#difference between varchar and varchar (max)
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
Convert the NUMBER data type from Oracle to PostgreSQL – Part 1
An Oracle to PostgreSQL migration in the AWS Cloud can be a multistage process with different technologies and skills involved, starting from the assessment stage to the cutover stage. For more information about the migration process, see Database Migration—What Do You Need to Know Before You Start? and the following posts on best practices, including the migration process and infrastructure considerations, source database considerations, and target database considerations for the PostgreSQL environment. In the migration process, data type conversion from Oracle to PostgreSQL is one of the key stages. Multiple tools are available on the market, such as AWS Schema Conversion Tool (AWS SCT) and Ora2PG, which help you with data type mapping and conversion. However, it’s always recommended that you do an upfront analysis on the source data to determine the target data type, especially when working with data types like NUMBER. Many tools often convert this data type to NUMERIC in PostgreSQL. Although it looks easy to convert Oracle NUMBER to PostgreSQL NUMERIC, it’s not ideal for performance because calculations on NUMERIC are very slow when compared to an integer type. Unless you have a large value without scale that can’t be stored in BIGINT, you don’t need to choose the column data type NUMERIC. And as long as the column data doesn’t have float values, you don’t need to define the columns as the DOUBLE PRECISION data type. These columns can be INT or BIGINT based on the values stored. Therefore, it’s worth the effort to do an upfront analysis to determine if you should convert the Oracle NUMBER data type to INT, BIGINT, DOUBLE PRECISION, or NUMERIC when migrating to PostgreSQL. This series is divided into two posts. In this post, we cover two analysis methods to define the target data type column in PostgreSQL depending on how the NUMBER data type is defined in the Oracle database and what values are stored in the columns’ data. In the second post, we cover how to change the data types in the target PostgreSQL database after analysis using the AWS SCT features and map data type using transformation. Before we suggest which of these data types in PostgreSQL is a suitable match for Oracle NUMBER, it’s important to know the key differences between these INT, BIGINT, DOUBLE PRECISION, and NUMERIC. Comparing numeric types in PostgreSQL One of the important differences between INT and BIGINT vs. NUMERIC is storage format. INT and BIGINT have a fixed length: INT has 4 bytes, and BIGINT has 8 bytes. However, the NUMERIC type is of variable length and stores 0–255 bytes as needed. So NUMERIC needs more space to store the data. Let’s look at the following example code (we’re using PostgreSQL 12), which shows the size differences of tables with integer columns and NUMERIC: postgres=# SELECT pg_column_size('999999999'::NUMERIC) AS "NUMERIC length", pg_column_size('999999999'::INT) AS "INT length"; NUMERIC length | INT length ---------------+------------ 12 | 4 (1 row) postgres=# CREATE TABLE test_int_length(id INT, name VARCHAR); CREATE TABLE postgres=# CREATE TABLE test_numeric_length(id NUMERIC, name VARCHAR); CREATE TABLE postgres=# INSERT INTO test_int_length VALUES (generate_series(100000,1000000)); INSERT 0 900001 postgres=# INSERT INTO test_numeric_length VALUES (generate_series(100000,1000000)); INSERT 0 900001 postgres=# SELECT sum(pg_column_size(id))/1024 as "INT col size", pg_size_pretty(pg_total_relation_size('test_int_length')) as "Size of table" FROM test_int_length; INT col size | Size of table --------------+---------------- 3515 | 31 MB (1 row) Time: 104.273 ms postgres=# SELECT sum(pg_column_size(id))/1024 as "NUMERIC col size", pg_size_pretty(pg_total_relation_size('test_numeric_length')) as "Size of table" FROM test_numeric_length; NUMERIC col size | Size of table ------------------+---------------- 6152 | 31 MB (1 row) From the preceding output, INT occupies 3,515 bytes and NUMERIC occupies 6,152 bytes for the same set of values. However, you see the same table size because PostgreSQL is designed such that its own internal natural alignment is 8 bytes, meaning consecutive fixed-length columns of differing size must be padded with empty bytes in some cases. We can see that with the following code: SELECT pg_column_size(row()) AS empty, pg_column_size(row(0::SMALLINT)) AS byte2, pg_column_size(row(0::BIGINT)) AS byte8, pg_column_size(row(0::SMALLINT, 0::BIGINT)) AS byte16; empty | byte2 | byte8 | byte16 -------+-------+-------+-------- 24 | 26 | 32 | 40 From the preceding output, it’s clear that an empty PostgreSQL row requires 24 bytes of various header elements, a SMALLINT is 2 bytes, and a BIGINT is 8 bytes. However, combining a SMALLINT and BIGINT takes 16 bytes. This is because PostgreSQL is padding the smaller column to match the size of the following column for alignment purposes. Instead of 2 + 8 = 10, the size becomes 8 + 8 = 16. Integer and floating point values representation and their arithmetic operations are implemented differently. In general, floating point arithmetic is more complex than integer arithmetic. It requires more time for calculations on numeric or floating point values as compared to the integer types. PostgreSQL BIGINT and INT data types store their own range of values. The BIGINT range (8 bytes) is -9223372036854775808 to 9223372036854775807: postgres=# select 9223372036854775807::bigint; int8 --------------------- 9223372036854775807 (1 row) postgres=# select 9223372036854775808::bigint; ERROR: bigint out of range The INT range (4 bytes) is -2147483648 to 2147483647: postgres=# select 2147483647::int; int4 ------------ 2147483647 (1 row) postgres=# select 2147483648::int; ERROR: integer out of range For information about these data types, see Numeric Types. With the NUMBER data type having precision and scale in Oracle, it can be either DOUBLE PRECISION or NUMERIC in PostgreSQL. One of the main differences between DOUBLE PRECISION and NUMERIC is storage format and total length of precision or scale supported. DOUBLE PRECISION is fixed at 8 bytes of storage and 15-decimal digit precision. DOUBLE PRECISION offers a similar benefit as compared to the NUMERIC data type as explained for BIGINT and INT in PostgreSQL. With DOUBLE PRECISION, because its limit is 15 decimals, for any data with higher precision or scale we might be affected by data truncation during data migration from Oracle. See the following code: postgres=> select 123456789.10111213::double precision as Scale_Truncated, 123456789101112.13::double precision as Whole_Scale_Truncated; scale_truncated | whole_scale_truncated ------------------+----------------------- 123456789.101112 | 123456789101112 When considering data type in PostgreSQL when the NUMBER data type has decimal information, we should check for max precision along with max scale and decide accordingly if the target data type is either DOUBLE PRECISION or NUMERIC. If you’re planning to store values that require a certain precision or arithmetic accuracy, the DOUBLE PRECISION data type may be the right choice for your needs. For example, if you try to store the result of 2/3, there is some rounding when the 15th digit is reached when you use DOUBLE PRECISION. It’s used for not only rounding the value based on precision limit, but also for the arithmetic accuracy. If you consider the following example, a double precision gives the wrong answer. postgres=# select 0.1::double precision + 0.2 as value; value --------------------- 0.30000000000000004 (1 row) postgres=# select 0.1::numeric + 0.2 as value; value ------- 0.3 (1 row) Starting with PostgreSQL 12, performance has been improved by using a new algorithm for output of real and double precision values. In previous versions (older than PostgreSQL 12), displayed floating point values were rounded to 6 (for real) or 15 (for double precision) digits by default, adjusted by the value of the parameter extra_float_digits. Now, whenever extra_float_digits is more than zero (as it is by default from PostgreSQL 12 and newer), only the minimum number of digits required to preserve the exact binary value are output. The behavior is the same as before when extra_float_digits is set to zero or less. postgres=# set extra_float_digits to 0; SET postgres=# select 0.1::double precision + 0.2 as value; value ------- 0.3 (1 row) Oracle NUMBER and PostgreSQL NUMERIC In Oracle, the NUMBER data type is defined as NUMBER(precision, scale) and in PostgreSQL, NUMERIC is defined as NUMERIC(precision, scale), with precision and scale defined as follows: Precision – Total count of significant digits in the whole number, that is, the number of digits to both sides of the decimal point Scale – Count of decimal digits in the fractional part, to the right of the decimal point Analysis before data type conversion Data type changes may have some side effects, which we discuss in this post. Before converting data types, you need to check with your service or application team if they have the following: Any dependency of these data types (INT and BIGINT) in application SQLs that require type casting Any change required in stored procedures or triggers for these data types Any dependency in Hibernate-generated code If these data type changes have any impact on future data growth Any plans in the future for these columns to store any fractional values Without proper analysis and information on the application code and the database code objects, it’s not recommended to change the data types. If you do so, your application queries may start showing performance issues because they require a type casting internally from NUMERIC to INT or BIGINT. If you have code objects like procedures or triggers with these data types’ dependency, you need to make changes to those objects to avoid performance issues. Future data growth may impact these conversions as well. If you convert it to INT based on the current data, however, it may go beyond INT value in the future. Make sure you don’t have any plans to store fractional values after migration is complete. If that is the requirement, you need to choose a different data type than INT or BIGINT. For this post, we examine two different methods to analyze the information to recommend INT, BIGINT, DOUBLE PRECISION, or NUMERIC: Metadata-based data type conversion Actual data-based data type conversion Analysis method: Metadata-based data type conversion By looking at the metadata information of Oracle tables with columns of the NUMBER or INTEGER data type, we can come up with the target data type recommendations. Conversion to PostgreSQL INT or BIGINT You can covert Oracle tables with columns of the data type NUMBER or INTEGER to PostgreSQL INT or BIGINT if they meet the following criteria: The data type is NUMERIC or INTEGER in Oracle DATA_PRECISION is NOT NULL (not a variable length NUMERIC) DATA_SCALE is 0 (integers and not float values) MAX_LENGTH is defined as <=18 (DATA_PRECISION <=18) If DATA_PRECISION is < 10, use INT. If DATA_PRECISION is 10–18, use BIGINT.` You can use the following query on Oracle to find candidate columns of NUMERIC or INTEGER data type that can be converted to BIGINT or INT in PostgreSQL: SELECT OWNER , TABLE_NAME , COLUMN_NAME , DATA_TYPE , DATA_PRECISION , DATA_SCALE FROM dba_tab_columns WHERE OWNER in ('owner_name') and (DATA_TYPE='NUMBER' or DATA_TYPE='INTEGER') and DATA_PRECISION is NOT NULL and (DATA_SCALE=0 or DATA_SCALE is NULL) and DATA_PRECISION <= 18; The following code is an example output of the preceding query, which shows precision and scale of NUMBER data types for a particular user: OWNER TABLE_NAME COLUMN_NAME DATA_TYPE DATA_PRECISION DATA_SCALE ---------- -------------------- -------------------- ---------- -------------- ---------- DEMO COUNTRIES REGION_ID NUMBER 10 0 DEMO CUSTOMER CUSTOMER_ID NUMBER 15 0 DEMO DEPARTMENTS DEPARTMENT_ID NUMBER 4 0 DEMO EMPLOYEES EMPLOYEE_ID NUMBER 6 0 DEMO EMPLOYEES MANAGER_ID NUMBER 6 0 DEMO EMPLOYEES DEPARTMENT_ID NUMBER 4 0 DEMO ORDERS ORDER_ID NUMBER 19 0 DEMO ORDERS VALUE NUMBER 14 0 DEMO PERSON PERSON_ID NUMBER 5 0 The output shows four columns (REGION_ID of the COUNTRIES table, CUSTOMER_ID of the CUSTOMER table, and ORDER_ID and VALUE of the ORDERS table) that have precision between 10–18, which can be converted to BIGINT in PostgreSQL. The remaining columns can be converted to INT. Conversion to PostgreSQL DOUBLE PRECISION or NUMERIC You can convert Oracle tables with columns of the data type NUMBER or INTEGER to PostgreSQL DOUBLE PRECISION or NUMERIC if they meet the following criteria: The data type is NUMERIC or NUMBER in Oracle DATA_PRECISION is NOT NULL DATA_SCALE is > 0 (float values) If DATA_PRECISION + DATA_SCALE <= 15, choose DOUBLE PRECISION. If DATA_PRECISION + DATA_SCALE > 15, choose NUMERIC. You can use the following query on Oracle to find candidate columns of NUMERIC or INTEGER data type that can be converted to DOUBLE PRECISION or NUMERIC in PostgreSQL: SELECT OWNER , TABLE_NAME , COLUMN_NAME , DATA_TYPE , DATA_PRECISION , DATA_SCALE FROM dba_tab_columns WHERE OWNER in ('owner_name') and (DATA_TYPE='NUMBER' or DATA_TYPE='INTEGER') and DATA_PRECISION is NOT NULL and DATA_SCALE >0; The following is an example output of the query: OWNER TABLE_NAME COLUMN_NAME DATA_TYPE DATA_PRECISION DATA_SCALE ------- ------------ -------------------- -------------- -------------- ---------- DEMO COORDINATES LONGI NUMBER 10 10 DEMO COORDINATES LATTI NUMBER 10 10 DEMO EMPLOYEES COMMISSION_PCT NUMBER 2 2 The output contains the column COMMISSION_PCT from the EMPLOYEES table, which can be converted as DOUBLE PRECISION. The output also contains two columns (LONGI and LATTI) that can be NUMERIC because they have (precision + scale) > 15. Changing the data type for all candidate columns may not have the same impact or performance gain. Most columns that are part of the key or index appear in joining conditions or in lookup, so changing the data type for those columns may have a big impact. The following are guidelines for converting the column data type in PostgreSQL, in order of priority: Consider changing the data type for columns that are part of a key (primary, unique, or reference) Consider changing the data type for columns that are part of an index Consider changing the data type for all candidate columns Analysis method: Actual data-based data type conversion In Oracle, the NUMBER data type is often defined with no scale, and those columns are used for storing integer value only. But because scale isn’t defined, the metadata doesn’t show if these columns store only integer values. In this case, we need to perform a full table scan for those columns to identify if the columns can be converted to BIGINT or INT in PostgreSQL. A NUMERIC column may be defined with DATA_PRECISION higher than 18, but all column values fit well in the BIGINT or INT range of PostgreSQL. You can use the following SQL code in an Oracle database to find if the actual DATA_PRECISION and DATA_SCALE is in use. This code performs a full table scan, so you need to do it in batches for some tables, and if possible run it during low peak hours in an active standby database (ADG): select /*+ PARALLEL(tab 4) */ max(length(trunc(num_col))) MAX_DATA_PRECISION, min(length(trunc(num_col))) MIN_DATA_PRECISION, max(length(num_col - trunc(num_col)) -1 ) MAX_DATA_SCALE from <> tab; Based on the result of the preceding code, use the following transform rules: If MAX_DATA_PRECISION < 10 and MAX_DATA_SCALE = 0, convert to INT If DATA_PRECISION is 10–18 and MAX_DATA_SCALE = 0, convert to BIGINT if MAX_DATA_SCALE > 0 and MAX_DATA_PRECISION + MAX_DATA_SCALE <= 15, convert to DOUBLE PRECISION if MAX_DATA_SCALE > 0 and MAX_DATA_PRECISION + MAX_DATA_SCALE > 15, convert to NUMERIC Let’s look at the following example. In Oracle, create the table number_col_test with four columns defined and a couple of rows inserted: SQL> CREATE TABLE DEMO.number_col_test ( col_canbe_int NUMBER(8,2), col_canbe_bigint NUMBER(19,2), col_canbe_doubleprecision NUMBER(15,2), col_should_be_number NUMBER(20,10) ); Table created. SQL> INSERT INTO demo.number_col_test VALUES (1234, 12345678900, 12345.12, 123456.123456); 1 row created. SQL> INSERT INTO demo.number_col_test VALUES (567890, 1234567890012345, 12345678.12, 1234567890.1234567890); 1 row created. SQL> set numwidth 25 SQL> select * from demo.number_col_test; COL_CANBE_INT COL_CANBE_BIGINT COL_CANBE_DOUBLEPRECISION COL_SHOULD_BE_NUMBER -------------- -------------- ------------------------- -------------------- 1234 12345678900 12345.12 123456.123456 567890 1234567890012345 12345678.12 1234567890.123456789 We next run a query to look at the data to find the actual precision and scale. From the following example, can_be_int has precision as 6 and scale as 0 even though it’s defined as NUMBER(8,4). So we can define this column as INT in PostgreSQL. SQL> select /*+ PARALLEL(tab 4) */ max(length(trunc(COL_CANBE_INT))) MAX_DATA_PRECISION, min(length(trunc(COL_CANBE_INT))) MIN_DATA_PRECISION, max(length(COL_CANBE_INT - trunc(COL_CANBE_INT)) -1 ) MAX_DATA_SCALE from demo.number_col_test; MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE ------------------------- ------------------------- ------------------------- 6 4 0 In the following output, can_be_bigint has precision as 16 and scale as 0 even though it’s defined as NUMBER(19,2). So we can define this column as BIGINT in PostgreSQL. SQL> select /*+ PARALLEL(tab 4) */ max(length(trunc(COL_CANBE_BIGINT))) MAX_DATA_PRECISION, min(length(trunc(COL_CANBE_BIGINT))) MIN_DATA_PRECISION, max(length(COL_CANBE_BIGINT - trunc(COL_CANBE_BIGINT)) -1 ) MAX_DATA_SCALE from demo.number_col_test; MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE ------------------------- ------------------------- ------------------------- 16 11 0 In the following output, can_be_doubleprecision has precision as 8 and scale as 2 even though it’s defined as NUMBER(15,2). We can define this column as DOUBLE PRECISION in PostgreSQL. SQL> select /*+ PARALLEL(tab 4) */ max(length(trunc(COL_CANBE_DOUBLEPRECISION))) MAX_DATA_PRECISION, min(length(trunc(COL_CANBE_DOUBLEPRECISION))) MIN_DATA_PRECISION, max(length(COL_CANBE_DOUBLEPRECISION - trunc(COL_CANBE_DOUBLEPRECISION)) -1 ) MAX_DATA_SCALE from demo.number_col_test; MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE ------------------------- ------------------------- ------------------------- 8 5 2 In the following output, should_be_numeric has precision as 10 and scale as 9 even though it’s defined as NUMBER(20,10). We can define this column as NUMERIC in PostgreSQL. SQL> select /*+ PARALLEL(tab 4) */ max(length(trunc(COL_SHOULD_BE_NUMBER))) MAX_DATA_PRECISION, min(length(trunc(COL_SHOULD_BE_NUMBER))) MIN_DATA_PRECISION, max(length(COL_SHOULD_BE_NUMBER - trunc(COL_SHOULD_BE_NUMBER)) -1 ) MAX_DATA_SCALE from demo.number_col_test; MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE ------------------------- ------------------------- ------------------------- 10 6 9 Summary Converting the NUMBER data type from Oracle to PostgreSQL is always tricky. It’s not recommended to convert all NUMBER data type columns to NUMERIC or DOUBLE PRECISION in PostgreSQL without a proper analysis of the source data. Having the appropriate data types helps improve performance. It pays long-term dividends by spending time upfront to determine the right data type for application performance. From the Oracle system tables, you get precision and scale of all the columns of all the tables for a user. With this metadata information, you can choose the target data type in PostgreSQL as INT, BIGINT, DOUBLE PRECISION, or NUMERIC. However, you can’t always depend on this information. Although this metadata shows the scale of some columns as >0, the actual data might not have floating values. Look at the actual data in every table’s NUMBER columns (which are scale >0), and decide on the target columns’ data types. Precision(m) Scale(n) Oracle PostgreSQL <= 9 0 NUMBER(m,n) INT 9 > m <=18 0 NUMBER(m,n) BIGINT m+n <= 15 n>0 NUMBER(m,n) DOUBLE PRECISION m+n > 15 n>0 NUMBER(m,n) NUMERIC In the next post in this series, we cover methods to convert the data type in PostgreSQL after analysis is complete, and we discuss data types for the source Oracle NUMBER data type. About the authors Baji Shaik is a Consultant with AWS ProServe, GCC India. His background spans a wide depth and breadth of expertise and experience in SQL/NoSQL database technologies. He is a Database Migration Expert and has developed many successful database solutions addressing challenging business requirements for moving databases from on-premises to Amazon RDS and Aurora PostgreSQL/MySQL. He is an eminent author, having written several books on PostgreSQL. A few of his recent works include “PostgreSQL Configuration“, “Beginning PostgreSQL on the Cloud”, and “PostgreSQL Development Essentials“. Furthermore, he has delivered several conference and workshop sessions. Sudip Acharya is a Sr. Consultant with the AWS ProServe team in India. He works with internal and external Amazon customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS. Deepak Mahto is a Consultant with the AWS Proserve Team in India. He has been working as Database Migration Lead, helping and enabling customers to migrate from commercial engines to Amazon RDS.His passion is automation and has designed and implemented multiple database or migration related tools. https://aws.amazon.com/blogs/database/convert-the-number-data-type-from-oracle-to-postgresql-part-1/
0 notes
Text
Select:-Things to know about select statement in SQL 2019
New Post has been published on https://is.gd/8cLrpG
Select:-Things to know about select statement in SQL 2019

(adsbygoogle = window.adsbygoogle || []).push();
Identity Column & Cascading referential Integrity
Constraints In SQL By Sagar Jaybhay
About Tables In DataBase By Sagar Jaybhay
SELECT Statement in SQL
The select clause can retrieve 0 or more rows from one or more tables from the database or it can retrieve rows from views also.
The select statement is used to select data from a table or database. The data which is our of our select query is called a result set. The select is a commonly used statement in SQL. Means for fetching the data from the database we use Select statement.
(adsbygoogle = window.adsbygoogle || []).push();
We can retrieve all rows or a selected row means this is according to condition. If you want to specify a selected column or we want specific columns you can specify in a select clause.
Select statement optional clauses
Where: it specifies a condition to which rows to retrieve
Group By: used to group similar items based on conditions
Having: select the rows among the group
Order by: it will specify the order
As: it is used for an alias
Select Syntax:
Select column1, column2,…. From table_name;
Ex
Select * from Person;
The above query will fetch all the data from the table along with all columns.
Distinct Clause in Select Statement
To select a distinct value from column value you can use distinct.
General Syntax
Select distinct column_name from table_name;
Ex
SELECT distinct [genederID] FROM [dbo].[Person]
When you specify multiple columns in a distinct keyword you tell SQL server to check and get distinct value from that number of column you provides.
General Syntax:
Select distinct column1, column2 from table_name;
Ex
SELECT distinct [genederID],[email] FROM [dbo].[Person];
How to Filter Values in Select statement?
You can filter the value by using where clause.
Where Clause in Select Statement
The where clause is used to filter records. By using where clause you can extract only those records which fulfilled our condition.
The where clause not only used in a select statement but also used in Update, Delete also.
SELECT column1, column2, ... FROM table_name WHERE condition;
Ex
SELECT * FROM [dbo].[Person] where email='[email protected]'
The Operators used in Where clause: –
Operator Description = Equal > Greater than < Less than >= Greater than or equal <= Less than or equal <> Not equal. Note: In some versions of SQL this operator may be written as != BETWEEN Between a certain range LIKE Search for a pattern IN To specify multiple possible values for a column
Select Query Evaluation :
select g.* from users u inner join groups g on g.Userid = u.Userid where u.LastName = 'Jaybhay' and u.FirstName = 'Sagar'
In the above query from clause is evaluated after that cross join or cartesian join is produced for these 2 tables and this from clause produced a virtual table might call as Vtable1.
After this on clause is evaluated for Vtable1 and it checks to join condition g. Userid =u.userid, then the records which met these conditions or full fill these conditions are inserted into another Vtable2.
If you specify outer join then the rest or remaining records from Vtable2 are inserted into Vtable3.
After this where clause is applied and the lastname=’Jaybhay’ and firstname=’sagar’ are verified or taken and put it into Vtable4.
After this select list is evaluated and return Vtable4.
Group by clause in Select Statement
It is an SQL command which is used to group rows that have the same values. It is used only in the select statement.
A group by clause is used to group a selected set of rows into a set of summary rows by using a value of one pr more columns expression. Mostly group by clause is used in conjunction with one or more aggregate functions, Like Count, Max, Min, Sum, Avg.
The main purpose of a group by clause is to arrange identical or similar data into groups it means rows have different value but one column is identical.
Create table person syntax USE [temp] GO /****** Object: Table [dbo].[Person] Script Date: 11/20/2019 12:12:09 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Person]( [ID] [int] NOT NULL, [name] [varchar](100) NULL, [email] [varchar](100) NULL, [genederID] [int] NULL, [age] [int] NULL, [salary] [int] NULL, [city] [varchar](100) NULL, PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[Person] ADD CONSTRAINT [df_value] DEFAULT ((3)) FOR [genederID] GO ALTER TABLE [dbo].[Person] WITH CHECK ADD CONSTRAINT [tbl_person_geneder_id_fk] FOREIGN KEY([genederID]) REFERENCES [dbo].[tbGeneder] ([genederID]) GO ALTER TABLE [dbo].[Person] CHECK CONSTRAINT [tbl_person_geneder_id_fk] GO ALTER TABLE [dbo].[Person] WITH CHECK ADD CONSTRAINT [chk_age] CHECK (([age]>(0) AND [age]<(150))) GO ALTER TABLE [dbo].[Person] CHECK CONSTRAINT [chk_age] GO
Demo data generated site :- https://mockaroo.com/
Group by query
select age,count(age) 'no of person',avg(salary) 'avg salary' from Person group by age
The above query has only one column in a group by clause
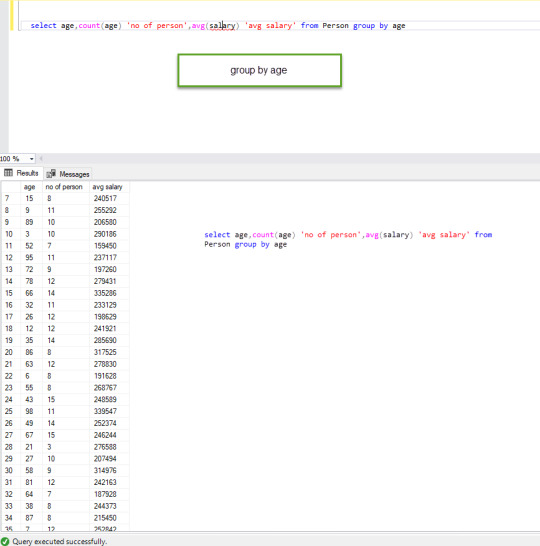
Group By Clause in Select Statement
Another query of an aggregate function
select age, sum(salary) from Person
the above query will result following
Msg 8120, Level 16, State 1, Line 25 Column ‘Person.age’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause
It clearly tells that if we want to age and sum of salary then we need to use group by function.
Group by multiple columns
select age,city,count(age) 'no of person',avg(salary) 'avg salary' from Person group by age,city
in this query, we use multiple columns in the group by clause age and city.

Group By Clause in Select Statement with 2 columns
Filtering Groups:
We can use where clause to filter rows before aggregation and Having clause is used to filter groups after aggregations.
select age, sum(salary) as 'Total salary' from person where age between 30 and 50 group by age; select age, sum(salary) as 'Total salary' from Person group by age having age between 30 and 50;
these are 2 queries which produce the same result but in one query we use where clause and in the second query we use having clause both having the same functionality but having is used only with the group by clause and where is used with any clause.
What is the difference between where and having clause?
When you used where clause it will filter the rows based on conditions and after this group by applied.
If you use having then the first group is created and aggregation is done before any filter and after this, having condition is applied.
Where clause can be used with select, insert, update and delete statement where having is used only with a select statement.
Where filters row before aggregation(grouping) where having clause filters a group and after the aggregation is performed.
Aggregate functions can not be used in the where clause. But if it is in the subquery you can use this. But in having a clause you can use an aggregate function.
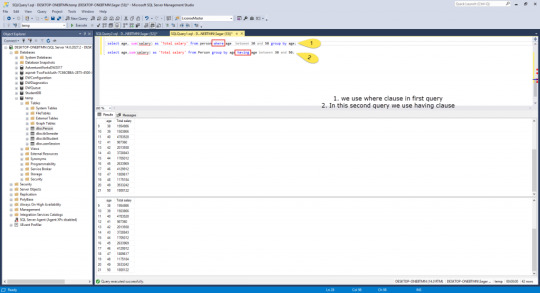
where and having difference
select age, email, sum(salary) as 'Total salary' from Person group by age having age between 30 and 50;
In the above query, we use email in the select clause but the query will result in an error why because when you use a group by clause and want to select element the column need to present in group by filter.
Msg 8120, Level 16, State 1, Line 30
Column ‘Person.email’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
This error we got.
0 notes
Text
Difference between varchar and varchar(max) in SQL Server
Difference between varchar and varchar(max) in SQL Server
Hello Readers,
The purpose of this post is to make it clear what to use and when with respect to varchar data type in SQL Server.
Varchar(max) was introduced in SQL Server 2005 version. A few years back, I wasn’t clear about the Difference between varchar and varchar max. It was always confusing for me which one to use.
[bctt…
View On WordPress
#difference between#difference between varchar and varchar (max)#SQL Server#varchar#varchar (max)#varchar and varchar (max)
0 notes
Text
MSSQL 문법정리
MS-SQL
** SQL문은 대소문자를 구분하지 않지만 데이타는 대문자와 소문자를 구분한다 주석을 다는 방법은 /* 주석 */ 이거나 한줄만 주석 처리를 할 경우는 문장 맨앞에 --를 붙인다 ** 각각의 데이타베이스의 SYSOBJECTS 테이블에 해당 데이타베이스의 모든 정보가 보관되어 있다 SYSOBJECTS의 TYPE 칼럼으로 'U'=사용자 테이블, 'P'=저장 프로시저, 'K'=프라이머리 키, 'F'=포린 키, 'V'=뷰, 'C'=체크 제약등 오브젝트 이름과 정보를 알 수 있다
데이타 검색 USE 데이타베이스명 /* USE 문을 사용한 데이타베이스 선택 */ SELECT * FROM 데이블명 /* 모든 칼럼 불러오기 */ SELECT TOP n * FROM 테이블명 /* 상위 n개의 데이타만 가져오기 */ SELECT 칼럼1, 칼럼2, 칼럼3 FROM 테이블명 /* 특정 칼럼 가져오기 */ SELECT 칼럼1 별명1, 칼럼2 AS 별명2 FROM 테이블명 /* 칼럼에 별명 붙이기 */ SELECT 칼럼3 '별 명3' FROM 테이블명 /* 칼럼 별명에 스페이스가 들어갈 경우는 작은따옴표 사용 */ SELECT DISTINCT 칼럼 FROM 테이블명 /* 중복되지 않는 데이타만 가져오기 */ ** 데이타는 오름차순으로 재배열된다 DISTINCT를 사용하면 재배열이 될때까지 데이타가 리턴되지 않으므로 수행 속도에 영향을 미친다 */ SELECT * FROM 테이블명 WHERE 조건절 /* 조건에 해당하는 데이타 가져오기 */ ** 조건식에 사용하는 비교는 칼럼=값, 칼럼!=값, 칼럼>값, 칼럼>=값, 칼럼<값, 칼럼<=값이 있다 문자열은 ''(작은따옴표)를 사용한다 날짜 비교를 할때는 'yy-mm-dd' 형식의 문자열로 한다(날짜='1992-02-02', 날짜>'1992-02-02') SELECT * FROM 테이블명 WHERE 칼럼 BETWEEN x AND y /* 칼럼이 x>=와 y<=사이의 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 IN (a, b...) /* 칼럼이 a이거나 b인 데이타 가져오기 */
SELECT * FROM 테이블명 WHERE 칼럼 LIKE '패턴' /* 칼럼이 패턴과 같은 데이타 가져오기 */ ** 패턴에 사용되는 기호는 %, _가 있다 'k%'(k로 시작되는), '%k%'(중간에 k가 있는), '%k'(k로 끝나는) 'p_'(p로 시작하는 2자리), 'p___'(p로 시작하는 4자리), '__p'(3자리 데이타중 p로 끝나는)
Like 패턴 주의점
- MSSQL LIKE 쿼리에서 와일드 카드(예약어) 문자가 들어간 결과 검색시
언더바(_)가 들어간 결과를 보기 위해 아래처럼 쿼리를 날리니
select * from 테이블명 where 컬럼명 like '%_%'
모든 데이터가 결과로 튀어나왔다. -_-;;
언더바가 와일드 카드(쿼리 예약어)이기 때문인데 이럴 땐
select * from 테이블명 where 컬럼명 like '%[_]%'
SELECT * FROM 테이블명 WHERE 칼럼 IS NULL /* 칼럼이 NULL인 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 NOT BETWEEN x AND y /* 칼럼이 x와 y 사이가 아닌 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 NOT IN (a, b...) /* 칼럼이 a나 b가 아닌 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 NOT LIKE '패턴' /* 칼럼이 패턴과 같지 않은 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼 IS NOT NULL /* 칼럼이 NULL이 아닌 데이타 가져오기 */ SELECT * FROM 테이블명 WHERE 칼럼>=x AND 칼럼<=y SELECT * FROM 테이블명 WHERE 칼럼=a or 칼럼=b SELECT * FROM 데이블명 WHERE 칼럼1>=x AND (칼럼2=a OR 칼럼2=b) ** 복수 조건을 연결하는 연산자는 AND와 OR가 있다 AND와 OR의 우선순위는 AND가 OR보다 높은데 우선 순위를 바꾸고 싶다면 ()을 사용한다 SELECT * FROM 테이블명 ORDER BY 칼럼 /* 칼럼을 오름차순으로 재배열하기 */ SELECT * FROM 테이블명 ORDER BY 칼럼 ASC SELECT * FROM 테이블명 ORDER BY 칼럼 DESC /* 칼럼을 내림차순으로 재배열하기 */ SELECT * FROM 테이블명 ORDER BY 칼럼1 ASC, 칼럼2 DESC /* 복수 칼럼 재배열하기 */ SELECT * FROM 테이블명 ORDER BY 1 ASC, DESC 3 /* 칼럼 순서로 재배열하기 */ ** 기본적으로 SELECT ���에서는 출력순서가 보증되지 않기 때문에 데이타의 등록 상태나 서버의 부하 상태에 따라 출력되는 순서가 달라질 수 있다 따라서 출력하는 경우 되도록이면 ORDER BY를 지정한다 ** 칼럼 번호는 전체 칼럼에서의 번호가 아니라 SELECT문에서 선택한 칼럼의 번호이고 1부터 시작한다
연산자 ** 1순위는 수치 앞에 기술되는 + - 같은 단항 연산자 2순위는 사칙 연산의 산술 연산자인 * / + - 3순위는 = > 비교 연산자 4순위는 AND OR 같은 논리 연산자 ()을 붙이면 우선 순위를 바꿀수 있다
1. SELECT 문의 연산 SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 2. ORDER BY 구의 연산 SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 ORDER BY 칼럼3+칼럼4 DESC SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 ORDER BY 3 DESC 3. WHERE 구의 연산 SELECT 칼럼1, 칼럼2, 칼럼3+칼럼4 AS '별명' FROM 테이블명 WHERE 칼럼2>=(칼럼3+칼럼4) 4. NULL 연산 SELECT 칼럼1, 칼럼2, ISNULL(칼럼3, 0) + ISNULL(칼럼4, 0) AS '별명' FROM 테이블명 ** 수치형 데이타와 NULL값과의 연산 결과는 항상 NULL이다 만약 NULL 값을 원치 않으면 ISNULL(칼럼, 기준값) 함수를 사용해서 기준값을 변환시킨다 5. 날짜 연산 SELECT GETDATE() /* 서버의 현재 날짜를 구한다 */ SELECT 날짜칼럼, 날짜칼럼-7 FROM 테이블명 SELECT 날짜칼럼, 날짜칼럼+30 FROM 테이블명 SELECT 날짜칼럼, DATEDIFF(day, 날짜칼럼, GETDATE()) FROM 테이블명 ** 날짜의 가산과 감산은 + -로 할 수 있다 날짜와 날짜 사이의 계산은 DATEDIFF(돌려주는값, 시작날짜, 끝날짜) 함수를 사용한다 6. 문자 연산 SELECT 칼럼1 + 칼럼2 FROM 테이블명 SELECT 칼럼 + '문자열' FROM 테이블명 SELECT 칼럼1 + '문자열' + 칼럼2 FROM 테이블명 ** 기본 연결은 문자와 문자이고 문자와 숫자의 연결은 CONVERT 함수를 사용해야 한다
함수 1. 수치 함수 ROUND(수치값, 반올림위치) /* 반올림 및 자르기 */ ABS(수치 데이타) /* 절대값 */ SIGN(수치 데이타) /* 부호 */ SQRT(수치값) /* 제곱근 */ POWER(수치값, n) /* n승 */ 2. 문자열 함수 정리
1) Ascii() - 문자열의 제일 왼쪽 문자의 아스키 코드 값을 반환(Integer)
예) SELECT Ascii('abcd')
>> 결과는 a의 아스키 코드값인 97 반환
2) Char() - 정수 아스키 코드를 문자로 반환(Char)
예) SELECT Char(97)
>> 결과는 a 반환
3) Charindex() - 문자열에서 지정한 식의 위치를 반환
예) SELECT Charindex('b','abcde') >> 결과 : 2 SELECT Charindex('b','abcde',2) >> 결과 : 2 SELECT Charindex('b','abcde',3) >> 결과 : 0
-- 인수값이 3개일때 마지막은 abcde 에서의 문자열 검색 시작위치를 말하며
2인경우는 bcde 라는 문자열에 대해서 검색
3인 경우는 cde 라는 문자열에 대해서 검색 하게 된다.
4) Difference() - 두 문자식에 SUONDEX 값 간의 차이를 정수로 반환
예) SELECT Difference('a','b')
5) Left() - 문자열에서 왼쪽에서부터 지정한 수만큼의 문자를 반환
예) SELECT Left('abced',3) 결과 >> 3
6) Len() - 문자열의 길이 반환
예) SELECT Len('abced') 결과>>5
7) Lower() - 대문자를 소문자로 반환
예) SELECT Lower('ABCDE') 결과 >> abcde
8) Ltrim() - 문자열의 왼쪽 공백 제거
예) SELECT Ltrim(' AB CDE') 결과>> AB CDE
9)Nchar() - 지정한 정수 코드의 유니코드 문자 반환
예) SELECT Nchar(20) 결과 >>
10) Replace - 문자열에서 바꾸고 싶은 문자 다른 문자로 변환
예) SELECT Replace('abcde','a','1') 결과>>1bcde
11) Replicate() - 문자식을 지정한 횟수만큼 반복
예) SELECT Replicate('abc',3) 결과>> abcabcabc
12) Reverse() - 문자열을 역순으로 출력
예) SELECT Reverse('abcde') 결과>> edcba
13) Right() - 문자열의 오른쪽에서 부터 지정한 수 만큼 반환(Left() 와 비슷 )
예) SELECT Right('abcde',3) 결과>> cde
14)Rtrim() - 문자열의 오른쪽 공백 제거
예) SELECT Rtrim(' ab cde ') 결과>> ' ab cde' <-- 공백구분을위해 ' 표시
15) Space() - 지정한 수만큼의 공백 문자 반환
예) SELECT Space(10) 결과 >> ' ' -- 그냥 공백이 나옴
확인을 위해서 SELECT 'S'+Space(10)+'E' 결과 >> S E
16) Substring() - 문자,이진,텍스트 또는 이미지 식의 일부를 반환
예) SELECT Substring('abcde',2,3) 결과>> bcd
17)Unicode() - 식에 있는 첫번째 문자의 유니코드 정수 값을 반환
예)SELECT Unicode('abcde') 결과 >> 97
18)Upper() - 소문자를 대문자로 반환
예) SELECT Upper('abcde') 결과>> ABCDE
※ 기타 함수 Tip
19) Isnumeric - 해당 문자열이 숫자형이면 1 아니면 0을 반환
>> 숫자 : 1 , 숫자X :0
예) SELECT Isnumeric('30') 결과 >> 1
SELECT Isnumeric('3z') 결과 >> 0
20) Isdate() - 해당 문자열이 Datetime이면 1 아니면 0 >> 날짜 : 1 , 날짜 X :0 예) SELECT Isdate('20071231') 결과 >> 1
SELECT Isdate(getdate()) 결과 >> 1 SELECT Isdate('2007123') 결과 >> 0
SELECT Isdate('aa') 결과 >> 0
※ 날짜및 시간함수 정리
getdate() >> 오늘 날짜를 반환(datetime)
1> DateAdd() - 지정한 날짜에 일정 간격을 + 새 일정을 반환
예) SELECT Dateadd(s,2000,getdate())
2> Datediff() - 지정한 두 날짜의 간의 겹치는 날짜 및 시간 범위 반환
예)SELECT DateDiff(d,getdate(),(getdate()+31))
3> Datename() -지정한 날짜에 특정 날짜부분을 나타내는 문자열을 반환
예) SELECT Datename(d,getdate())
4> Datepart() -지정한 날짜에 특정 날짜부분을 나타내는 정수를 반환
예) SELECT Datepart(d,getdate())
** 돌려주는값(약어) Year-yy, Quarter-qq, Month-mm, DayofYear-dy, Day-dd, Week-wk, Hour-hh, Minute-mi, Second-ss, Milisecond-ms SELECT DATEADD(dd, 7, 날짜칼럼)
>> Datename , Datepart 은 결과 값은 같으나 반환 값의 타입이 틀림.
5> Day() -지정한 날짜에 일 부분을 나타내는 정수를 반환
예) SELECT Day(getdate()) -- 일 반환
SELECT Month(getdate()) -- 월 반환
SELECT Year(getdate()) -- 년 반환 4. 형변환 함수 CONVERT(데이타 타입, 칼럼) /* 칼럼을 원하는 데이타 타입으로 변환 */ CONVERT(데이타 타입, 칼럼, 날짜형 스타일) /* 원하는 날짜 스타일로 변환 */ CAST(칼럼 AS 데이타 타입) /* 칼럼을 원하는 데이타 타입으로 변환 */ ** 스타일 1->mm/dd/yy, 2->yy.mm.dd, 3->dd/mm/yy, 4->dd.mm.yy, 5->dd-mm-yy, 8->hh:mm:ss, 10->mm-dd-yy, 11->yy/mm/dd, 12->yymmdd SELECT CONVERT(varchar(10), 날짜칼럼, 2)
그룹화 함수 SELECT COUNT(*) FROM 테이블명 /* 전체 데이타의 갯수 가져오기 */ SEELECT COUNT(칼럼) FROM 테이블명 /* NULL은 제외한 칼럼의 데이타 갯수 가져오기 */ SELECT SUM(칼럼) FROM 테이블명 /* 칼럼의 합계 구하기 */ SELECT MAX(칼럼) FROM 테이블명 /* 칼럼의 최대값 구하기 */ SELECT MIN(칼럼) FROM 테이블명 /* 칼럼의 최소값 구하기 */ SELECT AVG(칼럼) FROM 테이블명 /* 칼럼의 평균값 구하기 */ GROUP BY문 SELECT 칼럼 FROM 테이블명 GROUP BY 칼럼 SELECT 칼럼1, SUM(칼럼2) FROM 테이블명 GROUP BY 칼럼1 SELECT 칼럼1, COUNT(*) FROM 테이블명 GROUP BY 칼럼1 SELECT 칼럼1, 칼럼2, MAX(칼럼3) FROM 테이블명 GROUP BY 칼럼1, 칼럼2 ** GROUP BY를 지정한 경우 SELECT 다음에는 반드시 GROUP BY에서 지정한 칼럼 또는 그룹 함수만이 올 수 있다
조건 SELECT 칼럼1, SUM(칼럼2) FROM 테이블명 GROUP BY 칼럼1 HAVING SUM(칼럼2) < a SELECT 칼럼1, SUM(칼럼2) FROM 테이블명 ORDER BY 칼럼1 COMPUTE SUM(칼럼2) ** HAVING: 그룹 함수를 사용할 경우의 조건을 지정한다 HAVING의 위치: GROUP BY의 뒤 ORDER BY의 앞에 지정한다 COMPUTE: 각 그룹의 소계를 요약해서 보여준다 ORDER BY가 항상 선행해서 나와야 한다 조건절의 서브 쿼리 ** SELECT 또는 INSERTY, UPDATE, DELETE 같은 문의 조건절에서 SELECT문을 또 사용하는 것이다 SELECT문 안에 또 다른 SELECT문이 포함되어 있다고 중첩 SELECT문(NESTED SELECT)이라고 한다 ** 데이타베이스에는 여러명이 엑세스하고 있기 때문에 쿼리를 여러개 나누어서 사용하면 데이타의 값이 달라질수 있기때문에 트랜잭션 처리를 하지 않는다면 복수의 쿼리를 하나의 쿼리로 만들어 사용해야 한다 SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 칼럼2 = (SELECT 칼럼2 FROM 테이블명 WHERE 조건) SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 칼럼1 IN (SELECT 칼럼1 FROM 테이블명 WHERE 조건) ** 서브 쿼리에서는 다른 테이블을 포함할 수 있다 두개의 테이블에서 읽어오는 서브쿼리의 경우 서브 쿼리쪽에 데이타가 적은 테이블을 주 쿼리쪽에 데이타가 많은 테이블을 지정해야 처리 속도가 빨라진다 SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 칼럼1 IN (SELECT 칼럼2-1 FROM 테이블명2 WHERE 조건) ** FROM구에서 서브 쿼리를 사용할 수 있다 사용시 반드시 별칭을 붙여야 하고 처리 속도가 빨라진다 SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 조건1 AND 조건2 SEELCT 칼럼1, 칼럼2 FROM (SELECT 칼럼1, 칼럼2 FROM 테이블명 WHERE 조건1) 별칭 WHERE 조건2
데이타 편집
추가 ** NULL 값을 허용하지도 않고 디폴트 값도 지정되어 있지 않은 칼럼에 값을 지정하지 않은채 INSERT를 수행하면 에러가 발생한다 ** 수치값은 그대로 문자값은 ''(작은따옴표)로 마무리 한다 ** SELECT INTO는 칼럼과 데이타는 복사하지만 칼럼에 설정된 프라이머리, 포린 키등등의 제약 조건은 복사되지 않기 때문에 복사가 끝난후 새로 설정해 주어야 한다
INSERT INTO 테이블명 VALUES (값1, 값2, ...) /* 모든 필드에 데이타를 넣을 때 */ INSERT INTO 테이블명 (칼럼1, 칼럼2, ...) VALUES (값1, 값2, ...) /* 특정 칼럼에만 데이타를 넣을 때 */ INSERT INTO 테이블명 SELECT * FROM 테이블명2 /* 이미 존재하는 테이블에 데이타 추가 */ INSERT INTO 테이블명(칼럼1, 칼럼2, ...) SELECT 칼럼1, 칼럼2, ...) FROM 테이블명2 SELECT * INTO 테이블명 FROM 테이블명2 /* 새로 만든 테이블에 데이타 추가 */ SELECT 칼럼1, 칼럼2, ... 테이블명 FROM 테이블명2 갱신 UPDATE 테이블명 SET 칼럼1=값1, 칼럼2=값2 /* 전체 데이타 갱신 */ UPDATE 테이블명 SET 칼럼1=값1, 칼럼2=값2 WHERE 조건 /* 조건에 해당되는 데이타 갱신 */
- UPDATE~SELECT
UPDATE A SET A.cyberLectures = B.bizAddress FROM OF_Member A, OF_Member B WHERE A.no = B.no
삭제 DELETE FROM 테이블명 /* 전체 데이타 삭제 */ DELETE FROM 테이블명 WHERE 조건 /* 조건에 해당되는 데이타 삭제 */
오브젝트 ** 데이타베이스는 아래 오브젝트들을 각각의 유저별로 관리를 하는데 Schema(스키마)는 각 유저별 소유 리스트이다
1. Table(테이블) ** CREATE일때 프라이머리 키를 설정하지 않는다면 (칼럼 int IDENTITY(1, 1) NOT NULL) 자동 칼럼을 만든다 데이타들의 입력 순서와 중복된 데이타를 구별하기 위해서 반드시 필요하다 ** 테이블 정보 SP_HELP 테이블명, 제약 조건은 SP_HELPCONSTRAINT 테이블명 을 사용한다
CREATE TABLE 데이타베이스이름.소유자이름.테이블이름 (칼럼 데이타형 제약, ...) /* 테이블 만들기 */ DROP TABLE 테이블명 /* 테이블 삭제 */ ALTER TABLE 테이블명 ADD 칼럼 데이타형 제약, ... /* 칼럼 추가 */ ALTER TABLE 테이블명 DROP COLUMN 칼럼 /* 칼럼 삭제 */ ** DROP COLUMN으로 다음 칼럼은 삭제를 할 수 없다 - 복제된 칼럼 - 인덱스로 사용하는 칼럼 - PRIMARY KEY, FOREGIN KEY, UNIQUE, CHECK등의 제약 조건이 지정된 칼럼 - DEFAULT 키워드로 정의된 기본값과 연결되거나 기본 개체에 바인딩된 칼럼 - 규칙에 바인딩된 칼럼 CREATE TABLE 테이블명 (칼럼 데이타형 DEFAULT 디폴트값, ...) /* 디폴트 지정 */ CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 UNIQUE, ...) /* 유니크 설정 */ ** UNIQUE란 지정한 칼럼에 같은 값이 들어가는것을 금지하는 제약으로 기본 키와 비슷하지만 NULL 값을 하용하는것이 다르다 CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 NOT NULL, ...) /* NOT NULL 설정 */ CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 PRIMARY KEY, ...) /* 기본 키 설정 */ ** 기본 키는 유니크와 NOT NULL이 조합된 제약으로 색인이 자동적으로 지정되고 데이타를 유일하게 만들어 준다 ** 기본 키는 한 테이블에 한개의 칼럼만 가능하다 CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 FOREIGN KEY REFERENCES 부모테이블이름(부모칼럼), ...) CREATE TABLE 테이블명 (칼럼 데이타형 CONSTRAINT 이름 CHECK(조건), ...) /* CHECK 설정 */ ** CHECK는 조건을 임의로 정의할 수 있는 제약으로 설정되면 조건을 충족시키는 데이타만 등록할 수 있고 SELECT의 WHERE구와 같은 조건을 지정한다 ** CONSTRAINT와 제약 이름을 쓰지 않으면 데이타베이스가 알아서 이름을 붙이지만 복잡한 이름이 되기 때문에 되도록이면 사용자가 지정하도록 한다 ** CONSTRAINT는 칼럼과 데이타형을 모두 정의한 뒤에 맨 마지막에 설정할 수 있다 CREATE TABLE 테이블명 (칼럼1 데이타형, 칼럼2 데이타형, ... CONSTRAINT 이름 PRIMARY KEY(칼럼1) CONSTRAINT 이름 CHECK(칼럼2 < a) ...) ALTER TABLE 테이블명 ADD CONSTRAINT 이름 제약문 /* 제약 추가 */ ALTER TABLE 테이블명 DROP CONSTRAINT 제약명 /* 제약 삭제 */ ALTER TABLE 테이블명 NOCHECK CONSTRAINT 제약명 /* 제약 효력 정지 */ ALTER TABLE 테이블명 CHECK CONSTRAINT 제약명 /* 제약 효력 유효 */ ** 제약명은 테이블을 만들때 사용자가 지정한 파일 이름을 말한다
2. View(뷰) ** 자주 사용하는 SELECT문이 있을때 사용한다 테이블에 존재하는 칼럼들중 특정 칼럼을 보이고 싶지 않을때 사용한다 테이블간의 결합���으로 인해 복잡해진 SELECT문을 간단히 다루고 싶을때 사용한다 ** 뷰를 만들때 COMPUTE, COMPUTE BY, SELECT INTO, ORDER BY는 사용할 수 없고 #, ##으로 시작되는 임시 테이블도 뷰의 대상으로 사용할 수 없다 ** 뷰의 내용을 보고 싶으면 SP_HELPTEXT 뷰명 을 사용한다 CREATE VIEW 뷰명 AS SELECT문 /* 뷰 만들기 */ CREATE VIEW 뷰명 (별칭1, 별칭2, ...) AS SELECT문 /* 칼럼의 별칭 붙이기 */ CREATE VIEW 뷰명 AS (SELECT 칼럼1 AS 별칭1, 칼럼2 AS 별칭2, ...) ALTER VIEW 뷰명 AS SELECT문 /* 뷰 수정 */ DROP VIEW 뷰명 /* 뷰 삭제 */ CREATE VIEW 뷰명 WITH ENCRYPTION AS SELECT문 /* 뷰 암호 */ ** 한번 암호화된 뷰는 소스 코드를 볼 수 없으므로 뷰를 암호화하기전에 뷰의 내용을 스크립트 파일로 저장하여 보관한다 INSERT INTO 뷰명 (칼럼1, 칼럼2, ...) VALUES (값1, 값2, ...) UPDATE 뷰명 SET 칼럼=값 WHERE 조건 ** 원래 테이블에 있는 반드시 값을 입력해야 하는 칼럼이 포함되어 있지 않거나 원래 칼럼을 사용하지 않고 변형된 칼럼을 사용하는 뷰는 데이타를 추가하거나 갱신할 수 없다 ** WHERE 조건을 지정한 뷰는 뷰를 만들었을때 WITH CHECK OPTION을 지정하지 않았다면 조건에 맞지 않는 데이타를 추가할 수 있지만 뷰에서는 보이지 않는다 또한 뷰를 통해서 가져온 조건을 만족하는 값도 뷰의 조건에 만족하지 않는 값으로도 갱신할 수 있다 CREATE VIEW 뷰명 AS SELECT문 WITH CHECK OPTION ** 뷰의 조건에 맞지 않는 INSERT나 UPDATE를 막을려면 WITH CHECK OPTION을 설정한다
3. Stored Procedure(저장 프로시저) ** 데이타베이스내에서 SQL 명령을 컴파일할때 캐시를 이용할 수 있으므로 처리가 매우 빠르다 반복적으로 SQL 명령을 실행할 경우 매회 명령마다 네트워크를 경유할 필요가 없다 어플리케이션마다 새로 만들 필요없이 이미 만들어진 프로시저를 반복 사용한다 데이타베이스 로직을 수정시 프로시저는 서버측에 있으므로 어플리케이션을 다시 컴파일할 필요가 없다 ** 저장 프로시저의 소스 코드를 보고 싶으면 SP_HELPTEXT 프로시저명 을 사용한다
CREATE PROC 프로시저명 AS SQL문 /* 저장 프로시저 */ CREATE PROC 프로시저명 변수선언 AS SQL문 /* 인수를 가지는 저장 프로시저 */ CREATE PROC 프로시저명 WITH ENCRYPTION AS SQL문 /* 저장 프로시저 보안 설정 */ CREATE PROC 프로시저명 /* RETURN 값을 가지는 저장 프로시저 */ 인수1 데이타형, ... 인수2 데이타형 OUTPUT AS SQL문 RETURN 리턴값 DROP PROCEDURE 프로시저명1, 프로시저명2, ... /* 저장 프로시저 삭제 */ 명령어 BEGIN ... END /* 문장의 블록 지정 */ DECLARE @변수명 데이타형 /* 변수 선언 */ SET @변수명=값 /* 변수에 값 지정 */ PRINT @변수명 /* 한개의 변수 출력 */ SELECT @변수1, @변수2 /* 여러개의 변수 출력 */ IF 조건 /* 조건 수행 */ 수행1 ELSE 수행2 WHILE 조건1 /* 반복 수행 */ BEGIN IF 조건2 BREAK - WHILE 루프를 빠져 나간다 CONTINUE - 수행을 처리하지 않고 조건1로 되돌아간다 수행 END EXEC 저장프로시저 /* SQL문을 실행 */ EXEC @(변수로 지정된 SQL문) GO /* BATCH를 구분 지정 */
에제 1. 기본 저장 프로시저 CREATE PROC pUpdateSalary AS UPDATE Employee SET salary=salary*2
2. 인수를 가지는 저장 프로시저 CREATE PROC pUpdateSalary @mul float=2, @mul2 int AS UPDATE Employee SET salary=salary* @Mul* @mul2 EXEC pUpdateSalary 0.5, 2 /* 모든 변수에 값을 대입 */ EXEC pUpdateSalary @mul2=2 /* 원하는 변수에만 값을 대입 */
3. 리턴값을 가지는 저장 프로시저 CREATE PROC pToday @Today varchar(4) OUTPUT AS SELECT @Today=CONVERT(varchar(2), DATEPART(dd, GETDATE())) RETURN @Today DECLARE @answer varchar(4) EXEC pToday @answer OUTPUT SELECT @answer AS 오늘날짜
4. 변수 선언과 대입, 출력 ** @는 사용자 변수이고 @@는 시스템에서 사용하는 변수이다
DECLARE @EmpNum int, @t_name VARCHAR(20) SET @EmpNum=10
SET @t_name = '강우정' SELECT @EmpNum
이런식으로 다중입력도 가능함.
SELECT @no = no, @name = name, @level = level FROM OF_Member WHERE userId ='"
4. Trigger(트리거) ** 한 테이블의 데이타가 편집(INSERT/UPDATE/DELETE)된 경우에 자동으로 다른 테이블의 데이타를 삽입, 수정, 삭제한다 ** 트리거 내용을 보고 싶으면 SP_HELPTRIGGER 트리거명 을 사용한다
CREATE TRIGGER 트리거명 on 테이블명 FOR INSERT AS SQL문 /* INSERT 작업이 수행될때 */ CREATE TRIGGER 트리거명 on 테이블명 AFTER UPDATE AS SQL문 /* UPDATE 작업이 수행되고 난 후 */ CREATE TRIGGER 트리거명 on 테이블명 INSTEAD OF DELETE AS SQL문 DROP TRIGGER 트리거명
5. Cursor(커서) ** SELECT로 가져온 결과들을 하나씩 읽어들여 처리하고 싶을때 사용한다 ** 커서의 사용방법은 OPEN, FETCH, CLOSE, DEALLOCATE등 4단계를 거친다 ** FETCH에는 NEXT, PRIOR, FIRST, LAST, ABSOLUTE {n / @nvar}, RELATIVE {n / @nvar}가 있다
SET NOCOUNT on /* SQL문의 영향을 받은 행수를 나타내는 메시지를 숨긴다 */ DECLARE cStatus SCROLL CURSOR /* 앞뒤로 움직이는 커서 선언 */ FOR SELECT ID, Year, City FROM aPlane FOR READ onLY OPEN cStatus /* 커서를 연다 */ DECLARE @ID varchar(50), @Year int, @City varchar(50), @Status char(1) FETCH FROM cStatus INTO @ID, @Year, @City /* 커서에서 데이타를 하나씩 가져온다 */ WHILE @@FETCH_STATUS=0 /* 커서가 가르키는 결과의 끝까지 */ BEGIN IF @Year <= 5 SET @Status='A' ELSE IF @Year> 6 AND @Year <= 9 SET @Status='B' ELSE SET @Status='C' INSERT INTO aPlane(ID, City, Status) VALUES(@ID, @Year, @Status) FETCH FROM cStatus INTO @ID, @Year, @City /* 커서에서 데이타를 하나씩 가져온다 */ END CLOSE cStaus /* 커서를 닫는다 */ DEALLOCATE cStatus /* 커서를 해제한다 */
보안과 사용자 권한 ** 보안의 설정 방법은 크게 WINDOWS 보안과 SQL 보안으로 나뉘어 진다 ** 사용자에게 역할을 부여하는데는 서버롤과 데이타베이스롤이 있다
1. SA(System Administrator) ** 가장 상위의 권한으로 SQL 서버에 관한 전체 권한을 가지고 모든 오브젝트를 만들거나 수정, 삭제할 수 있다
2. DBO(Database Owner) ** 해당 데이타베이스에 관한 모든 권한을 가지며 SA로 로그인해서 데이타베이스에서 테이블을 만들어도 사용자는 DBO로 매핑된다 ** 테이블이름의 구조는 서버이름.데이타베이스이름.DBO.테이블이름이다
3. DBOO(Database Object Owner) ** 테이블, 인덱스, 뷰, 트리거, 함수, 스토어드 프로시저등의 오브젝트를 만드는 권한을 가지며 SA나 DBO가 권한을 부여한다
4. USER(일반 사용자) ** DBO나 DBOO가 해당 오브젝트에 대한 사용 권한을 부여한다
[SQL 서버 2005 실전 활용] ① 더 강력해진 T-SQL : http://blog.naver.com/dbwpsl/60041936511
MSSQL 2005 추가 쿼리 http://kuaaan.tistory.com/42 or=#747474>사용 방법 http://kuaaan.tistory.com/42 or=#747474>사용 방법 http://kuaaan.tistory.com/42
-- ANY (OR 기능)
WHERE 나이 >= (SELECT 나이 FROM .......)
-- GROUP BY ALL (WHERE 절과 일치 하지 않는 내용은 NULL 로 표시)
SELECT 주소, AVG(나이) AS 나이 FROM MEMBER
WHERE 성별='남'
GROUP BY ALL 주소
-- 모든 주소는 나오며 성별에 따라 나이 데이터는 NULL
-- WITH ROLLUP
SELECT 생일, 주소, SUM(나이) AS 나이
FROM MEMBER
GROUP BY 생일, 주소 WITH ROLLUP
-- 생일 과 주소를 요약행이 만들어짐
-- WITH CUBE (위의 예제를 기준으로, 주소에 대한 별도 그룹 요약데이터가 하단에 붙어나옴)
-- GROUPING(컬럼명) ROLLUP 또는 CUBE 의 요약행인지 여부 판단(요약행이면 1 아니면 0)
SELECT 생일, 주소, GROUPING(생일) AS 생일요약행여부
-- COMPUTE (GROUP BY 와 상관없이 별도의 테이블로 요약정보 생성)
SELECT 생일, 나이
FROM MEMBER
COMPUTE SUM(나이), AVG(나이)
-- PIVOT (세로 컬럼을 가로 변경)
EX)
학년/ 반 / 학생수
1 1 40
1 2 45
2 1 30
2 2 40
3 1 10
3 2 10
위와 같이 SCHOOL 테이블이 있다면
SELECT 그룹할컬럼명, [열로변환시킬 행]
FROM 테이블
PIVOT(
SUM(검색할열)
FOR 옆으로만들 컬럼명
IN([열로변환시킬 행])
) AS 별칭
--실제 쿼리는
SELECT 학년, [1반], [2반]
FROM SCHOOL
PIVOT(
SUM(학생수)
FOR 반
IN([1반], [2반])
) AS PVT
-- UNPIVOT (가로 컬럼을 세로로)
SELECT 학년, 반, 학생수
FROM SCHOOL
UNPIVOT(
FOR 반
IN( [1반], [2반] )
) AS UNPVT
-- RANK (순위)
SELECT 컬럼명, RANK() OVER( ORDER BY 순위 기준 컬럼명) AS 순위
FROM 테이블
-- PARTITION BY (그룹별로 순위 생성)
SELECT 컬럼명, RANK() OVER( PARTITION BY 그룹기준컬러명 ORDER BY 순위기준컬럼명) AS 순위
FROM 테이블
-- FULL OUTER JOIN (LEFT 조인과 RIGHT 조인을 합한것)
양쪽 어느 하나라도 데이가 있으면 나옴
-- ROW_NUMBER (순차번호 생성)
SELECT ROW_NUMBER() OVER( ORDER BY 기준열) AS 번호, 컬럼명
FROM 테이블
자료형 (데이터타입)
MSSQL 서버에서 사용하는 데이터 타입(자료형)은 두가지가 있다.
1. 시스템에서 제공하는 System data type
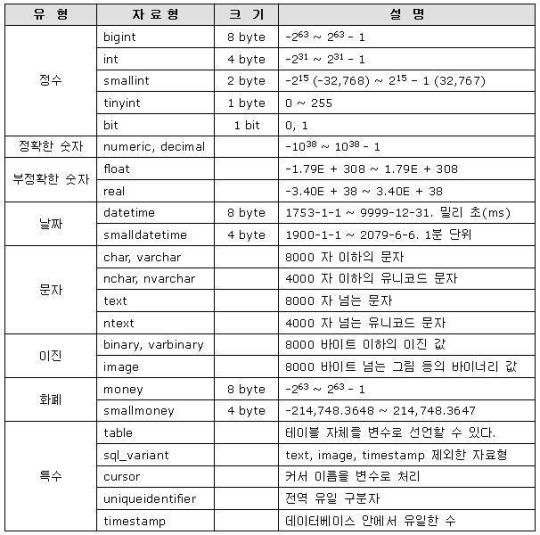
내가 생각해도 참 깔끔하게 정리를 잘 해놨다. -_-;;
성능향상을 위해서라면 가능한 작은 자료형을 사용하도록 하자.
불필요하게 int를 쓰는 경우가 흔한데, 사용될 데이터의 범위를 생각해 본 후, 가장 작은 범위의 자료형을 사용하도록 하자.
2. 사용자가 정의 하는 User data type
사용자 정의 자료형이 왜 필요한가?
C언어를 비로한 몇 가지 언어에서 나타나는 사용자 정의 데이터 유형과 같다.
프로젝트에 참가하는 사람들이 동일한 데이터 타입을 사용하고자 원하거나,
한 컬럼에 대한 데이터 유형을 더 쉽게 사용하려고 할 때 적용시킬 수 있다.
사용 방법
sp_addtype [새로운 타입 이름], '[SQL 데이터 타입]'
예
sp_addtype empID, 'CHAR(10)'
sp_addtype empNO, 'CHAR(12)'
* 참고로 자료형을 바꾸는 함수로는 CONVERT() 가 있다.
사용방법
SELECT CONVERT(CHAR(30), title) FROM BOOKS
--> title 라는 컬럼을 CHAR(30) 으로 변환하여 가져오는 것이다.
SELECT CONVERT(VARCHAR(10), 35)
--> 35 라는 숫자를 VARCHAR(10) 으로 변환한다.
흐름 제어문의 종류
흐름 제어문이란 언어의 처리 순서를 변경하거나 변수를 선언하는 등의 문장을 말한다.
○ GOTO 라벨
- GOTO 를 만나면 라벨 부분으로 무조건 건너뛴다. 라벨은 라벨: 으로 정의한다.
예)
DECLARE...
SET...
table_label1:
.
.
IF .... GOTO table_label1
.
--> GOTO table_label1 을 만나면 table_label1: 부분으로 건너 뛴다.
○ RETURN
- RETURN 은 무조건 수행을 중지 하고 원래 호출된 곳으로 돌아간다.
○ IF / ELSE
- 이름만 들어도 알만한 문법이다. 주의 할 점은 조건문 안의 SQL문장이 둘 이상이라면 BEGIN / END 로 묶어 준다.
예)
IF @begin > @end
BEGIN
SELECT * FROM 테이블1 WHERE 조건
RETURN
END
ELSE
SELECT * FROM.........
○ WHILE / BREAK / CONTINUE
- WHILE 다음에 조건으로 반복을 하게 되고,
BREAK 를 만나면 무조건 WHILE 을 벗어나고,
CONTINUE 를 만나면 무조건 WHILE 로 돌아간다.
예)
WHILE 조건
BEGIN
반복하는 동안 실행할 문장들...
IF 조건
BREAK
IF 조건
CONTINUE
END
○ EXEC[UTE]
- EXEC 와 EXECUTE 는 같은 의미이다.
- 두가지 용도로 사용되는데,
- 첫 번째, 스토어드 프로시저를 실행할 때 사용한다.
예)
EXEC stored_procedure
- 두 번재, SQL 문장을 동적으로 변화시키며 수행할 수 있다.
예)
DECLARE @sql VARCHAR(255)
SET @sql = 'SELECT COUNT(*) FROM '
SET @sql = @sql + 'titles '
EXEC(@sql)
--> 실제 수행되는 문장은 SELECT COUNT(*) FROM titles 가 된다.
○ CASE
- 단순 CASE
예)
SELECT
CASE type
WHEN 'a' THEN 'Apple'
WHEN 'b' THEN 'Banana'
ELSE 'No Data'
END AS 과일
, price
FROM titles
- 검색된 CASE
예)
SELECT title_id
, qty AS '수량'
, CASE
WHEN qty >= 50 THEN 'A'
WHEN qty >= 30 THEN 'B'
ELSE 'C'
END AS '등급'
FROM titles
NULLIF : 표현식 1과, 2를 비교
>> 표현식 1과, 2를 비교 두 표현식이 같으면 NULL 을 리턴, 같지 않으면 표현식 1을 리턴 SELECT NULLIF(2,3) -- 2 리턴 SELECT NULLIF(3,3) -- NULL 리턴 사용예 : 양쪽필드에서 수량이 같으면 NULL을 리턴하고 하니면 첫 필드의 값을 리턴할때
COALESCE : 뒤에 오는 표현식중에 처음으로 오는 NULL 이 아닌 값을 리턴
SELECT COALESCE(NULL, 3, 4) -- 3 리턴 SELECT COALESCE(1,NULL,) -- 1 리턴 SELECT COALESCE(NULL,NULL,4) -- 4 리턴
SELECT COALESCE(NULL,NULL, NULL)--문법오류
사용예 : 하나만 값을 가지고 있는 컬럼에서 비교해서 값을 가져올때 매우 좋다
SET : 세성 옵션 (한번설정하면 세션이 끊어 질때까지 유용)
=====================================================================================
SET nocount OFF : 몇개 행이 처리 되었는지 결과보여주는 것을 설정한다 '
SET rowcount [n]
ex) SET rowcount 4 SELECT title_id FROM titles ORDER BY TITLE
SET rowcount 0
: 보여줄 목록의 행수를 선택한다. 목록의 정렬의 임의로 설정되므로 필요한 순서가 있다면 ORDER BY 를 사용해야 한다. 사용후엔 반드시 SET ROWCOUNT 0 을 이용해서 원위치 시켜놓아야 한다 '
============================== 유니크 키 넣기 ============================== ALTER TABLE 테이블명 ADD UNIQUE(컬럼1, 컬럼2) ALTER TABLE 테이블명 DROP CONSTRAINT 유니크명
============================== IDENTITY 관련 ==============================
http://l2j.co.kr/1460
http://mcdasa.cafe24.com/wordpress/mssql-identity-scope_identity%ec%9d%98-%ec%b0%a8%ec%9d%b4%ec%a0%90/
============================== INSERT SELECT ==============================
http://blog.naver.com/sorkanj2000/50106968790
============================== UPDATE SELECT ==============================
http://applejara.tistory.com/302
============================== JOIN UPDATE ==============================
http://blog.naver.com/ballkiss/30096524074
sp_addtype [새로운 타입 이름], '[SQL 데이터 타입]'
예
sp_addtype empID, 'CHAR(10)'
sp_addtype empNO, 'CHAR(12)'
* 참고로 자료형을 바꾸는 함수로는 CONVERT() 가 있다.
사용방법
SELECT CONVERT(CHAR(30), title) FROM BOOKS
--> title 라는 컬럼을 CHAR(30) 으로 변환하여 가져오는 것이다.
SELECT CONVERT(VARCHAR(10), 35)
--> 35 라는 숫자를 VARCHAR(10) 으로 변환한다.
흐름 제어문의 종류
흐름 제어문이란 언어의 처리 순서를 변경하거나 변수를 선언하는 등의 문장을 말한다.
○ GOTO 라벨
- GOTO 를 만나면 라벨 부분으로 무조건 건너뛴다. 라벨은 라벨: 으로 정의한다.
예)
DECLARE...
SET...
table_label1:
.
.
IF .... GOTO table_label1
.
--> GOTO table_label1 을 만나면 table_label1: 부분으로 건너 뛴다.
○ RETURN
- RETURN 은 무조건 수행을 중지 하고 원래 호출된 곳으로 돌아간다.
○ IF / ELSE
- 이름만 들어도 알만한 문법이다. 주의 할 점은 조건문 안의 SQL문장이 둘 이상이라면 BEGIN / END 로 묶어 준다.
예)
IF @begin > @end
BEGIN
SELECT * FROM 테이블1 WHERE 조건
RETURN
END
ELSE
SELECT * FROM.........
○ WHILE / BREAK / CONTINUE
- WHILE 다음에 조건으로 반복을 하게 되고,
BREAK 를 만나면 무조건 WHILE 을 벗어나고,
CONTINUE 를 만나면 무조건 WHILE 로 돌아간다.
예)
WHILE 조건
BEGIN
반복하는 동안 실행할 문장들...
IF 조건
BREAK
IF 조건
CONTINUE
END
○ EXEC[UTE]
- EXEC 와 EXECUTE 는 같은 의미이다.
- 두가지 용도로 사용되는데,
- 첫 번째, 스토어드 프로시저를 실행할 때 사용한다.
예)
EXEC stored_procedure
- 두 번재, SQL 문장을 동적으로 변화시키며 수행할 수 있다.
예)
DECLARE @sql VARCHAR(255)
SET @sql = 'SELECT COUNT(*) FROM '
SET @sql = @sql + 'titles '
EXEC(@sql)
--> 실제 수행되는 문장은 SELECT COUNT(*) FROM titles 가 된다.
○ CASE
- 단순 CASE
예)
SELECT
CASE type
WHEN 'a' THEN 'Apple'
WHEN 'b' THEN 'Banana'
ELSE 'No Data'
END AS 과일
, price
FROM titles
- 검색된 CASE
예)
SELECT title_id
, qty AS '수량'
, CASE
WHEN qty >= 50 THEN 'A'
WHEN qty >= 30 THEN 'B'
ELSE 'C'
END AS '등급'
FROM titles
NULLIF : 표현식 1과, 2를 비교
>> 표현식 1과, 2를 비교 두 표현식이 같으면 NULL 을 리턴, 같지 않으면 표현식 1을 리턴 SELECT NULLIF(2,3) -- 2 리턴 SELECT NULLIF(3,3) -- NULL 리턴 사용예 : 양쪽필드에서 수량이 같으면 NULL을 리턴하고 하니면 첫 필드의 값을 리턴할때
COALESCE : 뒤에 오는 표현식중에 처음으로 오는 NULL 이 아닌 값을 리턴
SELECT COALESCE(NULL, 3, 4) -- 3 리턴 SELECT COALESCE(1,NULL,) -- 1 리턴 SELECT COALESCE(NULL,NULL,4) -- 4 리턴
SELECT COALESCE(NULL,NULL, NULL)--문법오류
사용예 : 하나만 값을 가지고 있는 컬럼에서 비교해서 값을 가져올때 매우 좋다
SET : 세성 옵션 (한번설정하면 세션이 끊어 질때까지 유용)
=====================================================================================
SET nocount OFF : 몇개 행이 처리 되었는지 결과보여주는 것을 설정한다 '
SET rowcount [n]
ex) SET rowcount 4 SELECT title_id FROM titles ORDER BY TITLE
SET rowcount 0
: 보여줄 목록의 행수를 선택한다. 목록의 정렬의 임의로 설정되므로 필요한 순서가 있다면 ORDER BY 를 사용해야 한다. 사용후엔 반드시 SET ROWCOUNT 0 을 이용해서 원위치 시켜놓아야 한다 '
============================== 유니크 키 넣기 ============================== ALTER TABLE 테이블명 ADD UNIQUE(컬럼1, 컬럼2) ALTER TABLE 테이블명 DROP CONSTRAINT 유니크명
============================== IDENTITY 관련 ==============================
http://l2j.co.kr/1460
http://mcdasa.cafe24.com/wordpress/mssql-identity-scope_identity%ec%9d%98-%ec%b0%a8%ec%9d%b4%ec%a0%90/
============================== INSERT SELECT ==============================
http://blog.naver.com/sorkanj2000/50106968790
============================== UPDATE SELECT ==============================
http://applejara.tistory.com/302
============================== JOIN UPDATE ==============================
http://blog.naver.com/ballkiss/30096524074
sp_addtype [새로운 타입 이름], '[SQL 데이터 타입]'
예
sp_addtype empID, 'CHAR(10)'
sp_addtype empNO, 'CHAR(12)'
* 참고로 자료형을 바꾸는 함수로는 CONVERT() 가 있다.
사용방법
SELECT CONVERT(CHAR(30), title) FROM BOOKS
--> title 라는 컬럼을 CHAR(30) 으로 변환하여 가져오는 것이다.
SELECT CONVERT(VARCHAR(10), 35)
--> 35 라는 숫자를 VARCHAR(10) 으로 변환한다.
흐름 제어문의 종류
흐름 제어문이란 언어의 처리 순서를 변경하거나 변수를 선언하는 등의 문장을 말한다.
○ GOTO 라벨
- GOTO 를 만나면 라벨 부분으로 무조건 건너뛴다. 라벨은 라벨: 으로 정의한다.
예)
DECLARE...
SET...
table_label1:
.
.
IF .... GOTO table_label1
.
--> GOTO table_label1 을 만나면 table_label1: 부분으로 건너 뛴다.
○ RETURN
- RETURN 은 무조건 수행을 중지 하고 원래 호출된 곳으로 돌아간다.
○ IF / ELSE
- 이름만 들어도 알만한 문법이다. 주의 할 점은 조건문 안의 SQL문장이 둘 이상이라면 BEGIN / END 로 묶어 준다.
예)
IF @begin > @end
BEGIN
SELECT * FROM 테이블1 WHERE 조건
RETURN
END
ELSE
SELECT * FROM.........
○ WHILE / BREAK / CONTINUE
- WHILE 다음에 조건으로 반복을 하게 되고,
BREAK 를 만나면 무조건 WHILE 을 벗어나고,
CONTINUE 를 만나면 무조건 WHILE 로 돌아간다.
예)
WHILE 조건
BEGIN
반복하는 동안 실행할 문장들...
IF 조건
BREAK
IF 조건
CONTINUE
END
○ EXEC[UTE]
- EXEC 와 EXECUTE 는 같은 의미이다.
- 두가지 용도로 사용되는데,
- 첫 번째, 스토어드 프로시저를 실행할 때 사용한다.
예)
EXEC stored_procedure
- 두 번재, SQL 문장을 동적으로 변화시키며 수행할 수 있다.
예)
DECLARE @sql VARCHAR(255)
SET @sql = 'SELECT COUNT(*) FROM '
SET @sql = @sql + 'titles '
EXEC(@sql)
--> 실제 수행되는 문장은 SELECT COUNT(*) FROM titles 가 된다.
○ CASE
- 단순 CASE
예)
SELECT
CASE type
WHEN 'a' THEN 'Apple'
WHEN 'b' THEN 'Banana'
ELSE 'No Data'
END AS 과일
, price
FROM titles
- 검색된 CASE
예)
SELECT title_id
, qty AS '수량'
, CASE
WHEN qty >= 50 THEN 'A'
WHEN qty >= 30 THEN 'B'
ELSE 'C'
END AS '등급'
FROM titles
NULLIF : 표현식 1과, 2를 비교
>> 표현식 1과, 2를 비교 두 표현식이 같으면 NULL 을 리턴, 같지 않으면 표현식 1을 리턴 SELECT NULLIF(2,3) -- 2 리턴 SELECT NULLIF(3,3) -- NULL 리턴 사용예 : 양쪽필드에서 수량이 같으면 NULL을 리턴하고 하니면 첫 필드의 값을 리턴할때
COALESCE : 뒤에 오는 표현식중에 처음으로 오는 NULL 이 아닌 값을 리턴
SELECT COALESCE(NULL, 3, 4) -- 3 리턴 SELECT COALESCE(1,NULL,) -- 1 리턴 SELECT COALESCE(NULL,NULL,4) -- 4 리턴
SELECT COALESCE(NULL,NULL, NULL)--문법오류
사용예 : 하나만 값을 가지고 있는 컬럼에서 비교해서 값을 가져올때 매우 좋다
SET : 세성 옵션 (한번설정하면 세션이 끊어 질때까지 유용)
=====================================================================================
SET nocount OFF : 몇개 행이 처리 되었는지 결과보여주는 것을 설정한다 '
SET rowcount [n]
ex) SET rowcount 4 SELECT title_id FROM titles ORDER BY TITLE
SET rowcount 0
: 보여줄 목록의 행수를 선택한다. 목록의 정렬의 임의로 설정되므로 필요한 순서가 있다면 ORDER BY 를 사용해야 한다. 사용후엔 반드시 SET ROWCOUNT 0 을 이용해서 원위치 시켜놓아야 한다 '
============================== 유니크 키 넣기 ============================== ALTER TABLE 테이블명 ADD UNIQUE(컬럼1, 컬럼2) ALTER TABLE 테이블명 DROP CONSTRAINT 유니크명
============================== IDENTITY 관련 ==============================
http://l2j.co.kr/1460
http://mcdasa.cafe24.com/wordpress/mssql-identity-scope_identity%ec%9d%98-%ec%b0%a8%ec%9d%b4%ec%a0%90/
============================== INSERT SELECT ==============================
http://blog.naver.com/sorkanj2000/50106968790
============================== UPDATE SELECT ==============================
http://applejara.tistory.com/302
============================== JOIN UPDATE ==============================
http://blog.naver.com/ballkiss/30096524074
0 notes
Text
SQL Lesson 16: Creating tables
When you have new entities and relationships to store in your database, you can create a new database table using the CREATE TABLE statement.
Create table statement w/ optional table constraint and default value
CREATE TABLE IF NOT EXISTS mytable ( column DataType TableConstraint DEFAULT default_value, another_column DataType TableConstraint DEFAULT default_value, … );
The structure of the new table is defined by its table schema, which defines a series of columns. Each column has a name, the type of data allowed in that column, an optional table constraint on values being inserted, and an optional default value.
If there already exists a table with the same name, the SQL implementation will usually throw an error, so to suppress the error and skip creating a table if one exists, you can use the IF NOT EXISTS clause.
Table data types
Different databases support different data types, but the common types support numeric, string, and other miscellaneous things like dates, booleans, or even binary data. Here are some examples that you might use in real code.
Data typeDescription
INTEGER
,
BOOLEAN
The integer datatypes can store whole integer values like the count of a number or an age. In some implementations, the boolean value is just represented as an integer value of just 0 or 1.
FLOAT
,
DOUBLE
,
REAL
The floating point datatypes can store more precise numerical data like measurements or fractional values. Different types can be used depending on the floating point precision required for that value.
CHARACTER(num_chars)
,
VARCHAR(num_chars)
,
TEXT
The text based datatypes can store strings and text in all sorts of locales. The distinction between the various types generally amount to underlaying efficiency of the database when working with these columns.
Both the CHARACTER and VARCHAR (variable character) types are specified with the max number of characters that they can store (longer values may be truncated), so can be more efficient to store and query with big tables.
DATE
,
DATETIME
SQL can also store date and time stamps to keep track of time series and event data. They can be tricky to work with especially when manipulating data across timezones.
BLOB
Finally, SQL can store binary data in blobs right in the database. These values are often opaque to the database, so you usually have to store them with the right metadata to requery them.
Docs:
MySQL
,
Postgres
,
SQLite
,
Microsoft SQL Server
Table constraints
We aren't going to dive too deep into table constraints in this lesson, but each column can have additional table constraints on it which limit what values can be inserted into that column. This is not a comprehensive list, but will show a few common constraints that you might find useful.
ConstraintDescription
PRIMARY KEY
This means that the values in this column are unique, and each value can be used to identify a single row in this table.
AUTOINCREMENT
For integer values, this means that the value is automatically filled in and incremented with each row insertion. Not supported in all databases.
UNIQUE
This means that the values in this column have to be unique, so you can't insert another row with the same value in this column as another row in the table. Differs from the `PRIMARY KEY` in that it doesn't have to be a key for a row in the table.
NOT NULL
This means that the inserted value can not be `NULL`.
CHECK (expression)
This allows you to run a more complex expression to test whether the values inserted are valid. For example, you can check that values are positive, or greater than a specific size, or start with a certain prefix, etc.
FOREIGN KEY
This is a consistency check which ensures that each value in this column corresponds to another value in a column in another table.
For example, if there are two tables, one listing all Employees by ID, and another listing their payroll information, the `FOREIGN KEY` can ensure that every row in the payroll table corresponds to a valid employee in the master Employee list.
An example
Here's an example schema for the Movies table that we've been using in the lessons up to now.
Movies table schema
CREATE TABLE movies ( id INTEGER PRIMARY KEY, title TEXT, director TEXT, year INTEGER, length_minutes INTEGER );
0 notes
Text
Get paid ($$$) : Difference Between Sql Server VARCHAR and VARCHAR(MAX) Data Type
http://dlvr.it/PyDvGK
0 notes
Text
Q33. What is the difference between Unicode data types and Non-Unicode data types? Q34. What is the difference between fixed-length data type and variable-length data type? Q35. What is the difference between CHAR vs VARCHAR data types? Q36. What is the difference between VARCHAR vs NVARCHAR data types? Q37. What is the max size of a VARCHAR and NVARCHAR data type in SQL, Why? Q38. What is the difference between VARCHAR(MAX) and VARCHAR(n) data types? Q39. What is the difference between VARCHAR(MAX) and TEXT(n) data types? Q40. What is the difference between LEN() and DATALENGTH() in SQL? Q41. What is the difference between DateTime and DateTime2 data types in SQL?
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda#techpoint#interview
0 notes
Text
Q01. What is the use of FOREIGN KEY constraints? What is the difference between Primary Key and Foreign Key Constraints? Q02. Can a Unique Key be referenced by a FOREIGN KEY Constraint? Q03. How many Foreign Keys can be created in a table? Q04. Can a FOREIGN KEY reference multiple columns of the Parent Table? Q05. Is NULL value allowed in the FOREIGN KEY column? Q06. Can a FOREIGN KEY have more than one matching record in the parent table? Q07. Can a FOREIGN KEY exist without the key name? Q08. Can you create a FOREIGN KEY on a Composite Primary Key? Q09. Can you create a Composite FOREIGN KEY? Q10. Which type of index is created by default for the FOREIGN KEY Constraint? Q11. Can a FOREIGN KEY contain duplicate values? Q12. Can you create a FOREIGN KEY without referencing any other table? or Can a FOREIGN KEY reference a column of the same table? Q13. Can a FOREIGN KEY reference the FOREIGN KEY column of other tables? Q14. What is the use of the CASCADE Keyword? or What is CASCADE DELETE or UPDATE in SQL? Q15. How many tables are required for creating a FOREIGN KEY constraint? or How can you create the FOREIGN KEY in a single table? Q16. Can a FOREIGN KEY reference the Non-KEY column of the parent table? Q17. What is the use of "WITH CHECK" and "WITH NOCHECK" Clause in the FOREIGN KEY Constraint? Q18. How can you create a FOREIGN KEY Constraint after creating a table? Q19. Are duplicate Key Names allowed in the database? Q20. What is a Trusted and Non-Trusted referential integrity constraint? Q21. Can a FOREIGN KEY column contain NULL values? Q22. How many NULL values are allowed in a FOREIGN KEY column? Q23. Can a FOREIGN KEY Contain an empty(blank) value or whitespace? Q24. Can you make the FOREIGN KEY column an Identity Column? Q25. Can you create an index on the FOREIGN KEY column? Q26. How can you delete or update the records referenced by the FOREIGN KEY constraint? Q27. Can you disable the FOREIGN KEY constraint? Q28. What is the use of the 'NOT FOR REPELCIATION' option in the FOREIGN KEY constraint? Q29. Can you add FOREIGN KEY REFERENCES on the Temp Table? Q30. Can you add multiple FOREIGN KEY REFERENCES on the same column? Q31. Can you modify the existing FOREIGN KEY REFERENCES? Q32. Can you create a FOREIGN KEY constraint on the computed column? Q33. Can you reference a column in the FOREIGN KEY which is neither Primary Key nor Unique Key but has a Unique Index? Q34. Can you create a FOREIGN KEY constraint without referencing any column name? Q35. Can a FOREIGN KEY REFERENCES across the database table? or Can you reference an external database table for creating the FOREIGN KEY REFERENCES? Q36. What will happen if a Foreign Key column has multiple foreign key constraints with different CASCADE actions that reference the same column? Q37. What is the difference between INSERT INTO and BULK INSERT when you have to add the data into a table which has FOREIGN KEY REFERENCES? Q38. Can you DROP the UNIQUE INDEX of the column that is referenced by the FOREIGN KEY Constraint? Q39. Can you add a FOREIGN KEY constraint on the varchar(max) column? Q40. How do the FOREIGN KEY constraints maintain the referential integrity of the database?
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda
1 note
·
View note
Text
Q01. What is the difference between INDEX vs KEY? Q02. What is the difference between PRIMARY KEY vs UNIQUE KEY? Q03. What is the difference between UNIQUE KEY vs Non-Nullable UNIQUE KEY? Q04. What is the difference between the UNIQUE KEY and UNIQUE Index? Q05. Are NULL values allowed in a UNIQUE KEY column? Q06. Can a UNIQUE KEY Contains an empty(blank) value or whitespace? Q07. Can a UNIQUE KEY column contain duplicate values? Q08. Can you add a Non-Clustered Index explicitly on any column in SQL? Q09. Is it mandatory for the UNIQUE KEY to be a Non-Clustered Index? Can a UNIQUE KEY have a Clustered index? Q10. Can you create a UNIQUE KEY on a table that has already a Clustered Index? Q11. Can you add both Clustered and Non-Clustered Indexes on a column? Q12. If a column contains a Non-Clustered Index, is it mandatory that the column must be UNIQUE KEY as well? Q13. Can you add multiple UNIQUE KEY or Non-Clustered Indexes on any table? Q14. Can you create a UNIQUE KEY on the Temp Table? Q15. Can you add a UNIQUE KEY on view? Q16. What is the difference between table level and column level UNIQUE KEY Constraint? Q17. When the database table is in First Normal Form (1NF)? Q18. Can you update or delete the UNIQUE KEY value of a table? Q19. Can you add the UNIQUE KEY Constraint on a column that contains data already? Q20. What is IAM (Index Allocation Map) Page in SQL? Q21. What is a Composite Key? Q22. What is a Candidate Key? Q23. What is an Alternate Key? Q24. Can you add a UNIQUE Key Constraint on a nullable column? Q25. How many UNIQUE KEYs are allowed in a table? Q26. How many NonClustered Indexes are allowed in any table? Q27. Can you remove the index created by the Unique Key? Q28. How can you Remove the Unique Key Constraint? Q29. Can you add UNIQUE KEY on a VARCHAR(MAX) column, why? Q30. Can you make the UNIQUE KEY column an Identity Column? Q31. Can you use UNIQUE KEY as a replacement for Primary Key? If the Primary Key can uniquely identify every row, then why bother about UNIQUE KEY? Q32. Can you add UNIQUE KEY to the Primary Key column? Q33. If a NULL value never equals other NULL values, it means they are unique. So why only one NULL value is allowed in the UNIQUE Key column? Q34. What is a HEAP in SQL? Q35. Can you create a UNIQUE KEY on the table variable? Q36. Can you create a UNIQUE KEY on the Table Valued Type (TVP)?
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda
1 note
·
View note
Text
Q01. What is the difference between INDEX vs KEY? Q02. What is the difference between PRIMARY KEY vs UNIQUE KEY? Q03. What is the difference between PRIMARY KEY vs Non-Nullable UNIQUE KEY? Q04. What is the difference between the PRIMARY KEY and UNIQUE Clustered Index? Q05. How many NULL values are allowed in a PRIMARY KEY column? Q06. Can a PRIMARY KEY Contains an empty(blank) value or whitespace? Q07. Can a PRIMARY KEY column contain duplicate values? Q08. Can you add a Clustered Index explicitly on any column in SQL? Q09. Is it mandatory for a PRIMARY KEY to be a Clustered Index? Can a PRIMARY KEY have a Non-Clustered index? Q10. Can you create a PRIMARY KEY on a table that has already a Clustered Index? Q11. Can you add both Clustered and Non-Clustered Indexes on a column? Q12. If a column contains a Clustered Index, is it mandatory that the column must be PRIMARY KEY as well? Q13. Can you add multiple PRIMARY KEY or Clustered Indexes on any table? Q14. Can you create a PRIMARY KEY on the Temp Table? Q15. Can you add a PRIMARY KEY on view? Q16. What is the difference between table level and column level PRIMARY KEY? Q17. When the database table is in First Normal Form (1NF)? Q18. Can you update or delete the PRIMARY KEY value of a table? Q19. Can you add the PRIMARY KEY constraint on a column that contains data? Q20. What is IAM (Index Allocation Map) Page in SQL? Q21. What is a Composite Key? Q22. What is a Candidate Key? Q23. What is an Alternate Key? Q24. Can you add a PRIMARY Key Constraint on a nullable column? Q25. How many PRIMARY KEYs are allowed in a table? Q26. How many Clustered Indexes are allowed in any table? Q27. Can you delete the index created by the Primary Key? Q28. How can you remove the Primary Key Constraint? Q29. Can you make a VARCHAR(MAX) column as a PRIMARY KEY column in SQL? Why? Q30. Is it mandatory to make the PRIMARY KEY column an Identity Column? What will happen if two users will try to add the same value in PRIMARY KEY at the same time? Q31. If you have Clustered Index already on a column i.e. UserName in a table, Now you have to create a PRIMARY KEY on the UserId column. How will you do that? Q32. In which order the data will be displayed by default if executing the SELECT command on the table without any ORDER BY clause? Q33. Why does PRIMARY KEY enforce it to be Non-Nullable and UNIQUE KEY as Nullable? Q34. What is a HEAP in SQL? Q35. Can you create a PRIMARY KEY on the table variable? Q36. Can you create a PRIMARY KEY on the Table Valued Type (TVP)?
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda
1 note
·
View note
Text
Q01. What is the difference between UNIQUE Constraint and UNIQUE INDEX in SQL?
Q02. If the primary key uniquely identified rows, then why bother about UNIQUE KEY?
Q03. Is NUll value allowed in the UNIQUE KEY column?
Q04. Can a UNIQUE KEY contain an empty(blank) value or whitespace?
Q05. Can you make the UNIQUE KEY column an Identity column?
Q06. Can you create a UNIQUE KEY constraint on a PRIMARY KEY column?
Q07. Which type of index is created by default for the UNIQUE KEY constraint?
Q08. If you DROP the UNIQUE constraint, does it also drop the UNIQUE index?
Q09. Can you add UNIQUE Constraint on Clustered Index?
Q10. Can you use UNIQUE KEY as a replacement for PRIMARY KEY?
Q11. Is it mandatory for a UNIQUE KEY to be a NonClustered index?
Q12. Can you add the UNIQUE KEY constraint on a column that contains data already?
Q13. Can you update or delete the UNIQUE KEY value of a table that is referenced by the foreign key?
Q14. Can you make a varchar(max) column as UNIQUE KEY in SQL?
Q15. Can you add Unique Key on view?
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda#interviewquestions#interviewpreparation
1 note
·
View note
Text
Q01. What is the difference between PRIMARY KEY and Non-Nullable UNIQUE KEY?
Q02. What is the difference between the PRIMARY KEY and Unique Clustered Index?
Q03. How many NULL values are allowed in a PRIMARY KEY column?
Q04. Can a PRIMARY KEY Contains an empty(blank) value or whitespace?
Q05. Can the PRIMARY KEY columns contain duplicate values?
Q06. Can you add a clustered index on any non-primary key column in SQL?
Q07. Is it mandatory for a PRIMARY KEY to be clustered index? or Can a PRIMARY KEY have a non-clustered index?
Q08. Can you create a PRIMARY KEY on a table that has already a clustered index?
Q09. Can you add both clustered and non clustered indexes on a column?
Q10. If a column contains a clustered index, is it mandatory that the column must be PRIMARY KEY also?
Q11. Can you add both clustered and non-clustered indexes on the same column of the database?
Q12. Can you add multiple PRIMARY KEY or clustered indexes on any table?
Q13. Can you create a PRIMARY KEY on the temp table?
Q14. Can you add a PRIMARY KEY on view?
Q15. What is the difference between table level and column level PRIMARY KEY?
Q16. When the database is in first normal form (1NF)?
Q17. Can you update or delete the PRIMARY KEY value of a table?
Q18. Can you add the PRIMARY KEY constraint on a column that contains data?
Q19. Can you add a PRIMARY Key constraint on a nullable column?
Q20. How many PRIMARY KEYs are allowed in a table?
Q21. How many clustered indexes are allowed in any table?
Q22. Can you DROP the index created by the Primary Key?
Q23. Can you make a varchar(max) column as PRIMARY KEY in SQL?
Q24. Is it mandatory to make the PRIMARY KEY column an identity column?
Q25. What is the difference between PRIMARY KEY and UNIQUE KEY?
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda
0 notes
Video
youtube
SQL Non-Clustered Index | SQL Non-Clustered Indexed View | Non-Clustered...
SQL Non-Clustered Index:
-----------------------------------------------
Q01. What is a Non-Clustered Index in SQL? How can you create a Non-Clustered Index? Q02. What is the main difference between a Non-clustered index that is built over a Heap table and a Non-clustered index that is built over a Clustered table? Q03. What does the leaf node of the non-clustered index store if there is no clustered index in the table? Q04. Why non-clustered index is slower than the clustered index? Q05. What is the difference between the Non-Clustered Index and the UNIQUE Non-Clustered Index? Q06. What is the difference between the Clustered Index and the Non-Clustered Index in SQL? Q07. How many non-clustered indexes can you have in a table? Q08. Can you create a Non-Clustered Index on a varchar(max) type column in SQL? Q09. Can you create a Non-Clustered Index on a View?
https://www.youtube.com/watch?v=-705pO6yw2s
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda
0 notes
Video
youtube
SQL CLUSTERED INDEX | CLUSTERED INDEX vs PRIMARY KEY
SQL CLUSTERED INDEX and CLUSTERED INDEX vs PRIMARY KEY: ------------------------------------------------------------------------------------------------
Q01. What is Heap in SQL? Q02. What is the difference between Table Scan and CLUSTERED INDEX Scan? Q03. What is CLUSTERED INDEX in SQL? How can you create a CLUSTERED INDEX? Q04. How many CLUSTERED INDEX can you have on a table? Q05. On what basis the data is physically stored in the SQL, based on PRIMARY KEY or CLUSTERED INDEX? Q06. Does a CLUSTERED INDEX always UNIQUE? Q07. Does CLUSTERED INDEX always contain only the UNIQUE value in that column? Q08. Does it mandatory for the CLUSTERED INDEX to be unique? Q09. What type of index is created by the PRIMARY KEY in SQL? Q10. Can you create a CLUSTERED INDEX on the table which has a PRIMARY KEY? Q11. Can you create a PRIMARY KEY on the table which has CLUSTERED INDEX? Q12. What is the difference between CLUSTERED INDEX and PRIMARY KEY in SQL? Q13. Can you create a Clustered Index on a varchar(max) type column in SQL? Q14. Can you add a CLUSTERED INDEX on a View? Q15. Is Non-Unique CLUSTERED INDEX is allowed on View? Q16. If you have to change the CLUSTERED INDEX column, how can you do that?
https://www.youtube.com/watch?v=YaooHJfK-d8
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda
0 notes
Video
youtube
PRIMARY KEY vs UNIQUE KEY vs FOREIGN KEY-Part 2 | UNIQUE KEY CONSTRAINT ...
UNIQUE KEY CONSTRAINT: ------------------------------------------------------------- QA. What is the difference between PRIMARY KEY and UNIQUE KEY? QB. What is the difference between UNIQUE KEY and FOREIGN KEY? QC. What is the difference between UNIQUE KEY and UNIQUE INDEX?
Q01. What is the difference between UNIQUE Constraint and UNIQUE INDEX in SQL? Q02. If the primary key uniquely identified rows, then why bother about UNIQUE KEY? Q03. Is NUll value allowed in the UNIQUE KEY column? Q04. Can a UNIQUE KEY contain an empty(blank) value or whitespace? Q05. Can you make the UNIQUE KEY column an identity column? Q06. Can you create a UNIQUE KEY constraint on a PRIMARY KEY column? Q07. Which type of index created by default for the UNIQUE KEY constraint? Q08. If you DROP the UNIQUE constraint, does it also drop the UNIQUE index? Q09. Can you add clustered Unique Index in any table? Q10. Can you use UNIQUE KEY as a replacement for PRIMARY KEY? Q11. Is it mandatory for a UNIQUE KEY to being a NonClustered index? Can a UNIQUE Key be created on Clustered Index? Q12. Can you add the UNIQUE KEY constraint on a column that contains data already? Q13. Can you update or delete the UNIQUE KEY value of a table that is referenced by the foreign key? Q14. Can you make a varchar(max) column as UNIQUE KEY in SQL? Q15. If you have to store the data in such a way that each and every record can be identified by a unique value. What will be your approach PRIMARY KEY or Unique Key? Q16. If a NULL value never equals another NULL value, it means they are unique, then why only one NULL value is allowed in a UNIQUE key column?
#sqlinterviewquestions2021#mostfrequentlyaskedsqlinterviewquestions#interviewquestionsandanswers#techpointfundamentals#techpointfunda#uniquekey
0 notes
Text
Migrating from SAP ASE to Amazon Aurora PostgreSQL
Enterprise customers often have legacy applications running on an older variant of databases, which impedes the applications’ scalability. In this high-speed cloud computing world, businesses are anxiously looking for solutions to migrate these databases to the cloud. Amazon Aurora is a highly available and managed relational database service with automatic scaling and high-performance features. The combination of PostgreSQL compatibility with Aurora enterprise database capabilities provides an ideal target for commercial database migrations. In this post, we cover the best practices to migrate an on-premises SAP ASE (Sybase) database to an Aurora PostgreSQL database using AWS Schema Conversion Tool (AWS SCT) and AWS Database Migration Service (AWS DMS). We discuss the multiple phases involved in a migration: Preparation and assessment Migration Cutover procedures As of this writing, AWS SCT only supports Sybase version 15.7 and 16.0. AWS DMS only supports version 12.5.3 and higher. For the latest product supported versions on Sybase, see What Is the AWS Schema Conversion Tool? and Using an SAP ASE database as a source for AWS DMS. You should also know the product limitations when Sybase is the source and the limitations for PostgresSQL as the target. Preparing and assessing on the source database Preparation and assessment is the initial phase. Before we start moving data, we need to monitor and analyze the source database schema for the data lifecycle. To provide the best migration solution, you need to have a better understanding on the workload, data access patterns, and data dependencies. In this post, we discuss the following areas: Character set Entity relationships Largest table size Unused tables and indexes Largest LOB size Integration with other databases or OS Prerequisites To complete this step, you need the following: A SQL client tool (for this post, we use SQL Developer) An entitity relationship (ER) tool to retrieve the ER A Sybase user with admin privileges to query the system tables. The user must have following roles: sa_role replication_role sybase_ts_role If you rely on AWS DMS to enable Sybase replication on table (which is mandatory), you need to grant permissions to run the stored procedure sp_setreptable. Alternatively, set the extra connect attribute enableReplication=false, which means you have to manually enable sp_retreptable on the table to migrate ongoing replication changes. Character set To find out the default character set and sort order for your SAP ASE database, enter the following query: exec sp_default_charset Note: If your application uses a different charcter set, you can find it from your session via the checking global variable @@client_csname or @@client_csid. PostgreSQL supports various character sets, from single byte to multiple bytes. When you create a new Aurora PostgreSQL database, the default character set is UTF8. PostgreSQL also supports automatic character set conversion for certain character set combinations. In our testing environment, we used AWS DMS to migrate an SAP ASE 12.5 database with character set ISO8859 to Aurora PostgreSQL ISO8559 with no conversion issue. If you have a non-default character set that you want to migrate, you have to use an extra connect attribute to specify the character set being used by the source database. For example, if a customer’s default character set is UTF8, they have to specify charset=utf8 as an extra connect attribute to correctly migrate the data. Entity relationship If possible, reverse engineer your data model using an ER tool (such as Erwin). The ER diagram gives you a clear picture of the relationships between your database objects. When you set up an AWS DMS task, you need to migrate the dependent tables together to ensure transactional consistency. Largest table size Study your largest and busiest tables to find out their sizes and rate of change. This gives you an accurate estimate of where time will be spent when you do the initial data migration using the AWS DMS full load feature. You can try to parallelize the load on the table level with one task to save time. The SAP ASE server only allows one replication thread for each database, so you can only start one AWS DMS task at one time for each database. You can’t run multiple tasks, which is common when migrating other database engines. For more information, see Limitations on using SAP ASE as a source for AWS DMS. For version 15 and later, you need to query sysobjects to list the top 10 in row count and space used. See the following code: select top 10 convert(varchar(30),o.name) AS table_name, row_count(db_id(), o.id) AS row_count, data_pages(db_id(), o.id, 0) AS pages, data_pages(db_id(), o.id, 0) * (@@maxpagesize/1024) AS kbs from sysobjects o where type = 'U' order by kbs DESC, table_name ASC We need to identify tables with the TEXT, UNITEXT and IMAGE data type, because AWS DMS converts these objects to LOB. It’s always recommended to identify the size of LOB columns and choose LOB settings (limited or full mode) and max LOB size appropriately. See the following code: Select o.name as table_name, c.name as column_name, c.type as data_type_code from sysobjects o join syscolumns c on o.id=c.id where o.type=’U’ and c.type in (34,35,174) For older versions, query sysindexes: select top 10 object_name(id) as "name", rowcnt(doampg) as "rowcount" from sysindexes order by rowcnt(doampg) desc select top 10 object_name(id) as "name", maxlen as "row width" from sysindexes order by maxlen desc Unused tables and indexes You first need to set up auditing on your Sybase server. You need to install a security database, restart the server, and enable auditing. You use the sp_audit procedure to audit all the tables and indexes for select, insert, update, and delete for a data cycle of 3–30 days, depending on your application usage pattern. If you want to migrate tables that haven’t been accessed in the last 30 days, it should be fine to also include those. See the following code: sp_audit "insert", "all", "yourtablename", "on" sp_audit "select", "all", "yourtablename", "on" Largest LOB size LOB typically takes the longest to migrate, unlike data types such as number and character, due to time spent encoding, storing, decoding, and retrieving them. You can use the following dynamic SQL to generate a query for each table: select 'select max(datalength(',c.name, ')) from dbo.', o.name,';' from sysobjects o, syscolumns c where o.type = 'U' and o.id = c.id and c.type in (34,35,174); After running the preceding queries, compare the results and pick the top one. For example, we found the largest LOB column in our SAP ASE database is 119 KB. We used this number as input in our task settings with limited LOB mode. The speed of the full load is greatly improved with limited LOB mode compared to full LOB mode. For performance reasons, we recommend using limited LOB mode but increase the maximum LOB size (KB) so it’s big enough to cover the actual size you find from your query. For more information about speeding up LOB migration, see How can I improve the speed of an AWS DMS task that has LOB data? Integration with other databases or OS If you have remote objects or interfaces in your code, you need to replace them with other AWS services or equivalent external services. For example, in the SAP ASE database, you may send out email using the xp_sendmail procedure. Because Aurora PostgreSQL doesn’t support email natively, you need to redesign the process. This involves using an AWS Lambda function to send email from the database. For more information, see Sending notifications from Amazon Aurora PostgreSQL. Note: If we have database links from source database to remote server in SAP ASE, we will need to update the data. The workaround will involve redesign some of these use cases with foreign data wrappers (FDW). Migrating the database The two major tasks in this section are code conversion and data loading. We use AWS SCT to convert the schema objects (tables, views, procedures, functions). We then use AWS DMS to load the table data. Converting schema and code objects from Sybase to Aurora PostgreSQL The following screenshot shows that AWS SCT can’t convert some particular procedure or objects. When this occurs, you see a red exclamation mark on the object that it’s failing to migrate. When you choose the failed object, you see more details about the error. For example, in this case, Postgres doesn’t support the @@rowcount function. You need to manually convert this outside of AWS SCT. Prerequisites Before you get started, make sure you have the following prerequisites: AWS SCT downloaded and installed with the required Sybase and PostgreSQL JDBC drivers to your client machine. For instructions, see Installing, Verifying, and Updating the AWS Schema Conversion Tool. The latest version of AWS SCT (support for Aurora Postgres version 11 started from the AWS SCT 633 build). A Sybase database user with select privilege on the system and user schema tables and views. If you plan to use the same user for AWS DMS migration with change data capture (CDC) later, grant sa-role to it. An Aurora PostgreSQL database as your target. An Aurora PostgreSQL database user with superuser or proper privileges required. For more information, see Configure Your PostgreSQL Target Database. Converting the schema When you have the required resources, complete the following steps: Connect to the source and target databases and convert your schema. For instructions, see Migrate Your Procedural SQL Code with the AWS Schema Converstion Tool. Save the SQL scripts after you convert your schema. Run them in your target PostgreSQL database. Create tables with primary keys only. Add the foreign keys and secondary indexes after the full load is complete. As of this writing, AWS SCT doesn’t support Sybase of versions older than 15.7. You have to manually convert your schema objects. For more information about data type mapping between Sybase and PostgreSQL, see Source data types for SAP ASE. Migrating SAP ASE to Aurora PostgreSQL using AWS DMS In this section, we walk through the steps to migrate an SAP ASE database to Aurora PostgreSQL using AWS DMS. AWS DMS creates the schema in the target if the schema doesn’t exist. However, AWS DMS only creates the tables with primary keys. It doesn’t create foreign keys or secondary indexes. Even the default values may be missing. The best practice is to create the schema objects using the scripts AWS SCT generated in the prior step, then start AWS DMS to load table data. Prerequisites Before you get started, make sure you meet the prerequisites for using an SAP ASE database as a source for AWS DMS. Regarding the sa_role permissions you need to grant, you may be reluctant to grant this role to the AWS DMS user. However, AWS DMS needs this privilege to run DBCC TRACEON(3604). The AWS DMS application turns this flag on so that the output is redirected to the AWS DMS client. DBCC TRACEON is a sysadmin right. If you don’t want to grant the sa_role directly, you can work around it by developing a trigger to grant the role at the session level. Make sure you have foreign keys and triggers disabled in the target. Additionally, your AWS account should have privileges on AWS DMS and Amazon Relational Database Service (Amazon RDS). Creating your replication instance To start your migration, you first create an AWS DMS replication instance. For performance reasons, we recommend creating it in the same Region as your target Aurora database. On the AWS DMS console, choose Replication instance. Choose Create replication instance. Enter your desired instance configuration. For Instance class, you can choose from t, c, or r types. We recommend the C5 type for production due to its network and memory optimization. Creating your source endpoint You next create a source endpoint for Sybase and test the connection using the preceding replication instance. On the AWS DMS console, choose Endpoints. Choose Create endpoint. For Endpoint type, select Source endpoint. Enter your desired endpoint configuration. For instructions on using an on-premises name server and using a hostname instead of IP, see Using your own on-premises name server. After you create the endpoint, select it and choose Test connection from the Actions drop-down menu. If your SAP ASE version is 15.7 and higher and you’re willing to use TLS, you have to use ECA provider =Adaptive Server Enterprise 16.03.06. Make sure the database port 1526 is opened to the IP range of your replication instance before you test the connection. If the firewall is open but you still experience a connection issue, please contact AWS Support. Creating a target endpoint You now create your target endpoint for Aurora PostgreSQL. On the AWS DMS console, choose Endpoints. Choose Create endpoint. For Endpoint type, select Target endpoint. Enter your desired endpoint configuration. Test the connection using the preceding replication instance. For the connection to be successful, you must edit the security group for the RDS DB instance with PostgreSQL port 5432 open to the replication instance’s private IP or IP range. On the Amazon RDS console, choose your Aurora PostgreSQL DB instance. On the Connectivity & security tab, locate your security group name under Security. Choose the security group link. A new page opens to the security group interface. Choose Inbound rules. Choose Edit inbound rules. Add the IP range of the replication instance. Creating and starting the migration task To create a migration task using the source and target endpoints, complete the following steps: On the AWS DMS console, choose Database migration tasks. Choose Create task. Provide information for the task identifier, replication instance, source database endpoint, and target database endpoint. For Migration type, choose Migrage existing data and replicate ongoing changes (recommended to minimize downtime). In the Task settings section, for Target table preparation mode, select Do nothing (assuming your tables are created in the target database already). For Stop task after full load completes, select Stop after applying cached changes (at this time, you enable foreign keys and triggers in the target, then resume the task). For Include LOB columns in replication, choose Limited LOB mode (recommended for performance reasons). For Maximum LOB size, enter the larger LOB size you found from the earlier query (for this use case, 199 KB). For Enable validation, leave deselected. As of this writing, AWS DMS doesn’t support validation for SAP ASE migrations. Select Enable CloudWatch logs. This is the file that you need to monitor for task progress and errors. You can also raise the debug level when needed. In the Table mappings section, choose the JSON Delete the lines in the text box and enter your own JSON file with the table selection and transformation rules. See the following example code: { "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "dbo", "table-name": "tax_master" }, "rule-action": "include" } ] } The preceding code migrates the table tax_master in the dbo schema. For more information, see Using table mapping to specify task settings. In the Advanced task settings, for Create control table in target using schema, enter a target schema for these tables. If you don’t provide a schema, your task fails with the following error: [TARGET_APPLY ]E: RetCode: SQL_ERROR SqlState: 3F000 NativeError: 1 Message: ERROR: no schema has been selected to create in;, Error while executing the query [1022502] (ar_odbc_stmt.c:4428) Enable your desired control tables. AWS DMS can create four control tables for you: Apply exceptions Replication status Suspended tables Replication history . You need to purge these tables manually if they grow too large. For more information, see Control table task settings. For Maximum number of tables to load in parallel, enter a number depending on your source and target database capacity. After you create your task, its status shows as Ready. When you start or resume it, the status shows as Starting and changes to Running. To monitor the process, choose Task Monitoring, Table Statistics, Logs. For more information about monitoring, see Monitoring Database Migration Service metrics and How can I enable monitoring for an AWS DMS task? When the full load is complete, the task stops. You can take this opportunity to add or enable your foreign keys or constraints and triggers in your target. If your migration type is Migrate existing data and replicate ongoing changes, you need to resume the task so that it picks up the cached changes. When you have tasks running, you also need to monitor the on-premises source host, your replication instance, and your target RDS. Make sure you create alarms and get notified on key metrics like CPU utilization, freeable memory, and IOPS. The following screenshot shows various Amazon CloudWatch metrics. Cutting over to Aurora PostgreSQL When AWS DMS finishes the full load and applies cached changes, it moves to the CDC stage. This is when you can cut over to Aurora. You run SQL queries to validate data and use AWS services to set up backup and monitor jobs. Complete the following steps: Before cutover, analyze the indexes in Aurora PostgreSQL and test the performance of critical queries. Shut down all the application servers and stop all the client connections to SAP ASE. Close any user sessions if necessary. Verify target data has been synced with the source database. Stop the AWS DMS task. Create the foreign keys and secondary indexes in Aurora PostgreSQL if you didn’t create them before CDC started. Validate tables, views, procedures, functions, and triggers within your schema. In SAP ASE, all these objects are kept in the same sysobjects See the following code: SELECT CASE type WHEN 'U' THEN 'User Defined Tables' WHEN 'S' THEN 'System Tables' WHEN 'P' THEN 'Stored Procedures' WHEN 'XP' THEN 'Extended Stored Procedures' WHEN 'V' THEN 'Views' WHEN 'TR' THEN 'Triggers' WHEN 'F' THEN 'Functions' END, COUNT(*) FROM sysobjects WHERE type IN ('U', 'P', 'S', 'XP','V','TR','F') GROUP BY type; In Aurora PostgreSQL, you need to count each object type by querying different system tables. For more information, see Validating database objects after migration using AWS SCT and AWS DMS. Validate count indexes. In SAP ASE, enter the following code: select count(*) from sysindexes; In Aurora PostgreSQL, download the script from Validating database objects after migration using AWS SCT and AWS DMS. Validate table column default values. During the migration process, AWS DMS may have set NULL as default value for some columns. For this post, we created a table test_table with the default value set to net_live for the dname column. In SAP ASE, find the ID of the default value from syscolumns and feed it to syscomments table to generate the actual default value. See the following code: select substring(c.name,1,5) column_name,c.cdefault column_default_value from syscolumns c join sysobjects o on c.id = o.id where o.name = ‘test_table' and o.type = 'U' and cdefault <> 0; Example output may look like the following: column_name column_default_value_id dname 1326835989 You then use this ID to get the actual default value for the column. See the following code: select text column_default_value from syscomments where id = 1326835989; Example output may look like the following: column_default_value DEFAULT 'net_live' In Aurora PostgreSQL, run the following script for each table and compare your results with SAP ASE: SELECT table_name, column_name, column_default FROM information_schema.columns WHERE (table_schema, table_name) = ('dbo', ‘test_table') ORDER BY ordinal_position; Validate primary keys, foreign keys, and check constraints. In SAP ASE, enter the following code: --Note: type 1 for primary keys, type 2 for foreign keys SELECT t.name, CASE k.type WHEN 1 THEN 'PK' WHEN 2 THEN 'FK' WHEN 3 THEN 'Common' END, c.name FROM sysobjects t INNER JOIN syscolumns c ON c.id = t.id INNER JOIN syskeys k ON k.id = t.id AND c.colid IN (k.key1, k.key2, k.key3, k.key4, k.key5, k.key6, k.key7, k.key8) WHERE t.type = 'U' AND k.type in (1,2) The code status=128 brings up check constraints: select object_name(tableid) as "table name", object_name(constrid) as "constraint name", col_name(tableid,sysconstraints.colid) as "column name", text as "constraint text" from sysconstraints,syscomments where sysconstraints.status=128 and sysconstraints.constrid=syscomments.id; In Aurora PostgreSQL, download and run the scripts from the constraint section of Validating database objects after migration using AWS SCT and AWS DMS. Create the CloudWatch alarms based on your desired DB metrics, such as the following: CPU utilization Freeable memory DB connections Write latency Read latency Network metrics For more information, see Key Metrics for Amazon Aurora and Monitoring an Amazon Aurora DB Cluster. When an alarm triggers, a notification goes to the on-call team using Amazon Simple Notification Service (Amazon SNS). Add a reader node to an existing Aurora PostgreSQL cluster. By default at the storage level, Aurora replicates data across three Availability Zones in one Region. It’s fault tolerant by design. For enhanced availability, we recommend you add a reader node for a production database to automate failover in case of instance failure. You need to modify the DB cluster to enable it. A) On the Amazon RDS Console, choose Databases. B) Select your database. C) From the Actions drop-down menu, choose Add reader. D) Choose your replica source. E) For DB instance identifier, enter a name. For more information about Aurora DB cluster high availability features, see High Availability for Amazon Aurora. Switch the application servers and other clients and jobs to the Aurora PostgreSQL database. Conclusion We have demonstrated the end-to-end steps for migrating an SAP ASE database to Aurora PostgreSQL using AWS DMS. These are proven and tested steps with real customer use cases. We hope this guide has provided you the basic instructions needed to perform a similar migration. We will continue writing on SAP ASE to Aurora PostgreSQL migration topics, including post-migration rollback to SAP ASE procedures. We sincerely welcome any feedback from you! About the Authors Li Liu is a Database Cloud Architect with Amazon Web Services. Samujjwal Roy is a Database Specialty Architect with the Professional Services team at Amazon Web Services. He has been with Amazon for 15+ years and has led migration projects for internal and external Amazon customers to move their on-premises database environment to AWS Cloud database solutions. https://aws.amazon.com/blogs/database/migrating-from-sap-ase-to-amazon-aurora-postgresql/
1 note
·
View note