#kubernetes zookeeper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
Advantages and Difficulties of Using ZooKeeper in Kubernetes

Advantages and Difficulties of Using ZooKeeper in Kubernetes
Integrating ZooKeeper with Kubernetes can significantly enhance the management of distributed systems, offering various benefits while also presenting some challenges. This post explores the advantages and difficulties associated with deploying ZooKeeper in a Kubernetes environment.
Advantages
Utilizing ZooKeeper in Kubernetes brings several notable advantages. Kubernetes excels at resource management, ensuring that ZooKeeper nodes are allocated effectively for optimal performance. Scalability is streamlined with Kubernetes, allowing you to easily adjust the number of ZooKeeper instances to meet fluctuating demands. Automated failover and self-healing features ensure high availability, as Kubernetes can automatically reschedule failed ZooKeeper pods to maintain continuous operation. Kubernetes also simplifies deployment through StatefulSets, which handle the complexities of stateful applications like ZooKeeper, making it easier to manage and scale clusters. Furthermore, the Kubernetes ZooKeeper Operator enhances this integration by automating configuration, scaling, and maintenance tasks, reducing manual intervention and potential errors.
Difficulties
Deploying ZooKeeper on Kubernetes comes with its own set of challenges. One significant difficulty is ZooKeeper’s inherent statefulness, which contrasts with Kubernetes’ focus on stateless applications. This necessitates careful management of state and configuration to ensure data consistency and reliability in a containerized environment. Ensuring persistent storage for ZooKeeper data is crucial, as improper storage solutions can impact data durability and performance. Complex network configurations within Kubernetes can pose hurdles for reliable service discovery and communication between ZooKeeper instances. Additionally, security is a critical concern, as containerized environments introduce new potential vulnerabilities, requiring stringent access controls and encryption practices. Resource allocation and performance tuning are essential to prevent bottlenecks and maintain efficiency. Finally, upgrading ZooKeeper and Kubernetes components requires thorough testing to ensure compatibility and avoid disruptions.
In conclusion, deploying ZooKeeper in Kubernetes offers a range of advantages, including enhanced scalability and simplified management, but also presents challenges related to statefulness, storage, network configuration, and security. By understanding these factors and leveraging tools like the Kubernetes ZooKeeper Operator, organizations can effectively navigate these challenges and optimize their ZooKeeper deployments.
To gather more knowledge about deploying ZooKeeper on Kubernetes, Click here.
1 note
·
View note
Text
🛠 Open Source Instant Messaging (IM) Project OpenIM Source Code Deployment Guide
Deploying OpenIM involves multiple components and supports various methods, including source code, Docker, and Kubernetes. This requires ensuring compatibility between different deployment methods while effectively managing differences between versions. Indeed, these are complex issues involving in-depth technical details and precise system configurations. Our goal is to simplify the deployment process while maintaining the system's flexibility and stability to suit different users' needs. Currently, version 3.5 has simplified the deployment process, and this version will be maintained for a long time. We welcome everyone to use it.
1. Environment and Component Requirements
🌐 Environmental Requirements
NoteDetailed DescriptionOSLinux systemHardwareAt least 4GB of RAMGolangv1.19 or higherDockerv24.0.5 or higherGitv2.17.1 or higher
💾 Storage Component Requirements
Storage ComponentRecommended VersionMongoDBv6.0.2 or higherRedisv7.0.0 or higherZookeeperv3.8Kafkav3.5.1MySQLv5.7 or higherMinIOLatest version
2. Deploying OpenIM Server (IM)
2.1 📡 Setting OPENIM_IP
# If the server has an external IP export OPENIM_IP="external IP" # If only providing internal network services export OPENIM_IP="internal IP"
2.2 🏗️ Deploying Components (mongodb/redis/zookeeper/kafka/MinIO, etc.)
git clone https://github.com/OpenIMSDK/open-im-server && cd open-im-server # It's recommended to switch to release-v3.5 or later release branches make init && docker compose up -d
2.3 🛠️ Compilation
make build
2.4 🚀 Starting/Stopping/Checking
# Start make start # Stop make stop # Check make check
3. Deploying App Server (Chat)
3.1 🏗️ Deploying Components (mysql)
# Go back to the previous directory cd .. # Clone the repository, recommended to switch to release-v1.5 or later release branches git clone https://github.com/OpenIMSDK/chat chat && cd chat # Deploy mysql docker run -d --name mysql2 -p 13306:3306 -p 33306:33060 -v "$(pwd)/components/mysql/data:/var/lib/mysql" -v "/etc/localtime:/etc/localtime" -e MYSQL_ROOT_PASSWORD="openIM123" --restart always mysql:5.7
3.2 🛠️ Compilation
make init make build
3.3 🚀 Starting/Stopping/Checking
# Start make start # Stop make stop # Check make check
4. Quick Validation
📡 Open Ports
IM Ports
TCP PortDescriptionActionTCP:10001ws protocol, messaging port, for client SDKAllow portTCP:10002API port, like user, friend, group, message interfacesAllow portTCP:10005Required when choosing MinIO storage (OpenIM defaults to MinIO storage)Allow port
Chat Ports
TCP PortDescriptionActionTCP:10008Business system, like registration, login, etc.Allow portTCP:10009Management backend, like statistics, account banning, etc.Allow port
PC Web and Management Backend Frontend Resource Ports
TCP PortDescriptionActionTCP:11001PC Web frontend resourcesAllow portTCP:11002Management backend frontend resourcesAllow port
Grafana Port
TCP PortDescriptionActionTCP:13000Grafana portAllow port
Verification
PC Web Verification
Note: Enter http://ip:11001 in your browser to access the PC Web. This IP should be the server's OPENIM_IP to ensure browser accessibility. For first-time use, please register using your mobile phone number, with the default verification code being 666666.
App Verification
Scan the following QR code or click here to download.

Note: Double-click on OpenIM and change the IP to the server's OPENIM_IP then restart the App. Please ensure related ports are open, and restart the App after making changes. For first-time use, please register first through your mobile phone number, with the default verification code being 666666.


5. Modifying Configuration Items
5.1 🛠️ Modifying Shared Configuration Items
Configuration ItemFiles to be ModifiedActionmongo/kafka/minio related.env, openim-server/config/config.yamlRestart components and IMredis/zookeeper related.env, openim-server/config/config.yaml, chat/config/config.yamlRestart components, IM, and ChatSECRETopenim-server/config/config.yaml, chat/config/config.yamlRestart IM and Chat
5.2 🔄 Modifying Special Configuration Items
Special configuration items: API_OPENIM_PORT/MINIO_PORT/OPENIM_IP/GRAFANA_PORT
Modify the special configuration items in the .env file
Modify the configuration in openim-server/config/config.yaml according to the rules
Modify the configuration in chat/config/config.yaml according to the rules
Restart IM and Chat
5.3 🛠️ Modifying Other Configuration Items
For other configuration items in .env, chat/config/config.yaml, and openim-server/config/config.yaml, you can modify these items directly in the respective files.
5.4 Modifying Ports
Note that for any modification of IM-related ports, it's necessary to synchronize the changes in open-im-server/scripts/install/environment.sh.
6. Frequently Asked Questions
6.1 📜 Viewing Logs
Runtime logs: logs/OpenIM.log.all.*
Startup logs: _output/logs/openim_*.log
6.2 🚀 Startup Order
The startup order is as follows:
Components IM depends on: mongo/redis/kafka/zookeeper/minio, etc.
IM
Components Chat depends on: mysql
Chat
6.3 🐳 Docker Version
The new version of Docker has integrated docker-compose.
Older versions of Docker might not support the gateway feature. It's recommended to upgrade to a newer version, such as 23.0.1.
7. About OpenIM
Thanks to widespread developer support, OpenIM maintains a leading position in the open-source instant messaging (IM) field, with the number of stars on Github exceeding 12,000. In the current context of increasing attention to data and privacy security, the demand for IM private deployment is growing, which aligns with the rapid development trend of China's software industry. Especially in government and enterprise sectors, with the rapid development of information technology and the widespread application of innovative
industries, the demand for IM solutions has surged. Further, the continuous expansion of the collaborative office software market has made "secure and controllable" a key attribute.
Repository address: https://github.com/openimsdk
1 note
·
View note
Text
Apache Storm 2.0 Improvements
By Kishor Patil, Principal Software Systems Engineer at Verizon Media, and PMC member of Apache Storm & Bobby Evans, Apache Member and PMC member of Apache Hadoop, Spark, Storm, and Tez
We are excited to be part of the new release of Apache Storm 2.0.0. The open source community has been working on this major release, Storm 2.0, for quite some time. At Yahoo we had a long time and strong commitment to using and contributing to Storm; a commitment we continue as part of Verizon Media. Together with the Apache community, we’ve added more than 1000 fixes and improvements to this new release. These improvements include sending real-time infrastructure alerts to the DevOps folks running Storm and the ability to augment ingested content with related content, thereby giving the users a deeper understanding of any one piece of content.
Performance
Performance and utilization are very important to us, so we developed a benchmark to evaluate various stream processing platforms and the initial results showed Storm to be among the best. We expect to release new numbers by the end of June 2019, but in the interim, we ran some smaller Storm specific tests that we’d like to share.
Storm 2.0 has a built-in load generation tool under examples/storm-loadgen. It comes with the requisite word count test, which we used here, but also has the ability to capture a statistical representation of the bolts and spouts in a running production topology and replay that load on another topology, or another version of Storm. For this test, we backported that code to Storm 1.2.2. We then ran the ThroughputVsLatency test on both code bases at various throughputs and different numbers of workers to see what impact Storm 2.0 would have. These were run out of the box with no tuning to the default parameters, except to set max.spout.pending in the topologies to be 1000 sentences, as in the past that has proven to be a good balance between throughput and latency while providing flow control in the 1.2.2 version that lacks backpressure.
In general, for a WordCount topology, we noticed 50% - 80% improvements in latency for processing a full sentence. Moreover, 99 percentile latency in most cases, is lower than the mean latency in the 1.2.2 version. We also saw the maximum throughput on the same hardware more than double.

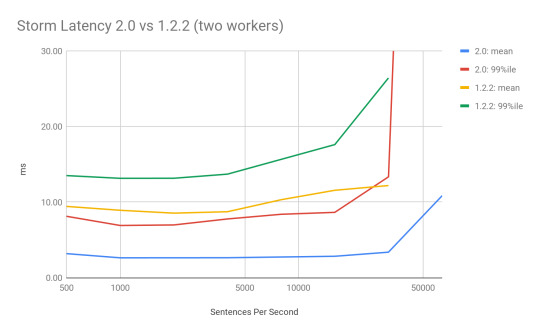
Why did this happen? STORM-2306 redesigned the threading model in the workers, replaced disruptor queues with JCTools queues, added in a new true backpressure mechanism, and optimized a lot of code paths to reduce the overhead of the system. The impact on system resources is very promising. Memory usage was untouched, but CPU usage was a bit more nuanced.

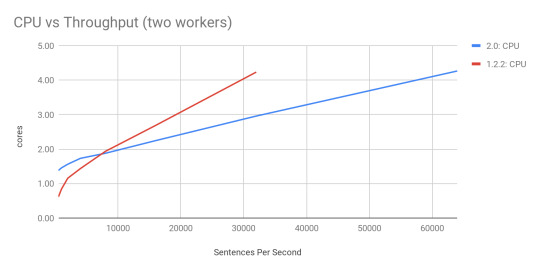
At low throughput (< 8000 sentences per second) the new system uses more CPU than before. This can be tuned as the system does not auto-tune itself yet. At higher rates, the slope of the line is much lower which means Storm has less overhead than before resulting in being able to process more data with the same hardware. This also means that we were able to max out each of these configurations at > 100,000 sentences per second on 2.0.0 which is over 2x the maximum 45,000 sentences per second that 1.2.2 could do with the same setup. Note that we did nothing to tune these topologies on either setup. With true backpressure, a WordCount Topology could consistently process 230,000 sentences per second by disabling the event tracking feature. Due to true backpressure, when we disabled it entirely, then we were able to achieve over 230,000 sentences per second in a stable way, which equates to over 2 million messages per second being processed on a single node.
Scalability
In 2.0, we have laid the groundwork to make Storm even more scalable. Workers and supervisors can now heartbeat directly into Nimbus instead of going through ZooKeeper, resulting in the ability to run much larger clusters out of the box.
Developer Friendly
Prior to 2.0, Storm was primarily written in Clojure. Clojure is a wonderful language with many advantages over pure Java, but its prevalence in Storm became a hindrance for many developers who weren’t very familiar with it and didn’t have the time to learn it. Due to this, the community decided to port all of the daemon processes over to pure Java. We still maintain a backward compatible storm-clojure package for those that want to continue using Clojure for topologies.
Split Classpath
In older versions, Storm was a single jar, that included code for the daemons as well as the user code. We have now split this up and storm-client provides everything needed for your topology to run. Storm-core can still be used as a dependency for tests that want to run a local mode cluster, but it will pull in more dependencies than you might expect.
To upgrade your topology to 2.0, you’ll just need to switch your dependency from storm-core-1.2.2 to storm-client-2.0.0 and recompile.
Backward Compatible
Even though Storm 2.0 is API compatible with older versions, it can be difficult when running a hosted multi-tenant cluster. Coordinating upgrading the cluster with recompiling all of the topologies can be a massive task. Starting in 2.0.0, Storm has the option to run workers for topologies submitted with an older version with a classpath for a compatible older version of Storm. This important feature which was developed by our team, allows you to upgrade your cluster to 2.0 while still allowing for upgrading your topologies whenever they’re recompiled to use newer dependencies.
Generic Resource Aware Scheduling
With the newer generic resource aware scheduling strategy, it is now possible to specify generic resources along with CPU and memory such as Network, GPU, and any other generic cluster level resource. This allows topologies to specify such generic resource requirements for components resulting in better scheduling and stability.
More To Come
Storm is a secure enterprise-ready stream but there is always room for improvement, which is why we’re adding in support to run workers in isolated, locked down, containers so there is less chance of malicious code using a zero-day exploit in the OS to steal data.
We are working on redesigning metrics and heartbeats to be able to scale even better and more importantly automatically adjust your topology so it can run optimally on the available hardware. We are also exploring running Storm on other systems, to provide a clean base to run not just on Mesos but also on YARN and Kubernetes.
If you have any questions or suggestions, please feel free to reach out via email.
P.S. We’re hiring! Explore the Big Data Open Source Distributed System Developer opportunity here.
3 notes
·
View notes
Link
0 notes
Text
Kubernetes must know:

First thing to know is that Kubernetes has many competitors such as Docker Swarm, Zookeeper, Nomad etc.. and Kubernetes is not the solution for every architecture so please define your requirements and check other alternatives first before starting with Kuberenetes as it can be complex or not really that beneficial in your case and that an easier orchestrator can do the job.
If you are using a cloud provider, and you want a managed kubernetes service, you can check EKS for AWS, GCP for Google Cloud or AKS for Azure.
Make sure to have proper monitoring and alerting for your cluster as this enables more visibility and eases the management of containerized infrastructure by tracking utilization of cluster resources including memory, CPU, storage and networking performance. It is also recommended to monitor pods and applications in the cluster. The most common tools used for Kubernetes monitoring are ELK/EFK, datadog, Prometheus and Grafana which will be my topic for the next article, etc..
Please make sure to backup your cluster’s etcd data regularly.
In order to ensure that your kubernetes cluster resources are only accessed by certain people, it's recommended to use RBAC in your cluster in order to build roles with the right access.
Scalability and what's more important than scalability, 3 types we must know and include in our cluster architecture are Cluster autoscaler, HPA and VPA.
Resource management is important as well, setting and rightsizing cluster resources requests and limits will help avoiding issues like OOM and Pod eviction and saves you money!
You may want to check Kubernetes CIS Benchmark which is a set of recommendations for configuring Kubernetes to support a strong security posture, you can take a look at this article to learn more about it.
Try to always get the latest Kubernetes stable GA version for newer functionalities and if using cloud, for supported versions.
Scan containers for security vulnerabilities is very important as well, here we can talk about tools like Kube Hunter, Kube Bench etc..
Make use of Admission controllers when possible as they intercept and process requests to the Kubernetes API prior to persistence of the object, but after the request is authenticated and authorized, which is used when you have a set of constraints/behavior to be checked before a resource is deployed. It can also block vulnerable images from being deployed.
Speaking about Admission controller, you can also enforce policies in Kubernetes using a tool like OPA which lets you define sets of security and compliance policies as code.
Using a tool like Falco for auditing the cluster, this is a nice way to log and monitor real time activities and interactions with the API.
Another thing to take a look at is how to handle logging of applications running in containers (I recommend checking logging agents such fluentd/fluentbit) and especially how to setup Log rotation to reduce the storage growth and avoid performance issues.
In case you have multiple microservices running in the cluster, you can also implement a service mesh solution in order to have a reliable and secure architecture and other features such as encryption, authentication, authorization, routing between services and versions and load balancing. One of the famous service mesh solutions is Istio. You can take a look at this article for more details about service mesh.
One of the most important production ready clusters features is to have a backup&restore solution and especially a solution to take snapshots of your cluster’s Persistent Volumes. There are multiple tools to do this that you might check and benchmark like velero, portworx etc..
You can use quotas and limit ranges to control the amount of resources in a namespace for multi-tenancy.
For multi cluster management, you can check Rancher, weave Flux, Lens etc..
0 notes
Quote
Open Source Definitely Changed Storage Industry With Linux and other technologies and products, it impacts all areas. By Philippe Nicolas | February 16, 2021 at 2:23 pm It’s not a breaking news but the impact of open source in the storage industry was and is just huge and won’t be reduced just the opposite. For a simple reason, the developers community is the largest one and adoption is so wide. Some people see this as a threat and others consider the model as a democratic effort believing in another approach. Let’s dig a bit. First outside of storage, here is the list some open source software (OSS) projects that we use every day directly or indirectly: Linux and FreeBSD of course, Kubernetes, OpenStack, Git, KVM, Python, PHP, HTTP server, Hadoop, Spark, Lucene, Elasticsearch (dual license), MySQL, PostgreSQL, SQLite, Cassandra, Redis, MongoDB (under SSPL), TensorFlow, Zookeeper or some famous tools and products like Thunderbird, OpenOffice, LibreOffice or SugarCRM. The list is of course super long, very diverse and ubiquitous in our world. Some of these projects initiated some wave of companies creation as they anticipate market creation and potentially domination. Among them, there are Cloudera and Hortonworks, both came public, promoting Hadoop and they merged in 2019. MariaDB as a fork of MySQL and MySQL of course later acquired by Oracle. DataStax for Cassandra but it turns out that this is not always a safe destiny … Coldago Research estimated that the entire open source industry will represent $27+ billion in 2021 and will pass the barrier of $35 billion in 2024. Historically one of the roots came from the Unix – Linux transition. In fact, Unix was largely used and adopted but represented a certain price and the source code cost was significant, even prohibitive. Projects like Minix and Linux developed and studied at universities and research centers generated tons of users and adopters with many of them being contributors. Is it similar to a religion, probably not but for sure a philosophy. Red Hat, founded in 1993, has demonstrated that open source business could be big and ready for a long run, the company did its IPO in 1999 and had an annual run rate around $3 billion. The firm was acquired by IBM in 2019 for $34 billion, amazing right. Canonical, SUSE, Debian and a few others also show interesting development paths as companies or as communities. Before that shift, software developments were essentially applications as system software meant cost and high costs. Also a startup didn’t buy software with the VC money they raised as it could be seen as suicide outside of their mission. All these contribute to the open source wave in all directions. On the storage side, Linux invited students, research centers, communities and start-ups to develop system software and especially block storage approach and file system and others like object storage software. Thus we all know many storage software start-ups who leveraged Linux to offer such new storage models. We didn’t see lots of block storage as a whole but more open source operating system with block (SCSI based) storage included. This is bit different for file and object storage with plenty of offerings. On the file storage side, the list is significant with disk file systems and distributed ones, the latter having multiple sub-segments as well. Below is a pretty long list of OSS in the storage world. Block Storage Linux-LIO, Linux SCST & TGT, Open-iSCSI, Ceph RBD, OpenZFS, NexentaStor (Community Ed.), Openfiler, Chelsio iSCSI, Open vStorage, CoprHD, OpenStack Cinder File Storage Disk File Systems: XFS, OpenZFS, Reiser4 (ReiserFS), ext2/3/4 Distributed File Systems (including cluster, NAS and parallel to simplify the list): Lustre, BeeGFS, CephFS, LizardFS, MooseFS, RozoFS, XtreemFS, CohortFS, OrangeFS (PVFS2), Ganesha, Samba, Openfiler, HDFS, Quantcast, Sheepdog, GlusterFS, JuiceFS, ScoutFS, Red Hat GFS2, GekkoFS, OpenStack Manila Object Storage Ceph RADOS, MinIO, Seagate CORTX, OpenStack Swift, Intel DAOS Other data management and storage related projects TAR, rsync, OwnCloud, FileZilla, iRODS, Amanda, Bacula, Duplicati, KubeDR, Velero, Pydio, Grau Data OpenArchive The impact of open source is obvious both on commercial software but also on other emergent or small OSS footprint. By impact we mean disrupting established market positions with radical new approach. It is illustrated as well by commercial software embedding open source pieces or famous largely adopted open source product that prevent some initiatives to take off. Among all these scenario, we can list XFS, OpenZFS, Ceph and MinIO that shake commercial models and were even chosen by vendors that don’t need to develop themselves or sign any OEM deal with potential partners. Again as we said in the past many times, the Build, Buy or Partner model is also a reality in that world. To extend these examples, Ceph is recommended to be deployed with XFS disk file system for OSDs like OpenStack Swift. As these last few examples show, obviously open source projets leverage other open source ones, commercial software similarly but we never saw an open source project leveraging a commercial one. This is a bit antinomic. This acts as a trigger to start a development of an open source project offering same functions. OpenZFS is also used by Delphix, Oracle and in TrueNAS. MinIO is chosen by iXsystems embedded in TrueNAS, Datera, Humio, Robin.IO, McKesson, MapR (now HPE), Nutanix, Pavilion Data, Portworx (now Pure Storage), Qumulo, Splunk, Cisco, VMware or Ugloo to name a few. SoftIron leverages Ceph and build optimized tailored systems around it. The list is long … and we all have several examples in mind. Open source players promote their solutions essentially around a community and enterprise editions, the difference being the support fee, the patches policies, features differences and of course final subscription fees. As we know, innovations come often from small agile players with a real difficulties to approach large customers and with doubt about their longevity. Choosing the OSS path is a way to be embedded and selected by larger providers or users directly, it implies some key questions around business models. Another dimension of the impact on commercial software is related to the behaviors from universities or research centers. They prefer to increase budget to hardware and reduce software one by using open source. These entities have many skilled people, potentially time, to develop and extend open source project and contribute back to communities. They see, in that way to work, a positive and virtuous cycle, everyone feeding others. Thus they reach new levels of performance gaining capacity, computing power … finally a decision understandable under budget constraints and pressure. Ceph was started during Sage Weil thesis at UCSC sponsored by the Advanced Simulation and Computing Program (ASC), including Sandia National Laboratories (SNL), Lawrence Livermore National Laboratory (LLNL) and Los Alamos National Laboratory (LANL). There is a lot of this, famous example is Lustre but also MarFS from LANL, GekkoFS from University of Mainz, Germany, associated with the Barcelona Supercomputing Center or BeeGFS, formerly FhGFS, developed by the Fraunhofer Center for High Performance Computing in Germany as well. Lustre was initiated by Peter Braam in 1999 at Carnegie Mellon University. Projects popped up everywhere. Collaboration software as an extension to storage see similar behaviors. OwnCloud, an open source file sharing and collaboration software, is used and chosen by many universities and large education sites. At the same time, choosing open source components or products as a wish of independence doesn’t provide any kind of life guarantee. Rremember examples such HDFS, GlusterFS, OpenIO, NexentaStor or Redcurrant. Some of them got acquired or disappeared and create issue for users but for sure opportunities for other players watching that space carefully. Some initiatives exist to secure software if some doubt about future appear on the table. The SDS wave, a bit like the LMAP (Linux, MySQL, Apache web server and PHP) had a serious impact of commercial software as well as several open source players or solutions jumped into that generating a significant pricing erosion. This initiative, good for users, continues to reduce also differentiators among players and it became tougher to notice differences. In addition, Internet giants played a major role in open source development. They have talent, large teams, time and money and can spend time developing software that fit perfectly their need. They also control communities acting in such way as they put seeds in many directions. The other reason is the difficulty to find commercial software that can scale to their need. In other words, a commercial software can scale to the large corporation needs but reaches some limits for a large internet player. Historically these organizations really redefined scalability objectives with new designs and approaches not found or possible with commercial software. We all have example in mind and in storage Google File System is a classic one or Haystack at Facebook. Also large vendors with internal projects that suddenly appear and donated as open source to boost community effort and try to trigger some market traction and partnerships, this is the case of Intel DAOS. Open source is immediately associated with various licenses models and this is the complex aspect about source code as it continues to create difficulties for some people and entities that impact projects future. One about ZFS or even Java were well covered in the press at that time. We invite readers to check their preferred page for that or at least visit the Wikipedia one or this one with the full table on the appendix page. Immediately associated with licenses are the communities, organizations or foundations and we can mention some of them here as the list is pretty long: Apache Software Foundation, Cloud Native Computing Foundation, Eclipse Foundation, Free Software Foundation, FreeBSD Foundation, Mozilla Foundation or Linux Foundation … and again Wikipedia represents a good source to start.
Open Source Definitely Changed Storage Industry - StorageNewsletter
0 notes
Link
You might ask this very reasonable question:
But writing code is pretty hard already. Does it really only get harder from there?
And I'll hit you with one-worder:
yes
Production?
Before we move on, let me take a second to explain what "production" is:
It's a distributed system. Wikipedia says it best: A distributed system is a system whose components are located on different networked computers
Your code getting relentlessly pounded by the forces of nature
(If you have an app with a DB, you're running a distributed system)
In other words, "production" is a harsh, brutal hellscape that'll chew your code up and spit it out like it was nothing 😱.

Uh, thanks a lot, sad man!
Yea, that was a little bit of hyperbole but to be honest, I'm hitting you with all these scary things to ... scare you. But only a bit.
Why? To get my point across, of course! And to recommend some tools to make your life easier now and down the line.
Obviously I'm gonna talk about Dapr here, but here are other good tools you can and should consider. Here are some I can personally recommend from experience:
PaaS systems take your code, run it on some internal/proprietary system, and give you a few APIs you can call to do useful things.
Azure App Services, Google App Engine, Heroku
FaaS platforms let you upload a function in the language of your choice to the system, and tell it when to run the function (e.g. an HTTP request to GET /dostuff)
Azure Functions, Google Cloud Functions
Orchestrators take your code and make sure it's always running exactly as you tell it to
Kubernetes, Nomad
Service meshes take care of making talking over any network more reliable. You get mTLS for free too 🎉
LinkerD
Dapr
Dapr takes some of the above things and builds on some others. The idea is that you run this daprd process (and maybe some others) "next to" your code (on localhost). You talk to this thing via a standard API (HTTP or gRPC) to get lots of things done:
Service discovery
Getting the IP for the REST API that you need, when all you know is the name. Kind of like DNS for your app, but designed for apps in production instead of billions of connected devices on the internet. Design tradeoffs, amirite!?
Databases
Storing your data somewhere, of course :)
Dapr calls these "State Stores"
Publish/subscribe
One part of your app broadcasts "I did X" into the world. Another app hears it and does things
Bindings
Automatically calling your app when something in the outside world happens
Or automatically calling something in the outside world when your app does something
These have some overlap with publish/subscribe
Actors
Write pieces of your app like it's running on their own, and let dapr run each piece in the right place at the right time (or keep them running forever!)
These are great if you need to break your app up into tons of little pieces
Observability
Collecting logs and various metrics so you can figure out how to fix your app when it spectacularly fails :)
and so you can figure out how it's doing before it fails!
Secrets management
Safely storing your database password, API keys, and other stuff you'd rather not check into your GitHub repo
And, getting them back when your app starts up
Each of these things is a standard API backed by pluggable implementations. Dapr takes care of the dirty details behind the scenes. Database implementations take care of getting the right SDK, hooking you to the right DB in the right place, helping you make sure you don't accidentally overwrite or corrupt your data at runtime, and more.
As I write this, there are 15 implementations you can use for Databases, from Aerospike to Zookeeper.
Possibly most importantly, you don't have to pick up any SDKs to use any of this stuff. It's compiled into Dapr itself.
Next up
If you took nothing else away, just remember that you should pick up "distributed systems tools" to help you build your app. Even if you don't think that your app is a "hardcore distributed system". The best ones will make your life easier while you're building it, too.
I think Dapr is one of those tools. Right when I start building, I can just use the simple(ish) REST API for my database instead of picking up some new SDK and reading all the DB docs up front. Same goes for some of the other features, they just come later. I recommend giving the README a skim and seeing if it fits your app.
0 notes
Link
A pod in Kubernetes represents the fundamental deployment unit. It may contain one or more containers packaged and deployed as a logical entity. A cloud native application running in Kubernetes may contain multiple pods mapped to each microservice. Pods are also the unit of scaling in Kubernetes. Here are five best practices to follow before deploying pods in Kubernetes. Even though there are other configurations that may be applied, these are the most essential practices that bring basic hygiene to cloud native applications. 1) Choose the Most Appropriate Kubernetes Controller While it may be tempting to deploy and run a container image as a generic pod, you should select the right controller type based on the workload characteristics. Kubernetes has a primitive called the controller which aligns with the key characteristic of the workload. Deployment, StatefulSet, and DaemonSet are the most often used controllers in Kubernetes. When deploying stateless pods, always use the deployment controller. This brings PaaS-like capabilities to pods through scaling, deployment history, and rollback features. When a deployment is configured with a minimum replica count of two, Kubernetes ensures that at least two pods are always running which brings fault tolerance. Even when deploying the pod with just one replica, it is highly recommended that you use a deployment controller instead of a plain vanilla pod specification. For workloads such as database clusters, a StatefulSet controller will create a highly available set of pods that have a predictable naming convention. Stateful workloads such as Cassandra, Kafka, ZooKeeper, and SQL Server that need to be highly available are deployed as StatefulSets in Kubernetes. When you need to run a pod on every node of the cluster, you should use the DaemonSet controller. Since Kubernetes automatically schedules a DaemonSet in newly provisioned worker nodes, it becomes an ideal candidate to configure and prepare the node for the workload. For example, if you want to mount an existing NFS or Gluster file share on the node before deploying the workload, package and deploy the pod as a DaemonSet. Make sure you are choosing the most appropriate controller type before deploying pods. 2) Configure Health Checks for Pods By default, all the running pods have the restart policy set to always which means the kubelet running within a node will automatically restart a pod when the container encounters an error. Health checks extend this capability of kubelet through the concept of container probes. There are three probes that can be configured for each pod — Readiness, liveness, and startup. You would have encountered a situation where the pod is in running state but the ready column shows 0/1. This indicates that the pod is not ready to accept requests. A readiness probe ensures that the prerequisites are met before starting the pod. For example, a pod serving a machine learning model needs to download the latest version of the model before serving the inference. The readiness probe will constantly check for the presence of the file before moving the pod to the ready state. Similarly, the readiness probe in a CMS pod will ensure that the datastore is mounted and accessible. The liveness probe will periodically check the health of the container and report to the kubelet. When this health check fails, the pod will not receive the traffic. The service will ignore the pod until the liveness probe reports a positive state. For example, a MySQL pod may include a liveness probe that continuously checks the state of the database engine. The startup probe which is still in alpha as of version 1.16, allows containers to wait for longer periods before handing over the health check to the liveness probe. This is helpful when porting legacy applications to Kubernetes that take unusual startup times. All the above health checks can be configured with commands, HTTP probes, and TCP probes. Refer to the Kubernetes documentation on the steps to configure health checks. 3) Make use of an Init Container to Prepare the Pod There are scenarios where the container needs initialization before becoming ready. The initialization can be moved to another container to does the groundwork before the pod moves to a ready state. An init container can be used to download files, create directories, change file permissions, and more. An init container can even be used to ensure that the pods are started in a specific sequence. For example, an Init Container will wait till the MySQL pod becomes available before starting the WordPress pod. A pod may contain multiple init containers with each container performing a specific initializing task. 4) Apply Node/Pod Affinity and Anti-Affinity Rules Kubernetes scheduler does a good job of placing the pods on associated nodes based on the resource requirements of the pod and resource consumption within the cluster. However, there may be a need to control the way pods are scheduled on nodes. Kubernetes provides two mechanisms — Node Affinity/anti-affinity and pod affinity/anti-affinity. Node affinity extends the already powerful nodeSelector rule to cover additional scenarios. Like the way Kubernetes annotations make labels/selectors more expressive and extensible, node affinity makes nodeSelector more expressive through additional rules. Node affinity will ensure that pods are scheduled on nodes that meet specific criteria. For example, a stateful database pod can be forced to be scheduled on a node that has an SSD attached. Similarly, node anti-affinity will help in avoiding scheduling the pods on the nodes that may cause issues. While node affinity does matchmaking between pods and nodes, there may be scenarios where you need to co-locate pods for performance or compliance. Pod affinity will help us place pods that need to share the same node. For example, an Nginx web server pod must be scheduled on the same node that has a Redis pod. This will ensure low latency between the web app and the cache. In other scenarios, you may want to avoid running two pods on the same node. When deploying HA workloads, you may want to force that no two instances of the same pod run on the same node. Pod anti-affinity will enforce rules that prevent this possibility. Analyze your workload to assess if you need to utilize node and pod affinity strategies for the deployments. 5) Take Advantage of Auto Scalers Hyperscale cloud platforms such as Amazon Web Services, Microsoft Azure, and Google Cloud Platform have built-in auto-scaling engines that can scale-in and scale-out a fleet of VMs based on the average resource consumption or external metrics. Kubernetes has similar auto-scaling capabilities for the deployments in the form of horizontal pod autoscaler (HPA), vertical pod autoscaler (VPA), and cluster auto-scaling. Horizontal pod autoscaler automatically scales the number of pods in a replication controller, deployment, replica set or stateful set based on observed CPU utilization. HPA is represented as an object within Kubernetes which means it can be declared through a YAML file controlled via the kubectl CLI. Similar to the IaaS auto-scaling engines, HPA supports defining the CPU threshold, min and max instances of a pod, cooldown period and even custom metrics. Vertical pod autoscaling removes the guesswork involved in defining the CPU and memory configurations of a pod. This autoscaler has the ability to recommend appropriate values for CPU and memory requests and limits, or it can automatically update the values. The auto-update flag will decide if existing pods will be evicted or continue to run with the old configuration. Querying the VPA object will show the optimal CPU and memory requests through upper and lower bounds. While HPA and VPA scale the deployments and pods, Cluster Autoscaler will expand and shrink the size of the pool of worker nodes. It is a standalone tool to adjust the size of a Kubernetes cluster based on the current utilization. Cluster Autoscaler increases the size of the cluster when there are pods that failed to schedule on any of the current nodes due to insufficient resources or when adding a new node would increase the overall availability of cluster resources. Behind the scenes, Cluster Autoscaler negotiates with the underlying IaaS provider to add or remove nodes. Combining HPA with Cluster Autoscaler delivers maximum performance and availability of workloads. In the upcoming tutorials, I will cover each of the best practices in detail with use cases and scenarios. Stay tuned. Janakiram MSV’s Webinar series, “Machine Intelligence and Modern Infrastructure (MI2)” offers informative and insightful sessions covering cutting-edge technologies. Sign up for the upcoming MI2 webinar at http://mi2.live. Feature image via Pixabay.
0 notes
Text
Google Analytics (GA) like Backend System Architecture
There are numerous way of designing a backend. We will take Microservices route because the web scalability is required for Google Analytics (GA) like backend. Micro services enable us to elastically scale horizontally in response to incoming network traffic into the system. And a distributed stream processing pipeline scales in proportion to the load.
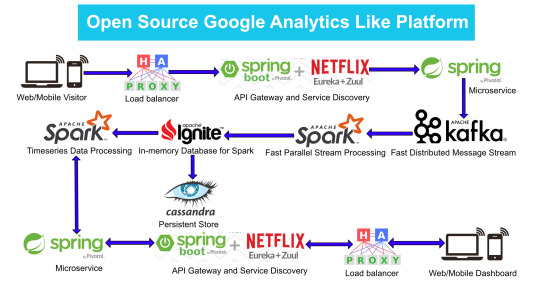
Here is the High Level architecture of the Google Analytics (GA) like Backend System.
Components Breakdown
Web/Mobile Visitor Tracking Code
Every web page or mobile site tracked by GA embed tracking code that collects data about the visitor. It loads an async script that assigns a tracking cookie to the user if it is not set. It also sends an XHR request for every user interaction.
HAProxy Load Balancer
HAProxy, which stands for High Availability Proxy, is a popular open source software TCP/HTTP Load Balancer and proxying solution. Its most common use is to improve the performance and reliability of a server environment by distributing the workload across multiple servers. It is used in many high-profile environments, including: GitHub, Imgur, Instagram, and Twitter.
A backend can contain one or many servers in it — generally speaking, adding more servers to your backend will increase your potential load capacity by spreading the load over multiple servers. Increased reliability is also achieved through this manner, in case some of your backend servers become unavailable.
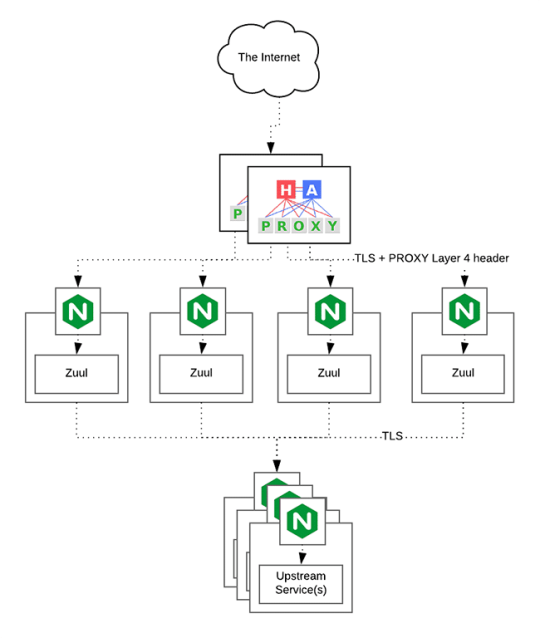
HAProxy routes the requests coming from Web/Mobile Visitor site to the Zuul API Gateway of the solution. Given the nature of a distributed system built for scalability and stateless request and response handling we can distribute the Zuul API gateways spread across geographies. HAProxy performs load balancing (layer 4 + proxy) across our Zuul nodes. High-Availability (HA ) is provided via Keepalived.
Spring Boot & Netflix OSS Eureka + Zuul
Zuul is an API gateway and edge service that proxies requests to multiple backing services. It provides a unified “front door” to the application ecosystem, which allows any browser, mobile app or other user interface to consume services from multiple hosts. Zuul is integrated with other Netflix stack components like Hystrix for fault tolerance and Eureka for service discovery or use it to manage routing rules, filters and load balancing across your system. Most importantly all of those components are well adapted by Spring framework through Spring Boot/Cloud approach.
An API gateway is a layer 7 (HTTP) router that acts as a reverse proxy for upstream services that reside inside your platform. API gateways are typically configured to route traffic based on URI paths and have become especially popular in the microservices world because exposing potentially hundreds of services to the Internet is both a security nightmare and operationally difficult. With an API gateway, one simply exposes and scales a single collection of services (the API gateway) and updates the API gateway’s configuration whenever a new upstream should be exposed externally. In our case Zuul is able to auto discover services registered in Eureka server.
Eureka server acts as a registry and allows all clients to register themselves and used for Service Discovery to be able to find IP address and port of other services if they want to talk to. Eureka server is a client as well. This property is used to setup Eureka in highly available way. We can have Eureka deployed in a highly available way if we can have more instances used in the same pattern.
Spring Boot Microservices
Using a microservices approach to application development can improve resilience and expedite the time to market, but breaking apps into fine-grained services offers complications. With fine-grained services and lightweight protocols, microservices offers increased modularity, making applications easier to develop, test, deploy, and, more importantly, change and maintain. With microservices, the code is broken into independent services that run as separate processes.
Scalability is the key aspect of microservices. Because each service is a separate component, we can scale up a single function or service without having to scale the entire application. Business-critical services can be deployed on multiple servers for increased availability and performance without impacting the performance of other services. Designing for failure is essential. We should be prepared to handle multiple failure issues, such as system downtime, slow service and unexpected responses. Here, load balancing is important. When a failure arises, the troubled service should still run in a degraded functionality without crashing the entire system. Hystrix Circuit-breaker will come into rescue in such failure scenarios.
The microservices are designed for scalability, resilience, fault-tolerance and high availability and importantly it can be achieved through deploying the services in a Docker Swarm or Kubernetes cluster. Distributed and geographically spread Zuul API gateways route requests from web and mobile visitors to the microservices registered in the load balanced Eureka server.
The core processing logic of the backend system is designed for scalability, high availability, resilience and fault-tolerance using distributed Streaming Processing, the microservices will ingest data to Kafka Streams data pipeline.
Apache Kafka Streams
Apache Kafka is used for building real-time streaming data pipelines that reliably get data between many independent systems or applications.
It allows:
Publishing and subscribing to streams of records
Storing streams of records in a fault-tolerant, durable way
It provides a unified, high-throughput, low-latency, horizontally scalable platform that is used in production in thousands of companies.
Kafka Streams being scalable, highly available and fault-tolerant, and providing the streams functionality (transformations / stateful transformations) are what we need — not to mention Kafka being a reliable and mature messaging system.
Kafka is run as a cluster on one or more servers that can span multiple datacenters spread across geographies. Those servers are usually called brokers.
Kafka uses Zookeeper to store metadata about brokers, topics and partitions.
Kafka Streams is a pretty fast, lightweight stream processing solution that works best if all of the data ingestion is coming through Apache Kafka. The ingested data is read directly from Kafka by Apache Spark for stream processing and creates Timeseries Ignite RDD (Resilient Distributed Datasets).
Apache Spark
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
It provides a high-level abstraction called a discretized stream, or DStream, which represents a continuous stream of data.
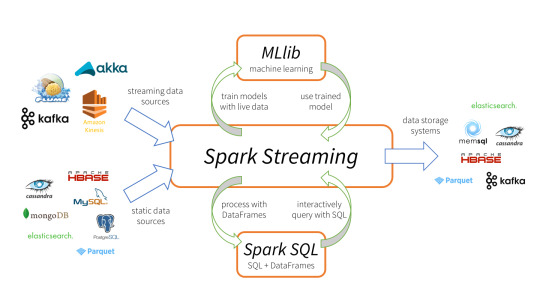
DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs (Resilient Distributed Datasets).
Apache Spark is a perfect choice in our case. This is because Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
In our scenario Spark streaming process Kafka data streams; create and share Ignite RDDs across Apache Ignite which is a distributed memory-centric database and caching platform.
Apache Ignite
Apache Ignite is a distributed memory-centric database and caching platform that is used by Apache Spark users to:
Achieve true in-memory performance at scale and avoid data movement from a data source to Spark workers and applications.
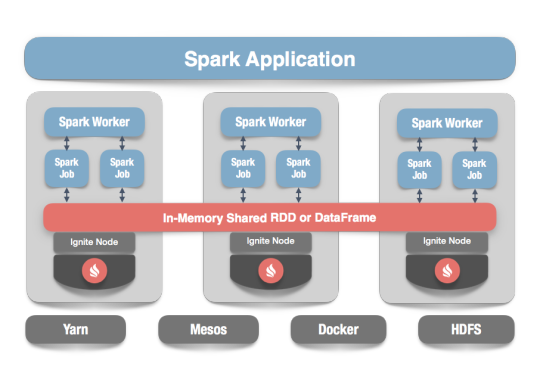
More easily share state and data among Spark jobs.
Apache Ignite is designed for transactional, analytical, and streaming workloads, delivering in-memory performance at scale. Apache Ignite provides an implementation of the Spark RDD which allows any data and state to be shared in memory as RDDs across Spark jobs. The Ignite RDD provides a shared, mutable view of the same data in-memory in Ignite across different Spark jobs, workers, or applications.
The way an Ignite RDD is implemented is as a view over a distributed Ignite table (aka. cache). It can be deployed with an Ignite node either within the Spark job executing process, on a Spark worker, or in a separate Ignite cluster. It means that depending on the chosen deployment mode the shared state may either exist only during the lifespan of a Spark application (embedded mode), or it may out-survive the Spark application (standalone mode).
With Ignite, Spark users can configure primary and secondary indexes that can bring up to 1000x performance gains.
Apache Cassandra
We will use Apache Cassandra as storage for persistence writes from Ignite.
Apache Cassandra is a highly scalable and available distributed database that facilitates and allows storing and managing high velocity structured data across multiple commodity servers without a single point of failure.
The Apache Cassandra is an extremely powerful open source distributed database system that works extremely well to handle huge volumes of records spread across multiple commodity servers. It can be easily scaled to meet sudden increase in demand, by deploying multi-node Cassandra clusters, meets high availability requirements, and there is no single point of failure.
Apache Cassandra has best write and read performance.
Characteristics of Cassandra:
It is a column-oriented database
Highly consistent, fault-tolerant, and scalable
The data model is based on Google Bigtable
The distributed design is based on Amazon Dynamo
Right off the top Cassandra does not use B-Trees to store data. Instead it uses Log Structured Merge Trees (LSM-Trees) to store its data. This data structure is very good for high write volumes, turning updates and deletes into new writes.
In our scenario we will configure Ignite to work in write-behind mode: normally, a cache write involves putting data in memory, and writing the same into the persistence source, so there will be 1-to-1 mapping between cache writes and persistence writes. With the write-behind mode, Ignite instead will batch the writes and execute them regularly at the specified frequency. This is aimed at limiting the amount of communication overhead between Ignite and the persistent store, and really makes a lot of sense if the data being written rapidly changes.
Analytics Dashboard
Since we are talking about scalability, high availability, resilience and fault-tolerance, our analytics dashboard backend should be designed in a pretty similar way we have designed the web/mobile visitor backend solution using HAProxy Load Balancer, Zuul API Gateway, Eureka Service Discovery and Spring Boot Microservices.
The requests will be routed from Analytics dashboard through microservices. Apache Spark will do processing of time series data shared in Apache Ignite as Ignite RDDs and the results will be sent across to the dashboard for visualization through microservices
0 notes
Text
How I Spent the Remainder of My Education Budget This Year.
I had an education budget that needed burning.
I'm a huge believer in conferences for networking, not at all for learning. People with something truly meaningful to say write it down. If it's something that's cutting edge they publish it in a journal. If it's something that's a little more ossified or lengthy, they write a book. If I want to learn something I read about it.
So what did I want to invest in? Well, there's a couple of areas that I've been eyeing for quite awhile and, as it turns out, these kinds of books are expensive, so I had no trouble whatsoever using the remainder of the extremely generous education budget my company provides (which just invites me to say, you should come work with me!).
Programming Languages
I've long bemoaned how little I understand programming languages at the meta level. I chalk this up to the fact that I've only professionally used 3 of note (Java, Python, and Clojure if you're interested) and I really wouldn't say I've given Python a fair shake.
Clojure and Java are pretty diametrically opposed languages but they also have a weird relationship because Clojure is hosted by Java and so Java things are easily within reach. I enjoyed Java while I was writing it but when Moore's law failed and I read JCIP I needed to head for hills.
Python's strange because lots of people I respect like it quite a bit but when I write it I feel like I'm doing everything wrong. I don't yet know if that's because of me or because of it. I suspect the former.
That said, I believe that studying programming languages, especially languages with vastly different takes on what Turing Completeness means, makes you a fundamentally better programmer in whatever language you happen to be using at your day job. I also believe that the days of of the monoglot programmer are thoroughly at an end. Even if you do managed to land a stable gig somewhere you're still most likely going to be writing software in several different languages. At my current employer we have a healthy mix of Clojure, Python, SQL, Chef (if you'll allow it), Terraform (again), Elisp (my baby), and Bash. Not to mention the various services we install and maintain. I simply can't afford to specialize in any of those if I want to stay productive.
So that's what I chose to really dig deep on with the remainder of this years education budget.
Essentials of Programming Languages by Friedman and Wand
What I'm most excited for in this book is a truly thorough examination of programming languages as languages. I'm hoping that this gives me a bunch of vocabulary and terms with which to explore languages as I learn them.
Seven Languages in Seven Weeks: A Pragmatic Guide to Learning Programming Languages by Tate
I chose this book because it's literally a guide to doing what I'm hoping to be doing for 7 languages. It's possible to teach yourself anything but it's often easier with a teacher.
The 7 languages covered are Clojure, Haskell, Io, Prolog, Scala, Erlang, and Ruby.
I'm covering some of the same ground here as I will in future books but, like I said, the main point of this book is learning how to quickly grok a language, not what any of the specific languages have to offer.
The Go Programming Language by Donovan and Kernighan
I'm primarily interested in Go because Rob Pike has been trying to get the world to accept CSP as the way to organize systems for 30 years and he seems finally to have done it here.
Learn You a Haskell for Great Good!: A Beginner's Guide by Miran
I want to learn Haskell because I want to truly grok laziness. No other language of any degree of use is fully lazy. I want to know what falls out of that.
Learn You Some Erlang for Great Good!: A Beginner's Guide by Hébert
I want to learn Erlang because people tell me that nothing teaches you about parallelism better than Erlang. I'm also interested in it's QuickCheck implementation although that may be proprietary.
The Little Schemer by Friedman and Felleisen
I'm mostly interested in Scheme because it was the language used by SICP, a book of nearly mythical importance, and because of Continuations. Ever since Kyle Burton tried to explain them to me I've been interested in them.
The Reasoned Schemer by Friedman, Byrd, and Kiselyov
I hope to pick up logic programming from this book.
Real World OCaml by Minsky, Madhavapeddy, and Hickey
Technomancy recommends OCaml. So does Yegge. Lisp with a strong typing system? I guess that sounds pretty cool. Maybe I'll learn to love type systems from this. :)
Let Over Lambda by Hoyte
This cringe-inducingly introduced book claims to be about macros. Clojure's never taught me much about those. I'd love to learn more.
Elements of Clojure by Tellman
Everything I've ever seen or heard from Zach Tellman is worth listening to. If he wrote a guiding philosophy book about how to use Clojure I want in.
Applications/Services
I think you need to learn about what you have in production. It's OK to be quick and dirty when you're rushing to ship but eventually you've gotta hunker down and actually understand what's going on. At least someone does. And I'm willing to be that someone.
Effective Python: 59 Specific Ways to Write Better Python by Slatkin
As I mentioned, even though I did Python professionally for almost 18 months I never felt like I gave it a fair shot. And I still feel like I'm fighting it all the time. It feels like a toy. I'd like a no-nonsense guide on how to do it right. You could argue that this book belongs in the languages section but, and I'm sorry if this sounds snobbish, I don't think Python's going to teach me anything interesting about languages or programming. Some of the most critical components of my employer's systems are written in Python. I want to know how to make them sing.
Kafka: The Definitive Guide: Real-Time Data and Stream Processing at Scale by Narkhede
Kafka is an important component of our data ingestion architecture which is basically one half of what my company does. We don't push it that hard though, and we still see some consistent, shady behavior from it. I want to stop that.
Kubernetes: Up and Running: Dive into the Future of Infrastructure by Hightower and Docker in Action by Nickoloff
My company recently took the dive into the containerization buzzcraze. I do not think very highly of that. I believe there's a ton of complexity introduced by it that people ignore because it sounds cool.
That said, it's the world I live in and I want to know how to be good at it. K8s: Up and Running is the book recommended to me.
Java Concurrency in Practice by Goetz
It used to be said that there were basically two vectors into the Clojure ecosystem: Ruby developers sick of performance woes and piss-poor compatibility stories and Java developers who had finally gotten around to reading JCIP, were scared out of their mind (👋), and had bad memories of C++ (I'm looking at you, Scala).
These days, though, I actually know a lot more Clojure developers (at least at my company) with little to no prior Java experience. This is a shame because Effective Java is very nearly required reading for writing truly Effective (or at least, Performant) Clojure. In fact, there's been a bunch of discussion lately among the engineers at my company about wrapper libraries like clj-time that are misused because the wrapped library was misunderstood.
Clojure's concurrency primitives are really interesting but they're hosted on the JVM and so thoroughly understanding Java Concurrency actually is important if you want to actually grok them.
I've read JCIP before but had to leave it behind at a former employer. I wanted this one for my shelf.
Building Evolutionary Architectures: Support Constant Change by Ford, Parsons, and Kua
I heard about this book from Fowler. I generally think Fowler is always worth listening to. I'm hoping to continue to learn about architecture from this book.
The Terraform Book by Turnbull
We use Terraform to manage the vast majority of our infrastructure. It's always been something I've poked at until it works and then moved on from. That needs to stop.
Problem Solving
I have always felt like a very weak problem solver. I feel trapped by Cognitive Biases and don't really understand how to overcome them. I fear failure and it shuts my thinking down. I latch on to solutions that I see rather than thinking broadly. I want to be better here.
Thinking, Fast and Slow by Kahneman
I'm interested in this because of the recent national conversations around Cognitive Biases. I distrust myself deeply, but I want to be smart about it. I'm hoping to learn more about my cognition here and to learn strategies for overcoming my biases.
Thinking Forth by Brodie
This could go in the languages section. The reason I put it here is because, on the tin, it reports to be about how to think about applying programming languages to the problems you face.
The Little Prover by Friedman and Eastlund
I believe that my revulsion to proofs in Math has made me a weaker software developer. Ever since watching through the SICP course I was blown away by the power of wishful thinking and it only occurred to me much later that the thing that annoyed me most about proofs was essentially an educated wishful though, just like I apply every day at my job. I want to be better at proofs.
How to Solve It: A New Aspect of Mathematical Method by Polya
I heard about this book from Rich Hickey. Rich Hickey's another person that you should just always listen to. Hammock Driven Development is a talk every single developer in the world should listen to.
One key assertion in that talk is the problem solving is not about innate intelligence or something that some people are good at and everyone else is bad at. Instead, it's a skill that we can practice. This is the book he recommended to practice it.
Leadership
The Manager's Path: A Guide for Tech Leaders Navigating Growth and Change by Fournier
I've heard nothing but good things about this book. At my stage of life I need to manage better or I'm going to sink. I don't have enough personal time to leverage to accomplish all the things I want or need to accomplish. I've been on a long-ish course of study on this topic and I want to continue.
DevOps
So why aren't there any books here? Primarily because I already used some of my education budget to get books in this vein and I haven't gotten to consume them yet. I'm especially excited to dig into The DevOps Handbook after having read through The Phoenix Project, a book I can't recommend more that was given to me by Connor McArthur. It's also arguable that some of the other books I've picked up like the Kafka and k8s resources would fit in this category. But, I ran out of money and felt that the rest of the books on this list were more important.
One technology I really should be better at than I am is Chef. A big reason that I didn't buy a Chef book though is that there apparently aren't really any good ones. Oh well, I'll stick with the docs.
If I haven't said so publicly before: The Interlibrary Loan system is a National Treasure. So why didn't I get all these books from there? Well, for some of them, I did. I'm currently reading a copy of ZooKeeper by Reed and Junqueira and Building Evolutionary Architectures and I have several more on order. Sadly, these sorts of technical books can sometimes take a while to find. I had the budget, I figured it was worth spending. If any of the books don't prove to be worth it, I'm planning on donating them to the library.
Finally, what didn't make the cut just yet? In the interest of time I'm not going to be explicit about what interests me about every one of these.
Making Work Visible by Degrandis
Effective DevOps by Davis
Release It! by Nygard
Effective Java (3rd Edition) by Bloch
SICP by Abelson and Sussman
How to Design Computer Programs by Felleisen
Bootstrapping by Bardini
The Creative Computer by Michie
The Linux Programming Interface by Kerrisk
The Rust Programming Language by Klabnik
Compilers by Lam and Aho
Enterprise Integration Patterns by Hohpe
Infrastructure as Code by Morris
Paradigms of Artificial Intelligence Programming by Norvig
ANSI Common Lisp by Graham
Practical Common Lisp by Siebel
The Art of the Metaobject Protocol by Kiczales
The Scheme Programming Language by Dybvig
The Practice of Programming by Kernighan
Lisp in Small Pieces by Queinnecc
Clean Code by Martin
The Seasoned Schemer by Friedman
Purely Functional Data Structures by Okasaki
The Little MLer by Felleisen
The Clean Coder by Martin
The Unix Programming Interface by Kernighan
Thanks to everyone who recommend books to me and chatted with me on Twitter. I got help from #erlang, #haskell, and #go-nuts on freenode. Special thanks to fogus for putting together a really interesting list of books that I can't wait to dig through.
#clojure#reading#languages#haskell#erlang#forth#python#java#kubernetes#DevOps#zookeeper#ocaml#docker#cognitive biases#golang#kafka#scheme#continuations#csp
0 notes
Link
Article URL: https://product.hubspot.com/blog/zookeeper-to-kubernetes-migration
Comments URL: https://news.ycombinator.com/item?id=22814599
Points: 16
# Comments: 0
0 notes
Link
Location : South West London, UK, South West London Company: Morson International Description: Azure * Linux * Docker * Kubernetes * AWS Applicants will ideally be able to demonstrate the Docker, Kubernetes, Hadoop, Postgres, and CoreOS * Hortonworks, Kafka, Zookeeper, ArtifactoryApply Now ➣
The post Devops Engineer – Big Data appeared first on Get a Hot Job.
0 notes
Text
Senior DevOps Engineer with PRI Search
The position listed below is not with New York Interviews but with PRI SearchNew York Interviews is a private organization that works in collaboration with government agencies to promote emerging careers. Our goal is to connect you with supportive resources to supplement your skills in order to attain your dream career. New York Interviews has also partnered with industry leading consultants & training providers that can assist during your career transition. We look forward to helping you reach your career goals! If you any questions please visit our contact page to connect with us directlyJob DescriptionDevOps EngineerThe firm is seeking a DevOps Engineer who is looking to join a team that's committed to ensuring the stability of systems and code running one of the hottest social gaming venues available. You will be responsible for assisting with the design, deployment, and maintenance of a full stack Kubernetes environment, running on Google Cloud Environment. You'll also participate in fostering a DevOps culture, and building strong cross functional collaboration with all areas of development, product, and QA.Responsibilities:Design, develop and support scalable, redundant infrastructure to include physical and virtualized environmentsMaintain and develop docker images for a tech stack including Cassandra, Kafka, Apache, and several in house written java services, running in Google Cloud on KubernetesMaintain and develop automation using tools like ansible and pythonImprove existing infrastructure to incorporate latest technology best practices and cross application integrationsDay-to-day collaboration with developers and QA teams, to influence design, and architect solutions in multitiered environmentsOrchestrate staging and production deploymentManage individual project priorities, deliverables, and deadlinesProduce clear documentation for delivered solutionsAssist in designing and rolling out a revamped monitoring and alerting system using DataDog, Splunk and PagerDutyParticipate in on-call rotationRequirements:BS in Computer Science, Engineering, or related technical field; or equivalent experience5+ years in systems administration with a focus on DevOps (9+ years without BS)Proficiency in python, bash, or other comparable scripting languageExperience with cloud technology, and virtualization with docker / kubernetes. Google cloud experience a huge plus.Networking (TCP/UDP, ICMP, DNS, etc), OSI Layers, infrastructure services and securityProficiency in linux administration (CentOS a plus)Ability to work well with people from many different disciplines with varying degrees of technical experienceAbility to express complex technical concepts effectively, both verbally and in writingWorking knowledge of technologies listed below (but not limited to).Technical SkillsAnsible, Puppet, CentOS, Git, Perforce, Python, DataDog, Splunk, , Elasticsearch, Logstash, Graphite, IPA, AWS, OpenStack, Java 8, Kafka, Zookeeper, Cassandra, Hadoop, Hazelcast, Fabric, R10K (and related design concept), Apache, NginxHighly desired but not a must: Experience configuring Google CS, DataFlow, DataProc, BigQuery Company DescriptionPRI Search is a full service recruiting, search, consulting and staff augmentation comprised of industry professionals with more than 100 years of cumulative staffing experience. We employ the utilization of cutting edge recruiting technologies which allow for greater optimization of our capabilities in serving our candidates and clients needs. Associated topics: algorithm, application, backend, back end, devops, matlab, sde, software development engineer, software engineer, sw SeniorDevOpsEngineerwithPRISearch from Job Portal http://www.jobisite.com/extrJobView.htm?id=79304
0 notes
Text
Senior DevOps Engineer with PRI Search
The position listed below is not with New York Interviews but with PRI SearchNew York Interviews is a private organization that works in collaboration with government agencies to promote emerging careers. Our goal is to connect you with supportive resources to supplement your skills in order to attain your dream career. New York Interviews has also partnered with industry leading consultants & training providers that can assist during your career transition. We look forward to helping you reach your career goals! If you any questions please visit our contact page to connect with us directlyJob DescriptionDevOps EngineerThe firm is seeking a DevOps Engineer who is looking to join a team that's committed to ensuring the stability of systems and code running one of the hottest social gaming venues available. You will be responsible for assisting with the design, deployment, and maintenance of a full stack Kubernetes environment, running on Google Cloud Environment. You'll also participate in fostering a DevOps culture, and building strong cross functional collaboration with all areas of development, product, and QA.Responsibilities:Design, develop and support scalable, redundant infrastructure to include physical and virtualized environmentsMaintain and develop docker images for a tech stack including Cassandra, Kafka, Apache, and several in house written java services, running in Google Cloud on KubernetesMaintain and develop automation using tools like ansible and pythonImprove existing infrastructure to incorporate latest technology best practices and cross application integrationsDay-to-day collaboration with developers and QA teams, to influence design, and architect solutions in multitiered environmentsOrchestrate staging and production deploymentManage individual project priorities, deliverables, and deadlinesProduce clear documentation for delivered solutionsAssist in designing and rolling out a revamped monitoring and alerting system using DataDog, Splunk and PagerDutyParticipate in on-call rotationRequirements:BS in Computer Science, Engineering, or related technical field; or equivalent experience5+ years in systems administration with a focus on DevOps (9+ years without BS)Proficiency in python, bash, or other comparable scripting languageExperience with cloud technology, and virtualization with docker / kubernetes. Google cloud experience a huge plus.Networking (TCP/UDP, ICMP, DNS, etc), OSI Layers, infrastructure services and securityProficiency in linux administration (CentOS a plus)Ability to work well with people from many different disciplines with varying degrees of technical experienceAbility to express complex technical concepts effectively, both verbally and in writingWorking knowledge of technologies listed below (but not limited to).Technical SkillsAnsible, Puppet, CentOS, Git, Perforce, Python, DataDog, Splunk, , Elasticsearch, Logstash, Graphite, IPA, AWS, OpenStack, Java 8, Kafka, Zookeeper, Cassandra, Hadoop, Hazelcast, Fabric, R10K (and related design concept), Apache, NginxHighly desired but not a must: Experience configuring Google CS, DataFlow, DataProc, BigQuery Company DescriptionPRI Search is a full service recruiting, search, consulting and staff augmentation comprised of industry professionals with more than 100 years of cumulative staffing experience. We employ the utilization of cutting edge recruiting technologies which allow for greater optimization of our capabilities in serving our candidates and clients needs. Associated topics: algorithm, application, backend, back end, devops, matlab, sde, software development engineer, software engineer, sw SeniorDevOpsEngineerwithPRISearch from Job Portal http://www.jobisite.com/extrJobView.htm?id=79304
0 notes
Text
Core Kubernetes: Jazz Improv over Orchestration
This is the first in a progression of blog entries that subtle elements a portion of the internal workings of Kubernetes. In the event that you are essentially an administrator or client of Kubernetes you don't really need to comprehend these points of interest. Be that as it may, on the off chance that you lean toward profundity initially learning and truly need to comprehend the points of interest of how things function, this is for you.
This article accept a working learning of Kubernetes. I'm not going to characterize what Kubernetes is or the center parts (e.g. Case, Node, Kubelet).
In this article we discuss about the center moving parts and how they function with each other to get things going. The general class of frameworks like Kubernetes is normally called compartment arrangement. However, organization infers there is a focal conductor with an in advance arrangement. Nonetheless, this isn't generally an awesome portrayal of Kubernetes. Rather, Kubernetes is more similar to jazz improv. There is an arrangement of performing artists that are playing off of each other to facilitate and respond.
We'll begin by going once again the center segments and what they do. At that point we'll take a gander at a common stream that timetables and runs a Pod.
Datastore: etcd
etcd is the center state store for Kubernetes. While there are imperative in-memory stores all through the framework, etcd is viewed as the arrangement of record.
Snappy synopsis of etcd: etcd is a grouped database that prizes consistency above segment resistance. Frameworks of this class (ZooKeeper, parts of Consul) are designed after a framework created at Google called pudgy. These frameworks are regularly called "bolt servers" as they can be utilized to organize securing a conveyed frameworks. Actually, I find that name somewhat confounding. The information display for etcd (and pudgy) is a basic pecking order of keys that store straightforward unstructured esteems. It really looks a great deal like a document framework. Strangely, at Google, rotund is most as often as possible got to utilizing a dreamy File interface that works crosswise over nearby records, protest stores, and so on. The exceedingly predictable nature, be that as it may, accommodates strict requesting of composes and enables customers to do nuclear updates of an arrangement of qualities.
Overseeing state dependably is one of the more troublesome things to do in any framework. In an appropriated framework it is significantly more troublesome as it gets numerous inconspicuous calculations like pontoon or paxos. By utilizing etcd, Kubernetes itself can focus on different parts of the framework.
Watch in etcd (and comparable frameworks) is basic for how Kubernetes works. These frameworks enable customers to play out a lightweight membership for changes to parts of the key namespace. Customers get advised quickly when something they are watching changes. This can be utilized as a coordination instrument between segments of the appropriated framework. One part can write to etcd and different componenents can promptly respond to that change.
One approach to think about this is as a reversal of the basic pubsub instruments. In many line frameworks, the themes store no genuine client information however the messages that are distributed to those points contain rich information. For frameworks like etcd the keys (closely resembling points) store the genuine information while the messages (notices of changes) contain no interesting rich data. As it were, for lines the themes are basic and the messages rich while frameworks like etcd are the inverse.
The regular example is for customers to reflect a subset of the database in memory and afterward respond to changes of that database. Watches are utilized as a proficient component to stay up with the latest. In the event that the watch fizzles for reasons unknown, the customer can fall back to surveying at the cost of expanded load, organize activity and dormancy.
Approach Layer: API Server
The heart of Kubernetes is a part that is, inventively, called the API Server. This is the main part in the framework that discussions to etcd. Truth be told, etcd is truly a usage detail of the API Server and it is hypothetically conceivable to back Kubernetes with some other stockpiling framework.
The API Server is an approach part that gives sifted access to etcd. Its obligations are generally nonexclusive in nature and it is at present being broken out with the goal that it can be utilized as a control plane nexus for different sorts of frameworks.
The primary money of the API Server is an asset. These are uncovered by means of a basic REST API. There is a standard structure to the majority of these assets that empowers some extended elements. The nature and thinking for that API structure is left as a point for a future post. In any case, the API Server enables different parts to make, read, compose, refresh and look for changes of assets.
How about we detail the duties of the API Server:
Validation and approval. Kubernetes has a pluggable auth framework. There are some worked in systems for both verification clients and approving those clients to get to assets. What's more there are techniques to shout to outer administrations (possibly self-facilitated on Kubernetes) to give these administrations. This kind of extensiblity is center to how Kubernetes is fabricated.
Next, the API Server runs an arrangement of confirmation controllers that can dismiss or adjust demands. These enable strategy to be connected and default esteems to be set. This is a basic place for ensuring that the information entering the framework is substantial while the API Server customer is as yet sitting tight for demand affirmation. While these confirmation controllers are as of now aggregated into the API Server, there is progressing work to make this be another extensibility system.
The API server assists with API forming. A basic issue while forming APIs is to take into consideration the portrayal of the assets to develop. Fields will be included, censured, re-sorted out and in different ways changed. The API Server stores a "genuine" portrayal of an asset in etcd and proselytes/renders that asset relying upon the rendition of the API being fulfilled. Making arrangements for forming and the advancement of APIs has been a key exertion for Kubernetes since right on time in the venture. This is a piece of what enables Kubernetes to offer a tolerable belittling strategy moderately right off the bat in its lifecycle.
A basic component of the API Server is that it likewise bolsters watch. This implies customers of the API Server can utilize a similar coordination designs as with etcd. Most coordination in Kubernetes comprises of a segment keeping in touch with an API Server asset that another segment is viewing. The second part will then respond to changes very quickly.
Business Logic: Controller Manager and Scheduler
The last bit of the perplex is the code that really makes the thing work! These are the parts that arrange through the API Server. These are packaged into particular servers called the Controller Manager and the Scheduler. The decision to break these out was so they proved unable "swindle". On the off chance that the center parts of the framework needed to converse with the API Server like each other segment it would help guarantee that we were building an extensible framework from the begin. The way that there are only two of these is a mishap of history. They could possibly be joined into one major parallel or broken out into a dozen+ separate servers.
The parts here do a wide range of things to make the framework work. The scheduler, particularly, (a) searches for Pods that aren't allocated to a hub (unbound Pods), (b) analyzes the condition of the bunch (stored in memory), (c) picks a hub that has free space and meets different limitations, and (d) ties that Pod to a hub.
Thus, there is code ("controller") in the Controller Manager to actualize the conduct of a ReplicaSet. (As an update, the ReplicaSet guarantees that there are a set number of imitations of a Pod Template running at any one time) This controller will watch both the ReplicaSet asset and an arrangement of Pods in view of the selector in that asset. It at that point makes a move to make/crush Pods with a specific end goal to keep up a steady arrangement of Pods as portrayed in the ReplicaSet. Most controllers take after this sort of example.
Hub Agent: Kubelet
At long last, there is the operator that sits on the hub. This likewise confirms to the API Server like some other part. It is in charge of watching the arrangement of Pods that are bound to its hub and ensuring those Pods are running. It at that point reports back status as things change as for those Pods.
A Typical Flow
To help see how this functions, how about we work through a case of how things complete in Kubernetes.
This grouping outline indicates how a run of the mill stream works for booking a Pod. This demonstrates the (to some degree uncommon) situation where a client is making a Pod straightforwardly. All the more ordinarily, the client will make something like a ReplicaSet and it will be the ReplicaSet that makes the Pod.
The essential stream:
The client makes a Pod through the API Server and the API server composes it to etcd.
The scheduler sees an "unbound" Pod and chooses which hub to run that Pod on. It composes that authoritative back to the API Server.
The Kubelet sees an adjustment in the arrangement of Pods that are bound to its hub. It, thus, runs the compartment by means of the holder runtime (i.e. Docker).
The Kubelet screens the status of the Pod by means of the holder runtime. As things change, the Kubelet will mirror the present status back to the API Server.
Summing Up
By utilizing the API Server as a focal coordination point, Kubernetes can have an arrangement of segments interface with each other in an approximately coupled way. Ideally this gives you a thought of how Kubernetes is more jazz improv than coordination.
0 notes
Text
Træfik
New Post has been published on http://vivihome.net/2017/04/21/traefik/
Træfik
Træfik (pronounced like traffic) is a modern HTTP reverse proxy and load balancer made to deploy microservices with ease. It supports several backends (Docker, Swarm, Kubernetes, Marathon, Mesos, Consul, Etcd, Zookeeper, BoltDB, Eureka, Amazon DynamoDB, Rest API, file…) to manage its configuration automatically and dynamically.
Source : Træfik
A voir !
0 notes