#chaosengineering
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
Software Blind Spot? Fix Your Chaos Engineering with Supply Chain Security Tools!

By leveraging modern SSCS practices, organizations gain deeper visibility and design more effective chaos engineering experiments. https://tinyurl.com/mufmyawr
#chaosengineering#softwaresecurity#supplychainsecurity#securitytesting#blackboxsoftware#softwaretransparency
0 notes
Text
What are the latest trends in software testing in 2024?
"Stay ahead of the curve with these cutting-edge trends shaping software testing in 2024:
Shift-Left Testing: Embrace early testing integration to catch defects sooner.
AI and Machine Learning: Utilize AI for smarter test automation and predictive analytics.
Test Automation for CI/CD: Streamline development pipelines with automated testing.
Shift-Right and Chaos Engineering: Proactively test in production to ensure system resilience.
Security Testing: Protect against cyber threats with robust security testing practices.
Performance Engineering: Prioritize performance throughout the development lifecycle.
API Testing: Ensure reliability and functionality of interconnected systems through API testing.
Shift to Exploratory Testing: Combine manual and exploratory testing for comprehensive coverage.
Keep your software quality top-notch with these trends driving innovation in the testing landscape!"
#magistersign#onlinetraining#support#usa#cannada#SoftwareTesting#QualityAssurance#TechTrends#AIinTesting#TestAutomation#DevOps#CI_CD#SecurityTesting#PerformanceEngineering#APItesting#ExploratoryTesting#ChaosEngineering#SoftwareDevelopment#Innovation#TechTrends2024
0 notes
Text
Boosting Employee Productivity with Chaos Engineering Practices
In today's fast-paced and ever-evolving business landscape, organizations are constantly striving to enhance employee productivity and ensure the resilience of their systems and applications. One innovative approach that's gaining momentum in the tech world is "Chaos Engineering." Chaos Engineering is not only about testing the reliability of your systems but can also have a profound impact on employee productivity and collaboration. In this blog, we'll delve into how the principles of Chaos Engineering can be harnessed to boost employee productivity and foster a culture of innovation and resilience within your organization.
Understanding Chaos Engineering
Chaos Engineering is the practice of deliberately injecting controlled and measured forms of chaos, such as system failures or performance bottlenecks, into your applications and infrastructure. The primary objective is to proactively identify weaknesses, vulnerabilities, and dependencies within your systems and fix them before they cause unexpected outages or issues. But how does this relate to employee productivity?
Resilience Breeds Confidence
Chaos Engineering instills a sense of confidence and resilience among employees. When your teams are confident in the system's ability to withstand unexpected failures, they are more likely to focus on their work, knowing that the technology will support their efforts. This boost in confidence leads to increased productivity, as employees spend less time worrying about system failures and more time on their tasks.
Collaboration and Learning
Chaos Engineering practices often involve cross-functional teams working together to design, execute, and learn from experiments. These collaborative efforts break down silos and encourage different departments to share their knowledge and insights. In the process, employees not only become more aware of the system's behavior but also of their colleagues' roles and responsibilities. The knowledge sharing and improved collaboration that stem from Chaos Engineering practices can lead to more effective problem-solving and a better work environment.
Reduction in Downtime
Downtime can be a significant productivity killer. Chaos Engineering helps identify and address weaknesses in your systems before they result in unexpected outages. This reduction in unplanned downtime means employees can carry on with their tasks uninterrupted, resulting in higher productivity and efficiency.
Encouraging Innovation
Chaos Engineering encourages a culture of innovation and continuous improvement. By actively seeking out weaknesses and vulnerabilities, teams become more open to trying new approaches and technologies. This can lead to the development of more efficient processes and solutions, further boosting productivity.
Enhanced Problem-Solving Skills
Chaos Engineering challenges employees to think critically, adapt to rapidly changing situations, and develop their problem-solving skills. These skills not only benefit the Chaos Engineering process but also transfer to other aspects of their work, making employees more adept at handling unexpected challenges and boosting overall productivity.
Conclusion
Incorporating Chaos Engineering practices into your organization's culture can have a profound impact on employee productivity. By instilling confidence, fostering collaboration, reducing downtime, encouraging innovation, and enhancing problem-solving skills, Chaos Engineering empowers employees to work more efficiently and effectively. It's not just about improving system resilience; it's about creating an environment where employees can thrive and contribute their best to the organization's success. Embracing Chaos Engineering can lead to a more resilient, productive, and innovative workforce.
0 notes
Text
Commodore Amiga: a visual compendium
Check out our collection of Commodore books: https://www.bitmapbooks.com/collections/commodore-books
With a mixture of pixel-perfect arcade conversions and mind-bending original titles, the Commodore Amiga was the go-to games machine of the late ’80s/early ’90s. Rediscover its glory days in this visual compendium.
#bitmapbooks #book #retrogaming #retrogames #gaming #art #reading #foryou #guardian #amiga #commodore #thechaosengine #chaosengine
3 notes
·
View notes
Text
Rapping Teddy Hack?
What are you good at? Coding robot dogs to fetch snacks + turning homework into solve-it-yourself escape rooms. Secret flex? I hacked my sister’s teddy to rap Hamilton. #ChaosEngineer
0 notes
Text
Chaos Engineering: Der unerwartete Pfad zur Systemstabilität

Wie oft haben Sie sich in einer Situation wiedergefunden, in der Ihr perfekt geplantes System unter dem Gewicht unerwarteter Fehler zusammengebrochen ist? Wenn Sie wie ich sind, dann wahrscheinlich mehr als einmal. Aber hier kommt die gute Nachricht: Es gibt eine Lösung, und die heißt Chaos Engineering. Chaos Engineering, meine Damen und Herren, ist nicht einfach nur ein weiterer technischer Begriff, den man kennen sollte. Es ist eine revolutionäre Methode, die Ihre Systeme nicht nur auf Fehler prüft, sondern sie auch absichtlich verursacht! Klingt verrückt, nicht wahr? Warum sollte jemand absichtlich Fehler in einem System verursachen wollen? Nun, die Antwort ist einfach: Um zu lernen und sich vorzubereiten. Beim Chaos Engineering geht es darum, das Unvorhersehbare vorhersehbar zu machen. Es geht nicht darum, Fehler zu vermeiden, sondern darum, sie zu erwarten. So können Sie proaktiv Maßnahmen ergreifen, um die Resilienz Ihres Systems zu stärken, bevor echte Probleme auftreten. Dieser Prozess beinhaltet das absichtliche Einleiten von Störungen in das System in einer kontrollierten Umgebung, um zu sehen, wie es reagiert. Aber wie fängt man damit an? Hier sind einige Schritte, um Sie auf den richtigen Weg zu bringen: - Definieren Sie Ihre Stabilitätsmetriken: Bevor Sie Chaos anrichten können, müssen Sie wissen, was Stabilität für Ihr System bedeutet. Das können sein: Antwortzeiten, Fehlerraten oder Systemauslastung. Kennen Sie Ihre Metriken, kennen Sie Ihr System. - Planen Sie Ihre Experimente sorgfältig: Chaos ohne Planung ist einfach nur Chaos. Das ist nicht, was wir wollen. Überlegen Sie sich, welche Teile Ihres Systems Sie testen möchten und welche Ausfälle Sie simulieren möchten. Ein geplanter Ansatz ist der Schlüssel. - Führen Sie Chaos-Experimente durch: Jetzt, wo alles bereit ist, lassen Sie das Chaos beginnen! Aber denken Sie daran, in einer sicheren und kontrollierten Umgebung zu bleiben. Überwachen Sie Ihre Systeme und lernen Sie von dem, was passiert. - Lernen und Anpassen: Dies ist der wichtigste Teil. Jedes Experiment ist wertlos, wenn Sie nicht davon lernen und Anpassungen vornehmen. Verstehen Sie, wie Ihr System reagiert hat, machen Sie Änderungen und stärken Sie es für die Zukunft. Nun, was halten Sie davon? Ist Chaos Engineering der fehlende Link in Ihrem Stabilitäts-Puzzle? Ich würde behaupten, für viele von uns ist das so. Es lehrt uns, unsere Systeme auf eine Weise zu verstehen, die sonst nicht möglich wäre. Es lehrt uns Demut vor der Unvorhersehbarkeit und bereitet uns darauf vor, besser, stärker und widerstandsfähiger zu sein. In der dritten Person gesprochen, bringt Chaos Engineering Teams dazu, über den Tellerrand hinaus zu denken. Es ist nicht nur ein Tool, sondern eine Denkweise. Unternehmen, die Chaos Engineering anwenden, berichten von einer signifikanten Verbesserung der Systemstabilität und -zuverlässigkeit. Und in einer Welt, in der jeder Ausfall Geld kostet, kann das den Unterschied bedeuten. Abschließend möchte ich Sie ermutigen, Chaos Engineering als die Chance zu sehen, die es ist. Es ist nicht nur eine Methode, um Ihr System zu testen; es ist eine Gelegenheit zu wachsen und zu lernen. Also, warum nicht das Chaos umarmen und sehen, wohin es Sie führt? Sie könnten überrascht sein, was Sie über Ihre Systeme - und sich selbst - herausfinden. #ChaosEngineering #Systemstabilität# Fehlerprävention #ResilienteSysteme #IngenieurwesenInnovation Read the full article
0 notes
Text
Azure cloud infrastructure and application testing

Introduction to quality assurance
Quality assurance (QA) is an umbrella term which encompasses all software and infrastructure quality tests that are performed to verify software application and infrastructure functional and non-functional attributes, including performance, scalability, availability and security. Azure cloud infrastructure and application testing is a major part of quality assurance. There are QA frameworks to be used for both software application and cloud infrastructure testing. Whether you perform QA using testing frameworks or you manually perform a baseline of tests, you need to have test scripts available. Each test script describes the steps to be carried out to test a certain aspect of an application or infrastructure system, as well as the result of each test and subsequent action items, if needed. This article provides a baseline reference of the steps to be included in each type of infrastructure or application test script alongside with a testing script template available for download.
Azure cloud infrastructure and application testing types
The following types of infrastructure and application test scripts are available: - Application unit testing. A unit test is a test that exercises individual software components or methods, also known as a "unit of work." Unit tests should only test code within the developer's control. They don't test infrastructure concerns. Infrastructure concerns include interacting with databases, file systems, and network resources. xUnit.net is a free, open source, community-focused unit testing tool for the .NET Framework. - Application integration testing. An integration test differs from a unit test in that it exercises two or more software components' ability to function together, also known as their "integration." These tests operate on a broader spectrum of the system under test, whereas unit tests focus on individual components. Often, integration tests do include infrastructure concerns. - Application load (or stress) testing. A load test aims to determine whether or not a system can handle a specified load. For example, the number of concurrent users using an application and the app's ability to handle interactions responsively. Refer to my KB article on Azure App Service load testing (using JUnit) for an example of carrying out load testing for an Azure-based Web application. - Infrastructure functional testing. This aims to test all operating systems, firmware and the functional attributes of on-prem or cloud infrastructure components involved in a solution. - Performance and scalability testing. During performance and scalability testing, you measure the performance metrics of your infrastructure as your application workload increases. This is combined with application software stress/load testing. The performance and scale tests involve setting up and testing autoscale policies for scaling horizontally or vertically when the application load requires it. - Availability testing. Availability tests mainly focus on testing the resiliency of your infrastructure in the event of hardware or software components failures and the associated potential downtime incurred during these failures. This should test your infrastructure and application code high availability, redundancy and resiliency. Resiliency can come in many forms, including load balancing, failover clustering (active-active or active-passive) and always on availability groups, virtual machine availability sets as well as cloud infrastructure fault domains, update domains, cloud zone and cloud region redundancy. The availability tests focus on creating deliberate failure simulation events, such as for example having an Azure VNET or subnet or storage account going down, to check the impact on the overall architecture. - Security testing. Security testing aims to test the attack surface of your architecture, the resiliency against malicious attacks, including ransomware, malware and hacking attempts and to discover potential vulnerabilities and security weaknesses in your security configuration by employing techniques such as penetration testing to evaluate IDS/IPS, Web Application Firewall protection, SIEM/SOAR/XDR systems. Azure Advisor, Azure Security Center, Azure Advisor, Microsoft Defender for Cloud and Azure Sentinel are all good tools to employ for security testing.
Site Reliability Engineering (SRE)
The success of your cloud solution depends on its reliability. Reliability can be broadly defined as the probability that the system functions as expected, under the specified environmental conditions, within a specified time. Site reliability engineering (SRE) is a set of principles and practices for creating scalable and highly reliable software systems. Increasingly, SRE is used during the design of digital services to ensure greater reliability. The degree of reliability that's required for a solution depends on the business context. Reliability is defined and measured using service level objectives (SLOs) that define the target level of reliability for a service. Achieving the target level assures that consumers are satisfied. The SLO goals can evolve or change depending on the demands of the business. Another important term to note is service level indicator (SLI), which is the metric that's used to calculate the SLO. SLIs are based on insights that are derived from data that's captured as the customer consumes the service. SLIs are always measured from a customer's point of view. SLOs and SLIs always go hand in hand, and are usually defined in an iterative manner. SLOs are driven by key business objectives, whereas SLIs are driven by what's possible to be measured while implementing the service. The relationship between the monitored metric, the SLI, and the SLO is depicted below:

Refer to the Reliability and Performance Efficiency pillars of Azure Well Architected Framework for guidance on building scalable and reliable applications.
Chaos Engineering and Azure Chaos Studio
Chaos engineering is a methodology that helps developers attain consistent reliability by hardening services against failures in production. Another way to think about chaos engineering is that it's about embracing the inherent chaos in complex systems and, through experimentation, growing confidence in your solution's ability to handle it. A common way to introduce chaos is to deliberately inject faults that cause system components to fail. The goal is to observe, monitor, respond to, and improve your system's reliability under adverse circumstances. For example, taking dependencies offline (stopping API apps, shutting down VMs, etc.), restricting access (enabling firewall rules, changing connection strings, etc.), or forcing failover (database level, Azure Front Door, etc.), is a good way to validate that the application is able to handle faults gracefully. Azure Chaos Studio is a managed service that uses chaos engineering to help you measure, understand, and improve your cloud application and service resilience. Chaos engineering is a methodology by which you inject real-world faults into your application to run controlled fault injection experiments. Chaos Studio helps you avoid negative consequences by validating that your application responds effectively to disruptions and failures. You can use Chaos Studio to test resilience against real-world incidents, like outages or high CPU utilization on virtual machines (VMs).

In Azure Chaos Studio, you first select and enable your targets (either service-direct targets or agent-based targets, such as VMs and VM Scalability Sets).
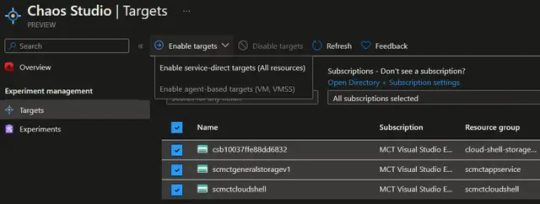
Then you create Chaos experiments on selected Azure resources, as shown in the example below. Each experiment can introduce either faults or delays, to test the resiliency of the overall infrastructure in relation to the tested Azure resources.

Infrastructure as Code (IaC) testing frameworks and tools
The most prominent Infrastructure As Code languages in Azure are Azure ARM (JSON), Bicep and Terraform. Each of them has its own methods and tools for testing the IaC configuration. - Terratest is a tool to be used for testing Terraform modules. Terratest is implemented as a Go library. Terratest provides a collection of helper functions and patterns for common infrastructure testing tasks, like making HTTP requests and using SSH to access a specific virtual machine. - Bicep code can be tested by using Azure Pipelines or Powershell PSRule or even combine PSRule in Azure Pipelines. - ARM templates can be tested by employing the ARM template test toolkit. The Azure Resource Manager template (ARM template) test toolkit checks whether your template uses recommended practices. When your template isn't compliant with recommended practices, it returns a list of warnings with the suggested changes. By using the test toolkit, you can learn how to avoid common problems in template development. You can also test ARM Templates by using Pester and Azure DevOps. - Use Pester for Powershell or Powershell DSC scripts. - - Azure Policy Test Framework is a command line tool to test Azure Policy relying on Terraform + Golang.
Testing script template
You can find a free testing script template in the "Free Downloads" section.
References
https://learn.microsoft.com/en-us/azure/architecture/example-scenario/apps/scalable-apps-performance-modeling-site-reliability https://learn.microsoft.com/en-us/azure/chaos-studio/chaos-studio-overview https://learn.microsoft.com/en-us/azure/architecture/framework/resiliency/chaos-engineering https://learn.microsoft.com/en-us/dotnet/core/testing/ https://learn.microsoft.com/en-us/azure/developer/terraform/test-modules-using-terratest Read the full article
0 notes
Text
Chaos Engineering: Unleashing havoc in production

Nigel Pereira explains why organisations are exploring chaos engineering, and disrupting their own chain of operations to discover the weaknesses within Read More. https://www.sify.com/cloud/chaos-engineering-unleashing-havoc-in-production/
0 notes
Text
How a Change Resistant RPA Testing Strategy Can Help Reduce Bot Fragility

Robotic Process Automation, or RPA, is increasingly embraced by business enterprises to automate repetitive and mundane activities related to software development and testing. The technology can be categorized as a disruptor given its estimated market value to touch $2,467 million by 2022 at a CAGR of 30.14% from 2017 to 2022 (Source: marketsandmarkets.com). The benefits of RPA technology for the industry are immense and include the ability to reduce operational costs, create business value, increase productivity, enhance quality, and others. However, notwithstanding the benefits that brought the technology to the center stage, it continues to be plagued by a serious problem – the breaking of bots due to change.
For instance, users may seldom notice changes in the software interface, such as login to logon or username to userid. Besides, these changes won’t get in the way of users’ completing specific tasks. However, when it comes to the RPA bots, they won’t budge or execute a particular task on noticing a change. In such a situation, the developers must dig deep into the problem to fix it. If this is the scenario for just one change for one process, then imagine the situation where hundreds of processes are involved.
Developers have to willy-nilly edit all processes to resolve a single change to one object. And should such changes occur frequently because of today’s dynamically changing IT environment, one can only imagine the prospect of making so many changes to the UI or connected APIs, among others. The result of such a situation will be the faltering of automation strategies, downtime, and lost business value. So, what needs to be done? The answer lies in crafting an RPA testing strategy that is resilient to change.
RPA testing strategies to make bots more adaptable?
To mitigate the fragility of RPA technology and drive efficiencies, RPA testing solutions should include the following:
Change management and resilient automation: Enterprise RPA should leverage a model-based intelligent object framework to streamline the maintenance of automation suites. Here, the object action framework, instead of manually updating every instance of a change across applications and processes, applies a one-to-many approach to replicate the change automatically across the software. In the RPA software testing model, a single definition is attached to a particular object. So, applying a fix to that definition can fix every bot or process that uses it. Thus, by fixing the central definition of an object, the effort to find the processes that use the object is eliminated.
Codeless automation: Debugging codes written by others is time-consuming and complex. It’s no wonder codeless technology is gaining popularity across the board for building applications. Also, enterprises do not need to write code to garner the benefits of RPA anymore, for there are codeless solutions to simplify the process of building and maintaining bots. This also enables non-technical users to become involved in bot maintenance.
Scalable automation: The true value of automation lies in reusing and sharing it across the value chain. Further, building an easily maintainable automation process is different from executing a thousand processes in an hour. In other words, automation can only benefit if it is scaled across the enterprise, especially to complex and high-volume processes. So, any RPA testing strategy should check the scalability of automation to processes and whether the outcomes of such processes are accurate and consistent with expectations.
Integrated automation: Any automation process running in production should not fail, for the consequences can be dire for the entire value chain. Robotic test automation has become an efficient approach to executing testing in production environments. It can validate complex business processes across the production pipeline. Given that most applications and their processes are highly integrated within the production environments, the robotic process automation approach should apply to all applications.
Conclusion
There should be a synergy between RPA and testing in order to automate testing and apply the same across processes, teams, and projects. It should enhance the capabilities of business enterprises for governance, RPA orchestration, and security. Also, by executing the automated process in testing in the same way you would be running in RPA, you can ensure the bots work properly. Finally, should you want automation to deliver ROI, it is better to implement a change-resilient robotic process software testing solution. This allows you to make the best use of your time while expanding RPA and adding value to your business.
Resource
James Daniel is a software Tech enthusiastic & works at Cigniti Technologies. I'm having a great understanding of today's software testing quality that yields strong results and always happy to create valuable content & share thoughts.
Article Source: tealfeed.com
0 notes
Photo

#chaosengine #retro #80s #computerscience (en Los Dos Caminos - C.C Millenium) https://www.instagram.com/p/CMuVJFgrb-9/?igshid=19w0gdyq30gjb
0 notes
Photo

Nuevo estilo para la Renegada hijos de P... #Fortnite #UnChapuzónDeAventuras #FortniteC2T3 #AquaMan #FortniteXAquaMan #FortniteC2S3 #FortniteCapítulo2 #FortniteChapter2 #Desafios #FortniteBattleRoyale #FortniteChapter2Season3 #FortniteCapítulo2Temporada3 #ChaosEngine https://www.instagram.com/p/CBhtqbqlNjm/?igshid=1ey62vw8i9nki
#fortnite#unchapuzóndeaventuras#fortnitec2t3#aquaman#fortnitexaquaman#fortnitec2s3#fortnitecapítulo2#fortnitechapter2#desafios#fortnitebattleroyale#fortnitechapter2season3#fortnitecapítulo2temporada3#chaosengine
0 notes
Photo

#studio #georgedawnay #tumblr #chaosengine #infulleffect
7 notes
·
View notes
Photo

Gremlin Certified Chaos Engineering Practitioner (GCCEP)
0 notes
Text
The Chaos Engine - Featured in our book - Commodore Amiga: a visual compendium
Relive the halcyon gaming days of the Commodore Amiga in this stunning visual compendium – 420 pages packed with classic 16-bit games.
Reprints due 23rd July 📚
Sign up for a handy email reminder: https://www.bitmapbooks.com/collections/all-books/products/commodore-amiga-a-visual-commpendium
#bitmapbooks #book #retrogaming #amiga #commodore #chaosengine
1 note
·
View note
Photo

Old Skool Friday! Go back in time to a period where the only thing that was serious, was the amount of time you had left before you missed the bus to school! Our Officially licensed Bitmap Brothers logo tee is available on our website now with worldwide shipping! #bitmapbrothers #speedball #xenon2 #chaosengine #16bit #atari #amiga #megadrive #sega #nintendo #n64 #snes #xbox #ps3 #ps4 #retrogamer #retro #gamer #vintage #classic #sonicthehedgehog #mariobros #geek #gamergeek #retrogeek #retronerd #gamernerd #gamergirl
#xenon2#16bit#retrogeek#chaosengine#ps4#bitmapbrothers#sonicthehedgehog#sega#gamergirl#retrogamer#retronerd#mariobros#classic#speedball#vintage#ps3#xbox#snes#gamergeek#gamer#nintendo#geek#megadrive#atari#gamernerd#amiga#retro#n64
0 notes