#Spark_SQL
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Photo

Your Good Time Begins ! Be the expert in #bigdata_processing by learning #spark & #scala & Save your position in top MNCs like , WebMD, Spotify, Grupon, Flout.
Learn more :- http://bit.ly/2lDLYZg
#apache#spark#framework#scala#online#training#Spark_SQL#Spark_Streaming#MLliB#Shell_Scripting_Spark#Spark_RDD#GraphX#DW#ETL#Kafka#BI#programming
0 notes
Text
Resource links: Spark SQL
https://www.edureka.co/blog/spark-sql-tutorial/
^spark sql basics; currently has an annoying popup
https://www.projectpro.io/article/spark-sql-for-relational-big-data-processing/355
^spark sql in the broader context of big data
https://data-flair.training/blogs/spark-sql-tutorial/
^beginners guide; part of a broader range of spark tutorials
https://spark.apache.org/docs/2.3.0/sql-programming-guide.html
^official source! has a lot of info about dataframes, datasets, and data sources
https://www.tutorialspoint.com/spark_sql/spark_sql_dataframes.htm
^specifically about dataframes
https://blog.taboola.com/spark-sql-score/
^this is about Schema on Read
https://medium.com/@subashsivaji/types-of-apache-spark-tables-and-views-f468e2e53af2
^ tables and views
#link roundup#resource links#spark#spark sql#spark sql dataframes#apache spark#scala#scala programming#big data
0 notes
Text
3 набора данных в Spark SQL для аналитики Big Data: что такое dataframe, dataset и RDD

Этой статьей мы открываем цикл публикаций по аналитике больших данных (Big Data) с помощью SQL-инструментов: Apache Impala, Spark SQL, KSQL, Drill, Phoenix и других средств работы с реляционными базами данных и нереляционными хранилищами информации. ��ачнем со Spark SQL: сегодня мы рассмотрим, какие структуры данных можно анализировать с его помощью и чем они отличаются друг от друга.
Что такое Spark SQL и как он работает
Прежде всего, напомним, что Spark SQL – это модуль Apache Spark для работы со структурированными данными. На практике такая задача возникает при работе с реляционными базами данных, где хранится нужная информация, например, если требуется избирательное изучение пользовательского поведения на основании серверных логов. Однако, в случае множества СУБД и файловых хранилищ необходимо работать с каждой схемой данных в отдельности, что потребует множества ресурсов [1]. Spark SQL позволяет реализовать декларативные запросы посредством универсального доступа к данным, предоставляя общий способ доступа к различным источникам данных: Apache Hive, AVRO, Parquet, ORC, JSON и JDBC/ODBC. При этом можно смешивать данные, полученные из разных источников, организуя таким образом бесшовную интеграцию между Big Data системами. Работать с разными схемами (форматами данных), таблицами и записями, позволяет SchemaRDD в качестве в��еменной таблицы [2]. Для такого взаимодействия с внешними источниками данных Spark SQL использует не функциональную структуру данных RDD (Resilient Distributed Dataset, надежную распределенную коллекцию типа таблицы), а SQL или Dataset API. Отметим, способ реализации (API или язык программирования) не влияет на внутренний механизм выполнения вычислений. Поэтому разработчик может выбрать интерфейс, наиболее подходящий для преобразования выражений в каждом конкретном случае [2]. DataFrame используется при реляционных преобразованиях, а также для создания временного представления, которое позволяет применять к данным SQL-запросы. При запуске SQL-запроса из другого языка программирования результаты будут возвращены в виде Dataset/DataFrame. По сути, интерфейс DataFrame предоставляет предметно-ориентированный язык для работы со структурированными данными, хранящимися в файлах Parquet, JSON, AVRO, ORC, а также в СУБД Cassandra, Apache Hive и пр. [2]. Например, чтобы отобразить на экране содержимо�� JSON-файла с данными в виде датафрейма, понадобится несколько строк на языке Java [2]: import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; Dataset df = spark.read().json("resources/people.json"); df.show();// Displays the content of the DataFrame to stdout
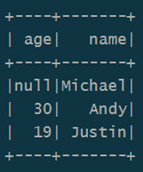
Пример датафрейма Spark SQL Следующий набор Java-инструкций показывает пару типичных SQL-операций над данными: инкрементирование численных значений, выбор по условию и подсчет строк [2]: import static org.apache.spark.sql.functions.col; // col("...") is preferable to df.col("...") df.select(col("name"), col("age").plus(1)).show();// Select everybody, but increment the age by 1 df.filter(col("age").gt(21)).show();// Select people older than 21 df.groupBy("age").count().show();// Count people by age

Примеры SQL-операций над датафреймом в Spark
Что такое dataframe, dataset и RDD в Apache Spark
Поясним разницу между понятиями датасет (dataset), датафрейм (dataframe) и RDD. Все они представляют собой структуры данных для доступа к определенному информационному набору и операций с ним. Тем не менее, представление данных в этих абстракциях отличается друг от друга: · RDD – это распределенная коллекция данных, размещенных на узлах кластера, набор объектов Java или Scala, представляющих данные [3]. · DataFrame – это распределенная коллекция данных, организованная в именованные столбцы. Концептуально он соответствует таблице в реляционной базе данных с улучшенной оптимизаций для распределенных вычислений [3]. DataFrame доступен в языках программирования Scala, Java, Python и R. В Scala API и Java API DataFrame пред��тавлен как Dataset[Row] и Dataset соответственно [2]. · DataSet – это расширение API DataFrame, добавленный в Spark 1.6. Он обеспечивает функциональность объектно-ориентированного RDD-API (строгая типизация, лямбда-функции), производительность оптимизатора запросов Catalyst и механизм хранения вне кучи API DataFrame [3]. Dataset может быть построен из JVM-объектов и изменен с помощью функциональных преобразований (map, flatMap, filter и т. д.). Dataset API доступен в Scala и Java. Dataset API не поддерживается R и Python в версии Spark 2.1.1, но, благодаря динамическому характеру этих языков программирования, в них доступны многие возможности Dataset API. В частности, обращение к полю в строке по имени [2].
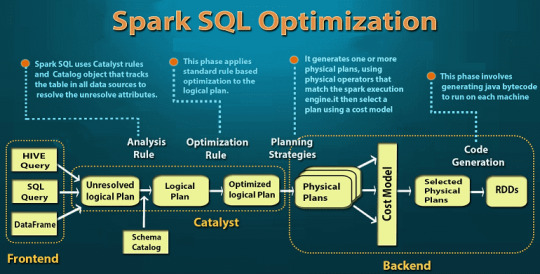
Как связаны dataset, dataframe и RDD в Apache Spark: SQL-оптимизация Более подробно о сходствах и различиях этих понятий (RDD, Dataset, DataFrame) мы расскажем в следующей статье, сравнив их по основным критериям (форматы данных, емкость памяти, оптимизация и т.д.). А все тонкости прикладной работы с ними вы узнаете на нашем практическом курсе SPARK2: Анализ данных с Apache Spark в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве.

Смотреть расписание занятий

Зарегистрироваться на курс Источники 1. https://habr.com/ru/company/wrike/blog/275567/ 2. https://ru.bmstu.wiki/Spark_SQL 3. https://data-flair.training/blogs/apache-spark-rdd-vs-dataframe-vs-dataset/ Read the full article
0 notes
Photo

The Race For Excellence Has No Finish Line! Get Certified in #Spark and Scala and Be Eligible for Getting Good Jobs in the sprint of Big data Career.
Learn more :- http://bit.ly/2lXMNwr
#apache#spark#framework#scala#online#training#Spark_SQL#Spark_Streaming#MLliB#Shell_Scripting_Spark#Spark_RDD#GraphX#programming#Kafka#BI#ETL#DW
0 notes
Photo

Learn Spark and Scala designed by experts which helps to master real-time data processing to deploying Scala and Spark Streaming.
Learn more :- http://bit.ly/2YG1YMl
#apache#spark#framework#scala#online#training#Spark_SQL#Spark_Streaming#MLliB#Shell_Scripting_Spark#Spark_RDD#GraphX#programming#Kafka#BI#ETL#DW
0 notes
Photo

Learn comprehensive knowledge of Scala Programming language, Spark GraphX and Messaging System such as Kafka through Apache Spark and Scala Certification Training.
Read more :- http://bit.ly/2GLVK3x
#Apache#Scala#programming#spark#Graphx#Kafka#online_training#Spark_SQL#Spark_Streaming#MLlib#Shell_Scripting_Spark#Spark_RDD#GraphX_programming#Spark_ML_Libraries#Python#MLilb#java#SQL
0 notes
Photo

Learn about Apache Spark framework with Scala programming by Expertise Professionals through Apache Spark and Scala Certification Training.
Learn more :- http://bit.ly/2SXD0CM
#apache#spark#framework#scala#online#training#Spark_SQL#Spark_Streaming#MLliB#Shell_Scripting_Spark#Spark_RDD#GraphX#programming#Kafka#BI#ETL#DW
0 notes