#SI506F18
Text
SI 506: Programming I (Python)
One of my proudest assignments from this course, being able to code the M.

Please click on “Keep reading” to view the code.

0 notes
Text
SI 506: Programming I (Python)
Here is my Final Project Code to create a Rest API with New York Times and the Guardian searching for Rugby articles and creating a CSV file.
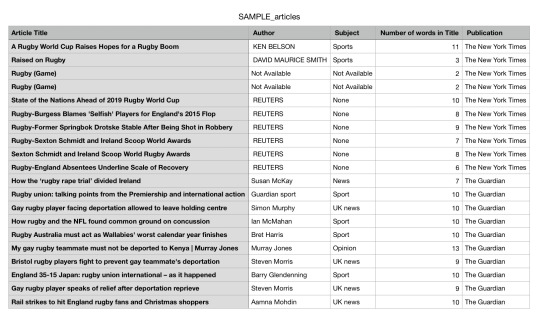
To view my code on creating the CSV file above click on ‘Keep reading’
#Angela Chih
#SI 506_Final Project
import json
import requests
#Use that investigation to define a class `NYTArticle` and a class `GuardianArticle` that fulfill requirements, and that you can use as tools to complete the rest of the project.
#Access data from each source with data about articles, and create a list of instances of `NYTArticle` and a list of instances of `GuardianArticle`.
CACHE_FNAME = "cache_file_name.json"
# if I already have cached data, I want to load that data into a python dictionary
try:
cache_file = open(CACHE_FNAME, 'r')
cache_contents = cache_file.read()
cache_diction = json.loads(cache_contents)
cache_file.close()
# if I don't have cached data, I will create an empty dictionary to save data later
except:
cache_diction = {}
def params_unique_combination(baseurl, params_d, private_keys=["api_key"]):
alphabetized_keys = sorted(params_d.keys())
res = []
for k in alphabetized_keys:
if k not in private_keys:
res.append("{}-{}".format(k, params_d[k]))
return baseurl + "_".join(res)
def get_from_NYT(a):
# put together base url and parameters
baseurl = "https://api.nytimes.com/svc/search/v2/articlesearch.json"
params_diction = {}
params_diction["api_key"] = "TakenOffDueToRestrictions"
params_diction["q"] = a
unique_ident = params_unique_combination(baseurl,params_diction)
# see if the url identifier is already in cache dictionary
if unique_ident in cache_diction:
# if so, get data from cache dictionary and return
return cache_diction[unique_ident]
# if not, make a new API call using the requests module
else:
resp = requests.get(baseurl, params_diction)
# Or as:
# resp = requests.get(unique_ident)
# save the data in the cache dictionary, using unique url identifier
## as a key and the response data as value
cache_diction[unique_ident] = json.loads(resp.text)
# convert the cache dictionary to a JSON string
dumped_json_cache = json.dumps(cache_diction)
# save the JSON string in the cache file
fw = open(CACHE_FNAME,"w")
fw.write(dumped_json_cache)
fw.close() # Close the open file
# return the data
return cache_diction[unique_ident]
def get_from_Guard(a):
baseurl = "https://content.guardianapis.com/search"
params_diction = {}
params_diction["q"] = a
params_diction["show-tags"]= "contributor"
params_diction["api-key"] = "TakenOffDueToRestrictions"
unique_ident = params_unique_combination(baseurl,params_diction)
# see if the url identifier is already in cache dictionary
if unique_ident in cache_diction:
# if so, get data from cache dictionary and return
return cache_diction[unique_ident]
# if not, make a new API call using the requests module
else:
resp = requests.get(baseurl, params_diction)
# Or as:
# resp = requests.get(unique_ident)
# save the data in the cache dictionary, using unique url identifier
## as a key and the response data as value
cache_diction[unique_ident] = json.loads(resp.text)
# convert the cache dictionary to a JSON string
dumped_json_cache = json.dumps(cache_diction)
# save the JSON string in the cache file
fw = open(CACHE_FNAME,"w")
fw.write(dumped_json_cache)
fw.close() # Close the open file
# return the data
return cache_diction[unique_ident]
cache_NYT = get_from_NYT("Rugby")
cache_Guard = get_from_Guard("Rugby")
###Citation: Retrieved from Week 11 Discussion problem set
class NYT(object):
def __init__(self, times_diction):
self.title = times_diction["headline"]["main"].replace(",","")
try:
self.author = times_diction["byline"]["original"].replace("By","")
except:
self.author = "Not Available"
try:
self.subject = times_diction["news_desk"]
except:
self.subject = "Not Available"
self.publication = "The New York Times"
def words_title(self):
total_words = 0
title = self.title.split(' ')
for word in title:
total_words += 1
return total_words
def __str__(self):
return "{},{},{},{},{}".format(self.title, self.author, self.subject, self.words_title(), self.publication)
class Guard(object):
def __init__(self, guardian_diction):
self.title = guardian_diction["webTitle"].replace("\r\n","")
self.author = guardian_diction["tags"][0]["webTitle"]
self.subject = guardian_diction["sectionName"]
self.publication = "The Guardian"
def words_title(self):
total_words = 0
title = self.title.split(' ')
for word in title:
total_words += 1
return total_words
def __str__(self):
return "{},{},{},{},{}".format(self.title, self.author, self.subject, self.words_title(), self.publication)
list_NYT = []
for data in cache_NYT["response"]["docs"]:
list_NYT.append(NYT(data))
#print(str(list_NYT[0]))
list_Guard = []
for data in cache_Guard["response"]["results"]:
list_Guard.append(Guard(data))
#print(str(list_Guard[0]))
finalprj = open("articles.csv","w")
finalprj.write("Article Title, Author, Subject, Number of words in Title, Publication\n")
for data in list_NYT:
data_string = str(data)
finalprj.write(data_string)
finalprj.write('\n')
for data in list_Guard:
data_string = str(data)
finalprj.write(data_string)
finalprj.write('\n')
finalprj.close()
###Citation: Retrieved from SI506F18_ps11.py -- problem set #11
0 notes
Last Seen Blogs

dirtymvrley
Natives Worldwide
• • •

kannibaleherzen
~ weekend at mort's ~

jaygaeze
Jay Gaeze

uranomannia
AH, POOR BIRD

candycatstuffs
Buh