#varchar and varchar (max)
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Text
SQL Programming Tutorial: Essential Skills for Beginners Explained
Introduction:
Welcome to the world of SQL programming! Whether you're a novice or just dipping your toes into the vast ocean of data management, SQL (Structured Query Language) is an essential skill to learn. In this comprehensive tutorial, we'll walk you through the fundamentals of SQL in simple terms, making it easy for beginners to grasp the concepts and start their journey into the realm of databases.
What is SQL?
SQL stands for Structured Query Language. It is a powerful programming language used for managing and manipulating relational databases. SQL allows users to interact with databases by performing tasks such as querying data, inserting new records, updating existing records, and deleting records.
Why Learn SQL?
Learning SQL opens up a world of opportunities in the field of data management and analysis. Whether you're interested in pursuing a career as a data analyst, database administrator, or software developer, SQL skills are highly sought after by employers. With SQL, you can efficiently retrieve and analyze data, make informed business decisions, and create reports and visualizations.
Basic SQL Syntax:
SQL syntax consists of a set of rules for writing SQL statements. The basic structure of an SQL statement includes keywords such as SELECT, FROM, WHERE, INSERT INTO, UPDATE, and DELETE. Here's a simple example of a SELECT statement:
sql
Copy code
SELECT * FROM employees WHERE department = 'Finance';
This statement selects all columns from the "employees" table where the department is 'Finance'.
Data Manipulation:
SQL provides powerful commands for manipulating data within databases. These include:
INSERT INTO: Adds new records to a table.
UPDATE: Modifies existing records in a table.
DELETE: Removes records from a table.
These commands allow you to maintain the integrity and accuracy of your data.
Querying Data:
One of the primary functions of SQL is to retrieve data from databases using SELECT statements. You can specify which columns to retrieve, filter the results based on certain conditions, and sort the results in ascending or descending order. For example:
sql
Copy code
SELECT first_name, last_name FROM employees WHERE department = 'HR' ORDER BY last_name ASC;
This statement selects the first name and last name of employees in the HR department and sorts the results alphabetically by last name.
Creating and Managing Tables:
In SQL, you can create new tables within a database to store data. You define the structure of the table, including the column names and data types. Here's an example of creating a simple table:
sql
Copy code
CREATE TABLE students (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
grade CHAR(1)
);
This statement creates a table named "students" with columns for ID, name, age, and grade.
Joining Tables:
In relational databases, data is often spread across multiple tables. SQL allows you to combine data from different tables using JOIN operations. There are several types of joins, including INNER JOIN, LEFT JOIN, RIGHT JOIN, and FULL JOIN, each serving different purposes. Joins are used to retrieve related data from multiple tables based on a common column.
sql
Copy code
SELECT orders.order_id, customers.customer_name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id;
This statement retrieves the order ID and customer name from the "orders" and "customers" tables, respectively, by matching the customer ID column.
Aggregate Functions:
SQL provides built-in functions for performing calculations on groups of rows in a table. These include functions such as SUM, AVG, COUNT, MIN, and MAX. Aggregate functions are often used with the GROUP BY clause to group rows based on certain criteria.
vbnet
Copy code
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;
This statement calculates the average salary for each department in the "employees" table.
Practice, Practice, Practice:
The best way to master SQL programming is through hands-on practice. There are plenty of online resources, tutorials, and exercises available to help you sharpen your skills. Consider building sample databases, writing complex queries, and solving real-world problems to reinforce your understanding of SQL concepts.
Conclusion:
SQL is a fundamental tool for anyone working with databases or dealing with data management tasks. By mastering the basics of SQL programming, beginners can unlock a world of opportunities in the fields of data analysis, database administration, and software development. With dedication and practice, you'll soon become proficient in SQL and be able to tackle even the most complex data challenges with confidence. So, roll up your sleeves, dive into the world of SQL, and let your data journey begin!
0 notes
Text
-- последняяч дата в базе --SELECT MAX(o_date) FROM test.orders_20190822 o --** 31.12.2017 /* по задаче исходных данных было недостаточно https://habr.com/ru/company/unisender/blog/131225/ */ -- 1. Определяем критерии для каждой буквы R, F, M (т.е. к примеру, R – 3 для клиентов, которые покупали <= 30 дней от последней даты в базе, -- R – 2 для клиентов, которые покупали > 30 и менее 60 дней от последней даты в базе и т.д.) -- 2. Для каждого пользователя получаем набор из 3 цифр (от 111 до 333, где 333 – самые классные пользователи) -- 3. Вводим группировку, к примеру, 333 и 233 – это Vip, 1XX – это Lost, остальные Regular ( можете ввести боле глубокую сегментацию) -- 4. Для каждой группы из п. 3 находим кол-во пользователей, кот. попали в них и % товарооборота, которое они сделали на эти 2 года. -- 5. Проверяем, что общее кол-во пользователей бьется с суммой кол-во пользователей по группам из п. 3 (если у вас есть логические ошибки в создании групп, у вас не собьются цифры). То же самое делаем и по деньгам. -- 6. Результаты присылаем. WITH R AS (SELECT o.user_id, MAX(CASE WHEN (SELECT MAX(o_date) FROM test.orders_20190822) - o_date <= 30 THEN 3 WHEN (SELECT MAX(o_date) FROM test.orders_20190822) - o_date BETWEEN 31 AND 60 THEN 2 --WHEN (SELECT MAX(o_date) FROM test.orders_20190822) - o_date BETWEEN 61 AND 90 THEN 1 ELSE 1 END)::varchar(1) AS r FROM test.orders_20190822 o GROUP BY user_id), F AS (SELECT o.user_id, MAX(CASE WHEN o.price >= 1500000 THEN 3 WHEN o.price >= 500000 THEN 2 ELSE 1 END)::varchar(1) AS f FROM (SELECT co.user_id user_id, SUM(co.price) price FROM test.orders_20190822 co GROUP BY user_id) AS o GROUP BY user_id), M AS (SELECT o.user_id, MAX(CASE WHEN o.id_o >= 1000 THEN 3 WHEN o.id_o >= 300 THEN 2 ELSE 1 END)::varchar(1) AS m FROM (SELECT co.user_id user_id, COUNT(co.id_o) id_o FROM test.orders_20190822 co GROUP BY user_id) AS o GROUP BY user_id), RFM AS ( SELECT o.*, R.r||F.f||M.m rfm FROM test.orders_20190822 o INNER JOIN R ON o.user_id = R.user_id INNER JOIN F ON o.user_id = F.user_id INNER JOIN M ON o.user_id = M.user_id) SELECT RFM.rfm, SUM(RFM.price)/(SELECT SUM(so.price) FROM test.orders_20190822 so) FROM RFM GROUP BY RFM.rfm ORDER BY 1 DESC
4 notes
·
View notes
Text
Unscramble decibel

#UNSCRAMBLE DECIBEL UPDATE#
Inner join sys.columns columns on tables.object_id=columns.object_id When types.name = 'nvarchar' then columns.max_length / 2 Return left(SUBSTRING(_varbintohexstr(HashBytes('SHA1', cast(cast(cast(dbo.randUniform() * 10000 as int) as varchar(8)) as varchar(40)) + 3, 32), transaction If exists (select 1 where object_id('randUniform') is not null)Ĭreate view random(value) as select rand() Ĭreate function dbo.randUniform() returns real If exists (select 1 where object_id('random') is not null) If exists (select 1 where object_id('fnGetSanitizedName') is not null) if exists (select 1 where object_id('tempdb.#columnsToUpdate') is not null)Ĭreate table #columnsToUpdate(tableName varchar(max), columnName varchar(max), max_length int) I made a fairly basic scramble function that will just sha1 the data (with a random salt) so that it should be secure enough for most purposes.
#UNSCRAMBLE DECIBEL UPDATE#
WHERE value."type" = 'P' -Limit "number" to integers between 0-2047Īnd value.number are couple simple methods that have quite nice performance and can be applied to a table: use master ĭeclare as int = 50 -acts as maximum length for random length expressionsĬONVERT( VARCHAR(max), crypt_gen_random( )) as FixedLengthText
0 notes
Text
Generate DDL Script for Index in SQL Server
Generate DDL Script for Index in SQL Server
Generate DDL script for the index in SQL Server USE DBNAME GO declare @SchemaName varchar(100)declare @TableName varchar(256) declare @IndexName varchar(256) declare @ColumnName varchar(100) declare @is_unique varchar(100) declare @IndexTypeDesc varchar(100) declare @FileGroupName varchar(100) declare @is_disabled varchar(100) declare @IndexOptions varchar(max) declare @IndexColumnId…
View On WordPress
0 notes
Text
MySQL Column Aliases using the AS keyword
Be it running reports or displaying data in some other visualization, SQL SELECT column expressions should be meaningful and understandable. To provide those valuable query results, SQL Developers, use a multitude of available functions, adjacent columns, or other means not readily apparent to end-users. All that being said, the column names often suffer the most as far as readability is concerned, taking on long function call names or other combined expressions. But, as luck would be on our side, there is an easy fix and that is aliasing columns using the AS keyword. Although AS is optional – in this particular context – I err on the side of readability and use it when aliasing SELECT column expressions. Image by Settergren from Pixabay OS and DB used: Linux Mint 20 “Ulyana” MySQL 8.0.23 Self-Promotion: If you enjoy the content written here, by all means, share this blog and your favorite post(s) with others who may benefit from or like it as well. Since coffee is my favorite drink, you can even buy me one if you would like! For the examples in this post, I’ll use this ‘friends’ table with the following structure: DESC friends;+------------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+------------+-------------+------+-----+---------+-------+| country | char(3) | YES | | NULL | || first_name | varchar(25) | NO | | NULL | || last_name | varchar(25) | NO | | NULL | || state | char(2) | YES | | NULL | || phone_num | char(12) | YES | | NULL | || birthday | date | YES | | NULL | || age | int | YES | | NULL | |+------------+-------------+------+-----+---------+-------+7 rows in set (0.0035 sec) You can imagine that a common request might involve displaying the ‘first_name’ and ‘last_name’ columns into a full name type of output. Nothing difficult at all in MySQL. Using nested CONCAT() function calls, the query results look like this: SELECT CONCAT(CONCAT(first_name, ' '), last_name) FROM friends;+--------------------------------------------+| CONCAT(CONCAT(first_name, ' '), last_name) |+--------------------------------------------+| Max Maxer || Mary Murphy || Charlie Charles || Humpty Dumpty || Roger Dodger || Jim Russ || Jupyter Moonbeam |+--------------------------------------------+7 rows in set (0.0012 sec) Would you look at that column name? Show that in a report and users’ heads will likely spin. What is there to do about it? Use the AS keyword and alias the column to a more appropriate or display-friendly name: SELECT CONCAT(CONCAT(first_name, ' '), last_name) AS full_name FROM friends;+------------------+| full_name |+------------------+| Max Maxer || Mary Murphy || Charlie Charles || Humpty Dumpty || Roger Dodger || Jim Russ || Jupyter Moonbeam |+------------------+7 rows in set (0.0010 sec) Much better isn’t it? Truth be told, you can even omit the AS keyword all-together and get the same results: SELECT CONCAT(CONCAT(first_name, ' '), last_name) full_nameFROM friends;+------------------+| full_name |+------------------+| Max Maxer || Mary Murphy || Charlie Charles || Humpty Dumpty || Roger Dodger || Jim Russ || Jupyter Moonbeam |+------------------+7 rows in set (0.0011 sec) Consider making a small donation to support my efforts as I continue to provide valuable content here on my blog. Thanks so much! Gotchas and Extras Just to be clear, you can’t do this: SELECT CONCAT(CONCAT(first_name, ' '), last_name) AS full_nameFROM friendsWHERE full_name LIKE 'M%'; ERROR: 1054: Unknown column 'full_name' in 'where clause' SELECT columns and expressions are not yet available when the WHERE clause executes, hence the error message of “Unknown column full_name in where clause”. But, you can use the column alias in the ORDER BY clause: SELECT CONCAT(CONCAT(first_name, ' '), last_name) AS full_nameFROM friendsORDER BY full_name ASC;+------------------+| full_name |+------------------+| Charlie Charles || Humpty Dumpty || Jim Russ || Jupyter Moonbeam || Mary Murphy || Max Maxer || Roger Dodger |+------------------+7 rows in set (0.0598 sec) The next time your SELECT list column names need to be better named, alias them with (or without) the AS keyword. Like what you have read? See anything incorrect? Please comment below and thank you for reading!!! A Call To Action! Thank you for taking the time to read this post. I truly hope you discovered something interesting and enlightening. Please share your findings here, with someone else you know who would get the same value out of it as well. Visit the Portfolio-Projects page to see blog post/technical writing I have completed for clients. To receive email notifications (Never Spam) from this blog (“Digital Owl’s Prose”) for the latest blog posts as they are published, please subscribe (of your own volition) by clicking the ‘Click To Subscribe!’ button in the sidebar on the homepage! (Feel free at any time to review the Digital Owl’s Prose Privacy Policy Page for any questions you may have about: email updates, opt-in, opt-out, contact forms, etc…) Be sure and visit the “Best Of” page for a collection of my best blog posts. Josh Otwell has a passion to study and grow as a SQL Developer and blogger. Other favorite activities find him with his nose buried in a good book, article, or the Linux command line. Among those, he shares a love of tabletop RPG games, reading fantasy novels, and spending time with his wife and two daughters. Disclaimer: The examples presented in this post are hypothetical ideas of how to achieve similar types of results. They are not the utmost best solution(s). The majority, if not all, of the examples provided, are performed on a personal development/learning workstation-environment and should not be considered production quality or ready. Your particular goals and needs may vary. Use those practices that best benefit your needs and goals. Opinions are my own. The post MySQL Column Aliases using the AS keyword appeared first on Digital Owl's Prose. https://joshuaotwell.com/mysql-column-aliases-using-the-as-keyword/
0 notes
Text
5 Sertifikasi SQL Terbaik untuk Meningkatkan Karir Anda di Tahun 2021

Jika Anda ingin bekerja dibidang data seperti data scientist, database administrator dan big data architect structured query language atau SQL adalah salah satu bahasa pemrograman yang wajib Anda kuasai. Akan tetapi, jika Anda ingin cepat direkrut oleh perusahaan besar, serttifikasi SQL wajib dimiliki. Banyak sertifikasi SQL yang bisa Anda dapatkan, apa saja sih? yuk simak ulasannya dibawah ini.
5 Sertifikasi SQL Terbaik
1. Bootcamp MySQL Utama: Udemy
Kursus Udemy ini menyediakan banyak sekali latihan untuk meningkatkan skill Anda, dimulai dengan dasar-dasar MySQL dan berlanjut hingga mengajarkan beberapa konsep lainnya. Kursus ini menyediakan banyak latihan. Terserah Anda untuk mengambil kursus dengan kecepatan yang Anda inginkan.
Kurikulum pelatihan
Ringkasan dan penginstalan SQL: SQL vs. MySQL, penginstalan di Windows dan Mac
Membuat database dan tabel: Pembuatan dan pelepasan tabel, tipe data dasar
Penyisipan data, NULL, NOT NULL, Primary keys, table constraints
Perintah CRUD: SELECT, UPDATE, DELETE, challenge exercises
Fungsi string: concat, substring, replace, reverse, char length, upper dan lower
Menggunakan karakter pengganti yang berbeda, order by, limit, like, wildcards
Fungsi agregat: count, group by, min, max, sum, avg
Tipe Data secara detail: char, varchar, decimal, float, double, date, time, datetime, now, curdate, curtime, timestamp
Operator logika: not equal, not like, greater than, less than, AND, OR, between, not in, in, case statements
Satu ke banyak: Joins, foreign keys, cross join, inner join, left join, right join, Many to many
Klon data Instagram: nstagram Clone Schema, Users Schema, likes, comments, photos, hashtags, complete schema
Bekerja dengan Big Data : JUMBO dataset, exercises
Memperkenalkan Node: Crash course on Node.js, npm, MySQL, and other languages
Membangun aplikasi web: setting up, connecting Express and MySQL, adding EJS templates, connecting the form
Database triggers: writing triggers, Preventing Instagram Self-Follows With Triggers, creating logger triggers, Managing Triggers, And A Warning
2. Learn SQL Basics for Data Science Specialization
Pelatihan ini bertujuan untuk menerapkan semua konsep SQL yang digunakan untuk ilmu data secara praktis. Kursus pertama dari spesialisasi ini adalah kursus dasar yang akan memungkinkan Anda mempelajari semua pengetahuan SQL yang nantinya akan Anda perlukan untuk kursus lainnya. Dalam pelatihan ini akan ada empat kursus:
SQL untuk Ilmu Data.
Data Wrangling, Analisis, dan Pengujian AB dengan SQL.
Komputasi Terdistribusi dengan Spark SQL.
SQL untuk Proyek Capstone Sains Data.
Kurikulum pelatihan
1. SQL for Data Science (14 hours)
Introduction, selecting, and fetching data using SQL.
Filtering, Sorting, and Calculating Data with SQL.
Subqueries and Joins in SQL.
Modifying and Analyzing Data with SQL.
2. Data Wrangling, Analysis, and AB Testing with SQL
Data of Unknown Quality.
Creating Clean Datasets.
SQL Problem Solving.
Case Study: AB Testing.
3. Distributed Computing with Spark SQL
Introduction to Spark.
Spark Core Concepts.
Engineering Data Pipelines.
Machine Learning Applications of Spark.
4. SQL for Data Science Capstone Project
Project Proposal and Data Selection/Preparation.
Descriptive Stats & Understanding Your Data.
Beyond Descriptive Stats (Dive Deeper/Go Broader).
Presenting Your Findings (Storytelling).
3. Excel to MySQL: Analytic Techniques for Business Specialization
Pelatihan Ini adalah spesialisasi dari Coursera yang bertujuan untuk menyentuh SQL dari sudut pandang bisnis. Jika Anda ingin mendalami ilmu data atau bidang terkait, pelatihan ini sangat bagus. Bersama dengan SQL, Anda juga akan mendapatkan berbagai keterampilan seperti Microsoft Excel, Analisis Bisnis, alat sains data, dan algoritme, serta lebih banyak lagi tentang proses bisnis. Ada lima materi dalam pelatihan ini:
Metrik Bisnis untuk Perusahaan Berdasarkan Data.
Menguasai Analisis Data di Excel.
Visualisasi Data dan Komunikasi dengan Tableau.
Mengelola Big Data dengan MySQL.
Meningkatkan Keuntungan Manajemen Real Estat: Memanfaatkan Analisis Data.
Kurikulum pelatihan
Metrik Bisnis untuk Perusahaan Berdasarkan Data (8 jam): Pengenalan metrik bisnis, pasar analitik bisnis, menerapkan metrik bisnis ke studi kasus bisnis.
Menguasai Analisis Data di Excel (21 jam): Esensi Excel, klasifikasi biner, pengukuran informasi, regresi linier, pembuatan model.
Visualisasi Data dan Komunikasi dengan Tableau (25 jam): Tableau, visualisasi, logika, proyek.
Mengelola Big Data dengan MySQL (41 jam): database relasional, kueri untuk satu tabel, mengelompokkan data, menangani data kompleks melalui kueri.
Meningkatkan Keuntungan Manajemen Real Estat: Memanfaatkan Analisis Data (23 jam): Ekstraksi dan Visualisasi data, pemodelan, arus kas, dan keuntungan, dasbor data.
4. MySQL for Data Analytics and BI
Pelatihan ini mencakup MySQL secara mendalam dan mulai dari dasar-dasar kemudian beralih ke topik SQL lanjutan. Pelatihan ni juga memiliki banyak latihan untuk menyempurnakan pengetahuan Anda.
Kurikulum pelatihan
Introduction to databases, SQL, and MySQL.
SQL theory: SQL as a declarative language, DDL, keywords, DML, DCL, TCL.
Basic terminologies: Relational database, primary key, foreign key, unique key, null values.
Installing MySQL: client-server model, setting up a connection, MySQL interface.
First steps in SQL: SQL files, creating a database, introduction to data types, fixed and floating data types, table creating, using the database, and tables.
MySQL constraints: Primary key constraints, Foreign key constraints, Unique key constraint, NOT NULL
SQL Best practices.
SQL Select, Insert, Update, Delete, Aggregate functions, joins, subqueries, views, Stored routines.
Advanced SQL Topics: Types of MySQL variables, session, and global variables, triggers, user-defined system variables, the CASE statement.
Combining SQL and Tableau.
5, Learning SQL Programming
Pelatihan ini sangat cocok untuk pemula dan mencakup semua aspek penting dari SQL. Pelatihan ini juga mencakup banyak file latihan yang dapat meningkatkan skill Anda.
Kurikulum pelatihan
Memilih data dari database.
Memahami jenis JOIN.
Tipe data, Matematika, dan fungsi yang membantu: Pilih gabungan, ubah data, menggunakan alias untuk mempersingkat nama bidang.
Tambahkan atau ubah data.
Mengatasi kesalahan SQL umum.
Itulah berbagai sertifikasi SQL yang bisa Anda ikuti demi menaikan skill agar cepat diterima oleh perusahaan besar. Tentu saja, pengalaman dan pengetahuan teknis itu penting, tetapi sertifikasi SQL menjadi faktor penentu ketika kandidat dengan profil serupa harus disaring.Baca juga :
3 Manfaat Mengikuti Training SQL Server Jakarta
0 notes
Text
Get List while comparing two Comma Separated columns
/****** Object: StoredProcedure [dbo].[spGetListUsingTwoDifferentCommaSeparatedColumns] Script Date: 30-Dec-2020 12:17:44 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO ALTER PROCEDURE [dbo].[spGetListUsingTwoDifferentCommaSeparatedColumns] @MultipleUserID int = 2 AS BEGIN SET NOCOUNT ON
DECLARE @MultipleUser VARCHAR(max) = ( select distinct stuff(( select ',' + CONVERT(nvarchar(max), ISNULL(u.UserID, '''')) from tblFirstTable u where u.UserID = UserID and MultipleUserID like cast(@MultipleUserID as varchar(50) ) or MultipleUserID like '%,'+cast( @MultipleUserID as varchar(50) ) or MultipleUserID like '%,'+ cast( @MultipleUserID as varchar(50) ) +',%' or MultipleUserID like cast( @MultipleUserID as varchar(50) )+',%' order by u.UserID for xml path('') ),1,1,'') from tblFirstTable group by MultipleUserID )
DECLARE @split TABLE (MultipleUserIDVal VARCHAR(64))
DECLARE @word VARCHAR(64),@start INT, @end INT, @stop INT
-- string split in 8 lines
SELECT @MultipleUser += ',',@start = 1,@stop = Len(@MultipleUser) + 1
WHILE @start < @stop
BEGIN
SELECT @end = Charindex(',', @MultipleUser, @start),
@word = Rtrim(Ltrim(Substring(@MultipleUser, @start, @end - @start))),
@start = @end + 1
INSERT @split VALUES (@word)
END
-------------------------------------------------------------------------------
--SELECT * FROM @split
SELECT * FROM tblSecondTable a WHERE active=1 and EXISTS (SELECT *
FROM @split w
WHERE Charindex(',' + w.MultipleUserIDVal + ',', ',' + a.MultipleUserID + ',') > 0) END
Reference Link - https://www.c-sharpcorner.com/blogs/compare-comma-separated-value-with-comma-separated-column-in-sql-server1
0 notes
Text
Q33. What is the difference between Unicode data types and Non-Unicode data types? Q34. What is the difference between fixed-length data type and variable-length data type? Q35. What is the difference between CHAR vs VARCHAR data types? Q36. What is the difference between VARCHAR vs NVARCHAR data types? Q37. What is the max size of a VARCHAR and NVARCHAR data type in SQL, Why? Q38. What is the difference between VARCHAR(MAX) and VARCHAR(n) data types? Q39. What is the difference between VARCHAR(MAX) and TEXT(n) data types? Q40. What is the difference between LEN() and DATALENGTH() in SQL? Q41. What is the difference between DateTime and DateTime2 data types in SQL?
#sqlinterviewquestions#mostfrequentlyaskedsqlinterviewquestions#sqlinterviewquestionsandanswers#interviewquestionsandanswers#techpointfundamentals#techpointfunda#techpoint#interview
0 notes
Text
Hướng dẫn INSERT hình ảnh vào SQL Server
BaĐể chèn vào và truy xuất hình ảnh từ cơ sở dữ liệu máy chủ SQL mà không cần sử dụng các thủ tục được lưu trữ và cũng để thực hiện các thao tác chèn, tìm kiếm, cập nhật và xóa và điều hướng các bản ghi.
Khi chúng ta muốn chèn hình ảnh vào cơ sở dữ liệu, trước tiên chúng ta phải tạo một bảng trong cơ sở dữ liệu, chúng ta có thể sử dụng kiểu dữ liệu 'image' hoặc 'binary' để lưu trữ hình ảnh.
create table student(sno int primary key,sname varchar(50),course varchar(50),fee money,photo image)
Truy vấn để tạo bảng trong ứng dụng của chúng ta
Thiết kế giao diện
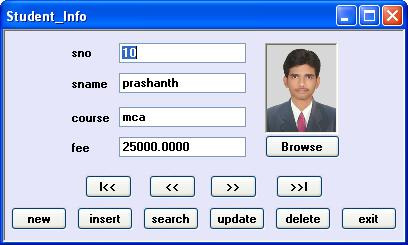
Thiết kế biểu mẫu như trên với 1 control PictureBox, 1 control OpenFileDialog, 4 Labels, 4 control TextBox và 11 control Buttons.
Thuộc tính PictureBox1
BorderStyle = Cố định3D; SizeMode = StrechImage
Lưu ý rằng control OpenFileDialog xuất hiện bên dưới biểu mẫu (không phải trên biểu mẫu), có thể được sử dụng để duyệt hình ảnh.
Bắt đầu lập trình
using thư viện
using System.Data.SqlClient
Trong ứng dụng này, chúng ta sẽ tìm kiếm một bản ghi bằng cách lấy đầu vào từ InputBox. Đối với điều này, chúng tôi phải thêm tham chiếu đến Microsoft.VisualBasic.
Thêm tham chiếu vào 'Microsoft.VisualBasic'
Goto Project Menu -> Add Reference -> chọn 'Microsoft.VisualBasic' từ tab .NET.
Để sử dụng tham chiếu này, chúng tôi phải bao gồm không gian tên:
using Microsoft.VisualBasic
Chuyển đổi hình ảnh thành dữ liệu nhị phân
Chúng ta không thể lưu trữ hình ảnh trực tiếp vào cơ sở dữ liệu. Đối với điều này, chúng tôi có hai giải pháp: Để lưu trữ vị trí của hình ảnh trong cơ sở dữ liệu
Chuyển đổi hình ảnh thành dữ liệu nhị phân và chèn dữ liệu nhị phân đó vào cơ sở dữ liệu và chuyển đổi dữ liệu đó trở lại hình ảnh trong khi truy xuất các bản ghi. Nếu chúng ta lưu trữ vị trí của một hình ảnh trong cơ sở dữ liệu và giả sử nếu hình ảnh đó bị xóa hoặc di chuyển khỏi vị trí đó, chúng tôi sẽ gặp phải vấn đề khi truy xuất các bản ghi. Vì vậy, tốt hơn là chuyển đổi hình ảnh thành dữ liệu nhị phân và chèn dữ liệu nhị phân đó vào cơ sở dữ liệu và chuyển đổi lại thành hình ảnh trong khi truy xuất bản ghi.
Chúng ta có thể chuyển đổi một hình ảnh thành dữ liệu nhị phân bằng cách sử dụng
FileStream
MemoryStream
1. FileStream sử dụng vị trí tệp để chuyển đổi hình ảnh thành dữ liệu nhị phân mà chúng ta có thể / không cung cấp trong khi cập nhật bản ghi.
FileStream fs = new FileStream(openFileDialog1.FileName, FileMode.Open, FileAccess.Read); byte[] photo_aray = new byte[fs.Length]; fs.Read(photo_aray, 0, photo_aray.Length);
2. Vì vậy, tốt hơn là sử dụng MemoryStream sử dụng hình ảnh trong PictureBox để chuyển đổi hình ảnh thành dữ liệu nhị phân.
MemoryStream ms = new MemoryStream(); pictureBox1.Image.Save(ms, ImageFormat.Jpeg); byte[] photo_aray = new byte[ms.Length]; ms.Position = 0; ms.Read(photo_aray, 0, photo_aray.Length);
Để sử dụng FileStream hoặc MemoryStream, chúng ta phải using thư viên:
using System.IO
OpenFileDialog Control Chúng ta sử dụng điều khiển OpenFileDialog để duyệt các hình ảnh (ảnh) để chèn vào bản ghi
Tải chi tiết ràng buộc vào dataTable
Trong ứng dụng này. chúng ta sử dụng phương thức Find () để tìm kiếm một bản ghi, yêu cầu chi tiết về cột khóa chính, có thể được cung cấp bằng câu lệnh:
adapter.MissingSchemaAction = MissingSchemaAction.AddWithKey;
Trỏ tới bản ghi hiện tại trong dataTable
Sau khi tìm kiếm một bản ghi, chúng ta phải lấy chỉ mục của bản ghi đó để có thể điều hướng các bản ghi tiếp theo và trước đó.
rno= ds.Tables[0].Rows.IndexOf(drow);
code tham khảo
using System; using System.Windows.Forms; using System.Data; using System.Data.SqlClient; using System.Drawing; using System.Drawing.Imaging; using System.IO; using Microsoft.VisualBasic; namespace inserting_imgs { public partial class Form1 : Form { public Form1() { InitializeComponent(); } SqlConnection con; SqlCommand cmd; SqlDataAdapter adapter; DataSet ds; int rno = 0; MemoryStream ms; byte[] photo_aray; private void Form1_Load(object sender, EventArgs e) { con = new SqlConnection("user id=sa;password=123;database=prash"); loaddata(); showdata(); } void loaddata() { adapter = new SqlDataAdapter("select sno,sname,course,fee,photo from student", con); adapter.MissingSchemaAction = MissingSchemaAction.AddWithKey; ds = new DataSet(); adapter.Fill(ds, "student"); } void showdata() { if (ds.Tables[0].Rows.Count > 0) { textBox1.Text = ds.Tables[0].Rows[rno][0].ToString(); textBox2.Text = ds.Tables[0].Rows[rno][1].ToString(); textBox3.Text = ds.Tables[0].Rows[rno][2].ToString(); textBox4.Text = ds.Tables[0].Rows[rno][3].ToString(); pictureBox1.Image = null; if (ds.Tables[0].Rows[rno][4] != System.DBNull.Value) { photo_aray = (byte[])ds.Tables[0].Rows[rno][4]; MemoryStream ms = new MemoryStream(photo_aray); pictureBox1.Image = Image.FromStream(ms); } } else MessageBox.Show("No Records"); } private void browse_Click(object sender, EventArgs e) { openFileDialog1.Filter = "jpeg|*.jpg|bmp|*.bmp|all files|*.*"; DialogResult res = openFileDialog1.ShowDialog(); if (res == DialogResult.OK) { pictureBox1.Image = Image.FromFile(openFileDialog1.FileName); } } private void newbtn_Click(object sender, EventArgs e) { cmd = new SqlCommand("select max(sno)+10 from student", con); con.Open(); textBox1.Text = cmd.ExecuteScalar().ToString(); con.Close(); textBox2.Text = textBox3.Text = textBox4.Text = ""; pictureBox1.Image = null; } private void insert_Click(object sender, EventArgs e) { cmd = new SqlCommand("insert into student(sno,sname,course,fee,photo) values(" + textBox1.Text + ",'" + textBox2.TabIndex + "','" + textBox3.Text + "'," + textBox4.Text + ",@photo)", con); conv_photo(); con.Open(); int n = cmd.ExecuteNonQuery(); con.Close(); if (n > 0) { MessageBox.Show("record inserted"); loaddata(); } else MessageBox.Show("insertion failed"); } void conv_photo() { //converting photo to binary data if (pictureBox1.Image != null) { //using FileStream:(will not work while updating, if image is not changed) //FileStream fs = new FileStream(openFileDialog1.FileName, FileMode.Open, FileAccess.Read); //byte[] photo_aray = new byte[fs.Length]; //fs.Read(photo_aray, 0, photo_aray.Length); //using MemoryStream: ms = new MemoryStream(); pictureBox1.Image.Save(ms, ImageFormat.Jpeg); byte[] photo_aray = new byte[ms.Length]; ms.Position = 0; ms.Read(photo_aray, 0, photo_aray.Length); cmd.Parameters.AddWithValue("@photo", photo_aray); } } private void search_Click(object sender, EventArgs e) { try { int n = Convert.ToInt32(Interaction.InputBox("Enter sno:", "Search", "20", 100, 100)); DataRow drow; drow = ds.Tables[0].Rows.Find(n); if (drow != null) { rno = ds.Tables[0].Rows.IndexOf(drow); textBox1.Text = drow[0].ToString(); textBox2.Text = drow[1].ToString(); textBox3.Text = drow[2].ToString(); textBox4.Text = drow[3].ToString(); pictureBox1.Image = null; if (drow[4] != System.DBNull.Value) { photo_aray = (byte[])drow[4]; MemoryStream ms = new MemoryStream(photo_aray); pictureBox1.Image = Image.FromStream(ms); } } else MessageBox.Show("Record Not Found"); } catch { MessageBox.Show("Invalid Input"); } } private void update_Click(object sender, EventArgs e) { cmd = new SqlCommand("update student set sname='" + textBox2.Text + "', course='" + textBox3.Text + "', fee='" + textBox4.Text + "', photo=@photo where sno=" + textBox1.Text, con); conv_photo(); con.Open(); int n = cmd.ExecuteNonQuery(); con.Close(); if (n > 0) { MessageBox.Show("Record Updated"); loaddata(); } else MessageBox.Show("Updation Failed"); } private void delete_Click(object sender, EventArgs e) { cmd = new SqlCommand("delete from student where sno=" + textBox1.Text, con); con.Open(); int n = cmd.ExecuteNonQuery(); con.Close(); if (n > 0) { MessageBox.Show("Record Deleted"); loaddata(); rno = 0; showdata(); } else MessageBox.Show("Deletion Failed"); } private void first_Click(object sender, EventArgs e) { rno = 0; showdata(); MessageBox.Show("First record"); } private void previous_Click(object sender, EventArgs e) { if (rno > 0) { rno--; showdata(); } else MessageBox.Show("First record"); } private void next_Click(object sender, EventArgs e) { if (rno < ds.Tables[0].Rows.Count - 1) { rno++; showdata(); } else MessageBox.Show("Last record"); } private void last_Click(object sender, EventArgs e) { rno = ds.Tables[0].Rows.Count - 1; showdata(); MessageBox.Show("Last record"); } private void exit_Click(object sender, EventArgs e) { this.Close(); } } }
Bài viết gốc: https://www.c-sharpcorner.com/UploadFile/e628d9/inserting-retrieving-images-from-sql-server-database-without-using-stored-procedures/
0 notes
Photo

Using a tMSSQLSP component as your source for a SQL result set seems like a pretty straightforward concept, especially if you come from an SSIS background. However, there are a few things that make it not so intuitive.
I’m quite green when it comes to Talend, but have well over a decade of experience in ETL design in the Microsoft stack. Recently, I had the opportunity through my employer to work on this specific issue with a Talend-centric consulting firm, ETL Advisors. If you’re looking to add extra skills to your team, you should check them out.
Back to the topic at hand:
First of all, you’ll need to pass in any parameters to the stored procedure, which you can find various articles for. I won’t go into great detail here.
Second, the resultset that is your “select statement” within the stored procedure will need to be schema-defined as an object within Talend, and mapped as a RECORD SET.

Third, on a tParseRecordSet object that you’ll connect to the main row out from your tMSSQLSP object, you’ll need to define out the schema of all the columns that come from the stored procedure results. As you have likely encountered in your ETL career, this can sometimes be dozens of columns. If you hate yourself, get 2 monitors and start hand keying all of the output schema. If you want a possible shortcut, keep reading.
When you are in the output portion of the schema definition screen, you can import from an XML file using the folder icon highlighted below.

Where would you get this XML from? Well, with a little help from your friends, that’s where. SQL server has a ton of system stored procedures and DMVs that give you all types of information. I’ve enhanced the “sp_describe_first_result_set” in a way that presents it as valid XML. You’ll be able to copy the XML column, and paste it into an XML file that gets imported above.

This is accomplished with the following stored procedure creation/execution to suit your needs. There is plenty of help on how to use sp_describe_first_result_set natively, if you want to just see it in action without my enhancements.
But in the meantime, here’s my T-SQL if you want to get started on the rest of your life. Keep in mind there are a few data types that are probably not included, and it is mainly because I didn’t see a quick way to map them to Talend-equivalents. (Feel free to edit it up!) :
--+PROCEDURE TO COMPILE TO A LOCAL DATABASE WHERE USE IS WARRANTED ALTER PROCEDURE USP_HELPER_INTERROGATE_SP ( @PROC AS NVARCHAR(max), @PARAMS_IN AS NVARCHAR(MAX) ) AS BEGIN --+author: Radish --+date: 3/8/2018 --+comments: For demonstration purposes only, results will very with more complex stored procedures
--+/// --+create a holder table variable for manipulation of the returns results from the sp DECLARE @temp TABLE ( is_hidden BIT , column_ordinal INT, [name] SYSNAME, is_nullable BIT, system_type_id INT, system_type_name NVARCHAR(256), max_length SMALLINT, [precision] TINYINT, scale TINYINT, collation_name SYSNAME NULL, user_type_id INT, user_type_database SYSNAME NULL, user_type_schema SYSNAME NULL, user_type_name SYSNAME NULL, assembly_qualified_type_name NVARCHAR(4000), xml_collection_id INT, xml_collection_database SYSNAME NULL, xml_collection_schema SYSNAME NULL, xml_collection_name SYSNAME NULL, is_xml_document BIT, is_case_sensitive BIT , is_fixed_length_clr_type BIT, source_server SYSNAME NULL, source_database SYSNAME NULL, source_schema SYSNAME NULL, source_table SYSNAME NULL, source_column SYSNAME NULL, is_identity_column BIT, is_part_of_unique_key BIT, is_updateable BIT, is_computed_column BIT, is_sparse_column_set BIT, ordinal_in_order_by_list SMALLINT, order_by_is_descending SMALLINT, order_by_list_length SMALLINT, [tds_type_id] INT, [tds_length] INT, [tds_collation_id] INT, [tds_collation_sort_id] INT )
--+/// --+fill the holder table variable with the sp resultset INSERT @temp EXEC sp_describe_first_result_set @tsql = @PROC, @params = @PARAMS_IN --+/// --+ do the talend formatting, from the above results set and a join to the system types for sql server SELECT * FROM ( --+Talend Data Services Platform 6.4.1 XML layout for tParseRecordSet schema OUTPUT SELECT -1 AS column_ordinal, '<?xml version="1.0" encoding="UTF-8"?><schema>' AS XML_SQL_OUTPUT_SCHEMA UNION ALL SELECT column_ordinal, '<column comment="" default="" key="false" label="' + T.name + '" length="'+ CAST(max_length AS VARCHAR(50)) + '" nullable="false" originalDbColumnName="' + T.name+ '" originalLength="-1" pattern="" precision="0" talendType="' + CASE WHEN T.system_type_id IN (106,108,122) THEN 'id_BigDecimal' WHEN T.system_type_id = 104 THEN 'id_Boolean' WHEN system_type_id IN ( 40, 42,61 ) THEN 'id_Date' WHEN T.system_type_id IN (62) THEN 'id_Float' WHEN system_type_id IN ( 52, 56, 63 ) THEN 'id_Integer' WHEN T.system_type_id IN (127) THEN 'id_Long' WHEN system_type_id IN ( 39, 47 ) THEN 'id_String' WHEN T.system_type_id IN (48) THEN 'id_Short' ELSE 'id_String' END + '" type="' + UPPER(ST.name) + '"/>' FROM @temp T INNER JOIN sys.systypes ST ON T.system_type_id = ST.xusertype UNION ALL SELECT 999999999 AS column_ordinal, '</schema>' ) A ORDER BY column_ordinal END
And finally, below is an example execution of this stored procedure against a popular system stored procedure (but you should be able to put most user defined stored procedures in the place of the first parameter). Also, please note the parameter list for your stored procedure is supplied in the second ‘’, in the format ‘@[parameter name] DATATYPE, et. al’. So if you have a @NAME VARCHAR(20) and a @AGE INT, you’d pass that in as ‘@NAME VARCHAR, @AGE INT’

--+HELPFUL FOR GETTING SCHEMA DETAILS FROM FIRST RESULTSET IN A STORED PROC
--+example use with basic stored procedure on any recent SQL Server instance
--- stored proc DB.SCHEMA.NAME--,-- comma delimited params list @[NAME] DATATYPE,... EXEC DBO.USP_HELPER_INTERROGATE_SP 'msdb.sys.sp_databases' , ''
1 note
·
View note
Text
Select:-Things to know about select statement in SQL 2019
New Post has been published on https://is.gd/8cLrpG
Select:-Things to know about select statement in SQL 2019

(adsbygoogle = window.adsbygoogle || []).push();
Identity Column & Cascading referential Integrity
Constraints In SQL By Sagar Jaybhay
About Tables In DataBase By Sagar Jaybhay
SELECT Statement in SQL
The select clause can retrieve 0 or more rows from one or more tables from the database or it can retrieve rows from views also.
The select statement is used to select data from a table or database. The data which is our of our select query is called a result set. The select is a commonly used statement in SQL. Means for fetching the data from the database we use Select statement.
(adsbygoogle = window.adsbygoogle || []).push();
We can retrieve all rows or a selected row means this is according to condition. If you want to specify a selected column or we want specific columns you can specify in a select clause.
Select statement optional clauses
Where: it specifies a condition to which rows to retrieve
Group By: used to group similar items based on conditions
Having: select the rows among the group
Order by: it will specify the order
As: it is used for an alias
Select Syntax:
Select column1, column2,…. From table_name;
Ex
Select * from Person;
The above query will fetch all the data from the table along with all columns.
Distinct Clause in Select Statement
To select a distinct value from column value you can use distinct.
General Syntax
Select distinct column_name from table_name;
Ex
SELECT distinct [genederID] FROM [dbo].[Person]
When you specify multiple columns in a distinct keyword you tell SQL server to check and get distinct value from that number of column you provides.
General Syntax:
Select distinct column1, column2 from table_name;
Ex
SELECT distinct [genederID],[email] FROM [dbo].[Person];
How to Filter Values in Select statement?
You can filter the value by using where clause.
Where Clause in Select Statement
The where clause is used to filter records. By using where clause you can extract only those records which fulfilled our condition.
The where clause not only used in a select statement but also used in Update, Delete also.
SELECT column1, column2, ... FROM table_name WHERE condition;
Ex
SELECT * FROM [dbo].[Person] where email='[email protected]'
The Operators used in Where clause: –
Operator Description = Equal > Greater than < Less than >= Greater than or equal <= Less than or equal <> Not equal. Note: In some versions of SQL this operator may be written as != BETWEEN Between a certain range LIKE Search for a pattern IN To specify multiple possible values for a column
Select Query Evaluation :
select g.* from users u inner join groups g on g.Userid = u.Userid where u.LastName = 'Jaybhay' and u.FirstName = 'Sagar'
In the above query from clause is evaluated after that cross join or cartesian join is produced for these 2 tables and this from clause produced a virtual table might call as Vtable1.
After this on clause is evaluated for Vtable1 and it checks to join condition g. Userid =u.userid, then the records which met these conditions or full fill these conditions are inserted into another Vtable2.
If you specify outer join then the rest or remaining records from Vtable2 are inserted into Vtable3.
After this where clause is applied and the lastname=’Jaybhay’ and firstname=’sagar’ are verified or taken and put it into Vtable4.
After this select list is evaluated and return Vtable4.
Group by clause in Select Statement
It is an SQL command which is used to group rows that have the same values. It is used only in the select statement.
A group by clause is used to group a selected set of rows into a set of summary rows by using a value of one pr more columns expression. Mostly group by clause is used in conjunction with one or more aggregate functions, Like Count, Max, Min, Sum, Avg.
The main purpose of a group by clause is to arrange identical or similar data into groups it means rows have different value but one column is identical.
Create table person syntax USE [temp] GO /****** Object: Table [dbo].[Person] Script Date: 11/20/2019 12:12:09 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Person]( [ID] [int] NOT NULL, [name] [varchar](100) NULL, [email] [varchar](100) NULL, [genederID] [int] NULL, [age] [int] NULL, [salary] [int] NULL, [city] [varchar](100) NULL, PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[Person] ADD CONSTRAINT [df_value] DEFAULT ((3)) FOR [genederID] GO ALTER TABLE [dbo].[Person] WITH CHECK ADD CONSTRAINT [tbl_person_geneder_id_fk] FOREIGN KEY([genederID]) REFERENCES [dbo].[tbGeneder] ([genederID]) GO ALTER TABLE [dbo].[Person] CHECK CONSTRAINT [tbl_person_geneder_id_fk] GO ALTER TABLE [dbo].[Person] WITH CHECK ADD CONSTRAINT [chk_age] CHECK (([age]>(0) AND [age]<(150))) GO ALTER TABLE [dbo].[Person] CHECK CONSTRAINT [chk_age] GO
Demo data generated site :- https://mockaroo.com/
Group by query
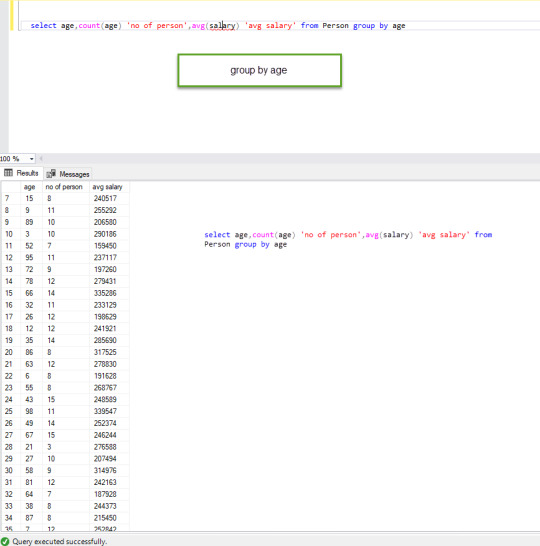
select age,count(age) 'no of person',avg(salary) 'avg salary' from Person group by age
The above query has only one column in a group by clause
Group By Clause in Select Statement
Another query of an aggregate function
select age, sum(salary) from Person
the above query will result following
Msg 8120, Level 16, State 1, Line 25 Column ‘Person.age’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause
It clearly tells that if we want to age and sum of salary then we need to use group by function.
Group by multiple columns
select age,city,count(age) 'no of person',avg(salary) 'avg salary' from Person group by age,city
in this query, we use multiple columns in the group by clause age and city.

Group By Clause in Select Statement with 2 columns
Filtering Groups:
We can use where clause to filter rows before aggregation and Having clause is used to filter groups after aggregations.
select age, sum(salary) as 'Total salary' from person where age between 30 and 50 group by age; select age, sum(salary) as 'Total salary' from Person group by age having age between 30 and 50;
these are 2 queries which produce the same result but in one query we use where clause and in the second query we use having clause both having the same functionality but having is used only with the group by clause and where is used with any clause.
What is the difference between where and having clause?
When you used where clause it will filter the rows based on conditions and after this group by applied.
If you use having then the first group is created and aggregation is done before any filter and after this, having condition is applied.
Where clause can be used with select, insert, update and delete statement where having is used only with a select statement.
Where filters row before aggregation(grouping) where having clause filters a group and after the aggregation is performed.
Aggregate functions can not be used in the where clause. But if it is in the subquery you can use this. But in having a clause you can use an aggregate function.
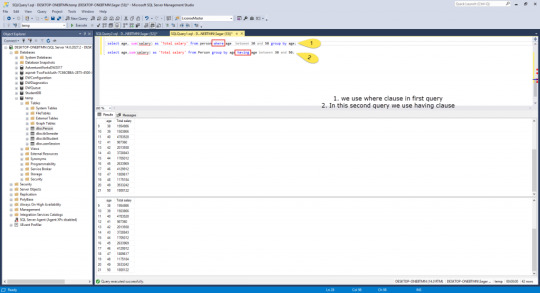
where and having difference
select age, email, sum(salary) as 'Total salary' from Person group by age having age between 30 and 50;
In the above query, we use email in the select clause but the query will result in an error why because when you use a group by clause and want to select element the column need to present in group by filter.
Msg 8120, Level 16, State 1, Line 30
Column ‘Person.email’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
This error we got.
0 notes
Text
300+ TOP Apache PRESTO Interview Questions and Answers
Apache Presto Interview Questions for freshers experienced :-
1. What is Presto? Presto is a distributed SQL query engine. It is an open source software project to develop a database. 2. What are the features of Presto? There are following features of Presto: It is simple to use. It provides pluggable connectors. It provides pipelined executions. It provides user define functions. 3. What are the Presto applications? There are various Presto applications: Facebook Teradata Airbnb 4. Why should we use Presto? We should use Presto because of its features: It supports standard ANSI SQL. It is built in Java. It has connector architecture that is Hadoop. It runs on multiple Hadoop distributions. 5. What are the components of Presto architecture? Presto architecture components are given below: Client : Clint submits SQL statements to a coordinator to get the result. Coordinator: It parses the SQL queries. Connector : Storage plugin is called as connectors. Worker : It assigns task to worker nodes. 6. What are the log files of the Presto server? The logs files of the Presto server are given below: Launcher.log Server.log http-request.log 7. What is Presto verifier? Presto verifier is used to test Presto against another database (such as MySQL). 8. What is the default port of Presto? The default port of Presto is 8080. 9. What are the Config properties of Presto? The Config properties of Presto are given below table: Config Properties----->Descriptiontask. info -refresh-max-wait:It reduces coordinator work load. Task.max-worker-threads:It splits the process and assigns to each worker nodes. distributed-joins-enabled:It is Hashed based distributed joins. node-scheduler.network-topology:It sets network topology to scheduler. 10. What are the various data types in Presto? In Presto, there are various data types in Presto. Varchar Bigint Double Decimal Json etc.

Apache PRESTO Interview Questions 11. What are the functions of Presto? There are various functions of Presto that are given below: Function--->Description Abs(x):It returns the absolute value of X. Cbrt(x):It returns the cube root of x. Ceiling(x):It returns the x value rounded up to nearest integer. Ceil(x):Arial for ceiling(x) Log2(x):It returns the base 2 logarithm of x. 12. What is the use of MySQL Connector? MYSQL Connector is used to query an external MySQL database. 13. How can we create table by using command? We can create table by using command: presto:tutorials> create table mysql.tutorials.sample as select * from mysql.tutorials.author; presto:tutorials> create table mysql.tutorials.sample as select * from mysql.tutorials.author; 14. What is JMX Connector? JMX stands for Java Management Extension. It gives information about the java virtual machine and software running inside JVM. Apache Presto - Overview Data analytics is the process of analyzing raw data to gather relevant information for better decision making. It is primarily used in many organizations to make business decisions. Well, big data analytics involves a large amount of data and this process is quite complex, hence companies use different strategies. For example, Facebook is one of the leading data driven and largest data warehouse company in the world. Facebook warehouse data is stored in Hadoop for large scale computation. Later, when warehouse data grew to petabytes, they decided to develop a new system with low latency. In the year of 2012, Facebook team members designed “Presto” for interactive query analytics that would operate quickly even with petabytes of data. What is Apache Presto? Apache Presto is a distributed parallel query execution engine, optimized for low latency and interactive query analysis. Presto runs queries easily and scales without down time even from gigabytes to petabytes. A single Presto query can process data from multiple sources like HDFS, MySQL, Cassandra, Hive and many more data sources. Presto is built in Java and easy to integrate with other data infrastructure components. Presto is powerful, and leading companies like Airbnb, DropBox, Groupon, Netflix are adopting it. Presto − Features Presto contains the following features − Simple and extensible architecture. Pluggable connectors - Presto supports pluggable connector to provide metadata and data for queries. Pipelined executions - Avoids unnecessary I/O latency overhead. User-defined functions - Analysts can create custom user-defined functions to migrate easily. Vectorized columnar processing. Presto − Benefits Here is a list of benefits that Apache Presto offers − Specialized SQL operations Easy to install and debug Simple storage abstraction Quickly scales petabytes data with low latency Presto − Applications Presto supports most of today’s best industrial applications. Let’s take a look at some of the notable applications. Facebook − Facebook built Presto for data analytics needs. Presto easily scales large velocity of data. Teradata − Teradata provides end-to-end solutions in Big Data analytics and data warehousing. Teradata contribution to Presto makes it easier for more companies to enable all analytical needs. Airbnb − Presto is an integral part of the Airbnb data infrastructure. Well, hundreds of employees are running queries each day with the technology. Why Presto? Presto supports standard ANSI SQL which has made it very easy for data analysts and developers. Though it is built in Java, it avoids typical issues of Java code related to memory allocation and garbage collection. Presto has a connector architecture that is Hadoop friendly. It allows to easily plug in file systems. Presto runs on multiple Hadoop distributions. In addition, Presto can reach out from a Hadoop platform to query Cassandra, relational databases, or other data stores. This cross-platform analytic capability allows Presto users to extract maximum business value from gigabytes to petabytes of data. Apache Presto Questions and Answers Pdf Download Read the full article
0 notes
Text
SQL Queries (if_else,string,for_loop alike )
DECLARE @SomeString varchar(MAX) = ''; /*String*/ DECLARE @MyDay varchar(max) = ''; DECLARE @Day varchar(8000) = '1';
WHILE @Day <32 /*For loop*/ BEGIN
SET @MyDay += 'count(case when DAY(date_time) = ' + @Day + ' AND MONTH(date_time) = replaceTHIS AND YEAR(date_time) = 2019 then 0 end) as Day' + @Day + ' '
IF @Day !=31 /*If Else*/ SET @MyDay += ', '
SET @Day = @Day + 1;
END;
SET @MyDay = 'SELECT ' + @MyDay + ' from Attendance';
DECLARE @Month varchar(8000) = '1';
WHILE @Month < 13 /*For loop*/ BEGIN
SET @SomeString += @MyDay
IF @Month !=12 /*If Else*/ SET @SomeString += ' UNION ALL ';
set @SomeString = REPLACE(@SomeString,'replaceTHIS',' ' + @Month + ''); /*Replace String*/ SET @Month = @Month +1;
END; exec(@SomeString)
0 notes
Text
Convert the NUMBER data type from Oracle to PostgreSQL – Part 1
An Oracle to PostgreSQL migration in the AWS Cloud can be a multistage process with different technologies and skills involved, starting from the assessment stage to the cutover stage. For more information about the migration process, see Database Migration—What Do You Need to Know Before You Start? and the following posts on best practices, including the migration process and infrastructure considerations, source database considerations, and target database considerations for the PostgreSQL environment. In the migration process, data type conversion from Oracle to PostgreSQL is one of the key stages. Multiple tools are available on the market, such as AWS Schema Conversion Tool (AWS SCT) and Ora2PG, which help you with data type mapping and conversion. However, it’s always recommended that you do an upfront analysis on the source data to determine the target data type, especially when working with data types like NUMBER. Many tools often convert this data type to NUMERIC in PostgreSQL. Although it looks easy to convert Oracle NUMBER to PostgreSQL NUMERIC, it’s not ideal for performance because calculations on NUMERIC are very slow when compared to an integer type. Unless you have a large value without scale that can’t be stored in BIGINT, you don’t need to choose the column data type NUMERIC. And as long as the column data doesn’t have float values, you don’t need to define the columns as the DOUBLE PRECISION data type. These columns can be INT or BIGINT based on the values stored. Therefore, it’s worth the effort to do an upfront analysis to determine if you should convert the Oracle NUMBER data type to INT, BIGINT, DOUBLE PRECISION, or NUMERIC when migrating to PostgreSQL. This series is divided into two posts. In this post, we cover two analysis methods to define the target data type column in PostgreSQL depending on how the NUMBER data type is defined in the Oracle database and what values are stored in the columns’ data. In the second post, we cover how to change the data types in the target PostgreSQL database after analysis using the AWS SCT features and map data type using transformation. Before we suggest which of these data types in PostgreSQL is a suitable match for Oracle NUMBER, it’s important to know the key differences between these INT, BIGINT, DOUBLE PRECISION, and NUMERIC. Comparing numeric types in PostgreSQL One of the important differences between INT and BIGINT vs. NUMERIC is storage format. INT and BIGINT have a fixed length: INT has 4 bytes, and BIGINT has 8 bytes. However, the NUMERIC type is of variable length and stores 0–255 bytes as needed. So NUMERIC needs more space to store the data. Let’s look at the following example code (we’re using PostgreSQL 12), which shows the size differences of tables with integer columns and NUMERIC: postgres=# SELECT pg_column_size('999999999'::NUMERIC) AS "NUMERIC length", pg_column_size('999999999'::INT) AS "INT length"; NUMERIC length | INT length ---------------+------------ 12 | 4 (1 row) postgres=# CREATE TABLE test_int_length(id INT, name VARCHAR); CREATE TABLE postgres=# CREATE TABLE test_numeric_length(id NUMERIC, name VARCHAR); CREATE TABLE postgres=# INSERT INTO test_int_length VALUES (generate_series(100000,1000000)); INSERT 0 900001 postgres=# INSERT INTO test_numeric_length VALUES (generate_series(100000,1000000)); INSERT 0 900001 postgres=# SELECT sum(pg_column_size(id))/1024 as "INT col size", pg_size_pretty(pg_total_relation_size('test_int_length')) as "Size of table" FROM test_int_length; INT col size | Size of table --------------+---------------- 3515 | 31 MB (1 row) Time: 104.273 ms postgres=# SELECT sum(pg_column_size(id))/1024 as "NUMERIC col size", pg_size_pretty(pg_total_relation_size('test_numeric_length')) as "Size of table" FROM test_numeric_length; NUMERIC col size | Size of table ------------------+---------------- 6152 | 31 MB (1 row) From the preceding output, INT occupies 3,515 bytes and NUMERIC occupies 6,152 bytes for the same set of values. However, you see the same table size because PostgreSQL is designed such that its own internal natural alignment is 8 bytes, meaning consecutive fixed-length columns of differing size must be padded with empty bytes in some cases. We can see that with the following code: SELECT pg_column_size(row()) AS empty, pg_column_size(row(0::SMALLINT)) AS byte2, pg_column_size(row(0::BIGINT)) AS byte8, pg_column_size(row(0::SMALLINT, 0::BIGINT)) AS byte16; empty | byte2 | byte8 | byte16 -------+-------+-------+-------- 24 | 26 | 32 | 40 From the preceding output, it’s clear that an empty PostgreSQL row requires 24 bytes of various header elements, a SMALLINT is 2 bytes, and a BIGINT is 8 bytes. However, combining a SMALLINT and BIGINT takes 16 bytes. This is because PostgreSQL is padding the smaller column to match the size of the following column for alignment purposes. Instead of 2 + 8 = 10, the size becomes 8 + 8 = 16. Integer and floating point values representation and their arithmetic operations are implemented differently. In general, floating point arithmetic is more complex than integer arithmetic. It requires more time for calculations on numeric or floating point values as compared to the integer types. PostgreSQL BIGINT and INT data types store their own range of values. The BIGINT range (8 bytes) is -9223372036854775808 to 9223372036854775807: postgres=# select 9223372036854775807::bigint; int8 --------------------- 9223372036854775807 (1 row) postgres=# select 9223372036854775808::bigint; ERROR: bigint out of range The INT range (4 bytes) is -2147483648 to 2147483647: postgres=# select 2147483647::int; int4 ------------ 2147483647 (1 row) postgres=# select 2147483648::int; ERROR: integer out of range For information about these data types, see Numeric Types. With the NUMBER data type having precision and scale in Oracle, it can be either DOUBLE PRECISION or NUMERIC in PostgreSQL. One of the main differences between DOUBLE PRECISION and NUMERIC is storage format and total length of precision or scale supported. DOUBLE PRECISION is fixed at 8 bytes of storage and 15-decimal digit precision. DOUBLE PRECISION offers a similar benefit as compared to the NUMERIC data type as explained for BIGINT and INT in PostgreSQL. With DOUBLE PRECISION, because its limit is 15 decimals, for any data with higher precision or scale we might be affected by data truncation during data migration from Oracle. See the following code: postgres=> select 123456789.10111213::double precision as Scale_Truncated, 123456789101112.13::double precision as Whole_Scale_Truncated; scale_truncated | whole_scale_truncated ------------------+----------------------- 123456789.101112 | 123456789101112 When considering data type in PostgreSQL when the NUMBER data type has decimal information, we should check for max precision along with max scale and decide accordingly if the target data type is either DOUBLE PRECISION or NUMERIC. If you’re planning to store values that require a certain precision or arithmetic accuracy, the DOUBLE PRECISION data type may be the right choice for your needs. For example, if you try to store the result of 2/3, there is some rounding when the 15th digit is reached when you use DOUBLE PRECISION. It’s used for not only rounding the value based on precision limit, but also for the arithmetic accuracy. If you consider the following example, a double precision gives the wrong answer. postgres=# select 0.1::double precision + 0.2 as value; value --------------------- 0.30000000000000004 (1 row) postgres=# select 0.1::numeric + 0.2 as value; value ------- 0.3 (1 row) Starting with PostgreSQL 12, performance has been improved by using a new algorithm for output of real and double precision values. In previous versions (older than PostgreSQL 12), displayed floating point values were rounded to 6 (for real) or 15 (for double precision) digits by default, adjusted by the value of the parameter extra_float_digits. Now, whenever extra_float_digits is more than zero (as it is by default from PostgreSQL 12 and newer), only the minimum number of digits required to preserve the exact binary value are output. The behavior is the same as before when extra_float_digits is set to zero or less. postgres=# set extra_float_digits to 0; SET postgres=# select 0.1::double precision + 0.2 as value; value ------- 0.3 (1 row) Oracle NUMBER and PostgreSQL NUMERIC In Oracle, the NUMBER data type is defined as NUMBER(precision, scale) and in PostgreSQL, NUMERIC is defined as NUMERIC(precision, scale), with precision and scale defined as follows: Precision – Total count of significant digits in the whole number, that is, the number of digits to both sides of the decimal point Scale – Count of decimal digits in the fractional part, to the right of the decimal point Analysis before data type conversion Data type changes may have some side effects, which we discuss in this post. Before converting data types, you need to check with your service or application team if they have the following: Any dependency of these data types (INT and BIGINT) in application SQLs that require type casting Any change required in stored procedures or triggers for these data types Any dependency in Hibernate-generated code If these data type changes have any impact on future data growth Any plans in the future for these columns to store any fractional values Without proper analysis and information on the application code and the database code objects, it’s not recommended to change the data types. If you do so, your application queries may start showing performance issues because they require a type casting internally from NUMERIC to INT or BIGINT. If you have code objects like procedures or triggers with these data types’ dependency, you need to make changes to those objects to avoid performance issues. Future data growth may impact these conversions as well. If you convert it to INT based on the current data, however, it may go beyond INT value in the future. Make sure you don’t have any plans to store fractional values after migration is complete. If that is the requirement, you need to choose a different data type than INT or BIGINT. For this post, we examine two different methods to analyze the information to recommend INT, BIGINT, DOUBLE PRECISION, or NUMERIC: Metadata-based data type conversion Actual data-based data type conversion Analysis method: Metadata-based data type conversion By looking at the metadata information of Oracle tables with columns of the NUMBER or INTEGER data type, we can come up with the target data type recommendations. Conversion to PostgreSQL INT or BIGINT You can covert Oracle tables with columns of the data type NUMBER or INTEGER to PostgreSQL INT or BIGINT if they meet the following criteria: The data type is NUMERIC or INTEGER in Oracle DATA_PRECISION is NOT NULL (not a variable length NUMERIC) DATA_SCALE is 0 (integers and not float values) MAX_LENGTH is defined as <=18 (DATA_PRECISION <=18) If DATA_PRECISION is < 10, use INT. If DATA_PRECISION is 10–18, use BIGINT.` You can use the following query on Oracle to find candidate columns of NUMERIC or INTEGER data type that can be converted to BIGINT or INT in PostgreSQL: SELECT OWNER , TABLE_NAME , COLUMN_NAME , DATA_TYPE , DATA_PRECISION , DATA_SCALE FROM dba_tab_columns WHERE OWNER in ('owner_name') and (DATA_TYPE='NUMBER' or DATA_TYPE='INTEGER') and DATA_PRECISION is NOT NULL and (DATA_SCALE=0 or DATA_SCALE is NULL) and DATA_PRECISION <= 18; The following code is an example output of the preceding query, which shows precision and scale of NUMBER data types for a particular user: OWNER TABLE_NAME COLUMN_NAME DATA_TYPE DATA_PRECISION DATA_SCALE ---------- -------------------- -------------------- ---------- -------------- ---------- DEMO COUNTRIES REGION_ID NUMBER 10 0 DEMO CUSTOMER CUSTOMER_ID NUMBER 15 0 DEMO DEPARTMENTS DEPARTMENT_ID NUMBER 4 0 DEMO EMPLOYEES EMPLOYEE_ID NUMBER 6 0 DEMO EMPLOYEES MANAGER_ID NUMBER 6 0 DEMO EMPLOYEES DEPARTMENT_ID NUMBER 4 0 DEMO ORDERS ORDER_ID NUMBER 19 0 DEMO ORDERS VALUE NUMBER 14 0 DEMO PERSON PERSON_ID NUMBER 5 0 The output shows four columns (REGION_ID of the COUNTRIES table, CUSTOMER_ID of the CUSTOMER table, and ORDER_ID and VALUE of the ORDERS table) that have precision between 10–18, which can be converted to BIGINT in PostgreSQL. The remaining columns can be converted to INT. Conversion to PostgreSQL DOUBLE PRECISION or NUMERIC You can convert Oracle tables with columns of the data type NUMBER or INTEGER to PostgreSQL DOUBLE PRECISION or NUMERIC if they meet the following criteria: The data type is NUMERIC or NUMBER in Oracle DATA_PRECISION is NOT NULL DATA_SCALE is > 0 (float values) If DATA_PRECISION + DATA_SCALE <= 15, choose DOUBLE PRECISION. If DATA_PRECISION + DATA_SCALE > 15, choose NUMERIC. You can use the following query on Oracle to find candidate columns of NUMERIC or INTEGER data type that can be converted to DOUBLE PRECISION or NUMERIC in PostgreSQL: SELECT OWNER , TABLE_NAME , COLUMN_NAME , DATA_TYPE , DATA_PRECISION , DATA_SCALE FROM dba_tab_columns WHERE OWNER in ('owner_name') and (DATA_TYPE='NUMBER' or DATA_TYPE='INTEGER') and DATA_PRECISION is NOT NULL and DATA_SCALE >0; The following is an example output of the query: OWNER TABLE_NAME COLUMN_NAME DATA_TYPE DATA_PRECISION DATA_SCALE ------- ------------ -------------------- -------------- -------------- ---------- DEMO COORDINATES LONGI NUMBER 10 10 DEMO COORDINATES LATTI NUMBER 10 10 DEMO EMPLOYEES COMMISSION_PCT NUMBER 2 2 The output contains the column COMMISSION_PCT from the EMPLOYEES table, which can be converted as DOUBLE PRECISION. The output also contains two columns (LONGI and LATTI) that can be NUMERIC because they have (precision + scale) > 15. Changing the data type for all candidate columns may not have the same impact or performance gain. Most columns that are part of the key or index appear in joining conditions or in lookup, so changing the data type for those columns may have a big impact. The following are guidelines for converting the column data type in PostgreSQL, in order of priority: Consider changing the data type for columns that are part of a key (primary, unique, or reference) Consider changing the data type for columns that are part of an index Consider changing the data type for all candidate columns Analysis method: Actual data-based data type conversion In Oracle, the NUMBER data type is often defined with no scale, and those columns are used for storing integer value only. But because scale isn’t defined, the metadata doesn’t show if these columns store only integer values. In this case, we need to perform a full table scan for those columns to identify if the columns can be converted to BIGINT or INT in PostgreSQL. A NUMERIC column may be defined with DATA_PRECISION higher than 18, but all column values fit well in the BIGINT or INT range of PostgreSQL. You can use the following SQL code in an Oracle database to find if the actual DATA_PRECISION and DATA_SCALE is in use. This code performs a full table scan, so you need to do it in batches for some tables, and if possible run it during low peak hours in an active standby database (ADG): select /*+ PARALLEL(tab 4) */ max(length(trunc(num_col))) MAX_DATA_PRECISION, min(length(trunc(num_col))) MIN_DATA_PRECISION, max(length(num_col - trunc(num_col)) -1 ) MAX_DATA_SCALE from <> tab; Based on the result of the preceding code, use the following transform rules: If MAX_DATA_PRECISION < 10 and MAX_DATA_SCALE = 0, convert to INT If DATA_PRECISION is 10–18 and MAX_DATA_SCALE = 0, convert to BIGINT if MAX_DATA_SCALE > 0 and MAX_DATA_PRECISION + MAX_DATA_SCALE <= 15, convert to DOUBLE PRECISION if MAX_DATA_SCALE > 0 and MAX_DATA_PRECISION + MAX_DATA_SCALE > 15, convert to NUMERIC Let’s look at the following example. In Oracle, create the table number_col_test with four columns defined and a couple of rows inserted: SQL> CREATE TABLE DEMO.number_col_test ( col_canbe_int NUMBER(8,2), col_canbe_bigint NUMBER(19,2), col_canbe_doubleprecision NUMBER(15,2), col_should_be_number NUMBER(20,10) ); Table created. SQL> INSERT INTO demo.number_col_test VALUES (1234, 12345678900, 12345.12, 123456.123456); 1 row created. SQL> INSERT INTO demo.number_col_test VALUES (567890, 1234567890012345, 12345678.12, 1234567890.1234567890); 1 row created. SQL> set numwidth 25 SQL> select * from demo.number_col_test; COL_CANBE_INT COL_CANBE_BIGINT COL_CANBE_DOUBLEPRECISION COL_SHOULD_BE_NUMBER -------------- -------------- ------------------------- -------------------- 1234 12345678900 12345.12 123456.123456 567890 1234567890012345 12345678.12 1234567890.123456789 We next run a query to look at the data to find the actual precision and scale. From the following example, can_be_int has precision as 6 and scale as 0 even though it’s defined as NUMBER(8,4). So we can define this column as INT in PostgreSQL. SQL> select /*+ PARALLEL(tab 4) */ max(length(trunc(COL_CANBE_INT))) MAX_DATA_PRECISION, min(length(trunc(COL_CANBE_INT))) MIN_DATA_PRECISION, max(length(COL_CANBE_INT - trunc(COL_CANBE_INT)) -1 ) MAX_DATA_SCALE from demo.number_col_test; MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE ------------------------- ------------------------- ------------------------- 6 4 0 In the following output, can_be_bigint has precision as 16 and scale as 0 even though it’s defined as NUMBER(19,2). So we can define this column as BIGINT in PostgreSQL. SQL> select /*+ PARALLEL(tab 4) */ max(length(trunc(COL_CANBE_BIGINT))) MAX_DATA_PRECISION, min(length(trunc(COL_CANBE_BIGINT))) MIN_DATA_PRECISION, max(length(COL_CANBE_BIGINT - trunc(COL_CANBE_BIGINT)) -1 ) MAX_DATA_SCALE from demo.number_col_test; MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE ------------------------- ------------------------- ------------------------- 16 11 0 In the following output, can_be_doubleprecision has precision as 8 and scale as 2 even though it’s defined as NUMBER(15,2). We can define this column as DOUBLE PRECISION in PostgreSQL. SQL> select /*+ PARALLEL(tab 4) */ max(length(trunc(COL_CANBE_DOUBLEPRECISION))) MAX_DATA_PRECISION, min(length(trunc(COL_CANBE_DOUBLEPRECISION))) MIN_DATA_PRECISION, max(length(COL_CANBE_DOUBLEPRECISION - trunc(COL_CANBE_DOUBLEPRECISION)) -1 ) MAX_DATA_SCALE from demo.number_col_test; MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE ------------------------- ------------------------- ------------------------- 8 5 2 In the following output, should_be_numeric has precision as 10 and scale as 9 even though it’s defined as NUMBER(20,10). We can define this column as NUMERIC in PostgreSQL. SQL> select /*+ PARALLEL(tab 4) */ max(length(trunc(COL_SHOULD_BE_NUMBER))) MAX_DATA_PRECISION, min(length(trunc(COL_SHOULD_BE_NUMBER))) MIN_DATA_PRECISION, max(length(COL_SHOULD_BE_NUMBER - trunc(COL_SHOULD_BE_NUMBER)) -1 ) MAX_DATA_SCALE from demo.number_col_test; MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE ------------------------- ------------------------- ------------------------- 10 6 9 Summary Converting the NUMBER data type from Oracle to PostgreSQL is always tricky. It’s not recommended to convert all NUMBER data type columns to NUMERIC or DOUBLE PRECISION in PostgreSQL without a proper analysis of the source data. Having the appropriate data types helps improve performance. It pays long-term dividends by spending time upfront to determine the right data type for application performance. From the Oracle system tables, you get precision and scale of all the columns of all the tables for a user. With this metadata information, you can choose the target data type in PostgreSQL as INT, BIGINT, DOUBLE PRECISION, or NUMERIC. However, you can’t always depend on this information. Although this metadata shows the scale of some columns as >0, the actual data might not have floating values. Look at the actual data in every table’s NUMBER columns (which are scale >0), and decide on the target columns’ data types. Precision(m) Scale(n) Oracle PostgreSQL <= 9 0 NUMBER(m,n) INT 9 > m <=18 0 NUMBER(m,n) BIGINT m+n <= 15 n>0 NUMBER(m,n) DOUBLE PRECISION m+n > 15 n>0 NUMBER(m,n) NUMERIC In the next post in this series, we cover methods to convert the data type in PostgreSQL after analysis is complete, and we discuss data types for the source Oracle NUMBER data type. About the authors Baji Shaik is a Consultant with AWS ProServe, GCC India. His background spans a wide depth and breadth of expertise and experience in SQL/NoSQL database technologies. He is a Database Migration Expert and has developed many successful database solutions addressing challenging business requirements for moving databases from on-premises to Amazon RDS and Aurora PostgreSQL/MySQL. He is an eminent author, having written several books on PostgreSQL. A few of his recent works include “PostgreSQL Configuration“, “Beginning PostgreSQL on the Cloud”, and “PostgreSQL Development Essentials“. Furthermore, he has delivered several conference and workshop sessions. Sudip Acharya is a Sr. Consultant with the AWS ProServe team in India. He works with internal and external Amazon customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS. Deepak Mahto is a Consultant with the AWS Proserve Team in India. He has been working as Database Migration Lead, helping and enabling customers to migrate from commercial engines to Amazon RDS.His passion is automation and has designed and implemented multiple database or migration related tools. https://aws.amazon.com/blogs/database/convert-the-number-data-type-from-oracle-to-postgresql-part-1/
0 notes
Text
Database Oluştur
localhost/phpmyadmin’e git. türkçe olduğu için pek anlatılması gerektiğini düşünmesem de phparsiv adında bir veritabanı oluştur. bu veritabanının içine konum adında bir tablo oluştur. tabloyu aşağıdaki ssteki gibi doldur.

Açıklama: id = kimlik numarası, sayı değeri alacağı için türü INT ve otomatik artacağı için A_I açık. sehir/bölge= yazı değeri alacağı için text ve çok uzun şeyler yazılmayacağı için max 20ye sabitli. varchar da seçebilirdim ama varcharda sayı da girilebiliyor diye gereksiz buldum.
0 notes