Single View of the Customer (Hybris Marketing Platform)
Provide Corporate Marketing and business units with models (both segmentation and propensity) to aid targeting and understanding of customer behavior across businesses and Brands.
Own the delivery of insight and business intelligence which are cross-divisional, making recommendations to divisions and brands, for them to implement
Review customer data for trends, patterns and casual analysis to assist Brand and Divisions in understanding customer behavior cross brand and divisions
Advise business units of appropriate marketing actions based on the relevant information to ensure maximum Return on digital campaign investment, in collaboration with division marketing team
Propose appropriate and common measurement methodologies across the Brand and Divisions to understand digital campaign performance and implement for corporate digital campaigns
Perform and support marketing campaigns analysis to determine business impacts and Design, enhance, and distribute marketing reports that clearly communicate campaign and/or business results, for corporate campaigns
Identify data quality issues in the CRM DB and address the data cleansing actions that will be managed and executed at Division/Brand level
Industry Experience (Must Have):
Previous experience from working as a data analyst with focus on CRM and Customer Analytics
Mathematics and/or Statistics Bachelor’s degree or higher with at least 3-5 years previous work experience within Insight CRM space and 3-5 years in a Consulting or Market Research Agency
Strong understanding of data mining techniques, statistical concepts and predictive modelling. (e.g., neural networks, multi-scalar dimensional models, logistic regression techniques, machine-based learning)
Experience with Big Data technologies (eg. Hadoop, Cassandra, Hive, Pig, Impala, Parquet, etc.) and large Data Warehouse implementation (Oracle, Teradata, GreenPlum, SAP Hana, Netezza TF) or Data Lakes implementation (Microsoft, Oracle, Teradata, Cloudera, Amazon, …)
Experience in Reporting architectures (eg. SAS, MicroStrategy, Oracle, SAP BO, Pentaho, Tableau and Cognos)
Experience with predictive analytics tools (eg. SAS, SPSS, MATLAB)
Experience in CRM Modelling, Analytics & Campaign Execution (eg. MS Dynamics, SAS, Unica, Teradata, Oracle
Expertise with the Microsoft Office suite (including advanced Excel skills with embedded Pivot Tables & Macros; advanced PowerPoint usage for storyboard design and presentation)
Familiarity with marketing disciplines and particularly CRM to aid understanding and delivery of business objectives.
Passion for Analytics
Understanding of business financials, ROI & profitability
Ability to present complex information in simple terms with clear recommendations based on data insight
Maintain a good knowledge of relevant analytical and statistical techniques
Maintain a good technical knowledge of SAS, SPSS and other analytical and modelling software.
Ability to work in a fast paced environment, adapt easily to changing situations and demonstrates flexibility in juggling priorities
Problem solver with a can do attitude
Strong customer focus mentality
Teamwork
REF: AW
We’re here to provide excellent service but a little help from you can ensure a five-star candidate experience from start to finish.
Before you click “apply”: Please read the job description carefully to ensure you can confidently demonstrate why this opportunity is right for you and take the time to put together a well-crafted and personalised CV to further boost your visibility. Our global Talent Acquisition team members are all assigned to specific businesses to ensure that we make the best matches between talent and opportunities. We not only consider the requisite compatibility of skills and behaviours, but also how candidates align with our Values of Respect, Integrity, Collaboration, and Excellence.
As part of our candidate experience promise, we also want to make ourselves available to you throughout the application process. We make every effort to review and respond to every application.
0 notes