#cursor in rdbms
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
Cursor In RDBMS By Sagar Jaybhay 2020
New Post has been published on https://is.gd/fMZkWz
Cursor In RDBMS By Sagar Jaybhay 2020

In this article we will understand cursor in rdbms in our case we show example on SQL Server By Sagar Jaybhay. Also we will understand Merge statement in SQL Server and rerunnable SQL scripts and How to create a stored procedure with an optional parameter?
Cursors In RDBMS
In a relational database management system takes into consideration then it would process the data in sets inefficient manner.
But when you have a need to process the data row by row basis then the cursor is the choice. The cursor is very bad at performance and it should be avoided and also you can replace the cursor with join.
Different Types of Cursors In RDBMS
Their are four types of cursors in rdbms which are listed below
Forward only
Static
Keyset
Dynamic
The cursor is loop through each record one by one so that’s why it’s performance is not good.
declare @empid int declare @deptid int declare @fullname varchar(200) declare empcurose cursor for select EmpID,full_name,DepartmentID from Employee open empcurose fetch next from empcurose into @empid,@fullname,@deptid while(@@FETCH_STATUS=0) begin print 'EmpID '+cast(@empid as varchar(10))+ ' Name '+cast(@fullname as varchar(100)) + ' deptid '+cast(@deptid as varchar(100)) fetch next from empcurose into @empid,@fullname,@deptid end close empcurose deallocate empcurose
deallocate empcurose
This line is used to deallocate all resources which are allocated for that cursor.
What is rerunnable SQL scripts?
A re-runnable SQL script is a script that runs multiple times on the machine will not throw any kind of error.
For example, if you use create table statement to create a table then use if not exist in create a statement so it will not throw an error.
How to create a stored procedure with an optional parameter?
create procedure searchemployee @name varchar(10)=null, @deptid int=null, @gender varchar(10)=null as begin if(@name is not null) print 'i am in name '+cast(@name as varchar(20)) select * from tblEmp where [name]=@name; return; if(@deptid is not null) print 'i am in deptid '+cast(@deptid as varchar(20)) select * from tblEmp where deptid=@deptid; return; if(@gender is not null) print 'i am in gender '+cast(@gender as varchar(20)) select * from tblEmp where geneder=@gender; return; print 'i m here '+cast(@gender as varchar(20))+' '+cast(@deptid as varchar(20)) +' '+cast(@name as varchar(20)) select * from tblEmp end execute searchemployee @deptid=2
Simply pass default values to stored procedure variables.
Merge statement In SQL server
Merge statement is introduced in SQL server 2008 it allows to insert, update, deletes in one statement. It means there is no need to use multiple statements for insert update and delete.
In this, if you want to use merge statement you need to 2 tables
Source table– it contains the changes that need to apply to the target table.
Target table– this is the table that requires changes insert, update, delete.
Merge statement joins the target table to source table by using a common column in both tables based on how you match up we perform insert, update and delete.
Transaction Link: https://www.codementor.io/@sagarjaybhay18091988/transaction-in-sql-server-155l4qr7f4
2 notes
·
View notes
Text
Sql Interview Questions
If a WHERE clause is used in cross join after that the inquiry will certainly function like an INTERNAL SIGN UP WITH. A DISTINCT restraint ensures that all values in a column are various. This supplies uniqueness for the column and also assists identify each row distinctively. It promotes you to manipulate the data stored in the tables by using relational drivers. Instances of the relational data source administration system are Microsoft Gain access to, MySQL, SQLServer, Oracle database, etc. One-of-a-kind crucial restriction uniquely identifies each document in the data source. https://geekinterview.net This vital provides uniqueness for the column or set of columns. A database arrow is a control framework that permits traversal of documents in a data source. Cursors, on top of that, promotes handling after traversal, such as access, addition as well as deletion of database documents. They can be considered as a reminder to one row in a set of rows. An alias is a feature of SQL that is sustained by a lot of, otherwise all, RDBMSs. It is a temporary name designated to the table or table column for the purpose of a specific SQL inquiry. Furthermore, aliasing can be employed as an obfuscation technique to protect the actual names of database fields. A table pen name is also called a relationship name. students; Non-unique indexes, on the other hand, are not utilized to enforce restrictions on the tables with which they are linked. Rather, non-unique indexes are made use of solely to improve query performance by keeping a sorted order of data worths that are used regularly. A database index is a data structure that offers quick lookup of data in a column or columns of a table. It boosts the speed of operations accessing data from a data source table at the cost of additional creates as well as memory to keep the index information framework. Prospects are most likely to be asked standard SQL interview concerns to progress degree SQL concerns relying on their experience and different other aspects. The listed below list covers all the SQL meeting concerns for betters in addition to SQL interview questions for knowledgeable degree candidates as well as some SQL question meeting concerns. SQL provision helps to restrict the outcome set by offering a problem to the query. A clause assists to filter the rows from the entire set of records. Our SQL Meeting Questions blog site is the one-stop source where you can improve your meeting prep work. It has a set of leading 65 concerns which an interviewer intends to ask throughout an interview procedure. Unlike primary vital, there can be numerous distinct restrictions specified per table. The code syntax for UNIQUE is rather comparable to that of PRIMARY SECRET and can be utilized mutually. A lot of modern data source management systems like MySQL, Microsoft SQL Server, Oracle, IBM DB2 as well as Amazon Redshift are based upon RDBMS. SQL clause is specified to restrict the result set by providing problem to the query. This typically filterings system some rows from the whole collection of records. Cross join can be defined as a cartesian product of both tables included in the join. The table after sign up with contains the same number of rows as in the cross-product of number of rows in the two tables. Self-join is set to be query made use of to contrast to itself. This is utilized to contrast values in a column with other worths in the exact same column in the same table. PEN NAME ES can be utilized for the same table contrast. This is a key words used to inquire information from even more tables based upon the partnership between the areas of the tables. A international trick is one table which can be associated with the main key of another table. Partnership requires to be produced in between 2 tables by referencing international key with the main key of another table. A Distinct essential restraint uniquely recognized each record in the data source. It begins with the fundamental SQL interview questions and later on remains to sophisticated inquiries based on your conversations and also solutions. These SQL Interview concerns will aid you with various knowledge levels to reap the optimum take advantage of this blog. A table has a specified number of the column called fields however can have any kind of variety of rows which is called the document. So, the columns in the table of the database are called the fields and they represent the feature or attributes of the entity in the document. Rows below describes the tuples which stand for the easy data item and also columns are the quality of the information products existing particularly row. Columns can classify as vertical, as well as Rows are straight. There is provided sql meeting questions and also responses that has actually been asked in lots of business. For PL/SQL interview questions, visit our following web page. A view can have information from several tables integrated, as well as it depends on the connection. Views are used to apply security system in the SQL Server. The sight of the database is the searchable object we can use a inquiry to browse the view as we use for the table. RDBMS means Relational Database Monitoring System. It is a data source administration system based upon a relational version. RDBMS stores the data right into the collection of tables and also links those table using the relational drivers easily whenever called for. This provides uniqueness for the column or set of columns. A table is a collection of information that are organized in a version with Columns and Rows. Columns can be categorized as vertical, as well as Rows are straight. A table has specified number of column called areas but can have any kind of number of rows which is called record. RDBMS save the data into the collection of tables, which is connected by common areas between the columns of the table. It also provides relational operators to manipulate the information stored into the tables. Adhering to is a curated listing of SQL interview concerns as well as answers, which are most likely to be asked during the SQL meeting.

1 note
·
View note
Text
What is the best SQL for MongoDB and Cassandra?
What is the best SQL for MongoDB and Cassandra?
This Cassandra vs. MongoDB comparison focuses on the two most significant NoSQL database products currently on the market: Cassandra and MongoDB.

Although both of these NoSQL databases have a tendency to look similar, they differ from one another in a number of ways, so we'll talk about them for a while anyway.
Cassandra vs MongoDB: NoSQL DB Comparison
Let's try to understand some of the similarities between these two NoSQL databases now that we have a better understanding of them both:
These are both examples of NoSQL databases.
None of these can be used in place of the standard RDBMS database types.
These two databases do not both adhere to ACID standards.
Because they skew more toward RDBMS database types, these two database types do not satisfy the concepts of consistency and normalization.
Visit Mindmajix, a global online training platform, and search for "MongoDB Certification Training" if you want to advance your career and become an expert in MongoDB. With the assistance of this course, you can succeed in this field.
Larger companies like Google, Adobe, Forbes, eBay, Cisco, and many others use MongoDB.
What is Cassandra?
To understand Cassandra a little better, consider that it was first introduced in 2008 by a few Facebook developers and later made available as an Open Source project. The Apache Software Foundation is currently supporting it, and Apache is currently maintaining this project for any future improvements.
Third-party companies like Impetus, Datastax, and imagination provide support for this database. In companies like Facebook, Instagram, IBM, Reddit, and Netflix, Cassandra is used.
What is MongoDB?
A company called 10gen introduced MongoDB in 2009, just to give you some background information.
Later, 10gen changed its name to MongoDB Inc., which is now in charge of software development and also sells the enterprise version of the MongoDB database. With their excellent round-the-clock enterprise-grade support, MongoDB Inc. manages all the support.
Since they offer lifetime support, customers can use any version of MongoDB and can upgrade at any time with no interruption in service. Additionally, it gives them the chance to keep up with all the security updates that the company releases continuously.
Cassandra vs MongoDB: Difference between Cassandra and MongoDB
Features
Cassandra
MongoDB
Modeling Data
Rows and columns make up the more traditional data model used by Cassandra.
In the case of Cassandra, data is organized, and each of these columns belongs to a particular type that is assigned at the time the table is created.
MongoDB provides a richer data model than Cassandra, in comparison.
The data model in MongoDB can be either data-oriented or object-oriented.
Depending on the user domain, this model can also be represented using any data structure.
If necessary, data can also be nested into a number of levels.
Node Master
One master node in the Cassandra cluster can be replaced by another if it goes down because there are multiple master nodes in the cluster.
Due to the aforementioned, The cluster is not affected and is always accessible.
In contrast to MongoDB, Cassandra offers a higher level of availability.
MongoDB only has one master node in a cluster, which controls a number of slave nodes.
A slave is chosen to take over as master if the master falls, and it takes about 20–30 seconds for the same. In this duration, the cluster won’t be able to accept any incoming requests.
Secondary Indices
The cursor support in Cassandra is restricted to a single column and equality comparison for the secondary index.
Any property that is kept in the MongoDB database can be easily indexed.
If your application needs flexibility in the data model and secondary indices, MongoDB is preferable to Cassandra.
Scalability
Cassandra is the best option for scalability because it can have multiple master nodes in a cluster.
As it can have multiple master nodes in a cluster, Cassandra is more scalable than MongoDB.
Only one master node, which acts as the only point of contact for incoming requests, is present at any given time in the MongoDB cluster. Hence, it is not ideal when we think about scalability.
Query Language
There is a proprietary query language for Cassandra named CQL, which is very similar to SQL.
Cassandra has a user-friendly set of queries with CQL and is adaptable to the developers who have prior knowledge of SQL.
There is no support for any query language for MongoDB.
Queries are structured as JSON fragments in MongoDB.
Aggregation
Cassandra doesn’t have any built-in support for aggregation and heavily relies on tools like Hadoop or Apache Spark
MongoDB has built-in support for aggregation which can be used to run an ETL pipeline in transforming the required data.
MongoDB’s aggregation framework supports both small and medium data traffic. With the increased complexity, the framework gets tougher to debug as well.
MongoDB is better in comparison with Cassandra, as it has a built-in aggregation framework.
Schema
Cassandra doesn’t provide the facility to alter schema but provides static typing.
MongoDB provides the facility to alter schema for the Users
Performance
Cassandra performs better in applications with heavy data load as it can provide multiple master nodes in a cluster.
MongoDB is not ideal for applications with heavy data load as it can’t scale with the performance.
Conclusion
In this article comparing Cassandra and MongoDB, we have examined two NoSQL database variants that are currently on the market, thoroughly understood each of these NoSQL databases, and also seen the majority of similarities between these two database products. In addition, we have carefully examined the variations between these two database products and comprehended the areas where these products are most frequently used.
#mongodb#html#css#javascript#nodejs#python#programming#mysql#java#webdeveloper#reactjs#php#webdevelopment#angular#software#jquery#android#laravel#nosql#vuejs#js#webdesigner#rubyonrails#machinelearning#webdesign#react#coding#sql#artificialintelligence#reactnative
0 notes
Text
MongoDB
What is MongoDB?
MongoDB is a document-oriented NoSQL database used for high volume data storage. Instead of using tables and rows as in the traditional relational databases, MongoDB makes use of collections and documents. Documents consist of key-value pairs which are the basic unit of data in MongoDB. Collections contain sets of documents and function which is the equivalent of relational database tables. MongoDB is a database which came into light around the mid-2000s.
In this tutorial, you will learn-
Read More
MongoDB Features
Each database contains collections which in turn contains documents. Each document can be different with a varying number of fields. The size and content of each document can be different from each other.
The document structure is more in line with how developers construct their classes and objects in their respective programming languages. Developers will often say that their classes are not rows and columns but have a clear structure with key-value pairs.
The rows (or documents as called in MongoDB) doesn’t need to have a schema defined beforehand. Instead, the fields can be created on the fly.
The data model available within MongoDB allows you to represent hierarchical relationships, to store arrays, and other more complex structures more easily.
Scalability — The MongoDB environments are very scalable. Companies across the world have defined clusters with some of them running 100+ nodes with around millions of documents within the database
MongoDB Example
Read More
The below example shows how a document can be modeled in MongoDB.
The _id field is added by MongoDB to uniquely identify the document in the collection
What you can note is that the Order Data (OrderID, Product, and Quantity ) which in RDBMS will normally be stored in a separate table, while in MongoDB it is actually stored as an embedded document in the collection itself. This is one of the key differences in how data is modeled in MongoDB.
Key Components of MongoDB Architecture
Below are a few of the common terms used in MongoDB
_id — This is a field required in every MongoDB document. The _id field represents a unique value in the MongoDB document. The _id field is like the document’s primary key. If you create a new document without an _id field, MongoDB will automatically create the field. So for example, if we see the example of the above customer table, Mongo DB will add a 24 digit unique identifier to each document in the collection.
Collection — This is a grouping of MongoDB documents. A collection is the equivalent of a table which is created in any other RDMS such as Oracle or MS SQL. A collection exists within a single database. As seen from the introduction collections don’t enforce any sort of structure.
Cursor — This is a pointer to the result set of a query. Clients can iterate through a cursor to retrieve results. Read More
Database — This is a container for collections like in RDMS wherein it is a container for tables. Each database gets its own set of files on the file system. A MongoDB server can store multiple databases.
Document — A record in a MongoDB collection is basically called a document. The document, in turn, will consist of field name and values.
Field — A name-value pair in a document. A document has zero or more fields. Fields are analogous to columns in relational databases.The following diagram shows an example of Fields with Key value pairs. So in the example below CustomerID and 11 is one of the key value pair’s defined in the document.
JSON — This is known as JavaScript Object Notation. This is a human-readable, plain text format for expressing structured data. JSON is currently supported in many programming languages.
Just a quick note on the key difference between the _id field and a normal collection field. The _id field is used to uniquely identify the documents in a collection and is automatically added by MongoDB when the collection is created.
Why Use MongoDB?
Below are the few of the reasons as to why one should start using MongoDB
Document-oriented — Since MongoDB is a NoSQL type database, instead of having data in a relational type format, it stores the data in documents. This makes MongoDB very flexible and adaptable to real business world situation and requirements.
Ad hoc queries — MongoDB supports searching by field, range queries, and regular expression searches. Queries can be made to return specific fields within documents.
Indexing — Indexes can be created to improve the performance of searches within MongoDB. Any field in a MongoDB document can be indexed.
Replication — MongoDB can provide high availability with replica sets. A replica set consists of two or more mongo DB instances. Each replica set member may act in the role of the primary or secondary replica at any time. The primary replica is the main server which interacts with the client and performs all the read/write operations. The Secondary replicas maintain a copy of the data of the primary using built-in replication. When a primary replica fails, the replica set automatically switches over to the secondary and then it becomes the primary server.
Load balancing — MongoDB uses the concept of sharding to scale horizontally by splitting data across multiple MongoDB instances. MongoDB can run over multiple servers, balancing the load and/or duplicating data to keep the system up and running in case of hardware failure.
Data Modelling in MongoDB
As we have seen from the Introduction section, the data in MongoDB has a flexible schema. Unlike in SQL databases, where you must have a table’s schema declared before inserting data, MongoDB’s collections do not enforce document structure. This sort of flexibility is what makes MongoDB so powerful.
When modeling data in Mongo, keep the following things in mind
Read More
What are the needs of the application — Look at the business needs of the application and see what data and the type of data needed for the application. Based on this, ensure that the structure of the document is decided accordingly.
What are data retrieval patterns — If you foresee a heavy query usage then consider the use of indexes in your data model to improve the efficiency of queries.
Are frequent inserts, updates and removals happening in the database? Reconsider the use of indexes or incorporate sharding if required in your data modeling design to improve the efficiency of your overall MongoDB environment.
Difference between MongoDB & RDBMS
Below are some of the key term differences between MongoDB and RDBMS
Read More
Relational databases are known for enforcing data integrity. This is not an explicit requirement in MongoDB.
RDBMS requires that data be normalized first so that it can prevent orphan records and duplicates Normalizing data then has the requirement of more tables, which will then result in more table joins, thus requiring more keys and indexes.As databases start to grow, performance can start becoming an issue. Again this is not an explicit requirement in MongoDB. MongoDB is flexible and does not need the data to be normalized first.
1 note
·
View note
Text
MongoDB
What is MongoDB?
MongoDB is a document-oriented NoSQL database used for high volume data storage. Instead of using tables and rows as in the traditional relational databases, MongoDB makes use of collections and documents. Documents consist of key-value pairs which are the basic unit of data in MongoDB. Collections contain sets of documents and function which is the equivalent of relational database tables. MongoDB is a database which came into light around the mid-2000s.
In this tutorial, you will learn-
Read More
MongoDB Features
Each database contains collections which in turn contains documents. Each document can be different with a varying number of fields. The size and content of each document can be different from each other.
The document structure is more in line with how developers construct their classes and objects in their respective programming languages. Developers will often say that their classes are not rows and columns but have a clear structure with key-value pairs.
The rows (or documents as called in MongoDB) doesn’t need to have a schema defined beforehand. Instead, the fields can be created on the fly.
The data model available within MongoDB allows you to represent hierarchical relationships, to store arrays, and other more complex structures more easily.
Scalability – The MongoDB environments are very scalable. Companies across the world have defined clusters with some of them running 100+ nodes with around millions of documents within the database
MongoDB Example
Read More
The below example shows how a document can be modeled in MongoDB.
The _id field is added by MongoDB to uniquely identify the document in the collection
What you can note is that the Order Data (OrderID, Product, and Quantity ) which in RDBMS will normally be stored in a separate table, while in MongoDB it is actually stored as an embedded document in the collection itself. This is one of the key differences in how data is modeled in MongoDB.
Key Components of MongoDB Architecture
Below are a few of the common terms used in MongoDB
_id – This is a field required in every MongoDB document. The _id field represents a unique value in the MongoDB document. The _id field is like the document’s primary key. If you create a new document without an _id field, MongoDB will automatically create the field. So for example, if we see the example of the above customer table, Mongo DB will add a 24 digit unique identifier to each document in the collection.
Collection – This is a grouping of MongoDB documents. A collection is the equivalent of a table which is created in any other RDMS such as Oracle or MS SQL. A collection exists within a single database. As seen from the introduction collections don’t enforce any sort of structure.
Cursor – This is a pointer to the result set of a query. Clients can iterate through a cursor to retrieve results. Read More
Database – This is a container for collections like in RDMS wherein it is a container for tables. Each database gets its own set of files on the file system. A MongoDB server can store multiple databases.
Document – A record in a MongoDB collection is basically called a document. The document, in turn, will consist of field name and values.
Field – A name-value pair in a document. A document has zero or more fields. Fields are analogous to columns in relational databases.The following diagram shows an example of Fields with Key value pairs. So in the example below CustomerID and 11 is one of the key value pair’s defined in the document.
JSON – This is known as JavaScript Object Notation. This is a human-readable, plain text format for expressing structured data. JSON is currently supported in many programming languages.
Just a quick note on the key difference between the _id field and a normal collection field. The _id field is used to uniquely identify the documents in a collection and is automatically added by MongoDB when the collection is created.
Why Use MongoDB?
Below are the few of the reasons as to why one should start using MongoDB
Document-oriented – Since MongoDB is a NoSQL type database, instead of having data in a relational type format, it stores the data in documents. This makes MongoDB very flexible and adaptable to real business world situation and requirements.
Ad hoc queries – MongoDB supports searching by field, range queries, and regular expression searches. Queries can be made to return specific fields within documents.
Indexing – Indexes can be created to improve the performance of searches within MongoDB. Any field in a MongoDB document can be indexed.
Replication – MongoDB can provide high availability with replica sets. A replica set consists of two or more mongo DB instances. Each replica set member may act in the role of the primary or secondary replica at any time. The primary replica is the main server which interacts with the client and performs all the read/write operations. The Secondary replicas maintain a copy of the data of the primary using built-in replication. When a primary replica fails, the replica set automatically switches over to the secondary and then it becomes the primary server.
Load balancing – MongoDB uses the concept of sharding to scale horizontally by splitting data across multiple MongoDB instances. MongoDB can run over multiple servers, balancing the load and/or duplicating data to keep the system up and running in case of hardware failure.
Data Modelling in MongoDB
As we have seen from the Introduction section, the data in MongoDB has a flexible schema. Unlike in SQL databases, where you must have a table’s schema declared before inserting data, MongoDB’s collections do not enforce document structure. This sort of flexibility is what makes MongoDB so powerful.
When modeling data in Mongo, keep the following things in mind
Read More
What are the needs of the application – Look at the business needs of the application and see what data and the type of data needed for the application. Based on this, ensure that the structure of the document is decided accordingly.
What are data retrieval patterns – If you foresee a heavy query usage then consider the use of indexes in your data model to improve the efficiency of queries.
Are frequent inserts, updates and removals happening in the database? Reconsider the use of indexes or incorporate sharding if required in your data modeling design to improve the efficiency of your overall MongoDB environment.
Difference between MongoDB & RDBMS
Below are some of the key term differences between MongoDB and RDBMS
Read More
Relational databases are known for enforcing data integrity. This is not an explicit requirement in MongoDB.
RDBMS requires that data be normalized first so that it can prevent orphan records and duplicates Normalizing data then has the requirement of more tables, which will then result in more table joins, thus requiring more keys and indexes.As databases start to grow, performance can start becoming an issue. Again this is not an explicit requirement in MongoDB. MongoDB is flexible and does not need the data to be normalized first.
1 note
·
View note
Text
Sql Interview Questions
If a WHERE provision is used in cross join after that the inquiry will certainly work like an INNER SIGN UP WITH. A UNIQUE constraint makes sure that all values in a column are various. This provides uniqueness for the column and aids recognize each row distinctively. It promotes you to control the information kept in the tables by utilizing relational operators. Examples of the relational database management system are Microsoft Gain access to, MySQL, SQLServer, Oracle database, etc. One-of-a-kind crucial constraint distinctly identifies each record in the data source. This crucial offers uniqueness for the column or collection of columns. A database cursor is a control structure that enables traversal of records in a database. Cursors, furthermore, facilitates handling after traversal, such as retrieval, enhancement and also removal of database records. They can be viewed as a guideline to one row in a collection of rows. An pen names is a attribute of SQL that is supported by most, if not all, RDBMSs. It is a temporary name assigned to the table or table column for the function of a particular SQL inquiry. In addition, aliasing can be employed as an obfuscation method to protect the real names of database areas. A table pen name is also called a relationship name. trainees; Non-unique indexes, on the other hand, are not made use of to impose restrictions on the tables with which they are associated. Instead, non-unique indexes are utilized exclusively to boost query performance by preserving a sorted order of information values that are used often. A database index is a information structure that provides quick lookup of information in a column or columns of a table. It boosts the speed of operations accessing data from a data source table at the expense of additional creates and memory to preserve the index data framework. Candidates are most likely to be asked standard SQL meeting questions to advance degree SQL questions depending upon their experience as well as numerous other aspects. The listed below list covers all the SQL meeting questions for betters along with SQL meeting concerns for seasoned level candidates and also some SQL inquiry meeting concerns. SQL stipulation helps to limit the result established by offering a condition to the question. A stipulation aids to filter the rows from the whole set of records. Our SQL Interview Questions blog site is the one-stop source from where you can boost your meeting prep work. It has a collection of leading 65 concerns which an recruiter intends to ask throughout an interview process. Unlike https://geekinterview.net , there can be numerous unique restraints defined per table. The code syntax for UNIQUE is rather similar to that of PRIMARY SECRET and can be made use of mutually. The majority of modern data source monitoring systems like MySQL, Microsoft SQL Web Server, Oracle, IBM DB2 and Amazon.com Redshift are based upon RDBMS. SQL provision is defined to limit the outcome established by giving condition to the inquiry. This usually filterings system some rows from the entire set of records. Cross join can be specified as a cartesian product of the two tables included in the join. The table after join contains the same variety of rows as in the cross-product of number of rows in both tables. Self-join is readied to be query made use of to contrast to itself. This is made use of to compare worths in a column with other values in the exact same column in the exact same table. ALIAS ES can be made use of for the very same table comparison. This is a search phrase made use of to quiz information from even more tables based upon the connection between the areas of the tables. A foreign trick is one table which can be connected to the primary trick of one more table. Relationship requires to be produced in between 2 tables by referencing international key with the main secret of one more table. A Unique vital restraint distinctly recognized each record in the data source. It starts with the basic SQL meeting questions as well as later continues to sophisticated concerns based on your conversations and also responses. These SQL Meeting inquiries will assist you with different knowledge levels to gain the optimum gain from this blog site. A table has a defined number of the column called areas however can have any type of variety of rows which is referred to as the document. So, the columns in the table of the data source are known as the fields and also they stand for the quality or characteristics of the entity in the document. Rows right here refers to the tuples which stand for the simple information item as well as columns are the quality of the information items existing in particular row. Columns can classify as vertical, and also Rows are horizontal. There is provided sql meeting questions and responses that has actually been asked in lots of firms. For PL/SQL meeting questions, see our next page.

A sight can have information from several tables integrated, and it relies on the connection. Views are used to use security device in the SQL Server. The sight of the database is the searchable item we can make use of a inquiry to look the deem we utilize for the table. RDBMS stands for Relational Data source Management System. It is a data source administration system based on a relational model. RDBMS stores the information right into the collection of tables as well as links those table using the relational operators conveniently whenever needed. This offers uniqueness for the column or collection of columns. go to my blog is a collection of data that are organized in a design with Columns as well as Rows. https://bit.ly/3tmWIsh can be categorized as vertical, as well as Rows are straight. A table has specified number of column called areas however can have any kind of variety of rows which is called document. RDBMS save the data into the collection of tables, which is connected by typical areas between the columns of the table. https://tinyurl.com/c7k3vf9t provides relational drivers to control the information saved into the tables. Complying with is a curated checklist of SQL meeting inquiries and also responses, which are likely to be asked throughout the SQL interview.
0 notes
Text
Sql Interview Questions
If a WHERE condition is made use of in cross sign up with after that the query will work like an INNER SIGN UP WITH. A UNIQUE restriction ensures that all worths in a column are different. This gives uniqueness for the column as well as helps determine each row distinctively. It promotes you to manipulate the information saved in the tables by using relational drivers. Examples of the relational data source monitoring system are Microsoft Access, MySQL, SQLServer, Oracle data source, and so on. Distinct vital constraint uniquely identifies each record in the data source. This crucial supplies uniqueness for the column or collection of columns. A database cursor is a control structure that allows for traversal of documents in a database. Cursors, additionally, assists in handling after traversal, such as retrieval, enhancement and deletion of database records. They can be viewed as a reminder to one row in a collection of rows. An pen names is a attribute of SQL that is supported by many, if not all, RDBMSs. It is a temporary name designated to the table or table column for the objective of a specific SQL inquiry. In look at this site , aliasing can be used as an obfuscation method to safeguard the actual names of database areas. A table alias is likewise called a connection name. pupils; Non-unique indexes, on the other hand, are not made use of to implement constraints on the tables with which they are linked. Rather, non-unique indexes are made use of solely to enhance inquiry performance by maintaining a arranged order of information worths that are used frequently. A database index is a data framework that supplies fast lookup of information in a column or columns of a table. It boosts the rate of procedures accessing information from a database table at the price of extra creates as well as memory to keep the index data structure. Candidates are most likely to be asked basic SQL interview concerns to progress level SQL concerns depending upon their experience and numerous other variables. The listed below listing covers all the SQL meeting questions for betters as well as SQL interview concerns for experienced degree candidates and some SQL query meeting concerns. SQL condition helps to restrict the outcome established by providing a problem to the query. A stipulation helps to filter the rows from the entire set of documents. Our SQL Meeting Questions blog is the one-stop source where you can increase your interview preparation. It has a collection of leading 65 concerns which an recruiter prepares to ask during an interview procedure. Unlike main vital, there can be several distinct constraints defined per table. The code syntax for UNIQUE is quite similar to that of PRIMARY TRICK and can be made use of interchangeably. A lot of modern data source administration systems like MySQL, Microsoft SQL Server, Oracle, IBM DB2 and also Amazon.com Redshift are based on RDBMS. SQL provision is specified to restrict the result established by providing problem to the query. This normally filters some rows from the whole collection of records. Cross join can be specified as a cartesian item of the two tables consisted of in the sign up with. The table after sign up with includes the exact same number of rows as in the cross-product of number of rows in both tables. Self-join is readied to be query utilized to compare to itself. https://tinyurl.com/c7k3vf9t is made use of to compare values in a column with other worths in the exact same column in the exact same table. PEN NAME ES can be made use of for the same table comparison. This is a key words made use of to quiz information from more tables based on the partnership between the areas of the tables. A international trick is one table which can be connected to the primary trick of another table. Relationship requires to be produced in between 2 tables by referencing foreign secret with the main secret of another table. A Unique crucial restriction distinctively determined each document in the database. It starts with the standard SQL interview concerns and later on remains to innovative concerns based on your conversations and solutions. These SQL Interview inquiries will certainly help you with various competence levels to reap the optimum take advantage of this blog site. A table consists of a specified number of the column called areas yet can have any kind of variety of rows which is referred to as the record. So, the columns in the table of the database are known as the areas and they stand for the characteristic or features of the entity in the record. Rows here describes the tuples which stand for the easy data thing and columns are the characteristic of the data products present particularly row. Columns can classify as upright, and Rows are straight. There is given sql interview concerns and also answers that has been asked in several firms. For PL/SQL interview concerns, see our following page. A sight can have data from one or more tables incorporated, and it relies on the relationship. https://geekinterview.net are used to use safety mechanism in the SQL Web server. The sight of the database is the searchable object we can utilize a question to browse the deem we make use of for the table. RDBMS represents Relational Database Administration System. It is a data source management system based upon a relational model. RDBMS shops the data into the collection of tables and also links those table utilizing the relational drivers conveniently whenever needed. This supplies individuality for the column or set of columns. A table is a set of information that are arranged in a version with Columns and Rows. Columns can be classified as vertical, as well as Rows are horizontal. A table has actually defined number of column called fields but can have any kind of number of rows which is called document. RDBMS keep the data into the collection of tables, which is connected by typical areas in between the columns of the table. It likewise provides relational operators to control the data kept right into the tables. Following is a curated checklist of SQL meeting inquiries and responses, which are most likely to be asked throughout the SQL interview.
0 notes
Text
Sql Meeting Questions
If a IN WHICH stipulation is used in cross join after that the inquiry will certainly work like an INNER JOIN. A DISTINCT restriction ensures that all values in a column are different. This gives originality for the column and helps identify each row uniquely. It facilitates you to adjust the data stored in the tables by using relational drivers. Instances of the relational data source administration system are Microsoft Gain access to, MySQL, SQLServer, Oracle database, and so on. Unique key restriction distinctly identifies each document in the data source. This vital supplies individuality for the column or set of columns. A data source arrow is a control framework that enables traversal of documents in a data source. Cursors, furthermore, helps with handling after traversal, such as access, enhancement and also deletion of data source documents. They can be deemed a pointer to one row in a set of rows. An alias is a function of SQL that is sustained by many, if not all, RDBMSs. It is a short-lived name assigned to the table or table column for the objective of a particular SQL question. In addition, aliasing can be used as an obfuscation technique to protect the genuine names of database fields. A table pen name is additionally called a connection name. trainees; Non-unique indexes, on the other hand, are not used to apply restraints on the tables with which they are connected. Rather, non-unique indexes are used solely to improve inquiry efficiency by keeping a arranged order of information worths that are made use of frequently. A database index is a data framework that offers fast lookup of data in a column or columns of a table. It boosts the speed of operations accessing data from a database table at the price of added writes as well as memory to maintain the index information structure. Candidates are most likely to be asked fundamental SQL interview concerns to advance level SQL inquiries depending upon their experience and also numerous other aspects. The listed below list covers all the SQL meeting questions for betters as well as SQL interview inquiries for knowledgeable degree candidates and also some SQL query meeting inquiries. SQL clause helps to restrict the outcome set by offering a problem to the inquiry. A clause helps to filter the rows from the entire set of documents. Our SQL Meeting Questions blog site is the one-stop source from where you can boost your interview preparation. It has a collection of leading 65 questions which an recruiter intends to ask during an meeting procedure. Unlike primary essential, there can be several one-of-a-kind restraints defined per table. The code syntax for UNIQUE is quite similar to that of PRIMARY TRICK and also can be made use of mutually. The majority of modern database management systems like MySQL, Microsoft SQL Server, Oracle, IBM DB2 as well as Amazon Redshift are based upon RDBMS. SQL provision is defined to limit the result established by offering condition to the inquiry. https://tinyurl.com/c7k3vf9t from the whole set of documents. Cross join can be defined as a cartesian item of the two tables included in the join. The table after join contains the exact same variety of rows as in the cross-product of variety of rows in the two tables. Self-join is set to be query utilized to contrast to itself. This is used to contrast worths in a column with other values in the very same column in the very same table. PEN NAME ES can be made use of for the exact same table comparison. This is a key phrase utilized to quiz data from more tables based upon the relationship in between the areas of the tables. A international secret is one table which can be associated with the main secret of one more table. Relationship requires to be produced in between two tables by referencing international trick with the main secret of an additional table. A Distinct vital restraint distinctively identified each record in the data source. It starts with the fundamental SQL interview inquiries and also later on continues to sophisticated concerns based upon your conversations and also answers. These SQL Meeting questions will certainly assist you with different competence levels to enjoy the maximum gain from this blog site. A table has a specified number of the column called areas however can have any kind of variety of rows which is referred to as the document. So, webpage in the table of the data source are known as the fields and also they represent the attribute or qualities of the entity in the document. Rows below refers to the tuples which represent the simple information product as well as columns are the characteristic of the information products present in particular row. Columns can categorize as upright, as well as Rows are horizontal. There is given sql interview inquiries as well as solutions that has actually been asked in many companies. For PL/SQL interview questions, see our following page. A sight can have information from several tables incorporated, and it depends on the partnership. Views are made use of to apply safety and security system in the SQL Server. The sight of the database is the searchable things we can use a inquiry to search the consider as we make use of for the table. RDBMS represents Relational Database Administration System. It is a database management system based upon a relational model. RDBMS stores the data right into the collection of tables as well as links those table utilizing the relational drivers conveniently whenever called for.

This provides originality for the column or collection of columns. facebook sql interview questions is a set of data that are organized in a model with Columns and Rows. https://geekinterview.net can be classified as upright, as well as Rows are straight. A table has specified variety of column called fields however can have any number of rows which is called document. RDBMS store the information right into the collection of tables, which is associated by common areas between the columns of the table. It also gives relational operators to control the data stored into the tables. Complying with is a curated list of SQL interview inquiries and solutions, which are most likely to be asked during the SQL meeting.
0 notes
Text
How to get started with MongoDB: Beginner’s guide
MongoDB is a document-oriented NoSQL database used for high volume data storage. Instead of using tables and rows as in the traditional relational databases, it makes use of collections and documents. Documents consist of key-value pairs which are the basic unit of data in MongoDB. Also, collections contain sets of documents and functions which is the equivalent of relational database tables. MongoDB is a database that came into light around the mid-2000s.
Features
Each database contains collections which in turn contain documents. However, each document can be different with a varying number of fields. The size and content of each document can be different from each other.
Equally, the document structure is more in line with how developers construct their classes and objects in their respective programming languages. Developers will often say that their classes are not rows and columns but have a clear structure with key-value pairs.
The rows (or documents as called in MongoDB) don’t need to have a schema defined beforehand. Instead, the fields can create on the fly.
The data model available within MongoDB allows you to represent hierarchical relationships. To store arrays, and other more complex structures more easily.
Scalability – The MongoDB environments are very scalable. Companies across the world have defined clusters with some of them running 100+ nodes. With millions of documents within the database approximately.
Example
The _id field added by it to uniquely identify the document in the collection.
What you can note is that the Order Data (OrderID, Product, and Quantity ). Which in RDBMS will normally store in a separate table. While in MongoDB it is actually stored as an embedded document in the collection itself. This is one of the key differences in how data modeled in MongoDB.
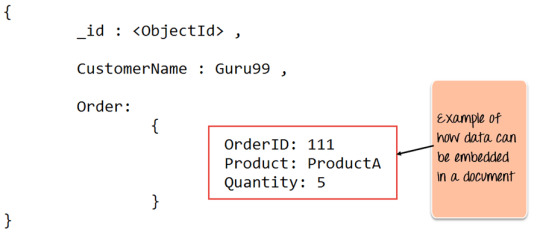
Key Components of MongoDB Architecture

_id – This field required in every MongoDB document. The _id field represents a unique value in it document. It is like the document’s primary key. If you create a new document without an _id field then it will automatically create the field. So for example, if we see the example of the above customer table, Mongo DB will add a 24 digit unique identifier to each document in the collection.
Collection – This is a grouping of MongoDB documents. A collection is the equivalent of a table. Which created in any other RDMS such as Oracle or MS SQL. A collection exists within a single database. But it doesn’t enforce any sort of structure.
Cursor – This is a pointer to the result set of a query. Clients can iterate through a cursor to retrieve results.
Database – This is a container for collections like in RDMS. Wherein it is a container for tables. Also, each database gets its own set of files on the file system. Surprisingly, A MongoDB server can store multiple databases.
Document – A record in a MongoDB collection basically called a document. The document will also consist of field names and values.
Field – A name-value pair in a document. A document has zero or more fields. Fields are analogous to columns in relational databases. The following diagram shows an example of Fields with Key-value pairs. So in the example below CustomerID and 11 is one of the key-value pair’s defined in the document.
JSON – This known as JavaScript Object Notation. It is a human-readable, plain text format for expressing structured data. JSON currently supported in many programming languages.

Just a quick note on the key difference between the _id field and a normal collection field. The _id field is used to uniquely identify the documents in a collection and is automatically added by MongoDB when the collection is created.
Why Use MongoDB?
Document-oriented – Since MongoDB is a NoSQL type database, instead of having data in a relational type format, it stores the data in documents. Hence, it makes MongoDB very flexible and adaptable to real business world situations and requirements.
Ad hoc queries – it supports search by field, range queries, and regular expression searches. And these queries can make to return specific fields within documents.
Indexing – Indexes can be created to improve the performance of searches within MongoDB. So, any field in its document can be indexed.
Replication – MongoDB can provide high availability with replica sets. And replica set consists of two or more mongo DB instances. Hence, each replica set member may act in the role of the primary or secondary replica at any time. Whereas the primary replica is the main server that interacts with the client and performs all the read/write operations. While the Secondary replicas maintain a copy of the data of the primary using built-in replication. When a primary replica fails, the replica set automatically switches over to the secondary, and then it becomes the primary server.
Load balancing – However, MongoDB uses the concept of sharding to scale horizontally by splitting data across multiple MongoDB instances. It can run over multiple servers, balancing the load and/or duplicating data to keep the system up and running in case of hardware failure.
Data Modelling in MongoDB
As we have seen from the Introduction section, the data in MongoDB has a flexible schema. Unlike in SQL databases, where you must have a table’s schema declared before inserting data, MongoDB’s collections do not enforce document structure. This sort of flexibility is what makes MongoDB so powerful.
When modeling data in Mongo, keep the following things in mind
What are the needs of the application – Look at the business needs of the application and see what data and the type of data needed for the application. Based on this, ensure that the structure of the document is decided accordingly.
What are data retrieval patterns – If you foresee a heavy query usage then consider the use of indexes in your data model to improve the efficiency of queries.
Are frequent inserts, updates, and removals happening in the database? Reconsider the use of indexes or incorporate sharding if required in your data modeling design to improve the efficiency of your overall MongoDB environment.
Difference between MongoDB & RDBMS
Below are some of the key term differences between MongoDB and RDBMS.
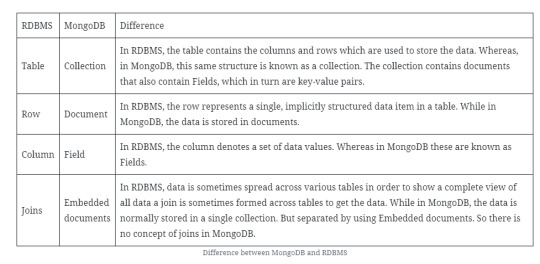
Apart from the terms differences, a few other differences listed below
Relational databases are also known for enforcing data integrity. Further, this is not an explicit requirement in MongoDB.
RDBMS requires that data be normalized first. So that it can prevent orphan records and duplicates Normalizing data then has the requirement of more tables, which will then result in more table joins, thus requiring more keys and indexes. If databases start to grow then performance can start becoming an issue. Also, this is not an explicit requirement in MongoDB. Because MongoDB is flexible and does not need the data to be normalized first.
In the worlds of JavaScript and Node.js, MongoDB has established itself as the go-to database.
#mongodb#database#database management#mysql#mongodb tutorial#rdbms#sql#trending#trends#webdesign#web developers#web development#web developing company#whitelion infosystems
0 notes
Text
300+ TOP JDBC Interview Questions and Answers
JDBC Interview Questions for freshers experienced
1. What is the JDBC? Java Database Connectivity (JDBC) is a standard Java API to interact with relational databases form Java. JDBC has set of classes and interfaces which can use from Java application and talk to database without learning RDBMS details and using Database Specific JDBC Drivers. 2. What are the new features added to JDBC 4.0? The major features added in JDBC 4.0 include : Auto-loading of JDBC driver class Connection management enhancements Support for RowId SQL type DataSet implementation of SQL using Annotations SQL exception handling enhancements SQL XML support 3. Explain Basic Steps in writing a Java program using JDBC? JDBC makes the interaction with RDBMS simple and intuitive. When a Java application needs to access database : Load the RDBMS specific JDBC driver because this driver actually communicates with the database (Incase of JDBC 4.0 this is automatically loaded). Open the connection to database which is then used to send SQL statements and get results back. Create JDBC Statement object. This object contains SQL query. Execute statement which returns resultset(s). ResultSet contains the tuples of database table as a result of SQL query. Process the result set. Close the connection. 4. Exaplain the JDBC Architecture. The JDBC Architecture consists of two layers:

JDBC Architecture The JDBC API, which provides the application-to-JDBC Manager connection. The JDBC Driver API, which supports the JDBC Manager-to-Driver Connection. The JDBC API uses a driver manager and database-specific drivers to provide transparent connectivity to heterogeneous databases. The JDBC driver manager ensures that the correct driver is used to access each data source. The driver manager is capable of supporting multiple concurrent drivers connected to multiple heterogeneous databases. The location of the driver manager with respect to the JDBC drivers and the Java application is shown in Figure 1. 5. What are the main components of JDBC ? The life cycle of a servlet consists of the following phases: DriverManager: Manages a list of database drivers. Matches connection requests from the java application with the proper database driver using communication subprotocol. The first driver that recognizes a certain subprotocol under JDBC will be used to establish a database Connection. Driver: The database communications link, handling all communication with the database. Normally, once the driver is loaded, the developer need not call it explicitly. Connection: Interface with all methods for contacting a database.The connection object represents communication context, i.e., all communication with database is through connection object only. Statement : Encapsulates an SQL statement which is passed to the database to be parsed, compiled, planned and executed. ResultSet: The ResultSet represents set of rows retrieved due to query execution. 6. How the JDBC application works? A JDBC application can be logically divided into two layers:

JDBC application works Driver layer Application layer Driver layer consists of DriverManager class and the available JDBC drivers. The application begins with requesting the DriverManager for the connection. An appropriate driver is choosen and is used for establishing the connection. This connection is given to the application which falls under the application layer. The application uses this connection to create Statement kind of objects, through which SQL commands are sent to backend and obtain the results. 7. How do I load a database driver with JDBC 4.0 / Java 6? Provided the JAR file containing the driver is properly configured, just place the JAR file in the classpath. Java developers NO longer need to explicitly load JDBC drivers using code like Class.forName() to register a JDBC driver.The DriverManager class takes care of this by automatically locating a suitable driver when the DriverManager.getConnection() method is called. This feature is backward-compatible, so no changes are needed to the existing JDBC code. 8. What is JDBC Driver interface? The JDBC Driver interface provides vendor-specific implementations of the abstract classes provided by the JDBC API. Each vendor driver must provide implementations of the java.sql.Connection,Statement,PreparedStatement, CallableStatement, ResultSet and Driver. 9. What does the connection object represents? The connection object represents communication context, i.e., all communication with database is through connection object only. 10. Can the JDBC-ODBC Bridge be used with applets? Use of the JDBC-ODBC bridge from an untrusted applet running in a browser, such as Netscape Navigator, isn't allowed. The JDBC-ODBC bridge doesn't allow untrusted code to call it for security reasons. This is good because it means that an untrusted applet that is downloaded by the browser can't circumvent Java security by calling ODBC. Remember that ODBC is native code, so once ODBC is called the Java programming language can't guarantee that a security violation won't occur. On the other hand, Pure Java JDBC drivers work well with applets. They are fully downloadable and do not require any client-side configuration. Finally, we would like to note that it is possible to use the JDBC-ODBC bridge with applets that will be run in appletviewer since appletviewer assumes that applets are trusted. In general, it is dangerous to turn applet security off, but it may be appropriate in certain controlled situations, such as for applets that will only be used in a secure intranet environment. Remember to exercise caution if you choose this option, and use an all-Java JDBC driver whenever possible to avoid security problems.

JDBC Interview Questions 11. How do I start debugging problems related to the JDBC API? A good way to find out what JDBC calls are doing is to enable JDBC tracing. The JDBC trace contains a detailed listing of the activity occurring in the system that is related to JDBC operations. If you use the DriverManager facility to establish your database connection, you use the DriverManager.setLogWriter method to enable tracing of JDBC operations. If you use a DataSource object to get a connection, you use the DataSource.setLogWriter method to enable tracing. (For pooled connections, you use the ConnectionPoolDataSource.setLogWriter method, and for connections that can participate in distributed transactions, you use the XADataSource.setLogWriter method.) 12. What is new in JDBC 2.0? With the JDBC 2.0 API, you will be able to do the following: Scroll forward and backward in a result set or move to a specific row (TYPE_SCROLL_SENSITIVE,previous(), last(), absolute(), relative(), etc.) Make updates to database tables using methods in the Java programming language instead of using SQL commands.(updateRow(), insertRow(), deleteRow(), etc.) Send multiple SQL statements to the database as a unit, or batch (addBatch(), executeBatch()) Use the new SQL3 datatypes as column values like Blob, Clob, Array, Struct, Ref. 13. How to move the cursor in scrollable resultset ? a. create a scrollable ResultSet object. Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_READ_ONLY); ResultSet srs = stmt.executeQuery("SELECT COLUMN_1, COLUMN_2 FROM TABLE_NAME"); b. use a built in methods like afterLast(), previous(), beforeFirst(), etc. to scroll the resultset. srs.afterLast(); while (srs.previous()) { String name = srs.getString("COLUMN_1"); float salary = srs.getFloat("COLUMN_2"); //... c. to find a specific row, use absolute(), relative() methods. srs.absolute(4); // cursor is on the fourth row int rowNum = srs.getRow(); // rowNum should be 4 srs.relative(-3); int rowNum = srs.getRow(); // rowNum should be 1 srs.relative(2); int rowNum = srs.getRow(); // rowNum should be 3 d. use isFirst(), isLast(), isBeforeFirst(), isAfterLast() methods to check boundary status. 14. How to update a resultset programmatically? a. create a scrollable and updatable ResultSet object. Statement stmt = con.createStatement (ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE); ResultSet uprs = stmt.executeQuery("SELECT COLUMN_1, COLUMN_2 FROM TABLE_NAME"); b. move the cursor to the specific position and use related method to update data and then, call updateRow() method. uprs.last(); uprs.updateFloat("COLUMN_2", 25.55);//update last row's data uprs.updateRow();//don't miss this method, otherwise, // the data will be lost. 15. How can I use the JDBC API to access a desktop database like Microsoft Access over the network? Most desktop databases currently require a JDBC solution that uses ODBC underneath. This is because the vendors of these database products haven't implemented all-Java JDBC drivers. The best approach is to use a commercial JDBC driver that supports ODBC and the database you want to use. See the JDBC drivers page for a list of available JDBC drivers. The JDBC-ODBC bridge from Sun's Java Software does not provide network access to desktop databases by itself. The JDBC-ODBC bridge loads ODBC as a local DLL, and typical ODBC drivers for desktop databases like Access aren't networked. The JDBC-ODBC bridge can be used together with the RMI-JDBC bridge, however, to access a desktop database like Access over the net. This RMI-JDBC-ODBC solution is free. 16. Are there any ODBC drivers that do not work with the JDBC-ODBC Bridge? Most ODBC 2.0 drivers should work with the Bridge. Since there is some variation in functionality between ODBC drivers, the functionality of the bridge may be affected. The bridge works with popular PC databases, such as Microsoft Access and FoxPro. 17. What causes the "No suitable driver" error? "No suitable driver" is an error that usually occurs during a call to the DriverManager.getConnection method. The cause can be failing to load the appropriate JDBC drivers before calling the getConnection method, or it can be specifying an invalid JDBC URL--one that isn't recognized by your JDBC driver. Your best bet is to check the documentation for your JDBC driver or contact your JDBC driver vendor if you suspect that the URL you are specifying is not being recognized by your JDBC driver. In addition, when you are using the JDBC-ODBC Bridge, this error can occur if one or more the the shared libraries needed by the Bridge cannot be loaded. If you think this is the cause, check your configuration to be sure that the shared libraries are accessible to the Bridge. 18. Why isn't the java.sql.DriverManager class being found? This problem can be caused by running a JDBC applet in a browser that supports the JDK 1.0.2, such as Netscape Navigator 3.0. The JDK 1.0.2 does not contain the JDBC API, so the DriverManager class typically isn't found by the Java virtual machine running in the browser. Here's a solution that doesn't require any additional configuration of your web clients. Remember that classes in the java.* packages cannot be downloaded by most browsers for security reasons. Because of this, many vendors of all-Java JDBC drivers supply versions of the java.sql.* classes that have been renamed to jdbc.sql.*, along with a version of their driver that uses these modified classes. If you import jdbc.sql.* in your applet code instead of java.sql.*, and add the jdbc.sql.* classes provided by your JDBC driver vendor to your applet's codebase, then all of the JDBC classes needed by the applet can be downloaded by the browser at run time, including the DriverManager class. This solution will allow your applet to work in any client browser that supports the JDK 1.0.2. Your applet will also work in browsers that support the JDK 1.1, although you may want to switch to the JDK 1.1 classes for performance reasons. Also, keep in mind that the solution outlined here is just an example and that other solutions are possible. How to insert and delete a row programmatically? (new feature in JDBC 2.0) Make sure the resultset is updatable. 1. move the cursor to the specific position. uprs.moveToCurrentRow(); 2. set value for each column. uprs.moveToInsertRow();//to set up for insert uprs.updateString("col1" "strvalue"); uprs.updateInt("col2", 5); ... 3. call inserRow() method to finish the row insert process. uprs.insertRow(); To delete a row: move to the specific position and call deleteRow() method: uprs.absolute(5); uprs.deleteRow();//delete row 5 To see the changes call refreshRow(); uprs.refreshRow(); 19. What are the two major components of JDBC? One implementation interface for database manufacturers, the other implementation interface for application and applet writers. 20. What is JDBC Driver interface? The JDBC Driver interface provides vendor-specific implementations of the abstract classes provided by the JDBC API. Each vendor driver must provide implementations of the java.sql.Connection,Statement,PreparedStatement, CallableStatement, ResultSet and Driver. 21. How do I retrieve a whole row of data at once, instead of calling an individual ResultSet.getXXX method for each column? The ResultSet.getXXX methods are the only way to retrieve data from a ResultSet object, which means that you have to make a method call for each column of a row. It is unlikely that this is the cause of a performance problem, however, because it is difficult to see how a column could be fetched without at least the cost of a function call in any scenario. We welcome input from developers on this issue. 22. What are the common tasks of JDBC? Create an instance of a JDBC driver or load JDBC drivers through jdbc.drivers Register a driver Specify a database Open a database connection Submit a query Receive results Process results Why does the ODBC driver manager return 'Data source name not found and no default driver specified Vendor: 0' This type of error occurs during an attempt to connect to a database with the bridge. First, note that the error is coming from the ODBC driver manager. This indicates that the bridge-which is a normal ODBC client-has successfully called ODBC, so the problem isn't due to native libraries not being present. In this case, it appears that the error is due to the fact that an ODBC DSN (data source name) needs to be configured on the client machine. Developers often forget to do this, thinking that the bridge will magically find the DSN they configured on their remote server machine 23. How to use JDBC to connect Microsoft Access? There is a specific tutorial at javacamp.org. Check it out. 24. What are four types of JDBC driver? Type 1 Drivers Bridge drivers such as the jdbc-odbc bridge. They rely on an intermediary such as ODBC to transfer the SQL calls to the database and also often rely on native code. It is not a serious solution for an application Type 2 Drivers Use the existing database API to communicate with the database on the client. Faster than Type 1, but need native code and require additional permissions to work in an applet. Client machine requires software to run. Type 3 Drivers JDBC-Net pure Java driver. It translates JDBC calls to a DBMS-independent network protocol, which is then translated to a DBMS protocol by a server. Flexible. Pure Java and no native code. Type 4 Drivers Native-protocol pure Java driver. It converts JDBC calls directly into the network protocol used by DBMSs. This allows a direct call from the client machine to the DBMS server. It doesn't need any special native code on the client machine. Recommended by Sun's tutorial, driver type 1 and 2 are interim solutions where direct pure Java drivers are not yet available. Driver type 3 and 4 are the preferred way to access databases using the JDBC API, because they offer all the advantages of Java technology, including automatic installation. For more info, visit Sun JDBC page 25. Which type of JDBC driver is the fastest one? JDBC Net pure Java driver(Type IV) is the fastest driver because it converts the jdbc calls into vendor specific protocol calls and it directly interacts with the database. 26. Are all the required JDBC drivers to establish connectivity to my database part of the JDK? No. There aren't any JDBC technology-enabled drivers bundled with the JDK 1.1.x or Java 2 Platform releases other than the JDBC-ODBC Bridge. So, developers need to get a driver and install it before they can connect to a database. We are considering bundling JDBC technology- enabled drivers in the future. 27. Is the JDBC-ODBC Bridge multi-threaded? No. The JDBC-ODBC Bridge does not support concurrent access from different threads. The JDBC-ODBC Bridge uses synchronized methods to serialize all of the calls that it makes to ODBC. Multi-threaded Java programs may use the Bridge, but they won't get the advantages of multi-threading. In addition, deadlocks can occur between locks held in the database and the semaphore used by the Bridge. We are thinking about removing the synchronized methods in the future. They were added originally to make things simple for folks writing Java programs that use a single-threaded ODBC driver. 28. Does the JDBC-ODBC Bridge support multiple concurrent open statements per connection? No. You can open only one Statement object per connection when you are using the JDBC-ODBC Bridge. 29. What is the query used to display all tables names in SQL Server (Query analyzer)? select * from information_schema.tables 30. Why can't I invoke the ResultSet methods afterLast and beforeFirst when the method next works? You are probably using a driver implemented for the JDBC 1.0 API. You need to upgrade to a JDBC 2.0 driver that implements scrollable result sets. Also be sure that your code has created scrollable result sets and that the DBMS you are using supports them. 31. How can I retrieve a String or other object type without creating a new object each time? Creating and garbage collecting potentially large numbers of objects (millions) unnecessarily can really hurt performance. It may be better to provide a way to retrieve data like strings using the JDBC API without always allocating a new object. We are studying this issue to see if it is an area in which the JDBC API should be improved. Stay tuned, and please send us any comments you have on this question. 32. How many types of JDBC Drivers are present and what are they? There are 4 types of JDBC Drivers Type 1: JDBC-ODBC Bridge Driver Type 2: Native API Partly Java Driver Type 3: Network protocol Driver Type 4: JDBC Net pure Java Driver 33. What is the fastest type of JDBC driver? JDBC driver performance will depend on a number of issues: (a) the quality of the driver code, (b) the size of the driver code, (c) the database server and its load, (d) network topology, (e) the number of times your request is translated to a different API. In general, all things being equal, you can assume that the more your request and response change hands, the slower it will be. This means that Type 1 and Type 3 drivers will be slower than Type 2 drivers (the database calls are make at least three translations versus two), and Type 4 drivers are the fastest (only one translation). 34. There is a method getColumnCount in the JDBC API. Is there a similar method to find the number of rows in a result set? No, but it is easy to find the number of rows. If you are using a scrollable result set, rs, you can call the methods rs.last and then rs.getRow to find out how many rows rs has. If the result is not scrollable, you can either count the rows by iterating through the result set or get the number of rows by submitting a query with a COUNT column in the SELECT clause. I would like to download the JDBC-ODBC Bridge for the Java 2 SDK, Standard Edition (formerly JDK 1.2). I'm a beginner with the JDBC API, and I would like to start with 35. the Bridge. How do I do it? The JDBC-ODBC Bridge is bundled with the Java 2 SDK, Standard Edition, so there is no need to download it separately. 36. If I use the JDBC API, do I have to use ODBC underneath? No, this is just one of many possible solutions. We recommend using a pure Java JDBC technology-enabled driver, type 3 or 4, in order to get all of the benefits of the Java programming language and the JDBC API. 37. Once I have the Java 2 SDK, Standard Edition, from Sun, what else do I need to connect to a database? You still need to get and install a JDBC technology-enabled driver that supports the database that you are using. There are many drivers available from a variety of sources. You can also try using the JDBC-ODBC Bridge if you have ODBC connectivity set up already. The Bridge comes with the Java 2 SDK, Standard Edition, and Enterprise Edition, and it doesn't require any extra setup itself. The Bridge is a normal ODBC client. Note, however, that you should use the JDBC-ODBC Bridge only for experimental prototyping or when you have no other driver available. 38. How can I know when I reach the last record in a table, since JDBC doesn't provide an EOF method? Answer1 You can use last() method of java.sql.ResultSet, if you make it scrollable. You can also use isLast() as you are reading the ResultSet. One thing to keep in mind, though, is that both methods tell you that you have reached the end of the current ResultSet, not necessarily the end of the table. SQL and RDBMSes make no guarantees about the order of rows, even from sequential SELECTs, unless you specifically use ORDER BY. Even then, that doesn't necessarily tell you the order of data in the table. Answer2 Assuming you mean ResultSet instead of Table, the usual idiom for iterating over a forward only resultset is: ResultSet rs=statement.executeQuery(...); while (rs.next()) { // Manipulate row here } 39. Where can I find info, frameworks and example source for writing a JDBC driver? There a several drivers with source available, like MM.MySQL, SimpleText Database, FreeTDS, and RmiJdbc. There is at least one free framework, the jxDBCon-Open Source JDBC driver framework. Any driver writer should also review For Driver Writers. 40. How can I create a custom RowSetMetaData object from scratch? One unfortunate aspect of RowSetMetaData for custom versions is that it is an interface. This means that implementations almost have to be proprietary. The JDBC RowSet package is the most commonly available and offers the sun.jdbc.rowset.RowSetMetaDataImpl class. After instantiation, any of the RowSetMetaData setter methods may be used. The bare minimum needed for a RowSet to function is to set the Column Count for a row and the Column Types for each column in the row. For a working code example that includes a custom RowSetMetaData, 41. How does a custom RowSetReader get called from a CachedRowSet? The Reader must be registered with the CachedRowSet using CachedRowSet.setReader(javax.sql.RowSetReader reader). Once that is done, a call to CachedRowSet.execute() will, among other things, invoke the readData method. How do I implement a RowSetReader? I want to populate a CachedRowSet myself and the documents specify that a RowSetReader should be used. The single method accepts a 42. RowSetInternal caller and returns void. What can I do in the readData method? "It can be implemented in a wide variety of ways..." and is pretty vague about what can actually be done. In general, readData() would obtain or create the data to be loaded, then use CachedRowSet methods to do the actual loading. This would usually mean inserting rows, so the code would move to the insert row, set the column data and insert rows. Then the cursor must be set to to the appropriate position. 43. How can I instantiate and load a new CachedRowSet object from a non-JDBC source? The basics are: * Create an object that implements javax.sql.RowSetReader, which loads the data. * Instantiate a CachedRowset object. * Set the CachedRowset's reader to the reader object previously created. * Invoke CachedRowset.execute(). Note that a RowSetMetaData object must be created, set up with a description of the data, and attached to the CachedRowset before loading the actual data. The following code works with the Early Access JDBC RowSet download available from the Java Developer Connection and is an expansion of one of the examples: // Independent data source CachedRowSet Example import java.sql.*; import javax.sql.*; import sun.jdbc.rowset.*; public class RowSetEx1 implements RowSetReader { CachedRowSet crs; int iCol2; RowSetMetaDataImpl rsmdi; String sCol1, sCol3; public RowSetEx1() { try { crs = new CachedRowSet(); crs.setReader(this); crs.execute(); // load from reader System.out.println( "Fetching from RowSet..."); while(crs.next()) { showTheData(); } // end while next if(crs.isAfterLast() == true) { System.out.println( "We have reached the end"); System.out.println("crs row: " + crs.getRow()); } System.out.println( "And now backwards..."); while(crs.previous()) { showTheData(); } // end while previous if(crs.isBeforeFirst() == true) { System.out.println( "We have reached the start"); } crs.first(); if(crs.isFirst() == true) { System.out.println( "We have moved to first"); } System.out.println("crs row: " + crs.getRow()); if(crs.isBeforeFirst() == false) { System.out.println( "We aren't before the first row."); } crs.last(); if(crs.isLast() == true) { System.out.println( "...and now we have moved to the last"); } System.out.println("crs row: " + crs.getRow()); if(crs.isAfterLast() == false) { System.out.println( "we aren't after the last."); } } // end try catch (SQLException ex) { System.err.println("SQLException: " + ex.getMessage()); } } // end constructor public void showTheData() throws SQLException { sCol1 = crs.getString(1); if(crs.wasNull() == false) { System.out.println("sCol1: " + sCol1); } else { System.out.println("sCol1 is null"); } iCol2 = crs.getInt(2); if (crs.wasNull() == false) { System.out.println("iCol2: " + iCol2); } else { System.out.println("iCol2 is null"); } sCol3 = crs.getString(3); if (crs.wasNull() == false) { System.out.println("sCol3: " + sCol3 + "\n" ); } else { System.out.println("sCol3 is null\n"); } } // end showTheData // RowSetReader implementation public void readData(RowSetInternal caller) throws SQLException { rsmdi = new RowSetMetaDataImpl(); rsmdi.setColumnCount(3); rsmdi.setColumnType(1, Types.VARCHAR); rsmdi.setColumnType(2, Types.INTEGER); rsmdi.setColumnType(3, Types.VARCHAR); crs.setMetaData( rsmdi ); crs.moveToInsertRow(); crs.updateString( 1, "StringCol11" ); crs.updateInt( 2, 1 ); crs.updateString( 3, "StringCol31" ); crs.insertRow(); crs.updateString( 1, "StringCol12" ); crs.updateInt( 2, 2 ); crs.updateString( 3, "StringCol32" ); crs.insertRow(); crs.moveToCurrentRow(); crs.beforeFirst(); } // end readData public static void main(String args) { new RowSetEx1(); } } // end class RowSetEx1 44. Can I set up a connection pool with multiple user IDs? The single ID we are forced to use causes problems when debugging the DBMS. Since the Connection interface ( and the underlying DBMS ) requires a specific user and password, there's not much of a way around this in a pool. While you could create a different Connection for each user, most of the rationale for a pool would then be gone. Debugging is only one of several issues that arise when using pools. However, for debugging, at least a couple of other methods come to mind. One is to log executed statements and times, which should allow you to backtrack to the user. Another method that also maintains a trail of modifications is to include user and timestamp as standard columns in your tables. In this last case, you would collect a separate user value in your program. How can I protect my database password ? I'm writing a client-side java application that will access a database over the internet. I have concerns about the security of the database passwords. The client will have access in one way or another to the class files, where the connection string to the database, including user and 45. password, is stored in as plain text. What can I do to protect my passwords? This is a very common question. Conclusion: JAD decompiles things easily and obfuscation would not help you. But you'd have the same problem with C/C++ because the connect string would still be visible in the executable. SSL JDBC network drivers fix the password sniffing problem (in MySQL 4.0), but not the decompile problem. If you have a servlet container on the web server, I would go that route (see other discussion above) then you could at least keep people from reading/destroying your mysql database. Make sure you use database security to limit that app user to the minimum tables that they need, then at least hackers will not be able to reconfigure your DBMS engine. Aside from encryption issues over the internet, it seems to me that it is bad practice to embed user ID and password into program code. One could generally see the text even without decompilation in almost any language. This would be appropriate only to a read-only database meant to be open to the world. Normally one would either force the user to enter the information or keep it in a properties file. Detecting Duplicate Keys I have a program that inserts rows in a table. My table has a column 'Name' that has a unique constraint. If the user attempts to insert a duplicate name into the table, I want to display an error message by processing the error code from the database. How can I capture this error code in a Java program? A solution that is perfectly portable to all databases, is to execute a query for checking if that unique value is present before inserting the row. The big advantage is that you can handle your error message in a very simple way, and the obvious downside is that you are going to use more time for inserting the record, but since you're working on a PK field, performance should not be so bad. You can also get this information in a portable way, and potentially avoid another database access, by capturing SQLState messages. Some databases get more specific than others, but the general code portion is 23 - "Constraint Violations". UDB2, for example, gives a specific such as 23505, while others will only give 23000. 46. What driver should I use for scalable Oracle JDBC applications? Sun recommends using the thin ( type 4 ) driver. * On single processor machines to avoid JNI overhead. * On multiple processor machines, especially running Solaris, to avoid synchronization bottlenecks. 48. How do I write Greek ( or other non-ASCII/8859-1 ) characters to a database? From the standard JDBC perspective, there is no difference between ASCII/8859-1 characters and those above 255 ( hex FF ). The reason for that is that all Java characters are in Unicode ( unless you perform/request special encoding ). Implicit in that statement is the presumption that the data store can handle characters outside the hex FF range or interprets different character sets appropriately. That means either: * The OS, application and database use the same code page and character set. For example, a Greek version of NT with the DBMS set to the default OS encoding. * The DBMS has I18N support for Greek ( or other language ), regardless of OS encoding. This has been the most common for production quality databases, although support varies. Particular DBMSes may allow setting the encoding/code page/CCSID at the database, table or even column level. There is no particular standard for provided support or methods of setting the encoding. You have to check the DBMS documentation and set up the table properly. * The DBMS has I18N support in the form of Unicode capability. This would handle any Unicode characters and therefore any language defined in the Unicode standard. Again, set up is proprietary. 49. How can I insert images into a Mysql database? This code snippet shows the basics: File file = new File(fPICTURE); FileInputStream fis = new FileInputStream(file); PreparedStatement ps = ConrsIn.prepareStatement("insert into dbPICTURE values (?,?)"); // ***use as many ??? as you need to insert in the exact order*** ps.setString(1,file.getName()); ps.setBinaryStream(2,fis,(int)file.length()); ps.close(); fis.close(); 50. Is possible to open a connection to a database with exclusive mode with JDBC? I think you mean "lock a table in exclusive mode". You cannot open a connection with exclusive mode. Depending on your database engine, you can lock tables or rows in exclusive mode. In Oracle you would create a statement st and run st.execute("lock table mytable in exclusive mode"); Then when you are finished with the table, execute the commit to unlock the table. Mysql, Informix and SQLServer all have a slightly different syntax for this function, so you'll have to change it depending on your database. But they can all be done with execute(). 51. What are the standard isolation levels defined by JDBC? The values are defined in the class java.sql.Connection and are: * TRANSACTION_NONE * TRANSACTION_READ_COMMITTED * TRANSACTION_READ_UNCOMMITTED * TRANSACTION_REPEATABLE_READ * TRANSACTION_SERIALIZABLE Update fails without blank padding. Although a particular row is present in the database for a given key, executeUpdate() shows 0 rows updated and, in fact, the table is not updated. If I pad the Key with spaces for the column length (e.g. if the key column is 20 characters long, and key is msgID, length 6, I pad it with 14 spaces), 52. the update then works!!! Is there any solution to this problem without padding? In the SQL standard, CHAR is a fixed length data type. In many DBMSes ( but not all), that means that for a WHERE clause to match, every character must match, including size and trailing blanks. As Alessandro indicates, defining CHAR columns to be VARCHAR is the most general answer. 53. What isolation level is used by the DBMS when inserting, updating and selecting rows from a database? The answer depends on both your code and the DBMS. If the program does not explicitly set the isolation level, the DBMS default is used. You can determine the default using DatabaseMetaData.getDefaultTransactionIsolation() and the level for the current Connection with Connection.getTransactionIsolation(). If the default is not appropriate for your transaction, change it with Connection.setTransactionIsolation(int level). 54. How can I determine the isolation levels supported by my DBMS? Use DatabaseMetaData.supportsTransactionIsolationLevel(int level). Connecting to a database through the Proxy I want to connect to remote database using a program that is running in the local network behind the proxy. Is that possible? I assume that your proxy is set to accept http requests only on port 80. If you want to have a local class behind the proxy connect to the database for you, then you need a servlet/JSP to receive an HTTP request and use the local class to connect to the database and send the response back to the client. You could also use RMI where your remote computer class that connects to the database acts as a remote server that talks RMI with the clients. if you implement this, then you will need to tunnel RMI through HTTP which is not that hard. In summary, either have a servlet/JSP take HTTP requests, instantiate a class that handles database connections and send HTTP response back to the client or have the local class deployed as RMI server and send requests to it using RMI. 55. How do I receive a ResultSet from a stored procedure? Stored procedures can return a result parameter, which can be a result set. For a discussion of standard JDBC syntax for dealing with result, IN, IN/OUT and OUT parameters, see Stored Procedures. 56. How can I write to the log used by DriverManager and JDBC drivers? The simplest method is to use DriverManager.println(String message), which will write to the current log. 57. How can I get or redirect the log used by DriverManager and JDBC drivers? As of JDBC 2.0, use DriverManager.getLogWriter() and DriverManager.setLogWriter(PrintWriter out). Prior to JDBC 2.0, the DriverManager methods getLogStream() and setLogStream(PrintStream out) were used. These are now deprecated. 58. What does it mean to "materialize" data? This term generally refers to Array, Blob and Clob data which is referred to in the database via SQL locators "Materializing" the data means to return the actual data pointed to by the Locator. For Arrays, use the various forms of getArray() and getResultSet(). For Blobs, use getBinaryStream() or getBytes(long pos, int length). For Clobs, use getAsciiStream() or getCharacterStream(). 59. Why do I have to reaccess the database for Array, Blob, and Clob data? Most DBMS vendors have implemented these types via the SQL3 Locator type Some rationales for using Locators rather than directly returning the data can be seen most clearly with the Blob type. By definition, a Blob is an arbitrary set of binary data. It could be anything; the DBMS has no knowledge of what the data represents. Notice that this effectively demolishes data independence, because applications must now be aware of what the Blob data actually represents. Let's assume an employee table that includes employee images as Blobs. Say we have an inquiry program that presents multiple employees with department and identification information. To see all of the data for a specific employee, including the image, the summary row is selected and another screen appears. It is only at this pont that the application needs the specific image. It would be very wasteful and time consuming to bring down an entire employee page of images when only a few would ever be selected in a given run. Now assume a general interactive SQL application. A query is issued against the employee table. Because the image is a Blob, the application has no idea what to do with the data, so why bring it down, killing performance along the way, in a long running operation? Clearly this is not helpful in those applications that need the data everytime, but these and other considerations have made the most general sense to DBMS vendors. 60. What is an SQL Locator? A Locator is an SQL3 data type that acts as a logical pointer to data that resides on a database server. Read "logical pointer" here as an identifier the DBMS can use to locate and manipulate the data. A Locator allows some manipulation of the data on the server. While the JDBC specification does not directly address Locators, JDBC drivers typically use Locators under the covers to handle Array, Blob, and Clob data types. 61. How do I set properties for a JDBC driver and where are the properties stored? A JDBC driver may accept any number of properties to tune or optimize performance for the specific driver. There is no standard, other than user and password, for what these properties should be. Therefore, the developer is dependent on the driver documentation to automatically pass properties. For a standard dynamic method that can be used to solicit user input for properties, see What properties should I supply to a database driver in order to connect to a database? In addition, a driver may specify its own method of accepting properties. Many do this via appending the property to the JDBC Database URL. However, a JDBC Compliant driver should implement the connect(String url, Properties info) method. This is generally invoked through DriverManager.getConnection(String url, Properties info). The passed properties are ( probably ) stored in variables in the Driver instance. This, again, is up to the driver, but unless there is some sort of driver setup, which is unusual, only default values are remembered over multiple instantiations. 62. What is the JDBC syntax for using a literal or variable in a standard Statement? First, it should be pointed out that PreparedStatement handles many issues for the developer and normally should be preferred over a standard Statement. Otherwise, the JDBC syntax is really the same as SQL syntax. One problem that often affects newbies ( and others ) is that SQL, like many languages, requires quotes around character ( read "String" for Java ) values to distinguish from numerics. So the clause: "WHERE myCol = " + myVal is perfectly valid and works for numerics, but will fail when myVal is a String. Instead use: "WHERE myCol = '" + myVal + "'" if myVal equals "stringValue", the clause works out to: WHERE myCol = 'stringValue' You can still encounter problems when quotes are embedded in the value, which, again, a PreparedStatement will handle for you. 63. How do I check in my code whether a maximum limit of database connections have been reached? Use DatabaseMetaData.getMaxConnections() and compare to the number of connections currently open. Note that a return value of zero can mean unlimited or, unfortunately, unknown. Of course, driverManager.getConnection() will throw an exception if a Connection can not be obtained. 64. Why do I get UnsatisfiedLinkError when I try to use my JDBC driver? The first thing is to be sure that this does not occur when running non-JDBC apps. If so, there is a faulty JDK/JRE installation. If it happens only when using JDBC, then it's time to check the documentation that came with the driver or the driver/DBMS support. JDBC driver types 1 through 3 have some native code aspect and typically require some sort of client install. Along with the install, various environment variables and path or classpath settings must be in place. Because the requirements and installation procedures vary with the provider, there is no reasonable way to provide details here. A type 4 driver, on the other hand, is pure Java and should never exhibit this problem. The trade off is that a type 4 driver is usually slower. Many connections from an Oracle8i pooled connection returns statement closed. I am using import oracle.jdbc.pool.* with thin driver. If I test with many simultaneous connections, I get an SQLException that the statement is closed. ere is an example of concurrent operation of pooled connections from the OracleConnectionPoolDataSource. There is an executable for kicking off threads, a DataSource, and the workerThread. The Executable Member package package6; /** * package6.executableTester * */ public class executableTester { protected static myConnectionPoolDataSource dataSource = null; static int i = 0; /** * Constructor */ public executableTester() throws java.sql.SQLException { } /** * main * @param args */ public static void main(String args) { try{ dataSource = new myConnectionPoolDataSource(); } catch ( Exception ex ){ ex.printStackTrace(); } while ( i++ try{ workerClass worker = new workerClass(); worker.setThreadNumber( i ); worker.setConnectionPoolDataSource ( dataSource.getConnectionPoolDataSource() ); worker.start(); System.out.println( "Started Thread#"+i ); } catch ( Exception ex ){ ex.printStackTrace(); } } } } The DataSource Member package package6; import oracle.jdbc.pool.*; /** * package6.myConnectionPoolDataSource. * */ public class myConnectionPoolDataSource extends Object { protected OracleConnectionPoolDataSource ocpds = null; /** * Constructor */ public myConnectionPoolDataSource() throws java.sql.SQLException { // Create a OracleConnectionPoolDataSource instance ocpds = new OracleConnectionPoolDataSource(); // Set connection parameters ocpds.setURL("jdbc:oracle:oci8:@mydb"); ocpds.setUser("scott"); ocpds.setPassword("tiger"); } public OracleConnectionPoolDataSource getConnectionPoolDataSource() { return ocpds; } } The Worker Thread Member package package6; import oracle.jdbc.pool.*; import java.sql.*; import javax.sql.*; /** * package6.workerClass . * */ public class workerClass extends Thread { protected OracleConnectionPoolDataSource ocpds = null; protected PooledConnection pc = null; protected Connection conn = null; protected int threadNumber = 0; /** * Constructor */ public workerClass() { } public void doWork( ) throws SQLException { // Create a pooled connection pc = ocpds.getPooledConnection(); // Get a Logical connection conn = pc.getConnection(); // Create a Statement Statement stmt = conn.createStatement (); // Select the ENAME column from the EMP table ResultSet rset = stmt.executeQuery ("select ename from emp"); // Iterate through the result and print the employee names while (rset.next ()) // System.out.println (rset.getString (1)); ; // Close the RseultSet rset.close(); rset = null; // Close the Statement stmt.close(); stmt = null; // Close the logical connection conn.close(); conn = null; // Close the pooled connection pc.close(); pc = null; System.out.println( "workerClass.thread# "+threadNumber+" completed.."); } public void setThreadNumber( int assignment ){ threadNumber = assignment; } public void setConnectionPoolDataSource (OracleConnectionPoolDataSource x){ ocpds = x; } public void run() { try{ doWork(); } catch ( Exception ex ){ ex.printStackTrace(); } } } The OutPut Produced Started Thread#1 Started Thread#2 Started Thread#3 Started Thread#4 Started Thread#5 Started Thread#6 Started Thread#7 Started Thread#8 Started Thread#9 Started Thread#10 workerClass.thread# 1 completed.. workerClass.thread# 10 completed.. workerClass.thread# 3 completed.. workerClass.thread# 8 completed.. workerClass.thread# 2 completed.. workerClass.thread# 9 completed.. workerClass.thread# 5 completed.. workerClass.thread# 7 completed.. workerClass.thread# 6 completed.. workerClass.thread# 4 completed.. The oracle.jdbc.pool.OracleConnectionCacheImpl class is another subclass of the oracle.jdbc.pool.OracleDataSource which should also be looked over, that is what you really what to use. Here is a similar example that uses the oracle.jdbc.pool.OracleConnectionCacheImpl. The general construct is the same as the first example but note the differences in workerClass1 where some statements have been commented ( basically a clone of workerClass from previous example ). The Executable Member package package6; import java.sql.*; import javax.sql.*; import oracle.jdbc.pool.*; /** * package6.executableTester2 * */ public class executableTester2 { static int i = 0; protected static myOracleConnectCache connectionCache = null; /** * Constructor */ public executableTester2() throws SQLException { } /** * main * @param args */ public static void main(String args) { OracleConnectionPoolDataSource dataSource = null; try{ dataSource = new OracleConnectionPoolDataSource() ; connectionCache = new myOracleConnectCache( dataSource ); } catch ( Exception ex ){ ex.printStackTrace(); } while ( i++ try{ workerClass1 worker = new workerClass1(); worker.setThreadNumber( i ); worker.setConnection( connectionCache.getConnection() ); worker.start(); System.out.println( "Started Thread#"+i ); } catch ( Exception ex ){ ex.printStackTrace(); } } } protected void finalize(){ try{ connectionCache.close(); } catch ( SQLException x) { x.printStackTrace(); } this.finalize(); } } The ConnectCacheImpl Member package package6; import javax.sql.ConnectionPoolDataSource; import oracle.jdbc.pool.*; import oracle.jdbc.driver.*; import java.sql.*; import java.sql.SQLException; /** * package6.myOracleConnectCache * */ public class myOracleConnectCache extends OracleConnectionCacheImpl { /** * Constructor */ public myOracleConnectCache( ConnectionPoolDataSource x) throws SQLException { initialize(); } public void initialize() throws SQLException { setURL("jdbc:oracle:oci8:@myDB"); setUser("scott"); setPassword("tiger"); // // prefab 2 connection and only grow to 4 , setting these // to various values will demo the behavior //clearly, if it is not // obvious already // setMinLimit(2); setMaxLimit(4); } } The Worker Thread Member package package6; import oracle.jdbc.pool.*; import java.sql.*; import javax.sql.*; /** * package6.workerClass1 * */ public class workerClass1 extends Thread { // protected OracleConnectionPoolDataSource ocpds = null; // protected PooledConnection pc = null; protected Connection conn = null; protected int threadNumber = 0; /** * Constructor */ public workerClass1() { } public void doWork( ) throws SQLException { // Create a pooled connection // pc = ocpds.getPooledConnection(); // Get a Logical connection // conn = pc.getConnection(); // Create a Statement Statement stmt = conn.createStatement (); // Select the ENAME column from the EMP table ResultSet rset = stmt.executeQuery ("select ename from EMP"); // Iterate through the result // and print the employee names while (rset.next ()) // System.out.println (rset.getString (1)); ; // Close the RseultSet rset.close(); rset = null; // Close the Statement stmt.close(); stmt = null; // Close the logical connection conn.close(); conn = null; // Close the pooled connection // pc.close(); // pc = null; System.out.println( "workerClass1.thread# "+threadNumber+" completed.."); } public void setThreadNumber( int assignment ){ threadNumber = assignment; } // public void setConnectionPoolDataSource (OracleConnectionPoolDataSource x){ // ocpds = x; // } public void setConnection( Connection assignment ){ conn = assignment; } public void run() { try{ doWork(); } catch ( Exception ex ){ ex.printStackTrace(); } } } The OutPut Produced Started Thread#1 Started Thread#2 workerClass1.thread# 1 completed.. workerClass1.thread# 2 completed.. Started Thread#3 Started Thread#4 Started Thread#5 workerClass1.thread# 5 completed.. workerClass1.thread# 4 completed.. workerClass1.thread# 3 completed.. Started Thread#6 Started Thread#7 Started Thread#8 Started Thread#9 workerClass1.thread# 8 completed.. workerClass1.thread# 9 completed.. workerClass1.thread# 6 completed.. workerClass1.thread# 7 completed.. Started Thread#10 workerClass1.thread# 10 completed.. 65. DB2 Universal claims to support JDBC 2.0, But I can only get JDBC 1.0 functionality. What can I do? DB2 Universal defaults to the 1.0 driver. You have to run a special program to enable the 2.0 driver and JDK support. For detailed information, see Setting the Environment in Building Java Applets and Applications. The page includes instructions for most supported platforms. 66. How do I disallow NULL values in a table? Null capability is a column integrity constraint, normally applied at table creation time. Note that some databases won't allow the constraint to be applied after table creation. Most databases allow a default value for the column as well. The following SQL statement displays the NOT NULL constraint: CREATE TABLE CoffeeTable ( Type VARCHAR(25) NOT NULL, Pounds INTEGER NOT NULL, Price NUMERIC(5, 2) NOT NULL ) 67. How to get a field's value with ResultSet.getxxx when it is a NULL? I have tried to execute a typical SQL statement: select * from T-name where (clause); But an error gets thrown because there are some NULL fields in the table. You should not get an error/exception just because of null values in various columns. This sounds like a driver specific problem and you should first check the original and any chained exceptions to determine if another problem exists. In general, one may retrieve one of three values for a column that is null, depending on the data type. For methods that return objects, null will be returned; for numeric ( get Byte(), getShort(), getInt(), getLong(), getFloat(), and getDouble() ) zero will be returned; for getBoolean() false will be returned. To find out if the value was actually NULL, use ResultSet.wasNull() before invoking another getXXX method. 68. How do I insert/update records with some of the columns having NULL value? Use either of the following PreparedStatement methods: public void setNull(int parameterIndex, int sqlType) throws SQLException public void setNull(int paramIndex, int sqlType, String typeName) throws SQLException These methods assume that the columns are nullable. In this case, you can also just omit the columns in an INSERT statement; they will be automatically assigned null values. Is there a way to find the primary key(s) for an Access Database table? Sun's JDBC-ODBC driver does not implement the getPrimaryKeys() method for the DatabaseMetaData Objects. // Use meta.getIndexInfo() will //get you the PK index. Once // you know the index, retrieve its column name DatabaseMetaData meta = con.getMetaData(); String key_colname = null; // get the primary key information rset = meta.getIndexInfo(null,null, table_name, true,true); while( rset.next()) { String idx = rset.getString(6); if( idx != null) { //Note: index "PrimaryKey" is Access DB specific // other db server has diff. index syntax. if( idx.equalsIgnoreCase("PrimaryKey")) { key_colname = rset.getString(9); setPrimaryKey( key_colname ); } } } 69. Why can't Tomcat find my Oracle JDBC drivers in classes111.zip? TOMCAT 4.0.1 on NT4 throws the following exception when I try to connect to Oracle DB from JSP. javax.servlet.ServletException : oracle.jdbc.driver.OracleDriver java.lang.ClassNotFoundException: oracle:jdbc:driver:OracleDriver But, the Oracle JDBC driver ZIP file (classes111.zip)is available in the system classpath. Copied the Oracle Driver class file (classes111.zip) in %TOMCAT_Home - Home%\lib directory and renamed it to classess111.jar. Able to connect to Oracle DB from TOMCAT 4.01 via Oracle JDBC-Thin Driver. I have an application that queries a database and retrieves the results into a JTable. This is the code in the model that seems to be taken forever to execute, especially for a large result set: while ( myRs.next() ) { Vector newRow =new Vector(); for ( int i=1;i Read the full article
0 notes
Text
Using 7 Mysql Strategies Like The Pros
MySQL gives you Let to host lots of databases and it is named by you. Using MySQL and PHPMyAdmin ( my favorite management GUI ) has enabled me to insource numerous solutions we used to cover.
MySql is a database application of It is FREE on media and small scales business, it is supported on systems that were considered. Since 2009 Oracle buy Sun Microsystems ( such as MySQL ) to get 7.5 billons inducing user and programmers to start to debate the fate of their open - source database.
Almost any operating system and is operated in by mySQL Includes a controlled rate that is good I think it's the database manager together with all the rate of reaction to the procedures. Subqueries were one of the significant flaws of MySQL for quite a very long time; it had been notorious for dropping its way using a few degrees of sub-questions.
With MySQL, on the other hand, the Customer library is GPL, and that means you need to pay a commercial charge to Oracle or provide the source code of your program.PostgreSQL additionally supports data about data types, purposes and access methods from the system catalogs together with the typical information regarding databases, tables, and columns which relational databases maintain.

There are ways around the MySQL client library's licensing, the Route Atlassian decide to choose would be telling you where to get the JDBC connector out of for MySQL if you would like to join your Atlassian programs to a MySQL 38, and in which to drop the jar.
Seasoned staff if You'd like competently Accessible on-call assistance without paying serious cash ( DB2 or Oracle - degree paying ) Percona ( and MySQL ) is the friend. Matt Aslett of 451 Research unites ScaleBase to talk: scaling - outside of your MySQL DB, high availability strategies that are fresh, smartly managing a MySQL environment that is dispersed.
Conclusion Scalability is a matter of a theoretical Number of nodes It is also about the capacity to provide predictable performance And also to do this without adding management sophistication, proliferation of cloud, and geo-dispersed programs are adding to the sophistication MySQL hasn't been under so much strain that the mixture of innovative clustering/load balancing and management technology provides a possible solution ( c ) 2013 from The 451 Group.
Flexibility: no need to oversupply Online data Redistribution No downtime Read / Write dividing Optimal for scaling read - intensive software Replication lag - established routing Enhances data consistency and isolation Read stickiness following writes Ensure consistent and dispersed database functioning 100% compatible MySQL proxy Software unmodified Standard MySQL interfaces and tools MySQL databases unmodified Info is protected within MySQL InnoDB / MyISAM / etc.
The dilemma is solved by database encryption, but Once the root accounts are compromised, it can't prevent access. You get rid of the ability of SQL, although application level encryption has become easily the most flexible and protected - it is pretty difficult to use columns in WHERE or JOIN clauses.
It is possible to incorporate with Hashicorp Vault server through A keyring_vault plugin, fitting ( and even expanding - binary log encryption ) the features available in Oracle's MySQL Enterprise version. Whichever MySQL taste you use, so long as it's a current version, you'd have choices to apply data at rest encryption through the database server, so ensuring your information is also secured.
Includes storage - engine frame that System administrators to configure the MySQL database for performance. Whether your system is Microsoft Linux, Macintosh or UNIX, MySQL is a solution that is comprehensive with self - handling features that automate all from configuration and space expansion to database management and information design.
By migrating database programs that are current to MySQL, businesses are currently enjoying substantial cost savings on jobs that are brand new. MySQL is an open source, multi-threaded, relational database management system ( RDBMS ) written in C and C++.
The server is Acceptable for assignment - Critical, heavy - load production systems in addition to for embedding into mass installed applications. MySQL is interactive and straightforward to use, in comparison to other DBMS applications and is protected with a data protection layer providing information with encryption.
MariaDB is a general - purpose DBMS engineered with extensible Structure to support a wide group of use cases through pluggable storage engines.MySQL users may get tens of thousands of metrics in the database, and so this guide we will concentrate on a small number of important metrics that will let you obtain real-time insight into your database wellbeing and functionality.
Users have a number of options for monitoring Latency, by taking advantage of MySQL's both built-in metrics and from querying the operation schema. The default storage engine, InnoDB of MySQL, utilizes an area of memory known as the buffer pool to indexes and tables.
Since program databases -- and information warehouses -- are Constructed on SQL databases, also because MySQL is among the most well-known flavors of SQL, we compiled a listing of the highest MySQL ETL tools that will assist you to transfer data in and from MySQL database programs. KETL is XML - based and operates with MySQL to develop and deploy complex ETL conversion projects which require scheduling.
Blendo's ETL - as - a - service product makes it Simple to get data From several data sources such as S3 buckets, CSVs, and also a massive selection of third - party information sources such as Google Analytics, MailChimp, Salesforce and many others.
In we, Seravo Migrated all our databases from MySQL into MariaDB in late 2013 and through 2014 we also migrated our client's systems to utilize MariaDB. Dynamic column service ( MariaDB just ) is interesting since it allows for NoSQL form performance, and thus a single database port may offer both SQL and" not just SQL" for varied software project requirements.
MariaDB as the Number of storage motors and in excels Other plugins it ships together: Link and Cassandra storage motors for NoSQL backends or rolling migrations from legacy databases, Spider such as sharding, TokuDB with fractal indexes, etc.
MySQL is a relational database - Standard information schema also is composed of columns, tables, views, procedures, triggers, cursors, etc. MariaDB, therefore, has exactly the database structure and indicator and, on the other hand, is a branch of MySQL. Everything -- from the information, table definitions, constructions, and APIs -- stays identical when updating from MySQL into MariaDB.
MariaDB has experienced an increase in terms of Security features such as internal password and security management, PAM and LDAP authentication, Kerberos, user functions, and robust encryption within tablespaces, logs, and tables. MySQL can not do hash link or sort merge join - it merely can perform nested loops method that demands a lot of index lookups which might be arbitrary.
In MySQL single question runs as only ribbon ( with exception Of MySQL Cluster ) and MySQL problems IO requests one for question implementation, so if only query execution time is the concern many hard drives and the large variety of CPUs won't help.
With table layout and application design, you Can build programs working with huge data collections according to MySQL.OPTIMIZE assists for specific issues - ie it types indexes themselves and removers row fragmentation ( all for MyISAM tables ).
Even though it's Booted up to 8 TB, MySQL can't operate effectively with a large database. Mysql continues to be my favorite database because I started programming, so it's simple to install, it is easy to obtain an application that links to the database and perform the management in a graphical manner, many articles supervisors and e-commerce stores utilize MySQL by default, and it has let me execute many projects, I enjoy that many hosting providers have MySQL tutorial service at no extra price.
Mysql is fast the setup, and light requirements Are minimal and with few tools, I've used it in Windows and Linux with no difficulty in either, but the server operating system hasn't been a restriction and that I utilize it in a Linux environment whenever it is potential.
MySQL provides its code Beneath the GPL and gives the choice of Non - GPL commercial supply in the kind of MySQL Enterprise. MariaDB also supplies motor - separate table numbers to enhance the optimizer's functionality, speeding up query processing and data evaluation on the dimensions and arrangement of their tables.
Utilization in MySQL is sub - InnoDB and Optimum tables eventually become fragmented over time, undermining functionality. Shifting from MySQL into MariaDB is relatively simple and is a slice of cake for most systems administrators.
For program, Example Hosts ( even though they need to be okay with attaining MySQL via proxies ), the proxy layer, and perhaps a management host. You ought to check of the logs and settings files and confirm that they're not readable by others.
Data may be moved between MySQL servers, For instance via MySQL replication that is regular or inside a Galera cluster. Flexibility is incorporating the features your company needs, although pushing arbitrary JSON seems elastic.
Among those enterprise qualities, Informix relational Databases, recently launched a new variant ( v12.10. XC2 ) which supports JSON / BSON info as a native from inside the relational database frame and fully supports each the MongoDB APIs so that any program is composed to the MongoDB, protocol may just be pointed in the Informix server and it'll just work.
On top of the IBM Engineers ( Informix Is currently an IBM product ) extended the JSON kind to encourage files Up to 2 GB in size ( MongoDB limitations files to 16 MB). In MySQL and Oracle, working memory Is shared links because links Are serviced by a single procedure.
Noted Also :⇒ Use Of Quit SEO In 5 Days
0 notes
Text
Sql Interview Questions
If a WHERE stipulation is made use of in cross join then the inquiry will function like an INNER JOIN. A SPECIAL restriction guarantees that all worths in a column are different. This supplies originality for the column and also aids identify each row distinctly. It promotes you to manipulate the information kept in the tables by utilizing relational drivers. Instances of the relational data source monitoring system are Microsoft Access, MySQL, SQLServer, Oracle database, and so on. Unique vital restraint distinctly identifies each document in the data source. This vital supplies individuality for the column or collection of columns. A database cursor is a control framework that allows for traversal of documents in a data source. Cursors, in addition, facilitates handling after traversal, such as access, enhancement and also deletion of database records. They can be viewed as a reminder to one row in a collection of rows. An alias is a attribute of SQL that is sustained by a lot of, otherwise all, RDBMSs. It is a momentary name appointed to the table or table column for the objective of a specific SQL inquiry. Additionally, aliasing can be used as an obfuscation strategy to protect the real names of data source fields. A table pen name is additionally called a connection name.

pupils; Non-unique indexes, on the other hand, are not made use of to impose restraints on the tables with which they are associated. Rather, non-unique indexes are made use of only to enhance query efficiency by maintaining a sorted order of data values that are made use of regularly. A data source index is a information framework that provides quick lookup of information in a column or columns of a table. It improves the speed of procedures accessing information from a database table at the price of added creates and memory to preserve the index data structure. Prospects are likely to be asked basic SQL interview questions to advance degree SQL concerns relying on their experience and also different other elements. The below list covers all the SQL interview concerns for betters as well as SQL meeting concerns for knowledgeable degree candidates as well as some SQL query interview questions. SQL clause helps to limit the result set by providing a condition to the question. A clause helps to filter the rows from the whole collection of records. Our SQL Meeting Questions blog is the one-stop resource from where you can improve your meeting prep work. It has a collection of leading 65 concerns which an interviewer intends to ask during an interview procedure. Unlike main crucial, there can be multiple one-of-a-kind restraints specified per table. The code syntax for UNIQUE is quite comparable to that of PRIMARY SECRET and also can be utilized interchangeably. The majority of modern database monitoring systems like MySQL, Microsoft SQL Server, Oracle, IBM DB2 as well as Amazon Redshift are based upon RDBMS. SQL stipulation is specified to restrict the outcome set by providing problem to the query. This typically filters some rows from the entire collection of documents. Cross sign up with can be defined as a cartesian item of the two tables included in the join. https://bit.ly/3tmWIsh after sign up with has the exact same variety of rows as in the cross-product of number of rows in the two tables. Self-join is readied to be query utilized to compare to itself. This is utilized to compare values in a column with various other worths in the exact same column in the same table. https://geekinterview.net can be made use of for the very same table contrast. This is a key words utilized to inquire information from more tables based on the partnership between the fields of the tables. A foreign secret is one table which can be associated with the main key of an additional table. Partnership requires to be produced in between 2 tables by referencing foreign secret with the primary secret of one more table. A Distinct crucial constraint uniquely identified each record in the data source. It starts with the fundamental SQL interview inquiries as well as later on remains to sophisticated inquiries based upon your discussions and solutions. These SQL Interview concerns will assist you with different proficiency levels to reap the maximum gain from this blog. A table contains a specified variety of the column called fields but can have any type of number of rows which is known as the record. So, the columns in the table of the data source are known as the fields and also they represent the feature or attributes of the entity in the document. Rows right here refers to the tuples which represent the simple data thing and columns are the quality of the data things present specifically row. Columns can categorize as upright, and also Rows are horizontal. There is offered sql meeting inquiries as well as responses that has been asked in many firms. For PL/SQL interview concerns, see our following web page. A sight can have information from several tables integrated, as well as it relies on the connection. https://tinyurl.com/c7k3vf9t are utilized to use safety and security mechanism in the SQL Web server. The sight of the database is the searchable things we can utilize a question to search the consider as we utilize for the table. RDBMS means Relational Database Monitoring System. It is a database monitoring system based upon a relational version. RDBMS stores the information right into the collection of tables and also links those table utilizing the relational drivers conveniently whenever called for. This gives uniqueness for the column or set of columns. A table is a set of information that are arranged in a design with Columns and Rows. https://is.gd/snW9y3 can be classified as upright, and also Rows are straight. A table has actually defined number of column called fields yet can have any kind of variety of rows which is called document. RDBMS store the information into the collection of tables, which is related by typical areas in between the columns of the table. It likewise offers relational drivers to control the information stored into the tables. Adhering to is a curated listing of SQL interview concerns as well as responses, which are most likely to be asked throughout the SQL interview.
0 notes
Text
oracle database training in ameerpet
Oracle Database is an object-relational database management system (ORDBMS) developed and marketed by Oracle Corporation. Oracle Database is commonly referred. In the early 70’s Dr. EFT Codd, a computer scientist, invented the relational model for database management. The relational model deals with many issues caused by the flat file model or the FMS (File Management System). According to his model, instead of combining everything in a single structure, data is organized in entities and attributes to make it more effecient. Oracle has the SQL (Structured Query Language) and also support PL/SQL (Procedural Language using SQL).

Career Prospects
This course is meant for everyone who would like to visualize how information gets stored and delivered to end users and a solid understanding of the Oracle products used in professional job roles.
Application Developer
Database Developer
Support Analyst
Curriculum
Introduction to DBMS • DBMS, Data, Information, Database Data models – FMS/ HDBMS/ NDBMS/ RDBMS/ ORDBMS • E-R Diagram, Normalization, Codd Rules • RDBMS Packages • Versions SQL (Structured Query Language) • SQL and SQL*Plus Commands • Types of commands in SQL • How to login into SQL • HR user, locking & unlocking user Retrieving data • Select statement usage • Alias names – columns & expressions • Applying filters using operators • Operators – Relational/ Logical / Special • Distinct clause, Order by clause • Sorting NULL values Working with tables • Datatypes in Oracle • Naming conventions; Rules – tables/columns • Creating Tables in different methods DML operations • Insert data in different methods • Update / Delete data DDL commands • Alter / Truncate / Rename / Drop table • Recyclebin concept • Flashback / Purge Table Constraints • Data Integrity and importance • Not Null/Unique/Primary Key/ Check • References/Foreign Key • Add/enable/disable/drop constraints • Composite primary key/unique key • About ‘User_constraints’ table TCL commands (Transaction Handling) • About login session • Redo log files • Commit / Rollback / Savepoint • Working with multiple savepoints DCL Commands • User management, SYSTEM user • Create user, Grant basic privileges • Change password, lock/unlock user • Grant/Revoke a user as DBA • Data sharing between users • Grant and Revoke commands • Accessing another user data • Dead lock situations About ‘User_tab_privs_made’, ‘User_tab_privs_recd’ Database functions • Group / Row / Numeric / String • Conversion functions • Dates & date formats • Date functions, Misc. functions • Pseudo columns Data grouping • Group by / Having clause • ‘where’ versus ‘having’ clause • Using expressions in group by Set operators • Union/ Intersect/ Minus/ Union All Subqueries • Simple / Multiple row subquery • Nested / Co-related subquery Joins tables • Simple join (equi and non-equi) • Self/ inner / Outer join (Left/Right/Full) • Cartesian/Cross join • ANSI Standard of joins Oracle Database objects • Synonyms • Views • Sequences • Indexes PLSQL PL/SQL architecture • PL/SQL engine • Structure of a PL/SQL program • Different section of a program • Datatypes in PL/SQL • Operators, I/O operations • Write expressions, simple program • Extracting data from tables Control statements • If-Then-Else – Simple, Nested • Compound conditions (and/or/not) • Case – End Case • Loops – For/ While/ Simple/ ForALL Exception Handling • Introduction • Types of Exceptions • Runtime errors vs Exceptions • System / User defined exceptions • Using multiple exceptions • Raise_Application_Error() Cursor management • Cursor types – Implicit / Explicit • Cursor attributes • Declaring, opening, closing • Fetching, checking End of cursor • Parameterized cursor • For loops in cursor processing • DML operations using cursors • Cursor using joins Sub programs Stored Procedures • Creating a simple procedure • Compiling, verifying errors • Executing procedure from SQL prompt • Calling procedure in another PL/SQL program • Procedure including DML operations • Procedures with parameters • Types of parameters (IN, OUT & IN OUT) • Cursors in a procedure User defined Functions • Writing a user’s function • About ‘Return’ statement • Compiling, verifying errors • Executing from SQL prompt • Functions with parameters (IN, OUT & IN OUT) Packages • Create package specification / body • Calling the elements of a package • Adv of package over procedure/function • Implementing Polymorphism • Function overloading • Procedure overloading Database Triggers • Types of triggers • Creating before/after triggers • :OLD, :NEW reference for data references • DML operations using triggers • ‘Instead of’ triggers • Triggers Vs constraints • Transaction auditing using triggers
Related searchers are : oracle admin online training,oracle admin training in hyderabad,oracle administration course in ameerpet,oracle administration course in hyderabad,oracle administration online training in hyderabad,best oracle online training institutes in hyderabad,oracle training in ameerpet,oracle admin training institute in ameerpet hyderabad,oracle admin online training institute in ameerpet hyderabad,oracle Admin Training Institutes in Hyderabad
For More info : www.datadot.in
Call us : 9052641113
0 notes
Text
Learn How to Work With Ref Cursor in ORACLE 12C For Beginner
http://bit.ly/2Hbq6eN Learn How to Work With Ref Cursor in ORACLE 12C For Beginner, Learn Step By Step Execute the Ref Cursor Program in Oracle 12C For Beginners to Expert. SQL is used to interact with Database Systems. As per ANSI (American National Standards Institute), SQL is the standard language for Relational Database Management Systems. SQL has been the prominent language to interact with various Database Systems for many decades. While many languages that existed two decades ago are extinct now, SQL has always maintained its supremacy in the RDBMS world. Over the time, it has only advanced with new features and standards. And it seems to stay that way for years to come.
0 notes
Text
300+ TOP JDBC Interview Questions and Answers
JDBC Interview Questions for freshers experienced
1. What is the JDBC? Java Database Connectivity (JDBC) is a standard Java API to interact with relational databases form Java. JDBC has set of classes and interfaces which can use from Java application and talk to database without learning RDBMS details and using Database Specific JDBC Drivers. 2. What are the new features added to JDBC 4.0? The major features added in JDBC 4.0 include : Auto-loading of JDBC driver class Connection management enhancements Support for RowId SQL type DataSet implementation of SQL using Annotations SQL exception handling enhancements SQL XML support 3. Explain Basic Steps in writing a Java program using JDBC? JDBC makes the interaction with RDBMS simple and intuitive. When a Java application needs to access database : Load the RDBMS specific JDBC driver because this driver actually communicates with the database (Incase of JDBC 4.0 this is automatically loaded). Open the connection to database which is then used to send SQL statements and get results back. Create JDBC Statement object. This object contains SQL query. Execute statement which returns resultset(s). ResultSet contains the tuples of database table as a result of SQL query. Process the result set. Close the connection. 4. Exaplain the JDBC Architecture. The JDBC Architecture consists of two layers:
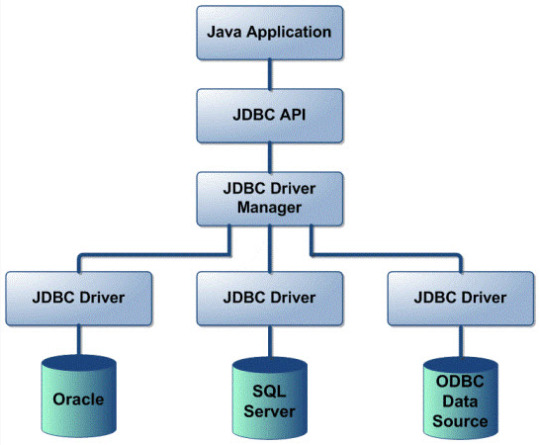
JDBC Architecture The JDBC API, which provides the application-to-JDBC Manager connection. The JDBC Driver API, which supports the JDBC Manager-to-Driver Connection. The JDBC API uses a driver manager and database-specific drivers to provide transparent connectivity to heterogeneous databases. The JDBC driver manager ensures that the correct driver is used to access each data source. The driver manager is capable of supporting multiple concurrent drivers connected to multiple heterogeneous databases. The location of the driver manager with respect to the JDBC drivers and the Java application is shown in Figure 1. 5. What are the main components of JDBC ? The life cycle of a servlet consists of the following phases: DriverManager: Manages a list of database drivers. Matches connection requests from the java application with the proper database driver using communication subprotocol. The first driver that recognizes a certain subprotocol under JDBC will be used to establish a database Connection. Driver: The database communications link, handling all communication with the database. Normally, once the driver is loaded, the developer need not call it explicitly. Connection: Interface with all methods for contacting a database.The connection object represents communication context, i.e., all communication with database is through connection object only. Statement : Encapsulates an SQL statement which is passed to the database to be parsed, compiled, planned and executed. ResultSet: The ResultSet represents set of rows retrieved due to query execution. 6. How the JDBC application works? A JDBC application can be logically divided into two layers:

JDBC application works Driver layer Application layer Driver layer consists of DriverManager class and the available JDBC drivers. The application begins with requesting the DriverManager for the connection. An appropriate driver is choosen and is used for establishing the connection. This connection is given to the application which falls under the application layer. The application uses this connection to create Statement kind of objects, through which SQL commands are sent to backend and obtain the results. 7. How do I load a database driver with JDBC 4.0 / Java 6? Provided the JAR file containing the driver is properly configured, just place the JAR file in the classpath. Java developers NO longer need to explicitly load JDBC drivers using code like Class.forName() to register a JDBC driver.The DriverManager class takes care of this by automatically locating a suitable driver when the DriverManager.getConnection() method is called. This feature is backward-compatible, so no changes are needed to the existing JDBC code. 8. What is JDBC Driver interface? The JDBC Driver interface provides vendor-specific implementations of the abstract classes provided by the JDBC API. Each vendor driver must provide implementations of the java.sql.Connection,Statement,PreparedStatement, CallableStatement, ResultSet and Driver. 9. What does the connection object represents? The connection object represents communication context, i.e., all communication with database is through connection object only. 10. Can the JDBC-ODBC Bridge be used with applets? Use of the JDBC-ODBC bridge from an untrusted applet running in a browser, such as Netscape Navigator, isn't allowed. The JDBC-ODBC bridge doesn't allow untrusted code to call it for security reasons. This is good because it means that an untrusted applet that is downloaded by the browser can't circumvent Java security by calling ODBC. Remember that ODBC is native code, so once ODBC is called the Java programming language can't guarantee that a security violation won't occur. On the other hand, Pure Java JDBC drivers work well with applets. They are fully downloadable and do not require any client-side configuration. Finally, we would like to note that it is possible to use the JDBC-ODBC bridge with applets that will be run in appletviewer since appletviewer assumes that applets are trusted. In general, it is dangerous to turn applet security off, but it may be appropriate in certain controlled situations, such as for applets that will only be used in a secure intranet environment. Remember to exercise caution if you choose this option, and use an all-Java JDBC driver whenever possible to avoid security problems.

JDBC Interview Questions 11. How do I start debugging problems related to the JDBC API? A good way to find out what JDBC calls are doing is to enable JDBC tracing. The JDBC trace contains a detailed listing of the activity occurring in the system that is related to JDBC operations. If you use the DriverManager facility to establish your database connection, you use the DriverManager.setLogWriter method to enable tracing of JDBC operations. If you use a DataSource object to get a connection, you use the DataSource.setLogWriter method to enable tracing. (For pooled connections, you use the ConnectionPoolDataSource.setLogWriter method, and for connections that can participate in distributed transactions, you use the XADataSource.setLogWriter method.) 12. What is new in JDBC 2.0? With the JDBC 2.0 API, you will be able to do the following: Scroll forward and backward in a result set or move to a specific row (TYPE_SCROLL_SENSITIVE,previous(), last(), absolute(), relative(), etc.) Make updates to database tables using methods in the Java programming language instead of using SQL commands.(updateRow(), insertRow(), deleteRow(), etc.) Send multiple SQL statements to the database as a unit, or batch (addBatch(), executeBatch()) Use the new SQL3 datatypes as column values like Blob, Clob, Array, Struct, Ref. 13. How to move the cursor in scrollable resultset ? a. create a scrollable ResultSet object. Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_READ_ONLY); ResultSet srs = stmt.executeQuery("SELECT COLUMN_1, COLUMN_2 FROM TABLE_NAME"); b. use a built in methods like afterLast(), previous(), beforeFirst(), etc. to scroll the resultset. srs.afterLast(); while (srs.previous()) { String name = srs.getString("COLUMN_1"); float salary = srs.getFloat("COLUMN_2"); //... c. to find a specific row, use absolute(), relative() methods. srs.absolute(4); // cursor is on the fourth row int rowNum = srs.getRow(); // rowNum should be 4 srs.relative(-3); int rowNum = srs.getRow(); // rowNum should be 1 srs.relative(2); int rowNum = srs.getRow(); // rowNum should be 3 d. use isFirst(), isLast(), isBeforeFirst(), isAfterLast() methods to check boundary status. 14. How to update a resultset programmatically? a. create a scrollable and updatable ResultSet object. Statement stmt = con.createStatement (ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE); ResultSet uprs = stmt.executeQuery("SELECT COLUMN_1, COLUMN_2 FROM TABLE_NAME"); b. move the cursor to the specific position and use related method to update data and then, call updateRow() method. uprs.last(); uprs.updateFloat("COLUMN_2", 25.55);//update last row's data uprs.updateRow();//don't miss this method, otherwise, // the data will be lost. 15. How can I use the JDBC API to access a desktop database like Microsoft Access over the network? Most desktop databases currently require a JDBC solution that uses ODBC underneath. This is because the vendors of these database products haven't implemented all-Java JDBC drivers. The best approach is to use a commercial JDBC driver that supports ODBC and the database you want to use. See the JDBC drivers page for a list of available JDBC drivers. The JDBC-ODBC bridge from Sun's Java Software does not provide network access to desktop databases by itself. The JDBC-ODBC bridge loads ODBC as a local DLL, and typical ODBC drivers for desktop databases like Access aren't networked. The JDBC-ODBC bridge can be used together with the RMI-JDBC bridge, however, to access a desktop database like Access over the net. This RMI-JDBC-ODBC solution is free. 16. Are there any ODBC drivers that do not work with the JDBC-ODBC Bridge? Most ODBC 2.0 drivers should work with the Bridge. Since there is some variation in functionality between ODBC drivers, the functionality of the bridge may be affected. The bridge works with popular PC databases, such as Microsoft Access and FoxPro. 17. What causes the "No suitable driver" error? "No suitable driver" is an error that usually occurs during a call to the DriverManager.getConnection method. The cause can be failing to load the appropriate JDBC drivers before calling the getConnection method, or it can be specifying an invalid JDBC URL--one that isn't recognized by your JDBC driver. Your best bet is to check the documentation for your JDBC driver or contact your JDBC driver vendor if you suspect that the URL you are specifying is not being recognized by your JDBC driver. In addition, when you are using the JDBC-ODBC Bridge, this error can occur if one or more the the shared libraries needed by the Bridge cannot be loaded. If you think this is the cause, check your configuration to be sure that the shared libraries are accessible to the Bridge. 18. Why isn't the java.sql.DriverManager class being found? This problem can be caused by running a JDBC applet in a browser that supports the JDK 1.0.2, such as Netscape Navigator 3.0. The JDK 1.0.2 does not contain the JDBC API, so the DriverManager class typically isn't found by the Java virtual machine running in the browser. Here's a solution that doesn't require any additional configuration of your web clients. Remember that classes in the java.* packages cannot be downloaded by most browsers for security reasons. Because of this, many vendors of all-Java JDBC drivers supply versions of the java.sql.* classes that have been renamed to jdbc.sql.*, along with a version of their driver that uses these modified classes. If you import jdbc.sql.* in your applet code instead of java.sql.*, and add the jdbc.sql.* classes provided by your JDBC driver vendor to your applet's codebase, then all of the JDBC classes needed by the applet can be downloaded by the browser at run time, including the DriverManager class. This solution will allow your applet to work in any client browser that supports the JDK 1.0.2. Your applet will also work in browsers that support the JDK 1.1, although you may want to switch to the JDK 1.1 classes for performance reasons. Also, keep in mind that the solution outlined here is just an example and that other solutions are possible. How to insert and delete a row programmatically? (new feature in JDBC 2.0) Make sure the resultset is updatable. 1. move the cursor to the specific position. uprs.moveToCurrentRow(); 2. set value for each column. uprs.moveToInsertRow();//to set up for insert uprs.updateString("col1" "strvalue"); uprs.updateInt("col2", 5); ... 3. call inserRow() method to finish the row insert process. uprs.insertRow(); To delete a row: move to the specific position and call deleteRow() method: uprs.absolute(5); uprs.deleteRow();//delete row 5 To see the changes call refreshRow(); uprs.refreshRow(); 19. What are the two major components of JDBC? One implementation interface for database manufacturers, the other implementation interface for application and applet writers. 20. What is JDBC Driver interface? The JDBC Driver interface provides vendor-specific implementations of the abstract classes provided by the JDBC API. Each vendor driver must provide implementations of the java.sql.Connection,Statement,PreparedStatement, CallableStatement, ResultSet and Driver. 21. How do I retrieve a whole row of data at once, instead of calling an individual ResultSet.getXXX method for each column? The ResultSet.getXXX methods are the only way to retrieve data from a ResultSet object, which means that you have to make a method call for each column of a row. It is unlikely that this is the cause of a performance problem, however, because it is difficult to see how a column could be fetched without at least the cost of a function call in any scenario. We welcome input from developers on this issue. 22. What are the common tasks of JDBC? Create an instance of a JDBC driver or load JDBC drivers through jdbc.drivers Register a driver Specify a database Open a database connection Submit a query Receive results Process results Why does the ODBC driver manager return 'Data source name not found and no default driver specified Vendor: 0' This type of error occurs during an attempt to connect to a database with the bridge. First, note that the error is coming from the ODBC driver manager. This indicates that the bridge-which is a normal ODBC client-has successfully called ODBC, so the problem isn't due to native libraries not being present. In this case, it appears that the error is due to the fact that an ODBC DSN (data source name) needs to be configured on the client machine. Developers often forget to do this, thinking that the bridge will magically find the DSN they configured on their remote server machine 23. How to use JDBC to connect Microsoft Access? There is a specific tutorial at javacamp.org. Check it out. 24. What are four types of JDBC driver? Type 1 Drivers Bridge drivers such as the jdbc-odbc bridge. They rely on an intermediary such as ODBC to transfer the SQL calls to the database and also often rely on native code. It is not a serious solution for an application Type 2 Drivers Use the existing database API to communicate with the database on the client. Faster than Type 1, but need native code and require additional permissions to work in an applet. Client machine requires software to run. Type 3 Drivers JDBC-Net pure Java driver. It translates JDBC calls to a DBMS-independent network protocol, which is then translated to a DBMS protocol by a server. Flexible. Pure Java and no native code. Type 4 Drivers Native-protocol pure Java driver. It converts JDBC calls directly into the network protocol used by DBMSs. This allows a direct call from the client machine to the DBMS server. It doesn't need any special native code on the client machine. Recommended by Sun's tutorial, driver type 1 and 2 are interim solutions where direct pure Java drivers are not yet available. Driver type 3 and 4 are the preferred way to access databases using the JDBC API, because they offer all the advantages of Java technology, including automatic installation. For more info, visit Sun JDBC page 25. Which type of JDBC driver is the fastest one? JDBC Net pure Java driver(Type IV) is the fastest driver because it converts the jdbc calls into vendor specific protocol calls and it directly interacts with the database. 26. Are all the required JDBC drivers to establish connectivity to my database part of the JDK? No. There aren't any JDBC technology-enabled drivers bundled with the JDK 1.1.x or Java 2 Platform releases other than the JDBC-ODBC Bridge. So, developers need to get a driver and install it before they can connect to a database. We are considering bundling JDBC technology- enabled drivers in the future. 27. Is the JDBC-ODBC Bridge multi-threaded? No. The JDBC-ODBC Bridge does not support concurrent access from different threads. The JDBC-ODBC Bridge uses synchronized methods to serialize all of the calls that it makes to ODBC. Multi-threaded Java programs may use the Bridge, but they won't get the advantages of multi-threading. In addition, deadlocks can occur between locks held in the database and the semaphore used by the Bridge. We are thinking about removing the synchronized methods in the future. They were added originally to make things simple for folks writing Java programs that use a single-threaded ODBC driver. 28. Does the JDBC-ODBC Bridge support multiple concurrent open statements per connection? No. You can open only one Statement object per connection when you are using the JDBC-ODBC Bridge. 29. What is the query used to display all tables names in SQL Server (Query analyzer)? select * from information_schema.tables 30. Why can't I invoke the ResultSet methods afterLast and beforeFirst when the method next works? You are probably using a driver implemented for the JDBC 1.0 API. You need to upgrade to a JDBC 2.0 driver that implements scrollable result sets. Also be sure that your code has created scrollable result sets and that the DBMS you are using supports them. 31. How can I retrieve a String or other object type without creating a new object each time? Creating and garbage collecting potentially large numbers of objects (millions) unnecessarily can really hurt performance. It may be better to provide a way to retrieve data like strings using the JDBC API without always allocating a new object. We are studying this issue to see if it is an area in which the JDBC API should be improved. Stay tuned, and please send us any comments you have on this question. 32. How many types of JDBC Drivers are present and what are they? There are 4 types of JDBC Drivers Type 1: JDBC-ODBC Bridge Driver Type 2: Native API Partly Java Driver Type 3: Network protocol Driver Type 4: JDBC Net pure Java Driver 33. What is the fastest type of JDBC driver? JDBC driver performance will depend on a number of issues: (a) the quality of the driver code, (b) the size of the driver code, (c) the database server and its load, (d) network topology, (e) the number of times your request is translated to a different API. In general, all things being equal, you can assume that the more your request and response change hands, the slower it will be. This means that Type 1 and Type 3 drivers will be slower than Type 2 drivers (the database calls are make at least three translations versus two), and Type 4 drivers are the fastest (only one translation). 34. There is a method getColumnCount in the JDBC API. Is there a similar method to find the number of rows in a result set? No, but it is easy to find the number of rows. If you are using a scrollable result set, rs, you can call the methods rs.last and then rs.getRow to find out how many rows rs has. If the result is not scrollable, you can either count the rows by iterating through the result set or get the number of rows by submitting a query with a COUNT column in the SELECT clause. I would like to download the JDBC-ODBC Bridge for the Java 2 SDK, Standard Edition (formerly JDK 1.2). I'm a beginner with the JDBC API, and I would like to start with 35. the Bridge. How do I do it? The JDBC-ODBC Bridge is bundled with the Java 2 SDK, Standard Edition, so there is no need to download it separately. 36. If I use the JDBC API, do I have to use ODBC underneath? No, this is just one of many possible solutions. We recommend using a pure Java JDBC technology-enabled driver, type 3 or 4, in order to get all of the benefits of the Java programming language and the JDBC API. 37. Once I have the Java 2 SDK, Standard Edition, from Sun, what else do I need to connect to a database? You still need to get and install a JDBC technology-enabled driver that supports the database that you are using. There are many drivers available from a variety of sources. You can also try using the JDBC-ODBC Bridge if you have ODBC connectivity set up already. The Bridge comes with the Java 2 SDK, Standard Edition, and Enterprise Edition, and it doesn't require any extra setup itself. The Bridge is a normal ODBC client. Note, however, that you should use the JDBC-ODBC Bridge only for experimental prototyping or when you have no other driver available. 38. How can I know when I reach the last record in a table, since JDBC doesn't provide an EOF method? Answer1 You can use last() method of java.sql.ResultSet, if you make it scrollable. You can also use isLast() as you are reading the ResultSet. One thing to keep in mind, though, is that both methods tell you that you have reached the end of the current ResultSet, not necessarily the end of the table. SQL and RDBMSes make no guarantees about the order of rows, even from sequential SELECTs, unless you specifically use ORDER BY. Even then, that doesn't necessarily tell you the order of data in the table. Answer2 Assuming you mean ResultSet instead of Table, the usual idiom for iterating over a forward only resultset is: ResultSet rs=statement.executeQuery(...); while (rs.next()) { // Manipulate row here } 39. Where can I find info, frameworks and example source for writing a JDBC driver? There a several drivers with source available, like MM.MySQL, SimpleText Database, FreeTDS, and RmiJdbc. There is at least one free framework, the jxDBCon-Open Source JDBC driver framework. Any driver writer should also review For Driver Writers. 40. How can I create a custom RowSetMetaData object from scratch? One unfortunate aspect of RowSetMetaData for custom versions is that it is an interface. This means that implementations almost have to be proprietary. The JDBC RowSet package is the most commonly available and offers the sun.jdbc.rowset.RowSetMetaDataImpl class. After instantiation, any of the RowSetMetaData setter methods may be used. The bare minimum needed for a RowSet to function is to set the Column Count for a row and the Column Types for each column in the row. For a working code example that includes a custom RowSetMetaData, 41. How does a custom RowSetReader get called from a CachedRowSet? The Reader must be registered with the CachedRowSet using CachedRowSet.setReader(javax.sql.RowSetReader reader). Once that is done, a call to CachedRowSet.execute() will, among other things, invoke the readData method. How do I implement a RowSetReader? I want to populate a CachedRowSet myself and the documents specify that a RowSetReader should be used. The single method accepts a 42. RowSetInternal caller and returns void. What can I do in the readData method? "It can be implemented in a wide variety of ways..." and is pretty vague about what can actually be done. In general, readData() would obtain or create the data to be loaded, then use CachedRowSet methods to do the actual loading. This would usually mean inserting rows, so the code would move to the insert row, set the column data and insert rows. Then the cursor must be set to to the appropriate position. 43. How can I instantiate and load a new CachedRowSet object from a non-JDBC source? The basics are: * Create an object that implements javax.sql.RowSetReader, which loads the data. * Instantiate a CachedRowset object. * Set the CachedRowset's reader to the reader object previously created. * Invoke CachedRowset.execute(). Note that a RowSetMetaData object must be created, set up with a description of the data, and attached to the CachedRowset before loading the actual data. The following code works with the Early Access JDBC RowSet download available from the Java Developer Connection and is an expansion of one of the examples: // Independent data source CachedRowSet Example import java.sql.*; import javax.sql.*; import sun.jdbc.rowset.*; public class RowSetEx1 implements RowSetReader { CachedRowSet crs; int iCol2; RowSetMetaDataImpl rsmdi; String sCol1, sCol3; public RowSetEx1() { try { crs = new CachedRowSet(); crs.setReader(this); crs.execute(); // load from reader System.out.println( "Fetching from RowSet..."); while(crs.next()) { showTheData(); } // end while next if(crs.isAfterLast() == true) { System.out.println( "We have reached the end"); System.out.println("crs row: " + crs.getRow()); } System.out.println( "And now backwards..."); while(crs.previous()) { showTheData(); } // end while previous if(crs.isBeforeFirst() == true) { System.out.println( "We have reached the start"); } crs.first(); if(crs.isFirst() == true) { System.out.println( "We have moved to first"); } System.out.println("crs row: " + crs.getRow()); if(crs.isBeforeFirst() == false) { System.out.println( "We aren't before the first row."); } crs.last(); if(crs.isLast() == true) { System.out.println( "...and now we have moved to the last"); } System.out.println("crs row: " + crs.getRow()); if(crs.isAfterLast() == false) { System.out.println( "we aren't after the last."); } } // end try catch (SQLException ex) { System.err.println("SQLException: " + ex.getMessage()); } } // end constructor public void showTheData() throws SQLException { sCol1 = crs.getString(1); if(crs.wasNull() == false) { System.out.println("sCol1: " + sCol1); } else { System.out.println("sCol1 is null"); } iCol2 = crs.getInt(2); if (crs.wasNull() == false) { System.out.println("iCol2: " + iCol2); } else { System.out.println("iCol2 is null"); } sCol3 = crs.getString(3); if (crs.wasNull() == false) { System.out.println("sCol3: " + sCol3 + "\n" ); } else { System.out.println("sCol3 is null\n"); } } // end showTheData // RowSetReader implementation public void readData(RowSetInternal caller) throws SQLException { rsmdi = new RowSetMetaDataImpl(); rsmdi.setColumnCount(3); rsmdi.setColumnType(1, Types.VARCHAR); rsmdi.setColumnType(2, Types.INTEGER); rsmdi.setColumnType(3, Types.VARCHAR); crs.setMetaData( rsmdi ); crs.moveToInsertRow(); crs.updateString( 1, "StringCol11" ); crs.updateInt( 2, 1 ); crs.updateString( 3, "StringCol31" ); crs.insertRow(); crs.updateString( 1, "StringCol12" ); crs.updateInt( 2, 2 ); crs.updateString( 3, "StringCol32" ); crs.insertRow(); crs.moveToCurrentRow(); crs.beforeFirst(); } // end readData public static void main(String args) { new RowSetEx1(); } } // end class RowSetEx1 44. Can I set up a connection pool with multiple user IDs? The single ID we are forced to use causes problems when debugging the DBMS. Since the Connection interface ( and the underlying DBMS ) requires a specific user and password, there's not much of a way around this in a pool. While you could create a different Connection for each user, most of the rationale for a pool would then be gone. Debugging is only one of several issues that arise when using pools. However, for debugging, at least a couple of other methods come to mind. One is to log executed statements and times, which should allow you to backtrack to the user. Another method that also maintains a trail of modifications is to include user and timestamp as standard columns in your tables. In this last case, you would collect a separate user value in your program. How can I protect my database password ? I'm writing a client-side java application that will access a database over the internet. I have concerns about the security of the database passwords. The client will have access in one way or another to the class files, where the connection string to the database, including user and 45. password, is stored in as plain text. What can I do to protect my passwords? This is a very common question. Conclusion: JAD decompiles things easily and obfuscation would not help you. But you'd have the same problem with C/C++ because the connect string would still be visible in the executable. SSL JDBC network drivers fix the password sniffing problem (in MySQL 4.0), but not the decompile problem. If you have a servlet container on the web server, I would go that route (see other discussion above) then you could at least keep people from reading/destroying your mysql database. Make sure you use database security to limit that app user to the minimum tables that they need, then at least hackers will not be able to reconfigure your DBMS engine. Aside from encryption issues over the internet, it seems to me that it is bad practice to embed user ID and password into program code. One could generally see the text even without decompilation in almost any language. This would be appropriate only to a read-only database meant to be open to the world. Normally one would either force the user to enter the information or keep it in a properties file. Detecting Duplicate Keys I have a program that inserts rows in a table. My table has a column 'Name' that has a unique constraint. If the user attempts to insert a duplicate name into the table, I want to display an error message by processing the error code from the database. How can I capture this error code in a Java program? A solution that is perfectly portable to all databases, is to execute a query for checking if that unique value is present before inserting the row. The big advantage is that you can handle your error message in a very simple way, and the obvious downside is that you are going to use more time for inserting the record, but since you're working on a PK field, performance should not be so bad. You can also get this information in a portable way, and potentially avoid another database access, by capturing SQLState messages. Some databases get more specific than others, but the general code portion is 23 - "Constraint Violations". UDB2, for example, gives a specific such as 23505, while others will only give 23000. 46. What driver should I use for scalable Oracle JDBC applications? Sun recommends using the thin ( type 4 ) driver. * On single processor machines to avoid JNI overhead. * On multiple processor machines, especially running Solaris, to avoid synchronization bottlenecks. 48. How do I write Greek ( or other non-ASCII/8859-1 ) characters to a database? From the standard JDBC perspective, there is no difference between ASCII/8859-1 characters and those above 255 ( hex FF ). The reason for that is that all Java characters are in Unicode ( unless you perform/request special encoding ). Implicit in that statement is the presumption that the data store can handle characters outside the hex FF range or interprets different character sets appropriately. That means either: * The OS, application and database use the same code page and character set. For example, a Greek version of NT with the DBMS set to the default OS encoding. * The DBMS has I18N support for Greek ( or other language ), regardless of OS encoding. This has been the most common for production quality databases, although support varies. Particular DBMSes may allow setting the encoding/code page/CCSID at the database, table or even column level. There is no particular standard for provided support or methods of setting the encoding. You have to check the DBMS documentation and set up the table properly. * The DBMS has I18N support in the form of Unicode capability. This would handle any Unicode characters and therefore any language defined in the Unicode standard. Again, set up is proprietary. 49. How can I insert images into a Mysql database? This code snippet shows the basics: File file = new File(fPICTURE); FileInputStream fis = new FileInputStream(file); PreparedStatement ps = ConrsIn.prepareStatement("insert into dbPICTURE values (?,?)"); // ***use as many ??? as you need to insert in the exact order*** ps.setString(1,file.getName()); ps.setBinaryStream(2,fis,(int)file.length()); ps.close(); fis.close(); 50. Is possible to open a connection to a database with exclusive mode with JDBC? I think you mean "lock a table in exclusive mode". You cannot open a connection with exclusive mode. Depending on your database engine, you can lock tables or rows in exclusive mode. In Oracle you would create a statement st and run st.execute("lock table mytable in exclusive mode"); Then when you are finished with the table, execute the commit to unlock the table. Mysql, Informix and SQLServer all have a slightly different syntax for this function, so you'll have to change it depending on your database. But they can all be done with execute(). 51. What are the standard isolation levels defined by JDBC? The values are defined in the class java.sql.Connection and are: * TRANSACTION_NONE * TRANSACTION_READ_COMMITTED * TRANSACTION_READ_UNCOMMITTED * TRANSACTION_REPEATABLE_READ * TRANSACTION_SERIALIZABLE Update fails without blank padding. Although a particular row is present in the database for a given key, executeUpdate() shows 0 rows updated and, in fact, the table is not updated. If I pad the Key with spaces for the column length (e.g. if the key column is 20 characters long, and key is msgID, length 6, I pad it with 14 spaces), 52. the update then works!!! Is there any solution to this problem without padding? In the SQL standard, CHAR is a fixed length data type. In many DBMSes ( but not all), that means that for a WHERE clause to match, every character must match, including size and trailing blanks. As Alessandro indicates, defining CHAR columns to be VARCHAR is the most general answer. 53. What isolation level is used by the DBMS when inserting, updating and selecting rows from a database? The answer depends on both your code and the DBMS. If the program does not explicitly set the isolation level, the DBMS default is used. You can determine the default using DatabaseMetaData.getDefaultTransactionIsolation() and the level for the current Connection with Connection.getTransactionIsolation(). If the default is not appropriate for your transaction, change it with Connection.setTransactionIsolation(int level). 54. How can I determine the isolation levels supported by my DBMS? Use DatabaseMetaData.supportsTransactionIsolationLevel(int level). Connecting to a database through the Proxy I want to connect to remote database using a program that is running in the local network behind the proxy. Is that possible? I assume that your proxy is set to accept http requests only on port 80. If you want to have a local class behind the proxy connect to the database for you, then you need a servlet/JSP to receive an HTTP request and use the local class to connect to the database and send the response back to the client. You could also use RMI where your remote computer class that connects to the database acts as a remote server that talks RMI with the clients. if you implement this, then you will need to tunnel RMI through HTTP which is not that hard. In summary, either have a servlet/JSP take HTTP requests, instantiate a class that handles database connections and send HTTP response back to the client or have the local class deployed as RMI server and send requests to it using RMI. 55. How do I receive a ResultSet from a stored procedure? Stored procedures can return a result parameter, which can be a result set. For a discussion of standard JDBC syntax for dealing with result, IN, IN/OUT and OUT parameters, see Stored Procedures. 56. How can I write to the log used by DriverManager and JDBC drivers? The simplest method is to use DriverManager.println(String message), which will write to the current log. 57. How can I get or redirect the log used by DriverManager and JDBC drivers? As of JDBC 2.0, use DriverManager.getLogWriter() and DriverManager.setLogWriter(PrintWriter out). Prior to JDBC 2.0, the DriverManager methods getLogStream() and setLogStream(PrintStream out) were used. These are now deprecated. 58. What does it mean to "materialize" data? This term generally refers to Array, Blob and Clob data which is referred to in the database via SQL locators "Materializing" the data means to return the actual data pointed to by the Locator. For Arrays, use the various forms of getArray() and getResultSet(). For Blobs, use getBinaryStream() or getBytes(long pos, int length). For Clobs, use getAsciiStream() or getCharacterStream(). 59. Why do I have to reaccess the database for Array, Blob, and Clob data? Most DBMS vendors have implemented these types via the SQL3 Locator type Some rationales for using Locators rather than directly returning the data can be seen most clearly with the Blob type. By definition, a Blob is an arbitrary set of binary data. It could be anything; the DBMS has no knowledge of what the data represents. Notice that this effectively demolishes data independence, because applications must now be aware of what the Blob data actually represents. Let's assume an employee table that includes employee images as Blobs. Say we have an inquiry program that presents multiple employees with department and identification information. To see all of the data for a specific employee, including the image, the summary row is selected and another screen appears. It is only at this pont that the application needs the specific image. It would be very wasteful and time consuming to bring down an entire employee page of images when only a few would ever be selected in a given run. Now assume a general interactive SQL application. A query is issued against the employee table. Because the image is a Blob, the application has no idea what to do with the data, so why bring it down, killing performance along the way, in a long running operation? Clearly this is not helpful in those applications that need the data everytime, but these and other considerations have made the most general sense to DBMS vendors. 60. What is an SQL Locator? A Locator is an SQL3 data type that acts as a logical pointer to data that resides on a database server. Read "logical pointer" here as an identifier the DBMS can use to locate and manipulate the data. A Locator allows some manipulation of the data on the server. While the JDBC specification does not directly address Locators, JDBC drivers typically use Locators under the covers to handle Array, Blob, and Clob data types. 61. How do I set properties for a JDBC driver and where are the properties stored? A JDBC driver may accept any number of properties to tune or optimize performance for the specific driver. There is no standard, other than user and password, for what these properties should be. Therefore, the developer is dependent on the driver documentation to automatically pass properties. For a standard dynamic method that can be used to solicit user input for properties, see What properties should I supply to a database driver in order to connect to a database? In addition, a driver may specify its own method of accepting properties. Many do this via appending the property to the JDBC Database URL. However, a JDBC Compliant driver should implement the connect(String url, Properties info) method. This is generally invoked through DriverManager.getConnection(String url, Properties info). The passed properties are ( probably ) stored in variables in the Driver instance. This, again, is up to the driver, but unless there is some sort of driver setup, which is unusual, only default values are remembered over multiple instantiations. 62. What is the JDBC syntax for using a literal or variable in a standard Statement? First, it should be pointed out that PreparedStatement handles many issues for the developer and normally should be preferred over a standard Statement. Otherwise, the JDBC syntax is really the same as SQL syntax. One problem that often affects newbies ( and others ) is that SQL, like many languages, requires quotes around character ( read "String" for Java ) values to distinguish from numerics. So the clause: "WHERE myCol = " + myVal is perfectly valid and works for numerics, but will fail when myVal is a String. Instead use: "WHERE myCol = '" + myVal + "'" if myVal equals "stringValue", the clause works out to: WHERE myCol = 'stringValue' You can still encounter problems when quotes are embedded in the value, which, again, a PreparedStatement will handle for you. 63. How do I check in my code whether a maximum limit of database connections have been reached? Use DatabaseMetaData.getMaxConnections() and compare to the number of connections currently open. Note that a return value of zero can mean unlimited or, unfortunately, unknown. Of course, driverManager.getConnection() will throw an exception if a Connection can not be obtained. 64. Why do I get UnsatisfiedLinkError when I try to use my JDBC driver? The first thing is to be sure that this does not occur when running non-JDBC apps. If so, there is a faulty JDK/JRE installation. If it happens only when using JDBC, then it's time to check the documentation that came with the driver or the driver/DBMS support. JDBC driver types 1 through 3 have some native code aspect and typically require some sort of client install. Along with the install, various environment variables and path or classpath settings must be in place. Because the requirements and installation procedures vary with the provider, there is no reasonable way to provide details here. A type 4 driver, on the other hand, is pure Java and should never exhibit this problem. The trade off is that a type 4 driver is usually slower. Many connections from an Oracle8i pooled connection returns statement closed. I am using import oracle.jdbc.pool.* with thin driver. If I test with many simultaneous connections, I get an SQLException that the statement is closed. ere is an example of concurrent operation of pooled connections from the OracleConnectionPoolDataSource. There is an executable for kicking off threads, a DataSource, and the workerThread. The Executable Member package package6; /** * package6.executableTester * */ public class executableTester { protected static myConnectionPoolDataSource dataSource = null; static int i = 0; /** * Constructor */ public executableTester() throws java.sql.SQLException { } /** * main * @param args */ public static void main(String args) { try{ dataSource = new myConnectionPoolDataSource(); } catch ( Exception ex ){ ex.printStackTrace(); } while ( i++ try{ workerClass worker = new workerClass(); worker.setThreadNumber( i ); worker.setConnectionPoolDataSource ( dataSource.getConnectionPoolDataSource() ); worker.start(); System.out.println( "Started Thread#"+i ); } catch ( Exception ex ){ ex.printStackTrace(); } } } } The DataSource Member package package6; import oracle.jdbc.pool.*; /** * package6.myConnectionPoolDataSource. * */ public class myConnectionPoolDataSource extends Object { protected OracleConnectionPoolDataSource ocpds = null; /** * Constructor */ public myConnectionPoolDataSource() throws java.sql.SQLException { // Create a OracleConnectionPoolDataSource instance ocpds = new OracleConnectionPoolDataSource(); // Set connection parameters ocpds.setURL("jdbc:oracle:oci8:@mydb"); ocpds.setUser("scott"); ocpds.setPassword("tiger"); } public OracleConnectionPoolDataSource getConnectionPoolDataSource() { return ocpds; } } The Worker Thread Member package package6; import oracle.jdbc.pool.*; import java.sql.*; import javax.sql.*; /** * package6.workerClass . * */ public class workerClass extends Thread { protected OracleConnectionPoolDataSource ocpds = null; protected PooledConnection pc = null; protected Connection conn = null; protected int threadNumber = 0; /** * Constructor */ public workerClass() { } public void doWork( ) throws SQLException { // Create a pooled connection pc = ocpds.getPooledConnection(); // Get a Logical connection conn = pc.getConnection(); // Create a Statement Statement stmt = conn.createStatement (); // Select the ENAME column from the EMP table ResultSet rset = stmt.executeQuery ("select ename from emp"); // Iterate through the result and print the employee names while (rset.next ()) // System.out.println (rset.getString (1)); ; // Close the RseultSet rset.close(); rset = null; // Close the Statement stmt.close(); stmt = null; // Close the logical connection conn.close(); conn = null; // Close the pooled connection pc.close(); pc = null; System.out.println( "workerClass.thread# "+threadNumber+" completed.."); } public void setThreadNumber( int assignment ){ threadNumber = assignment; } public void setConnectionPoolDataSource (OracleConnectionPoolDataSource x){ ocpds = x; } public void run() { try{ doWork(); } catch ( Exception ex ){ ex.printStackTrace(); } } } The OutPut Produced Started Thread#1 Started Thread#2 Started Thread#3 Started Thread#4 Started Thread#5 Started Thread#6 Started Thread#7 Started Thread#8 Started Thread#9 Started Thread#10 workerClass.thread# 1 completed.. workerClass.thread# 10 completed.. workerClass.thread# 3 completed.. workerClass.thread# 8 completed.. workerClass.thread# 2 completed.. workerClass.thread# 9 completed.. workerClass.thread# 5 completed.. workerClass.thread# 7 completed.. workerClass.thread# 6 completed.. workerClass.thread# 4 completed.. The oracle.jdbc.pool.OracleConnectionCacheImpl class is another subclass of the oracle.jdbc.pool.OracleDataSource which should also be looked over, that is what you really what to use. Here is a similar example that uses the oracle.jdbc.pool.OracleConnectionCacheImpl. The general construct is the same as the first example but note the differences in workerClass1 where some statements have been commented ( basically a clone of workerClass from previous example ). The Executable Member package package6; import java.sql.*; import javax.sql.*; import oracle.jdbc.pool.*; /** * package6.executableTester2 * */ public class executableTester2 { static int i = 0; protected static myOracleConnectCache connectionCache = null; /** * Constructor */ public executableTester2() throws SQLException { } /** * main * @param args */ public static void main(String args) { OracleConnectionPoolDataSource dataSource = null; try{ dataSource = new OracleConnectionPoolDataSource() ; connectionCache = new myOracleConnectCache( dataSource ); } catch ( Exception ex ){ ex.printStackTrace(); } while ( i++ try{ workerClass1 worker = new workerClass1(); worker.setThreadNumber( i ); worker.setConnection( connectionCache.getConnection() ); worker.start(); System.out.println( "Started Thread#"+i ); } catch ( Exception ex ){ ex.printStackTrace(); } } } protected void finalize(){ try{ connectionCache.close(); } catch ( SQLException x) { x.printStackTrace(); } this.finalize(); } } The ConnectCacheImpl Member package package6; import javax.sql.ConnectionPoolDataSource; import oracle.jdbc.pool.*; import oracle.jdbc.driver.*; import java.sql.*; import java.sql.SQLException; /** * package6.myOracleConnectCache * */ public class myOracleConnectCache extends OracleConnectionCacheImpl { /** * Constructor */ public myOracleConnectCache( ConnectionPoolDataSource x) throws SQLException { initialize(); } public void initialize() throws SQLException { setURL("jdbc:oracle:oci8:@myDB"); setUser("scott"); setPassword("tiger"); // // prefab 2 connection and only grow to 4 , setting these // to various values will demo the behavior //clearly, if it is not // obvious already // setMinLimit(2); setMaxLimit(4); } } The Worker Thread Member package package6; import oracle.jdbc.pool.*; import java.sql.*; import javax.sql.*; /** * package6.workerClass1 * */ public class workerClass1 extends Thread { // protected OracleConnectionPoolDataSource ocpds = null; // protected PooledConnection pc = null; protected Connection conn = null; protected int threadNumber = 0; /** * Constructor */ public workerClass1() { } public void doWork( ) throws SQLException { // Create a pooled connection // pc = ocpds.getPooledConnection(); // Get a Logical connection // conn = pc.getConnection(); // Create a Statement Statement stmt = conn.createStatement (); // Select the ENAME column from the EMP table ResultSet rset = stmt.executeQuery ("select ename from EMP"); // Iterate through the result // and print the employee names while (rset.next ()) // System.out.println (rset.getString (1)); ; // Close the RseultSet rset.close(); rset = null; // Close the Statement stmt.close(); stmt = null; // Close the logical connection conn.close(); conn = null; // Close the pooled connection // pc.close(); // pc = null; System.out.println( "workerClass1.thread# "+threadNumber+" completed.."); } public void setThreadNumber( int assignment ){ threadNumber = assignment; } // public void setConnectionPoolDataSource (OracleConnectionPoolDataSource x){ // ocpds = x; // } public void setConnection( Connection assignment ){ conn = assignment; } public void run() { try{ doWork(); } catch ( Exception ex ){ ex.printStackTrace(); } } } The OutPut Produced Started Thread#1 Started Thread#2 workerClass1.thread# 1 completed.. workerClass1.thread# 2 completed.. Started Thread#3 Started Thread#4 Started Thread#5 workerClass1.thread# 5 completed.. workerClass1.thread# 4 completed.. workerClass1.thread# 3 completed.. Started Thread#6 Started Thread#7 Started Thread#8 Started Thread#9 workerClass1.thread# 8 completed.. workerClass1.thread# 9 completed.. workerClass1.thread# 6 completed.. workerClass1.thread# 7 completed.. Started Thread#10 workerClass1.thread# 10 completed.. 65. DB2 Universal claims to support JDBC 2.0, But I can only get JDBC 1.0 functionality. What can I do? DB2 Universal defaults to the 1.0 driver. You have to run a special program to enable the 2.0 driver and JDK support. For detailed information, see Setting the Environment in Building Java Applets and Applications. The page includes instructions for most supported platforms. 66. How do I disallow NULL values in a table? Null capability is a column integrity constraint, normally applied at table creation time. Note that some databases won't allow the constraint to be applied after table creation. Most databases allow a default value for the column as well. The following SQL statement displays the NOT NULL constraint: CREATE TABLE CoffeeTable ( Type VARCHAR(25) NOT NULL, Pounds INTEGER NOT NULL, Price NUMERIC(5, 2) NOT NULL ) 67. How to get a field's value with ResultSet.getxxx when it is a NULL? I have tried to execute a typical SQL statement: select * from T-name where (clause); But an error gets thrown because there are some NULL fields in the table. You should not get an error/exception just because of null values in various columns. This sounds like a driver specific problem and you should first check the original and any chained exceptions to determine if another problem exists. In general, one may retrieve one of three values for a column that is null, depending on the data type. For methods that return objects, null will be returned; for numeric ( get Byte(), getShort(), getInt(), getLong(), getFloat(), and getDouble() ) zero will be returned; for getBoolean() false will be returned. To find out if the value was actually NULL, use ResultSet.wasNull() before invoking another getXXX method. 68. How do I insert/update records with some of the columns having NULL value? Use either of the following PreparedStatement methods: public void setNull(int parameterIndex, int sqlType) throws SQLException public void setNull(int paramIndex, int sqlType, String typeName) throws SQLException These methods assume that the columns are nullable. In this case, you can also just omit the columns in an INSERT statement; they will be automatically assigned null values. Is there a way to find the primary key(s) for an Access Database table? Sun's JDBC-ODBC driver does not implement the getPrimaryKeys() method for the DatabaseMetaData Objects. // Use meta.getIndexInfo() will //get you the PK index. Once // you know the index, retrieve its column name DatabaseMetaData meta = con.getMetaData(); String key_colname = null; // get the primary key information rset = meta.getIndexInfo(null,null, table_name, true,true); while( rset.next()) { String idx = rset.getString(6); if( idx != null) { //Note: index "PrimaryKey" is Access DB specific // other db server has diff. index syntax. if( idx.equalsIgnoreCase("PrimaryKey")) { key_colname = rset.getString(9); setPrimaryKey( key_colname ); } } } 69. Why can't Tomcat find my Oracle JDBC drivers in classes111.zip? TOMCAT 4.0.1 on NT4 throws the following exception when I try to connect to Oracle DB from JSP. javax.servlet.ServletException : oracle.jdbc.driver.OracleDriver java.lang.ClassNotFoundException: oracle:jdbc:driver:OracleDriver But, the Oracle JDBC driver ZIP file (classes111.zip)is available in the system classpath. Copied the Oracle Driver class file (classes111.zip) in %TOMCAT_Home - Home%\lib directory and renamed it to classess111.jar. Able to connect to Oracle DB from TOMCAT 4.01 via Oracle JDBC-Thin Driver. I have an application that queries a database and retrieves the results into a JTable. This is the code in the model that seems to be taken forever to execute, especially for a large result set: while ( myRs.next() ) { Vector newRow =new Vector(); for ( int i=1;i Read the full article
0 notes
Text
Sql Meeting Questions
If click is made use of in cross sign up with then the question will certainly function like an INNER SIGN UP WITH. A ONE-OF-A-KIND restraint makes sure that all values in a column are different. https://is.gd/snW9y3 offers uniqueness for the column and also assists identify each row uniquely. It promotes you to manipulate the information saved in the tables by using relational drivers. Examples of the relational data source management system are Microsoft Accessibility, MySQL, SQLServer, Oracle database, etc. Unique crucial constraint distinctly identifies each record in the database. This vital gives originality for the column or collection of columns.

A database arrow is a control structure that allows for traversal of documents in a database. Cursors, furthermore, facilitates handling after traversal, such as retrieval, enhancement as well as removal of database documents. They can be considered as a reminder to one row in a collection of rows. An pen names is a attribute of SQL that is supported by most, otherwise all, RDBMSs. It is a short-term name appointed to the table or table column for the objective of a certain SQL query. In addition, aliasing can be utilized as an obfuscation method to secure the real names of data source areas. A table pen name is additionally called a correlation name. trainees; Non-unique indexes, on the other hand, are not made use of to apply restrictions on the tables with which they are connected. Instead, non-unique indexes are made use of exclusively to enhance question efficiency by preserving a sorted order of data worths that are utilized frequently. A data source index is a data structure that offers fast lookup of information in a column or columns of a table. It boosts the speed of operations accessing data from a data source table at the expense of added writes and also memory to preserve the index data structure. Candidates are most likely to be asked standard SQL interview questions to progress degree SQL questions depending on their experience and numerous other elements. The listed below list covers all the SQL interview concerns for betters as well as SQL meeting questions for skilled level prospects as well as some SQL query meeting questions. SQL condition helps to limit the outcome set by supplying a condition to the inquiry. click to find out more aids to filter the rows from the entire collection of records. Our SQL Interview Questions blog is the one-stop resource where you can enhance your meeting prep work. It has a collection of top 65 concerns which an job interviewer intends to ask during an interview process. Unlike main vital, there can be multiple unique restraints specified per table. The code phrase structure for UNIQUE is quite similar to that of PRIMARY SECRET and also can be made use of reciprocally. Most modern database management systems like MySQL, Microsoft SQL Server, Oracle, IBM DB2 as well as Amazon.com Redshift are based upon RDBMS. SQL clause is specified to limit the outcome established by giving condition to the inquiry. This usually filters some rows from the entire collection of records. Cross sign up with can be defined as a cartesian product of the two tables included in the join. The table after join contains the very same variety of rows as in the cross-product of number of rows in the two tables. Self-join is readied to be query used to contrast to itself. This is utilized to contrast worths in a column with other values in the exact same column in the very same table. PEN NAME ES can be used for the very same table contrast. This is a keyword phrase made use of to inquire information from even more tables based on the partnership in between the fields of the tables. A international key is one table which can be connected to the main secret of another table. Relationship needs to be created in between 2 tables by referencing foreign trick with the primary key of one more table. A One-of-a-kind crucial restriction distinctively recognized each record in the database. It starts with the basic SQL interview questions and also later remains to innovative concerns based on your discussions as well as responses. These SQL Meeting questions will certainly aid you with different know-how degrees to gain the optimum benefit from this blog. A table consists of a defined variety of the column called areas yet can have any number of rows which is called the record. So, the columns in the table of the data source are known as the areas as well as they represent the attribute or features of the entity in the document. Rows here refers to the tuples which stand for the simple data thing and columns are the quality of the information items existing in particular row. Columns can classify as vertical, and Rows are horizontal. There is offered sql interview questions and also solutions that has actually been asked in numerous firms. For PL/SQL interview questions, see our next page. A view can have data from one or more tables incorporated, and also it depends on the partnership. Views are used to use safety device in the SQL Web server. you can check here of the data source is the searchable things we can make use of a inquiry to search the consider as we make use of for the table. RDBMS represents Relational Database Administration System. It is a data source administration system based upon a relational version. RDBMS shops the information right into the collection of tables and also links those table making use of the relational operators quickly whenever needed. This gives originality for the column or set of columns. A table is a collection of information that are arranged in a version with Columns and Rows. Columns can be classified as upright, as well as Rows are straight. A table has actually specified number of column called areas but can have any kind of number of rows which is called document. RDBMS keep the information right into the collection of tables, which is connected by common areas in between the columns of the table. It likewise provides relational operators to manipulate the information saved right into the tables. Following is a curated checklist of SQL meeting inquiries and answers, which are likely to be asked during the SQL meeting.
0 notes