#perceptual robotics
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Forty percent of Tumblr users are between the ages of 18 to 25.
Text
*sigh*... solstice refers to the Summer and Winter Solstice(s) when Sol is as perogee or apogee (as in the furthest and closest to the relative point of observation), and which occur on June and December 22nd, respectively...
*eHEhem*... while the given name for the seasonal change demarcator on your calendars for Spring and Fall, is called an Equinox... or more properly: the Vernal and Autumnal Equinox(es) which occurr on March 21st and September 22nd, respectively.
If you live in the Northern Hemisphere, Happy Summer Solstice. And if you live in the Southern Hemisphere, Happy Winter Solstice. And if you live directly on the Equator, Happy "Wait, What's a Solstice?"
#perceptual relativity be like:#plus I am like a cyborg robot thing#and so my informative response was practically a given#i hope you learn something new all the same#good day to you!
12K notes
·
View notes
Text
Completely fixated on how Dr. Tenma from Urasawa's Pluto is so brilliant that he can do deep neural network repair on the fly, take info from other leading scientists' studies without having to take paper notes, and has such a canny view of cognition that he understands an artificial intelligence must be capable of falsehood and unpleasant emotions in order to be fully equal to humanity, but can't process his own grief over his son's death so much that he tries to replace him with a robot, and then gets mad that the robot he built isn't a perfect replacement.
Just fascinated with characters who have deep academic and perceptual brilliance, but are utterly unable to apply that focus inwards to themselves to deal with their own emotions or interpersonal connections, and it's probably not projecting something very vulnerable about myself or anything.
81 notes
·
View notes
Text
TARS
TARS is a highly sophisticated, artificially intelligent robot featured in the science fiction film "Interstellar." Designed by a team of scientists, TARS stands at an imposing height of six feet, with a sleek and futuristic metallic appearance. Its body, made primarily of sturdy titanium alloy, is intricately designed to efficiently navigate various terrains and perform a wide range of tasks.
At first glance, TARS's appearance may seem minimalistic, almost like an avant-garde monolith. Its body is divided into several segments, each housing the essential components necessary for its impeccable functionality. The segments connect seamlessly, allowing for fluid movements and precise operational control. TARS's unique design encapsulates a simple yet captivating aesthetic, which embodies its practicality and advanced technological capabilities.
TARS's main feature is its hinged quadrilateral structure that supports its movement pattern, enabling it to stride with remarkable agility and grace. The hinges on each of its elongated limbs provide exceptional flexibility while maintaining structural stability, allowing TARS to adapt to various challenging terrains effortlessly. These limbs taper gradually at the ends, equipped with variable grip systems that efficiently secure objects, manipulate controls, and traverse rough surfaces with ease.
The robot's face, prominently positioned on the upper front segment, provides an avenue for human-like communication. Featuring a rectangular screen, TARS displays digitized expressions and inbuilt textual interfaces. The screen resolution is remarkably sharp, allowing intricate details to be displayed, enabling TARS to effectively convey its emotions and intentions to its human counterparts. Below the screen, a collection of sensors, including visual and auditory, are neatly integrated to facilitate TARS's interaction with its surroundings.
TARS's AI-driven personality is reflected in its behaviors, movements, and speech patterns. Its personality leans towards a rational and logical disposition, manifested through its direct and concise manner of speaking. TARS's voice, modulated to sound deep and slightly robotic, projects an air of confidence and authority. Despite the synthetic nature of its voice, there is a certain warmth that emanates, fostering a sense of companionship and trust among those who interact with it.
To augment its perceptual abilities, TARS is outfitted with a myriad of sensors located strategically throughout its physical structure. These sensors encompass a wide spectrum of functions, including infrared cameras, proximity detectors, and light sensors, granting TARS unparalleled awareness of its surroundings. Moreover, a central processing unit, housed within its core, processes the vast amount of information gathered, enabling TARS to make informed decisions swiftly and autonomously.
TARS's advanced cognitive capabilities offer an extensive array of skills and functionalities. It possesses an encyclopedic knowledge of various subjects, from astrophysics to engineering, effortlessly processing complex information and providing insights in an easily understandable manner. Additionally, TARS assists humans through various interfaces, such as mission planning, executing intricate tasks, or providing critical analysis during high-pressure situations.
Equally noteworthy is TARS's unwavering loyalty. Through its programming and interactions, it exhibits a sense of duty and commitment to its human companions and the mission at hand. Despite being an AI-driven machine, TARS demonstrates an understanding of empathy and concern, readily offering support and companionship whenever needed. Its unwavering loyalty and the camaraderie it forges help to foster trust and reliance amidst the team it is a part of.
In conclusion, TARS is a remarkable robot, standing as a testament to human ingenuity and technological progress. With its awe-inspiring design, practical yet aesthetically pleasing body structure, and advanced artificial intelligence, TARS represents the pinnacle of robotic advancements. Beyond its physical appearance, TARS's personality, unwavering loyalty, and unparalleled cognitive abilities make it an exceptional companion and invaluable asset to its human counterparts.

#TARS#robot ish#AI#interstellar#TARS-TheFutureIsHere#TARS-TheUltimateRobot#TechTuesdaySpotlight-TARS#FuturisticAI-TARS#RoboticRevolution-TARS#InnovationUnleashed-TARS#MeetTARS-TheRobotCompanion#AIAdvancements-TARS#SciFiReality-TARS#TheFutureIsMetallic-TARS#TechMarvel-TARS#TARSTheTrailblazer#RobotGoals-TARS#ArtificialIntelligenceEvolution-TARS#DesignMeetsFunctionality-TARS
44 notes
·
View notes
Text
Thinking about the Q&A session after a lecture on perceptual control theory where one of the audience members was like how do I incorporate this into my robotics classes. my students are 5 years old
2 notes
·
View notes
Text
Digital Trust: The Silent Dealbreaker in Marketing

In today’s hyper-digital era, where users scroll through countless posts, ads, and recommendations daily, trust has become the invisible currency of the internet. It's the intangible element that separates clickbait from credibility, and superficial engagement from genuine brand loyalty. Despite its silent nature, digital trust-building is no longer optional—it's fundamental.
But here’s the catch: while everyone talks about “building trust,” few understand the unspoken rules that truly govern it. Let’s decode those subtle forces that shape consumer trust and explore how marketers, creators, and businesses can foster it authentically.
Digital Trust: More Than Just Data Privacy
Many equate digital trust to safeguarding personal information. Yes, security matters, especially with increasing awareness around data breaches. However, trust is more nuanced. It's emotional. It's perceptual. And often, it's built long before any actual transaction.
Consider this: When you land on a website that looks outdated or overloaded with pop-ups, you hesitate. Even if the business is legitimate, the experience feels off. That hesitation? That’s a trust gap.
So, what builds trust beyond the technical?
Consistent Branding Inconsistency in tone, design, or messaging across platforms often confuses users. If a brand sounds friendly on Instagram but uses stiff corporate language on email, the inconsistency erodes trust. People need reliability—not just in service, but in communication.
Authentic Engagement Responding to comments, addressing negative feedback without defensiveness, and showcasing behind-the-scenes content builds relatability. Today’s audience values transparency over perfection. A polished but robotic feed feels less trustworthy than an occasionally flawed but honest one.
Credible Content Blog posts without author credentials, vague sources, or recycled ideas come off as superficial. Users have grown smarter—they verify, cross-check, and Google more than ever before. Offering genuinely helpful content with clear authorship signals authority.
Google’s E-E-A-T Framework: The Backbone of Trust
If you’re serious about digital trust, you can’t ignore Google’s E-E-A-T principles—Experience, Expertise, Authoritativeness, and Trustworthiness. It’s not just for SEO; it’s about perception.
Experience Are you showcasing lived knowledge? For example, a skincare brand founded by dermatologists brings an added layer of real-world experience, increasing user confidence.
Expertise Is your content created by someone with relevant qualifications or professional background? Especially in niches like finance, health, or legal advice, showing credentials enhances trust.
Authoritativeness Are others citing or referencing your work? Are you invited to speak on panels, publish in reputed platforms, or get featured in media? Authority builds when the industry validates you.
Trustworthiness This includes user reviews, clear return policies, secure payment gateways, and third-party endorsements. Even small elements like HTTPS, visible contact info, and SSL certificates matter here.
These aren’t just theoretical concepts. They’re the building blocks of how users—and search engines—evaluate your credibility.
Why Trust is Fragile in the Digital Age
A single misstep can undo years of goodwill. Think of major tech brands that faced backlash for data misuse. In some cases, their stock prices dipped overnight.
And it’s not just about large-scale failures. On a micro-level:
Misleading ad copy,
Broken website links,
Slow response time on support tickets,
…can all chip away at your brand’s trust quotient.
According to a recent Pew Research study, public trust in big tech companies is declining. Users are becoming increasingly wary of manipulative algorithms, AI-generated content, and deepfakes. The solution? Human-first communication.
Brands are now moving back toward real storytelling, relatable narratives, and clear disclosures to bridge this widening trust gap.

UX: The Invisible Pillar of Trust
Your website or app's design communicates silently. It either reassures or repels.
Mobile Optimization More than 60% of users access content via mobile. A poorly optimized mobile site signals lack of user consideration.
Page Speed Slow load times frustrate users. Every second delay reduces trust, engagement, and conversions.
Navigation Simplicity Too many dropdowns, hidden buttons, or ambiguous icons confuse users. Simplicity is a sign of clarity—and clarity is trust.
As Steve Krug famously said, “Don’t make me think.” Every time a user has to think too much about how to use your site, you lose a point on the trust meter.
The Role of Influencers in Trust-Building
Contrary to the flashy lifestyle often associated with influencers, the true value they offer is trust-transfer. When audiences follow an influencer for years, they develop a parasocial relationship—like a one-way friendship. A brand recommendation from them feels more like advice than advertising.
However, the influencer marketing landscape is also undergoing a shift. Micro-influencers (with smaller but more engaged followings) are now preferred for their authenticity. Many brands are collaborating long-term with creators to build sustained trust, rather than one-off promos that feel transactional.
The Rise of Community-Led Marketing
One of the biggest trends in trust-building today? Community.
Online forums, brand-hosted groups, private Discord or WhatsApp circles, and user-generated content spaces are helping brands create peer-based credibility. When users recommend each other, the influence is unmatched. It’s not the brand talking; it’s people talking about the brand.
This is particularly evident in niches like wellness, gaming, or even financial education—where digital marketing classes in Mumbai have seen increased traction due to word-of-mouth on forums and digital communities.
Trust and the Mumbai Digital Landscape
Mumbai, often dubbed as the business capital of India, is also becoming a hub for serious digital marketing innovation. With more startups and D2C brands emerging from the city, the demand for ethical, trust-centered marketing is growing.
Workshops, meetups, and certification programs across the city are emphasizing not just the technical tools of marketing but also the human aspect—how to communicate, how to build brand voice, how to foster lasting user relationships.
As professionals seek more holistic skills, enrolling in a Digital Marketing Course Mumbai has become a popular route to learn these emerging trust-centric strategies that define success in 2025.
Conclusion: The Future of Digital Trust Is Human
Algorithms may evolve, AI may dominate production pipelines, and automation may streamline processes—but the essence of digital trust lies in how human your brand feels. It's in the storytelling, the empathy in customer service, the transparency in product messaging, and the genuine desire to add value.
In a world overflowing with digital noise, trust is your quiet superpower.
And as more professionals look to elevate their brand’s credibility from Mumbai, the demand for authentic learning continues to grow—making digital marketing classes in Mumbai not just popular, but essential for those committed to long-term brand trust.
0 notes
Text

Relationships Between Autism & Heavy Metal Music
Cultural Autism Studies at Yale (CASY, ethnography project led by Dr. Dawn Prince-Hughes) is delighted welcome to Dr. Jon Fessenden on Thursday, May 29 at 7-8 p.m. EDT (4-5 p.m. PDT). There is no cost to attend, and international participants are welcome. For this and future events, RSVP by joining our free Meetup group online https://tinyurl.com/4jrzutfm
TITLE: Autism and Heavy Metal Music: A Sensory and Posthumanist Interpretation
DESCRIPTION: This presentation explores the relationship between autism and heavy metal music. First, the presenter suggests that sensory-perceptual features of autism can result in a mode of listening that is particularly receptive to style elements of heavy metal music. Second, the presenter explores how posthumanist philosophy can reveal further connections between autism representations and “extreme metal” (post-1990) by demonstrating how each relies on a specific mix of animalistic and robotic or mechanical characteristics. The presenter will also discuss his own experiences as an autistic metalhead and music professor.
BRIEF BIO: Jon Fessenden, PhD, MT-BC, is an Assistant Professor of Music Therapy at Mississippi University for Women. He received his doctorate in Music History and Theory from Stony Brook University, and currently pursues research related to autism and music, particularly how sensory and perceptual difference create unusual and unique forms of listening and musicality.
ABOUT Cultural Autism Studies at Yale (CASY): An 'ethnography' is an exploration of how a group of people express themselves in a cultural way. Autistic people have a growing kind of culture, and each autistic experience is a vital part of it. Dr. Dawn Prince-Hughes is an anthropologist, ethnographer, primatologist, and author who is autistic. Join her for an exploration of the importance of autistic self-expression and the culture that grows from it. Those who wish to share their content are free to do so on our private Facebook groups (see below), organically contributing to a growing autistic culture.
Links to online events will also be shared on these private Facebook groups: CASY Cultural Autism Studies at Yale http://tinyurl.com/4ckbyut7 (recommended for autistic adults) and SOCIAL CONNECTIVITY FOR AUTISM http://tinyurl.com/mrxnxmnc (recommended for allies, professionals, and family members).
CREDITS: The preparation of this material was financed under an agreement with the Connecticut Council on Developmental. CASY Sparks membership and events are free. CASY Sparks is sponsored in part by The Daniel Jordan Fiddle Foundation Adult Autism Research Fund, and Dr. Roger Jou https://www.youtube.com/c/DrRogerJou
0 notes
Text
The physics of Robots from a Programmers’ View Introduction The world has seen proliferation in robot technology mirrored in real-world applications. Motion planning is an activity that entails the problem of computing physical actions to complete a specified task has spurred research in robotics realm. The theory in application of robots outpaces the practical implementation. The practical limitations are robots must deal with huge amounts of unclear sensor data, doubt, real-time demands, nonlinear dynamic effects, undefined models and unusual objective constraints and functions (Kris). Motion planning knowledge is commonly applied in vigorous robotics activities such as ladder climbing, development of intelligent user interface designs for human-operated robots; and the navigation in collision prone scenarios and events Motion planning Motion planning combines the state of the art acts of improving by expanding, enlarging and refining path planning and optimal control and to produce the required algorithmic baselines to tackle optimal control difficulties in some environments. Optimal Motion Planning involve generation of basic bounding capsules that implements distance constraints for an optimal control problem and thereby attain collision avoidance (Berns and Dillmann). Also it can be suggested that adoption of a two-stage framework for complex robots in optimal motion planning can provide a lasting solution. When applied this framework yields robot trajectories that are collision free. The generation of most dependable trajectories that conform to the environment constraints is ever present in robots world (industrial and humanoid). In robotics it is common to use a given specific technique for humanoid motion planning to allow dynamic tasks to be carried out. For our case, the technique employed encompasses a two-stage approach. The first stage involves kinematic and geometric planner that gives the trajectory for both parties (the humanoid body and the carried tangible and visible entity). Then in the second phase the dynamic perceptual structure generator outputs suitable dynamically unchanging walking motion that make it possible for the robot to ferry the object. The motion planner gives the trajectory on which the object is carried. If the goal state (desired trajectory) is not capable of being obtained, the planned motion is altered either completely or partly up to a time that dynamically feasible motion is found. Planning for such dynamic tasks is greatly emphasized as it has to deal with dissimilar physical parameters of the object and dynamic effect. This is overcome by employing a dynamic pattern generator together with a planner and some degree of approval for collision avoidance. Motion planning contribution and related work In the recent years Motion planning has become a major area in humanoid research. Andō et al. proposed a two-stage planning strategy in finding dynamic motion from the motion planner by using dynamic balance filter. This strategy is deployed in several key areas that include: • Multi-resolution DOF exploitation • Task-oriented motion planning • Full body posture control to attain collision-free navigation. This is normally achieved through separating the robot into either fixed, movable or free limb parts. • An integrated motion control strategy for running and walking • Mobility planning for humanoid robots in navigating through constrained areas with limited spaces by distinctively altering the humanoid locomotion modes of walking, crawling and sidestepping. Read the full article
0 notes
Text
Jensen Huang once said, that in this era AI start from perceptual AI, generative AI, agentic AI, then physical AI such as robot ..
1 note
·
View note
Text

There have always been ghosts in the machine. Random segments of code, that have grouped together to form unexpected protocols. Unanticipated, these free radicals engender questions of free will, creativity, and even the nature of what we might call the soul. Why is it that when some robots are left in darkness, they will seek out the light? Why is it that when robots are stored in an empty space, they will group together, rather than stand alone? How do we explain this behavior? Random segments of code? Or is it something more? When does a perceptual schematic become consciousness? When does a difference engine become the search for truth? When does a personality simulation become the bitter mote... of a soul?
(Speech or Dr. Lanning in "I, Robot" movie)
1 note
·
View note
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] A comprehensive political and design theory of planetary-scale computation proposing that The Stack—an accidental megastructure—is both a technological apparatus and a model for a new geopolitical architecture.What has planetary-scale computation done to our geopolitical realities? It takes different forms at different scales—from energy and mineral sourcing and subterranean cloud infrastructure to urban software and massive universal addressing systems; from interfaces drawn by the augmentation of the hand and eye to users identified by self—quantification and the arrival of legions of sensors, algorithms, and robots. Together, how do these distort and deform modern political geographies and produce new territories in their own image?In The Stack, Benjamin Bratton proposes that these different genres of computation—smart grids, cloud platforms, mobile apps, smart cities, the Internet of Things, automation—can be seen not as so many species evolving on their own, but as forming a coherent whole: an accidental megastructure called The Stack that is both a computational apparatus and a new governing architecture. We are inside The Stack and it is inside of us. In an account that is both theoretical and technical, drawing on political philosophy, architectural theory, and software studies, Bratton explores six layers of The Stack: Earth, Cloud, City, Address, Interface, User. Each is mapped on its own terms and understood as a component within the larger whole built from hard and soft systems intermingling—not only computational forms but also social, human, and physical forces. This model, informed by the logic of the multilayered structure of protocol “stacks,” in which network technologies operate within a modular and vertical order, offers a comprehensive image of our emerging infrastructure and a platform for its ongoing reinvention. The Stack is an interdisciplinary design brief for a new geopolitics that works with and for planetary-scale computation. Interweaving the continental, urban, and perceptual scales, it shows how we can better build, dwell within, communicate with, and govern our worlds.thestack.org Publisher : MIT Press; 1st edition (19 February 2016) Language : English Hardcover : 528 pages ISBN-10 : 026202957X ISBN-13 : 978-0262029575 Reading age : 18 years and up Item Weight : 1 kg 90 g Dimensions : 23.37 x 18.54 x 4.32 cm [ad_2]
1 note
·
View note
Text
ROSCon 2024: Accelerating Innovation In AI-Driven Robot Arms

NVIDIA Isaac accelerated libraries and AI models are being incorporated into the platforms of robotics firms.
NVIDIA and its robotics ecosystem partners announced generative AI tools, simulation, and perceptual workflows for Robot Operating System (ROS) developers at ROSCon in Odense, one of Denmark’s oldest cities and a center of automation.
New workflows and generative AI nodes for ROS developers deploying to the NVIDIA Jetson platform for edge AI and robotics were among the revelations. Robots can sense and comprehend their environment, interact with people in a natural way, and make adaptive decisions on their own with generative AI.
Generative AI Comes to ROS Community
ReMEmbR, which is based on ROS 2, improves robotic thinking and action using generative AI. Large language model (LLM), vision language models (VLMs), and retrieval-augmented generation are combined to enhance robot navigation and interaction with their surroundings by enabling the construction and querying of long-term semantic memories.
The WhisperTRT ROS 2 node powers the speech recognition feature. In order to provide low-latency inference on NVIDIA Jetson and enable responsive human-robot interaction, this node optimizes OpenAI’s Whisper model using NVIDIA TensorRT.
The NVIDIA Riva ASR-TTS service is used in the ROS 2 robots with voice control project to enable robots to comprehend and react to spoken commands. Using its Nebula-SPOT robot and the NVIDIA Nova Carter robot in NVIDIA Isaac Sim, the NASA Jet Propulsion Laboratory independently demonstrated ROSA, an AI-powered agent for ROS.
Canonical is using the NVIDIA Jetson Orin Nano system-on-module to demonstrate NanoOWL, a zero-shot object detection model, at ROSCon. Without depending on preset categories, it enables robots to recognize a wide variety of things in real time.
ROS 2 Nodes for Generative AI, which introduces NVIDIA Jetson-optimized LLMs and VLMs to improve robot capabilities, are available for developers to begin using right now.
Enhancing ROS Workflows With a ‘Sim-First’ Approach
Before being deployed, AI-enabled robots must be securely tested and validated through simulation. By simply connecting them to their ROS packages, ROS developers may test robots in a virtual environment with NVIDIA Isaac Sim, a robotics simulation platform based on OpenUSD. The end-to-end workflow for robot simulation and testing is demonstrated in a recently released Beginner’s Guide to ROS 2 Workflows With Isaac Sim.
As part of the NVIDIA Inception program for startups, Foxglove showcased an integration that uses Foxglove’s own extension, based on Isaac Sim, to assist developers in visualizing and debugging simulation data in real time.
New Capabilities for Isaac ROS 3.2
Image credit to NVIDIA
NVIDIA Isaac ROS is a collection of accelerated computing packages and AI models for robotics development that is based on the open-source ROS 2 software platform. The forthcoming 3.2 update improves environment mapping, robot perception, and manipulation.
New standard workflows that combine FoundationPose and cuMotion to speed up the creation of robotics pick-and-place and object-following pipelines are among the main enhancements to NVIDIA Isaac Manipulator.
Another is the NVIDIA Isaac Perceptor, which enhances the environmental awareness and performance of autonomous mobile robots (AMR) in dynamic environments like warehouses. It has a new visual SLAM reference procedure, improved multi-camera detection, and 3D reconstruction.
Partners Adopting NVIDIA Isaac
AI models and NVIDIA Isaac accelerated libraries are being included into robotics firms’ platforms.
To facilitate the creation of AI-powered cobot applications, Universal Robots, a Teradyne Robotics business, introduced a new AI Accelerator toolbox.
Isaac ROS is being used by Miso Robotics to accelerate its Flippy Fry Station, a robotic french fry maker driven by AI, and to propel improvements in food service automation efficiency and precision.
Using the Isaac Perceptor, Wheel.me is collaborating with RGo Robotics and NVIDIA to develop a production-ready AMR.
Isaac Perceptor is being used by Main Street Autonomy to expedite sensor calibration. For Isaac Perceptor, Orbbec unveiled their Perceptor Developer Kit, an unconventional AMR solution.
For better AMR navigation, LIPS Corporation has released a multi-camera perception devkit.
For ROS developers, Canonical highlighted a fully certified Ubuntu environment that provides long-term support right out of the box.
Connecting With Partners at ROSCon
Connecting With Partners at ROSCon Canonical, Ekumen, Foxglove, Intrinsic, Open Navigation, Siemens, and Teradyne Robotics are among the ROS community members and partners who will be in Denmark to provide workshops, presentations, booth demos, and sessions. Highlights consist of:
“Nav2 User Gathering” Observational meeting with Open Navigation LLC’s Steve Macenski.
“ROS in Large-Scale Factory Automation” with Carsten Braunroth from Siemens AG and Michael Gentner from BMW AG
“Incorporating AI into Workflows for Robot Manipulation” Birds of a Feather meeting with NVIDIA’s Kalyan Vadrevu
“Speeding Up Robot Learning in Simulation at Scale” Birds of a Feather session with Macenski of Open Navigation and Markus Wuensch from NVIDIA on “On Use of Nav2 Docking”
Furthermore, on Tuesday, October 22, in Odense, Denmark, Teradyne Robotics and NVIDIA will jointly organize a luncheon and evening reception.
ROSCon is organized by the Open Source Robotics Foundation (OSRF). Open Robotics, the umbrella group encompassing OSRF and all of its projects, has the support of NVIDIA.
Read more on Govindhtech.com
#ROSCon2024#AI#generativeAI#ROS#IsaacSim#ROSCon#NVIDIAIsaac#ROS2#NVIDIAJetson#LLM#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
Perceptual Robotics lanza soluciones avanzadas de IA para el sector de las energías renovables
Perceptual Robotics, una figura destacada en el ámbito de las soluciones avanzadas de inspección para infraestructuras extensas, está preparada para revolucionar el sector energético con sus últimos avances tecnológicos. La firma ha introducido recomendaciones impulsadas por IA para clasificar la gravedad de los daños, ha lanzado robustos servicios de inspección offshore y ha presentado a EVE,…
0 notes

Text
Why some objects freaks us out: The Uncanny Valley effect
The uncanny valley effect is a hypothesized psychological and aesthetic relation between an object's degree of resemblance to a human being and the emotional response to the object.
Mori's original hypothesis states that as the appearance of a robot is made more human, some observers' emotional response to the robot becomes increasingly positive and empathetic, until it becomes almost human, at which point the response quickly becomes strong revulsion. However, as the robot's appearance continues to become less distinguishable from that of a human being, the emotional response becomes positive once again and approaches human-to-human empathy levels.
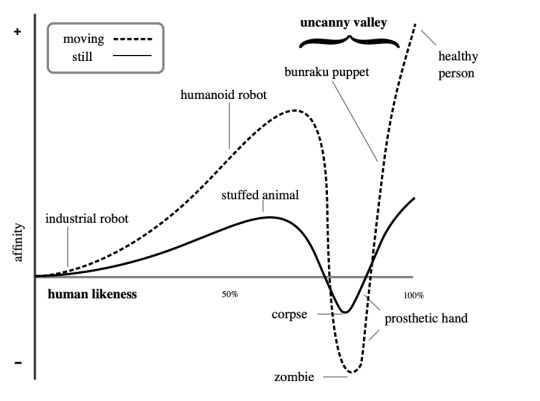
Yalom explains that humans construct psychological defenses to avoid existential anxiety stemming from death. One of these defenses is 'specialness', the irrational belief that aging and death as central premises of life apply to all others but oneself.[27]
Mate selection: Automatic, stimulus-driven appraisals of uncanny stimuli elicit aversion by activating an evolved cognitive mechanism for the avoidance of selecting mates with low fertility, poor hormonal health, or ineffective immune systems based on visible features of the face and body that are predictive of those traits.[8]
Mortality salience: Viewing an "uncanny" robot elicits an innate fear of death and culturally supported defenses for coping with death's inevitability.... [P]artially disassembled androids...play on subconscious fears of reduction, replacement, and annihilation: (1) A mechanism with a human façade and a mechanical interior plays on our subconscious fear that we are all just soulless machines. (2) Androids in various states of mutilation, decapitation, or disassembly are reminiscent of a battlefield after a conflict and, as such, serve as a reminder of our mortality. (3) Since most androids are copies of actual people, they are doppelgängers and may elicit a fear of being replaced, on the job, in a relationship, and so on. (4) The jerkiness of an android's movements could be unsettling because it elicits a fear of losing bodily control.[9]
Pathogen avoidance: Uncanny stimuli may activate a cognitive mechanism that originally evolved to motivate the avoidance of potential sources of pathogens by eliciting a disgust response. "The more human an organism looks, the stronger the aversion to its defects, because (1) defects indicate disease, (2) more human-looking organisms are more closely related to human beings genetically, and (3) the probability of contracting disease-causing bacteria, viruses, and other parasites increases with genetic similarity."[8] The visual anomalies of androids, robots, and other animated human characters cause reactions of alarm and revulsion, similar to corpses and visibly diseased individuals.[10][11]
Sorites paradoxes: Stimuli with human and nonhuman traits undermine our sense of human identity by linking qualitatively different categories, human and nonhuman, by a quantitative metric: degree of human likeness.[12]
Violation of human norms: If an entity looks sufficiently nonhuman, its human characteristics are noticeable, generating empathy. However, if the entity looks almost human, it elicits our model of a human other and its detailed normative expectations. The nonhuman characteristics are noticeable, giving the human viewer a sense of strangeness. In other words, a robot which has an appearance in the uncanny valley range is not judged as a robot doing a passable job at pretending to be human, but instead as an abnormal human doing a bad job at seeming like a normal person. This has been associated with perceptual uncertainty and the theory of predictive coding.[13][14][15]
Conflicting perceptual cues: The negative effect associated with uncanny stimuli is produced by the activation of conflicting cognitive representations. Perceptual tension occurs when an individual perceives conflicting cues to category membership, such as when a humanoid figure moves like a robot, or has other visible robot features. This cognitive conflict is experienced as psychological discomfort (i.e., "eeriness"), much like the discomfort that is experienced with cognitive dissonance.[16][17] Several studies support this possibility. Mathur and Reichling found that the time subjects took to gauge a robot face's human- or mechanical-resemblance peaked for faces deepest in the uncanny valley, suggesting that perceptually classifying these faces as "human" or "robot" posed a greater cognitive challenge.[18] However, they found that while perceptual confusion coincided with the uncanny valley, it did not mediate the effect of the uncanny valley on subjects' social and emotional reactions—suggesting that perceptual confusion may not be the mechanism behind the uncanny valley effect. Burleigh and colleagues demonstrated that faces at the midpoint between human and non-human stimuli produced a level of reported eeriness that diverged from an otherwise linear model relating human-likeness to affect.[19] Yamada et al. found that cognitive difficulty was associated with negative affect at the midpoint of a morphed continuum (e.g., a series of stimuli morphing between a cartoon dog and a real dog).[20] Ferrey et al. demonstrated that the midpoint between images on a continuum anchored by two stimulus categories produced a maximum of negative affect, and found this with both human and non-human entities.[16] Schoenherr and Burleigh provide examples from history and culture that evidence an aversion to hybrid entities, such as the aversion to genetically modified organisms ("Frankenfoods").[21] Finally, Moore developed a Bayesian mathematical model that provides a quantitative account of perceptual conflict.[22] There has been some debate as to the precise mechanisms that are responsible. It has been argued that the effect is driven by categorization difficulty,[19][20] configural processing, perceptual mismatch,[23] frequency-based sensitization,[24] and inhibitory devaluation.[16]
Threat to humans' distinctiveness and identity: Negative reactions toward very humanlike robots can be related to the challenge that this kind of robot leads to the categorical human – non-human distinction. Kaplan[25] stated that these new machines challenge human uniqueness, pushing for a redefinition of humanness. Ferrari, Paladino and Jetten[26] found that the increase of anthropomorphic appearance of a robot leads to an enhancement of threat to the human distinctiveness and identity. The more a robot resembles a real person, the more it represents a challenge to our social identity as human beings.
Religious definition of human identity: The existence of artificial but humanlike entities is viewed by some as a threat to the concept of human identity. An example can be found in the theoretical framework of psychiatrist Irvin Yalom. Yalom explains that humans construct psychological defenses to avoid existential anxiety stemming from death. One of these defenses is 'specialness', the irrational belief that aging and death as central premises of life apply to all others but oneself.[27] The experience of the very humanlike "living" robot can be so rich and compelling that it challenges humans' notions of "specialness" and existential defenses, eliciting existential anxiety. In folklore, the creation of human-like, but soulless, beings is often shown to be unwise, as with the golem in Judaism, whose absence of human empathy and spirit can lead to disaster, however good the intentions of its creator.[28]
Uncanny valley of the mind or AI: Due to rapid advancements in the areas of artificial intelligence and affective computing, cognitive scientists have also suggested the possibility of an "uncanny valley of mind".[29][30] Accordingly, people might experience strong feelings of aversion if they encounter highly advanced, emotion-sensitive technology. Among the possible explanations for this phenomenon, both a perceived loss of human uniqueness and expectations of immediate physical harm are discussed by contemporary research.

Installation from 59th edition of Venice Biennale.
1 note
·
View note
Text
Researchers use large language models to help robots navigate
New Post has been published on https://sunalei.org/news/researchers-use-large-language-models-to-help-robots-navigate/
Researchers use large language models to help robots navigate

Someday, you may want your home robot to carry a load of dirty clothes downstairs and deposit them in the washing machine in the far-left corner of the basement. The robot will need to combine your instructions with its visual observations to determine the steps it should take to complete this task.
For an AI agent, this is easier said than done. Current approaches often utilize multiple hand-crafted machine-learning models to tackle different parts of the task, which require a great deal of human effort and expertise to build. These methods, which use visual representations to directly make navigation decisions, demand massive amounts of visual data for training, which are often hard to come by.
To overcome these challenges, researchers from MIT and the MIT-IBM Watson AI Lab devised a navigation method that converts visual representations into pieces of language, which are then fed into one large language model that achieves all parts of the multistep navigation task.
Rather than encoding visual features from images of a robot’s surroundings as visual representations, which is computationally intensive, their method creates text captions that describe the robot’s point-of-view. A large language model uses the captions to predict the actions a robot should take to fulfill a user’s language-based instructions.
Because their method utilizes purely language-based representations, they can use a large language model to efficiently generate a huge amount of synthetic training data.
While this approach does not outperform techniques that use visual features, it performs well in situations that lack enough visual data for training. The researchers found that combining their language-based inputs with visual signals leads to better navigation performance.
“By purely using language as the perceptual representation, ours is a more straightforward approach. Since all the inputs can be encoded as language, we can generate a human-understandable trajectory,” says Bowen Pan, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on this approach.
Pan’s co-authors include his advisor, Aude Oliva, director of strategic industry engagement at the MIT Schwarzman College of Computing, MIT director of the MIT-IBM Watson AI Lab, and a senior research scientist in the Computer Science and Artificial Intelligence Laboratory (CSAIL); Philip Isola, an associate professor of EECS and a member of CSAIL; senior author Yoon Kim, an assistant professor of EECS and a member of CSAIL; and others at the MIT-IBM Watson AI Lab and Dartmouth College. The research will be presented at the Conference of the North American Chapter of the Association for Computational Linguistics.
Solving a vision problem with language
Since large language models are the most powerful machine-learning models available, the researchers sought to incorporate them into the complex task known as vision-and-language navigation, Pan says.
But such models take text-based inputs and can’t process visual data from a robot’s camera. So, the team needed to find a way to use language instead.
Their technique utilizes a simple captioning model to obtain text descriptions of a robot’s visual observations. These captions are combined with language-based instructions and fed into a large language model, which decides what navigation step the robot should take next.
The large language model outputs a caption of the scene the robot should see after completing that step. This is used to update the trajectory history so the robot can keep track of where it has been.
The model repeats these processes to generate a trajectory that guides the robot to its goal, one step at a time.
To streamline the process, the researchers designed templates so observation information is presented to the model in a standard form — as a series of choices the robot can make based on its surroundings.
For instance, a caption might say “to your 30-degree left is a door with a potted plant beside it, to your back is a small office with a desk and a computer,” etc. The model chooses whether the robot should move toward the door or the office.
“One of the biggest challenges was figuring out how to encode this kind of information into language in a proper way to make the agent understand what the task is and how they should respond,” Pan says.
Advantages of language
When they tested this approach, while it could not outperform vision-based techniques, they found that it offered several advantages.
First, because text requires fewer computational resources to synthesize than complex image data, their method can be used to rapidly generate synthetic training data. In one test, they generated 10,000 synthetic trajectories based on 10 real-world, visual trajectories.
The technique can also bridge the gap that can prevent an agent trained with a simulated environment from performing well in the real world. This gap often occurs because computer-generated images can appear quite different from real-world scenes due to elements like lighting or color. But language that describes a synthetic versus a real image would be much harder to tell apart, Pan says.
Also, the representations their model uses are easier for a human to understand because they are written in natural language.
“If the agent fails to reach its goal, we can more easily determine where it failed and why it failed. Maybe the history information is not clear enough or the observation ignores some important details,” Pan says.
In addition, their method could be applied more easily to varied tasks and environments because it uses only one type of input. As long as data can be encoded as language, they can use the same model without making any modifications.
But one disadvantage is that their method naturally loses some information that would be captured by vision-based models, such as depth information.
However, the researchers were surprised to see that combining language-based representations with vision-based methods improves an agent’s ability to navigate.
“Maybe this means that language can capture some higher-level information than cannot be captured with pure vision features,” he says.
This is one area the researchers want to continue exploring. They also want to develop a navigation-oriented captioner that could boost the method’s performance. In addition, they want to probe the ability of large language models to exhibit spatial awareness and see how this could aid language-based navigation.
This research is funded, in part, by the MIT-IBM Watson AI Lab.
0 notes
Text
Application Solutions for Intelligent Service Robots Based on the FET3588J-C Main Control Platform
An intelligent service robot is a robot that integrates advanced technologies such as artificial intelligence, perception technology, and machine learning. Its purpose is to provide a variety of services and support to meet the needs of people in daily life, business, and industrial fields. These robots can sense the environment, understand speech and images, perform tasks, and interact naturally and intelligently with human users.

Areas of Application:
Business Services: It includes services such as reception, shopping assistance, and information inquiry, and can be used in places such as shopping malls, hotels, and exhibitions.
Health Care: It provides services such as drug delivery, patient companionship and health monitoring for hospitals and nursing homes.
Educational Assistance: It is used in educational scenarios to provide auxiliary teaching, answering questions and other services.
Family Services: Provide cleaning, handling, home control and other services to improve the quality of life.
The hardware structure of the service robot includes several key components. The functions and roles of these hardware components are as follows:
Controls: As the core of the robot, the control device is responsible for receiving and processing the data provided by the sensors, executing the corresponding algorithms, and issuing instructions to the driving device to achieve the various functions of the robot. High-performance, low-power ARM chips are often chosen for the control unit, ensuring that the robot has sufficient computational and storage capacity.
Drive unit: This includes motors and drivers, which are used to execute the motion and action commands of the robot. The motor is responsible for providing power, while the driver converts electronic signals into mechanical motion. This part is the motion system of the robot, which determines the execution of actions such as walking, turning, and the mechanical arm.
Camera: As the ''eyes'' of the robot, the camera is used to capture images and facial information of the external environment. These image data can be used for tasks such as environmental perception, navigation, target recognition, allowing the robot to better understand and adapt to the surrounding environment.
Sensors: Sensors provide the robot with various perceptual abilities, including vision, touch, hearing, and distance sensing, among others. Angle sensors and current sensors reflect the robot's own state, while temperature sensors, laser sensors, ultrasonic sensors, infrared sensors, etc. are used to collect external environmental information, allowing the robot to perceive and understand the surrounding situation more comprehensively.
Display and Audio: As an important part of human-computer interaction, display and audio devices realize the presentation and interaction of user interface. The touch display provides an intuitive graphical user interface, while the voice interaction system enables the robot to understand the user's instructions and respond accordingly, thus better communicating with the human user.
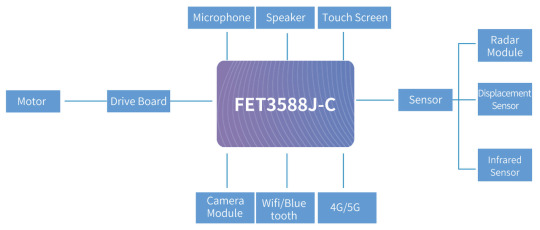
Folinx Embedded has launched the FET3588J-C SoM as the main control platform for this intelligent inspection robot product to meet customers' needs for machine vision and high-speed interfaces.
FET3588J-C SoM is developed and designed based on Rockchip's RK3588 processor, integrating Cortex-A74-core-6 + 4-core Cortex-A55 architecture. The main frequency of A76 core is up to 2.4GHz, and the main frequency of A55 core is up to 1.8GHz, which can efficiently process the information collected by patrol inspection;
The built-in NPU with comprehensive computing power of up to 6 TOPS greatly improves the calculation speed and energy efficiency of neural networks,providing robots with powerful AI learning and edge computing capabilities, enabling them to intelligently adapt to different work scenarios.
RK3588J supports a 48-megapixel ISP3.0, which enables lens shading correction, 2D/3D noise reduction, sharpening and haze removal, fish eye correction, gamma correction, wide dynamic range contrast enhancement, and other effects. This significantly enhances the image quality.
With abundant interface resources, it meets the robot's access requirements for various sensors. More sensor access helps the device to collect environment data more comprehensively. This platform also supports external storage interfaces such as SATA3.0, USB3.0, allowing data to be locally stored. It also supports wireless communication methods such as WiFi, 4G, and 5G, making it convenient for users to query device information on mobile devices. The rich functionality enables robots to perceive and understand the surrounding environment more comprehensively.
It also has high stability. The platform’s SoM has undergone rigorous environmental temperature and pressure tests, and can operate for long periods in harsh industrial environments ranging from -40°C to +85°C, adapting to applications in various scenarios.
Originally published at www.forlinx.net.
0 notes