#XByteSolution
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Web Scraping 102: Scraping Product Details from Amazon

Now that we understand the basics of web scraping, let's proceed with a practical guide. We'll walk through each step to extract data from an online ecommerce platform and save it in either Excel or CSV format. Since manually copying information online can be tedious, in this guide we'll focus on scraping product details from Amazon. This hands-on experience will deepen our understanding of web scraping in practical terms.
Before we start, make sure you have Python installed in your system, you can do that from this link: python.org. The process is very simple just install it like you would install any other application.
Install Anaconda using this link: https://www.anaconda.com/download . Be sure to follow the default settings during installation. For more guidance, please click here.
We can use various IDEs, but to keep it beginner-friendly, let's start with Jupyter Notebook in Anaconda. You can watch the video linked above to understand and get familiar with the software.
Now that everything is set let’s proceed:
Open up the Anaconda software and you will find `jupyter notebook` option over there, just click and launch it or search on windows > jupyter and open it.
Steps for Scraping Amazon Product Detail's:
At first we will create and save our 'Notebook' by selecting kernel as 'python 3' if prompted, then we'll rename it to 'AmazonProductDetails' following below steps:

So, the first thing we will do is to import required python libraries using below commands and then press Shift + Enter to run the code every time:

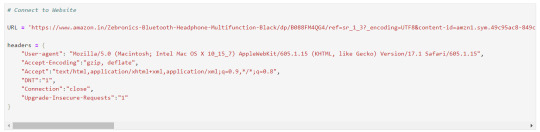
Let's connect to URL from which we want to extract the data and then define Headers to avoid getting our IP blocked.
Note : You can search `my user agent` on google to get your user agent details and replace it in below “User-agent”: “here goes your useragent line” below in headers.
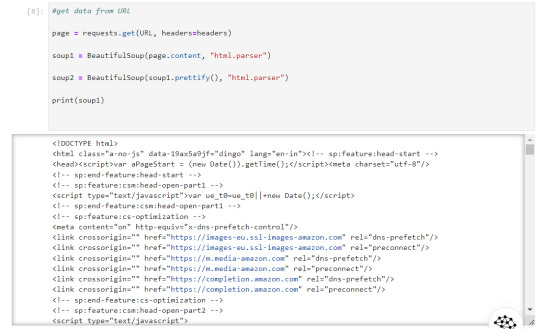
Now that our URL is defined let's use the imported libraries and pull some data.
Now, let's start with scraping product title and price for that we need to use `inspect element` on the product URL page to find the ID associated to the element:
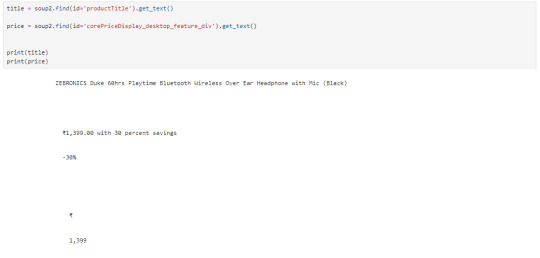
The data that we got is quite ugly as it has whitespaces and price are repeated let's trim the white space and just slice prices:

Let's create a timespan to keep note on when the data was extracted.

We need to save this data that we extracted, to a .csv or excel file. the 'w' below is use to write the data

Now you could see the file has been created at the location where the Anaconda app has been installed, in my case I had installed at path :"C:\Users\juver" and so the file is saved at path: "C:\Users\juver\AmazonProductDetailDataset"
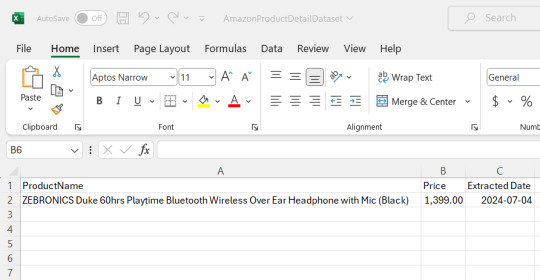
Instead of opening it by each time looking for path, let's read it in our notebook itself.

This way we could extract the data we need and save it for ourselves, by the time I was learning this basics, I came across this amazing post by Tejashwi Prasad on the same topic which I would highly recommend to go through.
Next, we’ll elevate our skills and dive into more challenging scraping projects soon.
0 notes
Text
Digital Marketing and web development company
xbytesolution LLP a website designing company and premium web development and digital marketing company in coimbatore, providing complete web design services that are cheap, best in quality and result oriented. We furnish custom web solutions that focus on quality, innovation and speed.
0 notes
Photo

xbytesolution have all around prepared workforce of engineers and originators who cooperates for custom Android application improvement. Our Android master group is consistently mindful with most recent changes in Android application platform.If you are searching for most innovative android portable application improvement in and around coimbatore,we are the best android versatile application,Hybrid portable applications,IOS versatile applications,Windows versatile applications,black berry versatile applications,Phone hole portable application advancement organization
0 notes