#proc sql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
Mastering Data Wrangling in SAS: Best Practices and Techniques
Data wrangling, also known as data cleaning or data preparation, is a crucial part of the data analysis process. It involves transforming raw data into a format that's structured and ready for analysis. While building models and drawing insights are important tasks, the quality of the analysis often depends on how well the data has been prepared beforehand.
For anyone working with SAS, having a good grasp of the tools available for data wrangling is essential. Whether you're working with missing values, changing variable formats, or restructuring datasets, SAS offers a variety of techniques that can make data wrangling more efficient and error-free. In this article, we’ll cover the key practices and techniques for mastering data wrangling in SAS.
1. What Is Data Wrangling in SAS?
Before we dive into the techniques, it’s important to understand the role of data wrangling. Essentially, data wrangling is the process of cleaning, restructuring, and enriching raw data to prepare it for analysis. Datasets are often messy, incomplete, or inconsistent, so the task of wrangling them into a clean, usable format is essential for accurate analysis.
In SAS, you’ll use several tools for data wrangling. DATA steps, PROC SQL, and various procedures like PROC SORT and PROC TRANSPOSE are some of the most important tools for cleaning and structuring data effectively.
2. Key SAS Procedures for Data Wrangling
SAS offers several powerful tools to manipulate and clean data. Here are some of the most commonly used procedures:
- PROC SORT: Sorting is usually one of the first steps in data wrangling. This procedure organizes your dataset based on one or more variables. Sorting is especially useful when preparing to merge datasets or remove duplicates.
- PROC TRANSPOSE: This procedure reshapes your data by converting rows into columns or vice versa. It's particularly helpful when you have data in a "wide" format that you need to convert into a "long" format or vice versa.
- PROC SQL: PROC SQL enables you to write SQL queries directly within SAS, making it easier to filter, join, and aggregate data. It’s a great tool for working with large datasets and performing complex data wrangling tasks.
- DATA Step: The DATA step is the heart of SAS programming. It’s a versatile tool that allows you to perform a wide range of data wrangling operations, such as creating new variables, filtering data, merging datasets, and applying advanced transformations.
3. Handling Missing Data
Dealing with missing data is one of the most important aspects of data wrangling. Missing values can skew your analysis or lead to inaccurate results, so it’s crucial to address them before proceeding with deeper analysis.
There are several ways to manage missing data:
- Identifying Missing Values: In SAS, missing values can be detected using functions such as NMISS() for numeric data and CMISS() for character data. Identifying missing data early helps you decide how to handle it appropriately.
- Replacing Missing Values: In some cases, missing values can be replaced with estimates, such as the mean or median. This approach helps preserve the size of the dataset, but it should be used cautiously to avoid introducing bias.
- Deleting Missing Data: If missing data is not significant or only affects a small portion of the dataset, you might choose to remove rows containing missing values. This method is simple, but it can lead to data loss if not handled carefully.
4. Transforming Data for Better Analysis
Data transformation is another essential part of the wrangling process. It involves converting or modifying variables so they are better suited for analysis. Here are some common transformation techniques:
- Recoding Variables: Sometimes, you might want to recode variables into more meaningful categories. For instance, you could group continuous data into categories like low, medium, or high, depending on the values.
- Standardization or Normalization: When preparing data for machine learning or certain statistical analyses, it might be necessary to standardize or normalize variables. Standardizing ensures that all variables are on a similar scale, preventing those with larger ranges from disproportionately affecting the analysis.
- Handling Outliers: Outliers are extreme values that can skew analysis results. Identifying and addressing outliers is crucial. Depending on the nature of the outliers, you might choose to remove or transform them to reduce their impact.
5. Automating Tasks with SAS Macros
When working with large datasets or repetitive tasks, SAS macros can help automate the wrangling process. By using macros, you can write reusable code that performs the same transformations or checks on multiple datasets. Macros save time, reduce errors, and improve the consistency of your data wrangling.
For example, if you need to apply the same set of cleaning steps to multiple datasets, you can create a macro to perform those actions automatically, ensuring efficiency and uniformity across your work.
6. Working Efficiently with Large Datasets
As the size of datasets increases, the process of wrangling data can become slower and more resource-intensive. SAS provides several techniques to handle large datasets more efficiently:
- Indexing: One way to speed up data manipulation in large datasets is by creating indexes on frequently used variables. Indexes allow SAS to quickly locate and access specific records, which improves performance when working with large datasets.
- Optimizing Data Steps: Minimizing the number of iterations in your DATA steps is also crucial for efficiency. For example, combining multiple operations into a single DATA step reduces unnecessary reads and writes to disk.
7. Best Practices and Pitfalls to Avoid
When wrangling data, it’s easy to make mistakes that can derail the process. Here are some best practices and common pitfalls to watch out for:
- Check Data Types: Make sure your variables are the correct data type (numeric or character) before performing transformations. Inconsistent data types can lead to errors or inaccurate results.
- Be Cautious with Deleting Data: When removing missing values or outliers, always double-check that the data you're removing won’t significantly affect your analysis. It's important to understand the context of the missing data before deciding to delete it.
- Regularly Review Intermediate Results: Debugging is a key part of the wrangling process. As you apply transformations or filter data, regularly review your results to make sure everything is working as expected. This step can help catch errors early on and save time in the long run.
Conclusion
Mastering data wrangling in SAS is an essential skill for any data analyst or scientist. By taking advantage of SAS’s powerful tools like PROC SORT, PROC TRANSPOSE, PROC SQL, and the DATA step, you can clean, transform, and reshape your data to ensure it's ready for analysis.
Following best practices for managing missing data, transforming variables, and optimizing for large datasets will make the wrangling process more efficient and lead to more accurate results. For those who are new to SAS or want to improve their data wrangling skills, enrolling in a SAS programming tutorial or taking a SAS programming full course can help you gain the knowledge and confidence to excel in this area. With the right approach, SAS can help you prepare high-quality, well-structured data for any analysis.
#sas programming tutorial#sas programming#sas online training#data wrangling#proc sql#proc transpose#proc sort
0 notes
Text
Master the Future of Analytics at the Top Advanced SAS Training Centre in Pune
In today’s data-driven world, tools like SAS (Statistical Analysis System) play a crucial role in helping professionals turn raw data into actionable insights. From finance and healthcare to retail and manufacturing, SAS is the backbone of smart decision-making. However, the tool alone isn’t enough—mastery is key. That’s where an advanced SAS training centre in Pune can set you apart.
SAS remains a gold standard in the analytics industry due to its robustness, flexibility, and deep statistical capabilities. Even with the rise of newer platforms, organizations continue to rely heavily on SAS for complex data analysis and predictive modeling. By honing your skills through expert guidance, you're not just learning software—you’re learning how to lead in the data age.
Pune: The Data Capital in the Making
It’s no surprise that Pune is fast becoming a hotspot for IT and analytics talent. With its thriving tech ecosystem, proximity to major corporate hubs, and a culture of education, the city is ideal for upskilling in specialized fields like SAS.
Choosing an advanced SAS training centre in Pune means you gain access to world-class mentors, peer learning opportunities, and real-world projects. Unlike online-only courses, Pune’s top institutes offer a hybrid approach, combining theory with hands-on experience—preparing you for the rigors of professional analytics roles.
What Makes an SAS Training Centre Truly “Advanced”?
Not all training centers are created equal. An advanced SAS training centre in Pune focuses on more than just teaching syntax. It immerses students in real business scenarios and advanced concepts like machine learning, clinical trial analysis, and risk modeling.
Look for a curriculum that includes:
Predictive analytics using SAS Enterprise Miner
Data manipulation with advanced PROC SQL and macros
Integration with R and Python for hybrid analytics
Case studies from healthcare, banking, and retail sectors
By covering such expansive topics, these programs help you gain not just proficiency but mastery.
Career Outcomes That Speak for Themselves
Graduating from an advanced SAS training centre in Pune opens doors to a wide array of opportunities. From MNCs to government projects, trained SAS professionals are always in demand. Roles like Data Analyst, Statistical Programmer, and Business Intelligence Consultant await those with proven SAS expertise.
Even better, many Pune-based training centers have strong placement support. Thanks to tie-ups with top firms, students often receive job offers right after course completion. This seamless transition from training to employment is a game-changer in today’s competitive job market.
Making the Right Choice: What to Look For
So, how do you choose the right advanced SAS training centre in Pune? Start with the basics—check for certification programs recognized by SAS Institute. Then, look deeper:
Are the trainers industry experts or just academic professionals?
Is there a capstone project or internship module?
How many hours of practical sessions are included?
What do alumni say about job support and learning experience?
Visit the centres if possible, ask questions, and attend demo sessions. Making an informed decision here will directly influence your career trajectory in the data science world.
Final Thoughts: Your SAS Journey Starts Here
Enrolling in an advanced SAS training centre in Pune could be the smartest move of your career. It’s more than just a course—it’s an investment in a future where data is the new oil and analytics is the engine that powers progress.
0 notes
Text
"ANSIEDAD EN ADOLESCENTES ASOCIADA A UN ENTORNO DE FAMILIARES CON TRASTORNOS DE PERSONALIDAD"
CONFIGURACIÓN DEL PROGRAMA:
PROC SQL; CREATE TABLE WORK.query AS SELECT ETHRACE2A , ETOTLCA2 , IDNUM , PSU , STRATUM , WEIGHT , CDAY , CMON , CYEAR , REGION , CENDIV , CCS , FIPSTATE , BUILDTYP , NUMPERS , NUMPER18 , NUMREL , NUMREL18 , CHLD0 , CHLD1_4 , CHLD5_12 , CHLD13_15 , CHLD16_17 , CHLD0_17 , SPOUSE , FATHERIH , MOTHERIH , ADULTCH , OTHREL , NONREL FROM WORK.'NEW'n WHERE ETHRACE2A="5" AND REGION=4 AND CYEAR=2002; RUN; QUIT;
PROC DATASETS NOLIST NODETAILS; CONTENTS DATA=WORK.query OUT=WORK.details; RUN;
PROC PRINT DATA=WORK.details; RUN;
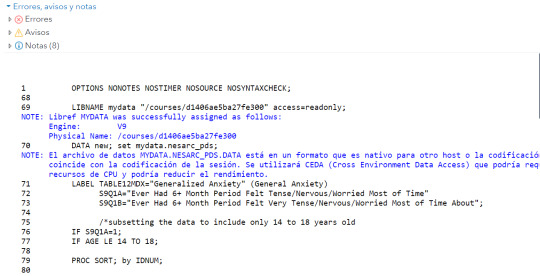
1 OPTIONS NONOTES NOSTIMER NOSOURCE NOSYNTAXCHECK;
68
69 LIBNAME mydata "/courses/d1406ae5ba27fe300" access=readonly;
NOTE: Libref MYDATA was successfully assigned as follows:
Engine: V9
Physical Name: /courses/d1406ae5ba27fe300
70 DATA new; set mydata.nesarc_pds;
NOTE: El archivo de datos MYDATA.NESARC_PDS.DATA está en un formato que es nativo para otro host o la codificación del archivo no
coincide con la codificación de la sesión. Se utilizará CEDA (Cross Environment Data Access) que podría requerir más
recursos de CPU y podría reducir el rendimiento.
71 LABEL TABLE12MDX="Generalized Anxiety" (General Anxiety)
72 S9Q1A="Ever Had 6+ Month Period Felt Tense/Nervous/Worried Most of Time"
73 S9Q1B="Ever Had 6+ Month Period Felt Very Tense/Nervous/Worried Most of Time About";
74
75 /*subsetting the data to include only 14 to 18 years old
76 IF S9Q1A=1;
77 IF AGE LE 14 TO 18;
78
79 PROC SORT; by IDNUM;
80
81 PROC FREQ; TABLES S9Q1A S9Q1B AGE;
82
83 RUN;
84
85
86 OPTIONS NONOTES NOSTIMER NOSOURCE NOSYNTAXCHECK;
87 ODS HTML CLOSE;
88 &GRAPHTERM; ;*';*";*/;RUN;
NOTE: Variable TABLE12MDX is uninitialized.
NOTE: There were 43093 observations read from the data set MYDATA.NESARC_PDS.
NOTE: The data set WORK.NEW has 43093 observations and 3008 variables.
NOTE: DATA statement ha utilizado (Tiempo de proceso total):
real time 10.39 seconds
user cpu time 9.57 seconds
system cpu time 0.75 seconds
memory 5713.28k
OS Memory 27548.00k
Timestamp 06/01/2025 05:18:08 a.m.
Step Count 48 Switch Count 21
Page Faults 0
Page Reclaims 1225
Page Swaps 0
Voluntary Context Switches 67
Involuntary Context Switches 48
Block Input Operations 0
Block Output Operations 2207248
88 ! QUIT;
89 QUIT;RUN;
90 ODS HTML5 (ID=WEB) CLOSE;
91
92 FILENAME _GSFNAME;
NOTE: Fileref _GSFNAME has been deassigned.
93 DATA _NULL_;
94 RUN;
NOTE: DATA statement ha utilizado (Tiempo de proceso total):
real time 0.00 seconds
user cpu time 0.00 seconds
system cpu time 0.00 seconds
memory 460.87k
OS Memory 20904.00k
Timestamp 06/01/2025 05:18:08 a.m.
Step Count 49 Switch Count 0
Page Faults 0
Page Reclaims 21
Page Swaps 0
Voluntary Context Switches 0
Involuntary Context Switches 0
Block Input Operations 0
Block Output Operations 0
95 OPTIONS NOTES STIMER SOURCE SYNTAXCHECK;
0 notes
Text
"Advanced SAS Techniques: Unlocking the Power of Data Analytics"
Unlocking the power of data analytics with advanced SAS techniques can significantly enhance your analytical capabilities. Here’s how to harness these techniques effectively:
Complex Data Manipulation: Use SAS procedures like PROC SQL and DATA STEP to perform intricate data transformations, merges, and aggregations, allowing you to handle large and complex datasets efficiently.
Advanced Statistical Analysis: Leverage SAS’s robust statistical procedures such as PROC REG for regression analysis, PROC ANOVA for analysis of variance, and PROC LOGISTIC for logistic regression to uncover deep insights and patterns in your data.
Predictive Modelling: Implement predictive modelling techniques using PROC HPFOREST or PROC HPLOGISTIC to develop and validate models that can forecast future trends and behaviours based on historical data.
Custom Reporting: Create customized and dynamic reports with PROC REPORT and PROC TABULATE to present data in meaningful ways that facilitate decision-making.
Automation and Efficiency: Utilize SAS macros to automate repetitive tasks and enhance the efficiency of your data processing and analysis workflows.
Mastering these advanced techniques enables you to unlock the full potential of SAS for sophisticated data analytics and drive impactful business decisions.SAS Online Training Institute, Power BI, Python Pune, India (saspowerbisasonlinetraininginstitute.in)
#sas training institute#sas course online#top sas training institute india#top sas training institute pune
0 notes
Text
Breathing New Life into Legacy Apps: An App Modernization Success Story in Hospitality Management
The hospitality industry thrives on seamless experiences. Behind the scenes, however, complex application landscapes can hinder agility and innovation. This article explores how a hospitality management company overcame these challenges through a strategic application modernization service offered by Celebal Technologies by leveraging Microsoft Azure.
The Challenge: A Disjointed Application Landscape
The client, a leading hospitality management company, faced a tangled web of applications. Heterogeneous interfaces, reliance on disparate services (SSIS packages and SQL Procs), and point-to-point connections created a rigid and cumbersome system. Tight coupling between processes limits scalability and reusability. Additionally, the lack of support for custom triggers and reliance on manual execution hampered automation. This disjointed landscape hindered the company's ability to adapt to changing customer demands and integrate with new technologies.
The Solution: Modernization with Azure App Modernization Services
The company partnered with Celebal Technologies, a leading provider of AMS. Celebal leveraged app modernization Azure services to breathe new life into legacy applications. Here's how:
Reusable APIs and Unified Interface: Celebal transformed the point-to-point connections and disparate services into a set of well-defined, reusable APIs. This not only simplified integration but also ensured consistency and maintainability. Additionally, a hierarchical arrangement and unified interface provided a user-friendly experience for developers.
Enhanced Developer Experience: Celebal prioritized developer experience with comprehensive documentation for the newly created APIs. This documentation served as a valuable resource, streamlining development and reducing onboarding time for new developers. Easy monitoring tools were also implemented, allowing developers to track API performance and identify issues proactively.
Decoupled and Modular Architecture: Tight coupling between processes was a major bottleneck. Celebal implemented a decoupled and modular architecture, isolating functions and improving scalability. This modular approach allowed for independent development, testing, and deployment of individual components.
Full API Lifecycle Management: Celebal's solution provided complete lifecycle management for the APIs. This included version control, deployment automation, and security management. This holistic approach ensured the APIs remained secure, reliable, and up-to-date.
Cloud-Native Benefits: By leveraging Azure, the modernized application benefited from elastic scalability, managed upgrades, and high availability. This ensured the solution could efficiently handle fluctuating workloads and minimize downtime.
Centralized Management and Orchestration: Azure's centralized management capabilities provided a unified platform for managing, orchestrating, scheduling, and monitoring the entire application ecosystem. This streamlined operations and improved visibility into the overall health of the system.
The Outcome: A Streamlined and Scalable Application Landscape
The app modernization strategy delivered significant benefits for the hospitality management company. The new, unified interface and reusable APIs simplified integration efforts and accelerated development cycles. The decoupled architecture improved scalability and facilitated independent deployments. Additionally, the cloud-native approach ensured high availability and cost-effective operation.
Beyond the Success Story: The Power of App Modernization Strategies
The success story of this hospitality company highlights the transformative power of app modernization Azure services. By embracing AMS and Azure, organizations can:
Enhance agility and innovation: Modernized applications are easier to adapt to changing business needs and integrate with new technologies.
Reduce maintenance costs: Legacy applications often require significant resources to maintain. Modernization can streamline maintenance and reduce costs.
Improve security and compliance: Cloud-based platforms like Azure offer robust security features and compliance certifications.
Unlock new opportunities: Modernized applications empower businesses to explore new revenue streams and enhance customer experiences.
Conclusion
Application modernization is no longer a choice, but a necessity in today's dynamic business landscape. By partnering with an experienced App Modernization Service provider and leveraging the power of Azure, organizations can breathe new life into their legacy applications, unlocking a future of agility, scalability, and innovation. If you want to embark on a digital transformation journey, then contact the industry experts of Celebal Technologies at [email protected]
0 notes
Text
How to Easily Sync Stored Proc Changes Across SQL Server AG Replicas
Introduction Have you ever made changes to stored procedures on your primary SQL Server Availability Group (AG) replica, only to realize those changes didn’t automatically propagate to the secondary replicas? It’s a common issue that can lead to inconsistencies and confusion. In this article, I’ll share the best way I’ve found to easily synchronize stored proc changes across all your AG…
View On WordPress
0 notes
Photo

To: Sabrina Christiansen- @sabrina-christiansen
proc sql;
Insert into sabrina.birthday (
Select h.appropriate_birthday_greetings,
a.awesome_gifts
from hallmarky.shit as h,
student_masters.ace as a);
quit;



5 notes
·
View notes
Text
Stored Procedures with SQL
Welcome to presume technologies, I am venker. This is part 18 of sequel server in this session, we'll understand what a stored procedure is. A simple stored procedure example creating a stored procedure with parameters altering a stored procedure, viewing the text of a stored procedure and finally, we will see how to drop a stored procedure. A stored procedure is a group of transaxial statements. If you ever have a situation where you have to write the same query over and over again, you can save that specific query as a stored procedure and call it just by its name. Let'S understand what we mean by this with an example. Now I have this table called TBL employee, which has got you know the ID name, gender and department ID columns.
Let'S say I want name and gender of an employee, so we type in select name agenda from TBL employee. So, every time I want the name and gender of an employee, you know I have to write this query. Okay, instead of that, what we can actually do is wrap this query inside a stored procedure and call that stored procedure rather than you having to write. This query again and again: so how do we create a stored procedure to create a stored procedure? We use, create procedure, command so create procedure, and then you have to give this procedure an name. Okay, so SP, let us say, get employees okay, since this procedure is getting us, you know the employee name and gender, I'm giving it get employees and look at this in the name. I have this letters. Sp. A common naming convention for store procedures is that we usually prefix that, with small letter S and small letter, P, okay, indicating that you know just by looking at this name, you can tell okay.
This is a stored procedure. Alright so create procedure procedure name and then you will use as begin and and okay. So the definition of your stored procedure goes between this begin and end okay. So this is the body of your stored procedure. Okay. Now, when I execute this command, what's going to happen is a stored procedure with this name gets created in this database, which is nothing but sample that we have selected here. Okay. Now, if you want to look at the stored procedure that you have just created, you know you want to make sure whether if this procedure is actually created or not, okay go into that database which is sample, and then you have this folder called program ability expand That and you should see a folder called stored procedures.
If you expand that you know we don't have it currently listed there, just refresh that, and you should see that stored procedure which we have just created, which is sp, get employees okay, so anytime, you want the name and gender of an employee. Instead of writing. This query again, what you can actually do is execute the stored procedure. Okay, so if you want to execute, you just need the name of the procedure. So what happens when I execute the stored procedure? Okay, to execute the stored procedure, you just highlight that and click execute and you get the name and gender. You don't have to write that query any more. Now you might be wondering it's a very simple query. Why don't I write that rather than having to create this procedure and then invoke it now, this procedure may be simple in reality, the procedures will be long.
You know there are very no stored procedures with over three thousands of lines, for example, okay, and not only that there are several other benefits of using stored procedures from security to network, reducing network traffic, etc. We will be talking about the advantages of stored procedures in a very great detail in a later session. Ok, so we use create procedure or create proc statement to create sp, I mean you can either say create procedure or you can just say, create proc for shortcut. Ok to create a stored procedure, we will talk about the naming convention of the stored procedures in just a bit okay and to execute the stored procedure. We have seen how to execute that stored procedure.
You know you just copy that the name of the stored procedure and you click this execute button and what happens the sequence statement within that short procedure gets executed and it returns the name and gender columns all right. So that's one way to execute it or you can use the exact keyword and then click this or you can use a full, execute keyword and then again, plus f5, or you can also graphically execute the stored procedure. Just right-click on the stored procedure and select execute stored procedure and the moment you do that it shows this vendor. This procedure doesn't have any parameters. Otherwise you will have to supply the values for the parameters. In just a bit. We will see how to create a stored procedure that takes parameters now, when I click OK, it executes that stored procedure.
Look at that alright, so those are the different ways to execute stored procedure. Now let us look at a simple example of how to create a stored procedure with parameters. Okay, so let's go back to that table TBL employees all right now. What I want to do is I: I want to create a stored procedure which takes two parameters. Maybe gender and the department ID okay, for example, if I pass gender as male and Department IDs one tier stored procedure, it should give me employees only within that gender and within that department. Okay, so your store procedure needs to have these parameters. Okay. So, let's see how to do that so as usual to create a stored procedure, we use create procedure command so create procedure and give your procedure a meaningful name, so SP get employees by gender and department okay. So I want the employees by gender and Department. Now look at this now this procedure.
Okay, the user who invokes your stored procedure, is going to pass the stored procedure, the gender and the department ID so for them to be able to pass the values for gender and department ID. They should be parameters just like how functions have parameters in c-sharp or any other programming. Language stood procedures can also have parameters. Okay, so one is the gender parameter and if you look at gender, it's text here, so the data type is going to be n, where care of maybe 20 and department ID Department ID is going to be integers or Department ID integer as begin, and so the Definition of your stored procedure goes in between these lines.
Okay, so what do we want from the table? We want the name, and maybe just the gender and also the department ID from which table we wanted from TBL employee table, but we don't want all names genders and department IDs. We want to filter them with what the user is going to pass in is going to pass in the gender and department ID. So we are going to say, the gender column here should be equal to whatever the user is passing in at gender and along the same lines and department ID let's bring this to. Another line is equal to whatever the user is going to pass in okay. So these parameters are like placeholders when users execute your stored procedure, they're going to pass in values for this gender and department ID which will be replaced at execution time. Okay. So let's create the store procedure so to create that select the entire stored procedure. Click execute button command completed successfully. Now, if you refresh the stored procedures folder, you should see SP get employees, Genda and department, okay, now to execute the stored procedure. I just need the name of the stored procedure and look at this. This stored procedure now is expecting gender and department ID parameters. Now look at this. If I don't pass the parameters and if I did try to execute that stored procedure, see highlight that and then plus execute. What'S going to happen, this procedure or function, SP get employees by gender and department, expects parameter, add gender which was not supplied, and that makes sense it's expecting a gender parameter which is not supplied. So we need to pass in the gender parameter since gender is of type and we're care I have to use single quotes, so I want the male employees within you know: department ID 1, so department ID is 1. So these are the two parameters that this stored procedure expects and we need to pass them. So when I press f5 now look at that, I only get male employees within that. You know department ID 1, okay. On the other hand, if I want all the male employees and department ID do a 2, I can do so all right now, when you have parameters like this, you know what you're doing is you're just passing in the parameters. So so so this male value will be taken into at gender parameter where, as this number 1 is passed into department, ID parameter. Okay, now what happens? If I put it the other way on, I am passing one first, okay, so what's going to happen, it will take this one into gender and one is an integer, but gender is of type and where cab and this one will be converted into n we're care. Implicitly, no problem, but it comes to the second parameter male. It tries to take this into Department ID parameter and if you look at the data type of department ID parameter, it is integer okay, so it tries to convert this string into integer and it fails - and it throws an exception - look at this. If I try to execute this now, I get an exception saying that error converting data type where care to integer, so it is trying to convert this mail. You know string of type and where care into integer and we get that error. Okay. So when you have multiple parameters that the stored procedure is expecting and if you're passing just values the values order, you know the order in which you pass them is important. Okay, the first parameter will be used. I mean the value here. The first argument will be used with the first parameter and the second argument will be used with the second parameter. Okay, that's why the order is important, but if you use the parameter names like this, let's say I want to pass one two at Department ID. I can specify the name of the parameter like so and similarly I can specify the name of the parameter for gender.
So when I execute this now, I will have no issues because you are specifying the name of the parameter. Okay, so sequence of a knows. Okay, this one is meant, you know to be the value for Department, ID parameter and mail is the value for gender parameter. It'S only when you don't specify the names of the parameter. The order of the the order in which you pass the parameter is parameters is important. Alright and okay. So we have seen how to create a simple stored procedure and how to create a procedure with parameters as well, and we have seen how to execute them as well. Okay, now, once you have the stored procedures, let's say I have created two procedures until now. Sp get employees and, as we get employees by gender and Department.
Now, if I want to view the text of these two procedures, what are the different ways that are available? One way is to simply right: click on that stored procedure, script, stored procedure as create two new query - editor window - this you know, generates the contents of that stored procedure. Look at this. This is the stored procedure. Definition that we have created create procedure procedure named. As begin and and then our query, this is one way to look at the definition of a stored procedure and the other way is to use a system stored procedure. You know these stored procedures that we have created here are user-defined stored procedures.
These are not system, stored procedures, now, sequel server, you know, has some system stored procedures defined okay and we use it for certain tasks. For example, I want to find the text of a stored procedure. How do I do that? I can use a system stored procedure called SP underscore health text. Okay, so look at this. This is the name of the system store procedure. Sp underscore help text, okay, SP help text and then, if I pass in the name of the stored procedure, there SP get employees and then, when I select them together and execute this look at this, I get the text of my stored procedure. You can then copy that paste it here and see. How does the implementation of the stored procedure looks like okay, so to view the definition of a stored procedure, you can either right-click on that script. Stored procedure as create two new query, editor window or you can use the system stored procedure, SP underscore health text, followed by the name of the stored procedure, which gives you the text of the stored procedure. Okay, now in this slide, if you look at this, you know whenever we name user-defined stored procedure, microsoft recommends not to use SP underscore.
You know prefix for user-defined stored procedures, because the reason is system stored procedures has that prefix. Okay. Now, if you happen to use SP underscore prefix for your user-defined stored procedures, there are two problems number one. There will be an ambiguity between user-defined stored procedures and system defined stored procedures, just by looking at the name. We cannot tell you know. Is this a user define, stored procedure or system defines stored procedure? Okay and another problem is, with future releases of you, know new sequence of a version. There may be name conflicts, you know if you create, let's say SP underscore ket date. Just you know, stored procedure and in the future release there is a system stored procedure, which is you know similarly named SP underscore get date. You know it's going to conflict with the user stored procedure, okay. So, to avoid problems like this, it's always better not to prefix user-defined, stored procedures with SP underscore prefix, alright. So to change the stored procedure.
Now, once we have created a stored procedure, for example, I have the stored procedure, SP get employees after I have created the stored procedure. Let'S say I want to change its implementation in some way. How do I do that? Let'S say at the moment when I execute this SP get employee stored procedure. I am NOT getting the names sorted, you know I mean the names are basically not sorted. I want them to be sorted, so how do I do that? I will use the order by Clause so order by name okay, so I am changing the implementation of this tour procedure now, if I execute this create procedure once again, look at this, we get an error stating that there is already an object named SP get employees. Why we already have that and we are trying to create that again with the same name. So obviously we get that error. Our intention here is to change the definition of that stored procedure, not to create another stored procedure. So if you want to change the definition of the stored procedure, then you say alter procedure and I press f5.
The stored procedure gets changed now. If we execute that we should have the name sorted okay, so we use all the procedures statement to change the definition of a stored procedure and to delete the stored procedure. We use drop procedure procedure name just like you know. If you want to drop a table, you will use drop table, table name. Okay, so, similarly to drop a procedure, you will say: drop, drop procedure and procedure. Name, for example, I want to drop or delete SP get employees. You know I just pass it there. I press f5 and then, if i refresh the stored procedures, folder it's gone now it's deleted or what you can do: alternately right-click on that and select delete okay. Now it's also possible to encrypt the text of the stored procedure and it's very simple to do. For example, I have the stored procedure now as we get employees by gender and Department look at this now.
This is not encrypted at the moment. So when I use SP underscore health text and when I press f5, I am able to get the text of that stored procedure. So that's how the stored procedure is implemented. Now, if I want to encrypt the contents, the text of the stored procedure, I can do that. How do I do that? All you have to do is to use this switch, this option with encryption, okay, and we want to alter that. So I will say alter now when I press f5 look at this command completed successfully and now the moment i refresh this folder look at this. We get a little lock symbol there indicating that this stored procedure is now encrypted.
Okay, now, if somebody tries to you, know, get the text of the encrypted stored procedure, we get a message saying that the text for the object is encrypted and - and we cannot retrieve the text of that - ok and you get the same kind of message when you Kind of use script stored procedure as create two new query: editor window. Okay, we get this error box, you know. If you look at here. It says that text is encrypted, so once a stored procedure is encrypted. You cannot view the text of that stored procedure, but, however, if you want to delete the stored procedure, you can go ahead and delete it and I'll just right click and select delete it gets deleted, but you cannot view the contents of his stored procedure that is Encrypted all right in the next session, we will see how to create an invocation procedure with output parameters. In this session, we have seen how to create a stored procedure with input parameters in the next session. We'Ll talk about creating stored procedures with output parameters. On this slide, you can find resources for asp.net in c-sharp interview questions. That'S it for today. Thank you for listening. Have a great day,
1 note
·
View note
Text
Mastering PROC SQL in SAS for Data Manipulation and Analysis
When it comes to SAS programming, one of the most powerful and versatile features is PROC SQL. This procedure allows you to use SQL (Structured Query Language) within the SAS environment to manage, manipulate, and analyze data in a highly efficient manner. Whether you're a beginner or an experienced user, understanding how to work with PROC SQL is an essential skill that can greatly boost your ability to analyze large datasets, perform complex queries, and generate meaningful reports.
In this SAS programming full course, we will dive into the ins and outs of PROC SQL to help you master this critical SAS tool. Through SAS programming tutorials, you will learn how to harness the full power of SQL within SAS, improving both the speed and flexibility of your data analysis workflows.
What is PROC SQL in SAS?
PROC SQL is a procedure within SAS that enables you to interact with data using SQL syntax. SQL is one of the most widely used languages in data manipulation and database management, and PROC SQL combines the power of SQL with the data management capabilities of SAS. By using PROC SQL, you can query SAS datasets, join multiple tables, summarize data, and even create new datasets, all within a single step.
One of the key benefits of using PROC SQL is that it allows you to perform complex data tasks in a more concise and efficient manner compared to traditional SAS programming methods. For example, you can use SQL to easily filter, aggregate, and group data, which would otherwise require multiple SAS programming steps. This streamlines your workflow and makes it easier to work with large datasets, especially when combined with SAS's powerful data manipulation features.
Why Learn PROC SQL for SAS?
Mastering PROC SQL in SAS is essential for anyone looking to elevate their data analysis skills. Whether you’re working in finance, healthcare, marketing, or any other data-driven field, PROC SQL enables you to quickly and efficiently manipulate large datasets, make complex queries, and perform data summarization tasks.
Here are some reasons why learning PROC SQL should be at the top of your SAS learning agenda:
Simplifies Data Management: SQL is designed specifically for managing and querying large datasets. By learning PROC SQL, you can quickly and efficiently access, filter, and aggregate data without having to write long, complicated code.
Improves Data Analysis: With PROC SQL, you can combine multiple datasets using joins, subqueries, and unions. This makes it easier to work with data from various sources and create unified reports that bring together key insights from different tables.
Boosts Efficiency: SQL is known for its ability to handle large datasets with ease. By mastering PROC SQL, you'll be able to manipulate data more quickly and effectively, making it easier to work with complex datasets and produce high-quality analysis.
Widely Used in Industry: SQL is a universal language for database management, making it a highly transferable skill. Many companies use SQL-based databases and tools, so understanding how to work with SQL in SAS will make you more valuable to potential employers and help you stay competitive in the job market.
What You’ll Learn in This SAS Programming Full Course
In this comprehensive SAS programming full course, you will learn everything you need to know about PROC SQL. The course is designed for beginners and advanced users alike, providing a step-by-step guide to mastering the procedure. Below is a breakdown of the key concepts and techniques covered in this training:
Introduction to SQL in SAS
What is PROC SQL and how does it integrate with SAS?
Key differences between traditional SAS programming and SQL-based data manipulation.
Basic syntax of SQL and how it applies to SAS programming.
Querying Data with SQL
How to write SELECT statements to extract specific data from your SAS datasets.
Using WHERE clauses to filter data based on conditions.
How to sort and order your data using the ORDER BY clause.
Applying aggregate functions (e.g., SUM, AVG, COUNT) to summarize data.
Advanced SQL Queries
Using JOIN operations to merge data from multiple tables.
Combining data from different sources with INNER, LEFT, RIGHT, and OUTER joins.
Subqueries: How to use nested queries to retrieve data from related tables.
Union and Union All: Combining multiple result sets into a single table.
Creating New Datasets with SQL
Using CREATE TABLE and INSERT INTO statements to create new datasets from your queries.
How to use SQL to write the results of a query to a new SAS dataset.
Optimizing SQL Queries
Tips for writing more efficient SQL queries to improve performance.
How to handle lard healthcare data management.
Working with data from external databases and importing/exporting data using SQL.
Learning Path and Benefits of SAS Online Training
Whether you are just starting your journey with SAS or looking to enhance your existing knowledge, our SAS online training provides you with all the resources you need to succeed. This SAS programming tutorial will guide you through every step of the learning process, ensuring you have the support you need to master PROC SQL.
Self-Paced Learning: Our SAS online training is designed to be flexible, allowing you to learn at your own pace. You can watch the videos, review the materials, and practice the exercises whenever it’s convenient for you.
Access to Expert Instructors: The training course is led by experienced SAS professionals who are there to help you whenever you need assistance. If you have any questions or need clarification, our instructors are available to guide you through any challenges you may encounter.
Comprehensive Resources: With access to a wide variety of tutorials, practice exercises, and real-world examples, you'll have everything you need to become proficient in SAS programming. Each tutorial is designed to build on the last, helping you gradually develop a complete understanding of SAS programming.
Community Support: Join a community of learners who are also working through the SAS programming full course. Share ideas, ask questions, and collaborate with others to improve your understanding of the material.
Conclusion
Mastering PROC SQL in SAS is a valuable skill for anyone looking to improve their data analysis capabilities. By learning how to use SQL within the SAS environment, you can efficiently manage and manipulate data, perform complex queries, and create meaningful reports. Our SAS programming tutorials will provide you with the knowledge and practical skills you need to succeed in the world of data analysis.
Enroll in our SAS online training today and start learning PROC SQL! With this powerful tool in your SAS programming toolkit, you’ll be ready to tackle even the most complex data tasks with ease.
#sas programming course#sas programming tutorial#sas online training#sas programming#proc sql#data manipulation#data analytics
0 notes
Text
PG Certificate
The rapid pace at which digital data is being generated has resulted in very large amounts of data, usually referred to as Big Data,” which require new techniques for processing and analysis. GangBoard Offers Best Data Science Training in Bangalore will help you master skills and tools like Clustering, Statistics, Decision trees, Hypothesis testing, Linear and Logistic regression, R Studio, Hadoop ,Data Visualization, Regression models, Spark, PROC SQL, Statistical procedures, SAS Macros, tools and analytics, and many more. As a creation business partner, Viasat will make a contribution to the HDSI, helping to shape the educational degree programs, as well as assist in the development of translational programs ranging from short coaching programs to longer-term engagements with business developing information science-engineered solutions.
Candidate from these programs will reach job roles, such as business analysts, data analysts, data engineer, analytics engineer, AWS Cloud Architect, SysOps Administrator, Cloud DevOps Engineer, RPA architect, RPA Developer, Digital Marketers and Digital selling Analysts therefore forth by learning relevant information science, big data, AWS and RPA techniques, tools and innovations and hands-on application through industry case investigations in information science, business development strategies in digital marketing and real time projects. Here ar the foremost topics we have a tendency to cowl underneath this information Science course curriculum Basic Statistics, Linear Regression, Logistic Regression, Decision tree and Case Study for Decision tree, Unsupervised Classification Algorithms Time Series and Case Study for Time Series, K Nearest Neighbor's Algorithm for Classification, Naïve Bayes Algorithm for Multi Class Prediction, Artificial Neural network with case study, Support vector machines with case study and Recommender Systems.
With big data becoming the life blood of business, data analysts and data scientists with expertise in Hadoop, NoSQL, and Python and R language are hard to come by. Students or professionals UN agency wish an additional edge for his or her next huge information job or ar fishing for a promotion-DeZyre Certification offered at the completion of Python and R course could be a third-party proof of skills that has other advantage.
Projects are thing about course is you can attend multiple classroom batch and finish the course at your ,You have option to attend the training online from home if you are not able to travel room.Instructor utkarsh is admittedly smart and he can teach complicated machine learning rule in terribly straightforward means.
1 note
·
View note
Text
Generating SQL Scripts on SQL Workbench/J to Create Amazon Redshift Stored Procedures
#amazonredshift #postgresql
The task of generating a SQL script for a stored procedure or function is fairly simple in Microsoft SQL Server using SQL Server Management Studio, or in Oracle Database, using SQL Developer. However, if your database is Amazon Redshift, you’re probably using SQL Workbench/J to interact with your database, and unfortunately, its ability to script out stored procs is limited. I recently…

View On WordPress
0 notes
Text
Why Data Scientist Stays As The Top Job In Malaysia?
The Data Scientist Master’s program focuses on in depth Data Science coaching, combining on-line teacher-led lessons and relaxed self-paced learning. The Data Scientist occupation is among the hottest IT-associated professions available right now. IBM predicts that the need for Data Scientists will enhance by 28% in 2020.
Yes, we do offer a cash-back assure for many of our coaching applications. Refer to our Refund Policy and submit refund requests by way of our Help and Support portal. We will refund the course price after deducting an administration charge. Upon completion of the next minimal necessities, you may be eligible to obtain the Data Scientist Master’s certificate that may testify to your skills as an professional in Data Science. To discover a course that provides Data Science Training in Kuala Lumpur, a possible candidate can use Internet analysis. The results will present them an inventory of institutes with various courses that are helpful in the commerce.
The knowledge is gathered from quite a few sources, remodeled into an evaluation-ready format, and fed into an analytics system, the place it's statistically analyzed for actionable insights. Data science is a vast matter that entails working with huge quantities of information to seek out hidden tendencies and patterns and extract helpful data to assist choice-making. Companies employ varied information science instruments and methodologies to develop predictive models as a service as they collect vast volumes of knowledge. Data Science courses from 360digitmgwill help you study all of the ideas from the ground up.
Companies are embracing digital transformation and the rising dependency on data makes a career in data science fairly promising. Businesses are accelerating their digital initiatives and data science abilities will stay in high demand within the close to future. Moreover, with the present expertise gap, firms are even able to pay higher salaries to information scientists. With 360digitmg Data Scientist course, you can qualify for this rewarding career. These Data Science programs co-developed with IBM will give you an perception into Data Science instruments and methodologies, which is sufficient to put together you to excel in your next function as a Data Scientist.

Even if these instruments are automated, there is all the time a need of manipulation to suit the work construction correctly. This makes the career of a Data Scientist a choice that is apart and unique from a traditional career. It can also be plain that you have to be repeatedly rising and growing new abilities and methods which might be coming into the market. A Data Scientist, with the assistance of information, analyzes the condition of the enterprise in the market and takes main choices related to enterprise attributes. So, what corporations actually need is a multi-expert skilled who can develop and study constantly from the forthcoming issues in the future. Due to these types of problems, there is a large demand for Data Scientists at present.
The course additionally explores Hadoop, PROC SQL, SAS Macros, Spark, advice engine, supervised and unsupervised learning, and different priceless expertise. A main branch of examine in information science is Machine Learning additionally referred to as Data Mining Supervised Learning or Predictive Modelling. One will learn about K Nearest Neighbors , Decision Tree , Random Forest , Stacking, Ensemble models and Naïve Bayes. One will learn in regards to the numerous regularization techniques as well as understand tips on how to evaluate for overfitting and underfitting .
As firms are slowly changing into information-pushed, a lot of difficulties have risen in dealing with their knowledge. The skills like data wrangling and data cleaning or changing the data to bring it in a usable format are still extremely demanded. Companies want expert professionals to handle and organize these knowledge for analysis. Data preparation is the time period used for organizing information into usable system code. It additionally contains dealing with data that is incomplete or most often known as dangerous information. Statistics show that by the yr 2020, there will be about two million job openings for data professionals and that the demand for folks with this information and talent will outstrip supply by a ratio of two to at least one.
We may even be adding extra integrations with Webex and Microsoft Teams. However, all the periods and recordings shall be out there proper from within our studying platform. Learners is not going to have to wait for any notifications or hyperlinks or install any additional software program. The Data Science with Python course is delivered by main practitioners who convey trending, greatest practices, and case research from their experience to the reside, interactive coaching periods.
Explore more on -Data Science Training in Malaysia
INNODATATICS SDN BHD (1265527-M)
360DigiTMG - Data Science, IR 4.0, AI, Machine Learning Training in Malaysia
Level 16, 1 Sentral, Jalan Stesen Sentral 5, KL Sentral, 50740, Kuala Lumpur, Malaysia.
+ 601 9383 1378 / + 603 2092 9488
Hours: Sunday - Saturday 7 AM - 11 PM
#data science course#data scientist course in malaysia#data scientist course#data science course in malaysia#data science training#data science training in malaysia#data scientist training in malaysia#data scientist certification malaysia#data science courses in malaysia
0 notes
Text
This Week in Rust 465
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Newsletters
This Month in Rust GameDev #38 - September 2022
Project/Tooling Updates
Progress report on rustc_codegen_cranelift (Okt 2022)
Announcing KataOS and Sparrow
rust-analyzer changelog #151
A Memory Safe Implementation of the Network Time Protocol
Zenoh 0.6.0, a Pub/Sub/Query protocol, was released and it is packed with new features.
GlueSQL v0.13 - FSM based SQL query builder is newly added
Rust on Espressif chips - 17-10-2022
Introducing BastionAI, an open-source privacy-friendly AI training framework in Rust
Observations/Thoughts
Platform Agnostic Drivers in Rust: Publishing to Crates.io
A first look at Rust in the 6.1 kernel
Asynchronous programming in Rust
Why Rust?
What If LaTeX Had Instant Preview?
Magical handler functions in Rust
Rust Walkthroughs
Rust: Type Concealment With Any Trait and FnMut
Practical Parsing in Rust with nom
The Little Joys of Code: Proc Macros
How to Build a Machine Learning Model in Rust
[video] Building Awesome Desktop App with Rust, Tauri, and SurrealDB
[video] AsRef/Borrow Traits, and the ?Sized Marker - Rust
Using Neovim for Rust Development
[series] Sqlite File Parser Pt 3
Research
Simulating C++ references in Rust
Crate of the Week
This week's crate is HyperQueue, a runtime for ergonomic execution of programs on a distributed cluster.
Thanks to Jakub Beránek for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
zerocopy - Add defensive programming in FromBytes::new_box_slice_zeroed
zerocopy - Add tests for compilation failure
Fornjot - export-validator does not support Windows
Ockam - Add clap based ockam sub command to create a vault without creating a node
Ockam - Add clap based ockam sub command to rotate identity keys
Ockam - Partition rust test jobs with nextest
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
388 pull requests were merged in the last week
support casting boxes to dyn*
support default-body trait functions with return-position impl Trait in traits
mark derived StructuralEq as automatically derived
allow compiling the wasm32-wasi std library with atomics
detect and reject out-of-range integers in format string literals
drop temporaries created in a condition, even if it's a let chain
fix let keyword removal suggestion in structs
make dyn* casts into a coercion, allow dyn* upcasting
make overlapping_impls not generic
point out incompatible closure bounds
populate effective visibilities in rustc_resolve
print return-position impl Trait in trait verbosely if -Zverbose
add suggestion to the "missing native library" error
suggest == to the first expr which has ExprKind::Assign kind
suggest candidates for unresolved import
suggest parentheses for possible range method calling
suppress irrefutable let patterns lint for prefixes in match guards
unify tcx.constness query and param env constness checks
remove type traversal for mir constants
scoped threads: pass closure through MaybeUninit to avoid invalid dangling references
never panic in thread::park and thread::park_timeout
use semaphores for thread parking on Apple platforms
nicer errors from assert_unsafe_precondition
optimize TLS on Windows
stabilize map_first_last
constify Location methods
add MaybeUninit array transpose From impls
add Box<[T; N]>: TryFrom<Vec<T>>
add IsTerminal trait to determine if a descriptor or handle is a terminal
add is_empty() method to core::ffi::CStr
panic for invalid arguments of {integer primitive}::ilog{,2,10} in all modes
impl AsFd and AsRawFd for io::{Stdin, Stdout, Stderr}, not the sys versions
prevent UB in child process after calling libc::fork
fix Duration::{try_,}from_secs_f{32,64}(-0.0)
SIMD: mark more mask functions inline
futures: fix soundness hole in join macros
cargo: fix deadlock when build scripts are waiting for input on stdin
cargo: support 'publish.timeout' config behind '-Zpublish-timeout'
rustdoc: change default level of invalid_html_tags to warning and stabilize it
clippy: add as_ptr_cast_mut lint
clippy: add unused_format_specs lint
clippy: add a suggestion and a note about orphan rules for from_over_into
clippy: add new lint partial_pub_fields
clippy: change uninlined_format_args into a style lint
clippy: don't lint ptr_arg when used as an incompatible trait object
clippy: fix to_string_in_format_args in parens
clippy: don't lint default_numeric_fallback on constants
clippy: don't lint unnecessary_cast on negative hexadecimal literals when cast as floats
clippy: zero_prefixed_literal: Do not advise to use octal form if not possible
clippy: add cast-nan-to-int lint
clippy: fix box-default linting no_std non-boxes
clippy: fix: uninlined_format_args shouldn't inline panic! before 2021 edition
rust-analyzer: migrate assists to format args captures, part 2
rust-analyzer: diagnose some incorrect usages of the question mark operator
rust-analyzer: fix formatting requests hanging when r-a is still starting
Rust Compiler Performance Triage
Overall a fairly busy week, with many improvements and regressions, though the net result ends up being a small regression. Pretty busy week in terms of regressions in rollups as well, which unfortunately mostly were not followed up on prior to the report being put together, despite the relative ease of running perf against individual PRs now.
Triage done by @simulacrum. Revision range: 1e926f06..e0f8e60
2 Regressions, 4 Improvements, 4 Mixed; 4 of them in rollups 47 artifact comparisons made in total
See full report for details.
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
No Tracking Issues or PRs entered Final Comment Period this week.
New and Updated RFCs
[new] Add RFC for calling default trait methods
[new] Add lang-team advisors team
Upcoming Events
Rusty Events between 2022-10-19 - 2022-11-16 🦀
Virtual
2022-10-19 | Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2022-10-19 | Virtual (Chennai, IN) | Techceleration at Toyota Connected
Techceleration's! Let's Talk Tech! Rust | BreakTheCode Contest - 14th Edition
2022-10-19 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rapid Prototyping in Rust: Write fast like Python; Run fast like C
2022-10-19 | Virtual | Boston NoSQL Database Group (ScyllaDB)
p99 Conf: All Things Performance (including talks on Rust) - Free | Official conference page
2022-10-20 | Virtual (Bellingham, WA, US) | bellingham.codes
Software Forum 8 (with Language small groups: Rust)
2022-10-20 | Virtual (Buenos Aires, AR) | Nerdearla
Rust y el desarrollo de software en la próxima década
2022-10-20 | Virtual (México City, MX) | Rust MX
Graphul, un web framework escrito en Rust
2022-10-20 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2022-10-25 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn
2022-10-25 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2022-10-26 | Virtual (Redmond, WA, US / New York, NY, US / Toronto, CA / Stockholm, SE / London, UK) | Microsoft Reactor Redmond
Your First Rust Project: Rust Basics | New York Mirror | Toronto Mirror | Stockholm Mirror | London Mirror
2022-10-27 | Virtual (Charlottesville, VA, US) | Charlottesville Rust Meetup
Using Applicative Functors to parse command line options
2022-10-27 | Virtual (Karlsruhe, DE) | The Karlsruhe Functional Programmers Meetup Group
Stammtisch (gemeinsam mit der C++ UG KA) (various topics, from C++ to Rust...)
2022-10-29 | Virtual (Ludwigslust, DE) | Ludwigslust Rust Meetup
Von Nullen und Einsen | Rust Meetup Ludwigslust #1
2022-11-01 | Virtual (Beijing, CN) | WebAssembly and Rust Meetup (Rustlang)
Monthly WasmEdge Community Meeting, a CNCF sandbox WebAssembly runtime
2022-11-01 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2022-11-02 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Rust and C++ Cardiff Virtual Meet
2022-11-02 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2022-11-02 | Virtual (Redmond, WA, US / San Francisco, SF, US / New York, NY, US / Toronto, CA / London, UK) | Microsoft Reactor Redmond
Getting Started with Rust: From Java Dev to Rust Developer | San Francisco Mirror | New York Mirror | Toronto Mirror | London Mirror
2022-11-02 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2022-11-08 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2022-11-08 | Virtual (Stockholm, SE) | Func Prog Sweden
Tenth Func Prog Sweden MeetUp 2022 – Online (with "Ready for Rust" by Erik Dörnenburg)
2022-11-10 | Virtual (Budapest, HU) | HWSW free!
RUST! RUST! RUST! meetup (online formában!)
2022-11-12 | Virtual | Rust GameDev
Rust GameDev Monthly Meetup
2022-11-15 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
2022-11-16 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
Europe
2022-10-20 | London, UK | Rust London User Group
Rust London x JFrog SwampUP After Party
2022-10-25 | Paris, FR | Rust Paris
Rust Paris meetup #53
2022-10-25 | Roma, IT | Rust Roma
Meetup Golang Roma - Go + Rust Hacknight - Hacktoberfest 2022
2022-10-26 | London, UK | Rust London User Group
LDN Talks October 2022: Host by Amazon Prime Video
2022-10-26 | Bristol, UK | Rust and C++ Cardiff/Rust Bristol
Programming Veloren & Rust for a living
2022-10-27 | København, DK | Copenhagen Rust Group
Hack Night #30
North America
2022-10-20 | New York, NY, US | Rust NYC
Anyhow ? Turbofish ::<> / HTTP calls and errors in Rust.
2022-10-20 | New York, NY, US | Cloud Native New York
Cloud-native Search Engine for Log Management and Analytics.
2022-10-25 | Toronto, ON, CA | Rust Toronto
Rust DHCP
2022-10-27 | Lehi, UT, US | Utah Rust
Bevy Crash Course with Nathan and Food!
2022-11-10 | Columbus, OH, US | Columbus Rust Society
Monthly Meeting
Oceania
2022-10-20 | Brisbane, QLD, AU | Rust Brisbane
October Meetup
2022-10-20 | Wellington, NZ | Rust Wellington
Tune Up Edition: software engineering management
2022-10-25 | Melbourne, VIC, AU | Rust Melbourne
October 2022 Meetup
2022-11-09 | Sydney, NSW, AU | Rust Sydney
RustAU Sydney - Last physical for 2022 !
South America
2022-11-05 | São Paulo, SP, BR | Rust São Paulo Meetup
Rust-SP meetup Outubro 2022
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
I think it's worth noting that the fact that this program fails to compile whereas the analogous Python runs but gives the wrong answer is exactly what Rust's ownership and borrowing system is about.
– Kevin Reid on rust-users
Thanks to Kill The Mule for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
Data Management and Visualization - Part Two
After thinking on which software tool to use, I have decided to go for SAS. The reason behind this is that I actually use SAS Enterprise Guide at work, but normally by using PROC SQL, so it will be great to boost my SAS language skills as well.
This is how the code looks like by using the dataset and variables I’ve chosen previously.

Few things to mention:
No logic statements / filters have been applied, since I prefer to consider all the data to analyze my research questions.
The variables showed too many decimals, for that reason I have done some data manipulation (rounding), so the data is more readable in the frequency tables.
Frequency tables:
CO2 Emissions (Tons):
This variable takes 200 distinct values that are different for each country. Those varies from 132,000 to 334,220,872,333 tons of CO2 emissions.
Out of the 213 countries, we have values for 200 countries (94%), and we are missing information for 13 of them (6%).

Income per person (GDP in $):
This variable takes 185 distinct values, and those varies from 104 to 105,147 $. 50% of the countries have an income per person between 268-2,550 $, while the other 50% have it between 2,550-105,147 $.
Out of the 213 countries, we have values for 190 countries (89%), and we are missing information for 23 of them (11%).

Life expectancy (Years):
This variable takes 34 distinct values, and those varies from 48 to 83 years old. 50% of the countries have a life expectancy between 48-72 years old, while the other 50% are between 73-83 years old.
Out of the 213 countries, we have values for 191 countries (90%), and we are missing information for 22 of them (10%).

More to come! :)
1 note
·
View note
Text
Finest Data Science Blogs

Our SWAT Data Science group helps solve complex business problems, develop the corporate's Data DNA through Data Literacy packages, & ship fast ROI utilizing machine learning, deep studying, & AI. You can discover a detailed description of basic terminologies & superior phrases in these articles. This popular data science blog is owned by InData Labs, which presents data science consulting services. They also present AI-powered software program improvement to shoppers who need it. The blog covers matters similar to computer vision, pure language processing, and predictive analysis.
visit to know more about : data science training in hyderabad Revolutions is a blog devoted to information and data of interest to members of the R neighborhood. Learn extra about utilizing open supply R for giant knowledge analysis, predictive modeling, information science, and extra from the employees of Revolution Analytics. Many universities offer undergraduate and advanced levels in data science. They are extra inexpensive and supply hands-on experiences and a pathway to a career in tech. Content facilities round massive information, information science, blockchain, AI, and rising applied sciences topics aimed towards both shopper and technical audiences. This is my collection of interesting, noteworthy and helpful links to articles, blogs and resources in all areas of knowledge science. Learn about Base SAS, Advanced SAS, SAS Macros, Proc SQL, information analytics, statistics tools and techniques. Covering broad matters associated to Bioinformatics, Statistics, Machine studying, Python, and R for knowledge evaluation and visualization. This is an official weblog of Pivotal Data the place the info science team shares articles in huge knowledge, information science & analytics. The articles feature a number of the best real-life problems solved by Pivotal Data. He writes about neural networks, implementation of deep learning for gross sales automation. Additionally, they must be proficient in programming languages and statistical software program to have the ability to manipulate information. Internships are an efficient way to get your foot within the door to firms hiring knowledge scientists. Seek jobs that include keywords such as knowledge analyst, enterprise intelligence analyst, statistician, or data engineer. This is an official blog by Cloudera and features articles on machine studying, neural networks, bigdata and analytics. The articles have been authored by data science practitioners at Cloudera. Oliver leads the self-driving car team at Udacity and he explains intensive functions of Deep Learning. This weblog additionally has special sections masking Hadoop, Spark, Developers, Data Science a hundred and one along with a assets part with job postings. This well-liked information science weblog is understood for its wide range of data science matters. Both skilled and beginner information scientists can read up on the most recent information and developments in the subject. It is an interactive platform the place folks can study more about data science and exchange concepts and knowledge science articles. Analytics Vidhya is a passionate group to be taught each aspect of Analytics from internet analytics to massive information, advanced predictive modeling strategies and software of analytics in enterprise. To process all of that info, Netflix uses superior knowledge science metrics. This permits it to current a better film and show recommendations to its users and in addition create better exhibits for them. The Netflix hit collection House of Cards was developed utilizing knowledge science and big knowledge. Netflix collected user data from the show, West Wing, one other drama happening within the White House. The firm took into consideration the place folks stopped after they fast-forwarded and where they stopped watching the show. Analyzing this knowledge allowed Netflix to create what it believed was a perfectly engrossing show. This is a wonderful blog to observe if you need to specialize within the machine studying facet of data science. You will learn about machine studying and the means it can help you advance as an information scientist. The greatest information science blogs provide suggestions that will help you succeed as an information scientist regardless of your level of expertise. We’ve included a couple of examples of useful information that you'll find on a blog devoted to information science beneath. About weblog — The Domino Data Science Blog options news and in-depth articles on knowledge science greatest practices, trends, and tools. Crayon Data is a fast-growing huge knowledge and AI company, founded in 2012 in Singapore, with a vision to simplify the world's decisions. The main know-how blog in the Big Data, Artificial Intelligence, Data Analytics, BI, Machine Learning, Personalization, and Data Science sectors. AYLIEN leverages Artificial Intelligence to empower thousands of forward-thinking enterprises and builders to collect, analyze, and perceive vast quantities of human-generated content material. Check out our weblog for danger analyst information similar to danger intelligence developments or threat management frameworks. We're deeply focused on solving for the largest bottleneck in the data lifecycle, knowledge wrangling, by making it extra intuitive and environment friendly for anyone who works with data. He shares blogs on Deep Learning and how it is dwelling as much as the hype it has created. Learn about self-driving cars, photonic neural community, neural artwork, lip studying with deep studying and many more. He shares his perspective and expertise of working with deep learning in these blogs. Simply Statistics is a blog run by 3 biostatistics professors who are excited about this new information age the place knowledge is a gold mine and statisticians are scientists that get hold of the gold from uncooked data. There are varied articles on the weblog regarding statistics and also its interconnected fields like data science, synthetic intelligence, and so forth. The founders of this weblog have additionally created some courses about Data Science and Life Sciences you could access from Coursera or the weblog itself. Mastering the field of knowledge science begins with understanding and dealing with the core know-how frameworks used for analyzing massive data. The insights you will glean from the data are presented as consumable reviews utilizing knowledge visualization platforms corresponding to Tableau. Data Science Report supplies you with a whole report on this subject in all of the codecs you presumably can imagine! 360DigiTMG is a group of world class engineers taking up the hardest challenges. To deliver novel insights and create data science options that increase growth and push companies to larger technological literacy. Checkout Shiny dashboard tutorials, knowledge science and machine studying insights, open-source bulletins, and developer group information. Becoming a data scientist generally requires a really strong background in arithmetic and laptop science, in addition to expertise working with massive quantities of knowledge. In addition, it is often helpful to have expertise with machine studying and statistical modeling. Every week they curate finest machine studying & digital reality articles.
For more information: best institute for data science in hyderabad
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad
Address - 2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081
099899 94319
Visit on map : https://g.page/Best-Data-Science
0 notes
Text
Why Clinical SAS Training is a Smart Career Move for Life Sciences Graduates in India
In India, life sciences graduates often find themselves at a crossroads after completing their degrees. While the pharmaceutical and biotech industries are growing rapidly, many students are unsure about the right path forward. If you're one of them, Clinical SAS Training could be your ticket to a thriving career in clinical research and data analysis.
Understanding Clinical SAS
Clinical SAS refers to the use of the SAS (Statistical Analysis System) software in clinical trials. SAS is a powerful data analytics tool used extensively by pharmaceutical companies, CROs (Contract Research Organizations), and healthcare providers to analyze and report clinical trial data.
With the growing number of clinical trials being outsourced to India, the demand for skilled Clinical SAS professionals has increased significantly. India has become a hub for clinical research, and companies are looking for trained SAS programmers to ensure high-quality data handling and regulatory compliance.
Growing Job Market in India
According to industry trends, India is among the top destinations for global clinical trials. Cities like Hyderabad, Bangalore, and Pune are witnessing increased hiring of SAS programmers. Clinical SAS training prepares you for roles such as Clinical Data Analyst, SAS Programmer, and Statistical Analyst.
Employers expect professionals who are not only technically sound but also understand the clinical trial lifecycle. A certified Clinical SAS programmer becomes a valuable asset to any company involved in drug development and regulatory submissions.
What You Learn in Clinical SAS Training
A typical Clinical SAS training course will cover:
SAS Base Programming: Learn the fundamentals like data steps, PROC steps, libraries, and datasets.
SAS Advanced Programming: Dive deeper into macros, SQL procedures, and data manipulations.
Clinical Domain Knowledge: Understand the clinical trial process, CDISC standards (SDTM and ADaM), and how data is submitted to regulatory authorities like the FDA.
Hands-On Projects: Many training programs now include real-time case studies and data handling scenarios to simulate on-the-job challenges.
These elements are essential to bridge the gap between academic knowledge and industry expectations.
Certification: A Game-Changer
Although not mandatory, SAS certification (like Base SAS or Clinical Trials Programmer certification) adds significant value to your resume. Recruiters in India often prioritize certified candidates because it assures them of your proficiency and seriousness about the profession.
Many training institutes offer certification support, practice tests, and placement assistance. If you're choosing a course, check if these services are included.
Advantages of Clinical SAS Training in India
Affordable: Compared to other countries, training in India is more cost-effective.
Accessible: With the rise of online learning, students across India—whether in metropolitan areas or small towns—can access high-quality training.
Job-Ready Skills: Most programs focus on practical, hands-on training which aligns well with employer expectations.
Final Thoughts
If you're a life sciences graduate looking to break into the clinical research industry, Clinical SAS training can open up a world of opportunities. The blend of statistical skills and clinical domain expertise makes you highly employable in a competitive market. With India’s growing role in global clinical trials, now is the perfect time to consider this career move.
0 notes