#SERPAPI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
2 notes
·
View notes
Text
#google#serpapi#serphouse#bing#google search#google serp api#sales#animation#artificial intelligence#black tumblr
0 notes
Text
Unlock the potential of your projects with Google Maps APIs!
In today's interconnected world, location intelligence plays a pivotal role in various projects, from mobile applications to logistics management systems. Here's why mastering Google Maps APIs can elevate your endeavours:
Easy Integration: Google Maps APIs provide easy-to-use interfaces and comprehensive documentation, making it straightforward to integrate location-based functionalities into your project.
Real-Time Updates: With real-time data updates and reliable infrastructure, Google Maps APIs ensure that your project stays current and responsive to changes in the geographic landscape.
By mastering Google Maps APIs, you unlock the potential to create innovative solutions that leverage the power of location intelligence to enhance user experiences, streamline operations, and drive business growth.
@science70 @theratking647 @thelostcanyon
0 notes
Link
0 notes
Text
Multi-Agent Systems: The Next Evolution in Automation
#Automaton is a discipline that has developed greatly; Multi-Agent Systems (MAS) represent a revolutionary development. By using Multi-agent systems (MAS) handling different tasks, multi-agent systems (MAS) offer quicker, smarter, and more efficient workflows. Emphasizing its part in increasing efficiency and simplifying processes, this article investigates the design, functionality, and benefits of a Multi-Agent System. Examined in great depth, key components, including the Manager Agent, Task Manager Agent, Email Agent, Calendar Agent, and Research Agent, show their possible uses in corporate automation and workflow synchronization.
Introduction
Automation has become an essential aspect of modern businesses, enhancing efficiency and reducing human effort. Traditionally, single-agent workflows dominated the automation landscape, offering limited functionality and scalability. However, the emergence of Multi-Agent Systems marks a transformative step forward. MAS consist of multiple specialized agents working in unison to handle complex workflows seamlessly. This paper examines the architecture, benefits, and practical applications of a Multi-Agent System designed to optimize tasks such as onboarding, scheduling, and research. Additionally, it explores the advantages of Multi-Agent Systems and their role in shaping Multi-Agent Systems trends in automation.
System Architecture
A Multi-Agent System is composed of distinct agents, each designed to perform specific tasks. These agents interact through a central Manager Agent, ensuring smooth operations and eliminating bottlenecks. The architecture includes the following components:
Manager Agent (The Brain): Acts as the central hub, receiving information and delegating tasks to the appropriate agents.
Task Manager Agent: Organizes tasks into actionable steps and integrates with tools like Airtable or ClickUp.
Email Agent: Automates email drafting and personalization, saving time and ensuring accuracy.
Calendar Agent: Manages scheduling and syncs with tools like Google Calendar and Calendly.
Research Agent: Processes complex queries and delivers actionable insights using APIs like SerpAPI or Perplexity API.
The accompanying diagram (refer to Figure 1) visually represents the interactions between these agents and their roles in the system.
Functional Description of Agents
Automation evolution has enhanced agents' capabilities in a Multi-Agent System. Each agent is designed for specific functions, improving efficiency, adaptability, and coordination within complex environments.
Manager Agent
The Manager Agent serves as the brain of the system, orchestrating workflows and ensuring seamless communication between agents. It prevents delays by instantly delegating tasks based on priority and relevance.
Task Manager Agent - This agent converts incoming tasks into manageable steps, streamlining workflows for faster execution. Tasks are organized into tools like Airtable or ClickUp, enabling teams to maintain a structured approach.
Email Agent - By automating email communication, the Email Agent eliminates the need for manual intervention. It drafts and personalizes emails based on input data, significantly reducing the time spent on correspondence.
Calendar Agent - The Calendar Agent handles all scheduling needs, integrating seamlessly with tools such as Google Calendar and Calendly. It ensures efficient time management and eliminates scheduling conflicts.
Research Agent - The Research Agent leverages APIs like SerpAPI and Perplexity API to process complex queries and provide detailed insights. This agent is particularly useful for data-driven decision-making.
Advantages of Multi-Agent Systems
The advantages of multi-agent systems include enhanced efficiency, scalability, and adaptability. These systems optimize task distribution, improve decision-making, and drive automation evolution, making them valuable across various industries.
Efficiency and Speed - Multi-agent systems (MAS) allow specialized agents to perform tasks simultaneously, reducing overall processing time and enhancing efficiency.
Scalability - As business needs evolve, new agents can be integrated into the system, making MAS highly adaptable to changing requirements.
Intelligence - By utilizing advanced APIs and chat models, Multi-agent systems (MAS) deliver intelligent solutions tailored to specific tasks.
Practical Applications
Client Onboarding: Automates form inputs and initial communications, ensuring a smooth onboarding process.
Workflow Coordination: Streamlines multi-step tasks across departments, enhancing collaboration.
Research and Analysis: Provides actionable insights for strategic decision-making.
Technical Tools and Integration
The described Multi-agent systems (MAS) integrates several cutting-edge tools:
Airtable and ClickUp: For task management and organization.
Google Calendar and Calendly: For scheduling and synchronization.
SerpAPI and Perplexity API: For research and data processing.
OpenAI Chat Models: To enable intelligent communication and decision-making.
Case Study: Application Scenarios
Consider a business onboarding a new client. The Manager Agent receives client details through an onboarding form and delegates tasks:
The Task Manager Agent organizes client information in Airtable.
The Email Agent drafts a welcome email.
The Calendar Agent schedules an introductory meeting.
The Research Agent provides market insights relevant to the client’s industry. This coordinated effort ensures efficiency and enhances the client experience.
Future Scope and Challenges
Expansion Opportunities
Multi-agent systems (MAS) can be expanded to include advanced capabilities such as predictive analytics, real-time monitoring, and autonomous decision-making.
Challenges
Despite the advantages of Multi-agent systems, they face challenges such as:
Integration complexities with existing systems.
Data privacy and ethical concerns.
High initial development and deployment costs.
Ethical Considerations
As multi-agent systems (MAS) handle sensitive data, ensuring compliance with privacy regulations and ethical standards is crucial.
Conclusion
#Multi-agent systems (MAS) represent a significant advancement in automation, offering unparalleled efficiency, scalability, and intelligence. By integrating specialized systems, businesses can streamline workflows, save time, and boost productivity. As the evolution continues, multi-agent systems will play a pivotal role in shaping the future of automation. With the rise of multi-agent systems trends, organizations can unlock the advantages of multi-agent systems, achieving new heights of operational excellence.
References
APIs and tools documentation: SerpAPI, Perplexity API, Airtable, Google Calendar.
Research on automation trends and Multi-Agent Systems.
Case studies on MAS applications in business environments.
0 notes
Link
看看網頁版全文 ⇨ 讓Dify使用自己管理的搜尋引擎:SearXNG / Let Dify Use My Self-Hosting Search Engine: SearXNG https://blog.pulipuli.info/2024/12/let-dify-use-my-selfhosting-search-engine-searxng.html 我在「自行架設大型語言模式應用程式:Dify」這篇講到我用SerpAPI作為Dify的搜尋引擎,但除了使用別人提供的API之外,我們也可以用SearXNG自行架設客製化的搜尋引擎,並將它跟Dify結合一起使用。 In the article "Self-Hosting a Large Language Model Application: Dify," I mentioned using SerpAPI as the search engine for Dify. However, besides using third-party APIs, we can also utilize SearXNG to set up a customized search engine and integrate it with Dify.。 ---- # SearXNG:可自訂的後設搜尋引擎 / SearXNG: A Customizable Metasearch Engine。 https://docs.searxng.org/。 SearXNG 是一個免費且開源的後設搜尋引擎(metasearch engine),它可以彙整來自超過上百種不同的搜尋服務(例如Google、Bing、DuckDuckGo等)的結果,讓使用者一次搜尋就能得到更全面的資訊。 SearXNG 實際上是從另一個開源專案 Searx 延伸出來的分支,並在其基礎上進行了改進和更新。 SearXNG 提供了一個簡潔易用的介面,讓使用者可以輕鬆地輸入關鍵字並快速得到搜尋結果。 除了基本的網頁搜尋之外,SearXNG 也支援圖片、影片、新聞、地圖等不同類別的搜尋,滿足使用者多元的搜尋需求。 使用者還可以透過設定偏好設定(preferences)來自訂搜尋引擎的行為,例如選擇想要使用的搜尋服務、設定搜尋結果的語言和地區等等,打造個人化的搜尋體驗。 https://searx.space/ 有別於其他的搜尋引擎服務,SearXNG 大多是使用者自行建置在私人伺服器的個體(instance)。 我們可以在 searx.space 找到許多公開的 SearXNG 執行個體,但更多時候,我們會需要用它架設一個私人使用的 SearXNG 執行個體,不僅讓自己完全掌控自己的搜尋資料,更可以作為Dify等其他系統的資料來源。 ---- 繼續閱讀 ⇨ 讓Dify使用自己管理的搜尋引擎:SearXNG / Let Dify Use My Self-Hosting Search Engine: SearXNG https://blog.pulipuli.info/2024/12/let-dify-use-my-selfhosting-search-engine-searxng.html
0 notes
Text
Nokolexbor: Drop-in replacement for Nokogiri. 5.2x faster at parsing HTML
https://github.com/serpapi/nokolexbor
0 notes
Text
Scrape Google Results - Google Scraping Services

In today's data-driven world, access to vast amounts of information is crucial for businesses, researchers, and developers. Google, being the world's most popular search engine, is often the go-to source for information. However, extracting data directly from Google search results can be challenging due to its restrictions and ever-evolving algorithms. This is where Google scraping services come into play.
What is Google Scraping?
Google scraping involves extracting data from Google's search engine results pages (SERPs). This can include a variety of data types, such as URLs, page titles, meta descriptions, and snippets of content. By automating the process of gathering this data, users can save time and obtain large datasets for analysis or other purposes.
Why Scrape Google?
The reasons for scraping Google are diverse and can include:
Market Research: Companies can analyze competitors' SEO strategies, monitor market trends, and gather insights into customer preferences.
SEO Analysis: Scraping Google allows SEO professionals to track keyword rankings, discover backlink opportunities, and analyze SERP features like featured snippets and knowledge panels.
Content Aggregation: Developers can aggregate news articles, blog posts, or other types of content from multiple sources for content curation or research.
Academic Research: Researchers can gather large datasets for linguistic analysis, sentiment analysis, or other academic pursuits.
Challenges in Scraping Google
Despite its potential benefits, scraping Google is not straightforward due to several challenges:
Legal and Ethical Considerations: Google’s terms of service prohibit scraping their results. Violating these terms can lead to IP bans or other penalties. It's crucial to consider the legal implications and ensure compliance with Google's policies and relevant laws.
Technical Barriers: Google employs sophisticated mechanisms to detect and block scraping bots, including IP tracking, CAPTCHA challenges, and rate limiting.
Dynamic Content: Google's SERPs are highly dynamic, with features like local packs, image carousels, and video results. Extracting data from these components can be complex.
Google Scraping Services: Solutions to the Challenges
Several services specialize in scraping Google, providing tools and infrastructure to overcome the challenges mentioned. Here are a few popular options:
1. ScraperAPI
ScraperAPI is a robust tool that handles proxy management, browser rendering, and CAPTCHA solving. It is designed to scrape even the most complex pages without being blocked. ScraperAPI supports various programming languages and provides an easy-to-use API for seamless integration into your projects.
2. Zenserp
Zenserp offers a powerful and straightforward API specifically for scraping Google search results. It supports various result types, including organic results, images, and videos. Zenserp manages proxies and CAPTCHA solving, ensuring uninterrupted scraping activities.
3. Bright Data (formerly Luminati)
Bright Data provides a vast proxy network and advanced scraping tools to extract data from Google. With its residential and mobile proxies, users can mimic genuine user behavior to bypass Google's anti-scraping measures effectively. Bright Data also offers tools for data collection and analysis.
4. Apify
Apify provides a versatile platform for web scraping and automation. It includes ready-made actors (pre-configured scrapers) for Google search results, making it easy to start scraping without extensive setup. Apify also offers custom scraping solutions for more complex needs.
5. SerpApi
SerpApi is a specialized API that allows users to scrape Google search results with ease. It supports a wide range of result types and includes features for local and international searches. SerpApi handles proxy rotation and CAPTCHA solving, ensuring high success rates in data extraction.
Best Practices for Scraping Google
To scrape Google effectively and ethically, consider the following best practices:
Respect Google's Terms of Service: Always review and adhere to Google’s terms and conditions. Avoid scraping methods that could lead to bans or legal issues.
Use Proxies and Rotate IPs: To avoid detection, use a proxy service and rotate your IP addresses regularly. This helps distribute the requests and mimics genuine user behavior.
Implement Delays and Throttling: To reduce the risk of being flagged as a bot, introduce random delays between requests and limit the number of requests per minute.
Stay Updated: Google frequently updates its SERP structure and anti-scraping measures. Keep your scraping tools and techniques up-to-date to ensure continued effectiveness.
0 notes
Link
6 notes
·
View notes
Text
Free Intel for SEO Success!

Feeling lost in the SEO jungle? Don't worry! A treasure trove of FREE resources is available to help you spy on the competition and boost your website's ranking.
These Free SERP API Providers offer valuable insights like keyword rankings and competitor strategies. While they might have limitations compared to paid tools, they're a fantastic way to get started and see the power of data-driven SEO.
So, unleash your inner SEO sleuth, leverage these free tools, and watch your website climb the search engine ladder!
#serpapi#serphouse#seo#google serp api#serpdata#serp scraping api#api#google search api#bing#google#yahoo
5 notes
·
View notes
Text
#google#serpapi#serphouse#bing#google search#google serp api#2024#artificial intelligence#tumblrposts#tumblraesthetic#tumblrs
0 notes
Text
LangChain:快速构建自然语言处理应用程序的工具
(封面图由文心一格生成���
LangChain:快速构建自然语言处理应用程序的工具
LangChain 是一个用于构建端到端语言模型应用的Python框架。它提供了一系列模块,这些模块可以组合在一起,用于创建复杂的应用程序,也可以单独用于简单的应用程序。在本篇博客中,我们将重点介绍以下几个方面:
安装和环境设置
构建语言模型应用
Prompt Templates:管理LLMs的提示
Chains:组合LLMs和Prompt Templates以进行多步骤工作流
Agents:根据用户输入动态调用Chains
Memory:为Chains和Agents添加状态
1. 安装和环境设置
首先,我们需要使用以下命令安装LangChain:pip install langchain
使用LangChain通常需要与一个或多个模型提供程序、数据存储、API等集成。在本例中,我们将使用OpenAI的API,因此我们首先需要安装他们的SDK:pip install openai
然后,在终端中设置环境变量:export OPENAI_API_KEY="..."
或者,可以从Jupyter notebook(或Python脚本)中执行此操作:import os os.environ["OPENAI_API_KEY"] = "..."
2. 构建语言模型应用
有了安装的LangChain和设置的环境变量,我们现在可以开始构建语言模型应用了。LangChain提供了许多模块,用于构建语言模型应用。这些模块可以组合在一起,用于创建复杂的应用程序,也可以单独用于简单的应用程序。
LLMs:从语言模型获取预测 LangChain的最基本的构建块是在一些输入上调用LLM。让我们通过一个简单的例子来演示如何实现这一点。为此,让我们假装我们正在构建一个服务,根据公司的产品生成公司名称。
首先,我们需要导入LLM包装器:from langchain.llms import OpenAI
然后,我们可以使用任何参数初始化包装器。在这个例子中,我们可能希望输出更随机,因此我们将使用高temperature进行初始化:llm = OpenAI(temperature=0.9)
现在我们可以在一些输入上调用它!text = "What would be a good company name for a company that makes colorful socks?" print(llm(text))
3. Prompt Templates:管理LLMs的提示
调用LLM是一个很好的第一步,但这只是个开始。通常,在应用程序中使用LLM时,不会直接将用户输入直接发送到LLM。相反,你可能会获取用户输入并构造一个提示,然后将提示发送到LLM中。 例如,在上一个例子中,我们传递的文本是硬编码的,要求为制造彩色袜子的公司取一个名称。在这个想象的服务中,我们想要做的是仅取用户描述公司所做的事情,然后使用该信息格式化提示。
使用LangChain可以轻松实现这一点!
首先定义提示模板:from langchain.prompts import PromptTemplateprompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?", )
现在我们来看看它是如何工作的!我们可以调用.format方法进行格式化。print(prompt.format(product="colorful socks"))
4. Chains:将LLMs和Prompts结合在多步骤工作流中
到目前为止,我们已经单独使用Prompt Template和LLM基元。但是,一个真正的应用程序不仅仅是一个原语,而是由它们的组合构成的。
在LangChain中,一个链由链接组成,这些链接可以是LLM、Prompt Template或其他链。
LLMChain是最核心的链类型,它由Prompt Template和LLM组成。
扩展上一个例子,我们可以构建一个LLMChain,该链接受用户输入,使用Prompt Template格式化它,然后将格式化的响应传递给LLM。from langchain.prompts import PromptTemplate from langchain.llms import OpenAIllm = OpenAI(temperature=0.9) prompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?", )
我们现在可以创建一个非常简单的链,该链将获取用户输入,使用Prompt Template对其进行格式化,然后将其发送到LLM:from langchain.chains import LLMChain chain = LLMChain(llm=llm, prompt=prompt)
现在我们可以运行该链,只需指定产品即可!chain.run("colorful socks") # -> '\n\nSocktastic!'
5. Agents:根据用户输入动态调用Chains
到目前为止,我们已经看到的链都是按照预定顺序运行的。Agents不再如此:它们使用LLM确定要采取的动作及其顺序。一个动作可以是使用工具并观察其输出,或者返回给用户。
如果正确使用Agents,它们可以非常强大。在本教程中,我们通过最简单、最高级别的API向你展示如何轻松使用代理。
为了加载代理,你应该了解以下概念:
Tool: 执行特定任务的功能。这可以是类似Google搜索、数据库查找、Python REPL、其他链的东西。工具的接口目前是期望有一个字符串作为输入,输出一个字符串的函数。 LLM: 驱动代理的语言模型。
Agent: 要使用的代理。这应该是引用支持代理类的字符串。因为本笔记本专注于最简单、最高级别的API,所以仅涵盖使用标准支持的代理。如果要实现自定义代理,请参见自定义代理的文档(即将推出)。 代理: 支持的代理及其规格的列表,请参见此处。
工具: 预定义工具及其规格的列表,请参见此处。
对于此示例,你还需要安装SerpAPI Python包。pip install google-search-results
并设置适当的环境变量。import os os.environ["SERPAPI_API_KEY"] = "..."
现在我们可以开始!from langchain.agents import load_tools from langchain.agents import initialize_agent from langchain.llms import OpenAI# 首先,让我们加载我们要用来控制代理的语言模型。 llm = OpenAI(temperature=0)# 接下来,让我们加载一些要使用的工具。请注意,`llm-math`工具使用LLM,因此我们需要将其传递给它。 tools = load_tools(["serpapi", "llm-math"], llm=llm)# 最后,让我们使用工具、语言模型和我们想要使用的代理类型来初始化一个代理。 agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)# 现在让我们测试一下! agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?") Entering new AgentExecutor chain...I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power. Action: Search Action Input: "Olivia Wilde boyfriend" Observation: Jason Sudeikis Thought: I need to find out Jason Sudeikis' age Action: Search Action Input: "Jason Sudeikis age" Observation: 47 years Thought: I need to calculate 47 raised to the 0.23 power Action: Calculator Action Input: 47^0.23 Observation: Answer: 2.4242784855673896Thought: I now know the final answer Final Answer: Jason Sudeikis, Olivia Wilde's boyfriend, is 47 years old and his age raised to the 0.23 power is 2.4242784855673896. > Finished AgentExecutor chain. "Jason Sudeikis, Olivia Wilde's boyfriend, is 47 years old and his age raised to the 0.23 power is 2.4242784855673896."
6. Memory:向链和代理添加状态
到目前为止,我们所讨论的所有链和代理都是无状态的。但通常,你可能希望链或代理具有一些“记忆”概念,以便它们可以记住有关其先前交互的信息。 这是在设计聊天机器人时最明显和简单的例子-你希望它记住以前的消息,以便它可以使用上下文来进行更好的对话。这将是一种“短期记忆”。在更复杂的一面,你可以想象链/代理随时间记住关键信息-这将是一种“长期记忆”。关于后者的更具体想法,请参见此出色的论文。
LangChain提供了几个专门为此目的创建的链。本笔记本介绍了使用其中一个链(ConversationChain)的两种不同类型的内存。
默认情况下,ConversationChain具有一种简单类型的内存,该内存记住所有先前的输入/输出并将它们添加到传递的上下文中。让我们看看如何使用此链(将verbose=True设置为我们可以看到提示)。from langchain import OpenAI, ConversationChainllm = OpenAI(temperature=0) conversation = ConversationChain(llm=llm, verbose=True)conversation.predict(input="Hi there!") > Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:Human: Hi there! AI:> Finished chain. ' Hello! How are you today?' conversation.predict(input="I'm doing well! Just having a conversation with an AI.") > Entering new chain... Prompt after formatting: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:Human: Hi there! AI: Hello! How are you today? Human: I'm doing well! Just having a conversation with an AI. AI:> Finished chain. " That's great! What would you like to talk about?"
1 note
·
View note
Link
0 notes
Text
how to scrape product data from home depot website ?

Are you the one who is very fond of shopping online? Or constantly scrolling through multiple shopping websites? If yes, you might know better about DIY furniture and home accessories. Home Depot is a highly renowned website known for having home enhancement items. You can find here all your home décor requirements under one roof. From supplies, DIY furniture, barbeque setup, garden décor, etc., everything thing is available here. When talking about the data, Home Depot is a gold mine of data. So it becomes vital to scrape the Home Depot website.
Reasons for Scraping Home Depot Data
We are aware of the fact that the market is unpredictable. If you try to monitor the market trends continuously, all critical tasks will lag. But you can’t neglect the market trends to succeed. In such a situation scraping data is the best solution as it gives massive data in a short duration. If you look to know different trends in the home décor market and how Home Depot deals with them, scrape the website using iWeb Data Scraping. We scrape the website by setting the store location to Se Austin #6542 3600 Interstate Hwy 35 S
Scrape product from Home Depot website
to know what your competitors are doing. It becomes easy to follow the same or better strategies to attract customers. By scraping this data, you will analyze how the Home Depot website deals with the customers and what marketing strategies they follow. It will help you monitor your competitors and their strategies.
At iWeb Data Scraping, we help you scrape Home Depot website with following categories:
Bath & Faucets
Building Materials
Hardware
Heating & Cooling
Kitchen & Kitchenware
Lawn & Garden
Outdoor Living
Plumbing
Tools
List of Data Fields
The following data fields are available from Home Depot Website
category_1 (i.e. top level category)
category_2 (i.e. the subcategory under the top level category)
category_3 (if applicable)
category_4 (if applicable)
category_5 (if applicable)
product_name
brand
model_number (e.g. 27013 - number at end of URL before the slash)
product_id (e.g. 202826586 - number at end of URL after the slash)
current_price (numeric/decimal - should not be a range)
time_of_scrape
product_url
product_image_url
Benefits of Using Home Depot Scraper
Competitive Pricing Data: Scraping data for prices is the best way to track your price point. It is helpful for those selling goods, homes, electronics, or other things on Home Depot. Analyzing which Home Depot prices are high or affordable will help you set your owing pricing strategy.
Customer Feedback Data: Online reviews are the main thing customers verify about trusted brands or products. Reviews and ratings contain enormous data that is beneficial for any organization. Scraping customer reviews using e-commerce data scraping services can give innumerable data on customer sentiment, giving you knowledge about demanding and non-demanding products.
Product Information: Scraping product data from Home Depot help you analyze which materials, physical attributes, dimensions, colors, etc., are more popular. In the case of furniture, the number of drawers or shelves, assembly information, style, etc., are highly prevalent.
Steps of Scraping Home Depot
First, we will create a Node.js project and introduce npm, serpapi, and dotenv to scrape product Home Depot data. Open the command line and enter.$ npm init -y
Then$ npm i serpapi dotenv
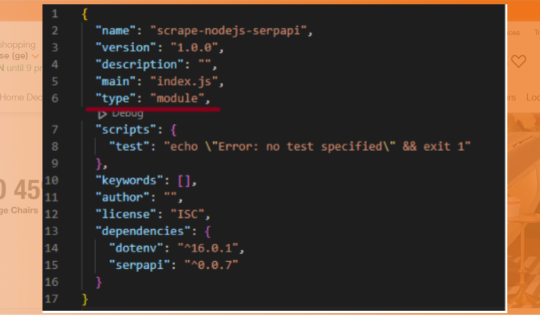
Code Explanation
First, we will import dotenv from the dotenv library, config, and getJson from the serpapi library.1 import dotenv from "dotenv"; 2 import { config, getJson } from "serpapi";
Next, we will then apply some config.1 dotenv.config(); 2 config.api_key = process.env.API_KEY; //your API key from serpapi.com
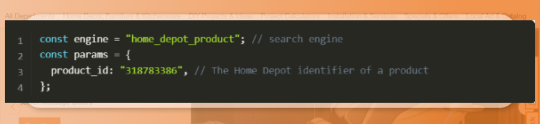

In this function, we found json with results and returned products_results from json1 const json = await getJson(engine, params); 2 return json.product_results;
Finally, we run the getResults function and print the received information using the method.1 getResults().then((result) => console.dir(result, { depth: null }));
Output
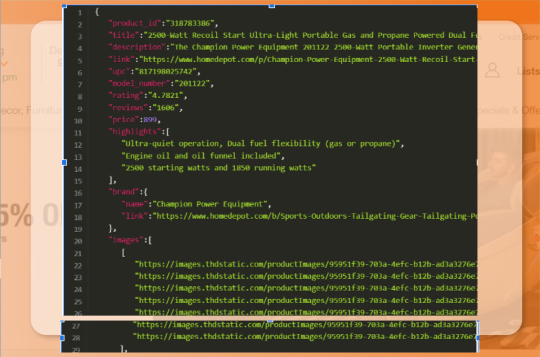
Conclusion
Home Depot is a popular retailer of household goods, construction materials, tools, and other items. Scraping the website using a Home Depot Scraper for items, pricing, or customer reviews is an excellent option to make your brand popular.
For more information, get in touch with iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping requirements.
0 notes
Link
看看網頁版全文 ⇨ 雜談:是時候該來處理一下Dify的問題了 / TALK: It's Time to Address the Issues with Dify https://blog.pulipuli.info/2024/12/talkits-time-to-address-the-issues-with-dify.html 在「自行架設大型語言模式應用程式:Dify」這篇裡面,我用Dify在筆電架設了可客製化、具備RAG的大型語言模型應用程式。 但這段期間用下來還是遭遇了很多問題。 以下就稍微列舉一下我遭遇的狀況。 ---- # 呼叫外部API的限制 / Limitions of external API calls。 https://huggingface.co/docs/api-inference/rate-limits。 我在使用的Dify並沒有內建各種資料處理的核心功能,大多重要功能都要呼叫外部API,例如文字嵌入處理使用了Hugging Face、大型語言模型推理就用到Gemini、網頁爬蟲使用了Firecrawl、搜尋引擎則是使用SerpAPI。 每種API都有一定程度的免費額度,同時也有禁止短時間內大量取用的限流設定。 其中讓我感到最困擾的是在Hugging Face使用文字嵌入處理的這個環節。 由於Dify的RAG設定採用了向量(vector)形式來搜尋,從一開始建立知識庫(knowledge base),到後面查詢這些知識庫的操作,全部都會用到文字嵌入的API。 這就讓Hugging Face API的限流成為了使用上最主要的瓶頸。 另一方面,Hugging Face API在第一次呼叫的時候,伺服器端的模型需要花一段時間才能載入,大概要等快一分鐘才能處理完成。 加上限流的限制,這讓我沒辦法真正地處理大量文件資料。 https://serpapi.com/plan。 說到免費流量的另一個限制,那就是搜尋引擎SerpApi僅提供了每個月100次的搜尋結果。 100次乍看之下似乎綽綽有餘,但這是在你很明確知道自己想要搜尋什麼的時候很有用。 但如果想要作一些探索、嘗試各種關鍵字的搜尋,那100次的數量很快就會用盡。 這也是讓我不敢在Dify用SerpApi作大量搜尋的原因。 # 檔案處理的困擾 / Unable to Process Files Quickly。 在Dify 0.6.14版本裡面,如果要分析文件檔案裡面的內容,做法是在知識庫裡匯入檔案,然後再進行切分(chunk)、建立索引等步驟。 但如果每次都要額外建立知識庫的話,看起來並不是合理的做法。 https://docs.dify.ai/guides/workflow/node/doc-extractor。 ---- 繼續閱讀 ⇨ 雜談:是時候該來處理一下Dify的問題了 / TALK: It's Time to Address the Issues with Dify https://blog.pulipuli.info/2024/12/talkits-time-to-address-the-issues-with-dify.html
0 notes