#SQL Server parallelism
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
Understanding Parallelism Wait Statistics in SQL Server
Are you struggling with performance issues in your SQL Server? High wait statistics of the parallelism type might be the culprit. This article will demystify what parallelism wait statistics are, when they indicate a problem, and how you can address these issues to ensure your SQL Server runs smoothly. What Are Parallelism Wait Statistics? Parallelism in SQL Server refers to the ability of the…

View On WordPress
#high wait statistics#parallelism issues#SQL Server parallelism#SQL Server performance#SQL Server troubleshooting
0 notes
Text
Full Stack Development Trends in 2025: What to Expect
In the rapidly evolving tech landscape, full stack development continues to be a crucial area for innovation and career growth. As we step into 2025, the demand for skilled professionals who can handle both front-end and back-end technologies is only expected to surge. From artificial intelligence integration to serverless architectures, this field is experiencing some major transformations.
Whether you're a student, a working professional, or someone planning to switch careers, understanding these full stack development trends is essential. And if you're planning to learn full stack development in Pune, one of India’s tech hubs, staying updated with these trends will give you a competitive edge.
Why Full Stack Development Matters More Than Ever
Modern businesses seek agility and efficiency in software development. Full stack developers can handle various layers of a web or app project—from UI/UX to database management and server logic. This ability to operate across multiple domains makes full stack professionals highly valuable.
Here’s what’s changing in 2025 and why it matters:
Key Full Stack Development Trends to Watch in 2025
1. AI and Machine Learning-Driven Development
Integration of AI for predictive user experiences
Chatbots and intelligent systems as part of app architecture
Developers using AI tools to assist with debugging, code generation, and optimization
With these technologies becoming more accessible, full stack developers are expected to understand how AI models work and how to implement them efficiently.
2. Serverless Architectures on the Rise
Reduction in infrastructure management tasks
Focus shifts to writing quality code without worrying about deployment
Increased use of platforms like AWS Lambda, Azure Functions, and Google Cloud Functions
Serverless frameworks will empower developers to build scalable applications faster, and those enrolled in a Java programming course with placement are already being introduced to these platforms as part of their curriculum.
3. Micro Frontends and Component-Based Architectures
Projects are being split into smaller, manageable front-end components
Encourages reuse and parallel development
Helps large teams work on different parts of an application efficiently
This trend is changing the way teams collaborate, especially in agile environments.
4. Progressive Web Applications (PWAs) Becoming the Norm
PWAs offer app-like experiences in browsers
Offline support, push notifications, and fast load times
Ideal for startups and enterprises alike
A full stack developer in 2025 must be proficient in building PWAs using modern tools like React, Angular, and Vue.js.
5. API-First Development
Focus on creating flexible, scalable backend systems
REST and GraphQL APIs powering multiple frontends (web, mobile, IoT)
Encourages modular architecture
Many courses teaching full stack development in Pune are already emphasizing this model to prepare students for real-world industry demands.
6. Focus on Security and Compliance
Developers now need to consider security during initial coding phases
Emphasis on secure coding practices, data privacy, and GDPR compliance
DevSecOps becoming a standard practice
7. DevOps and Automation
CI/CD pipelines becoming essential in full stack workflows
Containerization using Docker and Kubernetes is standard
Developers expected to collaborate closely with DevOps engineers
8. Real-Time Applications with WebSockets and Beyond
Messaging apps, live dashboards, and real-time collaboration tools are in demand
Tools like Socket.IO and WebRTC are becoming essential in the developer toolkit
Skills That Will Define the Future Full Stack Developer
To thrive in 2025, here are the skills you need to master:
Strong foundation in JavaScript, HTML, CSS
Backend frameworks like Node.js, Django, or Spring Boot
Proficiency in databases – both SQL and NoSQL
Familiarity with Java programming, especially if pursuing a Java programming course with placement
Understanding of cloud platforms like AWS, GCP, or Azure
Working knowledge of version control (Git), CI/CD, and Docker
Why Pune is the Ideal Place to Start Your Full Stack Journey
If you're serious about making a career in this domain, it's a smart move to learn full stack development in Pune. Here's why:
Pune is home to hundreds of tech companies and startups, offering abundant internship and placement opportunities
Numerous training institutes offer industry-aligned courses, often bundled with certifications and placement assistance
Exposure to real-world projects through bootcamps, hackathons, and meetups
Several programs in Pune combine full stack development training with a Java programming course with placement, ensuring you gain both frontend/backend expertise and a strong OOP (Object-Oriented Programming) base.
Final Thoughts
The field of full stack development is transforming, and 2025 is expected to bring more intelligent, scalable, and modular application ecosystems. Whether you’re planning to switch careers or enhance your current skill set, staying updated with the latest full stack development trends will be essential to succeed.
Pune’s tech ecosystem makes it an excellent place to start. Enroll in a trusted institute that offers you a hands-on experience and includes in-demand topics like Java, serverless computing, DevOps, and microservices.
To sum up:
2025 Full Stack Development Key Highlights:
AI integration and smart development tools
Serverless and micro-frontend architectures
Real-time and API-first applications
Greater focus on security and cloud-native environments
Now is the time to upskill, get certified, and stay ahead of the curve. Whether you learn full stack development in Pune or pursue a Java programming course with placement, the tech world of 2025 is full of opportunities for those prepared to seize them.
0 notes
Text
How to resolve CXPACKET wait in SQL Server
CXPACKET:o Happens when a parallel query runs and some threads are slower than others.o This wait type is common in highly parallel environments. How to resolve CXPACKET wait in SQL Server Adjust the MAXDOP Setting:o The MAXDOP (Maximum Degree of Parallelism) setting controls the number ofprocessors used for parallel query execution. Reducing the MAXDOP value can helpreduce CXPACKET waits.o You…
0 notes
Text
Understanding Data Movement in Azure Data Factory: Key Concepts and Best Practices
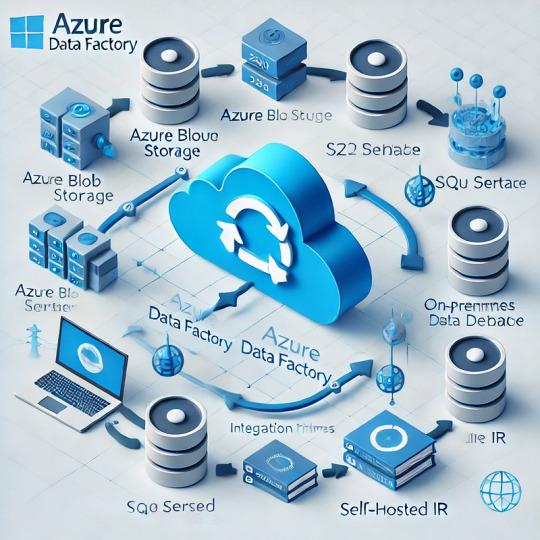
Introduction
Azure Data Factory (ADF) is a fully managed, cloud-based data integration service that enables organizations to move and transform data efficiently. Understanding how data movement works in ADF is crucial for building optimized, secure, and cost-effective data pipelines.
In this blog, we will explore: ✔ Core concepts of data movement in ADF ✔ Data flow types (ETL vs. ELT, batch vs. real-time) ✔ Best practices for performance, security, and cost efficiency ✔ Common pitfalls and how to avoid them
1. Key Concepts of Data Movement in Azure Data Factory
1.1 Data Movement Overview
ADF moves data between various sources and destinations, such as on-premises databases, cloud storage, SaaS applications, and big data platforms. The service relies on integration runtimes (IRs) to facilitate this movement.
1.2 Integration Runtimes (IRs) in Data Movement
ADF supports three types of integration runtimes:
Azure Integration Runtime (for cloud-based data movement)
Self-hosted Integration Runtime (for on-premises and hybrid data movement)
SSIS Integration Runtime (for lifting and shifting SSIS packages to Azure)
Choosing the right IR is critical for performance, security, and connectivity.
1.3 Data Transfer Mechanisms
ADF primarily uses Copy Activity for data movement, leveraging different connectors and optimizations:
Binary Copy (for direct file transfers)
Delimited Text & JSON (for structured data)
Table-based Movement (for databases like SQL Server, Snowflake, etc.)
2. Data Flow Types in ADF
2.1 ETL vs. ELT Approach
ETL (Extract, Transform, Load): Data is extracted, transformed in a staging area, then loaded into the target system.
ELT (Extract, Load, Transform): Data is extracted, loaded into the target system first, then transformed in-place.
ADF supports both ETL and ELT, but ELT is more scalable for large datasets when combined with services like Azure Synapse Analytics.
2.2 Batch vs. Real-Time Data Movement
Batch Processing: Scheduled or triggered executions of data movement (e.g., nightly ETL jobs).
Real-Time Streaming: Continuous data movement (e.g., IoT, event-driven architectures).
ADF primarily supports batch processing, but for real-time processing, it integrates with Azure Stream Analytics or Event Hub.
3. Best Practices for Data Movement in ADF
3.1 Performance Optimization
✅ Optimize Data Partitioning — Use parallelism and partitioning in Copy Activity to speed up large transfers. ✅ Choose the Right Integration Runtime — Use self-hosted IR for on-prem data and Azure IR for cloud-native sources. ✅ Enable Compression — Compress data during transfer to reduce latency and costs. ✅ Use Staging for Large Data — Store intermediate results in Azure Blob or ADLS Gen2 for faster processing.
3.2 Security Best Practices
🔒 Use Managed Identities & Service Principals — Avoid using credentials in linked services. 🔒 Encrypt Data in Transit & at Rest — Use TLS for transfers and Azure Key Vault for secrets. 🔒 Restrict Network Access — Use Private Endpoints and VNet Integration to prevent data exposure.
3.3 Cost Optimization
💰 Monitor & Optimize Data Transfers — Use Azure Monitor to track pipeline costs and adjust accordingly. 💰 Leverage Data Flow Debugging — Reduce unnecessary runs by debugging pipelines before full execution. 💰 Use Incremental Data Loads — Avoid full data reloads by moving only changed records.
4. Common Pitfalls & How to Avoid Them
❌ Overusing Copy Activity without Parallelism — Always enable parallel copy for large datasets. ❌ Ignoring Data Skew in Partitioning — Ensure even data distribution when using partitioned copy. ❌ Not Handling Failures with Retry Logic — Use error handling mechanisms in ADF for automatic retries. ❌ Lack of Logging & Monitoring — Enable Activity Runs, Alerts, and Diagnostics Logs to track performance.
Conclusion
Data movement in Azure Data Factory is a key component of modern data engineering, enabling seamless integration between cloud, on-premises, and hybrid environments. By understanding the core concepts, data flow types, and best practices, you can design efficient, secure, and cost-effective pipelines.
Want to dive deeper into advanced ADF techniques? Stay tuned for upcoming blogs on metadata-driven pipelines, ADF REST APIs, and integrating ADF with Azure Synapse Analytics!
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Automated Testing in the Cloud: Ensuring Quality at Speed
In the fast-paced world of software development, ensuring application quality without compromising release speed is critical. Automated testing in the cloud plays a vital role in achieving this by streamlining testing processes, improving accuracy, and accelerating feedback loops.
By integrating automated testing into cloud environments, organizations can deliver high-performing applications faster while reducing manual effort and human error. This blog explores the key benefits, strategies, and tools for implementing cloud-based automated testing to achieve quality at speed.
Why Automated Testing is Essential in the Cloud
Traditional testing methods often struggle to keep up with modern cloud environments due to:
❌ Frequent Code Changes: Continuous updates increase testing demands. ❌ Scalability Challenges: Testing across multiple environments is complex. ❌ Resource Constraints: Manual testing slows down release cycles.
By leveraging cloud-based automated testing, teams can test faster, identify issues earlier, and ensure applications run reliably in dynamic cloud environments.
Key Benefits of Automated Testing in the Cloud
✅ Faster Release Cycles: Automated tests quickly validate code changes. ✅ Improved Accuracy: Automated scripts reduce the risk of human error. ✅ Scalable Testing Environments: Easily scale tests across multiple devices, browsers, and platforms. ✅ Cost Efficiency: Pay only for resources used during testing. ✅ Enhanced Collaboration: Cloud-based platforms enable global teams to collaborate seamlessly.
Types of Automated Tests for Cloud Applications
🔹 1. Unit Testing
Validates individual components or functions to ensure they perform as expected. ✅ Ideal for testing logic, algorithms, and isolated code units. ✅ Provides fast feedback to developers.
🔧 Tools: JUnit, NUnit, PyTest
🔹 2. Integration Testing
Ensures multiple components or services work together correctly. ✅ Ideal for testing APIs, database interactions, and microservices. ✅ Detects issues in service-to-service communication.
🔧 Tools: Postman, REST Assured, Karate
🔹 3. Functional Testing
Validates application features against defined business requirements. ✅ Ensures UI elements, workflows, and key features behave as expected. ✅ Ideal for cloud-based SaaS platforms and web applications.
🔧 Tools: Selenium, Cypress, Playwright
🔹 4. Performance Testing
Simulates user traffic to measure application speed, scalability, and stability. ✅ Identifies performance bottlenecks and capacity limits. ✅ Ensures applications remain responsive under load.
🔧 Tools: JMeter, k6, Gatling
🔹 5. Security Testing
Ensures cloud applications are resilient to security threats. ✅ Identifies vulnerabilities like SQL injection, XSS, and data breaches. ✅ Ensures compliance with security standards.
🔧 Tools: OWASP ZAP, Burp Suite, Astra
🔹 6. Regression Testing
Verifies that new code changes don’t break existing functionality. ✅ Critical for continuous integration pipelines. ✅ Ensures stability in frequent cloud deployments.
🔧 Tools: TestNG, Selenium, Robot Framework
Best Practices for Implementing Automated Cloud Testing
🔹 1. Integrate Testing into CI/CD Pipelines
Embedding automated tests directly into your CI/CD pipeline ensures continuous validation of new code.
✅ Trigger automated tests on every code commit or merge. ✅ Use parallel testing to run multiple tests simultaneously for faster results. ✅ Implement fail-fast strategies to identify issues early.
🔧 Tools: Jenkins, GitLab CI/CD, Azure DevOps
🔹 2. Use Scalable Test Environments
Leverage cloud platforms to create dynamic and scalable test environments.
✅ Automatically spin up cloud-based test servers as needed. ✅ Simulate real-world user environments across browsers, devices, and networks. ✅ Scale test environments based on project size or workload.
🔧 Tools: AWS Device Farm, BrowserStack, Sauce Labs
🔹 3. Implement Test Data Management
Effective data management ensures test accuracy and consistency.
✅ Use data masking and anonymization for sensitive data. ✅ Generate synthetic data to test various scenarios. ✅ Manage dynamic test data across environments.
🔧 Tools: TDM, Datprof, GenRocket
🔹 4. Automate Infrastructure Setup with IaC
Infrastructure as Code (IaC) ensures test environments are consistent and reproducible.
✅ Use IaC tools to define testing infrastructure as code. ✅ Automate environment setup to eliminate manual provisioning errors. ✅ Easily create, update, or destroy test environments as needed.
🔧 Tools: Terraform, AWS CloudFormation, Azure Resource Manager
🔹 5. Leverage Service Virtualization for Reliable Testing
Service virtualization enables testing of application components even when dependent services are unavailable.
✅ Simulate APIs, databases, and third-party integrations. ✅ Test applications in isolated environments without dependencies.
🔧 Tools: WireMock, Mountebank, Hoverfly
🔹 6. Monitor Test Performance and Results
Monitoring provides insights into test coverage, success rates, and performance bottlenecks.
✅ Use dashboards to track key metrics. ✅ Set alerts for test failures or performance anomalies. ✅ Continuously analyze test trends for process improvement.
🔧 Tools: Grafana, Datadog, TestRail
Salzen Cloud’s Approach to Automated Cloud Testing
At Salzen Cloud, we help businesses adopt scalable and effective automated testing frameworks. Our solutions include:
✔️ Implementing comprehensive CI/CD pipelines with integrated testing. ✔️ Designing scalable test environments to support complex cloud infrastructures. ✔️ Leveraging advanced tools to ensure application performance, security, and reliability.
Conclusion
Automated testing in the cloud accelerates development cycles while ensuring software quality. By combining scalable test environments, CI/CD integration, and comprehensive test coverage, businesses can achieve faster releases and improved reliability.
With Salzen Cloud, you can implement cutting-edge testing strategies to deliver high-performing cloud applications with confidence.
Need guidance on building a robust cloud testing strategy? Let's connect! 🚀
0 notes
Text
What are the top Python libraries for data science in 2025? Get Best Data Analyst Certification Course by SLA Consultants India
Python's extensive ecosystem of libraries has been instrumental in advancing data science, offering tools for data manipulation, visualization, machine learning, and more. As of 2025, several Python libraries have emerged as top choices for data scientists:
1. NumPy
NumPy remains foundational for numerical computations in Python. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on them. Its efficiency and performance make it indispensable for data analysis tasks. Data Analyst Course in Delhi
2. Pandas
Pandas is essential for data manipulation and analysis. It offers data structures like DataFrames, which allow for efficient handling and analysis of structured data. With tools for reading and writing data between in-memory structures and various formats, Pandas simplifies data preprocessing and cleaning.
3. Matplotlib
For data visualization, Matplotlib is a versatile library that enables the creation of static, animated, and interactive plots. It supports various plot types, including line plots, scatter plots, and histograms, making it a staple for presenting data insights.
4. Seaborn
Built on top of Matplotlib, Seaborn provides a high-level interface for drawing attractive statistical graphics. It simplifies complex visualization tasks and integrates seamlessly with Pandas data structures, enhancing the aesthetic appeal and interpretability of plots. Data Analyst Training Course in Delhi
5. Plotly
Plotly is renowned for creating interactive and web-ready plots. It offers a wide range of chart types, including 3D plots and contour plots, and is particularly useful for dashboards and interactive data applications.
6. Scikit-Learn
Scikit-Learn is a comprehensive library for machine learning, providing simple and efficient tools for data mining and data analysis. It supports various machine learning tasks, including classification, regression, clustering, and dimensionality reduction, and is built on NumPy, SciPy, and Matplotlib. Data Analyst Training Institute in Delhi
7. Dask
Dask is a parallel computing library that scales Python code from multi-core local machines to large distributed clusters. It integrates seamlessly with libraries like NumPy and Pandas, enabling scalable and efficient computation on large datasets.
8. PyMC
PyMC is a probabilistic programming library for Bayesian statistical modeling and probabilistic machine learning. It utilizes advanced Markov chain Monte Carlo and variational fitting algorithms, making it suitable for complex statistical modeling.
9. TensorFlow and PyTorch
Both TensorFlow and PyTorch are leading libraries for deep learning. They offer robust tools for building and training neural networks and have extensive communities supporting their development and application in various domains, from image recognition to natural language processing. Online Data Analyst Course in Delhi
10. NLTK and SpaCy
For natural language processing (NLP), NLTK and SpaCy are prominent libraries. NLTK provides a wide range of tools for text processing, while SpaCy is designed for industrial-strength NLP, offering fast and efficient tools for tasks like tokenization, parsing, and entity recognition.
These libraries collectively empower data scientists to efficiently process, analyze, and visualize data, facilitating the extraction of meaningful insights and the development of predictive models.
Data Analyst Training Course Modules Module 1 - Basic and Advanced Excel With Dashboard and Excel Analytics Module 2 - VBA / Macros - Automation Reporting, User Form and Dashboard Module 3 - SQL and MS Access - Data Manipulation, Queries, Scripts and Server Connection - MIS and Data Analytics Module 4 - MS Power BI | Tableau Both BI & Data Visualization Module 5 - Free Python Data Science | Alteryx/ R Programing Module 6 - Python Data Science and Machine Learning - 100% Free in Offer - by IIT/NIT Alumni Trainer
Regarding the "Best Data Analyst Certification Course by SLA Consultants India," I couldn't find specific information on such a course in the provided search results. For the most accurate and up-to-date details, I recommend visiting SLA Consultants India's official website or contacting them directly to inquire about their data analyst certification offerings. For more details Call: +91-8700575874 or Email: [email protected]
0 notes
Text
Informatica Training in Chennai | Informatica Cloud IDMC
The Role of the Secure Agent in Informatica Cloud
Introduction
Informatica Cloud is a powerful data integration platform that enables businesses to connect, transform, and manage data across cloud and on-premises environments. One of its core components is the Secure Agent, which plays a crucial role in facilitating secure communication between Informatica Cloud and an organization's local network. This article explores the role, functionality, and benefits of the Secure Agent in Informatica Cloud.

What is the Secure Agent?
The Secure Agent is a lightweight, self-upgrading runtime engine installed on a customer’s local network or cloud infrastructure. It acts as a bridge between on-premises applications, databases, and Informatica Intelligent Cloud Services (IICS). By using the Secure Agent, businesses can process, integrate, and synchronize data between cloud and on-premises sources securely. Informatica Cloud IDMC Training
Key Roles and Responsibilities of the Secure Agent
1. Secure Data Movement
The Secure Agent ensures safe and encrypted data transmission between on-premises systems and Informatica Cloud. It eliminates the need to expose sensitive business data directly to the internet by handling all connections securely behind a company’s firewall.
2. Data Integration and Processing
A primary function of the Secure Agent is executing ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes. It extracts data from source systems, applies necessary transformations, and loads it into the target system. By running these processes locally, organizations can optimize performance while maintaining data security.
3. Job Execution and Management
The Secure Agent is responsible for executing data integration tasks, mapping configurations, and workflow automation. It supports various Informatica Cloud services, including: Informatica IICS Training
Data Integration
Application Integration
API Management
Data Quality
Master Data Management (MDM)
It efficiently manages job execution, ensuring data pipelines operate smoothly.
4. Connectivity with On-Premises and Cloud Sources
Organizations often have hybrid environments where some data resides in on-premises databases while others exist in cloud platforms. The Secure Agent enables seamless connectivity to databases like Oracle, SQL Server, MySQL, and applications such as SAP, Salesforce, Workday, and more.
5. Security and Compliance
Security is a major concern for enterprises handling sensitive data. The Secure Agent ensures that data remains within the organization’s control by encrypting data at rest and in transit. It complies with industry standards like GDPR, HIPAA, and SOC 2 to maintain robust data security.
Benefits of Using the Secure Agent: Informatica IDMC Training
1. Enhanced Security
Prevents data exposure to the internet
Uses encryption and secure authentication mechanisms
Runs behind the firewall, ensuring compliance with security policies
2. Performance Optimization
Enables on-premises data processing, reducing latency
Supports parallel execution of tasks for better efficiency
Handles large volumes of data with optimized performance
3. Scalability and Reliability
Auto-upgrades to the latest versions without manual intervention
Distributes workloads efficiently, ensuring high availability
Handles failures through automatic retries and error logging
4. Simplified Management
Intuitive UI for monitoring and managing tasks
Seamless integration with Informatica Cloud for centralized administration
No need for complex firewall configurations or VPN setups
How to Install and Configure the Secure Agent
Setting up the Secure Agent is straightforward: Informatica Cloud Training
Download the Secure Agent from the Informatica Cloud UI.
Install the agent on a local server or cloud instance.
Authenticate the agent using the provided credentials.
Configure connectivity to required on-premises or cloud applications.
Verify the installation and start running data integration tasks.
Conclusion
The Secure Agent in Informatica Cloud is a crucial component for organizations looking to integrate and process data securely across hybrid environments. It ensures seamless connectivity, secure data movement, optimized performance, and compliance with industry standards. By leveraging the Secure Agent, businesses can achieve robust data integration without compromising security or performance, making it an essential tool in the modern data landscape.
For More Information about Informatica Cloud Online Training
Contact Call/WhatsApp: +91 7032290546
Visit: https://www.visualpath.in/informatica-cloud-training-in-hyderabad.html
#Informatica Training in Hyderabad#IICS Training in Hyderabad#IICS Online Training#Informatica Cloud Training#Informatica Cloud Online Training#Informatica IICS Training#Informatica IDMC Training#Informatica Training in Ameerpet#Informatica Online Training in Hyderabad#Informatica Training in Bangalore#Informatica Training in Chennai#Informatica Training in India#Informatica Cloud IDMC Training
0 notes
Text
Best Practices for Optimizing ETL Performance on Oracle Cloud

Extract, Transform, Load (ETL) processes are crucial for managing and integrating data in enterprise environments. As businesses increasingly migrate to the cloud, optimizing Oracle Cloud ETL workflows is essential for improving efficiency, reducing costs, and ensuring data accuracy. Oracle Cloud provides a robust ETL ecosystem with tools like Oracle Data Integrator (ODI), Oracle Cloud Infrastructure Data Integration (OCI DI), and Oracle GoldenGate, offering powerful solutions for handling large-scale data integration.
In this article, we’ll explore best practices for optimizing ETL performance on Oracle Cloud to ensure faster data processing, lower latency, and improved scalability.
1. Choose the Right Oracle Cloud ETL Tool
Oracle Cloud offers multiple ETL solutions, each suited for different business needs. Selecting the right tool can significantly impact performance and efficiency.
Oracle Data Integrator (ODI): Best for traditional ETL workloads that require batch processing and complex transformations.
Oracle Cloud Infrastructure Data Integration (OCI DI): A serverless ETL solution ideal for low-code/no-code integrations and real-time data movement.
Oracle GoldenGate: Recommended for real-time data replication and streaming ETL across multiple cloud and on-premise databases.
Tip: If your ETL workload involves large batch processing, ODI is ideal. If you need real-time data replication, GoldenGate is a better choice.
2. Optimize Data Extraction for Faster Processing
Efficient data extraction is the first step in ETL performance optimization. Poor extraction methods can slow down the entire process.
Best Practices for Data Extraction:
Use Incremental Data Extraction: Instead of loading the entire dataset, extract only new or changed data to reduce processing time.
Leverage Parallel Processing: Use multi-threading to extract data from multiple sources simultaneously.
Optimize Source Queries: Use indexed tables, partitioning, and query optimization to speed up data retrieval from databases.
Tip: In Oracle Autonomous Database, use Partition Pruning to retrieve only relevant data, reducing query execution time.
3. Improve Data Transformation Efficiency
The transformation step is where most of the performance bottlenecks occur, especially with complex business logic.
Best Practices for Data Transformation:
Push Transformations to the Database: Oracle Cloud ETL tools allow ELT (Extract, Load, Transform) processing, where transformations run within Oracle Autonomous Database instead of external ETL servers.
Use Bulk Operations Instead of Row-by-Row Processing: Batch processing is faster and reduces database overhead.
Leverage Oracle Cloud Compute Power: Scale up Oracle Cloud Compute Instances to handle heavy transformations efficiently.
Tip: Oracle Data Integrator (ODI) uses Knowledge Modules to execute transformations directly within the database, improving efficiency.
4. Optimize Data Loading for High-Speed Performance
Loading large datasets into Oracle Cloud databases requires optimized strategies to prevent slowdowns and failures.
Best Practices for Data Loading:
Use Direct Path Load: In Oracle Cloud, SQL*Loader Direct Path Load speeds up bulk data insertion.
Enable Parallel Data Loading: Divide large datasets into smaller partitions and load them in parallel.
Compress Data Before Loading: Reducing file size minimizes data transfer time, improving ETL performance.
Monitor and Tune Network Latency: Ensure low-latency cloud storage and database connectivity for fast data transfer.
Tip: Oracle GoldenGate supports real-time, low-latency data replication, ideal for high-speed data loading.
5. Leverage Oracle Cloud Storage and Compute Resources
Oracle Cloud offers high-performance storage and compute services that enhance ETL processing speeds.
Best Practices for Cloud Resource Optimization:
Use Oracle Cloud Object Storage: Store large files efficiently and process data directly from cloud storage instead of moving it.
Auto-Scale Compute Instances: Oracle Cloud’s Autoscaling feature ensures compute resources adjust based on workload demand.
Enable Oracle Exadata for High-Performance Workloads: If handling petabyte-scale data, Oracle Exadata Cloud Service offers extreme performance for ETL.
Tip: Oracle Autonomous Database automates indexing, partitioning, and caching, reducing ETL overhead.
6. Implement Monitoring and Performance Tuning
Regular monitoring and performance tuning ensure smooth ETL operations without unexpected failures.
Best Practices for ETL Monitoring:
Use Oracle Cloud Monitoring Services: Track ETL execution time, CPU usage, and query performance.
Enable Logging and Alerts: Set up real-time alerts in OCI Logging and Performance Hub to detect failures early.
Optimize Execution Plans: Use EXPLAIN PLAN and SQL Tuning Advisor to identify and improve slow SQL queries.
Tip: Oracle Cloud Autonomous Database provides AI-driven performance tuning, reducing manual optimization efforts.
7. Secure Your ETL Pipelines
Data security is crucial in Oracle Cloud ETL to protect sensitive information and comply with industry regulations.
Best Practices for ETL Security:
Use Encryption: Enable TDE (Transparent Data Encryption) for securing data at rest and SSL/TLS encryption for in-transit data.
Implement Role-Based Access Control (RBAC): Restrict access to ETL jobs, logs, and sensitive data based on user roles.
Enable Data Masking for Compliance: Use Oracle Data Safe to anonymize sensitive data in non-production environments.
Tip: Oracle Cloud automatically encrypts storage and databases, ensuring secure data handling in ETL workflows.
Final Thoughts: Optimize Oracle Cloud ETL for Maximum Efficiency
Optimizing Oracle Cloud ETL is essential for fast, cost-effective, and reliable data integration. By following these best practices, businesses can enhance performance, reduce processing time, and ensure seamless data workflows in Oracle Cloud.
✔️ Choose the right Oracle ETL tool for batch or real-time processing. ✔️ Optimize extraction, transformation, and loading using parallelism and direct path loading. ✔️ Leverage Oracle Cloud’s compute, storage, and database features for efficiency. ✔️ Implement performance monitoring and security best practices to ensure smooth ETL operations.
By adopting these strategies, businesses can fully utilize the power of Oracle Cloud ETL to accelerate data-driven decision-making and innovation.
0 notes
Text
GPU Hosting Server Windows By CloudMinnister Technologies
Cloudminister Technologies GPU Hosting Server for Windows
Businesses and developers require more than just conventional hosting solutions in the data-driven world of today. Complex tasks that require high-performance computing capabilities that standard CPUs cannot effectively handle include artificial intelligence (AI), machine learning (ML), and large data processing. Cloudminister Technologies GPU hosting servers can help with this.
We will examine GPU hosting servers on Windows from Cloudminister Technologies' point of view in this comprehensive guide, going over their features, benefits, and reasons for being the best option for your company.
A GPU Hosting Server: What Is It?
A dedicated server with Graphical Processing Units (GPUs) for high-performance parallel computing is known as a GPU hosting server. GPUs can process thousands of jobs at once, in contrast to CPUs, which handle tasks sequentially. They are therefore ideal for applications requiring real-time processing and large-scale data computations.
Cloudminister Technologies provides cutting-edge GPU hosting solutions to companies that deal with:
AI and ML Model Training:- Quick and precise creation of machine learning models.
Data analytics:- It is the rapid processing of large datasets to produce insights that may be put to use.
Video processing and 3D rendering:- fluid rendering for multimedia, animation, and gaming applications.
Blockchain Mining:- Designed with strong GPU capabilities for cryptocurrency mining.
Why Opt for GPU Hosting from Cloudminister Technologies?
1. Hardware with High Performance
The newest NVIDIA and AMD GPUs power the state-of-the-art hardware solutions used by Cloudminister Technologies. Their servers are built to provide resource-intensive applications with exceptional speed and performance.
Important Points to Remember:
High-end GPU variants are available for quicker processing.
Dedicated GPU servers that only your apps can use; there is no resource sharing, guaranteeing steady performance.
Parallel processing optimization enables improved output and quicker work completion.
2. Compatibility with Windows OS
For companies that depend on Windows apps, Cloudminister's GPU hosting servers are a great option because they completely support Windows-based environments.
The Benefits of Windows Hosting with Cloudminister
Smooth Integration: Utilize programs developed using Microsoft technologies, like PowerShell, Microsoft SQL Server, and ASP.NET, without encountering compatibility problems.
Developer-Friendly: Enables developers to work in a familiar setting by supporting well-known development tools including Visual Studio,.NET Core, and DirectX.
Licensing Management: To ensure compliance and save time, Cloudminister handles Windows licensing.
3. The ability to scale
Scalability is a feature of Cloudminister Technologies' technology that lets companies expand without worrying about hardware constraints.
Features of Scalability:
Flexible Resource Allocation: Adjust your storage, RAM, and GPU power according to task demands.
On-Demand Scaling: Only pay for what you use; scale back when not in use and increase resources during periods of high usage.
Custom Solutions: Custom GPU configurations and enterprise-level customization according to particular business requirements.
4. Robust Security:-
Cloudminister Technologies places a high premium on security. Multiple layers of protection are incorporated into their GPU hosting solutions to guarantee the safety and security of your data.
Among the security features are:
DDoS Protection: Prevents Distributed Denial of Service (DDoS) assaults that might impair the functionality of your server.
Frequent Backups: Automatic backups to ensure speedy data recovery in the event of an emergency.
Secure data transfer:- across networks is made possible via end-to-end encryption, or encrypted connections.
Advanced firewalls: Guard against malware attacks and illegal access.
5. 24/7 Technical Assistance:-
Cloudminister Technologies provides round-the-clock technical assistance to guarantee prompt and effective resolution of any problems. For help with server maintenance, configuration, and troubleshooting, their knowledgeable staff is always on hand.
Support Services:
Live Monitoring: Ongoing observation to proactively identify and address problems.
Dedicated Account Managers: Tailored assistance for business customers with particular technical needs.
Managed Services: Cloudminister provides fully managed hosting services, including upkeep and upgrades, for customers who require a hands-off option.
Advantages of Cloudminister Technologies Windows-Based GPU Hosting
There are numerous commercial benefits to using Cloudminister to host GPU servers on Windows.
User-Friendly Interface:- The Windows GUI lowers the learning curve for IT staff by making server management simple.
Broad Compatibility:- Complete support for Windows-specific frameworks and apps, including Microsoft Azure SDK, DirectX, and the.NET Framework.
Optimized Performance:- By ensuring that the GPU hardware operates at its best, Windows-based drivers and upgrades reduce downtime.
Use Cases at Cloudminister Technologies for GPU Hosting
Cloudminister's GPU hosting servers are made to specifically cater to the demands of different sectors.
Machine learning and artificial intelligence:- With the aid of powerful GPU servers, machine learning models can be developed and trained more quickly. Perfect for PyTorch, Keras, TensorFlow, and other deep learning frameworks.
Media and Entertainment:- GPU servers provide the processing capacity required for VFX creation, 3D modeling, animation, and video rendering. These servers support programs like Blender, Autodesk Maya, and Adobe After Effects.
Big Data Analytics:- Use tools like Apache Hadoop and Apache Spark to process enormous amounts of data and gain real-time insights.
Development of Games:- Using strong GPUs that enable 3D rendering, simulations, and game engine integration with programs like Unreal Engine and Unity, create and test games.
Flexible Pricing and Plans
Cloudminister Technologies provides adjustable pricing structures to suit companies of all sizes:
Pay-as-you-go: This approach helps organizations efficiently manage expenditures by only charging for the resources you utilize.
Custom Packages: Hosting packages designed specifically for businesses with certain needs in terms of GPU, RAM, and storage.
Free Trials: Before making a long-term commitment, test the service risk-free.
Reliable Support and Services
To guarantee optimum server performance, Cloudminister Technologies provides a comprehensive range of support services:
24/7 Monitoring:- Proactive server monitoring to reduce downtime and maximize uptime.
Automated Backups:- To avoid data loss, create regular backups with simple restoration choices.
Managed Services:- Professional hosting environment management for companies in need of a full-service outsourced solution.
In conclusion
Cloudminister Technologies' GPU hosting servers are the ideal choice if your company relies on high-performance computing for AI, large data, rendering, or simulation. The scalability, security, and speed required to manage even the most resource-intensive workloads are offered by their Windows-compatible GPU servers.
Cloudminister Technologies is the best partner for companies looking for dependable GPU hosting solutions because of its flexible pricing, strong support, and state-of-the-art technology.
To find out how Cloudminister Technologies' GPU hosting services may improve your company's operations, get in contact with them right now.
VISIT:- www.cloudminister.com
0 notes
Text
Azure Data Engineer Course In Bangalore | Azure Data
PolyBase in Azure SQL Data Warehouse: A Comprehensive Guide
Introduction to PolyBase
PolyBase is a technology in Microsoft SQL Server and Azure Synapse Analytics (formerly Azure SQL Data Warehouse) that enables querying data stored in external sources using T-SQL. It eliminates the need for complex ETL processes by allowing seamless data integration between relational databases and big data sources such as Hadoop, Azure Blob Storage, and external databases.
PolyBase is particularly useful in Azure SQL Data Warehouse as it enables high-performance data virtualization, allowing users to query and import large datasets efficiently without moving data manually. This makes it an essential tool for organizations dealing with vast amounts of structured and unstructured data. Microsoft Azure Data Engineer

How PolyBase Works
PolyBase operates by creating external tables that act as a bridge between Azure SQL Data Warehouse and external storage. When a query is executed on an external table, PolyBase translates it into the necessary format and fetches the required data in real-time, significantly reducing data movement and enhancing query performance.
The key components of PolyBase include:
External Data Sources – Define the external system, such as Azure Blob Storage or another database.
File Format Objects – Specify the format of external data, such as CSV, Parquet, or ORC.
External Tables – Act as an interface between Azure SQL Data Warehouse and external data sources.
Data Movement Service (DMS) – Responsible for efficient data transfer during query execution. Azure Data Engineer Course
Benefits of PolyBase in Azure SQL Data Warehouse
Seamless Integration with Big Data – PolyBase enables querying data stored in Hadoop, Azure Data Lake, and Blob Storage without additional transformation.
High-Performance Data Loading – It supports parallel data ingestion, making it faster than traditional ETL pipelines.
Cost Efficiency – By reducing data movement, PolyBase minimizes the need for additional storage and processing costs.
Simplified Data Architecture – Users can analyze external data alongside structured warehouse data using a single SQL query.
Enhanced Analytics – Supports machine learning and AI-driven analytics by integrating with external data sources for a holistic view.
Using PolyBase in Azure SQL Data Warehouse
To use PolyBase effectively, follow these key steps:
Enable PolyBase – Ensure that PolyBase is activated in Azure SQL Data Warehouse, which is typically enabled by default in Azure Synapse Analytics.
Define an External Data Source – Specify the connection details for the external system, such as Azure Blob Storage or another database.
Specify the File Format – Define the format of the external data, such as CSV or Parquet, to ensure compatibility.
Create an External Table – Establish a connection between Azure SQL Data Warehouse and the external data source by defining an external table.
Query the External Table – Data can be queried seamlessly without requiring complex ETL processes once the external table is set up. Azure Data Engineer Training
Common Use Cases of PolyBase
Data Lake Integration: Enables organizations to query raw data stored in Azure Data Lake without additional data transformation.
Hybrid Data Solutions: Facilitates seamless data integration between on-premises and cloud-based storage systems.
ETL Offloading: Reduces reliance on traditional ETL tools by allowing direct data loading into Azure SQL Data Warehouse.
IoT Data Processing: Helps analyze large volumes of sensor-generated data stored in cloud storage.
Limitations of PolyBase
Despite its advantages, PolyBase has some limitations:
It does not support direct updates or deletions on external tables.
Certain data formats, such as JSON, require additional handling.
Performance may depend on network speed and the capabilities of the external data source. Azure Data Engineering Certification
Conclusion
PolyBase is a powerful Azure SQL Data Warehouse feature that simplifies data integration, reduces data movement, and enhances query performance. By enabling direct querying of external data sources, PolyBase helps organizations optimize their big data analytics workflows without costly and complex ETL processes. For businesses leveraging Azure Synapse Analytics, mastering PolyBase can lead to better data-driven decision-making and operational efficiency.
Implementing PolyBase effectively requires understanding its components, best practices, and limitations, making it a valuable tool for modern cloud-based data engineering and analytics solutions.
For More Information about Azure Data Engineer Online Training
Contact Call/WhatsApp: +91 7032290546
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
#Azure Data Engineer Course#Azure Data Engineering Certification#Azure Data Engineer Training In Hyderabad#Azure Data Engineer Training#Azure Data Engineer Training Online#Azure Data Engineer Course Online#Azure Data Engineer Online Training#Microsoft Azure Data Engineer#Azure Data Engineer Course In Bangalore#Azure Data Engineer Course In Chennai#Azure Data Engineer Training In Bangalore#Azure Data Engineer Course In Ameerpet
0 notes
Text
Optimizing SQL Server Performance: Addressing Bottlenecks in Repartition Streams
Repartition Streams The term “Repartition Streams” in SQL Server refers to a phase in the query execution process, particularly in the context of parallel processing. It’s a mechanism used to redistribute data across different threads to ensure that the workload is evenly balanced among them. This operation is crucial for optimizing the performance of queries that are executed in parallel,…
View On WordPress
#database performance tuning#parallel execution bottleneck#Repartition Streams optimization#SQL query efficiency#SQL Server parallel processing
0 notes
Text
Tips for Optimizing Software Performance
Optimizing software performance is a critical aspect of software development, ensuring applications run efficiently and provide users with a seamless experience. Poorly performing software can lead to user dissatisfaction, higher operational costs, and scalability issues. This article outlines actionable tips and best practices for enhancing software performance.
1. Understand Software Performance
Software performance refers to how efficiently an application utilizes system resources to deliver results. Key aspects include:
Speed: How quickly the application performs tasks.
Scalability: The ability to handle increased loads.
Resource Utilization: Efficient use of CPU, memory, and storage.
Responsiveness: How the application responds to user interactions.
2. Identify Performance Bottlenecks
Before optimizing, identify the root causes of performance issues. Common bottlenecks include:
Slow Database Queries: Inefficient queries can significantly impact performance.
Excessive Network Requests: Overuse of APIs or poorly managed requests can cause latency.
Memory Leaks: Unreleased memory can degrade performance over time.
Inefficient Code: Poorly written or unoptimized code can slow down applications.
Use profiling tools like New Relic, AppDynamics, or VisualVM to detect bottlenecks.
3. Optimize Code Efficiency
Efficient code is the foundation of a high-performing application. Follow these practices:
a. Write Clean Code
Avoid redundant operations.
Use meaningful variable names and modular functions.
b. Use Efficient Algorithms
Choose algorithms with better time and space complexity.
Example: Replace nested loops with hash tables for faster lookups.
c. Minimize Loops and Conditions
Avoid unnecessary loops and complex conditional statements.
Combine similar operations where possible.
4. Optimize Database Performance
Databases are often the backbone of applications. Optimize their performance with these strategies:
a. Indexing
Index frequently queried columns to speed up retrieval.
b. Query Optimization
Use optimized SQL queries to minimize execution time.
Avoid SELECT *; retrieve only required columns.
c. Caching
Use caching tools like Redis or Memcached to store frequently accessed data.
d. Connection Pooling
Reuse database connections instead of creating new ones for each request.
5. Leverage Caching
Caching reduces the need to recompute or fetch data repeatedly.
Browser Caching: Store static assets like images and scripts on the client side.
Server-Side Caching: Cache API responses and database query results.
CDNs (Content Delivery Networks): Use CDNs to cache and deliver content from servers closer to users.
6. Optimize Front-End Performance
Front-end optimization directly impacts user experience. Here’s how to improve it:
a. Minify Resources
Minify CSS, JavaScript, and HTML files to reduce file size.
Use tools like UglifyJS and CSSNano.
b. Optimize Images
Compress images using tools like TinyPNG or ImageOptim.
Use modern formats like WebP for better compression.
c. Asynchronous Loading
Load scripts and assets asynchronously to prevent blocking.
d. Lazy Loading
Load images and other resources only when they are needed.
7. Monitor and Profile Regularly
Continuous monitoring ensures you catch performance issues early. Use these tools:
APM Tools: Application Performance Monitoring tools like Dynatrace and Datadog.
Profilers: Analyze resource usage with profilers like Chrome DevTools for front-end and PyCharm Profiler for Python.
Logs: Implement robust logging to identify errors and performance trends.
8. Use Multithreading and Parallel Processing
For computationally intensive tasks:
Multithreading: Divide tasks into smaller threads to run concurrently.
Parallel Processing: Distribute tasks across multiple cores or machines.
Use frameworks like OpenMP for C++ or Concurrent Futures in Python.
9. Optimize Resource Management
Efficient resource management prevents slowdowns and crashes.
Garbage Collection: Use garbage collection to reclaim unused memory.
Pooling: Reuse expensive resources like threads and connections.
Compression: Compress data before transmission to save bandwidth.
10. Adopt Cloud Scalability
Cloud services offer scalability and resource optimization:
Use auto-scaling features to handle varying loads.
Distribute workloads using load balancers like AWS ELB or NGINX.
Utilize managed services for databases, storage, and caching.
11. Test for Scalability
Scalability testing ensures the application performs well under increased loads.
Load Testing: Simulate high user traffic using tools like Apache JMeter or LoadRunner.
Stress Testing: Test the application’s limits by overwhelming it with traffic.
Capacity Planning: Plan resources for peak loads to prevent outages.
12. Best Practices for Long-Term Performance Optimization
a. Adopt a Performance-First Culture
Encourage teams to prioritize performance during development.
Include performance benchmarks in design and code reviews.
b. Automate Performance Testing
Integrate performance tests into CI/CD pipelines.
Use tools like Gatling or K6 for automated load testing.
c. Keep Dependencies Updated
Regularly update libraries and frameworks to benefit from performance improvements.
d. Document Performance Metrics
Maintain records of performance metrics to identify trends and plan improvements.
Conclusion
Optimizing software performance is an ongoing process that requires attention to detail, proactive monitoring, and adherence to best practices. By addressing bottlenecks, writing efficient code, leveraging caching, and adopting modern tools and methodologies, developers can deliver fast, reliable, and scalable applications. Embrace a performance-first mindset to ensure your software not only meets but exceeds user expectations.
0 notes
Text
Golang developer,
Golang developer,
In the evolving world of software development, Go (or Golang) has emerged as a powerful programming language known for its simplicity, efficiency, and scalability. Developed by Google, Golang is designed to make developers’ lives easier by offering a clean syntax, robust standard libraries, and excellent concurrency support. Whether you're starting as a new developer or transitioning from another language, this guide will help you navigate the journey of becoming a proficient Golang developer.
Why Choose Golang?
Golang’s popularity has grown exponentially, and for good reasons:
Simplicity: Go's syntax is straightforward, making it accessible for beginners and efficient for experienced developers.
Concurrency Support: With goroutines and channels, Go simplifies writing concurrent programs, making it ideal for systems requiring parallel processing.
Performance: Go is compiled to machine code, which means it executes programs efficiently without requiring a virtual machine.
Scalability: The language’s design promotes building scalable and maintainable systems.
Community and Ecosystem: With a thriving developer community, extensive documentation, and numerous open-source libraries, Go offers robust support for its users.
Key Skills for a Golang Developer
To excel as a Golang developer, consider mastering the following:
1. Understanding Go Basics
Variables and constants
Functions and methods
Control structures (if, for, switch)
Arrays, slices, and maps
2. Deep Dive into Concurrency
Working with goroutines for lightweight threading
Understanding channels for communication
Managing synchronization with sync package
3. Mastering Go’s Standard Library
net/http for building web servers
database/sql for database interactions
os and io for system-level operations
4. Writing Clean and Idiomatic Code
Using Go’s formatting tools like gofmt
Following Go idioms and conventions
Writing efficient error handling code
5. Version Control and Collaboration
Proficiency with Git
Knowledge of tools like GitHub, GitLab, or Bitbucket
6. Testing and Debugging
Writing unit tests using Go’s testing package
Utilizing debuggers like dlv (Delve)
7. Familiarity with Cloud and DevOps
Deploying applications using Docker and Kubernetes
Working with cloud platforms like AWS, GCP, or Azure
Monitoring and logging tools like Prometheus and Grafana
8. Knowledge of Frameworks and Tools
Popular web frameworks like Gin or Echo
ORM tools like GORM
API development with gRPC or REST
Building a Portfolio as a Golang Developer
To showcase your skills and stand out in the job market, work on real-world projects. Here are some ideas:
Web Applications: Build scalable web applications using frameworks like Gin or Fiber.
Microservices: Develop microservices architecture to demonstrate your understanding of distributed systems.
Command-Line Tools: Create tools or utilities to simplify repetitive tasks.
Open Source Contributions: Contribute to Golang open-source projects on platforms like GitHub.
Career Opportunities
Golang developers are in high demand across various industries, including fintech, cloud computing, and IoT. Popular roles include:
Backend Developer
Cloud Engineer
DevOps Engineer
Full Stack Developer
Conclusion
Becoming a proficient Golang developer requires dedication, continuous learning, and practical experience. By mastering the language’s features, leveraging its ecosystem, and building real-world projects, you can establish a successful career in this growing field. Start today and join the vibrant Go community to accelerate your journey.
0 notes
Text
Checklist for performance tuning in MS SQL Server
Database & Server Configuration ✅ Ensure SQL Server is running on an optimized hardware setup.✅ Configure max server memory to avoid excessive OS paging.✅ Set max degree of parallelism (MAXDOP) based on CPU cores.✅ Optimize cost threshold for parallelism (default 5 is often too low).✅ Enable Instant File Initialization for faster data file growth.✅ Keep TempDB on fast storage & configure…
0 notes
Text
Innovations in Data Orchestration: How Azure Data Factory is Adapting

Introduction
As businesses generate and process vast amounts of data, the need for efficient data orchestration has never been greater. Data orchestration involves automating, scheduling, and managing data workflows across multiple sources, including on-premises, cloud, and third-party services.
Azure Data Factory (ADF) has been a leader in ETL (Extract, Transform, Load) and data movement, and it continues to evolve with new innovations to enhance scalability, automation, security, and AI-driven optimizations.
In this blog, we will explore how Azure Data Factory is adapting to modern data orchestration challenges and the latest features that make it more powerful than ever.
1. The Evolution of Data Orchestration
🚀 Traditional Challenges
Manual data integration between multiple sources
Scalability issues in handling large data volumes
Latency in data movement for real-time analytics
Security concerns in hybrid and multi-cloud setups
🔥 The New Age of Orchestration
With advancements in cloud computing, AI, and automation, modern data orchestration solutions like ADF now provide: ✅ Serverless architecture for scalability ✅ AI-powered optimizations for faster data pipelines ✅ Real-time and event-driven data processing ✅ Hybrid and multi-cloud connectivity
2. Key Innovations in Azure Data Factory
✅ 1. Metadata-Driven Pipelines for Dynamic Workflows
ADF now supports metadata-driven data pipelines, allowing organizations to:
Automate data pipeline execution based on dynamic configurations
Reduce redundancy by using parameterized pipelines
Improve reusability and maintenance of workflows
✅ 2. AI-Powered Performance Optimization
Microsoft has introduced AI-powered recommendations in ADF to:
Suggest best data pipeline configurations
Automatically optimize execution performance
Detect bottlenecks and improve parallelism
✅ 3. Low-Code and No-Code Data Transformations
Mapping Data Flows provide a visual drag-and-drop interface
Wrangling Data Flows allow users to clean data using Power Query
Built-in connectors eliminate the need for custom scripting
✅ 4. Real-Time & Event-Driven Processing
ADF now integrates with Event Grid, Azure Functions, and Streaming Analytics, enabling:
Real-time data movement from IoT devices and logs
Trigger-based workflows for automated data processing
Streaming data ingestion into Azure Synapse, Data Lake, or Cosmos DB
✅ 5. Hybrid and Multi-Cloud Data Integration
ADF now provides:
Expanded connector support (AWS S3, Google BigQuery, SAP, Databricks)
Enhanced Self-Hosted Integration Runtime for secure on-prem connectivity
Cross-cloud data movement with Azure, AWS, and Google Cloud
✅ 6. Enhanced Security & Compliance Features
Private Link support for secure data transfers
Azure Key Vault integration for credential management
Role-based access control (RBAC) for governance
✅ 7. Auto-Scaling & Cost Optimization Features
Auto-scaling compute resources based on workload
Cost analysis tools for optimizing pipeline execution
Pay-per-use model to reduce costs for infrequent workloads
3. Use Cases of Azure Data Factory in Modern Data Orchestration
🔹 1. Real-Time Analytics with Azure Synapse
Ingesting IoT and log data into Azure Synapse
Using event-based triggers for automated pipeline execution
🔹 2. Automating Data Pipelines for AI & ML
Integrating ADF with Azure Machine Learning
Scheduling ML model retraining with fresh data
🔹 3. Data Governance & Compliance in Financial Services
Secure movement of sensitive data with encryption
Using ADF with Azure Purview for data lineage tracking
🔹 4. Hybrid Cloud Data Synchronization
Moving data from on-prem SAP, SQL Server, and Oracle to Azure Data Lake
Synchronizing multi-cloud data between AWS S3 and Azure Blob Storage
4. Best Practices for Using Azure Data Factory in Data Orchestration
✅ Leverage Metadata-Driven Pipelines for dynamic execution ✅ Enable Auto-Scaling for better cost and performance efficiency ✅ Use Event-Driven Processing for real-time workflows ✅ Monitor & Optimize Pipelines using Azure Monitor & Log Analytics ✅ Secure Data Transfers with Private Endpoints & Key Vault
5. Conclusion
Azure Data Factory continues to evolve with innovations in AI, automation, real-time processing, and hybrid cloud support. By adopting these modern orchestration capabilities, businesses can:
Reduce manual efforts in data integration
Improve data pipeline performance and reliability
Enable real-time insights and decision-making
As data volumes grow and cloud adoption increases, Azure Data Factory’s future-ready approach ensures that enterprises stay ahead in the data-driven world.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
7 Best Data Warehouse Tools to Explore in 2025

What is a Data Warehouse?
A data warehouse is a centralized repository designed to store large volumes of data from various sources in an organized, structured format. It facilitates efficient querying, analysis, and reporting of data, serving as a vital component for business intelligence and analytics.
Types of Data Warehouses
Data warehouses can be classified into the following categories:
Enterprise Data Warehouse (EDW): A unified storage hub for all enterprise data.
Operational Data Store (ODS): Stores frequently updated, real-time data.
Online Analytical Processing (OLAP): Designed for complex analytical queries on large datasets.
Data Mart: A focused subset of a data warehouse for specific departments or business units.
Why Use Data Warehouses?
The primary purpose of data warehouses is to store and organize data centrally, enabling faster and more efficient analysis of large datasets. Other benefits include:
Improved Data Quality: Processes ensure data integrity and consistency.
Historical Data Storage: Supports trend analysis and forecasting.
Enhanced Accessibility: Allows seamless access and querying of data from multiple sources.
Who Uses Data Warehouses?
Data warehouses cater to various professionals across industries:
Data Analysts: Query and analyze data for actionable insights.
Data Engineers: Build and maintain the underlying infrastructure.
Business Intelligence Analysts: Generate reports and visualizations for stakeholders.
Analytics Engineers: Optimize data pipelines for efficient loading.
Companies often use data warehouses to store vast amounts of customer data, sales information, and financial records. Modern trends include adopting data lakes and data lake houses for advanced analytics.
Top Data Warehouse Tools to Watch in 2025
1. Snowflake
Snowflake is a cloud-native data warehouse renowned for its flexibility, security, and scalability.
Key Features:
Multi-cluster Architecture: Supports scalability and separates compute from storage.
Virtual Warehouses: On-demand setup for parallel workload handling.
Data Sharing: Facilitates secure data sharing across organizations.
Snowflake integrates seamlessly with tools like dbt, Tableau, and Looker, making it a cornerstone of the modern data stack.
2. Amazon S3
Amazon S3 is a highly scalable, object-based storage service, widely used as a data warehousing solution.
Key Features:
Scalability: Capable of handling any data volume.
AWS Ecosystem Integrations: Enhances processing and analytics workflows.
Cost-effectiveness: Pay-as-you-go pricing model.
Ideal for organizations already leveraging AWS services, Amazon S3 offers unparalleled flexibility and durability.
3. Google Big Query
Google Big Query is a server less, highly scalable solution designed for real-time insights.
Key Features:
Fast Querying: Processes petabytes of data in seconds.
Automatic Scaling: No manual resource management required.
Integrated Machine Learning: Supports advanced analytics.
Big Query’s seamless integration with Google Cloud services and third-party tools makes it a top choice for modern data stacks.
4. Data bricks
Data bricks is a unified analytics platform combining data engineering, science, and business intelligence.
Key Features:
Spark-based Engine: Enables fast, large-scale data processing.
ML flow: Streamlines machine learning lifecycle management.
Real-time Analytics: Processes streaming data effortlessly.
Data bricks supports Python, SQL, R, and Scala, appealing to diverse data professionals.
5. Amazon Redshift
Amazon Redshift is a fully managed, high-performance data warehouse tailored for structured and semi-structured data.
Key Features:
Columnar Storage: Optimized query performance.
Massively Parallel Processing (MPP): Accelerates complex queries.
AWS Integrations: Works well with S3, DynamoDB, and Elastic MapReduce.
Its scalability and cost-effectiveness make it popular among startups and enterprises alike.
6. Oracle Autonomous Data Warehouse
Oracle Autonomous Data Warehouse automates the creation and management of data warehouses using machine learning.
Key Features:
Autonomous Operations: Self-tuning and optimized storage.
Elastic Scalability: Adjusts resources dynamically based on workload.
Built-in ML Algorithms: Facilitates advanced analytics.
Best suited for enterprises seeking robust, automated solutions with high performance.
7. PostgreSQL
PostgreSQL is a versatile, open-source relational database that supports data warehousing needs.
Key Features:
ACID Compliance: Ensures data integrity.
Multi-version Concurrency Control (MVCC): Allows simultaneous access.
Extensibility: Offers plugins like PostgreSQL Data Warehousing by Citus.
Its robust community support and adaptability make PostgreSQL a reliable choice for organizations of all sizes.
Next Steps
Key Takeaways:
Data warehouses enable efficient organization and analysis of large datasets.
Popular tools include Snowflake, Amazon S3, Google BigQuery, Databricks, Amazon Redshift, Oracle, and PostgreSQL.
How to Advance Your Knowledge:
Explore Data Analytics Tools: Get acquainted with platforms like Tableau and dbt.
Learn Data Analytics: Try Career Foundry’s free, 5-day data analytics short course.
Join Live Events: Participate in online events with industry experts.
Take the first step towards becoming a data analyst. Enroll in Career Foundry’s data analytics program and unlock a new career path today.
0 notes