#YOLOv5
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
🚀 Getting Started with rknn_yolov5_demo on RK3568!
Want to run YOLOv5 object detection on the RK3568 NPU? 🤖 Follow our step-by-step guide to compile and execute rknn_yolov5_demo seamlessly!
✅ Set up the cross-compilation toolchain
✅ Compile the test program
✅ Transfer files to your development board
✅ Run the object detection model
✅ Evaluate the performance of the RK3568 NPU
Check out the full guide and start optimizing your AI applications today!
0 notes
Text
So, you want to build AI models that can detect enemy equipment, but you don’t exactly have a military budget lying around? What’s the game plan? Here’s a guide to building highly accurate AI detection models for enemy hardware - without breaking the bank.
By using synthetic data from 3D models, you can train powerful object detection models like YOLOv5 to recognize even the most elusive assets on the cheap.
When gathering real-world images is tough or expensive, synthetic data from 3D models becomes a game-changer for training object detection models like YOLOv5. Known for its speed and accuracy, YOLOv5 processes images in a single pass, making it ideal for real-time applications like video analysis and autonomous systems.
Using 3D models, synthetic images of objects - such as Russian, Chinese, and North Korean T-90 tanks (for example) - can be generated from every angle, under different conditions, and in varied environments. This flexibility lets YOLOv5 learn robust features and generalize well, even for highly specific detection needs.
Ultimately, synthetic data from 3D models offers an efficient, cost-effective way to build accurate, custom detection models where real-world data collection is limited or impractical.
Steps to Building Detection Models Using Synthetic 3D Images
1. Generating Synthetic Images from 3D Models
● Use a 3D graphics tools like Blender or Unity, to render images of the tank model from every conceivable angle. These tools allow control over orientation, distance, lighting, and environment.
● Render the tank against various backgrounds to simulate different settings, or start with plain backgrounds for initial training, adding realistic ones later to improve robustness.
● Add variety by changing:
■ Lighting conditions (daylight, overcast, night)
■ Viewing angles (front, back, top-down, low angle)
■ Distances and zoom levels to simulate visibility and scale variations.
2. Applying Realistic Textures and Weather Effects
● Apply textures (like camouflage) and surface details (scratches, wear) to enhance realism.
● Simulate weather effects—rain, snow, or fog—to make the images resemble real-world conditions, helping the model generalize better.
3. Generating Annotation Labels for Synthetic Images
● Use the 3D rendering software to generate bounding box annotations along with the images. Many tools can output annotation data directly in YOLO format or in formats that are easily converted.
4. Using Domain Randomization for Improved Generalization
● Domain randomization involves varying elements like background, lighting, and texture randomly in each image to force the model to generalize.
● Change the background or adjusting color schemes helps the model perform better when exposed to real-world images, focusing on the shape and structure rather than specific synthetic features.
5. Fine-Tuning with Real Images (recommended)
● While synthetic images provide a strong foundation, adding even a small number of real images during training can boost accuracy and robustness. Real images add natural variations in lighting, texture, and environment that are hard to replicate fully.
● For optimal fine-tuning, aim for 50–100 real images per tank type if available.
YOLOv5 URL: https://github.com/ultralytics/yolov5
Oh, by the way... the video is just one of 365 different rotations for this background and lighting.
0 notes
Text
💡 Hướng Dẫn Chi Tiết Huấn Luyện Dữ Liệu Tùy Chỉnh Với YOLOv5 💡
YOLOv5 là một trong những mô hình phát hiện đối tượng mạnh mẽ và linh hoạt nhất hiện nay! 🔥 Nếu bạn đang tìm kiếm một giải pháp để phát hiện các đối tượng cụ thể trong ảnh, hoặc bạn muốn tự huấn luyện dữ liệu riêng để phù hợp với dự án cá nhân, thì bài viết này chính là dành cho bạn. 👨💻
Tại sao nên chọn YOLOv5? YOLOv5 không chỉ có khả năng xử lý nhanh chóng mà còn đem lại độ chính xác cao. Với cấu trúc tinh gọn và dễ tùy chỉnh, nó phù hợp cho cả những người mới bắt đầu và những nhà nghiên cứu chuyên nghiệp. Bạn sẽ dễ dàng thực hiện các bước chuẩn bị và huấn luyện dữ liệu mà không cần quá nhiều kiến thức phức tạp.
Bài viết này bao gồm những gì? 📌 Chuẩn bị dữ liệu: Hướng dẫn cách thu thập và gắn nhãn dữ liệu sao cho phù hợp với mô hình YOLOv5. 📌 Cài đặt môi trường: Các bước cài đặt Python, PyTorch, và tất cả các thư viện cần thiết. 📌 Cấu hình mô hình: Điều chỉnh các tham số của YOLOv5 để phù hợp với dữ liệu tùy chỉnh của bạn, giúp đạt hiệu quả cao nhất. 📌 Huấn luyện và đánh giá: Theo dõi quá trình huấn luyện và kiểm tra độ chính xác của mô hình trên dữ liệu mới.
🚀 Bạn đã sẵn sàng tạo mô hình của riêng mình chưa? Đừng chần chừ nữa! Bắt đầu ngay với hướng dẫn chi tiết này để tự tin huấn luyện dữ liệu tùy chỉnh cùng YOLOv5. Đây sẽ là bước đầu tiên để bạn khám phá tiềm năng của AI và thị giác máy tính trong các dự án của riêng mình. 📷
Hướng dẫn chi tiết cách huấn luyện dữ liệu tùy chỉnh với YOLO5
Khám phá thêm những bài viết giá trị tại aicandy.vn
4 notes
·
View notes
Text
YOLO Python Projects in Chennai
YOLO Python Projects in Chennai teach object detection using Python, OpenCV, and YOLOv5/v8 models. These projects focus on real-time computer vision tasks with practical datasets. Chennai provides expert-led guidance to help you master vision-based AI with hands-on applications.
0 notes
Text
YOLO V/s Embeddings: A comparison between two object detection models
YOLO-Based Detection Model Type: Object detection Method: YOLO is a single-stage object detection model that divides the image into a grid and predicts bounding boxes, class labels, and confidence scores in a single pass. Output: Bounding boxes with class labels and confidence scores. Use Case: Ideal for real-time applications like autonomous vehicles, surveillance, and robotics. Example Models: YOLOv3, YOLOv4, YOLOv5, YOLOv8 Architecture
YOLO processes an image in a single forward pass of a CNN. The image is divided into a grid of cells (e.g., 13×13 for YOLOv3 at 416×416 resolution). Each cell predicts bounding boxes, class labels, and confidence scores. Uses anchor boxes to handle different object sizes. Outputs a tensor of shape [S, S, B*(5+C)] where: S = grid size (e.g., 13×13) B = number of anchor boxes per grid cell C = number of object classes 5 = (x, y, w, h, confidence) Training Process
Loss Function: Combination of localization loss (bounding box regression), confidence loss, and classification loss.
Labels: Requires annotated datasets with labeled bounding boxes (e.g., COCO, Pascal VOC).
Optimization: Typically uses SGD or Adam with a backbone CNN like CSPDarknet (in YOLOv4/v5). Inference Process
Input image is resized (e.g., 416×416). A single forward pass through the model. Non-Maximum Suppression (NMS) filters overlapping bounding boxes. Outputs detected objects with bounding boxes. Strengths
Fast inference due to a single forward pass. Works well for real-time applications (e.g., autonomous driving, security cameras). Good performance on standard object detection datasets. Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high-dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
Weaknesses
Struggles with overlapping objects (compared to two-stage models like Faster R-CNN). Fixed number of anchor boxes may not generalize well to all object sizes. Needs retraining for new classes. Embeddings-Based Detection Model Type: Feature-based detection Method: Instead of directly predicting bounding boxes, embeddings-based models generate a high- dimensional representation (embedding vector) for objects or regions in an image. These embeddings are then compared against stored embeddings to identify objects. Output: A similarity score (e.g., cosine similarity) that determines if an object matches a known category. Use Case: Often used for tasks like face recognition (e.g., FaceNet, ArcFace), anomaly detection, object re-identification, and retrieval-based detection where object categories might not be predefined. Example Models: FaceNet, DeepSORT (for object tracking), CLIP (image-text matching) Architecture
Uses a deep feature extraction model (e.g., ResNet, EfficientNet, Vision Transformers). Instead of directly predicting bounding boxes, it generates a high-dimensional feature vector (embedding) for each object or image. The embeddings are stored in a vector database or compared using similarity metrics. Training Process Uses contrastive learning or metric learning. Common loss functions:
Triplet Loss: Forces similar objects to be closer and different objects to be farther in embedding space.
Cosine Similarity Loss: Maximizes similarity between identical objects.
Center Loss: Ensures class centers are well-separated. Training datasets can be either:
Labeled (e.g., with identity labels for face recognition).
Self-supervised (e.g., CLIP uses image-text pairs). Inference Process
Extract embeddings from a new image using a CNN or transformer. Compare embeddings with stored vectors using cosine similarity or Euclidean distance. If similarity is above a threshold, the object is recognized. Strengths
Scalable: New objects can be added without retraining.
Better for recognition tasks: Works well for face recognition, product matching, anomaly detection.
Works without predefined classes (zero-shot learning). Weaknesses
Requires a reference database of embeddings. Not good for real-time object detection (doesn’t predict bounding boxes directly). Can struggle with hard negatives (objects that look similar but are different).
1 note
·
View note
Text
Building a Real-Time Object Detection System with YOLOv5
1. Introduction What is YOLOv5? YOLOv5 is an open-source object detection model that is part of the popular You Only Look Once (YOLO) family. It is known for its high performance, ease of use, and flexibility, making it a popular choice for real-time object detection tasks. In this guide, we will explore how to build a real-time object detection system using YOLOv5. Why Use YOLOv5? Speed and…
0 notes
Text
Real-Time QR Code Detection Using YOLO: A Step-by-Step Guide

Introduction
Quick Response (QR) codes are everywhere—from product packaging to payment gateways. Detecting them efficiently in real-time is crucial for various applications, such as automated checkout systems, digital payments, and augmented reality. One of the best ways to achieve this is by leveraging YOLO (You Only Look Once), a deep-learning-based object detection model that is both fast and accurate.
In this guide, we will walk through the key steps of using YOLO for real-time QR code detection, explaining the process conceptually without delving into coding details. If you want to get started with a dataset, check out this QR Code Detection YOLO dataset.
Why Use YOLO for QR Code Detection?
YOLO represents an advanced deep learning framework specifically developed for real-time object detection. In contrast to conventional techniques that analyze an image repeatedly, YOLO evaluates the entire image in one go, resulting in exceptional efficiency. The following points illustrate why YOLO is particularly suitable for QR code detection:
Speed: It enables real-time image processing, making it ideal for mobile and embedded systems.
Accuracy: YOLO is capable of identifying small objects, such as QR codes, with remarkable precision.
Flexibility: It can be trained on tailored datasets, facilitating the detection of QR codes across various environments and conditions.
Step-by-Step Guide to Real-Time QR Code Detection Using YOLO
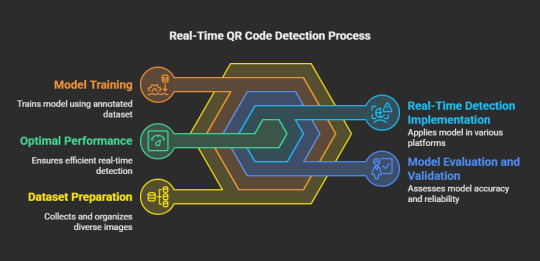
Assemble and Organize the Dataset
The initial phase in training a YOLO model for QR code detection involves the collection of a varied dataset. This dataset must encompass images featuring QR codes under different lighting scenarios, orientations, and backgrounds. You may utilize pre-existing datasets or generate your own by manually capturing images. A well-structured dataset is essential for achieving model precision.
Label the QR Codes
After preparing the dataset, the subsequent step is to annotate it. This process entails marking the QR codes in each image with annotation tools such as LabelImg or Roboflow. The objective is to create bounding boxes around the QR codes, which will act as ground truth data for the model's training.
Train the YOLO Model
To initiate the training of the YOLO model, a deep learning framework such as Darknet, TensorFlow, or PyTorch is required. During the training process, the model acquires the ability to detect QR codes based on the annotated dataset. Important considerations include:
Selecting the appropriate YOLO version (YOLOv4, YOLOv5, or YOLOv8) according to your computational capabilities and accuracy requirements.
Fine-tuning hyperparameters to enhance performance.
Implementing data augmentation techniques to bolster generalization across various conditions.
Evaluate and Validate the Model
Following the training phase, it is imperative to assess the model's performance using previously unseen images. Evaluation metrics such as precision, recall, and mean Average Precision (mAP) are instrumental in gauging the model's effectiveness in detecting QR codes. Should the results indicate a need for improvement, fine-tuning and retraining may enhance the model's accuracy.
Implement the Model for Real-Time Detection
Upon successful validation, the trained YOLO model can be implemented for real-time QR code detection across various platforms, including:
Web applications (for instance, integration with a web camera interface)
Mobile applications (such as QR code scanning features in shopping applications)
Embedded systems (including IoT devices and smart kiosks)
Enhance for Optimal Performance
To ensure efficiency in real-time applications, it is crucial to optimize the model. Strategies may include:
Minimizing model size through quantization and pruning techniques
Leveraging hardware acceleration via GPUs or TPUs
Utilizing efficient inference engines like TensorRT or OpenVINO .These measures contribute to seamless and rapid QR code detection.
Final Thoughts
Real-time detection of QR codes utilizing YOLO represents an effective method that merges rapidity with precision. By adhering to the aforementioned steps—data gathering, annotation, training, validation, and deployment—you can create a resilient QR code detection system customized to your requirements. Whether your project involves a mobile application, an automated payment solution, or an intelligent retail system, YOLO provides a dependable technique to improve QR code recognition in practical scenarios. With Globose Technology Solution, you can further enhance your development process and leverage advanced technologies for better performance.
For an accessible dataset, consider exploring the QR Code Detection YOLO Dataset. Wishing you success in your development endeavors!
0 notes


Text
🚀 HƯỚNG DẪN CHI TIẾT HUẤN LUYỆN DỮ LIỆU TÙY CHỈNH VỚI YOLOv5 📊📷
🔥 Bạn đang tìm cách tối ưu mô hình nhận diện vật thể với dữ liệu riêng của mình? Hay bạn muốn áp dụng YOLOv5 - một trong những framework mạnh mẽ nhất hiện nay - vào dự án thực tế? 🧑💻💡 Đây là bài viết bạn KHÔNG THỂ BỎ LỠ!
🌟 Trong bài viết này, bạn sẽ khám phá: ✅ Bước 1: Chuẩn bị dữ liệu và gán nhãn (labeling) 📝🎯 ✅ Bước 2: Tùy chỉnh cấu hình YOLOv5 phù hợp với dataset của bạn 🛠️⚙️ ✅ Bước 3: Huấn luyện mô hình với các tham số tối ưu 📈🔥 ✅ Bước 4: Đánh giá hiệu suất và cải thiện kết quả 💪📊 ✅ Bước 5: Triển khai mô hình vào thực tế 🌐🤖
👉 Không chỉ dừng lại ở lý thuyết, bài viết còn đi kèm với hình ảnh minh họa, code mẫu, và các mẹo hay giúp bạn xử lý những tình huống khó nhằn.
🌐 Đừng chần chừ! Xem ngay bài viết chi tiết tại: ➡️ Link bài viết: Hướng dẫn huấn luyện YOLOv5
📌 Hãy lưu lại bài viết và chia sẻ ngay cho bạn bè, đồng nghiệp của bạn nhé! Ai cũng có thể trở thành chuyên gia AI nếu bắt đầu đúng cách! 💼✨
0 notes
Text
Danh sách bài viết trên AIcandy.vn
Học tập toàn diện: Kết nối lý thuyết, thực hành và dữ liệu thực tế
Kiến thức nền tảng trí tuệ nhân tạo
Trí tuệ nhân tạo (AI): Lịch sử phát triển và ứng dụng thực tiễn
Từ điển AI cho người mới bắt đầu: Giải thích các khái niệm chính
Khám phá sự khác biệt giữa AI, ML và DL
Tổng quan 4 phương pháp học máy chính trong trí tuệ nhân tạo
Hồi quy tuyến tính: Kỹ thuật cơ bản và ứng dụng trong học máy
K-Means Clustering: Ưu điểm, nhược điểm và khi nào nên sử dụng
Khám phá K-nearest neighbors cho phân loại và hồi quy
Phân loại dữ liệu là gì? Giải thích đơn giản và ví dụ thực tế
Random Forest: Giải thích chi tiết và ứng dụng
SVM trong xử lý dữ liệu phi tuyến tính: Kỹ thuật kernel và ứng dụng
Mạng nơ-ron nhân tạo: Công nghệ đột phá trong trí tuệ nhân tạo
Convolutional Neural Networks (CNN) trong Deep Learning
Recurrent Neural Network (RNN): Ứng dụng và cách hoạt động
Tăng tốc huấn luyện mô hình với phương pháp Gradient Descent
Các phương pháp đánh giá hiệu suất mô hình Machine Learning
Tìm hiểu phân loại hình ảnh trong AI: Cách thức và ứng dụng
Tìm hiểu nhận diện đối tượng trong AI: Cách thức và ứng dụng
Xử lý ngôn ngữ tự nhiên: Công nghệ phân tích ngôn ngữ bằng AI
Giới thiệu chi tiết về học tăng cường: Phương pháp và ứng dụng
MobileNet: Mô hình hiệu quả trên thiết bị di động
Mô hình ResNet: Đột phá trong nhận diện hình ảnh
SSD: Giải pháp hiệu quả cho bài toán phát hiện đối tượng
EfficientNet: Cách mạng hóa mạng neural hiện đại
DenseNet: Cấu trúc, nguyên lý và ưu điểm trong mạng nơ-ron sâu
Tìm hiểu mô hình YOLOv5: Hiệu quả trong nhận diện đối tượng
YOLOv8: Nhận diện đối tượng với hiệu suất vượt trội
RetinaNet: Cải tiến mạnh mẽ trong công nghệ phát hiện đối tượng
GoogleNet: Cột mốc đột phá trong lĩnh vực trí tuệ nhân tạo
AlexNet: Bước đột phá trong trí tuệ nhân tạo
Tìm hiểu mô hình FaceNet cho bài toán nhận diện khuôn mặt
Imbalanced Dataset: Thách thức và giải pháp trong Machine Learning
PyTorch trong học máy cho người mới bắt đầu
Từ lý thuyết đến thực hành AI-ML
Ứng dụng mạng MobileNet vào phân loại hình ảnh
Ứng dụng mạng GoogleNet vào phân loại hình ảnh
Ứng dụng mạng DenseNet vào phân loại hình ảnh
Ứng dụng mạng AlexNet vào phân loại hình ảnh
Ứng dụng mạng Efficientnet vào phân loại hình ảnh
Ứng dụng mạng ResNet-18 vào phân loại hình ảnh
Ứng dụng mạng ResNet-50 vào phân loại hình ảnh
Hướng dẫn chi tiết cách huấn luyện dữ liệu tùy chỉnh với YOLO5
Hướng dẫn chi tiết cách huấn luyện dữ liệu tùy chỉnh với YOLO8
Ứng dụng mạng SSD300 vào nhận diện đối tượng
Ứng dụng mạng RetinaNet vào nhận diện đối tượng
Cách dự đoán giá cổ phiếu hiệu quả bằng mô hình LSTM
Ứng dụng Machine Learning vào chơi game Flappy Bird
Triển khai phân loại hình ảnh trên thiết bị Android
Triển khai nhận diện đối tượng trên thiết bị Android với YOLO
Hướng dẫn triển khai phân loại hình ảnh trên Website miễn phí
Kho dữ liệu dành cho học máy
Tổng hợp công cụ hỗ trợ phát triển AI, ML, DL
1 note
·
View note
Text
Mixtile Edge 2 Kit– AI based bee detection and tracking
Here I describe usage of Mixtile Edge 2 Kit in agriculture, bee detection, which can be essential for health and survival of bees.

Story

Mixtile is professional IoT hardware solution provider specialized in Linux and Android-based embedded systems.Mixtile Edge 2 Kit is high-performance ARM single board computer. It comes in variants of 2GB of LPDDR4 DRAM and 16GB eMMC Flash storage, or 4GB of LPDDR4 DRAM and 32GB eMMC Flash storage. This single board computer comes with preinstalled Android 11, and it runs Ubuntu Linux operating system in Android container. It comes with large connectivity options (Bluetooth, 4G/5G Cellular, GPS, and Lora, Zigbee and Z-Wave). For those, you will need module, but it comes with default onboard Wi-Fi connectivity, Gigabit Ethernet Port (RJ45) and Serial Port (RS-485). Because it comes with RS-485 port, which is industrial standard, and it comes within a strong metal case, it seems to me that it can be really used in industrial projects. I used official Raspberry Pi 5 power supply in order to power up my Mixtile Edge 2 Kit.So, an idea came to me why not to use it in agriculture, bee detection, which can be essential for health and survival of bees.This project will cover setting up Mixtile Edge 2 Kit, and custom photo dataset form video in order to train custom YOLOv5 bee detection model. YOLOv5 models must be trained on labelled data in order to learn classes of objects in that data.I gathered data from video and trained model on my PC.To train a model, I used python and typed in command line:
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights best.pt
My training results are summarized in the following table:
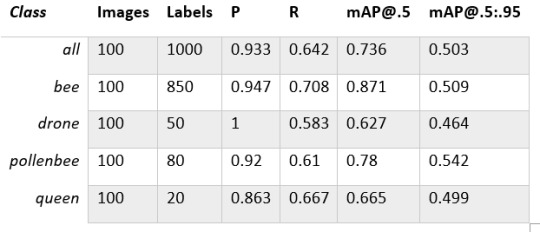
Training results
From this table you can see that images are divided into 4 detection classes:
Bee
Drone
Pollenbee
Queen
Example for each class is summarized in a table below:

Bee classes
1. Getting started
First, I will write about software part of the project, and later on steps of starting the recognition.
1.1 What is YOLOv5?
If you have been in the field of machine learning and deep learning for some time now, there is a high chance that you have already heard about YOLO. YOLO is short for You Only Look Once. It is a family of single-stage deep learning-based object detectors. It was written using Python language, and the framework used is PyTorch.
To ease control, I connected usb mouse to the one of three Mixtile Edge 2 Kit USB3 port. I used Ubuntu Linux for this project. Ubuntu on container is installed in Android system of Mixtile Edge 2 Kit by default. When you boot Mixtile Edge 2 Kit, you get Android OS. Since I wanted to access Edge 2 Kit remotely, and get easier control, I installed droidVNC server from this link:
It is an Android VNC server using Android 5+ APIs. It does not require root access.
I started the VNC server, connected with VNC Viewer and I got the following Android 11 screen:

Android 11
After that, I installed SimpleSSHD from this link:
SimpleSSHD is a SSH server Android app, based on Dropbear.It allows user access (user ssh) or full root access (by setting the login shell to /system/xbin/su) (if root is allowed).
After I installed SSH server, I connected to it via putty SSH terminal. Username and Password are root/root.
Com.hubware.ubuntu is ubuntu on a container and we are connected to it immidiately.
Now we are going to install required software.
First, you will need to upgrade Ubuntu by typing in the command: apt-get upgrade.
Second, I installed python by typing: apt-get install python.
You will also need pip, the package installer for Python.
2. Installing the YOLOv5 Environment
To start off we first clone the YOLOv5 repository and install dependencies. This will set up our programming environment to be ready to running object detection training and inference commands.
Install git: apt-get install git
Clone YOLOv5 repository:
git clone https://github.com/ultralytics/yolov5
Move to YOLOv5 folder:
cd yolov5
Install dependencies:
pip install -r requirements.txt
Wait some time to download and install all requirement packages, I waited 25 minutes, because there are a lot of python packages to install besides YOLOv5. YOLOv5 needs numpy package, scipy, OpenCV, etc.
The putty connection and installation process looks like below:
I transferred my model best.pt to the yolov5 installation folder via SCP, with MobaXterm.
You can simply download my model immidiate by typing:
wget https://github.com/sdizdarevic/beedetectionyolov5/raw/main/best.pt
Also, download original video by typing:
wget https://sdizdarevic.typepad.com/cr/bees-orig.mp4
Now, the final step is detection, and we are interested in the “result” content video.
python3 detect.py --weights best.pt --source bees-orig.mp4
The process of detection looks like below:

In the last lines from last picture we can see the detected number of bees at any point in time.
The summarized short steps to follow are below:
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
wget https://github.com/sdizdarevic/beedetectionyolov5/raw/main/best.pt
wget https://sdizdarevic.typepad.com/cr/bees-orig.mp4
python3 detect.py --weights best.pt --source
Demonstrated videos are on urls with detection finished completely on Mixtile Edge 2 Kit. Output video is in folder runs/detect/exp2.
Original video:
youtube
Result video:
youtube
Last, but not less important: If you want to safely turn off your Mixtile Edge 2 Kit, I recommend you to install Shutdown (no Root) application: https://play.google.com/store/apps/details?id=com.samiadom.Shutdown&hl=en.
3.Conclusion:
After testing I found out that the Mixtile Edge 2 Kit is designed with wide range of applications, from industrial applications, IOT devices, smart home automation, to more than capable AI and edge detection. It is low powered device, with a lot of built-in connectivity options.
I would like to thank amazing Mixtile people for creating this amazing peace of hardware and especially for sending me the Mixtile Edge 2 Kit. Also, Mixtile nurtures the open source values and software, and I believe more people and companies will be involved in making projects with this board.
All in all, I recommend this board for implementing types of projects I described here.
0 notes
Text
📸✨ #NhậnDiệnĐốiTượng – Công nghệ đột phá trong thế giới AI!
Bạn đã bao giờ tự hỏi làm thế nào một chiếc điện thoại 📱 có thể tự động nhận diện khuôn mặt bạn trong ảnh, hay một chiếc xe tự lái 🚗 có thể xác định chướng ngại vật trên đường? Đó chính là nhờ công nghệ #NhậnDiệnĐốiTượng (Object Detection)!
🤖 AI Nhận Diện Đối Tượng Hoạt Động Thế Nào? Nhờ các thuật toán tiên tiến như YOLOv5, SSD, và Faster R-CNN, máy tính có thể “nhìn thấy” và phân biệt các đối tượng trong ảnh hoặc video một cách chính xác đáng kinh ngạc. Đây là bước tiến lớn trong việc đưa trí tuệ nhân tạo vào đời sống thực tế.
🌟 Ứng dụng tuyệt vời trong cuộc sống: ✔️ Bảo mật thông minh: Nhận diện biển số xe 🚘, khuôn mặt trong camera giám sát 📹. ✔️ Y tế: Phát hiện khối u 🩺 từ ảnh chụp y khoa. ✔️ Thương mại: Gợi ý sản phẩm 🛍️ dựa trên hình ảnh.
👉 Còn rất nhiều điều thú vị hơn đang chờ bạn khám phá! Đọc ngay bài viết chi tiết tại đây: 🔗 Tìm hiểu nhận diện đối tượng trong AI: Cách thức và ứng dụng
🎯 Hãy chia sẻ bài viết này nếu bạn thấy hữu ích và cùng lan tỏa sức mạnh của công nghệ AI! 💡
0 notes
Text
YOLOv5 on FPGA with Hailo-8 and 4 Pi Cameras
https://www.fpgadeveloper.com/multi-camera-yolov5-on-zynq-ultrascale-with-hailo-8-ai-acceleration/
0 notes
Text
Mobile App Scraping for Retail | eCommerce

How to Leveraging Mobile App Scraping for Retail Success?
July 13, 2023
Mobile apps have become a vital consumer shopping channel in today's post-pandemic world. With smartphone users spending an average of over 3 hours on their phones daily, it's clear that mobile apps are increasingly preferred over traditional eCommerce apps. Recognizing this shift, Mobile App Scraping has introduced an innovative mobile app scraping solution to complement its successful eCommerce app scraping technology. This advanced solution is designed to help businesses thrive in the evolving retail landscape.
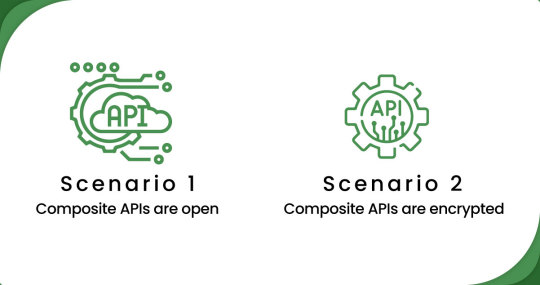
Scenario 1:
When composite APIs are open (e.g., Amazon) - In such cases, the scraping process is similar to standard app scraping, with some initial setup required. Mobile App Scraping can utilize the available APIs of platforms like Amazon to access and extract the desired data. The process involves making API requests, handling responses, and parsing the retrieved data.
Scenario 2:
Whenever composite APIs get encrypted (e.g., Dollar General, HEB, Target, Stop & Shop, etc.) - This scenario presents a more complex challenge. Mobile App Scraping employs specialized techniques such as mobile device extraction, OCR (Optical Character Recognition), as well as other machine learning methods to overcome the encryption and extract data from these apps. Mobile App Scraping leverages advanced technologies to navigate the encrypted APIs and interfaces, ensuring accurate and reliable data extraction.
In both scenarios, Mobile App Scraping utilizes its expertise and advanced methodologies to scrape mobile apps efficiently and effectively, providing businesses with valuable data insights to enhance their operations and decision-making processes.
Methodology
Step 1: Recording a mobile session/navigation using unique visual navigation scrapers Technology consideration
Mobile App Scraping employs a virtual device cloud infrastructure to ensure scalability and efficiency. It utilizes an emulated cluster of devices that connect through an intelligent proxy network.
In the first step of the methodology, special visual navigation scrapers are utilized to record mobile sessions and navigation. These scrapers interact with the mobile app interface, mimicking user actions and capturing the relevant data. This approach allows Mobile App Scraping to navigate the app, access different screens, and interact with various elements to gather the desired information.
To achieve scalability, a virtual device cloud infrastructure is employed. This infrastructure emulates a cluster of devices, ensuring that the scraping process can be performed at scale. Additionally, an intelligent proxy network handles communication between the devices and the app, ensuring efficient data retrieval.

Step 2: Identify product ROI (Region of Interest)
To accurately scrape text for each product, Mobile App Scraping utilizes an Object Detection algorithm to identify the ROI of individual products within a frame, regardless of the number of products present.
The input files are passed through a custom fine-tuned version of the YOLOv5 (You Only Look Once) architecture, which excels in fast and accurate inference. YOLOv5 can swiftly detect and localize each product's ROI within the frame.
Since a video typically consists of multiple frames per second, the exact product ROIs are possible. To address this, a deduplication stage is introduced. This stage eliminates identical product ROIs, allowing faster and more efficient data processing. The resulting ROIs from the video frames are then cached as images, ready for further analysis and extraction.

Step 3: Identify product components
In this stage, Mobile App Scraping focuses on identifying specific components of the products, such as price, product information, product image, and more. The same components to be identified may vary based on the specific mobile app being scraped.
To achieve precise component identification, Mobile App Scraping applies YOLOv5 again, but with a different instance or configuration compared to Step 2. This allows for more granular consideration in detecting and localizing the desired components within the product ROIs.
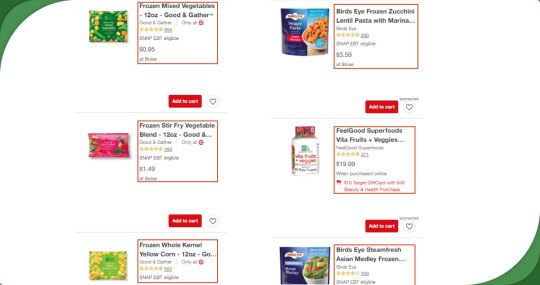
Step 4: Extract components with OCR
In this stage, Mobile App Scraping completes the textual extraction process now that all details of the products have been identified. A custom-trained OCR (Optical Character Recognition) framework is deployed to achieve this.
The OCR framework is specifically trained to recognize and extract text from the identified components of the products. It utilizes advanced algorithms and machine learning techniques to accurately extract textual information such as product names, prices, descriptions, and other relevant details.

Step 5: Accessing the final output
In the final stage, the text extraction output and relevant metadata are stored in a database. Mobile App Scraping applies unit tests and quality checks to ensure the accuracy and integrity of the extracted data.
Once the data is verified and validated, it is transformed into the desired format suitable for the client's needs. This transformation process ensures the information is structured appropriately and ready to be accessed, sent, uploaded, or requested via API (Application Programming Interface).

Conclusion
In conclusion, as the retail landscape evolves with the rise of mobile and social commerce and the emergence of the metaverse, the need for advanced AI and analytics becomes paramount. Mobile App Scraping recognizes this need and is dedicated to providing retailers and brands with sophisticated and accurate analytics across the retail ecosystem. They have developed an cutting-edge mobile app scraping solution to cater to the evolving needs of the retail industry.
Moreover, Mobile App Scraping has extended its proprietary technology to the metaverse, enabling the scraping of retail stores in virtual platforms like Decentraland, Roblox, Sandbox, Meta, and more. This expansion reflects their commitment to staying at the forefront of technological advancements and ensuring that retailers have access to critical data and insights across multiple platforms.
With the growing popularity of mobile commerce and the increasing competition in the retail space, mobile app scraping has become essential for maintaining competitive prices, assortments, and digital shelf ranking. By leveraging Mobile App Scraping's cutting-edge solutions, retailers can stay ahead of the curve and make informed decisions based on accurate and real-time data.
In summary, Mobile App Scraping offers innovative mobile app scraping solutions alongside their established eCommerce app scraping technology, empowering retailers to thrive in the dynamic retail landscape and meet the demands of modern consumers.
know more: https://www.mobileappscraping.com/mobile-app-scraping-for-retail-success.php
#RetailAppScraping#AppScrapingForRetail#EcommerceAppScraping#ScrapeEcommerceAppData#ExtractRetailAppData
0 notes
Text
Unlock Real-time Object Detection with YOLOv5 and OpenCV Tutorial
Implementing Real-time Object Detection using YOLOv5 and OpenCV Introduction Real-time object detection is a critical component in various applications such as surveillance, robotics, and autonomous vehicles. The YOLOv5 (You Only Look Once version 5) architecture is a state-of-the-art real-time object detection model that achieves high accuracy and speed. OpenCV is a widely-used computer vision…
0 notes