#CloudFront
Text
#AWS#AWS Cloudformation#Cloudformation#AWS Lambda#Lambda#AWS Certificate Manager#Certificate Manager#ACM#Lambda@Edge#AWS WAF#WAF#AWS Secrets Manager#Secrets Manager#Amazon S3#S3#Amazon CloudFront#CloudFront#Custom Resources#Custom Resource#Cross-Region#Cross Region#CI/CD#DevOps
0 notes
Text
Boosting Performance: CloudFront KeyValueStore Optimization

You may safely distribute both static and dynamic content with fast transfer speeds and minimal latency by using Amazon CloudFront. You can handle millions of requests per second and latency-sensitive customizations with CloudFront Functions. CloudFront Functions, for example, can be used to rewrite URLs, authorize requests, normalize cache keys, and change headers.
AWS are pleased to present CloudFront KeyValueStore, a safe, low-latency global key value datastore that can be accessed readly from within CloudFront Functions. This feature enables highly customized logic to be implemented at CloudFront edge locations.
In the past, configuration data had to be included directly into the function code. For instance, information for choosing which URL to send the viewer to when a URL needs to be redirected. Every tiny change in configuration when embedding it with the function code necessitates a code change and a redeployment of the function code. There is a chance that code will be accidentally altered when new lookup additions need updating and deploying code. Additionally, since the maximum function size is 10 KB, many use cases will struggle to fit all of the data within the code.
You can now update the function code and the data associated with it separately using CloudFront KeyValueStore. As a result, function code is made simpler and data updates are made simple without requiring code modifications to be deployed.
Let’s examine how this functions in real life.
Building a key value store for CloudFront
You select Functions from the navigation pane in the CloudFront dashboard. Then now you select Create KeyValueStore under the KeyValueStores menu.
This allows you to import key-value pairs into an Amazon Simple Storage Service (Amazon S3) bucket from a JSON file. If you want to start with no keys, therefore you not doing that right now. You finish the key value store creation by entering a name and description.
You select Edit under the Key value pairs area and then Add pair once the key value store has been established. You enter Hello World for the value and hello for the key before saving the adjustments. For now, one key is sufficient, but you can add more keys and values.
Changes made to a key value store propagate quickly to all CloudFront edge locations, allowing functions connected with the key value store to use it with little latency.
Utilizing CloudFront Functions’ CloudFront KeyValueStore
You select Functions from the navigation pane in the CloudFront console, followed by Create function. You give the function a name, choose the cloudfront-js-2.0 runtime, and finish the function’s creation. Then you correlate this function with the key value store using the newly available option.
You can use the console’s key value store ID, which you copy, in the function code that follows:
This function answers with the name of the key and its value, using the first segment of the request path as the key.
Now you publish the function and save the modifications. You can link the function to a CloudFront distribution which you previously made in the Publish tab of the function. You can intercept all requests to the distribution using the Default (*) cache action and the Viewer Request event type.
You return to the functions list in the console and watch for the function to be deployed. Next, you download content from the distribution using curl from the command line and verify the function’s outcome.
Initially, you can test a few pathways that call the method and checkup the previous key you made (hello): Success! Next, you experiment with a different approach to observe that, in the event that the key cannot be retrieved, the code returns the default value.
Now that we have this basic example working, let’s try a more sophisticated and practical one.
Using CloudFront KeyValueStore configuration data, rewrite the URL
Let’s create a function that looks up the custom path that CloudFront should use to send the actual request in a key-value store using the content of the URL in the HTTP request. This feature can assist in managing the various services that make up a website.
Things to consider
Today, CloudFront KeyValueStore is accessible in every edge location across the world. Pay just for the read/write operations from the public API and the read operations from within CloudFront Functions when using CloudFront KeyValueStore. View the CloudFront pricing page for additional details.
The AWS Management Console, AWS Command Line Interface (AWS CLI), and AWS SDKs can all be used to manage a key value store. Support for AWS CloudFormation is on the horizon. You can link a single key value store to every function, and key value stores have a maximum capacity of 5 MB. A key can have a maximum size of 512 bytes. Values may have a maximum value of 1KB. Using a source file on Amazon S3, you can import key/value data while building a key-value store. This file has the following JSON structure:
Key/value data imports during creation provide easy configuration replication between environments (e.g., preproduction and production) and can automate the setup of a new environment (e.g., test or dev).
Read more on Govindhtech.com
#CloudFront#AWS#amazon#API#data#keyvaluestore#AWSManagementConsole#AWSCommandLineInterface#technews#technology#govindhtech
0 notes
Text
How to Choose the Right CDN — AWS CloudFront Vs Cloudflare
Cloudflare vs CloudFront
Cloudflare and CloudFront are services that can help reduce your website’s load time. In addition to speeding up your content delivery and load times, they can provide many advantages to your organization. They both work similarly by distributing server loads across multiple servers, but they have fundamental differences. Cloudflare is a service that provides other application services such as DNS, load balancing, video streaming, DDoS attacks protection, web application firewall (WAF), analytics, domain registry, and more. At the same time, Cloudfront is just a CDN provider with the sole purpose of accelerating content delivery.
What is a CDN?
“Content Delivery Network,” or “CDN,” is a network of computers, servers, and nodes worldwide. You upload your website files to the ‘cloud,’ and then this content will be delivered via dedicated servers/nodes that are geographically closer to your end customers than the original hosting server.
What is Cloudflare?
Cloudflare is a buzzing brand in the CDN industry for its ability to provide cutting-edge performance capabilities and robust security features. It functions essentially as a reverse proxy, and its infrastructure is built from scratch, without any legacy system. It was originally intended to keep fraudsters off your website and stop them from harvesting emails. Their global infrastructure and algorithm provide advanced security systems along with performance enhancement. The incorporation of machine learning into the Cloudflare infrastructure enables it to continuously learn, adapt, and integrate to meet the complex needs of the ever-evolving technical environment.
What is CloudFront?
A relatively different or conventional CDN tool does not require you to change nameservers as you did in Cloudflare. Amazon Cloudfront is entirely different from the “Reverse Proxy” approach of Cloudflare.
Cloudfront is another well-known global CDN (Content Delivery Network) that retrieves data from the Amazon S3 bucket and distributes it to multiple data centers it acquires. It uses a network of data centers, often referred to as Edge Locations, to deliver the data centers, often referred to as Edge Locations. When a user requests data on the internet, the nearest edge location is routed, resulting in the lowest latency, low network traffic, faster access to content, and an overall better web experience.
Amazon CloudFront vs. Cloudflare: The Key Differences
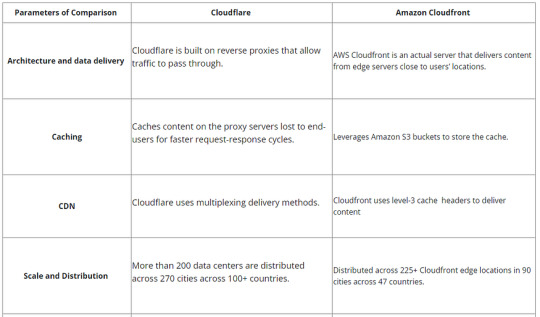
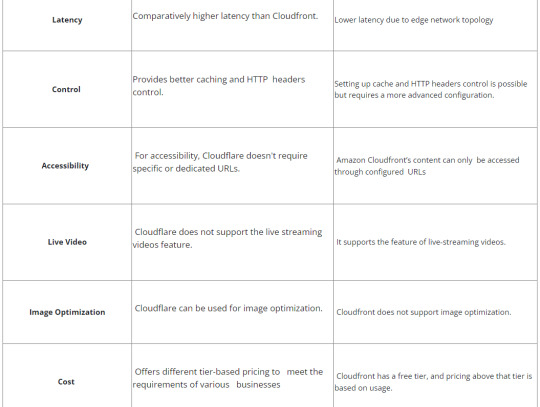
Cloudflare and AWS Cloudfront are both well-established names in the CDN industry. They both provide a wide range of features, which is why it can be confusing when choosing one of them. Amazon Cloudfront and Cloudflare are both highly recommended & suited Delivery Networks to users and can be used as per your requirements. Ultimately, the best choice depends on your specific business requirements. As you’ve seen, there are essential differences between the two services. So, to select the CDN service that best suits your business model, you’ll want to accurately and thoroughly understand the benefits and capabilities of both choices.
Still confused? KnackForge experts can help you choose the best option for your business! Contact our Cloud technical consultants today for a free consultation.
0 notes
Text

AWS CloudFront helps you to perform various tasks including retrieving data. To do that, you need a Python library named boto3. This library allows you to interact with resources in AWS with the help of Python code. One more thing to consider while using boto3 to connect to AWS resources is selecting the right AWS resource explore.
0 notes
Text
Create a static website using Amazon S3 and deliver it seamlessly through an Amazon CloudFront distribution.
0 notes
Text
let me tell you a story
there once was a little fish who loved to scrape website's API endpoints to gather information for their apps
then cloudfront blocked their vps and ruined their day
the end
0 notes
Text
Amazon Web Service & Adobe Experience Manager:- A Journey together (Part-5)
In the previous parts (1,2,3 & 4) we discussed how one day digital market leader meet with the a friend AWS in the Cloud and become very popular pair. It bring a lot of gifts for the digital marketing persons. Then we started a journey into digital market leader house basement and structure, mainly repository CRX and the way its MK organized. Ways how both can live and what smaller modules they used to give architectural benefits.Also visited how the are structured together to give more.
In this part as well will see on the more in architectural side.
AEM scale in the cloud
A dynamic architecture with a variable number of AEM images is required to fulfill the operational business needs.

AEM as a Cloud Service is based on the use of an orchestration engine.Dynamically scales each of the service instances as per the actual needs; both scaling up or down as appropriate.
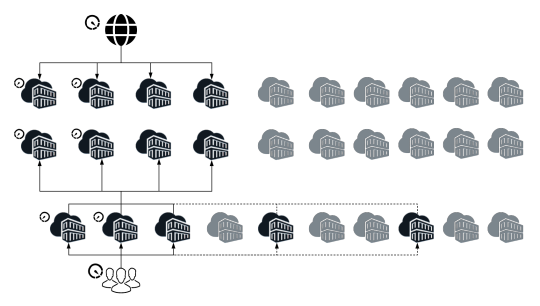
Scaling is a very simple task in AWS with creating separate Amazon Machine Images(AMIs) for publish , publish-dispatcher and author- dispatcher instance.
Use an AMI
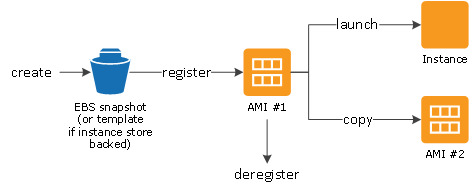
Three separate launch configurations can be created using these AMIs and included in separate Auto Scaling groups(Auto Scaling groups - Amazon EC2 Auto Scaling).
AWS Lambda can provide scaling logic for scale up/down events from Auto Scaling groups.
Scaling logic consists of pairing/unpairing the newly launched dispatcher instance to an available publish instance or vice versa, updating the replication agent (reverse replication, if applicable) between the newly launched publish and author, and updating AEM content health check alarms.
One more approach for the quicker startup and synchronization, AEM installation can place on a separate EBS volume. A frequent snapshots of the volume and attachment to the newly-launched instances, Cut-down need of replicate large amounts of author data. Also it ensure the latest content.
CDN:-Content Delivery Network or Content Distribution Network
A CDN is a group of geographically distributed and interconnected servers. They provide cached internet content from a network location closest to a user to speed up its delivery.
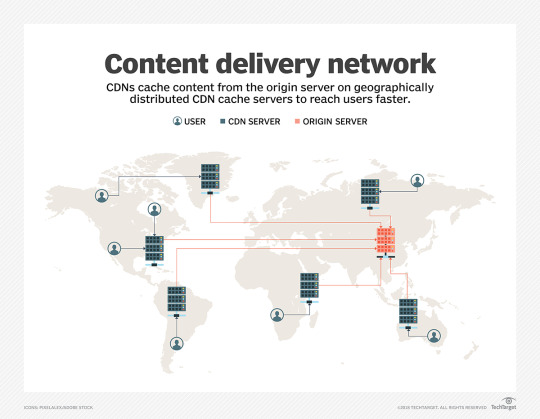
AWS is having answer of CDN requirement as well in the form of Amazon CloudFront a Low-Latency Content Delivery Network (CDN)
How it works
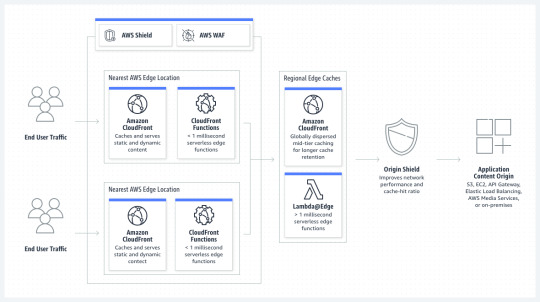
It will act as an additional caching layer with AEM dispatcher. Also it require proper content invalidation when it refreshed.
Explicit configuration of duration of particular resources are held in the CloudFront cache, expiration and cache-control headers sent by dispatcher required to control caching into CloudFront .
Cache control headers controlled by using mod_expires Apache Module.
Another approach will be API-based invalidation a custom invalidation workflow and set up an AEM Replication Agent that will use your own ContentBuilder and TransportHandler to invalidate the Amazon CloudFront cache using API.
These all about caching of static content only what is the solution or way to handle Dynamic content will see now.
Content which is Dynamic in Nature
Dispatcher is the key element of caching layer with the AEM. But it will not give full benefit when complete page is not cacheable. Now the question arise how dynamic content can fit into page without breaking the caching feature. There are some standard suggestion available. Like Edge Side Includes (ESIs),client-side JavaScript or Server Side Includes (SSIs) incorporate dynamic elements in a static page.
AWS is also have one solution as Varnish(replacing the dispatcher) to handle ESIs . But its not recommended by Adobe.
Till here we have seen structure of content dynamic static and various ways, but digital solution also have huge number of Assets mainly binary data. These need to configure handle properly to ensure performance of the site.
Again AWS is equipped with great solution called Amazon S3.
AEM Data Store with Amazon S3
Adobe Experience Manager (AEM), binary data can be stored independently from the content nodes. The binary data is stored in a data store, whereas content nodes are stored in a node store.
Both data stores and node stores can be configured using OSGi configuration. Each OSGi configuration is referenced using a persistent identifier (PID).
AEM can be configured to store data in Amazon’s Simple Storage Service (S3), with following PID for configuration
org.apache.jackrabbit.oak.plugins.blob.datastore.S3DataStore.config
To enable the S3 data store functionality, a feature pack containing the S3 Datastore Connector must be downloaded and installed. For more detail please refer Configuring node stores and data stores in AEM 6 | Adobe Experience Manager
This will simplifying management and backups. Also, sharing of binary data store across author and between author & publish instances will be possible and easier task with AWS S3 solution.
it will reduce overall storage and data transfer requirements.
Already this great combination walkthroug of the structure combination posibbilities , we will see one more variation available for the Cloud version of AEM with AWS in next (AEM OpenCloud)
Thanks for being with me till this , we will meet in next part with some amazing journey of OpenClode.
Hope you enjoy most till this part, kindly keep your blessings and love to motivate me.
Continue............
#aem#aws#adobe#cloud#wcm#programing#ELB#Amzon S3#OpenClode#OSGi#SSIs#ESI#CloudFront#Datastore#connector#Dispatcher#API#ContentBuilder#TransportHandler#CDN#AWS Lambda#aws lambda#Amazon EC2 Auto Scaling#ASG Auto Scaling Group#Amazon Machine Images(AMIs)#AEM AUTHOR#AEM Publish
1 note
·
View note
Text
CloudFront 支援 JA3 資訊 (SSL/TLS fingerprint)
CloudFront 支援 JA3 資訊 (SSL/TLS fingerprint)
看到 CloudFront 宣佈支援帶入 JA3 資訊了:「Amazon CloudFront now supports JA3 fingerprint headers」:
Details: Amazon CloudFront now supports Cloudfront-viewer-ja3-fingerprint headers, enabling customers to access incoming viewer requests’ JA3 fingerprints. Customers can use the JA3 fingerprints to implement custom logic to block malicious clients or allow requests from expected clients only.
JA3 的頁面上可以看到說明,針對…
View On WordPress
0 notes

Text
I love when its muggy outside bc i get to say ITS MUGGY TODAY ISNT IT to everyone i meet. This is my friendly orange tabby cat moment and it lasts until the sun burns it away
#sweating out of every pore out here at the farmers market but i love it#just#a girl#standing in front of a cloudfront#asking it to last
0 notes
Text
This blog post dives into the world of Round-Trip Time (RTT) and its impact on network performance. It explains how RTT affects user experience and outlines actionable strategies to optimize your network for faster data transfer and smoother operation. You'll learn about the factors that contribute to latency, along with effective techniques to reduce RTT and improve overall network efficiency. Additionally, the post explores how Amazon CloudFront can be leveraged to achieve significant performance gains.
0 notes
Text
The AWS CloudFront helps you to perform various tasks including retrieving data. To do that, you need a Python library named boto3. This library allows you to interact with resources in AWS with the help of Python code. One more thing to consider while using boto3 to connect to AWS resources is selecting the right AWS profile.
0 notes
Text
#AWS#AWS Amplify#AWS Amplify Hosting#AWS Amplify CLI#Amazon S3#Amazon CloudFront#AWS CloudFormation#AWS CodeCommit#Git#GitHub#CI/CD#Serverless#Static Website#Static Website Hosting#Architecture as Code#AaC
0 notes
Text
Exploring Live Streaming Capabilities with AWS Elemental Link

Experience Secure and High-Speed Live Streaming with AWS Elemental Link: Connect with Top Certified AWS Partners for Immediate Service
#aws live streaming#aws elemental link#aws live streaming architecture#live streaming with aws#aws live audio streaming#aws Cloudfront live streaming#aws live streaming pricing
0 notes
Text
Deliver your content worldwide at a high data transfer speed and avoid DDoS attacks with AWS CloudFront to boost the video viewing experience of users.
0 notes


Last Seen Blogs

tw0tiem
IP Blog

skulzinsoupz
Skully

patel55
Untitled

numetalfication
Whats Up Numetalfication Nation

lebenslabyrinth
Ertrinke in Gedanken und ersticke an Emotionen