#dbms assignments and solutions
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text

Database Management Assignment Help
Database Management is a serious computer science, IT, and data subject that educates students on storing, organizing, and managing information. Database management assignments in themselves are not quite easy. Therefore, here is The Tutors Help to assist you through the best support.
What Is Database Management?
Database Management is the art of processing information using a computer program in the form of a Database Management System (DBMS). Database Management is the skill of storing data, retrieving data, maintaining records, and having plenty of data at your fingertips and secure.
MySQL, Oracle, Microsoft SQL Server, and PostgreSQL are some of the most popular DBMS packages. They are used in everyday business, applications, and websites to store customer information, sales information, and other information.
Why Database Management Assignments Are Challenging
Database assignments are always challenging for students. Some of the frequent problems are as follows:
Ambiguous Queries: SQL queries are difficult to code, especially for JOINs, subqueries, or functions.
Normalization: Concepts of database normalization are abstract to study and apply in order to avoid redundancy and design data.
ER Diagrams: To design Entity-Relationship diagrams to show interaction between employees between data entities, a practice and thinking process is needed.
Theory and Practice: Theory cannot be taught; it has to be applied in real problems, and for that purpose, practice and time are necessary.
Time Management: It becomes difficult for the students to maintain a time sheet for assignments and other classes and subjects.
How The Tutors Help Helps You
The Tutors Help offers the best Database Management Assignment Help to the students worldwide. You are a new or an old student, we have you with the correct guidance.
Why students trust us:
Expert Tutors: We provide tutors who have first-hand experience with database systems and computer programming.
Step-by-Step Solutions: We give step-by-step solutions to each component of the assignment in a manner that you can understand it and improve upon your knowledge.
Plagiarism-Free Work: It's written from scratch and requested to be plagiarism-free.
On-Time Delivery: We respect your time constraints and complete your task on time.
Affordable Prices: We are student-pocket-friendly.
Topics We Cover
Our assignment help for database covers a series of topics such as:
SQL Queries
Relational Databases
Normalization (1NF, 2NF, 3NF)
Entity-Relationship Diagrams
NoSQL Databases
Data Modeling
Database Security
Looking for Help from The Tutors Help Made Easy:
We can begin simply:
Share Your Assignment: Give us your assignment specification and deadline.
Get a Quote: We will provide you a reasonable price for the assignment.
Get Expert Help: Our experts will complete the assignment on your specification.
Learn and Perform Well in Exams: Learn and perform well in exams through the assignment.
Final Thoughts
Database management is perhaps the most valuable skill of our age of technological advancement. If your project is just too overwhelming, relax—The Tutors Help is on hand to rescue you. With us as your guides, you will learn more, have more free time, and get higher grades.
Chat with us immediately and obtain the best Database Management Assignment Help at The Tutors Help!
https://www.thetutorshelp.com/database-management-assignment-help.php
0 notes
Text

Acquire our Database Management Systems Assignment Help and Solution Service!! Grab the chance to secure A++ grade in University Assessment!! Order Now on WhatsApp: +44 141 628 6080!!
#DatabaseManagementSystems #AssignmentHelp #DBMS #Solution #AssessmentWritingService #UK #HND #HigherNationalDiploma #Computing #UKAssessment #AssessmentWriting #BTEC #Assessment #HNC #OnlineTutor
0 notes
Text
Assignment 4:
K-means Cluster Analysis in the banking system
Introduction:
A personal equity plan (PEP) was an investment plan introduced in the United Kingdom that encouraged people over the age of 18 to invest in British companies. Participants could invest in shares, authorized unit trusts, or investment trusts and receive both income and capital gains free of tax. The PEP was designed to encourage investment by individuals. Banks engage in data analysis related to Personal Equity Plans (PEPs) for various reasons. They use it to assess the risk associated with these investment plans. By examining historical performance, market trends, and individual investor behavior, banks can make informed decisions about offering PEPs to their clients.
In general, banks analyze PEP-related data to make informed investment decisions, comply with regulations, and tailor their offerings to customer needs. The goal is to provide equitable opportunities for investors while managing risks effectively.
SAS Code
proc import out=mylib.mydata datafile='/home/u63879373/bank1.csv' dbms=CSV replace;
proc print data=mylib.mydata;
run;
/********************************************************************
DATA MANAGEMENT
*********************************************************************/
data new_clust; set mylib.mydata;
* create a unique identifier to merge cluster assignment variable with
the main data set;
idnum=_n_;
keep idnum age sex region income married children car save_act current_act mortgage pep;
* delete observations with missing data;
if cmiss(of _all_) then delete;
run;
ods graphics on;
* Split data randomly into test and training data;
proc surveyselect data=new_clust out=traintest seed = 123
samprate=0.7 method=srs outall;
run;
data clus_train;
set traintest;
if selected=1;
run;
data clus_test;
set traintest;
if selected=0;
run;
* standardize the clustering variables to have a mean of 0 and standard deviation of 1;
proc standard data=clus_train out=clustvar mean=0 std=1;
var age sex region income married children car save_act current_act mortgage;
run;
%macro kmean(K);
proc fastclus data=clustvar out=outdata&K. outstat=cluststat&K. maxclusters= &K. maxiter=300;
var age sex region income married children car save_act current_act mortgage;
run;
%mend;
%kmean(1);
%kmean(2);
%kmean(3);
%kmean(4);
%kmean(5);
%kmean(6);
%kmean(7);
%kmean(8);
%kmean(9);
* extract r-square values from each cluster solution and then merge them to plot elbow curve;
data clus1;
set cluststat1;
nclust=1;
if _type_='RSQ';
keep nclust over_all;
run;
data clus2;
set cluststat2;
nclust=2;
if _type_='RSQ';
keep nclust over_all;
run;
data clus3;
set cluststat3;
nclust=3;
if _type_='RSQ';
keep nclust over_all;
run;
data clus4;
set cluststat4;
nclust=4;
if _type_='RSQ';
keep nclust over_all;
run;
data clus5;
set cluststat5;
nclust=5;
if _type_='RSQ';
keep nclust over_all;
run;
data clus6;
set cluststat6;
nclust=6;
if _type_='RSQ';
keep nclust over_all;
run;
data clus7;
set cluststat7;
nclust=7;
if _type_='RSQ';
keep nclust over_all;
run;
data clus8;
set cluststat8;
nclust=8;
if _type_='RSQ';
keep nclust over_all;
run;
data clus9;
set cluststat9;
nclust=9;
if _type_='RSQ';
keep nclust over_all;
run;
data clusrsquare;
set clus1 clus2 clus3 clus4 clus5 clus6 clus7 clus8 clus9;
run;
* plot elbow curve using r-square values;
symbol1 color=blue interpol=join;
proc gplot data=clusrsquare;
plot over_all*nclust;
run;
*****************************************************************************
Number of clusters suggested by the elbow curve
*****************************************************************************
*the proposed numbers are: 2,5,7, and 8
* plot clusters for 5 cluster solution;
proc candisc data=outdata5 out=clustcan;
class cluster;
var age sex region income married children car save_act current_act mortgage;
run;
proc sgplot data=clustcan;
scatter y=can2 x=can1 / group=cluster;
run;
* validate clusters on PEP; The categorial target variable
* first merge clustering variable and assignment data with PEP data;
data pep_data;
set clus_train;
keep idnum pep;
run;
proc sort data=outdata5;
by idnum;
run;
proc sort data=pep_data;
by idnum;
run;
data merged;
merge outdata5 pep_data;
by idnum;
run;
proc sort data=merged;
by cluster;
run;
proc means data=merged;
var pep;
by cluster;
run;
proc anova data=merged;
class cluster;
model pep = cluster;
means cluster/tukey;
run;
Dataset
The dataset I used in this assignment contains information about customers in a bank. The Data analysis used will help the bank take know the important features that can affect the PEP of a client from the following features: age, sex, region, income, married, children, car, save_act, current_act and the mortgage.
Id: a unique identification number,
age: age of customer in years (numeric),
income: income of customer (numeric)
sex: 0 for MALE / 1 for FEMALE
married: is the customer married (1 for YES/ 0 for NO)
children: number of children (numeric)
car: does the customer own a car (1 for YES/ 0 for NO)
save_acct: does the customer have a saving account (1 for YES/ 0 for NO)
current_acct: does the customer have a current account (1 for YES/ 0 for NO)
mortgage: does the customer have a mortgage (1 for YES/ 0 for NO)
Figure1: dataset

K-means Clustering Algorithm
Cluster analysis is an unsupervised learning method used to group or cluster observations into subsets based on the similarity of responses on multiple variables. Observations that have similar response patterns are grouped together to form clusters. The goal is to partition the observations in a data set into a smaller set of clusters and each observation belongs to only one cluster.
Cluster analysis will be used in this assignment to develop individual banks’ customers profiles to target the ones that will benefit from the pep from those who shouldn’t.
With cluster analysis, we want customers within clusters to be more similar to each other than they are to observations in other clusters.
K-means Cluster Analysis
I used the libname statement to call my dataset. All the data is numerical (continues or logical depending on the feature description).
We'll first create a dataset that includes only my clustering variables and the PEP variable which will be used to externally validate the clusters. Then, we will assign each observation a unique identifier so that we can merge the cluster assignment variable back with the main dataset later on.
data new_clust; set mylib.mydata;
idnum=_n_; * create a unique identifier to merge cluster assignment variable with the main data set;
keep age sex region income married children car save_act current_act mortgage pep;
The SURVEYSELECT procedure
ODS graphics is turned on for the SAS to plot graphics. The data set is randomly split into a training data set consisting of 70% of the total observations in the data set, and a test data set consisting of the other 30% of the observations. Data equals, specifies the name of my managed dataset, called new_clust as seen in the figure below.
Figure 2
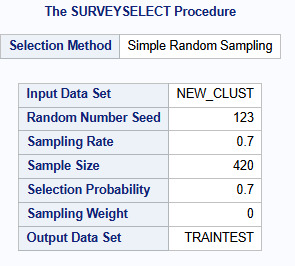
Statistics for variables
proc surveyselect data=new_clust out=traintest seed = 123
samprate=0.7 method=srs outall;
run;
method = srs specifies that the data are to be split using simple random sampling.
out=traintest to include both the training and test observations in a single output data set that has a new variable called selected.
The selected variable is 1 when an observation belongs to the training data set and 0 when an observation belongs to the test data set.
In cluster analysis, variables with large values contribute more to the distance calculations. Variables measured on different scales should be standardized prior to clustering. So, that the solution is not driven by variables measured on larger scales. We use the following code to standardize the clustering variables to have a mean of zero and a standard deviation of one.
proc standard data=clus_train out=clustvar mean=0 std=1;
var age sex region income married children car save_act current_act mortgage; run;
Figure 3

The Elbow curve
%macro kmean(K); indicates that the code is part of a Sass macro called knean and the K in parenthesis indicates that the macro will run the procedure code for number of different values of K. the output is then printed and the output data sets for K from 1 to 11 clusters is created.
Figure4
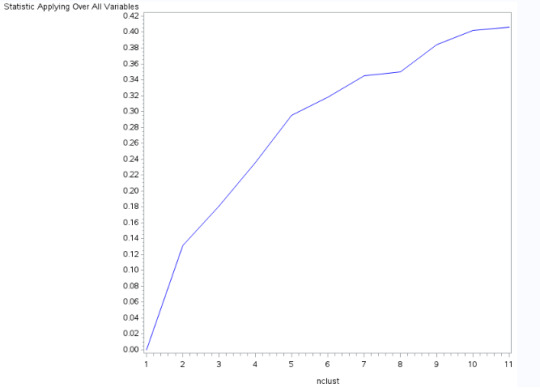
To view the different R-squared values for each of the k equals 1 to 11, the elbow plot is drawn as shown in the figure 5. We start with the K equals 1 with an R-squared=0 zero because there's no clustering yet. 2 cluster solution accounts for about 13% of the variance. The R-square value increases as more clusters are specified. We are looking for the bend in the elbow that shows where the R-square value might be leveling off. From the graph we can notice that there is a bend at 2 clusters, 5 clusters, 7 clusters, and 10 clusters. To help us figure out which solutions is best, we should further examine the results for the 2, 5, 7, and 10 cluster solutions.
Figure 5
The Canonical discriminate analysis
We should further examine the results for the 2, 5, 7, and 10 cluster solutions to see whether the clusters overlap or the patterns of means on the clustering variables are unique and meaningful and whether there are significant differences between the clusters on our external validation variable, PEP. We will interpret the result for the 5 cluster solution.
Since we have 10 variables, we will not be able to plot a scatter chart to see whether or not the clusters overlap with each other in terms of their location in the 10-dimensional space. For this, we have to use the canonical discriminate analysis which is a data reduction technique that creates a smaller number of variables that are linear combinations of the 10 clustering variables. Usually, the majority of the variants in the clustering variable will be accounted for by the first couple of canonical variables and those are the variables we can plot.
Figure 6
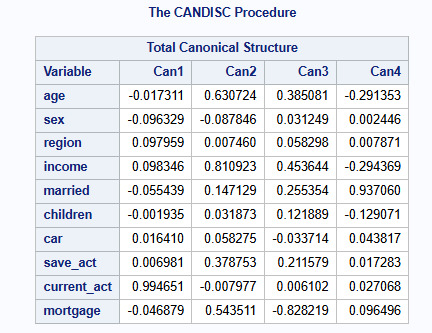
Results in Figure 6 show that the 10 variables are now reduced to 4 canonical variables that can be used to visualize the location of the clusters in a two or three dimensional space as shown in Figure 7.
Figure 7

What this shows is that the observations in cluster 5 is little more spread out, indicating less correlation among the observations and higher within cluster variance. Clusters 2 and 3 are relatively distinct with the exception that some of the observations are closer to each other indicating some overlap with these clusters. The same thing applies to cluster 2 and cluster 4. However, cluster 1 is all over the place. There is some indication of a cluster but the observations are spread out more than the other clusters. This means that the within cluster variance is high as there is less correlation between the observations in this cluster, so we don't really know what's going to happen with that cluster. So, the best cluster solution may have fewer than 5 clusters.
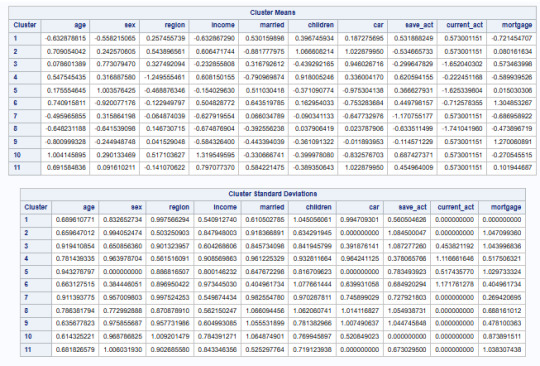
Cluster means table
We will consider for the rest that k=5. We will take a look at the cluster means table to examine the patterns of means on the clustering variables for each cluster which was shown in Figure8.
Figure 8

The means on the clustering variables show that compared to the other clusters, customers in cluster 2 and 5 have relatively good income, a current and saving accounts with no mortgage while customers in cluster 1 and 3 they have a low income, married and less number of children. Cluster 4 includes customers with a low income, low saving account and a mortgage.
Fit criteria for pep
The last part of this analysis will show how the clusters differ in PEP. We first have to extract the PEP variable from the training data set, then sort both data sets by the unique identifier, ID num which we will use to link the data sets and finally merge it with the data set that includes the cluster assignment variable.
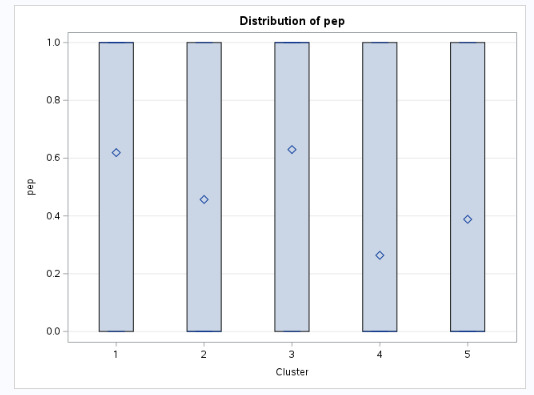
The graph in Figure 9 below shows the mean PEP by cluster. As it was described in the mean table before, customers in cluster 1 and 3 they have a low income, married and less number of children so these customers will be certainly accorded a PEP with 60% while customers in cluster 2 and 5 who have relatively good income, a current and saving accounts with no mortgage will be accorded also a PEP with 40%. However, customers in cluster 4 with a low income, low saving account and a mortgage will be accorded a pep with 25% as this is logic as they already have mortgage.
Figure 9
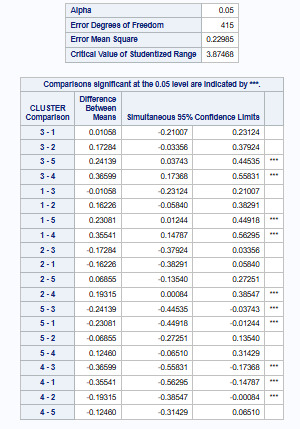
The tukey test
The anova procedure is used to test whether there are significant differences between clusters and PEP as follows:
proc anova data=merged;
class cluster;
model pep = cluster;
means cluster/tukey;
run;
The tukey test shows that the clusters differed significantly in mean PEP as shown in figure 10, with the exception of clusters 2 and 3, which did not differ significantly from each other.
Figure 10
Conclusion
Kmeans is Cluster analysis is an unsupervised learning method used to group or cluster observations into subsets based on the similarity of responses on multiple variables. It is a useful machine learning method that can be applied in any field. However, k-means cluster analysis will have to give us the correct number of clusters and figuring out the correct number clusters that represent the true number of clusters in the population is pretty subjective. Also, if results can change depending on the location of the observations that are randomly chosen as initial centroids. It also assumes that the underlying clusters in the population are spherical, distinct, and are of approximately equal size. As a result, tends to identify clusters with these characteristics. It won't work as well if clusters are elongated or not equal in size.
0 notes
Link
Are you looking for DBMS homework help? Our experts provide database management system assignment help service to colleges and universities students.
0 notes
Photo

Database Management Assignment Help
Are you looking for Help with Database Management Assignment? Our database management assignment writing experts create fresh and unique content. Moreover, the DBMS Assignment Help experts are highly professional as they have been working with numerous other companies present in the industry before joining us. Apart from this, the database management assignment solution experts also possess sound problem-solving, analytical, written, and communication skillsets. Furthermore, the database management assignment answers are always submitted within a strict deadline.
#databasemanagement#databasemanagementassignment#dbms#dbmsassignmenthelp#informationtechnology#allassignmentservices
9 notes
·
View notes
Text
btec hnd level 5 higher national diploma in engineering
Ozpaperhelp is one of the leading online writing services provider basically based in the UK and US. We can boost up their academic career and score on top within less acquired time. Our Academic Content Writer Experts provide the best sample of dissertation, assignments, thesis, and essay writing services which are compatible top the guidelines of almost every University. Ozpaperhelp provides 100% unique and plagiarism free writing services to all the students, who are pursuing their career in their relevant courses at the Best Universities based in Australia, UK, and the US.
We are reaching out to you for a mutually beneficial partnership wherein we can assist you if you can offload your work to us and we can reach out to you whenever we need some help in our work.
We're doing the assignment in the following subjects: a) Business managements, b) Business Intelligence, c) Nursing and Healthcare, d) Law Management e) Finance & accounting d) Project Management (SPSS ) (STATA) e) Auditing and Taxation f) Marketing Management g) Sociology & Criminology h) IT & Systems i) Economic & Journalism j) Media Management k) Education & Social welfare.
Academic Writing: We cover all subjects, areas from all levels whether it is school, college, or university.
Engineering: Mechanical, Civil, IT, Computer Science, Chemical, Electrical, Electronics, Automobile
Management: Finance, Accounts, HR, Marketing, CTH, Organisation Behavior, Project Management, Law
Statistical: SPSS, STATA, MATLAB, MINITAB, AUTOCAD, CATIA, E-VIEWS, EXCEL, SOLID WORKS, CAD-CAM
Software Language: C, C++, C#, Php, JAVA, .Net, DBMS, Python, etc
Exams: Perdisco, MYOB, and other online exams
Web Development: WordPress, Drupal, .Net, PHP, Javascript, etc
Apps: Android, IOS
WHY US:
a) Proper subject knowledge
b) Deadline wise delivery
c) Unique plagiarism free solutions
d) Proof-reading
e) 24 x 7 customer support
f) Minimum possible pricing
g) 9 years experience
What we provide along with Jobs:
1. Plagiarism report
2. Research file (Books, journals, links which we use to prepare the respective assignments).
#hnd level#hnd level 5#btec hnd#computing and it#hnd in computer science#maths in computing#level 5 higher national diploma in engineering#hnd in computing#btec national certificate#btec in it#btec higher national certificate#btec higher national diploma
2 notes
·
View notes
Photo

Ozpaperhelp.com is one of the leading online writing services provider basically based in the Australia, UK and US. With the support of Ozpaperhelp.com, an individual can boost up their academic career and score on top within less acquired time. Our Academic Content Writer Experts provide the best sample of dissertation, assignments, thesis and essay writing services which are compatible top the guidelines of almost every University. Ozpaperhelp.com provides 100% unique and plagiarism free writing services to all the Students, who are pursuing their career in their relevant courses at the Best Universities based in Australia, UK and US.
We are reaching out to you for a mutually beneficial partnership wherein we can assist you if you can offload your work to us and we can reach out to you whenever we need some help in our work.
We're doing assignment in following subjects: a) Business managements, b) Business Intelligence, c) Nursing and Healthcare, d) Law Management e) Finance & accounting d) Project Management (SPSS ) (STATA) e) Auditing and Taxation f) Marketing Management g) Sociology & Criminology h) IT & Systems i) Economic & Journalism j) Media Management k) Education & Social welfare.
Academic Writing : We cover all subjects, areas from all levels whether it is school, college or university.
Engineering: Mechanical, Civil, IT, Computer Science, Chemical, Electrical, Electronics, Automobile
Management: Finance, Accounts, HR, Marketing, CTH, Organisation Behavior, Project Management, Law
Statistical: SPSS, STATA, MATLAB, MINITAB, AUTOCAD, CATIA, E-VIEWS, EXCEL, SOLID WORKS, CAD-CAM
Software Language: C, C++, C#, Php, JAVA, .Net, DBMS, Python etc
Exams : Perdisco, MYOB and other online exams
Web Development : Wordpress, Drupal, .Net, PHP, Javascript etc
Apps : Android, IOS
WHY US:
a) Proper subject knowledge
b) Deadline wise delivery
c) Unique plagiarism free solutions
d) Proof-reading
e) 24 x 7 customer support
f) Minimum possible pricing
g) 9 years experience
What we provide along with Jobs:
1. Plagiarism report
2. Research file (Books, journals, links which we use to prepare the respective assignments)
1 note
·
View note
Text
Database Project Help
Avail Database Management System Assignment Solution At The Best Price
All the prices of our database management assignment help services are quite reasonable. Whether you want an advanced database management system assignment solution or a distributed database management system homework, you won't have a problem affording the service. Moreover, there are several deals and discounts that allow you to get database management system assignment answers at a much lower price.
Flat 25% off for all the new users
Exciting combo offers for regular customers
$20 signup bonus that can be redeemed later
Amazing referral bonus on every successful referral
Seasonal deals and discounts for loyal customers
Database Software Paradigms
Network Model: The network is an elaborated version of the hierarchical structure, giving access to many-to-many relationships through a tree-like structure, thus, allowing multiple parents. It organizes data through two fundamental concepts; records and sets.
Entity-Relationship Model: This model was developed for database design by Peter Chen. An entity is a thing that exists either physically or logically. For example, car, house, book, etc. Entities are linked to each other through relationships.
Relational Model: It was first described in 1969 by E.F. Codd. In this model, data is stored in form of tables called relations. Each row of table holds one record known as TUPLE. Each columnof table is called ATTRIBUTES.
Also, the price of our online DBMS assignment help will depend on the deadlines and the academic level of the solution. So, if you want the DBMS homework help at a lower price, simply place the order with a longer deadline. You can also generate the price quote of the required database management assignment help for free by submitting your requirements.
#databaseassignmenthelpers#databasehomeworkhelp#databaseassignmenthelp#databaseassignmenthelpexperts#database#databaseonlinehelpers#bestassignmentsupport.com
1 note
·
View note
Text
Subjects/Courses in Degree Of Information technology (IT) - ACEIT
BTech IT syllabus is a mix of theory and practical knowledge. The BTech IT 1st year syllabus at best engineering colleges in Jaipur covers the primary science, math, and engineering subjects. In the 2nd year syllabus, the B. Tech IT programme touches upon the specialized and elective subjects. Important B. Tech IT subjects include digital electronics, programming language, electronic mathematics, etc. For B. Tech IT jobs, graduates become adept at the latest new technologies, arriving at the most optimal solutions (consuming less time and effort) for any technological problems that might occur, whether small or large.
This course is divided into 4 years, 8 semesters that are 2 semesters each year. The marks of the students are based on their performances, in theory, lab work, and research projects assigned to them.
Apart from the chief course, the students of top engineering colleges Jaipur have to study a parallel course which instills helps them in improving and sharpening their skills. The course may also comprise of lectures, tutorials, training, research projects, and workshops. This helps students to learn more. Moreover, it helps in getting hands-on subjects like Discrete Structures, Web Technologies, Android Applications Development, Artificial Intelligence, Design and Analysis of Algorithm, and many other subjects.
Semester-Wise Syllabus For B.Tech IT
B. Tech IT course syllabus is made up of 8 semesters in 4 years. Students study core subjects in the first year and then move to elective subjects according to their interest in the second year. The course also focuses on practical learning through projects and internships. Semester wise subjects are as follows:
1. First Year Syllabus
a. Semester Ⅰ – It includes subjects like Applied Mathematics, Environment Studies, Engineering Mathematics, Electrical Science, Applied Physics Lab, Programming in C Lab, Engineering Graphics Lab, Engineering Mechanics Lab, English.
b. Semester Ⅱ – It includes subjects like Applied Mathematics, Applied Physics - II (Modern Physics), Data Structures using C, Applied Chemistry, Elements of Mechanical Engineering, Data Structures Using C Lab, English, Engineering Mechanics, Engineering Graphics.
2. Second Year Syllabus
a. Semester Ⅲ – It includes subjects like Analog Electronics, Database Management Systems, Operating Systems, Object-Oriented Programming using C++, Applied Mathematics – III, Analog Electronics Lab, UNIX Programming Lab – I.
b. Semester Ⅳ – It include subjects like Discrete Mathematics, Communication Systems, Computer Graphics, Management Information System, Digital Electronics, Digital Electronics Lab, Communication Systems Lab.
3. Third Year Syllabus
a. Semester Ⅴ – It include subjects like Software Engineering, VHDL Programming, Computer Architecture, Data Communication & Computer Networks, Java Programming, VHDL Programming Lab, Software Engineering Lab.
b. Semester Ⅵ – It include subjects like Microprocessor, System Programming, E-Commerce and ERP, Advanced Networking, Advanced Java programming, System Programming Lab, Microprocessor Lab.
4. Fourth Year Syllabus
a. Semester Ⅶ – It include subjects like Artificial Intelligence, Programming with ASP.Net, Software Project Management, Advance DBMS, Operational Research Lab, Mobile Computing, Information Security, Grid Computing.
b. Semester Ⅷ – It include subjects like Digital Image Processing, Information Storage & Management, Project Submission, Comprehension Viva-voce, Network Operating System, Linux Administration, Software Testing & Quality Assurance, Real-time systems.
Types Of Subjects In B. Tech IT
B. Tech IT at best BTech colleges Jaipur includes two kinds of subjects like core and the elective subjects. Along with this, internship and project submissions are included. In this course, students learn through group discussions and presentations prepared by themselves.
a. Core subjects - Some core subjects involve Engineering Mathematics, Basics of Electronics, Computer Languages, Introduction to Web Technology, Operating Systems, Concepts of Database, Software Project Management, Introduction to Microprocessor, Computer Graphics and Simulation, Data Mining and Data Warehousing.
b. Lab Subjects – Some lab subjects like VHDL Programming Lab, Programming with ASP.Net, Software Engineering Lab, System Programming Lab, Microprocessor Lab.
c. Elective Subjects – Some elective subjects include Introduction to Linux, Penetration Testing, Information Assurance and Security Management for IT, Network Programming, Network Security and Firewalls, Data and Information Security, Human Security, Malware Analysis, Mobile and Wireless Security.
Course Structure For B. Tech IT
B. Tech IT syllabus at engineering colleges Jaipur focuses on building holistic learning of information technology. In the first year, subjects are similar to aspirant studies in class 12. From the second year, core and elective subjects form the main course of the curriculum. In this way, students can choose the topics which are of interest to them. The course structure is a mix of theoretical knowledge and practical use of this knowledge through projects, research papers, group discussions, and internships. The course structure includes Ⅳ Semesters, Core and Elective Subjects, Research Papers, Surveys, Practical, Thesis Writing, Seminars, Projects, etc.
Teaching Methodology And Techniques
Teaching methodology for the students of BTech IT college Jaipur has a mixture of both theoretical as well as practical knowledge. This teaching methodology helps in building a comprehensive understanding of information technology. Through this methodology, students can understand the world of coding, networking, app development, cybersecurity, etc. Some methodology techniques used by colleges are Discussions, Problem-based Projects, E-learning, Co-curricular Activities, Field Trips, Practical Learnings.
Important Facts For Information Technology
This four-year course at private engineering colleges in Jaipur is divided into 8 semesters. The marks are rewarded according to the number of subjects in each semester.
Subjects related to Data Structures and Algorithms, Operating Systems, Parallel Computing, Artificial Intelligence, Computer Graphics, Soft Computing, Genetic Algorithms, Bioinformatics, Virtual Reality, Cloud Computing, Semantic Web Technologies, Software Architecture, Simulation and Modelling, Advances Database Structures, etc., are part of this course.
These subjects help the students gain an insight into various developments in technology and their applications in computer science engineering. A lot of innovation and self-equipped skills would be essential for the duration of this course. Much research and improvisation are required to keep up with the growing trend of producing unique technologies.
Every student of BTech college must score the minimum score to complete the respective course. Everyone should need to undertake a final year project as well. The type and the duration of the project, along with the respective credit score, are decided by the university/college.
Besides the respective core subjects, a student is free to take up elective courses as well. It is based on their interest and choices. A student can opt-in for such electives at the beginning of any semester at their own discretion. The choices of such electives may vary based on colleges or universities.
0 notes
Audio
Are you in need of immediate assistance with your database assignment? Don't worry, you're not the only one going through this. Professional assistance is sought by students studying computer science at different universities. Dbms Assignment Help from Great Assignment Help is the best online. Our database management experts can prepare quality database management assignment solutions that will help you achieve A+ grades. You no longer have to worry about completing multiple assignments in a short timeframe. Scholars are relieved of all their database assignment burdens, regardless of their complexity level. We offer programming homework help to students who need help with their database assignments and hold in-depth knowledge on the subject.
0 notes
Text
Database Management System
Database Management System (DBMS) & Decision Support System (DSS) Description Marks out of Wtg(%) Assignment 1 100.00 20.00 IMPORTANT INFORMATION Academic Integrity This assignment must be all your own work. It is acceptable to discuss course content with others to improve your understanding and clarify requirements, but solutions to assignment questions must be done on your…
View On WordPress
0 notes
Text
Database Management System
Database Management System (DBMS) & Decision Support System (DSS) Description Marks out of Wtg(%) Assignment 1 100.00 20.00 IMPORTANT INFORMATION Academic Integrity This assignment must be all your own work. It is acceptable to discuss course content with others to improve your understanding and clarify requirements, but solutions to assignment questions must be done on your…
View On WordPress
0 notes
Text
Database Management System
Database Management System (DBMS) & Decision Support System (DSS) Description Marks out of Wtg(%) Assignment 1 100.00 20.00 IMPORTANT INFORMATION Academic Integrity This assignment must be all your own work. It is acceptable to discuss course content with others to improve your understanding and clarify requirements, but solutions to assignment questions must be done on your…
View On WordPress
0 notes
Text
Database Management System
Database Management System (DBMS) & Decision Support System (DSS) Description Marks out of Wtg(%) Assignment 1 100.00 20.00 IMPORTANT INFORMATION Academic Integrity This assignment must be all your own work. It is acceptable to discuss course content with others to improve your understanding and clarify requirements, but solutions to assignment questions must be done on your…
View On WordPress
0 notes
Text
Mongodb compass create user

#Mongodb compass create user how to
#Mongodb compass create user install
#Mongodb compass create user update
#Mongodb compass create user update
The main page will list the new user in the “Users” column with options to change the password or remove the user.ĬWP Admin and regular users can also update MongoDB user passwords from the “Users” tab. Then type a strong password for the user. Otherwise, type a username and user role (“ReadOnly” or “ReadWrite”).
If the CWP user already has MongoDB users, you can select Add existing user to add them.
To the right of a MongoDB database, select the first (user) icon from the “Actions” column.
In this tutorial, you have used MongoDB compass on operations like insert, delete, and querying documents with filter and find. It helps users in activities like Indexing and Document Validation. Regular users can access this function from the left-side panel by selecting Databases > Mongo Database. You can create, insert, update and delete documents in databases with straightforward options rather than writing manual queries in MongoDB Compass. Create MongoDB Users in CWPĬWP admin and regular users can create MongoDB users.
#Mongodb compass create user how to
Now that you know how to create MongoDB databases on your CWP server, there are some related tasks you should be familiar with. CWP users currently logged in may need to refresh their browser page to see the new section. Once you’ve made your decision, select Save options. Then, check the box for “MongoDB available in user panel.” You can enable MongoDB access for all accounts or specific ones. (Optional) If you want to allow regular users to manage their MongoDB databases, select Options at the top.The main page will now show your new database with options to add MongoDB users or delete the database. The full database name will include the database user as a prefix (e.g. Assign the database to a CWP user account.Select Add new database in the upper-right corner.Regulars users cannot create MongoDB databases. Create MongoDB Databases in CWPīelow we’ll cover how to create a MongoDB database and assign it to a CWP end user. Now you can create MongoDB databases and users. On the right-hand side you’ll see the MongoDB version installed and service status (should be “Running”). The installation may take a minute.Īfter the page refreshes, you’ll see three system databases (“admin,” “config,” and “local”). Select Continue to confirm the installation process.
#Mongodb compass create user install
At the center you’ll see a mostly blank section reading “Mongo DB not installed.” Click Select version to install and choose which MongoDB version to install on your CWP server.
On the left, search for and select MongoDB Manager.
Apps that use MongoDB NoSQL solutions include the Rocket.Chat online communications platform and ApostropheCMS.īelow we’ll cover how to install and manage MongoDB databases in Control Web Panel (CWP).Īn administrator will need to install MongoDB before end users can manage databases. MongoDB is a non-relational database management system (DBMS) that is great for processing unstructured data at blazing fast speeds.
0 notes
Text
Sql tabs postgresql super user

SQL TABS POSTGRESQL SUPER USER SOFTWARE
SQL TABS POSTGRESQL SUPER USER SOFTWARE
Restrict write access on Postgres configuration file(s) the database service account, software owner accounts, Administrators, DBAs, System group, or other documented users authorized to edit the file(s).ģ) Database Users Assigned Superuser Privileges: If the postgresql configuration file(s) is owned by an unauthorized user, change ownership to an authorized user. Restrict access on the postgresql data directory to the database service account, software owner accounts, Administrators, DBAs, System group, or other documented users authorized to start a postgresql database cluster.Ģ) Postgresql Configuration File Ownership and Permissions: If the postgresql data directory and its contents are owned by unauthorized users, change ownership to an authorized user. If EDB Auditing is being used, perform the following actions as necessary to address any findings:ġ) Postgresql Data Directory Ownership and Permissions: If a non-EDB provided database auditing solution or a custom auditing solution is being used, configure the DBMS's settings according to the documentation provided for those solutions to allow designated personnel to select which auditable events are audited. CCI-000171 - The information system allows organization-defined personnel or roles to select which auditable events are to be audited by specific components of the information system.STIGQter: STIG Summary: EDB Postgres Advanced Server v11 on Windows Security Technical Implementation Guide Version: 2 Release: 1 Benchmark Date: : The EDB Postgres Advanced Server must allow only the ISSM (or individuals or roles appointed by the ISSM) to select which auditable events are to be audited.
0 notes