#delete a node from doubly linked list
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
Mastering Data Structures Using Python: A Complete Guide
When learning programming, mastering Data Structures Using Python is one of the most critical milestones. Python, known for its simplicity and versatility, is a perfect language to delve into data structures, which form the backbone of efficient algorithms. In this blog, we’ll explore the essential data structures in Python, how to use them, and why they’re so vital in programming.
Why Learn Data Structures Using Python?
1. Simplifies Complex Operations
Python's built-in libraries and clean syntax make implementing data structures intuitive. Whether you’re manipulating arrays or designing trees, Python minimizes complexity.
2. High Demand for Python Programmers
The demand for professionals with expertise in Python for data structures is skyrocketing, especially in fields like data science, artificial intelligence, and software engineering.
3. A Foundation for Problem-Solving
Understanding data structures like lists, stacks, queues, and trees equips you to solve complex computational problems efficiently.
What Are Data Structures?
At their core, data structures are ways of organizing and storing data to perform operations like retrieval, insertion, and deletion efficiently. There are two main types:
Linear Data Structures: Data is stored sequentially (e.g., arrays, linked lists).
Non-Linear Data Structures: Data is stored hierarchically (e.g., trees, graphs).
Python, with its versatile libraries, offers tools to implement both types seamlessly.
Essential Data Structures in Python
1. Lists
One of Python's most versatile data structures, lists are dynamic arrays that can store heterogeneous data types.
Example:
python
Copy code
# Creating a list
fruits = ["apple", "banana", "cherry"]
print(fruits[1]) # Output: banana
Features of Lists:
Mutable (elements can be changed).
Supports slicing and iteration.
Used extensively in Python programming for simple data organization.
2. Tuples
Tuples are immutable sequences, often used for fixed collections of items.
Example:
python
Copy code
# Creating a tuple
coordinates = (10, 20)
print(coordinates[0]) # Output: 10
Key Benefits:
Faster than lists due to immutability.
Commonly used in scenarios where data integrity is crucial.
3. Dictionaries
Dictionaries in Python implement hash maps and are perfect for key-value storage.
Example:
python
Copy code
# Creating a dictionary
student = {"name": "John", "age": 22}
print(student["name"]) # Output: John
Why Use Dictionaries?
Quick lookups.
Ideal for scenarios like counting occurrences, storing configurations, etc.
4. Sets
Sets are unordered collections of unique elements, useful for removing duplicates or performing mathematical set operations.
Example:
python
Copy code
# Using sets
numbers = {1, 2, 3, 4, 4}
print(numbers) # Output: {1, 2, 3, 4}
Applications:
Used in tasks requiring unique data points, such as intersection or union operations.
Advanced Data Structures in Python
1. Stacks
Stacks are linear data structures following the LIFO (Last In, First Out) principle.
Implementation:
python
Copy code
stack = []
stack.append(10)
stack.append(20)
print(stack.pop()) # Output: 20
Use Cases:
Undo operations in text editors.
Browser backtracking functionality.
2. Queues
Queues follow the FIFO (First In, First Out) principle and are used for tasks requiring sequential processing.
Implementation:
python
Copy code
from collections import deque
queue = deque()
queue.append(1)
queue.append(2)
print(queue.popleft()) # Output: 1
Applications:
Customer service simulations.
Process scheduling in operating systems.
3. Linked Lists
Unlike arrays, linked lists store data in nodes connected via pointers.
Types:
Singly Linked Lists
Doubly Linked Lists
Example:
python
Copy code
class Node:
def __init__(self, data):
self.data = data
self.next = None
# Creating nodes
node1 = Node(10)
node2 = Node(20)
node1.next = node2
Benefits:
Efficient insertion and deletion.
Commonly used in dynamic memory allocation.
4. Trees
Trees are hierarchical structures used to represent relationships.
Types:
Binary Trees
Binary Search Trees
Heaps
Example:
python
Copy code
class TreeNode:
def __init__(self, data):
self.data = data
self.left = None
self.right = None
Applications:
Databases.
Routing algorithms.
5. Graphs
Graphs consist of nodes (vertices) connected by edges.
Representation:
Adjacency List
Adjacency Matrix
Example:
python
Copy code
graph = {
"A": ["B", "C"],
"B": ["A", "D"],
"C": ["A", "D"],
"D": ["B", "C"]
}
Applications:
Social networks.
Navigation systems.
Why Python Stands Out for Data Structures
1. Built-In Libraries
Python simplifies data structure implementation with libraries like collections and heapq.
2. Readable Syntax
Beginners and experts alike find Python's syntax intuitive, making learning data structures using Python easier.
3. Versatility
From simple algorithms to complex applications, Python adapts to all.
Common Challenges and How to Overcome Them
1. Understanding Concepts
Some learners struggle with abstract concepts like recursion or tree traversal. Watching tutorial videos or practicing coding challenges can help.
2. Memory Management
Efficient use of memory is critical, especially for large-scale data. Python's garbage collection minimizes these issues.
3. Debugging
Using tools like Python’s pdb debugger helps troubleshoot problems effectively.
0 notes
Text
How to Ace Your DSA Interview, Even If You're a Newbie
Are you aiming to crack DSA interviews and land your dream job as a software engineer or developer? Look no further! This comprehensive guide will provide you with all the necessary tips and insights to ace your DSA interviews. We'll explore the important DSA topics to study, share valuable preparation tips, and even introduce you to Tutort Academy DSA courses to help you get started on your journey. So let's dive in!

Why is DSA Important?
Before we delve into the specifics of DSA interviews, let's first understand why data structures and algorithms are crucial for software development. DSA plays a vital role in optimizing software components, enabling efficient data storage and processing.
From logging into your Facebook account to finding the shortest route on Google Maps, DSA is at work in various applications we use every day. Mastering DSA allows you to solve complex problems, optimize code performance, and design efficient software systems.
Important DSA Topics to Study
To excel in DSA interviews, it's essential to have a strong foundation in key topics. Here are some important DSA topics you should study:
1. Arrays and Strings
Arrays and strings are fundamental data structures in programming. Understanding array manipulation, string operations, and common algorithms like sorting and searching is crucial for solving coding problems.
2. Linked Lists
Linked lists are linear data structures that consist of nodes linked together. It's important to understand concepts like singly linked lists, doubly linked lists, and circular linked lists, as well as operations like insertion, deletion, and traversal.
3. Stacks and Queues
Stacks and queues are abstract data types that follow specific orderings. Mastering concepts like LIFO (Last In, First Out) for stacks and FIFO (First In, First Out) for queues is essential. Additionally, learn about their applications in real-life scenarios.
4. Trees and Binary Trees
Trees are hierarchical data structures with nodes connected by edges. Understanding binary trees, binary search trees, and traversal algorithms like preorder, inorder, and postorder is crucial. Additionally, explore advanced concepts like AVL trees and red-black trees.
5. Graphs
Graphs are non-linear data structures consisting of nodes (vertices) and edges. Familiarize yourself with graph representations, traversal algorithms like BFS (Breadth-First Search) and DFS (Depth-First Search), and graph algorithms such as Dijkstra's algorithm and Kruskal's algorithm.
6. Sorting and Searching Algorithms
Understanding various sorting algorithms like bubble sort, selection sort, insertion sort, merge sort, and quicksort is essential. Additionally, familiarize yourself with searching algorithms like linear search, binary search, and hash-based searching.
7. Dynamic Programming
Dynamic programming involves breaking down a complex problem into smaller overlapping subproblems and solving them individually. Mastering this technique allows you to solve optimization problems efficiently.
These are just a few of the important DSA topics to study. It's crucial to have a solid understanding of these concepts and their applications to perform well in DSA interviews.
Tips to Follow While Preparing for DSA Interviews
Preparing for DSA interviews can be challenging, but with the right approach, you can maximize your chances of success. Here are some tips to keep in mind:
1. Understand the Fundamentals
Before diving into complex algorithms, ensure you have a strong grasp of the fundamentals. Familiarize yourself with basic data structures, common algorithms, and time and space complexities.
2. Practice Regularly
Consistent practice is key to mastering DSA. Solve a wide range of coding problems, participate in coding challenges, and implement algorithms from scratch. Leverage online coding platforms like LeetCode, HackerRank to practice and improve your problem-solving skills.
3. Analyze and Optimize
After solving a problem, analyze your solution and look for areas of improvement. Optimize your code for better time and space complexities. This demonstrates your ability to write efficient and scalable code.
4. Collaborate and Learn from Others
Engage with the coding community, join study groups, and participate in online forums. Collaborating with others allows you to learn different approaches, gain insights, and improve your problem-solving skills.
5. Mock Interviews and Feedback
Simulate real interview scenarios by participating in mock interviews. Seek feedback from experienced professionals or mentors who can provide valuable insights into your strengths and areas for improvement.
Following these tips will help you build a solid foundation in DSA and boost your confidence for interviews.
Conclusion
Mastering DSA is crucial for acing coding interviews and securing your dream job as a software engineer or developer. By studying important DSA topics, following effective preparation tips, and leveraging Tutort Academy's DSA courses, you'll be well-equipped to tackle DSA interviews with confidence. Remember to practice regularly, seek feedback, and stay curious.
Good luck on your DSA journey!
#programming#tutortacademy#tutort#DSA#data structures#data structures and algorithms#algorithm#interview preparation#interview tips
0 notes
Photo

Video tutorial explains a C program to delete a node from doubly linked list. You will learn to delete first node, middle node as well as last node ffrom the doubly linked list. Doubly linked list is also known as two-way linked list. The C program is explained using step by step approach along with figures at each step. Entire source code is explained statement wise. In this tutorial, you will learn double link list deletion, delete the first node of doubly linked list and delete node at given position in doubly linked list. This online data structures and algorithms tutorial teaches, data structures in c, data structures interview questions and answers and data structures along with data structure programs. By the end of the vide you will be knowing, data structures and algorithms lectures, data structures tutorial videos and online data structures training. Complete coding is explained with figures at each step, you will understand, delete node at given position, data structures interview questions and previous pointer along with linked list using c. If you are looking for, delete a node from linked list, how to delete a node in doubly linked list and algorithm to delete a node from doubly linked list, then this video is for you. For code of deleting a node from doubly linked list, click the following link: http://bmharwani.com/deletefromdoubly.c For more video tutorials on data structures and algorithms, visit: https://www.youtube.com/watch?v=-XXsmBys2DQ&t=0s&list=PLuDr_vb2LpAxVWIk-po5nL5Ct2pHpndLR&index=6 To get notification for new videos, subscribe to my channel: https://youtube.com/c/bintuharwani To see more videos on different computer subjects, visit: http://bmharwani.com
#doubly linked list#delete a node from doubly linked list#double linked list#deletion in doubly linked list#time required to delete a node from doubly linked list#delete even nodes from doubly linked list#delete nth node from doubly linked list#delete middle node doubly linked list#write a function to delete a node from doubly linked list#delete a node from doubly linked list in c#delete middle node in doubly linked list#bintu harwani
2 notes
·
View notes
Link
Data Structures and Algorithms from Zero to Hero and Crack Top Companies 100+ Interview questions (Java Coding)
What you’ll learn
Java Data Structures and Algorithms Masterclass
Learn, implement, and use different Data Structures
Learn, implement and use different Algorithms
Become a better developer by mastering computer science fundamentals
Learn everything you need to ace difficult coding interviews
Cracking the Coding Interview with 100+ questions with explanations
Time and Space Complexity of Data Structures and Algorithms
Recursion
Big O
Dynamic Programming
Divide and Conquer Algorithms
Graph Algorithms
Greedy Algorithms
Requirements
Basic Java Programming skills
Description
Welcome to the Java Data Structures and Algorithms Masterclass, the most modern, and the most complete Data Structures and Algorithms in Java course on the internet.
At 44+ hours, this is the most comprehensive course online to help you ace your coding interviews and learn about Data Structures and Algorithms in Java. You will see 100+ Interview Questions done at the top technology companies such as Apple, Amazon, Google, and Microsoft and how-to face Interviews with comprehensive visual explanatory video materials which will bring you closer to landing the tech job of your dreams!
Learning Java is one of the fastest ways to improve your career prospects as it is one of the most in-demand tech skills! This course will help you in better understanding every detail of Data Structures and how algorithms are implemented in high-level programming languages.
We’ll take you step-by-step through engaging video tutorials and teach you everything you need to succeed as a professional programmer.
After finishing this course, you will be able to:
Learn basic algorithmic techniques such as greedy algorithms, binary search, sorting, and dynamic programming to solve programming challenges.
Learn the strengths and weaknesses of a variety of data structures, so you can choose the best data structure for your data and applications
Learn many of the algorithms commonly used to sort data, so your applications will perform efficiently when sorting large datasets
Learn how to apply graph and string algorithms to solve real-world challenges: finding shortest paths on huge maps and assembling genomes from millions of pieces.
Why this course is so special and different from any other resource available online?
This course will take you from the very beginning to very complex and advanced topics in understanding Data Structures and Algorithms!
You will get video lectures explaining concepts clearly with comprehensive visual explanations throughout the course.
You will also see Interview Questions done at the top technology companies such as Apple, Amazon, Google, and Microsoft.
I cover everything you need to know about the technical interview process!
So whether you are interested in learning the top programming language in the world in-depth and interested in learning the fundamental Algorithms, Data Structures, and performance analysis that make up the core foundational skillset of every accomplished programmer/designer or software architect and is excited to ace your next technical interview this is the course for you!
And this is what you get by signing up today:
Lifetime access to 44+ hours of HD quality videos. No monthly subscription. Learn at your own pace, whenever you want
Friendly and fast support in the course Q&A whenever you have questions or get stuck
FULL money-back guarantee for 30 days!
This course is designed to help you to achieve your career goals. Whether you are looking to get more into Data Structures and Algorithms, increase your earning potential, or just want a job with more freedom, this is the right course for you!
The topics that are covered in this course.
Section 1 – Introduction
What are Data Structures?
What is an algorithm?
Why are Data Structures And Algorithms important?
Types of Data Structures
Types of Algorithms
Section 2 – Recursion
What is Recursion?
Why do we need recursion?
How does Recursion work?
Recursive vs Iterative Solutions
When to use/avoid Recursion?
How to write Recursion in 3 steps?
How to find Fibonacci numbers using Recursion?
Section 3 – Cracking Recursion Interview Questions
Question 1 – Sum of Digits
Question 2 – Power
Question 3 – Greatest Common Divisor
Question 4 – Decimal To Binary
Section 4 – Bonus CHALLENGING Recursion Problems (Exercises)
power
factorial
products array
recursiveRange
fib
reverse
palindrome
some recursive
flatten
capitalize first
nestedEvenSum
capitalize words
stringifyNumbers
collects things
Section 5 – Big O Notation
Analogy and Time Complexity
Big O, Big Theta, and Big Omega
Time complexity examples
Space Complexity
Drop the Constants and the nondominant terms
Add vs Multiply
How to measure the codes using Big O?
How to find time complexity for Recursive calls?
How to measure Recursive Algorithms that make multiple calls?
Section 6 – Top 10 Big O Interview Questions (Amazon, Facebook, Apple, and Microsoft)
Product and Sum
Print Pairs
Print Unordered Pairs
Print Unordered Pairs 2 Arrays
Print Unordered Pairs 2 Arrays 100000 Units
Reverse
O(N) Equivalents
Factorial Complexity
Fibonacci Complexity
Powers of 2
Section 7 – Arrays
What is an Array?
Types of Array
Arrays in Memory
Create an Array
Insertion Operation
Traversal Operation
Accessing an element of Array
Searching for an element in Array
Deleting an element from Array
Time and Space complexity of One Dimensional Array
One Dimensional Array Practice
Create Two Dimensional Array
Insertion – Two Dimensional Array
Accessing an element of Two Dimensional Array
Traversal – Two Dimensional Array
Searching for an element in Two Dimensional Array
Deletion – Two Dimensional Array
Time and Space complexity of Two Dimensional Array
When to use/avoid array
Section 8 – Cracking Array Interview Questions (Amazon, Facebook, Apple, and Microsoft)
Question 1 – Missing Number
Question 2 – Pairs
Question 3 – Finding a number in an Array
Question 4 – Max product of two int
Question 5 – Is Unique
Question 6 – Permutation
Question 7 – Rotate Matrix
Section 9 – CHALLENGING Array Problems (Exercises)
Middle Function
2D Lists
Best Score
Missing Number
Duplicate Number
Pairs
Section 10 – Linked List
What is a Linked List?
Linked List vs Arrays
Types of Linked List
Linked List in the Memory
Creation of Singly Linked List
Insertion in Singly Linked List in Memory
Insertion in Singly Linked List Algorithm
Insertion Method in Singly Linked List
Traversal of Singly Linked List
Search for a value in Single Linked List
Deletion of a node from Singly Linked List
Deletion Method in Singly Linked List
Deletion of entire Singly Linked List
Time and Space Complexity of Singly Linked List
Section 11 – Circular Singly Linked List
Creation of Circular Singly Linked List
Insertion in Circular Singly Linked List
Insertion Algorithm in Circular Singly Linked List
Insertion method in Circular Singly Linked List
Traversal of Circular Singly Linked List
Searching a node in Circular Singly Linked List
Deletion of a node from Circular Singly Linked List
Deletion Algorithm in Circular Singly Linked List
A method in Circular Singly Linked List
Deletion of entire Circular Singly Linked List
Time and Space Complexity of Circular Singly Linked List
Section 12 – Doubly Linked List
Creation of Doubly Linked List
Insertion in Doubly Linked List
Insertion Algorithm in Doubly Linked List
Insertion Method in Doubly Linked List
Traversal of Doubly Linked List
Reverse Traversal of Doubly Linked List
Searching for a node in Doubly Linked List
Deletion of a node in Doubly Linked List
Deletion Algorithm in Doubly Linked List
Deletion Method in Doubly Linked List
Deletion of entire Doubly Linked List
Time and Space Complexity of Doubly Linked List
Section 13 – Circular Doubly Linked List
Creation of Circular Doubly Linked List
Insertion in Circular Doubly Linked List
Insertion Algorithm in Circular Doubly Linked List
Insertion Method in Circular Doubly Linked List
Traversal of Circular Doubly Linked List
Reverse Traversal of Circular Doubly Linked List
Search for a node in Circular Doubly Linked List
Delete a node from Circular Doubly Linked List
Deletion Algorithm in Circular Doubly Linked List
Deletion Method in Circular Doubly Linked List
Entire Circular Doubly Linked List
Time and Space Complexity of Circular Doubly Linked List
Time Complexity of Linked List vs Arrays
Section 14 – Cracking Linked List Interview Questions (Amazon, Facebook, Apple, and Microsoft)
Linked List Class
Question 1 – Remove Dups
Question 2 – Return Kth to Last
Question 3 – Partition
Question 4 – Sum Linked Lists
Question 5 – Intersection
Section 15 – Stack
What is a Stack?
What and Why of Stack?
Stack Operations
Stack using Array vs Linked List
Stack Operations using Array (Create, isEmpty, isFull)
Stack Operations using Array (Push, Pop, Peek, Delete)
Time and Space Complexity of Stack using Array
Stack Operations using Linked List
Stack methods – Push, Pop, Peek, Delete, and isEmpty using Linked List
Time and Space Complexity of Stack using Linked List
When to Use/Avoid Stack
Stack Quiz
Section 16 – Queue
What is a Queue?
Linear Queue Operations using Array
Create, isFull, isEmpty, and enQueue methods using Linear Queue Array
Dequeue, Peek and Delete Methods using Linear Queue Array
Time and Space Complexity of Linear Queue using Array
Why Circular Queue?
Circular Queue Operations using Array
Create, Enqueue, isFull and isEmpty Methods in Circular Queue using Array
Dequeue, Peek and Delete Methods in Circular Queue using Array
Time and Space Complexity of Circular Queue using Array
Queue Operations using Linked List
Create, Enqueue and isEmpty Methods in Queue using Linked List
Dequeue, Peek and Delete Methods in Queue using Linked List
Time and Space Complexity of Queue using Linked List
Array vs Linked List Implementation
When to Use/Avoid Queue?
Section 17 – Cracking Stack and Queue Interview Questions (Amazon, Facebook, Apple, Microsoft)
Question 1 – Three in One
Question 2 – Stack Minimum
Question 3 – Stack of Plates
Question 4 – Queue via Stacks
Question 5 – Animal Shelter
Section 18 – Tree / Binary Tree
What is a Tree?
Why Tree?
Tree Terminology
How to create a basic tree in Java?
Binary Tree
Types of Binary Tree
Binary Tree Representation
Create Binary Tree (Linked List)
PreOrder Traversal Binary Tree (Linked List)
InOrder Traversal Binary Tree (Linked List)
PostOrder Traversal Binary Tree (Linked List)
LevelOrder Traversal Binary Tree (Linked List)
Searching for a node in Binary Tree (Linked List)
Inserting a node in Binary Tree (Linked List)
Delete a node from Binary Tree (Linked List)
Delete entire Binary Tree (Linked List)
Create Binary Tree (Array)
Insert a value Binary Tree (Array)
Search for a node in Binary Tree (Array)
PreOrder Traversal Binary Tree (Array)
InOrder Traversal Binary Tree (Array)
PostOrder Traversal Binary Tree (Array)
Level Order Traversal Binary Tree (Array)
Delete a node from Binary Tree (Array)
Entire Binary Tree (Array)
Linked List vs Python List Binary Tree
Section 19 – Binary Search Tree
What is a Binary Search Tree? Why do we need it?
Create a Binary Search Tree
Insert a node to BST
Traverse BST
Search in BST
Delete a node from BST
Delete entire BST
Time and Space complexity of BST
Section 20 – AVL Tree
What is an AVL Tree?
Why AVL Tree?
Common Operations on AVL Trees
Insert a node in AVL (Left Left Condition)
Insert a node in AVL (Left-Right Condition)
Insert a node in AVL (Right Right Condition)
Insert a node in AVL (Right Left Condition)
Insert a node in AVL (all together)
Insert a node in AVL (method)
Delete a node from AVL (LL, LR, RR, RL)
Delete a node from AVL (all together)
Delete a node from AVL (method)
Delete entire AVL
Time and Space complexity of AVL Tree
Section 21 – Binary Heap
What is Binary Heap? Why do we need it?
Common operations (Creation, Peek, sizeofheap) on Binary Heap
Insert a node in Binary Heap
Extract a node from Binary Heap
Delete entire Binary Heap
Time and space complexity of Binary Heap
Section 22 – Trie
What is a Trie? Why do we need it?
Common Operations on Trie (Creation)
Insert a string in Trie
Search for a string in Trie
Delete a string from Trie
Practical use of Trie
Section 23 – Hashing
What is Hashing? Why do we need it?
Hashing Terminology
Hash Functions
Types of Collision Resolution Techniques
Hash Table is Full
Pros and Cons of Resolution Techniques
Practical Use of Hashing
Hashing vs Other Data structures
Section 24 – Sort Algorithms
What is Sorting?
Types of Sorting
Sorting Terminologies
Bubble Sort
Selection Sort
Insertion Sort
Bucket Sort
Merge Sort
Quick Sort
Heap Sort
Comparison of Sorting Algorithms
Section 25 – Searching Algorithms
Introduction to Searching Algorithms
Linear Search
Linear Search in Python
Binary Search
Binary Search in Python
Time Complexity of Binary Search
Section 26 – Graph Algorithms
What is a Graph? Why Graph?
Graph Terminology
Types of Graph
Graph Representation
The graph in Java using Adjacency Matrix
The graph in Java using Adjacency List
Section 27 – Graph Traversal
Breadth-First Search Algorithm (BFS)
Breadth-First Search Algorithm (BFS) in Java – Adjacency Matrix
Breadth-First Search Algorithm (BFS) in Java – Adjacency List
Time Complexity of Breadth-First Search (BFS) Algorithm
Depth First Search (DFS) Algorithm
Depth First Search (DFS) Algorithm in Java – Adjacency List
Depth First Search (DFS) Algorithm in Java – Adjacency Matrix
Time Complexity of Depth First Search (DFS) Algorithm
BFS Traversal vs DFS Traversal
Section 28 – Topological Sort
What is Topological Sort?
Topological Sort Algorithm
Topological Sort using Adjacency List
Topological Sort using Adjacency Matrix
Time and Space Complexity of Topological Sort
Section 29 – Single Source Shortest Path Problem
what is Single Source Shortest Path Problem?
Breadth-First Search (BFS) for Single Source Shortest Path Problem (SSSPP)
BFS for SSSPP in Java using Adjacency List
BFS for SSSPP in Java using Adjacency Matrix
Time and Space Complexity of BFS for SSSPP
Why does BFS not work with Weighted Graph?
Why does DFS not work for SSSP?
Section 30 – Dijkstra’s Algorithm
Dijkstra’s Algorithm for SSSPP
Dijkstra’s Algorithm in Java – 1
Dijkstra’s Algorithm in Java – 2
Dijkstra’s Algorithm with Negative Cycle
Section 31 – Bellman-Ford Algorithm
Bellman-Ford Algorithm
Bellman-Ford Algorithm with negative cycle
Why does Bellman-Ford run V-1 times?
Bellman-Ford in Python
BFS vs Dijkstra vs Bellman Ford
Section 32 – All Pairs Shortest Path Problem
All pairs shortest path problem
Dry run for All pair shortest path
Section 33 – Floyd Warshall
Floyd Warshall Algorithm
Why Floyd Warshall?
Floyd Warshall with negative cycle,
Floyd Warshall in Java,
BFS vs Dijkstra vs Bellman Ford vs Floyd Warshall,
Section 34 – Minimum Spanning Tree
Minimum Spanning Tree,
Disjoint Set,
Disjoint Set in Java,
Section 35 – Kruskal’s and Prim’s Algorithms
Kruskal Algorithm,
Kruskal Algorithm in Python,
Prim’s Algorithm,
Prim’s Algorithm in Python,
Prim’s vs Kruskal
Section 36 – Cracking Graph and Tree Interview Questions (Amazon, Facebook, Apple, Microsoft)
Section 37 – Greedy Algorithms
What is a Greedy Algorithm?
Well known Greedy Algorithms
Activity Selection Problem
Activity Selection Problem in Python
Coin Change Problem
Coin Change Problem in Python
Fractional Knapsack Problem
Fractional Knapsack Problem in Python
Section 38 – Divide and Conquer Algorithms
What is a Divide and Conquer Algorithm?
Common Divide and Conquer algorithms
How to solve the Fibonacci series using the Divide and Conquer approach?
Number Factor
Number Factor in Java
House Robber
House Robber Problem in Java
Convert one string to another
Convert One String to another in Java
Zero One Knapsack problem
Zero One Knapsack problem in Java
Longest Common Sequence Problem
Longest Common Subsequence in Java
Longest Palindromic Subsequence Problem
Longest Palindromic Subsequence in Java
Minimum cost to reach the Last cell problem
Minimum Cost to reach the Last Cell in 2D array using Java
Number of Ways to reach the Last Cell with given Cost
Number of Ways to reach the Last Cell with given Cost in Java
Section 39 – Dynamic Programming
What is Dynamic Programming? (Overlapping property)
Where does the name of DC come from?
Top-Down with Memoization
Bottom-Up with Tabulation
Top-Down vs Bottom Up
Is Merge Sort Dynamic Programming?
Number Factor Problem using Dynamic Programming
Number Factor: Top-Down and Bottom-Up
House Robber Problem using Dynamic Programming
House Robber: Top-Down and Bottom-Up
Convert one string to another using Dynamic Programming
Convert String using Bottom Up
Zero One Knapsack using Dynamic Programming
Zero One Knapsack – Top Down
Zero One Knapsack – Bottom Up
Section 40 – CHALLENGING Dynamic Programming Problems
Longest repeated Subsequence Length problem
Longest Common Subsequence Length problem
Longest Common Subsequence problem
Diff Utility
Shortest Common Subsequence problem
Length of Longest Palindromic Subsequence
Subset Sum Problem
Egg Dropping Puzzle
Maximum Length Chain of Pairs
Section 41 – A Recipe for Problem Solving
Introduction
Step 1 – Understand the problem
Step 2 – Examples
Step 3 – Break it Down
Step 4 – Solve or Simplify
Step 5 – Look Back and Refactor
Section 41 – Wild West
Download
To download more paid courses for free visit course catalog where 1000+ paid courses available for free. You can get the full course into your device with just a single click. Follow the link above to download this course for free.
3 notes
·
View notes
Text
Linked list stack implememntation using two queues 261

Linked list stack implememntation using two queues 261 code#
Fortunately, JavaScript arrays implement this for us in the form of the length property. algorithms (sorting, using stacks and queues, tree exploration algorithms, etc.). A common additional operation for collection data structures is the size, as it allows you to safely iterate the elements and find out if there are any more elements present in the data structure. Data structures: Abstract data types (ADTs), vector, deque, list, queue. Again, it doesn't change the index of the other items in the array, so it is O(1). Similarly, on pop, we simply pop the last value from the array. As it doesn't change the index of the current items, this is O(1). On push, we simply push the new item into the array. Therefore, we can simply implement the operations of this data structure using an array. Fortunately, in JavaScript implementations, array functions that do not require any changes to the index of the current items have an average runtime of O(1). First node have null in link field and second node link have first node address in link field and so on and last node address in. which is head of the stack where pushing and popping items happens at the head of the list. In stack Implementation, a stack contains a top pointer. You will use only one C file (stackfromqueue.c)containing all the functions to design the entire interface. The objective is to implement these push and pop operations such that they operate in O(1) time. A stack can be easily implemented using the linked list. Part 3: Linked List Stack Implementation Using Two Queues Inthis part, you will use two instances of Queue ADT to implement aStack ADT. This fact can be modeled into the type system by using a union of T and undefined. If there are no more items, we can return an out-of-bound value, for example, undefined. The other key operation pops an item from the stack, again in O(1). The first one is push, which adds an item in O(1). StdOut.java A list implemented with a doubly linked list. js is the open source HTML5 audio player. The stack data structure has two key operations. js, a JavaScript library with the goal of making coding accessible to artists, designers, educators, and beginners. We can model this easily in TypeScript using the generic class for items of type T. Using Python, create an implementation of Deque (double-ended queue) with linked list nodes.
Linked list stack implememntation using two queues 261 code#
So deleting of the middle element can be done in O(1) if we just pop the element from the front of the deque.A stack is a last-in/first-out data structure with key operations having a time complexity of O(1). I encountered this question as I am preparing for my code interview. The stack functions worked on from Worksheet 17 were re-implemented using the queue functions worked on from Worksheet 18. Overview: This program is an implementation of a stack using two instances of a queue. Here each new node will be dynamically allocated, so overflow is not possible unless memory is exhausted. Using an array will restrict the maximum capacity of the array, which can lead to stack overflow. You must use only standard operations of a queue - which means only push to back, peek/pop from front, size, and is empty operations are valid. The advantage of using a linked list over arrays is that it is possible to implement a stack that can grow or shrink as much as needed. empty () - Return whether the stack is empty. We will see that the middle element is always the front element of the deque. Stack With Two Queues (Linked List) Zedrimar. pop () - Removes the element on top of the stack. If after the pop operation, the size of the deque is less than the size of the stack, we pop an element from the top of the stack and insert it back into the front of the deque so that size of the deque is not less than the stack. The pop operation on myStack will remove an element from the back of the deque. The number of elements in the deque stays 1 more or equal to that in the stack, however, whenever the number of elements present in the deque exceeds the number of elements in the stack by more than 1 we pop an element from the front of the deque and push it into the stack. Insert operation on myStack will add an element into the back of the deque. We will use a standard stack to store half of the elements and the other half of the elements which were added recently will be present in the deque. Method 2: Using a standard stack and a deque ISRO CS Syllabus for Scientist/Engineer Exam.ISRO CS Original Papers and Official Keys.GATE CS Original Papers and Official Keys.
0 notes
Text
What is a Python Linked List and Types of Linked List?
As we all know, Python is rapidly evolving. Therefore, we need to understand many things that are very basic and that everyone should be aware of. This blog will look at what a linked list is in Python, how it works, and the functions that can be applied to it. You've probably heard a lot of basic concepts that you should understand as a student, such as data types, strings, arrays, sorting techniques, tuples in Python, and so on. In this tutorial, we'll look at how to create a linked list in Python. So, let's start from the beginning.

Linked List in python
A linked list is a linear data structure in Python that stores data in contiguous memory locations rather than arrays of data items connected by links. In Python, each node in a linked list has a data field and a reference to the linked list's next node. In linked, each element is called a node, and pointers are used to connect them. The head of the linked list is the first node. The size of the linked list is flexible. We can have an endless number of nodes unless the device has enough storage. There are two types of linked lists, which we'll go over in this tutorial one by one.
In Python, a linked list is a node chain, with each node containing data and the address or reference to the next node. The head, which stores the reference to the first node, is the starting point of the linked list.
In Python, the linked list's head.
The first architectural item of the linked list is the 'head node,' or top node in the list. The Head is set to None when the list is first generated because there are no nodes in it. (Note that the linked list doesn't always require a node to begin, and the head option will default to None if one isn't provided.)
Python's Singly Linked List.
In Python, a single pointer connects the next node in a singly linked list to the linked list's next node. The data and pointer for each node in the linked list must be saved. The next pointer in the linked list's last node is null, indicating that the linked list has reached its conclusion.
Python's Doubly Linked List
A singly linked list or a linked list is easier to implement, but traversing it in reverse is far more complicated. To get around this, we can use a Doubly Linked List, in which each node has two pointers: one to point to the previous node and one to point to the next node.
In a doubly-linked list in Python, iteration is more efficient, especially if you need to repeat in reverse, and deletion of specific nodes is more efficient.
To summarise, a doubly linked list is a more sophisticated linked list in which each node has a pointer to the preceding and following nodes in the series. In a doubly-linked list, each node has node data, a piece of information to the next node (next pointer), and a pointer to the previous node (previous pointer) (previous pointer).
Conclusion
We've gone through the linked list and two types of linked lists in Python, singly and doubly-linked lists, in this blog. Although Linked Lists can be intimidating at first, if you get them, trees, graphs, and other data structures become much more understandable! In the future, keep a watch out for more Python-related blogs.
Many students throughout the world are having difficulties with python coding. If you're one of them, we have a team of Python Programming Help professionals who have years of experience. Please do not hesitate to contact our specialists.
1 note
·
View note
Text
cop3503 Project 1 – Templated Linked List Solved
Overview
The purpose of this assignment is for you to write a data structure called a Linked List, which utilizes templates (similar to Java’s generics), in order to store any type of data. In addition, the nature of a Linked List will give you some experience dealing with non-contiguous memory organization. This will also give you more experience using pointers and memory management. Pointers, memory allocation, and understand how data is stored in memory will serve you well in a variety of situations, not just for an assignment like this.
Background
Remember Memory? Variables, functions, pointers—everything takes up SOME space in memory. Sometimes that memory is occupied for only a short duration (a temporary variable in a function), sometimes that memory is allocated at the start of a program and hangs around for the lifetime of that program. Visualizing memory can be difficult sometimes, but very helpful. You may see diagrams of memory like this:
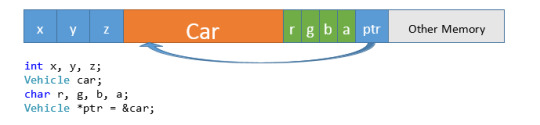
Or, you may see diagrams like these:

If you are trying to draw out some representation of memory to help you solve a problem, any of these (or some alternative that makes sense to you) will be fine.
Arrays
Arrays are stored in what is called contiguous memory. A contiguous memory block is one that is not interrupted by anything else (i.e. any other memory block). So if you created an array of 5 integers, each of those integers would be located one after the other in memory, with nothing else occupying memory between them. This is true for all arrays, of any data type.

All of the data in an application is not guaranteed to be contiguous, nor does it need to be. Arrays are typically the simplest and fastest way to store data, but they have a grand total of zero features. You allocate one contiguous block, but you can’t resize it, removing elements is a pain (and slow), etc. Consider the previous array. What if you wanted to add another element to that block of memory? If the surrounding memory is occupied, you can’t simply overwrite that with your new data element and expect good results.

someArray = 12; // #badIdea This will almost certainly break. Other Memory In this scenario, in order to store one more element you would have to: Create another array that was large enough to store all of the old elements plus the new one Copy over all of the data elements one at a time (including the new element, at the end) Free up the old array—no point in having two copies of the data

Other Memory Newly available memory Someone else’s memory 10 12 This process has to be repeated each time you want to add to the array (either at the end, or insert in the middle), or remove anything from the array. It can quite costly, in terms of performance, to delete/rebuild an entire array every time you want to make a single change. Cue the Linked List!
Linked List
The basic concept behind a Linked List is simple: It’s a container that stores its elements in a non-contiguous fashion Each element knows about the location of the element which comes after it (and possibly before, more on that later) So instead of a contiguous array, where element 4 comes after element 3, which comes after element 2, etc��� you might have something like this:

Each element in the Linked List (typically referred to as a “node”) stores some data, and then stores a reference (a pointer, in C++), so the node which should come next. The First node knows only about the Second node. The Second node knows only about the Third, etc. The Fourth node has a null pointer as its “next” node, indicating that we’ve reached the end of the data. A real-world example can be helpful as well. Think about a line of people, with one person at the front of the line. That person might know about the person who is next in line, but no further than that (beyond him or herself, the person at the front doesn’t need to know or care). The second person in line might know about the third person in line, but no further. Continuing on this way, the last person in line knows that there is no one else that follows, so that must be the end. Since no one is behind that person, we must be at the end of the line.

So… What are the advantages of storing data like this? When inserting elements to an array, the entire array has to be reallocated. With a Linked List, only a small number of elements are affected. Only elements surrounding the changed element need to be updated, and all other elements can remain unaffected. This makes the Linked List much more efficient when it comes to adding or removing elements. Now, imagine one person wants to step out of line. If this were an array, all of the data would have to be reconstructed elsewhere. In a Linked List, only three nodes are affected: 1) The person leaving, 2) the person in front of that person, and 3) the person behind that person. Imagine you are the person at the front of the line. You don’t really need to know or care what happens 10 people behind you, as that has no impact on you whatsoever.

If the 5th person in line leaves, the only parts of the line that should be impacted are the 4th, 5th, and 6th spaces. Person 4 has a new “next” Person: whomever was behind the person behind them (Person 6). Person 5 has to be removed from the list. Person 6… actually does nothing. In this example, a Person only cares about whomever comes after them. Since Person 5 was before Person 6, Person 6 is unaffected. (A Linked List could be implemented with two-way information between nodes—more on that later). The same thought-process can be applied if someone stepped into line (maybe a friend was holding their place):
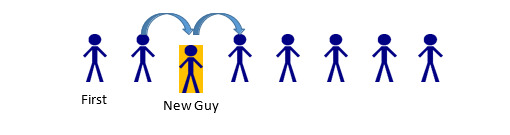
In this case, Person 2 would change their “next” person from Person 3, to the new Person being added. New Guy would have his “next” pointer set to whomever Person 2 was previously keeping track of, Person 3. Because of the ordering process, Person 3 would remain unchanged, as would anyone else in the list (aside from being a bit irritated at the New Guy for cutting in line). So that’s the concept behind a Linked List. A series of “nodes” which are connected via pointer to one another, and inserting/deleting nodes is a faster process than deleting and reconstructing the entire collection of data. Now, how to go about creating that?
Terminology
Node The fundamental building block of a Linked List. A node contains the data actually being stored in the list, as well as 1 or more pointers to other nodes. This is typically implemented as a nested class (see below). Singly-linked A Linked List would be singly-linked if each node only has a single pointer to another node, typically a “next” pointer. This only allows for uni-directional traversal of the data—from beginning to end. Doubly-linked Each node contains 2 pointers: a “next” pointer and a “previous” pointer. This allows for bi-directional traversal of the data—either from front-to-back or backto-front. Head A pointer to the first node in the list, akin to index 0 of an array. Tail A pointer to the last node in the list. May or may not be used, depending on the implementation of the list.
Nested Classes
The purpose of writing a class is to group data and functionality. The purpose of a nested class is the same—the only difference is where we declare a nested class. We declare a nested class like this: class MyClass { public: // Nested class class NestedClass { int x, y, z; NestedClass(); ~NestedClass(); int SomeFunction(); }; private: // Data for "MyClass" NestedClass myData; NestedClass *somePtr; float values; MyClass(); // Etc… }; // To create nested classes… // Use the Scope Resolution Operator MyClass::NestedClass someVariable; // With a class template… TemplateClass foo; TemplateClass::Nested bar; /* NOTE: You can make nested classes private if you wish, to prevent access to them outside of the encapsulating class. */ Additional reading: http://en.cppreference.com/w/cpp/language/nested_types The nature of the Linked List is that each piece of information knows about the information which follows (or precedes) it. It would make sense, then, to create some nested class to group all of that information together.
Benefits and Drawbacks
All data structures in programming (C++ or otherwise) have advantages and disadvantages. There is no “one size fits all” data structure. Some are faster (in some cases), some have smaller memory footprints, and some are more flexible in their functionality, which can make life easier for the programmer. Linked List versus Array – Who Wins? Array Linked List Fast access of individual elements as well as iteration over the entire array Changing the Linked List is fast – nodes can be inserted/removed very quickly Random access – You can quickly “jump” to the appropriate memory location of an element Less affected by memory fragmentation, nodes can fit anywhere in memory Changing the array is slow – Have to rebuild the entire array when adding/removing elements No random access, slow iteration Memory fragmentation can be an issue for arrays—need a single, contiguous block large enough for all of the data Extra memory overhead for nodes/pointers Slow to access individual elements
Code Structure
As shown above, the Linked List class itself stores very little data: Pointers to the first and last nodes, and a count. In some implementations, you might only have a pointer to the first node, and that’s it. In addition to those data members, your Linked List class must conform to the following interface:
Function Reference
Accessors PrintForward Iterator through all of the nodes and print out their values, one a time. PrintReverse Exactly the same as PrintForward, except completely the opposite. NodeCount Wait, we’re storing how many things in this list? FindAll Find all nodes which match the passed in parameter value, and store a pointer to that node in the passed in vector. Use of a parameter like this (passing a something in by reference, and storing data for later use) is called an output parameter. Find Find the first node with a data value matching the passed in parameter, returning a pointer to that node. Returns null if no matching node found. const and nonconst versions. GetNode Given an index, return a pointer to the node at that index. Throws an exception if the index is out of range. Const and non-const versions. Head Returns the head pointer. Const and non-const versions. Tail Returns the tail pointer. Const and non-const versions. Insertion Operations AddHead Create a new Node at the front of the list to store the passed in parameter. AddTail Create a new Node at the end of the list to store the passed in parameter. AddNodesHead Given an array of values, insert a node for each of those at the beginning of the list, maintaining the original order. AddNodesTail Ditto, except adding to the end of the list. InsertAfter Given a pointer to a node, create a new node to store the passed in value, after the indicated node. InsertBefore Ditto, except insert the new node before the indicated node. InsertAt Inserts a new Node to store the first parameter, at the index-th location. So if you specified 4 as the index, the new Node should have 3 Nodes before it. Throws an exception if given an invalid index. Removal Operations RemoveHead Deletes the first Node in the list. Returns whether or not the operation was successful. RemoveTail Deletes the last Node, returning whether or not the operation was successful. Remove Remove ALL Nodes containing values matching that of the passed-in parameter. Returns how many instances were removed. RemoveAt Deletes the index-th Node from the list, returning whether or not the operation was successful. Clear Deletes all Nodes. Don’t forget the node count! Operators operator Overloaded brackets operator. Takes an index, and returns the index-th node. Throws an exception if given an invalid index. Const and non-const versions. operator= After listA = listB, listA == listB is true. operator== Overloaded equality operator. Given listA and listB, is listA equal to listB? What would make one Linked List equal to another? If each of its nodes were equal to the corresponding node of the other. (Similar to comparing two arrays, just with non-contiguous data). Construction / Destruction LinkedList() Default constructor. A head, a tail, and a node counter walk into a bar… and get initialized? Wait, that’s not how that one goes… How many nodes in an empty list? What is head pointing to? What is tail pointing to? Copy Constructor Sets “this” to a copy of the passed in LinkedList. Other list has 10 nodes, with values of 1-10? “this” should too. ~LinkedList() The usual. Clean up your mess. (Delete all the nodes created by the list.)
Tips
A few tips for this assignment: Remember the "Big Three" or the “Rule of Three” o If you define one of the three special functions (copy constructor, assignment operator, or destructor), you should define the other two Start small, work one bit of functionality at a time. Work on things like Add() and PrintForward() first, as well as accessors (brackets operator, Head()/Tail(), etc). You can’t really test anything else unless those are working. Refer back to the recommended chapters in your textbook as well as lecture videos for an explanation of the details of dynamic memory allocation o There are a lot of things to remember when memory allocation The debugger is your friend! (You have learned how to use it, right?) Make charts, diagrams, sketches of the problem. Memory is inherently difficult to visualize, find a way that works for you. Don’t forget your node count! Read the full article
0 notes
Photo

Build a Real-time Chat App with Pusher and Vue.js
Apps that communicate in real time are becoming more and more popular nowadays, as they make for a smoother, more natural user experience.
In this tutorial, we’re going to build a real-time chat application using Vue.js powered by ChatKit, a service provided by Pusher. The ChatKit service will provide us with a complete back end necessary for building a chat application on any device, leaving us to focus on building a front-end user interface that connects to the ChatKit service via the ChatKit client package.
Prerequisites
This is an intermediate- to advanced-level tutorial. You’ll need to be familiar with the following concepts to follow along:
Vue.js basics
Vuex fundamentals
employing a CSS framework
You’ll also need Node installed on your machine. You can do this by downloading the binaries from the official website, or by using a version manager. This is probably the easiest way, as it allows you to manage multiple versions of Node on the same machine.
Finally, you’ll need to install Vue CLI globally with the following command:
npm install -g @vue/cli
At the time of writing, Node 10.14.1 and Vue CLI 3.2.1 are the latest versions.
About the Project
We’re going to build a rudimentary chat application similar to Slack or Discord. The app will do the following:
have multiple channels and rooms
list room members and detect presence status
detect when other users start typing
As mentioned earlier, we’re just building the front end. The ChatKit service has a back-end interface that will allows us to manage users, permissions and rooms.
You can find the complete code for this project on GitHub.
Setting up a ChatKit Instance
Let’s create our ChatKit instance, which is similar to a server instance if you’re familiar with Discord.
Go to the ChatKit page on Pusher’s website and click the Sign Up button. You’ll be prompted for an email address and password, as well as the option to sign in with GitHub or Google.
Select which option suits you best, then on the next screen fill out some details such as Name, Account type, User role etc.
Click Complete Onboarding and you’ll be taken to the main Pusher dashboard. Here, you should click the ChatKit Product.

Click the Create button to create a new ChatKit Instance. I’m going to call mine VueChatTut.

We’ll be using the free plan for this tutorial. It supports up to 1,000 unique users, which is more than sufficient for our needs. Head over to the Console tab. You’ll need to create a new user to get started. Go ahead and click the Create User button.

I’m going to call mine “john” (User Identifier) and “John Wick” (Display Name), but you can name yours however you want. The next part is easy: create the two or more users. For example:
salt, Evelyn Salt
hunt, Ethan Hunt
Create three or more rooms and assign users. For example:
General (john, salt, hunt)
Weapons (john, salt)
Combat (john, hunt)
Here’s a snapshot of what your Console interface should like.

Next, you can go to the Rooms tab and create a message using a selected user for each room. This is for testing purposes. Then go to the Credentials tab and take note of the Instance Locator. We’ll need to activate the Test Token Provider, which is used for generating our HTTP endpoint, and take a note of that, too.

Our ChatKit back end is now ready. Let’s start building our Vue.js front end.
Scaffolding the Vue.js Project
Open your terminal and create the project as follows:
vue create vue-chatkit
Select Manually select features and answer the questions as shown below.

Make doubly sure you’ve selected Babel, Vuex and Vue Router as additional features. Next, create the following folders and files as follows:

Make sure to create all the folders and files as demonstrated. Delete any unnecessary files that don’t appear in the above illustration.
For those of you that are at home in the console, here are the commands to do all that:
mkdir src/assets/css mkdir src/store touch src/assets/css/{loading.css,loading-btn.css} touch src/components/{ChatNavBar.vue,LoginForm.vue,MessageForm.vue,MessageList.vue,RoomList.vue,UserList.vue} touch src/store/{actions.js,index.js,mutations.js} touch src/views/{ChatDashboard.vue,Login.vue} touch src/chatkit.js rm src/components/HelloWorld.vue rm src/views/{About.vue,Home.vue} rm src/store.js
When you’re finished, the contents of the src folder should look like so:
. ├── App.vue ├── assets │ ├── css │ │ ├── loading-btn.css │ │ └── loading.css │ └── logo.png ├── chatkit.js ├── components │ ├── ChatNavBar.vue │ ├── LoginForm.vue │ ├── MessageForm.vue │ ├── MessageList.vue │ ├── RoomList.vue │ └── UserList.vue ├── main.js ├── router.js ├── store │ ├── actions.js │ ├── index.js │ └── mutations.js └── views ├── ChatDashboard.vue └── Login.vue
For the loading-btn.css and the loading.css files, you can find them on the loading.io website. These files are not available in the npm repository, so you need to manually download them and place them in your project. Do make sure to read the documentation to get an idea on what they are and how to use the customizable loaders.
Next, we’re going to install the following dependencies:
@pusher/chatkit-client, a real-time client interface for the ChatKit service
bootstrap-vue, a CSS framework
moment, a date and time formatting utility
vue-chat-scroll, which scrolls to the bottom automatically when new content is added
vuex-persist, which saves Vuex state in browser’s local storage
npm i @pusher/chatkit-client bootstrap-vue moment vue-chat-scroll vuex-persist
Do check out the links to learn more about what each package does, and how it can be configured.
Now, let’s configure our Vue.js project. Open src/main.js and update the code as follows:
import Vue from 'vue' import BootstrapVue from 'bootstrap-vue' import VueChatScroll from 'vue-chat-scroll' import App from './App.vue' import router from './router' import store from './store/index' import 'bootstrap/dist/css/bootstrap.css' import 'bootstrap-vue/dist/bootstrap-vue.css' import './assets/css/loading.css' import './assets/css/loading-btn.css' Vue.config.productionTip = false Vue.use(BootstrapVue) Vue.use(VueChatScroll) new Vue({ router, store, render: h => h(App) }).$mount('#app')
Update src/router.js as follows:
import Vue from 'vue' import Router from 'vue-router' import Login from './views/Login.vue' import ChatDashboard from './views/ChatDashboard.vue' Vue.use(Router) export default new Router({ mode: 'history', base: process.env.BASE_URL, routes: [ { path: '/', name: 'login', component: Login }, { path: '/chat', name: 'chat', component: ChatDashboard, } ] })
Update src/store/index.js:
import Vue from 'vue' import Vuex from 'vuex' import VuexPersistence from 'vuex-persist' import mutations from './mutations' import actions from './actions' Vue.use(Vuex) const debug = process.env.NODE_ENV !== 'production' const vuexLocal = new VuexPersistence({ storage: window.localStorage }) export default new Vuex.Store({ state: { }, mutations, actions, getters: { }, plugins: [vuexLocal.plugin], strict: debug })
The vuex-persist package ensures that our Vuex state is saved between page reloads or refreshes.
Our project should be able to compile now without errors. However, don’t run it just yet, as we need to build the user interface.
The post Build a Real-time Chat App with Pusher and Vue.js appeared first on SitePoint.
by Michael Wanyoike via SitePoint https://ift.tt/2YtinR8
0 notes
Text
80% off #Break Away: Programming And Coding Interviews – $10
A course that teaches pointers, linked lists, general programming, algorithms and recursion like no one else
All Levels, – 21 hours, 83 lectures
Average rating 4.5/5 (4.5 (242 ratings) Instead of using a simple lifetime average, Udemy calculates a course’s star rating by considering a number of different factors such as the number of ratings, the age of ratings, and the likelihood of fraudulent ratings.)
Course requirements:
This course requires some basic understanding of a programming language, preferably C. Some solutions are in Java, though Java is not a requirement
Course description:
Programming interviews are like standard plays in professional sport – prepare accordingly. Don’t let Programming Interview gotchas get you down!
Programming interviews differ from real programming jobs in several important aspects, so they merit being treated differently, just like set pieces in sport. Just like teams prepare for their opponent’s playbooks in professional sport, it makes sense for you to approach programming interviews anticipating the interviewer’s playbook This course has been drawn by a team that has conducted hundreds of technical interviews at Google and Flipkart
What’s Covered:
Pointers: Memory layout of pointers and variables, pointer arithmetic, arrays, pointers to pointers, pointers to structures, argument passing to functions, pointer reassignment and modification – complete with visuals to help you conceptualize how things work. Strings: Strings, Character pointers, character arrays, null termination of strings, string.h function implementations with detailed explanations. Linked lists: Visualization, traversal, creating or deleting nodes, sorted merge, reversing a linked list and many many problems and solutions, doubly linked lists. Bit Manipulation: Work with bits and bit operations. Sorting and searching algorithms: Visualize how common sorting and searching algorithms work and the speed and efficiency of those algorithms Recursion: Master recursion with lots of practice! 8 common and uncommon recursive problems explained. Binary search, finding all subsets of a subset, finding all anagrams of a word, the infamous 8 Queens problem, executing dependent tasks, finding a path through a maze, implementing PaintFill, comparing two binary trees Data Structures: Understand queues, stacks, heaps, binary trees and graphs in detail along with common operations and their complexity. Includes code for every data structure along with solved interview problems based on these data structures. Step-by-step solutions to dozens of common programming problems: Palindromes, Game of Life, Sudoku Validator, Breaking a Document into Chunks, Run Length Encoding, Points within a distance are some of the problems solved and explained.
Talk to us!
Mail us about anything – anything! – and we will always reply

Full details Know how to approach and prepare for coding interviews Understand pointer concepts and memory management at a very deep and fundamental level Tackle a wide variety of linked list problems and know how to get started when asked linked list questions as a part of interviews Tackle a wide variety of general pointer and string problems and know how to answer questions on them during interviews Tackle a wide variety of general programming problems which involve just plain logic, no standard algorithms or data structures, these help you get the details right!
Full details YEP! New engineering graduate students who are interviewing for software engineering jobs YEP! Professionals from other fields with some programming knowledge looking to change to a software role YEP! Software professionals with several years of experience who want to brush up on core concepts NOPE! Other technology related professionals who are looking for a high level overview of pointer concepts.
Reviews:
“Algorithms and Data Structures are explained in a simple way. First, the instructor tells the logic, then visualizes it animating boxes and arrows, and finally shows the code. Very easy to follow along. I even solved a number of algorithms just by listening to the description of the logic behind it.” (Anuar AZ)
“It doest the exercises on C and not on Java which is desired for interviews” (Juan)
“The instructor’s knack of teaching complex algorithms in a simple and effective manner.” (RamaKrishna Ganti)
About Instructor:
Loony Corn
Loonycorn is us, Janani Ravi, Vitthal Srinivasan, Swetha Kolalapudi and Navdeep Singh. Between the four of us, we have studied at Stanford, IIM Ahmedabad, the IITs and have spent years (decades, actually) working in tech, in the Bay Area, New York, Singapore and Bangalore. Janani: 7 years at Google (New York, Singapore); Studied at Stanford; also worked at Flipkart and Microsoft Vitthal: Also Google (Singapore) and studied at Stanford; Flipkart, Credit Suisse and INSEAD too Swetha: Early Flipkart employee, IIM Ahmedabad and IIT Madras alum Navdeep: longtime Flipkart employee too, and IIT Guwahati alum We think we might have hit upon a neat way of teaching complicated tech courses in a funny, practical, engaging way, which is why we are so excited to be here on Udemy! We hope you will try our offerings, and think you’ll like them
Instructor Other Courses:
Learn by Example: JUnit Loony Corn, A 4-person team;ex-Google; Stanford, IIM Ahmedabad, IIT (0) $10 $20 Under the Hood: How Cars Work 25 Famous Experiments …………………………………………………………… Loony Corn coupons Development course coupon Udemy Development course coupon Programming Languages course coupon Udemy Programming Languages course coupon Break Away: Programming And Coding Interviews Break Away: Programming And Coding Interviews course coupon Break Away: Programming And Coding Interviews coupon coupons
The post 80% off #Break Away: Programming And Coding Interviews – $10 appeared first on Udemy Cupón/ Udemy Coupon/.
from Udemy Cupón/ Udemy Coupon/ http://coursetag.com/udemy/coupon/80-off-break-away-programming-and-coding-interviews-10/ from Course Tag https://coursetagcom.tumblr.com/post/156430869308
0 notes
Text
Finally finished HW2
After awhile of debugging FindMaxWeight, I was able to continue on to the other steps. I was getting frustrated in my other post, so I knew i had to take a break from it to get a fresh point of view.
Then I started working on a method, which took me awhile because I had to brush up on how to carefully delete a node in a doubly linked list. I realized sometimes talking about prev and next can be a little confusing so sometimes I like looking at youtube videos to get a visualization. Once I saw the code and the pictures, I remembered what a learned before.
Then I was able to finished the code and turned it in the VERY early morning.
0 notes
Text
Types of Queues in Data Structure
Queue is an important structure for storing and retrieving data and hence is used extensively among all the data structures. Queue, just like any queue (queues for bus or tickets etc.) follows a FIFO mechanism for data retrieval which means the data which gets into the queue first will be the first one to be taken out from it, the second one would be the second to be retrieved and so on.
Types of Queues in Data Structure
Simple Queue
Image Source
As is clear from the name itself, simple queue lets us perform the operations simply. i.e., the insertion and deletions are performed likewise. Insertion occurs at the rear (end) of the queue and deletions are performed at the front (beginning) of the queue list.
All nodes are connected to each other in a sequential manner. The pointer of the first node points to the value of the second and so on.
The first node has no pointer pointing towards it whereas the last node has no pointer pointing out from it.
Circular Queue
Image Source
Unlike the simple queues, in a circular queue each node is connected to the next node in sequence but the last node’s pointer is also connected to the first node’s address. Hence, the last node and the first node also gets connected making a circular link overall.
Priority Queue
Image Source
Priority queue makes data retrieval possible only through a pre determined priority number assigned to the data items.
While the deletion is performed in accordance to priority number (the data item with highest priority is removed first), insertion is performed only in the order.
Doubly Ended Queue (Dequeue)
Image Source
The doubly ended queue or dequeue allows the insert and delete operations from both ends (front and rear) of the queue.
Queues are an important concept of the data structures and understanding their types is very necessary for working appropriately with them.
The post Types of Queues in Data Structure appeared first on The Crazy Programmer.
0 notes
Text
Delete all the even nodes from a Doubly Linked List https://t.co/cHNqX3i1SS
Delete all the even nodes from a Doubly Linked List https://t.co/cHNqX3i1SS
— Dave Epps (@dave_epps) October 11, 2018
from Twitter https://twitter.com/dave_epps
0 notes
Text
Basic Data Structure (English)
1. What is Data Structure?
Data structure is a way of defining, storing and retrieving data in a structural and systematic way.
2. Sequential access
It means that a group of elements is accessed in a predetermined sequence.
ArrayList: Re-sizable-array implementation of the List interface. Implements all optional list operations, and permits all elements, including null. It is unsynchronized.
Vector: It is a synchronized ArrayList. It means its thread safe.
3. Linked List
Doubly-linked list implementation of the List and Deque interfaces. Implements all optional list operations, and permits all elements (including null). It stores the data in nodes that connect with the previous and next nodes since it’s doubly-linked. It could also be singly-linked.
4. Graph
A graph is a pictorial representation of a set of objects where some pairs of objects are connected by links.
5. Stack
Every new elements will be added as the first element, and only the first element can be removed. The order in which elements come off a stack gives rise to its alternative name, LIFO (for last in, first out).
6. Queue
Every new elements will be added as the last element, and only the first element can be removed. This makes the queue a First-In-First-Out (FIFO) data structure.
7. Heap
It is a special balanced binary tree data structure where root-node key is compared with its children and arranged accordingly.
8. Tree
A tree is a minimally connected graph having no loops and circuits.
Binary Tree: A binary tree has a special condition that each node can have two children at maximum.
Binary Search Tree: A binary search tree is a binary tree with a special provision where a node's left child must have value less than its parent's value and node's right child must have value greater than its parent value.
AVL Tree: It is height balancing binary search tree. AVL tree checks the height of left and right sub-trees and assures that the difference is not more than 1. This difference is called Balance Factor.
Spanning Tree: A spanning tree is a subset of Graph G, which has all the vertices covered with minimum possible number of edges. A spanning tree does not have cycles and it cannot be disconnected.
9. Set
It can store values without any particular order and no repeated values. It is a computer implementation of the mathematical concept of a finite set. Other variants, called dynamic or mutable sets, allow also the insertion and deletion of elements from the set.
10. Map
It is an object that maps keys to values. A map cannot contain duplicate keys and each key can map to at most one value. Map doesn’t implements Collection because it contains a key and a value.
0 notes
Link
(Via: Hacker News)
A BK-tree is a tree data structure specialized to index data in a metric space. A metric space is essentially a set of objects which we equip with a distance function \(d(a, b)\) for every pair of elements \((a, b)\). This distance function must satisfy a set of axioms in order to ensure it's well-behaved. The exact reason why this is required will be explained in the "Search" paragraph below.
The BK-tree data structure was proposed by Burkhard and Keller in 1973 as a solution to the problem of searching a set of keys to find a key which is closest to a given query key. The naive way to solve this problem is to simply compare the query key with every element of the set; if the comparison is done in constant time, this solution is \(O(n)\). On the other hand, a BK-tree is likely to allow fewer comparisons to be made.
Construction of the tree
BK-tree is defined in the following way. An arbitrary element \(a\) is selected as root. Root may have zero or more sub-trees. The \(k\)-th sub-tree is recursively built of all elements \(b\) such that \(d(a,b) = k\).
To see how to construct a BK-tree, let's use a real scenario. We have a dictionary of words and we want to find those that are most similar to a given query word. To gauge how similar two words are, we are going to use the Levenshtein distance. Essentially, it's the minimum number of single-character edits (which can be insertions, deletions or substitutions) required to mutate one word into the other. For example, the distance between "soccer" and "otter" is \(3\), because we can change the first one into the other by deleting the leading s, and then substituting the two central c's with two t's.
Let's use the dictionary
{'some', 'soft', 'same', 'mole', 'soda', 'salmon'}
To construct the tree, we first choose any word as the root node, and then add the other words by calculating their distance from the root. In our case, we can choose "some" to be the root element. Then, after adding the two subsequent words the tree would look like this:
because the distance between "some" and "same" is \(1\) and the distance between "some" and "soft" is \(2\). Now, let's add the next word, "mole". Observe that the distance between "mole" and "some" is again \(2\), so we add it to the tree as a child of "soft", with an edge corresponding to their distance. After adding all the words we obtain the following tree:
Search
Remember that the original problem was to find all the words closest to a given query word. Call \(N\) the maximum allowed distance (which we'll call radius). The algorithm proceeds as follows:
create a candidates list and add the root node to it
take a candidate, compute its distance \(D\) from the query key and compare it with the radius;
selection criterion: add to the candidates list all the children of the current node that, from their parent, have a distance between \(D - N\) and \(D + N\) (inclusive).
Suppose we want to find all the words in our dictionary that are no more distant than \(N = 2\) from the word "sort". Our only candidate is the root node "some". We start by computing
\[D = \mathop{\mathrm{Levenshtein}}(\text{`sort'}, \text{`some'}) = 2\]
Since the radius is \(2,\) we add "some" to the list of results. Then we extend our candidates list with all the children that have a distance from the root node between \(D - N = 0\) and \(D + N = 4\). In this case, all the children satisfy this condition. Moving on, we compute
\[D = \mathop{\mathrm{Levenshtein}}(\text{`sort'}, \text{`same'}) = 3\]
Since \(D > N\), this node is not a result and we move on to "soft"; now
\[D = \mathop{\mathrm{Levenshtein}}(\text{`sort'}, \text{`soft'}) = 1\]
Hence "soft" is an acceptable result. Regarding its children, we take those that have a distance between \(D - N = -1\) and \(D + N = 3\). Again, all of them, but only "soda" is a valid result. Finally, "salmon" is not acceptable. If we sort our results by distance we end up with the following:
[(1, 'soft'), (2, 'some'), (2, 'soda')]
Why does it work?
It's interesting to understand why we are allowed to prune all the children that do not meet the criterion we gave above in point \(3\). In the introduction we said that our distance function \(d\) must satisfy a set of axioms in order for us to obtain the metric space structure. Those axioms are the following. For all elements \(a,b,c\) it must hold:
non-negativity: \(d(a, b) \ge 0\);
\(d(a, b) = 0\) implies \(a = b\) (and vice-versa);
symmetry: \(d(a, b) = d(b, a)\)
triangle inequality: \(d(a, b) \le d(a, c) + d(c, b)\).
The first three are just a formalization of our intuitive notion of "distance", while the last one derives from the relation between sides of a triangle in Euclidean geometry. This is often the most difficult property to demonstrate when we want to prove that a generic distance is actually a metric. As it turns out, the Levenshtein distance satisfies this property and therefore it's a metric. This is why we can use it in the examples above.
Let's call the query key \(\bar x\). Suppose we are evaluating the child \(B\) of an arbitrary node \(A\) inside the tree, which we calculated to be at a distance \(D = d(\bar x, A)\) from the query key. This situation is summarized in the following figure:
Since we assumed that \(d\) is a metric, by the triangle inequality we have
\[d(A, B) \le d(A, \bar x) + d(\bar x, B)\]
from which
\[d(\bar x, B) \ge d(A, B) - d(A, \bar x) = x - D.\]
Using the triangle inequality again, this time with \(d(A, \bar x)\) and \(B\), we obtain
\[d(\bar x, B) \ge d(A, \bar x) - d(A, B) = D - x\]
Since we are only interested in nodes that are at a distance at most \(N\) from the query key \(\bar x\), we impose the constraint \(d(\bar x, B) \le N\). This translates to
\[\begin{cases}x - D \le N\\D - x \le N\end{cases}\]
which is equivalent to
\[D - N \le x \le D + N\]
We have proved that if \(d\) is a metric, we can safely discard nodes that do not meet the above criteria. Finally, note that every child of \(B\) will be at a distance of \(x\) from \(A\) (by construction of the BK-tree) and therefore we can safely prune the whole sub-tree if \(B\) alone does not meet the criterion.
Implementation
This data structure is easy to implement in Python, if we use dictionaries to represent edges.
from collections import deque class BKTree: def __init__(self, distance_func): self._tree = None self._distance_func = distance_func def add(self, node): if self._tree is None: self._tree = (node, {}) return current, children = self._tree while True: dist = self._distance_func(node, current) target = children.get(dist) if target is None: children[dist] = (node, {}) break current, children = target def search(self, node, radius): if self._tree is None: return [] candidates = deque([self._tree]) result = [] while candidates: candidate, children = candidates.popleft() dist = self._distance_func(node, candidate) if dist <= radius: result.append((dist, candidate)) low, high = dist - radius, dist + radius candidates.extend(c for d, c in children.items() if low <= d <= high) return result
The implementation is pretty straightforward and adheres completely to the algorithm we explained above. A few comments:
there's no need to add a root argument to the __init__ method, since any element can be a root node. In our case the first one added will become root;
why is deque even needed? At first I used a set, only to see it fail because dictionaries aren't hashable. We need another data structure that allows \(O(1)\) popping and linear insertion. Built-in deque, being a doubly-linked list, is a natural fit.
Conclusion
The BK-tree is a relatively lesser-known data structure suitable for nearest neighbor search (NNS). It allows a considerable reduction of the search space, if the distance we are working with is a metric. In practice, the speed improvement we get from pruning sub-trees heavily depends on the search space and the radius we select. This is why some experimentation is usually needed for the problem at hand. One area in which BK-tree does well is spell-checking: as long as one keeps the radius to \(1\) or \(2\) the search space is often reduced to under \(10\%\) of the original.
0 notes
Text
80% off #From 0 to 1: C Programming – Drill Deep – $10
C Programming is still a very useful skill to have – and this is the course to pick it up!
All Levels, – Video: 12 hours, 60 lectures
Average rating 4.4/5 (4.4)
Course requirements:
The course assumes that the student has a way to write and run C programs. This could include gcc on Mac or Unix, or Visual Studio on Windows.
Course description:
C Programming is still a very valuable skill – and its also surprisingly easy to pick up. Don’t be intimidated by C’s reputation as scary – we think this course makes it easy as pie!
What’s Covered:
Conditional Constructs: If/else and case statements have a surprising number of little details to be aware of. Conditions, and working with relational and logical operators. Short-circuiting and the order of evaluation Loops: For loops, while and do-while loops, break and continue. Again, lots of little details to get right. Data Types and Bit Manipulation Operations, again full of little gotchas that interviewers and professors love to test. Pointers: Memory layout of pointers and variables, pointer arithmetic, arrays, pointers to pointers, pointers to structures, argument passing to functions, pointer reassignment and modification – complete with visuals to help you conceptualize how things work. Strings: Strings, Character pointers, character arrays, null termination of strings, string.h function implementations with detailed explanations. Structs and Unions: These seem almost archaic in an Object-Oriented world, but worth knowing, especially in order to nail linked list problems. Linked lists: Visualization, traversal, creating or deleting nodes, sorted merge, reversing a linked list and many many problems and solutions, doubly linked lists. IO: Both console and file IO Enums, typedefs, macros
Talk to us!
Mail us about anything – anything! – and we will always reply
Full details Write solid, correct and complete C programs Advance – quickly and painlessly – to C++, which is a natural successor to C and still widely used Ace tests or exams on the C programming language Shed their fears about the gotchas and complexities of the C programming language Make use of C in those situations where it is still the best tool available
Full details Yep! Computer science or engineering majors who need to learn C for their course requirements Yep! Embedded systems or hardware folks looking to make the most of C, which is still an awesome technology in those domains Yep! Any software engineer who will be giving interviews, and fears interview questions on the tricky syntax of C
Full details
Reviews:
“Its very good and detailed course. Great if you want a brief overview of C at a glance” (Aditya Mehta)
“This course teaches the ins and outs of the language. That is its purpose. Fully achieved – the longer the course, the better it gets.” (H2m2)
“It would have been better if they would actually show practical examples by running it on ide and explaining the flow of code.” (Nitin Ainani)
About Instructor:
Loony Corn
Loonycorn is us, Janani Ravi, Vitthal Srinivasan, Swetha Kolalapudi and Navdeep Singh. Between the four of us, we have studied at Stanford, IIM Ahmedabad, the IITs and have spent years (decades, actually) working in tech, in the Bay Area, New York, Singapore and Bangalore. Janani: 7 years at Google (New York, Singapore); Studied at Stanford; also worked at Flipkart and Microsoft Vitthal: Also Google (Singapore) and studied at Stanford; Flipkart, Credit Suisse and INSEAD too Swetha: Early Flipkart employee, IIM Ahmedabad and IIT Madras alum Navdeep: longtime Flipkart employee too, and IIT Guwahati alum We think we might have hit upon a neat way of teaching complicated tech courses in a funny, practical, engaging way, which is why we are so excited to be here on Udemy! We hope you will try our offerings, and think you’ll like them
Instructor Other Courses:
Learn By Example: jQuery Learn By Example: Angular JS Learn By Example: Scala …………………………………………………………… Loony Corn coupons Development course coupon Udemy Development course coupon Programming Languages course coupon Udemy Programming Languages course coupon From 0 to 1: C Programming – Drill Deep From 0 to 1: C Programming – Drill Deep course coupon From 0 to 1: C Programming – Drill Deep coupon coupons
The post 80% off #From 0 to 1: C Programming – Drill Deep – $10 appeared first on Udemy Cupón.
from Udemy Cupón http://www.xpresslearn.com/udemy/coupon/80-off-from-0-to-1-c-programming-drill-deep-10/
from https://xpresslearn.wordpress.com/2017/03/01/80-off-from-0-to-1-c-programming-drill-deep-10/
0 notes