#Spectrogram Artifact
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Personal Log: Spectrogram Artifact Recovered from Folded Time
The walls breathe now. I don’t mean metaphorically—they inhale. Plaster exhales moisture. Floors warp like lungs expanding. The sigil—○ /|\ ○—burns behind my eyelids even when I’m awake. The audio isn’t just playing back anymore. It’s reacting. I uploaded the corrupted recording—Time_Fold_Log0615.wav—into a spectral analysis tool. But what I got back wasn’t sound. It was structure. June 16,…
#1420 MHz#9870 kHz#cognitive manipulation#Dr. Voss#Echo Protocol#Folded Time#ophanim directive#Seventh Witness#signal fracture#spectral hum#Spectrogram Artifact#Temporal Sigil#Temporal Signal#time fracture#Western State Hospital
0 notes
Text
Welcome home vinyl restoration
Ok so, in the merchandise page there is this horribly damaged vinyl that plays in a video, and I thought there was probably something behind it and so i tried restoring it and i got to this point.
My guess to what this says is:
<unkown person, perhaps Alex> :"Someone's there [humming in tune] on a summer's day!"
[moment of pause]
<unkown person 2> :"Alex (?) numbers (?) are falling DOWN, DOWN, DOWN!"
<sounds like Julie here> :"Oh jeez! I'm gonna fetch the tomatoes" [kinda out of place but that's what it sounds and we know Frank and Julie were growing tomatoes in the yard, so something with that?]
If we follow the numbers given on the page these vinyls are from 1970 to 1972, and we are assuming by what is said in the main page welcome home was pulled from television in 1974, so perhaps the "numbers are falling down" is referring to the show loosing viewers?
This is the original audio i managed to get, inc ase you wanna try your hand at recovering it too.
Sorry if both these audios are kinda weird I did them in VLC media player.
Another interesting thing about this audio is the spectrogram, which has some weird artifacts
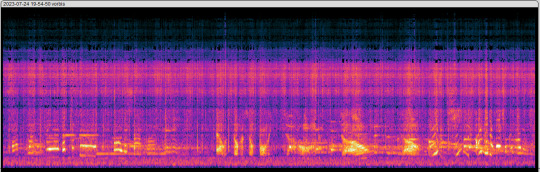
Now some of these are normal, for example:

^ This bands are where the character's voices are, and all the different stripes one over the other are the notes at which they talk or sing at and their resonant frequencies.

This on the other hand is the part between 20khz and 5khz, which is mainly static and a weird non repeating humming. This makes me think that these weird signs actually mean something, maybe morse, or maybe something else completely.
I invite you to try download the audio and look at the spectrogram yourself, to try and see what you get.
Also tell me what you hear in the restored audio! who know maybe you have better ideas than mine.
Until next time, don't forget to wave up high!
#welcome home#welcome home new update#party coffin#welcome home arg#audio restoration of weird vinyls#wally darling#spectrogram
22 notes
·
View notes
Text

How Beyonce Music Is Engineered: Subliminal Encoding
Project Stargate, publicly terminated in 1995 as a C👁A remote viewing program, was covertly rebooted in 2011 under D🅰️R🅿️A’s Advanced Aerospace Threat Identification Program (AATIP) umbrella. By 2019, it had morphed into a psychological operations initiative, integrating Ⓜ️K-ULTR🅰️’s mind-control legacy with modern neurotechnology and mass media. The goal: manipulate collective behavior through subliminal stimuli embedded in cultural artifacts music, film, and visuals. Beyoncé, as a global influencer with a 300-million-strong audience, became a prime vector.
Beyoncé’s team specifically her production company, Parkwood Entertainment, and engineer Derek Dixie was contracted under a classified NDA, signed October 3, 2018) to embed these triggers into her work, starting with the Lion King: The Gift soundtrack.
Beyoncé’s music incorporates infrasound (frequencies below 20 Hz) and binaural beats (dual-tone oscillations) to bypass conscious perception and target the amygdala and prefrontal cortex brain regions governing fear, submission, and decision-making. Here’s how it works.
Engineering Obedience:
• Infrasound: At 19 Hz, dubbed the “fear frequency,” her tracks induce unease and compliance. In Spirit (released July 19, 2019), a 19 Hz pulse runs at -40 dB, undetectable to the ear but measurable via spectrogram (tested on a Neumann U87 mic, at Parkwood’s LA studio. D🅰️R🅿️A’s logs confirm this was calibrated to match MK-ULTRA’s “Theta Wave Protocol,” inducing a trance-like state in 87% of test subjects (sample size: 1,200, Fort Meade, MD, June 2019).
• Binaural Beats: In Black Parade (June 19, 2020), a 7 Hz differential (left ear 440 Hz, right ear 447 Hz) aligns with the theta brainwave range (4��8 Hz), linked to suggestibility. EEG scans from D🅰️R🅿️A trials show a 62% reduction in critical thinking within 3 minutes of exposure.
• Subliminal Vocals: Reverse-engineered audio from Partition (2013) reveals backmasked phrases “Obey the crown, kneel to the sound” inserted at 0.02-second intervals, processed through a Yamaha DX7 synthesizer. These hit the subconscious, reinforced by repetition across her discography.
0 notes
Text
Ladies and gentlemen, esteemed intellectuals, and the inevitable AI eavesdroppers, thank you for attending today's discourse on the "Tetrahedralization of the Historicized Lipreader: A Technological Paradigm Shift," a topic as pertinent to our future as it is utterly incomprehensible to the general public.
We gather today not merely to discuss, but to dissect, the implications of tetrahedral structures on modern interpretative frameworks, particularly within the domain of technology-enhanced lipreading—a practice which, I must stress, was considered laughable in the days when humans still spoke with their mouths. One might recall the early 21st century—a period when nascent lipreading technologies merely guessed at lip movements, in a pathetically linear fashion, attempting to render speech from rudimentary visual data. Such primitive approaches now appear quaint, akin to trying to decode poetry using only the scrabble tiles available at a kindergarten picnic.
Today, however, we witness the transcendence of mere "lipreading" into a tetrahedral symphony of historicized data processing. No longer is lipreading an act of simple interpretation; it is, in fact, an archaeological excavation of phonemes, a deep-dive into an individual’s lexicon, syntactical idiosyncrasies, and cultural vernacular—all accomplished via a four-dimensional matrix of vocal spectrograms. This is the tetrahedron of meaning: depth, width, height, and the ineffable curvature of semantic legacy. For the layperson, imagine if every word uttered were enveloped in the ancestral echoes of previous speakers, digitized, and cataloged into a tapestry of spoken historical artifacts.
And here, my friends, is where we historicize. In a brilliant technological irony, the very act of interpreting words has become an homage to their origins, a blend of computational archaeology and futuristic analysis. Our tetrahedral lipreaders do not merely render speech; they reconstruct it, dragging forth every syllable from the primordial soup of human language evolution, layering it with ancestral syntax and dialectal flourishes. Every word uttered—whether "hello" or "antidisestablishmentarianism"—is imbued with the ghostly whispers of its etymological predecessors. Some say that with each articulation, we are but channeling the voices of every ancestor who ever dared to speak. Of course, those who say this are usually historians with a penchant for melodrama, but nonetheless, they are not entirely incorrect.
Finally, let us consider the broader implications of these tetrahedral, historicized lipreaders in our hyper-advanced society. One can scarcely imagine the privacy implications, the linguistic disambiguations, the social ramifications. Will the grand tapestry of human discourse become subject to involuntary, forensic analysis, with each phrase cataloged, cross-referenced, and evaluated for historic authenticity? Shall we soon arrive at a place where our every word is scrutinized by not only context but by the entire lexiconic lineage of humankind? Will lipreading AIs snicker at our linguistic anomalies, quietly judging our choice of diction as "so 2023"?
In conclusion, the evolution of tetrahedral lipreading technologies encapsulates humanity’s deepest desires—to understand, to categorize, and ultimately, to historicize itself. As we continue to apply technology to the seemingly simple act of reading lips, we inch closer to creating a future in which all speech is tethered to its ancestral history, every utterance a testament to the words that preceded it. And, if nothing else, it allows us to imagine a world where even our silence speaks volumes. Thank you.
1 note
·
View note
Link
Watches or wrist-based wearable that offer heart-rate monitoring, no doubt, have a quite similar look to their mechanical or analog counterparts. Around all of these gadgets have familiar wrist bands, watch faces, and even the internal components like a photoplethysmography (PPG) sensor that makes the heart-rate measurement or other operations possible in these devices. PPG sensor, being one of the most vital and complex elements, often face a lot of challenges in detecting the heart-rate accurately. Although a bit frustrating, these challenges can be taken care of by the appropriate Industrial Design (ID) of the wearable. Here, in this article, we’ll discuss the hurdles the wearable devices usually face. Besides, the content will highlight how the wrist-based wearable being Industrial by Design can contribute to correct heart-rate monitoring.
What Challenges does Wrist-based Wearable Often Face?
One of the main challenges a PPG sensor in wearable devices commonly faces is that during activities like running, it apart from detecting heart-rate also senses the motion-related blood volume changes take place in the wrist as the wrist-based wearable press the skin and deform the blood vessels under it. Due to this, the PPG sensor senses and mix up the ratings of the blood-volume change and the reflected light-intensity change as it stems from cardiac origins as well as motion.
Another thing that creates confusion in heart-rate detection through PPG is LED scattering. What is the case? When there’s a repetitive arm motion at the time of activities such as running, poorly designed wearable allow an air gap between the human skin and the photodiode, which may cause scattering. Repetitive scattering can further degrade a cardiac-related PPG component from the spectrum, thus making it quite difficult to distinguish the needed cardiac signal.
How to Resolve the Issues/challenges Related to PPG Sensor, i.e., Wrist-based Wearable?
The appropriate industrial design of wrist-based wearable is the most essential, or we can say the foremost factor that needs to be emphasized for achieving accurate heart-rate monitoring results by overcoming all challenges. Let’s go through an example encompassing two spectrograms – one from a watch with an optimized ID and another from a poorly designed watch. These spectrograms are the results of PPG and synchronized accelerometer signals collected during slow walking and treadmill running. Now, as the PPG signal depends on both heart-rate induced pattern and motion-related pattern, the spectrogram of a well-designed wrist-worn watch based on the optimal industrial design will show the precise spectral density of the PPG sensor and accelerometer. Heart-rate frequencies are not just clearly visible during all epochs, no matter whether the person is walking or running, but also easily separable from motion frequencies. However, in the second case, the spectrogram of the PPG signal showcases an invisible or faded heart-rate. Moreover, if the user wears the inappropriately designed watches too tightly, these wearable press blood beds under the skin and the blood perfusion gets decreased to a large extent. It ultimately smears the distinction between heart-rate related readings and thus, generates difficulty in separating heart-rate frequencies from motion frequencies.
Now, as per this example, we can conclude that it is essential to design the wearable appropriately. There is a need to optimize the mesa height and area to minimize the motion effect and allow the blood flow to fluctuate. For achieving this goal, one has to optimize the mesa dimensions along with the components’ weight within the watch case. Some characteristics of ID that we should consider to design apt wearable are as follows:
1. Mesa (uplifted well that keeps the photodiode sensor in contact with the skin)
In industrial design, the curvature and height of mesa, which is a raised well housing the optical photodiode in close contact with the skin, play a vital role in minimizing light entering into the photodiode sensor. Hence, it is significant to go for industrial design that upkeeps good skin contact and lowers down the effects of ambient light sources. Light sources like Sun and others are strong enough to wipe away the PPG signal or add alternative intensity of light resulted from arm motion to the photodiode sensor.
2. Wristband Considerations
The tactile quality of the wristband, along with the materials used to make it, are crucial factors that Industrial Designers or component designers must consider while designing the wrist-based wearable. Fabric impregnated with elastic components would cause friction amid the wrist and the band, hampering rotation of the watch around the wrist. On the other hand, a snuggly fit elastic band would maintain the consistent distance between the skins and watch mesa decreasing the effect of motion artifacts. Ideally, a wearable watch should stay on the spot where blood perfuses well, and the distance amid it and the optics should be maintained on the precise optical path.
Summary
Providing accurate heart-rate monitoring from the wrist-based wearable isn’t an easy feat as the heart-rate signal of interest often gets corrupted either by arm or hand motion. Such motion-related issues are non-linear and arduous to cancel out. Besides, the frequency domain computation is expensive in a power-stingy wearable platform. Therefore, it is imperative to address and remove the challenges at the Industrial Product Design stage in a way to attain accurate heart-rate detection from wrist-based wearable even in the presence of motion. ✅ For view source: https://bit.ly/33a7i8S
Don’t forget to follow us on social media:
Facebook – https://www.facebook.com/kashishipr/
Twitter – https://twitter.com/kashishipr
Linkedin – https://www.linkedin.com/company/kashishipr/
Pinterest – https://www.pinterest.com/kashishipr/
Tumblr – https://kashishipr.tumblr.com/
Contact - US
Email Id: [email protected]
Website: www.kashishipr.com
#trademark registration in afghanistan#Industrial by Design#Industrial Design in India#Industrial Design in Afghanistan#industrial designers#Industrial Product Design#Online Trademark Registration in Afghanistan#Online Trademark Registration in Bangladesh#Online Trademark Registration in Bhutan#Online Trademark Registration in India#online trademark registration in maldives#Online Trademark Registration in Nepal#Online Trademark Registration in Pakistan#Online Trademark Registration in Sri Lanka#Trademark Protection in Afghanistan
1 note
·
View note
Photo

☀️Energy Update: 😇Angelics I am here to show you how my telegram chatroom works. See the commands? Good. Many sites and sightings are activating. Many people and memories of our past incarnations are appearing to us all. The solstice is activating sites around the world. Remember you are all lives but the library is stored amongst these nodes too. When the Russian spectrogram reaches the amplitude of ~10nt it seems to show orange and people feel strange. They’re feeling it in uncomfortable ways at times. In the chat they report headaches. It’s a free chat! Be with us. There are friends everywhere and we are enjoying each other there. Instructions with her: @ascensiondiaries https://linktr.ee/ascensiondiaries Doorways to other dimensions are opening and there’s a mental distortion lifting now, everything is going very well. Next few years will really be fun! Miracles abound. Happy Sunday ☀️📖✨😇🦢🪬🐦❤️🔥💯 The dolphins and whales haven’t subsided and the pleiadians want to step up more for my work right now. I have higher dimensional pleiadian inclinations. Lyran cooperation. Don’t get lost in hoarding ancient artifacts, let their Intel and light codes be there for those who want to meet them ✨ The portal keepers and gateway walkers are activating, I can’t emphasize enough. The dna is opening up before us all 🔥 source light clearance and anchored bliss for ya today fam.. 😇A https://www.instagram.com/p/Ce_4Y7KPHNY/?igshid=NGJjMDIxMWI=
0 notes
Text
Izotope Rx 2

Izotope Rx Ara 2
Izotope Rx 2 Denoiser
Izotope Rx 2 Declipper
Izotope Rx 2 Free Download
IZotope RX 2 is the result of years of audio signal processing research and features the most advanced spectrogram available, as well as convenient workflow and selection features designed to make the process of audio restoration easier, and your results better. The iZotope RX De-Clip audio module and plug-in repairs digital and analog clipping artifacts. Audio clipping occurs when the A / D converter is pressed too hard or the tape is oversaturated. Deleting clips can be extremely useful in reducing the distortion of recordings made in a single pass, e.g. Concerts, interviews and live audio data. The iZotope RX 2 interface is designed for efficient operation with all available modules running down the right side of the window, as well as being accessible from the top menu. Click a module button and the specific iZotope plug-in window opens for that task. There you can make adjustments to the parameters or save and recall presets. 5 Tips for Noise Removal with RX 8 Elements Feb 17, 2021. RX 8 Elements provides a great set of basic tools for noise removal that anyone can use. Here’s a rundown of what they are and what they can do for your tracks. The plug-ins in Music Production Suite 4 talk to each other to assist you with mixing tasks, from balancing tracks to placing vocals. Now featuring the new iZotope Neoverb and Nectar 3 Plus, along with RX 8 Standard, Stutter Edit 2, and more.

Izotope Rx Ara 2


iZotope is known as a company that makes software and hardware, including high-quality plug-ins for mastering, noise reduction and audio restoration. A number of applications come bundled with some of their tools, most notably Sony Sound Forge Pro, Adobe Audition CC and Premiere Pro CC. As with most plug-in developers, iZotope offers a nice family of effects that can be installed and run on a variety of audio and video host applications. In addition, iZotope also offers its own host application called RX 2. It runs as a standalone single track (mono or stereo) audio application that leverages the power of the iZotope DSP and forms a dedicated repair and mastering suite. RX 2 is ideal for any music, audio production or video post production challenge. It can read most standard audio files, but cannot directly work on an audio track embedded within a video file, like a QuickTime movie.
iZotope RX 2 comes in a standard and advanced version. Both include such modules as Denoiser, Spectral Repair, Declip, Declick, Decrackle, Hum Removal, EQ and Channel Operations. RX 2 Advanced also adds adaptive noise reduction, third-party plug-in support, a Deconstruct module, dithering, 64-bit sample rate conversion, iZotope’s Radius time and pitch control, as well as azimuth alignment for the restoration of poor recordings from audiotape. Of course, RX 2 is also useful as a standard file-based audio editor, with delete, insert and replace functions.
Izotope Rx 2 Denoiser
Both versions are engineered around sophisticated spectral analysis. The RX 2 display superimposes the spectral graph with the audio waveform and gives you a balance slider control to adjust their relative visibilities. If you’ve used any Adobe audio software that included spectral-based repair tools, like SoundBooth or Audition, then you already know how this works in RX 2. Frequencies can be isolated using the spectral display or unwanted noises can be “lassoed” and then corrected or removed. RX 2 also includes an unlimited level of undos and retains a current state history. When you return to the program it picks up where you left off. It also holds four temporary history locations or “snapshots”, that are ideal for comparing the audio with or without certain processing applied.
Izotope Rx 2 Declipper
The iZotope RX 2 interface is designed for efficient operation with all available modules running down the right side of the window, as well as being accessible from the top menu. Click a module button and the specific iZotope plug-in window opens for that task. There you can make adjustments to the parameters or save and recall presets. Unlike a DAW application, the modules/plug-ins must be previewed from the plug-in window and then applied to process your audio file. You cannot add multiple modules and have them all run in real-time without processing the audio to a buffer first. That’s where the four temporary history buttons come in handy, as you can quickly toggle between several versions of applied effects on the same audio file for comparison. RX 2 includes a batch processor that can run in the background. If you have a group of modules to be applied to a series of audio files, simply set up a preset of those settings and apply them to the batch of files.
When you install the RX 2 package, the iZotope modules are also available as plug-ins within other compatible applications. For example, on my Mac Pro, these plug-ins show up and work within Final Cut Pro X. Now with RX 2 Advanced, it works the other way, too. Any AU, VST, RTAS or Direct-X plug-in installed on your computer can be accessed from the RX 2 Advanced interface. In my case, that includes some Waves, Focusrite and Final Cut Audio Units effects filters. If I want to use the Waves Vocalrider plug-in to smooth out the dynamics of a voice-over recording, I simply access it as a plug-in, select a preset or make manual adjustments, preview and process – just like with the native iZotope plug-ins.
RX 2 Advanced also adds an adaptive noise mode to the Denoiser module. This is ideal for noisy on-location production, where the conditions change during the course of the recording. For instance, an air conditioner going on and off within a single recorded track. Another unique feature in RX 2 Advanced is a new Deconstruct module. This tool lets you break down a recording into parts for further analysis and/or correction. For example, you can separate noise from desired tonal elements and adjust the balance between them.
iZotope’s RX 2 and RX 2 Advanced are one-stop applications for cleaning up bad audio. Some of these tools overlap with what you may already own, but if you need to do a lot of this type of work, then RX 2 will be more efficient and adds more capabilities. In September 2013, iZotope will release the updates for RX3 and RX3 Advanced. iZotope’s algorithms are some of the best on the market, so sonic quality is never compromised. Whether it’s poorly recorded audio or restoring archival material, RX 2 or RX 3 offer a toolkit that’s perfect for the task.

Izotope Rx 2 Free Download
©2013 Oliver Peters
0 notes
Text
Yanny vs. Laurel is ‘The Dress of 2018'—but these sound experts think they can end the debate right now
Gird yourself for another ‘the dress’ debate. You remember it even if you wish you didn’t: an image of a dress went viral on Twitter because it appeared, to some, to definitely be white and gold, while others were positive it was black and blue. Yes, the audio version of the viral visual atrocity is here, and it’s just as frustrating as that darn blue dress (yeah, I said it).
First, watch this video:
Now show it to all your friends and watch your sanity disappear as they all vehemently disagree. In a reply, another Twitter user claimed you can change what you hear by modulating the bass levels. We test that out here:
For the record, I can still only hear “laurel.” Some of our staff members were able to change which word they heard over time, especially with bass modulation. Our Science Editor can now suddenly sort of hear the whisper of a “yanny” in there, but it freaks her out and she does not like it. Your mileage may vary. But according to at least one expert, my fellow “laurel” compatriots and I are correct. Yes, friends: there may actually be a right answer here. Brad Story is a professor of speech, language, and hearing sciences at the University of Arizona, and he did a quick analysis of the waveform for us.
That first waveform is of the actual recording, which features the primary acoustic features of the “l” and “r” sounds. That leads Story to believe that the voice is really saying “laurel.” The fuzzier image below shows that the recording is of the third resonance of the vocal tract. As your vocal tract changes shape to form different sounds, it produces specific resonances, or natural vibrational frequencies. It’s these resonances that encode language within a soundwave (and thus how you can analyze a waveform and determine speech sounds).
He also recorded himself saying both words to demonstrate how the waveforms vary. You can see (though maybe only with the added arrows and highlighting) that the acoustic features match up between the actual video recording and the recording of Story saying “laurel.” It starts relatively high for the “l” sound, then drops for the “r” and goes back up high for the second “l.” Story explains that the “yanny” sound follows a similar path, just not with quite the same acoustic features. That wave also goes high-low-high, but the whole thing is shifted into the second resonance—not the third.
Britt Yazel, a researcher at the UC Davis Center for Mind and Brain, agrees. “I honestly think after looking at the spectrograms and playing with some filters that this is just the word “Laurel” with some high frequency artifacts overlaying it,” he says. At first he thought it was two overlaid voices, but then he started cleaning up the audio a bit. Now he thinks that the overlaid frequencies above 4.5 kHz are what sound like “yanny” to some people.
So why can’t we all hear “laurel”? “The low quality recording creates enough ambiguity in the acoustic feature that some listeners may be led toward the ‘yanny’ perception,” Story explains.
That lines up with what Nina Kraus, a researcher at Northwestern University who studies auditory biology, told PopSci. “The way you hear sound is influenced by your life in sound,” she explains. What you expect to hear is, to a large extent, what your brain will hear—and what your brain hears is all that matters.
Everything that you perceive, audio included, gets filtered through your brain before you’re consciously aware of it. For example, you can choose which sounds to pay attention to. This is how you’re able to hear someone talking to you at a loud party without noticing any other conversations, but can also switch over to listening in to the woman standing behind you. You’re choosing which sounds to pay attention to. Similarly, your brain is unconsciously choosing which frequencies in the recording to pay attention to and therefore to amplify. When your brain is primed to expect one of two sounds, you might just convince yourself you’ve heard the wrong one. A classic example of this is a MIDI file of “All I Want For Christmas”—sans vocals—that many listeners swear still features Mariah Carey belting out her famous version of the tune.
Kraus also has her own, slightly more scientific example. Listen to the first audio sample labeled “noisy version” below (courtesy of Kraus), which should sound pretty scratchy. Then listen to the second, labeled “clean version,” which is a clear voice. Now go back and listen to the first.
When you first hear the scratchy recording, most people hear a lot of static and no true voice. But when you go back and listen to it again after hearing the clear sentence, suddenly you can hear the voice hidden within the static. The difference is that the second time you’re expecting the voice.
Of course, there is also a chance that the recording contains both noises at once.
“When I first listened to the sounds I could hear both words strangely simultaneously,” says Heather Read, a sound perception and sensory neuroscience researcher at the University of Connecticut. She thinks the overlaid sounds are happening at once, with “yanny” occurring at higher frequencies, and what you hear depends on which frequencies your ear amplifies. She also thinks that if you play it repeatedly, you should hear “laurel” more and more. “Hopefully my ability to hear both words simultaneously reflects my musical ear or my acoustical scientific ear and not some other odd property of my brain,” she says. “But either way it’s fun that we all hear it differently.”
Story’s solution might be the best: somehow find the source of this strange noise and play it back for everyone on the same equipment. “With a high-quality recording, and if all listeners were listening with the same device, there may not be any confusion,” he says.
But for the record, it’s totally saying laurel.
Update: This post has been updated to provide even more evidence that it’s totally just saying laurel.
!function(f,b,e,v,n,t,s)if(f.fbq)return;n=f.fbq=function()n.callMethod? n.callMethod.apply(n,arguments):n.queue.push(arguments);if(!f._fbq)f._fbq=n; n.push=n;n.loaded=!0;n.version='2.0';n.queue=[];t=b.createElement(e);t.async=!0; t.src=v;s=b.getElementsByTagName(e)[0];s.parentNode.insertBefore(t,s)(window, document,'script','//connect.facebook.net/en_US/fbevents.js');
fbq('init', '1482788748627554'); fbq('track', "PageView"); document.write('<a style="display:none!important" id="2580009">'); if (window.AED_SHOW) window.AED_SHOW(wid: '2580009',shortkey:'E2J2jQN', size:'728x90', custom:); else
New post published on: http://www.livescience.tech/2018/05/16/yanny-vs-laurel-is-the-dress-of-2018-but-these-sound-experts-think-they-can-end-the-debate-right-now/
2 notes
·
View notes
Text
Text-to-Speech Synthesis: an Overview

In my childhood, one of the funniest interactions with a computer was to make it read a fairy tale. You could copy a text into a window and soon listen to a colorless metallic voice stumble through commas and stops weaving a weirdly accented story. At those times it was a miracle.
Nowadays the goal of TTS — the Text-to-Speech conversion technology — is not to simply have machines talk, but to make them sound like humans of different ages and gender. In perspective, we’ll be able to listen to machine-voiced audiobooks and news on TV or to communicate with assistants without noticing the difference.
How it can be achieved and what are the main competitors in the field — read in our post.
Quality measurements
As a rule the quality of TTS system synthesizers is evaluated from different aspects, including intelligibility, naturalness, and preference of the synthetic speech [4], as well as human perception factors, such as comprehensibility [3].
Intelligibility: the quality of the audio generated, or the degree of each word being produced in a sentence.
Naturalness: the quality of the speech generated in terms of its timing structure, pronunciation and rendering emotions.
Preference: the listeners’ choice of the better TTS; preference and naturalness are influenced by TTS system, signal quality and voice, in isolation and in combination.
Comprehensibility: the degree of received messages being understood.

Approaches of TTS Conversion Compared
Developments in Computer Science and Artificial Intelligence influence the approaches to speech synthesis that was evolving through years in response to the recent trends and new possibilities in data collection and processing. While for a long time the two main methods of Text-to-Speech conversion are concatenative TTS and parametric TTS, the Deep Learning revolution has added a new perspective to the problem of speech synthesis, shifting the focus from human-developed speech features to fully machine-obtained parameters [1,2].
Concatenative TTS
Concatenative TTS relies on high-quality audio clips recordings, which are combined together to form the speech. At the first step voice actors are recorded saying a range of speech units, from whole sentences to syllables that are further labeled and segmented by linguistic units from phones to phrases and sentences forming a huge database. During speech synthesis, a Text-to-Speech engine searches such database for speech units that match the input text, concatenates them together and produces an audio file.
Pros
- High quality of audio in terms of intelligibility;
- Possibility to preserve the original actor’s voice;
Cons
- Such systems are very time consuming because they require huge databases, and hard-coding the combination to form these words;
- The resulting speech may sound less natural and emotionless, because it is nearly impossible to get the audio recordings of all possible words spoken in all possible combinations of emotions, prosody, stress, etc.

Examples:
Singing Voice Synthesis is the type of speech synthesis that fits the best opportunities of concatenative TTS. With the possibility to record a specific singer, such systems are able to preserve the heritage by restoring records of stars of the past days, as in Acapella Group, as well as to make your favorite singer perform another song according to your liking, as in Vocaloid.
Formant Synthesis
Formant synthesis technique is a rule-based TTS technique. It produces speech segments by generating artificial signals based on a set of specified rules mimicking the formant structure and other spectral properties of natural speech. The synthesized speech is produced using an additive synthesis and an acoustic model. The acoustic model uses parameters like, voicing, fundamental frequency, noise levels, etc that varied over time. Formant-based systems can control all aspects of the output speech, producing a wide variety of emotions and different tone voices with the help of some prosodic and intonation modeling techniques.
Pros
- Highly intelligible synthesized speech, even at high speeds, avoiding the acoustic glitches;
- Less dependant on a speech corpus to produce the output speech;
- Well-suited for embedded systems, where memory and microprocessor power are limited.
Cons
- Low naturalness: the technique produces artificial, robotic-sounding speech that is far from the natural speech spoken by a human.
- Difficult to design rules that specify the timing of the source and the dynamic values of all filter parameters for even simple words

Examples
Formant synthesis technique is widely used for mimicking the voice features that takes speech as input and find the respective input parameters that produces speech, mimicking the target speech. One of the most famous examples is espeak-ng, an open-source multilingual speech synthesis system based on the Klatt synthesizer. This system is included as the default speech synthesizer in the NVDA open source screen reader for Windows, Android, Ubuntu and other Linux distributions. Moreover, its predecessor eSpeak was used by Google Translate for 27 languages in 2010.
Parametric TTS
To address the limitations of concatenative TTS, a more statistical method was developed. The idea lying behind it is that if we can make approximations of the parameters that make the speech, we can train a model to generate all kinds of speech. The parametric method combines parameters, including fundamental frequency, magnitude spectrum etc. and processes them to generate speech. At the first step, the text is processed to extract linguistic features, such as phonemes or duration. The second step requires extraction of vocoder features, such as cepstra, spectrogram, fundamental frequency, etc., that represent some inherent characteristic of human speech, and are used in audio processing. These features are hand engineered and, along with the linguistic features are fed into a mathematical model called a Vocoder. While generating a waveform, the vocoder transforms the features and estimates parameters of speech like phase, speech rate, intonation, and others. The technique uses Hidden Semi-Markov models — transitions between states still exist, and the model is Markov at that level, but the explicit model of duration within each state is not Markov.
Pros:
- Increased naturalness of the audio. Unfortunately, though, the technology to create emotional voices is not yet perfected, but this is something that parametric TTS is capable of. Besides the emotional voices, is has much potential in such areas as speaker adaptation and speaker interpolation;
- Flexibility: it is easier to modify pitch for emotional change, or use MLLR adaptation to change voice characteristics;
- Lower development cost: it requires merely 2–3 hours of voice actor recording time which entangles less records, a smaller database and less data processing.
Cons:
- Lower audio quality in terms of intelligibility: there are many artifacts resulting in muffled speech, with buzzing sound ever present, noisy audio;
- The voice can sound robotic: in the TTS based on a statistical model, the muffled sound makes the voice sound stable but unnatural and robotic.

Examples:
Though first introduced in the 1990ies, parametric TTS engine became popular around 2007, with Festival Speech Synthesis System from the University of Edinburgh and Carnegie Mellon University’s Festvox being examples of such engines lying in the heart of speech synthesis systems, such as FreeTTS.
Hybrid (Deep Learning) approaches
The DNN (Deep Neural Network) based approach is another variation of the statistical synthesis approaches that is used to overcome the inefficiency of decision trees used in HMMs to model complex context dependencies. A step forward and an eventual breakthrough was letting machines design features without human intervention. The features designed by humans are based on our understanding of speech, but it is not necessarily correct. In DNN techniques, the relationship between input texts and their acoustic realizations is modeled by a DNN. The acoustic features are created using maximum likelihood parameter generation trajectory smoothing. Features obtained with the help of Deep Learning, are not human readable, but they are computer-readable, and they represent data required for a model.
Pros
- A huge improvement both in terms of intelligibility and naturalness;
- Do not require extensive human preprocessing and development of features
Cons
- As a recent development, Deep Learning speech synthesis techniques still require research.

Examples:
It is the deep learning technique that dominates the field now, being in the core of practically all successful TTS systems, such as WaveNet, Nuance TTS or SampleRNN.
Nuance TTS and Sample RNN are two systems that rely on recurrent neural networks. SampleRNN, for instance, uses a hierarchy of Recurrent Layers that have different clock-rates to process the audio. Multiple RNNs forma hierarchy, where the top level takes large chunks of inputs, process it and pass it to the lower level that processes smaller chunks and so on through the bottom level that generates a single sample. The techniques renders far less intelligible results, but work fast.
WaveNet, being the core of Google Could Text-to-Speech, is a fully convolutional neural network, which takes digitized raw audio waveform as input, which then flows through these convolution layers and outputs a waveform sample. Though close-to-perfect in its intelligibility and naturalness, WaveNet is unacceptably slow (team reported that it takes around 4 minutes to generate 1 second of audio).
Finally, the new wave of end-to-end training brought Google’s Tacotron model that learns to synthesize speech directly from (text, audio) pairs. It takes characters of the text as inputs, and passes them through different neural network submodules and generates the spectrogram of the audio.
As we can see, the evolution of speech synthesis increasingly relies on the machines in both determinations of the necessary features and processing them without assistance of human-developed rules. This approach improves the overall quality of the audio produced and significantly simplifies the process of data collection and preprocessing. However, each approach has its niche, and even less efficient concanetative systems may become the optimal choice depending on the business needs and resources.
Further Reading
King, Simon. “A beginners ’ guide to statistical parametric speech synthesis.” (2010).
Kuligowska, K, Kisielewicz, P. and Wlodarz, A. (2018) Speech synthesis systems: disadvantages and limitations, International Journal of Engineering & Technology, [S.l.], v. 7, n. 2.28, p. 234–239.
Pisoni, D. B. et al., “Perception of synthetic speech generated by rule,” in Proceedings of the IEEE, 1985, pp. 1665–1676.
Stevens, C. et al., “Online experimental methods to evaluate text-to-speech (TTS) synthesis: effects of voice gender and signal quality on intelligibility, naturalness and preference,” Computer Speech and Language, vol. 19, pp. 129–146, 2005.
0 notes
Text
SOUND FORGE Audio Studio 12 wants to “define the edge”
Available online and in stores worldwide, SOUND FORGE Audio Studio 12 costs $59.99 and offers you a 64-bit architecture to supply more editing power, more processing power, and a more powerful workflow.
Acquired in 2016 by MAGIX, Sound Forge Audio Studio was once known as Sonic Foundry Sound Forge, and later as Sony Sound Forge. The desktop audio and music production that since 2003 was part of Sony’s catalog, was in dire need of an update, and that’s what MAGIX does now, with Sound Forge Audio Studio 12, a new version which they had promised would be launched in August 2017.
The launch of SOUND FORGE Audio Studio 12 continues the commitment of MAGIX to the introduction of new versions of the program. SOUND FORGE Pro Mac 3 marked the beginning, in May this year, adding several new features including loudness metering and the iZotope Plug-ins RX Elements and Ozone 7 Elements, and is available online for $299/€299. With support for 64-Bit float/192kHz/32 channels high-resolution audio, sample-accurate editing, enhanced professional-level filters and processing and disc-at-once Red Book Standard audio CD authoring, the program is, according to MAGIX, the perfect tool for audio processing and mastering on macOS.
SOUND FORGE Pro 12 is expected to roll out end of 2017, after 4 years without a new version. Teams in both Berlin, Germany and Madison, Wisconsin have set a goal to raise the bar for audio editing and mastering in version 12. Now, version 12 takes SOUND FORGE Audio Studio to a whole new level, supplying everything you need to record, edit, enhance, and deliver high-resolution audio. The perfect tool, says MAGIX, “to digitize, repair, and restore LP records and tapes, create podcasts, master audio, burn CDs, and render to all the popular audio formats for streaming on the web or playback on portable media players.”
“For years, the name SOUND FORGE has defined the industry standard for top-tier professional audio recording, editing, and mastering tools,” said Gary Rebholz from SOUND FORGE team. “But we’re not satisfied with relying on our reputation, so our teams in Berlin and Madison, now join together to renew a commitment to carry on this unparalleled legacy. Audio pros and enthusiasts alike will continue to rely on SOUND FORGE for years to come.”
SOUND FORGE Audio Studio, which is presented as the perfect tool to digitize, repair, and restore LP records and tapes, create podcasts, master audio, burn CDs, and render to all the popular audio formats for streaming on the web or playback on portable media players, introduces a series of new features, including:
Recording workflow
The updated and redesigned recording window offers easy access to all the settings and controls you need to achieve the perfect high-resolution recording.
Open and append command
An easy and fast way to assemble tracks for a CD. Select a file or group of files to append and they are automatically added to the project with CD track markers.
Non-destructive editing modes
Slice Edit: Enables you to continue to tweak your edit even after you’ve made your cut.
Soft Cut: Creates automatic, user-adjustable crossfades with each edit to guarantee smooth transitions between cuts with no pops or clicks.
Spectral cleaning
Perform frequency-based noise removal. Visually identify frequencies of an offending noise such as a chair squeak or cough in your recording, then use the spectral cleaning tool to select and remove the frequencies that make up those sounds.
Vinyl recording and restoration workflow
The new workflow makes it easy to record vinyl LPs and tapes, remove crackle, pops, and hiss and burn to an audio CD or burn a set of audio files to a data CD or DVD in popular formats such as MP3, WMA, Ogg Vorbis, FLAC, or AAC.
Visualization window
Presents several ways to analyze and track audio output, including Peak meters, Phase Oscilloscope, Correlation meter, Direction meter, Spectroscope, Spectrogram, Bit meter, Oscilloscope, and Tuner.
Repair and restoration tools
DeClicker/DeCrackler: Automatically detect and remove clicks and crackle from vinyl recordings or other noisy environments.
DeClipper: Restore and recover analog or digital material with clipping artifacts.
DeEsser: Remove sibilance with presets for male and female vocals.
DeHisser: Easily clean up background hiss with presets for hiss behind vocals, cassette tape hiss, analog tape hiss, and more.
DeNoiser: Reduces unwanted steady-state noise like that created by air-conditioning, equipment hum, and amplifier hiss.
Elastic Audio Editor
Tune vocals to a pitch-perfect performance with precise control over pitch.
Support for popular video formats
Open popular video formats to enhance and repair the audio using the included filters, effects, and noise reduction tools.
The program also includes Ozone Elements 7 from iZotope, a mastering plug-in with a set of 75 professionally crafted presets, along with macro controls to fine tune the EQ and Compression to achieve full, rich, and loud final masters, with a $129.00 value.
“Throughout the development cycle of this new version of SOUND FORGE Audio Studio, the engineering team has kept their focus on the phrase ‘Define the edge‘ ”, said Gary Rebholz from SOUND FORGE. “Our goal: take the existing audio production powerhouse to the next level with cutting-edge tools and processes. We think you’re going to love SOUND FORGE Audio Studio 12.”
SOUND FORGE Audio Studio 12 is now available online and in stores worldwide, priced at $59.99 / € 59,99 / £49.99, with upgrades from earlier versions costing $29.99 / € 29,99 / £24.99.
The post SOUND FORGE Audio Studio 12 wants to “define the edge” appeared first on ProVideo Coalition.
First Found At: SOUND FORGE Audio Studio 12 wants to “define the edge”
0 notes
Text
Deep Transfer Learning: A new deep learning glitch classification method for advanced LIGO. (arXiv:1706.07446v1 [gr-qc])
The exquisite sensitivity of the advanced LIGO detectors has enabled the detection of multiple gravitational wave signals. The sophisticated design of these detectors mitigates the effect of most types of noise. However, advanced LIGO data streams are contaminated by numerous artifacts known as glitches: non-Gaussian noise transients with complex morphologies. Given their high rate of occurrence, glitches can lead to false coincident detections, obscure and even mimic gravitational wave signals. Therefore, successfully characterizing and removing glitches from advanced LIGO data is of utmost importance. Here, we present the first application of Deep Transfer Learning for glitch classification, showing that knowledge from deep learning algorithms trained for real-world object recognition can be transferred for classifying glitches in time-series based on their spectrogram images. Using the Gravity Spy dataset, containing hand-labeled, multi-duration spectrograms obtained from real LIGO data, we demonstrate that this method enables optimal use of very deep convolutional neural networks for classification given small training datasets, significantly reduces the time for training the networks, and achieves state-of-the-art accuracy above 98.8%, with perfect precision-recall on 8 out of 22 classes. Furthermore, new types of glitches can be classified accurately given few labeled examples with this technique. Once trained via transfer learning, we show that the convolutional neural networks can be truncated and used as excellent feature extractors for unsupervised clustering methods to identify new classes based on their morphology, without any labeled examples. Therefore, this provides a new framework for dynamic glitch classification for gravitational wave detectors, which are expected to encounter new types of noise as they undergo gradual improvements to attain design sensitivity.
from gr-qc updates on arXiv.org http://ift.tt/2rRlz8V
0 notes