#kubernetes controller manager components
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
What is Argo CD? And When Was Argo CD Established?

What Is Argo CD?
Argo CD is declarative Kubernetes GitOps continuous delivery.
In DevOps, ArgoCD is a Continuous Delivery (CD) technology that has become well-liked for delivering applications to Kubernetes. It is based on the GitOps deployment methodology.
When was Argo CD Established?
Argo CD was created at Intuit and made publicly available following Applatix’s 2018 acquisition by Intuit. The founding developers of Applatix, Hong Wang, Jesse Suen, and Alexander Matyushentsev, made the Argo project open-source in 2017.
Why Argo CD?
Declarative and version-controlled application definitions, configurations, and environments are ideal. Automated, auditable, and easily comprehensible application deployment and lifecycle management are essential.
Getting Started
Quick Start
kubectl create namespace argocd kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
For some features, more user-friendly documentation is offered. Refer to the upgrade guide if you want to upgrade your Argo CD. Those interested in creating third-party connectors can access developer-oriented resources.
How it works
Argo CD defines the intended application state by employing Git repositories as the source of truth, in accordance with the GitOps pattern. There are various approaches to specify Kubernetes manifests:
Applications for Customization
Helm charts
JSONNET files
Simple YAML/JSON manifest directory
Any custom configuration management tool that is set up as a plugin
The deployment of the intended application states in the designated target settings is automated by Argo CD. Deployments of applications can monitor changes to branches, tags, or pinned to a particular manifest version at a Git commit.
Architecture
The implementation of Argo CD is a Kubernetes controller that continually observes active apps and contrasts their present, live state with the target state (as defined in the Git repository). Out Of Sync is the term used to describe a deployed application whose live state differs from the target state. In addition to reporting and visualizing the differences, Argo CD offers the ability to manually or automatically sync the current state back to the intended goal state. The designated target environments can automatically apply and reflect any changes made to the intended target state in the Git repository.
Components
API Server
The Web UI, CLI, and CI/CD systems use the API, which is exposed by the gRPC/REST server. Its duties include the following:
Status reporting and application management
Launching application functions (such as rollback, sync, and user-defined actions)
Cluster credential management and repository (k8s secrets)
RBAC enforcement
Authentication, and auth delegation to outside identity providers
Git webhook event listener/forwarder
Repository Server
An internal service called the repository server keeps a local cache of the Git repository containing the application manifests. When given the following inputs, it is in charge of creating and returning the Kubernetes manifests:
URL of the repository
Revision (tag, branch, commit)
Path of the application
Template-specific configurations: helm values.yaml, parameters
A Kubernetes controller known as the application controller keeps an eye on all active apps and contrasts their actual, live state with the intended target state as defined in the repository. When it identifies an Out Of Sync application state, it may take remedial action. It is in charge of calling any user-specified hooks for lifecycle events (Sync, PostSync, and PreSync).
Features
Applications are automatically deployed to designated target environments.
Multiple configuration management/templating tools (Kustomize, Helm, Jsonnet, and plain-YAML) are supported.
Capacity to oversee and implement across several clusters
Integration of SSO (OIDC, OAuth2, LDAP, SAML 2.0, Microsoft, LinkedIn, GitHub, GitLab)
RBAC and multi-tenancy authorization policies
Rollback/Roll-anywhere to any Git repository-committed application configuration
Analysis of the application resources’ health state
Automated visualization and detection of configuration drift
Applications can be synced manually or automatically to their desired state.
Web user interface that shows program activity in real time
CLI for CI integration and automation
Integration of webhooks (GitHub, BitBucket, GitLab)
Tokens of access for automation
Hooks for PreSync, Sync, and PostSync to facilitate intricate application rollouts (such as canary and blue/green upgrades)
Application event and API call audit trails
Prometheus measurements
To override helm parameters in Git, use parameter overrides.
Read more on Govindhtech.com
#ArgoCD#CD#GitOps#API#Kubernetes#Git#Argoproject#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
DevOps Landscape: Building Blocks for a Seamless Transition
In the dynamic realm where software development intersects with operations, the role of a DevOps professional has become instrumental. For individuals aspiring to make the leap into this dynamic field, understanding the key building blocks can set the stage for a successful transition. While there are no rigid prerequisites, acquiring foundational skills and knowledge areas becomes pivotal for thriving in a DevOps role.

1. Embracing the Essence of Software Development: At the core of DevOps lies collaboration, making it essential for individuals to have a fundamental understanding of software development processes. Proficiency in coding practices, version control, and the collaborative nature of development projects is paramount. Additionally, a solid grasp of programming languages and scripting adds a valuable dimension to one's skill set.
2. Navigating System Administration Fundamentals: DevOps success is intricately linked to a foundational understanding of system administration. This encompasses knowledge of operating systems, networks, and infrastructure components. Such familiarity empowers DevOps professionals to adeptly manage and optimize the underlying infrastructure supporting applications.
3. Mastery of Version Control Systems: Proficiency in version control systems, with Git taking a prominent role, is indispensable. Version control serves as the linchpin for efficient code collaboration, allowing teams to track changes, manage codebases, and seamlessly integrate contributions from multiple developers.
4. Scripting and Automation Proficiency: Automation is a central tenet of DevOps, emphasizing the need for scripting skills in languages like Python, Shell, or Ruby. This skill set enables individuals to automate repetitive tasks, fostering more efficient workflows within the DevOps pipeline.
5. Embracing Containerization Technologies: The widespread adoption of containerization technologies, exemplified by Docker, and orchestration tools like Kubernetes, necessitates a solid understanding. Mastery of these technologies is pivotal for creating consistent and reproducible environments, as well as managing scalable applications.
6. Unveiling CI/CD Practices: Continuous Integration and Continuous Deployment (CI/CD) practices form the beating heart of DevOps. Acquiring knowledge of CI/CD tools such as Jenkins, GitLab CI, or Travis CI is essential. This proficiency ensures the automated execution of code testing, integration, and deployment processes, streamlining development pipelines.
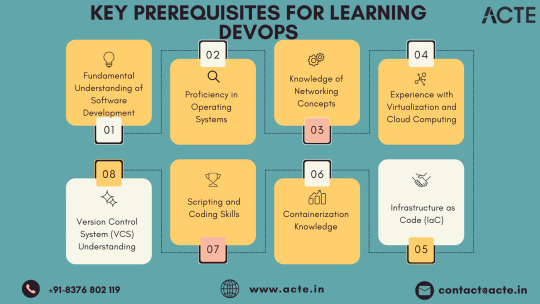
7. Harnessing Infrastructure as Code (IaC): Proficiency in Infrastructure as Code (IaC) tools, including Terraform or Ansible, constitutes a fundamental aspect of DevOps. IaC facilitates the codification of infrastructure, enabling the automated provisioning and management of resources while ensuring consistency across diverse environments.
8. Fostering a Collaborative Mindset: Effective communication and collaboration skills are non-negotiable in the DevOps sphere. The ability to seamlessly collaborate with cross-functional teams, spanning development, operations, and various stakeholders, lays the groundwork for a culture of collaboration essential to DevOps success.
9. Navigating Monitoring and Logging Realms: Proficiency in monitoring tools such as Prometheus and log analysis tools like the ELK stack is indispensable for maintaining application health. Proactive monitoring equips teams to identify issues in real-time and troubleshoot effectively.
10. Embracing a Continuous Learning Journey: DevOps is characterized by its dynamic nature, with new tools and practices continually emerging. A commitment to continuous learning and adaptability to emerging technologies is a fundamental trait for success in the ever-evolving field of DevOps.
In summary, while the transition to a DevOps role may not have rigid prerequisites, the acquisition of these foundational skills and knowledge areas becomes the bedrock for a successful journey. DevOps transcends being a mere set of practices; it embodies a cultural shift driven by collaboration, automation, and an unwavering commitment to continuous improvement. By embracing these essential building blocks, individuals can navigate their DevOps journey with confidence and competence.
5 notes
·
View notes
Text
Elevating Your Full-Stack Developer Expertise: Exploring Emerging Skills and Technologies
Introduction: In the dynamic landscape of web development, staying at the forefront requires continuous learning and adaptation. Full-stack developers play a pivotal role in crafting modern web applications, balancing frontend finesse with backend robustness. This guide delves into the evolving skills and technologies that can propel full-stack developers to new heights of expertise and innovation.

Pioneering Progress: Key Skills for Full-Stack Developers
1. Innovating with Microservices Architecture:
Microservices have redefined application development, offering scalability and flexibility in the face of complexity. Mastery of frameworks like Kubernetes and Docker empowers developers to architect, deploy, and manage microservices efficiently. By breaking down monolithic applications into modular components, developers can iterate rapidly and respond to changing requirements with agility.
2. Embracing Serverless Computing:
The advent of serverless architecture has revolutionized infrastructure management, freeing developers from the burdens of server maintenance. Platforms such as AWS Lambda and Azure Functions enable developers to focus solely on code development, driving efficiency and cost-effectiveness. Embrace serverless computing to build scalable, event-driven applications that adapt seamlessly to fluctuating workloads.
3. Crafting Progressive Web Experiences (PWEs):
Progressive Web Apps (PWAs) herald a new era of web development, delivering native app-like experiences within the browser. Harness the power of technologies like Service Workers and Web App Manifests to create PWAs that are fast, reliable, and engaging. With features like offline functionality and push notifications, PWAs blur the lines between web and mobile, captivating users and enhancing engagement.
4. Harnessing GraphQL for Flexible Data Management:
GraphQL has emerged as a versatile alternative to RESTful APIs, offering a unified interface for data fetching and manipulation. Dive into GraphQL's intuitive query language and schema-driven approach to simplify data interactions and optimize performance. With GraphQL, developers can fetch precisely the data they need, minimizing overhead and maximizing efficiency.

5. Unlocking Potential with Jamstack Development:
Jamstack architecture empowers developers to build fast, secure, and scalable web applications using modern tools and practices. Explore frameworks like Gatsby and Next.js to leverage pre-rendering, serverless functions, and CDN caching. By decoupling frontend presentation from backend logic, Jamstack enables developers to deliver blazing-fast experiences that delight users and drive engagement.
6. Integrating Headless CMS for Content Flexibility:
Headless CMS platforms offer developers unprecedented control over content management, enabling seamless integration with frontend frameworks. Explore platforms like Contentful and Strapi to decouple content creation from presentation, facilitating dynamic and personalized experiences across channels. With headless CMS, developers can iterate quickly and deliver content-driven applications with ease.
7. Optimizing Single Page Applications (SPAs) for Performance:
Single Page Applications (SPAs) provide immersive user experiences but require careful optimization to ensure performance and responsiveness. Implement techniques like lazy loading and server-side rendering to minimize load times and enhance interactivity. By optimizing resource delivery and prioritizing critical content, developers can create SPAs that deliver a seamless and engaging user experience.
8. Infusing Intelligence with Machine Learning and AI:
Machine learning and artificial intelligence open new frontiers for full-stack developers, enabling intelligent features and personalized experiences. Dive into frameworks like TensorFlow.js and PyTorch.js to build recommendation systems, predictive analytics, and natural language processing capabilities. By harnessing the power of machine learning, developers can create smarter, more adaptive applications that anticipate user needs and preferences.
9. Safeguarding Applications with Cybersecurity Best Practices:
As cyber threats continue to evolve, cybersecurity remains a critical concern for developers and organizations alike. Stay informed about common vulnerabilities and adhere to best practices for securing applications and user data. By implementing robust security measures and proactive monitoring, developers can protect against potential threats and safeguard the integrity of their applications.
10. Streamlining Development with CI/CD Pipelines:
Continuous Integration and Deployment (CI/CD) pipelines are essential for accelerating development workflows and ensuring code quality and reliability. Explore tools like Jenkins, CircleCI, and GitLab CI/CD to automate testing, integration, and deployment processes. By embracing CI/CD best practices, developers can deliver updates and features with confidence, driving innovation and agility in their development cycles.
#full stack developer#education#information#full stack web development#front end development#web development#frameworks#technology#backend#full stack developer course
2 notes
·
View notes
Text
How a Web Development Company Builds Scalable SaaS Platforms
Building a SaaS (Software as a Service) platform isn't just about writing code—it’s about designing a product that can grow with your business, serve thousands of users reliably, and continuously evolve based on market needs. Whether you're launching a CRM, learning management system, or a niche productivity tool, scalability must be part of the plan from day one.
That’s why a professional Web Development Company brings more than just technical skills to the table. They understand the architectural, design, and business logic decisions required to ensure your SaaS product is not just functional—but scalable, secure, and future-proof.
1. Laying a Solid Architectural Foundation
The first step in building a scalable SaaS product is choosing the right architecture. Most development agencies follow a modular, service-oriented approach that separates different components of the application—user management, billing, dashboards, APIs, etc.—into layers or even microservices.
This ensures:
Features can be developed and deployed independently
The system can scale horizontally (adding more servers) or vertically (upgrading resources)
Future updates or integrations won’t require rebuilding the entire platform
Development teams often choose cloud-native architectures built on platforms like AWS, Azure, or GCP for their scalability and reliability.
2. Selecting the Right Tech Stack
Choosing the right technology stack is critical. The tech must support performance under heavy loads and allow for easy development as your team grows.
Popular stacks for SaaS platforms include:
Frontend: React.js, Vue.js, or Angular
Backend: Node.js, Django, Ruby on Rails, or Laravel
Databases: PostgreSQL or MongoDB for flexibility and performance
Infrastructure: Docker, Kubernetes, CI/CD pipelines for automation
A skilled agency doesn’t just pick trendy tools—they choose frameworks aligned with your app’s use case, team skills, and scaling needs.
3. Multi-Tenancy Setup
One of the biggest differentiators in SaaS development is whether the platform is multi-tenant—where one codebase and database serve multiple customers with logical separation.
A web development company configures multi-tenancy using:
Separate schemas per tenant (isolated but efficient)
Shared databases with tenant identifiers (cost-effective)
Isolated instances for enterprise clients (maximum security)
This architecture supports onboarding multiple customers without duplicating infrastructure—making it cost-efficient and easy to manage.
4. Building Secure, Scalable User Management
SaaS platforms must support a range of users—admins, team members, clients—with different permissions. That’s why role-based access control (RBAC) is built into the system from the start.
Key features include:
Secure user registration and login (OAuth2, SSO, MFA)
Dynamic role creation and permission assignment
Audit logs and activity tracking
This layer is integrated with identity providers and third-party auth services to meet enterprise security expectations.
5. Ensuring Seamless Billing and Subscription Management
Monetization is central to SaaS success. Development companies build subscription logic that supports:
Monthly and annual billing cycles
Tiered or usage-based pricing models
Free trials and discounts
Integration with Stripe, Razorpay, or other payment gateways
They also ensure compliance with global standards (like PCI DSS for payment security and GDPR for user data privacy), especially if you're targeting international customers.
6. Performance Optimization from Day One
Scalability means staying fast even as traffic and data grow. Web developers implement:
Caching systems (like Redis or Memcached)
Load balancers and auto-scaling policies
Asynchronous task queues (e.g., Celery, RabbitMQ)
CDN integration for static asset delivery
Combined with code profiling and database indexing, these enhancements ensure your SaaS stays performant no matter how many users are active.
7. Continuous Deployment and Monitoring
SaaS products evolve quickly—new features, fixes, improvements. That’s why agencies set up:
CI/CD pipelines for automated testing and deployment
Error tracking tools like Sentry or Rollbar
Performance monitoring with tools like Datadog or New Relic
Log management for incident response and debugging
This allows for rapid iteration and minimal downtime, which are critical in SaaS environments.
8. Preparing for Scale from a Product Perspective
Scalability isn’t just technical—it’s also about UX and support. A good development company collaborates on:
Intuitive onboarding flows
Scalable navigation and UI design systems
Help center and chatbot integrations
Data export and reporting features for growing teams
These elements allow users to self-serve as the platform scales, reducing support load and improving retention.
Conclusion
SaaS platforms are complex ecosystems that require planning, flexibility, and technical excellence. From architecture and authentication to billing and performance, every layer must be built with growth in mind. That’s why startups and enterprises alike trust a Web Development Company to help them design and launch SaaS solutions that can handle scale—without sacrificing speed or security.
Whether you're building your first SaaS MVP or upgrading an existing product, the right development partner can transform your vision into a resilient, scalable reality.
0 notes
Text
CNAPP Explained: The Smartest Way to Secure Cloud-Native Apps with EDSPL

Introduction: The New Era of Cloud-Native Apps
Cloud-native applications are rewriting the rules of how we build, scale, and secure digital products. Designed for agility and rapid innovation, these apps demand security strategies that are just as fast and flexible. That’s where CNAPP—Cloud-Native Application Protection Platform—comes in.
But simply deploying CNAPP isn’t enough.
You need the right strategy, the right partner, and the right security intelligence. That’s where EDSPL shines.
What is CNAPP? (And Why Your Business Needs It)
CNAPP stands for Cloud-Native Application Protection Platform, a unified framework that protects cloud-native apps throughout their lifecycle—from development to production and beyond.
Instead of relying on fragmented tools, CNAPP combines multiple security services into a cohesive solution:
Cloud Security
Vulnerability management
Identity access control
Runtime protection
DevSecOps enablement
In short, it covers the full spectrum—from your code to your container, from your workload to your network security.
Why Traditional Security Isn’t Enough Anymore
The old way of securing applications with perimeter-based tools and manual checks doesn’t work for cloud-native environments. Here’s why:
Infrastructure is dynamic (containers, microservices, serverless)
Deployments are continuous
Apps run across multiple platforms
You need security that is cloud-aware, automated, and context-rich—all things that CNAPP and EDSPL’s services deliver together.
Core Components of CNAPP
Let’s break down the core capabilities of CNAPP and how EDSPL customizes them for your business:
1. Cloud Security Posture Management (CSPM)
Checks your cloud infrastructure for misconfigurations and compliance gaps.
See how EDSPL handles cloud security with automated policy enforcement and real-time visibility.
2. Cloud Workload Protection Platform (CWPP)
Protects virtual machines, containers, and functions from attacks.
This includes deep integration with application security layers to scan, detect, and fix risks before deployment.
3. CIEM: Identity and Access Management
Monitors access rights and roles across multi-cloud environments.
Your network, routing, and storage environments are covered with strict permission models.
4. DevSecOps Integration
CNAPP shifts security left—early into the DevOps cycle. EDSPL’s managed services ensure security tools are embedded directly into your CI/CD pipelines.
5. Kubernetes and Container Security
Containers need runtime defense. Our approach ensures zero-day protection within compute environments and dynamic clusters.
How EDSPL Tailors CNAPP for Real-World Environments
Every organization’s tech stack is unique. That’s why EDSPL never takes a one-size-fits-all approach. We customize CNAPP for your:
Cloud provider setup
Mobility strategy
Data center switching
Backup architecture
Storage preferences
This ensures your entire digital ecosystem is secure, streamlined, and scalable.
Case Study: CNAPP in Action with EDSPL
The Challenge
A fintech company using a hybrid cloud setup faced:
Misconfigured services
Shadow admin accounts
Poor visibility across Kubernetes
EDSPL’s Solution
Integrated CNAPP with CIEM + CSPM
Hardened their routing infrastructure
Applied real-time runtime policies at the node level
✅ The Results
75% drop in vulnerabilities
Improved time to resolution by 4x
Full compliance with ISO, SOC2, and GDPR
Why EDSPL’s CNAPP Stands Out
While most providers stop at integration, EDSPL goes beyond:
🔹 End-to-End Security: From app code to switching hardware, every layer is secured. 🔹 Proactive Threat Detection: Real-time alerts and behavior analytics. 🔹 Customizable Dashboards: Unified views tailored to your team. 🔹 24x7 SOC Support: With expert incident response. 🔹 Future-Proofing: Our background vision keeps you ready for what’s next.
EDSPL’s Broader Capabilities: CNAPP and Beyond
While CNAPP is essential, your digital ecosystem needs full-stack protection. EDSPL offers:
Network security
Application security
Switching and routing solutions
Storage and backup services
Mobility and remote access optimization
Managed and maintenance services for 24x7 support
Whether you’re building apps, protecting data, or scaling globally, we help you do it securely.
Let’s Talk CNAPP
You’ve read the what, why, and how of CNAPP — now it’s time to act.
📩 Reach us for a free CNAPP consultation. 📞 Or get in touch with our cloud security specialists now.
Secure your cloud-native future with EDSPL — because prevention is always smarter than cure.
0 notes
Text
Legacy Software Modernization Services In India – NRS Infoways
In today’s hyper‑competitive digital landscape, clinging to outdated systems is no longer an option. Legacy applications can slow innovation, inflate maintenance costs, and expose your organization to security vulnerabilities. NRS Infoways bridges the gap between yesterday’s technology and tomorrow’s possibilities with comprehensive Software Modernization Services In India that revitalize your core systems without disrupting day‑to‑day operations.
Why Modernize?
Boost Performance & Scalability
Legacy architectures often struggle under modern workloads. By re‑architecting or migrating to cloud‑native frameworks, NRS Infoways unlocks the flexibility you need to scale on demand and handle unpredictable traffic spikes with ease.
Reduce Technical Debt
Old codebases are costly to maintain. Our experts refactor critical components, streamline dependencies, and implement automated testing pipelines, dramatically lowering long‑term maintenance expenses.
Strengthen Security & Compliance
Obsolete software frequently harbors unpatched vulnerabilities. We embed industry‑standard security protocols and data‑privacy controls to safeguard sensitive information and keep you compliant with evolving regulations.
Enhance User Experience
Customers expect snappy, intuitive interfaces. We upgrade clunky GUIs into sleek, responsive designs—whether for web, mobile, or enterprise portals—boosting user satisfaction and retention.
Our Proven Modernization Methodology
1. Deep‑Dive Assessment
We begin with an exhaustive audit of your existing environment—code quality, infrastructure, DevOps maturity, integration points, and business objectives. This roadmap pinpoints pain points, ranks priorities, and plots the most efficient modernization path.
2. Strategic Planning & Architecture
Armed with data, we design a future‑proof architecture. Whether it’s containerization with Docker/Kubernetes, serverless microservices, or hybrid-cloud setups, each blueprint aligns performance goals with budget realities.
3. Incremental Refactoring & Re‑engineering
To mitigate risk, we adopt a phased approach. Modules are refactored or rewritten in modern languages—often leveraging Java Spring Boot, .NET Core, or Node.js—while maintaining functional parity. Continuous integration pipelines ensure rapid, reliable deployments.
4. Data Migration & Integration
Smooth, loss‑less data transfer is critical. Our team employs advanced ETL processes and secure APIs to migrate databases, synchronize records, and maintain interoperability with existing third‑party solutions.
5. Rigorous Quality Assurance
Automated unit, integration, and performance tests catch issues early. Penetration testing and vulnerability scans validate that the revamped system meets stringent security and compliance benchmarks.
6. Go‑Live & Continuous Support
Once production‑ready, we orchestrate a seamless rollout with minimal downtime. Post‑deployment, NRS Infoways provides 24 × 7 monitoring, performance tuning, and incremental enhancements so your modernized platform evolves alongside your business.
Key Differentiators
Domain Expertise: Two decades of transforming systems across finance, healthcare, retail, and logistics.
Certified Talent: AWS, Azure, and Google Cloud‑certified architects ensure best‑in‑class cloud adoption.
DevSecOps Culture: Security baked into every phase, backed by automated vulnerability management.
Agile Engagement Models: Fixed‑scope, time‑and‑material, or dedicated team options adapt to your budget and timeline.
Result‑Driven KPIs: We measure success via reduced TCO, improved response times, and tangible ROI, not just code delivery.
Success Story Snapshot
A leading Indian logistics firm grappled with a decade‑old monolith that hindered real‑time shipment tracking. NRS Infoways migrated the application to a microservices architecture on Azure, consolidating disparate data silos and introducing RESTful APIs for third‑party integrations. The results? A 40 % reduction in server costs, 60 % faster release cycles, and a 25 % uptick in customer satisfaction scores within six months.
Future‑Proof Your Business Today
Legacy doesn’t have to mean liability. With NRS Infoways’ Legacy Software Modernization Services In India, you gain a robust, scalable, and secure foundation ready to tackle tomorrow’s challenges—whether that’s AI integration, advanced analytics, or global expansion.
Ready to transform?
Contact us for a free modernization assessment and discover how our Software Modernization Services In India can accelerate your digital journey, boost operational efficiency, and drive sustainable growth.
0 notes
Text
Inside the World of Full Stack Development: Crafting Seamless Digital Experiences
In today’s fast-paced digital age, the demand for adaptable, versatile developers has reached an all-time high. As businesses continue to evolve in a technology-driven landscape, the role of full stack developers has emerged as a pivotal force in shaping seamless digital experiences. From the front-end visuals to the back-end functionality, these professionals orchestrate entire applications with precision and efficiency.
But what does it really mean to live inside the world of full stack development?
Understanding the Full Stack Ecosystem
Full stack development refers to the ability to work on both the front end and back end of web and software applications. While front-end development focuses on user interface (UI) and user experience (UX), the back end includes server logic, databases, APIs, and integration systems.
To craft a seamless digital experience, a full stack developer must have a working command over multiple layers of technology. A few core components include:
Front-end technologies such as HTML, CSS, JavaScript, React, or Angular.
Back-end development using tools like Node.js, Python, Ruby, or Java.
Database management with MySQL, MongoDB, or PostgreSQL.
Version control systems like Git for code management.
Server and deployment practices using Docker, Kubernetes, or AWS.
But mastering tools isn’t enough. What truly sets apart today’s developers is how they learn and apply these skills in real-time environments.
Project-Based Full Stack Learning: The Key to Practical Expertise
Traditional learning models often focus too much on theory. But in the evolving tech ecosystem, practical exposure wins the race. This is where project-based full stack learning steps in.
Instead of merely learning syntax or reading documentation, learners build actual applications that reflect real-world use cases. This method:
Encourages hands-on coding from day one.
Teaches students how different components interact in a live environment.
Helps learners grasp error handling, debugging, and optimization organically.
Boosts confidence and provides a portfolio to showcase in interviews.
In short, it bridges the gap between conceptual understanding and workplace application.
Solving Real-World Challenges with Java
A core part of being a well-rounded full stack developer is problem-solving. And Java, being one of the most stable and widely-used programming languages, plays a crucial role in that journey.
Real-time problem-solving with Java introduces developers to scenarios where high-performance, secure, and scalable systems are required. Think of things like:
Building payment gateways
Developing REST APIs for e-commerce platforms
Creating server-side logic for mobile applications
Ensuring thread safety and memory management in multi-user systems
Using Java in full stack development isn’t just about writing back-end logic; it’s about integrating robust performance and security within scalable architectures. And when these solutions are executed in real-time, they provide a rich learning ground for both novices and seasoned developers.
Why Full Stack Development Matters Today
Crafting seamless digital experiences isn't simply about attractive interfaces. It's about delivering responsive, secure, and optimized platforms that feel effortless to users.
Here’s why full stack development has become a cornerstone in the tech world:
Efficiency: One person can handle both front and back-end, reducing development time and communication gaps.
Flexibility: Developers can switch roles depending on project needs.
Comprehension: Better understanding of how components interact improves debugging and integration.
Value: Companies save costs while ensuring faster delivery and consistency.
In fact, many startups and small businesses now prefer hiring full stack developers over segmented teams, as they can iterate rapidly and pivot when needed.
Building a Career Inside the Full Stack World
To thrive in this space, aspiring developers must combine technical skills with the right mindset. Here’s what helps:
Focus on end-to-end project development. Not just coding snippets, but building from concept to deployment.
Practice debugging in live environments. Mistakes are your best teachers.
Engage in real-time problem-solving with Java and other back-end tools.
Join developer communities. Platforms like GitHub, Stack Overflow, and Dev.to offer immense collaborative learning.
Stay updated. The tech world evolves fast — full stack developers must keep up.
Top Skills Every Full Stack Developer Should Master
HTML5, CSS3, JavaScript (ES6+)
Front-end frameworks like React, Vue, or Angular
Back-end platforms like Node.js, Java Spring Boot, or Express.js
Databases: SQL & NoSQL
Version Control: Git & GitHub
Web Hosting & Deployment: Heroku, AWS, Netlify
Soft Skills: Communication, Time Management, and Critical Thinking
Final Thoughts
Inside the world of full stack development, the journey is as important as the destination. From learning through project-based full stack learning modules to encountering real-time problem-solving with Java, the process transforms a beginner into a professional equipped to handle dynamic digital challenges.
Crafting seamless digital experiences isn’t just about code — it’s about vision, innovation, and adaptability. Full stack developers are not just builders of websites or apps; they are the architects of digital transformation.
Whether you're a curious beginner or a tech enthusiast looking to upskill, stepping into this world is a decision that will shape not just your career, but the way you understand and influence technology.
0 notes
Text
Where Can I Find DevOps Training with Placement Near Me?
Introduction: Unlock Your Tech Career with DevOps Training
In today’s digital world, companies are moving faster than ever. Continuous delivery, automation, and rapid deployment have become the new norm. That’s where DevOps comes in a powerful blend of development and operations that fuels speed and reliability in software delivery.
Have you ever wondered how companies like Amazon, Netflix, or Facebook release features so quickly without downtime? The secret lies in DevOps an industry-demanded approach that integrates development and operations to streamline software delivery. Today, DevOps skills are not just desirable they’re essential. If you’re asking, “Where can I find DevOps training with placement near me?”, this guide will walk you through everything you need to know to find the right training and land the job you deserve.

Understanding DevOps: Why It Matters
DevOps is more than a buzzword it’s a cultural and technical shift that transforms how software teams build, test, and deploy applications. It focuses on collaboration, automation, continuous integration (CI), continuous delivery (CD), and feedback loops.
Professionals trained in DevOps can expect roles like:
DevOps Engineer
Site Reliability Engineer
Cloud Infrastructure Engineer
Release Manager
The growing reliance on cloud services and rapid deployment pipelines has placed DevOps engineers in high demand. A recent report by Global Knowledge ranks DevOps as one of the highest-paying tech roles in North America.
Why DevOps Training with Placement Is Crucial
Many learners begin with self-study or unstructured tutorials, but that only scratches the surface. A comprehensive DevOps training and placement program ensures:
Structured learning of core and advanced DevOps concepts
Hands-on experience with DevOps automation tools
Resume building, interview preparation, and career support
Real-world project exposure to simulate a professional environment
Direct pathways to job interviews and job offers
If you’re looking for DevOps training with placement “near me,” remember that “location” today is no longer just geographic—it’s also digital. The right DevOps online training can provide the accessibility and support you need, no matter your zip code.
Core Components of a DevOps Course Online
When choosing a DevOps course online, ensure it covers the following modules in-depth:
1. Introduction to DevOps Culture and Principles
Evolution of DevOps
Agile and Lean practices
Collaboration and communication strategies
2. Version Control with Git and GitHub
Branching and merging strategies
Pull requests and code reviews
Git workflows in real-world projects
3. Continuous Integration (CI) Tools
Jenkins setup and pipelines
GitHub Actions
Code quality checks and automated builds
4. Configuration Management
Tools like Ansible, Chef, or Puppet
Managing infrastructure as code (IaC)
Role-based access control
5. Containerization and Orchestration
Docker fundamentals
Kubernetes (K8s) clusters, deployments, and services
Helm charts and autoscaling strategies
6. Monitoring and Logging
Prometheus and Grafana
ELK Stack (Elasticsearch, Logstash, Kibana)
Incident alerting systems
7. Cloud Infrastructure and DevOps Automation Tools
AWS, Azure, or GCP fundamentals
Terraform for IaC
CI/CD pipelines integrated with cloud services
Real-World Applications: Why Hands-On Learning Matters
A key feature of any top-tier DevOps training online is its practical approach. Without hands-on labs or real projects, theory can only take you so far.
Here’s an example project structure:
Project: Deploying a Multi-Tier Application with Kubernetes
Such projects help learners not only understand tools but also simulate real DevOps scenarios, building confidence and clarity.
DevOps Training and Certification: What You Should Know
Certifications validate your knowledge and can significantly improve your job prospects. A solid DevOps training and certification program should prepare you for globally recognized exams like:
DevOps Foundation Certification
Certified Kubernetes Administrator (CKA)
AWS Certified DevOps Engineer
Docker Certified Associate
While certifications are valuable, employers prioritize candidates who demonstrate both theoretical knowledge and applied skills. This is why combining training with placement offers the best return on investment.
What to Look for in a DevOps Online Course
If you’re on the hunt for the best DevOps training online, here are key features to consider:
Structured Curriculum
It should cover everything from fundamentals to advanced automation practices.
Expert Trainers
Trainers should have real industry experience, not just academic knowledge.
Hands-On Projects
Project-based assessments help bridge the gap between theory and application.
Flexible Learning
A good DevOps online course offers recordings, live sessions, and self-paced materials.
Placement Support
Look for programs that offer:
Resume writing and LinkedIn profile optimization
Mock interviews with real-time feedback
Access to a network of hiring partners
Benefits of Enrolling in DevOps Bootcamp Online
A DevOps bootcamp online fast-tracks your learning process. These are intensive, short-duration programs designed for focused outcomes. Key benefits include:
Rapid skill acquisition
Industry-aligned curriculum
Peer collaboration and group projects
Career coaching and mock interviews
Job referrals and hiring events
Such bootcamps are ideal for professionals looking to upskill, switch careers, or secure a DevOps role without spending years in academia.
DevOps Automation Tools You Must Learn
Git & GitHub Git is the backbone of version control in DevOps, allowing teams to track changes, collaborate on code, and manage development history. GitHub enhances this by offering cloud-based repositories, pull requests, and code review tools—making it a must-know for every DevOps professional.
Jenkins Jenkins is the most popular open-source automation server used to build and manage continuous integration and continuous delivery (CI/CD) pipelines. It integrates with almost every DevOps tool and helps automate testing, deployment, and release cycles efficiently.
Docker Docker is a game-changer in DevOps. It enables you to containerize applications, ensuring consistency across environments. With Docker, developers can package software with all its dependencies, leading to faster development and more reliable deployments.
Kubernetes Once applications are containerized, Kubernetes helps manage and orchestrate them at scale. It automates deployment, scaling, and load balancing of containerized applications—making it essential for managing modern cloud-native infrastructures.
Ansible Ansible simplifies configuration management and infrastructure automation. Its agentless architecture and easy-to-write YAML playbooks allow you to automate repetitive tasks across servers and maintain consistency in deployments.
Terraform Terraform enables Infrastructure as Code (IaC), allowing teams to provision and manage cloud resources using simple, declarative code. It supports multi-cloud environments and ensures consistent infrastructure with minimal manual effort.
Prometheus & Grafana For monitoring and alerting, Prometheus collects metrics in real-time, while Grafana visualizes them beautifully. Together, they help track application performance and system health essential for proactive operations.
ELK Stack (Elasticsearch, Logstash, Kibana) The ELK stack is widely used for centralized logging. Elasticsearch stores logs, Logstash processes them, and Kibana provides powerful visualizations, helping teams troubleshoot issues quickly.
Mastering these tools gives you a competitive edge in the DevOps job market and empowers you to build reliable, scalable, and efficient software systems.
Job Market Outlook for DevOps Professionals
According to the U.S. Bureau of Labor Statistics, software development roles are expected to grow 25% by 2032—faster than most other industries. DevOps roles are a large part of this trend. Companies need professionals who can automate pipelines, manage scalable systems, and deliver software efficiently.
Average salaries in the U.S. for DevOps engineers range between $95,000 to $145,000, depending on experience, certifications, and location.
Companies across industries—from banking and healthcare to retail and tech—are hiring DevOps professionals for critical digital transformation roles.
Is DevOps for You?
If you relate to any of the following, a DevOps course online might be the perfect next step:
You're from an IT background looking to transition into automation roles
You enjoy scripting, problem-solving, and system management
You're a software developer interested in faster and reliable deployments
You're a system admin looking to expand into cloud and DevOps roles
You want a structured, placement-supported training program to start your career
How to Get Started with DevOps Training and Placement
Step 1: Enroll in a Comprehensive Program
Choose a program that covers both foundational and advanced concepts and includes real-time projects.
Step 2: Master the Tools
Practice using popular DevOps automation tools like Docker, Jenkins, and Kubernetes.
Step 3: Work on Live Projects
Gain experience working on CI/CD pipelines, cloud deployment, and infrastructure management.
Step 4: Prepare for Interviews
Use mock sessions, Q&A banks, and technical case studies to strengthen your readiness.
Step 5: Land the Job
Leverage placement services, interview support, and resume assistance to get hired.
Key Takeaways
DevOps training provides the automation and deployment skills demanded in modern software environments.
Placement support is crucial to transitioning from learning to earning.
Look for comprehensive online courses that offer hands-on experience and job assistance.
DevOps is not just a skill it’s a mindset of collaboration, speed, and innovation.
Ready to launch your DevOps career? Join H2K Infosys today for hands-on learning and job placement support. Start your transformation into a DevOps professional now.
#devops training#DevOps course#devops training online#devops online training#devops training and certification#devops certification training#devops training with placement#devops online courses#best devops training online#online DevOps course#advanced devops course#devops training and placement#devops course online#devops real time training#DevOps automation tools
0 notes
Text
Kubernetes Cluster Management at Scale: Challenges and Solutions
As Kubernetes has become the cornerstone of modern cloud-native infrastructure, managing it at scale is a growing challenge for enterprises. While Kubernetes excels in orchestrating containers efficiently, managing multiple clusters across teams, environments, and regions presents a new level of operational complexity.
In this blog, we’ll explore the key challenges of Kubernetes cluster management at scale and offer actionable solutions, tools, and best practices to help engineering teams build scalable, secure, and maintainable Kubernetes environments.
Why Scaling Kubernetes Is Challenging
Kubernetes is designed for scalability—but only when implemented with foresight. As organizations expand from a single cluster to dozens or even hundreds, they encounter several operational hurdles.
Key Challenges:
1. Operational Overhead
Maintaining multiple clusters means managing upgrades, backups, security patches, and resource optimization—multiplied by every environment (dev, staging, prod). Without centralized tooling, this overhead can spiral quickly.
2. Configuration Drift
Cluster configurations often diverge over time, causing inconsistent behavior, deployment errors, or compliance risks. Manual updates make it difficult to maintain consistency.
3. Observability and Monitoring
Standard logging and monitoring solutions often fail to scale with the ephemeral and dynamic nature of containers. Observability becomes noisy and fragmented without standardization.
4. Resource Isolation and Multi-Tenancy
Balancing shared infrastructure with security and performance for different teams or business units is tricky. Kubernetes namespaces alone may not provide sufficient isolation.
5. Security and Policy Enforcement
Enforcing consistent RBAC policies, network segmentation, and compliance rules across multiple clusters can lead to blind spots and misconfigurations.
Best Practices and Scalable Solutions
To manage Kubernetes at scale effectively, enterprises need a layered, automation-driven strategy. Here are the key components:
1. GitOps for Declarative Infrastructure Management
GitOps leverages Git as the source of truth for infrastructure and application deployment. With tools like ArgoCD or Flux, you can:
Apply consistent configurations across clusters.
Automatically detect and rollback configuration drifts.
Audit all changes through Git commit history.
Benefits:
· Immutable infrastructure
· Easier rollbacks
· Team collaboration and visibility
2. Centralized Cluster Management Platforms
Use centralized control planes to manage the lifecycle of multiple clusters. Popular tools include:
Rancher – Simplified Kubernetes management with RBAC and policy controls.
Red Hat OpenShift – Enterprise-grade PaaS built on Kubernetes.
VMware Tanzu Mission Control – Unified policy and lifecycle management.
Google Anthos / Azure Arc / Amazon EKS Anywhere – Cloud-native solutions with hybrid/multi-cloud support.
Benefits:
· Unified view of all clusters
· Role-based access control (RBAC)
· Policy enforcement at scale
3. Standardization with Helm, Kustomize, and CRDs
Avoid bespoke configurations per cluster. Use templating and overlays:
Helm: Define and deploy repeatable Kubernetes manifests.
Kustomize: Customize raw YAMLs without forking.
Custom Resource Definitions (CRDs): Extend Kubernetes API to include enterprise-specific configurations.
Pro Tip: Store and manage these configurations in Git repositories following GitOps practices.
4. Scalable Observability Stack
Deploy a centralized observability solution to maintain visibility across environments.
Prometheus + Thanos: For multi-cluster metrics aggregation.
Grafana: For dashboards and alerting.
Loki or ELK Stack: For log aggregation.
Jaeger or OpenTelemetry: For tracing and performance monitoring.
Benefits:
· Cluster health transparency
· Proactive issue detection
· Developer fliendly insights
5. Policy-as-Code and Security Automation
Enforce security and compliance policies consistently:
OPA + Gatekeeper: Define and enforce security policies (e.g., restrict container images, enforce labels).
Kyverno: Kubernetes-native policy engine for validation and mutation.
Falco: Real-time runtime security monitoring.
Kube-bench: Run CIS Kubernetes benchmark checks automatically.
Security Tip: Regularly scan cluster and workloads using tools like Trivy, Kube-hunter, or Aqua Security.
6. Autoscaling and Cost Optimization
To avoid resource wastage or service degradation:
Horizontal Pod Autoscaler (HPA) – Auto-scales pods based on metrics.
Vertical Pod Autoscaler (VPA) – Adjusts container resources.
Cluster Autoscaler – Scales nodes up/down based on workload.
Karpenter (AWS) – Next-gen open-source autoscaler with rapid provisioning.
Conclusion
As Kubernetes adoption matures, organizations must rethink their management strategy to accommodate growth, reliability, and governance. The transition from a handful of clusters to enterprise-wide Kubernetes infrastructure requires automation, observability, and strong policy enforcement.
By adopting GitOps, centralized control planes, standardized templates, and automated policy tools, enterprises can achieve Kubernetes cluster management at scale—without compromising on security, reliability, or developer velocity.
0 notes
Text
Scaling Agentic AI in 2025: Unlocking Autonomous Digital Labor with Real-World Success Stories
Introduction
Agentic AI is revolutionizing industries by seamlessly integrating autonomy, adaptability, and goal-driven behavior, enabling digital systems to perform complex tasks with minimal human intervention. This article explores the evolution of Agentic AI, its integration with Generative AI, and delivers actionable insights for scaling these systems. We will examine the latest deployment strategies, best practices for scalability, and real-world case studies, including how an Agentic AI course in Mumbai with placements is shaping talent pipelines for this emerging field. Whether you are a software engineer, data scientist, or technology leader, understanding the interplay between Generative AI and Agentic AI is key to unlocking digital transformation.

The Evolution of Agentic and Generative AI in Software
AI’s evolution has moved from rule-based systems and machine learning toward today’s advanced generative models and agentic systems. Traditional AI excels in narrow, predefined tasks like image recognition but lacks flexibility for dynamic environments. Agentic AI, by contrast, introduces autonomy and continuous learning, empowering systems to adapt and optimize outcomes over time without constant human oversight.
This paradigm shift is powered by Generative AI, particularly large language models (LLMs), which provide contextual understanding and reasoning capabilities. Agentic AI systems can orchestrate multiple AI services, manage workflows, and execute decisions, making them essential for real-time, multi-faceted applications across logistics, healthcare, and customer service. The rise of agentic capabilities marks a transition from AI as a tool to AI as an autonomous digital labor force, expanding workforce definitions and operational possibilities. Professionals seeking to enter this field often consider a Generative AI and Agentic AI course to gain the necessary skills and practical experience.
Latest Frameworks, Tools, and Deployment Strategies
LLM Orchestration and Autonomous Agents
Modern Agentic AI depends on orchestrating multiple LLMs and AI components to execute complex workflows. Frameworks like LangChain, Haystack, and OpenAI’s Function Calling enable developers to build autonomous agents that chain together tasks, query databases, and interact with APIs dynamically. These frameworks support multi-turn dialogue management, contextual memory, and adaptive decision-making, critical for real-world agentic applications. For those interested in hands-on learning, enrolling in an Agentic AI course in Mumbai with placements offers practical exposure to these advanced frameworks.
MLOps for Generative Models
Traditional MLOps pipelines are evolving to support the unique requirements of generative AI, including:
Continuous Fine-Tuning: Updating models based on new data or feedback without full retraining, using techniques like incremental and transfer learning.
Prompt Engineering Lifecycle: Versioning and testing prompts as critical components of model performance, including methodologies for prompt optimization and impact evaluation.
Monitoring Generation Quality: Detecting hallucinations, bias, and drift in outputs, and implementing quality control measures.
Scalable Inference Infrastructure: Managing high-throughput, low-latency model serving with cost efficiency, leveraging cloud and edge computing.
Leading platforms such as MLflow, Kubeflow, and Amazon SageMaker are integrating MLOps for generative AI to streamline deployment and monitoring. Understanding MLOps for generative AI is now a foundational skill for teams building scalable agentic systems.
Cloud-Native and Edge Deployment
Agentic AI deployments increasingly leverage cloud-native architectures for scalability and resilience, using Kubernetes and serverless functions to manage agent workloads. Edge deployments are emerging for latency-sensitive applications like autonomous vehicles and IoT devices, where agents operate closer to data sources. This approach ensures real-time processing and reduces reliance on centralized infrastructure, topics often covered in advanced Generative AI and Agentic AI course curricula.
Advanced Tactics for Scalable, Reliable AI Systems
Modular Agent Design
Breaking down agent capabilities into modular, reusable components allows teams to iterate rapidly and isolate failures. Modular design supports parallel development and easier integration of new skills or data sources, facilitating continuous improvement and reducing system update complexity.
Robust Error Handling and Recovery
Agentic systems must anticipate and gracefully handle failures in external APIs, data inconsistencies, or unexpected inputs. Implementing fallback mechanisms, retries, and human-in-the-loop escalation ensures uninterrupted service and trustworthiness.
Data and Model Governance
Given the autonomy of agentic systems, governance frameworks are critical to manage data privacy, model biases, and compliance with regulations such as GDPR and HIPAA. Transparent logging and explainability tools help maintain accountability. This includes ensuring that data collection and processing align with ethical standards and legal requirements, a topic emphasized in MLOps for generative AI best practices.
Performance Optimization
Balancing model size, latency, and cost is vital. Techniques such as model distillation, quantization, and adaptive inference routing optimize resource use without sacrificing agent effectiveness. Leveraging hardware acceleration and optimizing software configurations further enhances performance.
Ethical Considerations and Governance
As Agentic AI systems become more autonomous, ethical considerations and governance practices become increasingly important. This includes ensuring transparency in decision-making, managing potential biases in AI outputs, and complying with regulatory frameworks. Recent developments in AI ethics frameworks emphasize the need for responsible AI deployment that prioritizes human values and safety. Professionals completing a Generative AI and Agentic AI course are well-positioned to implement these principles in practice.
The Role of Software Engineering Best Practices
The complexity of Agentic AI systems elevates the importance of mature software engineering principles:
Version Control for Code and Models: Ensures reproducibility and rollback capability.
Automated Testing: Unit, integration, and end-to-end tests validate agent logic and interactions.
Continuous Integration/Continuous Deployment (CI/CD): Automates safe and frequent updates.
Security by Design: Protects sensitive data and defends against adversarial attacks.
Documentation and Observability: Facilitates collaboration and troubleshooting across teams.
Embedding these practices into AI development pipelines is essential for operational excellence and long-term sustainability. Training in MLOps for generative AI equips teams with the skills to maintain these standards at scale.
Cross-Functional Collaboration for AI Success
Agentic AI projects succeed when data scientists, software engineers, product managers, and business stakeholders collaborate closely. This alignment ensures:
Clear definition of agent goals and KPIs.
Shared understanding of technical constraints and ethical considerations.
Coordinated deployment and change management.
Continuous feedback loops for iterative improvement.
Cross-functional teams foster innovation and reduce risks associated with misaligned expectations or siloed workflows. Those enrolled in an Agentic AI course in Mumbai with placements often experience this collaborative environment firsthand.
Measuring Success: Analytics and Monitoring
Effective monitoring of Agentic AI deployments includes:
Operational Metrics: Latency, uptime, throughput.
Performance Metrics: Accuracy, relevance, user satisfaction.
Behavioral Analytics: Agent decision paths, error rates, escalation frequency.
Business Outcomes: Cost savings, revenue impact, process efficiency.
Combining real-time dashboards with anomaly detection and alerting enables proactive management and continuous optimization of agentic systems. Mastering these analytics is a core outcome for participants in a Generative AI and Agentic AI course.
Case Study: Autonomous Supply Chain Optimization at DHL
DHL, a global logistics leader, exemplifies successful scaling of Agentic AI in 2025. Facing challenges of complex inventory management, fluctuating demand, and delivery delays, DHL deployed an autonomous supply chain agent powered by generative AI and real-time data orchestration.
The Journey
DHL’s agentic system integrates:
LLM-based demand forecasting models.
Autonomous routing agents coordinating with IoT sensors on shipments.
Dynamic inventory rebalancing modules adapting to disruptions.
The deployment involved iterative prototyping, cross-team collaboration, and rigorous MLOps for generative AI practices to ensure reliability and compliance across global operations.
Technical Challenges
Handling noisy sensor data and incomplete information.
Ensuring real-time decision-making under tight latency constraints.
Managing multi-regional regulatory compliance and data sovereignty.
Integrating legacy IT systems with new AI workflows.
Business Outcomes
20% reduction in delivery delays.
15% decrease in inventory holding costs.
Enhanced customer satisfaction through proactive communication.
Scalable platform enabling rapid rollout across regions.
DHL’s success highlights how agentic AI can transform complex, dynamic environments by combining autonomy with robust engineering and collaborative execution. Professionals trained through an Agentic AI course in Mumbai with placements are well-prepared to tackle similar challenges.
Additional Case Study: Personalized Healthcare with Agentic AI
In healthcare, Agentic AI is revolutionizing patient care by providing personalized treatment plans and improving patient outcomes. For instance, a healthcare provider might deploy an agentic system to analyze patient data, adapt treatment strategies based on real-time health conditions, and optimize resource allocation in hospitals. This involves integrating AI with electronic health records, wearable devices, and clinical decision support systems to enhance care quality and efficiency.
Technical Implementation
Data Integration: Combining data from various sources to create comprehensive patient profiles.
AI-Driven Decision Support: Using machine learning models to predict patient outcomes and suggest personalized interventions.
Real-Time Monitoring: Continuously monitoring patient health and adjusting treatment plans accordingly.
Business Outcomes
Improved patient satisfaction through personalized care.
Enhanced resource allocation and operational efficiency.
Better clinical outcomes due to real-time decision-making.
This case study demonstrates how Agentic AI can improve healthcare outcomes by leveraging autonomy and adaptability in dynamic environments. A Generative AI and Agentic AI course provides the multidisciplinary knowledge required for such implementations.
Actionable Tips and Lessons Learned
Start small but think big: Pilot agentic AI on well-defined use cases to gather data and refine models before scaling.
Invest in MLOps tailored for generative AI: Automate continuous training, testing, and monitoring to ensure robust deployments.
Design agents modularly: Facilitate updates and integration of new capabilities.
Prioritize explainability and governance: Build trust with stakeholders and comply with regulations.
Foster cross-functional teams: Align technical and business goals early and often.
Monitor holistically: Combine operational, performance, and business metrics for comprehensive insights.
Plan for human-in-the-loop: Use human oversight strategically to handle edge cases and improve agent learning.
For those considering a career shift, an Agentic AI course in Mumbai with placements offers a structured pathway to acquire these skills and gain practical experience.
Conclusion
Scaling Agentic AI in 2025 is both a technical and organizational challenge demanding advanced frameworks, rigorous engineering discipline, and tight collaboration across teams. The evolution from narrow AI to autonomous, adaptive agents unlocks unprecedented efficiencies and capabilities across industries. Real-world deployments like DHL’s autonomous supply chain agent demonstrate the transformative potential when cutting-edge AI meets sound software engineering and business acumen.
For AI practitioners and technology leaders, success lies in embracing modular architectures, investing in MLOps for generative AI, prioritizing governance, and fostering cross-functional collaboration. Monitoring and continuous improvement complete the cycle, ensuring agentic systems deliver measurable business value while maintaining reliability and compliance.
Agentic AI is not just an evolution of technology but a revolution in how businesses operate and innovate. The time to build scalable, trustworthy agentic AI systems is now. Whether you are looking to upskill or transition into this field, a Generative AI and Agentic AI course can provide the knowledge, tools, and industry connections to accelerate your journey.
0 notes
Text
Multicluster Management with Red Hat OpenShift Platform Plus (DO480)
In today’s hybrid and multi-cloud environments, managing multiple Kubernetes clusters can quickly become complex and time-consuming. Enterprises need a robust solution that provides centralized visibility, policy enforcement, and automation across clusters—whether they are running on-premises, in public clouds, or at the edge. Red Hat OpenShift Platform Plus rises to this challenge, offering a comprehensive set of tools to simplify multicluster management. The DO480 training course equips IT professionals with the skills to harness these capabilities effectively.
What is Red Hat OpenShift Platform Plus?
OpenShift Platform Plus is the most advanced OpenShift offering from Red Hat. It includes everything in OpenShift Container Platform, along with key components like:
Red Hat Advanced Cluster Management (RHACM) for Kubernetes
Red Hat Advanced Cluster Security (RHACS) for hardened security posture
Red Hat Quay for trusted image storage and management
These integrated tools make OpenShift Platform Plus the go-to solution for enterprises managing workloads across multiple clusters and cloud environments.
Why Multicluster Management Matters
As organizations scale their cloud-native applications, they often deploy multiple OpenShift clusters to:
Improve availability and fault tolerance
Support global or regional application deployments
Comply with data residency and regulatory requirements
Isolate development, staging, and production environments
But managing these clusters in silos can lead to inefficiencies, inconsistencies, and security gaps. This is where Advanced Cluster Management (ACM) comes in, providing:
Centralized cluster lifecycle management (provisioning, scaling, updating)
Global policy enforcement and governance
Application lifecycle management across clusters
Central observability and health metrics
About the DO480 Course
The DO480 – Multicluster Management with Red Hat OpenShift Platform Plus course is designed for system administrators, DevOps engineers, and cloud architects who want to master multicluster management using OpenShift Platform Plus.
Key Learning Objectives:
Deploy and manage multiple OpenShift clusters with RHACM
Enforce security, configuration, and governance policies across clusters
Use RHACS to monitor and secure workloads
Manage application deployments across clusters
Integrate Red Hat Quay for image storage and content trust
Course Format:
Duration: 4 days
Delivery: Instructor-led (virtual or classroom) and self-paced (via RHLS)
Hands-On Labs: Practical, scenario-based labs with real-world simulations
Who Should Attend?
This course is ideal for:
Platform engineers who manage large OpenShift environments
DevOps teams looking to standardize operations across multiple clusters
Security and compliance professionals enforcing policies at scale
IT leaders adopting hybrid cloud and edge computing strategies
Benefits of Multicluster Management
By mastering DO480 and OpenShift Platform Plus, organizations gain:
✅ Operational consistency across clusters and environments ✅ Reduced administrative overhead through automation ✅ Enhanced security with centralized control and policy enforcement ✅ Faster time-to-market for applications through streamlined deployment ✅ Scalability and flexibility to support modern enterprise needs
Conclusion
Red Hat OpenShift Platform Plus, with its powerful multicluster management capabilities, is shaping the future of enterprise Kubernetes. The DO480 course provides the essential skills IT teams need to deploy, monitor, and govern OpenShift clusters across hybrid and multicloud environments.
At HawkStack Technologies, we offer Red Hat Authorized Training for DO480 and other OpenShift certifications, delivered by industry-certified experts. Whether you're scaling your infrastructure or future-proofing your DevOps strategy, we're here to support your journey.
For more details www.hawkstack.com
0 notes
Text
Mastering DevOps: Your Path to Seamless Software Delivery
The digital realm is evolving at an unprecedented pace, and businesses worldwide are striving for agility, efficiency, and rapid software delivery. In this dynamic landscape, DevOps has emerged as a crucial discipline that bridges the gap between software development and IT operations, promoting collaboration, automation, and streamlined processes. DevOps professionals play a pivotal role in this transformation, making DevOps courses an essential step towards mastering this ever-evolving field. In this comprehensive blog, we'll delve into the world of DevOps education, exploring the key components of DevOps courses and how they prepare individuals to excel in this dynamic domain.

The Essence of DevOps: DevOps, a fusion of "Development" and "Operations," signifies a set of practices aimed at enhancing collaboration, efficiency, and automation within the software development lifecycle. DevOps professionals facilitate rapid, reliable software delivery by breaking down silos and promoting a culture of continuous improvement.
Key Areas Covered in a DevOps Course:
Version Control: Unlocking Collaboration and Efficiency
DevOps courses commence with an in-depth exploration of version control systems, which serve as the foundation for efficient collaboration and streamlined development. Git, a widely adopted version control tool, takes the center stage. Students become well-versed in its intricacies, understanding how it enables teams to work collaboratively, manage code changes efficiently, and maintain a cohesive development process. Version control's significance lies in its role as a collaborative linchpin, ensuring that every team member is on the same page, creating a harmonious synergy between development and operations.
Continuous Integration/Continuous Deployment (CI/CD): The Heart of Automation
Automation, a core tenet of DevOps, is unveiled in the form of Continuous Integration/Continuous Deployment (CI/CD) in DevOps courses. This dynamic duo is the driving force behind expedited and dependable software delivery. Through CI/CD pipelines, students embark on a journey to automate critical tasks that define the software development lifecycle. Processes like code building, thorough testing, and deployment to production environments become seamless, allowing for rapid iterations and accelerated releases. The result? Software delivery that is both swift and unwavering in its reliability, a hallmark of a well-oiled DevOps operation.
Automation Tools: Unleashing Efficiency
DevOps courses introduce students to a diverse array of automation tools, with Jenkins emerging as a prominent figure. This toolset empowers individuals to optimize tasks that were once manual and time-consuming. By harnessing the potential of these tools, DevOps professionals can streamline their workflows and eliminate the inefficiencies that often plague conventional development and operations processes. The introduction to automation tools is a pivotal step on the journey toward mastering DevOps, marking the transition from manual labor to efficient, streamlined operations.
Containerization: Navigating the Container Revolution
In the modern era of DevOps, containerization reigns supreme. Docker, a pioneer in container technology, takes center stage in DevOps courses. Students delve deep into the world of containers, learning to create, deploy, and manage these encapsulated application environments. Containerization ensures that applications perform consistently across a diverse range of environments, fostering portability and predictability. It's a fundamental skill that DevOps professionals must master to maintain the resilience and consistency of their applications.
Orchestration: Scaling Containerized Dreams
Containerization is not complete without orchestration, and DevOps courses introduce orchestration tools like Kubernetes to ensure the effective management and scaling of containerized applications. Students acquire proficiency in orchestrating containers to maintain the harmony of their applications' performance. The orchestration layer allows for seamless scaling, load balancing, and high availability, which are crucial elements of modern application deployment.
Cloud Services: Navigating the Cloudscape
As cloud computing continues its evolutionary journey, DevOps professionals are expected to navigate the cloud landscape with finesse. Cloud platforms such as AWS, Azure, and Google Cloud have become pivotal players in the world of DevOps. DevOps courses offer comprehensive training to equip students with the knowledge and skills needed to leverage these platforms effectively. From provisioning resources to optimizing infrastructure for DevOps workflows, cloud services are an integral part of the modern DevOps ecosystem.

A Practical Approach: A well-structured DevOps course doesn't stop at theoretical knowledge. Practical exercises and real-world projects are integral to the learning process. These components enable students to apply DevOps concepts in real-world scenarios, ensuring they are not just familiar with DevOps principles but also proficient in their application.
DevOps is at the heart of the IT industry's transformation. Businesses are increasingly recognizing the significance of DevOps in achieving faster, more reliable software delivery. DevOps professionals are in high demand, and this trend is likely to continue as organizations prioritize agility and efficiency.
ACTE Technologies, a distinguished institution, offers comprehensive DevOps courses meticulously designed to provide both theoretical knowledge and practical skills. Guided by experienced instructors who bring industry insights and expertise to the classroom, ACTE Technologies' courses equip individuals with the proficiency required to excel in the ever-evolving world of IT. By enrolling in DevOps courses at ACTE Technologies, individuals can embark on a journey to master this dynamic field and prepare themselves for rewarding career opportunities. The world of DevOps awaits, and the possibilities are limitless. Your voyage toward DevOps excellence begins here.
3 notes
·
View notes
Text
How Can You Build a Scalable Fintech Software Platform?

The fintech revolution is redefining the way individuals and businesses manage money. From mobile banking and peer-to-peer payments to wealth management and insurance tech, financial technology is driving innovation across all sectors. However, as customer bases grow and user demands increase, the need for scalable fintech software becomes critical.
Building a robust and scalable platform is not only about accommodating growth—it's about doing so efficiently, securely, and with the flexibility to evolve. In this guide, we’ll explore the essential steps and components required to build a scalable fintech software platform that can meet modern expectations and future demands.
1. Start with a Modular Architecture
Scalability starts at the architectural level. A monolithic structure may be easier to launch initially, but it can quickly become a bottleneck as your fintech services grow. Instead, opt for a modular or microservices architecture. This design principle allows each component (e.g., payments, authentication, user profiles) to function independently.
By using this structure, updates and scaling can be performed on specific services without affecting the entire platform. This modularity enhances agility, accelerates development, and minimizes downtime during maintenance or upgrades.
2. Leverage Cloud Infrastructure
Cloud computing has transformed the way fintech companies build and scale their platforms. Cloud providers offer flexible, on-demand resources that can grow with your needs. Instead of investing heavily in physical servers, you can scale horizontally by adding more virtual machines or containers during peak usage.
Cloud-native technologies like Kubernetes, Docker, and serverless computing allow for:
Auto-scaling of resources
Global accessibility
Faster deployment cycles
Cost optimization based on usage
A cloud-first approach ensures that your fintech software remains responsive, even under heavy load.
3. Implement API-First Design
Integration is a key element in delivering comprehensive fintech services. Whether you're connecting with payment gateways, third-party tools, or external data providers, an API-first strategy makes this process seamless.
APIs enable interoperability and extend the value of your platform. By designing your fintech software with well-documented, secure, and version-controlled APIs, you not only simplify integration but also empower partners, developers, and clients to innovate around your platform.
4. Ensure Security and Compliance from Day One
Security is not optional—it's foundational. Scalable fintech platforms must be built with data protection and compliance in mind from the outset. As your user base grows, so does the risk surface. Poor security can lead to data breaches, legal penalties, and damage to your brand.
Key security practices include:
End-to-end encryption
Role-based access control
Multi-factor authentication
Real-time monitoring and anomaly detection
Additionally, compliance with regulations such as GDPR, KYC, and AML must be embedded within your processes. Automating compliance through built-in regulatory frameworks saves time and ensures consistency as your platform scales.
5. Optimize for Performance and Reliability
No one wants to use a fintech app that crashes during a transaction. Performance and reliability are vital for user trust and retention. A scalable fintech software platform must maintain low latency and high availability, regardless of the number of users.
To achieve this:
Use content delivery networks (CDNs) to serve static assets faster
Implement load balancing to distribute traffic evenly
Monitor infrastructure with real-time analytics and alerts
Conduct performance and stress testing regularly
High availability ensures that your fintech services are accessible 24/7 without disruption, fostering user confidence.
6. Design for a Seamless User Experience
As your platform grows, so will the diversity of your user base. A scalable fintech software solution must accommodate varying user behaviors, device types, and accessibility needs. That means designing intuitive, mobile-first interfaces and providing responsive support features.
Key UX principles include:
Simple onboarding flows
Personalized dashboards
Fast and easy transaction processes
Interactive support (e.g., chatbots or AI assistants)
Consistent and thoughtful design improves usability and helps drive customer satisfaction, which is essential for long-term growth.
7. Adopt Agile and DevOps Practices
Building a scalable platform requires continuous improvement. By adopting Agile methodologies and DevOps practices, development and operations teams can collaborate more effectively. Continuous integration and continuous deployment (CI/CD) pipelines allow for faster updates, quicker bug fixes, and more frequent releases without compromising quality.
These practices also support automation in testing, monitoring, and deployment, reducing human error and speeding up development cycles.
8. Plan for Data Scalability and Advanced Analytics
Data is the backbone of any fintech platform. From transaction history to user behavior, every interaction generates valuable information. Your software must be able to store, manage, and analyze growing volumes of data efficiently.
Scalable fintech services should include:
Distributed databases
Real-time analytics engines
AI-powered decision-making tools
Data warehousing for long-term storage
With the right data strategy, you can gain actionable insights, optimize performance, and offer personalized financial experiences to users.
Final Thoughts
Scalability is not an afterthought—it’s a design requirement from the beginning. To build a fintech software platform that stands the test of time, companies must focus on modular architecture, robust security, seamless integration, and a user-first approach. Cloud-native development, data analytics, and continuous delivery practices are also key enablers of long-term growth.
Organizations like Xettle Technologies specialize in crafting scalable, secure, and future-ready fintech software platforms tailored to the specific needs of financial service providers. By embracing the right technologies and methodologies, you can ensure your fintech solution not only grows with demand but leads in innovation.
0 notes
Text
Streamline Cloud Deployments with CI/CD Pipelines and Automation
In today’s fast-paced digital world, speed and reliability are critical for delivering great software experiences. That’s why more enterprises are embracing CI/CD pipelines and automation to streamline their cloud deployments.
From reducing human error to accelerating time to market, this approach is transforming how modern businesses build, test, and ship software in the cloud.
🔄 What is CI/CD in the Cloud?
CI/CD (Continuous Integration and Continuous Deployment) is a modern DevOps practice that automates the software delivery process. It enables developers to integrate code frequently, test it automatically, and deploy changes rapidly and safely.
When paired with cloud platforms, CI/CD delivers:
Faster release cycles
Reliable rollbacks
Automated testing at every stage
Scalable, repeatable deployments
⚙️ Key Components of a Cloud-Native CI/CD Pipeline
Version Control System (e.g., Git, GitHub, GitLab)
CI Server (e.g., Jenkins, CircleCI, GitHub Actions)
Automated Test Framework (e.g., Selenium, JUnit, Postman)
Infrastructure as Code (IaC) for repeatable cloud infrastructure
Monitoring and Rollback Mechanisms for real-time feedback
⚡ Benefits of CI/CD Pipelines in Cloud Environments
BenefitImpact 🕒 Faster Releases Ship features, fixes, and updates quickly ✅ Higher Code Quality Automated testing reduces bugs in production 🔁 Repeatability Standardized deployment reduces errors 📈 Scalability Easily scale with demand across regions 🧪 Better Collaboration Developers can work in smaller, faster cycles
🔧 Automation in Cloud Deployments
Automation is the backbone of modern cloud operations. When integrated with CI/CD, automation ensures:
Zero-touch deployments across multiple environments
Infrastructure provisioning with tools like Terraform or AWS CloudFormation
Configuration management with Ansible, Chef, or Puppet
Cloud-native scaling with Kubernetes, Docker, and serverless platforms
🛠️ Tools to Build a CI/CD Pipeline in the Cloud
CategoryPopular Tools Version Control GitHub, GitLab, Bitbucket CI/CD Orchestration Jenkins, GitHub Actions, CircleCI, Argo CD IaC Terraform, Pulumi, AWS CDK Containerization Docker, Kubernetes, Helm Monitoring & Rollback Prometheus, Grafana, Datadog, Sentry
🔐 CI/CD Security and Compliance Considerations
As deployments speed up, so must your focus on security and governance:
Use secrets managers for API keys and credentials
Run static code analysis in your pipeline
Enforce access controls and audit logging
Integrate security testing tools (SAST, DAST) early in the pipeline
✅ Real-World Use Case: CI/CD at Salzen Cloud
At Salzen Cloud, our clients achieve:
70% faster deployment times
50% fewer production bugs
Fully automated, auditable release workflows
Our custom-built pipelines integrate with AWS, Azure, GCP, and container-based platforms to ensure secure, high-performance deployments at scale.
🧠 Final Thoughts
If you're still deploying software manually or with long release cycles, you're falling behind.
CI/CD and automation aren't just nice-to-haves — they are essential for cloud-native success. They reduce risk, improve agility, and allow teams to focus on what matters most: delivering great software faster.
Ready to modernize your cloud deployments? Let Salzen Cloud help you build a CI/CD pipeline that fits your business goals.
0 notes
Text
Effective Kubernetes cluster monitoring simplifies containerized workload management by measuring uptime, resource use (such as memory, CPU, and storage), and interaction between cluster components. It also enables cluster managers to monitor the cluster and discover issues such as inadequate resources, errors, pods that fail to start, and nodes that cannot join the cluster. Essentially, Kubernetes monitoring enables you to discover issues and manage Kubernetes clusters more proactively. What Kubernetes Metrics Should You Measure? Monitoring Kubernetes metrics is critical for ensuring the reliability, performance, and efficiency of applications in a Kubernetes cluster. Because Kubernetes constantly expands and maintains containers, measuring critical metrics allows you to spot issues early on, optimize resource allocation, and preserve overall system integrity. Several factors are critical to watch with Kubernetes: Cluster monitoring - Monitors the health of the whole Kubernetes cluster. It helps you find out how many apps are running on a node, if it is performing efficiently and at the right capacity, and how much resource the cluster requires overall. Pod monitoring - Tracks issues impacting individual pods, including resource use, application metrics, and pod replication or auto scaling metrics. Ingress metrics - Monitoring ingress traffic can help in discovering and managing a variety of issues. Using controller-specific methods, ingress controllers can be set up to track network traffic information and workload health. Persistent storage - Monitoring volume health allows Kubernetes to implement CSI. You can also use the external health monitor controller to track node failures. Control plane metrics - With control plane metrics we can track and visualize cluster performance while troubleshooting by keeping an eye on schedulers, controllers, and API servers. Node metrics - Keeping an eye on each Kubernetes node's CPU and memory usage might help ensure that they never run out. A running node's status can be defined by a number of conditions, such as Ready, MemoryPressure, DiskPressure, OutOfDisk, and NetworkUnavailable. Monitoring and Troubleshooting Kubernetes Clusters Using the Kubernetes Dashboard The Kubernetes dashboard is a web-based user interface for Kubernetes. It allows you to deploy containerized apps to a Kubernetes cluster, see an overview of the applications operating on the cluster, and manage cluster resources. Additionally, it enables you to: Debug containerized applications by examining data on the health of your Kubernetes cluster's resources, as well as any anomalies that have occurred. Create and modify individual Kubernetes resources, including deployments, jobs, DaemonSets, and StatefulSets. Have direct control over your Kubernetes environment using the Kubernetes dashboard. The Kubernetes dashboard is built into Kubernetes by default and can be installed and viewed from the Kubernetes master node. Once deployed, you can visit the dashboard via a web browser to examine extensive information about your Kubernetes cluster and conduct different operations like scaling deployments, establishing new resources, and updating application configurations. Kubernetes Dashboard Essential Features Kubernetes Dashboard comes with some essential features that help manage and monitor your Kubernetes clusters efficiently: Cluster overview: The dashboard displays information about your Kubernetes cluster, including the number of nodes, pods, and services, as well as the current CPU and memory use. Resource management: The dashboard allows you to manage Kubernetes resources, including deployments, services, and pods. You can add, update, and delete resources while also seeing extensive information about them. Application monitoring: The dashboard allows you to monitor the status and performance of Kubernetes-based apps. You may see logs and stats, fix issues, and set alarms.
Customizable views: The dashboard allows you to create and preserve bespoke dashboards with the metrics and information that are most essential to you. Kubernetes Monitoring Best Practices Here are some recommended practices to help you properly monitor and debug Kubernetes installations: 1. Monitor Kubernetes Metrics Kubernetes microservices require understanding granular resource data like memory, CPU, and load. However, these metrics may be complex and challenging to leverage. API indicators such as request rate, call error, and latency are the most effective KPIs for identifying service faults. These metrics can immediately identify degradations in a microservices application's components. 2. Ensure Monitoring Systems Have Enough Data Retention Having scalable monitoring solutions helps you to efficiently monitor your Kubernetes cluster as it grows and evolves over time. As your Kubernetes cluster expands, so will the quantity of data it creates, and your monitoring systems must be capable of handling this rise. If your systems are not scalable, they may get overwhelmed by the volume of data and be unable to offer accurate or relevant results. 3. Integrate Monitoring Systems Into Your CI/CD Pipeline Source Integrating Kubernetes monitoring solutions with CI/CD pipelines enables you to monitor your apps and infrastructure as they are deployed, rather than afterward. By connecting your monitoring systems to your pipeline for continuous integration and delivery (CI/CD), you can automatically collect and process data from your infrastructure and applications as it is delivered. This enables you to identify potential issues early on and take action to stop them from getting worse. 4. Create Alerts You may identify the problems with your Kubernetes cluster early on and take action to fix them before they get worse by setting up the right alerts. For example, if you configure alerts for crucial metrics like CPU or memory use, you will be informed when those metrics hit specific thresholds, allowing you to take action before your cluster gets overwhelmed. Conclusion Kubernetes allows for the deployment of a large number of containerized applications within its clusters, each of which has nodes that manage the containers. Efficient observability across various machines and components is critical for successful Kubernetes container orchestration. Kubernetes has built-in monitoring facilities for its control plane, but they may not be sufficient for thorough analysis and granular insight into application workloads, event logging, and other microservice metrics within Kubernetes clusters.
0 notes
Text
Cloud Migration Strategy: A Comprehensive Guide to Seamless IT Transformation
In today’s fast-paced digital world, businesses are increasingly adopting cloud technologies to gain flexibility, scalability, and cost-efficiency. However, moving IT systems and critical applications from on-premises infrastructure to the cloud requires careful planning and execution. This is where a well-defined cloud migration strategy becomes essential. At PufferSoft, we understand the complexities of this transition and help organizations craft and implement the right strategy to ensure a smooth and secure migration.
What Is a Cloud Migration Strategy?
A cloud migration strategy is a detailed plan that outlines how an organization will move its IT resources, including web servers, databases, enterprise applications, and critical IT functions, to cloud platforms such as AWS or Azure. This strategy covers everything from assessing the existing infrastructure to designing, deploying, and managing cloud environments. A successful migration strategy minimizes downtime, controls costs, and maximizes the benefits of cloud adoption.
Why Is a Cloud Migration Strategy Important?
Without a clear cloud migration strategy, companies risk facing disruptions, security vulnerabilities, and inflated costs during the migration process. A solid strategy ensures:
Seamless migration of all IT components, including web servers, databases, Microsoft enterprise applications, disaster recovery, backup, and logging systems.
Adoption of scalable and flexible cloud solutions that grow with your business.
Enhanced security and compliance through best practices and continuous monitoring.
Optimized cloud costs by identifying unnecessary expenses and right-sizing resources.
Implementation of modern DevOps practices such as Kubernetes and CI/CD pipelines for faster deployment and innovation.
Key Elements of a Cloud Migration Strategy
At PufferSoft, our approach to cloud migration involves several critical elements that together form a robust cloud migration strategy:
Assessment and Planning We begin by thoroughly assessing your current IT landscape. This includes understanding your applications, workloads, dependencies, and business objectives. From there, we design a migration roadmap that aligns with your specific needs.
Choosing the Right Cloud Platform We specialize in both AWS and Azure, selecting the platform best suited for your workloads. Our expertise in cloud services ensures that your systems are designed for optimal performance, cost-efficiency, and security.
Migration Execution Using proven tools and methodologies, we migrate your web servers, databases, enterprise applications, and critical IT functions like disaster recovery and backup. We ensure that the migration is seamless and causes minimal disruption to your operations.
Kubernetes and DevOps Integration We leverage Kubernetes for container orchestration and integrate CI/CD pipelines to automate your software delivery process. This modern approach improves scalability and accelerates innovation.
Security and Compliance Security is a top priority. Our team deploys fully redundant and secure cloud architectures with backup and disaster recovery. We also provide auditing services to help you secure cloud resources and comply with industry regulations.
24/7 Cloud Management and Support Post-migration, we offer round-the-clock monitoring and management services. This ensures your cloud infrastructure is always optimized, secure, and performing at its best.
Benefits of Implementing a Cloud Migration Strategy
A thoughtfully executed cloud migration strategy offers numerous benefits to organizations:
Improved Agility: Quickly scale resources up or down based on demand.
Cost Efficiency: Pay only for the resources you use, avoiding costly overprovisioning.
Enhanced Security: Implement robust security controls tailored to your environment.
Business Continuity: Ensure data protection and disaster recovery with redundant cloud setups.
Innovation Acceleration: Leverage DevOps and automation tools to speed up development cycles.
Why Partner with PufferSoft for Your Cloud Migration Strategy?
At PufferSoft, we bring extensive expertise in cloud migration and management. We help businesses move all their IT systems—including web servers, databases, Microsoft enterprise applications, and critical functions like disaster recovery and backup—to the cloud securely and efficiently. Our specialists are skilled in Kubernetes, DevOps, and Terraform, allowing us to deliver fully redundant, secure, and scalable cloud solutions tailored to your unique requirements.
Our comprehensive cloud services include design, deployment, migration, integration, development, and 24/7 management. We also provide auditing to help you secure your cloud environment and optimize costs, ensuring you get the best return on your cloud investment.
Conclusion
Developing and executing a robust cloud migration strategy is crucial for businesses looking to harness the power of the cloud while minimizing risks. Whether you are migrating legacy systems, enterprise applications, or critical IT functions, having a trusted partner like PufferSoft ensures a smooth transition and ongoing success in the cloud. With our expertise in AWS, Azure, Kubernetes, and DevOps, we help you transform your IT landscape into a secure, scalable, and cost-effective cloud environment.
If you are ready to take the next step in your cloud journey, contact PufferSoft today to develop a tailored cloud migration strategy that meets your business goals.
0 notes