#SourcesData
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
Apache Beam For Beginners: Building Scalable Data Pipelines
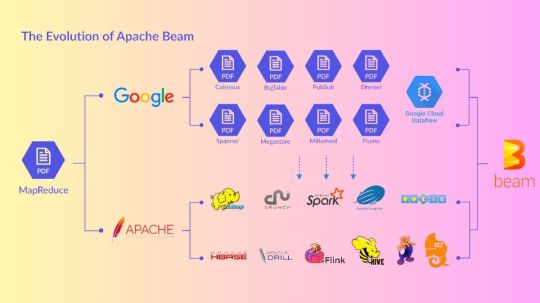
Apache Beam
Apache Beam, the simplest method for streaming and batch data processing. Data processing for mission-critical production workloads can be written once and executed anywhere.
Overview of Apache Beam
An open source, consistent approach for specifying batch and streaming data-parallel processing pipelines is called Apache Beam. To define the pipeline, you create a program using one of the open source Beam SDKs. One of Beam’s supported distributed processing back-ends, such as Google Cloud Dataflow, Apache Flink, or Apache Spark, then runs the pipeline.
Beam is especially helpful for situations involving embarrassingly parallel data processing, where the issue may be broken down into numerous smaller data bundles that can be handled separately and concurrently. Beam can also be used for pure data integration and Extract, Transform, and Load (ETL) activities. These operations are helpful for loading data onto a new system, converting data into a more suitable format, and transferring data between various storage media and data sources.Image credit to Apache Beam
How Does It Operate?
Sources of Data
Whether your data is on-premises or in the cloud, Beam reads it from a wide range of supported sources.
Processing Data
Your business logic is carried out by Beam for both batch and streaming usage cases.
Writing Data
The most widely used data sinks on the market receive the output of your data processing algorithms from Beam.
Features of Apache Beams
Combined
For each member of your data and application teams, a streamlined, unified programming model for batch and streaming use cases.
Transportable
Run pipelines across several execution contexts (runners) to avoid lock-in and provide flexibility.
Wide-ranging
Projects like TensorFlow Extended and Apache Hop are built on top of Apache Beam, demonstrating its extensibility.
Open Source
Open, community-based support and development to help your application grow and adapt to your unique use cases.
Apache Beam Pipeline Runners
The data processing pipeline you specify with your Beam program is converted by the Beam Pipeline Runners into an API that works with the distributed processing back-end of your choosing. You must designate a suitable runner for the back-end where you wish to run your pipeline when you run your Beam program.
Beam currently supports the following runners:
The Direct Runner
Runner for Apache Flink Apache Flink
Nemo Runner for Apache
Samza the Apache A runner Samza the Apache
Spark Runner for Apache Spark by Apache
Dataflow Runner for Google Cloud Dataflow on Google Cloud
Jet Runner Hazelcast Jet Hazelcast
Runner Twister 2
Get Started
Get Beam started on your data processing projects.
Visit our Getting started from Apache Spark page if you are already familiar with Apache Spark.
As an interactive online learning tool, try the Tour of Beam.
For the Go SDK, Python SDK, or Java SDK, follow the Quickstart instructions.
For examples that demonstrate different SDK features, see the WordCount Examples Walkthrough.
Explore our Learning Resources at your own speed.
on detailed explanations and reference materials on the Beam model, SDKs, and runners, explore the Documentation area.
Learn how to run Beam on Dataflow by exploring the cookbook examples.
Contribute
The Apache v2 license governs Beam, a project of the Apache Software Foundation. Contributions are highly valued in the open source community of Beam! Please refer to the Contribute section if you would want to contribute.
Apache Beam SDKs
Whether the input is an infinite data set from a streaming data source or a finite data set from a batch data source, the Beam SDKs offer a uniform programming model that can represent and alter data sets of any size. Both bounded and unbounded data are represented by the same classes in the Beam SDKs, and operations on the data are performed using the same transformations. You create a program that specifies your data processing pipeline using the Beam SDK of your choice.
As of right now, Beam supports the following SDKs for specific languages:
Java SDK for Apache Beam Java
Python’s Apache Beam SDK
SDK Go for Apache Beam Go
Apache Beam Python SDK
A straightforward yet effective API for creating batch and streaming data processing pipelines is offered by the Python SDK for Apache Beam.
Get started with the Python SDK
Set up your Python development environment, download the Beam SDK for Python, and execute an example pipeline by using the Beam Python SDK quickstart. Next, learn the fundamental ideas that are applicable to all of Beam’s SDKs by reading the Beam programming handbook.
For additional details on specific APIs, consult the Python API reference.
Python streaming pipelines
With Beam SDK version 2.5.0, the Python streaming pipeline execution is possible (although with certain restrictions).
Python type safety
Python lacks static type checking and is a dynamically typed language. In an attempt to mimic the consistency assurances provided by real static typing, the Beam SDK for Python makes use of type hints both during pipeline creation and runtime. In order to help you identify possible issues with the Direct Runner early on, Ensuring Python Type Safety explains how to use type hints.
Managing Python pipeline dependencies
Because the packages your pipeline requires are installed on your local computer, they are accessible when you execute your pipeline locally. You must, however, confirm that these requirements are present on the distant computers if you wish to run your pipeline remotely. Managing Python Pipeline Dependencies demonstrates how to enable remote workers to access your dependencies.
Developing new I/O connectors for Python
You can develop new I/O connectors using the flexible API offered by the Beam SDK for Python. For details on creating new I/O connectors and links to implementation guidelines unique to a certain language, see the Developing I/O connectors overview.
Making machine learning inferences with Python
Use the RunInference API for PyTorch and Scikit-learn models to incorporate machine learning models into your inference processes. You can use the tfx_bsl library if you’re working with TensorFlow models.
The RunInference API allows you to generate several kinds of transforms since it accepts different kinds of setup parameters from model handlers, and the type of parameter dictates how the model is implemented.
An end-to-end platform for implementing production machine learning pipelines is called TensorFlow Extended (TFX). Beam has been integrated with TFX. Refer to the TFX user handbook for additional details.
Python multi-language pipelines quickstart
Transforms developed in any supported SDK language can be combined and used in a single multi-language pipeline with Apache Beam. Check out the Python multi-language pipelines quickstart to find out how to build a multi-language pipeline with the Python SDK.
Unrecoverable Errors in Beam Python
During worker startup, a few typical mistakes might happen and stop jobs from commencing. See Unrecoverable faults in Beam Python for more information on these faults and how to fix them in the Python SDK.
Apache Beam Java SDK
A straightforward yet effective API for creating batch and streaming parallel data processing pipelines in Java is offered by the Java SDK for Apache Beam.
Get Started with the Java SDK
Learn the fundamental ideas that apply to all of Beam’s SDKs by beginning with the Beam Programming Model.
Further details on specific APIs can be found in the Java API Reference.
Supported Features
Every feature that the Beam model currently supports is supported by the Java SDK.
Extensions
A list of available I/O transforms may be found on the Beam-provided I/O Transforms page.
The following extensions are included in the Java SDK:
Inner join, outer left join, and outer right join operations are provided by the join-library.
For big iterables, sorter is a scalable and effective sorter.
The benchmark suite Nexmark operates in both batch and streaming modes.
A batch-mode SQL benchmark suite is called TPC-DS.
Euphoria’s Java 8 DSL for BEAM is user-friendly.
There are also a number of third-party Java libraries.
Java multi-language pipelines quickstart
Transforms developed in any supported SDK language can be combined and used in a single multi-language pipeline with Apache Beam. Check out the Java multi-language pipelines quickstart to find out how to build a multi-language pipeline with the Java SDK.
Read more on govindhtech.com
#ApacheBeam#BuildingScalableData#Pipelines#Beginners#ApacheFlink#SourcesData#ProcessingData#WritingData#TensorFlow#OpenSource#GoogleCloud#ApacheSpark#ApacheBeamSDK#technology#technews#Python#machinelearning#news#govindhtech
0 notes
Link
Power BI and Qlik Sense are two of the most popular business intelligence (BI) tools used by organizations to analyze their data and make informed decisions
0 notes
Text
Traversing Through eDiscovery Data Sources Amid the Hybrid Work Environment
A look at eDiscovery data sources, the issues they provide in today's hybrid work environment, and possible solutions
The COVID-19 pandemic unleashed a tsunami of new technologies, software, procedures, methodologies, and upgrades to old ones, allowing the world's suddenly remote workforce to interact and collaborate more effectively. Meanwhile, cloud service providers saw an unprecedented increase in product utilization since businesses now require it more than ever. However, after almost two years, as we transition from completely remote work culture to a hybrid or back-to-office work culture, companies are yet again struggling. This time, the concern is the ever-increasingly complex regulatory compliance environment. And it only requires more severe and strong systems and procedures to cater to the massive surplus of eDiscovery data sources generated recently.
Amid this chaos are the legal professionals, specifically the eDiscovery and compliance teams. They are entrusted with determining the long-term viability of existing policies, procedures, software, and litigation tactics. They are also assigned to develop more robust, functional processes and workflows to efficiently gather ESI to analyze these new data types in the cloud in response to updated regulatory requirements. Simultaneously, legal teams must prevent needless expenditures or delays during inquiries, investigations, or litigation. But all of it starts with collecting data.
eDiscovery Data Sources
Data security is one of the most challenging eDiscovery, and IT concerns in today's hybrid work culture. It necessitates considerable vigilance on both parties to protect the highly sensitive and confidential data they have been entrusted with. Someone, for example, maybe running an unapproved application on their work computer, putting the entire network at risk. So, how can this issue be adequately addressed?
One step toward the solution is a comprehensive and coordinated endeavor to reduce security threats on eDiscovery data sources. Firms, corporations, and legal professionals should have policies and procedures in place to secure data from collection through disposal. For example, making two-factor authentication essential for all apps. By carrying out this simple but critical step, you add another layer of protection between your sensitive data and malicious attackers. It is also crucial to avoid storing personal and corporate data together and managing personally identifiable information (PII) during institutional storage.
Furthermore, even though more individuals are working remotely than ever before, there must be a distinction between what is kept on personal devices and what is stored on business devices. Allowing your team members to work on their home computers may be convenient, but that device must have all the built-in security safeguards that a business computer has enforced by mobile device management systems in adherence to the eDiscovery software requirements. All of this improves security and protects data both before and during data collection. But that is not all; you need technology to make your policies and processes effective.
eDiscovery Technology
Every year, businesses squander millions of dollars troubleshooting data processing issues because the processing engine they utilize cannot proactively detect potential problems.
Companies should look for solutions that solve these flaws right away to avoid this scenario. One approach is to look for a processing engine that offers intelligent and dynamic processing by utilizing powerful analytics powered by built-in artificial intelligence technology. Such a system would approach all eDiscovery data sources with a governance-first orientation. To give the results, it must enable powerful search capable of skimming through millions, if not billions, of files and data simultaneously. It must have an early case assessment feature so that you can win your legal battle early on. Most significantly, it should take a defensible approach to all data, allowing for compliance by including audit trails.
0 notes