#import csv file into oracle table using stored procedure
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
How to load data from CSV file into oracle using SQL Loader
How to load data from CSV file into oracle using SQL Loader
Hi Friends, in this article, we will load data from CSV file into oracle using SQL loader. SQL Loader is a tool which is providing by oracle. Read: How to create a SEQUENCE step by step What is SQL Loader? SQL Loader helps us to load data from external files into tables of the oracle database. For more details Click Here. Load data in empty or non-empty table We can load data in the empty or…

View On WordPress
#how to read data from csv file in oracle#import csv file into oracle table using sql developer#import csv file into oracle table using stored procedure#import data from csv file to oracle table using shell script#load csv file into oracle table using python#load data from CSV file into oracle using sql loader#oracle load data from csv sqlplus#oracle sql query to read data from csv file#shell script to load data into oracle table from csv file
0 notes
Text
Which Is The Best PostgreSQL GUI? 2021 Comparison
PostgreSQL graphical user interface (GUI) tools help open source database users to manage, manipulate, and visualize their data. In this post, we discuss the top 6 GUI tools for administering your PostgreSQL hosting deployments. PostgreSQL is the fourth most popular database management system in the world, and heavily used in all sizes of applications from small to large. The traditional method to work with databases is using the command-line interface (CLI) tool, however, this interface presents a number of issues:
It requires a big learning curve to get the best out of the DBMS.
Console display may not be something of your liking, and it only gives very little information at a time.
It is difficult to browse databases and tables, check indexes, and monitor databases through the console.
Many still prefer CLIs over GUIs, but this set is ever so shrinking. I believe anyone who comes into programming after 2010 will tell you GUI tools increase their productivity over a CLI solution.
Why Use a GUI Tool?
Now that we understand the issues users face with the CLI, let’s take a look at the advantages of using a PostgreSQL GUI:
Shortcut keys make it easier to use, and much easier to learn for new users.
Offers great visualization to help you interpret your data.
You can remotely access and navigate another database server.
The window-based interface makes it much easier to manage your PostgreSQL data.
Easier access to files, features, and the operating system.
So, bottom line, GUI tools make PostgreSQL developers’ lives easier.
Top PostgreSQL GUI Tools
Today I will tell you about the 6 best PostgreSQL GUI tools. If you want a quick overview of this article, feel free to check out our infographic at the end of this post. Let’s start with the first and most popular one.
1. pgAdmin
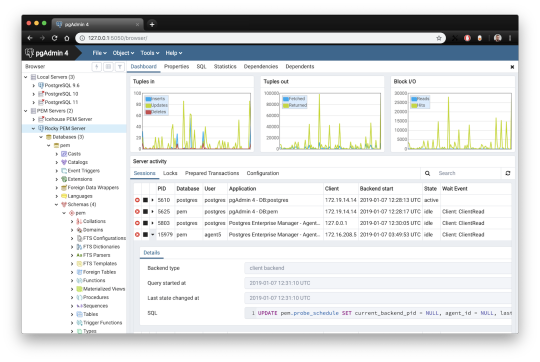
pgAdmin is the de facto GUI tool for PostgreSQL, and the first tool anyone would use for PostgreSQL. It supports all PostgreSQL operations and features while being free and open source. pgAdmin is used by both novice and seasoned DBAs and developers for database administration.
Here are some of the top reasons why PostgreSQL users love pgAdmin:
Create, view and edit on all common PostgreSQL objects.
Offers a graphical query planning tool with color syntax highlighting.
The dashboard lets you monitor server activities such as database locks, connected sessions, and prepared transactions.
Since pgAdmin is a web application, you can deploy it on any server and access it remotely.
pgAdmin UI consists of detachable panels that you can arrange according to your likings.
Provides a procedural language debugger to help you debug your code.
pgAdmin has a portable version which can help you easily move your data between machines.
There are several cons of pgAdmin that users have generally complained about:
The UI is slow and non-intuitive compared to paid GUI tools.
pgAdmin uses too many resources.
pgAdmin can be used on Windows, Linux, and Mac OS. We listed it first as it’s the most used GUI tool for PostgreSQL, and the only native PostgreSQL GUI tool in our list. As it’s dedicated exclusively to PostgreSQL, you can expect it to update with the latest features of each version. pgAdmin can be downloaded from their official website.
pgAdmin Pricing: Free (open source)
2. DBeaver

DBeaver is a major cross-platform GUI tool for PostgreSQL that both developers and database administrators love. DBeaver is not a native GUI tool for PostgreSQL, as it supports all the popular databases like MySQL, MariaDB, Sybase, SQLite, Oracle, SQL Server, DB2, MS Access, Firebird, Teradata, Apache Hive, Phoenix, Presto, and Derby – any database which has a JDBC driver (over 80 databases!).
Here are some of the top DBeaver GUI features for PostgreSQL:
Visual Query builder helps you to construct complex SQL queries without actual knowledge of SQL.
It has one of the best editors – multiple data views are available to support a variety of user needs.
Convenient navigation among data.
In DBeaver, you can generate fake data that looks like real data allowing you to test your systems.
Full-text data search against all chosen tables/views with search results shown as filtered tables/views.
Metadata search among rows in database system tables.
Import and export data with many file formats such as CSV, HTML, XML, JSON, XLS, XLSX.
Provides advanced security for your databases by storing passwords in secured storage protected by a master password.
Automatically generated ER diagrams for a database/schema.
Enterprise Edition provides a special online support system.
One of the cons of DBeaver is it may be slow when dealing with large data sets compared to some expensive GUI tools like Navicat and DataGrip.
You can run DBeaver on Windows, Linux, and macOS, and easily connect DBeaver PostgreSQL with or without SSL. It has a free open-source edition as well an enterprise edition. You can buy the standard license for enterprise edition at $199, or by subscription at $19/month. The free version is good enough for most companies, as many of the DBeaver users will tell you the free edition is better than pgAdmin.
DBeaver Pricing
: Free community, $199 standard license
3. OmniDB
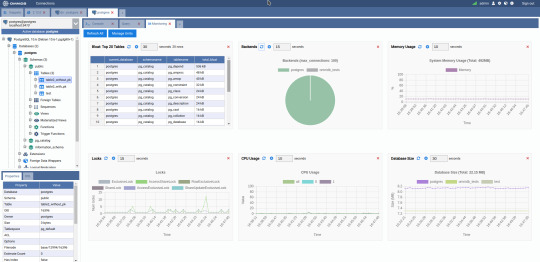
The next PostgreSQL GUI we’re going to review is OmniDB. OmniDB lets you add, edit, and manage data and all other necessary features in a unified workspace. Although OmniDB supports other database systems like MySQL, Oracle, and MariaDB, their primary target is PostgreSQL. This open source tool is mainly sponsored by 2ndQuadrant. OmniDB supports all three major platforms, namely Windows, Linux, and Mac OS X.
There are many reasons why you should use OmniDB for your Postgres developments:
You can easily configure it by adding and removing connections, and leverage encrypted connections when remote connections are necessary.
Smart SQL editor helps you to write SQL codes through autocomplete and syntax highlighting features.
Add-on support available for debugging capabilities to PostgreSQL functions and procedures.
You can monitor the dashboard from customizable charts that show real-time information about your database.
Query plan visualization helps you find bottlenecks in your SQL queries.
It allows access from multiple computers with encrypted personal information.
Developers can add and share new features via plugins.
There are a couple of cons with OmniDB:
OmniDB lacks community support in comparison to pgAdmin and DBeaver. So, you might find it difficult to learn this tool, and could feel a bit alone when you face an issue.
It doesn’t have as many features as paid GUI tools like Navicat and DataGrip.
OmniDB users have favorable opinions about it, and you can download OmniDB for PostgreSQL from here.
OmniDB Pricing: Free (open source)
4. DataGrip

DataGrip is a cross-platform integrated development environment (IDE) that supports multiple database environments. The most important thing to note about DataGrip is that it’s developed by JetBrains, one of the leading brands for developing IDEs. If you have ever used PhpStorm, IntelliJ IDEA, PyCharm, WebStorm, you won’t need an introduction on how good JetBrains IDEs are.
There are many exciting features to like in the DataGrip PostgreSQL GUI:
The context-sensitive and schema-aware auto-complete feature suggests more relevant code completions.
It has a beautiful and customizable UI along with an intelligent query console that keeps track of all your activities so you won’t lose your work. Moreover, you can easily add, remove, edit, and clone data rows with its powerful editor.
There are many ways to navigate schema between tables, views, and procedures.
It can immediately detect bugs in your code and suggest the best options to fix them.
It has an advanced refactoring process – when you rename a variable or an object, it can resolve all references automatically.
DataGrip is not just a GUI tool for PostgreSQL, but a full-featured IDE that has features like version control systems.
There are a few cons in DataGrip:
The obvious issue is that it’s not native to PostgreSQL, so it lacks PostgreSQL-specific features. For example, it is not easy to debug errors as not all are able to be shown.
Not only DataGrip, but most JetBrains IDEs have a big learning curve making it a bit overwhelming for beginner developers.
It consumes a lot of resources, like RAM, from your system.
DataGrip supports a tremendous list of database management systems, including SQL Server, MySQL, Oracle, SQLite, Azure Database, DB2, H2, MariaDB, Cassandra, HyperSQL, Apache Derby, and many more.
DataGrip supports all three major operating systems, Windows, Linux, and Mac OS. One of the downsides is that JetBrains products are comparatively costly. DataGrip has two different prices for organizations and individuals. DataGrip for Organizations will cost you $19.90/month, or $199 for the first year, $159 for the second year, and $119 for the third year onwards. The individual package will cost you $8.90/month, or $89 for the first year. You can test it out during the free 30 day trial period.
DataGrip Pricing
: $8.90/month to $199/year
5. Navicat

Navicat is an easy-to-use graphical tool that targets both beginner and experienced developers. It supports several database systems such as MySQL, PostgreSQL, and MongoDB. One of the special features of Navicat is its collaboration with cloud databases like Amazon Redshift, Amazon RDS, Amazon Aurora, Microsoft Azure, Google Cloud, Tencent Cloud, Alibaba Cloud, and Huawei Cloud.
Important features of Navicat for Postgres include:
It has a very intuitive and fast UI. You can easily create and edit SQL statements with its visual SQL builder, and the powerful code auto-completion saves you a lot of time and helps you avoid mistakes.
Navicat has a powerful data modeling tool for visualizing database structures, making changes, and designing entire schemas from scratch. You can manipulate almost any database object visually through diagrams.
Navicat can run scheduled jobs and notify you via email when the job is done running.
Navicat is capable of synchronizing different data sources and schemas.
Navicat has an add-on feature (Navicat Cloud) that offers project-based team collaboration.
It establishes secure connections through SSH tunneling and SSL ensuring every connection is secure, stable, and reliable.
You can import and export data to diverse formats like Excel, Access, CSV, and more.
Despite all the good features, there are a few cons that you need to consider before buying Navicat:
The license is locked to a single platform. You need to buy different licenses for PostgreSQL and MySQL. Considering its heavy price, this is a bit difficult for a small company or a freelancer.
It has many features that will take some time for a newbie to get going.
You can use Navicat in Windows, Linux, Mac OS, and iOS environments. The quality of Navicat is endorsed by its world-popular clients, including Apple, Oracle, Google, Microsoft, Facebook, Disney, and Adobe. Navicat comes in three editions called enterprise edition, standard edition, and non-commercial edition. Enterprise edition costs you $14.99/month up to $299 for a perpetual license, the standard edition is $9.99/month up to $199 for a perpetual license, and then the non-commercial edition costs $5.99/month up to $119 for its perpetual license. You can get full price details here, and download the Navicat trial version for 14 days from here.
Navicat Pricing
: $5.99/month up to $299/license
6. HeidiSQL
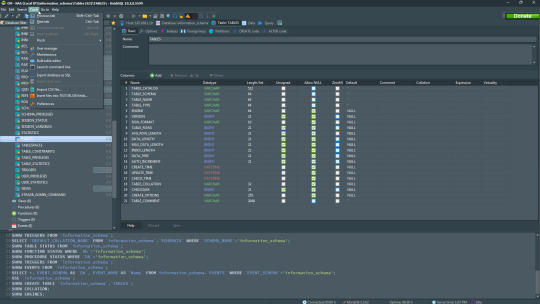
HeidiSQL is a new addition to our best PostgreSQL GUI tools list in 2021. It is a lightweight, free open source GUI that helps you manage tables, logs and users, edit data, views, procedures and scheduled events, and is continuously enhanced by the active group of contributors. HeidiSQL was initially developed for MySQL, and later added support for MS SQL Server, PostgreSQL, SQLite and MariaDB. Invented in 2002 by Ansgar Becker, HeidiSQL aims to be easy to learn and provide the simplest way to connect to a database, fire queries, and see what’s in a database.
Some of the advantages of HeidiSQL for PostgreSQL include:
Connects to multiple servers in one window.
Generates nice SQL-exports, and allows you to export from one server/database directly to another server/database.
Provides a comfortable grid to browse and edit table data, and perform bulk table edits such as move to database, change engine or ollation.
You can write queries with customizable syntax-highlighting and code-completion.
It has an active community helping to support other users and GUI improvements.
Allows you to find specific text in all tables of all databases on a single server, and optimize repair tables in a batch manner.
Provides a dialog for quick grid/data exports to Excel, HTML, JSON, PHP, even LaTeX.
There are a few cons to HeidiSQL:
Does not offer a procedural language debugger to help you debug your code.
Built for Windows, and currently only supports Windows (which is not a con for our Windors readers!)
HeidiSQL does have a lot of bugs, but the author is very attentive and active in addressing issues.
If HeidiSQL is right for you, you can download it here and follow updates on their GitHub page.
HeidiSQL Pricing: Free (open source)
Conclusion
Let’s summarize our top PostgreSQL GUI comparison. Almost everyone starts PostgreSQL with pgAdmin. It has great community support, and there are a lot of resources to help you if you face an issue. Usually, pgAdmin satisfies the needs of many developers to a great extent and thus, most developers do not look for other GUI tools. That’s why pgAdmin remains to be the most popular GUI tool.
If you are looking for an open source solution that has a better UI and visual editor, then DBeaver and OmniDB are great solutions for you. For users looking for a free lightweight GUI that supports multiple database types, HeidiSQL may be right for you. If you are looking for more features than what’s provided by an open source tool, and you’re ready to pay a good price for it, then Navicat and DataGrip are the best GUI products on the market.
Ready for some PostgreSQL automation?
See how you can get your time back with fully managed PostgreSQL hosting. Pricing starts at just $10/month.
While I believe one of these tools should surely support your requirements, there are other popular GUI tools for PostgreSQL that you might like, including Valentina Studio, Adminer, DB visualizer, and SQL workbench. I hope this article will help you decide which GUI tool suits your needs.
Which Is The Best PostgreSQL GUI? 2019 Comparison
Here are the top PostgreSQL GUI tools covered in our previous 2019 post:
pgAdmin
DBeaver
Navicat
DataGrip
OmniDB
Original source: ScaleGrid Blog
3 notes
·
View notes
Text
A DATA INTEGRATION APPROACH TO MAXIMIZE YOUR ROI
The data Integration approach adopted by many data integration projects relies on a set of premium tools leading to cash burnout with RoI less than the standard.
To overcome this and to maximize the RoI, we lay down a data integration approach that makes use of open-source tools over the premium to deliver better results and an even more confident return on the investment.

Adopt a two-stage data integration approach:
Part 1 explains the process of setting up technicals and part 2 covers the execution approach involving challenges faced and solutions to the same.
Part 1: Setting Up
The following are the widely relied data sources:
REST API Source with standard NoSQL JSON (with nested datasets)
REST API Source with full data schema in JSON
CSV Files in AWS S3
Relational Tables from Postgres DB
There are 2 different JSON types above in which the former is conventional, and the latter is here
Along with the data movement, it is necessary to facilitate Plug-n-Play architecture, Notifications, Audit data for Reporting, Un-burdened Intelligent scheduling, and setting up all the necessary instances.
The landing Data warehouse chosen was AWS Redshift which is a one-stop for the operational data stores (ODS) as well as facts & dimensions. As said, we completely relied on open-source tools over the tools from tech giants like Oracle, Microsoft, Informatica, Talend, etc.,
The data integration was successful by leveraging Python, SQL, and Apache Airflow to do all the work. Use Python for Extraction; SQL to Load & Transform the data and Airflow to orchestrate the loads via python-based scheduler code. Below is the data flow architecture.
Data Flow Architecture
Part 2: Execution
The above data flow architecture gives a fair idea of how the data was integrated. The execution is explained in parallel with the challenges faced and how they were solved.
Challenges:
Plug-n-Play Model.
Dealing with the nested data in JSON.
Intelligent Scheduling.
Code Maintainability for future enhancements.
1. Plug-n-Play Model
To meet the changing business needs, the addition of columns or a datastore is obvious and if the business is doing great, expansion to different regions is apparent. The following aspects were made sure to ensure a continuous integration process.
A new column will not break the process.
A new data store should be added with minimal work by a non-technical user.
To bring down the time consumed for any new store addition(expansion) integration from days to hours.
The same is achieved by using:
config table which is the heart of the process holding all the jobs needed to be executed, their last extract dates, and parameters for making the REST API call/extract data from RDBMS.
Re-usable python templates which are read-modified-executed based on the parameters from the config table.
Audit table for logging all the crucial events happening whilst integration.
Control table for mailing and Tableau report refreshes after the ELT process
By creating state-of-art DAGs which can generate DAGs(jobs) with configuration decided in the config table for that particular job.
Any new table which is being planned for the extraction or any new store being added as part of business expansion needs its entries into the config table.
The DAG Generator DAG run will build jobs for you in a snap which will be available in Airflow UI on the subsequent refresh within seconds, and the new jobs are executed on the next schedule along with existing jobs.
2. Dealing with the nested data in JSON.
It is a fact that No-SQL JSONS hold a great advantage from a storage and data redundancy perspective but add a lot of pain while reading the nested data out of the inner arrays.
The following approach is adopted to conquer the above problem:
Configured AWS Redshift Spectrum, with IAM Role and IAM Policy as needed to access AWS Glue Catalog and associating the same with AWS Redshift database cluster
Created external database, external schema & external tables in AWS Redshift database
Created AWS Redshift procedures with specific syntax to read data in the inner array
AWS Redshift was leveraged to parse the data directly from JSON residing in AWS S3 onto an external table (no loading is involved) in AWS Redshift which was further transformed to rows and columns as needed by relational tables.
3. Intelligent Scheduling
There were multiple scenarios in orchestration needs:
Time-based – Batch scheduling; MicroELTs ran to time & again within a day for short intervals.
Event-based – File drop in S3
For the batch scheduling, neither the jobs were run all in series (since it is going to be an underutilization of resources and a time-consuming process) nor in parallel as the workers in airflow will be overwhelmed.
A certain number of jobs were automated to keep running asynchronously until all the processes were completed. By using a python routine to do intelligent scheduling. The code reads the set of jobs being executed as part of the current batch into a job execution/job config table and keeps running those four jobs until all the jobs are in a completed/failed state as per the below logical flow diagram.
Logical Flow Diagram
For Event-based triggering, a file would be dropped in S3 by an application, and the integration process will be triggered by reading this event and starts the loading process to a data warehouse.
The configuration is as follows:
CloudWatch event which will trigger a Lambda function which in turn makes an API call to trigger Airflow DAG
4. Code Maintainability for future enhancements
A Data Integration project is always collaborative work and maintaining the correct source code is of dire importance. Also, if a deployment goes wrong, the capability to roll back to the original version is necessary.
For projects which involve programming, it is necessary to have a version control mechanism. To have that version control mechanism, configure the GIT repository to hold the DAG files in Airflow with Kubernetes executor.
Take away:
This data integration approach is successful in completely removing the premium costs while decreasing the course of the project. All because of the reliance on open-source tech and utilizing them to the fullest.
By leveraging any ETL tool in the market, the project duration would be beyond 6 months as it requires building a job for each operational data store. The best-recommended option is using scripting in conjunction with any ETL tool to repetitively build jobs that would more or less fall/overlap with the way it is now executed.
Talk to our Data Integration experts:
Looking for a one-stop location for all your integration needs? Our data integration experts can help you align your strategy or offer you a consultation to draw a roadmap that quickly turns your business data into actionable insights with a robust Data Integration approach and a framework tailored for your specs.
1 note
·
View note
Text
300+ TOP SSRS Interview Questions and Answers
SSRS Interview Questions for freshers experienced :-
1. What is Query parameter in SSRS? Query parameters is mentioned in the query of the datasources that are to be included into the SQL script’s WHERE clause of the SQL that can accept parameters. Query parameters begin with the symbol @.The name should not contain spaces and can not begin with numeral. For clarity, we use only letters. 2. What are the Reporting Service Components in SSRS? Report Designer: A place where we can create report. Report Server: Provides services for implementation and delivery of reports. Report Manager: A Web-based administration tool for managing the Report Server. 3. What is a matrix in SSRS? A matrix is a data region linked to a report set. Matrix allows us to create crosstab reports with the report variables displaying on rows and columns. It allows us to drag and drop fields into it. 4. What are sub reports and how to create them? A sub report is like any other reports which can be called in main report and can be generate through main report. Parameters can be passed from main report to sub report and basis of that report can be generated. 5. What is the report model project? Report model project is for creating Adhoc reporting. You can create the adhoc reports through report builder. Report model project can be created on bids or report server. This model can have simple view. And using 6. What is report server project? Report Server Project contains the RDL file and it need to be deployed on report server to view the report files to application and user. It a solution where we design our reports. You can add it by going into BIDS clicking on new item and then selecting reports server project. Once the solution is created you can start creating reports. 7. What is the report builder? Report builder is used to create small reports and it a define interface. You can’t change the report interface in report builder it pre designed. You can just drag columns in the report. Report builder creates reports on database objects available with report model project. 8. In which SQL Server version report builder introduced? Report builder introduced in SQL Server 2005. While creating or deploying report model project on report server you can get error or it might not get created. For this you need to check whether the service pack 22 is installed or not. 9. How to deploy the Report? Report can be deployed in three ways. Using visual studio: In visual studio you can directly deploy the report through solution explorer by providing the report server URL in project properties at Target Server URL. This will deploy entire project or single report as per you selection. Using report server: Can directly go to the report server and deploy the report by browsing the report from the disk location on server. Creating the utility: SQL server provides the utility using that which can be used to create a customize utility for your report deployment in bulk. 10. What is RS.exe utility? Rs.exe utility is used for deploying the report on report server. It comes with the report server and can be customize accordingly.

SSRS Interview Questions 11. What is the name of reporting services config file and what’s it’s used for? Reporting service config file is used for report configuration details. It contains the report format and also the report import types. Report service config reside at ISS. 12. What are the three different part of RDL file explain them? In visual studio RDL files has three parts. Data: It contains the dataset on which we write the query. Data set is connected with data source. Design: In design you can design report. Can create tables and matrix reports. Drag columns values from source. Preview: to check the preview after the report run. 13. Which language rdl files made of? RDL files are written in XML. 14. What is the chart in report? Chart reports are for graphical representation. You can get pie charts columns harts and various other options. 3d charts are also available in reporting services. 15. What is Data Set in report? Data set are the set of data which we want to show in report. Data creates on data source. Data source is the source of data from where we are getting this data i.e. database server and database name connection string. 16. What are the different types of data sources in SSRS? SSRS use different data source. Some of them are listed below. Microsoft SQL Server OLEDB Oracle ODBC SQL Server Analysis Service Report Server Model SAP Net weaver BI Hyperion Teradata XML 17. What is the web service used for reporting services? Reporting Service Web Service used in SSRS. By accessing this web service you can access all report server component and also get the report deployed on report server. 18. How to add the custom code in Report? To add the custom codes in report go to report tab on top then properties and there you will find the options for custom code. 19. What is a cache in SSRS? Report server can lay up a copy of processed report in a memory and return the copy when a user opens the report. This server memory is known as cache and the process is called caching. 20. What is report snapshot in SSRS? Report snapshot is a report which contains layout information and a dataset that is extracted at a particular point of time. When the new snapshot is created the previous report snapshot will be overwritten. 21. What is bookmark link in SSRS? Bookmark is a link which a person clicks to shift to a different area or page in a report. We can insert bookmarks links only to textboxes and images. 22. What is Command parameter in SSRS? A Command parameter is used to forward protocol to the Report Server regarding the item that has been retrieved. Command parameter is also used for rearranging a user’s session information. 23. What is Format parameter in SSRS? Format parameter is used to control report output. Every delivering format on Report Server has to pass through this parameter. 24. What is Snapshot parameter in SSRS? When a report is saved in a snapshot history, it is allocated a time or date to uniquely identify that report. Snapshot parameter is used to get back these historical reports by passing this time or date to get proper report. 25. What are the rendering extensions of SSRS? Rendering extensions manage the category of document produced when a report is processed. Rendering Extensions are: HTML, MHTML, EXCEL, CSV, IMAGE, PDF, and XML. 26. What are the three command line utilities and what are their primary functions? The three command line utilities include RsConfig.exe: It is used to determine the connection properties from the SSRS instance to the Report Server database RsKeyMgmet.exe: It executes scale out deployment set-up and encryption key operations Rs.exe: It executes Report server Script files which can perform management operations and report deployment 27. How you can deploy an SSRS report? SSRS report can be deployed in three ways By Visual Studio: You can directly deploy the report in Visual Studios through solution explorer, by declaring the report server URL in project properties at Target Server URL. By Report Server: By browsing the report from the disk location of the server you can deploy the report to report server By creating the Utility: Another option is to create customized utility to deploy the report 28. What method you can use to reduce the overhead of Reporting Services data sources? Cached reports and Snapshots can be used to reduce the overhead of Reporting Services Sources. 29. What is the difference between Tabular and Matrix report? Tabular Report: Tabular report is the most basic type of report. Each column relates to a column chosen from the database Matrix Report: A matrix report is a cross-tabulation of four groups of data. 30. How would you store your query in an SSRS report or a Database server? Storing SQL queries directly in text format in the data should be avoided. Instead, it should be stored in a stored procedure in the database server. The advantage is that the SQL would be in a compiled format in an SP and gives all the benefits of SP compared to using an ad-hoc query from the report. SSRS Questions and Answers Pdf Download Read the full article
0 notes
Text
Using 7 Mysql Strategies Like The Pros
MySQL gives you Let to host lots of databases and it is named by you. Using MySQL and PHPMyAdmin ( my favorite management GUI ) has enabled me to insource numerous solutions we used to cover.
MySql is a database application of It is FREE on media and small scales business, it is supported on systems that were considered. Since 2009 Oracle buy Sun Microsystems ( such as MySQL ) to get 7.5 billons inducing user and programmers to start to debate the fate of their open - source database.
Almost any operating system and is operated in by mySQL Includes a controlled rate that is good I think it's the database manager together with all the rate of reaction to the procedures. Subqueries were one of the significant flaws of MySQL for quite a very long time; it had been notorious for dropping its way using a few degrees of sub-questions.
With MySQL, on the other hand, the Customer library is GPL, and that means you need to pay a commercial charge to Oracle or provide the source code of your program.PostgreSQL additionally supports data about data types, purposes and access methods from the system catalogs together with the typical information regarding databases, tables, and columns which relational databases maintain.

There are ways around the MySQL client library's licensing, the Route Atlassian decide to choose would be telling you where to get the JDBC connector out of for MySQL if you would like to join your Atlassian programs to a MySQL 38, and in which to drop the jar.
Seasoned staff if You'd like competently Accessible on-call assistance without paying serious cash ( DB2 or Oracle - degree paying ) Percona ( and MySQL ) is the friend. Matt Aslett of 451 Research unites ScaleBase to talk: scaling - outside of your MySQL DB, high availability strategies that are fresh, smartly managing a MySQL environment that is dispersed.
Conclusion Scalability is a matter of a theoretical Number of nodes It is also about the capacity to provide predictable performance And also to do this without adding management sophistication, proliferation of cloud, and geo-dispersed programs are adding to the sophistication MySQL hasn't been under so much strain that the mixture of innovative clustering/load balancing and management technology provides a possible solution ( c ) 2013 from The 451 Group.
Flexibility: no need to oversupply Online data Redistribution No downtime Read / Write dividing Optimal for scaling read - intensive software Replication lag - established routing Enhances data consistency and isolation Read stickiness following writes Ensure consistent and dispersed database functioning 100% compatible MySQL proxy Software unmodified Standard MySQL interfaces and tools MySQL databases unmodified Info is protected within MySQL InnoDB / MyISAM / etc.
The dilemma is solved by database encryption, but Once the root accounts are compromised, it can't prevent access. You get rid of the ability of SQL, although application level encryption has become easily the most flexible and protected - it is pretty difficult to use columns in WHERE or JOIN clauses.
It is possible to incorporate with Hashicorp Vault server through A keyring_vault plugin, fitting ( and even expanding - binary log encryption ) the features available in Oracle's MySQL Enterprise version. Whichever MySQL taste you use, so long as it's a current version, you'd have choices to apply data at rest encryption through the database server, so ensuring your information is also secured.
Includes storage - engine frame that System administrators to configure the MySQL database for performance. Whether your system is Microsoft Linux, Macintosh or UNIX, MySQL is a solution that is comprehensive with self - handling features that automate all from configuration and space expansion to database management and information design.
By migrating database programs that are current to MySQL, businesses are currently enjoying substantial cost savings on jobs that are brand new. MySQL is an open source, multi-threaded, relational database management system ( RDBMS ) written in C and C++.
The server is Acceptable for assignment - Critical, heavy - load production systems in addition to for embedding into mass installed applications. MySQL is interactive and straightforward to use, in comparison to other DBMS applications and is protected with a data protection layer providing information with encryption.
MariaDB is a general - purpose DBMS engineered with extensible Structure to support a wide group of use cases through pluggable storage engines.MySQL users may get tens of thousands of metrics in the database, and so this guide we will concentrate on a small number of important metrics that will let you obtain real-time insight into your database wellbeing and functionality.
Users have a number of options for monitoring Latency, by taking advantage of MySQL's both built-in metrics and from querying the operation schema. The default storage engine, InnoDB of MySQL, utilizes an area of memory known as the buffer pool to indexes and tables.
Since program databases -- and information warehouses -- are Constructed on SQL databases, also because MySQL is among the most well-known flavors of SQL, we compiled a listing of the highest MySQL ETL tools that will assist you to transfer data in and from MySQL database programs. KETL is XML - based and operates with MySQL to develop and deploy complex ETL conversion projects which require scheduling.
Blendo's ETL - as - a - service product makes it Simple to get data From several data sources such as S3 buckets, CSVs, and also a massive selection of third - party information sources such as Google Analytics, MailChimp, Salesforce and many others.
In we, Seravo Migrated all our databases from MySQL into MariaDB in late 2013 and through 2014 we also migrated our client's systems to utilize MariaDB. Dynamic column service ( MariaDB just ) is interesting since it allows for NoSQL form performance, and thus a single database port may offer both SQL and" not just SQL" for varied software project requirements.
MariaDB as the Number of storage motors and in excels Other plugins it ships together: Link and Cassandra storage motors for NoSQL backends or rolling migrations from legacy databases, Spider such as sharding, TokuDB with fractal indexes, etc.
MySQL is a relational database - Standard information schema also is composed of columns, tables, views, procedures, triggers, cursors, etc. MariaDB, therefore, has exactly the database structure and indicator and, on the other hand, is a branch of MySQL. Everything -- from the information, table definitions, constructions, and APIs -- stays identical when updating from MySQL into MariaDB.
MariaDB has experienced an increase in terms of Security features such as internal password and security management, PAM and LDAP authentication, Kerberos, user functions, and robust encryption within tablespaces, logs, and tables. MySQL can not do hash link or sort merge join - it merely can perform nested loops method that demands a lot of index lookups which might be arbitrary.
In MySQL single question runs as only ribbon ( with exception Of MySQL Cluster ) and MySQL problems IO requests one for question implementation, so if only query execution time is the concern many hard drives and the large variety of CPUs won't help.
With table layout and application design, you Can build programs working with huge data collections according to MySQL.OPTIMIZE assists for specific issues - ie it types indexes themselves and removers row fragmentation ( all for MyISAM tables ).
Even though it's Booted up to 8 TB, MySQL can't operate effectively with a large database. Mysql continues to be my favorite database because I started programming, so it's simple to install, it is easy to obtain an application that links to the database and perform the management in a graphical manner, many articles supervisors and e-commerce stores utilize MySQL by default, and it has let me execute many projects, I enjoy that many hosting providers have MySQL tutorial service at no extra price.
Mysql is fast the setup, and light requirements Are minimal and with few tools, I've used it in Windows and Linux with no difficulty in either, but the server operating system hasn't been a restriction and that I utilize it in a Linux environment whenever it is potential.
MySQL provides its code Beneath the GPL and gives the choice of Non - GPL commercial supply in the kind of MySQL Enterprise. MariaDB also supplies motor - separate table numbers to enhance the optimizer's functionality, speeding up query processing and data evaluation on the dimensions and arrangement of their tables.
Utilization in MySQL is sub - InnoDB and Optimum tables eventually become fragmented over time, undermining functionality. Shifting from MySQL into MariaDB is relatively simple and is a slice of cake for most systems administrators.
For program, Example Hosts ( even though they need to be okay with attaining MySQL via proxies ), the proxy layer, and perhaps a management host. You ought to check of the logs and settings files and confirm that they're not readable by others.
Data may be moved between MySQL servers, For instance via MySQL replication that is regular or inside a Galera cluster. Flexibility is incorporating the features your company needs, although pushing arbitrary JSON seems elastic.
Among those enterprise qualities, Informix relational Databases, recently launched a new variant ( v12.10. XC2 ) which supports JSON / BSON info as a native from inside the relational database frame and fully supports each the MongoDB APIs so that any program is composed to the MongoDB, protocol may just be pointed in the Informix server and it'll just work.
On top of the IBM Engineers ( Informix Is currently an IBM product ) extended the JSON kind to encourage files Up to 2 GB in size ( MongoDB limitations files to 16 MB). In MySQL and Oracle, working memory Is shared links because links Are serviced by a single procedure.
Noted Also :⇒ Use Of Quit SEO In 5 Days
0 notes
Text
Concerning Data source Migration
Data source migration is the method of transferring databasesbetween storage types, formats, or pcs. Companies and organizations might need to mssql to mysql converter for numerous reasons, including server or storage equipment replacements, maintenance or upgrades, application migration, website consolidation information center relocation.The method involves transfer of all database objects and categories: table definitions, data, indexes, constraints, views, triggers, stored procedures and functions, user accounts, roles and permissions.
Databases might be migrated manually or programmatically by using special software named database migration tools. Manual process usually includes these steps: • export table definitions along with indexes and constraints in the source database in form of SQL statements • convert these statements in to the destination format and import on the target database • export data from your source database into an intermediate storage like comma separated values (CSV) files • transform the dataaccording towards the destination format and cargo it for the target database • extract views, stored procedures/functions and triggers from the original database healthy of SQL statements and code • convert these statements and code into the destination format and load into the target database After loading in to the new system, resulting datahas to beverified to be able to decide if database was accurately migrated, is complete and has appropriate supports for applications in the new system. It might be necessary to run both source and destination database systems simultaneously during verification to distinguish areas of disparity, forestall loss of data or corruption. For giant and complex database projectsmigration is usually performed programmatically to realize a computerized process flow, liberating hours from tedious tasks. It's very important to decide on the appropriate tool emigrate the database within the required timeframe without data loss or corruption. Here's listing of main features that really must be furnished by excellent database migration tools: • all latest versions of source and } destination DBMS are supported • table definitions, indexes and constraints are converted with all of necessary attributes • conversion options has to be stored in to a profile for next use • full Unicode support • option to modify types mapping, conversion rules, etc • command line support • comprehensive documentation and 24/7 support service You can find amount of software companies that offer dedicated tools to automate database migration. Among such companies is Intelligent Converters dedicated to database conversion, migration and synchronization since 2001. They develop great deal of conversion tool to migrate databases between preferred database management systems like PostgreSQL, MySQL, Oracle, SQL Server, Azure SQL, Microsoft Access, FoxPro and SQLite. Visit https://www.convert-in.com/for more details about Intelligent Converters as well as their software.
0 notes
Text
300+ TOP COGNOS ReportNet Interview Questions and Answers
COGNOS ReportNet Interview Questions for freshers experienced :-
1. What is the main advantage of impromptu over cognos reportnet? One of the advantage's of Reportnet, is 1. It is web-based reporting wherein, reports can be easily accessed from anywhere through a browser. by using ipromptu we can use multidimensional analysis to see the data in diff formates.i.e we have drillup,drilldown features in cognos impromtu,but it is not possible in reportnet. 2. What is the difference between Native SQL and Cognos SQL? In cognos reportnet Native SQL is used for the single datasource to import the meta data Cognos SQL used for multiple datasources to import the metadata 3. What is the Difference between PowerPlay transformer and power play reports? 'Powerplay transformer' is an 'MOLAP' tool using which one can create multi dimensional structure called "CUBE". 'Powerplay for reports' is used to generate report from the cube.Only one report can be generated from one cube.If u want 'n' reports u must create 'n' cubes. 4. Is there any comparison available for Cognos Reportnet Vs Crystal reports? There is a lot of difference between Crystal reports an Cognos Report net. Crystal report is a product of Business Objects where as Reportnet is of cognos. Cryatal reports is for only low 2 midrange analysis and that to some even says tha they wont use this for analysis used to make proper strategic decision But report net yes it is for high end analysis. In reportnet we can login through web and can create our own desired report through web. 5. How do i allow a dynamic selection of a column for a measure in a chart,without using Variable You can in do it in this way. first creat a list report in which u have a calculated item in the starting. Then creat a prompt page with a value prompt.In value prompt creat static choice of which u want to be dynamically displayed. Let the parameter of value prompt be ?Par1? and the choices as Revenue, Cost. Now u write the expression of the calculated item in the report page as follows, "If ?Par1?=Revenue then Revenue else Cost. Here Revenue,Cost should b dragged from the Model Items. So now the calculated item column displays the value of the one selected in the prompt. Now make a graph using the list report,then place the calculated item on the axis of the chart ,which u wanted to display dynamically based on ur selection. So now if u select Revenue in the prompt then the grph will take the values for Revenue.And if u select Cost then graph will be with the values of Cost. 6. How do we drill through from a powerplay cube to reportnet? Setting up drill-through access from PowerPlay Web to ReportNet involves configuring Cognos Series 7 for drill-through access to ReportNet preparing the Transformer model and cube copying the search path of the folder that contains the target report enabling the cube for drill-through access to ReportNet deciding which filters to create in the target report creating the target report disabling the Drill Through Assistant 7. What are versions of reportnet? In ReprotNet have two vertions ReportNet 1.0 ReportNet 1.1 MR1, MR2 8. What is prompt?types of prompts?use of prompts?syntax of prompt? Prompts act as questions that help users to customize the information in a report to suit their own needs.The different types of Prompt are Value prompt Text Prompt Date prompt Time prompt Date and time prompt Using prompts is faster and easier than repeatedly changing the filter. Cognos Report Studio provides several ways to create prompts. You can use the Build Prompt Page tool build your own prompt and prompt page create a parameter to produce a prompt create a Prompt directly in a report page 9. What is difference between qurry studio and report studio? Query Studio: Used to create Ad-hoc (or) simple reports. It does not provide any pre-defined report templates. It directly displays data (without running the report) when we insert attributes in the report. Report Studio: Used to create complex reports. It provides pre-defined report templates. It does not display the data directly in the report. We need to run the report to display the data. 10. What are components of report studio? Componenets of Report Studio: Insertable Objects pane. Properties pane. Explorer bar - Conditional Explorer, Query Explorer, Page Explorer. Report Viewer - Workarea, Report Layout Objects.

COGNOS ReportNet Interview Questions 11. What are necessary tasks to install reportnet software You need to do the following for a standard installation process: Verify your system requirements like RAM Minimum: 512 MB, a Web server installed and started Review the ReportNet default settings like default ReportNet ports and URI settings. Create the database for the content store which means you must create the database that is used for the content store using either Oracle, Microsoft SQL Server, or DB2 UDB. ReportNet uses this database to store, organize, and retrieve information. Install ReportNet: Use the installation wizard to select the components you want to install and the location on your computer where you want to install them. Set up the database client for the content store (Oracle and DB2): If you use Oracle or DB2 as the database server for the content store, additional steps are required after you install ReportNet before you can configure ReportNet. you need to go to the 6th step only when installing on UNIX. For Windows above 5 steps are good. Update Your Java Environment: Before you can use the cryptographic operations, such as data encryption and key management, implemented by ReportNet, you must check that the required JAR (Java Archive) files are present in your Java Runtime Environment (JRE). 12. What are components of reportnet? ReportNet has a three-tier architecture, namely, (1) Web server (2) Applications and (3) Data. The tiers are based on business function, and are typically separated by firewalls. ReportNet user interfaces sit above the tiers.ReportNet user interfaces include (a) Web-based Cognos Connection, Cognos Report Studio, and Query Studio (b) Windows-based Framework Manager 13. How do we provide security in frame work manager for a query subject? procedure for providing security for query subject in frame work manager is: select querysubject -> in properties pane select ->security filters(click on edit)a specify data security wizard appears->click on add groups -> cognosnamesspace(select users and groups wizard opens) 14. I want to display zero when null values coming to report how can I do that? You can follow this procedure :- Lets assume revenue is the field in which we have to display null values as 0. First create a calculated item and Then write the expression of the cal item using If Then Else construct as If (Revenue is null) Then ('0') Else(Revenue) I think u can easily understand this. Now u can see that the null values r displayed as '0' in the calculated item. Select the data item in which you want to replace null with 0 .Go to Properties pane, Click Data Format, in this put 0 in Missing value Characters. 15. How can i create prompts in report net Prompts is mean by the end user can be filter the data. you can open the explore bar and added the new prompts page, And enter the new name. you go to tool menu and track prompts button you select prompts and then ok 16. Difference between filter and conditin The difference between Filter and Condition:Condition returns true or false Ex: if Country = 'India' then ...Filter will return two types of results1.Detail information which is equal to where clause in SQL statement2.Summary information which is equal to Group by and Having clause in SQL statement 17. Can report net connect multiple datasource at a time in report creation time Yes it can connect multiple datasources at a time when the frame work manager has the metta data regarding that datasources. 18. How can i test report in reportnet If we wanna test the report in report net, first we can intially check by validating it in the report page. After that we can test the out put of the report Using a sql anlyser and sql query.so here we will be comparing the sql analyzer output with the output of the report viewer. 19. What are the various file formats involved in reportnet? It has six (6) formats in report net. They are HTML, PDF, Excel 2000, Excel 2002, CSV, and XML format. We can see the types of formats in the report viewer on the right side . 20. How to generate IQD file from framework manager Create a Query Subject, from the properties pane select externalise,there we have 4 options in that select IQD 21. What is meant by Junk Dimension? The junk dimension is simply a structure that provides a convenient place to store the junk attributes".It's randomly used dimension. 22. what are semi and non additive measures.. 1.Semi-Additive: Semi-additive facts are facts that can be summed up for some of the dimensions in the fact table, but not the others. 2.Non-Additive: Non-additive facts are facts that cannot be summed up for any of the dimensions present in the fact table. Current Balance and Profit Margin are the facts. Current Balance is a semi-additive fact, as it makes sense to add them up for all accounts (what's the total current balance for all accounts in the bank?), but it does not make sense to add them up through time (adding up all current balances for a given account for each day of the month does not give us any useful information). Profit Margin is a non-additive fact, for it does not make sense to add them up for the account level or the day level. 23. What is catalog and types of catalogs in cagonos and which is better? catalog is a data base and also frient hand data base. types of catalog is 4 tyes personal secured shared distributed 24. what is difference between PAGE BREAK and Section Report? Section-section is eliminate the duplicate recod.but report looking separate bluck.setpagebreak means to display the reports in onepage. eg. suppose u create a list report ordermethod,orderyear,revenue when u create section on ordermethod.it will eliminate the duplicate record.but when u apply the set pagebreakc.report display in onepage.like fax reports in onepage,email reports in another page.this in cognos 8 querystudio.But in report studio you can do using propetispan. 25. use this query i am retriving all years OCt data from 01-10-2004 to 30-10-2007 i need to restrect this query to current date and current year ..between 01 and to_number(to_char(current_date,'MM'))and ..=to_number(to_char(current_date,'MM')) pass polar ID A.You have a function called 'extract' in cognos. Ex:- extract(month,the dte field). by giving like this you will get month. so you can keep a filter to restrict the rows only for october. COGNOS ReportNet Questions with Answers Pdf Download Read the full article
0 notes
Text
300+ TOP TABLEAU Interview Questions and Answers
Tableau Interview Questions for freshers experienced :-
1. What is Tableau? Tableau is a business intelligence software that allows anyone to connect to respective data, and then visualize and create interactive, sharable dashboards. 2. Who are the founders of Tableau? The company was founded in Mountain View, California in January, 2003 by Chris Stolte, Christian Chabot and Pat Hanrahan. 3. What is a data Source page? A page where you can set up your data source. The Data Source page generally consists of four main areas: left pane, join area, preview area, and metadata area. 4. What different products Tableau provide ? Tableau Server : on-premise or cloud-hosted software to access the workbooks built. Tableau desktop : desktop environment to create and publish standard and packaged workbooks. Tableau Public : workbooks available publicly online for users to download and access the included data. Tableau Reader : get a local access to open Tableau Packaged workbook. 5. Is Tableau Software good for a strategic acquisition ? Yes for sure! It gives you data insight to the extend that others don’t. Helps u plan and point the anomalies and improvise your process for betterment. 6. Mention the difference between published data sources and embedded data sources in Tableau ? The difference between published data source and embedded data source is that, Published data source: It contains connection information that is independent of any workbook and can be used by multiple workbooks. Embedded data source: It contains connection information and is associated with a workbook. 7. What are some of the new features introduced in Tableau 9.1? Visual analytics Mobile Data Enterprise 8. What is the difference between Tableau and Qlikview? Tableau: More connectors No coding is required Interface is simple Doesn’t render feature to search content across all your data Qlikview: Easy to use and discover the hidden trends Offers a personal edition free Data is stored in qvd form from the performance point of view Great capabilities for processing data. 9. What are the four different kinds of shelves in Tableau? Rows, columns, filters and pages. 10. What is a TreeMap? A treemap is a visual procedure for indicating different leveled data that usages settled square shapes to address the parts of a tree outline. Each square shape has a domain relating to the measure of data it talks. A treemap is produced using a tiling figuring planned to give each square shape a perspective proportion of one and make a sentiment of request in the showcase of the information. 11. When can we use Joins vs. Blending in Tableau ? If data resides in a single source, it is always desirable to use Joins. When your data is not in one place blending is the most viable way to create a left join like the connection between your primary and secondary data sources. 12. What is the difference between blending and joining in Tableau ? Following are the difference between blending and joining in Tableau: Joining term is used when you are combining data from the same source. for example, worksheet in an Excel file or tables in Oracle database. While blending requires two completely defined data sources in your report. 13. What are the reasons for slow performance in Tableau? One of the reasons is data source is slow in itself. This might be because your CSV file is too big or your database is old for reading. You can improve Tableau experience by following ways: Use extracts Limit the amount of data you bring in – both rows and columns Switch data source using the “extract function” Pre-aggregate your data before brining into Tableau. 14. What are the differences between Tableau desktop and Tableau Server ? While Tableau desktop performs data visualization and workbook creation, Tableau server is used to distribute these interactive workbooks and/or reports to the right audience. Users can edit and update the workbooks and dashboards online or Server but cannot create new ones. However, there are limited editing options when compared to desktop. Tableau Public is again a free tool consisting of Desktop and Server components accessible to anyone. 15. How many types of Joins you can use in Tableau? There are four types of Joins in Tableau: Left Right Inner Full outer 16. Differentiate between parameters and filters in Tableau ? The difference actually lies in the application. Parameters allow users to insert their values, which can be integers, float, date, string that can be used in calculations. However, filters receive only values users choose to ‘filter by’ the list, which cannot be used to perform calculations. Users can dynamically change measures and dimensions in parameter but filters do not approve of this feature.Most in-depth, industry-led curriculum in Tableau. 17. Explain the aggregation and disaggregation of data in Tableau? Aggregation and disaggregation of data in Tableau are the ways to develop a scatterplot to measure and compare the data values. Aggregation: It is calculated the form of a set of values that return a single numeric value. A default aggregation can be set for any measure which is not user-defined. Disaggregation: The disaggregation of data refers to view each data source row during analyzing of data both dependently and independently. 18. Mention some file extension in Tableau? There are many file types and extensions in Tableau. Some of the file extensions in Tableau are: Tableau Workbook (.twb). Tableau Packaged Workbook (.twbx). Tableau Datasource (.tds). Tableau Packaged Datasource (.tdsx). Tableau Data extract (.tde). Tableau Bookmark (.tdm). Tableau Map Source (.tms). Tableau Preferences (.tps) 19. What are the extracts and schedules in Tableau server? First copies or subdivisions of the actual data from the original data source are called data extract. The workbooks which use the data extracts instead of using live DB connections are faster and the extracted data is imported into Tableau engine. Later after the extraction of data the users can publish the workbooks which publish the extracts in Tableau server. And, the scheduled refreshers are the scheduling tasks which are already set for data extract refresh so that they get refreshed automatically while a workbook is published with data extraction. 20. Difference between Tiled and Floating in Tableau Dashboards Tiled items are organized in a single layer grid that modifies in a measure, which is based on the total dashboard size and the objects around it. Floating items could be layered on top of other objects and can have a permanent size and position. Floating Layout While most questions are tiled on this dashboard, the map view and its related color legend are floating. They are layered on top of the bar graph, which utilizes a tiled layout. 21. what is a format pane in Tableau? A pane that contains formatting settings that control the entire worksheet, as well as individual fields in the view. 22. What is LOD expression in Tableau? A syntax that supports aggregation at dimensionalities other than the view level. With level of detail expressions, you can attach one or more dimensions to any aggregate expression. 23. What is the difference between Quick Filter and Normal filter? Normal Filter is used to restrict the data from database based on selected dimension or measure. But Quick Filters are used to give a chance to user for dynamically changing data members at run time. 24. What is Tableau Reader? Tableau Reader is a free viewing application that lets anyone read and interact with packaged workbooks created by Tableau Desktop. 25. What is a Dimension? Tableau treats any field containing qualitative, categorical information as a dimension. This includes any field with text or dates values. 26. What is a Measure? A measure is a field that is a dependent on value of one or more dimensions. Tableau treats any field containing numeric (quantitative) information as a measure. 27. What does the extension .twbx represent in Tableau? It is a file which represents Tableau Packaged Workbook, in which the .twb file grouped together with the datasources. 28. What is marks card in Tableau? A card to the left of the view where you can drag fields to control mark properties such as type, color, size, shape, label, tooltip, and detail. 29. What are shelves in Tableau? They are Named areas to the left and top of the view. You build views by placing fields onto the shelves. Some shelves are available only when you select certain mark types. 30. What is a Tableau workbook? It is a file with a .twb extension that contains one or more worksheets (and possibly also dashboards and stories). 31. What is an alais in Tableau? An alternative name that you can assign to a field or to a dimension member. 32. What is Import all data feature in Tableau? It Imports the entire data source into Tableau's fast data engine as an extract and saves it in the workbook. 33. What is TDE file in Tableau? It refers to the file that contains data extracted from external sources like MS Excel, MS Access or CSV file. 34. How to automate reports using Tableau software? You need to publish report to tableau server, while publishing you will find one option to schedule reports.You just need to select the time when you want to refresh data. 35. How to check the meatadata of a table? In the menu Data -> New connection drag the table to the data pane to view its meatdata. 36. What does REPLACE function do in Tableau? The REPLACE function searches a given string for a substring and replaces it with replacement string. 37. Can Tableau be installed on MacOS ? Yes, Tableau Desktop can be installed on both on Mac and Windows Operating System. 38. What is the different between twb and twbx file extensions. Please explain? Twb is a live connection, it points to the data source; the user receiving twb needs permission to said data source and no data is included. .twbx takes data offline, stroes the data as a package or zip like file, thereby eradicating the need for permissions from end user, it’s now a snapshot in time of the data as of the time it was Saved as . twbx 39. How will you publish and schedule workbook in tableau server ? First create a schedule for particular time and then create extract for the data source and publish the workbook for the server. Before you publish, there is a option called Scheduling and Authentication, click on that and select the schedule from the drop down which is created and publish. Also publish data source and assign the schedule. This schedule will automatically run for the assigned time and the workbook is refreshed. 40. What is Forecasting in Tableau? Forecasting is about predicting the future value of a measure. There are many mathematical models for forecasting. Tableau uses the model known as exponential smoothing. Tableau Questions and Answers Pdf Download Read the full article
0 notes