#trying to find answers to technical problems. i once had 20 tabs open and i was like okay i should like. have lunch
Photo

hgrng...thinking of love
#mine#original#yes i realise i keep posting felttip cats but. they are fun#my sketchbook is just felt tip cats. almost exclusively#ive had a DAY. some how spent 3 hours sitting at my laptop and achieved nothing#trying to find answers to technical problems. i once had 20 tabs open and i was like okay i should like. have lunch#also my mum kept talkin abt my childhood n i was like. almost completely dissociating..mental illness >:)#i have headache >:(#but now is weekend...hehe.....its gna be warm tomorrow im going to read my book#i would LIKE to finish it....maybe i will....can i read 300 pages in one day mm maybe not#i feel like this book is gna end in tears. hmm.#okay im going to bed now goodnight!#going to play rainworld hehehhehehe#song rec of the day is bible belt my dry the river#song rec is also the NEW mcr song. hohfhbgdfgk
27K notes
·
View notes
Text
moving step by step (together)
second and last thing i posted on wp that i haven't posted here ((i think)) feel free to ignore if you've read this on wattpad already, as i'm just posting it in case i need to refer to it later.
(not proofread. it never is)
prompt(?): domestic!simbar deciding to move in together (toanothercountry)
When her day began, she didn't imagine it'd end up the way it did. In fact, to Ámbar the day felt like an endless nightmare.
Between her washing machine breaking, one of her kitchen cloths accidentally catching on fire when she was making her breakfast, her car not starting and thus being late to her first class, forgetting an important paper at home and losing 1/5 of her grade for one of the toughest classes in her semester; Ámbar just wanted to call it a day and forget she even had to endure it.
"The professor told me he'd let me turn it the paper, as long as I added 10,000 words more; and hear this: he won't give me the 20% of the grade, but a 15%, tops." She still needed to get her laundry done, so she'd opted to come by Simón's loft (and Nico and Pedro's too) when her classes had ended. While she waited for it to be done, she'd grabbed a glass of wine while venting her boyfriend's ears off. "So now I need to find something to write about that's worth 1000 words of coherency, otherwise I'll be lucky to even have a 10%. And God knows I need it."
Simón kissed her head sympathetically, adjusting her head - previously leaning on his shoulder- a little bit closer to his neck. "You will, little gem. You're the smartest one in your class, I'm sure you'll find something and, it's penultimate semester, you can do it."
She groaned, "I wish it were as easy as that." He kissed her cheek this time, and she snuggled into him a bit more, needing his support to make her feel less stressed. "Enough of me, how was your day?"
He chuckled, "not as interesting as yours, I'm afraid. Did a little songwriting, had a video-call with a magazine, changed my sheets..." he winked at her, making her laugh.
"Aw, do you want me to give you a gold start? Maybe I should call your mom, tell her her little boy is a nice young man who makes his own bed." Simón leaned in to bite her cheek, causing her to and almost spill her wine all over the couch, and to prevent this, the red liquid ended up on her shirt. Technically, it was one of his, since today's clothes had been thrown in the washer with the rest of the laundry, but still, spilling wine on her clothes wasn't nice. "Simón!" she scoffed him, which only made him laugh at her. He told her to grab another of his old shirts, while he refilled her glass.
She stood up then, cursing him all the way to his room to grab one of the 'pajama' shirts he kept in his top drawer. Ámbar heard him call to her once she had put it on; "hey, is tacos okay with you for dinner? Or do you want me to order you something else?"
"What are the guys having?" she questioned, to prepare herself in case the others ordered less than what their stomachs wanted to eat, and later lead them to steal her food.
"Pedro's staying at Delfi's and Nico is out with his fling, so nothing." Simón answered her, entering his room with his cellphone at hand.
"Then the usual." She told him simply, her boyfriend nodded. "Hey, can I use your laptop to check my e-mail? My phone died."
Simón nodded again. "Sure. Hello? I would like to order two pastor gringas..." he left the room again, not before pointing at his desk, where his laptop was sitting on. She quickly turned it on, taking it to the living room to wait for Simón to finish the call.
Her boyfriend was one of those people who didn't put a password on the device itself, but on the archives in it (which were mostly lyrics, tracks, and unreleased songs), so it didn't take long until she had the browser opened.
Ámbar tried to ignore whatever Simón had open in his last tab, but the images displayed caught her attention.
No, it wasn't porn, nor was it anything compromising. At least not in that way.
Her boyfriend had a Real Estate website open, showing apartments in sale. However, that wasn't what surprised her – he'd talked about finding his own place before-, but that all the options listed Mexico City as their location.
He'd never mentioned moving back to Mexico. They'd planned vacations to his hometown Cancún, sure, but somehow in all their talks about the future she'd had assumed their plans took place in Buenos Aires, close to her family instead of his. She could deal with him going on tour for weeks – she didn't bear months as well as she did weeks, and for this he always flew her in- but to live in two different countries? How was their relationship supposed to work in that scenario? Would it even work out? Sure, she was almost over with her degree, but-
"Little gem," her eyes snapped from the screen to where Simón was standing, by the kitchen's door, "I ordered you an almond horchata, is that okay?" she kept staring at him. "What? Is my laptop giving you problems? Your mail?"
She sighed. "No, I actually haven't opened my mail yet." He gave her a confused look.
"Then what's it? You've been staring at the screen for at least two minutes."
"When were you planning on telling me you're moving to Mexico?"
His mouth shut, his eyes showed surprise and an underlying regret. "Uh... soon?"
"So it's true, then? You're moving there?" Ámbar didn't want her voice to sound as hurt as it did, but she couldn't conceal it, either. After all, this was her boyfriend, the guy she was in love with, and who she'd loved for years now... to imagine him living so far away from her, it hurt her deeply.
To find out like this, instead of from his own mouth, was like salt to the wound. Her already shitty day was turning for the worse.
Simón sighed, his demeanor showing he was ashamed of it. "It's an option." He pursed his lips slightly, walking over to the couch, taking the device off her lap to turn her body towards him. "I was planning on talking to you about this sooner than later, I promise."
"When? When you had already bought it? Or when I had to say goodbye at the airport?" she couldn't help but dab at him, her temper was talking for her right then, "and what do you mean with 'it's an option'? You're looking for a place already, surely it's more than simple 'option'."
Simón let out a sigh, a sign he wasn't sure how to explain it to her, "I- have you noticed how most of our label meetings have been taking place in México?" She nodded, it was hard not to. The boys and him didn't really leave the city unless they absolutely had to, which could be summed up in three reasons: touring, vacations, and meetings. She'd always frown a little when those meetings took place, because she couldn't really understand why they had to leave when their label had offices in BsAs, but never really dared to ask Simón, afraid she'd come out as clingy for not wanting him to leave her for a couple days.
"I just assumed all the 'important' people chose to meet there instead of flying down here."
He scratched his nape. "It's a little bigger than that. Their HQ has always been up there, and their offices here have worked on a smaller scale for years; however, they've wanted all their more... 'recognizable' artists to be closer for a while now."
"So, they're making you move there?"
"Yes and no. They've been nagging us since the beginning to move to Mexico City, but it's only now we've – well, I've- considered it as an option."
"Why? Don't Pedro and Nico want, too?"
Simón grimaced. "They've already been considering it for a couple of years." Oh. Now that she thought about it, Delfina had hinted multiple times over the months 'the possibility' of working in another country. She'd always assumed she meant taking international jobs for a short period while Pedro was out on tour too, but now she guessed she'd meant for her to imagine that possibility, too.
It seemed like she'd assumed lots of things, and it stung to know she'd been in the dark far longer than everyone else. Even Delfi – who'd been dating Pedro a considerably less time than she'd been with Simón- knew of this before her.
Which made her ask him once again. "Why didn't you tell me sooner?"
"Because you're still in uni, little gem, and I didn't want to move somewhere else while you were here; I still don't. I had a plan, honestly; I was going to wait until you neared graduation to slowly get you used to the idea, and, well, I also wanted to wait in case we didn't work out." She pursed her lips as she was still mad, but knew he had a point. He always did.
"You could've talked to me sooner, though. We could've planned this way sooner, make it easier for both." Ámbar sighed out, trying to get her anger out with it.
"I know, I get it now, and I'm very sorry." He apologized sincerely, grabbing one of her hands to kiss it. "This in no way is me telling you I'm moving tomorrow and leaving you here, little gem, I'd never do that. Hell, I don't even think I could. It's just..."
"An option." She finished for him, sighing again. "I guess I- I don't know, maybe I could start looking at internships in CDMX? When- when would this take place anyway? And I have to talk to my mo-" her eyes widened, "God, my mom! What do I tell her if we go? She'll be all alone here!" Her voice sounded panicky even to her.
"Hey, it's okay, there's no hurry. We've already postponed this for years with the boys, another year or so won't change anything, in fact, we'll need all we can get to get papers and stuff in check. And your mom can always come with us if you're worried about her, no biggie." He told her, as if the three of them moving countries wasn't a big deal, or, y'know, extremely expensive.
"Do you seriously want my mom living with us, Simón?" she snapped at him, and immediately felt bad to do so. He was just trying to help her and then here she was, bitching on his offers. "Sorry, sorry. I'm just... overwhelmed, sorry." He shrugged it off.
"I was actually thinking of you two getting your own apartment but since you're oh so kindly offering to live together..." Her eyes widened once more, shocked. She hadn't realized she'd implied that. "... I guess we can either buy or rent one for ourselves and rent another for your mom."
"That's not what- I mean it's not necessary. An apartment for my mom and I would be okay if she even agrees to move."
Her boyfriend started pouting. "Are you saying you don't want to move in with me?"
"No, no, that's not what I mean-" she stopped talking once she saw a teasing grin on his face. "You're messing with me."
He shook his head, silently laughing as he reached out to sit her on his lap, hugging her waist tightly. "I'm not. I'm actually happy you asked me to move with you, so I don't have to when the time comes."
"I didn't ask you." She felt the need to point it out. "You just assumed I did."
"Because you assumed we'd live together. It's okay; if it were up to me I'd be living with you in a heartbeat, I've thought about it for a while."
She gulped. "You have?"
"Yeah, but since I'm living with two dudes and you're living with your mom... it just isn't viable." That got her thinking.
"Why haven't you gotten your own apartment yet? Any of you?"
Simón shrugged, leaning into their coffee table to grab their glasses. "Rent is cheaper when you divide into three, and all of us have been saving up to get our own pads for when we moved to CDMX."
"It was never a matter of 'if', was it? It was always a 'when' you moved." She already knew the answer, of course, so she didn't wait for him to answer. "What took you so long to do so? I'm sure you could've done so years ago, and now you're waiting for Delfi and I, I guess, but before? What held you back?"
He pondered it for a minute, didn't speak immediately. "Something always came up. At first, we didn't have enough money saved, then Nico's mom had an accident, Pedro wanting to stay until his little sister finished high school... then you. My guess is the universe was waiting for us to meet to let me leave the city." She couldn't help but laugh at this.
"You're such a corny guy."
"Only for you, little gem, only for you." Ámbar took a sip of her wine before snuggling closer to his chest, earning her a kiss on her hair. "So, are we doing this?"
She pushed the anxiety of the unknown to the back of her mind, she knew that if she overthought about it she'd find reasons not to. Instead, she took a deep breath, intoxicating herself with the smell of soap and lotion that lingered on her boyfriend all the time.
"Yeah," she sighed, "but we're doing this together."
"Together," he repeated, giving her hand another kiss. "I like the sound of that."
11 notes
·
View notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
Google can consistently crawl our pages as intended.
We’re sending Google consistent signals about the status of our page.
Google is consistently rendering our pages as we expect.
Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
Look for errors
Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.
An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie"> </div> <p> <h1 itemprop="name">Avatar</h1> </p> <p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span> </p> <p> <span itemprop="genre">Science fiction</span> </p> <p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a> </p> <p></div> </p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
<title>
<style>
<base>
<link>
<meta>
<script>
<noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine.
Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
301 to https://www.client.com - This was the blanket HTTPS redirect
302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
What are the best brainteasers you've had?
Let’s hear them, people. What problems have you run into? Let us know in the comments.
Also credit to @RobinLord8, @TomAnthonySEO, @THCapper, @samnemzer, and @sergeystefoglo_ for help with this piece.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/2lfAXtQ
via IFTTT
2 notes
·
View notes
Text
Twenty Minutes of Awkward Silence
Keith needs help studying for an English midterm and Pidge knows exactly who can help.
Voltron, klance/laith, 3,218 words, rated G, modern/college AU
MASTERPOST
“How likely will I get out of this exam if I throw myself off a bridge?” Keith sighed.
“If you give your professor a heads up you’re gonna attempt suicide she’ll probably give you a couple days extension.” Pidge didn’t even look up from her textbook. “I heard she’s nice.”
“Yeah, she’s nice, but I have to read almost whole novels before every class on top of all the short stories and poems and a reading exercise. Who does she think I am, an English major?”
“This is a class aimed towards English majors, so, yeah, it’s right to assume so.”
Keith huffed. “I’m interested in American Lit. I was hoping we would go over Edgar Allen Poe, but he’s not even on the syllabus at all and I’m already too far in to drop the class.”
“Woe is me, my class doesn’t provide my emo poetry,” Pidge mocked, voice rising a little over a whisper. The guy sitting at the table next to them threw a dirty look their way over their ceaseless chatter, or really, aggressive whispering.
“Please let me live. I just really like The Raven. And I thought it would be a fun class, but this is the least fun I’ve had in my academic career.” Keith slumped over the table and rested on the open pages of the thick, bible-paged textbook.
There was a few moments of silence between the two, where Pidge focused on writing down some equations from her book and Keith kept sighing despondently into the abused book.
“Stop sighing and get a tutor,” Pidge snapped. “I have a midterm in two hours and my study guide isn’t even done.”
“I don’t know anyone in class and I don’t have money to buy one,” Keith groaned.
“Ask Lance,” she said simply.
Keith bolted upright from his textbook pillow. “What?”
“Ask Lance.” She finally looked up from her notes. “It’s his minor. He probably already took the class and has old notes he could give you.”
Keith’s mouth went dry. “Isn’t - isn’t Allura and English major? Wouldn’t it be easier to ask her?”
Pidge smirked. “Oh, you could, but she’s busy working on university applications on top of her midterms. Besides, I’m pretty sure she took World Lit instead, so she wouldn’t be able to help you.”
Keith bit his lip and absently flipped through the Bible-thin pages, the sides weighed down with numerous note tabs and crinkled at the tops. He didn’t want to look at her, would rather be looking at this specific chapter of Huckleberry Finn.
“He doesn’t bite dude.” Pidge reaches across the table and touched his hand. “Lance is a seriously sweet guy. Like, I know everyone’s he’s dated up to this point were all stupid to break up with him. He’s so dang sweet and considerate with them. If anyone deserves a guy like Lance, it’s you, okay?” Keith looked up and met her stern gaze. “I really think you should tell him how you feel. It’s stressing you out so much you’re scared to ask for help. And maybe, if he rejects you, it would help clear the air. Yeah, it’ll be awkward for a bit, but trust me, you’ll feel better.”
“When did you get smart on people’s feelings?” Keith snorted.
Pidge pulled back her hand with an anguished look on her face. “I may suck at emotions, but I’m clearly better than your pining ass if you need advice from me.”
“Didn’t ask for it. You freely gave it.”
“You looked so pathetic, I needed to do something. You didn’t say it, but your puppy dog eyes and depressive sighs said you did.”
“Um, thanks, I guess,” Keith said and looked back down at his book.
“No problem. Now text him because when’s this test?” Pidge cupped her hand over her ear and leaned foreward.
“In two days . . .”
“Yeah . . . text him. You need help.” Pidge slammed her book shut and started gathering her stuff.
Keith pulled out his phone and nervously typed out a message, erased it, then typed out a new one. It took him probably a good five minutes too long to type it out. He handed his phone over to Pidge, who was standing over him like a hawk and watching his progress, to double check if it was okay. Without even pausing to look she hit send.
“What was that for! I needed you to proofread it!” Keith snatched the phone from her hands, who was too busy cackling to actually stop him.
“Dude it’s a simple ‘I need help studying for English can you help me?’ Not a confession! Jesus, oh my God, Keith.” She snorted.
Before Keith could give her a retort, his phone vibrated and startled him enough to fumble with the phone for a second. His hands were so clammy he had to swipe a couple times to actually open up the text message.
Me
Today 10:43AM
Hey I’m not doing too
hot in my English class
right now but Pidge told
me it’s your minor and
you probably took the
class already would you
be able to help me
study? The exams on
Thursday.
Lance
Today 10:44AM
Ya sure what English is
it so I can find my
notes?
Today 10:45AM
& we can do it tonight?
Keith sucked in a breath. “Tonight?”
Pidge frowned. “Why are you asking me for permission? You’re a big boy now.”
“I’m scared?”
“Text him, ya goof! Now I gotta run to class. Stay safe and make good choices.” Pidge waved and she was gone. Keith gave a solemn wave and turned back to his phone.
Me
Today 10:47AM
American Lit 241 with
Corey this class is a
mistake but I already
put too much work in it.
And tonight works.
Lance
Today 10:47AM
OH I LOVE HIM I LOVE
241 YES I CAN HELP U
MY PLACE OR URS
OR LIKE A STARBUCKS
MY DUDE? A LIBRARY?
A LIBRARY MIGHT BE BAD
Me
Today 10:48AM
Would my place work?
Shiro’s out and from
what you told me your
roommates lowkey scare me.
Is 4 ok?
Lance
Today 10:48AM
I get off class @ 4:15 so
4:30ish?
Lance
Today 10:49AM
I’ll find all my old notes
and study guides & I’ll
bring some guac
Keith smiled and tucked his phone away so he could at least pretend he was reading. It was a little difficult with that weird fluttering in his chest and trying to contain the smile on his face. He couldn’t help it! He was going to have his first date with Lance! Well, no, this wasn’t technically a date, but this would be the first time they’ll be hanging out by themselves in the few months they’ve known each that’s actually planned ahead and not them running into each other in the courtyard or library. No one was bound to run into them, too. And best of all, Shiro’s gone for the night to a concert in the next city over with Matt and Allura.
Maybe Pidge is right, this is the perfect time to tell him how he feels. But maybe after they get some studying done to avoid any awkwardness that Keith is sure to bring.
Tonight couldn’t come fast enough.
Scratch that thought. By the time four came around Keith was stressed out.
At exactly 4:19, a knock rang through Keith’s little apartment. He sat there for a few moments trying to wipe the sweat off his palms and work up the courage to stand up. At 4:20, he stood outside the door with a hand hovering over the doorknob, that damn fluttering in his chest and belly kicked into overdrive. It was hard to breath with what felt like his lungs were full of beating wings.
At 4:21 he opened the apartment door to Lance’s near blinding grin.
“420 blaze it,” he said.
“It’s passed 4:20 you missed it,” Keith huffed and stepped aside to let him in.
“It’s your fault for taking so long to open the door,” Lance frowned and kicked off his shoes next to where Keith and Shiro had theirs neatly lined in the shoe rack by the door. “You ruined my joke, mullet.”
“Mullet?” Keith had instinctively went to touch the ends of the hair curled around his neck.
“Yeah, business in the front and party in the back. Although,” Lance reached up and caught a lock between his fingers. “You’re more like angry in the front scary in the back.”
Keith had locked up at the brush of fingertips to his hair but immediately melted at that comment. He frowned and said, “Shut up.”
Lance snorted and came fully into the apartment. “I have the guac but sadly, I don’t have the good tortilla chips. Just some generic party brand.”
“I’m not picky.” Keith took the tupperware full of the delicious, green goop and chips from him and put it on the ottoman tray where two textbooks, a handful of of pens, a notebook, and a half empty mug of coffee were already strewn across it.
“Alright so,” Lance plopped down in the couch and started rifling through the notes, ”if the test is in two days, and this is all your notes, then I’m really scared for you.”
Hesitantly, Keith took a seat as close as he could next to Lance so he could still reach the notes but left several inches of space between them. God, did hearts normally beat this fast? “I need so much help. I’m not even gonna pretend that I know what I’m doing.”
“Well,” Lance paused to eat a chip heaped with guacamole, “you need to know who wrote what and generally when, so that’s a start. Take notes on general information like a summary along with maybe like a little factoid about the author and the time period. Then, basic things like literary elements, themes, and characters. After that, we can go over discussion questions to help you get a better idea of what you’re doing.”
“What the fuck,” Keith whispered.
“Don’t worry,” Lance patted his arm. “Corey likes to hype you up and over-prepare you, but once you sit down, the exam’s like, ten questions, and only four of them are long answer.”
“Do you see all these tabs I have in here?! I have two days to learn all this!” Keith could feel the rising panic bubbling in this chest. It overpowered those beating wings.
“Hey, hey calm down, it’s alright.” Lance turned in his seat to run his hand up and down Keith’s back in a soothing gesture. “Yeah, it’s scary, but trust me it’s all the hype. We can cut down on a lot of the reading. You don’t need to know every single poem. Just breath, it’ll be okay.”
Keith took a steadying breath then finally nodded. “Okay. Where do we start?”
Lance reached into the backpack he brought and pulled out his laptop and two of his own copies of the textbooks. They were worn down and had probably twice as many tabs in it as Keith’s did. “Sparknotes,” he simply said.
“Why? I- I thought we couldn’t?” Keith felt like Lance just slapped him with some forbidden knowledge.
“Professors hate it when we cheat with Sparknotes, but I’m taking sixteen units this semester, so I’m allowed a break. Hand me your reading list. Let’s write down what we need to focus on first before we can write up a study guide. Then, after that, we can go over it.” Lance cracked open his worn book to one of the tabbed pages; the thin paper bled in a rainbow of pens and highlighters. There was almost as much text scribbled in the margins as there were in the text itself.
Keith gave a hum in acknowledgment and passed the reading list to Lance.
Much to Keith’s surprise, Lance was very no-nonsense when he came to studying. He helped Keith outline everything he needed to know, then pulled up Google, Sparknotes, and even his own notes (which, Keith noted, where near illegible) to go through every bit of information Lance believed he would need. It was tedious work going through a few dozen short stories and poems in great detail, but he would admit that this was actually fun. Lance kept the mood light and easy, but best of all, his endless stream of commentary actually felt like it helped Keith learn the material better. At first, Keith thought Lance was goofing off, but later realized in Lance’s own roundabout way this was helping the material stick, like:
“If you really think about it Luck of Roaring Camp is basically like a family can be fifty dads, a dead prostitute as the mother, and a singular baby they still somehow managed to kill. There’s fifty of them, Keith. Fifty.”
“Jim is perfect and doesn’t deserve any of this mistreatment. Huck? Yeah, he was a dick but he was actually getting character development until Tom Sawyer shows up and decides to ruin everything for the drama. God I hate Tom, that racist asshole. Why does he get a whole attraction at Disneyland and not Jim? Jim deserves an island.”
“I didn’t actually read Law of Life but it’s Jack London. It probably has something to do with nature and death, maybe socialism, too.”
“Hey, Lance?” Keith cut through one of their rare moments of silence. Lance grunted to cue Keith to keep talking. “You’re. . . really good at this. Like, you obviously love these classes, so why isn’t this a major?”
Lance put down the book he had buried his nose and gave a thoughtful hum before he turned to face Keith. “I’m passionate about English but this is something that’s more of a hobby than anything. But I can’t have three majors, I already tried it for like a semester and decided that it wasn’t worth it so I bumped it down to a minor. Linguistics and education are tough but I really want to take up a teaching job after college and teach kids languages. Maybe I’ll go back to school to get a full bachelors in English one day, who knows.”
“What language would you teach?”
“Spanish, probably. Or even Spanish to English. I know French and I’m learning ASL right now for the heck of it but I just really love learning new languages. After my ASL courses I’m gonna pick up either Korean or Japanese I haven’t decided yet. Oops, sorry,” Lance said as he jerked back, a dark hue coloring his face. “I got off topic a bit.”
“No, no it’s fine!” Was keith flapping his hands around again like an idiot? He was, wasn’t he. “I like listening to you talk. It’s nice.” He wanted to physically kick his own ass for letting that slip now.
“Oh, um, thanks.” Lance’s cheeks flushed darker and he turned away.
“Let’s uh, get back to work.” Keith slid the textbook closer to him and attempted to bury his face into the thin, ink soaked pages.
The silence that followed was the thickest, most awkward twenty minutes of his life. Keith couldn’t focus on the scribbled over text and his notes. Instead, he kept side eyeing Lance and the clock. He hated this. Lance was zeroed in on his laptop screen, lounged across the little loveseat like it was his own place. It was impossible to tell if he could feel the tension too between them, or if Keith imagined it on his own. He should just. . . break the silence and tell him. This is too much, the silence too thick and cloying. The weird fluttering in his chest had settled heavily in his gut, pounding harshly against his insides. Sweat had coated the inside of Keith’s hands and was it him or was it getting hotter and harder to breath in here?
Pidge told him it would be ideal to clear the air with Lance to at least get this off his chest. Of course, she’s right. Keith felt like once he told Lance he would feel so much better but he didn’t want to ruin this friendship they’ve developed and make it awkward. Like now, he thought bitterly. It’s hard for him to make new friends being as socially inept as he was. Lance is one of the few friendships he managed to make by himself without Shiro’s meddling and he’ll be damned if he ruined it over a stupid, gay crush.
But on the other hand, he needed to stop psyching himself out and give himself a solid do it, Kogane because he knows Lance is a sweet guy. He would never hurt him or intentionally push him away.
Before he could scare himself with more uncharacteristic inner monologuing, Keith decided he needed to shape the fuck up and tell this boy how he feels.
He took a deep steadying breath, put down the textbook in his lap, and turned to face Lance fully. “Hey,” he said softly.
Lance looked up from his laptop, his glazed over eyes snapped to attention. “What up?”
Do it, Kogane. “I like you.”
If Lance hadn’t been paying attention before he certainly is now. A crease formed between his brows and his mouth opened like a fish.
“I like you a lot, like, more than a friend? And uh, if you don’t feel the same way that’s fine I can get over it I just don’t want to mess us up, you know? And if-”
“Hey Keith?” Lance cut off his rambling. “I like you, too.”
“No, no! Lance, I really like you, like, I want to date you and hold your hand and stuff kind of like!”
Lance giggled, Keith felt his heart do a backflip. “Keith, I want to date you too.”
“You do?” Keith’s heart kept doing backflips but straight out of his chest.
“I do.”
“Seriously?”
“Yes, seriously. I want to hold your hand and be your boyfriend and stuff.”
Now it was Keith’s turn to gape like a fish. He could feel his cheeks getting hot under Lance’s gaze but he didn’t care at all because Lance wanted to hold his hand too. “Can we,” Keith hesitated. “Can we hold hands and be boyfriends now?”
The grin that split across Lance’s flushed face made Keith’s heart levitate. That deep, heavy feeling in his gut was gone. Keith tentatively reached over the loveseat where Lance reached out his own hand to meet in the middle. They gently held hands without interlacing their fingers; neither wanting to squeeze too hard, scared it would pop this little bubble of happiness they made.
This warmth Keith felt in his chest was overwhelming. He wasn’t complaining though; it felt wonderful. Lance was his boyfriend now.
Lance was the first to pop the comfortable bubble around them. “Hey, you started the explication paper, too, right? The one that’s due at midnight the same day as the midterm, I’m guessing?”
Keith froze. “The what?”
“You know, the six page minimum poetry explication with six academic sources that counts as a good 20% of your grade?”
Keith leaned away from Lance, then pinched the bridge of his nose and groaned loudly.
“You forgot, didn’t you?” Lance whispered, almost fearfully.
“I forgot the paper!”
34 notes
·
View notes
Text
Buying A Harp
New Post has been published on https://harmonicatabs.net/buying-a-harp/
Buying A Harp
Where can I get one?
Your local friendly music shop, on line or through specialist harp suppliers (see below). eBay isn’t recommended in this instance as you just don’t know what you’re gonna get or where it’s been!
Music shops are the obvious first choice, however in my experience very few know much about harmonicas. OK you can actually see the harp you want, but what happens if it’s out of tune (with regular pitch or with itself), has a duff reed or just isn’t fit for purpose. Believe me it happens. If you pay up front and try the harp out before you leave the store (no room for being bashful here), will they exchange it if the harp is out of whack? Or will they tell you either you’re not playing it right, you’ve just broken it, or you need to send it back to the manufacturer… Or best still – at a music store in Brighton specialising in guitars – ‘harps don’t go out of tune.’ REALITY CHECK!
Before buying any harmonica, check out the retailer’s ‘returns’ policy. Standard procedure in a music store used to be: pay for the instrument upfront, play it before you leave the premises and exchange any faulty goods on site. If the harp you’re buying is audibly out of tune or sub-spec, does not octave free of any tremolo effect, is not airtight, does not bend correctly or rattles when played – it should be exchanged for another unit. Retailers used to be happy with this.
Nowadays they can get funny. I spoke to Consumer Direct (South East), but they just rattled off the usual consumer advice: The Sales of Goods Act (1979) states that items purchased ‘must be of satisfactory quality and fit for purpose.’ In the UK, failure of the retailer to fulfill these terms is a breach of contract. They then went on to say items you’ve had for less than a month can be refunded. Items you’ve had for more than a month can be repaired or replaced. Thanks Consumer Direct. Try that with a harmonica. You might just as well be honest and tell me unless I present you with a real case, you have no interest in my dilemma. It gets worse if you travel over the pond…
Heads up if buying inside the USA. They’ll tell you that ‘State Law says’ you can’t blow a harmonica and then return it – on health and safety grounds. You must return any defect merchandise to the manufacturer…at your own cost. Hello. Contract with the retailer? They go deaf on you and start serving another punter. Believe me I’ve tried this in New York and San Francisco. No way will they let you blow that thing to check if it’s fit for purpose… And harps are half the UK price over there… Anyway I’ve flagged it up. If you have any feedback pleased get back to me.
So how do you obviate the apparent ignorance shared by high street retailers or the risk of purchasing a dodgy instrument you need to place between your lips? The short answer is work with people who understand your needs.
Of all the on-line distributors, I recommend Harmonicas Direct. They provide an informed, friendly, fast and personal service. I spoke to Peter at HD about all of the above and I can assure you he is on our side! Scroll to the foot of HD home page and select Technical. The returns policy is very clear and more than fair.
For that little bit of personal extra, I totally recommend West Weston’s customised harps. For £35 plus postage you receive an original spec Marine Band which West will check and calibrate before he sends it out. Any problems and he’s only a call away. His harps have the juiciest sound and you don’t have to pump ’em hard. Great for tongue blocking.
For an insight into ‘the dark side’….check out my experience with Haight-Ashbury Music in San Francisco. Later repeated on Tin Pan Alley off Times Square in New York.
Choosing a harp
There are so many types of harmonica on offer it can be bewildering at first. Without a doubt you need to start with a standard 10 hole diatonic (commonly called a blues style harmonica or short harp). THis is what the majority of players use for blues, rock, country, folk and celtic. The bulk of non-chromatic reference material is built round this type of harp. It’s going to take time to learn any harp at first, so at this stage the brand is not too important. They’ll all present you with the same obstacles as a beginner. Later on you can try different makes and models and begin to establish your favourites. Ultimately it’s down to personal taste. One man’s tin sandwich is another man’s gob iron. Most retailers will stock Lee Oskars or Hohners. These are fine.
Wooden bodied, plastic or alloy?
I play both. Arguably wooden bodies give a warmer tone. Occasionally they need a little breaking in from new. Then again alloy combs ring out. Plastic and alloy are more durable and won’t swell if they get damp. Currently I favour Hohner Marine Bands (wooden body) from West Weston and Hohner Big Rivers (plastic body) from the high street. I’ve used Herring before (plastic) – they were lovely and rich. I also had an alloy valved Suzuki once which sang out beautifully.
Which brand is best?
The main brands are Hohner, Seydel Söhne, Lee Oskar, Herring, Bushman, Huang, Tombo and Suzuki. The oldest and largest of these was the Hohner company until Seydel Söhne was resurrected.
Hohner produce a whole range of diatonic harps, which you wil find in most music stores or through mail order. Their wooden bodied varieties include the famous Marine Band. There is also the Blues Harp. Plastic bodied harps include the Special 20, Pro Harp, Cross Harp and Big River Harp. Hohner recently shifted their manufacturing plant from Germany to China, and quality has suffered somewhat. However they still offer a good full tone and reliability. The Marine Band can be prone to air seepage between the body and the cover plates making the harp harder to play, but go to West Weston and he’ll sort this out for you.
Another common brand of harp is the Lee Oskar made by Tombo in Japan who also produce good diatonics like the Folk/Blues and the Ultimo. Lee Oskars are really popular because they are airtight and ready to play. Their tone is not as full as a Hohner, but they are great performance instruments. You can venture into all types of tuning too and replace reed plates cheaply and easily.
The other makes of harp are perhaps less common although the Huang Silvertone Deluxe and Star Performer are widely available at the lower price end of the market. Don’t be put off by the low price tag; they are in fact very good value for money and make excellent practise harps. I would recommend these for anyone on a budget.
Which key should I start with?
Diatonic harmonicas are tuned to the key stamped on the cover plate or on the end of the comb. This is straight harp or 1st Position. It means if you buy a Harp in the key of C major you’ll be playing in the key of C major. With time and practice you will be able to switch to 2nd position (also known as cross harp or blues harp). C harps played in 2nd position will open up the key of G for you. Then there’s 3rd position – D minor and… Don’t panic. It will soon become clear. You’re just learning a new language!
Which to key start with? Definitely a C. It’s mid-range and most tutorial books use a C harp. Once you into blow bending, you’ll need something a bit lower like and A or Bb. You’ll certainly need A and D if you want to play along with guitarists. Then there’s F at the high end of things…unless you want to try Low F, Low A. But let’s not muddy the waters too much. But a C harp, buy a tutorial book, phone a friend, ask the audience, then come to me for a lesson.
Do you recommend any tutorial books?
Yes! Anything from Dave Barrett‘s range of books. Sign up for his free bi-monthly newsletter on-line too at HarmonicaMasterclass.com. Also Blues Harp from Scratch by Mick Kinsella is an exellent module for beginners – one or two typos in the tab, but the structure is superb and gets you off into very good habits from the start. Then again you have endless material on-line at You Tube – Jason Ricci and Adam Gussow have been amongst the most prolific and well-regarded contributors. If you have time or can’t sleep, pour yourself a pint, grab a harp and prepare to be dazzled! But beware – they can become addictive! (The lessons on line and the pints that is). And finally Steve Baker. Anything instructional by Steve is worth every penny. His Blues Harmonica Playalongs Vol. 1 is a seminal work – Double Crossed and Blue has to be one of the all time perfect examples of 3rd position harpooning.
0 notes
Text
1. An 8-Point Checklist for Debugging Strange Technical SEO Problems

Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
· The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
· The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
· When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
· The review pages of client & competitors all had rating rich snippets on Google.
· All the competitors had rating rich snippets on Bing; however, the client did not.
· The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
· Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
· A website was randomly throwing 302 errors.
· This never happened in the browser and only in crawlers.
· User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
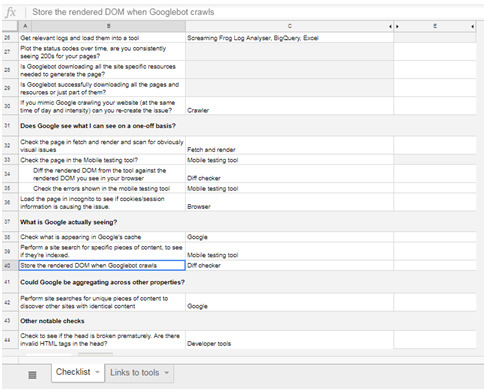
The full checklist

You can download the checklist template here (just make a copy of the Google Sheet):

The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
1. You’re underperforming from where you should be.
1. When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
2. You’ve suffered a sudden traffic drop.
1. Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
3. The wrong page is ranking for the wrong query.
1. In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
· A website that has a lot of client-side JavaScript.
· Bigger, older websites with more legacy.
· Your problem is related to a new Google property or features where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
1. Robots.txt: Open up Search Console and check in the robots.txt validator.
2. User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
1. To get the user agent switcher, open Dev Tools.
2. Check the console drawer is open (the toggle is the Escape key)
3. Hit the … and open "Network conditions"
4. Here, select your user agent!

1. IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
2. Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
1. I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
· No-index
· Canonical
· Mobile alternate tags
· AMP alternate tags
An example of providing mixed messages would be:
· No-indexing page A
· Page B canonicals to page A
Or:
· Page A has a canonical in a header to A with a parameter
· Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
· Sitemap
o Example: Mobile alternate tags can sit in a sitemap
· HTTP headers
o Example: Canonical and meta robots can be set in headers.
· HTML head
o This is where you’re probably looking, you’ll need this one for a comparison.
· JavaScript-rendered vs hard-coded directives
o You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
· Google Search Console settings
o There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
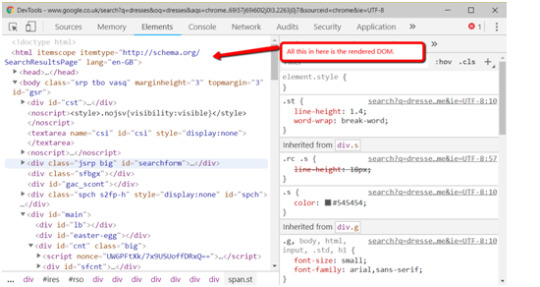
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
1. Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
2. Resources: Is Google downloading all the resources of the page?
1. Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
3. Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
1. It will crawl more than us
2. It is obviously a bot, rather than a human pretending to be a bot
3. It will crawl at different times of day
This means that:
· If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
· Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
· Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
· What happens to the servers under heavy load?
· When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
1. Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
2. If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
· Fetch & Render
o Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
· Mobile-friendly test
o Shows: Rendered DOM and returns rendered DOM for you to read.
o Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
· Googlebot crawls with cookies cleared between page requests
· Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
· Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
· Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
· Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
· JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
· There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
· Google’s cache
o Shows: Source code
o While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
· Site searches for specific content
o Shows: A tiny snippet of rendered content.
o By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
o Better yet, do the same thing with a rank tracker, to see if it changes over time.
· Storing the actual rendered DOM
o Shows: Rendered DOM
o Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
· This excellent talk, How does Google work - Paul Haahr, is a must-listen.
· At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
· Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
· How does Google index different JS frameworks? - Another great example of a widely read experiment by BartoszGóralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
· Similar/duplicate content to the pages that have the problem.
o This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux)which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
· De-duplication of content
· Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
· Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
· Google can consistently crawl our pages as intended.
· We’re sending Google consistent signals about the status of our page.
· Google is consistently rendering our pages as we expect.
· Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
· Look for errors
· Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.

An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie">
</div>
<p><h1 itemprop="name">Avatar</h1>
</p>
<p><span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span>
</p>
<p><span itemprop="genre">Science fiction</span>
</p>
<p><a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a>
</p>
<p></div>
</p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
· <title>
· <style>
· <base>
· <link>
· <meta>
· <script>
· <noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine.
Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
· 302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
· 301 to https://www.client.com - This was the blanket HTTPS redirect
· 302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
“SEO helps the search engines figure out what each page is about, and how it may be useful for users. Here at JVAC photo, we can help you solve all your SEO problems. Let’s get you in front of your prospect clients. Call us now at 561-346-7243” - JVAC Digital
Credits: moz.com
Written by: Dominic Woodman
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
Google can consistently crawl our pages as intended.
We’re sending Google consistent signals about the status of our page.
Google is consistently rendering our pages as we expect.
Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
Look for errors
Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.
An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie">
</div>
<p> <h1 itemprop="name">Avatar</h1>
</p>
<p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span>
</p>
<p> <span itemprop="genre">Science fiction</span>
</p>
<p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a>
</p>
<p></div>
</p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
<title>
<style>
<base>
<link>
<meta>
<script>
<noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine.
Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
301 to https://www.client.com - This was the blanket HTTPS redirect
302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
What are the best brainteasers you've had?
Let’s hear them, people. What problems have you run into? Let us know in the comments.
Also credit to @RobinLord8, @TomAnthonySEO, @THCapper, @samnemzer, and @sergeystefoglo_ for help with this piece.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
bạn xem thêm tại: https://ift.tt/2mXjlRS An 8-Point Checklist for Debugging Strange Technical SEO Problems xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe xem thêm tại: https://ift.tt/2mb4VST để biết thêm về địa chỉ bán tai nghe không dây giá rẻ An 8-Point Checklist for Debugging Strange Technical SEO Problems https://ift.tt/2lfxZWe Bạn có thể xem thêm địa chỉ mua tai nghe không dây tại đây https://ift.tt/2mb4VST
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist checkDoes it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other.. https://ift.tt/2tiSRPV
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist checkDoes it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other.. https://ift.tt/2tiSRPV
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist checkDoes it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other.. https://ift.tt/2tiSRPV
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist checkDoes it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other.. https://ift.tt/2tiSRPV
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist checkDoes it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other.. https://ift.tt/2tiSRPV
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist checkDoes it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other.. https://ift.tt/2tiSRPV
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist checkDoes it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other.. https://ift.tt/2tiSRPV
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
Google can consistently crawl our pages as intended.
We’re sending Google consistent signals about the status of our page.
Google is consistently rendering our pages as we expect.
Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
Look for errors
Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.
An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie"> </div> <p> <h1 itemprop="name">Avatar</h1> </p> <p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span> </p> <p> <span itemprop="genre">Science fiction</span> </p> <p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a> </p> <p></div> </p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
<title>
<style>
<base>
<link>
<meta>
<script>
<noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine.
Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
301 to https://www.client.com - This was the blanket HTTPS redirect
302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
What are the best brainteasers you've had?
Let’s hear them, people. What problems have you run into? Let us know in the comments.
Also credit to @RobinLord8, @TomAnthonySEO, @THCapper, @samnemzer, and @sergeystefoglo_ for help with this piece.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
via Blogger https://ift.tt/2M4D9zM
#blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
Google can consistently crawl our pages as intended.
We’re sending Google consistent signals about the status of our page.
Google is consistently rendering our pages as we expect.
Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
Look for errors
Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.
An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie"> </div> <p> <h1 itemprop="name">Avatar</h1> </p> <p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span> </p> <p> <span itemprop="genre">Science fiction</span> </p> <p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a> </p> <p></div> </p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
<title>
<style>
<base>
<link>
<meta>
<script>
<noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine.
Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
301 to https://www.client.com - This was the blanket HTTPS redirect
302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
What are the best brainteasers you've had?
Let’s hear them, people. What problems have you run into? Let us know in the comments.
Also credit to @RobinLord8, @TomAnthonySEO, @THCapper, @samnemzer, and @sergeystefoglo_ for help with this piece.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Last Seen Blogs

ladysapphire928
At This Point I Don’t Know Anymore


shittosquare
Shit

cocosik
because I'm happy!

everkidco
Everkid Co