#my first idea was to directly scrape the page html BUT
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
so the tumblr api lets you make requests to a certain blog and returns you all info matching your request criteria as a pretty json format. which you can in turn parse and take apart. looks nice.
#tütensuppe#my first idea was to directly scrape the page html BUT#this doesnt work bc every theme has different names for specific elements!#so for example post content might be named post-content or body or (in my theme) copy#tags go similarly and you have no way of anticipating what it will be.#unfortunately you have to register to use this so uh
1 note
·
View note
Text
How to Block AI Bots from Scraping Your Website
The Silmarillion Writers' Guild just recently opened its draft AI policy for comment, and one thing people wanted was for us, if possible, to block AI bots from scraping the SWG website. Twelve hours ago, I had no idea if it was possible! But I spent a few hours today researching the subject, and the SWG site is now much more locked down against AI bots than it was this time yesterday.
I know I am not the only person with a website or blog or portfolio online that doesn't want their content being used to train AI. So I thought I'd put together what I learned today in hopes that it might help others.
First, two important points:
I am not an IT professional. I am a middle-school humanities teacher with degrees in psychology, teaching, and humanities. I'm self-taught where building and maintaining websites is concerned. In other words, I'm not an expert but simply passing on what I learned during my research today.
On that note, I can't help with troubleshooting on your own site or project. I wouldn't even have been able to do everything here on my own for the SWG, but thankfully my co-admin Russandol has much more tech knowledge than me and picked up where I got lost.
Step 1: Block AI Bots Using Robots.txt
If you don't even know what this is, start here:
About /robots.txt
How to write and submit a robots.txt file
If you know how to find (or create) the robots.txt file for your website, you're going to add the following lines of code to the file. (Source: DataDome, How ChatGPT & OpenAI Might Use Your Content, Now & in the Future)
User-agent: CCBot Disallow: /
AND
User-agent: ChatGPT-User Disallow: /
Step Two: Add HTTPS Headers/Meta Tags
Unfortunately, not all bots respond to robots.txt. Img2dataset is one that recently gained some notoriety when a site owner posted in its issue queue after the bot brought his site down, asking that the bot be opt-in or at least respect robots.txt. He received a rather rude reply from the img2dataset developer. It's covered in Vice's An AI Scraping Tool Is Overwhelming Websites with Traffic.
Img2dataset requires a header tag to keep it away. (Not surprisingly, this is often a more complicated task than updating a robots.txt file. I don't think that's accidental. This is where I got stuck today in working on my Drupal site.) The header tags are "noai" and "noimageai." These function like the more familiar "noindex" and "nofollow" meta tags. When Russa and I were researching this today, we did not find a lot of information on "noai" or "noimageai," so I suspect they are very new. We used the procedure for adding "noindex" or "nofollow" and swapped in "noai" and "noimageai," and it worked for us.
Header meta tags are the same strategy DeviantArt is using to allow artists to opt out of AI scraping; artist Aimee Cozza has more in What Is DeviantArt's New "noai" and "noimageai" Meta Tag and How to Install It. Aimee's blog also has directions for how to use this strategy on WordPress, SquareSpace, Weebly, and Wix sites.
In my research today, I discovered that some webhosts provide tools for adding this code to your header through a form on the site. Check your host's knowledge base to see if you have that option.
You can also use .htaccess or add the tag directly into the HTML in the <head> section. .htaccess makes sense if you want to use the "noai" and "noimageai" tag across your entire site. The HTML solution makes sense if you want to exclude AI crawlers from specific pages.
Here are some resources on how to do this for "noindex" and "nofollow"; just swap in "noai" and "noimageai":
HubSpot, Using Noindex, Nofollow HTML Metatags: How to Tell Google Not to Index a Page in Search (very comprehensive and covers both the .htaccess and HTML solutions)
Google Search Documentation, Block Search Indexing with noindex (both .htaccess and HTML)
AngryStudio, Add noindex and nofollow to Whole Website Using htaccess
Perficient, How to Implement a NoIndex Tag (HTML)
Finally, all of this is contingent on web scrapers following the rules and etiquette of the web. As we know, many do not. Sprinkled amid the many articles I read today on blocking AI scrapers were articles on how to override blocks when scraping the web.
This will also, I suspect, be something of a game of whack-a-mole. As the img2dataset case illustrates, the previous etiquette around robots.txt was ignored in favor of a more complicated opt-out, one that many site owners either won't be aware of or won't have time/skill to implement. I would not be surprised, as the "noai" and "noimageai" tags gain traction, to see bots demanding that site owners jump through a new, different, higher, and possibly fiery hoop in order to protect the content on their sites from AI scraping. These folks serve to make a lot of money off this, which doesn't inspire me with confidence that withholding our work from their grubby hands will be an endeavor that they make easy for us.
69 notes
·
View notes
Text
4 FREE Ways for Spying On Your Competition’s SEO
It doesn’t have to be difficult or complicated to get started on an SEO journey.
Not knowing where to start is a normal feeling to have, and a lot of times can put you off from starting.
For starters, you have competition who likely motivated you to begin taking SEO seriously.
That means they have a head start on you.
Don’t worry – that’s excellent news.
Having competition who had a head start with SEO makes your life easier.
You should send them a thank you card for making your life easier. All you need to do now is emulate and improve on their strategy.
It’s easy to do once you have the right tools, and you know what to look for.
For our SEO Services, we use tools like ahrefs and SEMrush, which both start at $99 a month, and we pay way more than that.
We have to afford to do that because SEO and content marketing is what we do.
You don’t have to break the bank upfront to begin your SEO strategy. You can get started for free.
We’re going to explore how you can leverage free tools to look at your competitor’s strategy on each of these fronts:
What Keywords They Rank For
What Content Is Working Best
What Search Terms Are Profitable
How Often They Post
What Titles You Should Use
If you were going to try to figure this out all on your own, you would be reading a handful of SEO guides and would likely be persuaded to buy unnecessary tools.
You would be getting conflicting advice and self-serving recommendations.
I was there when I was first learning, and I have to admit I likely lined someone else’s pockets because they pushed a tool that I didn’t need (yet).
I don’t want you to waste time or money I did.
That’s why I’ve created this guide to uncovering your competition’s SEO strategy with free tools.
youtube
#1: WordPress SiteMap
According to Whois Hosting This, 455,000,000 self-hosted websites are on the WordPress platform.
Odds are your competitor’s website is on WordPress also. Of those websites, they’re likely one of the 7,412,434 sites using the Yoast plugin.
What you can take advantage of is that Yoast has the same URL structure for every sitemap.
A sitemap is a blueprint that shows Google crawlers, where every page on your website is to help Google crawl your site faster.
We take advantage of this by quickly uncovering pages and categories a website uses.
The way to get to a website’s site map is to type in their domain like this:
competitor.com/sitemap.xml
You should see something like this come up next:

Looking at a sitemap could get overwhelming for a large website, but for smaller or local sites, it’s a great way to uncover service location pages.
#2 Ubersuggest
I cannot speak highly enough about UberSuggest. UberSuggest is the tool I wish I had when I first began my SEO and Content Marketing Journey.
Before UberSuggest, I had to pay for tools like ahrefs and SEMrush (when I couldn’t afford it) and scraped by to get access.
Neil Patel put together a tool that’s 100% free to use and gives the services above a run for their money.
In case you don’t know, Neil is one of the world’s leading SEO/Content Marketers.
I learned the majority of my content marketing and SEO techniques by working directly with Neil and his team.
Some of the advice here actually comes straight from him (sorry, Niel :-P).
Ok, let’s get into the nuts and bolts of how to use UberSuggest to it’s fullest.
Steal your competition’s keywords
Take your competitor’s URL and paste it into the search bar on the screen.

The first thing you’re going to see is your competitor’s SEO stats like traffic, keywords, domain score, and backlinks.
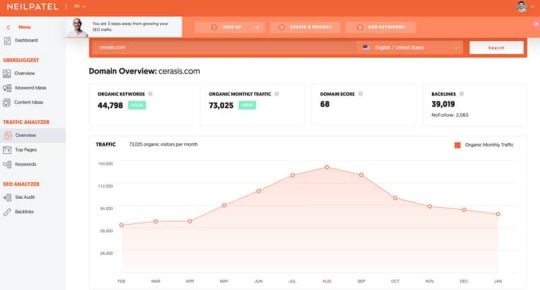
Click on top pages to see what content is performing the best for them.
Once the page loads, click on view all under the Estimated Visits column, and now you’ve uncovered all of the keywords that page is showing up for in Google.
Now you can go through their best pages and start to place them into your keyword research document.
Now create content that targets these keywords and create something better than what your competition created.
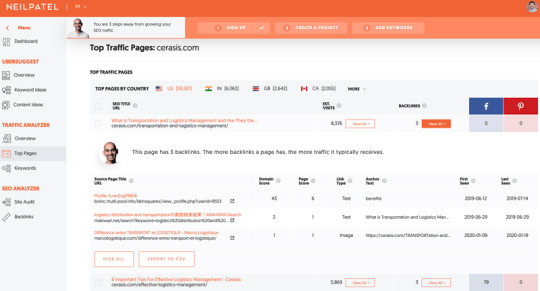
Steal their backlinks
Backlinks are when a website cites your website for information. Think of it as a vote for your content.
These votes get tallied by Google to establish how trustworthy your website is.
Not all votes are created equal, though. The more relevant the citating website is to your niche, the more influential the vote.
How are you supposed to find relevant websites out of the 1.74 billion sites that exist on the internet, according to Web Hosting Rating?
That’s easy, under the backlinks column on the same screen, press View All and it provides you with a list of everyone who’s linked to the content.
You know the keywords already, and you’ve created content that is better than their content.
It’s time to approach the websites which are linking to your competitor and say something along the lines of:
“Hey, Website Owner – I noticed you are linking to an outdated blog post about XYZ. I recently expanded and updated that topic to be more current, and I think your visitors will appreciate the most up to date info.”
On the surface, this might not sound that exciting, but consider this.
Your competitor didn’t know who would link to them and likely reached out to 100’s of people to get those links.
They’ve done the hard work for you by finding these websites interested in the blog post.
If your content is better, up to date, and expanded, they have no reason not to link to you.
You’ve now successfully stolen a link from your competitor.
It’s time to approach the websites which are linking to your competitor and say something along the lines of:
“Hey, Website Owner – I noticed you are linking to an outdated blog post about XYZ. I recently expanded and updated that topic to be more current, and I think your visitors will appreciate the most up to date info.”
On the surface, this might not sound that exciting, but consider this.
Your competitor didn’t know who would link to them and likely reached out to 100’s of people to get those links.
They’ve done the hard work for you by finding these websites interested in the blog post.
If your content is better, up to date, and expanded, they have no reason not to link to you.
You’ve now successfully stolen a link from your competitor.
#3 Screaming Frog
This next trick will show you which pages are most important to your competitor.
We are going to use a program called Screaming Frog.
Screaming Frog is a software that crawls your website or your competitors in this case and gives you a bunch of information.
When you first see the information, it can be overwhelming because you likely won’t know what most of it means.
That’s ok because we want to gather the purposeful information.
In this case, the purposeful information we are looking for is what pages matter most to your competition.
Download Screaming Frog to your computer then launch and type in your competitor’s URL:
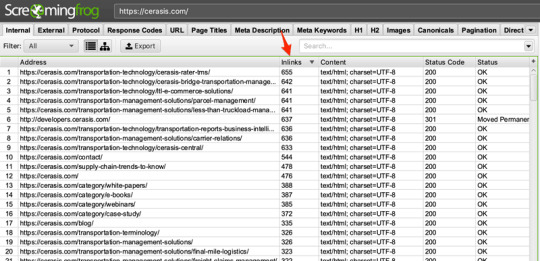
Go to the filter button and select HTML. Scroll to the right until you find the column “InLinks” and sort it from highest to lowest.
At the top of the list will be the pages that your competitors internally link to the most.
Think of your competitor’s site as if it were a museum or amusement park. Once you get in, you can’t get out without going through the gift shop first, where you might spend some money.
The concept is the same when it comes to websites. Your competition is going to do their best to guide their visitors to the pages where they can pitch their products.
Once you uncover these pages, you can see what their offer is and how they’re making the offer. From there, you can emulate their layout, sales angle, and calls to action.
#4 Google
How many times have you heard, “Google it?”
According to Hubspot, they estimate Google handles 5.8 BILLION searches a day.
Odds are you’ve likely heard the phrase once or twice a week. Well, keeping up with your competition is not different.
What we are going to show you is how often your competitor is creating content for their website.
Most people don’t know this, but You can dictate how Google performs your searches with special commands.
Here’s how you do it:
First type into Google’s search box, your competitor’s URL with “site:” in front of it.
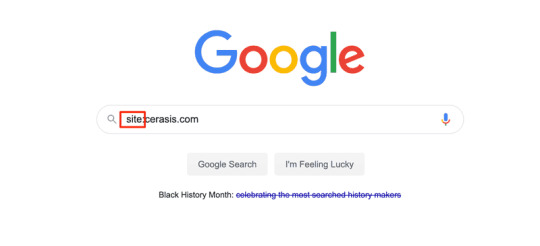
The command told Google you want to limit all the results to your competitor’s domain only.
Once the results come up, under the search bar, you can to click on the tools button.
Once you’ve done that, you’ll see two more buttons appear, “Any Time” and “All Results.”
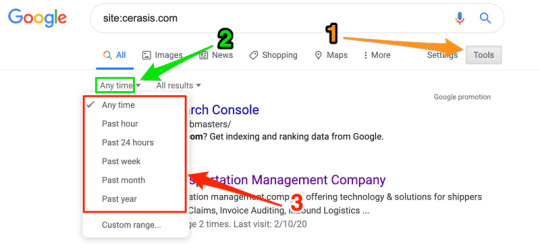
This shows you the amount of effort your competition is putting into SEO by how frequently they’re posting to their website.
From here, you have a few choices.
You can decide if you want to match, exceed, or do a little less than what your competition is doing.
There is no right answer here because, ultimately, frequency, along with quality, and many more factors play into Google rankings.
If you have the resources to meet or increase the frequency of your competition’s production rate, I would suggest it.
If you cannot, don’t sweat it. Just make sure you remain consistent and provide quality content.
#5 Ngram Analyzer
Ngram analyzer is an online analyzer that helps you take a handful of titles and find patterns.
What it does is it looks through the titles, and you ask it find strings of words that often go together.
Ngram Analyzer will provide you with is an idea of what type of content your competition is creating and how they are titling their content.
With the help of UberSuggest, we can export all of the top pieces of content to excel.
Copy all the titles from Excel and paste them into Ngram Analyzer.
I first start very narrow and use 4grams, which is a string of four words that are together more than once.
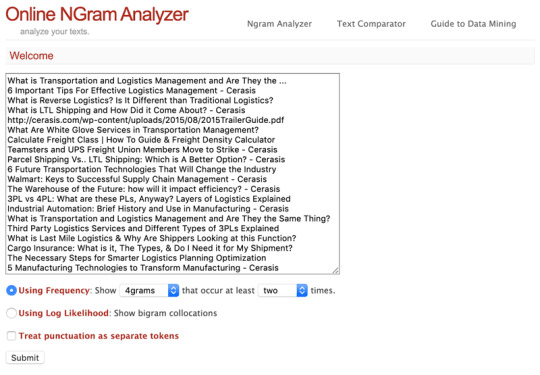
You should see results like this, which are terms and the number of times they show together.
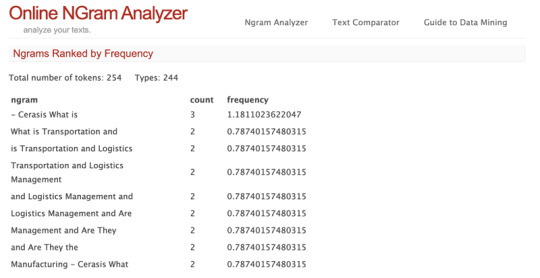
In this example, you can see phrases like “is transportation and logistics” and “transportation and logistics management” are important to them because they string them together a lot.
You can go further by broadening the criteria to 3gram and 2gram to see if you can gain any more insights.
You should see results like this, which are terms and the number of times they show together.
Conclusion
You may not be an expert in SEO, and that’s ok because you don’t have to be to develop a decent strategy.
If you know how to spy on your competitors for free, you can see what’s working for them.
Use the free tools we mentioned above, along with my strategies, and you’ll quickly uncover what they are doing right.
The post 4 FREE Ways for Spying On Your Competition’s SEO appeared first on Joseph Paul Digital Agency.
0 notes
Link
Hey guys, I've built a Hackernews-inspired newsletter containing the top 10 articles relevant to founders that were on the HN front-page last week.Why HackerNews? Because it's one of the last places on the internet with meaningful discussion & quality topics. See for yourself below if you don't believe me. Btw, if you want to get this via email every week, go here.1. Patio11's Law: The software economy is bigger than you think (1022 votes)There’s a thrill in finding quiet companies, operating in the background, cashing checks. Software has exploded the number of these businesses. Ten people working remotely can make millions of dollars a year.Austen Allred shared how, when matching Lambda graduates to jobs, he’ll discover software companies he’s never heard of in Oklahoma pocketing $10m/year in profit. Doing things like “making actuarial software for funeral homes.”3It’s not surprising. Of the 3,000+ software companies acquired over the last three years, only 7% got TechCrunch, Recode, HN, or other mainstream tech coverage.4Also, markets like SAP, worth $163B. There is a term for these companies, they're called Hidden Champioons, and you can see a few of them on Wikipedia.Some other useful quotes:I’ve had four jobs in my life and have always been stunned by what is still done by hand. Every company had a task which could be heavily automated but was instead consuming 4-30 people. So if you think the software market is large, consider all the stuff software never reached.I applied for a job at a company in my city, and they told me their product was entirely API connectors for the local banks. In fact all of the companies I've worked for here have been making software for local industries! From solar installers, energy efficient lighting manufacturers, local commerce and POS systems, mechanics software, creative market places, local lead generation.Oh yes, there are tons of giants creating software for health applications you never heard of, defense purposes you cannot hear about, logistic you would never consider (managing competitions, port services, private jet traffic, truck fleets...) and so on. I should know, I make half of my income going from company to company to train their team. They are everywhere. They make billions.Don’t require a user to be interested twice: lessons on reducing signup friction (390 votes)Long story short: A guy made a SaaS prototype and he got a few users by posting on forums. Thing is, his "flow" was to get them to "sign up" to the waitlist and then he manually sent them an invite hours or days later.His success increased when he changed the flow so people get an automatic email to register immediately after they sign up.Kind of obvious, but there's an important principle here:Don't require a user to be motivated twice. Instead, make use and ride of the motivation wide when they sign up. This is pretty obvious if you read BJ Fogg material.Some useful notes from HN comments on users:Treat signups as a leading indicator of success, not the ultimate goal.Asking for an email up front is already too much. Let the user use your service, they'll create some "content" or "configuration" in it. Once they do that, they'll want to preserve / persist it, and then you can ask for an email address. They're much more likely to give you a real email address and validate it, because they're already invested.I'm convinced one of the reasons Zoom is so successful (besides being a great product) is that there is no sign up required at all. Someone invites you to a conference and you just click the link, enter your name and go.Ask HN: What is the best way to target restaurants and small businesses? (28 votes)I really like these threads where you have very bright minds giving advice for a common pain point. Here are some amazing answers:Almost every brick and mortar company’s website includes a phone number. Call 5 of them and order a meal, when you pick it up ask to talk to the manager for a minute. Elevator pitch: you’ve got 5-10 seconds to get them to ask for more time. “When I was ordering food I noticed that I couldn’t prepay online, I almost thought of going somewhere else, how come you don’t have a way to pay before coming in?” “Don’t know how to do that”. “I built a plugin that takes 5-10 mins to set up and people can pay while they order so I don’t have to come inside, can we do a Skype call when you’re not busy to walk through this?”. Once you’ve gotten a handful of trials like this you can start calling but your options with restaurants(especially mom and pop) are to walk in the door or get to them directly on the phone.or this:You can also try to target other companies thay already have large restaurant customer bases, but then you become a SKU in their offerings. It may be more about lead genertion than anything else.OnlyFans, influencers, and the politics of selling nudes during a pandemic (133 votes)While sites like AirBnb have huge loses, OnlyFans grew 75% during last month. It was launched as a result of platforms like Instagram shutting out adult entertainment workers.I wonder if there is any way to integrate into this platform as a developer and "ride" on its growth :DThe coming disruption of colleges and universities (82 votes)Scott Galloway is a man who predicted a lot of things. He predicted Amazon’s $13.7 billion purchase of Whole Foods a month before it was announced. Last year, he called WeWork on its “seriously loco” $47 billion valuation a month before the company’s IPO imploded.Now, he predicts something happening with universities. . The post-pandemic future, he says, will entail partnerships between the largest tech companies in the world and elite universities. [MIT@Google](mailto:MIT@Google). iStanford. HarvardxFacebook. According to Galloway, these partnerships will allow universities to expand enrollment dramatically by offering hybrid online-offline degrees.How will this disrupt education? Well thousands of brick-and-mortar universties will go out of business.At the same time, more people than ever will have access to a solid education, albeit one that is delivered mostly over the internet.If this is true, it may open a lot of opportunities for makers in the edu space.Ask HN: Mind bending books to read and never be the same as before?Here are some recommendation for "brain expanding" books:"Rework", "Getting Real", the other books by the old 37signals crew, and of course "The Lean Startup" really changed the way I thought about software development and business. I credit them for much of my startup/programming success.Taleb's Incerto series changed how I thought about investing, risk, and life in general. "Fooled by Randomness" and "Antifragile" are especially good."Basic Economics: A Citizen's Guide to the Economy" by Thomas Sowell. I read this as a teenager with only limited exposure to economics and it cleared up many misconceptions I held."Alchemy: The Dark Art and Curious Science of Creating Magic in Brands, Business, and Life" by Rory Sutherland. Explains why we choose brands over cheaper alternatives, why we're willing to pay a lot more to lock in a deal, why we hate registering before buying the thing (but are more than happy to do so right after), why Sony removed the record button from the first Walkman, and much more.Meditations by Marcus Aurelius. This book makes every bit of life advice you receive afterwards feel shallow. It feels like a reference to western thought.Scraping Recipe Websites (461 votes)Do you do scraping as part of your job? Then you may want to read this how this site scrapes 99% of recipe website using a logical template.An interesting thing they mention is the concept of LCA (lowest common ancestor) and how they use it to identify part of the HTML most likely to contain all of the ingredients/instructionsMy blog is now generated by Google Docs (398 votes)Over and over and over again, I see businesses succeeding just because they tap into people existing habits.Most people are familiar with typing in Google Docs. If you can make a tool where they just press a button and 'voila', it turns it itno a blog post, they're way more likely to use you vs. someone who creates a separate interface (see BJ Fogg and his behavioral design theory).US video game sales have record quarter as consumers stay at home (376 votes)Video game sales are at historic hights. Traffic on gaming-related services like Discord, Twitch, Mixer, and others have hit historic highsThe current crisis probably accelerated video games adoption by 10 years.Ask HN: How to stop anxiety from too many choices? (286 votes)The best advice I've seen here is:Stop shopping start doing. All these decisions I call shopping, where you do a lot of research but never commit. At some point you have to start working on something.Have an ideas journal. Write new ideas down there, and don't start with any of them in less than two weeks. This lets you get over the initial enthusiasm - and perhaps new better ideas will push less useful ones out of the way in that time. If something stays at the top of your list for weeks, then perhaps it is useful.My advice is to lower the value of ideas. A lot of time people think, "If only I had a good idea I would be successful". You will see other people saying things like, "Buy my good idea!". But really, good ideas are a dime a dozen. Good ideas, bad ideas... it actually doesn't make much difference. What makes the difference is execution and timing.To be successful, really what you need is execution and to have the patience to wait until what you are doing is relevant. Of course there is the fear that it will never be relevant. However, if you accept the thesis that the good idea is not valuable in itself, then you realise that it is not really valuable to pivot without a really good reason. A good idea that is never relevant is just as worthless as a bad idea that is never relevant. However, even a bad idea that is executed very well and ready when the opportunity arises can be successful.see the first step, the very next step, and that's it. You don't need to know what step 2,748 is about let alone how to solve it to take the next door. (formally: no premature optimization).Make a decision, and stick to it. In other words, be quick to decide but slow to change. The trick in life is not to "do what you love" (or make the decisions you think are right: spoiler, you'll be wrong 50% of the time). The trick is to "love what you do"I have similar problems sometimes- and remind myself the power of "good enough". Striving for "the best" will often leave you unsatisfied. So instead of thinking "which is better?" think "is this one good enough?"If you want to get this via email every week, see http://founderweeklys.com/
0 notes
Text
What the web still is
Being a pessimist is an easy thing to fall back on, and I’m trying to be better about it. As we close the year out, I thought it would be a good exercise to take stock of the state of the web and count our blessings.
Versatile
We don't use the internet to do just one thing. With more than two decades of globally interconnected computers, the web allows us to use it for all manner of activity.
This includes platforms, processes, and products that existed before the web came into being, and also previously unimagined concepts and behaviors. Thanks to the web, we can all order takeout the same way we can all watch two women repair a space station in realtime.
Decentralized
There is still no one single arbiter you need to petition to sign off on the validity of your idea, or one accepted path for going about to make it happen. Any website can link out to, or be linked to, without having to pay a tax or file pre-approval paperwork.
While we have seen a consolidation of the services needed to run more sophisticated web apps, you can still put your ideas out for the entire world to see with nothing more than a static HTML page. This fact was, and still is, historically unprecedented.
Resilient
The internet has been called the most hostile environment to develop for. Someone who works on the web has to consider multiple browsers, the operating systems they are installed on, and all the popular release versions of both. They also need to consider screen size and quality, variable network conditions, different form factors and input modes, third party scripts, etc. This is to say nothing about serving an unknown amount of unknown users, each with their own thoughts, feelings, goals, abilities, motivations, proficiencies, and device modifications.
If you do it right, you can build a website or a web app so that it can survive a lot of damage before it is rendered completely inoperable. Frankly, the fact that the web works at all is nothing short of miraculous.
The failsafes, guardrails, redundancies, and other considerations built into the platform from the packet level on up allow this to happen. Honoring them honors the thought, care, and planning that went into the web's foundational principles.
Responsive
Most websites now make use of media queries to ensure their content reads and works well across a staggeringly large amount of devices. This efficient technology choice is fault-tolerant, has a low barrier of entry, and neatly side-steps the myriad problems you get with approaches such as device-sniffing and/or conditionally serving massive piles of JavaScript.
Responsive Design was, and still is revolutionary. It was the right answer, at the right place and time. It elegantly handled the compounding problem of viewport fragmentation as the web transformed from something new and novel into something that is woven into our everyday lives.
Adaptable
In addition to being responsive, the web works across a huge range of form factors, device capabilities, and specialized browsing modes. The post you are currently reading can show up on a laptop, a phone, a Kindle, a TV, a gas station pump, a video game console, a refrigerator, a car, a billboard, an oscilloscope—heck, even a space shuttle (if you’re reading this from space, please, please, please let me know).
It will work with a reading mode that helps a person focus, dark and high contrast modes that will help a person see, and any number of specialized browser extensions that help people get what they need. I have a friend who inverts her entire display to help prevent triggering migraines, and the web just rolls with it. How great is that?
Web content can be read, translated, spoken aloud, copied, clipped, piped into your terminal, forked, remixed, scraped by a robot, output as Braille, and even played as music. You can increase the size of its text, change its font and color, and block parts you don't want to deal with—all in the service of making it easier for you to consume. That is revolutionary when compared to the media that came before it.
Furthermore, thanks to things like Progressive Web Apps and Web Platform Features, the web now blends seamlessly into desktops and home screens. These features allow web content to behave like traditional apps and are treated as first-class citizens by the operating systems that support them. You don’t even necessarily need to be online for them to work!
Accessible
The current landscape of accessibility compliance is a depressing state of affairs. WebAIM’s Million report, and subsequent update, highlights this with a sobering level of detail.
Out of the top one million websites sampled, ~98% of home pages had programmatically detectable Web Content Accessibility Guideline (WCAG) errors. This represents a complete, categorical failure of our industry on every conceivable level, from developers and designers, to framework maintainers, all the way up to those who help steer the future of the platform.
And yet.
In that last stubborn two percent lives a promise of the web. Web accessibility—the ability for someone to use a website or web app regardless of their ability or circumstance—grants autonomy. It represents a rare space where a disabled individual may operate free from the immense amount of bias, misunderstanding, and outright hate that is pervasive throughout much of society. This autonomy represents not only freedom for social activities but also employment opportunities for a population that is routinely discriminated against.
There is a ton of work to do, and we do not have the luxury of defeatism. I’m actually optimistic about digital accessibility’s future. Things like Inclusive Design have shifted the conversation away from remediation into a more holistic, proactive approach to product design.
Accessibility, long viewed as an unglamorous topic, has started to appear as a mainstream, top-level theme in conference and workshop circuits, as well as popular industry blogs. Sophisticated automated accessibility checkers can help prevent you from shipping inaccessible code. Design systems are helping to normalize the practice at scale. And most importantly, accessibility practitioners are speaking openly about ableism.
Inexpensive
While the average size of a website continues to rise, the fact remains that you can achieve an incredible amount of functionality with a small amount of code. That’s an important thing to keep in mind.
It has never been more affordable to use the web. In the United States, you can buy an internet-ready smartphone for ~$40. Emerging markets are adopting feature phones such as the JioPhone (~$15 USD) at an incredible rate. This means that access to the world’s information is available to more people—people who traditionally may have never been able to have such a privilege.
Think about it: owning a desktop computer represented having enough steady income to be able to support permanent housing, as well as consistent power and phone service. This created an implicit barrier to entry during the web’s infancy.
The weakening of this barrier opens up unimaginable amounts of opportunity, and is an excellent reminder that the web really is for everyone. With that in mind, it remains vital to keep our payload sizes down. What might be a reflexive CMD + R for you might be an entire week’s worth of data for someone else.
Diverse
There are more browsers available than I have fingers and toes to count on. This is a good thing. Like any other category of software, each browser is an app that does the same general thing in the same general way, but with specific design decisions made to prioritize different needs and goals.
My favorite browser, Firefox, puts a lot of its attention towards maintaining the privacy and security of its users. Brave is similar in that regard. Both Edge and Safari are bundled with their respective operating systems, and have interfaces geared towards helping the widest range of users browse web content. Browsers like Opera and Vivaldi are geared towards tinkerers, people who like a highly customized browsing experience. Samsung Internet is an alternative browser for Android devices that can integrate with their proprietary hardware. KaiOS and UC browsers provide access to millions of feature phones, helping them to have smartphone-esque functionality. Chrome helps you receive more personalized ads efficiently debug JavaScript.
Browser engine diversity is important as well, although the ecosystem has been getting disturbingly small as of late. The healthy competition multiple engines generates translates directly to the experience becoming better for the most important people in the room: Those who rely on the web to live their everyday lives.
Speaking of people, let’s discuss the web’s quality of diversity and how it applies to them: Our industry, like many others, has historically been plagued by ills such as misogyny, racism, homophobia, transphobia, and classism. However, the fact remains that the ability to solve problems in the digital space represents a rare form of leverage that allows minoritized groups to have upward economic mobility.
If you can't be motivated by human decency, it’s no secret that more diverse teams perform better. We’ve made good strides in the past few years towards better representation, but there’s still a lot of work to be done.
Listen to, and signal boost the triumphs, frustrations, and fears of the underrepresented in our industry. Internalize their observations and challenge your preconceived notions and biases. Advocate for their right to be in this space. Educate yourself on our industry’s history. Support things like codes of conduct, which do the hard work of modeling and codifying expectations for behavior. All of this helps to push against a toxic status quo and makes the industry better for everyone.
Standardized
The web is built by consensus, enabling a radical kind of functionality. This interoperability—the ability for different computer systems to be able to exchange information—is built from a set of standards we have all collectively agreed on.
Chances are good that a web document written two decades ago will still work with the latest version of any major browser. Any web document written by someone else—even someone on the opposite side of the globe—will also work. It will also continue to work on browsers and devices that have yet to be invented. I challenge you to name another file format that supports this level of functionality that has an equivalent lifespan.
This futureproofing by way of standardization also allows for a solid foundation of support for whatever comes next. Remember the principle of versatile: It is important to remember that these standards are also not prescriptive. We’re free to take these building blocks use arrange them in a near-infinite number of ways.
Open
Furthermore, this consensus is transparent. While the process may seem slow sometimes, it is worth highlighting the fact that the process is highly transparent. Anyone who is invested may follow, and contribute to web standards, warts and all.
It’s this openness that helps to prevent things like hidden agendas, privatization, lock-in, and disproportionate influence from consolidating power. Open-source software and protocols and, most importantly, large-scale cooperation also sustain the web platform’s long-term growth and health. Think of web technologies that didn’t make it: Flash, Silverlight, ActiveX, etc. All closed, for-profit, brittle, and private.
It also helps to disincentive more abstract threats, things like adversarial interoperability and failure to disclose vulnerabilities. These kinds of hazards are a good thing to remember any time you find yourself frustrated with the platform.
Make no mistake: I feel a lot of what makes the web great is actively being dismantled, either inadvertently or deliberately. But as I mentioned earlier, cynicism is easy. My wish for next year? That all the qualities mentioned here are still present. My New Year’s resolution? To help ensure it.
The post What the web still is appeared first on CSS-Tricks.
What the web still is published first on https://deskbysnafu.tumblr.com/
0 notes
Text
A quick-start guide for SEO campaign management
SEO campaign management is the development, execution and monitoring of search engine optimisation tasks over a measurable period of time (typically three months to one year). The goal of these actions is to increase SERP visibility of your web pages, outrank competitors in search and funnel high-intent traffic to conversion landing pages.
There are many methods for achieving SEO success, so let’s talk through the variables you need to keep in mind along with a proven checklist of tried-and-true tactics that should keep your campaigns firing on all cylinders.
A quick primer on SEO in 2019
Changes to search engine algorithms are cited as the top B2B content marketing issue, so it’s clear SEO is more top of mind than ever.
So which factors should be highest on your radar when you launch your SEO strategy?
Ranking factors
Industry insiders love to make a bigger deal of ranking factors than is necessary. For the most part, the core ranking factors that Google uses to index and rank content have remained the same for several years.
SERP display changes
The way SERPs look is constantly changing.
Most recently, Google has experimented with double Featured Snippets displays, infinite “People also ask” boxes and expanded Google My Business functionality.
Expect regular search listings to be pushed further below the fold in favour of images, videos, paid ads, maps and direct answer boxes.
Algorithm updates
Moz records a rolling history of Google algorithm changes that you can frequently check in on. Last year, Moz lists 12 changes; however, Google is often cagey about revealing confirmed algorithm updates. Recent priorities for Google’s “broad core” updates have been devaluing spammy sites and penalising sites with unsecured domains and slow page speeds.
Voice search, mobile-first indexing and video, video, video
These are the biggest topics of conversation at the moment, and Google has given clear indications that text-based content is being displaced by audio and visual content. People are spending an increasing amount of time using voice assistants, listening to podcasts, watching videos on YouTube and consuming content within apps.
SEO, classified
Here’s a refresher on SEO definitions before we go any further:
On-page SEO
Any factors that relate to what exists on your web pages, including text, metadata, HTML tags, images, alt text and links.
Off-page SEO
Any activities that impact SEO but don’t actually occur on your website, including referring domains, inbound links, brand mentions, social media interactions and influencer marketing.
Technical SEO
Any actions that refer to your website’s core functionality and crawlability, including proper URL structures, redirects, structured data markup, XML sitemaps, HTTPs and mobile responsiveness.
SEO checklist: A campaign from scratch
Google SERPs are more competitive than ever, and it’s not hyperbolic to say that every positional increase in your organic rankings matters enormously. Take a look at how much traffic each ranking position gets:
You HAVE to be on page one, or you simply won’t be seen by anyone. So here’s a rundown of on-page, off-page and technical SEO steps to take:
Run a quick site audit to find and fix broken links, 404 errors and other penalties
Lay the groundwork for your content to perform well by uncovering and cleaning up site errors. Using a tool like SEMrush you can conduct an in-depth audit as well as receive regular optimisation ideas directly in your inbox, so you immediately know how and where to improve.
Use Google PageSpeed Insights to improve site speed
Users will bounce from your site if it loads too slowly, and Google may actually stop crawling your site regularly and prevent indexing. Fix that fast with Google PageSpeed Insights, thus adhering to one of Google’s key UX algorithm preferences.
Set up goal values in Google Analytics
How’s your SEO? You won’t have any idea if you don’t properly set up your Google Analytics account with customisable goal values. Doing so allows you to mathematically determine how much each organic lead is worth, who is actually reading your content and where in the buyer journey people may be tuning out.
Use Google Mobile-Friendly Test to optimise for mobile-first indexing
Google shows users the mobile version of your website when it appears in search results. So by optimising for mobile, you allow Google to display your content in the correct format – one that is conducive to smartphone scrolling and short attention spans.
Identify and prioritise high-value, low-volume keyword targets
Head into SEMrush’s Position Tracking tool to see whether you’re actually ranking for the keywords you wish to own. Filter out keyword targets that are too competitive (Keyword Difficulty score is too high), have a lot of SERP crowding (will have to compete with several paid ads and Featured Snippets that may distract searchers from your listing) and aren’t fully relevant to your commercial goals.
In general, the longer tail a keyword is, the lower its search volume and the lower the Keyword Difficulty score. These are the search terms you’re actually capable of ranking for, which can be found in SEMrush’s Keyword Magic tool.
Thoroughly fill out your Google My Business profile and other online directories
Featured Snippets and Google Maps scrape your company information from Google My Business, so if your GMB isn’t set up, you’re missing out on geo-targeted search queries.
Before any other content creation, rewrite core landing pages for greater authority and depth
Your landing pages are where conversions happen, so use a tool like Market Muse to see how thorough your content on these pages should actually be and whether there are gaps in your topic coverage. Once your landing pages are fully optimised, you can start directing all of your blog and social traffic to these pages.
Consolidate and streamline your social media presence
B2B brands are scaling down their social media channels in favor of a more focused online presence, and for good reason. Social media has indirect SEO benefits in the form of user engagement signals and content promotion, and it provides a strong distribution method that amplifies the reach of all of your content efforts.
Convert top-performing content into other types of assets and redistribute
Have a data-heavy whitepaper? Break it into several infographics and distribute via email. Generated a lot of great questions from registrants to a recent webinar of yours? Create a comprehensive FAQ page that addresses them all.
This type of cross-cutting allows you to spin single ideas into several marketing assets. It also shows Google that your site remains fresh and continually valuable to searchers.
In what areas have you increased spending?
[View our #contentmarketing report to see this and other findings. https://t.co/5gNxE9yi2c] pic.twitter.com/xXhRvblGKX
— Content Marketing Institute (@CMIContent) November 2, 2018
Automate your analytics reports and integrate with other platforms
Google Analytics is your bread and butter, but you should also be pulling data from your email marketing platforms, social tools and CRMs. Many of these platforms offer integrations with one another to provide a more comprehensive look into your total marketing performance.
Experiment with at least one new form of media
Videos, podcasts, PDFs and social posts, among others, are all indexed and featured in search engines just like trusty blogs or infographics are. Diversify your content offerings to better scale with ongoing SEO changes.
Share as much data as possible with your sales team (and vice versa)
SEO is more than a marketing tactic; it’s also an indicator of ROI, sales-readiness, lead quality and overall inbound success. Any data your analytics tools compile relating to user search behavior, on-site interactions, brand mentions, social media interactivity and content performance metrics can be leveraged as sales collateral for your reps.
Similarly, your sales team should prime the marketing department with information on customer lifecycles, cart abandonment, brand loyalty, referrals and other indicators of satisfaction or dissatisfaction that your content can potentially help with.
Bonus no-fail SEO tactics
Optimising for search never ends. There are literally 10-20 things you can do every single day to improve your backlink profile, increase conversion rates and win those SERP rankings you treasure so much.
Here are a few other tactics we recommend:
Map every upcoming asset to a specific stage of the sales funnel.
Reach out to high-value industry sites for link-building opportunities.
Build and segment email lists.
Send out a regular newsletter.
Create unique, clickable CTAs for every downloadable asset.
Simplify your opt-in forms.
One point of caution, if we may: Beware of SEO companies that promise the moon. If they can’t show you examples of client success, provide regular progress reports or can’t back up their SEO claims in any way, choose a different vendor.
from http://bit.ly/2oDmSvn
0 notes
Text
IF term & conditions - weeknotes Friday 23rd February 2018
The short version:
Last week we built a prototype tool to try and make it easier to read and understand terms and conditions
This week we interviewed four people who are very familiar with terms and conditions using the prototype as a prop
We realised terms documents need structure
We learned that automated checking terms is not the right place to start
We need to change how terms are published in the first place
There are some amazing projects in this area
The longer version:
We built a prototype reader for terms and conditions
Last week we roughly followed a GV-sprint process to quickly create a working prototype to test some ideas.
We wanted to know if we could demonstrate a tool that could make lives easier for people who have to read and understand terms and conditions documents.
More importantly, we wanted to build something very quickly to learn from. I find that putting a ‘working’ thing in front of an expert often yields more than simply asking them about it.
https://terms.projectsbyif.com
The tool automatically highlights certain phrases in a terms and conditions document, it calculates a reading age, and it links any definitions in the document back to the first place they’re mentioned.
We wanted to learn whether any of these things could make a document easier to read and understand.
We interviewed four people about terms
We put calls out on social media as well as directly contacting friends and journalists with experience in the area of terms and conditions in the past.
We were looking for people who were familiar with reading T&Cs to understand:
Why they read them
Their process for reading and understanding them
What sort of things they’re looking for
What difficulties they have, if any
What workarounds they use
Does our prototype help them at all?
Many thanks to the folks that agreed to speak to us — your input was incredibly valuable.
The biggest surprise was that simply presenting the document nicely was the most popular aspect of the tool. Having strong, semantic headings that make the document glanceable, using a decent font size and spacing. We heard about terms being presented in PDFs, walls of small text and 20,000 word printed documents(!)
The categories user interface was confusing, with people mistaking it for navigation. The upside is that we realised decent navigation is really valuable. Showing a table of contents linking to well structured headings is a win for people reading terms.
The highlighted terms was mildly useful to people, making it easier to spot things at a glance. But actually, people have their own lists of phrases they want to look for, so imposing our list was only partially helpful.
The automated analysis was helpful for one person (who does it via copy-paste into another tool) and bringing out definitions was popular — but perhaps instead as a hover, rather than jumping around the document.
Something that came up in discussion was being able to underline or highlight phrases or sections. It’s common to highlight a particular block of text and copy it, annotate it or refer to it somehow.
We realised terms documents need structure
Perhaps the most important thing we learned about terms documents — and where the ‘fiction’ of the prototype fell down — was that terms documents lack the structure we actually need to be able to make this sort of product for real.
As far as we know, terms documents aren’t published in any standard data format. They’re effectively a relic of print, often badly converted to web or PDF. There’s no structure to the underlying text — which bit’s a header, which bit’s a definition—- what each section is talking about.
To build our tool, we manually faked the import step — the bit where the tool fetches the document from the internet and restructures it. We copied a document from the internet and structured it by hand (turning it into Markdown). That allowed us to present the document as nice semantic HTML.
We also hand-structured definitions from the document (for example: “service data” means your location, your phone number), because it was hard to do that automatically.
This is particularly true for PDF documents which are fundamentally a page-layout format, not a structured text format (I remember this well from a past life scraping data from PDF documents).
Automated checking terms is not the right place to start
If we did try to progress this checker for real I suspect we’d spend all our time on the wrong thing — battling trying to turn myriad formats into a standard one.
Our parsing of the document was very simple — just simple pattern matching with regular expressions — and there’s much more clever stuff we could do with sophisticated natural language processing. But I think the lack of structure means the data isn’t available in the first place.
To be completely honest, for reviewing terms and conditions, it’s quite hard to beat copy-pasting a document into Google Docs. I can quickly reformat the headers, I can do collaborative annotation and commenting, and I can search through for keywords then underline them.
We need to change how terms are published in the first place
It’s silly that every service has its own bespoke ‘licence’ to use it. This is like the days before free software licences, or before Creative Commons. In those days, it was risky and time consuming to build on others work if it had a bespoke licence unless you had a legal team on hand.
The same applies to terms and conditions. We can’t possibly read them all, so we just ‘agree’ by default.
I can imagine a future where terms and conditions documents either don’t exist, or they’re so well standardised my browser can just read them for me. It can know my preferences well enough to decide whether to warn me about something. This would be a huge improvement over the biggest lie most of us make every time we sign up for something.
We need to figure out the path from where we are today — legacy documents designed for lawyers — to a future where terms are both clear to humans and machines. We need to work out how to turn terms into machine-readable data.
As a very minimal first step, terms should be published as valid, semantically correct HTML. This would at the least make it possible for other tools to display them nicely.
But what about microformats like schema.org? Imagine if types of personal information and names of third party companies were marked up as Corporations — that would be step in the direction of your browser being able to read them for you.
<p>All data is shared with <span itemprop="parentOrganization" itemscope itemtype="http://schema.org/Corporation"><a itemprop="url" href="http://example.com/"><span itemprop="name">ABC Holdings Ltd</span></a></span>.</p>
HTML marked up with microformats to help machines understand the meaning.
Or perhaps terms and conditions could be replaced entirely by something else, like inline-permissions?
There are some amazing projects working on this
Here are some of the projects doing related, interesting stuff in this area:
Terms of Service Didn’t Read - they manually review and score terms and conditions based on a number of rights.
TOSBack - periodically downloads terms and conditions and published them to Github. The website links to diffs so you can see what changed between versions.
Fairer Finance Clear & Simple Mark - they do transparency reports on financial services companies and reward them for having clear, readable terms and conditions (among other things)
Project VRM - a judo-flip of the CRM (customer relationship management) tools
These projects have shown us there are a lot of angles to look at this problem. We started the sprint thinking about checking terms and conditions — an important activity that won’t go away for a while — and ended it thinking about a completely different future.
That’s it for now — have a great weekend.
0 notes
Link
Why I startedI love building new things and sharing them. When I do, my excitement often turns to despair as my betas rarely catch on.Though I’m ok with this (and I usually learn a ton along the way) I often lament over how much time I had put into building a web app just to test the value prop. Sometimes the prospect of it all going to waste can even be a huge demotivating force during the build.Regardless, I had always considered it a necessary evil to test my idea. Without really thinking about it, I hadn’t considered that anything less would be a fair test of an idea. Perhaps it was the engineer in me that thought about the technical considerations before what it really took to test a business.What I builtMy latest beau is Catsnatcher — a tool that gives profitability and competitive metrics on 40,000+ highly-specific Amazon categories so that sellers can find the perfect niche.Having spent months developing the necessary scripts to gather and analyse the info, I finally completed the data stage three weeks ago. I then started to break ground on the web app that would present this data to users.“If you’re not embarrassed by the first version of your product, you’ve launched too late.” — Reid Hoffman As a lone wolf, I quickly found myself frustrated when dealing with the mundanity of non-value add pieces (pretty much everything on the frontend). I had the data ready, wasn’t that enough for people? The medium wasn’t going to affect people‘s success on Amazon. ‘People don’t pay for buttons’, I told myself after three hours of trying to fix the damn buttons.Thinking about myself and all the time I had wasted on the presentation of previous betas — I put myself in the shoes of the customer and realised that if I was them, I wouldn’t care how this was given to me. My purchase would depend on the data available and if it serviced my need to be the best Amazon seller. In fact, part of me would probably trust data from a file more than a typical web app.Following research on the specs and planning what adjustments I’d have to make (more on these below), Google Sheets quickly became the favourite. After all, it includes:Data presentation — the well-known tabular format first made famous by excel is easy to navigate and isn’t much worse looking than a custom frame that would have taken days to tweakSorting — viewing metrics from highest-to-lowest and vice-versa is very important for analysing Amazon data Filtering — as with the above, people will be searching criteria based on parameters (e.g. rating < 4.2)Copy protection — data is my product, so if I didn’t use Google Sheets I would have had to install CloudFlare to prevent illicit scraping of my dataSharing/auth of users — its so easy to add new emails and adjust permissions of existing ones, I can even add people who provide a non-Google email!All of this could have taken me weeks or even months to build myself, not to mention maintenance. As I closed my IDE (for what was hopefully the last time), I asked around to make sure I hadn’t lost my mind:Running MVP on Google SheetsWhat I learnedThe new stack would be a Google Sheet that I added people to once they had paid me through my simple static HTML landing page. As I could export directly from PostgreSQL to CSV getting the data in would be as simple as drag and drop; however the remainder of the setup wasn’t all plain sailing.Although Google Sheets was handling huge chunks of my app stack (data frames, authentication, frontend protection from copy/paste) there were several limitations that simply wouldn’t have been an issue if I had taken those extra weeks to code an app instead:The maximum allowed cells possible in Sheets is 2M. I needed two sheets — one for the Categories and another for their constituent Item listings. Considering I started out with 40,000 Categories and over 500,000 Items and about 10–15 columns of metrics for each; keeping this many rows would have meant a lot fewer metrics on each to be compliant (no fewer than four for Items, in fact). Instead, I filtered some protected categories and ones I thought were useless to bring it down to 28,000 and instead of showing the top 20 Items for each Category for beta I decided to show just the top five (for a total row count of just over 100,000). This meant I could show off most of the important analyses (columns) I had made for both. I think my final tally of cells was about 1.8M.User permissions were probably my biggest challenge. I wanted people to be able to explore the data but not make edits, copy or download the data, which meant a regular Edit user option was off limits. View-only ended up being a decent option only because of filter views, which allow viewer users to use Sheets’ sort and filter options without affecting anyone else’s view. I did mess up whilst adding one of my first users and left him as an Edit user for three hours. Thankfully he’s a nice dude and opted not to steal my data or blow shit up. Unfortunately these view-only users do see each other’s Google icons if they use at the same time which is a bit weird, but for now this isn’t a big issue.Ease of use was definitely not as polished as it would have been in a regular app. The most memorable example I have is that I wasn’t able to link from a niche that a user had shortlisted to jump to the next tab and filter the constituent items that were within that — this would have been possible with a Google Script but there aren’t accessible to view-only users. Instead, I added a tutorial in the welcome email on how to do this manually. I gave users more detail into what each datapoint meant using the notes feature, where if you hover over a cell you can get more insight.As expected, performance is touchy when you’re at 90% capacity presenting hundreds of megabytes of data to your users. From testing myself, I noticed most of the lag was when initially opening the sheets, particularly the 500,000 row list of Items. I made a note in my email tutorial to give it some time to load initially before using. Although I expected the lag to get worse and worse as I added more users, filter-only views actually helped here, my understanding of how they work suggest that they defer a lot of the work to the user’s computer rather than Google’s compute/memory allocated to a sheet, thus not affecting others’ experience. I’d assume more overhead in scaling Edit users as the changes are seen and saved on everyone’s version of the sheet.Pricing wasn’t a limitation per se but it was clear that it needed to be more attractive to beta users due to all of the above. I’ll also be gathering feedback from them as I tweak the final draft of v1 in the coming weeks — so its only fair that its a bit cheaper. As it stands I’m charging $60 for two months access to the list ($30/month) and for the full app the fee will be closer to $40-$50/month for access — billed quarterly. I know this won’t suit everyone but I’m looking to build up a cache of serious Amazon Sellers, regardless of their stage in the journey.Usage and event analytics are super important for a new product —not only for informing the features in the full build but also for ensuring people use it and keep using it long enough to give meaningful feedback. Unfortunately there really is no way to track this in Sheets. I’ve overcome this by reaching out a little bit more to my users than is necessary to check that everything is going ok or if they have any issues.My product has no free trial, so people have to make their judgement to sign up based on what I say and show on my landing page. I figured this might be troublesome as I’d just be showing them a screenshot of a Google Sheet alongside a promise that it could help them be more successful. Part of me expected laughter when people saw a $60 price tag on a Google Sheet. Thankfully they saw past the wallpaper (see below). On balance, I feel it was still worth it — anything major outlined above was either overcome or just wasn’t as important to the end users or getting access to the data.LaunchThough nervous about the my light stack I decided that data was worth it so I’d charge $60 for two month’s beta access. Last week I launched on Product Hunt and I got several paying users within hours, and many more newsletter signups! I followed this up with a BetaList launch and have more targeted stuff scheduled for the coming week. The plan is to continue adding users to the Sheet and get their feedback as I build out the full app on the side.Despite being only part of the way through, I can say with confidence that its by far the best launch I’ve ever had (in far less time)!I am almost certain this is a result of outsourcing the app to Google Sheets and thus having more time to focus on messaging, sharing and nurturing new customers. This is important. Use your newly-freed time wisely. In my previous launches, I had put all my energy into the app, pasted the link and hoped for the best. As much as it pains the engineer in me to say it, this stuff is the life and soul of a business.Feel free to reach out on Twitter if you’re thinking of running a product beta on Sheets. Also (shameless plug), if you are an Amazon seller or considering becoming one, check out the Catsnatcher beta file to find your perfect high-profit, low competition niche!
0 notes