#update postgres
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Note
Welcome back campers, to this weeks episode of TOTAL, DRAMA, HELLSITE! On this weeks episode, me and my handy Chef Hex will be cooking up a delicious meal of parpy goodness! But the campers will have to roll a single... WITH A PROMPT! The first one to get a proper Roleplay going gets the immunity marshmallow. Now watch out, cuz this ones gonna be a doozy, dudes!
Your September 2nd PARPdate: "Remember that time on TDI where they called god to make it rain? That happened" Edition.
News this month is sorta slow- those of you In The Know already know this, but Hex is being forced to move again. This hasn't impacted Dev TOO much, honestly, and I'm gonna break down WHY in this wonderful little post!
Ok so if you remember the August update, you likely recall us showing off our shiny new mod features and how we can now play funny roleplay police state in order to nail rulebreakers and bandodgers.
If you're also a huge Bubblehead (which is what you're called), you're also likely familiar with this bastard:
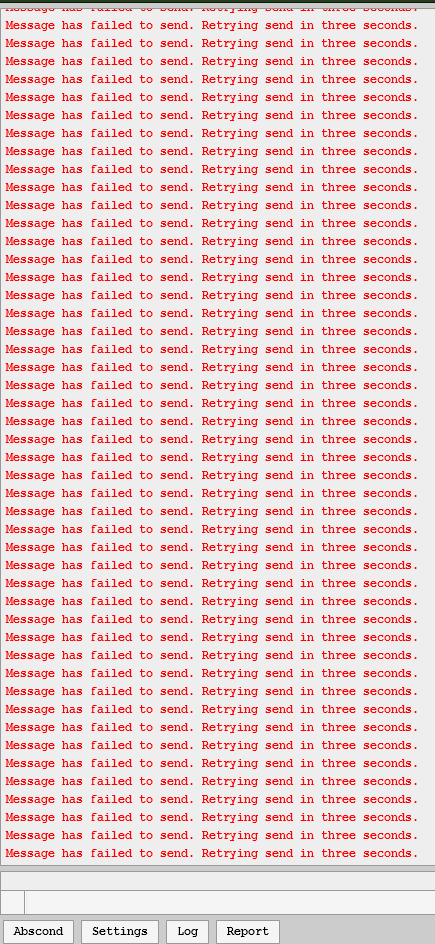
(Image description: The red miles, basically. Its a message failed message repeated like ninety times in a row in red font. Thanks to Alienoid from the server for posting this screenshot for me to steal!)
This is because, somehow, these new mod features almost completely broke Dreambubble in ways that make no sense (the new features use Redis, but for some reason their introduction is making PostGres, a completely different system, go absolutely haywire)
So, Hex decided to move forward with their pet project to rewrite Dreambubble. Normally, this would mean a development delay on Parp2 and I'd feel pretty bad about laying this on yalls feet after two years of parplessness.
But hey wait isn't this literally just how they made parp last time.
The answer is yes! The previous Msparp version was built using what is now Dreambubble as a skeleton, evolving on itself into the rickety but lovable RP site we knew before she tragically passed away last February after choking to death on fresh air. As such, Dev is actually going pretty good! Hex has been COOKING through the bones for Dreambubble 2, getting a ton of barebones stuff working right off the bat:

(Image description: A barebones but functional chat window using Felt theme; complete with system connection messages, text preview, and quirking)
Along with our first new feature preview in a while: PUSH NOTIFICATIONS!

(Image description: A felt-theme settings menu showing the ability to turn on and off push notifications, as well as a browser popup in the bottom corner showing that it's been activated)
These are also working on Android! What this does is it pings you when the chat you're in gets a new message, operating on a system level instead of a site level so you don't even need to have the tab, or the browser, open to keep up with your chats! This is gonna be especially useful for mobile users, since this means they can navigate away and use their phone for other things, and their phone'll just ping them when their partners' next message comes through. (These are gonna be off by default, btw. You'll have to turn them on yourself on a per-chat basis in the final release)
It should also be noted that we've Snagged Ourselves A UI Guy recently from the userbase, so we've got a dedicated Make It Look Good person for when things get closer to launch!
That's all for this update, though. Absolutely thrilled to be showing off some progress after the restart. Hopefully we'll have even more to show off next month!
Until then, cheers!
24 notes
·
View notes
Text
This Week in Rust 541
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.77.1
Changes to u128/i128 layout in 1.77 and 1.78
Newsletters
This Week In Bevy: 2d Lighting, Particle Systems, Meshlets, and more
Project/Tooling Updates
Dioxus 0.5: Signal Rewrite, Remove lifetimes, CSS Hotreloading, and more!
EtherCrab 0.4.0: Pure Rust EtherCAT, now with Distributed Clocks
nethsm 0.1.0 - first release for this high level library for the Nitrokey NetHSM
BugStalker v0.1.3 released - first release of rust debugger
git-cliff 2.2.0 is released! (highly customizable changelog generator)
Observations/Thoughts
On Reusing Arc and Rc in Rust
Who killed the network switch?
Xr0 Makes C Safer than Rust
Easy Mode Rust
Bashing Bevy To Bait Internet Strangers Into Improving My Code
Conway's Game of Life Through Time
Functions Everywhere, Only Once: Writing Functions for the Everywhere Computer
Rust Bytes: Is Rust the Future of JavaScript Tooling?
Explaining the internals of async-task from the ground up
Programming ESP32 with Rust: OTA firmware update
Fast Development In Rust, Part 2
Rust Walkthroughs
Modelling Universal Domain Types in Rust
[video] developerlife.com - Get started with unit testing in Rust
Research
Rust Digger: More than 14% of crates configure rustfmt. 35 Have both rustfmt.toml and .rustfmt.toml
Miscellaneous
Building a Managed Postgres Service in Rust: Part 1
Beware of the DashMap deadlock
Embedded Rust Bluetooth on ESP: BLE Client
Rust Unit and Integration Testing in RustRover
[podcast] cargo-semver-checks with Predrag Gruevski — Rustacean Station
[video] Data Types - Part 3 of Idiomatic Rust in Simple Steps
[video] Deconstructing WebAssembly Components by Ryan Levick @ Wasm I/O 2024
[video] Extreme Clippy for new Rust crates
[video] [playlist] Bevy GameDev Meetup #2 - March 2024
Building Stock Market Engine from scratch in Rust (I)
Crate of the Week
This week's crate is cargo-unfmt, a formatter that formats your code into block-justified text, which sacrifices some readability for esthetics.
Thanks to Felix Prasanna for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
greptimedb - Support specifying time ranges in the COPY FROM statement to avoid importing unwanted data
greptimedb - Support converting UNIX epoch numbers to specified timezone in to_timezone function
mirrord - Capability to modify the local listen address
mirrord - Fix all check-rust-docs warnings
Hyperswitch - [REFACTOR]: Remove Default Case Handling - Braintree
Hyperswitch - [REFACTOR]: Remove Default Case Handling - Fiserv
Hyperswitch - [REFACTOR]: Remove Default Case Handling - Globepay
If you are a Rust project owner and are looking for contributors, please submit tasks here.
CFP - Speakers
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
* RustConf 2024 | Closes 2024-04-25 | Montreal, Canada | Event date: 2024-09-10 * RustLab 2024 | Closes 2024-05-01 | Florence, Italy | Event date: 2024-11-09 - 2024-11-11 * EuroRust 2024| Closes 2024-06-03 | Vienna, Austria & online | Event date: 2024-10-10 * Scientific Computing in Rust 2024| Closes 2024-06-14 | online | Event date: 2024-07-17 - 2024-07-19 * Conf42 Rustlang 2024 | Closes 2024-07-22 | online | Event date: 2024-08-22
If you are an event organizer hoping to expand the reach of your event, please submit a link to the submission website through a PR to TWiR.
Updates from the Rust Project
431 pull requests were merged in the last week
CFI: (actually) check that methods are object-safe before projecting their receivers to dyn Trait in CFI
CFI: abstract Closures and Coroutines
CFI: fix drop and drop_in_place
CFI: fix methods as function pointer cast
CFI: support calling methods on supertraits
add a CurrentGcx type to let the deadlock handler access TyCtxt
add basic trait impls for f16 and f128
add detection of (Partial)Ord methods in the ambiguous_wide_pointer_comparisons lint
add rust-lldb pretty printing for Path and PathBuf
assert that ADTs have the right number of args
codegen const panic messages as function calls
coverage: re-enable UnreachablePropagation for coverage builds
delegation: fix ICE on wrong Self instantiation
delegation: fix ICE on wrong self resolution
do not attempt to write ty::Err on binding that isn't from current HIR Owner
don't check match scrutinee of postfix match for unused parens
don't inherit codegen attrs from parent static
eagerly instantiate closure/coroutine-like bounds with placeholders to deal with binders correctly
eliminate UbChecks for non-standard libraries
ensure std is prepared for cross-targets
fix diagnostics for async block cloning
fixup parsing of rustc_never_type_options attribute
function ABI is irrelevant for reachability
improve example on inserting to a sorted vector to avoid shifting equal elements
in ConstructCoroutineInClosureShim, pass receiver by mut ref, not mut pointer
load missing type of impl associated constant from trait definition
make TyCtxt::coroutine_layout take coroutine's kind parameter
match ergonomics 2024: implement mutable by-reference bindings
match lowering: build the Place instead of keeping a PlaceBuilder around
match lowering: consistently merge simple or-patterns
match lowering: handle or-patterns one layer at a time
match lowering: sort Eq candidates in the failure case too
pattern analysis: Require enum indices to be contiguous
replace regions in const canonical vars' types with 'static in next-solver canonicalizer
require Debug for Pointee::Metadata
require DerefMut and DerefPure on deref!() patterns when appropriate
rework opaque type region inference
simplify proc macro bridge state
simplify trim-paths feature by merging all debuginfo options together
store segment and module in UnresolvedImportError
suggest associated type bounds on problematic associated equality bounds
suggest correct path in include_bytes!
use the Align type when parsing alignment attributes
warn against implementing Freeze
enable cargo miri test doctests
miri: avoid mutating the global environment
miri: cotrol stacked borrows consistency check with its own feature flag
miri: experiment with macOS M1 runners
miri: extern-so: give the version script a better name; show errors from failing to build the C lib
miri: speed up Windows CI
miri: tree Borrows: Make tree root always be initialized
don't emit load metadata in debug mode
avoid some unnecessary query invocations
stop doing expensive work in opt_suggest_box_span eagerly
stabilize ptr.is_aligned, move ptr.is_aligned_to to a new feature gate
stabilize unchecked_{add,sub,mul}
make {integer}::from_str_radix constant
optimize core::char::CaseMappingIter
implement Vec::pop_if
remove len argument from RawVec::reserve_for_push
less generic code for Vec allocations
UnixStream: override read_buf
num::NonZero::get can be 1 transmute instead of 2
fix error message for env! when env var is not valid Unicode
futures: make access inner of futures::io::{BufReader,BufWriter} not require inner trait bound
regex-syntax: accept {,n} as an equivalent to {0,n}
cargo add: Preserve comments when updating simple deps
cargo generate-lockfile: hold lock before querying index
cargo toml: Warn on unused workspace.dependencies keys on virtual workspaces
cargo fix: bash completion fallback in nounset mode
clippy: large_stack_frames: print total size and largest component
clippy: type_id_on_box: lint on any Box<dyn _>
clippy: accept String in span_lint* functions directly to avoid unnecessary clones
clippy: allow filter_map_identity when the closure is typed
clippy: allow manual_unwrap_or_default in const function
clippy: don't emit duplicated_attribute lint on "complex" cfgs
clippy: elide unit variables linted by let_unit and use () directly instead
clippy: fix manual_unwrap_or_default suggestion ignoring side-effects
clippy: fix suggestion for len_zero with macros
clippy: make sure checked type implements Try trait when linting question_mark
clippy: move box_default to style, do not suggest turbofishes
clippy: move mixed_attributes_style to style
clippy: new lint legacy_numeric_constants
clippy: restrict manual_clamp to const case, bring it out of nursery
rust-analyzer: add rust-analyzer.cargo.allTargets to configure passing --all-targets to cargo invocations
rust-analyzer: implement resolving and lowering of Lifetimes (no inference yet)
rust-analyzer: fix crate IDs when multiple workspaces are loaded
rust-analyzer: ADT hover considering only type or const len not lifetimes
rust-analyzer: check for client support of relative glob patterns before using them
rust-analyzer: lifetime length are not added in count of params in highlight
rust-analyzer: revert debug extension priorities
rust-analyzer: silence mismatches involving unresolved projections
rust-analyzer: use lldb when debugging with C++ extension on MacOS
rust-analyzer: pattern analysis: Use contiguous indices for enum variants
rust-analyzer: prompt the user to reload the window when enabling test explorer
rust-analyzer: resolve tests per file instead of per crate in test explorer
Rust Compiler Performance Triage
A pretty quiet week, with most changes (dropped from the report below) being due to continuing bimodality in the performance data. No particularly notable changes landed.
Triage done by @simulacrum. Revision range: 73476d49..3d5528c
1 Regressions, 2 Improvements, 5 Mixed; 0 of them in rollups 61 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Merge RFC 3543: patchable-function-entry
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
Rust
[disposition: merge] Pass list of defineable opaque types into canonical queries
[disposition: merge] Document overrides of clone_from() in core/std
[disposition: merge] Tracking Issue for Seek::seek_relative
[disposition: merge] Tracking Issue for generic NonZero
[disposition: merge] Tracking Issue for cstr_count_bytes
[disposition: merge] privacy: Stabilize lint unnameable_types
[disposition: merge] Stabilize Wasm target features that are in phase 4 and 5
Cargo
[disposition: merge] feat(add): Stabilize MSRV-aware version req selection
New and Updated RFCs
[new] RFC: Add freeze intrinsic and related library functions
[new] RFC: Add a special TryFrom and Into derive macro, specifically for C-Style enums
[new] re-organise the compiler team
Upcoming Events
Rusty Events between 2024-04-03 - 2024-05-01 🦀
Virtual
2024-04-03 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Rust for Rustaceans Book Club: Chapter 4 - Error Handling
2024-04-03 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2024-04-04 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-04-09 | Virtual (Dallas, TX, US) | Dallas Rust
BlueR: a Rust Based Tool for Robust and Safe Bluetooth Control
2024-04-11 | Virtual + In Person (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-04-11 | Virtual (Nürnberg, DE) | Rust Nüremberg
Rust Nürnberg online
2024-04-15 & 2024-04-16 | Virtual | Mainmatter
Remote Workshop: Testing for Rust projects – going beyond the basics
2024-04-16 | Virtual (Dublin, IE) | Rust Dublin
A reverse proxy with Tower and Hyperv1
2024-04-16 | Virtual (Washinigton, DC, US) | Rust DC
Mid-month Rustful
2024-04-17 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2024-04-18 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-04-25 | Virtual + In Person (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack and Learn | Mirror: Rust Hack n Learn Meetup
2024-04-30 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2024-05-01 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
Africa
2024-04-05 | Kampala, UG | Rust Circle Kampala
Rust Circle Meetup
Europe
2024-04-10 | Cambridge, UK | Cambridge Rust Meetup
Rust Meetup Reboot 3
2024-04-10 | Cologne/Köln, DE | Rust Cologne
This Month in Rust, April
2024-04-10 | Manchester, UK | Rust Manchester
Rust Manchester April 2024
2024-04-10 | Oslo, NO | Rust Oslo
Rust Hack'n'Learn at Kampen Bistro
2024-04-11 | Bordeaux, FR | Rust Bordeaux
Rust Bordeaux #2 : Présentations
2024-04-11 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2024-04-15 | Zagreb, HR | impl Zagreb for Rust
Rust Meetup 2024/04: Building cargo projects with NIX
2024-04-16 | Bratislava, SK | Bratislava Rust Meetup Group
Rust Meetup by Sonalake #5
2024-04-16 | Leipzig, DE | Rust - Modern Systems Programming in Leipzig
winnow/nom
2024-04-16 | Munich, DE + Virtual | Rust Munich
Rust Munich 2024 / 1 - hybrid
2024-04-17 | Bergen, NO | Hubbel kodeklubb
Lær Rust med Conways Game of Life
2024-04-20 | Augsburg, DE | Augsburger Linux-Infotag 2024
Augsburger Linux-Infotag 2024: Workshop Einstieg in Embedded Rust mit dem Raspberry Pico WH
2024-04-23 | Berlin, DE | Rust Berlin
Rust'n'Tell - Rust for the Web
2024-04-25 | Aarhus, DK | Rust Aarhus
Talk Night at MFT Energy
2024-04-25 | Berlin, DE | Rust Berlin
Rust and Tell
2024-04-27 | Basel, CH | Rust Basel
Fullstack Rust - Workshop #2
North America
2024-04-04 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2024-04-04 | Portland, OR, US | PDXRust Meetup
Hack Night and First Post-Pandemic Meetup Restart
2024-04-09 | New York, NY, US | Rust NYC
Rust NYC Monthly Meetup
2024-04-10 | Boulder, CO, US | Boulder Rust Meetup
Rust Meetup: Better Builds w/ Flox + Hangs
2024-04-11 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group Meetup
2024-04-11 | Spokane, WA, US | Spokane Rust
Monthly Meetup: Topic TBD!
2024-04-15 | Somerville, MA, US | Boston Rust Meetup
Davis Square Rust Lunch, Apr 15
2024-04-16 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-04-16 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group: Meet Servo and Robius Open Source Projects
2024-04-18 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2024-04-24 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2024-04-25 | Nashville, TN, US | Music City Rust Developers
Music City Rust Developers - Async Rust on Embedded
2024-04-26 | Boston, MA, US | Boston Rust Meetup
North End Rust Lunch, Apr 26
Oceania
2024-04-30 | Canberra, ACT, AU | Canberra Rust User Group
April Meetup
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
Panstromek: I remember reading somewhere (probably here) that borrow checking has O(n^3) asymptotic complexity, relative to the size of the function.
Nadrieril: Compared to match exhaustiveness which is NP-hard and trait solving which is undecidable, a polynomial complexity feels refreshingly sane.
– Panstromek and Nadrieril on zulip
Thanks to Kevin Reid for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
2 notes
·
View notes
Text
Announcing LangChain Postgres open-source Improvements

Open-source LangChain PostgreSQL upgrades
Google Cloud contributed heavily to the library and updated LangChain Postgres at Google Cloud Next ’25. These upgrades enable all application developers to design database-backed agentic gen AI solutions utilising open source technologies.
LangChain, an open-source framework, simplifies agentic gen AI systems that use massive language models. It connects large language models (LLMs) to other data sources for more powerful and context-aware AI applications. LangChain regularly interacts with databases to efficiently manage and extract structured data. The langchain-postgres package integrates PostgreSQL databases to load documents, store chat history, and store vectors for embeddings. Connectivity is needed for LLM-powered apps to use relational data, perform semantic searches, and generate memory chatbots.
Google Cloud enhancements include enterprise-level connection pooling, faster SQL filtering with relational metadata columns, and optimised performance with asynchronous PostgreSQL drivers. It also included:
Developers can use LangChain to create vector databases with vector indexes.
Flexible database schemas for more robust and manageable applications
For better security, the LangChain vector store APIs follow the least privilege principle and clearly distinguish database setup and usage.
Some new enhancements
Improved security and connectivity
Developing secure and dependable generative AI systems requires careful consideration of how your application interacts with the data architecture. Its LangChain Postgres contributions have prioritised security and connection through several key changes.
Following the least privilege concept has been our focus. The revised API distinguishes between database schema creation and application use rights. This separation lets you restrict the application layer's database schema changes. Separating these tasks can boost AI application security and reduce the attack surface.
Maintaining a pool of database connections reduces the overhead of making new connections for each query. This stabilises your application by efficiently limiting resource utilisation and preventing thousands of idle PostgreSQL connections. It also improves speed, especially in high-throughput scenarios.
Designing schema better
The langchain-postgres package historically only allowed schemas with fixed table names and a single json metadata column to resemble vector databases. PostgreSQL's sophisticated querying features allow you to filter non-vector columns to improve vector search quality. Our LangChain postgres package modifications let you define metadata columns to combine vector search queries with SQL filters when querying your vector storage.
Use the new LangChain PostgreSQL package to turn your PostgreSQL database structure into an AI workload with a few lines of code. This eliminates data schema migration.
Features ready for production
Google Cloud introduced vector index management and first-class asynchronous driver integrations in LangChain to enable production-scale applications. Asynchronous drivers enable non-blocking I/O operations, improving performance. This helps your application grow efficiently, reduce resource consumption, and increase responsiveness to handle more concurrent requests.
LangChain may now directly create and maintain vector indexes. This lets you utilise LangChain to describe and build your entire application stack, from database schema to vector index creation, using an infrastructure-as-code technique for vector search. This end-to-end connection simplifies development and makes LangChain AI-powered apps easy to set up and manage by using asynchronous operations and vector search.
LangChain packages for Google Cloud databases were upgraded by Google Cloud. It upstreamed those changes from its packages into LangChain PostgreSQL so developers on any platform could use them. Generative AI applications increasingly rely on databases, therefore software libraries must offer high-quality database connectors to exploit your data. These databases root LLMs, provide RAG application knowledge, and fuel high-quality vector search.
Get started
A quickstart application and langchain-postgres package are available now! Use this guide to switch from the old langchain-postgres package to Google's. Use AlloyDB's LangChain package and Cloud SQL for PostgreSQL to use GCP-specific capabilities like AlloyDB AI's ScaNN index. Create agentic apps with MCP Toolbox.
#LangChainPostgreSQL#GoogleCloudNext25#LangChain#largelanguagemodels#generativeAI#AIapplications#PostgreSQL#LangChainpackage#ScaNNindex#AlloyDBAI#News#Technews#Techology#Technologynews#Technologytrendes#govindhtech
0 notes
Text
Top Reasons to Study MSc Computer Application in Pune
In today’s digital era, the demand for skilled IT professionals is rising. As businesses and services transition online, there's a growing need for experts who understand software systems, data analytics, cybersecurity, and emerging technologies. This is where a postgraduate degree like MSc Computer Application becomes a valuable asset—especially when pursued from a vibrant tech city like Pune.
So, why are more students choosing Pune for this programme? Let’s explore the top reasons why studying MSc Computer Application in Pune could be your smartest move yet.
1. Academic Excellence with Industry Relevance
Pune is home to several esteemed institutions offering high-quality technical education. MSc CA colleges in Pune are known for delivering a curriculum that blends academic depth with real-world relevance. The courses are regularly updated to keep pace with technological advancements, ensuring students are equipped with skills that employers actively seek.
2. Proximity to Major IT Hubs
One of Pune’s biggest advantages is its thriving IT ecosystem. With the presence of leading tech companies and startups, students have access to internships, live projects, and job opportunities right at their doorstep. This proximity allows for practical exposure, which enhances classroom learning and boosts employability.
3. Skill-Focused Learning Environment
MSc Computer Application programs in Pune emphasize a balanced mix of theory and application. Students get to work with programming languages, databases, software development tools, and cloud technologies—often through lab work, workshops, and collaborative projects. The emphasis is on building both conceptual understanding and hands-on capabilities.
4. Experienced Faculty and Research Opportunities
Pune attracts educators and researchers with a strong academic and industry background. This provides students with mentorship from professionals who understand both the technical and practical demands of the IT industry. For those interested in innovation, many colleges also offer opportunities for research in fields like machine learning, data science, and cybersecurity.
5. Strong Placement Support
One of the biggest reasons students prefer MSc CA colleges in Pune is the strong placement track record. Institutes in the city maintain active corporate relations and frequently host placement drives, career fairs, and industry interactions. With companies from diverse sectors recruiting in Pune, graduates enjoy access to a wide range of job profiles—from software developers to data analysts and systems administrators.
6. Holistic Development and Campus Life
Beyond academics, Pune offers a rich student experience. Most colleges promote holistic development through student clubs, tech fests, competitions, and leadership activities. This all-round exposure helps students build confidence, communication skills, and the ability to work in dynamic teams—qualities that are critical in the professional world.
7. Affordable Quality Education
Compared to many metro cities, Pune offers a relatively affordable cost of living without compromising on education quality. Students benefit from access to top-tier education and a growing tech network in a city that is budget-friendly and student-oriented.
8. Gateway to Global Careers
With the rise in global IT outsourcing and multinational firms hiring in India, an MSc Computer Application from a reputed Pune college can open doors to international job opportunities. The global curriculum design and emphasis on upskilling ensure students are competitive in both local and international job markets.
Conclusion
If you’re looking to combine quality education, strong industry exposure, and exciting career opportunities, studying MSc Computer Application in Pune is an excellent choice. The city’s academic institutions, vibrant tech community, and student-friendly atmosphere create the ideal environment for IT postgraduates to thrive.
Among the notable options, the Symbiosis Institute of Computer Studies and Research (SICSR) stands out as a preferred destination for aspiring IT professionals. With its industry-aligned curriculum, experienced faculty, and holistic learning approach, SICSR ensures students graduate with the skills and confidence needed to lead in the tech world.
1 note
·
View note
Text
蜘蛛池源码如何部署?
蜘蛛池,也被称为“爬虫池”或“爬虫集群”,是一种用于提高网络爬取效率的技术。通过将多个爬虫任务分配到不同的服务器上运行,可以显著提升数据抓取的速度和稳定性。本文将详细介绍如何部署蜘蛛池源码,帮助你快速搭建自己的爬虫集群。
1. 环境准备
在开始部署之前,确保你的服务器环境满足以下要求:
- 操作系统:Linux(推荐Ubuntu)
- Python环境:Python 3.x
- 其他依赖库:Scrapy、Twisted等
安装Python环境
如果你的服务器尚未安装Python 3.x,可以通过以下命令进行安装:
```bash
sudo apt-get update
sudo apt-get install python3
```
安装依赖库
使用pip安装所需的Python库:
```bash
pip3 install scrapy twisted
```
2. 获取源码
从GitHub或其他代码托管平台获取蜘蛛池的源码。假设源码位于`https://github.com/username/spiderpool.git`,你可以通过以下命令克隆项目:
```bash
git clone https://github.com/username/spiderpool.git
cd spiderpool
```
3. 配置文件
进入项目目录后,找到配置文件(通常为`settings.py`),根据你的需求进行配置。主要配置项包括数据库连接信息、爬虫任务队列等。
```python
DATABASE = {
'drivername': 'postgres',
'host': 'localhost',
'port': '5432',
'username': 'your_username',
'password': 'your_password',
'database': 'spiderpool'
}
```
4. 启动服务
启动蜘蛛池服务通常需要运行一个主进程和多个工作进程。具体命令可能因项目不同而异,但一般形式如下:
```bash
python manage.py startmaster
python manage.py startworker
```
5. 监控与维护
部署完成后,定期监控蜘蛛池的运行状态,确保所有工作进程正常运行。同时,根据实际需求调整配置参数,优化爬虫性能。
讨论点
你在部署蜘蛛池的过程中遇到了哪些问题?又是如何解决的呢?欢迎在评论区分享你的经验,让我们一起学习进步!
加飞机@yuantou2048

谷歌霸屏
Google外链购买
0 notes
Link
0 notes
Text
Recent Updates in Laravel 11: Enhancing the Developer Experience
Laravel, one of the most popular PHP frameworks, has consistently delivered powerful tools and features for developers. With the release of Laravel 11, the framework has introduced several enhancements and updates to make development faster, more reliable, and easier. Here, we take a closer look at the latest updates as of January 15, 2025, focusing on the improvements brought by the recent patch versions.
Patch Update: v11.38.2 (January 15, 2025)
The Laravel team continues to refine the framework by:
Simplifying the Codebase: The introduction of the qualifyColumn helper method helps streamline database interactions, making queries more intuitive and efficient.
Postgres Connection Fixes: Reverting support for missing Postgres connection options ensures compatibility with diverse database setups.
Database Aggregation Stability: A rollback of recent changes to database aggregate by group methods resolves issues with complex queries.
Patch Update: v11.38.1 (January 14, 2025)
This patch focused on ensuring stability by:
Reverting Breaking Changes: Addressing the unexpected impact of replacing string class names with ::class constants. This ensures existing projects continue to work without modifications.
Improving Test Coverage: Added a failing test case to highlight potential pitfalls, leading to better framework reliability.
Patch Update: v11.38.0 (January 14, 2025)
Version 11.38.0 brought significant new features, including:
Enhanced Eloquent Relations: New relation existence methods make working with advanced database queries easier.
Fluent Data Handling: Developers can now set data directly on a Fluent instance, streamlining how data structures are manipulated.
Advanced URI Parsing: URI parsing and mutation updates enable more flexible and dynamic routing capabilities.
Dynamic Builders: Fluent dynamic builders have been introduced for cache, database, and mail. This allows developers to write expressive and concise code.
Request Data Access: Simplified access to request data improves the overall developer experience when handling HTTP requests.

Why Laravel 11 Stands Out
Laravel 11 continues to prioritize developer convenience and project scalability. From simplified migrations to improved routing and performance optimizations, the framework is designed to handle modern web development challenges with ease. The following key features highlight its importance:
Laravel Reverb: A first-party WebSocket server for real-time communication, seamlessly integrating with Laravel's broadcasting capabilities.
Streamlined Directory Structure: Reducing default files makes project organization cleaner.
APP_KEY Rotation: Graceful handling of APP_KEY rotations ensures secure and uninterrupted application operation.
Which is the Best Software Development Company in Indore?As you explore the latest updates in Laravel 11 and enhance your development projects, you may also be wondering which is the best software development company in Indore to partner with for your next project. The city is home to a number of top-tier companies offering expert services in Laravel and other modern web development frameworks, making it an ideal location for both startups and enterprise-level businesses. Whether you need a Laravel-focused team or a full-stack development solution, Indore has options that can align with your technical and business requirements.
What’s Next for Laravel?
As the Laravel team prepares to release Laravel 12 in early 2025, developers can expect even more enhancements in performance, scalability, and advanced query capabilities. For those eager to explore the upcoming features, a development branch of Laravel 12 is already available for testing.
Conclusion
With each update, Laravel demonstrates its commitment to innovation and developer satisfaction. The latest updates in Laravel 11 showcase the framework's focus on stability, new features, and ease of use. Whether you’re building small applications or scaling to enterprise-level projects, Laravel 11 offers tools that make development smoother and more efficient.
For the latest updates and in-depth documentation, visit the official Laravel website.
#best software company in indore#software#web development#software design#ui ux design#development#technologies#network#developer#devops#erp
0 notes
Text
Why I launched AI Pulse
Like many engineers, I found myself drowning in AI tool directories that felt more like advertising platforms than actual resources. The breaking point came when our team wasted days evaluating LLM tools, only to discover the "top-rated" options were either outdated or buried in sponsored listings.
Coming back to JavaScript after a 5-year hiatus was... interesting. I chose Next.js, Neon Postgres and Vercel for their simplicity and performance. The developer experience blew me away - the ecosystem has matured incredibly. What started as a weekend project turned into a genuine love affair with modern JS tooling. The productivity boost from Next.js's app router and Neon's serverless Postgres made development feel effortless. Combined with Cursor, I got something built pretty quickly.
I started with a simple premise: strip away everything that doesn't directly help users find the right tools. No ads. No sponsored listings. Just blazing-fast search and real performance data. The focus on speed and simplicity resonated immediately - our first users were other engineering teams facing the same frustrations.
What's Working Today
Instant search that actually works (thanks, Next.js and Typesense!)
Clean, distraction-free interface
Curated, weekly newsletter
Automated monitoring that catches tool updates within hours
Looking Forward, we're building some exciting features:
Verified reviews from actual tool users
Deep technical comparisons between similar tools
Company and product performance metrics and technical deep-dives
Lessons Learned The biggest takeaway? Ship fast, but ship quality. While other directories chase feature bloat, we're staying focused on what engineers actually need. Every feature decision starts with "Does this help users find better tools faster?"
Would love to hear your experiences with AI tool discovery and what metrics would help you make better decisions.
Check out AI Pulse
1 note
·
View note
Text
Postgres Hosting: Solutions for Every Need
Postgres hosting simply referred to as PostgreSQL is a highly effective open-source RDBMS system that exhibits key strengths of flexibility. With a growing trend towards the use of big data in enterprises, Postgres hosting has become a viable solution: users can reliably host, administer, and update PostgreSQL databases.
0 notes
Note
Hey steve real quick question, on my normal browser whenever I get onto dreambubble and everything seems to immediately go to the blue screen saying that something went wrong, but whenever I go onto incognito it seems to work just fine, is this something to do with the site or is this a sealthy way to ban someone off of the site?
(If the latter idk what i did since i didn't break any of the rules)
Nah she's just Mad Fucky right now.
Those new mod features kinda fucked the site up a lil in some confusing ways (the new features use Redis, but for some reason its PostGres that's spiking up and crashing things). Hex is cooking up a solution in the background though, with occasional updates in the drambuggles channel in the server. I'll announce it here when it's ready!
4 notes
·
View notes
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] Craft resilient web applications with Supabase by leveraging advanced features such as authentication, data and user management, and seamless AI integration using its powerful Postgres infrastructure Key Features: - Learn how to integrate Supabase and Next.js to create powerful and scalable web apps - Explore real-world scenarios with a multi-tenant ticket system - Master real-time data handling, secure file storage, and application security enhancement, while discovering the full potential of the database beyond holding data - Purchase of the print or Kindle book includes a free PDF eBook Book Description: Discover the powerful capabilities of Supabase, the cutting-edge, open-source platform flipping the script on backend architecture. Guided by David Lorenz, a battle-tested software architect with over two decades of development experience, this book will transform the way you approach your projects and make you a Supabase expert. In this comprehensive guide, you'll build a secure, production-grade multi-tenant ticket system, seamlessly integrated with Next.js. You'll build essential skills for effective data manipulation, authentication, and file storage, as well as master Supabase's advanced capabilities including automating tasks with cron scheduling, performing similarity searches with artificial intelligence, testing your database, and leveraging real-time updates. By the end of the book, you'll have a deeper understanding of the platform and be able to confidently utilize Supabase in your own web applications, all thanks to David's excellent expertise. What You Will Learn: - Explore essential features for effective web app development - Handle user registration, login/logout processes, and user metadata - Navigate multi-tenant applications and understand the potential pitfalls and best practices - Discover how to implement real-time functionality - Find out how to upload, download, and manipulate files - Explore preventive measures against data manipulation and security breaches, ensuring robust web app security - Increase efficiency and streamline task automation through personalized email communication, webhooks, and cron jobs Who this book is for: This book is for developers looking for a hassle-free, universal solution to building robust apps using Supabase and its integration libraries. While a basic understanding of JavaScript is useful, it's not essential as the book focuses on Supabase for creating high-performance web apps using Next.js. Experienced professionals from non-JavaScript backgrounds will find this book useful. Familiarity with Postgres, although helpful, is not mandatory as the book explains all the SQL statements used. Table of Contents - Unveiling the Inner Workings of Supabase and Introducing the Book's Project - Setting Up Supabase with Next.js - Creating the Ticket Management Pages, Layout, and Components - Adding Authentication and Application Protection - Crafting Multi-Tenancy through Database and App Design - Enforcing Tenant Permissions with RLS and Handling Tenant Domains - Adding Tenant-Based Signups, including Google Login - Implementing Dynamic Ticket Management - Creating a User List with RPCs and Setting Ticket Assignees - Enhancing Interactivity with Realtime Comments - Adding, Securing, and Serving File Uploads with Supabase Storage - Avoiding Unwanted Data Manipulation and Undisclosed Exposures - Adding Supabase Superpowers and Reviewing Production Hardening Tips Publisher : Packt Publishing (9 August 2024)
Language : English Paperback : 534 pages ISBN-10 : 1837630682 ISBN-13 : 978-1837630684 Item Weight : 909 g Dimensions : 2.21 x 19.05 x 23.5 cm Country of Origin : India [ad_2]
0 notes
Text
AlloyDB Omni Version 15.7.0 Improves PostgreSQL Workflows

AlloyDB Omni boosts performance with vector search, analytics, and faster transactions.
With its latest release AlloyDB Omni version 15.7.0, AlloyDB Omni is back and is significantly improving your PostgreSQL workflows. These improvements include:
Quicker performance
A brand-new, lightning-fast disk cache
A better columnar engine
The widespread use of ScANN vector indexing
The AlloyDB Omni Kubernetes operator has been updated.
In your data center, on the edge, on your laptop, in any cloud, and with 100% PostgreSQL compatibility, this update offers on all fronts, from transactional and analytical workloads to state-of-the-art vector search.
AlloyDB Omni version 15.7.0 is now broadly accessible (GA). The following updates and features are included in version AlloyDB Omni version 15.7.0:
AlloyDB Version 15.7 of PostgreSQL is supported by Omni.
Previously known as postgres_scann, the alloydb_scann extension is now generally available (GA).
There is generally available (GA) support for Red Hat Enterprise Linux (RHEL) 8.
You can preview the AlloyDB Omni columnar engine on ARM.
Because disk cache and columnar storage cache speed up data access for AlloyDB Omni in a container and on a Kubernetes cluster, they can enhance AlloyDB Omni performance.
It has applied security updates for CVE-2023-50387 and CVE-2024-7348.
The documentation for the AlloyDB Omni Reference is accessible. This comprises AlloyDB Omni 15.7.0 metrics, database flags, model endpoint management reference, and extension documentation.
AlloyDB The pg_ivm extension, which offers incremental view maintenance for materialized views, is compatible with Omni.
Numerous efficiency enhancements and bug fixes.
Let’s get started.
Improved performance
When compared to regular PostgreSQL, many workloads already experience an improvement. For transactional workloads, AlloyDB Omni outperforms regular PostgreSQL by more than two times in performance testing. The majority of the tuning is done automatically for you without the need for additional setups. The memory agent that maximizes shared buffers while preventing out-of-memory issues is one of the main benefits. AlloyDB Omni generally runs better with more memory configured because it can serve more queries from the shared buffers and eliminate the need for disk calls, which can be significantly slower than memory, especially when utilizing durable network storage.
An extremely fast disk cache
The introduction of an ultra-fast disk cache also made the trade-off between memory and disk storage more flexible. As an extension of Postgres’ buffer cache, it enables you to set up a quick, local, and perhaps brittle storage device. AlloyDB Omni can store a copy of not-quite-hot data in the disk cache, where it can be accessed more quickly than from the permanent disk, rather than aging out of memory to create room for new data.
Improved columnar engine
The analytics accelerator from AlloyDB Omni is revolutionizing mixed workloads. Because it eliminates the need to manage additional data pipelines or databases, developers are finding it helpful for extracting real-time analytical insights from their transactional data. To speed up queries, you can instead activate the columnar engine, allocate a piece of your memory to it, and let AlloyDB Omni to choose which tables or columns to load in the columnar engine. The columnar engine outperforms regular PostgreSQL by up to 100x in our benchmarks for analytical queries.
The amount of RAM you can allocate to the columnar engine dictates the analytics accelerator’s practical size limit. The ability to set up a quick local storage device for the columnar engine to spill to is a new feature. This expands the amount of data on which you may do analytical queries.
SCaNN becomes GA
Finally, AlloyDB Omni already provides excellent performance with pgvector utilizing either the ivf or hnsw indexes for vector database use cases. Vector indexes, however, can be slow to build and reload even though they are a terrific method to speed up queries. It added the ScaNN index as an additional index type at Google Cloud Next 2024. The ScaNN index from AlloyDB AI provides up to 4 times faster vector queries than the HNSW index used in ordinary PostgreSQL. ScaNN offers substantial benefits for practical applications beyond only speed:
Rapid indexing: With noticeably quicker index build times, you may expedite development and remove bottlenecks in large-scale deployments.
Optimized memory usage: Cut memory usage by three to four times as compared to PostgreSQL’s HNSW index. This improves performance for a variety of hybrid applications and enables larger workloads to operate on smaller hardware.
In general, AlloyDB AI ScANN indexing is accessible as of AlloyDB Omni version 15.7.0.
A fresh Kubernetes administrator
Google Cloud has published version 1.2.0 of the AlloyDB Omni Kubernetes operator in addition to the latest version of AlloyDB Omni. With this release, you can now configure high availability to be enabled when a disaster recovery secondary cluster is promoted to primary, add more configuration options for health checks when high availability is enabled, and use log rotation to help manage the storage space used by PostgreSQL log files.
Version 1.2.0 of the AlloyDB Omni Kubernetes operator is now broadly accessible (GA). The following new features are included in version 1.2.0:
The interval between health checks can be set in seconds using the healthcheckPeriodSeconds option.
You can keep an eye on your database container’s performance with the following metrics. These measurements are all type gauge.
A database container’s memory limit is displayed by alloydb_omni_memory_limit_byte.
All replicas connected to the AlloyDB Omni primary node are shown in alloydb_omni_instance_postgresql_replication_state.
The database container’s memory usage is displayed in bytes via alloydb_omni_memory_used_byte.
When the following is true, a problem that briefly disrupted all database clusters has been resolved:
The AlloyDB Omni Kubernetes operator version 1.1.1 is being upgraded to a more recent version.
Version 15.5.5 or higher of the AlloyDB Omni database is what you’re using.
AI for AlloyDB is not activated.
Once promoted, high availability is supported on a secondary database cluster.
Model endpoint management can be enabled or disabled using Kubernetes manifests.
By setting thresholds depending on the size of the log files, the amount of time since the log file last rotated, or both, you may control when logs rotate.
To examine and troubleshoot the memory performance of the AlloyDB Omni Kubernetes operator, you can take a snapshot of its memory heap.
Note: Parameterized view features were accessible via the alloydb_ai_nl extension of AlloyDB Omni versions 15.5.5 and earlier. The parameterized_views extension, which you must develop before using parameterized views, contains the parameterized view features starting in AlloyDB Omni version 15.7.0. The associated function, google_exec_param_query, has also been renamed to execute_parameterized_query and is accessible through the parameterized_views extension as of AlloyDB Omni version 15.7.0.
Read more on Govindhtech.com
#AlloyDBOmni#AlloyDB#PostgreSQL#Omni#AlloyDBOmniversion15.7.0#Cloudcomputing#ScaNNindex#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
Sonarqube Setup with Postgresql
sonarqube installation along with java 17 Postgresql Database Prerequisites Need an AWS EC2 instance (min t2.small) Install Java 17 (openjdk-17) apt-get update apt list | grep openjdk-17 apt-get install openjdk-17-jdk -y Install & Setup Postgres Database for SonarQube Source: https://www.postgresql.org/download/linux/ubuntu/ Install Postgresql database Import the repository signing…
0 notes
Quote
B2Cで高負荷、UPDATEが多くDB同時接続が多い環境ではMySQLのアーキテクチャ的な優位があるがそれ以外のほとんどはPostgresが正解
XユーザーのKenn Ejimaさん: 「MySQL 8 vs PostgreSQL 10を比較した記事を昔HackerNoonに寄稿してバズったやつがあるので貼っておきます。 https://t.co/bPDPl3Iht6 B2Cで高負荷、UPDATEが多くDB同時接続が多い環境ではMySQLのアーキテクチャ的な優位があるがそれ以外のほとんどはPostgresが正解、という話をしてます。」 / X
0 notes
Text
Best Managed Postgres Hosting Solutions
PostgreSQL, or Postgres, is one of the most reliable open-source databases available today. Its flexibility, scalability, and robust features have made it a favorite for developers and businesses alike. But managing a Postgres database yourself can be annoying, especially when it comes to updates, backups, and security.
This is why we prefer managed Postgres solution. With the Postgres provider handling the heavy lifting, we can focus on our projects.
1 note
·
View note
Text
Public roadmap 🗺️
If you're new here, I'm André, a tech entrepreneur and founder of LaunchFast, a stack designed to help web developers significantly speed up their project development time. I post daily updates on my journey and progress.
Here's the menu for today 📖
Asked customers for feedback
Add upvotes to the roadmap
Allow people to discuss roadmap features publicly on 𝕏
Add mailing list for product updates
Spoke to Jan Sulaiman, Global Director at 1NCE about database performance needs
Lisboa Innovation For All
Current metrics
Next steps
Let's get to it.
I’ve engaged with my customers, asked how their experience had been, and asked for feedback
Today I’ve sent an email to all the people who bought LaunchFast.
I’ve asked for their feedback and haven’t received any replies yet, but I want to make them feel supported and that I’m here to help if they get into trouble or find any problems with the product.
Added upvotes to the roadmap
I’ve improved the current roadmap so customers can vote on their preferred features.
Non-customers can still see the roadmap, but cannot upvote.
This is how the roadmap looks at the moment.
(This is a screenshot from my local dev environment, that’s why there are no upvotes.)

Allow people to discuss features on 𝕏
You’ll also notice that every feature has a “Discuss on 𝕏” button. This isn’t in production yet, but it will be tomorrow.
Since the repo is private, users can click that button and discuss this feature, in public, on 𝕏. Each feature has a corresponding post with a small description, like so 👇
The downside is that users need an account on 𝕏, but I’ll try it like this for now and see how it goes.

Added a mailing list that users can subscribe to, for product updates
I’ve also added a newsletter subscription form for users who want to stay up-to-date with LaunchFast as new features are released.
If you’re one of them, feel free to subscribe!

Spoke to Jan Sulaiman, Global Director at 1NCE about database performance needs
I’ve spoken to Jan Sulaiman, Global Director at 1NCE, an IoT company, about their database performance needs. According to Jan, hitting the 500k writes/sec performance limitation of SQLite would “require hundreds of millions of devices.”
According to Jan (slightly edited for brevity): "[As] a very rough estimation, right now, we have around 5 Mio active devices. Our customers send, on average, one message per 15 minutes.
So that means we average 5556 messages/second.
This would also align with our overall Downlink/Uplink capacity. For our European Breakout, for example, we are currently averaging around 40 Mb/s downlink and 75 Mb/s uplink traffic. And that Breakout is handling around 2,2 Mio active devices.
Since you ask about write operations, we only need to look at the 75 Mb/s. Here I assume an average of 2 KB per message that needs to be written. If I use the bandwith, I also get roughly 4578 write operations per second.
So, it's pretty close to the first calculation.
Long story short - while we probably have quite a high number of operations we need to handle and millions of active devices - we still would never get to 500k+ transactions per second 😁"
This ties into first-principles thinking and my explanation for choosing SQLite over any other database (MySQL, Postgres, MongoDB, etc), even if hosted on the same machine - SQLite is a zero-configuration, zero-latency database, and it’s just a file, making it dead simple to manage. Other databases require you to manage a server, connections, and authentication (offering another attack surface for hackers), and you won’t benefit from their higher performance anyway.
Hosted databases like Firebase and Supabase solve this problem by managing the database for you, but you pay an even higher cost: your performance is now subjected and limited to the network’s bandwidth and latency.
In the best-case scenario, you add a 10 to 30ms overhead to every single query you make (this should be enough not to use them), and in the worst-case scenario, the database is being DDoS’d and you can’t connect to it, making your app dysfunctional.
But I digress…
So what’s the opportunity here?
Jan agreed to be my guest on one of the videos I will do as part of LaunchFast’s documentation 🎉
Lisboa Innovation For All
Lisboa innovation for all (https://lisboainnovationforall.com) is a social innovation prize from the Lisbon City Council, organized by the Unicorn Factory Lisboa and supported by the European Innovation Council, which aims to discover and support innovative and impactful solutions that can be applied practically in the city of Lisbon.
They’re offering 360.000€ for projects on education, healthcare, and migration, and now that LaunchFast has been released, it would be a perfect opportunity to show, in public, what a developer is capable of with a powerful tool like LaunchFast.
Current Metrics
LaunchFast will launch on @MicroLaunchHQ on the 1st of September: https://microlaunch.net/p/launchfastpro
MicroLaunch is a relatively new platform created by Said, and I’ve found a few errors, but I look forward to seeing how LaunchFast does on microlaunch and how much traffic it will bring.
At the moment, LaunchFast is hovering at around 40 users per day.

Next Steps
This was the plan yesterday:
Engage more with Product Hunters ahead of the next launch (after payment and AI integrations potentially)
Create the documentation for LaunchFast, which includes video format that will also serve as content for social media
Integrate payments and AI into LaunchFast
Allow customers to suggest and prioritize items in the roadmap ✅
Engage with current customers to assess their experience and potentially fix pain points ✅
Add a newsletter component to the landing page to allow users to get notified of updates to the stack ✅
As for the next steps, I don’t know in which order I will do them, but this is the general plan:
Engage more with Product Hunters ahead of the next launch (after payment and AI integrations potentially)
Create the documentation for LaunchFast, which includes video that will also serve as content for social media
Integrate payments and AI into LaunchFast
Register LaunchFast in more directories
Improve the current directory (https://launchfast.pro/launch-directories)
Possibly apply to “lisboa innovation for all”
That’s it for today, folks!
Have a great weekend and see you tomorrow!
P.S.: If you’re interested in LaunchFast, feel free to discuss and vote (https://x.com/andrecasaldev/status/1829538090135982455) on the features you’d like to see come onto the product!
0 notes