#exdb
Text
Deep Learning Assignment 1
Deep Neural Networks are becoming more and more popular and widely applied to many ML-related domains. In this assignment, you will complete a simple pipeline of training neural networks to recognize MNIST Handwritten Digits: http://yann.lecun.com/exdb/mnist/. You’ll implement two neural network architectures along with the code to load data, train and optimize these networks. You will also run…

View On WordPress
0 notes
Photo

How Smart is Today's Artificial Intelligence? Current AI is impressive, but it's not intelligent. Subscribe to our channel! http://goo.gl/0bsAjO Sources: https://hbr.org/2016/11/what-artificial-intelligence-can-and-cant-do-right-now https://www.mckinsey.com/global-themes/digital-disruption/harnessing-automation-for-a-future-that-works https://www.amazon.com/Master-Algorithm-Ultimate-Learning-Machine/dp/0465065708 https://ai100.stanford.edu/sites/default/files/ai_100_report_0831fnl.pdf https://www.bloomberg.com/professional/blog/business-focus-artificial-intelligence-rising-2/ http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.368.2254&rep=rep1&type=pdf http://yann.lecun.com/exdb/publis/pdf/jackel-95.pdf https://www.recode.net/2016/5/4/11634228/learning-about-deep-learning https://www.theverge.com/2016/7/12/12158238/first-click-deep-learning-algorithmic-black-boxes https://www.theverge.com/2017/3/30/15124466/ai-photo-style-transfer-deep-neural-nets-adobe https://www.techspot.com/news/71935-convolutional-neural-networks-used-fight-lung-cancer.html https://openreview.net/pdf?id=BkjLkSqxg https://med.stanford.edu/news/all-news/2016/08/computers-trounce-pathologists-in-predicting-lung-cancer-severity.html https://arxiv.org/pdf/1609.06647.pdf https://www.theverge.com/2017/4/12/15271874/ai-adversarial-images-fooling-attacks-artificial-intelligence https://arstechnica.com/gaming/2016/06/an-ai-wrote-this-movie-and-its-strangely-moving/ https://www.ibm.com/blogs/research/2017/12/ai-video-understanding/ https://hbr.org/cover-story/2017/07/the-business-of-artificial-intelligence https://rodneybrooks.com/the-seven-deadly-sins-of-predicting-the-future-of-ai/ Something incredible has taken place in the past 5 years: a revolution in artificial intelligence. After decades of little progress, the combination of big data and advances in computer hardware have brought AI applications to life: from self-driving cars to home assistants to augmented reality and instant language translation. If some of these applications feel like science fiction it's because deep learning algorithms are powering a true breakthrough in machine intelligence. But with these truly impressive advances comes a great deal of hype: fears of terminator-type bots turning on humans and stealing all our jobs. In this video we sort out the fact from fiction in this very exciting field. /// Vox.com is a news website that helps you cut through the noise and understand what's really driving the events in the headlines. Check out http://www.vox.com to get up to speed on everything from Kurdistan to the Kim Kardashian app. Check out our full video catalog: http://goo.gl/IZONyE Follow Vox on Twitter: http://goo.gl/XFrZ5H Or on Facebook: http://goo.gl/U2g06o
0 notes
Text
ECE Advanced Pattern Recognition (Homework 3) Solution
ECE Advanced Pattern Recognition (Homework 3) Solution
Objective: Implementation of handwritten number recognition by CNN.
This is our 3rd exercise in a series that deal with the MNIST Database (http://yann.lecun.com/exdb/mnist/). The MNIST Database is a collection of samples of handwritten digits from many people, originally collected by the National Institute of Standards and Technology (NIST), and modified to be more easily analyzed…

View On WordPress
0 notes
Text
Homework 1: Regression and Sparsity
Homework 1: Regression and Sparsity
AMATH 563
Homework 1: Regression and Sparsity
Download the MNIST data set (both training and test sets and labels): http://yann.lecun.com/exdb/mnist/.
The labels will tell you which digit it is: 1, 2, 3, 4, 5, 6, 7, 8, 9, 0. Let each output be denoted by the vector yj
.
“1” =
1
0
0
.
.
.
0
0
, “2” =
0
1
0
.
.
.
0
0
, · · · ,…

View On WordPress
0 notes
Photo

Old German.
#exDb#Ywagen#Halberstadterwagen#trains#nightlife#nightshot#nightrails#railway#railroad#railpassion#trainyard#i love trains#yardromance#documentary#poetry#atmosphere#action#before#before sunrise#hungary#magyarország#MÁV#fuck halbi
8 notes
·
View notes
Photo

Ex DB-Baureihe 120-205, aktuell bei Nürnberger Leasing GmbH, durchfährt gerade Brandenburg in Richtung Osten. Schaut gerne bei meinem Partner @lokomotive_deutschland_ vorbei! Tags: #brandenburg #brandenburganderhavel #brb #bahnhof #hauptbahnhof #baureihe120 #br120 #drehstromlok #exdb #nürnbergerleasinggmbh #trainspotter #trainspotter_europe #trainspotter_de #trainspottermitleidenschaft #trainspotterausleidenschaft #trainspotters #trainspotters_europe #trainspotting #trainspottingpictures #trainspotting_europe #trainspottingpicture #zugfotografie #zug #güterzug #ts_brandenburg #eisenbahn #eisenbahnfotografie #eisenbahnromantik #lokomotive #lok (hier: Brandenburg Hauptbahnhof) https://www.instagram.com/p/CBiRMunn60r/?igshid=adixg7nqwnby
#brandenburg#brandenburganderhavel#brb#bahnhof#hauptbahnhof#baureihe120#br120#drehstromlok#exdb#nürnbergerleasinggmbh#trainspotter#trainspotter_europe#trainspotter_de#trainspottermitleidenschaft#trainspotterausleidenschaft#trainspotters#trainspotters_europe#trainspotting#trainspottingpictures#trainspotting_europe#trainspottingpicture#zugfotografie#zug#güterzug#ts_brandenburg#eisenbahn#eisenbahnfotografie#eisenbahnromantik#lokomotive#lok
0 notes
Text
Feed-forward and back-propagation in neural networks as left- and right-fold
Description of the problem:
Today's post is about something (trivial) I realized a few days ago: one can reconceptualize feed-forward and back-propagation operations in a neural network as instances of left-fold and right-fold operations. Most of this post will be theoretical, and at the end, I will write some code in scala.
Feed-forward and Back-propagation in a Neural Network
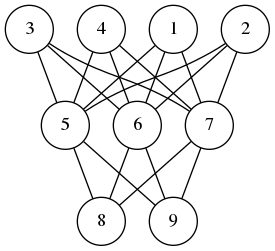
A neural network is composed of perceptrons connected via a computation graph.
A perceptron on the other hand is a computation unit which takes a vector $\mathbf{x}$ as an input and produces a scalar output
$$ f(\mathbf{w}\cdot\mathbf{x} + b) $$
Here $f$ is a function of type signature $f\colon\mathbb{R}\to \mathbb{R}$ and $\mathbf{w}$ and $b$ are parameters of the underlying perceptron.
In the simplest version of the neural networks, the network consists of layers of perceptrons where input propagates from one layer to the next. Then depending on the error produced, we back-propagate the error adjusting the weights of the perceptrons to produce the correct output. I wrote about perceptrons and back-propagation before (here, here and here)
The observation I made is this feed-forward is a left fold, while back-propagation is a right-fold operation. In pseudo-code we can express these operations as follows:
FeedForward(xs,nss) Input: a vector xs, and a list of layers nss where a layer is an ordered list of perceptron and each perceptron is a quintuple (w,b,f,eta,ys) where w is a vector, b is a real number, f is and activation function, eta is the learning rate of the perceptron and zs is the last input processed by the node. Output: a vector ys Begin If nss is empty Return xs Else Let ns <- head of nss Let ys <- () For each node=(w,f,b,zs) in ns Update zs <- xs Append f(<w,xs> + b) to ys End Call FeedForward(ys, tail of nss) End End BackPropagations(ds,nss) Input: a vector of errors, and a list of layers as before. Output: a vector Begin If nss is empty Return ds Else Let ns <- tail of nss Let zsum <- 0 For each ((w,b,f,eta,xs),d) in (ns,ds) Let zs <- (eta * d / f'(<w,xs> + b)) * xs Update w <- w - zs Update zsum <- zsum + zs End Call BackPropagation(zsum, all but the last element of nss) End End
A Scala Implementation
You can download the code and run it from my github repository. I am using mill instead of sbt.
The feed-forward part of the algorithm is easy to implement in the functional style, i.e. no mutable persistent state, such that the network as a computation unit is referentially transparent. However, the back-propagation phase requires that we update the weights of each perceptron. This means we must capture the whole state of the neural network in a data structure and propagate it along each step. As much as I like functional style and referential transparency, it is easier and cleaner to implement neural networks with mutable persistent state. Hence the choices of vars below.
package perceptron import breeze.linalg._ object neural { case class node(size: Int, fn: Double=>Double, eta: Double) { private var input = DenseVector.rand[Double](size+1) private var calc = 0.0 var weights = DenseVector.rand[Double](size+1) def forward(x: Array[Double]): Double = { input = DenseVector(Array(1.0) ++ x) calc = fn(weights.dot(input)) calc } def backprop(delta: Double): DenseVector[Double] = { val ider = eta/(fn(calc + eta/2) - fn(calc - eta/2) + eta*Math.random) val res = (-delta*eta*ider)*input weights += res res } } case class layer(size: Int, num: Int, fn: Double=>Double, eta: Double) { val nodes = (1 to num).map(i=>node(size,fn,eta)).toArray def forward(xs: Array[Double]) = nodes.map(_.forward(xs)) def backprop(ds: Array[Double]) = { val zero = DenseVector.zeros[Double](nodes(0).size+1) (nodes,ds).zipped .foldRight(zero)({ case((n,d),v) => v + n.backprop(d) }) .toArray } } case class network(shape:Array[(Int, Int, Double=>Double, Double)]) { val layers = shape.map({ case (n,m,fn,eta) => layer(n,m,fn,eta) }) def forward(xs:Array[Double]) = layers.foldLeft(xs)((ys,ns) => ns.forward(ys)) def backprop(ds:Array[Double]) = layers.foldRight(ds)((ns,ys) => ns.backprop(ys)) } } `
The only additional external dependency is the breeze math and statistics package. As for the utility code that we need for training and testing a neural network model for a given dataset, we have
package perceptron import perceptron.neural._ object Main { import scala.util.Random.nextInt import scala.io.Source.fromFile def sigmoid(x:Double) = 1.0/(1.0 + math.exp(-x)) def relu(x:Double) = math.max(x,0.0) def train(net:network, xs: Array[Array[Double]], ys: Array[Double], epochs: Int, batchSize: Int, tol: Double):Array[Double] = { val size = xs.length var err = Array[Double]() for(i <- 1 to epochs) { val j = math.abs(nextInt)%size val x = xs(j) val d = net.forward(x)(0) - ys(j) net.backprop(Array(d)) if(i % batchSize == 1) err = Array(0.0) ++ err if(math.abs(d)>tol) err(0) += 1.0/batchSize } return(err.reverse) } def main(args: Array[String]) { val file = fromFile(args(0)) val size = args(1).toInt val eta = args(2).toDouble val epochs = args(3).toInt val batchSize = args(4).toInt val tol = args(5).toDouble val data = file.mkString .split("\n") .map(x=>x.split("\t").map(_.toDouble).reverse) val ys = data.map(_.head) val xs = data.map(_.tail) val net = network(Array((size,4,relu,eta),(4,1,sigmoid,eta))) val err = train(net, xs, ys, epochs, batchSize, tol) err.foreach(x=>println("%4.3f".format(x))) } }
I know that MNIST is the de facto standard, but it is PIA to load and process the data. Instead, I am going to use the sonar dataset from UCI
I ran the model with the following parameters:
mill perceptron.run data/sonar.csv 60 0.0125 1750000 500 0.3
In the code above, the neural network has two layers: 60 nodes on the input layer, 1 hidden layer with 4 nodes, and a single output node. The perceptrons on the input layer use RELU meanwhile the other layer uses the sigmoid function.
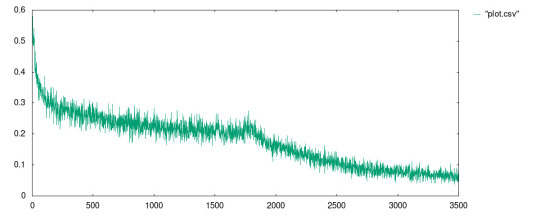
The best result I received is in the file data/plot.csv whose plot is given in
1 note
·
View note
Photo

How Smart is Today's Artificial Intelligence? Current AI is impressive, but it's not intelligent. Subscribe to our channel! http://goo.gl/0bsAjO Sources: https://hbr.org/2016/11/what-artificial-intelligence-can-and-cant-do-right-now https://www.mckinsey.com/global-themes/digital-disruption/harnessing-automation-for-a-future-that-works https://www.amazon.com/Master-Algorithm-Ultimate-Learning-Machine/dp/0465065708 https://ai100.stanford.edu/sites/default/files/ai_100_report_0831fnl.pdf https://www.bloomberg.com/professional/blog/business-focus-artificial-intelligence-rising-2/ http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.368.2254&rep=rep1&type=pdf http://yann.lecun.com/exdb/publis/pdf/jackel-95.pdf https://www.recode.net/2016/5/4/11634228/learning-about-deep-learning https://www.theverge.com/2016/7/12/12158238/first-click-deep-learning-algorithmic-black-boxes https://www.theverge.com/2017/3/30/15124466/ai-photo-style-transfer-deep-neural-nets-adobe https://www.techspot.com/news/71935-convolutional-neural-networks-used-fight-lung-cancer.html https://openreview.net/pdf?id=BkjLkSqxg https://med.stanford.edu/news/all-news/2016/08/computers-trounce-pathologists-in-predicting-lung-cancer-severity.html https://arxiv.org/pdf/1609.06647.pdf https://www.theverge.com/2017/4/12/15271874/ai-adversarial-images-fooling-attacks-artificial-intelligence https://arstechnica.com/gaming/2016/06/an-ai-wrote-this-movie-and-its-strangely-moving/ https://www.ibm.com/blogs/research/2017/12/ai-video-understanding/ https://hbr.org/cover-story/2017/07/the-business-of-artificial-intelligence https://rodneybrooks.com/the-seven-deadly-sins-of-predicting-the-future-of-ai/ Something incredible has taken place in the past 5 years: a revolution in artificial intelligence. After decades of little progress, the combination of big data and advances in computer hardware have brought AI applications to life: from self-driving cars to home assistants to augmented reality and instant language translation. If some of these applications feel like science fiction it's because deep learning algorithms are powering a true breakthrough in machine intelligence. But with these truly impressive advances comes a great deal of hype: fears of terminator-type bots turning on humans and stealing all our jobs. In this video we sort out the fact from fiction in this very exciting field. /// Vox.com is a news website that helps you cut through the noise and understand what's really driving the events in the headlines. Check out http://www.vox.com to get up to speed on everything from Kurdistan to the Kim Kardashian app. Check out our full video catalog: http://goo.gl/IZONyE Follow Vox on Twitter: http://goo.gl/XFrZ5H Or on Facebook: http://goo.gl/U2g06o
0 notes
Text
Tensorflow and XGBoost Write a paper on analyzing the MNIST data set with XGBoos
Tensorflow and XGBoost Write a paper on analyzing the MNIST data set with XGBoos
Tensorflow and XGBoost
Write a paper on analyzing the MNIST data set with XGBoost, Keras and Tensorflow
Section 1 introduction to the MNIST dataset
http://yann.lecun.com/exdb/mnist/
https://en.wikipedia.org/wiki/MNIST_database
Section 2 Apply XGBoost to the MNIST dataset
https://www.kaggle.com/idv2005/simple-xgboost-for-mnist
Section 3 Apply Keras & Tensorflow to the MNIST…
View On WordPress
0 notes
Text
Tensorflow and XGBoost Write a paper on analyzing the MNIST data set with XGBoos
Tensorflow and XGBoost Write a paper on analyzing the MNIST data set with XGBoos
Tensorflow and XGBoost
Write a paper on analyzing the MNIST data set with XGBoost, Keras and Tensorflow
Section 1 introduction to the MNIST dataset
http://yann.lecun.com/exdb/mnist/
https://en.wikipedia.org/wiki/MNIST_database
Section 2 Apply XGBoost to the MNIST dataset
https://www.kaggle.com/idv2005/simple-xgboost-for-mnist
Section 3 Apply Keras & Tensorflow to the MNIST…
View On WordPress
0 notes
Text
Advanced Pattern Recognition (Homework 3) Solution
Advanced Pattern Recognition (Homework 3) Solution
Objective: Implementation of handwritten number recognition by CNN.
This is our 3rd exercise in a series that deal with the MNIST Database (http://yann.lecun.com/exdb/mnist/). The MNIST Database is a collection of samples of handwritten digits from many people, originally collected by the National Institute of Standards and Technology (NIST), and modified to be more easily analyzed…

View On WordPress
0 notes
Link
0 notes
Text
ECE Pattern Recognition (Homework 2) Solution
ECE Pattern Recognition (Homework 2) Solution
Objective: Implementation of handwritten number recognition by ANN.
This is our 2nd exercise in a series that deal with the MNIST Database (http://yann.lecun.com/exdb/mnist/). The MNIST Database is a collection of samples of handwritten digits from many people, originally collected by the National Institute of Standards and Technology (NIST), and modified to be more easily analyzed…

View On WordPress
0 notes
Text
How do the Past Pupils of Don Bosco communicate?
How do the Past Pupils of Don Bosco communicate?
DB Past Pupils Magazines and Newsletters
By EXDB
EAO Region, 12 July 2020 — The 150th Jubilee Year (24 June 2020-2021) of the Past Pupils of Don Bosco offers a good opportunity to get to know the largest but actually not as well-known group of the Salesian Family better. While the Italian version of their magazine ‘Voci Fraterne’ (Fraternal voices) celebrates 100 years of history, probably the…
View On WordPress
0 notes
Text
ECE 4332/5332 Project 6-Realtime Digit Recognition Solved
ECE 4332/5332 Project 6-Realtime Digit Recognition Solved
Train a convolutional neural network to recognize the MNIST handwritten digits. You may obtain the training and test sets from http://yann.lecun.com/exdb/mnist/. Your implementation will be judged on the following criteria.
Successful training and testing of classifier indicating training and test accuracies.
Live demo presenting capture and detection of handwritten digits.
Extra Credit:Live Demo…
View On WordPress
0 notes
Last Seen Blogs

silentauthor96
Insert Pretentious Title Here

longliv3
Olivia🫶🏻🪩

spellshite
a spell shite's sparky magic

acertainrandomguy
A Certain Random Guy

danishacademia
Danish_academia