#ProcessingData
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
Apache Beam For Beginners: Building Scalable Data Pipelines
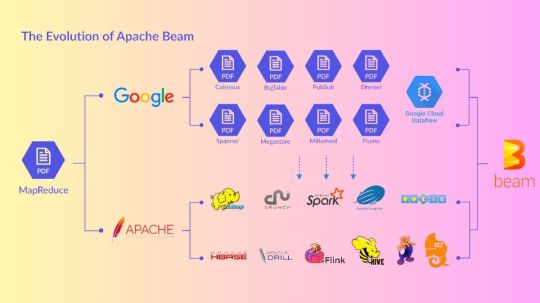
Apache Beam
Apache Beam, the simplest method for streaming and batch data processing. Data processing for mission-critical production workloads can be written once and executed anywhere.
Overview of Apache Beam
An open source, consistent approach for specifying batch and streaming data-parallel processing pipelines is called Apache Beam. To define the pipeline, you create a program using one of the open source Beam SDKs. One of Beam’s supported distributed processing back-ends, such as Google Cloud Dataflow, Apache Flink, or Apache Spark, then runs the pipeline.
Beam is especially helpful for situations involving embarrassingly parallel data processing, where the issue may be broken down into numerous smaller data bundles that can be handled separately and concurrently. Beam can also be used for pure data integration and Extract, Transform, and Load (ETL) activities. These operations are helpful for loading data onto a new system, converting data into a more suitable format, and transferring data between various storage media and data sources.Image credit to Apache Beam
How Does It Operate?
Sources of Data
Whether your data is on-premises or in the cloud, Beam reads it from a wide range of supported sources.
Processing Data
Your business logic is carried out by Beam for both batch and streaming usage cases.
Writing Data
The most widely used data sinks on the market receive the output of your data processing algorithms from Beam.
Features of Apache Beams
Combined
For each member of your data and application teams, a streamlined, unified programming model for batch and streaming use cases.
Transportable
Run pipelines across several execution contexts (runners) to avoid lock-in and provide flexibility.
Wide-ranging
Projects like TensorFlow Extended and Apache Hop are built on top of Apache Beam, demonstrating its extensibility.
Open Source
Open, community-based support and development to help your application grow and adapt to your unique use cases.
Apache Beam Pipeline Runners
The data processing pipeline you specify with your Beam program is converted by the Beam Pipeline Runners into an API that works with the distributed processing back-end of your choosing. You must designate a suitable runner for the back-end where you wish to run your pipeline when you run your Beam program.
Beam currently supports the following runners:
The Direct Runner
Runner for Apache Flink Apache Flink
Nemo Runner for Apache
Samza the Apache A runner Samza the Apache
Spark Runner for Apache Spark by Apache
Dataflow Runner for Google Cloud Dataflow on Google Cloud
Jet Runner Hazelcast Jet Hazelcast
Runner Twister 2
Get Started
Get Beam started on your data processing projects.
Visit our Getting started from Apache Spark page if you are already familiar with Apache Spark.
As an interactive online learning tool, try the Tour of Beam.
For the Go SDK, Python SDK, or Java SDK, follow the Quickstart instructions.
For examples that demonstrate different SDK features, see the WordCount Examples Walkthrough.
Explore our Learning Resources at your own speed.
on detailed explanations and reference materials on the Beam model, SDKs, and runners, explore the Documentation area.
Learn how to run Beam on Dataflow by exploring the cookbook examples.
Contribute
The Apache v2 license governs Beam, a project of the Apache Software Foundation. Contributions are highly valued in the open source community of Beam! Please refer to the Contribute section if you would want to contribute.
Apache Beam SDKs
Whether the input is an infinite data set from a streaming data source or a finite data set from a batch data source, the Beam SDKs offer a uniform programming model that can represent and alter data sets of any size. Both bounded and unbounded data are represented by the same classes in the Beam SDKs, and operations on the data are performed using the same transformations. You create a program that specifies your data processing pipeline using the Beam SDK of your choice.
As of right now, Beam supports the following SDKs for specific languages:
Java SDK for Apache Beam Java
Python’s Apache Beam SDK
SDK Go for Apache Beam Go
Apache Beam Python SDK
A straightforward yet effective API for creating batch and streaming data processing pipelines is offered by the Python SDK for Apache Beam.
Get started with the Python SDK
Set up your Python development environment, download the Beam SDK for Python, and execute an example pipeline by using the Beam Python SDK quickstart. Next, learn the fundamental ideas that are applicable to all of Beam’s SDKs by reading the Beam programming handbook.
For additional details on specific APIs, consult the Python API reference.
Python streaming pipelines
With Beam SDK version 2.5.0, the Python streaming pipeline execution is possible (although with certain restrictions).
Python type safety
Python lacks static type checking and is a dynamically typed language. In an attempt to mimic the consistency assurances provided by real static typing, the Beam SDK for Python makes use of type hints both during pipeline creation and runtime. In order to help you identify possible issues with the Direct Runner early on, Ensuring Python Type Safety explains how to use type hints.
Managing Python pipeline dependencies
Because the packages your pipeline requires are installed on your local computer, they are accessible when you execute your pipeline locally. You must, however, confirm that these requirements are present on the distant computers if you wish to run your pipeline remotely. Managing Python Pipeline Dependencies demonstrates how to enable remote workers to access your dependencies.
Developing new I/O connectors for Python
You can develop new I/O connectors using the flexible API offered by the Beam SDK for Python. For details on creating new I/O connectors and links to implementation guidelines unique to a certain language, see the Developing I/O connectors overview.
Making machine learning inferences with Python
Use the RunInference API for PyTorch and Scikit-learn models to incorporate machine learning models into your inference processes. You can use the tfx_bsl library if you’re working with TensorFlow models.
The RunInference API allows you to generate several kinds of transforms since it accepts different kinds of setup parameters from model handlers, and the type of parameter dictates how the model is implemented.
An end-to-end platform for implementing production machine learning pipelines is called TensorFlow Extended (TFX). Beam has been integrated with TFX. Refer to the TFX user handbook for additional details.
Python multi-language pipelines quickstart
Transforms developed in any supported SDK language can be combined and used in a single multi-language pipeline with Apache Beam. Check out the Python multi-language pipelines quickstart to find out how to build a multi-language pipeline with the Python SDK.
Unrecoverable Errors in Beam Python
During worker startup, a few typical mistakes might happen and stop jobs from commencing. See Unrecoverable faults in Beam Python for more information on these faults and how to fix them in the Python SDK.
Apache Beam Java SDK
A straightforward yet effective API for creating batch and streaming parallel data processing pipelines in Java is offered by the Java SDK for Apache Beam.
Get Started with the Java SDK
Learn the fundamental ideas that apply to all of Beam’s SDKs by beginning with the Beam Programming Model.
Further details on specific APIs can be found in the Java API Reference.
Supported Features
Every feature that the Beam model currently supports is supported by the Java SDK.
Extensions
A list of available I/O transforms may be found on the Beam-provided I/O Transforms page.
The following extensions are included in the Java SDK:
Inner join, outer left join, and outer right join operations are provided by the join-library.
For big iterables, sorter is a scalable and effective sorter.
The benchmark suite Nexmark operates in both batch and streaming modes.
A batch-mode SQL benchmark suite is called TPC-DS.
Euphoria’s Java 8 DSL for BEAM is user-friendly.
There are also a number of third-party Java libraries.
Java multi-language pipelines quickstart
Transforms developed in any supported SDK language can be combined and used in a single multi-language pipeline with Apache Beam. Check out the Java multi-language pipelines quickstart to find out how to build a multi-language pipeline with the Java SDK.
Read more on govindhtech.com
#ApacheBeam#BuildingScalableData#Pipelines#Beginners#ApacheFlink#SourcesData#ProcessingData#WritingData#TensorFlow#OpenSource#GoogleCloud#ApacheSpark#ApacheBeamSDK#technology#technews#Python#machinelearning#news#govindhtech
0 notes
Note
*watching the searchlights swim in the distance*
did u know the reason why they won't go away is because they think you're one of them and your spotlight is you saying "hey I found food"?
"That..."
>processingdata
>please_wait
>please_wait
"...makes so much sense actually."
5 notes
·
View notes
Text
HR Management Software UAE & Its Real Magic

The prospects of offering HR management software UAE to improve business functions cannot be overstated enough. What sets the whole game apart in dealing with general HR operations is its craft in developing personalized solutions. You may either go for a custom solution in this category or choose one that reflects well on the HR innovation technology.
The Effective Contribution of HR Management Software UAE
The crucial role and impact of UAE HR software can be summarized with the following points:
Best-in-class HR systemsEasy accessibility and consistent upgrades define the core HR management process of an organization. UAE-based service solutions offer the best HRMS process modules to clear their optimum workflow conditions and resource engagement patterns. A cloud based HR software solution can significantly aid in this regard.
Flexible operations platformFlexibility is key to the adoption of scalability for HR business models. An operations platform should undergo a transparent business process model, and it should help resources discover the integrity of an interesting HR portal.
Secure information processingData and information are an important part of the work that you are doing for security factors connected to the HR domain. Stay available with the full potential to build an engaging and exclusive HR management software portal that focuses on constant information processing techniques.
Extra attention to automationCore automation techniques and digital transformation tools should be widely considered and boosted to promote the authenticity of your firm’s HR domain. An inclusive technique of note here is the primary integration model that settles the HR and payroll software UAE.
Top-tier compliance detailsHR technology is incomplete if an innovative model for dealing with statutory compliance norms and regulatory measures is missing from the operations package. A standardized HR application software product is the best option to manage one-stop solutions that work for the compliance details in the final solution.
Pace and accuracy provisionsA large part of the HR management process evolves with the intangible values you receive from the system. These include the facilities for improving the pace, accuracy, and credibility of the entire HR process. HR payroll software UAE is one of the best takers for this model.
The efficiency in implementing HR management software UAE is a holistic process. It takes step-by-step execution measures to arrive at full-fledged, one-stop solutions meant to disrupt the whole HR operations domain.
#HRMS#HR MANAGEMENT SOFTWARE UAE#UAE HR SOFTWARE#PAYROLL SOFTWARE UAE#ATTENDANCE MANAGEMENT SOFTWARE UAE
0 notes
Text
Digital Data Engineering: Transforming Data into Insights
Data is becoming increasingly valuable in the digital age, and businesses are finding new and innovative ways to leverage data to gain insights and make more informed decisions. However, data on its own is not useful – it must be transformed into insights that can be used to drive business outcomes. Digital data engineering plays a crucial role in this process, transforming raw data into meaningful insights that can be used to drive business value. In this blog post, we'll explore the world of digital data engineering and how it is transforming data into insights.
What is Digital Data Engineering?
Digital data engineering involves the design, development, and management of data systems that can process and analyze large volumes of data. It is a field that combines computer science, data analytics, and data management to create systems that can extract value from data. It involves a wide range of activities, including data acquisition, data storage, data processing, data integration, and data visualization. It is a complex field that requires a deep understanding of data structures, algorithms, and computer systems.

Data Acquisition
Data acquisition is the process of collecting data from various sources. Data can come from a wide range of sources, including social media, web traffic, sales data, and customer feedback. This involves designing systems that can collect and store data from these sources in a secure and efficient manner. This requires an understanding of data storage technologies, data formats, and data transfer protocols.
Data Storage
Once data has been acquired, it must be stored in a way that is secure and accessible. This revolves around designing and implementing data storage systems that can handle large volumes of data. This includes the use of relational databases, NoSQL databases, and data lakes. The choice of data storage technology depends on the type of data being stored and the requirements for data access and processing.

Data Processing
Data processing is the process of transforming raw data into meaningful insights. Digital data engineering involves designing and implementing data processing systems that can handle large volumes of data and perform complex data transformations. This includes the use of data processing frameworks like Apache Spark, Apache Flink, and Apache Beam. These frameworks provide a way to process large volumes of data in parallel, making it possible to analyze and transform data in real-time.
Data Integration
Data integration is the process of combining data from multiple sources into a unified view. This deals with designing and implementing data integration systems that can handle complex data integration scenarios. This includes the use of data integration tools like Apache NiFi, Talend, and Informatica. These tools provide a way to integrate data from multiple sources, transform data into a common format, and load data into a data warehouse or data lake.
Data Visualization
Data visualization is the process of presenting data in a visual format that can be easily understood. Digital product engineering involves designing and implementing data visualization systems that can handle large volumes of data and present it in a meaningful way. This includes the use of data visualization tools like Tableau, Power BI, and QlikView. These tools provide a way to create interactive dashboards and reports that allow users to explore data and gain insights.

Transforming Data into Insights
Digital data engineering plays a crucial role in transforming data into insights. By designing and implementing data systems that can handle large volumes of data, digital data engineers make it possible to extract value from data. This involves a wide range of activities, including data acquisition, data storage, data processing, data integration, and data visualization. By combining these activities, digital data engineers create systems that can transform raw data into meaningful insights.
Data-driven Decision Making
The insights generated by digital data engineering can be used to drive data-driven decision making. By using data to inform decisions, businesses can make more informed choices that are based on data rather than intuition. This can lead to more accurate predictions, better resource allocation, and improved business outcomes. For example, a retailer can use data to identify the most popular products, optimize pricing strategies, and target promotions to specific customer segments. A healthcare provider can use data to identify patterns in patient behavior, improve patient outcomes, and reduce healthcare costs. By using data to drive decision making, businesses can gain a competitive advantage and achieve better results.
Challenges in Digital Data Engineering
While this field of engineering offers many benefits, it also presents significant challenges. One of the biggest challenges is the complexity of data systems. It involves designing and implementing systems that can handle large volumes of data and perform complex transformations. This requires a deep understanding of data structures, algorithms, and computer systems. Additionally, data systems are often distributed across multiple locations, making it difficult to ensure data consistency and security.
Another challenge is data quality. Raw data is often incomplete, inaccurate, or inconsistent. This can lead to errors in data processing and analysis, which can lead to incorrect insights and decisions. Digital data engineers must ensure that data is cleaned, transformed, and validated before it is used for analysis.
Finally, digital software product engineering requires a significant investment in infrastructure and talent. Building and maintaining data systems can be expensive, and the demand for digital data engineers is high. Businesses must invest in infrastructure, talent, and training to be successful in this field of engineering.
Conclusion
Digital data engineering plays a critical role in transforming data into insights. By designing and implementing data systems that can handle large volumes of data, digital data engineers make it possible to extract value from data. This involves a wide range of activities, including data acquisition, data storage, data processing, data integration, and data visualization. By combining these activities, digital data engineers create systems that can transform raw data into meaningful insights.
While digital data engineering offers many benefits, it also presents significant challenges. Businesses must invest in infrastructure, talent, and training to be successful in this field. By doing so, they can gain a competitive advantage and achieve better results through data-driven decision making. The future of business lies in the ability to leverage data to drive insights and make better decisions. It is the key to unlocking the power of data and transforming it into insights. Want to find out more? Visit us at Pratiti Technologies!
0 notes
Photo

Back Translation in Text Augmentation by nlpaug Author(s): Edward Ma Natural Language ProcessingData augmentation for NLP — generate synthetic data by back-translation in 4 lines of codePhoto by Edward Ma on UnsplashEnglish is one of the languages which has lots of training data for translation while some language may not has enough data to train a machine translation model. Sennrich et al. used the back-translation method to generate more training data to improve translation model performance.Given that we want to train a model for translating English (source language) → Cantonese (target language) and there is not enough training data for Cantonese. Back-translation is translating target language to source language and mixing both original source #MachineLearning #ML #ArtificialIntelligence #AI #DataScience #DeepLearning #Technology #Programming #News #Research #MLOps #EnterpriseAI #TowardsAI #Coding #Programming #Dev #SoftwareEngineering https://bit.ly/3F44Ch4 #naturallanguageprocessing
0 notes