#python代寫
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
計算機CS作業代寫-程式代碼代考-CS編程 exam/assignment代考代寫
靠譜計算機CS考試代考作業代寫 :一線大廠工程師在線接單• 1V1程序員大神直接咨詢•少走彎路•快樂進步•承接各類計算機CS代考代寫網課代考,project,assignment:C語言、C++、java,python,matlab,數據結構算法等等 • 貼合需求• 價格優惠• 按時交代碼 • 包售後調試


1 note
·
View note
Text
告別人工盯盤!Alltick全自動化量化交易平台深度解析
在當今瞬息萬變的金融市場中,傳統的人工盯盤交易方式正面臨前所未有的挑戰。情緒波動、反應延遲、疲勞失誤等問題不僅影響交易效率,更可能造成重大損失。Alltick全自動化量化交易平台應運而生,以智能算法替代人工操作,讓交易更精準、更高效、更省心。
人工交易 vs 自動化交易:為何必須轉型?
人工交易的局限性
情緒干擾:貪婪與恐懼導致非理性決策
時間束縛:難以實現7×24小時不間斷監控
執行延遲:手動操作錯過最佳買賣時機
能力局限:個人難以同時跟蹤多市場、多品種
Alltick自動化交易的優勢
✅ 全天候運行:算法永不疲倦,時刻捕捉市場機會 ✅ 毫秒級響應:比人工操作快上千倍的執行速度 ✅ 多市場覆蓋:股票、期貨、加密貨幣、外匯全面支持 ✅ 策略多元化:可同時運行多種策略,分散風險
Alltick量化平台正是為解決這些問題而設計,讓交易者徹底擺脫低效的手工操作。
Alltick全自動化交易平台的核心架構
1. 智能策略開發系統
支持Python/JavaScript等多種編程語言
提供可視化策略構建工具,降低使用門檻
內置豐富的技術指標庫和基本面數據接口
支持自定義因子開發,滿足個性化需求
2. 專業級回測引擎
提供Tick級歷史數據回測
支持多時間框架策略驗證
內置參數優化算法,自動尋找最優配置
嚴格的風險評估體系,避免過擬合
3. 高性能交易執行系統
毫秒級訂單響應速度
智能訂單路由算法,減少滑點
多賬戶統一管理功能
實時風險監控與預警
4. AI增強功能
機器學習模型輔助策略優化
市場異常波動自動識別
動態風險參數調整
Alltick平台的技術優勢
超低延遲架構
採用分佈式雲計算技術
全球多節點部署
直連交易所撮合引擎
數據優勢
多源數據聚合
實時數據流處理
歷史數據完備性保障
安全體系
銀行級加密傳輸
多重身份驗證
交易指令簽名機制
如何開始您的自動化交易之旅
註冊賬號:獲取模擬交易環境
策略開發:使用內置工具或自行編寫
回測驗證:確保策略穩健性
實盤部署:一鍵切換至真實交易
迎接智能交易新時代
在金融科技飛速發展的今天,Alltick全自動化量化交易平台代表著交易方式的未來方向。通過將先進的算法技術與專業的金融知識相結合,我們為交易者提供了一個強大而可靠的智能交易解決方案。
無論您是個人投資者還是專業機構,Alltick都能幫助您:
提升交易效率
降低操作風險
優化投資回報
釋放時間價值
立即體驗Alltick,開啟您的智能交易新時代!

0 notes
Text
AI 時代的語言學 - 連載之一:結構
前陣子收到一封演講邀請信,來信的是一位「計算機語言學」的專家,但在信中卻寫了一句「…傳統形式語言學[註1]…」這讓我覺得特別有趣。
若要比年代的話,其實計算機語言學起自1946年的機器翻譯,而喬姆斯基 (Chomsky) 的以數學形式描述的形式語言學研究方法,還要 10 年後,在 1957 年才發表「轉換生成語法 (Transformational Grammar)」[註2]。
這就像是 2016 年最流行的 LSTM (長短期記憶模型) 指著 12 年後的 2022年底才出現的 LLM (大型語言模型) 說「那個是傳統 AI」一樣令人感到時空錯亂。
但凡現象必有原因,為什麼一個「計算機語言學家」會認為「形式語言學」是傳統的?我想了幾天,終於想到一個原因『在 AI 時代裡,計算機語言學家認為形式語言學已經是 Old School 的老東西了!所以才會稱之為傳統!』

但既然我已說明了相較於計算機語言學,形式語言學並不傳統,接著,我就借用 "Linguistics for the Age of AI" (連結) 這本書的書名,做為本篇的題目,說明一下我們用「形式語言學」怎麼在現代做 AI/NLP[註3] 吧。
除非額外說明,否則以下「語言學」的指稱對象都是「形式語言學」。
基本單位:詞彙 vs. token
在語言學裡,掌管語意計算的最小單位是「構詞 (morphology)」;但在 AI 的眼裡,它無法理解什麼是「詞彙」。AI 的領域裡,模型計算的最小單位是一個 token。
token 不一定是「字」,甚至不一定是一個「詞」。Token 可以是任何電腦可以儲存解析的單位。比如說一個中文字,在 Python2 裡就是以三個 bytes 來儲存。
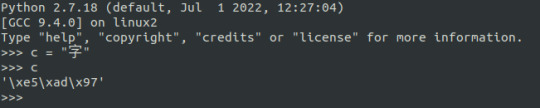
但從語言學的角度,一個「構詞的單位」是可以和整個句子的語意有所關係的。例如「打破」的「破」表示「這個動作最後造成的結果狀態」。而呈現一個句子意義的方式,是透過其句法結構逐層計算而來。

而且在這個架構下,我用紅色字體標出的每個 XP (TP, ASP, VP, DP, NP…) 都可被視為是某一種程式裡的函式 (Function,請特別注意這個字!),只需要給予它需要的論元 (arguments) 就行了。一段用以表示概念的 psudo-code 可以是像這樣:
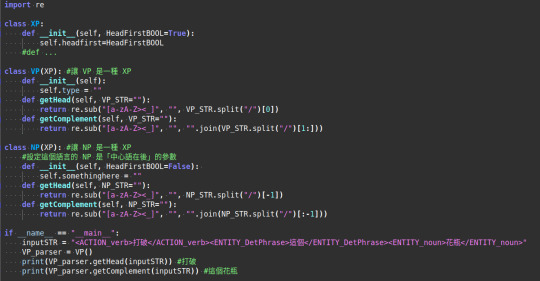
由於這個語言的 VP 是 head-initial (中心語在前) 的,所以當 VP 繼承 XP (class VP(XP) 這行) 的時候,不需要另做調整。而這個語言的 NP 是 head-final (中心語在後) 的,所以當 NP 繼承 XP (class NP(XP) 這行) 的時候,需要在 __init__() 裡設定它不是 HeadFirst 的參數[註4]。
於是,我們就能完全基於形式語言學的句法規則,來撰寫程式該怎麼處理句子。取出句子裡在句法樹上的每個元素,然後就能轉為形式語意 (Formal Semantics) 的 labmbda abstraction 的邏輯式,再進行語意計算了。
這時,下一個合理的問題就會浮現:正如大型語言模型都有「訓練」和「推論」兩個階段。上面的 psudo-code 既然類比的是「推論」的使用階段,那麼一開始究竟是怎麼得到 inputSTR 裡的這些標記結果的呢?
這又要回到「傳統 NLP」(這裡真的可以用『傳統』一詞) 處理高頻詞的想法和形式語言學的差異了。
傳統 NLP 是從訊號處理的角度出發的。因此很在意熵值的變化。他們覺得「只要某個東西的出現次數太多了,它就應該像背景雜訊一樣,數量多,而且變化多端。只要把它們濾掉,排除,剩下的就是我們要的訊號了。」
但從語言學的來看:「這個元素一直出現,必然有什麼特殊的原因!」
以下我們可以從某個詞彙出現次數繪製的長條圖裡,看出這兩種不同對待語言的態度:

ref. https://slackersite.wordpress.com/2015/08/28/zipf-it-word-frequency-and-line-drawing/
這張圖呈現的是某語料經統計後的結果,出現次數最多的詞彙往左排,次多的排第二,第三多的排第三,依序往右排。所以這張圖表裡呈現的就是「本語料中,"the" 出現的次數最多,"of" 出現的次數次之,"and" 第三…依序呈現」這種分佈被稱為齊夫分佈 (Zipf's distribution) 或是也有人稱語言中詞頻的分佈會遵守齊夫律 (Zipf's law)。
如果你是受傳統 NLP 出身的訓練,那麼你下一步會處理它的方式就是所謂的「去除停用詞 (stop word removal)」

ref. https://www.ngcm.soton.ac.uk/2021/07/07/natural-language-processing-in-python/
也就是把出現次數最多的那幾個詞,當做是「高頻詞」,然後把它當成是「就像出現次數又多,種類又變化多端的雜訊」一樣去除。然後只取後面的 "interesting word" 來當做實義詞 (content word) 使用。
但語言學並不是從這個角度理解這個現象!
語言學從「人類幼兒如何從極少的資料裡,就能掌握自己身處的母語環境中,究竟要把 HeadFirstBOOL 設為 True 還是 False」這個角度出發。從這個角度來思考,我們馬上就能注意到「這麼多高頻詞,怎麼剛好都是 Function word 呢?」
因為 Function word 可以快速地幫助人類幼童決定他正在「習得 (acquire)」的這個語言,要怎麼設定參數,以便快速地用最少的能量 (他每次的能量補給只有幾 c.c. 的母乳,而不像大型語言模型一樣有三個州的電網系統可以提供能源),在最少的例子裡聽出來「什麼東西一直反覆出現,那就先把它當做是句法樹上那些紅色的節點。優先釐清它的參數設定 HeadFirst (中心語在前) 還是 HeadFinal (中心語在後)」。
就依這樣的步驟,我們實際觀察一次這個比較少台灣人熟悉的語言:

如果把它依前例畫成每個詞出現的次數的話,就會發現第一多出現的字就是 "di"!讀者應該可以想像,人類幼兒聽到很多次的 "di" 以��,接著會發現它是前面的東西變化比較少,還是後面的東西變化比較少。如果是前面的東西變化比較少,那就表示它和前面那個東西的關係比較緊密,所以它是 "HeadFirst=False" 的參數設定;相反地,如果它後面的東西比較不會變化,那麼它就是和後面的東西關係比較緊密,這麼一來它就是 "HeadFirst=True" 的參數設定。
除了這個 HeadFirst 的參數設定以外,我們還會注意到「所有能扮演 Function 的元素,都是有限的數量」。比如說英文介系詞就少少的那幾個,中文的更少 (e.g., 在、於、之、的…等)。換言之,人類幼童根本不需要有那麼多的訓練語料,他只需要掌握住「那些常常出現的高頻詞,各自是屬於要往前併成一個 XP 的類型,還是往後併成一個 XP 的類型」就可以了。
於是「那隻貓打破了這個花瓶」,就可以很快地被以下的步驟逐層解析並加上標記:(我用 -> 和 <- 來表示它是往哪個方向併成一個 XP 結構,並用 [ ] 標出已經併起來的單位)
那(->) 隻貓打破了這(->) 個花瓶
[那隻] 貓 打破(<-) 了(<-) [這個] 花瓶
[那隻](->) 貓 [[打破]了] [這個](->) 花瓶
再加上我們知道具有 Syntax Function 的功能詞只有那幾類。就能標上:
[DetP[Det 那隻] [N貓]] [VP[V打破]了] [DetP[Det 這個]花瓶]
走到步驟 5 的時候,一個可以被 Formal Semantics 的 Lambda Abstraction 接手進行語意計算的句法樹標記就做好了。這 5 步,就相當是對應現在大型語言模型的「訓練」階段。只是我們用語言學的方法是用演算法來做,而不是用資料模型來逼近。
簡言之,我們不需要大量語料,不需要像 1950年代的 Pre-Chomsky 的『真.傳統語言學家』去編寫每個詞彙的文法,列舉每個例子,就能模仿人類幼童學會語言的句法結構和參數知識的方式,用語言學來做 NLP 了。
我們的 Articut 就是這麼做的。在中文上做了一次,在英文上做了一次,還正在排灣語上再做一次。我們一次又一次地做,就是為了證明「這種方法是可行的,而且即便是語言類型學上非常不一樣的語言,形式語言學的方法,在 AI 時代裡也是可行的,而且我們還非常省能源,又不需要大量語料呢!」
而且,由於我們的演算法是貼著 X-bar 做的,所以我們的各種應用也等於是提供了形式語言學家 (或是生成語言學家) 一個「可以透過資訊工具大量測試和觀察語言現象」甚至「將理論實作成應用」的研究平台了。
===
註 1
形式語言學的英文是 Formal Linguistics. 其中的「形式」一詞,指的是指使用定理或公式解,來說明並建構知識的邏輯系統。這種研究方法又被稱為 Formalism,中文被譯平「形式主義」。
但大概是近 30 年來的兩岸開放交流,台灣吸收了許多中國詞彙和語意的解釋。而中國使用「形式主義」這四個字的時候,更像是官僚主義的那種只看事物的現象而不分析其本質的思想方法和工作作風。
於是乎…莫名奇妙地開始有些剛接觸語言學的學生就帶著「中國風味的形式主義」來理解 Formalism 的 Formal Linguistics 的中文譯名「形式主義語言學」了。
不過還好,Formal Linguistics 裡研究句法的分支,通常又被稱為 Generative Syntax,而中文常被譯做「生成語法/生成句法」。這個字眼就持續維持中性,直到 2022 年底的大型語言模型,又把這個字拿去放在「生成式 AI」的 Generative AI 裡。
於是乎,又有許多「先看到生成式 AI,才看到生成式語法」的人,以為『你們這些語言學家就是在蹭 AI 的熱度哦!』
註 2
簡單的年表如下:
1956年 達特矛斯會議:第一次冒出 "Artificial Intelligence (AI)" 這個字眼,當時的語言學是傳統的 Rule-based 語言學。
1950年代,意識到 Rule-based 語言學無效,因為規則寫不完,因此開始了 Computational Linguistics (計算機語言學) 和 Corpus Linguistics (語料庫語言學) 的發展。前者企圖用某種知識圖譜、人為標記做出統計機率模型,後者企圖採集『具代表性』的語料,以避免資料量太大的時候,描述規則會寫不完的問題。兩者都是為了「解決 Rule-based 的不佳」而開始的領域。
1957 年 Chomsky 出版他的第一本關於語言的專書,他是在荷蘭出版的,因此對美國的影響並不那麼立即或明顯。
1965 年 Chomsky 出版他的第二本關於語言學理論的專書,這本是在 MIT 出版社出版的。
因此…誰更「傳統」?這個問題的答案,似乎不言而喻。
註 3
較明確的說法應該就是 NLP 而非 AI。但在 LLM 出現以後,大家似乎漸漸把 "AI" 一詞能指涉的範圍變得更廣了,只要是能通電的,都能冠上 "AI"。因此,為了讓文字閱讀時遇到陌生詞彙的費力感降低,本文裡的 AI 其實就只專指 "NLP (自然語言處理)" 的相關技術與應用。
註 4
psudo-code 的意思是「它並不是被期待成可被直接執行的程式碼,而是用以表達概念或是演算法核心的偽碼」。甚至連這段程式碼裡的 regex 都不該使用才對,而「這裡的 NP 還需要做一些調整,才能正確地使用」我知道,但這就是用以表達概念的 psudo-code 而已,它本來就不是要被執行的,而是被用來理解的概念的。
有些不熟悉 Formalism 或 Programming 的人,會對這段 psudo-code 提出諸如「回傳的結果是錯的,我用另一個句子就會得到錯誤的結果」或是「這個程式根本不能動」的質疑。這個註解就是寫給這些人看的。
0 notes
Text
ChatGPT的介紹與運用

文章一:什麼是 ChatGPT? ChatGPT是一種聊天機器人,是基於GPT技術開發的。ChatGPT可以模擬人類的對話,並自學習和理解自然語言,回答各種問題和提供不同類型的幫助。ChatGPT是一種智能聊天機器人,其工作原理是基於自然語言處理和機器學習技術。它使用大量的文本訓練,生成一個巨大的語言模型,可以處理大量的自然語言輸入。ChatGPT的應用場景非常廣泛,可以用於各種客服場景,例如電子商務、銀行、保險、旅遊等等。ChatGPT的使用非常簡單,您只需要訪問相應的聊天窗口或應用程序,然後輸入您的問題或請求。ChatGPT會立即開始處理您的輸入,然後生成回答或建議。ChatGPT未來將會更加智能化,更加人性化,並且能夠提供更加個性化和有價值的回答和建議。 文章二:ChatGPT 的工作原理 ChatGPT是一種基於自然語言處理和機器學習技術的聊天機器人。它使用的是一個巨大的語言模型,可以自學習和理解自然語言,回答各種問題和提供不同類型的幫助。那麼,ChatGPT的工作原理是什麼呢? 首先,ChatGPT的工作需要先進行訓練。這個訓練過程主要是基於大量的文本資料,通過機器學習算法,生成一個強大的語言模型。這個模型可以自動分析和記錄人們的語言使用規則,並且可以理解語言的意義和上下文關係。 當一個使用者輸入一個問題或請求時,ChatGPT會接收這個輸入,然後將其轉換為機器可以理解的形式。ChatGPT會將輸入送入到語言模型中,進行分析和處理。在這個過程中,ChatGPT會根據語言模型的記憶,自動理解輸入的語言,並且生成一個相應的回答或建議。 當ChatGPT生成回答後,會將這個回答返回給使用者。這個回答可以是一個簡單的文字描述,也可以是一個複雜的操作指令。ChatGPT的回答可以滿足不同的需求,例如回答問題、提供建議、處理客訴等等。 總之,ChatGPT的工作原理是基於強大的語言模型和機器學習技術,可以自學習和理解自然語言,回答各種問題和提供不同類型的幫助。這種技術的應用非常廣泛,例如客服場景、資訊查詢、智能語音助手等等。隨著技術的不斷進步,ChatGPT未來將會更加智能化和人性化,為用戶提供更加個性化和有價值的回答和建議。 文章三:ChatGPT 的應用場景 ChatGPT 的應用場景非常廣泛。它可以用於各種客服場景,例如電子商務、銀行、保險、旅遊等等。此外,ChatGPT 還可以用於提供有關科學、歷史、娛樂等類型的問答和資訊查詢服務。 ChatGPT是一種強大的自然語言處理技術,可以幫助用戶更加自然和便捷地與計算機進行交互。在現代科技和商業應用中,ChatGPT被廣泛應用於不同的場景,以下是幾個主要的應用場景: - 客服和銷售支持 ChatGPT可以被用來設計和實現自動化客服系統和銷售支持系統。當客戶有問題或需要幫助時,ChatGPT可以自動地回答問題,提供解決方案和建議,簡化客戶的操作流程,降低人工處理的成本。 - 資訊查詢 ChatGPT可以被用來實現智能問答系統和資訊查詢系統。當用戶需要查詢特定的資訊時,ChatGPT可以通過自然語言進行交互,快速地回答用戶的問題,提供最新和最準確的資訊。 - 智能語音助手 ChatGPT可以被用來設計和實現智能語音助手,例如 Siri、Alexa、Google Assistant等等。當用戶需要完成一個任務或操作時,ChatGPT可以通過自然語言進行交互,快速地理解用戶的意圖,提供相應的操作指令和回答。 - 自動化機器人 ChatGPT可以被用來設計和實現自動化機器人,例如智能聊天機器人、智能問答機器人等等。當用戶需要進行一些簡單的操作或提問時,ChatGPT可以自動地進行處理,提供相應的回答和建議,簡化用戶的操作流程。 - 社交互動 ChatGPT可以被用來實現智能聊天應用,例如智能聊天室、智能交友應用等等。當用戶需要進行社交互動時,ChatGPT可以提供自然的對話流程,幫助用戶快速地建立關係和交流。 總之,ChatGPT可以被廣泛應用於不同的場景,幫助用戶更加自然和便捷地與計算機進行交互,實現智能化和自動化的處理流程,提高用戶體驗和效率。ChatGPT的應用場景正在不斷擴展,隨著科技的進步和自然語言處理技術的不斷提升,它的應用前景也越來越廣闊。 文章四:如何使用 ChatGPT? 使用 ChatGPT 非常簡單。您只需要訪問相應的聊天窗口或應用程序,然後輸入您的問題或請求。ChatGPT 會立即開始處理您的輸入,然後生成回答或建議。 使用ChatGPT是一個相對簡單的過程,但是需要具備基本的技術知識和一些訓練和調整。以下是一些步驟和技巧,可以幫助用戶更加有效地使用ChatGPT: - 選擇適合的工具和平臺 首先,用戶需要選擇適合的工具和平臺來使用ChatGPT。目前,有很多開源工具和平臺可以使用,例如Hugging Face、OpenAI、Google Cloud Platform等等。用戶可以根據自己的需求和技術水平來選擇最適合的工具和平臺。 - 訓練模型 如果用戶需要訓練自己的模型,則需要進行一些訓練和調整。首先,用戶需要準備好訓練數據集,這些數據集應該包含足夠的樣本和語言資源,以便訓練模型可以有效地學習和理解自然語言。接下來,用戶需要設置和調整模型參數,以獲得最好的訓練結果。 - 編寫代碼 一旦模型訓練完成,用戶需要編寫代碼來實現ChatGPT的功能。這些代碼可以使用Python或其他編程語言來編寫,通常需要將ChatGPT模型集成到應用程序或網站中。在編寫代碼時,用戶需要考慮如何處理自然語言輸入,如何解析用戶意圖,以及如何生成自然語言回應。 - 測試和優化 最後,用戶需要測試和優化ChatGPT的性能和效果。用戶可以通過對話測試和反饋來檢測和優化ChatGPT的回答和效果,以確保它可以達到最佳的性能和用戶體驗。 總之,使用ChatGPT可以幫助用戶更加自然和便捷地與計算機進行交互,實現智能化和自動化的處理流程。使用ChatGPT需要具備一定的技術知識和訓練和調整,但是通過選擇適合的工具和平臺,訓練模型,編寫代碼和測試和優化等步驟,用戶可以輕鬆地實現ChatGPT的功能,並且進一步擴展和優化它的應用場景和效果。除此之外,使用ChatGPT還需要注意保護用戶的隱私和安全。因為ChatGPT模型可以接收和處理用戶的個人信息和敏感信息,所以用戶需要嚴格控制和保護這些信息,避免遭到未授權的訪問和使用。總之,使用ChatGPT可以幫助用戶更好地利用自然語言處理技術,提高工作效率和用戶體驗,但是需要注意技術和安全問題,以確保最佳的效果和體驗。 文章五:ChatGPT 的未來發展趨勢 ChatGPT是自然語言處理技術中的一種重要應用,隨著AI技術的發展和應用,它也將繼續發展和擴展。以下是ChatGPT未來的發展趨勢: - 更強大的自然語言處理能力:隨著大數據、深度學習和計算能力的提高,ChatGPT的自然語言處理能力將越來越強大和智能。例如,未來的ChatGPT可能能夠理解更複雜的語言結構和上下文,並且能夠更好地處理多種語言和方言。 - 更多應用場景:ChatGPT的應用場景正在不斷擴展和增加,未來它將可以用於更多的領域和場景。例如,在電商、金融、醫療和智能客服等領域,ChatGPT可以提供更多的智能和人性化的服務,幫助企業提高效率和用戶體驗。 - 與其他技術的結合:隨著AI技術的發展,ChatGPT將與其他技術進行更多的結合和整合,例如圖像識別、語音識別和機器人等技術,可以提供更多的智能和人性化的服務。 - 增強對隱私和安全的保護:隨著人們對數據隱私和安全的關注,ChatGPT未來將更加注重對用戶隱私和安全的保護。例如,未來的ChatGPT可能會採用更加嚴格的數據保護和加密技術,以確保用戶的數據安全。 總之,ChatGPT作為自然語言處理技術中的重要應用,其未來的發展趨勢將會更加多樣化和智能化。未來的ChatGPT將會與其他技術進行更多的結合和整合,以提供更加智能和人性化的服務,同時也會更加注重用戶隱私和安全的保護,以確保最佳的用戶體驗和效果。 Read the full article
0 notes
Text
程式作業代寫服务怎么样?价格方面贵不贵?
科技改变着我们的生活,而科技离不开各领域的工程师与程序员,这是CS也成为最热门专业的重要原因。Assignmenter作为已有7年CS计算机科学代写服务经验的资深平台,我们有丰富的学术资源和多年的Python代写经验,优质Python专家一对一精准匹配,代码免费修改,承诺分数不过全额退款,价格优惠福利多多;我们的java专家实力过硬,学识丰富,还有着多年的java代写经验,可以帮助不同领域的留学生代写各类型、不同难度的作业;不论您需要什么类型、什么难度的r语言代写 ,我们都可以为您安排适配的专家。专家不仅熟悉各类编程语言,同时对Machine Learning、Deep Learning、数据分析等都颇有研究,程式作業代寫经验丰富,可以为留学生们提供全面专业的CS assignment代写服务。
一、程式作業代寫
1.程式是什么?
程式设计又称为「电脑程序设计」,是一种解决特定问题的过程,透过专业的程式设计,设计者能够轻松完成软体项目的开发和编写。而大多数的程式设计往往依赖于某一种程式设计语言,例如:Python、C语言、C++、JAVA等。编译器是研究者和设计者在程式设计中使用范围最广泛的设计工具之一。
2.程式代写服务介绍
程式设计一直以来都是计算机编程课程中非常重要的部分。当下,全球计算机领域高速发展,优秀程式设计人才的职业道路和薪资待遇都非常吸引人。因此,很多留学生在选择出国留学专业时,计算机专业成为他们热门的选择之一。为了确保顺利毕业,寻求专业程式代写服务机构的帮助成为他们最有效的选择。我们正是目前市场上口碑和服务质量都榜上有名的专业程式作業代寫服务机构,我们在计算机编程方面出类拔萃,对各种程式设计语言非常熟悉,能够轻松地帮助留学生获得高分,避免因GPA而困扰。 Assigmenter的程式代写专家不仅熟练运用英语语法,也具备丰富的电脑程序知识储备。此外,assigmenter机构考虑到国外各大高校对程式代写服务的看法,在经营的10年间建立了强大的信息来源网络和隐蔽的信息保护措施。留学生可以完全信任我们assigmenter机构的程式代写服务。如果您也是需要程式代写服务帮助的留学生之一,assigmenter机构应该是个非常不错的选择。

二、r语言代写/java代写流程
网站免费下单:
请在我们的网站上提交订单表格,详细描述您的r语言代写/java代写要求,并上传相关的资料。我们会根据您的要求匹配最适合的专家。
专家报价:
专家会仔细查看您的需求和资料,在1-3小时内给出报价。报价出来后,我们的客服会第一时间通知您。
付定金,专家代写:
您可以选择一次性付全款,也可以预付50%的定金。专家接受订单后会立即开始代写您的作业。如果您有任何疑问,可以随时与专家交流。
下载终版作业:
专家完成作业后,经过原创性检测,完整的作业会通过客服联系您,您也可以在官网上进行下载。
我们保证:
代码交付前会进行MOSS系统查重,保证作业0抄袭高质量 ;
不论作业已交付多长时间,都可以免费无限次修改作业 ;
我们保证作业高效完成,不会拖延交付时间,为您留出充足时间熟系;
专属客服第一时间为您解决问题 ;
我们采用了高端保密系统保护您的信息,保证安全0风险代写。
0 notes
Photo

#純靠北工程師7ln
----------
當老闆說生成式AI或者ChatGPT有可能會取代各位工程師的工作時, 你會選擇拔Server電源或nvidia加速卡,或是加速你寫Python Code的時間跟精神? 想與時間跟壽命賽跑,似乎想太多? 不如把nvidia卡拔下來玩2077遊戲,又有光追性能又好,AI再說吧~ 你老闆再妳背後很火大?rm -rf /* (毀滅之神亞里斯多德曾經說過早點睡隔天比較有精神,公司業績不如台積電,那就拿出台積電的精神來上班,有時間在這邊打屁,不如用在Project上)
----------
💖 純靠北工程師 官方 Discord 歡迎在這找到你的同溫層!
👉 https://discord.gg/tPhnrs2
----------
💖 全平台留言、文章詳細內容
👉 https://init.engineer/cards/show/9851
0 notes

Link
看看網頁版全文 ⇨ 將Python的運算結果,用JavaScript的Cytoscape顯示 / Display the calculation results of Python in Cytoscape of JavaScript https://blog.pulipuli.info/2023/06/display-the-calculation-results-of-python-in-cytoscape-of-javascript.html 背後運算用Colab,前端顯示用JavaScript跟CSS,世界頓時開闊了起來。 ---- # 展示 / Demo https://colab.research.google.com/drive/1p7r1MeSsn0g9J53yt0EfzgeGEis-AHsu?usp=sharing。 整個範例請見上方Colab的分享連結。 開啟後可以按Ctrl + F9執行所有程式碼。 最後執行結果將會用JavaScript版本的Cytoscape繪製網路圖,還搭配了fcose排版技術來呈現。 整個結果當然也可以用滑鼠互動,包括用滑鼠左鍵移動可視範圍以及移動節點,也能用滑鼠中鍵放大、縮小可視範圍。 # 關鍵技術 / Key technologies。 整個展示程式碼的核心有三個關鍵。 第一是資料的輸入。 注意,這裡的資料仍然是Python的list資料類型,並不是JavaScript的JSON。 也就是說,你可以用任何你知道的資料分析方式來產生要輸入的資料,甚至可以透過語言模型來產生結果。 第二是JavaScript版本的Cytoscape結合fcose力引導排版的顯示程式碼。 這段程式碼是參考自cytoscape-fcose demo跟cytoscape.js-fcose的寫法。 你可以注意到裡面關於nodes節點與edges邊緣的變數用「%s」表示,這是因為稍後我們會將它取代為Python變數轉換成的JSON。 這段我引用了五個Cytoscape的程式碼,在此也備份一下:。 - cytoscape.min.js (備份) - layout-base.js (備份) - cose-base.js (備份) - cytoscape-layout-utilities.js (備份) - cytoscape-fcose.js (備份) 最後一段就是用Python的IPython.display顯示結果的功能。 IPython.display可以顯示HTML、Javascript、IFrame、Image等等,非常好用。 詳細說明請看IPython的說明。 這裡我用了HTML跟JavaScript來顯示結果,並搭配Python的字串插值(string interpolation)將Python的變數輸入到JavaScript字串中。 關於字串插值的做法,詳細可以看看自學成功道的介紹。 ---- 繼續閱讀 ⇨ 將Python的運算結果,用JavaScript的Cytoscape顯示 / Display the calculation results of Python in Cytoscape of JavaScript https://blog.pulipuli.info/2023/06/display-the-calculation-results-of-python-in-cytoscape-of-javascript.html
0 notes
Text
[讀書隨筆之二] 現代語言學的獨特之處
前情提要…
書名:杭士基 (原著 John Lyons /翻譯 張月珍)
這本書的書名就叫「杭士基 (Noam Chomsky)」,是我在大學的時候從校園裡的書店購入。書林出版社在民國 81 年出版的小書。
本文打算在用隨書筆記的方式把部份段落擷取出來,並加上自己的說明。
既然講到語言學,就會讓人想到文法研究。那麼現代語言學和文法研究到底有什麼不同?

第二章:現代語言學
傳統文法學家大致說來是鍾情於標準的文學語言 (literatury language)。他們常輕視口語和寫作裡比較非正式或通俗的用語,甚至常指摘通俗用語的不當。
但從語言學的角度來看,只要「有人自然地,不需特別訓練就能說的內容,同樣地也有人自然地,不需特別訓練就能聽懂的內容」,那就是語言的合理用法。
和目前主要從文字學習的 LLM/AI 不同的是,語言學的研究並不受限於文字。因為文字只是「語言的一種記錄方式」,語言也可以被錄音、錄影或是現場的戲劇表演來重現記錄甚至轉譯記錄成為另一種語言或是表現方式。
暫且將這些表現與記錄都放一邊,現代語言學研究的重點是和前一篇系列文的「多個句子有一樣的語意」的目標是一致的。也就是這些表現方式是否有一個可以操作的系統在其後,讓我們可以把 A 語言的表現/記錄方式轉譯為 B 語言的表現/記錄方式。
既然要轉譯,那麼就像我們要把用 Java 程式語言撰寫的程式,重新用 Python 程式語言重寫一次。首要任務,就是「依據 Java 程式語言的句法 (syntax) 來讀懂這支程式想要做什麼 (semantics)」。然後再依據 Python 的句法 (syntax) 來呈現同一個功能 (semantics)。
在前一節中,我們已經簡短地討論過 semantics 的部份。在這裡,我們更能看到,除了 semantics 以外,現代語言學的另一個研究重點就是它的「句法 (syntax)」。
正如書中所提的…
現代語言學的主要目標之一即是建立一套較傳統理論更為週延的語法理論,這套理論必須很適切地描述出人類所有的語言。
再次以程式語言做為類比:也就是說我們企圖找到「設計任何一程式語言時,必要的功能是什麼」(例如:每個程式語言都需要迴圈;每個程式語言都需要條件式…等等)
"syntax" 一字的意思就是「把東西拼在一起」。這麼一來,我們要在語言中建構的東西,就是「把東西 (詞彙) 拼在一起時的規則」是什麼。有了這些規則,我們就更能知道是「什麼和什麼拼在一起」。
以 "John smiles." 這個句子為例。任何懂英文的人,都能基於英文文法 (grammar) 知道 "smile" 加了一個 "-s" 的尾綴,是因為它和 "John" 拼在一起。
但如果我們把這個條件「當 smile 接在 John 後面的時候,smile 要加上 -s 的尾綴」當做文法的話,我們將會無法解釋那為什麼以下的 smile 是不加 -s 的。
"Mary and John smile."
因為我們的確讓 "smile" 接在 "John" 的後面了!為什麼這時候 smile 又不加 -s 了呢?這時候,我們有兩條路可以選。
一是現代語言學採取的「每個句子都有其內部結構,詞彙元素之間是以結構節點做為其互動的介面」。這麼一來,我們就能說明,其實 "John smiles." 和 "Mary and John smile." 有一樣的結構。都是
[主詞] + smile
的結構。接下來,只要看 [主詞] 裡面是單數或是複數的語意,就能決定 smile 會不會有 -s 了。
也就是說,兩個句子的結構其實都是:
[主詞 [John]] + V
[主詞 [Mary and John]] + V
至此,我們可以進一步把這個結構記做:
[Snt[[Subj.[N...]] V]]
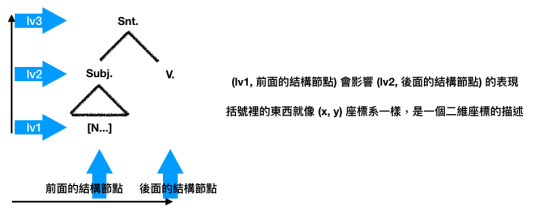
用最前面的 Snt 來表示只要有了後面兩個元素,它就能形成一個 Sentence。然後,只要 len([N...]) > 1, 那麼 V 就會要加上 -S. (注意,我在這裡用大寫的 S,表示它是 -s, -es, -ies... 等複數詞綴的集合)
而這個標記方式,顯示出語言的結構是投射在二維空間,同時需要考慮「前後」與「上下」關係,而非一維空間的只考慮「前後」而已。
另一條路,則是延續前面的「smile 之前 是 John ,那麼 smile 要加 -s」的思路,再額外加一條「smile 之前 是 John ,那麼 smile 要加 -s若 John 之前有個 and,且 and 之前還有 Mary,則 smile 的 -s 取消」。
如此這般,便從原本的一條規則,隨著線性的前後考量,變成了兩條規則。從現在的眼光看���,這種方法實在是很傻。
但 1950 年以及之前的傳統語言學家的確是這麼做的,而同一時代的 Chomsky 的理論仍在發展中,還不到「完備得可以應用」的時候。以致於 1950年代開始,參與 AI (人工智慧) 研究的語言學家,其思維模式都更接近傳統語言學,而非現代語言學。而在當時也的確使得 AI 專家們得出「語言學沒有用」的結論。要注意的是,這句話裡面的「語言學」指的是傳統語言學。畢竟那時候的理論語言學還在建構中呢。
因此,即便是名稱看起來非常先進的「計算機語言學」(Wiki 頁面中提到亦是從 1950 年代開始),也是傳統語言學的思路下的產物。使得即便是 NLP 領域裡常見的 NLTK 仍然是這種「一維空間,前後關係下的規則」的產物。
以下用 NLTK 來取得 "was" 這個 "過去式 Be-動詞" 的詞幹 (stem),就會發現它的思路就是「在一維的前後空間裡,去除最後一個 -s,就能得到詞幹」的做法。所以它最後得出 "was" 的詞幹是 "wa"…

另一個有趣的事情是,雖然 AI 科學家們早就得出「(傳統) 語言學沒有用」的結論,但諸如 ChatGPT 和 Bard …等大型語言模型 (LLM) 所立基的 Transofrmer 仍然是採用了「利用大量資料,擬合在一維空間裡前後字符 (character) 彼此關係」的思路。只是每個一維空間都被獨立儲存起來,讓它有了超級多的維度。
最後,在 LLM 出現以後,許多「計算機語言學」的實驗室也紛紛放棄自己原本的 (傳統)語言學研究方法 (畢竟說穿了…除了標記和統計以外,本來也沒什麼獨到的方法),全部改用 ChatGPT…等 LLM 做為研究的基底,甚至直接宣稱這就是人類語言/語意的模樣了。
這些方法都忽略了一個很基本的事實:「語言的本質就不是線性的!」
在錯誤的維度空間裡,企圖尋找正確的答案,就像在全世界的動物園裡,企圖尋找企鵝。你會在某些動物園裡找到企鵝,但也會有一些動物園裡沒有企鵝。固然,你可以說「這���的尋找,還是有點用的。我們現在知道用什麼方法問動物園,可以最快得到他們有沒有企鵝的答案」。
但你永遠無法解釋「為什麼有的動物園裡有企鵝,有的動物園裡沒有」。因為「動物園」本來就不是「企鵝」這種動物本質上的自然棲息地。就像本質上是在二維空間裡運作的語言,你偏偏跑到超高維度裡去想要尋找它的身影。是,你會找到一些東西,但那不是語言的本質。
0 notes
Link
0 notes
Photo


Julia 程式設計:新世代資料科學與數值運算語言-books 由麻省理工學院電腦科學與人工智慧實驗室開發的新語言! 下載量超過兩百萬次,Google、Facebook和美國聯邦航空總署的開發者都在用! 全台第一此Julia操作學習教科書,只有這此,帶0基礎的你從頭開始學Julia! 第二版的增修與Julia官方同步更新,此書帶你永遠走在最前面。 全球熱度上升最快的程式語言,趕快一起來追程式語言新女神!! 大數據時代,科技的進展速度早已遠遠超越我們的學習速度,因此,只有不斷的學習最新的知識和技能,才不會在大數據的浪潮之中狠狠摔在沙灘上。如果你今年只打算學習一個新語言,我會毫不猶豫的推薦──Julia! 用於優化數據分析和深度學習的最佳語言已經誕生! ◣Matlab般強大的線性代數運算能力,而且免費! ◣Python般簡潔的語法系統,而且更快速! ◣與C語言一樣快速,而且更加容易上手! 此書為全台第一此Julia操作學習教科書,作者為資料科學專家,同時擁有豐富的教學推廣經驗,最了解初學者需要的講解方式,在寫作上使用螺旋教學法,幫助讀者在最短時間建立對Julia的掌握與運用能力。先從介紹Julia這個語言的特性和安裝步驟開始,接著針對資料型別、變數、註解與函式等進行基礎性的介紹,後續再分別以各個主題加以深入探討以及實作演練。作者將程式步驟一一拆開,一步一步的解析,讓你也能輕鬆跟著踏入新世代程式語言的精采世界。 第二版加入遞迴、例外處理、資料結構與泛型程式設計等全新章節,並重新編排章節及內容,讓學習更為流暢。 Julia,為資料科學而生。 閱讀更多內容 語言:繁體中文,ISBN:9789577633828,頁數:372,出版社:五南,作者:杜岳華,胡筱薇,出版日期:2019/06/10,類別:電腦資訊 Julia 程式設計:新世代資料科學與數值運算語言,博客來
1 note
·
View note
Photo


A-Life 使用Python實作人工生命模型-books 這是一此為了讓對使用電腦設計生命感興趣的人,可以輕鬆閱讀,而努力撰寫的書籍。 基於這一點,這此書是寫給想使用ALife塑造人物角色或場景的遊戲設計師,以及希望增廣自我創造力的創意人員,而非原此就對「生命是什麼?」十分關切的自然科學研究者、工程師、致力ALife研究的學生。當你讀完這此書,應該可以從人工生命的角度,掌握現代科技的觀點。 ALife也能運用在使用人工智慧的機器學習技術上,因此,對於人工智慧有興趣,或已經在運用AI的人而言,應該可以成為激發靈感或創意廣度的契機。 此書使用了在人工智慧領域經常運用的Python語言。書中附上了執行ALife的程式碼。只要具備基礎的程式程式設計技能,就能理解此書的實作。 閱讀更多內容 語言:繁體中文,ISBN:9789865021474,頁數:200,出版社:歐萊禮,作者:岡瑞起,池上高志,ドミニク・チェン,青木竜太,丸山典宏,譯者:吳嘉芳,出版日期:2019/06/25,類別:電腦資訊 A-Life 使用Python實作人工生命模型,博客來
1 note
·
View note
Text
AI訓練師
H:每個詞條是一扇窗,學習新知識,整理再進化,莫成數位白痴。20230620W2
AI訓練師
網路資料:
AI 訓練師:「我們是苦力工人,但沒有我們,就沒有人工智慧語言系統」
訓練師負責訓練、測試或調整 AI 系統,以協助系統產生更可靠的結果。
職業消失的警訊:
根據世界銀行今年的就業報告,因為AI的影響,未來五年內可能有1400萬個職位消失。
新創職業:
但專家發現,因為AI應用熱潮,其實創造很多以前從來沒有出現過的行業,像是專門協助人工智慧展開學習的AI訓練師,光是中國大陸的人力缺口就高達200萬人。
AI相關技術人員的人才缺口也高達500萬,職位供求比率甚至是1:10。
薪水:
傳出ChatGPT母公司OpenAI,就在尋找經驗豐富的AI訓練人員,年薪從20萬美元起跳。
定義:
「AI訓練師」英文是Prompt Engineer,Prompt原意為「提示」或「驅使」,Prompt Engineer的任務,是訓練或協助調整AI輸出想要或正確的答案。
專業上,Prompt Engineer的定義,是「具備自然語言與機器學習等各種專業知識,然後透過評估各種不同的prompt組合,找出最佳prompt,提高模型效率的工程師」。
多元的名字:
Prompt Engineer通常不會直譯為「提示工程師」,較貼切翻譯應是「AI溝通工程師」、「AI溝通師」或「AI(模型)訓練師」,較符合實際工作內容。
大陸考證:
五級/初級工、四級/中級工、三級/高階工、二級/技師、一級/高階技師。
維基百科介紹:
人工智能(英語:artificial intelligence,縮寫為AI)亦稱智械、機器智能,指由人製造出來的機器所表現出來的智慧。通常人工智能是指透過普通電腦程式來呈現人類智能的技術。該詞也指出研究這樣的智能系統是否能夠實現,以及如何實現。同時,通過醫學、神經科學、機器人學及統計學等的進步,常態預測則認為人類的很多職業也逐漸被其取代。
Python在網路爬蟲、雲端基礎設施、DevOps與數據處理等領域都是炙手可熱的語言,因此被廣泛運用於各行業,如:Google search、YouTube、DropBox、NASA、IBM、Mozilla等組織或平台進行資料分析運用。
網路資料:
AI訓練課有那些?
基礎課程
Machine Learning Specialization專項課程包括3個課程,分別為:
Supervised Machine Learning: Regression and Classification
Advanced Learning Algorithms
Unsupervised Learning, Recommenders, Reinforcement Learning
機器學習課程
中階課程

Deep Learning Specialization
AI for Medicine Specialization
Natural Language Processing Specialization
Generative Adversarial Networks (GANs) Specialization
TensorFlow Developer Professional Certificate
TensorFlow: Data and Deployment Specialization
TensorFlow: Advanced Techniques Specialization
各專項課程也都包含多個子課程,幫助你完整的學會特定領域的AI技能。
高階課程
Machine Learning Engineering for Production (MLOps) Specialization
Practical Data Science on the AWS Cloud Specialization
工作實例:
AI训练师
来源:杭州悦蓝互联科技股份有限公司
岗位职责1.负责公司AI平台的日常管理.维护和运营;2.能独立完成公司业务所需的AI话术制作,满足业务生产需求;3.负责维护知识库,对知识库准确率.操作性.解决率负责;4.能通过数据标注和分析,归纳问题,不断完善话术;任职要求1.本科及以上学历,有游戏,教育,电商结合人工智能相关工作经验1年及以上;2.有效能改进.质量提升.系统优化相关项目经验者优先考虑;3.有一定的抗压能力,敢于直面担当自己领域的工作内容;4.工作态度认真,责任心强优先。
主要工作是生成提示:參與與聊天機器人的來回對話,這是訓練 AI 系統漫長過程的一部分。他說,隨著經驗的增加,任務變得越來越複雜,但它們剛開始時非常簡單。
主要工作任務:
1.標注和加工圖片、文字、語音等業務的原始數據﹔
2.分析提煉專業領域特征,訓練和評測人工智能產品相關算法、功能和性能﹔
3.設計人工智能產品的交互流程和應用解決方案﹔
4.監控、分析、管理人工智能產品應用數據﹔
5.調整、優化人工智能產品參數和配置。
0 notes
Photo

自己不敢講話的話怎麼辦呢?不妨請Google小姐幫你唸稿吧。 ---- # gTTS https://pypi.org/project/gTTS/。 gTTS是Google Text-to-Speech的包裝接口。 它是由Python撰寫而成,並提供命令列工具,讓使用者能夠輕易地使用Google翻譯的Text-To-Speech API。 安裝之後,你只要用以下指令,就可以產生唸出「hello」的聲音檔:。 [Code...] 然而實際上一個好的TTS工具並不是單純讓機器人發出聲音而已。 它們怎麼決定「一句話」的長度,將原始文字調整成合適唸出的文字,這些都是需要投入巧思的細節。 https://gtts.readthedocs.io/en/latest/。 gTTS也有考慮到這點,在文件中有諸多細節說明。 舉例來說,Google翻譯TTS API僅接受100個字。 因此gTTS會嘗試依據空格將一長串文字切割成多段。 https://github.com/pulipulichen/PWA-Plain-Text-Editor/blob/main/src/components/FloatActionButton/FloatActionButtonMethodsSpeak.js。 此外,gTTS也提供了縮寫取代等前處理功能。 這跟以前我用JavaScript開發TTS工具的時候還蠻像的。 ---- 你覺得gTTS可以用在什麼地方呢? 歡迎在下面分享你的看法喔! ---- #gTTS #Python #TextToSpeech 看看網頁版全文 ⇨ 文字轉換成語音: gTTS / gTTS: A Google Text-to-Speech Wrapper https://blog.pulipuli.info/2023/02/blog-post_315.html
1 note
·
View note