#Salesforce wave replication
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
Overview of Salesforce Einstein Analytics Replication
youtube
Salesforce Einstein Replication:
Salesforce Analytics Cloud includes a replication feature. Replicated data can greatly improve data flow execution times. If you have used the Data-set builder and selected the same object more than once, your data flow will digest that object multiple times.

How Does Replication Work?
When you enable replication, Wave looks at the SFDC Digest nodes in your existing scheduled user data flows to see which Salesforce objects and fields you’re currently extracting. Using this information, Wave sets up replication for each object, to extract the data separately. You can schedule this replication to run ahead of your data flows

If you later update your data flows, or create new ones, Wave automatically updates the replication with relevant changes.

Configuring Replication Settings
1. ENTER - Einstein analytics
2. Find QUICK FIND BOX
3. Click the SETTINGS
4. Select ENABLES REPLICATION
5. Click SAVE
When done with above steps, you can view the enabled Salesforce objects, set up a replication schedule, and run replication. If you found this post useful, Make sure, you can check out our online Learning courses for more tips, tricks and techniques for effectively to uncover unique insights from your data
#Salesforce wave replication#replication overview#Einstein analytics#youtube videos#wave replication videos
2 notes
·
View notes
Text
Tips To Migrate Legacy Data

Migrating legacy data is challenging.
Numerous associations have old and complex on-premise business CRM frameworks. Today, there are many cloud SaaS options, which accompany numerous advantages; pay more only as costs arise and to pay just for what you use. Along these lines, they choose to move to the new frameworks.
No one needs to leave important data about clients in the old framework and start with the void new framework, so we have to relocate this data. Lamentably, data relocation isn't a simple assignment, as data movement exercises devour around 50% of organizational exertion. As per Gartner, Salesforce is the head of cloud CRM arrangements. Along these lines, data movement is a significant theme for Salesforce sending.
Data Migration in General
1. Make Migration a Separate Project
Data movement isn't a "fare and import" thing taken care of by a cunning "press one catch" data relocation device that has predefined planning for target frameworks in the product arrangement agenda.
Data movement is an unpredictable action, meriting a different venture, plan, approach, spending plan, and group. A substance level extension and project must be made at the venture's start, guaranteeing no curveballs, for example, "Gracious, we neglected to stack those customers' visit reports, who will do that?" fourteen days before the cutoff time.
The data movement approach characterizes whether we will stack the data in one go (otherwise called the enormous detonation), or whether we will stack little bunches each week.
This isn't a simple choice, however. The methodology must be settled upon and conveyed to all business and specialized partners to ensure when and what data will show up in the new framework. This applies to framework blackouts as well.
2. Gauge Realistically
Try not to disparage the unpredictability of the data relocation. Many tedious errands go with this cycle, which might be invisible at the task's start.
For instance, stacking straight data sets for preparing purposes with valuable data, yet with touchy things muddled, so preparing exercises don't create email warnings to customers.
The fundamental factor for assessment is the number of fields moved from a source framework to an objective framework.
Some time is required in various phases of the venture for each field, including understanding the area, planning the source field to the objective field, arranging or building changes, performing tests, estimating data quality for the field, etc.
Utilizing sharp instruments, for example, Jitterbit, Informatica Cloud Data Wizard, Starfish ETL, Midas, and so forth, can decrease this time, particularly in the construction stage.
Specifically, understanding the source data – the most vital errand in any movement venture – can't be mechanized by apparatuses, yet expects examiners to require significant investment experiencing the rundown of fields individually.
The least complex gauge of the general exertion is a limited day for each field moved from the legacy framework.
An exemption is data replication between a similar source and target blueprints minus any additional change – at times known as 1:1 movement – where we can put together the gauge concerning the number of tables to duplicate.
A nitty-gritty gauge is its very own specialty.
3. Check Data Quality
Try not to overestimate source data's nature, regardless of whether no data quality issues are accounted for from the legacy frameworks.
New frameworks have new principles, which might be abused with legacy data. Here's a basic model. Contact email can be obligatory in the new framework; however, a 20-year-old legacy framework may have an alternate perspective.
There can be mines covered up in chronicled data that have not been contacted for quite a while; however, they could actuate when moving to the new framework. For instance, old data utilizing European monetary standards that don't exist any longer should be changed over to Euros; in any case, economic forms must be added to the new framework.
Data quality fundamentally impacts exertion, and the straightforward guideline is The further we go ever, the more splendid wreck we will find. Subsequently, it is fundamental to choose at a reasonable time how much history we need to move into the new framework.
4. Draw in Business People
Money managers are the main ones who genuinely comprehend the data and who can consequently choose what data can be discarded and what data to keep.
It is critical to have someone from the business group required during the planning exercise. For future backtracking, it is valuable to record planning choices and the explanations behind them.
Since an image is worth more than 1,000 words, load a test group into the new framework, and let the business group play with it.
Regardless of whether data relocation planning is looked into and affirmed by the business group, shocks can show up once the data appears in the new framework's UI.
"Goodness, presently I see, we need to transform it a piece," turns into a typical expression.
Neglecting to connect with topic specialists, generally bustling individuals, is the most widely recognized reason for issues after another framework goes live.
5. Focus on Automated Migration Solution
Data relocation is regularly seen as a one-time movement, and designers will, in general, wind up with arrangements brimming with manual activities wanting to execute them just a single time. Yet, there are numerous motivations to evade such a methodology.
On the off chance that relocation is part of various waves, we need to rehash similar activities on different occasions.
Commonly, there are in any event three relocation runs for each wave: a dry hurry to test the exhibition and usefulness of data movement, a full data approval burden to test the whole data set, and to perform business tests, and obviously, creation load. The quantity of runs increments with helpless data quality. Improving data quality is an iterative cycle, so we need a few emphases to arrive at the ideal achievement proportion.
Hence, regardless of whether relocation is a one-time action commonly, having manual activities can altogether hinder your tasks.
Salesforce Data Migration
Next, we will cover five hints for a fruitful Salesforce relocation. Remember, these tips are likely relevant to other cloud arrangements too.
6. Get ready for Lengthy Loads
If not the greatest, execution is one of the greatest tradeoffs while moving from an on-reason to a cloud arrangement – Salesforce not barred.
On-premise frameworks typically consider direct data load into an entire database, and with great equipment, we can undoubtedly arrive at a vast number of records every hour.
Be that as it may, not in the cloud. In the cloud, we are intensely restricted by a few variables.
Organization dormancy – Data is moved using the web.
Salesforce application layer – Data is traveled through a thick API multitenancy layer until they land in their Oracle databases.
Custom code in Salesforce – Custom approvals, triggers, work processes, duplication identification rules, etc. – a considerable lot of which debilitate equal or mass burdens.
Therefore, load execution can be a considerable number of records every hour.
It tends to be less, or it very well may be more, contingent upon things, for example, the number of fields, approvals, and triggers. However, it is a few evaluations slower than an immediate database load.
Execution debasement, which is subject to the volume of the Salesforce data, should likewise be thought of.
It is brought about by files in the primary RDBMS (Oracle) utilized for checking foreign keys, exceptional fields, and assessment of duplication rules. The basic recipe is around 50% log jam for each evaluation of 10, brought about by O(logN) the time unpredictability parcel in sort and B-tree activities.
Also, Salesforce has numerous asset utilization limits.
One of them is the Bulk API limit set to 5,000 clusters in 24-hour moving windows, with the limitation of 10,000 records in each bunch.
In this way, the hypothetical most extreme is 50 million records stacked in 24 hours.
In a genuine venture, the most extreme is a lot of lower because of restricted group size when utilizing, for instance, custom triggers.
This strongly affects the data movement approach.
In any event, for medium-sized datasets (from 100,000 to 1 million records), the vast explosion approach is not feasible, so we should part data into littler movement waves.
This impacts the whole arrangement cycle and builds the multifaceted movement of nature. We will include data increases into a framework previously populated by past relocations and data entered by clients.
We should likewise think about this current data in the relocation changes and approvals.
Further, protracted burdens can mean we can't perform relocations during a framework blackout.
On the off chance that all clients are situated in one nation, we can use an eight-hour blackout during the night.
For example, for an organization, Coca-Cola, with tasks everywhere in the world, is beyond the realm of imagination. When we have the U.S., Japan, and Europe in the framework, we range new zones, so Saturday is the leading blackout choice that doesn't influence clients.
Also, that may not be sufficient; thus, we should stack while on the web, when clients work with the framework.
7. Regard Migration Needs in Application Development
Application parts, for example, approvals and triggers, ought to have the option to deal with data movement exercises. Hard disablement of licenses at the relocation load hour isn't an alternative if the framework must be on the web. Instead, we need to execute a distinctive rationale in approvals for changes performed by a data relocation client.
Date fields should not be contrasted with the real framework date since that would cripple the stacking of recorded data. For instance, approval must permit entering a previous record start date for moved data.
Compulsory fields, which may not be populated with verifiable data, must be actualized as non-obligatory, yet with approval touchy to the client, permitting void qualities for data originating from the relocation dismissing void rates creating from standard clients using the GUI.
Triggers, particularly those sending new records to the combination, must have the option to be turned on/off for the data relocation client to forestall flooding the mix with moved data.
Another stunt is utilizing field Legacy ID or Migration ID in each moving article. There are two explanations behind this. The first is self-evident: To save the ID from the old framework for backtracking, after the data is in the new framework, individuals may at present need to look through their records utilizing the old IDs, found in places as messages, archives, and bug-global positioning frameworks. Unfortunate propensity? Possibly. In any case, clients will thank you on the off chance that you protect their old IDs. The subsequent explanation is specialized and originates from the reality that Salesforce doesn't acknowledge expressly gave IDs to new records (in contrast to Microsoft Dynamics) but creates them during the heap. The issue emerges when we need to stack youngster objects since we need to appoint them to the parent objects. Since we will know those IDs only after stacking, this is a worthless exercise.
How about we use Accounts and their Contacts, for instance:
Produce data for Accounts.
Burden Accounts into Salesforce, and get produced IDs.
Join new Account IDs in Contact data.
Produce data for Contacts.
Burden Contacts in Salesforce.
We can do this all the more by stacking Accounts with their Legacy IDs put away in an exceptional outer field. This field can be utilized as a parent reference, so when stacking Contacts, we nearly use the Account Legacy ID as a pointer to the parent Account:
Create data for Accounts, including Legacy ID.
Create data for Contacts, including Account Legacy ID.
Burden Accounts into Salesforce.
Burden Contacts in Salesforce, utilizing Account Legacy ID as parent reference.
Here, the pleasant thing is that we have isolated an age and a stacking stage, which takes into account better parallelism, decline blackout time, etc.
8. Know about Salesforce Specific Features
Like any framework, Salesforce has many dubious pieces of which we ought to know to evade upsetting shocks during data movement. Here are a modest bunch of models:
A few changes in dynamic Users consequently produce email warnings to client messages. In this manner, we have to deactivate clients first and actuate after changes are finished on the off chance that we need to play with client data. In test conditions, we scramble client messages, so any imagination stretch does not terminate warnings. Since dynamic clients devour expensive licenses, we can't have all clients involved in all test conditions. We need to oversee subsets of active clients, for instance, to initiate only those in a preparation climate.
Latent clients, for some standard items, for example, Account or Case, can be appointed simply in the wake of allowing the framework consent "Update Records with Inactive Owners." Yet, they can be allowed, for instance, to Contacts and every single custom article.
At the point when Contact is deactivated, all quit fields are quietly turned on.
When stacking a copy Account Team Member or Account Share object, the current record is quietly overwritten. Notwithstanding, whenever piling a copy Opportunity Partner, the form is essentially included bringing about a copy.
Framework fields, for example, Created Date, Created By ID, Last Modified Date, Last Modified By ID, can be expressly composed simply in the wake of conceding another framework authorization "Set Audit Fields upon Record Creation."
Any stretch of the imagination can't move History-of-field esteem changes.
Proprietors of information articles can't be indicated during the heap yet can be refreshed later.
The precarious part is the putting away of substance (archives, connections) into Salesforce. There are numerous approaches to do it (utilizing Attachments, Files, Feed connections, Documents), and every way has its upsides and downsides, including distinctive record size cutoff points.
Picklist fields power clients to choose one of the permitted qualities, for instance, a kind of record. However, when stacking data utilizing Salesforce API (or any device based upon it, Apex Data Loader or Informatica Salesforce connector), any worth will pass.
The rundown goes on. However, the reality is: Get acquainted with the framework, and realize what it can do and what it can't do before you make presumptions. Try not to expect standard conduct, particularly for center articles. Continuously exploration and test.
9. Try not to Use Salesforce as a Data Migration Platform
It is exceptionally enticing to utilize Salesforce as a stage for building a data relocation arrangement, particularly for Salesforce engineers. A similar innovation for the data movement arrangement concerning the Salesforce application customization, a similar GUI, a similar Apex programming language, a similar framework. Salesforce has objects that can go about as tables, and a SQL language, Salesforce Object Query Language (SOQL). In any case, kindly don't utilize it; it would be an essential building blemish.
Salesforce is a phenomenal SaaS application with many pleasant highlights, for example, progressed cooperation and rich customization; however, mass preparation of data isn't one of them. The three most huge reasons are:
Execution – The processing of data in Salesforce is a few evaluations slower than in RDBMS.
Absence of expository highlights – Salesforce SOQL doesn't uphold complex questions and scientific capacities supported by Apex language and would debase execution much more.
Architecture* – Putting a data relocation stage inside a particular Salesforce climate isn't advantageous. Ordinarily, we have various conditions for explicit purposes, frequently made impromptu so that we can put a great deal of time on code synchronization. Besides, you would likewise be depending on the network and accessibility of that particular Salesforce climate.
Instead, fabricate a data movement arrangement on a different occasion (it could be a cloud or on-premise) utilizing an RDBMS or ETL stage. Associate it with source frameworks, focus on the Salesforce conditions you need, move the data you need into your arranging territory, and cycle it there. This will permit you to:
Influence the full force and capacities of the SQL language or ETL highlights.
Have all code and data in one spot with the goal that you can run examinations overall frameworks.
For instance, you can join the freshest arrangement from the most exceptional test Salesforce climate with real data from the creation of a Salesforce climate.
You are not all that subordinate upon the innovation of the source and target frameworks, and you can reuse your answer for the following undertaking.
10. Oversight Salesforce Metadata
At the undertaking starts, we generally snatch a rundown of Salesforce fields and start the planning exercise. It regularly happens that the application development group includes new areas into Salesforce, or that some field properties are changed. We can ask the application group to tell the data movement group about each data model change, yet doesn't generally work. To be sheltered, we have to have all the data model changes under management.
A typical method to do this is to download, consistently, pertinent relocation metadata from Salesforce into some metadata archive. When we have this, we can recognize changes in the data model; however, we can likewise analyze data models of two Salesforce conditions.
See More: What Does Data Migration Mean?
0 notes
Link
The news of Zeit Vercel raising $21m (slide deck here) is great occasion for taking stock of what is going on with cloud startups. As Brian Leroux (who runs Begin.com) observes, with reference to Netlify's $55m Series C last month:
Between just Netlify and Vercel the VC community has put over 70MM in cloud focused on frontend dev in 2020.
Haven't AWS/GCP/Azure owned the cloud space? What is the full potential of this new generation of startups basically reselling their services with some value add?
Cloud's Deployment Age
I am reminded, again, of Fred Wilson's beloved Carlota Perez framework that I wrote about in React Distros. First you have an Installation Age, with a lot of creative destruction. Then, with the base primitives sorted out, we then build atop the installed layer, in a Deployment Age:
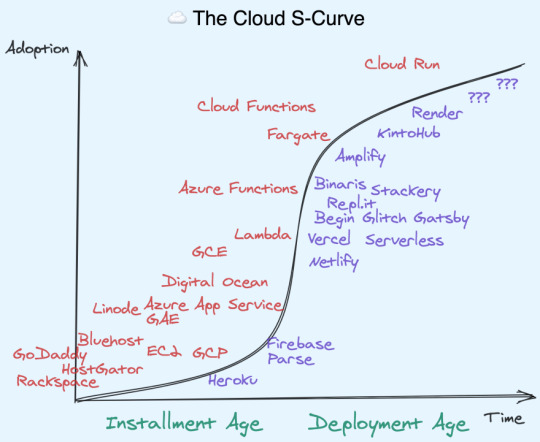
I think the same dynamics I outlined with frontend frameworks is happening here with cloud services. I'm obviously a LOT less well versed with the history of cloud, so please please take this with a grain of salt.
The "Failure" of PaaS
The argument is that the Big 3 Cloud Providers are mostly providing the new commoditized primitives on which the next generation of cloud services will be built. AWS is AWS, Azure maybe caters to the dotNet/Microsoft crowd better, whereas GCP maybe differentiates on Kubernetes and Machine Learning. Basically everyone has a container thing, a data thing, a file storage thing, a serverless thing, and so on.
A nice way to think about it, which I attribute to Guillermo (but I'm not sure about), is that these basic services are the new "Hardware". Instead of going to Fry's and picking up a motherboard, we now go to the AWS Console and pick up a t2.micro or to Azure for a Durable Function. Instead of debating Sandisk vs Western Digital we match up AWS Aurora vs Azure DocumentDB. The benefits are clear - we don't get our hands dirty, we can easily (too easily?) scale with a single API call, and thanks to Infra-as-Code we can truly treat our infra like cattle, not pets.
When the Big N clouds launched, the expectation was that Platform as a Service (PaaS) would win out over Infrastructure as a Service (IaaS). I mean - look at this chart! - if you were running a Software business, would you want to run it atop an IaaS or a PaaS? It made intuitive sense, and both Google App Engine and Azure originally launched with this vision, while Salesforce bought Heroku within 3 years of founding.
But this thesis was wrong. As Patrick McKenzie recently noted:
I'm surprised that Heroku's model didn't win over AWS' model and that DevOps is accordingly a core competence at most SaaS companies. This seems obviously terrible to me every time I'm doing DevOps, which probably took ~20% of all engineering cycles at my last company for surfacing very little customer value.
This rings true. As moderately successful as Heroku, Parse, and Firebase were, they are dwarfed by the size of the big clouds' IaaS businesses. It turns out that most people just wanted to lift and shift their workloads, rather than start new apps from scratch on underpowered platforms. Assisted by Docker, this acquired the rather unfortunate name of "cloud native". (Unfortunate, because there are now "more native" versions of building cloud-powered apps than "containerize everything and somehow mention agile")
But I don't think the PaaSes were wrong.
They were just early.
Developer Experience as a Differentiator
The thing about hardware providers is that they don't cater well to specific audiences. By nature, they build for general use. The best they can do is offer up a default "Operating System" to run them - the AWS Console, Google Cloud Console, Microsoft Azure Portal (Dave Cutler literally called Azure a Cloud OS when it began).
Meanwhile, the "undifferentiated heavy lifting" (aka Muck) of wrangling datacenters turned into "undifferentiated heavy lifting" of messing with 5 different AWS services just to set up a best practices workflow.
So increasingly, intermediate providers are rising up to provide a better developer experience and enforce opinionated architectures (like JAMstack):
Netlify
Vercel
Repl.it
Begin.com
Glitch
Render.com
Amplify
KintoHub
The working name for this new generation of cloud providers, used by Martin Casado, Amjad Masad, and Guillermo Rauch, is "second layer" or "higher level" cloud providers.
Nobody loves these names. It doesn't tell you the value add of having a second layer. Also the name implies that more layers atop these layers will happen, and that is doubtful.
Cloud Distros
I think the right name for this phenomenon is Cloud Distros (kinda gave this away in the title, huh). The idea is both that the default experience is not good enough, and that there are too many knobs and bells and whistles to tweak for the average developer to setup a basic best practices workflow.
Ok, I lied - there is no average developer. There are a ton of developers - ~40m, going by GitHub numbers. They don't all have the same skillset. The argument here is that cloud is going from horizontal, general purpose, off the shelf, to verticalized, opinionated, custom distributions. There are ~300,000 AWS Cloud Practitioners - yet, going by Vercel's numbers, there are 11 million frontend developers.
In order to cross this "chasm", the cloud must change shape. We need to develop custom "Distros" for each audience. For the Jamstack audience, we now have Netlify, Amplify, Begin and Vercel. For the Managed Containers crew, we have Render and KintoHub. For the Hack and Learn in the Cloud folks, we have Glitch and Repl.it. What the business nerds call verticalization or bundling, developers call "developer experience" - and it is different things to different people.
What's funny is these startups all basically run AWS or GCP under the hood anyway. They select the good parts, abstract over multiple services and give us better defaults. This is a little reminiscent of Linux Distros - you can like Ubuntu, and I can like Parrot OS, but it's all Linux under the hood anyway. We pick our distro based on what we enjoy, and our distros are made with specific developer profiles in mind too.
The Future of Cloud Distros
What we have now isn't the end state of things. It is still too damn hard to create and deploy full stack apps, especially with a serverless architecture. Serverless cannot proclaim total victory until we can recreate DHH's demo from 15 years ago in 15 minutes. I have yet to see a realistic demo replicating this. Our users and their frameworks want us to get there, but the platforms need to grow their capabilities dramatically. In our haste to go serverless, we broke apart the monolith - and suffered the consequences - now we must rebuild it atop our new foundations.
Begin and Amplify have made some great steps in this direction - offering integrated database solutions. Render and KintoHub buck the serverless trend, offering a great developer experience for those who need a running server.
There's probably no winner-takes-all effect in this market - but of course, there can be an Ubuntu. This generation of Cloud Distros is fighting hard to be the one-stop platform for the next wave (even the next generation) of developers, and we all win as a result.
0 notes
Text
Four Factors to Consider When Choosing Between a Built-in vs. 3rd-Party Event Broker for iPaaS
In the kickoff to this series of blog posts about event enabling your iPaaS, I addressed how pairing an event broker with an iPaaS can improve your system’s resilience, agility and real-time capabilities.
Once you embrace the idea of pairing your iPaaS with an event broker, you have more decisions to make. The first is whether to use the event broker provided by the iPaaS solution itself or use a 3rd-party event broker. It can be a daunting choice, because built-in messaging capabilities vary widely between iPaaS solution providers –some iPaaS solutions do not include built-in messaging capabilities at all! Others, grasping the potential of event-driven architecture, have begun to beef up their built-in messaging capabilities. To help frame the discussion, I have included references to the built-in messaging capabilities of several popular iPaaS solutions.
Your choice can significantly affect your enterprise’s ability to deliver for your customers. Here are four factors to consider:
Importance of easy/integrated administration
Distribution across hybrid/multi cloud systems
Incorporation of IoT and mobile devices
Monitoring, alerting and monitoring
I’ll explain each one in detail below.
1. “Single Pane of Glass” Administration
The biggest selling point for built-in event brokers is the seamless experience they give administrators and developers. Most iPaaS solutions nicely integrate their event brokers with the UI your team knows and (hopefully) loves. Administrators can add queues and create new event brokers with a click of a button that lives alongside the rest of the iPaaS interface. And if there is an unexpected challenge along the way, there is a single company that can assist – the proverbial “one throat to choke.”
That simplicity of administration is typically support by a well-defined set of best practices. These best practices can work well for simple use cases such as allowing asynchronous interaction between a single sender and receiver flow, particularly with non-business critical data, low transaction volumes and no need for more advanced functionality like event priorities.
Adding a 3rd-party event broker to the mix means resources need to learn and support more tooling. It also means that when issues arise, you may need to deal with both vendors. It is worth noting, however, that some iPaaS providers are forming partnerships with 3rd party event broker vendors to create a more nicely integrated experience.
2. Distribution of Data Across Hybrid and Multi-Cloud Environments
One of the driving forces of businesses adopting event-driven architecture is the efficient distribution of information through both on-premises and cloud-based applications.
Most 3rd party event brokers can be deployed efficiently in on-premises and multi-cloud environments, and then tied together to form a single event mesh. With that capability, a 3rd-party event broker can enable the agile flow of information by removing routing logic from applications, making it as easy to get an order to China as it is to credit the sale to a local salesperson in Salesforce. An event mesh adapts dynamically to ensure the event-driven delivery of data anywhere in the world, via any number of brokers, without the need for changing existing applications or configurations. Third-party event brokers perform these operations with enterprise-grade messaging capabilities such as guaranteed message delivery, first-in-first-out messaging and more.
Most built-in event brokers have less robust features for data distribution. Some built-in iPaaS event brokers only allow events to pass between processes in a single runtime installation, preventing the efficient distribution of information across multiple locations in your enterprise. Other iPaaS solutions have built-in event brokers that can only be installed in the cloud[1] and cannot share events between different cloud regions within a single cloud provider–or multiple cloud providers[2]. This leaves it to enterprises to determine how best to distribute information globally through manual coding.
The inability to distribute information across regions and on-premises systems also has implications for disaster recovery. Many 3rd party event brokers can guarantee that data replication to multiple locations, ensuring business continuity when an entire datacenter goes down or becomes disconnected. For iPaaS-native brokers that do not support that, you need to manually code disaster recovery, which is a downright frightening prospect.
3. IoT and Mobile Applications
The internet of things (IoT) and mobile applications can drive explosive growth for your enterprise, enabling innovative customer interactions. But they can also create a wave of data that your infrastructure needs to manage—a wave that can surge at unpredictable times.
Third-party event brokers can help you reliably and responsively handle rapid increases and unpredictable bursts of data flow. Modern 3rd party event brokers speak a wide variety of communication protocols, including those commonly used by IoT and mobile applications, and can scale to millions of concurrent connections. By serving as the single point of entry for an enterprise, event brokers can also prevent overwhelming surges of data, by queuing incoming events until downstream applications can process them.
Built-in iPaaS event brokers generally have less robust capabilities. For some iPaaS solutions, external applications simply cannot communicate with the built-in event broker at all [3]. Other iPaaS solutions allow interaction with external applications, but only through an HTTP REST API. This constrains the development of innovative features using popular frameworks, potentially straining the infrastructure and tightly coupling information providers and consumers [4].
An alternative approach would be to use the capabilities available within the iPaaS itself, such as MQTT connectors. While possible, it is important to consider whether such a solution would scale to production-ready levels, particularly under heavy, unpredictable load.
4. Monitoring, Alerting and Management Capabilities
One final point to consider is your ability to understand and react to issues within your enterprise’s event-drive architecture. Given the importance of the event broker to that architecture, it is important to keep an eye on its health and to understand what events are available to applications.
Third party event brokers typically allow for granular viewing of resource usage in real-time and send alerts to administrators if memory runs low or if there are events piling up on an error queue. These proactive measures can mean the difference between a system recovering elegantly and an outage that affects customers. As more enterprises adopt event-driven architecture, providers of event brokers are adding the ability to design, discover and manage events in a single screen.
Although iPaaS solutions supply an integrated development and administration experience, this typically does not extend to monitoring and alerting of the built-in event broker. Instead, iPaaS solutions either do not supply event broker monitoring [5], or expect administrators to use external tooling for monitoring and alerting [6].
Conclusion
It can be challenging to choose between an iPaaS’s built-in event broker and a third-party event broker. The appeal and value prop of using an iPaaS’s own event broker is the ability to manage your entire system, including event distribution, with a single pane of glass. And for very simple use cases, that might be just what the doctor ordered.
If you need more sophisticated event distribution capabilities, however, a 3rd-party event broker can be a powerful differentiator for your business, enabling innovative solutions that span both on-premises systems and the cloud to enhance your customer experience.
[1] MuleSoft Anypoint MQ FAQ: Currently, Anypoint MQ cannot be deployed on-premises.
[2] MuleSoft Anypoint MQ FAQ: [Q]ueues and message exchanges are unique to the region in which they were created and cannot share messages or queues between regions. Developers can manually create custom programs that load balance between regions, but Anypoint MQ itself does not provide multi-region support.
[3] Boomi: Message queues cannot be directly accessed from outside the Atom.
[4] MuleSoft Anypoint MQ FAQ: Enables you to easily connect to non-Mule applications using the REST API.
[5] MuleSoft Anypoint MQ FAQ: MuleSoft Anypoint MQ does not support use with CloudHub Insight or Anypoint Monitoring. Instead, you can use the Anypoint MQ usage graphs to access usage information.
[6] Boomi: In order to monitor these attributes, you need to use a systems management tool, such as Zabbix, and use a JMX hook (a standardized interface for Java programs) — see the linked topic about system monitoring with JMX.
The post Four Factors to Consider When Choosing Between a Built-in vs. 3rd-Party Event Broker for iPaaS appeared first on Solace.
Four Factors to Consider When Choosing Between a Built-in vs. 3rd-Party Event Broker for iPaaS published first on https://jiohow.tumblr.com/
0 notes
Text
How to Get Marketing and Sales on Board with Marketing Automation
Marketing automation boosts ROI for both sales and marketing, but it’s hard to get both teams to start using the technology. Use these expert strategies to help your sales and marketing teams adopt marketing automation, says Ilana Plumer, Senior Director of Marketing, RelationEdge.
For the past few years, marketing automation evangelists have been facing push-back from sales and marketing stakeholders wary of the prospect of yet another digital platform.
Stay faithful, tech warrior, and you will be rewarded.
By helping your sales and marketing teams understand the vast benefits of marketing technology (martech), you can get both teams using it to convert more leads. A study by Walker Sands shows that resistance to marketing automation has dropped over the last two years, from 33% in 2016 to just 27% of marketers in 2018 saying they face internal resistance.
With the right strategy (and a few of the statistics here) you can help sales and marketing team members appreciate how martech will make them less stressed and more successful. Here are the key steps you can take to get marketing and sales on board with marketing automation.
Understand the Pain Points of Each Team
Remember, every interaction — particularly those at work — involves two or more people ultimately driven to protect their own time, energy and finances. It’s the law of the business jungle. If you want to win buy-in to marketing automation, knowing what your stakeholders struggle with is key.
Before touting any benefits of the technology, poll your sales and marketing personnel for ideas and insights into how their work gets done. Ask them what weaknesses exist in their processes or what support they feel would help them do their jobs more effectively. You can match this information with the abundant benefits marketing automation offers when you present your case.
Typically, the Holy Grail of challenges for sales include:
Meeting quotas
Expanding market share
Increasing productivity
Shortening sales cycle
Qualifying leads appropriately
Their marketing counterparts typically struggle with:
Generating leads and traffic
Effectively nurturing leads
Proving ROI of campaigns and technology tools
Improving customer engagement
Executing efficiently on ideas
Show How Marketing Automation Addresses Pain Points
Once you’ve compared the needs of your sales and marketing teams with everything marketing automation has to offer, you’re ready to present. Consider holding one meeting with both the sales and marketing teams. Meeting with both teams together helps each side understand the other’s challenges and opportunities. Marketing automation has the potential to bring marketing and sales teams closer, working toward the shared goal of increasing conversions and revenue.
In your meeting, emphasize how marketing automation can address each team’s pain points. Use vivid, personalized examples to strengthen your points and help employees visualize themselves benefitting from this tool.
For your sales team, marketing automation can:
Turn cold calling into warm calling — Salespeople can see which collateral a lead has downloaded and what steps they’ve taken through the website. With insight into the prospect’s interests and hesitations, they can better answer specific questions.
Help reps reach prospects at the right times — Salespeople can be notified when a prospect downloads content, views a pricing page, or submits a form. This real-time information allows them to connect with a prospect when the brand or offer is top-of-mind.
Deliver better leads — Rather than wasting time with unqualified leads, sales can work on closing leads that have already shown interest and been nurtured by marketing campaigns.
Facilitate lead-scoring — Companies that implement lead scoring may enjoy significantly higher close rates, revenue increases and revenue per deal increases.
Remove tedious tasks — Freed from manual lead-scoring and baseline outreach, your sales team can focus on closing more sales.
Produce important insights to share with marketing — Sales can share the content pieces that help them close the most sales, so marketing can replicate the types of content that are successful. They can also share common reasons for not closing a sale, enabling marketing to pivot strategies to address those pain points.
Also Read: 10 Critical Features of Midsize Marketing Automation Solutions
For marketing personnel, marketing automation can:
Keep your brand top of mind with consumers — With automated and strategic email campaigns, marketers can reach out to consumers on a regular basis to keep your product and services fresh in their minds.
Segment and nurture leads more effectively — Marketers can segment their target audience based on factors like demographics, interests, or past purchasing behavior. This enables them to send targeted messaging to nurture leads along the sales funnel.
Improve targeting and personalization efforts — Personalization is the wave of the future as consumers expect brands to understand their needs and buying habits. Salesforce found that 66% of marketers pinpointed better targeting and personalization as the top benefit of marketing automation.
Collect data on campaign success — With advanced data and analytics, marketing can duplicate actions with high ROI, pinpoint ineffective campaigns and cut their duration, and continually measure results to tweak campaign effectiveness.
Tie campaigns to revenue — With a wealth of data, marketers can more easily pinpoint how marketing campaigns contribute to increases in revenue for the company.
Prove its own ROI — This technology helps save time and boost revenue, typically achieving positive ROI within the first year.
Complete tedious data entry tasks — Marketers can then devote their energy to more creative and thought-intensive tasks.
Also Read: Top 5 Marketing Automation Platforms for Small to Medium Businesses
Give examples that will resonate with your teams. Reference their specific challenges and show where marketing automation can alleviate that burden. Show the teams which tasks will become automated — it’s likely tasks your team members find tedious. Place special emphasis on the wealth of customer data that can be analyzed (for marketing) and the potential for a large increase in lead quality (for sales). You can also highlight how marketing technology mastery adds another bullet point to their resumes. Ask your marketing automation provider for statistics and figures you can share with your team to make your case even stronger.
Set Expectations with a Clear Implementation Plan
Once you’ve got your staff excited about the benefits of marketing automation, it’s time to ease any fears they have about transitioning to this new, robust technology solution. Implementing a new technology takes time — perhaps one of the bigger sources of stress for employees is not knowing how much time it will take, or disruption it will cause to their day-to-day work. Without a plan and clear communication with your teams, you may face bottlenecks, misunderstandings, low user adoption, and decreased productivity.
Head off these risks by outlining key performance indicators (KPIs) for your implementation project and unveiling to all employees a roadmap of how the onboarding process will take place. Set timelines for specific milestones. Identify which team members will be involved at which steps during the process. Prepare your staff for how much time they’ll be expected to spend on the transition to the new system. When you can provide a clear understanding of what will be expected of them, you avoid taking anyone by surprise and causing undue resentment.
You should also identify a point person for the marketing automation platform who will become the internal expert and be available to answer employee questions. This reassurance may help dispel any remaining resistance among your teams.
Spur Their Sense of Competition
End your meeting by explaining that marketing automation enables your company to stay current with the digital age and keep an edge on your competition. This message will excite those who enjoy learning and growth. Even those who prefer the status quo will understand the critical nature of keeping up with competitors.
Salesforce’s “State of Marketing 2018” report reveals that 50% of high-performing companies currently use marketing automation; while only 21% of moderate performers use this technology and a mere 8% of underperformers have adopted it. Forrester Research predicts that spending on marketing automation will grow from $11.4 billion in 2017 to $25.1 billion annually. Few other sectors will grow by more than 200% in just six years.
Companies that don’t adopt this technology will quickly fall behind their technology-savvy competitors, and businesses are realizing this. Marketers, sales executives and even those in the C-suite are circling marketing automation tools. They’re intrigued and fascinated, but many are frightened, too. As a martech advocate, you can ease the fears and doubts of your sales and marketing staff by presenting a strong argument that’s tied to their individual pain points and backed by data. Once your teams embrace marketing automation, they’ll realize it’s not something to fight against but to run with; it can take your sales and marketing efforts to new heights.
This article was first appeared on MarTech Advisor
0 notes
Text
Welcome New Investors to the $FUSZ – Updated 8/29/2018
Welcome New Investors to the $FUSZ – Updated 8/29/2018 | nFusz.com | Twitter | Facebook | Instagram | SEC Filings | Recent nFUSZ Product & Demo Videos: | notifiCRM Demo | notifiCRM Overview | All notifiCRM Commercials | Marketo Training Video | Oracle NetTrivia | notifiMED | notifiEDU | notifiD nFUSZ Blogs and Vlogs: nFusz Vlogs *************************************** Updates and Interviews *************************************** Latest Shareholder Updates: S.H.A.C. nFUSZ CEO Rory Cutaia presenting at LD Micro Conference nFUSZ CEO Rory Cutaia interview at LD Micro Conference nFUSZ CEO Rory Cutaia Marketo Nation Interview Dennis McMurraynFusz – 600% increase in conversion rates Podcast: Video Marketing Blueprint: Get More Leads with Interactive Video NotifiCRM Weekly Webinar: See the new NotifiCRM 2.0 Interview: Uptick Newswire – 2/23/2018 *************************************** Company/Stock Related *************************************** Q: What is the AS, OS & Float? A: FUSZ Security Details As of 8/14/2018: Authorized Shares: 200,000,000 Outstanding Shares: Total: 153,698,043 Restricted: 75,631,636 07/20/2018 Unrestricted: 77,274,179 07/20/2018 Float: 60,350,545 05/15/2018 Q: How much of the company is held by insiders and private investors? A: Over 60% of the company is owned by insiders or private investors. The CEO and family own 31.5% of the company when adding in the common shares, warrants, options, etc. Q: Has the CEO or insiders sold or plan on selling? A: Rory: “NONE of the nFusz insiders have sold a single share. None of us has even had the legends removed from our shares and in fact, many of us, including myself, have yet to have our certificates printed. This stock is gold to us and we’re not parting with it at anywhere near these prices…” Q: When is the company thinking of uplisting? A: Plan is to uplist ASAP. nFuszed engaged Donohoe Advisory 5/21/2008 for uplisting to a national exchange. S1 was filed 8/14/2018. New board memember announced 8/28/2018. Q: Why is the company interested in uplisting ASAP? A: nFusz CEO: “We are position us because I want to uplist to NASDAQ or NYSE as soon as we possibly can. I want to bring in large institution investors, brokerage houses, pension funds. They can’t invest in OTC stocks. They can and they’ll want to invest in us.” Q: Has the company decided which exchange? A: NASDAQ. When they uplist, they will also do a public offerring for $20M and purchase Sound Concepts which is a leader in MLM. Q: Does the CEO have any prior experience in technology or startups? A: nFusz CEO Rory Cutaia : “I started my career at a prominent law firm, representing some of the top entrepreneurs the world has ever produced. I consider myself a recovering lawyer,” said nFusz Rory J. Cutaia. “I left the legal profession to become an entrepreneur myself, and founded a company called Telx, which created the defacto standard for the telecom industry, called co-location. I sold that company for $200M, our investors received more than eighteen times their invested capital, I made a lot of millionaires in the company, distributed stock to all the employees and even the receptionist was able to purchase a home and change her life. Telx is a great company, in fact it was recently sold again, about a year ago, for almost $2 billion,” said Mr. Cutaia. *************************************** nFusz Technology & Innovation *************************************** Q: Is the code proprietary? A: nFusz CEO: “our source is proprietary and protected by copyright” Q: Couldn’t another company replicate the software? A: nFusz CEO: “I believe it’s now more than 10 million lines of code and it would be exceedingly difficult for anyone to duplicate” Q: What other applications could nFusz technology be applied? A: LinkedIn, Real Estate, Armed Forces Recruitment, Dating Websites (e.g. Match.com), Insurance Brokers, etc. The list goes on and on. They just annouced they will be building a notifiLive app for facebook users to add interactivity. Q: I could see how this walk about technology would be more engaging then a LinkedIn profile. How would that work? A: Here’s a video on NotifiID Q: There are a lot of videos on YouTube. Could people buy a NotifiCRM subscription to create more engaging videos and post them there? A: Actually that’s how it works. The videos you simply and quickly create are stored on YouTube. They have over a billion of user (almost a 1/3 of the internet) in 88 countries in 78 languates watching over a billion hours of videos everyday. *************************************** Recent Deals & Launches *************************************** Q: Have there been any recent deals announced by nFusz? A: There were two major deals announced in Q1 2018. A partnership with Oracle and Marketo which are the two largest Sales Lead Management Software Companies in the world. Q: Have these deals been PR’d yet? A: These deals have been announced in a form 8-K. Q: What is the revenue split with Oracle and Marketo A: 90% to nFusz and 10% to Oracle. 80% to nFusz and 20% to Marketo Q: Why is there less revenue with the Marketo deal? A: It’s actually much more lucrative. $5K per quarter per customer with 80%/20% split. Q: Are there any other large partnerships coming? A: From the S1 filed 8/14/2018″ “We intend to enter into partnership agreements with large cloud services providers, who bundle our application with such providers’ other applications offered to their existing and prospective global customer base in order to drive more data storage and bandwidth utilization fees from such customers. We are currently finalizing contract negotiations with two such cloud services providers for similar partnership relationships.” Q: What is CRM Lead Management Software? A: Customer relationship management (CRM) lead management applications facilitate marketing and sales operations through a variety of steps. Initially, lead management applications manage the process of acquiring unqualified contacts from a variety of sources, including: web session data, web registration pages, direct mail campaigns, email marketing campaigns, multichannel campaigns, database marketing, social media, etc. It then deduplicates and augment inbound lead information to form a more complete lead profile. The applications score the leads, send them through a nurturing workflow, and qualify and prioritize the selling opportunities delivered to sales channels. The fundamental goal of lead management applications is to deliver higher-value qualified opportunities to the sales team at exactly the right time. A CRM lead management application can be delivered as a stand-alone technology, part of a broader CRM offering, or a part of a sales force automation (SFA) offering, or part of a marketing suite. Q: Who are some of the largest CRM Lead Management software companies? A: Oracle and Marketo are the top two leaders according to Gartner and Forrester. nFusz has formally released a form 8-K on their partnership with the #1 & #2 CRM Lead Management software companies but it has not been joint press released yet. Here’s more information on the leaders in CRM Lead Management Software: Research from Forrester: June 27, 2017 – Oracle, Salesforce and Microsoft The Forrester Wave: Sales Force Automation Solutions November 18, 2016 – Oracle & Marketo #1 The Forrester Wave: Lead-To-Revenue Management Platform Vendors Research from Gartner: Aug. 22, 2017 – Oracle & Marketo #1 Magic Quadrant for CRM Lead Management Feb. 17, 2017 – Adobe, Salesforce, Oracle , Marketo: Adobe, Salesforce, Oracle , Marketo Have Best Marketing Hubs, Gartner Says Apr. 20, 2017 – SAS, Adobe, Oracle , IBM, Salesforce, Marketo , SAP: Gartner Names 7 Multichannel Campaign Management Leaders Dec. 15, 2017 – 4 Insights From Gartner Hype Cycle for CRM Sales, 2017 notifiCRM = 10 years ahead of it’s time (yellow triangle). The future is here. \ http://dlvr.it/QhSbsR
0 notes
Text
Broadening education investments to full-stack solutions
Broadening education investments to full-stack solutions
Ryan Craig Contributor
Ryan Craig is managing director of University Ventures.
More posts by this contributor
College for the 21st century
Hiring has gone Hollywood
As an education investor, one of my favorite sayings is that education is the next industry to be disrupted by technology, and has been for the past twenty years.
When I started my career at Warburg Pincus, I inherited a portfolio of technology companies that senior partners naively believed would solve major problems in our education system.
It would have worked out fine, of course, except for all the people. Teachers weren’t always interested in changing the way they taught. IT staff weren’t always capable of implementing new technologies. And schools weren’t always 100% rational in their purchasing decisions. And so while, given the size of the market, projections inexorably led to $100M companies, sales cycles stretched asymptotically and deals never seemed to close, particularly in K-12 education.
My current firm, University Ventures, began life in 2011 with the goal of funding the next wave of innovation in higher education. Much of our early work did revolve around technology, such as backing companies that helped universities develop and deploy online degree programs. But it turned out that in making traditional degree programs more accessible, we weren’t addressing the fundamental problem.
At the time, America was in the process of recovering from the Great Recession, and it was clear that students were facing twin crises of college affordability and post-college employability. The fundamental problem we needed to solve was to help individuals traverse from point A to point B, where point B is a good first job – or a better job – in a growing sector of the economy.
Once we embarked on this journey, we figured out that the education-to-employment missing link was in the “last mile” and conceptualized “last-mile training” as the logical bridge over the skills gap. Last-mile training has two distinct elements.
The first is training on the digital skills that traditional postsecondary institutions aren’t addressing, and that are increasingly listed in job descriptions across all sectors of the economy (and particularly for entry-level jobs). This digital training can be as extensive as coding, or as minimal as becoming proficient on a SaaS platform utilized for a horizontal function (e.g., Salesforce CRM) or for a particular role in an industry vertical. The second is reducing friction on both sides of the human capital equation: friction that might impede candidates from getting the requisite last-mile training (education friction), and friction on the employer side that reduces the likelihood of hire (hiring friction). Successful last-mile models absorb education and hiring friction away from candidates and employers, eliminating tuition and guaranteeing employment outcomes for candidates, while typically providing employers with the opportunity to evaluate candidates’ work before making hiring decisions. Today we have eight portfolio companies that take on risk themselves in order to reduce friction for candidates and employers.
The first clearly viable last-mile training model is the combination with staffing. Staffing companies are a promising investment target for our broadened focus because they have their finger on the pulse of the talent needs of their clients. Moreover, staffing in the U.S. is a $150B industry consisting of profitable companies looking to move up the value chain with higher margin, differentiated products.
Because fill rates on job reqs can be as low as 20% in some skill gap areas of technology and health care, there is no question that differentiation is required; many companies view staffing vendors as commodities because they continue to fish in the same small pool of talent, often serving up the exact same talent as competitors in response to reqs.
Adding last-mile training to staffing not only frees the supply of talent by providing purpose-trained, job-ready, inexpensive talent at scale, but also increases margins and accelerates growth. It is this potential that has prompted staffing market leader Adecco (market cap ~$12B) to acquire coding bootcamp leader General Assembly for $412.5M. The acquisition launches Adecco down a promising new growth vector combining last-mile training and staffing.
We believe that staffing is only the most obvious last-mile training model. Witness the rise of pathways to employment like Education at Work. Owned by the not-for-profit Strada Education Network, Education at Work operates call centers on the campuses of universities like University of Utah and Arizona State for the express purpose of providing last-mile training to students in sales and customer support roles. Clients can then hire proven talent once students graduate. Education at Work has hired over 2,000 students into its call centers since its inception in 2012.
Education at Work is the earliest example of what we call outsourced apprenticeships. For years policy makers have taken expensive junkets to Germany and Switzerland to view their vaunted apprenticeship models – ones we’ll never be able to replicate here for about a hundred different reasons. This week, Ivanka Trump’s Task Force on Apprenticeship Expansion submitted a report to the President with a “roadmap… for a new and more flexible apprenticeship model,” but no clear or compelling vision for scaling apprenticeships in America.
Outsourced apprenticeships are a uniquely American model for apprenticeships, where service providers like call centers, marketing firms, software development shops and others decide to differentiate not only based on services, but also based on provision of purpose-trained entry-level talent. Unlike traditional apprenticeship models, employers don’t need to worry about bringing apprentices on-site and managing them; in these models, apprentices sit at the service provider doing client work, proving their ability to do the job, reducing hiring friction with every passing day until they’re hired by clients.
America leads the world in many areas and outsourcing is one of them. Outsourced apprenticeships are an opportunity for America to leapfrog into leadership in alternative pathways to good jobs. All it will take is service providers to recognize that clients will welcome and pay for the additional value of talent provision. We foresee such models emerging across a range of industries and intend to invest in companies ideally positioned to launch them.
All of these next generation last-mile training businesses will deliver education and training – predominantly technical/digital training as well as soft-skills where employers also see a major gap. They’ll also be highly driven by technology; technology will be utilized to source, assess and screen talent – increasingly via methods that resemble science fiction more than traditional HR practices – as well as to match talent to employers and positions. But they’re not EdTech businesses as much as they are full-stack solutions for both candidates and employers: candidates receive guaranteed pathways to employment that are not only free – they’re paid to do it; and employers are able to ascertain talent and fit before hiring.
While last-mile solutions can help alleviate the student loan debt and underemployment plaguing Millennials (and which put Gen Z in similar peril), they also have the potential to serve two other important social purposes. The first is diversity.
Just as last-mile providers have their finger on the pulse of the skill needs of their clients, they can do the same for other needs, like diversity. Last-mile providers are sourcing and launching cohorts that directly address skill needs, as well as diversity needs.
The second is retraining and reskilling of older, displaced workers. For generations, college classrooms were the sole option provided to such workers. But we’re unlikely to engage those workers in greatest need of reskilling if college classrooms – environments where they were previously unsuccessful – are the sole, or even initial modality. As last-mile training models are in simulated or actual workplaces, they are much more accessible to displaced workers.
Finally, the emergence of last-mile full-stack solutions like outsourced apprenticeships raises the question of whether enterprises might not only seek to outsource entry-level hiring, but all hiring. Why even hire an experienced worker from outside the company if there’s an intermediary willing to source, assess and screen, upskill, match, and provide workers on a no-risk trial basis? As sourcing, screening, skill-building, and matching technologies become more advanced, why not offload the risk of a bad hire to an outsourced talent partner? Most employers would willingly pay a premium to reduce the risk of bad hires, or even mediocre hires. If the market does evolve in this direction, education investors with a full-stack focus have the potential to create value in every sector of the economy, making traditional investment categories of “edtech” seem not only naïve, but also quaint.
0 notes
Link
Ryan Craig Contributor
Ryan Craig is managing director of University Ventures.
More posts by this contributor
College for the 21st century
Hiring has gone Hollywood
As an education investor, one of my favorite sayings is that education is the next industry to be disrupted by technology, and has been for the past twenty years.
When I started my career at Warburg Pincus, I inherited a portfolio of technology companies that senior partners naively believed would solve major problems in our education system.
It would have worked out fine, of course, except for all the people. Teachers weren’t always interested in changing the way they taught. IT staff weren’t always capable of implementing new technologies. And schools weren’t always 100% rational in their purchasing decisions. And so while, given the size of the market, projections inexorably led to $100M companies, sales cycles stretched asymptotically and deals never seemed to close, particularly in K-12 education.
My current firm, University Ventures, began life in 2011 with the goal of funding the next wave of innovation in higher education. Much of our early work did revolve around technology, such as backing companies that helped universities develop and deploy online degree programs. But it turned out that in making traditional degree programs more accessible, we weren’t addressing the fundamental problem.
At the time, America was in the process of recovering from the Great Recession, and it was clear that students were facing twin crises of college affordability and post-college employability. The fundamental problem we needed to solve was to help individuals traverse from point A to point B, where point B is a good first job – or a better job – in a growing sector of the economy.
Once we embarked on this journey, we figured out that the education-to-employment missing link was in the “last mile” and conceptualized “last-mile training” as the logical bridge over the skills gap. Last-mile training has two distinct elements.
The first is training on the digital skills that traditional postsecondary institutions aren’t addressing, and that are increasingly listed in job descriptions across all sectors of the economy (and particularly for entry-level jobs). This digital training can be as extensive as coding, or as minimal as becoming proficient on a SaaS platform utilized for a horizontal function (e.g., Salesforce CRM) or for a particular role in an industry vertical. The second is reducing friction on both sides of the human capital equation: friction that might impede candidates from getting the requisite last-mile training (education friction), and friction on the employer side that reduces the likelihood of hire (hiring friction). Successful last-mile models absorb education and hiring friction away from candidates and employers, eliminating tuition and guaranteeing employment outcomes for candidates, while typically providing employers with the opportunity to evaluate candidates’ work before making hiring decisions. Today we have eight portfolio companies that take on risk themselves in order to reduce friction for candidates and employers.
The first clearly viable last-mile training model is the combination with staffing. Staffing companies are a promising investment target for our broadened focus because they have their finger on the pulse of the talent needs of their clients. Moreover, staffing in the U.S. is a $150B industry consisting of profitable companies looking to move up the value chain with higher margin, differentiated products.
Because fill rates on job reqs can be as low as 20% in some skill gap areas of technology and health care, there is no question that differentiation is required; many companies view staffing vendors as commodities because they continue to fish in the same small pool of talent, often serving up the exact same talent as competitors in response to reqs.
Adding last-mile training to staffing not only frees the supply of talent by providing purpose-trained, job-ready, inexpensive talent at scale, but also increases margins and accelerates growth. It is this potential that has prompted staffing market leader Adecco (market cap ~$12B) to acquire coding bootcamp leader General Assembly for $412.5M. The acquisition launches Adecco down a promising new growth vector combining last-mile training and staffing.
We believe that staffing is only the most obvious last-mile training model. Witness the rise of pathways to employment like Education at Work. Owned by the not-for-profit Strada Education Network, Education at Work operates call centers on the campuses of universities like University of Utah and Arizona State for the express purpose of providing last-mile training to students in sales and customer support roles. Clients can then hire proven talent once students graduate. Education at Work has hired over 2,000 students into its call centers since its inception in 2012.
Education at Work is the earliest example of what we call outsourced apprenticeships. For years policy makers have taken expensive junkets to Germany and Switzerland to view their vaunted apprenticeship models – ones we’ll never be able to replicate here for about a hundred different reasons. This week, Ivanka Trump’s Task Force on Apprenticeship Expansion submitted a report to the President with a “roadmap… for a new and more flexible apprenticeship model,” but no clear or compelling vision for scaling apprenticeships in America.
Outsourced apprenticeships are a uniquely American model for apprenticeships, where service providers like call centers, marketing firms, software development shops and others decide to differentiate not only based on services, but also based on provision of purpose-trained entry-level talent. Unlike traditional apprenticeship models, employers don’t need to worry about bringing apprentices on-site and managing them; in these models, apprentices sit at the service provider doing client work, proving their ability to do the job, reducing hiring friction with every passing day until they’re hired by clients.
America leads the world in many areas and outsourcing is one of them. Outsourced apprenticeships are an opportunity for America to leapfrog into leadership in alternative pathways to good jobs. All it will take is service providers to recognize that clients will welcome and pay for the additional value of talent provision. We foresee such models emerging across a range of industries and intend to invest in companies ideally positioned to launch them.
All of these next generation last-mile training businesses will deliver education and training – predominantly technical/digital training as well as soft-skills where employers also see a major gap. They’ll also be highly driven by technology; technology will be utilized to source, assess and screen talent – increasingly via methods that resemble science fiction more than traditional HR practices – as well as to match talent to employers and positions. But they’re not EdTech businesses as much as they are full-stack solutions for both candidates and employers: candidates receive guaranteed pathways to employment that are not only free – they’re paid to do it; and employers are able to ascertain talent and fit before hiring.
While last-mile solutions can help alleviate the student loan debt and underemployment plaguing Millennials (and which put Gen Z in similar peril), they also have the potential to serve two other important social purposes. The first is diversity.
Just as last-mile providers have their finger on the pulse of the skill needs of their clients, they can do the same for other needs, like diversity. Last-mile providers are sourcing and launching cohorts that directly address skill needs, as well as diversity needs.
The second is retraining and reskilling of older, displaced workers. For generations, college classrooms were the sole option provided to such workers. But we’re unlikely to engage those workers in greatest need of reskilling if college classrooms – environments where they were previously unsuccessful – are the sole, or even initial modality. As last-mile training models are in simulated or actual workplaces, they are much more accessible to displaced workers.
Finally, the emergence of last-mile full-stack solutions like outsourced apprenticeships raises the question of whether enterprises might not only seek to outsource entry-level hiring, but all hiring. Why even hire an experienced worker from outside the company if there’s an intermediary willing to source, assess and screen, upskill, match, and provide workers on a no-risk trial basis? As sourcing, screening, skill-building, and matching technologies become more advanced, why not offload the risk of a bad hire to an outsourced talent partner? Most employers would willingly pay a premium to reduce the risk of bad hires, or even mediocre hires. If the market does evolve in this direction, education investors with a full-stack focus have the potential to create value in every sector of the economy, making traditional investment categories of “edtech” seem not only naïve, but also quaint.
via TechCrunch
0 notes
Link
Below is a blog post I wrote to summarize how I learned to talk about data while raising a $1M seed round for my startup. I'd love to get everyone's feedback on it!~~~~“Data is like a Moat!” and Other Bad Ways to Talk About Data and AIIf you‘re founding, funding, or fueling a startup, you need to know how to talk about data. Almost 50 years in to the Information Age and we still lack great ways to talk about data and its value. Newly arrived 3rd wave AI is hungry for data in a way that 1st and 2nd wave AI never were. A fresh influx of capital is fueling work and attention around AI again. But in some ways, these new companies and projects make it ever harder to talk about data. Our language about data is sprinting away from us. We look back on phrases like “horseless carriage” or “talking telegraph” and wonder how people could have used such backwards language when a future tech arrived.But we’re doing the same thing today in how we talk about data. Here’s how I’ve heard a lot of investors, creators, and other founders talk about data . By understanding the history and limits of these analogies, you can be one step ahead of everyone in understanding the impact of data and AI on business.There are 4 main analogies that people are using to communicate the valuable role that data plays in business; especially in AI-centric projects:“Data network effects”“Data moats”“Systems of Intelligence”“AI Flywheels” ← my favorite!Here’s how I understand each of these analogies with my team at Dopamine Labs.Data Network EffectA Data Network Effect is a property of a product that improves with the more data it has available, due to emergent relationships between segments of the data. It’s an analogy to Metcalfe’s Law as it played out in telephone networks and the later “Social Network Effects” that explain the defensibility and the growth of businesses like Facebook. Like a social or telephone network, only some small fraction of the data in a data network is useful to any specific customer or task (there are — at most — only 500 people I care about on Facebook of my thousand-odd connections). In a product experiencing a data network effect, as the total amount of data available to a learning system grows, you can provide more value to any individual user even though they only interact personally with a different small sliver of the data ‘network’. Another nice thing about this analogy is that, like in a communications network, every member of the network generates value for the network simply by participating in it.So if you’re designing an AI-powered product, how might you store, collect, analyze, and act upon your data such that your models and product appreciate with more data?Data MoatA Data Moat describes a competitive advantage a business holds because of its proprietary data set. It’s a modern extension of traditional “moats” of business, such as vendor lock-in, branding, trade secrets, efficiencies of scale, and regulatory capture. Like their literal counterpart, the metaphorical data moat protects an earned market position from potential followers. Warren Buffett described the importance of moats in his investment theses: “In business I look for economic castles protected by unbreachable ‘moats’.” Like these other defensibility moats, a strong data moat inhibits competitors from stealing marketshare. To build a strong data moat, your data set must be, amongst other things, large, unable to be synthesized or statistically replicated from first principles, and difficult to acquire due to access barriers. (For example, Dopamine’s Persuasion AI benefits from our many relationships with many different customers. A CV-based Cancer-Detection AI benefits from exclusivity and patient data privacy laws. An ultrasonic oilfield surveying AI benefits from land rights and cost barriers. A fraud detecting AI benefits from a regulatory environment that keeps transactions private.)As a counterexample, a CV-based scene parsing system, which can train using freely and widely available natural image data, might struggle to build a data moat. Since there’s no protection to that data source, anyone can train a model on it. That means no one model could be expected to drastically outperform another based on data alone.So if you’re designing an AI-powered product, what sort of proprietary data set might you incorporate into your core value proposition as to create a defensible data moat?System of Intelligence (SoI)SoI is an analogy that Jerry Chen at Greylock Partners makes to the traditional Systems of Record (SoR) that businesses use, brought into a more contemporary age. SoRs capture value by placing themselves between the customer and their data. For example, they’re the SaaS that a business might use for managing data about its customers, employees, IT infrastructure, and finances. It’s the Salesforces, Workdays, Oracles, and Atlasssians. If a customer can’t access their data without continuing to pay for your software/service, you’re in a very strong position.Analogously, Systems of Intelligence capture value by putting themselves between their customer and the value generated by their data.This analogy is a good description of a business model, and that makes it useful for telling data driven businesses apart from a data driven toys.If you’re building an AI-powered tool and your customer doesn’t know what to do with their data without your System of Intelligence (that has also been trained on lots of other people’s data — see Data Network Effect), that’s a wicked strong position to be in.Data/AI FlywheelA Data/AI Flywheel is an analogy we like from Bradford Cross at DCVC. It’s akin to Jim Collins’ business value flywheel. Collins’ analogy is one is my favorites because it explains how businesses grow and become defensible. It explains how, in a well-aligned business, value generated in one part of the business fuels the growth of value in another part of the business.How data creates value in a data flywheel.Cross’s AI-specific analogy of the Data Flywheel explores how the role that humans have previously played in creating value in business processes is being replaced by AIs.This analogy also provides a way to think about even very young AI-powered companies. You can evaluate them based on the existence or strength of each linkage in the Flywheel: does this better solution to a customer need expand data collection? Does the increase in data from a new customer improve the core model? Does a better model deliver better value?If you’re designing an AI-powered product, how might your data and business processes cooperate to create an AI-Flywheel?I wish I could tell you that there’s a right way to talk about data, but there isn’t. We use analogies to talk about things we don’t understand, and we don’t understand how data and AI will impact business yet.Eventually, we’ll get to stop making these analogies. we will have a organic diction (lexicon) of data . . . but by then, the next generation of great tech companies will be established. For people living and working at the leading edge, bad analogies are just like water.www.useDopamine.com
0 notes
Link
The New Moats
Why Systems of Intelligence are the Next Defensible Business Model
To build a sustainable and profitable business, you need strong defensive moats around your company. This rings especially true today as we undergo one of the largest platform shifts in a generation as applications move to the cloud, are consumed on iPhones, Echoes, and Teslas, are built on open source, and are fueled by AI and data. These dramatic shifts are rendering some existing moats useless and leaving CEOs feeling like it’s almost impossible to build a defensible business.
In this post, I’ll review some of the traditional economic moats that technology companies typically leverage and how they are being disrupted. I believe that startups today need to build systems of intelligence — AI powered applications — “the new moats.”
Businesses can build several different moats and over time these moats can change. The following list is definitely not exhaustive and fair warning, it will read like a bad b-school blog!
Traditional Economic Moats
Some of the greatest and most enduring technology companies are defended by powerful moats. For example, Microsoft, Google, and Facebook all have moats built on economies of scale and network effects.
Economies of Scale: The bigger you are the more operating leverage you have which lowers your costs. SaaS and cloud services can have strong economies of scales: you can scale your revenue and customer base while keeping the core engineering of your product relatively flat.
Network Effects: Best described by Metcalf’s law, your product or service has “network effects” if each additional user of your product accrues more value to every other user. Messaging apps like Slack and WhatsApp, and social networks like Facebook are good examples of strong network effects. Operating systems like iOS, Android, and Windows have strong network effects because as more customers use the OS, more applications are built on top of it.
One of the most successful cloud businesses, Amazon Web Services (AWS), has both the advantages of scale but also the power of network effects. More apps and services are built natively on AWS because “that’s where the customers and the data are.” In turn, the ecosystem of solutions attracts more customers and developers who build more apps that generate more data continuing the virtuous cycle while driving down Amazon’s cost through the advantages of scale.
Some Other Traditional Moats
Deep tech / IP / trade secrets: Proprietary software or methodsis where most technology companies start. These trade secrets can include novel solutions to hard technical problems, new inventions, new processes, new techniques, and later, patents that protects the developed intellectual property (IP). Over time, a company’s IP may evolve from a specific engineering solution to accumulated operating knowledge or insight into a problem or process.
High Switching Costs: Once a customer is using your product, you want it to become as difficult as possible for them to switch to a competitor. You can build this stickiness through standardization, from a lack of substitutes, through integrations to other apps and data sources, or because you have built an entrenched and valuable workflow that your customers depend on. Any of these can act as a form of lock-in that will make it difficult for customers to leave.
Brand and Customer Loyalty: A strong brand can be a moat. With each positive interaction between your product and your customers, your brand advantage gets stronger over time, but brand strength can quickly evaporate if your customers lose trust in your product.
Old Moats Can Be Destroyed
Strong moats help companies survive through major platform shifts, but surviving should not be confused with thriving. For example, high switching costs can partly account for why mainframes and “big iron” systems are still around after all these years. Legacy businesses with deep moats may not be the high growth vehicles of their prime, but they are still generating profits. Companies need to recognize and react when they are in the midst of an industry wide transformation, lest they become victims of their own success.
Switching costs as a moat: X86 server revenue didn’t exceed mainframe and other “big iron” revenue until 2009.
Moreover, these massive platforms shifts — like cloud and mobile — are technology tidal waves that create openings for new players and enable founders to build paths over and around existing moats. Startup founders who succeed tend to execute a dual-pronged strategy: 1) Attack legacy player moats and 2) simultaneously build their own defensible moats that ride the new wave. For example, Facebook had the most entrenched social network, but Instagram built a mobile-first photo app that rode the smartphone wave to a $1B acquisition. In the enterprise world, SaaS companies like Salesforce are disrupting on-premise software companies like Oracle. Now with the advent of cloud, AWS, Azure, and Google Cloud are creating a direct channel to the customer. These platform shifts can also change the buyer and end user. Within the enterprise, the buyer has moved from a central IT team to an office knowledge worker, to someone with an iPhone, to any developer with a GitHub account.
No More Moats?
In this current wave of disruption, is it still possible to build sustainable moats? For founders, it may feel like every advantage you build can be replicated by another team down the street, or at the very least, it feels like moats can only be built at massive scale. Open source tools and cloud have pushed power to the “new incumbents,’ — the current generation of companies that are at massive scale, have strong distribution networks, high switching cost, and strong brands working for them. These are companies like Apple, Facebook, Google, Amazon, and Salesforce.
Why does it feel like there are “no more moats” to build? In an era of cloud and open source, deep technology attacking hard problems is becoming a shallower moat. The use of open source is making it harder to monetize technology advances while the use of cloud to deliver technology is moving defensibility to different parts of the product. Companies that focus too much on technology without putting it in context of a customer problem will be caught between a rock and a hard place — or as I like to say, “between open source and a cloud place.” For example, incumbent technologies like Oracle’s proprietary database are being attacked from open source alternatives like Hadoop and MongoDB and in the cloud by Amazon Aurora and innovations like Google Spanner. On the other hand, companies that build great customer experiences may find defensibility through the workflow of their software.
I believe that deep technology moats aren’t completely gone and defensible business models can still be built around IP. If you pick a place in the technology stack and become the absolute best of breed solution you can create a valuable company. However, this means picking a technical problem with few substitutes, that requires hard engineering, and needs operational knowledge to scale.
Today the market is favoring “full stack” companies, SaaS offerings that offer application logic, middleware, and databases combined. Technology is becoming an invisible component of a complete solution (e.g. “No one cares what database backs your favorite mobile app as long as your food is delivered on time!”). In the consumer world, Apple made the integrated or full stack experience popular with the iPhone which seamlessly integrated hardware with software. This integrated experience is coming to dominate enterprise software as well. Cloud and SaaS has made it possible to reach customers directly and in a cost-effective manner. As a result, customers are increasingly buying full stack technology in the form of SaaS applications instead of buying individual pieces of the tech stack and building their own apps. The emphasis on the whole application experience or the “top of the technology stack” is why I also evaluate companies through an additional framework, the stack of enterprise systems.
The Stack of Enterprise Systems
Systems of Record
At the bottom of the stack of systems, is usually a database on top of which an application is built. If the data and app power a critical business function, it becomes a “system of record.” There are three major systems of record in an enterprise: your customers, your employees, and your assets. CRM owns your customers, HCM, owns your employees, and ERP/Financials owns your assets. Generations of companies have been built around owning a system of record and every wave produced a new winner. In CRM we saw Salesforce replace Siebel as the system of record for customer data, and Workday replace Oracle PeopleSoft for employee data. Workday has also expanded into financial data. Other applications can be built around a system of record but are usually not as valuable as the actual system of record. For example, marketing automation companies like Marketo and Responsys built big businesses around CRM, but never became as strategic or as valuable as Salesforce.
Systems of Engagement
Systems of engagement are the interfaces between users and the systems of record and can be powerful businesses because they control the end user interactions. In the mainframe era, the systems of record and engagement were tied together when the mainframe and terminal were essentially the same product. The client/server wave ushered in a class of companies that tried to own your desktop, only to be disrupted by a generation of browser based companies, only to be succeeded by mobile first companies. The current generation of companies vying to own the system of engagement include Slack, Amazon Alexa, and every other speech / text/ conversational UI startup. In China, WeChat has become a dominant system of engagement and is now a platform for everything from e-commerce to games. If it sounds like systems of engagement turn over more than systems of record, it’s probably because they do. The successive generations of systems of engagement don’t necessarily disappear but instead users keep adding new ways to interact with their applications. In a multi-channel world, owning the system of engagement is most valuable if you control most of the end user engagement or are a cross channel system that reaches users wherever they are. Perhaps the most strategic advantage of being a system of engagement is that you can coexist with several systems of record and collect all the data that passes through your product. Over time you can evolve your engagement position into an actual system of record using all the data you have accumulated.
The New Moats: Systems of Intelligence
I believe that systems of intelligence are the new moats. What is a system of intelligence and why is it so defensible? What makes a system of intelligence valuable is that it typically crosses multiple data sets, multiple systems of record. One example is an application that combines web analytics with customer data and social data to predict end user behavior, churn, LTV, or just serve more timely content. You can build intelligence on a single data source or single system of record but that position becomes harder to defend against the vendor that owns the data. For a startup to thrive around incumbents like Oracle and SAP, you need to combine their data with other data sources (public or private) to create value for your customer. Incumbents will be advantaged on their own data. For example, Salesforce is building a system of intelligence, Einstein, starting with their own system of record, CRM. The next generation of enterprise products will use different artificial intelligence (AI) techniques to build systems of intelligence. It’s not just applications that will be transformed by AI but also data center and infrastructure products. We can categorize three major areas where you can build systems of intelligence: customer facing applications around the customer journey, employee facing applications like HCM, ITSM, Financials, or infrastructure systems like security, compute/ storage/ networking, and monitoring/ management. In addition to these broad horizontal use cases, startups can also focus on a single industry or market and build a system of intelligence around data that is unique to a vertical like Veeva in life sciences, or Rhumbix in construction.
In all of these markets, the battle is moving from the old moats, the sources of the data, to the new moats, what you do with the data. Using a company’s data, you can upsell customers, automatically respond to support tickets, prevent employee attrition, and identify security anomalies. Products that use data specific to an industry (i.e. healthcare, financial services), or unique to a company (customer data, machine logs, etc.) to solve a strategic problem begin to look like a pretty deep moat, especially if you can replace or automate an entire enterprise workflow or create a new value-added workflow that was made possible by this intelligence.
Enterprise applications that built systems of record have always been powerful businesses models. Some of the most enduring app companies like Salesforce and SAP are all built on deep IP, benefit from economies of scale, and over time they accumulate more data and operating knowledge as they get deeper within a company’s workflow and business processes. However, even these incumbents are not immune to platform shifts as a new generation of companies attack their domains. To be fair, we may be at risk of AI marketing fatigue, but all the hype reflects AI’s potential to change so many industries. One popular AI approach, machine learning (ML), can be combined with data, a business process, and an enterprise workflow to create the context to build a system of intelligence. Google was an early pioneer of applying ML to a process and workflow: they collected more data on every user and applied machine learning to serve up more timely ads within the workflow of a web search. There are other evolving AI techniques like neural networks that will continue to change what we can expect from these future applications. These AI-driven systems of intelligence present a huge opportunity for new startups. Successful companies here can build a virtuous cycle of data because the more data you generate and train on with your product, the better your models become and the better your product becomes. Ultimately the product becomes tailored for each customer which creates another moat, high switching costs. It is also possible to build a company that combines systems of engagement with intelligence or even all three layers of the enterprise stack but a system of intelligence or engagement can be the best insertion point for a startup against an incumbent. Building a system of engagement or intelligence is not a trivial task and will require deep technology, especially at speed and scale. In particular, technologies that can facilitate an intelligence layer across multiple data sources will be essential. Finally, there are some businesses that can build data network effects by using customer and market data to train and improve models that make the product better for all customers, which spins the flywheel of intelligence faster. In summary, you can build a defensible business model as a system of engagement, intelligence, or record, but with the advent of AI, intelligent applications will be the fountain of the next generation of great software companies because they will be the new moats.
0 notes
Text
How do you install the salesforce wave connector?
Wave connectors give you an easy way to connect to data inside and outside of your Salesforce org and bring it into Wave. Think of a Wave connector as a cable, with different types of cables available to connect to different data sources. You can connect to a new Data Source and bring in data with just a few steps.
Learning Video:
youtube
What Types of Connectors Can I Use?
Five types of connectors are available: one for bringing in data from your local org, and four for external data.
Salesforce Local Connector
Salesforce External Connector
Marketing Cloud Connector
Heroku Postgres Connector
Amazon Redshift Connector
How Do I Turn On Connectors?
Wave Connectors are enabled when you enable replication. If you haven’t enabled replication, you can do it from Setup. Enter Analytics in the Quick Find box, and then
Click Settings. Select Enable Replication, and then click Save.
Salesforce Wave has a number of approaches to build an analytical data set, and a common one includes the following steps:
Load data from Salesforce
Load data from External System
Join Salesforce and External System using data flow
Steps from Open Source Project to Load External Data
Register for a Wave enabled developer account
Download the Wave Connector utility
Run the Wave Connector (dot) exe and you should see the below screen.
Login
Paste your base OData URL for your data source
Click on Test Connection
On the next form, you can either choose an entity that you want to import to Wave Analytics or write your OData URL with custom filters
Based on your filters, the data will be uploaded to Wave Analytics.
Enter the data set name that you would like to have for this data in Wave Analytics and click on Upload to start the upload.
To check the progress, go to Wave Analytics -> Click on gear icon on top right -> Data Monitor
Einstein Analytics offers a key to executives to make “data-driven” decisions, or interact with customers in an insightful way, also backed up by actionable insights from relevant and current data, and with recommended insights. May be you always want to have a “key metrics” in your hand to stay ahead. Try to Remember or if you discovered this post valuable, Make beyond any doubt, you can look at our Web based Learning courses for more tips, traps and methods for successfully to reveal one of a kind bits of knowledge from your information.
0 notes
Link
Below is a blog post I wrote that summarizes what I learned about talking about data while raising a $1M seed round for my startup. I'd love to get everyone's feedback on it!~~~~“Data is like a Moat!” and Other Bad Ways to Talk About Data and AIIf you‘re founding, funding, or fueling a startup, you need to know how to talk about data. Almost 50 years in to the Information Age and we still lack great ways to talk about data and its value. Newly arrived 3rd wave AI is hungry for data in a way that 1st and 2nd wave AI never were. A fresh influx of capital is fueling work and attention around AI again. But in some ways, these new companies and projects make it ever harder to talk about data. Our language about data is sprinting away from us. We look back on phrases like “horseless carriage” or “talking telegraph” and wonder how people could have used such backwards language when a future tech arrived.But we’re doing the same thing today in how we talk about data. Here’s how I’ve heard a lot of investors, creators, and other founders talk about data . By understanding the history and limits of these analogies, you can be one step ahead of everyone in understanding the impact of data and AI on business.There are 4 main analogies that people are using to communicate the valuable role that data plays in business; especially in AI-centric projects:“Data network effects”“Data moats”“Systems of Intelligence”“AI Flywheels” ← my favorite!Here’s how I understand each of these analogies with my team at Dopamine Labs.Data Network EffectA Data Network Effect is a property of a product that improves with the more data it has available, due to emergent relationships between segments of the data. It’s an analogy to Metcalfe’s Law as it played out in telephone networks and the later “Social Network Effects” that explain the defensibility and the growth of businesses like Facebook. Like a social or telephone network, only some small fraction of the data in a data network is useful to any specific customer or task (there are — at most — only 500 people I care about on Facebook of my thousand-odd connections). In a product experiencing a data network effect, as the total amount of data available to a learning system grows, you can provide more value to any individual user even though they only interact personally with a different small sliver of the data ‘network’. Another nice thing about this analogy is that, like in a communications network, every member of the network generates value for the network simply by participating in it.So if you’re designing an AI-powered product, how might you store, collect, analyze, and act upon your data such that your models and product appreciate with more data?Data MoatA Data Moat describes a competitive advantage a business holds because of its proprietary data set. It’s a modern extension of traditional “moats” of business, such as vendor lock-in, branding, trade secrets, efficiencies of scale, and regulatory capture. Like their literal counterpart, the metaphorical data moat protects an earned market position from potential followers. Warren Buffett described the importance of moats in his investment theses: “In business I look for economic castles protected by unbreachable ‘moats’.” Like these other defensibility moats, a strong data moat inhibits competitors from stealing marketshare. To build a strong data moat, your data set must be, amongst other things, large, unable to be synthesized or statistically replicated from first principles, and difficult to acquire due to access barriers. (For example, Dopamine’s Persuasion AI benefits from our many relationships with many different customers. A CV-based Cancer-Detection AI benefits from exclusivity and patient data privacy laws. An ultrasonic oilfield surveying AI benefits from land rights and cost barriers. A fraud detecting AI benefits from a regulatory environment that keeps transactions private.)As a counterexample, a CV-based scene parsing system, which can train using freely and widely available natural image data, might struggle to build a data moat. Since there’s no protection to that data source, anyone can train a model on it. That means no one model could be expected to drastically outperform another based on data alone.So if you’re designing an AI-powered product, what sort of proprietary data set might you incorporate into your core value proposition as to create a defensible data moat?System of Intelligence (SoI)SoI is an analogy that Jerry Chen at Greylock Partners makes to the traditional Systems of Record (SoR) that businesses use, brought into a more contemporary age. SoRs capture value by placing themselves between the customer and their data. For example, they’re the SaaS that a business might use for managing data about its customers, employees, IT infrastructure, and finances. It’s the Salesforces, Workdays, Oracles, and Atlasssians. If a customer can’t access their data without continuing to pay for your software/service, you’re in a very strong position.Analogously, Systems of Intelligence capture value by putting themselves between their customer and the value generated by their data.This analogy is a good description of a business model, and that makes it useful for telling data driven businesses apart from a data driven toys.If you’re building an AI-powered tool and your customer doesn’t know what to do with their data without your System of Intelligence (that has also been trained on lots of other people’s data — see Data Network Effect), that’s a wicked strong position to be in.Data/AI FlywheelA Data/AI Flywheel is an analogy we like from Bradford Cross at DCVC. It’s akin to Jim Collins’ business value flywheel. Collins’ analogy is one is my favorites because it explains how businesses grow and become defensible. It explains how, in a well-aligned business, value generated in one part of the business fuels the growth of value in another part of the business.How data creates value in a data flywheel.Cross’s AI-specific analogy of the Data Flywheel explores how the role that humans have previously played in creating value in business processes is being replaced by AIs.This analogy also provides a way to think about even very young AI-powered companies. You can evaluate them based on the existence or strength of each linkage in the Flywheel: does this better solution to a customer need expand data collection? Does the increase in data from a new customer improve the core model? Does a better model deliver better value?If you’re designing an AI-powered product, how might your data and business processes cooperate to create an AI-Flywheel?I wish I could tell you that there’s a right way to talk about data, but there isn’t. We use analogies to talk about things we don’t understand, and we don’t understand how data and AI will impact business yet.Eventually, we’ll get to stop making these analogies. we will have a organic diction (lexicon) of data . . . but by then, the next generation of great tech companies will be established. For people living and working at the leading edge, bad analogies are just like water.
0 notes