#datasource servlet
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is funded by 13 investors.
Text
Accessing Component Policies in AEM via ResourceType-Based Servlet
Problem Statement: How can I leverage component policies chosen at the template level to manage the dropdown-based selection? Introduction: AEM has integrated component policies as a pivotal element of the editable template feature. This functionality empowers both authors and developers to provide options for configuring the comprehensive behavior of fully-featured components, including…
View On WordPress
#AEM#component behavior#component policies#datasource#datasource servlet#dialog-level listener#dropdown selection#dynamic adjustment#electronic devices#frontend developers#ResourceType-Based Servlet#Servlet#template level#user experience
0 notes
Text
300+ TOP JDBC Interview Questions and Answers
JDBC Interview Questions for freshers experienced
1. What is the JDBC? Java Database Connectivity (JDBC) is a standard Java API to interact with relational databases form Java. JDBC has set of classes and interfaces which can use from Java application and talk to database without learning RDBMS details and using Database Specific JDBC Drivers. 2. What are the new features added to JDBC 4.0? The major features added in JDBC 4.0 include : Auto-loading of JDBC driver class Connection management enhancements Support for RowId SQL type DataSet implementation of SQL using Annotations SQL exception handling enhancements SQL XML support 3. Explain Basic Steps in writing a Java program using JDBC? JDBC makes the interaction with RDBMS simple and intuitive. When a Java application needs to access database : Load the RDBMS specific JDBC driver because this driver actually communicates with the database (Incase of JDBC 4.0 this is automatically loaded). Open the connection to database which is then used to send SQL statements and get results back. Create JDBC Statement object. This object contains SQL query. Execute statement which returns resultset(s). ResultSet contains the tuples of database table as a result of SQL query. Process the result set. Close the connection. 4. Exaplain the JDBC Architecture. The JDBC Architecture consists of two layers:

JDBC Architecture The JDBC API, which provides the application-to-JDBC Manager connection. The JDBC Driver API, which supports the JDBC Manager-to-Driver Connection. The JDBC API uses a driver manager and database-specific drivers to provide transparent connectivity to heterogeneous databases. The JDBC driver manager ensures that the correct driver is used to access each data source. The driver manager is capable of supporting multiple concurrent drivers connected to multiple heterogeneous databases. The location of the driver manager with respect to the JDBC drivers and the Java application is shown in Figure 1. 5. What are the main components of JDBC ? The life cycle of a servlet consists of the following phases: DriverManager: Manages a list of database drivers. Matches connection requests from the java application with the proper database driver using communication subprotocol. The first driver that recognizes a certain subprotocol under JDBC will be used to establish a database Connection. Driver: The database communications link, handling all communication with the database. Normally, once the driver is loaded, the developer need not call it explicitly. Connection: Interface with all methods for contacting a database.The connection object represents communication context, i.e., all communication with database is through connection object only. Statement : Encapsulates an SQL statement which is passed to the database to be parsed, compiled, planned and executed. ResultSet: The ResultSet represents set of rows retrieved due to query execution. 6. How the JDBC application works? A JDBC application can be logically divided into two layers:

JDBC application works Driver layer Application layer Driver layer consists of DriverManager class and the available JDBC drivers. The application begins with requesting the DriverManager for the connection. An appropriate driver is choosen and is used for establishing the connection. This connection is given to the application which falls under the application layer. The application uses this connection to create Statement kind of objects, through which SQL commands are sent to backend and obtain the results. 7. How do I load a database driver with JDBC 4.0 / Java 6? Provided the JAR file containing the driver is properly configured, just place the JAR file in the classpath. Java developers NO longer need to explicitly load JDBC drivers using code like Class.forName() to register a JDBC driver.The DriverManager class takes care of this by automatically locating a suitable driver when the DriverManager.getConnection() method is called. This feature is backward-compatible, so no changes are needed to the existing JDBC code. 8. What is JDBC Driver interface? The JDBC Driver interface provides vendor-specific implementations of the abstract classes provided by the JDBC API. Each vendor driver must provide implementations of the java.sql.Connection,Statement,PreparedStatement, CallableStatement, ResultSet and Driver. 9. What does the connection object represents? The connection object represents communication context, i.e., all communication with database is through connection object only. 10. Can the JDBC-ODBC Bridge be used with applets? Use of the JDBC-ODBC bridge from an untrusted applet running in a browser, such as Netscape Navigator, isn't allowed. The JDBC-ODBC bridge doesn't allow untrusted code to call it for security reasons. This is good because it means that an untrusted applet that is downloaded by the browser can't circumvent Java security by calling ODBC. Remember that ODBC is native code, so once ODBC is called the Java programming language can't guarantee that a security violation won't occur. On the other hand, Pure Java JDBC drivers work well with applets. They are fully downloadable and do not require any client-side configuration. Finally, we would like to note that it is possible to use the JDBC-ODBC bridge with applets that will be run in appletviewer since appletviewer assumes that applets are trusted. In general, it is dangerous to turn applet security off, but it may be appropriate in certain controlled situations, such as for applets that will only be used in a secure intranet environment. Remember to exercise caution if you choose this option, and use an all-Java JDBC driver whenever possible to avoid security problems.

JDBC Interview Questions 11. How do I start debugging problems related to the JDBC API? A good way to find out what JDBC calls are doing is to enable JDBC tracing. The JDBC trace contains a detailed listing of the activity occurring in the system that is related to JDBC operations. If you use the DriverManager facility to establish your database connection, you use the DriverManager.setLogWriter method to enable tracing of JDBC operations. If you use a DataSource object to get a connection, you use the DataSource.setLogWriter method to enable tracing. (For pooled connections, you use the ConnectionPoolDataSource.setLogWriter method, and for connections that can participate in distributed transactions, you use the XADataSource.setLogWriter method.) 12. What is new in JDBC 2.0? With the JDBC 2.0 API, you will be able to do the following: Scroll forward and backward in a result set or move to a specific row (TYPE_SCROLL_SENSITIVE,previous(), last(), absolute(), relative(), etc.) Make updates to database tables using methods in the Java programming language instead of using SQL commands.(updateRow(), insertRow(), deleteRow(), etc.) Send multiple SQL statements to the database as a unit, or batch (addBatch(), executeBatch()) Use the new SQL3 datatypes as column values like Blob, Clob, Array, Struct, Ref. 13. How to move the cursor in scrollable resultset ? a. create a scrollable ResultSet object. Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_READ_ONLY); ResultSet srs = stmt.executeQuery("SELECT COLUMN_1, COLUMN_2 FROM TABLE_NAME"); b. use a built in methods like afterLast(), previous(), beforeFirst(), etc. to scroll the resultset. srs.afterLast(); while (srs.previous()) { String name = srs.getString("COLUMN_1"); float salary = srs.getFloat("COLUMN_2"); //... c. to find a specific row, use absolute(), relative() methods. srs.absolute(4); // cursor is on the fourth row int rowNum = srs.getRow(); // rowNum should be 4 srs.relative(-3); int rowNum = srs.getRow(); // rowNum should be 1 srs.relative(2); int rowNum = srs.getRow(); // rowNum should be 3 d. use isFirst(), isLast(), isBeforeFirst(), isAfterLast() methods to check boundary status. 14. How to update a resultset programmatically? a. create a scrollable and updatable ResultSet object. Statement stmt = con.createStatement (ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE); ResultSet uprs = stmt.executeQuery("SELECT COLUMN_1, COLUMN_2 FROM TABLE_NAME"); b. move the cursor to the specific position and use related method to update data and then, call updateRow() method. uprs.last(); uprs.updateFloat("COLUMN_2", 25.55);//update last row's data uprs.updateRow();//don't miss this method, otherwise, // the data will be lost. 15. How can I use the JDBC API to access a desktop database like Microsoft Access over the network? Most desktop databases currently require a JDBC solution that uses ODBC underneath. This is because the vendors of these database products haven't implemented all-Java JDBC drivers. The best approach is to use a commercial JDBC driver that supports ODBC and the database you want to use. See the JDBC drivers page for a list of available JDBC drivers. The JDBC-ODBC bridge from Sun's Java Software does not provide network access to desktop databases by itself. The JDBC-ODBC bridge loads ODBC as a local DLL, and typical ODBC drivers for desktop databases like Access aren't networked. The JDBC-ODBC bridge can be used together with the RMI-JDBC bridge, however, to access a desktop database like Access over the net. This RMI-JDBC-ODBC solution is free. 16. Are there any ODBC drivers that do not work with the JDBC-ODBC Bridge? Most ODBC 2.0 drivers should work with the Bridge. Since there is some variation in functionality between ODBC drivers, the functionality of the bridge may be affected. The bridge works with popular PC databases, such as Microsoft Access and FoxPro. 17. What causes the "No suitable driver" error? "No suitable driver" is an error that usually occurs during a call to the DriverManager.getConnection method. The cause can be failing to load the appropriate JDBC drivers before calling the getConnection method, or it can be specifying an invalid JDBC URL--one that isn't recognized by your JDBC driver. Your best bet is to check the documentation for your JDBC driver or contact your JDBC driver vendor if you suspect that the URL you are specifying is not being recognized by your JDBC driver. In addition, when you are using the JDBC-ODBC Bridge, this error can occur if one or more the the shared libraries needed by the Bridge cannot be loaded. If you think this is the cause, check your configuration to be sure that the shared libraries are accessible to the Bridge. 18. Why isn't the java.sql.DriverManager class being found? This problem can be caused by running a JDBC applet in a browser that supports the JDK 1.0.2, such as Netscape Navigator 3.0. The JDK 1.0.2 does not contain the JDBC API, so the DriverManager class typically isn't found by the Java virtual machine running in the browser. Here's a solution that doesn't require any additional configuration of your web clients. Remember that classes in the java.* packages cannot be downloaded by most browsers for security reasons. Because of this, many vendors of all-Java JDBC drivers supply versions of the java.sql.* classes that have been renamed to jdbc.sql.*, along with a version of their driver that uses these modified classes. If you import jdbc.sql.* in your applet code instead of java.sql.*, and add the jdbc.sql.* classes provided by your JDBC driver vendor to your applet's codebase, then all of the JDBC classes needed by the applet can be downloaded by the browser at run time, including the DriverManager class. This solution will allow your applet to work in any client browser that supports the JDK 1.0.2. Your applet will also work in browsers that support the JDK 1.1, although you may want to switch to the JDK 1.1 classes for performance reasons. Also, keep in mind that the solution outlined here is just an example and that other solutions are possible. How to insert and delete a row programmatically? (new feature in JDBC 2.0) Make sure the resultset is updatable. 1. move the cursor to the specific position. uprs.moveToCurrentRow(); 2. set value for each column. uprs.moveToInsertRow();//to set up for insert uprs.updateString("col1" "strvalue"); uprs.updateInt("col2", 5); ... 3. call inserRow() method to finish the row insert process. uprs.insertRow(); To delete a row: move to the specific position and call deleteRow() method: uprs.absolute(5); uprs.deleteRow();//delete row 5 To see the changes call refreshRow(); uprs.refreshRow(); 19. What are the two major components of JDBC? One implementation interface for database manufacturers, the other implementation interface for application and applet writers. 20. What is JDBC Driver interface? The JDBC Driver interface provides vendor-specific implementations of the abstract classes provided by the JDBC API. Each vendor driver must provide implementations of the java.sql.Connection,Statement,PreparedStatement, CallableStatement, ResultSet and Driver. 21. How do I retrieve a whole row of data at once, instead of calling an individual ResultSet.getXXX method for each column? The ResultSet.getXXX methods are the only way to retrieve data from a ResultSet object, which means that you have to make a method call for each column of a row. It is unlikely that this is the cause of a performance problem, however, because it is difficult to see how a column could be fetched without at least the cost of a function call in any scenario. We welcome input from developers on this issue. 22. What are the common tasks of JDBC? Create an instance of a JDBC driver or load JDBC drivers through jdbc.drivers Register a driver Specify a database Open a database connection Submit a query Receive results Process results Why does the ODBC driver manager return 'Data source name not found and no default driver specified Vendor: 0' This type of error occurs during an attempt to connect to a database with the bridge. First, note that the error is coming from the ODBC driver manager. This indicates that the bridge-which is a normal ODBC client-has successfully called ODBC, so the problem isn't due to native libraries not being present. In this case, it appears that the error is due to the fact that an ODBC DSN (data source name) needs to be configured on the client machine. Developers often forget to do this, thinking that the bridge will magically find the DSN they configured on their remote server machine 23. How to use JDBC to connect Microsoft Access? There is a specific tutorial at javacamp.org. Check it out. 24. What are four types of JDBC driver? Type 1 Drivers Bridge drivers such as the jdbc-odbc bridge. They rely on an intermediary such as ODBC to transfer the SQL calls to the database and also often rely on native code. It is not a serious solution for an application Type 2 Drivers Use the existing database API to communicate with the database on the client. Faster than Type 1, but need native code and require additional permissions to work in an applet. Client machine requires software to run. Type 3 Drivers JDBC-Net pure Java driver. It translates JDBC calls to a DBMS-independent network protocol, which is then translated to a DBMS protocol by a server. Flexible. Pure Java and no native code. Type 4 Drivers Native-protocol pure Java driver. It converts JDBC calls directly into the network protocol used by DBMSs. This allows a direct call from the client machine to the DBMS server. It doesn't need any special native code on the client machine. Recommended by Sun's tutorial, driver type 1 and 2 are interim solutions where direct pure Java drivers are not yet available. Driver type 3 and 4 are the preferred way to access databases using the JDBC API, because they offer all the advantages of Java technology, including automatic installation. For more info, visit Sun JDBC page 25. Which type of JDBC driver is the fastest one? JDBC Net pure Java driver(Type IV) is the fastest driver because it converts the jdbc calls into vendor specific protocol calls and it directly interacts with the database. 26. Are all the required JDBC drivers to establish connectivity to my database part of the JDK? No. There aren't any JDBC technology-enabled drivers bundled with the JDK 1.1.x or Java 2 Platform releases other than the JDBC-ODBC Bridge. So, developers need to get a driver and install it before they can connect to a database. We are considering bundling JDBC technology- enabled drivers in the future. 27. Is the JDBC-ODBC Bridge multi-threaded? No. The JDBC-ODBC Bridge does not support concurrent access from different threads. The JDBC-ODBC Bridge uses synchronized methods to serialize all of the calls that it makes to ODBC. Multi-threaded Java programs may use the Bridge, but they won't get the advantages of multi-threading. In addition, deadlocks can occur between locks held in the database and the semaphore used by the Bridge. We are thinking about removing the synchronized methods in the future. They were added originally to make things simple for folks writing Java programs that use a single-threaded ODBC driver. 28. Does the JDBC-ODBC Bridge support multiple concurrent open statements per connection? No. You can open only one Statement object per connection when you are using the JDBC-ODBC Bridge. 29. What is the query used to display all tables names in SQL Server (Query analyzer)? select * from information_schema.tables 30. Why can't I invoke the ResultSet methods afterLast and beforeFirst when the method next works? You are probably using a driver implemented for the JDBC 1.0 API. You need to upgrade to a JDBC 2.0 driver that implements scrollable result sets. Also be sure that your code has created scrollable result sets and that the DBMS you are using supports them. 31. How can I retrieve a String or other object type without creating a new object each time? Creating and garbage collecting potentially large numbers of objects (millions) unnecessarily can really hurt performance. It may be better to provide a way to retrieve data like strings using the JDBC API without always allocating a new object. We are studying this issue to see if it is an area in which the JDBC API should be improved. Stay tuned, and please send us any comments you have on this question. 32. How many types of JDBC Drivers are present and what are they? There are 4 types of JDBC Drivers Type 1: JDBC-ODBC Bridge Driver Type 2: Native API Partly Java Driver Type 3: Network protocol Driver Type 4: JDBC Net pure Java Driver 33. What is the fastest type of JDBC driver? JDBC driver performance will depend on a number of issues: (a) the quality of the driver code, (b) the size of the driver code, (c) the database server and its load, (d) network topology, (e) the number of times your request is translated to a different API. In general, all things being equal, you can assume that the more your request and response change hands, the slower it will be. This means that Type 1 and Type 3 drivers will be slower than Type 2 drivers (the database calls are make at least three translations versus two), and Type 4 drivers are the fastest (only one translation). 34. There is a method getColumnCount in the JDBC API. Is there a similar method to find the number of rows in a result set? No, but it is easy to find the number of rows. If you are using a scrollable result set, rs, you can call the methods rs.last and then rs.getRow to find out how many rows rs has. If the result is not scrollable, you can either count the rows by iterating through the result set or get the number of rows by submitting a query with a COUNT column in the SELECT clause. I would like to download the JDBC-ODBC Bridge for the Java 2 SDK, Standard Edition (formerly JDK 1.2). I'm a beginner with the JDBC API, and I would like to start with 35. the Bridge. How do I do it? The JDBC-ODBC Bridge is bundled with the Java 2 SDK, Standard Edition, so there is no need to download it separately. 36. If I use the JDBC API, do I have to use ODBC underneath? No, this is just one of many possible solutions. We recommend using a pure Java JDBC technology-enabled driver, type 3 or 4, in order to get all of the benefits of the Java programming language and the JDBC API. 37. Once I have the Java 2 SDK, Standard Edition, from Sun, what else do I need to connect to a database? You still need to get and install a JDBC technology-enabled driver that supports the database that you are using. There are many drivers available from a variety of sources. You can also try using the JDBC-ODBC Bridge if you have ODBC connectivity set up already. The Bridge comes with the Java 2 SDK, Standard Edition, and Enterprise Edition, and it doesn't require any extra setup itself. The Bridge is a normal ODBC client. Note, however, that you should use the JDBC-ODBC Bridge only for experimental prototyping or when you have no other driver available. 38. How can I know when I reach the last record in a table, since JDBC doesn't provide an EOF method? Answer1 You can use last() method of java.sql.ResultSet, if you make it scrollable. You can also use isLast() as you are reading the ResultSet. One thing to keep in mind, though, is that both methods tell you that you have reached the end of the current ResultSet, not necessarily the end of the table. SQL and RDBMSes make no guarantees about the order of rows, even from sequential SELECTs, unless you specifically use ORDER BY. Even then, that doesn't necessarily tell you the order of data in the table. Answer2 Assuming you mean ResultSet instead of Table, the usual idiom for iterating over a forward only resultset is: ResultSet rs=statement.executeQuery(...); while (rs.next()) { // Manipulate row here } 39. Where can I find info, frameworks and example source for writing a JDBC driver? There a several drivers with source available, like MM.MySQL, SimpleText Database, FreeTDS, and RmiJdbc. There is at least one free framework, the jxDBCon-Open Source JDBC driver framework. Any driver writer should also review For Driver Writers. 40. How can I create a custom RowSetMetaData object from scratch? One unfortunate aspect of RowSetMetaData for custom versions is that it is an interface. This means that implementations almost have to be proprietary. The JDBC RowSet package is the most commonly available and offers the sun.jdbc.rowset.RowSetMetaDataImpl class. After instantiation, any of the RowSetMetaData setter methods may be used. The bare minimum needed for a RowSet to function is to set the Column Count for a row and the Column Types for each column in the row. For a working code example that includes a custom RowSetMetaData, 41. How does a custom RowSetReader get called from a CachedRowSet? The Reader must be registered with the CachedRowSet using CachedRowSet.setReader(javax.sql.RowSetReader reader). Once that is done, a call to CachedRowSet.execute() will, among other things, invoke the readData method. How do I implement a RowSetReader? I want to populate a CachedRowSet myself and the documents specify that a RowSetReader should be used. The single method accepts a 42. RowSetInternal caller and returns void. What can I do in the readData method? "It can be implemented in a wide variety of ways..." and is pretty vague about what can actually be done. In general, readData() would obtain or create the data to be loaded, then use CachedRowSet methods to do the actual loading. This would usually mean inserting rows, so the code would move to the insert row, set the column data and insert rows. Then the cursor must be set to to the appropriate position. 43. How can I instantiate and load a new CachedRowSet object from a non-JDBC source? The basics are: * Create an object that implements javax.sql.RowSetReader, which loads the data. * Instantiate a CachedRowset object. * Set the CachedRowset's reader to the reader object previously created. * Invoke CachedRowset.execute(). Note that a RowSetMetaData object must be created, set up with a description of the data, and attached to the CachedRowset before loading the actual data. The following code works with the Early Access JDBC RowSet download available from the Java Developer Connection and is an expansion of one of the examples: // Independent data source CachedRowSet Example import java.sql.*; import javax.sql.*; import sun.jdbc.rowset.*; public class RowSetEx1 implements RowSetReader { CachedRowSet crs; int iCol2; RowSetMetaDataImpl rsmdi; String sCol1, sCol3; public RowSetEx1() { try { crs = new CachedRowSet(); crs.setReader(this); crs.execute(); // load from reader System.out.println( "Fetching from RowSet..."); while(crs.next()) { showTheData(); } // end while next if(crs.isAfterLast() == true) { System.out.println( "We have reached the end"); System.out.println("crs row: " + crs.getRow()); } System.out.println( "And now backwards..."); while(crs.previous()) { showTheData(); } // end while previous if(crs.isBeforeFirst() == true) { System.out.println( "We have reached the start"); } crs.first(); if(crs.isFirst() == true) { System.out.println( "We have moved to first"); } System.out.println("crs row: " + crs.getRow()); if(crs.isBeforeFirst() == false) { System.out.println( "We aren't before the first row."); } crs.last(); if(crs.isLast() == true) { System.out.println( "...and now we have moved to the last"); } System.out.println("crs row: " + crs.getRow()); if(crs.isAfterLast() == false) { System.out.println( "we aren't after the last."); } } // end try catch (SQLException ex) { System.err.println("SQLException: " + ex.getMessage()); } } // end constructor public void showTheData() throws SQLException { sCol1 = crs.getString(1); if(crs.wasNull() == false) { System.out.println("sCol1: " + sCol1); } else { System.out.println("sCol1 is null"); } iCol2 = crs.getInt(2); if (crs.wasNull() == false) { System.out.println("iCol2: " + iCol2); } else { System.out.println("iCol2 is null"); } sCol3 = crs.getString(3); if (crs.wasNull() == false) { System.out.println("sCol3: " + sCol3 + "\n" ); } else { System.out.println("sCol3 is null\n"); } } // end showTheData // RowSetReader implementation public void readData(RowSetInternal caller) throws SQLException { rsmdi = new RowSetMetaDataImpl(); rsmdi.setColumnCount(3); rsmdi.setColumnType(1, Types.VARCHAR); rsmdi.setColumnType(2, Types.INTEGER); rsmdi.setColumnType(3, Types.VARCHAR); crs.setMetaData( rsmdi ); crs.moveToInsertRow(); crs.updateString( 1, "StringCol11" ); crs.updateInt( 2, 1 ); crs.updateString( 3, "StringCol31" ); crs.insertRow(); crs.updateString( 1, "StringCol12" ); crs.updateInt( 2, 2 ); crs.updateString( 3, "StringCol32" ); crs.insertRow(); crs.moveToCurrentRow(); crs.beforeFirst(); } // end readData public static void main(String args) { new RowSetEx1(); } } // end class RowSetEx1 44. Can I set up a connection pool with multiple user IDs? The single ID we are forced to use causes problems when debugging the DBMS. Since the Connection interface ( and the underlying DBMS ) requires a specific user and password, there's not much of a way around this in a pool. While you could create a different Connection for each user, most of the rationale for a pool would then be gone. Debugging is only one of several issues that arise when using pools. However, for debugging, at least a couple of other methods come to mind. One is to log executed statements and times, which should allow you to backtrack to the user. Another method that also maintains a trail of modifications is to include user and timestamp as standard columns in your tables. In this last case, you would collect a separate user value in your program. How can I protect my database password ? I'm writing a client-side java application that will access a database over the internet. I have concerns about the security of the database passwords. The client will have access in one way or another to the class files, where the connection string to the database, including user and 45. password, is stored in as plain text. What can I do to protect my passwords? This is a very common question. Conclusion: JAD decompiles things easily and obfuscation would not help you. But you'd have the same problem with C/C++ because the connect string would still be visible in the executable. SSL JDBC network drivers fix the password sniffing problem (in MySQL 4.0), but not the decompile problem. If you have a servlet container on the web server, I would go that route (see other discussion above) then you could at least keep people from reading/destroying your mysql database. Make sure you use database security to limit that app user to the minimum tables that they need, then at least hackers will not be able to reconfigure your DBMS engine. Aside from encryption issues over the internet, it seems to me that it is bad practice to embed user ID and password into program code. One could generally see the text even without decompilation in almost any language. This would be appropriate only to a read-only database meant to be open to the world. Normally one would either force the user to enter the information or keep it in a properties file. Detecting Duplicate Keys I have a program that inserts rows in a table. My table has a column 'Name' that has a unique constraint. If the user attempts to insert a duplicate name into the table, I want to display an error message by processing the error code from the database. How can I capture this error code in a Java program? A solution that is perfectly portable to all databases, is to execute a query for checking if that unique value is present before inserting the row. The big advantage is that you can handle your error message in a very simple way, and the obvious downside is that you are going to use more time for inserting the record, but since you're working on a PK field, performance should not be so bad. You can also get this information in a portable way, and potentially avoid another database access, by capturing SQLState messages. Some databases get more specific than others, but the general code portion is 23 - "Constraint Violations". UDB2, for example, gives a specific such as 23505, while others will only give 23000. 46. What driver should I use for scalable Oracle JDBC applications? Sun recommends using the thin ( type 4 ) driver. * On single processor machines to avoid JNI overhead. * On multiple processor machines, especially running Solaris, to avoid synchronization bottlenecks. 48. How do I write Greek ( or other non-ASCII/8859-1 ) characters to a database? From the standard JDBC perspective, there is no difference between ASCII/8859-1 characters and those above 255 ( hex FF ). The reason for that is that all Java characters are in Unicode ( unless you perform/request special encoding ). Implicit in that statement is the presumption that the data store can handle characters outside the hex FF range or interprets different character sets appropriately. That means either: * The OS, application and database use the same code page and character set. For example, a Greek version of NT with the DBMS set to the default OS encoding. * The DBMS has I18N support for Greek ( or other language ), regardless of OS encoding. This has been the most common for production quality databases, although support varies. Particular DBMSes may allow setting the encoding/code page/CCSID at the database, table or even column level. There is no particular standard for provided support or methods of setting the encoding. You have to check the DBMS documentation and set up the table properly. * The DBMS has I18N support in the form of Unicode capability. This would handle any Unicode characters and therefore any language defined in the Unicode standard. Again, set up is proprietary. 49. How can I insert images into a Mysql database? This code snippet shows the basics: File file = new File(fPICTURE); FileInputStream fis = new FileInputStream(file); PreparedStatement ps = ConrsIn.prepareStatement("insert into dbPICTURE values (?,?)"); // ***use as many ??? as you need to insert in the exact order*** ps.setString(1,file.getName()); ps.setBinaryStream(2,fis,(int)file.length()); ps.close(); fis.close(); 50. Is possible to open a connection to a database with exclusive mode with JDBC? I think you mean "lock a table in exclusive mode". You cannot open a connection with exclusive mode. Depending on your database engine, you can lock tables or rows in exclusive mode. In Oracle you would create a statement st and run st.execute("lock table mytable in exclusive mode"); Then when you are finished with the table, execute the commit to unlock the table. Mysql, Informix and SQLServer all have a slightly different syntax for this function, so you'll have to change it depending on your database. But they can all be done with execute(). 51. What are the standard isolation levels defined by JDBC? The values are defined in the class java.sql.Connection and are: * TRANSACTION_NONE * TRANSACTION_READ_COMMITTED * TRANSACTION_READ_UNCOMMITTED * TRANSACTION_REPEATABLE_READ * TRANSACTION_SERIALIZABLE Update fails without blank padding. Although a particular row is present in the database for a given key, executeUpdate() shows 0 rows updated and, in fact, the table is not updated. If I pad the Key with spaces for the column length (e.g. if the key column is 20 characters long, and key is msgID, length 6, I pad it with 14 spaces), 52. the update then works!!! Is there any solution to this problem without padding? In the SQL standard, CHAR is a fixed length data type. In many DBMSes ( but not all), that means that for a WHERE clause to match, every character must match, including size and trailing blanks. As Alessandro indicates, defining CHAR columns to be VARCHAR is the most general answer. 53. What isolation level is used by the DBMS when inserting, updating and selecting rows from a database? The answer depends on both your code and the DBMS. If the program does not explicitly set the isolation level, the DBMS default is used. You can determine the default using DatabaseMetaData.getDefaultTransactionIsolation() and the level for the current Connection with Connection.getTransactionIsolation(). If the default is not appropriate for your transaction, change it with Connection.setTransactionIsolation(int level). 54. How can I determine the isolation levels supported by my DBMS? Use DatabaseMetaData.supportsTransactionIsolationLevel(int level). Connecting to a database through the Proxy I want to connect to remote database using a program that is running in the local network behind the proxy. Is that possible? I assume that your proxy is set to accept http requests only on port 80. If you want to have a local class behind the proxy connect to the database for you, then you need a servlet/JSP to receive an HTTP request and use the local class to connect to the database and send the response back to the client. You could also use RMI where your remote computer class that connects to the database acts as a remote server that talks RMI with the clients. if you implement this, then you will need to tunnel RMI through HTTP which is not that hard. In summary, either have a servlet/JSP take HTTP requests, instantiate a class that handles database connections and send HTTP response back to the client or have the local class deployed as RMI server and send requests to it using RMI. 55. How do I receive a ResultSet from a stored procedure? Stored procedures can return a result parameter, which can be a result set. For a discussion of standard JDBC syntax for dealing with result, IN, IN/OUT and OUT parameters, see Stored Procedures. 56. How can I write to the log used by DriverManager and JDBC drivers? The simplest method is to use DriverManager.println(String message), which will write to the current log. 57. How can I get or redirect the log used by DriverManager and JDBC drivers? As of JDBC 2.0, use DriverManager.getLogWriter() and DriverManager.setLogWriter(PrintWriter out). Prior to JDBC 2.0, the DriverManager methods getLogStream() and setLogStream(PrintStream out) were used. These are now deprecated. 58. What does it mean to "materialize" data? This term generally refers to Array, Blob and Clob data which is referred to in the database via SQL locators "Materializing" the data means to return the actual data pointed to by the Locator. For Arrays, use the various forms of getArray() and getResultSet(). For Blobs, use getBinaryStream() or getBytes(long pos, int length). For Clobs, use getAsciiStream() or getCharacterStream(). 59. Why do I have to reaccess the database for Array, Blob, and Clob data? Most DBMS vendors have implemented these types via the SQL3 Locator type Some rationales for using Locators rather than directly returning the data can be seen most clearly with the Blob type. By definition, a Blob is an arbitrary set of binary data. It could be anything; the DBMS has no knowledge of what the data represents. Notice that this effectively demolishes data independence, because applications must now be aware of what the Blob data actually represents. Let's assume an employee table that includes employee images as Blobs. Say we have an inquiry program that presents multiple employees with department and identification information. To see all of the data for a specific employee, including the image, the summary row is selected and another screen appears. It is only at this pont that the application needs the specific image. It would be very wasteful and time consuming to bring down an entire employee page of images when only a few would ever be selected in a given run. Now assume a general interactive SQL application. A query is issued against the employee table. Because the image is a Blob, the application has no idea what to do with the data, so why bring it down, killing performance along the way, in a long running operation? Clearly this is not helpful in those applications that need the data everytime, but these and other considerations have made the most general sense to DBMS vendors. 60. What is an SQL Locator? A Locator is an SQL3 data type that acts as a logical pointer to data that resides on a database server. Read "logical pointer" here as an identifier the DBMS can use to locate and manipulate the data. A Locator allows some manipulation of the data on the server. While the JDBC specification does not directly address Locators, JDBC drivers typically use Locators under the covers to handle Array, Blob, and Clob data types. 61. How do I set properties for a JDBC driver and where are the properties stored? A JDBC driver may accept any number of properties to tune or optimize performance for the specific driver. There is no standard, other than user and password, for what these properties should be. Therefore, the developer is dependent on the driver documentation to automatically pass properties. For a standard dynamic method that can be used to solicit user input for properties, see What properties should I supply to a database driver in order to connect to a database? In addition, a driver may specify its own method of accepting properties. Many do this via appending the property to the JDBC Database URL. However, a JDBC Compliant driver should implement the connect(String url, Properties info) method. This is generally invoked through DriverManager.getConnection(String url, Properties info). The passed properties are ( probably ) stored in variables in the Driver instance. This, again, is up to the driver, but unless there is some sort of driver setup, which is unusual, only default values are remembered over multiple instantiations. 62. What is the JDBC syntax for using a literal or variable in a standard Statement? First, it should be pointed out that PreparedStatement handles many issues for the developer and normally should be preferred over a standard Statement. Otherwise, the JDBC syntax is really the same as SQL syntax. One problem that often affects newbies ( and others ) is that SQL, like many languages, requires quotes around character ( read "String" for Java ) values to distinguish from numerics. So the clause: "WHERE myCol = " + myVal is perfectly valid and works for numerics, but will fail when myVal is a String. Instead use: "WHERE myCol = '" + myVal + "'" if myVal equals "stringValue", the clause works out to: WHERE myCol = 'stringValue' You can still encounter problems when quotes are embedded in the value, which, again, a PreparedStatement will handle for you. 63. How do I check in my code whether a maximum limit of database connections have been reached? Use DatabaseMetaData.getMaxConnections() and compare to the number of connections currently open. Note that a return value of zero can mean unlimited or, unfortunately, unknown. Of course, driverManager.getConnection() will throw an exception if a Connection can not be obtained. 64. Why do I get UnsatisfiedLinkError when I try to use my JDBC driver? The first thing is to be sure that this does not occur when running non-JDBC apps. If so, there is a faulty JDK/JRE installation. If it happens only when using JDBC, then it's time to check the documentation that came with the driver or the driver/DBMS support. JDBC driver types 1 through 3 have some native code aspect and typically require some sort of client install. Along with the install, various environment variables and path or classpath settings must be in place. Because the requirements and installation procedures vary with the provider, there is no reasonable way to provide details here. A type 4 driver, on the other hand, is pure Java and should never exhibit this problem. The trade off is that a type 4 driver is usually slower. Many connections from an Oracle8i pooled connection returns statement closed. I am using import oracle.jdbc.pool.* with thin driver. If I test with many simultaneous connections, I get an SQLException that the statement is closed. ere is an example of concurrent operation of pooled connections from the OracleConnectionPoolDataSource. There is an executable for kicking off threads, a DataSource, and the workerThread. The Executable Member package package6; /** * package6.executableTester * */ public class executableTester { protected static myConnectionPoolDataSource dataSource = null; static int i = 0; /** * Constructor */ public executableTester() throws java.sql.SQLException { } /** * main * @param args */ public static void main(String args) { try{ dataSource = new myConnectionPoolDataSource(); } catch ( Exception ex ){ ex.printStackTrace(); } while ( i++ try{ workerClass worker = new workerClass(); worker.setThreadNumber( i ); worker.setConnectionPoolDataSource ( dataSource.getConnectionPoolDataSource() ); worker.start(); System.out.println( "Started Thread#"+i ); } catch ( Exception ex ){ ex.printStackTrace(); } } } } The DataSource Member package package6; import oracle.jdbc.pool.*; /** * package6.myConnectionPoolDataSource. * */ public class myConnectionPoolDataSource extends Object { protected OracleConnectionPoolDataSource ocpds = null; /** * Constructor */ public myConnectionPoolDataSource() throws java.sql.SQLException { // Create a OracleConnectionPoolDataSource instance ocpds = new OracleConnectionPoolDataSource(); // Set connection parameters ocpds.setURL("jdbc:oracle:oci8:@mydb"); ocpds.setUser("scott"); ocpds.setPassword("tiger"); } public OracleConnectionPoolDataSource getConnectionPoolDataSource() { return ocpds; } } The Worker Thread Member package package6; import oracle.jdbc.pool.*; import java.sql.*; import javax.sql.*; /** * package6.workerClass . * */ public class workerClass extends Thread { protected OracleConnectionPoolDataSource ocpds = null; protected PooledConnection pc = null; protected Connection conn = null; protected int threadNumber = 0; /** * Constructor */ public workerClass() { } public void doWork( ) throws SQLException { // Create a pooled connection pc = ocpds.getPooledConnection(); // Get a Logical connection conn = pc.getConnection(); // Create a Statement Statement stmt = conn.createStatement (); // Select the ENAME column from the EMP table ResultSet rset = stmt.executeQuery ("select ename from emp"); // Iterate through the result and print the employee names while (rset.next ()) // System.out.println (rset.getString (1)); ; // Close the RseultSet rset.close(); rset = null; // Close the Statement stmt.close(); stmt = null; // Close the logical connection conn.close(); conn = null; // Close the pooled connection pc.close(); pc = null; System.out.println( "workerClass.thread# "+threadNumber+" completed.."); } public void setThreadNumber( int assignment ){ threadNumber = assignment; } public void setConnectionPoolDataSource (OracleConnectionPoolDataSource x){ ocpds = x; } public void run() { try{ doWork(); } catch ( Exception ex ){ ex.printStackTrace(); } } } The OutPut Produced Started Thread#1 Started Thread#2 Started Thread#3 Started Thread#4 Started Thread#5 Started Thread#6 Started Thread#7 Started Thread#8 Started Thread#9 Started Thread#10 workerClass.thread# 1 completed.. workerClass.thread# 10 completed.. workerClass.thread# 3 completed.. workerClass.thread# 8 completed.. workerClass.thread# 2 completed.. workerClass.thread# 9 completed.. workerClass.thread# 5 completed.. workerClass.thread# 7 completed.. workerClass.thread# 6 completed.. workerClass.thread# 4 completed.. The oracle.jdbc.pool.OracleConnectionCacheImpl class is another subclass of the oracle.jdbc.pool.OracleDataSource which should also be looked over, that is what you really what to use. Here is a similar example that uses the oracle.jdbc.pool.OracleConnectionCacheImpl. The general construct is the same as the first example but note the differences in workerClass1 where some statements have been commented ( basically a clone of workerClass from previous example ). The Executable Member package package6; import java.sql.*; import javax.sql.*; import oracle.jdbc.pool.*; /** * package6.executableTester2 * */ public class executableTester2 { static int i = 0; protected static myOracleConnectCache connectionCache = null; /** * Constructor */ public executableTester2() throws SQLException { } /** * main * @param args */ public static void main(String args) { OracleConnectionPoolDataSource dataSource = null; try{ dataSource = new OracleConnectionPoolDataSource() ; connectionCache = new myOracleConnectCache( dataSource ); } catch ( Exception ex ){ ex.printStackTrace(); } while ( i++ try{ workerClass1 worker = new workerClass1(); worker.setThreadNumber( i ); worker.setConnection( connectionCache.getConnection() ); worker.start(); System.out.println( "Started Thread#"+i ); } catch ( Exception ex ){ ex.printStackTrace(); } } } protected void finalize(){ try{ connectionCache.close(); } catch ( SQLException x) { x.printStackTrace(); } this.finalize(); } } The ConnectCacheImpl Member package package6; import javax.sql.ConnectionPoolDataSource; import oracle.jdbc.pool.*; import oracle.jdbc.driver.*; import java.sql.*; import java.sql.SQLException; /** * package6.myOracleConnectCache * */ public class myOracleConnectCache extends OracleConnectionCacheImpl { /** * Constructor */ public myOracleConnectCache( ConnectionPoolDataSource x) throws SQLException { initialize(); } public void initialize() throws SQLException { setURL("jdbc:oracle:oci8:@myDB"); setUser("scott"); setPassword("tiger"); // // prefab 2 connection and only grow to 4 , setting these // to various values will demo the behavior //clearly, if it is not // obvious already // setMinLimit(2); setMaxLimit(4); } } The Worker Thread Member package package6; import oracle.jdbc.pool.*; import java.sql.*; import javax.sql.*; /** * package6.workerClass1 * */ public class workerClass1 extends Thread { // protected OracleConnectionPoolDataSource ocpds = null; // protected PooledConnection pc = null; protected Connection conn = null; protected int threadNumber = 0; /** * Constructor */ public workerClass1() { } public void doWork( ) throws SQLException { // Create a pooled connection // pc = ocpds.getPooledConnection(); // Get a Logical connection // conn = pc.getConnection(); // Create a Statement Statement stmt = conn.createStatement (); // Select the ENAME column from the EMP table ResultSet rset = stmt.executeQuery ("select ename from EMP"); // Iterate through the result // and print the employee names while (rset.next ()) // System.out.println (rset.getString (1)); ; // Close the RseultSet rset.close(); rset = null; // Close the Statement stmt.close(); stmt = null; // Close the logical connection conn.close(); conn = null; // Close the pooled connection // pc.close(); // pc = null; System.out.println( "workerClass1.thread# "+threadNumber+" completed.."); } public void setThreadNumber( int assignment ){ threadNumber = assignment; } // public void setConnectionPoolDataSource (OracleConnectionPoolDataSource x){ // ocpds = x; // } public void setConnection( Connection assignment ){ conn = assignment; } public void run() { try{ doWork(); } catch ( Exception ex ){ ex.printStackTrace(); } } } The OutPut Produced Started Thread#1 Started Thread#2 workerClass1.thread# 1 completed.. workerClass1.thread# 2 completed.. Started Thread#3 Started Thread#4 Started Thread#5 workerClass1.thread# 5 completed.. workerClass1.thread# 4 completed.. workerClass1.thread# 3 completed.. Started Thread#6 Started Thread#7 Started Thread#8 Started Thread#9 workerClass1.thread# 8 completed.. workerClass1.thread# 9 completed.. workerClass1.thread# 6 completed.. workerClass1.thread# 7 completed.. Started Thread#10 workerClass1.thread# 10 completed.. 65. DB2 Universal claims to support JDBC 2.0, But I can only get JDBC 1.0 functionality. What can I do? DB2 Universal defaults to the 1.0 driver. You have to run a special program to enable the 2.0 driver and JDK support. For detailed information, see Setting the Environment in Building Java Applets and Applications. The page includes instructions for most supported platforms. 66. How do I disallow NULL values in a table? Null capability is a column integrity constraint, normally applied at table creation time. Note that some databases won't allow the constraint to be applied after table creation. Most databases allow a default value for the column as well. The following SQL statement displays the NOT NULL constraint: CREATE TABLE CoffeeTable ( Type VARCHAR(25) NOT NULL, Pounds INTEGER NOT NULL, Price NUMERIC(5, 2) NOT NULL ) 67. How to get a field's value with ResultSet.getxxx when it is a NULL? I have tried to execute a typical SQL statement: select * from T-name where (clause); But an error gets thrown because there are some NULL fields in the table. You should not get an error/exception just because of null values in various columns. This sounds like a driver specific problem and you should first check the original and any chained exceptions to determine if another problem exists. In general, one may retrieve one of three values for a column that is null, depending on the data type. For methods that return objects, null will be returned; for numeric ( get Byte(), getShort(), getInt(), getLong(), getFloat(), and getDouble() ) zero will be returned; for getBoolean() false will be returned. To find out if the value was actually NULL, use ResultSet.wasNull() before invoking another getXXX method. 68. How do I insert/update records with some of the columns having NULL value? Use either of the following PreparedStatement methods: public void setNull(int parameterIndex, int sqlType) throws SQLException public void setNull(int paramIndex, int sqlType, String typeName) throws SQLException These methods assume that the columns are nullable. In this case, you can also just omit the columns in an INSERT statement; they will be automatically assigned null values. Is there a way to find the primary key(s) for an Access Database table? Sun's JDBC-ODBC driver does not implement the getPrimaryKeys() method for the DatabaseMetaData Objects. // Use meta.getIndexInfo() will //get you the PK index. Once // you know the index, retrieve its column name DatabaseMetaData meta = con.getMetaData(); String key_colname = null; // get the primary key information rset = meta.getIndexInfo(null,null, table_name, true,true); while( rset.next()) { String idx = rset.getString(6); if( idx != null) { //Note: index "PrimaryKey" is Access DB specific // other db server has diff. index syntax. if( idx.equalsIgnoreCase("PrimaryKey")) { key_colname = rset.getString(9); setPrimaryKey( key_colname ); } } } 69. Why can't Tomcat find my Oracle JDBC drivers in classes111.zip? TOMCAT 4.0.1 on NT4 throws the following exception when I try to connect to Oracle DB from JSP. javax.servlet.ServletException : oracle.jdbc.driver.OracleDriver java.lang.ClassNotFoundException: oracle:jdbc:driver:OracleDriver But, the Oracle JDBC driver ZIP file (classes111.zip)is available in the system classpath. Copied the Oracle Driver class file (classes111.zip) in %TOMCAT_Home - Home%\lib directory and renamed it to classess111.jar. Able to connect to Oracle DB from TOMCAT 4.01 via Oracle JDBC-Thin Driver. I have an application that queries a database and retrieves the results into a JTable. This is the code in the model that seems to be taken forever to execute, especially for a large result set: while ( myRs.next() ) { Vector newRow =new Vector(); for ( int i=1;i Read the full article
0 notes
Text
Spring Interview Questions and Answers
Spring Interview Questions
What is Spring Framework?
What are some of the important features and advantages of Spring Framework?
What do you understand by Dependency Injection?
How do we implement DI in Spring Framework?
What are the new features in Spring 5?
What is Spring WebFlux?
What are the benefits of using Spring Tool Suite?
Name some of the important Spring Modules?
What do you understand by Aspect Oriented Programming?
What is Aspect, Advice, Pointcut, JointPoint and Advice Arguments in AOP?
What is the difference between Spring AOP and AspectJ AOP?
What is Spring IoC Container?
What is a Spring Bean?
What is the importance of Spring bean configuration file?
What are different ways to configure a class as Spring Bean?
What are different scopes of Spring Bean?
What is Spring Bean life cycle?
How to get ServletContext and ServletConfig object in a Spring Bean?
What is Bean wiring and @Autowired annotation?
What are different types of Spring Bean autowiring?
Does Spring Bean provide thread safety?
What is a Controller in Spring MVC?
What’s the difference between @Component, @Repository & @Service annotations in Spring?
What is DispatcherServlet and ContextLoaderListener?
What is ViewResolver in Spring?
What is a MultipartResolver and when it’s used?
How to handle exceptions in Spring MVC Framework?
How to create ApplicationContext in a Java Program?
Can we have multiple Spring configuration files?
What is ContextLoaderListener?
What are the minimum configurations needed to create Spring MVC application?
How would you relate Spring MVC Framework to MVC architecture?
How to achieve localization in Spring MVC applications?
How can we use Spring to create Restful Web Service returning JSON response?
What are some of the important Spring annotations you have used?
Can we send an Object as the response of Controller handler method?
How to upload file in Spring MVC Application?
How to validate form data in Spring Web MVC Framework?
What is Spring MVC Interceptor and how to use it?
What is Spring JdbcTemplate class and how to use it?
How to use Tomcat JNDI DataSource in Spring Web Application?
How would you achieve Transaction Management in Spring?
What is Spring DAO?
How to integrate Spring and Hibernate Frameworks?
What is Spring Security?
How to inject a java.util.Properties into a Spring Bean?
Name some of the design patterns used in Spring Framework?
What are some of the best practices for Spring Framework?
Spring Interview Questions and Answers
Spring is one of the most widely used Java EE framework. Spring framework core concepts are “Dependency Injection” and “Aspect Oriented Programming”.
Spring framework can be used in normal java applications also to achieve loose coupling between different components by implementing dependency injection and we can perform cross-cutting tasks such as logging and authentication using spring support for aspect-oriented programming.
I like spring because it provides a lot of features and different modules for specific tasks such as Spring MVC and Spring JDBC. Since it’s an open source framework with a lot of online resources and active community members, working with the Spring framework is easy and fun at the same time.
Recommended Read: Spring Framework
Spring Framework is built on top of two design concepts – Dependency Injection and Aspect Oriented Programming.
Some of the features of spring framework are:
Lightweight and very little overhead of using framework for our development.
Dependency Injection or Inversion of Control to write components that are independent of each other, spring container takes care of wiring them together to achieve our work.
Spring IoC container manages Spring Bean life cycle and project specific configurations such as JNDI lookup.
Spring MVC framework can be used to create web applications as well as restful web services capable of returning XML as well as JSON response.
Support for transaction management, JDBC operations, File uploading, Exception Handling etc with very little configurations, either by using annotations or by spring bean configuration file.
Some of the advantages of using Spring Framework are:
Reducing direct dependencies between different components of the application, usually Spring IoC container is responsible for initializing resources or beans and inject them as dependencies.
Writing unit test cases are easy in Spring framework because our business logic doesn’t have direct dependencies with actual resource implementation classes. We can easily write a test configuration and inject our mock beans for testing purposes.
Reduces the amount of boiler-plate code, such as initializing objects, open/close resources. I like JdbcTemplate class a lot because it helps us in removing all the boiler-plate code that comes with JDBC programming.
Spring framework is divided into several modules, it helps us in keeping our application lightweight. For example, if we don’t need Spring transaction management features, we don’t need to add that dependency on our project.
Spring framework support most of the Java EE features and even much more. It’s always on top of the new technologies, for example, there is a Spring project for Android to help us write better code for native Android applications. This makes spring framework a complete package and we don’t need to look after the different framework for different requirements.
Dependency Injection design pattern allows us to remove the hard-coded dependencies and make our application loosely coupled, extendable and maintainable. We can implement dependency injection pattern to move the dependency resolution from compile-time to runtime.
Some of the benefits of using Dependency Injection are Separation of Concerns, Boilerplate Code reduction, Configurable components, and easy unit testing.
Read more at Dependency Injection Tutorial. We can also use Google Guice for Dependency Injection to automate the process of dependency injection. But in most of the cases, we are looking for more than just dependency injection and that’s why Spring is the top choice for this.
We can use Spring XML based as well as Annotation-based configuration to implement DI in spring applications. For better understanding, please read Spring Dependency Injection example where you can learn both the ways with JUnit test case. The post also contains a sample project zip file, that you can download and play around to learn more.
Spring 5 brought a massive update to Spring framework. Some of the new features in Spring 5 are:
Spring 5 runs on Java 8+ and supports Java EE 7. So we can use lambda expressions and Servlet 4.0 features. It’s good to see Spring trying to support the latest versions.
Spring Framework 5.0 comes with its own Commons Logging bridge; spring-jcl instead of standard Commons Logging.
Support for providing spring components information through index file “META-INF/spring.components” rather than classpath scanning.
Spring WebFlux brings reactive programming to the Spring Framework.
Spring 5 also supports Kotlin programming now. This is a huge step towards supporting functional programming, just as Java is also moving towards functional programming.
Support for JUnit 5 and parallel testing execution in the Spring TestContext Framework.
You can read about these features in more detail at Spring 5 Features.
Spring WebFlux is the new module introduced in Spring 5. Spring WebFlux is the first step towards the reactive programming model in spring framework.
Spring WebFlux is the alternative to the Spring MVC module. Spring WebFlux is used to create a fully asynchronous and non-blocking application built on the event-loop execution model.
You can read more about it at Spring WebFlux Tutorial.
We can install plugins into Eclipse to get all the features of Spring Tool Suite. However, STS comes with Eclipse with some other important kinds of stuff such as Maven support, Templates for creating different types of Spring projects and tc server for better performance with Spring applications.
I like STS because it highlights the Spring components and if you are using AOP pointcuts and advice, then it clearly shows which methods will come under the specific pointcut. So rather than installing everything on our own, I prefer using STS when developing Spring-based applications.
Some of the important Spring Framework modules are:
Spring Context – for dependency injection.
Spring AOP – for aspect oriented programming.
Spring DAO – for database operations using DAO pattern
Spring JDBC – for JDBC and DataSource support.
Spring ORM – for ORM tools support such as Hibernate
Spring Web Module – for creating web applications.
Spring MVC – Model-View-Controller implementation for creating web applications, web services etc.
Enterprise applications have some common cross-cutting concerns that are applicable to different types of Objects and application modules, such as logging, transaction management, data validation, authentication etc. In Object Oriented Programming, modularity of application is achieved by Classes whereas in AOP application modularity is achieved by Aspects and they are configured to cut across different classes methods.
AOP takes out the direct dependency of cross-cutting tasks from classes that are not possible in normal object-oriented programming. For example, we can have a separate class for logging but again the classes will have to call these methods for logging the data. Read more about Spring AOP support at Spring AOP Example.
Aspect: Aspect is a class that implements cross-cutting concerns, such as transaction management. Aspects can be a normal class configured and then configured in Spring Bean configuration file or we can use Spring AspectJ support to declare a class as Aspect using @Aspect annotation.
Advice: Advice is the action taken for a particular join point. In terms of programming, they are methods that gets executed when a specific join point with matching pointcut is reached in the application. You can think of Advices as Spring interceptors or Servlet Filters.
Pointcut: Pointcut are regular expressions that are matched with join points to determine whether advice needs to be executed or not. Pointcut uses different kinds of expressions that are matched with the join points. Spring framework uses the AspectJ pointcut expression language for determining the join points where advice methods will be applied.
Join Point: A join point is a specific point in the application such as method execution, exception handling, changing object variable values etc. In Spring AOP a join point is always the execution of a method.
Advice Arguments: We can pass arguments in the advice methods. We can use args() expression in the pointcut to be applied to any method that matches the argument pattern. If we use this, then we need to use the same name in the advice method from where the argument type is determined.
These concepts seems confusing at first, but if you go through Spring Aspect, Advice Example then you can easily relate to them.
AspectJ is the industry-standard implementation for Aspect Oriented Programming whereas Spring implements AOP for some cases. Main differences between Spring AOP and AspectJ are:
Spring AOP is simpler to use than AspectJ because we don’t need to worry about the weaving process.
Spring AOP supports AspectJ annotations, so if you are familiar with AspectJ then working with Spring AOP is easier.
Spring AOP supports only proxy-based AOP, so it can be applied only to method execution join points. AspectJ support all kinds of pointcuts.
One of the shortcomings of Spring AOP is that it can be applied only to the beans created through Spring Context.
Inversion of Control (IoC) is the mechanism to achieve loose-coupling between Objects dependencies. To achieve loose coupling and dynamic binding of the objects at runtime, the objects define their dependencies that are being injected by other assembler objects. Spring IoC container is the program that injects dependencies into an object and makes it ready for our use.
Spring Framework IoC container classes are part of org.springframework.beans and org.springframework.context packages and provides us different ways to decouple the object dependencies.
Some of the useful ApplicationContext implementations that we use are;
AnnotationConfigApplicationContext: For standalone java applications using annotations based configuration.
ClassPathXmlApplicationContext: For standalone java applications using XML based configuration.
FileSystemXmlApplicationContext: Similar to ClassPathXmlApplicationContext except that the xml configuration file can be loaded from anywhere in the file system.
AnnotationConfigWebApplicationContext and XmlWebApplicationContext for web applications.
Any normal java class that is initialized by Spring IoC container is called Spring Bean. We use Spring ApplicationContext to get the Spring Bean instance.
Spring IoC container manages the life cycle of Spring Bean, bean scopes and injecting any required dependencies in the bean.
We use Spring Bean configuration file to define all the beans that will be initialized by Spring Context. When we create the instance of Spring ApplicationContext, it reads the spring bean XML file and initializes all of them. Once the context is initialized, we can use it to get different bean instances.
Apart from Spring Bean configuration, this file also contains spring MVC interceptors, view resolvers and other elements to support annotations based configurations.
There are three different ways to configure Spring Bean.
XML Configuration: This is the most popular configuration and we can use bean element in context file to configure a Spring Bean. For example:
Java Based Configuration: If you are using only annotations, you can configure a Spring bean using @Bean annotation. This annotation is used with @Configuration classes to configure a spring bean. Sample configuration is:
Annotation Based Configuration: We can also use @Component, @Service, @Repository and @Controller annotations with classes to configure them to be as spring bean. For these, we would need to provide base package location to scan for these classes. For example:
<bean name="myBean" class="com.journaldev.spring.beans.MyBean"></bean>
@Configuration @ComponentScan(value="com.journaldev.spring.main") public class MyConfiguration { @Bean public MyService getService(){ return new MyService(); } }
To get this bean from spring context, we need to use following code snippet:
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext( MyConfiguration.class); MyService service = ctx.getBean(MyService.class);
<context:component-scan base-package="com.journaldev.spring" />
There are five scopes defined for Spring Beans.
singleton: Only one instance of the bean will be created for each container. This is the default scope for the spring beans. While using this scope, make sure spring bean doesn’t have shared instance variables otherwise it might lead to data inconsistency issues because it’s not thread-safe.
prototype: A new instance will be created every time the bean is requested.
request: This is same as prototype scope, however it’s meant to be used for web applications. A new instance of the bean will be created for each HTTP request.
session: A new bean will be created for each HTTP session by the container.
global-session: This is used to create global session beans for Portlet applications.
Spring Framework is extendable and we can create our own scopes too, however most of the times we are good with the scopes provided by the framework.
To set spring bean scopes we can use “scope” attribute in bean element or @Scope annotation for annotation based configurations.
Spring Beans are initialized by Spring Container and all the dependencies are also injected. When the context is destroyed, it also destroys all the initialized beans. This works well in most of the cases but sometimes we want to initialize other resources or do some validation before making our beans ready to use. Spring framework provides support for post-initialization and pre-destroy methods in spring beans.
We can do this by two ways – by implementing InitializingBean and DisposableBean interfaces or using init-method and destroy-method attribute in spring bean configurations. For more details, please read Spring Bean Life Cycle Methods.
There are two ways to get Container specific objects in the spring bean.
Implementing Spring *Aware interfaces, for these ServletContextAware and ServletConfigAware interfaces, for complete example of these aware interfaces, please read Spring Aware Interfaces
Using @Autowired annotation with bean variable of type ServletContext and ServletConfig. They will work only in servlet container specific environment only though.
@Autowired ServletContext servletContext;
The process of injection spring bean dependencies while initializing it called Spring Bean Wiring.
Usually, it’s best practice to do the explicit wiring of all the bean dependencies, but the spring framework also supports auto-wiring. We can use @Autowired annotation with fields or methods for autowiring byType. For this annotation to work, we also need to enable annotation-based configuration in spring bean configuration file. This can be done by context:annotation-config element.
For more details about @Autowired annotation, please read Spring Autowire Example.
There are four types of autowiring in Spring framework.
autowire byName
autowire byType
autowire by constructor
autowiring by @Autowired and @Qualifier annotations
Prior to Spring 3.1, autowire by autodetect was also supported that was similar to autowire by constructor or byType. For more details about these options, please read Spring Bean Autowiring.
The default scope of Spring bean is singleton, so there will be only one instance per context. That means that all the having a class level variable that any thread can update will lead to inconsistent data. Hence in default mode spring beans are not thread-safe.
However, we can change spring bean scope to request, prototype or session to achieve thread-safety at the cost of performance. It’s a design decision and based on the project requirements.
Just like MVC design pattern, Controller is the class that takes care of all the client requests and send them to the configured resources to handle it. In Spring MVC, org.springframework.web.servlet.DispatcherServlet is the front controller class that initializes the context based on the spring beans configurations.
A Controller class is responsible to handle a different kind of client requests based on the request mappings. We can create a controller class by using @Controller annotation. Usually, it’s used with @RequestMapping annotation to define handler methods for specific URI mapping.
@Component is used to indicate that a class is a component. These classes are used for auto-detection and configured as bean when annotation based configurations are used.
@Controller is a specific type of component, used in MVC applications and mostly used with RequestMapping annotation.
@Repository annotation is used to indicate that a component is used as repository and a mechanism to store/retrieve/search data. We can apply this annotation with DAO pattern implementation classes.
@Service is used to indicate that a class is a Service. Usually, the business facade classes that provide some services are annotated with this.
We can use any of the above annotations for a class for auto-detection but different types are provided so that you can easily distinguish the purpose of the annotated classes.
DispatcherServlet is the front controller in the Spring MVC application and it loads the spring bean configuration file and initialize all the beans that are configured. If annotations are enabled, it also scans the packages and configure any bean annotated with @Component, @Controller, @Repository or @Service annotations.
ContextLoaderListener is the listener to start up and shut down Spring’s root WebApplicationContext. It’s important functions are to tie up the lifecycle of ApplicationContext to the lifecycle of the ServletContext and to automate the creation of ApplicationContext. We can use it to define shared beans that can be used across different spring contexts.
ViewResolver implementations are used to resolve the view pages by name. Usually we configure it in the spring bean configuration file. For example:
<!-- Resolves views selected for rendering by @Controllers to .jsp resources in the /WEB-INF/views directory --> <beans:bean class="org.springframework.web.servlet.view.InternalResourceViewResolver"> <beans:property name="prefix" value="/WEB-INF/views/" /> <beans:property name="suffix" value=".jsp" /> </beans:bean>
InternalResourceViewResolver is one of the implementation of ViewResolver interface and we are providing the view pages directory and suffix location through the bean properties. So if a controller handler method returns “home”, view resolver will use view page located at /WEB-INF/views/home.jsp.
MultipartResolver interface is used for uploading files – CommonsMultipartResolver and StandardServletMultipartResolver are two implementations provided by spring framework for file uploading. By default there are no multipart resolvers configured but to use them for uploading files, all we need to define a bean named “multipartResolver” with type as MultipartResolver in spring bean configurations.
Once configured, any multipart request will be resolved by the configured MultipartResolver and pass on a wrapped HttpServletRequest. Then it’s used in the controller class to get the file and process it. For a complete example, please read Spring MVC File Upload Example.
Spring MVC Framework provides the following ways to help us achieving robust exception handling.
Controller Based – We can define exception handler methods in our controller classes. All we need is to annotate these methods with @ExceptionHandler annotation.
Global Exception Handler – Exception Handling is a cross-cutting concern and Spring provides @ControllerAdvice annotation that we can use with any class to define our global exception handler.
HandlerExceptionResolver implementation – For generic exceptions, most of the times we serve static pages. Spring Framework provides HandlerExceptionResolver interface that we can implement to create global exception handler. The reason behind this additional way to define global exception handler is that Spring framework also provides default implementation classes that we can define in our spring bean configuration file to get spring framework exception handling benefits.
For a complete example, please read Spring Exception Handling Example.
There are following ways to create spring context in a standalone java program.
AnnotationConfigApplicationContext: If we are using Spring in standalone java applications and using annotations for Configuration, then we can use this to initialize the container and get the bean objects.
ClassPathXmlApplicationContext: If we have spring bean configuration xml file in standalone application, then we can use this class to load the file and get the container object.
FileSystemXmlApplicationContext: This is similar to ClassPathXmlApplicationContext except that the xml configuration file can be loaded from anywhere in the file system.
For Spring MVC applications, we can define multiple spring context configuration files through contextConfigLocation. This location string can consist of multiple locations separated by any number of commas and spaces. For example;
<servlet> <servlet-name>appServlet</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <init-param> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/spring/appServlet/servlet-context.xml,/WEB-INF/spring/appServlet/servlet-jdbc.xml</param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet>
We can also define multiple root level spring configurations and load it through context-param. For example;
<context-param> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/spring/root-context.xml /WEB-INF/spring/root-security.xml</param-value> </context-param>
Another option is to use import element in the context configuration file to import other configurations, for example:
<beans:import resource="spring-jdbc.xml"/>
ContextLoaderListener is the listener class used to load root context and define spring bean configurations that will be visible to all other contexts. It’s configured in web.xml file as:
<context-param> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/spring/root-context.xml</param-value> </context-param> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener>
For creating a simple Spring MVC application, we would need to do the following tasks.
Add spring-context and spring-webmvc dependencies in the project.
Configure DispatcherServlet in the web.xml file to handle requests through spring container.
Spring bean configuration file to define beans, if using annotations then it has to be configured here. Also we need to configure view resolver for view pages.
Controller class with request mappings defined to handle the client requests.
Above steps should be enough to create a simple Spring MVC Hello World application.
As the name suggests Spring MVC is built on top of Model-View-Controller architecture. DispatcherServlet is the Front Controller in the Spring MVC application that takes care of all the incoming requests and delegate it to different controller handler methods.
The model can be any Java Bean in the Spring Framework, just like any other MVC framework Spring provides automatic binding of form data to java beans. We can set model beans as attributes to be used in the view pages.
View Pages can be JSP, static HTMLs etc. and view resolvers are responsible for finding the correct view page. Once the view page is identified, control is given back to the DispatcherServlet controller. DispatcherServlet is responsible for rendering the view and returning the final response to the client.
Spring provides excellent support for localization or i18n through resource bundles. Basis steps needed to make our application localized are:
Creating message resource bundles for different locales, such as messages_en.properties, messages_fr.properties etc.
Defining messageSource bean in the spring bean configuration file of type ResourceBundleMessageSource or ReloadableResourceBundleMessageSource.
For change of locale support, define localeResolver bean of type CookieLocaleResolver and configure LocaleChangeInterceptor interceptor. Example configuration can be like below:
Use spring:message element in the view pages with key names, DispatcherServlet picks the corresponding value and renders the page in corresponding locale and return as response.
<beans:bean id="messageSource" class="org.springframework.context.support.ReloadableResourceBundleMessageSource"> <beans:property name="basename" value="classpath:messages" /> <beans:property name="defaultEncoding" value="UTF-8" /> </beans:bean> <beans:bean id="localeResolver" class="org.springframework.web.servlet.i18n.CookieLocaleResolver"> <beans:property name="defaultLocale" value="en" /> <beans:property name="cookieName" value="myAppLocaleCookie"></beans:property> <beans:property name="cookieMaxAge" value="3600"></beans:property> </beans:bean> <interceptors> <beans:bean class="org.springframework.web.servlet.i18n.LocaleChangeInterceptor"> <beans:property name="paramName" value="locale" /> </beans:bean> </interceptors>
For a complete example, please read Spring Localization Example.
We can use Spring Framework to create Restful web services that returns JSON data. Spring provides integration with Jackson JSON API that we can use to send JSON response in restful web service.
We would need to do following steps to configure our Spring MVC application to send JSON response:
Adding Jackson JSON dependencies, if you are using Maven it can be done with following code:
Configure RequestMappingHandlerAdapter bean in the spring bean configuration file and set the messageConverters property to MappingJackson2HttpMessageConverter bean. Sample configuration will be:
In the controller handler methods, return the Object as response using @ResponseBody annotation. Sample code:
You can invoke the rest service through any API, but if you want to use Spring then we can easily do it using RestTemplate class.
<!-- Jackson --> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>${jackson.databind-version}</version> </dependency>
<!-- Configure to plugin JSON as request and response in method handler --> <beans:bean class="org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter"> <beans:property name="messageConverters"> <beans:list> <beans:ref bean="jsonMessageConverter"/> </beans:list> </beans:property> </beans:bean> <!-- Configure bean to convert JSON to POJO and vice versa --> <beans:bean id="jsonMessageConverter" class="org.springframework.http.converter.json.MappingJackson2HttpMessageConverter"> </beans:bean>
@RequestMapping(value = EmpRestURIConstants.GET_EMP, method = RequestMethod.GET) public @ResponseBody Employee getEmployee(@PathVariable("id") int empId) { logger.info("Start getEmployee. ID="+empId); return empData.get(empId); }
For a complete example, please read Spring Restful Webservice Example.
Some of the Spring annotations that I have used in my project are:
@Controller – for controller classes in Spring MVC project.
@RequestMapping – for configuring URI mapping in controller handler methods. This is a very important annotation, so you should go through Spring MVC RequestMapping Annotation Examples
@ResponseBody – for sending Object as response, usually for sending XML or JSON data as response.
@PathVariable – for mapping dynamic values from the URI to handler method arguments.
@Autowired – for autowiring dependencies in spring beans.
@Qualifier – with @Autowired annotation to avoid confusion when multiple instances of bean type is present.
@Service – for service classes.
@Scope – for configuring scope of the spring bean.
@Configuration, @ComponentScan and @Bean – for java based configurations.
AspectJ annotations for configuring aspects and advices, @Aspect, @Before, @After, @Around, @Pointcut etc.
Yes we can, using @ResponseBody annotation. This is how we send JSON or XML based response in restful web services.
Spring provides built-in support for uploading files through MultipartResolver interface implementations. It’s very easy to use and requires only configuration changes to get it working. Obviously we would need to write controller handler method to handle the incoming file and process it. For a complete example, please refer Spring File Upload Example.
Spring supports JSR-303 annotation based validations as well as provide Validator interface that we can implement to create our own custom validator. For using JSR-303 based validation, we need to annotate bean variables with the required validations.
For custom validator implementation, we need to configure it in the controller class. For a complete example, please read Spring MVC Form Validation Example.
Spring MVC Interceptors are like Servlet Filters and allow us to intercept client request and process it. We can intercept client request at three places – preHandle, postHandle and afterCompletion.
We can create spring interceptor by implementing HandlerInterceptor interface or by extending abstract class HandlerInterceptorAdapter.
We need to configure interceptors in the spring bean configuration file. We can define an interceptor to intercept all the client requests or we can configure it for specific URI mapping too. For a detailed example, please refer Spring MVC Interceptor Example.
Spring Framework provides excellent integration with JDBC API and provides JdbcTemplate utility class that we can use to avoid bolier-plate code from our database operations logic such as Opening/Closing Connection, ResultSet, PreparedStatement etc.
For JdbcTemplate example, please refer Spring JDBC Example.
For using servlet container configured JNDI DataSource, we need to configure it in the spring bean configuration file and then inject it to spring beans as dependencies. Then we can use it with JdbcTemplate to perform database operations.
Sample configuration would be:
<beans:bean id="dbDataSource" class="org.springframework.jndi.JndiObjectFactoryBean"> <beans:property name="jndiName" value="java:comp/env/jdbc/MyLocalDB"/> </beans:bean>
For complete example, please refer Spring Tomcat JNDI Example.
Spring framework provides transaction management support through Declarative Transaction Management as well as programmatic transaction management. Declarative transaction management is most widely used because it’s easy to use and works in most of the cases.
We use annotate a method with @Transactional annotation for Declarative transaction management. We need to configure the transaction manager for the DataSource in the spring bean configuration file.
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource" /> </bean>
Spring DAO support is provided to work with data access technologies like JDBC, Hibernate in a consistent and easy way. For example we have JdbcDaoSupport, HibernateDaoSupport, JdoDaoSupport and JpaDaoSupport for respective technologies.
Spring DAO also provides consistency in exception hierarchy and we don’t need to catch specific exceptions.
We can use Spring ORM module to integrate Spring and Hibernate frameworks if you are using Hibernate 3+ where SessionFactory provides current session, then you should avoid using HibernateTemplate or HibernateDaoSupport classes and better to use DAO pattern with dependency injection for the integration.
Spring ORM provides support for using Spring declarative transaction management, so you should utilize that rather than going for Hibernate boiler-plate code for transaction management.
For better understanding you should go through following tutorials:
Spring Hibernate Integration Example
Spring MVC Hibernate Integration Example
Spring security framework focuses on providing both authentication and authorization in java applications. It also takes care of most of the common security vulnerabilities such as CSRF attack.
It’s very beneficial and easy to use Spring security in web applications, through the use of annotations such as @EnableWebSecurity. You should go through the following posts to learn how to use the Spring Security framework.
Spring Security in Servlet Web Application
Spring MVC and Spring Security Integration Example
We need to define propertyConfigurer bean that will load the properties from the given property file. Then we can use Spring EL support to inject properties into other bean dependencies. For example;
<bean id="propertyConfigurer" class="org.springframework.context.support.PropertySourcesPlaceholderConfigurer"> <property name="location" value="/WEB-INF/application.properties" /> </bean> <bean class="com.journaldev.spring.EmployeeDaoImpl"> <property name="maxReadResults" value="${results.read.max}"/> </bean>
If you are using annotation to configure the spring bean, then you can inject property like below.
@Value("${maxReadResults}") private int maxReadResults;
Spring Framework is using a lot of design patterns, some of the common ones are:
Singleton Pattern: Creating beans with default scope.
Factory Pattern: Bean Factory classes
Prototype Pattern: Bean scopes
Adapter Pattern: Spring Web and Spring MVC
Proxy Pattern: Spring Aspect Oriented Programming support
Template Method Pattern: JdbcTemplate, HibernateTemplate etc
Front Controller: Spring MVC DispatcherServlet
Data Access Object: Spring DAO support
Dependency Injection and Aspect Oriented Programming
Some of the best practices for Spring Framework are:
Avoid version numbers in schema reference, to make sure we have the latest configs.
Divide spring bean configurations based on their concerns such as spring-jdbc.xml, spring-security.xml.
For spring beans that are used in multiple contexts in Spring MVC, create them in the root context and initialize with listener.
Configure bean dependencies as much as possible, try to avoid autowiring as much as possible.
For application-level properties, the best approach is to create a property file and read it in the spring bean configuration file.
For smaller applications, annotations are useful but for larger applications, annotations can become a pain. If we have all the configuration in XML files, maintaining it will be easier.
Use correct annotations for components for understanding the purpose easily. For services use @Service and for DAO beans use @Repository.
Spring framework has a lot of modules, use what you need. Remove all the extra dependencies that get usually added when you create projects through Spring Tool Suite templates.
If you are using Aspects, make sure to keep the join pint as narrow as possible to avoid advice on unwanted methods. Consider custom annotations that are easier to use and avoid any issues.
Use dependency injection when there is an actual benefit, just for the sake of loose-coupling don’t use it because it’s harder to maintain.
That’s all for Spring Framework interview questions. I hope these questions will help you in coming Java EE interview. I will keep on adding more questions to the list as soon as I found them. If you know some more questions that should be part of the list, make sure to add a comment for it and I will include it
0 notes
Text
WHAT IS JBOSS? IS IT WORTH LEARNING JBOSS ADMINISTRATION TRAINING?
JBoss Application Server (or JBoss AS 7) is a software/open-source Java EE-based application server. An important distinction for this class of software is that it not only implements a server that runs on Java, but it actually implements the Java EE part of Java. Because it is Java-based, the JBoss administration training application server operates cross-platform: usable on any operating system that supports Java. JBoss AS was developed by JBoss, now a division of Red Hat.
Prerequisite to Learn MaxMunus Jboss administration Training
Windows operational skills like running commands from a command prompt and networking.
Familiarity with web based applications, Web severs are required for Jboss online training
Java is essential for Jboss online training
Key Features of Jboss administration Training
Eclipse-based Integrated Development Environment (IDE) is available using JBoss Developer Studio
Supports Java EE and Web Services standards
Enterprise Java Beans (EJB)
Java persistence using Hibernate
Object request broker (ORB) using JacORB for interoperability with CORBA objects
JBoss Seam framework, including Java annotations to enhance POJOs, and including JBoss jBPM
JavaServer Faces (JSF), including RichFaces
Web application services, including Apache Tomcat for JavaServer Pages (JSP) and Java Servlets
Caching, clustering, and high availability, including JBoss Cache, and including JNDI, RMI, and EJB types
Security services, including Java Authentication and Authorization Service (JAAS) and pluggable authentication modules (PAM)
Web Services and interoperability,including JAX-RPC, JAX-WS, many WS-* standards, and MTOM/XOP
Integration and messaging services, including J2EE Connector Architecture (JCA), Java Database Connectivity (JDBC), and Java Message Service (JMS)
Management and Service-Oriented Architecture (SOA) using Java Management Extensions (JMX)
Additional administration and monitoring features are available using JBoss Operations Network
Future/Scope of Jboss administration Training
Market/opening were much higher for weblogic earlier but now market is moving towards Jboss administration training and the main reason for Jboss admin online training is for its open source availability and huge community folks. Even going for enterprise, Jboss administration training is less burn to pockets as compare to weblogic.
Market is moving towards Jboss admin online training but its always recommended to have knowledge on more than 2 technologies, so learn all and expertise in one technologies.
Jboss online Training course covers all the important administrative tasks that are required to administer this new version of JBoss online training AS. It starts with installation, architecture, and basic configuration and monitoring. It covers management using the new and expanded Web console, as well as the structure of the management model and how to use it via the admin CLI (Command Line Interface) and via scripting. It includes coverage of using the management tools to deploy and configure Web and Enterprise applications, datasources, JMS resources (topics, queues), as well as covering the configuration of the major subsystems, including the Web (HTTP), Web Services, Messaging (including the new HornetQ based provider), Logging, and Security subsystems. You will also learn the structure and contents of the underlying XML configuration files that reflect the actual configuration. The course also covers the use of JBoss in standalone mode (consistent with previous releases of JBoss), and explains the new domain model for managing multiple JBoss admin online training nodes from a single management point.
To Learn Jboss administration Training,please feel free to call or email us.
Name ::Nitesh Kumar
Email : [email protected]
Skype id-nitesh_maxmunus
Contact No.-+91-8553912023
0 notes
Text
300+ TOP JDBC Interview Questions and Answers
JDBC Interview Questions for freshers experienced
1. What is the JDBC? Java Database Connectivity (JDBC) is a standard Java API to interact with relational databases form Java. JDBC has set of classes and interfaces which can use from Java application and talk to database without learning RDBMS details and using Database Specific JDBC Drivers. 2. What are the new features added to JDBC 4.0? The major features added in JDBC 4.0 include : Auto-loading of JDBC driver class Connection management enhancements Support for RowId SQL type DataSet implementation of SQL using Annotations SQL exception handling enhancements SQL XML support 3. Explain Basic Steps in writing a Java program using JDBC? JDBC makes the interaction with RDBMS simple and intuitive. When a Java application needs to access database : Load the RDBMS specific JDBC driver because this driver actually communicates with the database (Incase of JDBC 4.0 this is automatically loaded). Open the connection to database which is then used to send SQL statements and get results back. Create JDBC Statement object. This object contains SQL query. Execute statement which returns resultset(s). ResultSet contains the tuples of database table as a result of SQL query. Process the result set. Close the connection. 4. Exaplain the JDBC Architecture. The JDBC Architecture consists of two layers:
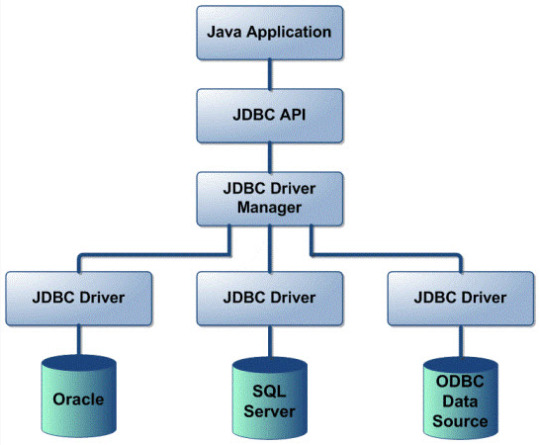
JDBC Architecture The JDBC API, which provides the application-to-JDBC Manager connection. The JDBC Driver API, which supports the JDBC Manager-to-Driver Connection. The JDBC API uses a driver manager and database-specific drivers to provide transparent connectivity to heterogeneous databases. The JDBC driver manager ensures that the correct driver is used to access each data source. The driver manager is capable of supporting multiple concurrent drivers connected to multiple heterogeneous databases. The location of the driver manager with respect to the JDBC drivers and the Java application is shown in Figure 1. 5. What are the main components of JDBC ? The life cycle of a servlet consists of the following phases: DriverManager: Manages a list of database drivers. Matches connection requests from the java application with the proper database driver using communication subprotocol. The first driver that recognizes a certain subprotocol under JDBC will be used to establish a database Connection. Driver: The database communications link, handling all communication with the database. Normally, once the driver is loaded, the developer need not call it explicitly. Connection: Interface with all methods for contacting a database.The connection object represents communication context, i.e., all communication with database is through connection object only. Statement : Encapsulates an SQL statement which is passed to the database to be parsed, compiled, planned and executed. ResultSet: The ResultSet represents set of rows retrieved due to query execution. 6. How the JDBC application works? A JDBC application can be logically divided into two layers:

JDBC application works Driver layer Application layer Driver layer consists of DriverManager class and the available JDBC drivers. The application begins with requesting the DriverManager for the connection. An appropriate driver is choosen and is used for establishing the connection. This connection is given to the application which falls under the application layer. The application uses this connection to create Statement kind of objects, through which SQL commands are sent to backend and obtain the results. 7. How do I load a database driver with JDBC 4.0 / Java 6? Provided the JAR file containing the driver is properly configured, just place the JAR file in the classpath. Java developers NO longer need to explicitly load JDBC drivers using code like Class.forName() to register a JDBC driver.The DriverManager class takes care of this by automatically locating a suitable driver when the DriverManager.getConnection() method is called. This feature is backward-compatible, so no changes are needed to the existing JDBC code. 8. What is JDBC Driver interface? The JDBC Driver interface provides vendor-specific implementations of the abstract classes provided by the JDBC API. Each vendor driver must provide implementations of the java.sql.Connection,Statement,PreparedStatement, CallableStatement, ResultSet and Driver. 9. What does the connection object represents? The connection object represents communication context, i.e., all communication with database is through connection object only. 10. Can the JDBC-ODBC Bridge be used with applets? Use of the JDBC-ODBC bridge from an untrusted applet running in a browser, such as Netscape Navigator, isn't allowed. The JDBC-ODBC bridge doesn't allow untrusted code to call it for security reasons. This is good because it means that an untrusted applet that is downloaded by the browser can't circumvent Java security by calling ODBC. Remember that ODBC is native code, so once ODBC is called the Java programming language can't guarantee that a security violation won't occur. On the other hand, Pure Java JDBC drivers work well with applets. They are fully downloadable and do not require any client-side configuration. Finally, we would like to note that it is possible to use the JDBC-ODBC bridge with applets that will be run in appletviewer since appletviewer assumes that applets are trusted. In general, it is dangerous to turn applet security off, but it may be appropriate in certain controlled situations, such as for applets that will only be used in a secure intranet environment. Remember to exercise caution if you choose this option, and use an all-Java JDBC driver whenever possible to avoid security problems.

JDBC Interview Questions 11. How do I start debugging problems related to the JDBC API? A good way to find out what JDBC calls are doing is to enable JDBC tracing. The JDBC trace contains a detailed listing of the activity occurring in the system that is related to JDBC operations. If you use the DriverManager facility to establish your database connection, you use the DriverManager.setLogWriter method to enable tracing of JDBC operations. If you use a DataSource object to get a connection, you use the DataSource.setLogWriter method to enable tracing. (For pooled connections, you use the ConnectionPoolDataSource.setLogWriter method, and for connections that can participate in distributed transactions, you use the XADataSource.setLogWriter method.) 12. What is new in JDBC 2.0? With the JDBC 2.0 API, you will be able to do the following: Scroll forward and backward in a result set or move to a specific row (TYPE_SCROLL_SENSITIVE,previous(), last(), absolute(), relative(), etc.) Make updates to database tables using methods in the Java programming language instead of using SQL commands.(updateRow(), insertRow(), deleteRow(), etc.) Send multiple SQL statements to the database as a unit, or batch (addBatch(), executeBatch()) Use the new SQL3 datatypes as column values like Blob, Clob, Array, Struct, Ref. 13. How to move the cursor in scrollable resultset ? a. create a scrollable ResultSet object. Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_READ_ONLY); ResultSet srs = stmt.executeQuery("SELECT COLUMN_1, COLUMN_2 FROM TABLE_NAME"); b. use a built in methods like afterLast(), previous(), beforeFirst(), etc. to scroll the resultset. srs.afterLast(); while (srs.previous()) { String name = srs.getString("COLUMN_1"); float salary = srs.getFloat("COLUMN_2"); //... c. to find a specific row, use absolute(), relative() methods. srs.absolute(4); // cursor is on the fourth row int rowNum = srs.getRow(); // rowNum should be 4 srs.relative(-3); int rowNum = srs.getRow(); // rowNum should be 1 srs.relative(2); int rowNum = srs.getRow(); // rowNum should be 3 d. use isFirst(), isLast(), isBeforeFirst(), isAfterLast() methods to check boundary status. 14. How to update a resultset programmatically? a. create a scrollable and updatable ResultSet object. Statement stmt = con.createStatement (ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE); ResultSet uprs = stmt.executeQuery("SELECT COLUMN_1, COLUMN_2 FROM TABLE_NAME"); b. move the cursor to the specific position and use related method to update data and then, call updateRow() method. uprs.last(); uprs.updateFloat("COLUMN_2", 25.55);//update last row's data uprs.updateRow();//don't miss this method, otherwise, // the data will be lost. 15. How can I use the JDBC API to access a desktop database like Microsoft Access over the network? Most desktop databases currently require a JDBC solution that uses ODBC underneath. This is because the vendors of these database products haven't implemented all-Java JDBC drivers. The best approach is to use a commercial JDBC driver that supports ODBC and the database you want to use. See the JDBC drivers page for a list of available JDBC drivers. The JDBC-ODBC bridge from Sun's Java Software does not provide network access to desktop databases by itself. The JDBC-ODBC bridge loads ODBC as a local DLL, and typical ODBC drivers for desktop databases like Access aren't networked. The JDBC-ODBC bridge can be used together with the RMI-JDBC bridge, however, to access a desktop database like Access over the net. This RMI-JDBC-ODBC solution is free. 16. Are there any ODBC drivers that do not work with the JDBC-ODBC Bridge? Most ODBC 2.0 drivers should work with the Bridge. Since there is some variation in functionality between ODBC drivers, the functionality of the bridge may be affected. The bridge works with popular PC databases, such as Microsoft Access and FoxPro. 17. What causes the "No suitable driver" error? "No suitable driver" is an error that usually occurs during a call to the DriverManager.getConnection method. The cause can be failing to load the appropriate JDBC drivers before calling the getConnection method, or it can be specifying an invalid JDBC URL--one that isn't recognized by your JDBC driver. Your best bet is to check the documentation for your JDBC driver or contact your JDBC driver vendor if you suspect that the URL you are specifying is not being recognized by your JDBC driver. In addition, when you are using the JDBC-ODBC Bridge, this error can occur if one or more the the shared libraries needed by the Bridge cannot be loaded. If you think this is the cause, check your configuration to be sure that the shared libraries are accessible to the Bridge. 18. Why isn't the java.sql.DriverManager class being found? This problem can be caused by running a JDBC applet in a browser that supports the JDK 1.0.2, such as Netscape Navigator 3.0. The JDK 1.0.2 does not contain the JDBC API, so the DriverManager class typically isn't found by the Java virtual machine running in the browser. Here's a solution that doesn't require any additional configuration of your web clients. Remember that classes in the java.* packages cannot be downloaded by most browsers for security reasons. Because of this, many vendors of all-Java JDBC drivers supply versions of the java.sql.* classes that have been renamed to jdbc.sql.*, along with a version of their driver that uses these modified classes. If you import jdbc.sql.* in your applet code instead of java.sql.*, and add the jdbc.sql.* classes provided by your JDBC driver vendor to your applet's codebase, then all of the JDBC classes needed by the applet can be downloaded by the browser at run time, including the DriverManager class. This solution will allow your applet to work in any client browser that supports the JDK 1.0.2. Your applet will also work in browsers that support the JDK 1.1, although you may want to switch to the JDK 1.1 classes for performance reasons. Also, keep in mind that the solution outlined here is just an example and that other solutions are possible. How to insert and delete a row programmatically? (new feature in JDBC 2.0) Make sure the resultset is updatable. 1. move the cursor to the specific position. uprs.moveToCurrentRow(); 2. set value for each column. uprs.moveToInsertRow();//to set up for insert uprs.updateString("col1" "strvalue"); uprs.updateInt("col2", 5); ... 3. call inserRow() method to finish the row insert process. uprs.insertRow(); To delete a row: move to the specific position and call deleteRow() method: uprs.absolute(5); uprs.deleteRow();//delete row 5 To see the changes call refreshRow(); uprs.refreshRow(); 19. What are the two major components of JDBC? One implementation interface for database manufacturers, the other implementation interface for application and applet writers. 20. What is JDBC Driver interface? The JDBC Driver interface provides vendor-specific implementations of the abstract classes provided by the JDBC API. Each vendor driver must provide implementations of the java.sql.Connection,Statement,PreparedStatement, CallableStatement, ResultSet and Driver. 21. How do I retrieve a whole row of data at once, instead of calling an individual ResultSet.getXXX method for each column? The ResultSet.getXXX methods are the only way to retrieve data from a ResultSet object, which means that you have to make a method call for each column of a row. It is unlikely that this is the cause of a performance problem, however, because it is difficult to see how a column could be fetched without at least the cost of a function call in any scenario. We welcome input from developers on this issue. 22. What are the common tasks of JDBC? Create an instance of a JDBC driver or load JDBC drivers through jdbc.drivers Register a driver Specify a database Open a database connection Submit a query Receive results Process results Why does the ODBC driver manager return 'Data source name not found and no default driver specified Vendor: 0' This type of error occurs during an attempt to connect to a database with the bridge. First, note that the error is coming from the ODBC driver manager. This indicates that the bridge-which is a normal ODBC client-has successfully called ODBC, so the problem isn't due to native libraries not being present. In this case, it appears that the error is due to the fact that an ODBC DSN (data source name) needs to be configured on the client machine. Developers often forget to do this, thinking that the bridge will magically find the DSN they configured on their remote server machine 23. How to use JDBC to connect Microsoft Access? There is a specific tutorial at javacamp.org. Check it out. 24. What are four types of JDBC driver? Type 1 Drivers Bridge drivers such as the jdbc-odbc bridge. They rely on an intermediary such as ODBC to transfer the SQL calls to the database and also often rely on native code. It is not a serious solution for an application Type 2 Drivers Use the existing database API to communicate with the database on the client. Faster than Type 1, but need native code and require additional permissions to work in an applet. Client machine requires software to run. Type 3 Drivers JDBC-Net pure Java driver. It translates JDBC calls to a DBMS-independent network protocol, which is then translated to a DBMS protocol by a server. Flexible. Pure Java and no native code. Type 4 Drivers Native-protocol pure Java driver. It converts JDBC calls directly into the network protocol used by DBMSs. This allows a direct call from the client machine to the DBMS server. It doesn't need any special native code on the client machine. Recommended by Sun's tutorial, driver type 1 and 2 are interim solutions where direct pure Java drivers are not yet available. Driver type 3 and 4 are the preferred way to access databases using the JDBC API, because they offer all the advantages of Java technology, including automatic installation. For more info, visit Sun JDBC page 25. Which type of JDBC driver is the fastest one? JDBC Net pure Java driver(Type IV) is the fastest driver because it converts the jdbc calls into vendor specific protocol calls and it directly interacts with the database. 26. Are all the required JDBC drivers to establish connectivity to my database part of the JDK? No. There aren't any JDBC technology-enabled drivers bundled with the JDK 1.1.x or Java 2 Platform releases other than the JDBC-ODBC Bridge. So, developers need to get a driver and install it before they can connect to a database. We are considering bundling JDBC technology- enabled drivers in the future. 27. Is the JDBC-ODBC Bridge multi-threaded? No. The JDBC-ODBC Bridge does not support concurrent access from different threads. The JDBC-ODBC Bridge uses synchronized methods to serialize all of the calls that it makes to ODBC. Multi-threaded Java programs may use the Bridge, but they won't get the advantages of multi-threading. In addition, deadlocks can occur between locks held in the database and the semaphore used by the Bridge. We are thinking about removing the synchronized methods in the future. They were added originally to make things simple for folks writing Java programs that use a single-threaded ODBC driver. 28. Does the JDBC-ODBC Bridge support multiple concurrent open statements per connection? No. You can open only one Statement object per connection when you are using the JDBC-ODBC Bridge. 29. What is the query used to display all tables names in SQL Server (Query analyzer)? select * from information_schema.tables 30. Why can't I invoke the ResultSet methods afterLast and beforeFirst when the method next works? You are probably using a driver implemented for the JDBC 1.0 API. You need to upgrade to a JDBC 2.0 driver that implements scrollable result sets. Also be sure that your code has created scrollable result sets and that the DBMS you are using supports them. 31. How can I retrieve a String or other object type without creating a new object each time? Creating and garbage collecting potentially large numbers of objects (millions) unnecessarily can really hurt performance. It may be better to provide a way to retrieve data like strings using the JDBC API without always allocating a new object. We are studying this issue to see if it is an area in which the JDBC API should be improved. Stay tuned, and please send us any comments you have on this question. 32. How many types of JDBC Drivers are present and what are they? There are 4 types of JDBC Drivers Type 1: JDBC-ODBC Bridge Driver Type 2: Native API Partly Java Driver Type 3: Network protocol Driver Type 4: JDBC Net pure Java Driver 33. What is the fastest type of JDBC driver? JDBC driver performance will depend on a number of issues: (a) the quality of the driver code, (b) the size of the driver code, (c) the database server and its load, (d) network topology, (e) the number of times your request is translated to a different API. In general, all things being equal, you can assume that the more your request and response change hands, the slower it will be. This means that Type 1 and Type 3 drivers will be slower than Type 2 drivers (the database calls are make at least three translations versus two), and Type 4 drivers are the fastest (only one translation). 34. There is a method getColumnCount in the JDBC API. Is there a similar method to find the number of rows in a result set? No, but it is easy to find the number of rows. If you are using a scrollable result set, rs, you can call the methods rs.last and then rs.getRow to find out how many rows rs has. If the result is not scrollable, you can either count the rows by iterating through the result set or get the number of rows by submitting a query with a COUNT column in the SELECT clause. I would like to download the JDBC-ODBC Bridge for the Java 2 SDK, Standard Edition (formerly JDK 1.2). I'm a beginner with the JDBC API, and I would like to start with 35. the Bridge. How do I do it? The JDBC-ODBC Bridge is bundled with the Java 2 SDK, Standard Edition, so there is no need to download it separately. 36. If I use the JDBC API, do I have to use ODBC underneath? No, this is just one of many possible solutions. We recommend using a pure Java JDBC technology-enabled driver, type 3 or 4, in order to get all of the benefits of the Java programming language and the JDBC API. 37. Once I have the Java 2 SDK, Standard Edition, from Sun, what else do I need to connect to a database? You still need to get and install a JDBC technology-enabled driver that supports the database that you are using. There are many drivers available from a variety of sources. You can also try using the JDBC-ODBC Bridge if you have ODBC connectivity set up already. The Bridge comes with the Java 2 SDK, Standard Edition, and Enterprise Edition, and it doesn't require any extra setup itself. The Bridge is a normal ODBC client. Note, however, that you should use the JDBC-ODBC Bridge only for experimental prototyping or when you have no other driver available. 38. How can I know when I reach the last record in a table, since JDBC doesn't provide an EOF method? Answer1 You can use last() method of java.sql.ResultSet, if you make it scrollable. You can also use isLast() as you are reading the ResultSet. One thing to keep in mind, though, is that both methods tell you that you have reached the end of the current ResultSet, not necessarily the end of the table. SQL and RDBMSes make no guarantees about the order of rows, even from sequential SELECTs, unless you specifically use ORDER BY. Even then, that doesn't necessarily tell you the order of data in the table. Answer2 Assuming you mean ResultSet instead of Table, the usual idiom for iterating over a forward only resultset is: ResultSet rs=statement.executeQuery(...); while (rs.next()) { // Manipulate row here } 39. Where can I find info, frameworks and example source for writing a JDBC driver? There a several drivers with source available, like MM.MySQL, SimpleText Database, FreeTDS, and RmiJdbc. There is at least one free framework, the jxDBCon-Open Source JDBC driver framework. Any driver writer should also review For Driver Writers. 40. How can I create a custom RowSetMetaData object from scratch? One unfortunate aspect of RowSetMetaData for custom versions is that it is an interface. This means that implementations almost have to be proprietary. The JDBC RowSet package is the most commonly available and offers the sun.jdbc.rowset.RowSetMetaDataImpl class. After instantiation, any of the RowSetMetaData setter methods may be used. The bare minimum needed for a RowSet to function is to set the Column Count for a row and the Column Types for each column in the row. For a working code example that includes a custom RowSetMetaData, 41. How does a custom RowSetReader get called from a CachedRowSet? The Reader must be registered with the CachedRowSet using CachedRowSet.setReader(javax.sql.RowSetReader reader). Once that is done, a call to CachedRowSet.execute() will, among other things, invoke the readData method. How do I implement a RowSetReader? I want to populate a CachedRowSet myself and the documents specify that a RowSetReader should be used. The single method accepts a 42. RowSetInternal caller and returns void. What can I do in the readData method? "It can be implemented in a wide variety of ways..." and is pretty vague about what can actually be done. In general, readData() would obtain or create the data to be loaded, then use CachedRowSet methods to do the actual loading. This would usually mean inserting rows, so the code would move to the insert row, set the column data and insert rows. Then the cursor must be set to to the appropriate position. 43. How can I instantiate and load a new CachedRowSet object from a non-JDBC source? The basics are: * Create an object that implements javax.sql.RowSetReader, which loads the data. * Instantiate a CachedRowset object. * Set the CachedRowset's reader to the reader object previously created. * Invoke CachedRowset.execute(). Note that a RowSetMetaData object must be created, set up with a description of the data, and attached to the CachedRowset before loading the actual data. The following code works with the Early Access JDBC RowSet download available from the Java Developer Connection and is an expansion of one of the examples: // Independent data source CachedRowSet Example import java.sql.*; import javax.sql.*; import sun.jdbc.rowset.*; public class RowSetEx1 implements RowSetReader { CachedRowSet crs; int iCol2; RowSetMetaDataImpl rsmdi; String sCol1, sCol3; public RowSetEx1() { try { crs = new CachedRowSet(); crs.setReader(this); crs.execute(); // load from reader System.out.println( "Fetching from RowSet..."); while(crs.next()) { showTheData(); } // end while next if(crs.isAfterLast() == true) { System.out.println( "We have reached the end"); System.out.println("crs row: " + crs.getRow()); } System.out.println( "And now backwards..."); while(crs.previous()) { showTheData(); } // end while previous if(crs.isBeforeFirst() == true) { System.out.println( "We have reached the start"); } crs.first(); if(crs.isFirst() == true) { System.out.println( "We have moved to first"); } System.out.println("crs row: " + crs.getRow()); if(crs.isBeforeFirst() == false) { System.out.println( "We aren't before the first row."); } crs.last(); if(crs.isLast() == true) { System.out.println( "...and now we have moved to the last"); } System.out.println("crs row: " + crs.getRow()); if(crs.isAfterLast() == false) { System.out.println( "we aren't after the last."); } } // end try catch (SQLException ex) { System.err.println("SQLException: " + ex.getMessage()); } } // end constructor public void showTheData() throws SQLException { sCol1 = crs.getString(1); if(crs.wasNull() == false) { System.out.println("sCol1: " + sCol1); } else { System.out.println("sCol1 is null"); } iCol2 = crs.getInt(2); if (crs.wasNull() == false) { System.out.println("iCol2: " + iCol2); } else { System.out.println("iCol2 is null"); } sCol3 = crs.getString(3); if (crs.wasNull() == false) { System.out.println("sCol3: " + sCol3 + "\n" ); } else { System.out.println("sCol3 is null\n"); } } // end showTheData // RowSetReader implementation public void readData(RowSetInternal caller) throws SQLException { rsmdi = new RowSetMetaDataImpl(); rsmdi.setColumnCount(3); rsmdi.setColumnType(1, Types.VARCHAR); rsmdi.setColumnType(2, Types.INTEGER); rsmdi.setColumnType(3, Types.VARCHAR); crs.setMetaData( rsmdi ); crs.moveToInsertRow(); crs.updateString( 1, "StringCol11" ); crs.updateInt( 2, 1 ); crs.updateString( 3, "StringCol31" ); crs.insertRow(); crs.updateString( 1, "StringCol12" ); crs.updateInt( 2, 2 ); crs.updateString( 3, "StringCol32" ); crs.insertRow(); crs.moveToCurrentRow(); crs.beforeFirst(); } // end readData public static void main(String args) { new RowSetEx1(); } } // end class RowSetEx1 44. Can I set up a connection pool with multiple user IDs? The single ID we are forced to use causes problems when debugging the DBMS. Since the Connection interface ( and the underlying DBMS ) requires a specific user and password, there's not much of a way around this in a pool. While you could create a different Connection for each user, most of the rationale for a pool would then be gone. Debugging is only one of several issues that arise when using pools. However, for debugging, at least a couple of other methods come to mind. One is to log executed statements and times, which should allow you to backtrack to the user. Another method that also maintains a trail of modifications is to include user and timestamp as standard columns in your tables. In this last case, you would collect a separate user value in your program. How can I protect my database password ? I'm writing a client-side java application that will access a database over the internet. I have concerns about the security of the database passwords. The client will have access in one way or another to the class files, where the connection string to the database, including user and 45. password, is stored in as plain text. What can I do to protect my passwords? This is a very common question. Conclusion: JAD decompiles things easily and obfuscation would not help you. But you'd have the same problem with C/C++ because the connect string would still be visible in the executable. SSL JDBC network drivers fix the password sniffing problem (in MySQL 4.0), but not the decompile problem. If you have a servlet container on the web server, I would go that route (see other discussion above) then you could at least keep people from reading/destroying your mysql database. Make sure you use database security to limit that app user to the minimum tables that they need, then at least hackers will not be able to reconfigure your DBMS engine. Aside from encryption issues over the internet, it seems to me that it is bad practice to embed user ID and password into program code. One could generally see the text even without decompilation in almost any language. This would be appropriate only to a read-only database meant to be open to the world. Normally one would either force the user to enter the information or keep it in a properties file. Detecting Duplicate Keys I have a program that inserts rows in a table. My table has a column 'Name' that has a unique constraint. If the user attempts to insert a duplicate name into the table, I want to display an error message by processing the error code from the database. How can I capture this error code in a Java program? A solution that is perfectly portable to all databases, is to execute a query for checking if that unique value is present before inserting the row. The big advantage is that you can handle your error message in a very simple way, and the obvious downside is that you are going to use more time for inserting the record, but since you're working on a PK field, performance should not be so bad. You can also get this information in a portable way, and potentially avoid another database access, by capturing SQLState messages. Some databases get more specific than others, but the general code portion is 23 - "Constraint Violations". UDB2, for example, gives a specific such as 23505, while others will only give 23000. 46. What driver should I use for scalable Oracle JDBC applications? Sun recommends using the thin ( type 4 ) driver. * On single processor machines to avoid JNI overhead. * On multiple processor machines, especially running Solaris, to avoid synchronization bottlenecks. 48. How do I write Greek ( or other non-ASCII/8859-1 ) characters to a database? From the standard JDBC perspective, there is no difference between ASCII/8859-1 characters and those above 255 ( hex FF ). The reason for that is that all Java characters are in Unicode ( unless you perform/request special encoding ). Implicit in that statement is the presumption that the data store can handle characters outside the hex FF range or interprets different character sets appropriately. That means either: * The OS, application and database use the same code page and character set. For example, a Greek version of NT with the DBMS set to the default OS encoding. * The DBMS has I18N support for Greek ( or other language ), regardless of OS encoding. This has been the most common for production quality databases, although support varies. Particular DBMSes may allow setting the encoding/code page/CCSID at the database, table or even column level. There is no particular standard for provided support or methods of setting the encoding. You have to check the DBMS documentation and set up the table properly. * The DBMS has I18N support in the form of Unicode capability. This would handle any Unicode characters and therefore any language defined in the Unicode standard. Again, set up is proprietary. 49. How can I insert images into a Mysql database? This code snippet shows the basics: File file = new File(fPICTURE); FileInputStream fis = new FileInputStream(file); PreparedStatement ps = ConrsIn.prepareStatement("insert into dbPICTURE values (?,?)"); // ***use as many ??? as you need to insert in the exact order*** ps.setString(1,file.getName()); ps.setBinaryStream(2,fis,(int)file.length()); ps.close(); fis.close(); 50. Is possible to open a connection to a database with exclusive mode with JDBC? I think you mean "lock a table in exclusive mode". You cannot open a connection with exclusive mode. Depending on your database engine, you can lock tables or rows in exclusive mode. In Oracle you would create a statement st and run st.execute("lock table mytable in exclusive mode"); Then when you are finished with the table, execute the commit to unlock the table. Mysql, Informix and SQLServer all have a slightly different syntax for this function, so you'll have to change it depending on your database. But they can all be done with execute(). 51. What are the standard isolation levels defined by JDBC? The values are defined in the class java.sql.Connection and are: * TRANSACTION_NONE * TRANSACTION_READ_COMMITTED * TRANSACTION_READ_UNCOMMITTED * TRANSACTION_REPEATABLE_READ * TRANSACTION_SERIALIZABLE Update fails without blank padding. Although a particular row is present in the database for a given key, executeUpdate() shows 0 rows updated and, in fact, the table is not updated. If I pad the Key with spaces for the column length (e.g. if the key column is 20 characters long, and key is msgID, length 6, I pad it with 14 spaces), 52. the update then works!!! Is there any solution to this problem without padding? In the SQL standard, CHAR is a fixed length data type. In many DBMSes ( but not all), that means that for a WHERE clause to match, every character must match, including size and trailing blanks. As Alessandro indicates, defining CHAR columns to be VARCHAR is the most general answer. 53. What isolation level is used by the DBMS when inserting, updating and selecting rows from a database? The answer depends on both your code and the DBMS. If the program does not explicitly set the isolation level, the DBMS default is used. You can determine the default using DatabaseMetaData.getDefaultTransactionIsolation() and the level for the current Connection with Connection.getTransactionIsolation(). If the default is not appropriate for your transaction, change it with Connection.setTransactionIsolation(int level). 54. How can I determine the isolation levels supported by my DBMS? Use DatabaseMetaData.supportsTransactionIsolationLevel(int level). Connecting to a database through the Proxy I want to connect to remote database using a program that is running in the local network behind the proxy. Is that possible? I assume that your proxy is set to accept http requests only on port 80. If you want to have a local class behind the proxy connect to the database for you, then you need a servlet/JSP to receive an HTTP request and use the local class to connect to the database and send the response back to the client. You could also use RMI where your remote computer class that connects to the database acts as a remote server that talks RMI with the clients. if you implement this, then you will need to tunnel RMI through HTTP which is not that hard. In summary, either have a servlet/JSP take HTTP requests, instantiate a class that handles database connections and send HTTP response back to the client or have the local class deployed as RMI server and send requests to it using RMI. 55. How do I receive a ResultSet from a stored procedure? Stored procedures can return a result parameter, which can be a result set. For a discussion of standard JDBC syntax for dealing with result, IN, IN/OUT and OUT parameters, see Stored Procedures. 56. How can I write to the log used by DriverManager and JDBC drivers? The simplest method is to use DriverManager.println(String message), which will write to the current log. 57. How can I get or redirect the log used by DriverManager and JDBC drivers? As of JDBC 2.0, use DriverManager.getLogWriter() and DriverManager.setLogWriter(PrintWriter out). Prior to JDBC 2.0, the DriverManager methods getLogStream() and setLogStream(PrintStream out) were used. These are now deprecated. 58. What does it mean to "materialize" data? This term generally refers to Array, Blob and Clob data which is referred to in the database via SQL locators "Materializing" the data means to return the actual data pointed to by the Locator. For Arrays, use the various forms of getArray() and getResultSet(). For Blobs, use getBinaryStream() or getBytes(long pos, int length). For Clobs, use getAsciiStream() or getCharacterStream(). 59. Why do I have to reaccess the database for Array, Blob, and Clob data? Most DBMS vendors have implemented these types via the SQL3 Locator type Some rationales for using Locators rather than directly returning the data can be seen most clearly with the Blob type. By definition, a Blob is an arbitrary set of binary data. It could be anything; the DBMS has no knowledge of what the data represents. Notice that this effectively demolishes data independence, because applications must now be aware of what the Blob data actually represents. Let's assume an employee table that includes employee images as Blobs. Say we have an inquiry program that presents multiple employees with department and identification information. To see all of the data for a specific employee, including the image, the summary row is selected and another screen appears. It is only at this pont that the application needs the specific image. It would be very wasteful and time consuming to bring down an entire employee page of images when only a few would ever be selected in a given run. Now assume a general interactive SQL application. A query is issued against the employee table. Because the image is a Blob, the application has no idea what to do with the data, so why bring it down, killing performance along the way, in a long running operation? Clearly this is not helpful in those applications that need the data everytime, but these and other considerations have made the most general sense to DBMS vendors. 60. What is an SQL Locator? A Locator is an SQL3 data type that acts as a logical pointer to data that resides on a database server. Read "logical pointer" here as an identifier the DBMS can use to locate and manipulate the data. A Locator allows some manipulation of the data on the server. While the JDBC specification does not directly address Locators, JDBC drivers typically use Locators under the covers to handle Array, Blob, and Clob data types. 61. How do I set properties for a JDBC driver and where are the properties stored? A JDBC driver may accept any number of properties to tune or optimize performance for the specific driver. There is no standard, other than user and password, for what these properties should be. Therefore, the developer is dependent on the driver documentation to automatically pass properties. For a standard dynamic method that can be used to solicit user input for properties, see What properties should I supply to a database driver in order to connect to a database? In addition, a driver may specify its own method of accepting properties. Many do this via appending the property to the JDBC Database URL. However, a JDBC Compliant driver should implement the connect(String url, Properties info) method. This is generally invoked through DriverManager.getConnection(String url, Properties info). The passed properties are ( probably ) stored in variables in the Driver instance. This, again, is up to the driver, but unless there is some sort of driver setup, which is unusual, only default values are remembered over multiple instantiations. 62. What is the JDBC syntax for using a literal or variable in a standard Statement? First, it should be pointed out that PreparedStatement handles many issues for the developer and normally should be preferred over a standard Statement. Otherwise, the JDBC syntax is really the same as SQL syntax. One problem that often affects newbies ( and others ) is that SQL, like many languages, requires quotes around character ( read "String" for Java ) values to distinguish from numerics. So the clause: "WHERE myCol = " + myVal is perfectly valid and works for numerics, but will fail when myVal is a String. Instead use: "WHERE myCol = '" + myVal + "'" if myVal equals "stringValue", the clause works out to: WHERE myCol = 'stringValue' You can still encounter problems when quotes are embedded in the value, which, again, a PreparedStatement will handle for you. 63. How do I check in my code whether a maximum limit of database connections have been reached? Use DatabaseMetaData.getMaxConnections() and compare to the number of connections currently open. Note that a return value of zero can mean unlimited or, unfortunately, unknown. Of course, driverManager.getConnection() will throw an exception if a Connection can not be obtained. 64. Why do I get UnsatisfiedLinkError when I try to use my JDBC driver? The first thing is to be sure that this does not occur when running non-JDBC apps. If so, there is a faulty JDK/JRE installation. If it happens only when using JDBC, then it's time to check the documentation that came with the driver or the driver/DBMS support. JDBC driver types 1 through 3 have some native code aspect and typically require some sort of client install. Along with the install, various environment variables and path or classpath settings must be in place. Because the requirements and installation procedures vary with the provider, there is no reasonable way to provide details here. A type 4 driver, on the other hand, is pure Java and should never exhibit this problem. The trade off is that a type 4 driver is usually slower. Many connections from an Oracle8i pooled connection returns statement closed. I am using import oracle.jdbc.pool.* with thin driver. If I test with many simultaneous connections, I get an SQLException that the statement is closed. ere is an example of concurrent operation of pooled connections from the OracleConnectionPoolDataSource. There is an executable for kicking off threads, a DataSource, and the workerThread. The Executable Member package package6; /** * package6.executableTester * */ public class executableTester { protected static myConnectionPoolDataSource dataSource = null; static int i = 0; /** * Constructor */ public executableTester() throws java.sql.SQLException { } /** * main * @param args */ public static void main(String args) { try{ dataSource = new myConnectionPoolDataSource(); } catch ( Exception ex ){ ex.printStackTrace(); } while ( i++ try{ workerClass worker = new workerClass(); worker.setThreadNumber( i ); worker.setConnectionPoolDataSource ( dataSource.getConnectionPoolDataSource() ); worker.start(); System.out.println( "Started Thread#"+i ); } catch ( Exception ex ){ ex.printStackTrace(); } } } } The DataSource Member package package6; import oracle.jdbc.pool.*; /** * package6.myConnectionPoolDataSource. * */ public class myConnectionPoolDataSource extends Object { protected OracleConnectionPoolDataSource ocpds = null; /** * Constructor */ public myConnectionPoolDataSource() throws java.sql.SQLException { // Create a OracleConnectionPoolDataSource instance ocpds = new OracleConnectionPoolDataSource(); // Set connection parameters ocpds.setURL("jdbc:oracle:oci8:@mydb"); ocpds.setUser("scott"); ocpds.setPassword("tiger"); } public OracleConnectionPoolDataSource getConnectionPoolDataSource() { return ocpds; } } The Worker Thread Member package package6; import oracle.jdbc.pool.*; import java.sql.*; import javax.sql.*; /** * package6.workerClass . * */ public class workerClass extends Thread { protected OracleConnectionPoolDataSource ocpds = null; protected PooledConnection pc = null; protected Connection conn = null; protected int threadNumber = 0; /** * Constructor */ public workerClass() { } public void doWork( ) throws SQLException { // Create a pooled connection pc = ocpds.getPooledConnection(); // Get a Logical connection conn = pc.getConnection(); // Create a Statement Statement stmt = conn.createStatement (); // Select the ENAME column from the EMP table ResultSet rset = stmt.executeQuery ("select ename from emp"); // Iterate through the result and print the employee names while (rset.next ()) // System.out.println (rset.getString (1)); ; // Close the RseultSet rset.close(); rset = null; // Close the Statement stmt.close(); stmt = null; // Close the logical connection conn.close(); conn = null; // Close the pooled connection pc.close(); pc = null; System.out.println( "workerClass.thread# "+threadNumber+" completed.."); } public void setThreadNumber( int assignment ){ threadNumber = assignment; } public void setConnectionPoolDataSource (OracleConnectionPoolDataSource x){ ocpds = x; } public void run() { try{ doWork(); } catch ( Exception ex ){ ex.printStackTrace(); } } } The OutPut Produced Started Thread#1 Started Thread#2 Started Thread#3 Started Thread#4 Started Thread#5 Started Thread#6 Started Thread#7 Started Thread#8 Started Thread#9 Started Thread#10 workerClass.thread# 1 completed.. workerClass.thread# 10 completed.. workerClass.thread# 3 completed.. workerClass.thread# 8 completed.. workerClass.thread# 2 completed.. workerClass.thread# 9 completed.. workerClass.thread# 5 completed.. workerClass.thread# 7 completed.. workerClass.thread# 6 completed.. workerClass.thread# 4 completed.. The oracle.jdbc.pool.OracleConnectionCacheImpl class is another subclass of the oracle.jdbc.pool.OracleDataSource which should also be looked over, that is what you really what to use. Here is a similar example that uses the oracle.jdbc.pool.OracleConnectionCacheImpl. The general construct is the same as the first example but note the differences in workerClass1 where some statements have been commented ( basically a clone of workerClass from previous example ). The Executable Member package package6; import java.sql.*; import javax.sql.*; import oracle.jdbc.pool.*; /** * package6.executableTester2 * */ public class executableTester2 { static int i = 0; protected static myOracleConnectCache connectionCache = null; /** * Constructor */ public executableTester2() throws SQLException { } /** * main * @param args */ public static void main(String args) { OracleConnectionPoolDataSource dataSource = null; try{ dataSource = new OracleConnectionPoolDataSource() ; connectionCache = new myOracleConnectCache( dataSource ); } catch ( Exception ex ){ ex.printStackTrace(); } while ( i++ try{ workerClass1 worker = new workerClass1(); worker.setThreadNumber( i ); worker.setConnection( connectionCache.getConnection() ); worker.start(); System.out.println( "Started Thread#"+i ); } catch ( Exception ex ){ ex.printStackTrace(); } } } protected void finalize(){ try{ connectionCache.close(); } catch ( SQLException x) { x.printStackTrace(); } this.finalize(); } } The ConnectCacheImpl Member package package6; import javax.sql.ConnectionPoolDataSource; import oracle.jdbc.pool.*; import oracle.jdbc.driver.*; import java.sql.*; import java.sql.SQLException; /** * package6.myOracleConnectCache * */ public class myOracleConnectCache extends OracleConnectionCacheImpl { /** * Constructor */ public myOracleConnectCache( ConnectionPoolDataSource x) throws SQLException { initialize(); } public void initialize() throws SQLException { setURL("jdbc:oracle:oci8:@myDB"); setUser("scott"); setPassword("tiger"); // // prefab 2 connection and only grow to 4 , setting these // to various values will demo the behavior //clearly, if it is not // obvious already // setMinLimit(2); setMaxLimit(4); } } The Worker Thread Member package package6; import oracle.jdbc.pool.*; import java.sql.*; import javax.sql.*; /** * package6.workerClass1 * */ public class workerClass1 extends Thread { // protected OracleConnectionPoolDataSource ocpds = null; // protected PooledConnection pc = null; protected Connection conn = null; protected int threadNumber = 0; /** * Constructor */ public workerClass1() { } public void doWork( ) throws SQLException { // Create a pooled connection // pc = ocpds.getPooledConnection(); // Get a Logical connection // conn = pc.getConnection(); // Create a Statement Statement stmt = conn.createStatement (); // Select the ENAME column from the EMP table ResultSet rset = stmt.executeQuery ("select ename from EMP"); // Iterate through the result // and print the employee names while (rset.next ()) // System.out.println (rset.getString (1)); ; // Close the RseultSet rset.close(); rset = null; // Close the Statement stmt.close(); stmt = null; // Close the logical connection conn.close(); conn = null; // Close the pooled connection // pc.close(); // pc = null; System.out.println( "workerClass1.thread# "+threadNumber+" completed.."); } public void setThreadNumber( int assignment ){ threadNumber = assignment; } // public void setConnectionPoolDataSource (OracleConnectionPoolDataSource x){ // ocpds = x; // } public void setConnection( Connection assignment ){ conn = assignment; } public void run() { try{ doWork(); } catch ( Exception ex ){ ex.printStackTrace(); } } } The OutPut Produced Started Thread#1 Started Thread#2 workerClass1.thread# 1 completed.. workerClass1.thread# 2 completed.. Started Thread#3 Started Thread#4 Started Thread#5 workerClass1.thread# 5 completed.. workerClass1.thread# 4 completed.. workerClass1.thread# 3 completed.. Started Thread#6 Started Thread#7 Started Thread#8 Started Thread#9 workerClass1.thread# 8 completed.. workerClass1.thread# 9 completed.. workerClass1.thread# 6 completed.. workerClass1.thread# 7 completed.. Started Thread#10 workerClass1.thread# 10 completed.. 65. DB2 Universal claims to support JDBC 2.0, But I can only get JDBC 1.0 functionality. What can I do? DB2 Universal defaults to the 1.0 driver. You have to run a special program to enable the 2.0 driver and JDK support. For detailed information, see Setting the Environment in Building Java Applets and Applications. The page includes instructions for most supported platforms. 66. How do I disallow NULL values in a table? Null capability is a column integrity constraint, normally applied at table creation time. Note that some databases won't allow the constraint to be applied after table creation. Most databases allow a default value for the column as well. The following SQL statement displays the NOT NULL constraint: CREATE TABLE CoffeeTable ( Type VARCHAR(25) NOT NULL, Pounds INTEGER NOT NULL, Price NUMERIC(5, 2) NOT NULL ) 67. How to get a field's value with ResultSet.getxxx when it is a NULL? I have tried to execute a typical SQL statement: select * from T-name where (clause); But an error gets thrown because there are some NULL fields in the table. You should not get an error/exception just because of null values in various columns. This sounds like a driver specific problem and you should first check the original and any chained exceptions to determine if another problem exists. In general, one may retrieve one of three values for a column that is null, depending on the data type. For methods that return objects, null will be returned; for numeric ( get Byte(), getShort(), getInt(), getLong(), getFloat(), and getDouble() ) zero will be returned; for getBoolean() false will be returned. To find out if the value was actually NULL, use ResultSet.wasNull() before invoking another getXXX method. 68. How do I insert/update records with some of the columns having NULL value? Use either of the following PreparedStatement methods: public void setNull(int parameterIndex, int sqlType) throws SQLException public void setNull(int paramIndex, int sqlType, String typeName) throws SQLException These methods assume that the columns are nullable. In this case, you can also just omit the columns in an INSERT statement; they will be automatically assigned null values. Is there a way to find the primary key(s) for an Access Database table? Sun's JDBC-ODBC driver does not implement the getPrimaryKeys() method for the DatabaseMetaData Objects. // Use meta.getIndexInfo() will //get you the PK index. Once // you know the index, retrieve its column name DatabaseMetaData meta = con.getMetaData(); String key_colname = null; // get the primary key information rset = meta.getIndexInfo(null,null, table_name, true,true); while( rset.next()) { String idx = rset.getString(6); if( idx != null) { //Note: index "PrimaryKey" is Access DB specific // other db server has diff. index syntax. if( idx.equalsIgnoreCase("PrimaryKey")) { key_colname = rset.getString(9); setPrimaryKey( key_colname ); } } } 69. Why can't Tomcat find my Oracle JDBC drivers in classes111.zip? TOMCAT 4.0.1 on NT4 throws the following exception when I try to connect to Oracle DB from JSP. javax.servlet.ServletException : oracle.jdbc.driver.OracleDriver java.lang.ClassNotFoundException: oracle:jdbc:driver:OracleDriver But, the Oracle JDBC driver ZIP file (classes111.zip)is available in the system classpath. Copied the Oracle Driver class file (classes111.zip) in %TOMCAT_Home - Home%\lib directory and renamed it to classess111.jar. Able to connect to Oracle DB from TOMCAT 4.01 via Oracle JDBC-Thin Driver. I have an application that queries a database and retrieves the results into a JTable. This is the code in the model that seems to be taken forever to execute, especially for a large result set: while ( myRs.next() ) { Vector newRow =new Vector(); for ( int i=1;i Read the full article
0 notes