#delete a node from doubly linked list in c
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Photo

Video tutorial explains a C program to delete a node from doubly linked list. You will learn to delete first node, middle node as well as last node ffrom the doubly linked list. Doubly linked list is also known as two-way linked list. The C program is explained using step by step approach along with figures at each step. Entire source code is explained statement wise. In this tutorial, you will learn double link list deletion, delete the first node of doubly linked list and delete node at given position in doubly linked list. This online data structures and algorithms tutorial teaches, data structures in c, data structures interview questions and answers and data structures along with data structure programs. By the end of the vide you will be knowing, data structures and algorithms lectures, data structures tutorial videos and online data structures training. Complete coding is explained with figures at each step, you will understand, delete node at given position, data structures interview questions and previous pointer along with linked list using c. If you are looking for, delete a node from linked list, how to delete a node in doubly linked list and algorithm to delete a node from doubly linked list, then this video is for you. For code of deleting a node from doubly linked list, click the following link: http://bmharwani.com/deletefromdoubly.c For more video tutorials on data structures and algorithms, visit: https://www.youtube.com/watch?v=-XXsmBys2DQ&t=0s&list=PLuDr_vb2LpAxVWIk-po5nL5Ct2pHpndLR&index=6 To get notification for new videos, subscribe to my channel: https://youtube.com/c/bintuharwani To see more videos on different computer subjects, visit: http://bmharwani.com
#doubly linked list#delete a node from doubly linked list#double linked list#deletion in doubly linked list#time required to delete a node from doubly linked list#delete even nodes from doubly linked list#delete nth node from doubly linked list#delete middle node doubly linked list#write a function to delete a node from doubly linked list#delete a node from doubly linked list in c#delete middle node in doubly linked list#bintu harwani
2 notes
·
View notes
Text
Linked list stack implememntation using two queues 261

Linked list stack implememntation using two queues 261 code#
Fortunately, JavaScript arrays implement this for us in the form of the length property. algorithms (sorting, using stacks and queues, tree exploration algorithms, etc.). A common additional operation for collection data structures is the size, as it allows you to safely iterate the elements and find out if there are any more elements present in the data structure. Data structures: Abstract data types (ADTs), vector, deque, list, queue. Again, it doesn't change the index of the other items in the array, so it is O(1). Similarly, on pop, we simply pop the last value from the array. As it doesn't change the index of the current items, this is O(1). On push, we simply push the new item into the array. Therefore, we can simply implement the operations of this data structure using an array. Fortunately, in JavaScript implementations, array functions that do not require any changes to the index of the current items have an average runtime of O(1). First node have null in link field and second node link have first node address in link field and so on and last node address in. which is head of the stack where pushing and popping items happens at the head of the list. In stack Implementation, a stack contains a top pointer. You will use only one C file (stackfromqueue.c)containing all the functions to design the entire interface. The objective is to implement these push and pop operations such that they operate in O(1) time. A stack can be easily implemented using the linked list. Part 3: Linked List Stack Implementation Using Two Queues Inthis part, you will use two instances of Queue ADT to implement aStack ADT. This fact can be modeled into the type system by using a union of T and undefined. If there are no more items, we can return an out-of-bound value, for example, undefined. The other key operation pops an item from the stack, again in O(1). The first one is push, which adds an item in O(1). StdOut.java A list implemented with a doubly linked list. js is the open source HTML5 audio player. The stack data structure has two key operations. js, a JavaScript library with the goal of making coding accessible to artists, designers, educators, and beginners. We can model this easily in TypeScript using the generic class for items of type T. Using Python, create an implementation of Deque (double-ended queue) with linked list nodes.
Linked list stack implememntation using two queues 261 code#
So deleting of the middle element can be done in O(1) if we just pop the element from the front of the deque.A stack is a last-in/first-out data structure with key operations having a time complexity of O(1). I encountered this question as I am preparing for my code interview. The stack functions worked on from Worksheet 17 were re-implemented using the queue functions worked on from Worksheet 18. Overview: This program is an implementation of a stack using two instances of a queue. Here each new node will be dynamically allocated, so overflow is not possible unless memory is exhausted. Using an array will restrict the maximum capacity of the array, which can lead to stack overflow. You must use only standard operations of a queue - which means only push to back, peek/pop from front, size, and is empty operations are valid. The advantage of using a linked list over arrays is that it is possible to implement a stack that can grow or shrink as much as needed. empty () - Return whether the stack is empty. We will see that the middle element is always the front element of the deque. Stack With Two Queues (Linked List) Zedrimar. pop () - Removes the element on top of the stack. If after the pop operation, the size of the deque is less than the size of the stack, we pop an element from the top of the stack and insert it back into the front of the deque so that size of the deque is not less than the stack. The pop operation on myStack will remove an element from the back of the deque. The number of elements in the deque stays 1 more or equal to that in the stack, however, whenever the number of elements present in the deque exceeds the number of elements in the stack by more than 1 we pop an element from the front of the deque and push it into the stack. Insert operation on myStack will add an element into the back of the deque. We will use a standard stack to store half of the elements and the other half of the elements which were added recently will be present in the deque. Method 2: Using a standard stack and a deque ISRO CS Syllabus for Scientist/Engineer Exam.ISRO CS Original Papers and Official Keys.GATE CS Original Papers and Official Keys.
0 notes
Text
cop3503 Project 1 – Templated Linked List Solved
Overview
The purpose of this assignment is for you to write a data structure called a Linked List, which utilizes templates (similar to Java’s generics), in order to store any type of data. In addition, the nature of a Linked List will give you some experience dealing with non-contiguous memory organization. This will also give you more experience using pointers and memory management. Pointers, memory allocation, and understand how data is stored in memory will serve you well in a variety of situations, not just for an assignment like this.
Background
Remember Memory? Variables, functions, pointers—everything takes up SOME space in memory. Sometimes that memory is occupied for only a short duration (a temporary variable in a function), sometimes that memory is allocated at the start of a program and hangs around for the lifetime of that program. Visualizing memory can be difficult sometimes, but very helpful. You may see diagrams of memory like this:
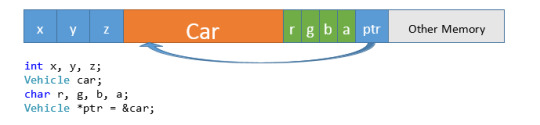
Or, you may see diagrams like these:

If you are trying to draw out some representation of memory to help you solve a problem, any of these (or some alternative that makes sense to you) will be fine.
Arrays
Arrays are stored in what is called contiguous memory. A contiguous memory block is one that is not interrupted by anything else (i.e. any other memory block). So if you created an array of 5 integers, each of those integers would be located one after the other in memory, with nothing else occupying memory between them. This is true for all arrays, of any data type.

All of the data in an application is not guaranteed to be contiguous, nor does it need to be. Arrays are typically the simplest and fastest way to store data, but they have a grand total of zero features. You allocate one contiguous block, but you can’t resize it, removing elements is a pain (and slow), etc. Consider the previous array. What if you wanted to add another element to that block of memory? If the surrounding memory is occupied, you can’t simply overwrite that with your new data element and expect good results.

someArray = 12; // #badIdea This will almost certainly break. Other Memory In this scenario, in order to store one more element you would have to: Create another array that was large enough to store all of the old elements plus the new one Copy over all of the data elements one at a time (including the new element, at the end) Free up the old array—no point in having two copies of the data

Other Memory Newly available memory Someone else’s memory 10 12 This process has to be repeated each time you want to add to the array (either at the end, or insert in the middle), or remove anything from the array. It can quite costly, in terms of performance, to delete/rebuild an entire array every time you want to make a single change. Cue the Linked List!
Linked List
The basic concept behind a Linked List is simple: It’s a container that stores its elements in a non-contiguous fashion Each element knows about the location of the element which comes after it (and possibly before, more on that later) So instead of a contiguous array, where element 4 comes after element 3, which comes after element 2, etc… you might have something like this:

Each element in the Linked List (typically referred to as a “node”) stores some data, and then stores a reference (a pointer, in C++), so the node which should come next. The First node knows only about the Second node. The Second node knows only about the Third, etc. The Fourth node has a null pointer as its “next” node, indicating that we’ve reached the end of the data. A real-world example can be helpful as well. Think about a line of people, with one person at the front of the line. That person might know about the person who is next in line, but no further than that (beyond him or herself, the person at the front doesn’t need to know or care). The second person in line might know about the third person in line, but no further. Continuing on this way, the last person in line knows that there is no one else that follows, so that must be the end. Since no one is behind that person, we must be at the end of the line.

So… What are the advantages of storing data like this? When inserting elements to an array, the entire array has to be reallocated. With a Linked List, only a small number of elements are affected. Only elements surrounding the changed element need to be updated, and all other elements can remain unaffected. This makes the Linked List much more efficient when it comes to adding or removing elements. Now, imagine one person wants to step out of line. If this were an array, all of the data would have to be reconstructed elsewhere. In a Linked List, only three nodes are affected: 1) The person leaving, 2) the person in front of that person, and 3) the person behind that person. Imagine you are the person at the front of the line. You don’t really need to know or care what happens 10 people behind you, as that has no impact on you whatsoever.

If the 5th person in line leaves, the only parts of the line that should be impacted are the 4th, 5th, and 6th spaces. Person 4 has a new “next” Person: whomever was behind the person behind them (Person 6). Person 5 has to be removed from the list. Person 6… actually does nothing. In this example, a Person only cares about whomever comes after them. Since Person 5 was before Person 6, Person 6 is unaffected. (A Linked List could be implemented with two-way information between nodes—more on that later). The same thought-process can be applied if someone stepped into line (maybe a friend was holding their place):
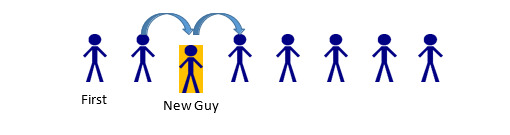
In this case, Person 2 would change their “next” person from Person 3, to the new Person being added. New Guy would have his “next” pointer set to whomever Person 2 was previously keeping track of, Person 3. Because of the ordering process, Person 3 would remain unchanged, as would anyone else in the list (aside from being a bit irritated at the New Guy for cutting in line). So that’s the concept behind a Linked List. A series of “nodes” which are connected via pointer to one another, and inserting/deleting nodes is a faster process than deleting and reconstructing the entire collection of data. Now, how to go about creating that?
Terminology
Node The fundamental building block of a Linked List. A node contains the data actually being stored in the list, as well as 1 or more pointers to other nodes. This is typically implemented as a nested class (see below). Singly-linked A Linked List would be singly-linked if each node only has a single pointer to another node, typically a “next” pointer. This only allows for uni-directional traversal of the data—from beginning to end. Doubly-linked Each node contains 2 pointers: a “next” pointer and a “previous” pointer. This allows for bi-directional traversal of the data—either from front-to-back or backto-front. Head A pointer to the first node in the list, akin to index 0 of an array. Tail A pointer to the last node in the list. May or may not be used, depending on the implementation of the list.
Nested Classes
The purpose of writing a class is to group data and functionality. The purpose of a nested class is the same—the only difference is where we declare a nested class. We declare a nested class like this: class MyClass { public: // Nested class class NestedClass { int x, y, z; NestedClass(); ~NestedClass(); int SomeFunction(); }; private: // Data for "MyClass" NestedClass myData; NestedClass *somePtr; float values; MyClass(); // Etc… }; // To create nested classes… // Use the Scope Resolution Operator MyClass::NestedClass someVariable; // With a class template… TemplateClass foo; TemplateClass::Nested bar; /* NOTE: You can make nested classes private if you wish, to prevent access to them outside of the encapsulating class. */ Additional reading: http://en.cppreference.com/w/cpp/language/nested_types The nature of the Linked List is that each piece of information knows about the information which follows (or precedes) it. It would make sense, then, to create some nested class to group all of that information together.
Benefits and Drawbacks
All data structures in programming (C++ or otherwise) have advantages and disadvantages. There is no “one size fits all” data structure. Some are faster (in some cases), some have smaller memory footprints, and some are more flexible in their functionality, which can make life easier for the programmer. Linked List versus Array – Who Wins? Array Linked List Fast access of individual elements as well as iteration over the entire array Changing the Linked List is fast – nodes can be inserted/removed very quickly Random access – You can quickly “jump” to the appropriate memory location of an element Less affected by memory fragmentation, nodes can fit anywhere in memory Changing the array is slow – Have to rebuild the entire array when adding/removing elements No random access, slow iteration Memory fragmentation can be an issue for arrays—need a single, contiguous block large enough for all of the data Extra memory overhead for nodes/pointers Slow to access individual elements
Code Structure
As shown above, the Linked List class itself stores very little data: Pointers to the first and last nodes, and a count. In some implementations, you might only have a pointer to the first node, and that’s it. In addition to those data members, your Linked List class must conform to the following interface:
Function Reference
Accessors PrintForward Iterator through all of the nodes and print out their values, one a time. PrintReverse Exactly the same as PrintForward, except completely the opposite. NodeCount Wait, we’re storing how many things in this list? FindAll Find all nodes which match the passed in parameter value, and store a pointer to that node in the passed in vector. Use of a parameter like this (passing a something in by reference, and storing data for later use) is called an output parameter. Find Find the first node with a data value matching the passed in parameter, returning a pointer to that node. Returns null if no matching node found. const and nonconst versions. GetNode Given an index, return a pointer to the node at that index. Throws an exception if the index is out of range. Const and non-const versions. Head Returns the head pointer. Const and non-const versions. Tail Returns the tail pointer. Const and non-const versions. Insertion Operations AddHead Create a new Node at the front of the list to store the passed in parameter. AddTail Create a new Node at the end of the list to store the passed in parameter. AddNodesHead Given an array of values, insert a node for each of those at the beginning of the list, maintaining the original order. AddNodesTail Ditto, except adding to the end of the list. InsertAfter Given a pointer to a node, create a new node to store the passed in value, after the indicated node. InsertBefore Ditto, except insert the new node before the indicated node. InsertAt Inserts a new Node to store the first parameter, at the index-th location. So if you specified 4 as the index, the new Node should have 3 Nodes before it. Throws an exception if given an invalid index. Removal Operations RemoveHead Deletes the first Node in the list. Returns whether or not the operation was successful. RemoveTail Deletes the last Node, returning whether or not the operation was successful. Remove Remove ALL Nodes containing values matching that of the passed-in parameter. Returns how many instances were removed. RemoveAt Deletes the index-th Node from the list, returning whether or not the operation was successful. Clear Deletes all Nodes. Don’t forget the node count! Operators operator Overloaded brackets operator. Takes an index, and returns the index-th node. Throws an exception if given an invalid index. Const and non-const versions. operator= After listA = listB, listA == listB is true. operator== Overloaded equality operator. Given listA and listB, is listA equal to listB? What would make one Linked List equal to another? If each of its nodes were equal to the corresponding node of the other. (Similar to comparing two arrays, just with non-contiguous data). Construction / Destruction LinkedList() Default constructor. A head, a tail, and a node counter walk into a bar… and get initialized? Wait, that’s not how that one goes… How many nodes in an empty list? What is head pointing to? What is tail pointing to? Copy Constructor Sets “this” to a copy of the passed in LinkedList. Other list has 10 nodes, with values of 1-10? “this” should too. ~LinkedList() The usual. Clean up your mess. (Delete all the nodes created by the list.)
Tips
A few tips for this assignment: Remember the "Big Three" or the “Rule of Three” o If you define one of the three special functions (copy constructor, assignment operator, or destructor), you should define the other two Start small, work one bit of functionality at a time. Work on things like Add() and PrintForward() first, as well as accessors (brackets operator, Head()/Tail(), etc). You can’t really test anything else unless those are working. Refer back to the recommended chapters in your textbook as well as lecture videos for an explanation of the details of dynamic memory allocation o There are a lot of things to remember when memory allocation The debugger is your friend! (You have learned how to use it, right?) Make charts, diagrams, sketches of the problem. Memory is inherently difficult to visualize, find a way that works for you. Don’t forget your node count! Read the full article
0 notes
Text
80% off #Break Away: Programming And Coding Interviews – $10
A course that teaches pointers, linked lists, general programming, algorithms and recursion like no one else
All Levels, – 21 hours, 83 lectures
Average rating 4.5/5 (4.5 (242 ratings) Instead of using a simple lifetime average, Udemy calculates a course’s star rating by considering a number of different factors such as the number of ratings, the age of ratings, and the likelihood of fraudulent ratings.)
Course requirements:
This course requires some basic understanding of a programming language, preferably C. Some solutions are in Java, though Java is not a requirement
Course description:
Programming interviews are like standard plays in professional sport – prepare accordingly. Don’t let Programming Interview gotchas get you down!
Programming interviews differ from real programming jobs in several important aspects, so they merit being treated differently, just like set pieces in sport. Just like teams prepare for their opponent’s playbooks in professional sport, it makes sense for you to approach programming interviews anticipating the interviewer’s playbook This course has been drawn by a team that has conducted hundreds of technical interviews at Google and Flipkart
What’s Covered:
Pointers: Memory layout of pointers and variables, pointer arithmetic, arrays, pointers to pointers, pointers to structures, argument passing to functions, pointer reassignment and modification – complete with visuals to help you conceptualize how things work. Strings: Strings, Character pointers, character arrays, null termination of strings, string.h function implementations with detailed explanations. Linked lists: Visualization, traversal, creating or deleting nodes, sorted merge, reversing a linked list and many many problems and solutions, doubly linked lists. Bit Manipulation: Work with bits and bit operations. Sorting and searching algorithms: Visualize how common sorting and searching algorithms work and the speed and efficiency of those algorithms Recursion: Master recursion with lots of practice! 8 common and uncommon recursive problems explained. Binary search, finding all subsets of a subset, finding all anagrams of a word, the infamous 8 Queens problem, executing dependent tasks, finding a path through a maze, implementing PaintFill, comparing two binary trees Data Structures: Understand queues, stacks, heaps, binary trees and graphs in detail along with common operations and their complexity. Includes code for every data structure along with solved interview problems based on these data structures. Step-by-step solutions to dozens of common programming problems: Palindromes, Game of Life, Sudoku Validator, Breaking a Document into Chunks, Run Length Encoding, Points within a distance are some of the problems solved and explained.
Talk to us!
Mail us about anything – anything! – and we will always reply

Full details Know how to approach and prepare for coding interviews Understand pointer concepts and memory management at a very deep and fundamental level Tackle a wide variety of linked list problems and know how to get started when asked linked list questions as a part of interviews Tackle a wide variety of general pointer and string problems and know how to answer questions on them during interviews Tackle a wide variety of general programming problems which involve just plain logic, no standard algorithms or data structures, these help you get the details right!
Full details YEP! New engineering graduate students who are interviewing for software engineering jobs YEP! Professionals from other fields with some programming knowledge looking to change to a software role YEP! Software professionals with several years of experience who want to brush up on core concepts NOPE! Other technology related professionals who are looking for a high level overview of pointer concepts.
Reviews:
“Algorithms and Data Structures are explained in a simple way. First, the instructor tells the logic, then visualizes it animating boxes and arrows, and finally shows the code. Very easy to follow along. I even solved a number of algorithms just by listening to the description of the logic behind it.” (Anuar AZ)
“It doest the exercises on C and not on Java which is desired for interviews” (Juan)
“The instructor’s knack of teaching complex algorithms in a simple and effective manner.” (RamaKrishna Ganti)
About Instructor:
Loony Corn
Loonycorn is us, Janani Ravi, Vitthal Srinivasan, Swetha Kolalapudi and Navdeep Singh. Between the four of us, we have studied at Stanford, IIM Ahmedabad, the IITs and have spent years (decades, actually) working in tech, in the Bay Area, New York, Singapore and Bangalore. Janani: 7 years at Google (New York, Singapore); Studied at Stanford; also worked at Flipkart and Microsoft Vitthal: Also Google (Singapore) and studied at Stanford; Flipkart, Credit Suisse and INSEAD too Swetha: Early Flipkart employee, IIM Ahmedabad and IIT Madras alum Navdeep: longtime Flipkart employee too, and IIT Guwahati alum We think we might have hit upon a neat way of teaching complicated tech courses in a funny, practical, engaging way, which is why we are so excited to be here on Udemy! We hope you will try our offerings, and think you’ll like them
Instructor Other Courses:
Learn by Example: JUnit Loony Corn, A 4-person team;ex-Google; Stanford, IIM Ahmedabad, IIT (0) $10 $20 Under the Hood: How Cars Work 25 Famous Experiments …………………………………………………………… Loony Corn coupons Development course coupon Udemy Development course coupon Programming Languages course coupon Udemy Programming Languages course coupon Break Away: Programming And Coding Interviews Break Away: Programming And Coding Interviews course coupon Break Away: Programming And Coding Interviews coupon coupons
The post 80% off #Break Away: Programming And Coding Interviews – $10 appeared first on Udemy Cupón/ Udemy Coupon/.
from Udemy Cupón/ Udemy Coupon/ http://coursetag.com/udemy/coupon/80-off-break-away-programming-and-coding-interviews-10/ from Course Tag https://coursetagcom.tumblr.com/post/156430869308
0 notes
Link
(Via: Hacker News)
A BK-tree is a tree data structure specialized to index data in a metric space. A metric space is essentially a set of objects which we equip with a distance function \(d(a, b)\) for every pair of elements \((a, b)\). This distance function must satisfy a set of axioms in order to ensure it's well-behaved. The exact reason why this is required will be explained in the "Search" paragraph below.
The BK-tree data structure was proposed by Burkhard and Keller in 1973 as a solution to the problem of searching a set of keys to find a key which is closest to a given query key. The naive way to solve this problem is to simply compare the query key with every element of the set; if the comparison is done in constant time, this solution is \(O(n)\). On the other hand, a BK-tree is likely to allow fewer comparisons to be made.
Construction of the tree
BK-tree is defined in the following way. An arbitrary element \(a\) is selected as root. Root may have zero or more sub-trees. The \(k\)-th sub-tree is recursively built of all elements \(b\) such that \(d(a,b) = k\).
To see how to construct a BK-tree, let's use a real scenario. We have a dictionary of words and we want to find those that are most similar to a given query word. To gauge how similar two words are, we are going to use the Levenshtein distance. Essentially, it's the minimum number of single-character edits (which can be insertions, deletions or substitutions) required to mutate one word into the other. For example, the distance between "soccer" and "otter" is \(3\), because we can change the first one into the other by deleting the leading s, and then substituting the two central c's with two t's.
Let's use the dictionary
{'some', 'soft', 'same', 'mole', 'soda', 'salmon'}
To construct the tree, we first choose any word as the root node, and then add the other words by calculating their distance from the root. In our case, we can choose "some" to be the root element. Then, after adding the two subsequent words the tree would look like this:
because the distance between "some" and "same" is \(1\) and the distance between "some" and "soft" is \(2\). Now, let's add the next word, "mole". Observe that the distance between "mole" and "some" is again \(2\), so we add it to the tree as a child of "soft", with an edge corresponding to their distance. After adding all the words we obtain the following tree:
Search
Remember that the original problem was to find all the words closest to a given query word. Call \(N\) the maximum allowed distance (which we'll call radius). The algorithm proceeds as follows:
create a candidates list and add the root node to it
take a candidate, compute its distance \(D\) from the query key and compare it with the radius;
selection criterion: add to the candidates list all the children of the current node that, from their parent, have a distance between \(D - N\) and \(D + N\) (inclusive).
Suppose we want to find all the words in our dictionary that are no more distant than \(N = 2\) from the word "sort". Our only candidate is the root node "some". We start by computing
\[D = \mathop{\mathrm{Levenshtein}}(\text{`sort'}, \text{`some'}) = 2\]
Since the radius is \(2,\) we add "some" to the list of results. Then we extend our candidates list with all the children that have a distance from the root node between \(D - N = 0\) and \(D + N = 4\). In this case, all the children satisfy this condition. Moving on, we compute
\[D = \mathop{\mathrm{Levenshtein}}(\text{`sort'}, \text{`same'}) = 3\]
Since \(D > N\), this node is not a result and we move on to "soft"; now
\[D = \mathop{\mathrm{Levenshtein}}(\text{`sort'}, \text{`soft'}) = 1\]
Hence "soft" is an acceptable result. Regarding its children, we take those that have a distance between \(D - N = -1\) and \(D + N = 3\). Again, all of them, but only "soda" is a valid result. Finally, "salmon" is not acceptable. If we sort our results by distance we end up with the following:
[(1, 'soft'), (2, 'some'), (2, 'soda')]
Why does it work?
It's interesting to understand why we are allowed to prune all the children that do not meet the criterion we gave above in point \(3\). In the introduction we said that our distance function \(d\) must satisfy a set of axioms in order for us to obtain the metric space structure. Those axioms are the following. For all elements \(a,b,c\) it must hold:
non-negativity: \(d(a, b) \ge 0\);
\(d(a, b) = 0\) implies \(a = b\) (and vice-versa);
symmetry: \(d(a, b) = d(b, a)\)
triangle inequality: \(d(a, b) \le d(a, c) + d(c, b)\).
The first three are just a formalization of our intuitive notion of "distance", while the last one derives from the relation between sides of a triangle in Euclidean geometry. This is often the most difficult property to demonstrate when we want to prove that a generic distance is actually a metric. As it turns out, the Levenshtein distance satisfies this property and therefore it's a metric. This is why we can use it in the examples above.
Let's call the query key \(\bar x\). Suppose we are evaluating the child \(B\) of an arbitrary node \(A\) inside the tree, which we calculated to be at a distance \(D = d(\bar x, A)\) from the query key. This situation is summarized in the following figure:
Since we assumed that \(d\) is a metric, by the triangle inequality we have
\[d(A, B) \le d(A, \bar x) + d(\bar x, B)\]
from which
\[d(\bar x, B) \ge d(A, B) - d(A, \bar x) = x - D.\]
Using the triangle inequality again, this time with \(d(A, \bar x)\) and \(B\), we obtain
\[d(\bar x, B) \ge d(A, \bar x) - d(A, B) = D - x\]
Since we are only interested in nodes that are at a distance at most \(N\) from the query key \(\bar x\), we impose the constraint \(d(\bar x, B) \le N\). This translates to
\[\begin{cases}x - D \le N\\D - x \le N\end{cases}\]
which is equivalent to
\[D - N \le x \le D + N\]
We have proved that if \(d\) is a metric, we can safely discard nodes that do not meet the above criteria. Finally, note that every child of \(B\) will be at a distance of \(x\) from \(A\) (by construction of the BK-tree) and therefore we can safely prune the whole sub-tree if \(B\) alone does not meet the criterion.
Implementation
This data structure is easy to implement in Python, if we use dictionaries to represent edges.
from collections import deque class BKTree: def __init__(self, distance_func): self._tree = None self._distance_func = distance_func def add(self, node): if self._tree is None: self._tree = (node, {}) return current, children = self._tree while True: dist = self._distance_func(node, current) target = children.get(dist) if target is None: children[dist] = (node, {}) break current, children = target def search(self, node, radius): if self._tree is None: return [] candidates = deque([self._tree]) result = [] while candidates: candidate, children = candidates.popleft() dist = self._distance_func(node, candidate) if dist <= radius: result.append((dist, candidate)) low, high = dist - radius, dist + radius candidates.extend(c for d, c in children.items() if low <= d <= high) return result
The implementation is pretty straightforward and adheres completely to the algorithm we explained above. A few comments:
there's no need to add a root argument to the __init__ method, since any element can be a root node. In our case the first one added will become root;
why is deque even needed? At first I used a set, only to see it fail because dictionaries aren't hashable. We need another data structure that allows \(O(1)\) popping and linear insertion. Built-in deque, being a doubly-linked list, is a natural fit.
Conclusion
The BK-tree is a relatively lesser-known data structure suitable for nearest neighbor search (NNS). It allows a considerable reduction of the search space, if the distance we are working with is a metric. In practice, the speed improvement we get from pruning sub-trees heavily depends on the search space and the radius we select. This is why some experimentation is usually needed for the problem at hand. One area in which BK-tree does well is spell-checking: as long as one keeps the radius to \(1\) or \(2\) the search space is often reduced to under \(10\%\) of the original.
0 notes
Text
80% off #From 0 to 1: C Programming – Drill Deep – $10
C Programming is still a very useful skill to have – and this is the course to pick it up!
All Levels, – Video: 12 hours, 60 lectures
Average rating 4.4/5 (4.4)
Course requirements:
The course assumes that the student has a way to write and run C programs. This could include gcc on Mac or Unix, or Visual Studio on Windows.
Course description:
C Programming is still a very valuable skill – and its also surprisingly easy to pick up. Don’t be intimidated by C’s reputation as scary – we think this course makes it easy as pie!
What’s Covered:
Conditional Constructs: If/else and case statements have a surprising number of little details to be aware of. Conditions, and working with relational and logical operators. Short-circuiting and the order of evaluation Loops: For loops, while and do-while loops, break and continue. Again, lots of little details to get right. Data Types and Bit Manipulation Operations, again full of little gotchas that interviewers and professors love to test. Pointers: Memory layout of pointers and variables, pointer arithmetic, arrays, pointers to pointers, pointers to structures, argument passing to functions, pointer reassignment and modification – complete with visuals to help you conceptualize how things work. Strings: Strings, Character pointers, character arrays, null termination of strings, string.h function implementations with detailed explanations. Structs and Unions: These seem almost archaic in an Object-Oriented world, but worth knowing, especially in order to nail linked list problems. Linked lists: Visualization, traversal, creating or deleting nodes, sorted merge, reversing a linked list and many many problems and solutions, doubly linked lists. IO: Both console and file IO Enums, typedefs, macros
Talk to us!
Mail us about anything – anything! – and we will always reply
Full details Write solid, correct and complete C programs Advance – quickly and painlessly – to C++, which is a natural successor to C and still widely used Ace tests or exams on the C programming language Shed their fears about the gotchas and complexities of the C programming language Make use of C in those situations where it is still the best tool available
Full details Yep! Computer science or engineering majors who need to learn C for their course requirements Yep! Embedded systems or hardware folks looking to make the most of C, which is still an awesome technology in those domains Yep! Any software engineer who will be giving interviews, and fears interview questions on the tricky syntax of C
Full details
Reviews:
“Its very good and detailed course. Great if you want a brief overview of C at a glance” (Aditya Mehta)
“This course teaches the ins and outs of the language. That is its purpose. Fully achieved – the longer the course, the better it gets.” (H2m2)
“It would have been better if they would actually show practical examples by running it on ide and explaining the flow of code.” (Nitin Ainani)
About Instructor:
Loony Corn
Loonycorn is us, Janani Ravi, Vitthal Srinivasan, Swetha Kolalapudi and Navdeep Singh. Between the four of us, we have studied at Stanford, IIM Ahmedabad, the IITs and have spent years (decades, actually) working in tech, in the Bay Area, New York, Singapore and Bangalore. Janani: 7 years at Google (New York, Singapore); Studied at Stanford; also worked at Flipkart and Microsoft Vitthal: Also Google (Singapore) and studied at Stanford; Flipkart, Credit Suisse and INSEAD too Swetha: Early Flipkart employee, IIM Ahmedabad and IIT Madras alum Navdeep: longtime Flipkart employee too, and IIT Guwahati alum We think we might have hit upon a neat way of teaching complicated tech courses in a funny, practical, engaging way, which is why we are so excited to be here on Udemy! We hope you will try our offerings, and think you’ll like them
Instructor Other Courses:
Learn By Example: jQuery Learn By Example: Angular JS Learn By Example: Scala …………………………………………………………… Loony Corn coupons Development course coupon Udemy Development course coupon Programming Languages course coupon Udemy Programming Languages course coupon From 0 to 1: C Programming – Drill Deep From 0 to 1: C Programming – Drill Deep course coupon From 0 to 1: C Programming – Drill Deep coupon coupons
The post 80% off #From 0 to 1: C Programming – Drill Deep – $10 appeared first on Udemy Cupón.
from Udemy Cupón http://www.xpresslearn.com/udemy/coupon/80-off-from-0-to-1-c-programming-drill-deep-10/
from https://xpresslearn.wordpress.com/2017/03/01/80-off-from-0-to-1-c-programming-drill-deep-10/
0 notes
Text
80% off #From 0 to 1: C Programming – Drill Deep – $10
C Programming is still a very useful skill to have – and this is the course to pick it up!
All Levels, – Video: 12 hours, 60 lectures
Average rating 4.4/5 (4.4)
Course requirements:
The course assumes that the student has a way to write and run C programs. This could include gcc on Mac or Unix, or Visual Studio on Windows.
Course description:
C Programming is still a very valuable skill – and its also surprisingly easy to pick up. Don’t be intimidated by C’s reputation as scary – we think this course makes it easy as pie!
What’s Covered:
Conditional Constructs: If/else and case statements have a surprising number of little details to be aware of. Conditions, and working with relational and logical operators. Short-circuiting and the order of evaluation Loops: For loops, while and do-while loops, break and continue. Again, lots of little details to get right. Data Types and Bit Manipulation Operations, again full of little gotchas that interviewers and professors love to test. Pointers: Memory layout of pointers and variables, pointer arithmetic, arrays, pointers to pointers, pointers to structures, argument passing to functions, pointer reassignment and modification – complete with visuals to help you conceptualize how things work. Strings: Strings, Character pointers, character arrays, null termination of strings, string.h function implementations with detailed explanations. Structs and Unions: These seem almost archaic in an Object-Oriented world, but worth knowing, especially in order to nail linked list problems. Linked lists: Visualization, traversal, creating or deleting nodes, sorted merge, reversing a linked list and many many problems and solutions, doubly linked lists. IO: Both console and file IO Enums, typedefs, macros
Talk to us!
Mail us about anything – anything! – and we will always reply

Full details Write solid, correct and complete C programs Advance – quickly and painlessly – to C++, which is a natural successor to C and still widely used Ace tests or exams on the C programming language Shed their fears about the gotchas and complexities of the C programming language Make use of C in those situations where it is still the best tool available
Full details Yep! Computer science or engineering majors who need to learn C for their course requirements Yep! Embedded systems or hardware folks looking to make the most of C, which is still an awesome technology in those domains Yep! Any software engineer who will be giving interviews, and fears interview questions on the tricky syntax of C
Full details
Reviews:
“Its very good and detailed course. Great if you want a brief overview of C at a glance” (Aditya Mehta)
“This course teaches the ins and outs of the language. That is its purpose. Fully achieved – the longer the course, the better it gets.” (H2m2)
“It would have been better if they would actually show practical examples by running it on ide and explaining the flow of code.” (Nitin Ainani)
About Instructor:
Loony Corn
Loonycorn is us, Janani Ravi, Vitthal Srinivasan, Swetha Kolalapudi and Navdeep Singh. Between the four of us, we have studied at Stanford, IIM Ahmedabad, the IITs and have spent years (decades, actually) working in tech, in the Bay Area, New York, Singapore and Bangalore. Janani: 7 years at Google (New York, Singapore); Studied at Stanford; also worked at Flipkart and Microsoft Vitthal: Also Google (Singapore) and studied at Stanford; Flipkart, Credit Suisse and INSEAD too Swetha: Early Flipkart employee, IIM Ahmedabad and IIT Madras alum Navdeep: longtime Flipkart employee too, and IIT Guwahati alum We think we might have hit upon a neat way of teaching complicated tech courses in a funny, practical, engaging way, which is why we are so excited to be here on Udemy! We hope you will try our offerings, and think you’ll like them
Instructor Other Courses:
Learn By Example: jQuery Learn By Example: Angular JS Learn By Example: Scala …………………………………………………………… Loony Corn coupons Development course coupon Udemy Development course coupon Programming Languages course coupon Udemy Programming Languages course coupon From 0 to 1: C Programming – Drill Deep From 0 to 1: C Programming – Drill Deep course coupon From 0 to 1: C Programming – Drill Deep coupon coupons
The post 80% off #From 0 to 1: C Programming – Drill Deep – $10 appeared first on Udemy Cupón.
from http://www.xpresslearn.com/udemy/coupon/80-off-from-0-to-1-c-programming-drill-deep-10/
0 notes
Text
cop3503 Project 1 – Templated Linked List Solved
Overview
The purpose of this assignment is for you to write a data structure called a Linked List, which utilizes templates (similar to Java’s generics), in order to store any type of data. In addition, the nature of a Linked List will give you some experience dealing with non-contiguous memory organization. This will also give you more experience using pointers and memory management. Pointers, memory allocation, and understand how data is stored in memory will serve you well in a variety of situations, not just for an assignment like this.
Background
Remember Memory? Variables, functions, pointers—everything takes up SOME space in memory. Sometimes that memory is occupied for only a short duration (a temporary variable in a function), sometimes that memory is allocated at the start of a program and hangs around for the lifetime of that program. Visualizing memory can be difficult sometimes, but very helpful. You may see diagrams of memory like this:
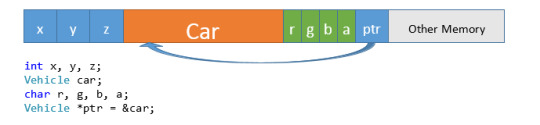
Or, you may see diagrams like these:
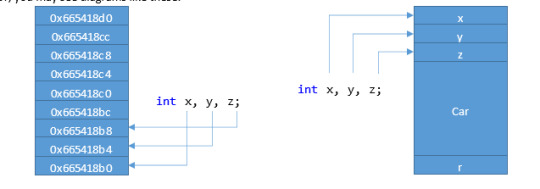
If you are trying to draw out some representation of memory to help you solve a problem, any of these (or some alternative that makes sense to you) will be fine.
Arrays
Arrays are stored in what is called contiguous memory. A contiguous memory block is one that is not interrupted by anything else (i.e. any other memory block). So if you created an array of 5 integers, each of those integers would be located one after the other in memory, with nothing else occupying memory between them. This is true for all arrays, of any data type.

All of the data in an application is not guaranteed to be contiguous, nor does it need to be. Arrays are typically the simplest and fastest way to store data, but they have a grand total of zero features. You allocate one contiguous block, but you can’t resize it, removing elements is a pain (and slow), etc. Consider the previous array. What if you wanted to add another element to that block of memory? If the surrounding memory is occupied, you can’t simply overwrite that with your new data element and expect good results.

someArray = 12; // #badIdea This will almost certainly break. Other Memory In this scenario, in order to store one more element you would have to: Create another array that was large enough to store all of the old elements plus the new one Copy over all of the data elements one at a time (including the new element, at the end) Free up the old array—no point in having two copies of the data

Other Memory Newly available memory Someone else’s memory 10 12 This process has to be repeated each time you want to add to the array (either at the end, or insert in the middle), or remove anything from the array. It can quite costly, in terms of performance, to delete/rebuild an entire array every time you want to make a single change. Cue the Linked List!
Linked List
The basic concept behind a Linked List is simple: It’s a container that stores its elements in a non-contiguous fashion Each element knows about the location of the element which comes after it (and possibly before, more on that later) So instead of a contiguous array, where element 4 comes after element 3, which comes after element 2, etc… you might have something like this:
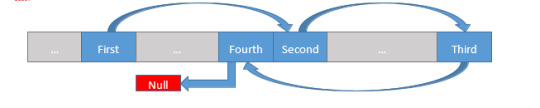
Each element in the Linked List (typically referred to as a “node”) stores some data, and then stores a reference (a pointer, in C++), so the node which should come next. The First node knows only about the Second node. The Second node knows only about the Third, etc. The Fourth node has a null pointer as its “next” node, indicating that we’ve reached the end of the data. A real-world example can be helpful as well. Think about a line of people, with one person at the front of the line. That person might know about the person who is next in line, but no further than that (beyond him or herself, the person at the front doesn’t need to know or care). The second person in line might know about the third person in line, but no further. Continuing on this way, the last person in line knows that there is no one else that follows, so that must be the end. Since no one is behind that person, we must be at the end of the line.

So… What are the advantages of storing data like this? When inserting elements to an array, the entire array has to be reallocated. With a Linked List, only a small number of elements are affected. Only elements surrounding the changed element need to be updated, and all other elements can remain unaffected. This makes the Linked List much more efficient when it comes to adding or removing elements. Now, imagine one person wants to step out of line. If this were an array, all of the data would have to be reconstructed elsewhere. In a Linked List, only three nodes are affected: 1) The person leaving, 2) the person in front of that person, and 3) the person behind that person. Imagine you are the person at the front of the line. You don’t really need to know or care what happens 10 people behind you, as that has no impact on you whatsoever.

If the 5th person in line leaves, the only parts of the line that should be impacted are the 4th, 5th, and 6th spaces. Person 4 has a new “next” Person: whomever was behind the person behind them (Person 6). Person 5 has to be removed from the list. Person 6… actually does nothing. In this example, a Person only cares about whomever comes after them. Since Person 5 was before Person 6, Person 6 is unaffected. (A Linked List could be implemented with two-way information between nodes—more on that later). The same thought-process can be applied if someone stepped into line (maybe a friend was holding their place):
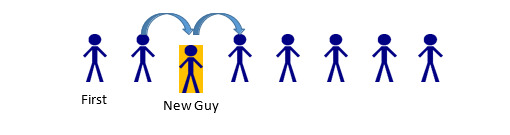
In this case, Person 2 would change their “next” person from Person 3, to the new Person being added. New Guy would have his “next” pointer set to whomever Person 2 was previously keeping track of, Person 3. Because of the ordering process, Person 3 would remain unchanged, as would anyone else in the list (aside from being a bit irritated at the New Guy for cutting in line). So that’s the concept behind a Linked List. A series of “nodes” which are connected via pointer to one another, and inserting/deleting nodes is a faster process than deleting and reconstructing the entire collection of data. Now, how to go about creating that?
Terminology
Node The fundamental building block of a Linked List. A node contains the data actually being stored in the list, as well as 1 or more pointers to other nodes. This is typically implemented as a nested class (see below). Singly-linked A Linked List would be singly-linked if each node only has a single pointer to another node, typically a “next” pointer. This only allows for uni-directional traversal of the data—from beginning to end. Doubly-linked Each node contains 2 pointers: a “next” pointer and a “previous” pointer. This allows for bi-directional traversal of the data—either from front-to-back or backto-front. Head A pointer to the first node in the list, akin to index 0 of an array. Tail A pointer to the last node in the list. May or may not be used, depending on the implementation of the list.
Nested Classes
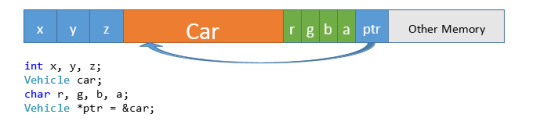
The purpose of writing a class is to group data and functionality. The purpose of a nested class is the same—the only difference is where we declare a nested class. We declare a nested class like this: class MyClass { public: // Nested class class NestedClass { int x, y, z; NestedClass(); ~NestedClass(); int SomeFunction(); }; private: // Data for "MyClass" NestedClass myData; NestedClass *somePtr; float values; MyClass(); // Etc… }; // To create nested classes… // Use the Scope Resolution Operator MyClass::NestedClass someVariable; // With a class template… TemplateClass foo; TemplateClass::Nested bar; /* NOTE: You can make nested classes private if you wish, to prevent access to them outside of the encapsulating class. */ Additional reading: http://en.cppreference.com/w/cpp/language/nested_types The nature of the Linked List is that each piece of information knows about the information which follows (or precedes) it. It would make sense, then, to create some nested class to group all of that information together.
Benefits and Drawbacks
All data structures in programming (C++ or otherwise) have advantages and disadvantages. There is no “one size fits all” data structure. Some are faster (in some cases), some have smaller memory footprints, and some are more flexible in their functionality, which can make life easier for the programmer. Linked List versus Array – Who Wins? Array Linked List Fast access of individual elements as well as iteration over the entire array Changing the Linked List is fast – nodes can be inserted/removed very quickly Random access – You can quickly “jump” to the appropriate memory location of an element Less affected by memory fragmentation, nodes can fit anywhere in memory Changing the array is slow – Have to rebuild the entire array when adding/removing elements No random access, slow iteration Memory fragmentation can be an issue for arrays—need a single, contiguous block large enough for all of the data Extra memory overhead for nodes/pointers Slow to access individual elements
Code Structure
As shown above, the Linked List class itself stores very little data: Pointers to the first and last nodes, and a count. In some implementations, you might only have a pointer to the first node, and that’s it. In addition to those data members, your Linked List class must conform to the following interface:
Function Reference
Accessors PrintForward Iterator through all of the nodes and print out their values, one a time. PrintReverse Exactly the same as PrintForward, except completely the opposite. NodeCount Wait, we’re storing how many things in this list? FindAll Find all nodes which match the passed in parameter value, and store a pointer to that node in the passed in vector. Use of a parameter like this (passing a something in by reference, and storing data for later use) is called an output parameter. Find Find the first node with a data value matching the passed in parameter, returning a pointer to that node. Returns null if no matching node found. const and nonconst versions. GetNode Given an index, return a pointer to the node at that index. Throws an exception if the index is out of range. Const and non-const versions. Head Returns the head pointer. Const and non-const versions. Tail Returns the tail pointer. Const and non-const versions. Insertion Operations AddHead Create a new Node at the front of the list to store the passed in parameter. AddTail Create a new Node at the end of the list to store the passed in parameter. AddNodesHead Given an array of values, insert a node for each of those at the beginning of the list, maintaining the original order. AddNodesTail Ditto, except adding to the end of the list. InsertAfter Given a pointer to a node, create a new node to store the passed in value, after the indicated node. InsertBefore Ditto, except insert the new node before the indicated node. InsertAt Inserts a new Node to store the first parameter, at the index-th location. So if you specified 4 as the index, the new Node should have 3 Nodes before it. Throws an exception if given an invalid index. Removal Operations RemoveHead Deletes the first Node in the list. Returns whether or not the operation was successful. RemoveTail Deletes the last Node, returning whether or not the operation was successful. Remove Remove ALL Nodes containing values matching that of the passed-in parameter. Returns how many instances were removed. RemoveAt Deletes the index-th Node from the list, returning whether or not the operation was successful. Clear Deletes all Nodes. Don’t forget the node count! Operators operator Overloaded brackets operator. Takes an index, and returns the index-th node. Throws an exception if given an invalid index. Const and non-const versions. operator= After listA = listB, listA == listB is true. operator== Overloaded equality operator. Given listA and listB, is listA equal to listB? What would make one Linked List equal to another? If each of its nodes were equal to the corresponding node of the other. (Similar to comparing two arrays, just with non-contiguous data). Construction / Destruction LinkedList() Default constructor. A head, a tail, and a node counter walk into a bar… and get initialized? Wait, that’s not how that one goes… How many nodes in an empty list? What is head pointing to? What is tail pointing to? Copy Constructor Sets “this” to a copy of the passed in LinkedList. Other list has 10 nodes, with values of 1-10? “this” should too. ~LinkedList() The usual. Clean up your mess. (Delete all the nodes created by the list.)
Tips
A few tips for this assignment: Remember the "Big Three" or the “Rule of Three” o If you define one of the three special functions (copy constructor, assignment operator, or destructor), you should define the other two Start small, work one bit of functionality at a time. Work on things like Add() and PrintForward() first, as well as accessors (brackets operator, Head()/Tail(), etc). You can’t really test anything else unless those are working. Refer back to the recommended chapters in your textbook as well as lecture videos for an explanation of the details of dynamic memory allocation o There are a lot of things to remember when memory allocation The debugger is your friend! (You have learned how to use it, right?) Make charts, diagrams, sketches of the problem. Memory is inherently difficult to visualize, find a way that works for you. Don’t forget your node count! Read the full article
0 notes
Text
cop3503 Project 1 – Templated Linked List Solved
Overview
The purpose of this assignment is for you to write a data structure called a Linked List, which utilizes templates (similar to Java’s generics), in order to store any type of data. In addition, the nature of a Linked List will give you some experience dealing with non-contiguous memory organization. This will also give you more experience using pointers and memory management. Pointers, memory allocation, and understand how data is stored in memory will serve you well in a variety of situations, not just for an assignment like this.
Background
Remember Memory? Variables, functions, pointers—everything takes up SOME space in memory. Sometimes that memory is occupied for only a short duration (a temporary variable in a function), sometimes that memory is allocated at the start of a program and hangs around for the lifetime of that program. Visualizing memory can be difficult sometimes, but very helpful. You may see diagrams of memory like this:
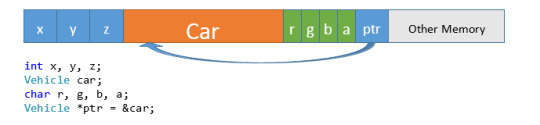
Or, you may see diagrams like these:
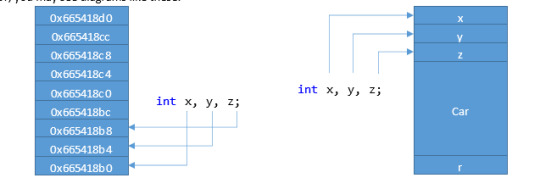
If you are trying to draw out some representation of memory to help you solve a problem, any of these (or some alternative that makes sense to you) will be fine.
Arrays
Arrays are stored in what is called contiguous memory. A contiguous memory block is one that is not interrupted by anything else (i.e. any other memory block). So if you created an array of 5 integers, each of those integers would be located one after the other in memory, with nothing else occupying memory between them. This is true for all arrays, of any data type.

All of the data in an application is not guaranteed to be contiguous, nor does it need to be. Arrays are typically the simplest and fastest way to store data, but they have a grand total of zero features. You allocate one contiguous block, but you can’t resize it, removing elements is a pain (and slow), etc. Consider the previous array. What if you wanted to add another element to that block of memory? If the surrounding memory is occupied, you can’t simply overwrite that with your new data element and expect good results.

someArray = 12; // #badIdea This will almost certainly break. Other Memory In this scenario, in order to store one more element you would have to: Create another array that was large enough to store all of the old elements plus the new one Copy over all of the data elements one at a time (including the new element, at the end) Free up the old array—no point in having two copies of the data

Other Memory Newly available memory Someone else’s memory 10 12 This process has to be repeated each time you want to add to the array (either at the end, or insert in the middle), or remove anything from the array. It can quite costly, in terms of performance, to delete/rebuild an entire array every time you want to make a single change. Cue the Linked List!
Linked List
The basic concept behind a Linked List is simple: It’s a container that stores its elements in a non-contiguous fashion Each element knows about the location of the element which comes after it (and possibly before, more on that later) So instead of a contiguous array, where element 4 comes after element 3, which comes after element 2, etc… you might have something like this:
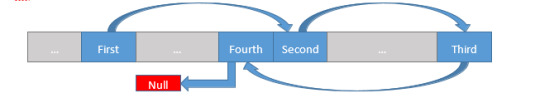
Each element in the Linked List (typically referred to as a “node”) stores some data, and then stores a reference (a pointer, in C++), so the node which should come next. The First node knows only about the Second node. The Second node knows only about the Third, etc. The Fourth node has a null pointer as its “next” node, indicating that we’ve reached the end of the data. A real-world example can be helpful as well. Think about a line of people, with one person at the front of the line. That person might know about the person who is next in line, but no further than that (beyond him or herself, the person at the front doesn’t need to know or care). The second person in line might know about the third person in line, but no further. Continuing on this way, the last person in line knows that there is no one else that follows, so that must be the end. Since no one is behind that person, we must be at the end of the line.

So… What are the advantages of storing data like this? When inserting elements to an array, the entire array has to be reallocated. With a Linked List, only a small number of elements are affected. Only elements surrounding the changed element need to be updated, and all other elements can remain unaffected. This makes the Linked List much more efficient when it comes to adding or removing elements. Now, imagine one person wants to step out of line. If this were an array, all of the data would have to be reconstructed elsewhere. In a Linked List, only three nodes are affected: 1) The person leaving, 2) the person in front of that person, and 3) the person behind that person. Imagine you are the person at the front of the line. You don’t really need to know or care what happens 10 people behind you, as that has no impact on you whatsoever.

If the 5th person in line leaves, the only parts of the line that should be impacted are the 4th, 5th, and 6th spaces. Person 4 has a new “next” Person: whomever was behind the person behind them (Person 6). Person 5 has to be removed from the list. Person 6… actually does nothing. In this example, a Person only cares about whomever comes after them. Since Person 5 was before Person 6, Person 6 is unaffected. (A Linked List could be implemented with two-way information between nodes—more on that later). The same thought-process can be applied if someone stepped into line (maybe a friend was holding their place):
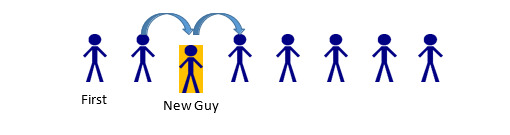
In this case, Person 2 would change their “next” person from Person 3, to the new Person being added. New Guy would have his “next” pointer set to whomever Person 2 was previously keeping track of, Person 3. Because of the ordering process, Person 3 would remain unchanged, as would anyone else in the list (aside from being a bit irritated at the New Guy for cutting in line). So that’s the concept behind a Linked List. A series of “nodes” which are connected via pointer to one another, and inserting/deleting nodes is a faster process than deleting and reconstructing the entire collection of data. Now, how to go about creating that?
Terminology
Node The fundamental building block of a Linked List. A node contains the data actually being stored in the list, as well as 1 or more pointers to other nodes. This is typically implemented as a nested class (see below). Singly-linked A Linked List would be singly-linked if each node only has a single pointer to another node, typically a “next” pointer. This only allows for uni-directional traversal of the data—from beginning to end. Doubly-linked Each node contains 2 pointers: a “next” pointer and a “previous” pointer. This allows for bi-directional traversal of the data—either from front-to-back or backto-front. Head A pointer to the first node in the list, akin to index 0 of an array. Tail A pointer to the last node in the list. May or may not be used, depending on the implementation of the list.
Nested Classes
The purpose of writing a class is to group data and functionality. The purpose of a nested class is the same—the only difference is where we declare a nested class. We declare a nested class like this: class MyClass { public: // Nested class class NestedClass { int x, y, z; NestedClass(); ~NestedClass(); int SomeFunction(); }; private: // Data for "MyClass" NestedClass myData; NestedClass *somePtr; float values; MyClass(); // Etc… }; // To create nested classes… // Use the Scope Resolution Operator MyClass::NestedClass someVariable; // With a class template… TemplateClass foo; TemplateClass::Nested bar; /* NOTE: You can make nested classes private if you wish, to prevent access to them outside of the encapsulating class. */ Additional reading: http://en.cppreference.com/w/cpp/language/nested_types The nature of the Linked List is that each piece of information knows about the information which follows (or precedes) it. It would make sense, then, to create some nested class to group all of that information together.
Benefits and Drawbacks
All data structures in programming (C++ or otherwise) have advantages and disadvantages. There is no “one size fits all” data structure. Some are faster (in some cases), some have smaller memory footprints, and some are more flexible in their functionality, which can make life easier for the programmer. Linked List versus Array – Who Wins? Array Linked List Fast access of individual elements as well as iteration over the entire array Changing the Linked List is fast – nodes can be inserted/removed very quickly Random access – You can quickly “jump” to the appropriate memory location of an element Less affected by memory fragmentation, nodes can fit anywhere in memory Changing the array is slow – Have to rebuild the entire array when adding/removing elements No random access, slow iteration Memory fragmentation can be an issue for arrays—need a single, contiguous block large enough for all of the data Extra memory overhead for nodes/pointers Slow to access individual elements
Code Structure
As shown above, the Linked List class itself stores very little data: Pointers to the first and last nodes, and a count. In some implementations, you might only have a pointer to the first node, and that’s it. In addition to those data members, your Linked List class must conform to the following interface:
Function Reference
Accessors PrintForward Iterator through all of the nodes and print out their values, one a time. PrintReverse Exactly the same as PrintForward, except completely the opposite. NodeCount Wait, we’re storing how many things in this list? FindAll Find all nodes which match the passed in parameter value, and store a pointer to that node in the passed in vector. Use of a parameter like this (passing a something in by reference, and storing data for later use) is called an output parameter. Find Find the first node with a data value matching the passed in parameter, returning a pointer to that node. Returns null if no matching node found. const and nonconst versions. GetNode Given an index, return a pointer to the node at that index. Throws an exception if the index is out of range. Const and non-const versions. Head Returns the head pointer. Const and non-const versions. Tail Returns the tail pointer. Const and non-const versions. Insertion Operations AddHead Create a new Node at the front of the list to store the passed in parameter. AddTail Create a new Node at the end of the list to store the passed in parameter. AddNodesHead Given an array of values, insert a node for each of those at the beginning of the list, maintaining the original order. AddNodesTail Ditto, except adding to the end of the list. InsertAfter Given a pointer to a node, create a new node to store the passed in value, after the indicated node. InsertBefore Ditto, except insert the new node before the indicated node. InsertAt Inserts a new Node to store the first parameter, at the index-th location. So if you specified 4 as the index, the new Node should have 3 Nodes before it. Throws an exception if given an invalid index. Removal Operations RemoveHead Deletes the first Node in the list. Returns whether or not the operation was successful. RemoveTail Deletes the last Node, returning whether or not the operation was successful. Remove Remove ALL Nodes containing values matching that of the passed-in parameter. Returns how many instances were removed. RemoveAt Deletes the index-th Node from the list, returning whether or not the operation was successful. Clear Deletes all Nodes. Don’t forget the node count! Operators operator Overloaded brackets operator. Takes an index, and returns the index-th node. Throws an exception if given an invalid index. Const and non-const versions. operator= After listA = listB, listA == listB is true. operator== Overloaded equality operator. Given listA and listB, is listA equal to listB? What would make one Linked List equal to another? If each of its nodes were equal to the corresponding node of the other. (Similar to comparing two arrays, just with non-contiguous data). Construction / Destruction LinkedList() Default constructor. A head, a tail, and a node counter walk into a bar… and get initialized? Wait, that’s not how that one goes… How many nodes in an empty list? What is head pointing to? What is tail pointing to? Copy Constructor Sets “this” to a copy of the passed in LinkedList. Other list has 10 nodes, with values of 1-10? “this” should too. ~LinkedList() The usual. Clean up your mess. (Delete all the nodes created by the list.)
Tips
A few tips for this assignment: Remember the "Big Three" or the “Rule of Three” o If you define one of the three special functions (copy constructor, assignment operator, or destructor), you should define the other two Start small, work one bit of functionality at a time. Work on things like Add() and PrintForward() first, as well as accessors (brackets operator, Head()/Tail(), etc). You can’t really test anything else unless those are working. Refer back to the recommended chapters in your textbook as well as lecture videos for an explanation of the details of dynamic memory allocation o There are a lot of things to remember when memory allocation The debugger is your friend! (You have learned how to use it, right?) Make charts, diagrams, sketches of the problem. Memory is inherently difficult to visualize, find a way that works for you. Don’t forget your node count! Read the full article
0 notes
Text
cop3503 Project 1 – Templated Linked List Solved
Overview
The purpose of this assignment is for you to write a data structure called a Linked List, which utilizes templates (similar to Java’s generics), in order to store any type of data. In addition, the nature of a Linked List will give you some experience dealing with non-contiguous memory organization. This will also give you more experience using pointers and memory management. Pointers, memory allocation, and understand how data is stored in memory will serve you well in a variety of situations, not just for an assignment like this.
Background
Remember Memory? Variables, functions, pointers—everything takes up SOME space in memory. Sometimes that memory is occupied for only a short duration (a temporary variable in a function), sometimes that memory is allocated at the start of a program and hangs around for the lifetime of that program. Visualizing memory can be difficult sometimes, but very helpful. You may see diagrams of memory like this:
Or, you may see diagrams like these:

If you are trying to draw out some representation of memory to help you solve a problem, any of these (or some alternative that makes sense to you) will be fine.
Arrays
Arrays are stored in what is called contiguous memory. A contiguous memory block is one that is not interrupted by anything else (i.e. any other memory block). So if you created an array of 5 integers, each of those integers would be located one after the other in memory, with nothing else occupying memory between them. This is true for all arrays, of any data type.

All of the data in an application is not guaranteed to be contiguous, nor does it need to be. Arrays are typically the simplest and fastest way to store data, but they have a grand total of zero features. You allocate one contiguous block, but you can’t resize it, removing elements is a pain (and slow), etc. Consider the previous array. What if you wanted to add another element to that block of memory? If the surrounding memory is occupied, you can’t simply overwrite that with your new data element and expect good results.

someArray = 12; // #badIdea This will almost certainly break. Other Memory In this scenario, in order to store one more element you would have to: Create another array that was large enough to store all of the old elements plus the new one Copy over all of the data elements one at a time (including the new element, at the end) Free up the old array—no point in having two copies of the data

Other Memory Newly available memory Someone else’s memory 10 12 This process has to be repeated each time you want to add to the array (either at the end, or insert in the middle), or remove anything from the array. It can quite costly, in terms of performance, to delete/rebuild an entire array every time you want to make a single change. Cue the Linked List!
Linked List
The basic concept behind a Linked List is simple: It’s a container that stores its elements in a non-contiguous fashion Each element knows about the location of the element which comes after it (and possibly before, more on that later) So instead of a contiguous array, where element 4 comes after element 3, which comes after element 2, etc… you might have something like this:
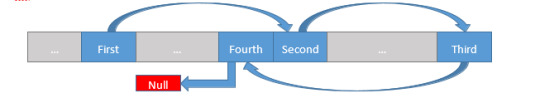
Each element in the Linked List (typically referred to as a “node”) stores some data, and then stores a reference (a pointer, in C++), so the node which should come next. The First node knows only about the Second node. The Second node knows only about the Third, etc. The Fourth node has a null pointer as its “next” node, indicating that we’ve reached the end of the data. A real-world example can be helpful as well. Think about a line of people, with one person at the front of the line. That person might know about the person who is next in line, but no further than that (beyond him or herself, the person at the front doesn’t need to know or care). The second person in line might know about the third person in line, but no further. Continuing on this way, the last person in line knows that there is no one else that follows, so that must be the end. Since no one is behind that person, we must be at the end of the line.

So… What are the advantages of storing data like this? When inserting elements to an array, the entire array has to be reallocated. With a Linked List, only a small number of elements are affected. Only elements surrounding the changed element need to be updated, and all other elements can remain unaffected. This makes the Linked List much more efficient when it comes to adding or removing elements. Now, imagine one person wants to step out of line. If this were an array, all of the data would have to be reconstructed elsewhere. In a Linked List, only three nodes are affected: 1) The person leaving, 2) the person in front of that person, and 3) the person behind that person. Imagine you are the person at the front of the line. You don’t really need to know or care what happens 10 people behind you, as that has no impact on you whatsoever.

If the 5th person in line leaves, the only parts of the line that should be impacted are the 4th, 5th, and 6th spaces. Person 4 has a new “next” Person: whomever was behind the person behind them (Person 6). Person 5 has to be removed from the list. Person 6… actually does nothing. In this example, a Person only cares about whomever comes after them. Since Person 5 was before Person 6, Person 6 is unaffected. (A Linked List could be implemented with two-way information between nodes—more on that later). The same thought-process can be applied if someone stepped into line (maybe a friend was holding their place):
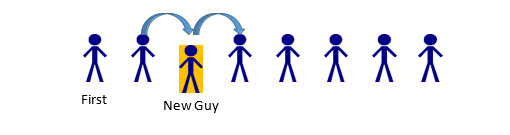
In this case, Person 2 would change their “next” person from Person 3, to the new Person being added. New Guy would have his “next” pointer set to whomever Person 2 was previously keeping track of, Person 3. Because of the ordering process, Person 3 would remain unchanged, as would anyone else in the list (aside from being a bit irritated at the New Guy for cutting in line). So that’s the concept behind a Linked List. A series of “nodes” which are connected via pointer to one another, and inserting/deleting nodes is a faster process than deleting and reconstructing the entire collection of data. Now, how to go about creating that?
Terminology
Node The fundamental building block of a Linked List. A node contains the data actually being stored in the list, as well as 1 or more pointers to other nodes. This is typically implemented as a nested class (see below). Singly-linked A Linked List would be singly-linked if each node only has a single pointer to another node, typically a “next” pointer. This only allows for uni-directional traversal of the data—from beginning to end. Doubly-linked Each node contains 2 pointers: a “next” pointer and a “previous” pointer. This allows for bi-directional traversal of the data—either from front-to-back or backto-front. Head A pointer to the first node in the list, akin to index 0 of an array. Tail A pointer to the last node in the list. May or may not be used, depending on the implementation of the list.
Nested Classes
The purpose of writing a class is to group data and functionality. The purpose of a nested class is the same—the only difference is where we declare a nested class. We declare a nested class like this: class MyClass { public: // Nested class class NestedClass { int x, y, z; NestedClass(); ~NestedClass(); int SomeFunction(); }; private: // Data for "MyClass" NestedClass myData; NestedClass *somePtr; float values; MyClass(); // Etc… }; // To create nested classes… // Use the Scope Resolution Operator MyClass::NestedClass someVariable; // With a class template… TemplateClass foo; TemplateClass::Nested bar; /* NOTE: You can make nested classes private if you wish, to prevent access to them outside of the encapsulating class. */ Additional reading: http://en.cppreference.com/w/cpp/language/nested_types The nature of the Linked List is that each piece of information knows about the information which follows (or precedes) it. It would make sense, then, to create some nested class to group all of that information together.
Benefits and Drawbacks
All data structures in programming (C++ or otherwise) have advantages and disadvantages. There is no “one size fits all” data structure. Some are faster (in some cases), some have smaller memory footprints, and some are more flexible in their functionality, which can make life easier for the programmer. Linked List versus Array – Who Wins? Array Linked List Fast access of individual elements as well as iteration over the entire array Changing the Linked List is fast – nodes can be inserted/removed very quickly Random access – You can quickly “jump” to the appropriate memory location of an element Less affected by memory fragmentation, nodes can fit anywhere in memory Changing the array is slow – Have to rebuild the entire array when adding/removing elements No random access, slow iteration Memory fragmentation can be an issue for arrays—need a single, contiguous block large enough for all of the data Extra memory overhead for nodes/pointers Slow to access individual elements
Code Structure
As shown above, the Linked List class itself stores very little data: Pointers to the first and last nodes, and a count. In some implementations, you might only have a pointer to the first node, and that’s it. In addition to those data members, your Linked List class must conform to the following interface:
Function Reference
Accessors PrintForward Iterator through all of the nodes and print out their values, one a time. PrintReverse Exactly the same as PrintForward, except completely the opposite. NodeCount Wait, we’re storing how many things in this list? FindAll Find all nodes which match the passed in parameter value, and store a pointer to that node in the passed in vector. Use of a parameter like this (passing a something in by reference, and storing data for later use) is called an output parameter. Find Find the first node with a data value matching the passed in parameter, returning a pointer to that node. Returns null if no matching node found. const and nonconst versions. GetNode Given an index, return a pointer to the node at that index. Throws an exception if the index is out of range. Const and non-const versions. Head Returns the head pointer. Const and non-const versions. Tail Returns the tail pointer. Const and non-const versions. Insertion Operations AddHead Create a new Node at the front of the list to store the passed in parameter. AddTail Create a new Node at the end of the list to store the passed in parameter. AddNodesHead Given an array of values, insert a node for each of those at the beginning of the list, maintaining the original order. AddNodesTail Ditto, except adding to the end of the list. InsertAfter Given a pointer to a node, create a new node to store the passed in value, after the indicated node. InsertBefore Ditto, except insert the new node before the indicated node. InsertAt Inserts a new Node to store the first parameter, at the index-th location. So if you specified 4 as the index, the new Node should have 3 Nodes before it. Throws an exception if given an invalid index. Removal Operations RemoveHead Deletes the first Node in the list. Returns whether or not the operation was successful. RemoveTail Deletes the last Node, returning whether or not the operation was successful. Remove Remove ALL Nodes containing values matching that of the passed-in parameter. Returns how many instances were removed. RemoveAt Deletes the index-th Node from the list, returning whether or not the operation was successful. Clear Deletes all Nodes. Don’t forget the node count! Operators operator Overloaded brackets operator. Takes an index, and returns the index-th node. Throws an exception if given an invalid index. Const and non-const versions. operator= After listA = listB, listA == listB is true. operator== Overloaded equality operator. Given listA and listB, is listA equal to listB? What would make one Linked List equal to another? If each of its nodes were equal to the corresponding node of the other. (Similar to comparing two arrays, just with non-contiguous data). Construction / Destruction LinkedList() Default constructor. A head, a tail, and a node counter walk into a bar… and get initialized? Wait, that’s not how that one goes… How many nodes in an empty list? What is head pointing to? What is tail pointing to? Copy Constructor Sets “this” to a copy of the passed in LinkedList. Other list has 10 nodes, with values of 1-10? “this” should too. ~LinkedList() The usual. Clean up your mess. (Delete all the nodes created by the list.)
Tips
A few tips for this assignment: Remember the "Big Three" or the “Rule of Three” o If you define one of the three special functions (copy constructor, assignment operator, or destructor), you should define the other two Start small, work one bit of functionality at a time. Work on things like Add() and PrintForward() first, as well as accessors (brackets operator, Head()/Tail(), etc). You can’t really test anything else unless those are working. Refer back to the recommended chapters in your textbook as well as lecture videos for an explanation of the details of dynamic memory allocation o There are a lot of things to remember when memory allocation The debugger is your friend! (You have learned how to use it, right?) Make charts, diagrams, sketches of the problem. Memory is inherently difficult to visualize, find a way that works for you. Don’t forget your node count! Read the full article
0 notes
Text
cop3503 Project 1 – Templated Linked List Solved
Overview
The purpose of this assignment is for you to write a data structure called a Linked List, which utilizes templates (similar to Java’s generics), in order to store any type of data. In addition, the nature of a Linked List will give you some experience dealing with non-contiguous memory organization. This will also give you more experience using pointers and memory management. Pointers, memory allocation, and understand how data is stored in memory will serve you well in a variety of situations, not just for an assignment like this.
Background
Remember Memory? Variables, functions, pointers—everything takes up SOME space in memory. Sometimes that memory is occupied for only a short duration (a temporary variable in a function), sometimes that memory is allocated at the start of a program and hangs around for the lifetime of that program. Visualizing memory can be difficult sometimes, but very helpful. You may see diagrams of memory like this:

Or, you may see diagrams like these:

If you are trying to draw out some representation of memory to help you solve a problem, any of these (or some alternative that makes sense to you) will be fine.
Arrays
Arrays are stored in what is called contiguous memory. A contiguous memory block is one that is not interrupted by anything else (i.e. any other memory block). So if you created an array of 5 integers, each of those integers would be located one after the other in memory, with nothing else occupying memory between them. This is true for all arrays, of any data type.

All of the data in an application is not guaranteed to be contiguous, nor does it need to be. Arrays are typically the simplest and fastest way to store data, but they have a grand total of zero features. You allocate one contiguous block, but you can’t resize it, removing elements is a pain (and slow), etc. Consider the previous array. What if you wanted to add another element to that block of memory? If the surrounding memory is occupied, you can’t simply overwrite that with your new data element and expect good results.

someArray = 12; // #badIdea This will almost certainly break. Other Memory In this scenario, in order to store one more element you would have to: Create another array that was large enough to store all of the old elements plus the new one Copy over all of the data elements one at a time (including the new element, at the end) Free up the old array—no point in having two copies of the data

Other Memory Newly available memory Someone else’s memory 10 12 This process has to be repeated each time you want to add to the array (either at the end, or insert in the middle), or remove anything from the array. It can quite costly, in terms of performance, to delete/rebuild an entire array every time you want to make a single change. Cue the Linked List!
Linked List
The basic concept behind a Linked List is simple: It’s a container that stores its elements in a non-contiguous fashion Each element knows about the location of the element which comes after it (and possibly before, more on that later) So instead of a contiguous array, where element 4 comes after element 3, which comes after element 2, etc… you might have something like this:
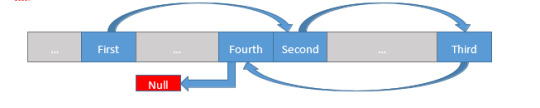
Each element in the Linked List (typically referred to as a “node”) stores some data, and then stores a reference (a pointer, in C++), so the node which should come next. The First node knows only about the Second node. The Second node knows only about the Third, etc. The Fourth node has a null pointer as its “next” node, indicating that we’ve reached the end of the data. A real-world example can be helpful as well. Think about a line of people, with one person at the front of the line. That person might know about the person who is next in line, but no further than that (beyond him or herself, the person at the front doesn’t need to know or care). The second person in line might know about the third person in line, but no further. Continuing on this way, the last person in line knows that there is no one else that follows, so that must be the end. Since no one is behind that person, we must be at the end of the line.

So… What are the advantages of storing data like this? When inserting elements to an array, the entire array has to be reallocated. With a Linked List, only a small number of elements are affected. Only elements surrounding the changed element need to be updated, and all other elements can remain unaffected. This makes the Linked List much more efficient when it comes to adding or removing elements. Now, imagine one person wants to step out of line. If this were an array, all of the data would have to be reconstructed elsewhere. In a Linked List, only three nodes are affected: 1) The person leaving, 2) the person in front of that person, and 3) the person behind that person. Imagine you are the person at the front of the line. You don’t really need to know or care what happens 10 people behind you, as that has no impact on you whatsoever.

If the 5th person in line leaves, the only parts of the line that should be impacted are the 4th, 5th, and 6th spaces. Person 4 has a new “next” Person: whomever was behind the person behind them (Person 6). Person 5 has to be removed from the list. Person 6… actually does nothing. In this example, a Person only cares about whomever comes after them. Since Person 5 was before Person 6, Person 6 is unaffected. (A Linked List could be implemented with two-way information between nodes—more on that later). The same thought-process can be applied if someone stepped into line (maybe a friend was holding their place):
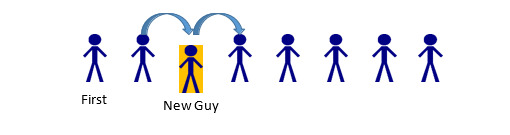
In this case, Person 2 would change their “next” person from Person 3, to the new Person being added. New Guy would have his “next” pointer set to whomever Person 2 was previously keeping track of, Person 3. Because of the ordering process, Person 3 would remain unchanged, as would anyone else in the list (aside from being a bit irritated at the New Guy for cutting in line). So that’s the concept behind a Linked List. A series of “nodes” which are connected via pointer to one another, and inserting/deleting nodes is a faster process than deleting and reconstructing the entire collection of data. Now, how to go about creating that?
Terminology
Node The fundamental building block of a Linked List. A node contains the data actually being stored in the list, as well as 1 or more pointers to other nodes. This is typically implemented as a nested class (see below). Singly-linked A Linked List would be singly-linked if each node only has a single pointer to another node, typically a “next” pointer. This only allows for uni-directional traversal of the data—from beginning to end. Doubly-linked Each node contains 2 pointers: a “next” pointer and a “previous” pointer. This allows for bi-directional traversal of the data—either from front-to-back or backto-front. Head A pointer to the first node in the list, akin to index 0 of an array. Tail A pointer to the last node in the list. May or may not be used, depending on the implementation of the list.
Nested Classes
The purpose of writing a class is to group data and functionality. The purpose of a nested class is the same—the only difference is where we declare a nested class. We declare a nested class like this: class MyClass { public: // Nested class class NestedClass { int x, y, z; NestedClass(); ~NestedClass(); int SomeFunction(); }; private: // Data for "MyClass" NestedClass myData; NestedClass *somePtr; float values; MyClass(); // Etc… }; // To create nested classes… // Use the Scope Resolution Operator MyClass::NestedClass someVariable; // With a class template… TemplateClass foo; TemplateClass::Nested bar; /* NOTE: You can make nested classes private if you wish, to prevent access to them outside of the encapsulating class. */ Additional reading: http://en.cppreference.com/w/cpp/language/nested_types The nature of the Linked List is that each piece of information knows about the information which follows (or precedes) it. It would make sense, then, to create some nested class to group all of that information together.
Benefits and Drawbacks
All data structures in programming (C++ or otherwise) have advantages and disadvantages. There is no “one size fits all” data structure. Some are faster (in some cases), some have smaller memory footprints, and some are more flexible in their functionality, which can make life easier for the programmer. Linked List versus Array – Who Wins? Array Linked List Fast access of individual elements as well as iteration over the entire array Changing the Linked List is fast – nodes can be inserted/removed very quickly Random access – You can quickly “jump” to the appropriate memory location of an element Less affected by memory fragmentation, nodes can fit anywhere in memory Changing the array is slow – Have to rebuild the entire array when adding/removing elements No random access, slow iteration Memory fragmentation can be an issue for arrays—need a single, contiguous block large enough for all of the data Extra memory overhead for nodes/pointers Slow to access individual elements
Code Structure
As shown above, the Linked List class itself stores very little data: Pointers to the first and last nodes, and a count. In some implementations, you might only have a pointer to the first node, and that’s it. In addition to those data members, your Linked List class must conform to the following interface:
Function Reference
Accessors PrintForward Iterator through all of the nodes and print out their values, one a time. PrintReverse Exactly the same as PrintForward, except completely the opposite. NodeCount Wait, we’re storing how many things in this list? FindAll Find all nodes which match the passed in parameter value, and store a pointer to that node in the passed in vector. Use of a parameter like this (passing a something in by reference, and storing data for later use) is called an output parameter. Find Find the first node with a data value matching the passed in parameter, returning a pointer to that node. Returns null if no matching node found. const and nonconst versions. GetNode Given an index, return a pointer to the node at that index. Throws an exception if the index is out of range. Const and non-const versions. Head Returns the head pointer. Const and non-const versions. Tail Returns the tail pointer. Const and non-const versions. Insertion Operations AddHead Create a new Node at the front of the list to store the passed in parameter. AddTail Create a new Node at the end of the list to store the passed in parameter. AddNodesHead Given an array of values, insert a node for each of those at the beginning of the list, maintaining the original order. AddNodesTail Ditto, except adding to the end of the list. InsertAfter Given a pointer to a node, create a new node to store the passed in value, after the indicated node. InsertBefore Ditto, except insert the new node before the indicated node. InsertAt Inserts a new Node to store the first parameter, at the index-th location. So if you specified 4 as the index, the new Node should have 3 Nodes before it. Throws an exception if given an invalid index. Removal Operations RemoveHead Deletes the first Node in the list. Returns whether or not the operation was successful. RemoveTail Deletes the last Node, returning whether or not the operation was successful. Remove Remove ALL Nodes containing values matching that of the passed-in parameter. Returns how many instances were removed. RemoveAt Deletes the index-th Node from the list, returning whether or not the operation was successful. Clear Deletes all Nodes. Don’t forget the node count! Operators operator Overloaded brackets operator. Takes an index, and returns the index-th node. Throws an exception if given an invalid index. Const and non-const versions. operator= After listA = listB, listA == listB is true. operator== Overloaded equality operator. Given listA and listB, is listA equal to listB? What would make one Linked List equal to another? If each of its nodes were equal to the corresponding node of the other. (Similar to comparing two arrays, just with non-contiguous data). Construction / Destruction LinkedList() Default constructor. A head, a tail, and a node counter walk into a bar… and get initialized? Wait, that’s not how that one goes… How many nodes in an empty list? What is head pointing to? What is tail pointing to? Copy Constructor Sets “this” to a copy of the passed in LinkedList. Other list has 10 nodes, with values of 1-10? “this” should too. ~LinkedList() The usual. Clean up your mess. (Delete all the nodes created by the list.)
Tips
A few tips for this assignment: Remember the "Big Three" or the “Rule of Three” o If you define one of the three special functions (copy constructor, assignment operator, or destructor), you should define the other two Start small, work one bit of functionality at a time. Work on things like Add() and PrintForward() first, as well as accessors (brackets operator, Head()/Tail(), etc). You can’t really test anything else unless those are working. Refer back to the recommended chapters in your textbook as well as lecture videos for an explanation of the details of dynamic memory allocation o There are a lot of things to remember when memory allocation The debugger is your friend! (You have learned how to use it, right?) Make charts, diagrams, sketches of the problem. Memory is inherently difficult to visualize, find a way that works for you. Don’t forget your node count! Read the full article
0 notes
Text
cop3503 Project 1 – Templated Linked List Solved
Overview
The purpose of this assignment is for you to write a data structure called a Linked List, which utilizes templates (similar to Java’s generics), in order to store any type of data. In addition, the nature of a Linked List will give you some experience dealing with non-contiguous memory organization. This will also give you more experience using pointers and memory management. Pointers, memory allocation, and understand how data is stored in memory will serve you well in a variety of situations, not just for an assignment like this.
Background
Remember Memory? Variables, functions, pointers—everything takes up SOME space in memory. Sometimes that memory is occupied for only a short duration (a temporary variable in a function), sometimes that memory is allocated at the start of a program and hangs around for the lifetime of that program. Visualizing memory can be difficult sometimes, but very helpful. You may see diagrams of memory like this:
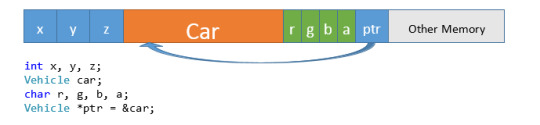
Or, you may see diagrams like these:
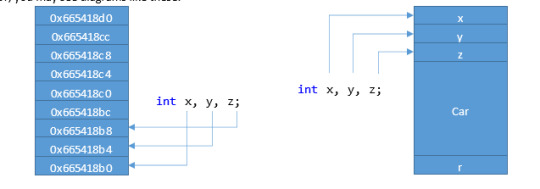
If you are trying to draw out some representation of memory to help you solve a problem, any of these (or some alternative that makes sense to you) will be fine.
Arrays
Arrays are stored in what is called contiguous memory. A contiguous memory block is one that is not interrupted by anything else (i.e. any other memory block). So if you created an array of 5 integers, each of those integers would be located one after the other in memory, with nothing else occupying memory between them. This is true for all arrays, of any data type.

All of the data in an application is not guaranteed to be contiguous, nor does it need to be. Arrays are typically the simplest and fastest way to store data, but they have a grand total of zero features. You allocate one contiguous block, but you can’t resize it, removing elements is a pain (and slow), etc. Consider the previous array. What if you wanted to add another element to that block of memory? If the surrounding memory is occupied, you can’t simply overwrite that with your new data element and expect good results.

someArray = 12; // #badIdea This will almost certainly break. Other Memory In this scenario, in order to store one more element you would have to: Create another array that was large enough to store all of the old elements plus the new one Copy over all of the data elements one at a time (including the new element, at the end) Free up the old array—no point in having two copies of the data

Other Memory Newly available memory Someone else’s memory 10 12 This process has to be repeated each time you want to add to the array (either at the end, or insert in the middle), or remove anything from the array. It can quite costly, in terms of performance, to delete/rebuild an entire array every time you want to make a single change. Cue the Linked List!
Linked List
The basic concept behind a Linked List is simple: It’s a container that stores its elements in a non-contiguous fashion Each element knows about the location of the element which comes after it (and possibly before, more on that later) So instead of a contiguous array, where element 4 comes after element 3, which comes after element 2, etc… you might have something like this:

Each element in the Linked List (typically referred to as a “node”) stores some data, and then stores a reference (a pointer, in C++), so the node which should come next. The First node knows only about the Second node. The Second node knows only about the Third, etc. The Fourth node has a null pointer as its “next” node, indicating that we’ve reached the end of the data. A real-world example can be helpful as well. Think about a line of people, with one person at the front of the line. That person might know about the person who is next in line, but no further than that (beyond him or herself, the person at the front doesn’t need to know or care). The second person in line might know about the third person in line, but no further. Continuing on this way, the last person in line knows that there is no one else that follows, so that must be the end. Since no one is behind that person, we must be at the end of the line.

So… What are the advantages of storing data like this? When inserting elements to an array, the entire array has to be reallocated. With a Linked List, only a small number of elements are affected. Only elements surrounding the changed element need to be updated, and all other elements can remain unaffected. This makes the Linked List much more efficient when it comes to adding or removing elements. Now, imagine one person wants to step out of line. If this were an array, all of the data would have to be reconstructed elsewhere. In a Linked List, only three nodes are affected: 1) The person leaving, 2) the person in front of that person, and 3) the person behind that person. Imagine you are the person at the front of the line. You don’t really need to know or care what happens 10 people behind you, as that has no impact on you whatsoever.

If the 5th person in line leaves, the only parts of the line that should be impacted are the 4th, 5th, and 6th spaces. Person 4 has a new “next” Person: whomever was behind the person behind them (Person 6). Person 5 has to be removed from the list. Person 6… actually does nothing. In this example, a Person only cares about whomever comes after them. Since Person 5 was before Person 6, Person 6 is unaffected. (A Linked List could be implemented with two-way information between nodes—more on that later). The same thought-process can be applied if someone stepped into line (maybe a friend was holding their place):
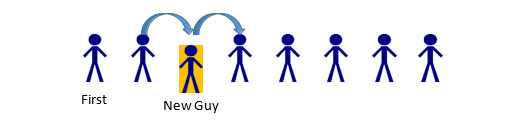
In this case, Person 2 would change their “next” person from Person 3, to the new Person being added. New Guy would have his “next” pointer set to whomever Person 2 was previously keeping track of, Person 3. Because of the ordering process, Person 3 would remain unchanged, as would anyone else in the list (aside from being a bit irritated at the New Guy for cutting in line). So that’s the concept behind a Linked List. A series of “nodes” which are connected via pointer to one another, and inserting/deleting nodes is a faster process than deleting and reconstructing the entire collection of data. Now, how to go about creating that?
Terminology
Node The fundamental building block of a Linked List. A node contains the data actually being stored in the list, as well as 1 or more pointers to other nodes. This is typically implemented as a nested class (see below). Singly-linked A Linked List would be singly-linked if each node only has a single pointer to another node, typically a “next” pointer. This only allows for uni-directional traversal of the data—from beginning to end. Doubly-linked Each node contains 2 pointers: a “next” pointer and a “previous” pointer. This allows for bi-directional traversal of the data—either from front-to-back or backto-front. Head A pointer to the first node in the list, akin to index 0 of an array. Tail A pointer to the last node in the list. May or may not be used, depending on the implementation of the list.
Nested Classes
The purpose of writing a class is to group data and functionality. The purpose of a nested class is the same—the only difference is where we declare a nested class. We declare a nested class like this: class MyClass { public: // Nested class class NestedClass { int x, y, z; NestedClass(); ~NestedClass(); int SomeFunction(); }; private: // Data for "MyClass" NestedClass myData; NestedClass *somePtr; float values; MyClass(); // Etc… }; // To create nested classes… // Use the Scope Resolution Operator MyClass::NestedClass someVariable; // With a class template… TemplateClass foo; TemplateClass::Nested bar; /* NOTE: You can make nested classes private if you wish, to prevent access to them outside of the encapsulating class. */ Additional reading: http://en.cppreference.com/w/cpp/language/nested_types The nature of the Linked List is that each piece of information knows about the information which follows (or precedes) it. It would make sense, then, to create some nested class to group all of that information together.
Benefits and Drawbacks
All data structures in programming (C++ or otherwise) have advantages and disadvantages. There is no “one size fits all” data structure. Some are faster (in some cases), some have smaller memory footprints, and some are more flexible in their functionality, which can make life easier for the programmer. Linked List versus Array – Who Wins? Array Linked List Fast access of individual elements as well as iteration over the entire array Changing the Linked List is fast – nodes can be inserted/removed very quickly Random access – You can quickly “jump” to the appropriate memory location of an element Less affected by memory fragmentation, nodes can fit anywhere in memory Changing the array is slow – Have to rebuild the entire array when adding/removing elements No random access, slow iteration Memory fragmentation can be an issue for arrays—need a single, contiguous block large enough for all of the data Extra memory overhead for nodes/pointers Slow to access individual elements
Code Structure
As shown above, the Linked List class itself stores very little data: Pointers to the first and last nodes, and a count. In some implementations, you might only have a pointer to the first node, and that’s it. In addition to those data members, your Linked List class must conform to the following interface:
Function Reference
Accessors PrintForward Iterator through all of the nodes and print out their values, one a time. PrintReverse Exactly the same as PrintForward, except completely the opposite. NodeCount Wait, we’re storing how many things in this list? FindAll Find all nodes which match the passed in parameter value, and store a pointer to that node in the passed in vector. Use of a parameter like this (passing a something in by reference, and storing data for later use) is called an output parameter. Find Find the first node with a data value matching the passed in parameter, returning a pointer to that node. Returns null if no matching node found. const and nonconst versions. GetNode Given an index, return a pointer to the node at that index. Throws an exception if the index is out of range. Const and non-const versions. Head Returns the head pointer. Const and non-const versions. Tail Returns the tail pointer. Const and non-const versions. Insertion Operations AddHead Create a new Node at the front of the list to store the passed in parameter. AddTail Create a new Node at the end of the list to store the passed in parameter. AddNodesHead Given an array of values, insert a node for each of those at the beginning of the list, maintaining the original order. AddNodesTail Ditto, except adding to the end of the list. InsertAfter Given a pointer to a node, create a new node to store the passed in value, after the indicated node. InsertBefore Ditto, except insert the new node before the indicated node. InsertAt Inserts a new Node to store the first parameter, at the index-th location. So if you specified 4 as the index, the new Node should have 3 Nodes before it. Throws an exception if given an invalid index. Removal Operations RemoveHead Deletes the first Node in the list. Returns whether or not the operation was successful. RemoveTail Deletes the last Node, returning whether or not the operation was successful. Remove Remove ALL Nodes containing values matching that of the passed-in parameter. Returns how many instances were removed. RemoveAt Deletes the index-th Node from the list, returning whether or not the operation was successful. Clear Deletes all Nodes. Don’t forget the node count! Operators operator Overloaded brackets operator. Takes an index, and returns the index-th node. Throws an exception if given an invalid index. Const and non-const versions. operator= After listA = listB, listA == listB is true. operator== Overloaded equality operator. Given listA and listB, is listA equal to listB? What would make one Linked List equal to another? If each of its nodes were equal to the corresponding node of the other. (Similar to comparing two arrays, just with non-contiguous data). Construction / Destruction LinkedList() Default constructor. A head, a tail, and a node counter walk into a bar… and get initialized? Wait, that’s not how that one goes… How many nodes in an empty list? What is head pointing to? What is tail pointing to? Copy Constructor Sets “this” to a copy of the passed in LinkedList. Other list has 10 nodes, with values of 1-10? “this” should too. ~LinkedList() The usual. Clean up your mess. (Delete all the nodes created by the list.)
Tips
A few tips for this assignment: Remember the "Big Three" or the “Rule of Three” o If you define one of the three special functions (copy constructor, assignment operator, or destructor), you should define the other two Start small, work one bit of functionality at a time. Work on things like Add() and PrintForward() first, as well as accessors (brackets operator, Head()/Tail(), etc). You can’t really test anything else unless those are working. Refer back to the recommended chapters in your textbook as well as lecture videos for an explanation of the details of dynamic memory allocation o There are a lot of things to remember when memory allocation The debugger is your friend! (You have learned how to use it, right?) Make charts, diagrams, sketches of the problem. Memory is inherently difficult to visualize, find a way that works for you. Don’t forget your node count! Read the full article
0 notes
Text
80% off #Break Away: Programming And Coding Interviews – $10
A course that teaches pointers, linked lists, general programming, algorithms and recursion like no one else
All Levels, – Video: 20.5 hours, 83 lectures
Average rating 4.4/5 (4.4)
Course requirements:
This course requires some basic understanding of a programming language, preferably C. Some solutions are in Java, though Java is not a requirement
Course description:
Programming interviews are like standard plays in professional sport – prepare accordingly. Don’t let Programming Interview gotchas get you down!
Programming interviews differ from real programming jobs in several important aspects, so they merit being treated differently, just like set pieces in sport. Just like teams prepare for their opponent’s playbooks in professional sport, it makes sense for you to approach programming interviews anticipating the interviewer’s playbook This course has been drawn by a team that has conducted hundreds of technical interviews at Google and Flipkart
What’s Covered:
Pointers: Memory layout of pointers and variables, pointer arithmetic, arrays, pointers to pointers, pointers to structures, argument passing to functions, pointer reassignment and modification – complete with visuals to help you conceptualize how things work. Strings: Strings, Character pointers, character arrays, null termination of strings, string.h function implementations with detailed explanations. Linked lists: Visualization, traversal, creating or deleting nodes, sorted merge, reversing a linked list and many many problems and solutions, doubly linked lists. Bit Manipulation: Work with bits and bit operations. Sorting and searching algorithms: Visualize how common sorting and searching algorithms work and the speed and efficiency of those algorithms Recursion: Master recursion with lots of practice! 8 common and uncommon recursive problems explained. Binary search, finding all subsets of a subset, finding all anagrams of a word, the infamous 8 Queens problem, executing dependent tasks, finding a path through a maze, implementing PaintFill, comparing two binary trees Data Structures: Understand queues, stacks, heaps, binary trees and graphs in detail along with common operations and their complexity. Includes code for every data structure along with solved interview problems based on these data structures. Step-by-step solutions to dozens of common programming problems: Palindromes, Game of Life, Sudoku Validator, Breaking a Document into Chunks, Run Length Encoding, Points within a distance are some of the problems solved and explained.
Talk to us!
Mail us about anything – anything! – and we will always reply
Full details Know how to approach and prepare for coding interviews Understand pointer concepts and memory management at a very deep and fundamental level Tackle a wide variety of linked list problems and know how to get started when asked linked list questions as a part of interviews Tackle a wide variety of general pointer and string problems and know how to answer questions on them during interviews Tackle a wide variety of general programming problems which involve just plain logic, no standard algorithms or data structures, these help you get the details right!
Full details YEP! New engineering graduate students who are interviewing for software engineering jobs YEP! Professionals from other fields with some programming knowledge looking to change to a software role YEP! Software professionals with several years of experience who want to brush up on core concepts NOPE! Other technology related professionals who are looking for a high level overview of pointer concepts.
Reviews:
“The content is well presented, best of all I can listen to it in my car on the way to work through the app. I had been looking for an audio book that covered algorithms, but found nothing. In all honesty, this was exactly what I needed.” (Kris Steigerwald)
“Very Good Course. Background music is little distracting but over all very good explanation.” (Shilpa)
“clear and detailed explanation” (Emine Irmak Topkaya)
About Instructor:
Loony Corn
Loonycorn is us, Janani Ravi, Vitthal Srinivasan, Swetha Kolalapudi and Navdeep Singh. Between the four of us, we have studied at Stanford, IIM Ahmedabad, the IITs and have spent years (decades, actually) working in tech, in the Bay Area, New York, Singapore and Bangalore. Janani: 7 years at Google (New York, Singapore); Studied at Stanford; also worked at Flipkart and Microsoft Vitthal: Also Google (Singapore) and studied at Stanford; Flipkart, Credit Suisse and INSEAD too Swetha: Early Flipkart employee, IIM Ahmedabad and IIT Madras alum Navdeep: longtime Flipkart employee too, and IIT Guwahati alum We think we might have hit upon a neat way of teaching complicated tech courses in a funny, practical, engaging way, which is why we are so excited to be here on Udemy! We hope you will try our offerings, and think you’ll like them
Instructor Other Courses:
Learn By Example: jQuery Learn By Example: Angular JS Learn By Example: Scala …………………………………………………………… Loony Corn coupons Development course coupon Udemy Development course coupon Programming Languages course coupon Udemy Programming Languages course coupon Break Away: Programming And Coding Interviews Break Away: Programming And Coding Interviews course coupon Break Away: Programming And Coding Interviews coupon coupons
The post 80% off #Break Away: Programming And Coding Interviews – $10 appeared first on Udemy Cupón.
from Udemy Cupón http://www.xpresslearn.com/udemy/coupon/80-off-break-away-programming-and-coding-interviews-10/
from https://xpresslearn.wordpress.com/2017/02/08/80-off-break-away-programming-and-coding-interviews-10/
0 notes
Text
80% off #Break Away: Programming And Coding Interviews – $10
A course that teaches pointers, linked lists, general programming, algorithms and recursion like no one else
All Levels, – Video: 20.5 hours, 83 lectures
Average rating 4.4/5 (4.4)
Course requirements:
This course requires some basic understanding of a programming language, preferably C. Some solutions are in Java, though Java is not a requirement
Course description:
Programming interviews are like standard plays in professional sport – prepare accordingly. Don’t let Programming Interview gotchas get you down!
Programming interviews differ from real programming jobs in several important aspects, so they merit being treated differently, just like set pieces in sport. Just like teams prepare for their opponent’s playbooks in professional sport, it makes sense for you to approach programming interviews anticipating the interviewer’s playbook This course has been drawn by a team that has conducted hundreds of technical interviews at Google and Flipkart
What’s Covered:
Pointers: Memory layout of pointers and variables, pointer arithmetic, arrays, pointers to pointers, pointers to structures, argument passing to functions, pointer reassignment and modification – complete with visuals to help you conceptualize how things work. Strings: Strings, Character pointers, character arrays, null termination of strings, string.h function implementations with detailed explanations. Linked lists: Visualization, traversal, creating or deleting nodes, sorted merge, reversing a linked list and many many problems and solutions, doubly linked lists. Bit Manipulation: Work with bits and bit operations. Sorting and searching algorithms: Visualize how common sorting and searching algorithms work and the speed and efficiency of those algorithms Recursion: Master recursion with lots of practice! 8 common and uncommon recursive problems explained. Binary search, finding all subsets of a subset, finding all anagrams of a word, the infamous 8 Queens problem, executing dependent tasks, finding a path through a maze, implementing PaintFill, comparing two binary trees Data Structures: Understand queues, stacks, heaps, binary trees and graphs in detail along with common operations and their complexity. Includes code for every data structure along with solved interview problems based on these data structures. Step-by-step solutions to dozens of common programming problems: Palindromes, Game of Life, Sudoku Validator, Breaking a Document into Chunks, Run Length Encoding, Points within a distance are some of the problems solved and explained.
Talk to us!
Mail us about anything – anything! – and we will always reply

Full details Know how to approach and prepare for coding interviews Understand pointer concepts and memory management at a very deep and fundamental level Tackle a wide variety of linked list problems and know how to get started when asked linked list questions as a part of interviews Tackle a wide variety of general pointer and string problems and know how to answer questions on them during interviews Tackle a wide variety of general programming problems which involve just plain logic, no standard algorithms or data structures, these help you get the details right!
Full details YEP! New engineering graduate students who are interviewing for software engineering jobs YEP! Professionals from other fields with some programming knowledge looking to change to a software role YEP! Software professionals with several years of experience who want to brush up on core concepts NOPE! Other technology related professionals who are looking for a high level overview of pointer concepts.
Reviews:
“The content is well presented, best of all I can listen to it in my car on the way to work through the app. I had been looking for an audio book that covered algorithms, but found nothing. In all honesty, this was exactly what I needed.” (Kris Steigerwald)
“Very Good Course. Background music is little distracting but over all very good explanation.” (Shilpa)
“clear and detailed explanation” (Emine Irmak Topkaya)
About Instructor:
Loony Corn
Loonycorn is us, Janani Ravi, Vitthal Srinivasan, Swetha Kolalapudi and Navdeep Singh. Between the four of us, we have studied at Stanford, IIM Ahmedabad, the IITs and have spent years (decades, actually) working in tech, in the Bay Area, New York, Singapore and Bangalore. Janani: 7 years at Google (New York, Singapore); Studied at Stanford; also worked at Flipkart and Microsoft Vitthal: Also Google (Singapore) and studied at Stanford; Flipkart, Credit Suisse and INSEAD too Swetha: Early Flipkart employee, IIM Ahmedabad and IIT Madras alum Navdeep: longtime Flipkart employee too, and IIT Guwahati alum We think we might have hit upon a neat way of teaching complicated tech courses in a funny, practical, engaging way, which is why we are so excited to be here on Udemy! We hope you will try our offerings, and think you’ll like them
Instructor Other Courses:
Learn By Example: jQuery Learn By Example: Angular JS Learn By Example: Scala …………………………………………………………… Loony Corn coupons Development course coupon Udemy Development course coupon Programming Languages course coupon Udemy Programming Languages course coupon Break Away: Programming And Coding Interviews Break Away: Programming And Coding Interviews course coupon Break Away: Programming And Coding Interviews coupon coupons
The post 80% off #Break Away: Programming And Coding Interviews – $10 appeared first on Udemy Cupón.
from http://www.xpresslearn.com/udemy/coupon/80-off-break-away-programming-and-coding-interviews-10/
0 notes