#mutex in os
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
Mutex Vs Semaphore | Difference Between Semaphore and Mutex

Hello Friends! Today, here we will explain about key difference between Semaphore and Mutex in OS as well as Mutex Vs Semaphore in tabular comparisons with ease. This is unique post over the Internet. Making ensure that after reading this content; you will definitely fully aware about Mutex Vs Semaphore in Operating System without getting any hindrance.
0 notes
Video
youtube
Dominando os Mutexes em Go: Sua Chave para Programação Concorrente Eficiente
Olá, Comunidade de Desenvolvedores!
Em nossa jornada contínua para desvendar os segredos da programação eficaz e avançada, nos deparamos com um desafio comum, mas muitas vezes mal compreendido: a concorrência. Especificamente, como gerenciamos o acesso concorrente a recursos compartilhados sem cair nas armadilhas das condições de corrida?
A resposta? Mutexes.
Por que Mutexes?
Mutexes, ou exclusões mútuas, são ferramentas cruciais no kit de ferramentas de qualquer desenvolvedor Go, permitindo o controle seguro e sincronizado sobre recursos compartilhados em um ambiente concorrente.
Eles são a base para evitar a sobreposição e a competição desenfreada entre goroutines, garantindo que seus programas sejam não apenas eficientes, mas também robustos e seguros.
Apresentando Nossa Nova Aula Gratuita
Para ajudá-lo a dominar este tópico essencial, estamos entusiasmados em anunciar uma aula inteiramente dedicada a Mutexes em Go.
Nesta aula, você vai aprender tudo o que precisa saber sobre mutexes - desde os conceitos básicos até técnicas avançadas - com uma abordagem prática que você pode aplicar imediatamente em seus projetos.
O que você vai aprender?
Os fundamentos dos mutexes e por que eles são necessários.
Como implementar mutexes em seus programas Go para controlar o acesso a recursos compartilhados.
Estratégias para evitar deadlocks e garantir que seus programas sejam eficientes e seguros.
Exemplos práticos e cenários do mundo real onde os mutexes podem ser aplicados.
Para Quem é Esta Aula?
Esta aula é perfeita para programadores Go de todos os níveis que desejam aprofundar seu conhecimento em programação concorrente.
Se você está apenas começando sua jornada em Go ou já é um desenvolvedor experiente, encontrarás insights valiosos e técnicas aplicáveis que levarão suas habilidades para o próximo nível.
Não Perca Esta Oportunidade
Este é o momento perfeito para aprimorar suas habilidades e se destacar no mundo do desenvolvimento de software.
Acesse a aula agora mesmo através do link abaixo e comece sua jornada para se tornar um mestre em programação concorrente com Go.
👉 Explore a Aula de Mutexes em Go
Junte-se a Nós
Mergulhe de cabeça nesta aula e descubra como os mutexes podem transformar a maneira como você desenvolve programas concorrentes em Go.
Estamos ansiosos para vê-lo dominar esses conceitos e aplicá-los em seus projetos inovadores!
Até lá, feliz codificação! #GoLang #ProgramaçãoConcorrente #Mutex #DesenvolvimentoDeSoftware #EngenhariaDeSoftware #Sincronização #GoProgramming #TutorialGo #AprendizadoDeCódigo #MutexesEmGo #ConcorrênciaEmGo #SegurançaDeDados #ControleDeConcorrência
0 notes
Text
An interesting discussion of the concept of "cancel safety", i.e. Future operations that can be cancelled without any ill effects, such as data loss, corrupt data etc. It defines levels of cancel safety and gives two examples of rewriting functions in lilos, the tiny async OS for microcontrollers, to be strictly cancel safe.
0 notes
Text
Apptober v2.0: Day 10
We’ve narrowed it down to five techniques. Let’s see how they fared in round 2!

I ran them each five times and took the average time. Two that stick out are “atomic_fetch” at just under 12 seconds and “lock_guard” at over 47 seconds.
First, lock_guard. While it does make the code easier to write, it also suffers a noticeable hit in performance. For some, that may be okay, but if I had to choose slightly harder code over a near 50% increase in time spent running, I’d pick the slightly harder code.
Then there’s the atomic_fetch. I didn’t get a chance to show what I meant by that, so this is the solution used:

It’s basically an integer that I can add and subtract numbers atomically, so it won’t be interrupted. This works so well in this case because that’s all we’re doing. However, if we’re coding something that isn’t just adding and subtracting 1 about two million times, it might not be that useful, so I’ll take this one away too. That being said, if you’re planning on writing a program based on more math, then this would be the way to go.
Now we’re down to three with all about similar results, and this is where it gets tricky to determine a “best”. One thing to take into consideration is how large are the variables used.
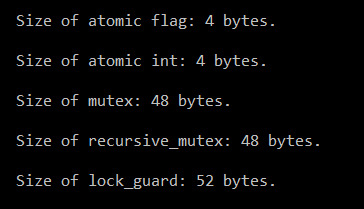
So seeing this, the atomic flag got the best result timewise of the three and is the smallest of the three as well. So performance-wise, the test_and_set method worked the best (go figure, it’s directly in the hardware).
Then between the mutexes, there’s no really significant difference. Sure, recursive mutex got a lower average time, but it also had the largest time out of both, so I wouldn’t say it’s fair to say that it’s “better” timewise. However, it does provide extra benefits over regular mutexes, so I would say it’s a little better in that regard.
So, in conclusion, atomic operations on numbers work really well for code working with numbers and not much else, hardware operations like test_and_set or compare_and_swap are faster than OS-provided tools but can be harder to use or understand, and recursive mutexes are the “best” tool from the operating system.
So which one is the absolute best? Well, it depends on the problem, but also the language. Why don’t we look at how the same techniques perform in other languages?
6 notes
·
View notes
Text
Dead Lock
What is Deadlock?
Deadlock is a situation that occurs in OS when any process enters a waiting state because another waiting process is holding the demanded resource. Deadlock is a common problem in multi-processing where several processes share a specific type of mutually exclusive resource known as a soft lock or software.
Example of Deadlock
A real-world example would be traffic, which is going only in one direction.
Here, a bridge is considered a resource.
So, when Deadlock happens, it can be easily resolved if one car backs up (Preempt resources and rollback).
Several cars may have to be backed up if a deadlock situation occurs.
So starvation is possible.
Read More
What is Circular wait?
One process is waiting for the resource, which is held by the second process, which is also waiting for the resource held by the third process etc. This will continue until the last process is waiting for a resource held by the first process. This creates a circular chain.
For example, Process A is allocated Resource B as it is requesting Resource A. In the same way, Process B is allocated Resource A, and it is requesting Resource B. This creates a circular wait loop.
Example of Circular wait
For example, a computer has three USB drives and three processes. Each of the three processes able to holds one of the USB drives. So, when each process requests another drive, the three processes will have the deadlock situation as each process will be waiting for the USB drive to release, which is currently in use. This will result in a circular chain.
Deadlock Detection in OS
A deadlock occurrence can be detected by the resource scheduler. A resource scheduler helps OS to keep track of all the resources which are allocated to different processes. So, when a deadlock is detected, it can be resolved using the below-given methods:
Deadlock Prevention in OS
It’s important to prevent a deadlock before it can occur. The system checks every transaction before it is executed to make sure it doesn’t lead the deadlock situations. Such that even a small change to occur dead that an operation which can lead to Deadlock in the future it also never allowed process to execute.
It is a set of methods for ensuring that at least one of the conditions cannot hold.
No preemptive action:
No Preemption — A resource can be released only voluntarily by the process holding it after that process has finished its task
If a process which is holding some resources request another resource that can’t be immediately allocated to it, in that situation, all resources will be released.
Preempted resources require the list of resources for a process that is waiting.
The process will be restarted only if it can regain its old resource and a new one that it is requesting.
If the process is requesting some other resource, when it is available, then it was given to the requesting process.
If it is held by another process that is waiting for another resource, we release it and give it to the requesting process.
Mutual Exclusion:
Read More
Mutual Exclusion is a full form of Mutex. It is a special type of binary semaphore which used for controlling access to the shared resource. It includes a priority inheritance mechanism to avoid extended priority inversion problems. It allows current higher priority tasks to be kept in the blocked state for the shortest time possible.
Resources shared such as read-only files never lead to deadlocks, but resources, like printers and tape drives, needs exclusive access by a single process.
Hold and Wait:
In this condition, processes must be stopped from holding single or multiple resources while simultaneously waiting for one or more others.
Circular Wait:
It imposes a total ordering of all resource types. Circular wait also requires that every process request resources in increasing order of enumeration.
Deadlock Avoidance Algorithms
It is better to avoid a deadlock instead of taking action after the Deadlock has occurred. It needs additional information, like how resources should be used. Deadlock avoidance is the simplest and most useful model that each process declares the maximum number of resources of each type that it may need.
Avoidance Algorithms
The deadlock-avoidance algorithm helps you to dynamically assess the resource-allocation state so that there can never be a circular-wait situation.
A single instance of a resource type.
Use a resource-allocation graph
Cycles are necessary which are sufficient for Deadlock
Multiples instances of a resource type.
Cycles are necessary but never sufficient for Deadlock.
Uses the banker’s algorithm
Advantages of Deadlock
Here, are pros/benefits of using Deadlock method
This situation works well for processes which perform a single burst of activity
No preemption needed for Deadlock.
Convenient method when applied to resources whose state can be saved and restored easily
Feasible to enforce via compile-time checks
Needs no run-time computation since the problem is solved in system design
Disadvantages of Deadlock
Here, are cons/ drawback of using deadlock method
Delays process initiation
Processes must know future resource need
Pre-empts more often than necessary
Dis-allows incremental resource requests
Inherent preemption losses.
#Dead Lock#explain Dead Lock#what is Dead Lock#how to over come Dead Lock#how to prevent from Dead Lock#advantages of Dead Lock
1 note
·
View note
Text
Dead Lock
What is Deadlock?
Deadlock is a situation that occurs in OS when any process enters a waiting state because another waiting process is holding the demanded resource. Deadlock is a common problem in multi-processing where several processes share a specific type of mutually exclusive resource known as a soft lock or software.
Example of Deadlock
A real-world example would be traffic, which is going only in one direction.
Here, a bridge is considered a resource.
So, when Deadlock happens, it can be easily resolved if one car backs up (Preempt resources and rollback).
Several cars may have to be backed up if a deadlock situation occurs.
So starvation is possible.
Read More
What is Circular wait?
One process is waiting for the resource, which is held by the second process, which is also waiting for the resource held by the third process etc. This will continue until the last process is waiting for a resource held by the first process. This creates a circular chain.
For example, Process A is allocated Resource B as it is requesting Resource A. In the same way, Process B is allocated Resource A, and it is requesting Resource B. This creates a circular wait loop.
Example of Circular wait
For example, a computer has three USB drives and three processes. Each of the three processes able to holds one of the USB drives. So, when each process requests another drive, the three processes will have the deadlock situation as each process will be waiting for the USB drive to release, which is currently in use. This will result in a circular chain.
Deadlock Detection in OS
A deadlock occurrence can be detected by the resource scheduler. A resource scheduler helps OS to keep track of all the resources which are allocated to different processes. So, when a deadlock is detected, it can be resolved using the below-given methods:
Deadlock Prevention in OS
It’s important to prevent a deadlock before it can occur. The system checks every transaction before it is executed to make sure it doesn’t lead the deadlock situations. Such that even a small change to occur dead that an operation which can lead to Deadlock in the future it also never allowed process to execute.
It is a set of methods for ensuring that at least one of the conditions cannot hold.
No preemptive action:
No Preemption – A resource can be released only voluntarily by the process holding it after that process has finished its task
If a process which is holding some resources request another resource that can’t be immediately allocated to it, in that situation, all resources will be released.
Preempted resources require the list of resources for a process that is waiting.
The process will be restarted only if it can regain its old resource and a new one that it is requesting.
If the process is requesting some other resource, when it is available, then it was given to the requesting process.
If it is held by another process that is waiting for another resource, we release it and give it to the requesting process.
Mutual Exclusion:
Read More
Mutual Exclusion is a full form of Mutex. It is a special type of binary semaphore which used for controlling access to the shared resource. It includes a priority inheritance mechanism to avoid extended priority inversion problems. It allows current higher priority tasks to be kept in the blocked state for the shortest time possible.
Resources shared such as read-only files never lead to deadlocks, but resources, like printers and tape drives, needs exclusive access by a single process.
Hold and Wait:
In this condition, processes must be stopped from holding single or multiple resources while simultaneously waiting for one or more others.
Circular Wait:
It imposes a total ordering of all resource types. Circular wait also requires that every process request resources in increasing order of enumeration.
Deadlock Avoidance Algorithms
It is better to avoid a deadlock instead of taking action after the Deadlock has occurred. It needs additional information, like how resources should be used. Deadlock avoidance is the simplest and most useful model that each process declares the maximum number of resources of each type that it may need.
Avoidance Algorithms
The deadlock-avoidance algorithm helps you to dynamically assess the resource-allocation state so that there can never be a circular-wait situation.
A single instance of a resource type.
Use a resource-allocation graph
Cycles are necessary which are sufficient for Deadlock
Multiples instances of a resource type.
Cycles are necessary but never sufficient for Deadlock.
Uses the banker’s algorithm
Advantages of Deadlock
Here, are pros/benefits of using Deadlock method
This situation works well for processes which perform a single burst of activity
No preemption needed for Deadlock.
Convenient method when applied to resources whose state can be saved and restored easily
Feasible to enforce via compile-time checks
Needs no run-time computation since the problem is solved in system design
Disadvantages of Deadlock
Here, are cons/ drawback of using deadlock method
Delays process initiation
Processes must know future resource need
Pre-empts more often than necessary
Dis-allows incremental resource requests
Inherent preemption losses.
#dead lock#explain dead lock#avoidence of dead lock#how to avoid a dead lock#advantages of dead lock#disadvantages of dead lock
1 note
·
View note
Text
OperatingSystem Lab6-Synchronization Solved
Goal: This lab helps student to practice with the synchronization in OS, and understand the reason why we need the synchronization. Content In detail, this lab requires student practice with examples using synchronization techniques to solve the problem called race condition. The synchronization is performed on Thread, including the following techniques: Mutex Condition…

View On WordPress
0 notes
Text
Best Post Production Software Film

Easy to implement collaborative editing solutions for your web application. If anyone else is working on the document, you'll see their presence and the changes they're making.
What makes a film successful?
But making a lot of movies doesn't necessarily make you the most influential person. Last year, the most prolific person in “film†was the adult director and cinematographer Miles Long, who was principally involved in 41 movies with 265 total collaborators.
It's happened a few times – we senda Google Doc to someone (accessed by a link) only to have them save it or paste it into a Word document and send it back to us with their changes. To save the changes you made, so that other users can view them, and get the updates saved by your co-editors, click the icon in the left upper corner of the top toolbar. ProseMirror is a simple but effective editor that favours minimalism, speed, and precision.
What does finishing mean in post production?
In film making, post-production jobs refer to activities that take place after the movie has been shot. Post-production crew members learn their craft at film schools or through apprenticeships. First jobs are often without pay, but offer valuable contacts and work experience.
The Tools of Color Correction
iWork is Apple's first party productivity apps that handles word processing (Pages), spreadsheet creation (Numbers), and presentations (Keynote). Weld supports real-time collaboration similar to Google Docs, allowing you to work more efficiently as a team. It would honestly be a dream for me to get something like that because I’ve wanted to be able to quickly show people code. It would make explaining things a lot faster when I can show them in real time without screensharing and have them run the code.
Your text is saved on the web, and more than one person can edit the same document at the same time. And I am not the only one who thinks so — almost all collaborative text editors that I have used, including Google Docs, can fail undo in the exact same ways. This is enough that you could render your text editor and those cursors however you want.
Both support collaboration and code merging in case of conflicts while working simultaneously on the same document. They can make notes and suggest changes that editors can carry out in real-time right in front of them. And because media managers have complete control over access permissions they can rest assured that clients see only what they need to see. In the fast-growing digital video economy, media managers need to ensure ongoing harmonious relationships with clients and stakeholders. Collaborative editing has the potential to revolutionize workflows and improve operational efficiency.
What are post production jobs?
Film PRoduction Schedule DEFINITION A film production schedule or shooting schedule is a plan that every film, TV show, or commercial follows to make sure that the video production goes smoothly. It's a simple breakdown of the scenes, talent, time, cast, company moves, and day breaks.
open source collaborative text editors
Team collaboration in the workplace is more than just teamwork—it’s an approach to project management that combines working together, innovative thinking, and equal participation to achieve a common goal. Successful team collaboration in the workplace is often supported by technology tools or collaboration software that improve communication, decision-making and workflow, as well as a work culture that values every individual’s contribution.
You can add annotations and these annotations are just X, Y, Z values, and you add this to the shared data structure. And the notion, I think, of peer-to-peer, decentralized, shared editing, allows for local copies of those documents to be on every single node, let's say, of every single person who's working on the document. Everyone on the team can view, edit, and update information easily at any time. Your team members can discuss requirements, elaborate on product design, create a conference agenda, and find solutions to problems. For instance, Google Documents allows multiple people to make edits, suggest changes, and leave comments simultaneously.
What is track freeze?
Sometimes Pro Tools will fail to launch because the wrong device is selected as the Current Device under Setup>Playback Engine. When this happens, you will likely see the following error message: â€Pro Tools could not initialize the current playback device.
Convergence Labs is a software development agency specializing in real-time collaborative applications, and the creators of Convergence, the real-time collaboration engine. A real time collaborative integrated development environment can provide developers with the facility to collaborate over software projects over a network even when developers are thousand of miles away. Real-time Collaborative IDE provide developers with the ability to collaboratively write code, build and test it as well as share their projects with other developers. Chatting with other fellow developers over a project is also possible. Besides several other useful features of a complete IDE including saving snapshots, project management are also provided to ease the entire project development process.
No Film School
Stop worrying about whether you remembered to save — Team Projects auto-saves all your personal edits and provides access to them if needed. When you’re ready to share changes as a new version with collaborators, an infinite-level versioning system makes it simple to quickly share a new version and collaborate on work in progress. The Google Docs team did a little bit of a case study around how the real time collaboration worked, but I can't find the blog entry. Just poll the server ever half second or second with the current user id, filename, line number and row number which can be stored in a database, and the return value of this polling request is the position of other user's cursors. ACE (Linux, Microsoft Windows, Mac OS X) is a free and easy-to-use collaborative text editor.
Bonus lesson: The Project Manager and Audio Conform Files

The option appears when two (or more) users join the same project. Another way to collaborate on documents is to use https://www.behance.net version control systems such as Subversion or Git, but these tools don't allow real-time collaboration. In the optimistic locking scheme all the users can have edit access of the document at the same time. This problem cannot be solved using traditional locks (so called Pessimistic locks) like Mutex or Semaphore because they give turn based access, and only allow one user to get edit access at a time.
In this post, we'll take a look at five open source collaborative text editors available to anyone. You can download the desktop client to work, and your changes will be uploaded to the online service when you next connect to the internet. The web app offers plenty of editing tools and is compatible with Microsoft Word. You can track changes, comment, and have full conversations either in real time or at your convenience, and you can choose to be notified whenever someone updates the document.
0 notes
Text
Why we chose to build the Arduino Nano 33 BLE core on Mbed OS
This post is from Martino Facchin, who is in charge of the firmware development team at Arduino. Hopefully this is the first of a series of posts describing the inner workings of what we do.

The new, shiny and tiny Nano 33 BLE and Nano 33 BLE Sense are on their way to becoming a serious threat to any hacker’s summer vacation. (I’d recommend spending a couple of days at the lake or beach anyway despite the board’s awesomeness!)
Quoting Sir Isaac Newton (who walked the same streets of Cambridge, UK that the Arm engineers use to get to work everyday), starting from scratch is not always a clever idea. Tens of thousands of man-hours have been spent since the beginning of computer science to reinvent the wheel, sometimes with great results, other times just bringing more fragmentation and confusion.
Since we didn’t have an official Arduino core for the Nordic nRF52840 Cortex-M4 microcontroller, which the Nano 33 BLE and Nano BLE Sense are based upon, we took a look at the various alternatives:
Using Nordic softdevice infrastructure
Writing a core from scratch
Using Mbed OS as a foundation
Option one looks juicy but clashes with a cornerstone of Arduino: open-source software. In fact, softdevice’s closed source approach limits the user’s freedom.
Option two would take a lot of burden on our shoulders for a single board, making the core not very reusable.
So, we went to option three: basing the core on Mbed OS foundation, sharing its drivers and libraries.
As many of you may know, Mbed is a fully preemptive RTOS (real-time operating system), meaning you can run multiple “programs” (more specifically, threads) at the same time, much like what happens in your notebook or smartphone. At Arduino, we have been looking for an RTOS to use on our more advanced boards for a long time but we never found something we liked until we started working with the Mbed OS. Programming an RTOS is usually quite complicated (every university grade course on operating systems will be full of frightening terms like ‘mutex’ and ‘starvation’), but you don’t have to worry if you just want to use it as an Arduino; setup() and loop() are in their usual place, and nobody will mess with your program while it’s running.
But if you want to do MORE, all Mbed infrastructure is there, hidden under the mbed:: namespace. As a side effect of reusing its drivers, we can now support every Mbed board in Arduino with minimal to no effort. Plus, the structure of the core allows any Mbed developer to use Arduino functions and libraries, simply by prepending arduino:: before the actual function call.
Mbed also supports tickless mode; in this way, every time you write delay() in your code, the board will try to go in low power modes, knowing exactly when to wake up for the next scheduled event (or any external interrupt). We are able to achieve an impressive 4.5uA of lower consumption while running a plain old Blink on the Nano 33 BLE (a minimal hardware modification is needed to obtain this value but another blog post is coming). As for Bluetooth support, you can start creating your BLE devices today using the wonderful https://github.com/arduino-libraries/ArduinoBLE but we support plain Cordio APIs as well, in case you need features not yet available in Arduino BLE.
And of course, it’s all open-source!
If you just want to make awesome projects with its plethora of onboard sensors, fire up your Arduino IDE, open the board manager and search for Nano 33 BLE; one click and you are ready to go!
If you want to hack the core, add another Mbed board or merely take a look, your next entry point is the GitHub repo. Don’t be shy if you find a bug or have a suggestion; we love our community, and will try to be as responsive as possible.
Why we chose to build the Arduino Nano 33 BLE core on Mbed OS was originally published on PlanetArduino
0 notes
Text
Something Awesome Sub-Chapter 3.1: Techniques to Gain a Foothold
This sub-chapter dives into the various components of exploitable systems, and the tools used to exploit them successfully.
3.1.1 - Shellcode
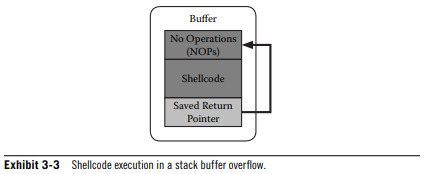
Shellcode; Injectable binary code used to perform custom tasks within another process. Written in the Assembly language.
Use of a low-level programming language means that shellcode attacks are OS specific.
Buffer; A segment of memory that can overflow by having more data assigned to the buffer than it can hold.
Buffer overflows attempt to overwrite the original function return pointer stored in memory to point to the shellcode for the CPU to execute.
Shellcodes can do anything from downloading and executing files, to sending a shell to a remote client.
Shellcodes can be detected through the process of intrusion detection and use of prevention systems and antivirus products.
Network-based prevention system appliances use pattern-matching signatures to search packets travelling over the network for signs of shellcode (antivirus products do the same thing, but for localised files).
Pattern-matching signatures are prone to false positives, and can be evaded by encrypted shellcode.
Some appliances can detect shellcode based on the behaviour of executing instructions found in network traffic and local files.
3.1.2 - Integer Overflow Vulnerabilities
Integer overflows result when programmers do not consider the possibility of invalid inputs.
Integer overflows can lead to 100% CPU usage, DoS conditions, arbitrary code execution, and elevations of privileges.
Two types of integers; signed and unsigned. Unsigned include 0 and all positive numbers (up to a cap of 2^n - 1), whereas signed integers include both negative and positive numbers from -2^(n-1) to 2^(n-1) - 1.
Two's Complement; A decimal number in binary is converted to its one's complement by inverting each of the bits (0->1 and vice versa). 1 is then added to the one's complement representation, resulting in the two's complement representation of the negative of the starting decimal number.

Integer overflow occurs when an arithmetic operation produces a result larger than the maximum expected value. Occurs in signed and unsigned integers.
Most integer errors are type range errors, and proper type range checking can eliminate most of them.
Mitigation strategies include range checking , strong typing, compiler-generated runtime checks, and safe integer operations.
Range checking involves validating an integer value to make sure that it is within a proper range before using it.
Strong typing involves using specific types, making it impossible to use a particular variable type improperly.
Safe integer operations involve using safe integer libraries of programming languages for operations where untrusted sources influence the inputs.

3.1.3 - Stack-Based Buffer Overflows
Overflows are the result of a finite-sized buffer receiving data that are larger than the allocated space.
The standard computer stack consists of an array of memory bytes that a programmer can access randomly or through a series of pop-and-push commands.
Two special registers are maintained for stack management; the stack pointer (ESP) and base pointer (EBP).
Functions move around the ESP in order to keep track of the most recent additions.
Most typical attack involves finding a buffer on the stack that is close enough to the return address and attempting to place enough data in the buffer such that the attacker can overwrite the return address.
To avoid this, a program should always validate any data taken from an external source for both size and content.
Data execution prevention (DEP) marks certain areas of memory, such as the stack, as non-executable and therefore much more difficult to exploit a buffer overflow.

3.1.4 - Format String Vulnerabilities
Revolves around the printf C function and its ability to accept a variable number of parameters as input.
The program pushes the parameters onto a stack before calling the printf function.
The printf function utilizes the specified formats (%s, %d or %x) to determine how many variables it should remove from the stack to populate the values.
A simple attack is performed by forcing printf to print a string ("AAAA", for example) followed by a format string. The format string instructs printf to show 8 digits of precision in hex repeatedly.
The resulting output allows the attacker to identify where in the stack the string is located, and subsequently find the value that represents the return address.
These attacks can be avoided if programmers can recompile the source code of a program; pass the input variable with a string (%s) format instead, preventing the user's input from affecting the format string.

3.1.5 - SQL Injection
Fundamentally an input validation error. Occurs when an application that interacts with a database passes data to an SQL query in an unsafe manner.
Attacks can lead to sensitive data leakage, website defacement, or destruction of the entire database.
SQL injection can be avoided by checking that the data does not include any special characters such as single quotations or semi-colons. Additionally, parameterized queries can be used, where the data is specified separately (the database becomes aware of what is code and what is data).
When testing is not available, administrators should consider deploying a Web App Firewall (WAF) to provide generic protection against SQL injection and other attacks.

3.1.6 - Malicious PDF Files
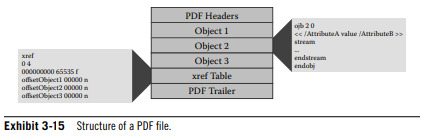
Malicious PDF files usually contain JavaScript because the instructions can allocate large blocks of memory.
PDFs include object with attribute tags that describe its purpose.
JavaScript code can be executed by assigning an 'action' attribute to the object containing the malicious code.
The malicious code can be embedded or injected into existing PDF files through publicly available applications and websites.
Risks of malicious PDF files can be reduced by disabling JavaScript in the PDF reader, as well as multimedia for less common attacks.
3.1.7 - Race Conditions
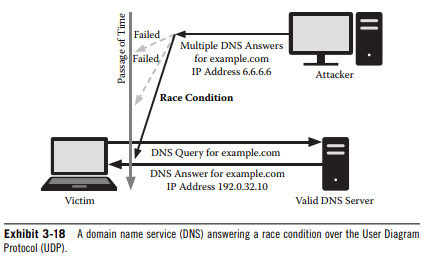
Result when an electronic device or process attempts to perform two or more operations at the same time, producing an illegal operation.
A type of vulnerability that an attacker can use to influence shared data, causing a program to use arbitrary data and allowing attacks to bypass access restrictions.
Can lead to data corruption, privilege escalation, or code execution.
An attacker who successfully alters memory through a race condition can execute any function with any parameters. Can also lead to privilege escalation.
Typically, attacks exploiting race conditions raise many anomalies and errors on the system, which can be detected quite easily.
Semaphores and mutual exclusions (mutexes) provide instructions that are not vulnerable to race conditions.
3.1.8 - Web Exploit Tools
Web exploit tools give attackers the ability to execute arbitrary code using vulnerabilities or social engineering.
Many tools hide exploits through encoding, obfuscation or redirection.
Exploit tools also use JavaScript or HTTP headers to profile the client and avoid sending content unless the client is vulnerable.
Some exploit services are market driven by supply and demand.
Pay-per-install services allow actors to by and sell installations.
Pay-per-traffic services allow attackers to attract a large number of victims to their Web exploit tools.
The copying and proliferation of exploit tools can be reduced through;
Source code obfuscation.
Per-domain licenses that check the local system before running.
Network functionality to confirm validity.
An end-user license agreement (EULA).

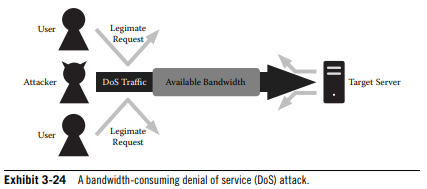
3.1.9 - DoS Conditions
A DoS condition arises when servers or services cannot respond to client requests.
Networks segments, network devices, the server and the application hosting the service itself are all susceptible to such an attack.
Flooding; The overwhelming traffic used to saturate network communications, preventing legitimate requests from being processed.
Distributed Denial of Service (DDoS) involves distributed systems joining forces and attacking simultaneously to overwhelm a target.
DoS conditions can also occur as a by-product of vulnerability exploitation.
Security safeguards include the patching of systems, the filtering out of erroneous traffic at edge routers and firewalls, and the discarding of illegitimate IP addresses.
DoS detection requires monitoring of network traffic patterns and the health of devices.
Adequate response procedures will reduce the impact and outage cause by a DoS significantly.
3.1.10 - Brute Force and Dictionary Attacks
Authentication systems that depend on passwords to determining the authenticity of a user are only as strong as the passwords used.
Password dictionaries are compilations of known words and variations that users are likely to have as passwords.
A rainbow table contains pre-computed hashed passwords that allow an attacker to quickly locate the hash of a user's password in the tables to relate this to the original text password.
Brute force attacks work on the principle that, given enough time, an attacks can find any password regardless of its length or complexity.
Character Set; The set of letters, numbers and symbols used in a password.
Maximum number of iterations required is based on the size of the character set and the maximum size of the password.
Given sufficient power processing, an attack can sharply reduce the time required for brute for password attacks to be successful.
Salts are random characters added to the beginning of a supplied text password prior to the hash generation.
The use of the salt increases the size of the possible password length exponentially.

0 notes
Text
Mutex in Operating System with Examples – Complete Guide

Hello Learners! Today, we are going to cover all possible stuffs about what is mutex in OS (Operating System) and their examples with ease. This is unique article over the internet. So making ensure that at the end of this post; you will definitely fully educate about Mutex in Operating System without getting any hindrance.
‘Mutex in OS’ Tutorial Headlines:
In this section, we will show you all headlines about this entire article; you can check them as your choice; below shown all:
What is Mutex in OS?
How Does Work Mutex in OS?
Types of Mutex Locks
Components of Mutex Locks
Example of Mutual Exclusion
Applications & Uses of Mutex in OS
Advantages of Mutex in OS
Disadvantages of Mutex in OS
Solve: Producer-Consumer Problem with Example
FAQs (Frequently Asked Questions)
Why is Mutex Important in OS?
Why mutex is faster than semaphore?
Why mutex is required?
What Does mutex prevent deadlock?
Can Mutexes be used across different processes?
Let’s Get Started!!
0 notes
Text
ignore this post, im just organizing resources before putting together a study plan
KA Algorithms
Asymptotic Notation, Binary search, Merge/Quick sort vs Insertion/Selection sort, Recursion, Graphs intro, BFS
KA Statistics, Combinatorics/Probability
Basic Probability, Combinatorics
CSO Notes
Recursion, Trees, Searching, possibly Dictionaries and Hash Sets/Maps/Tables?
OS Notes
Processes, Threads, Locks, Mutexes, Semaphores, Monitors, Deadlock, Livelock, Resources, Context-Switching, Scheduling, Concurrency Constructs
PC Notes
Concurrency Constructs/Issues/Design Principles
BA Notes
Divide and Conquer, Trees, Graphs, Asymptotic Notation, GASA (Greedy Algs in general), Recursion?
Algorithms Book
General Design, Divide and Conquer, Sorting (Heap, Quick, Counting, Radix, Bucket, Topological), Stacks, Queues, Linked Lists, Pointers/obj implementation, Tree representation, Hash tables, Trees (Binary Search, Red-Black, Interval, B-Trees, van Emde Boa), Fibonacci Heaps, Dynamic Programming, Graphs, BFS/DFS, Greedy Algs, Dijkstra, Counting/Probability
Coding Interview Book
Sample Q’s from interviews, general advice/review
Clean Code Book
Design principles
MIT Algorithms
Heaps, Trees, Other Sorting (Counting, Radix, Topological), Hashing, BFS/DFS, Dijkstra, Complexity, Dynamic Programming
MIT Math for CompSci
Euler’s Theorem, Directed Acyclic Graphs, Scheduling, Trees, Asymptotic Notation, Counting
0 notes
Text
Go言語のプロファイリングツール、「pprofのWeb UI」がめちゃくちゃ便利なので紹介する
from https://developers.eure.jp/tech/golang-pprof-web-ui/
エウレカのPairsグローバル事業部エンジニアの山下です。 この記事は、eureka Advent Calendar 2017 9日目の記事です。
昨日は天才Boxpさんの「GKE+CircleCI 2.0で継続的デプロイ可能なアプリケーションをシュッと作る」の話でした。 読み応え抜群なのでこちらも是非読んでみてください。
以下本題
pprofのWeb UIがすごい
pprofにWeb UIがあるのはご存知でしょうか? 最近User社が公開していた go-torch が本家のpprof側にビルトイ��されたりと盛り上がりを見せております。 下の画像が実際にWebUIを使っている時のイメージ画像です いかがでしょうか? インタラクティブでいい感じです。 それでは、pprofのWebUIの使い方を説明していきたいと思います。 後半部分ではpprofの設定方法も説明します。
1. WebUIの使い方(データの見方)
Seach regexp
まず目につくのが一番上の検索窓。 どの画面でも正規表現で絞り込みができるのでとても便利です。
Top
ViewからTopを選択すると下記のカラムのリストが表示されます。
Flat:関数の処理時間
Flat%:各Flatの全体に対する割合
Sum%:スタック履歴からの累計Flat%
Cum:待ち時間も含めた処理時間
Cum%:各Cumの全体に対する割合
Name:関数名
各カラムをクリックすることで並び順を簡単に変更することができます。
Graph
各ボックスはそれぞれ単一の関数に紐づいています。
ボックスのサイズが待ち時間も含めた処理時間の割合を表しています。
矢印の起点が呼び出し元関数で矢印の先が呼び出し関数です。
見方を詳しく説明したいのですが、このGraphをより読みやすくしたものが、 次に紹介するFlame Graphなので、そちらを見��いきましょう。
Flame Graph
・各ボックスはそれぞれ単一の関数に紐づいています。 ・積み上げがそのままスタックトレースとなっています。 ・ボックスの幅は、CPU上またはCPU上にあった親ボックスの一部(サンプル数に基づく)の合計処理時間を示します。広い幅のボックスは、狭い幅のボックスよりも実行ごとに多くのCPUを消費するか、単により頻繁に呼び出されることがあります。
見方
カーソルをあてると関数名と処理時間が表示されます。 複雑なプログラムであっても、処理時間の長い関数(ボックスの幅が広い関数)の実際にどこの処理(上に乗っている関数、もしくはその関数そのもの)に時間がかかっているかなどがインタラクティブにすぐ分かることができます。 一つのボックスをクリックするとその関数にフォーカスしたグラフになります。
source
上で説明した手順でプロファイルするコードのパスを指定していた場合、 コードのどの部分でどれだけ時間がかかっていたかすぐ見ることができます。
2. pprofのセットアップ方法
インストール
# Goがインストール済みなことを確認 $ go version go version go1.9.2 darwin/amd64 # pprofをインストール(すでに入っていればアップデート) $ go get -u github.com/google/pprof # graphvizが必要なのでインストール $ brew install graphviz
プロファイリングするアプリケーションを用意する
今回は試しにisucon2017の予選問題でやってみます。
# アプリケーションをクローン $ git clone https://github.com/isucon/isucon7-qualify
プロファイルできるようにアプリにpprofを仕込む
main関数に仕込むだけなのでとても簡単です。 isucon7-qualify/webapp/go/src/isubata/app.goを編集します。 差分は下記だけです。
diff --git a/webapp/go/src/isubata/app.go b/webapp/go/src/isubata/app.go index 06f864a..f45a367 100644 --- a/webapp/go/src/isubata/app.go +++ b/webapp/go/src/isubata/app.go @@ -12,6 +12,7 @@ import ( "log" "math/rand" "net/http" + _ "net/http/pprof" "os" "strconv" "strings" @@ -721,6 +722,10 @@ func tRange(a, b int64) []int64 { } func main() { + go func() { + log.Println(http.ListenAndServe("localhost:6060", nil)) + }() + e := echo.New() funcs := template.FuncMap{ "add": tAdd, (END)
[注意] 今回は常時起動のWebアプリケーションなので、 net/http/pprof を使用したプロファイリング用のWebServerを立てる手法で行います。簡単なCLIのアプリケーション等であれば、 pkg/profile を使ってシンプルにプロファイリングすることもできるので参考にしてみてください。
ベンチマーカーのセットアップ
# 各環境に合わせてMySQLを立ち上げておいてください $ mysql.server start # databese初期化 $ ~/isucon7-qualify/db/init.sh # buildする $ cd ~/isucon7-qualify/bench $ make # 初期データセットアップ $ ~/isucon7-qualify/bench/bin/gen-initial-dataset $ zcat ~/isucon7q-initial-dataset.sql.gz | mysql -uroot -h127.0.0.1 -P3306 --default-character-set=utf8 isubata (※ macOSの場合、zcatではなくgzcat) # webappビルド $ cd ~/isucon7-qualify/webapp/go/ $ make
詳しくは 下記参考に <a href="https://github.com/isucon/isucon7-qualify#ベンチマーカーの準備">https://github.com/isucon/isucon7-qualify#ベンチマーカーの準備</a> <a href="https://github.com/isucon/isucon7-qualify#データベース初期化">https://github.com/isucon/isucon7-qualify#データベース初期化</a>
実際にプロファイリングしてみる
# アプリケーション起動 $ ~/isucon7-qualify/webapp/go/isubata # ベンチマーク開始 $ ~/isucon7-qualifybench/bin/bench -remotes=127.0.0.1:5000
アプリケーションが起動していて、ベンチマークが動いている状態で下記を実行する
# プロファイリング開始(30秒後に自動でブラウザが開きます) $ pprof -http=localhost:8080 ~/isucon7-qualify/webapp/go/src/isubata/ http://localhost:6060/debug/pprof/profile
[POINT] 上記はpprof/profileのエンドポイントは、CPUに関してのプロファイルになりますが、エンドポイントを変えればメモリやブロック待ち時間など色々なプロファイリングが可能です。 http://localhost:6060/debug/pprof/heap http://localhost:6060/debug/pprof/block http://localhost:6060/debug/pprof/goroutine http://localhost:6060/debug/pprof/threadcreate http://localhost:6060/debug/pprof/mutex
さいごに
今回はCPUの処理時間に関してプロファイリングしてみましたが、 もちろんメモリ使用量やgoroutineごとのスタックトレースなども同じ手順でプロファイリングすることができます。 また、プロファイリングをすると必ず結果ファイルが生成されます。下記のように生成されたファイルを指定して再度結果を開くこともできます。(もちろんCLIでも)
$ pprof -http=localhost:8080 /path/to/binary_or_code /path/to/pprof.samples.cpu.001.pb.gz
WebアプリケーションやWorkerなどの常時起動型のアプリケーションであれば、上の手順で紹介したプロファイリング用のポートをあけておいて、気になった時にすぐ取れるようにしておいても良いと思います。
謎なメモリリークに頭を悩ませている方、はたまた上司からむちゃなパフォーマンス改善を迫られている方、もちろん今までpprof使ったことがない方でも簡単に気持ち良いインタラクティブなUIでプロファイリングできてしまうので一度お試しあれ。
参考にしたサイト https://github.com/google/pprof/blob/master/doc/pprof.md https://jvns.ca/blog/2017/09/24/profiling-go-with-pprof/ http://queue.acm.org/detail.cfm?id=2927301 http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
明日はエウレカのスーパースター二川にこさんが「社内Tinder風Webアプリ「Maybee」を会社忘年会のイベント用に作った話」を書いてく���ます。楽しみです!
https://developers.eure.jp/wp-content/uploads/2017/04/20151126beer_go.png
0 notes
Text
How to Fix 0x00000039 Error
SYSTEM EXIT OWNED MUTEX is one of the BSOD error messages on windows 10 PC. These BSOD errors are pretty usual on Windows 10 devices, and it happens in certain situations. This error message can appear with a bug value of 0x00000039. The error can be pretty hard to understand and fixed, but in this article, we are here to help you out. We will offer several solutions to fix this error from your device. Let’s begin.

Source: How to Fix 0x00000039 Error
Solution 1: Running Windows Update
We all aware of Microsoft’s timely updates that provide exiting additional functions, be it, repairing updates for bugs and glitches, as well as a few improvements. However, If your OS is not updated to the latest update, then your system might show some errors and issues. See the below instructions to fix the SYSTEM EXIT OWNED MUTEX error:
Hit Start + I keys altogether on your keyboard to trigger the System Settings.
Head to Update & security.
Choose Windows Update from the left menu.
Press on Check for updates.
Hit on Download.
If the updates are available, then it will be downloaded by itself, and in case it needs a restart, then makes sure to follow the instructions mentioned on your screen.
Solution 2: Reinstalling Audio Drivers
Some users found it helpful to fix the SYSTEM EXIT OWNED MUTEX error by simply updating their audio drivers on their devices. Now follow these instructions in order to fix the issue:
Navigate to the Run program by pressing “Start + R” keys altogether.
Put in devmgmt.msc and press OK.
The Device Manager would appear, open the Audio inputs and outputs option.
Now make a right-click on the audio driver you want to upgrade and then press on the Uninstall device option.
Make sure that the option saying Delete the driver software for this device is selected and then press on OK.
Now, once the driver is deleted, restart your equipment.
When the computer starts again, the error message saying SYSTEM EXIT OWNED MUTEX will be automatically solved.
Solution 3: Fixing Corrupted System Files
Let’s fix the system broken, corrupted, or outdated files by this method and follow the details mentioned down below to solve it:
Enter cmd.exe command into the Start menu search bar. Now find the Command Prompt icon and then make a right-click on it.
Choose the “Run as administrator” option.
Press on Yes if asked for confirmation.
Put in sfc /scannow and then press Enter.
The scan is a bit more time taking then the previous solutions mentioned in this article, but this might solve the SYSTEM EXIT OWNED MUTEX error message.
Now, make sure to restart your device to see the changes.
Solution 4: Remove Unused External Devices
Some unused external devices are likely to interfere in your system sound output. Make sure to remove all of the external devices apart from the basic system parts like CPU, Monitor, Mouse, Keyboard, and basic speakers. When you do this, your issue might get resolved within a few days and weeks.
Solution 5: Preventing Unwanted Services and Startup Programs
Follow the instructions mentioned down here to stop any services related to the audio on your Windows 10 PC:
Select the Run option after pressing the Start button located on your system screen in the lower-left corner.
Enter msconfig and then press on OK.
Unselect the “Load startup items” option.
Head to the Services option from the top menu.
Now select the option saying “Hide all Microsoft services” and then press on Disable all link.
Head to the Startup option from the top.
Now head to the Open Task Manager option.
Now see the list of the background running programs and applications.
Also, see their startup settings and then to stop any service simply right click on the service you want to turn off.
Now head to the Disable link.
Hit the Apply option.
Press on Ok and then reboot the device.
Solution 6: Performing the Full PC Scan
Head to the lower-right corner of the PC screen.
Now find the shield-like icon.
Press on that.
Head to the Virus & threat protection option.
Navigate to Scan options.
Make a click on Full scan. Press on the Scan now option.
Wait until the process wraps up and then make sure to apply recommended actions if any needed to remove malware.
Solution 7: Running the Blue Screen Troubleshooter
Hit Start + I button to trigger the Settings of your system.
Head to the Update & Security option.
Navigate to Troubleshoot.
Press on the Blue screen option.
Tap on Run the troubleshooter.
when the process completes, see if the error is fixed or not.
0 notes
Link
(Via: Hacker News)
By:
Linus Torvalds
([email protected]), January 3, 2020 6:05 pm
Beastian ([email protected]) on January 3, 2020 11:46 am wrote: > I'm usually on the other side of these primitives when I write code as a consumer of them, > but it's very interesting to read about the nuances related to their implementations: The whole post seems to be just wrong, and is measuring something completely different than what the author thinks and claims it is measuring. First off, spinlocks can only be used if you actually know you're not being scheduled while using them. But the blog post author seems to be implementing his own spinlocks in user space with no regard for whether the lock user might be scheduled or not. And the code used for the claimed "lock not held" timing is complete garbage. It basically reads the time before releasing the lock, and then it reads it after acquiring the lock again, and claims that the time difference is the time when no lock was held. Which is just inane and pointless and completely wrong. That's pure garbage. What happens is that (a) since you're spinning, you're using CPU time (b) at a random time, the scheduler will schedule you out (c) that random time might ne just after you read the "current time", but before you actually released the spinlock. So now you still hold the lock, but you got scheduled away from the CPU, because you had used up your time slice. The "current time" you read is basically now stale, and has nothing to do with the (future) time when you are actually going to release the lock. Somebody else comes in and wants that "spinlock", and that somebody will now spin for a long while, since nobody is releasing it - it's still held by that other thread entirely that was just scheduled out. At some point, the scheduler says "ok, now you've used your time slice", and schedules the original thread, and now the lock is actually released. Then another thread comes in, gets the lock again, and then it looks at the time and says "oh, a long time passed without the lock being held at all". And notice how the above is the good schenario. If you have more threads than CPU's (maybe because of other processes unrelated to your own test load), maybe the next thread that gets shceduled isn't the one that is going to release the lock. No, that one already got its timeslice, so the next thread scheduled might be another thread that wants that lock that is still being held by the thread that isn't even running right now! So the code in question is pure garbage. You can't do spinlocks like that. Or rather, you very much can do them like that, and when you do that you are measuring random latencies and getting nonsensical values, because what you are measuring is "I have a lot of busywork, where all the processes are CPU-bound, and I'm measuring random points of how long the scheduler kept the process in place". And then you write a blog-post blamings others, not understanding that it's your incorrect code that is garbage, and is giving random garbage values. And then you test different schedulers, and you get different random values that you think are interesting, because you think they show something cool about the schedulers. But no. You're just getting random values because different schedulers have different heuristics for "do I want to let CPU bound processes use long time slices or not"? Particularly in a load where everybody is just spinning on the silly and buggy benchmark, so they all look like they are pure throughput benchmarks and aren't actually waiting on each other. You might even see issues like "when I run this as a foreground UI process, I get different numbers than when I run it in the background as a batch process". Cool interesting numbers, aren't they? No, they aren't cool and interesting at all, you've just created a particularly bad random number generator. So what's the fix for this? Use a lock where you tell the system that you're waiting for the lock, and where the unlocking thread will let you know when it's done, so that the scheduler can actually work with you, instead of (randomly) working against you. Notice, how when the author uses an actual std::mutex, things just work fairly well, and regardless of scheduler. Because now you're doing what you're supposed to do. Yeah, the timing values might still be off - bad luck is bad luck - but at least now the scheduler is aware that you're "spinning" on a lock. Or, if you really want to use use spinlocks (hint: you don't), make sure that while you hold the lock, you're not getting scheduled away. You need to use a realtime scheduler for that (or be the kernel: inside the kernel spinlocks are fine, because the kernel itself can say "hey, I'm doing a spinlock, you can't schedule me right now"). But if you use a realtime scheduler, you need to be aware of the other implications of that. There are many, and some of them are deadly. I would suggest strongly against trying. You'll likely get all the other issues wrong anyway, and now some of the mistakes (like unfairness or [priority inversions) can literally hang your whole thing entirely and things go from "slow because I did bad locking" to "not working at all, because I didn't think through a lot of other things". Note that even OS kernels can have this issue - imagine what happens in virtualized environments with overcommitted physical CPU's scheduled by a hypervisor as virtual CPU's? Yeah - exactly. Don't do that. Or at least be aware of it, and have some virtualization-aware paravirtualized spinlock so that you can tell the hypervisor that "hey, don't do that to me right now, I'm in a critical region". Because otherwise you're going to at some time be scheduled away while you're holding the lock (perhaps after you've done all the work, and you're just about to release it), and everybody else will be blocking on your incorrect locking while you're scheduled away and not making any progress. All spinning on CPU's. Really, it's that simple. This has absolutely nothing to do with cache coherence latencies or anything like that. It has everything to do with badly implemented locking. I repeat: do not use spinlocks in user space, unless you actually know what you're doing. And be aware that the likelihood that you know what you are doing is basically nil. There's a very real reason why you need to use sleeping locks (like pthread_mutex etc). In fact, I'd go even further: don't ever make up your own locking routines. You will get the wrong, whether they are spinlocks or not. You'll get memory ordering wrong, or you'll get fairness wrong, or you'll get issues like the above "busy-looping while somebody else has been scheduled out". And no, adding random "sched_yield()" calls while you're spinning on the spinlock will not really help. It will easily result in scheduling storms while people are yielding to all the wrong processes. Sadly, even the system locking isn't necessarily wonderful. For a lot of benchmarks, for example, you want unfair locking, because it can improve throughput enormously. But that can cause bad latencies. And your standard system locking (eg pthread_mutex_lock() may not have a flag to say "I care about fair locking because latency is more important than throughput". So even if you get locking technically right and are avoiding the outright bugs, you may get the wrong kind of lock behavior for your load. Throughput and latency really do tend to have very antagonistic tendencies wrt locking. An unfair lock that keeps the lock with one single thread (or keeps it to one single CPU) can give much better cache locality behavior, and much better throughput numbers. But that unfair lock that prefers local threads and cores might thus directly result in latency spikes when some other core would really want to get the lock, but keeping it core-local helps cache behavior. In contrast, a fair lock avoids the latency spikes, but will cause a lot of cross-CPU cache coherency, because now the locked region will be much more aggressively moving from one CPU to another. In general, unfair locking can get so bad latency-wise that it ends up being entirely unacceptable for larger systems. But for smaller systems the unfairness might not be as noticeable, but the performance advantage is noticeable, so then the system vendor will pick that unfair but faster lock queueing algorithm. (Pretty much every time we picked an unfair - but fast - locking model in the kernel, we ended up regretting it eventually, and had to add fairness). So you might want to look into not the standard library implementation, but specific locking implentations for your particular needs. Which is admittedly very very annoying indeed. But don't write your own. Find somebody else that wrote one, and spent the decades actually tuning it and making it work. Because you should never ever think that you're clever enough to write your own locking routines.. Because the likelihood is that you aren't (and by that "you" I very much include myself - we've tweaked all the in-kernel locking over decades, and gone through the simple test-and-set to ticket locks to cacheline-efficient queuing locks, and even people who know what they are doing tend to get it wrong several times). There's a reason why you can find decades of academic papers on locking. Really. It's hard. Linus
0 notes
Text
Original Post from McAfee Author: McAfee Labs
Episode 1: What the Code Tells Us
McAfee’s Advanced Threat Research team (ATR) observed a new ransomware family in the wild, dubbed Sodinokibi (or REvil), at the end of April 2019. Around this same time, the GandCrab ransomware crew announced they would shut down their operations. Coincidence? Or is there more to the story?
In this series of blogs, we share fresh analysis of Sodinokibi and its connections to GandCrab, with new insights gleaned exclusively from McAfee ATR’s in-depth and extensive research.
Episode 1: What the Code Tells Us
Episode 2: The All-Stars
Episode 3: Follow the Money
Episode 4: Crescendo
In this first instalment we share our extensive malware and post-infection analysis and visualize exactly how big the Sodinokibi campaign is.
Background
Since its arrival in April 2019, it has become very clear that the new kid in town, “Sodinokibi” or “REvil” is a serious threat. The name Sodinokibi was discovered in the hash ccfde149220e87e97198c23fb8115d5a where ‘Sodinokibi.exe’ was mentioned as the internal file name; it is also known by the name of REvil.
At first, Sodinokibi ransomware was observed propagating itself by exploiting a vulnerability in Oracle’s WebLogic server. However, similar to some other ransomware families, Sodinokibi is what we call a Ransomware-as-a-Service (RaaS), where a group of people maintain the code and another group, known as affiliates, spread the ransomware.
This model allows affiliates to distribute the ransomware any way they like. Some affiliates prefer mass-spread attacks using phishing-campaigns and exploit-kits, where other affiliates adopt a more targeted approach by brute-forcing RDP access and uploading tools and scripts to gain more rights and execute the ransomware in the internal network of a victim. We have investigated several campaigns spreading Sodinokibi, most of which had different modus operandi but we did notice many started with a breach of an RDP server.
Who and Where is Sodinokibi Hitting?
Based on visibility from MVISION Insights we were able to generate the below picture of infections observed from May through August 23rd, 2019:
Who is the target? Mostly organizations, though it really depends on the skills and expertise from the different affiliate groups on who, and in which geo, they operate.
Reversing the Code
In this first episode, we will dig into the code and explain the inner workings of the ransomware once it has executed on the victim’s machine.
Overall the code is very well written and designed to execute quickly to encrypt the defined files in the configuration of the ransomware. The embedded configuration file has some interesting options which we will highlight further in this article.
Based on the code comparison analysis we conducted between GandCrab and Sodinokibi we consider it a likely hypothesis that the people behind the Sodinokibi ransomware may have some type of relationship with the GandCrab crew.
FIGURE 1.1. OVERVIEW OF SODINOKIBI’S EXECUTION FLAW
Inside the Code
Sodinokibi Overview
For this article we researched the sample with the following hash (packed):
The main goal of this malware, as other ransomware families, is to encrypt your files and then request a payment in return for a decryption tool from the authors or affiliates to decrypt them.
The malware sample we researched is a 32-bit binary, with an icon in the packed file and without one in the unpacked file. The packer is programmed in Visual C++ and the malware itself is written in pure assembly.
Technical Details
The goal of the packer is to decrypt the true malware part and use a RunPE technique to run it from memory. To obtain the malware from memory, after the decryption is finished and is loaded into the memory, we dumped it to obtain an unpacked version.
The first action of the malware is to get all functions needed in runtime and make a dynamic IAT to try obfuscating the Windows call in a static analysis.
FIGURE 2. THE MALWARE GETS ALL FUNCTIONS NEEDED IN RUNTIME
The next action of the malware is trying to create a mutex with a hardcoded name. It is important to know that the malware has 95% of the strings encrypted inside. Consider that each sample of the malware has different strings in a lot of places; values as keys or seeds change all the time to avoid what we, as an industry do, namely making vaccines or creating one decryptor without taking the values from the specific malware sample to decrypt the strings.
FIGURE 3. CREATION OF A MUTEX AND CHECK TO SEE IF IT ALREADY EXISTS
If the mutex exists, the malware finishes with a call to “ExitProcess.” This is done to avoid re-launching of the ransomware.
After this mutex operation the malware calculates a CRC32 hash of a part of its data using a special seed that changes per sample too. This CRC32 operation is based on a CRC32 polynomial operation instead of tables to make it faster and the code-size smaller.
The next step is decrypting this block of data if the CRC32 check passes with success. If the check is a failure, the malware will ignore this flow of code and try to use an exploit as will be explained later in the report.
FIGURE 4. CALCULATION OF THE CRC32 HASH OF THE CRYPTED CONFIG AND DECRYPTION IF IT PASSES THE CHECK
In the case that the malware passes the CRC32 check and decrypts correctly with a key that changes per sample, the block of data will get a JSON file in memory that will be parsed. This config file has fields to prepare the keys later to encrypt the victim key and more information that will alter the behavior of the malware.
The CRC32 check avoids the possibility that somebody can change the crypted data with another config and does not update the CRC32 value in the malware.
After decryption of the JSON file, the malware will parse it with a code of a full JSON parser and extract all fields and save the values of these fields in the memory.
FIGURE 5. PARTIAL EXAMPLE OF THE CONFIG DECRYPTED AND CLEANED
Let us explain all the fields in the config and their meanings:
pk -> This value encoded in base64 is important later for the crypto process; it is the public key of the attacker.
pid -> The affiliate number that belongs to the sample.
sub -> The subaccount or campaign id for this sample that the affiliate uses to keep track of its payments.
dbg -> Debug option. In the final version this is used to check if some things have been done or not; it is a development option that can be true or false. In the samples in the wild it is in the false state. If it is set, the keyboard check later will not happen. It is useful for the malware developers to prove the malware works correctly in the critical part without detecting his/her own machines based on the language.
fast -> If this option is enabled, and by default a lot of samples have it enabled, the malware will crypt the first 1 megabyte of each target file, or all files if it is smaller than this size. In the case that this field is false, it will crypt all files.
wipe -> If this option is ‘true’, the malware will destroy the target files in the folders that are described in the json field “wfld”. This destruction happens in all folders that have the name or names that appear in this field of the config in logic units and network shares. The overwriting of the files can be with trash data or null data, depending of the sample.
wht -> This field has some subfields: fld -> Folders that should not be crypted; they are whitelisted to avoid destroying critical files in the system and programs. fls -> List of whitelists of files per name; these files will never be crypted and this is useful to avoid destroying critical files in the system. ext -> List of the target extensions to avoid encrypting based on extension.
wfld -> A list of folders where the files will be destroyed if the wipe option is enabled.
prc -> List of processes to kill for unlocking files that are locked by this/these program/s, for example, “mysql.exe”.
dmn -> List of domains that will be used for the malware if the net option is enabled; this list can change per sample, to send information of the victim.
net -> This value can be false or true. By default, it is usually true, meaning that the malware will send information about the victim if they have Internet access to the domain list in the field “dmn” in the config.
nbody -> A big string encoded in base64 that is the template for the ransom note that will appear in each folder where the malware can create it.
nname -> The string of the name of the malware for the ransom note file. It is a template that will have a part that will be random in the execution.
exp -> This field is very important in the config. By default it will usually be ‘false’, but if it is ‘true’, or if the check of the hash of the config fails, it will use the exploit CVE-2018-8453. The malware has this value as false by default because this exploit does not always work and can cause a Blue Screen of Death that avoids the malware’s goal to encrypt the files and request the ransom. If the exploit works, it will elevate the process to SYSTEM user.
img -> A string encoded in base64. It is the template for the image that the malware will create in runtime to change the wallpaper of the desktop with this text.
After decrypting the malware config, it parses it and the malware will check the “exp” field and if the value is ‘true’, it will detect the type of the operative system using the PEB fields that reports the major and minor version of the OS.
FIGURE 6. CHECK OF THE VERSION OF THE OPERATIVE SYSTEM
Usually only one OS can be found but that is enough for the malware. The malware will check the file-time to verify if the date was before or after a patch was installed to fix the exploit. If the file time is before the file time of the patch, it will check if the OS is 64-bit or 32-bit using the function “GetSystemNativeInfoW”. When the OS system is 32-bit, it will use a shellcode embedded in the malware that is the exploit and, in the case of a 64-bit OS, it will use another shellcode that can use a “Heaven´s Gate” to execute code of 64 bits in a process of 32 bits.
FIGURE 7. CHECK IF OS IS 32- OR 64-BIT
In the case that the field was false, or the exploit is patched, the malware will check the OS version again using the PEB. If the OS is Windows Vista, at least it will get from the own process token the level of execution privilege. When the discovered privilege level is less than 0x3000 (that means that the process is running as a real administrator in the system or SYSTEM), it will relaunch the process using the ‘runas’ command to elevate to 0x3000 process from 0x2000 or 0x1000 level of execution. After relaunching itself with the ‘runas’ command the malware instance will finish.
FIGURE 8. CHECK IF OS IS WINDOWS VISTA MINIMAL AND CHECK OF EXECUTION LEVEL
The malware’s next action is to check if the execute privilege is SYSTEM. When the execute privilege is SYSTEM, the malware will get the process “Explorer.exe”, get the token of the user that launched the process and impersonate it. It is a downgrade from SYSTEM to another user with less privileges to avoid affecting the desktop of the SYSTEM user later.
After this it will parse again the config and get information of the victim’s machine This information is the user of the machine, the name of the machine, etc. The malware prepares a victim id to know who is affected based in two 32-bit values concat in one string in hexadecimal.
The first part of these two values is the serial number of the hard disk of the Windows main logic unit, and the second one is the CRC32 hash value that comes from the CRC32 hash of the serial number of the Windows logic main unit with a seed hardcoded that change per sample.
FIGURE 9. GET DISK SERIAL NUMBER TO MAKE CRC32 HASH
After this, the result is used as a seed to make the CRC32 hash of the name of the processor of the machine. But this name of the processor is not extracted using the Windows API as GandCrab does; in this case the malware authors use the opcode CPUID to try to make it more obfuscated.
FIGURE 10. GET THE PROCESSOR NAME USING CPUID OPCODE
Finally, it converts these values in a string in a hexadecimal representation and saves it.
Later, during the execution, the malware will write in the Windows registry the next entries in the subkey “SOFTWARErecfg” (this subkey can change in some samples but usually does not).
The key entries are:
0_key -> Type binary; this is the master key (includes the victim’s generated random key to crypt later together with the key of the malware authors).
sk_key -> As 0_key entry, it is the victim’s private key crypted but with the affiliate public key hardcoded in the sample. It is the key used in the decryptor by the affiliate, but it means that the malware authors can always decrypt any file crypted with any sample as a secondary resource to decrypt the files.
pk_key -> Victim public key derivate from the private key.
subkey -> Affiliate public key to use.
stat -> The information gathered from the victim machine and used to put in the ransom note crypted and in the POST send to domains.
rnd_ext -> The random extension for the encrypted files (can be from 5 to 10 alphanumeric characters).
The malware tries to write the subkey and the entries in the HKEY_LOCAL_MACHINE hive at first glance and, if it fails, it will write them in the HKEY_CURRENT_USER hive.
FIGURE 11. EXAMPLE OF REGISTRY ENTRIES AND SUBKEY IN THE HKLM HIVE
The information that the malware gets from the victim machine can be the user name, the machine name, the domain where the machine belongs or, if not, the workgroup, the product name (operating system name), etc.
After this step is completed, the malware will check the “dbg” option gathered from the config and, if that value is ‘true’, it will avoid checking the language of the machine but if the value is ‘false’ ( by default), it will check the machine language and compare it with a list of hardcoded values.
FIGURE 12. GET THE KEYBOARD LANGUAGE OF THE SYSTEM
The malware checks against the next list of blacklisted languages (they can change per sample in some cases):
0x818 – Romanian (Moldova)
0x419 – Russian
0x819 – Russian (Moldova)
0x422 – Ukrainian
0x423 – Belarusian
0x425 – Estonian
0x426 – Latvian
0x427 – Lithuanian
0x428 – Tajik
0x429 – Persian
0x42B – Armenian
0x42C – Azeri
0x437 – Georgian
0x43F – Kazakh
0x440 – Kyrgyz
0x442 –Turkmen
0x443 – Uzbek
0x444 – Tatar
0x45A – Syrian
0x2801 – Arabic (Syria)
We observed that Sodinokibi, like GandCrab and Anatova, are blacklisting the regular Syrian language and the Syrian language in Arabic too. If the system contains one of these languages, it will exit without performing any action. If a different language is detected, it will continue in the normal flow.
This is interesting and may hint to an affiliate being involved who has mastery of either one of the languages. This insight became especially interesting later in our investigation.
If the malware continues, it will search all processes in the list in the field “prc” in the config and terminate them in a loop to unlock the files locked for this/these process/es.
FIGURE 13. SEARCH FOR TARGET PROCESSES AND TERMINATE THEM
After this it will destroy all shadow volumes of the victim machine and disable the protection of the recovery boot with this command:
exe /c vssadmin.exe Delete Shadows /All /Quiet & bcdedit /set {default} recoveryenabled No & bcdedit /set {default} bootstatuspolicy ignoreallfailures
It is executed with the Windows function “ShellExecuteW”.
FIGURE 14. LAUNCH COMMAND TO DESTROY SHADOW VOLUMES AND DESTROY SECURITY IN THE BOOT
Next it will check the field of the config “wipe” and if it is true will destroy and delete all files with random trash or with NULL values. If the malware destroys the files , it will start enumerating all logic units and finally the network shares in the folders with the name that appear in the config field “wfld”.
FIGURE 15. WIPE FILES IN THE TARGET FOLDERS
In the case where an affiliate creates a sample that has defined a lot of folders in this field, the ransomware can be a solid wiper of the full machine.
The next action of the malware is its main function, encrypting the files in all logic units and network shares, avoiding the white listed folders and names of files and extensions, and dropping the ransom note prepared from the template in each folder.
FIGURE 16. CRYPT FILES IN THE LOGIC UNITS AND NETWORK SHARES
After finishing this step, it will create the image of the desktop in runtime with the text that comes in the config file prepared with the random extension that affect the machine.
The next step is checking the field “net” from the config, and, if true, will start sending a POST message to the list of domains in the config file in the field “dmn”.
FIGURE 17. PREPARE THE FINAL URL RANDOMLY PER DOMAIN TO MAKE THE POST COMMAND
This part of the code has similarities to the code of GandCrab, which we will highlight later in this article.
After this step the malware cleans its own memory in vars and strings but does not remove the malware code, but it does remove the critical contents to avoid dumps or forensics tools that can gather some information from the RAM.
FIGURE 18. CLEAN MEMORY OF VARS
If the malware was running as SYSTEM after the exploit, it will revert its rights and finally finish its execution.
FIGURE 19. REVERT THE SYSTEM PRIVILEGE EXECUTION LEVEL
Code Comparison with GandCrab
Using the unpacked Sodinokibi sample and a v5.03 version of GandCrab, we started to use IDA and BinDiff to observe any similarities. Based on the Call-Graph it seems that there is an overall 40 percent code overlap between the two:
FIGURE 20. CALL-GRAPH COMPARISON
The most overlap seems to be in the functions of both families. Although values change, going through the code reveals similar patterns and flows:
Although here and there are some differences, the structure is similar:
We already mentioned that the code part responsible for the random URL generation has similarities with regards to how it is generated in the GandCrab malware. Sodinokibi is using one function to execute this part where GandCrab is using three functions to generate the random URL. Where we do see some similar structure is in the parts for the to-be-generated URL in both malware codes. We created a visual to explain the comparison better:
FIGURE 21. URL GENERATION COMPARISON
We observe how even though the way both ransomware families generate the URL might differ, the URL directories and file extensions used have a similarity that seems to be more than coincidence. This observation was also discovered by Tesorion in one of its blogs.
Overall, looking at the structure and coincidences, either the developers of the GandCrab code used it as a base for creating a new family or, another hypothesis, is that people got hold of the leaked GandCrab source code and started the new RaaS Sodinokibi.
Conclusion
Sodinokibi is a serious new ransomware threat that is hitting many victims all over the world.
We executed an in-depth analysis comparing GandCrab and Sodinokibi and discovered a lot of similarities, indicating the developer of Sodinokibi had access to GandCrab source-code and improvements. The Sodinokibi campaigns are ongoing and differ in skills and tools due to the different affiliates operating these campaigns, which begs more questions to be answered. How do they operate? And is the affiliate model working? McAfee ATR has the answers in episode 2, “The All Stars.”
Coverage
McAfee is detecting this family by the following signatures:
“Ransom-Sodinokibi”
“Ransom-REvil!”.
MITRE ATT&CK Techniques
The malware sample uses the following MITRE ATT&CK techniques:
File and Directory Discovery
File Deletion
Modify Registry
Query Registry
Registry modification
Query information of the user
Crypt Files
Destroy Files
Make C2 connections to send information of the victim
Modify system configuration
Elevate privileges
YARA Rule
rule Sodinokobi
{
/*
This rule detects Sodinokobi Ransomware in memory in old samples and perhaps future.
*/
meta:
author = “McAfee ATR team”
version = “1.0”
description = “This rule detect Sodinokobi Ransomware in memory in old samples and perhaps future.”
strings:
$a = { 40 0F B6 C8 89 4D FC 8A 94 0D FC FE FF FF 0F B6 C2 03 C6 0F B6 F0 8A 84 35 FC FE FF FF 88 84 0D FC FE FF FF 88 94 35 FC FE FF FF 0F B6 8C 0D FC FE FF FF }
$b = { 0F B6 C2 03 C8 8B 45 14 0F B6 C9 8A 8C 0D FC FE FF FF 32 0C 07 88 08 40 89 45 14 8B 45 FC 83 EB 01 75 AA }
condition:
all of them
}
The post McAfee ATR Analyzes Sodinokibi aka REvil Ransomware-as-a-Service – What The Code Tells Us appeared first on McAfee Blogs.
#gallery-0-5 { margin: auto; } #gallery-0-5 .gallery-item { float: left; margin-top: 10px; text-align: center; width: 33%; } #gallery-0-5 img { border: 2px solid #cfcfcf; } #gallery-0-5 .gallery-caption { margin-left: 0; } /* see gallery_shortcode() in wp-includes/media.php */
Go to Source Author: McAfee Labs McAfee ATR Analyzes Sodinokibi aka REvil Ransomware-as-a-Service – What The Code Tells Us Original Post from McAfee Author: McAfee Labs Episode 1: What the Code Tells Us McAfee’s Advanced Threat Research team (ATR) observed a new ransomware family in the wild, dubbed Sodinokibi (or REvil), at the end of April 2019.
0 notes