#where clause in mysql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
Structured Query Language (SQL): A Comprehensive Guide
Structured Query Language, popularly called SQL (reported "ess-que-ell" or sometimes "sequel"), is the same old language used for managing and manipulating relational databases. Developed in the early 1970s by using IBM researchers Donald D. Chamberlin and Raymond F. Boyce, SQL has when you consider that end up the dominant language for database structures round the world.
Structured query language commands with examples
Today, certainly every important relational database control system (RDBMS)—such as MySQL, PostgreSQL, Oracle, SQL Server, and SQLite—uses SQL as its core question language.
What is SQL?
SQL is a website-specific language used to:
Retrieve facts from a database.
Insert, replace, and delete statistics.
Create and modify database structures (tables, indexes, perspectives).
Manage get entry to permissions and security.
Perform data analytics and reporting.
In easy phrases, SQL permits customers to speak with databases to shop and retrieve structured information.
Key Characteristics of SQL
Declarative Language: SQL focuses on what to do, now not the way to do it. For instance, whilst you write SELECT * FROM users, you don’t need to inform SQL the way to fetch the facts—it figures that out.
Standardized: SQL has been standardized through agencies like ANSI and ISO, with maximum database structures enforcing the core language and including their very own extensions.
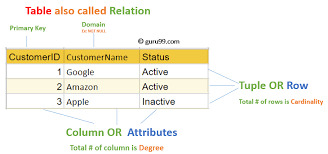
Relational Model-Based: SQL is designed to work with tables (also called members of the family) in which records is organized in rows and columns.
Core Components of SQL
SQL may be damaged down into numerous predominant categories of instructions, each with unique functions.
1. Data Definition Language (DDL)
DDL commands are used to outline or modify the shape of database gadgets like tables, schemas, indexes, and so forth.
Common DDL commands:
CREATE: To create a brand new table or database.
ALTER: To modify an present table (add or put off columns).
DROP: To delete a table or database.
TRUNCATE: To delete all rows from a table but preserve its shape.
Example:
sq.
Copy
Edit
CREATE TABLE personnel (
id INT PRIMARY KEY,
call VARCHAR(one hundred),
income DECIMAL(10,2)
);
2. Data Manipulation Language (DML)
DML commands are used for statistics operations which include inserting, updating, or deleting information.
Common DML commands:
SELECT: Retrieve data from one or more tables.
INSERT: Add new records.
UPDATE: Modify existing statistics.
DELETE: Remove information.
Example:
square
Copy
Edit
INSERT INTO employees (id, name, earnings)
VALUES (1, 'Alice Johnson', 75000.00);
three. Data Query Language (DQL)
Some specialists separate SELECT from DML and treat it as its very own category: DQL.
Example:
square
Copy
Edit
SELECT name, income FROM personnel WHERE profits > 60000;
This command retrieves names and salaries of employees earning more than 60,000.
4. Data Control Language (DCL)
DCL instructions cope with permissions and access manage.
Common DCL instructions:
GRANT: Give get right of entry to to users.
REVOKE: Remove access.
Example:
square
Copy
Edit
GRANT SELECT, INSERT ON personnel TO john_doe;
five. Transaction Control Language (TCL)
TCL commands manage transactions to ensure data integrity.
Common TCL instructions:
BEGIN: Start a transaction.
COMMIT: Save changes.
ROLLBACK: Undo changes.
SAVEPOINT: Set a savepoint inside a transaction.
Example:
square
Copy
Edit
BEGIN;
UPDATE personnel SET earnings = income * 1.10;
COMMIT;
SQL Clauses and Syntax Elements
WHERE: Filters rows.
ORDER BY: Sorts effects.
GROUP BY: Groups rows sharing a assets.
HAVING: Filters companies.
JOIN: Combines rows from or greater tables.
Example with JOIN:
square
Copy
Edit
SELECT personnel.Name, departments.Name
FROM personnel
JOIN departments ON personnel.Dept_id = departments.Identity;
Types of Joins in SQL
INNER JOIN: Returns statistics with matching values in each tables.
LEFT JOIN: Returns all statistics from the left table, and matched statistics from the right.
RIGHT JOIN: Opposite of LEFT JOIN.
FULL JOIN: Returns all records while there is a in shape in either desk.
SELF JOIN: Joins a table to itself.
Subqueries and Nested Queries
A subquery is a query inside any other query.
Example:
sq.
Copy
Edit
SELECT name FROM employees
WHERE earnings > (SELECT AVG(earnings) FROM personnel);
This reveals employees who earn above common earnings.
Functions in SQL
SQL includes built-in features for acting calculations and formatting:
Aggregate Functions: SUM(), AVG(), COUNT(), MAX(), MIN()
String Functions: UPPER(), LOWER(), CONCAT()
Date Functions: NOW(), CURDATE(), DATEADD()
Conversion Functions: CAST(), CONVERT()
Indexes in SQL
An index is used to hurry up searches.
Example:
sq.
Copy
Edit
CREATE INDEX idx_name ON employees(call);
Indexes help improve the performance of queries concerning massive information.
Views in SQL
A view is a digital desk created through a question.
Example:
square
Copy
Edit
CREATE VIEW high_earners AS
SELECT call, salary FROM employees WHERE earnings > 80000;
Views are beneficial for:
Security (disguise positive columns)
Simplifying complex queries
Reusability
Normalization in SQL
Normalization is the system of organizing facts to reduce redundancy. It entails breaking a database into multiple related tables and defining overseas keys to link them.
1NF: No repeating groups.
2NF: No partial dependency.
3NF: No transitive dependency.
SQL in Real-World Applications
Web Development: Most web apps use SQL to manipulate customers, periods, orders, and content.
Data Analysis: SQL is extensively used in information analytics systems like Power BI, Tableau, and even Excel (thru Power Query).
Finance and Banking: SQL handles transaction logs, audit trails, and reporting systems.
Healthcare: Managing patient statistics, remedy records, and billing.
Retail: Inventory systems, sales analysis, and consumer statistics.
Government and Research: For storing and querying massive datasets.
Popular SQL Database Systems
MySQL: Open-supply and extensively used in internet apps.
PostgreSQL: Advanced capabilities and standards compliance.
Oracle DB: Commercial, especially scalable, agency-degree.
SQL Server: Microsoft’s relational database.
SQLite: Lightweight, file-based database used in cellular and desktop apps.
Limitations of SQL
SQL can be verbose and complicated for positive operations.
Not perfect for unstructured information (NoSQL databases like MongoDB are better acceptable).
Vendor-unique extensions can reduce portability.
Java Programming Language Tutorial
Dot Net Programming Language
C ++ Online Compliers
C Language Compliers
2 notes
·
View notes
Text
Master SQL in 2025: The Only Bootcamp You’ll Ever Need

When it comes to data, one thing is clear—SQL is still king. From business intelligence to data analysis, web development to mobile apps, Structured Query Language (SQL) is everywhere. It’s the language behind the databases that run apps, websites, and software platforms across the world.
If you’re looking to gain practical skills and build a future-proof career in data, there’s one course that stands above the rest: the 2025 Complete SQL Bootcamp from Zero to Hero in SQL.
Let’s dive into what makes this bootcamp a must for learners at every level.
Why SQL Still Matters in 2025
In an era filled with cutting-edge tools and no-code platforms, SQL remains an essential skill for:
Data Analysts
Backend Developers
Business Intelligence Specialists
Data Scientists
Digital Marketers
Product Managers
Software Engineers
Why? Because SQL is the universal language for interacting with relational databases. Whether you're working with MySQL, PostgreSQL, SQLite, or Microsoft SQL Server, learning SQL opens the door to querying, analyzing, and interpreting data that powers decision-making.
And let’s not forget—it’s one of the highest-paying skills on the job market today.
Who Is This Bootcamp For?
Whether you’re a complete beginner or someone looking to polish your skills, the 2025 Complete SQL Bootcamp from Zero to Hero in SQL is structured to take you through a progressive learning journey. You’ll go from knowing nothing about databases to confidently querying real-world datasets.
This course is perfect for:
✅ Beginners with no prior programming experience ✅ Students preparing for tech interviews ✅ Professionals shifting to data roles ✅ Freelancers and entrepreneurs ✅ Anyone who wants to work with data more effectively
What You’ll Learn: A Roadmap to SQL Mastery
Let’s take a look at some of the key skills and topics covered in this course:
🔹 SQL Fundamentals
What is SQL and why it's important
Understanding databases and tables
Creating and managing database structures
Writing basic SELECT statements
🔹 Filtering & Sorting Data
Using WHERE clauses
Logical operators (AND, OR, NOT)
ORDER BY and LIMIT for controlling output
🔹 Aggregation and Grouping
COUNT, SUM, AVG, MIN, MAX
GROUP BY and HAVING
Combining aggregate functions with filters
🔹 Advanced SQL Techniques
JOINS: INNER, LEFT, RIGHT, FULL
Subqueries and nested SELECTs
Set operations (UNION, INTERSECT)
Case statements and conditional logic
🔹 Data Cleaning and Manipulation
UPDATE, DELETE, and INSERT statements
Handling NULL values
Using built-in functions for data formatting
🔹 Real-World Projects
Practical datasets to work on
Simulated business cases
Query optimization techniques
Hands-On Learning With Real Impact
Many online courses deliver knowledge. Few deliver results.
The 2025 Complete SQL Bootcamp from Zero to Hero in SQL does both. The course is filled with hands-on exercises, quizzes, and real-world projects so you actually apply what you learn. You’ll use modern tools like PostgreSQL and pgAdmin to get your hands dirty with real data.
Why This Course Stands Out
There’s no shortage of SQL tutorials out there. But this bootcamp stands out for a few big reasons:
✅ Beginner-Friendly Structure
No coding experience? No problem. The course takes a gentle approach to build your confidence with simple, clear instructions.
✅ Practice-Driven Learning
Learning by doing is at the heart of this course. You’ll write real queries, not just watch someone else do it.
✅ Lifetime Access
Revisit modules anytime you want. Perfect for refreshing your memory before an interview or brushing up on a specific concept.
✅ Constant Updates
SQL evolves. This bootcamp evolves with it—keeping you in sync with current industry standards in 2025.
✅ Community and Support
You won’t be learning alone. With a thriving student community and Q&A forums, support is just a click away.
Career Opportunities After Learning SQL
Mastering SQL can open the door to a wide range of job opportunities. Here are just a few roles you’ll be prepared for:
Data Analyst: Analyze business data and generate insights
Database Administrator: Manage and optimize data infrastructure
Business Intelligence Developer: Build dashboards and reports
Full Stack Developer: Integrate SQL with web and app projects
Digital Marketer: Track user behavior and campaign performance
In fact, companies like Amazon, Google, Netflix, and Facebook all require SQL proficiency in many of their job roles.
And yes—freelancers and solopreneurs can use SQL to analyze marketing campaigns, customer feedback, sales funnels, and more.
Real Testimonials From Learners
Here’s what past students are saying about this bootcamp:
⭐⭐⭐⭐⭐ “I had no experience with SQL before taking this course. Now I’m using it daily at my new job as a data analyst. Worth every minute!” – Sarah L.
⭐⭐⭐⭐⭐ “This course is structured so well. It’s fun, clear, and packed with challenges. I even built my own analytics dashboard!” – Jason D.
⭐⭐⭐⭐⭐ “The best SQL course I’ve found on the internet—and I’ve tried a few. I was up and running with real queries in just a few hours.” – Meera P.
How to Get Started
You don’t need to enroll in a university or pay thousands for a bootcamp. You can get started today with the 2025 Complete SQL Bootcamp from Zero to Hero in SQL and build real skills that make you employable.
Just grab a laptop, follow the course roadmap, and dive into your first database. No fluff. Just real, useful skills.
Tips to Succeed in the SQL Bootcamp
Want to get the most out of your SQL journey? Keep these pro tips in mind:
Practice regularly: SQL is a muscle—use it or lose it.
Do the projects: Apply what you learn to real datasets.
Take notes: Summarize concepts in your own words.
Explore further: Try joining Kaggle or GitHub to explore open datasets.
Ask questions: Engage in course forums or communities for deeper understanding.
Your Future in Data Starts Now
SQL is more than just a skill. It’s a career-launching power tool. With this knowledge, you can transition into tech, level up in your current role, or even start your freelance data business.
And it all begins with one powerful course: 👉 2025 Complete SQL Bootcamp from Zero to Hero in SQL
So, what are you waiting for?
Open the door to endless opportunities and unlock the world of data.
0 notes
Text
This SQL Trick Cut My Query Time by 80%
How One Simple Change Supercharged My Database Performance
If you work with SQL, you’ve probably spent hours trying to optimize slow-running queries — tweaking joins, rewriting subqueries, or even questioning your career choices. I’ve been there. But recently, I discovered a deceptively simple trick that cut my query time by 80%, and I wish I had known it sooner.

Here’s the full breakdown of the trick, how it works, and how you can apply it right now.
🧠 The Problem: Slow Query in a Large Dataset
I was working with a PostgreSQL database containing millions of records. The goal was to generate monthly reports from a transactions table joined with users and products. My query took over 35 seconds to return, and performance got worse as the data grew.
Here’s a simplified version of the original query:
sql
SELECT
u.user_id,
SUM(t.amount) AS total_spent
FROM
transactions t
JOIN
users u ON t.user_id = u.user_id
WHERE
t.created_at >= '2024-01-01'
AND t.created_at < '2024-02-01'
GROUP BY
u.user_id, http://u.name;
No complex logic. But still painfully slow.
⚡ The Trick: Use a CTE to Pre-Filter Before the Join
The major inefficiency here? The join was happening before the filtering. Even though we were only interested in one month’s data, the database had to scan and join millions of rows first — then apply the WHERE clause.
✅ Solution: Filter early using a CTE (Common Table Expression)
Here’s the optimized version:
sql
WITH filtered_transactions AS (
SELECT *
FROM transactions
WHERE created_at >= '2024-01-01'
AND created_at < '2024-02-01'
)
SELECT
u.user_id,
SUM(t.amount) AS total_spent
FROM
filtered_transactions t
JOIN
users u ON t.user_id = u.user_id
GROUP BY
u.user_id, http://u.name;
Result: Query time dropped from 35 seconds to just 7 seconds.
That’s an 80% improvement — with no hardware changes or indexing.
🧩 Why This Works
Databases (especially PostgreSQL and MySQL) optimize join order internally, but sometimes they fail to push filters deep into the query plan.
By isolating the filtered dataset before the join, you:
Reduce the number of rows being joined
Shrink the working memory needed for the query
Speed up sorting, grouping, and aggregation
This technique is especially effective when:
You’re working with time-series data
Joins involve large or denormalized tables
Filters eliminate a large portion of rows
🔍 Bonus Optimization: Add Indexes on Filtered Columns
To make this trick even more effective, add an index on created_at in the transactions table:
sql
CREATE INDEX idx_transactions_created_at ON transactions(created_at);
This allows the database to quickly locate rows for the date range, making the CTE filter lightning-fast.
🛠 When Not to Use This
While this trick is powerful, it’s not always ideal. Avoid it when:
Your filter is trivial (e.g., matches 99% of rows)
The CTE becomes more complex than the base query
Your database’s planner is already optimizing joins well (check the EXPLAIN plan)
🧾 Final Takeaway
You don’t need exotic query tuning or complex indexing strategies to speed up SQL performance. Sometimes, just changing the order of operations — like filtering before joining — is enough to make your query fly.
“Think like the database. The less work you give it, the faster it moves.”
If your SQL queries are running slow, try this CTE filtering trick before diving into advanced optimization. It might just save your day — or your job.
Would you like this as a Medium post, technical blog entry, or email tutorial series?
0 notes
Text
Master SQL with the Best Online Course in Hyderabad – Offered by Gritty Tech
SQL (Structured Query Language) is the backbone of data handling in modern businesses. Whether you're aiming for a career in data science, software development, or business analytics, SQL is a must-have skill. If you're based in Hyderabad or even outside but seeking the best SQL online course that delivers practical learning with real-world exposure, Gritty Tech has crafted the perfect program for you For More…
What Makes Gritty Tech's SQL Course Stand Out?
Practical, Job-Focused Curriculum
Gritty Tech’s SQL course is meticulously designed to align with industry demands. The course content is structured around the real-time requirements of IT companies, data-driven businesses, and startups.
You'll start with the basics of SQL and gradually move to advanced concepts such as:
Writing efficient queries
Managing large datasets
Building normalized databases
Using SQL with business intelligence tools
SQL for data analytics and reporting
Every module is project-based. This means you won’t just learn the theory—you’ll get your hands dirty with practical assignments that mirror real-world tasks.
Learn from Industry Experts
The faculty at Gritty Tech are not just trainers; they are seasoned professionals from top MNCs and startups. Their teaching combines theory with examples drawn from years of hands-on experience. They understand what companies expect from an SQL developer and prepare students accordingly.
Each mentor brings valuable insights into how SQL works in day-to-day business scenarios—whether it's managing millions of records in a customer database or optimizing complex queries in a financial system.
Interactive and Flexible Online Learning
Learning online doesn’t mean learning alone. Gritty Tech ensures you’re part of a vibrant student community where peer interaction, discussion forums, and collaborative projects are encouraged.
Key features of their online delivery model include:
Live instructor-led sessions with real-time query solving
Access to session recordings for future reference
Weekly challenges and hackathons to push your skills
1:1 mentorship to clarify doubts and reinforce learning
You can choose batch timings that suit your schedule, making this course ideal for both working professionals and students.
Comprehensive Module Coverage
The course is divided into logical modules that build your expertise step by step. Here's an overview of the key topics covered:
Introduction to SQL and RDBMS
Understanding data and databases
Relational models and primary concepts
Introduction to MySQL and PostgreSQL
Data Definition Language (DDL)
Creating and modifying tables
Setting primary and foreign keys
Understanding constraints and data types
Data Manipulation Language (DML)
Inserting, updating, and deleting records
Transaction management
Working with auto-commits and rollbacks
Data Query Language (DQL)
SELECT statements in depth
Filtering data with WHERE clause
Using ORDER BY, GROUP BY, and HAVING
Advanced SQL Queries
JOINS: INNER, LEFT, RIGHT, FULL OUTER
Subqueries and nested queries
Views and materialized views
Indexing and performance tuning
Stored Procedures and Triggers
Creating stored procedures for reusable logic
Using triggers to automate actions
SQL in Real Projects
Working with business databases
Creating reports and dashboards
Integrating SQL with Excel and BI tools
Interview Preparation & Certification
SQL interview Q&A sessions
Mock technical interviews
Industry-recognized certification on course completion
Real-Time Projects and Case Studies
Nothing beats learning by doing. At Gritty Tech, every student works on multiple real-time projects, such as:
Designing a complete eCommerce database
Building a report generation system for a retail chain
Analyzing customer data for a telecom company
Creating dashboards with SQL-backed queries for business decisions
These projects simulate real job roles and ensure you're not just certified but genuinely skilled.
Placement Assistance and Resume Building
Gritty Tech goes the extra mile to help you land your dream job. They offer:
Resume and LinkedIn profile optimization
Personalized career guidance
Referrals to hiring partners
Mock interview practice with real-time feedback
Graduates of Gritty Tech have successfully secured jobs as Data Analysts, SQL Developers, Business Intelligence Executives, and more at top companies.
Affordable Pricing with Installment Options
Quality education should be accessible. Gritty Tech offers this high-value SQL course at a very competitive price. Students can also opt for EMI-based payment options. There are often discounts available for early registration or referrals.
Support After Course Completion
Your learning doesn't stop when the course ends. Gritty Tech provides post-course support where you can:
Revisit lectures and materials
Get help with ongoing SQL projects at work
Stay connected with alumni and mentors
They also host webinars, advanced workshops, and alumni meetups that keep you updated and networked.
Who Should Join This Course?
This SQL course is ideal for:
College students and fresh graduates looking to boost their resume
Working professionals in non-technical roles aiming to switch to tech
Data enthusiasts and aspiring data scientists
Business analysts who want to strengthen their data querying skills
Developers who wish to enhance their backend capabilities
No prior coding experience is required. The course begins from scratch, making it beginner-friendly while progressing toward advanced topics for experienced learners.
0 notes
Text
MySQL Assignment Help
Are you a programming student? Are you looking for help with programming assignments and homework? Are you nervous because the deadline is approaching and you are unable to understand how to complete the boring and complex MySQL assignment? If the answer is yes, then don’t freak out as we are here to help. We have a team of nerdy programmers who provide MySQL assignment help online. If you need an A Grade in your entire MySQL coursework then you need to reach out to our experts who have solved more than 3500 projects in MySQL. We will not only deliver the work on time but will ensure that your university guidelines are met completely, thus ensuring excellent solutions for the programming work.
However, before you take MySQL Help from our experts, you must read the below content in detail to understand more about the subject:
About MySQL
MySQL is an open-source database tool that helps us to make different databases and assist them to implement the various programming languages that make both online and offline software. MySQL is a backend tool for computer programming and software that allows one to make big databases and store the different information collected by the software.
In today’s education system all around the globe, there is no need to be in touch with the theory that you have been reading but now there is a demand for the practical applications of the theory. The grades will be increased only when the student will be able to implement what he/she has learned in their studies.
Finally, the complete implementation will be explained in a step-by-step manner to the student
Since we are a globe tutor and also the best online assignment help provider, we have people who know every education system throughout the world. We are not only limited to the US or the UK, but we are here to help each and every student around the world.
Conclusively, you will not regret choosing the All Assignments Experts because we assure to give you the best MySQL assignment service within time. So what are you waiting for? If you need MySQL assignment help, sign up today with the All Assignments Experts. You can email your requirements to us at [email protected]
Popular MySQL Programming topics for which students come to us for online assignment help are:
MySQL Assignment help
Clone Tables Create Database
Drop Database Introduction to SQL
Like Clause MySQL - Connection
MySQL - Create Tables MySQL - Data Types
Database Import and Export MySQL - Database Info
MySQL - Handling Duplicates Insert Query & Select Query
MySQL - Installation NULL Values
SQL Injection MySQL - Update Query and Delete Query
MySQL - Using Sequences PHP Syntax
Regexps Relational Database Management System (RDBMS)
Select Database Temporary Tables
WAMP and LAMP Where Clause
0 notes
Text
ETL Pipeline Performance Tuning: How to Reduce Processing Time
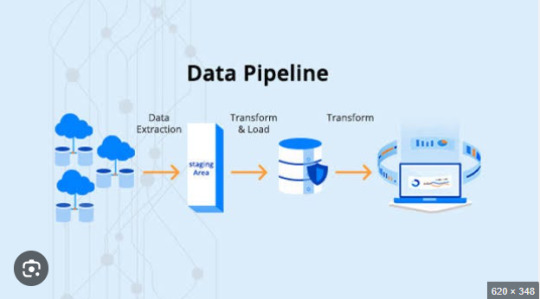
In today’s data-driven world, businesses rely heavily on ETL pipelines to extract, transform, and load large volumes of data efficiently. However, slow ETL processes can lead to delays in reporting, bottlenecks in data analytics, and increased infrastructure costs. Optimizing ETL pipeline performance is crucial for ensuring smooth data workflows, reducing processing time, and improving scalability.
In this article, we’ll explore various ETL pipeline performance tuning techniques to help you enhance speed, efficiency, and reliability in data processing.
1. Optimize Data Extraction
The extraction phase is the first step of the ETL pipeline and involves retrieving data from various sources. Inefficient data extraction can slow down the entire process. Here’s how to optimize it:
a) Extract Only Required Data
Instead of pulling all records, use incremental extraction to fetch only new or modified data.
Implement change data capture (CDC) to track and extract only updated records.
b) Use Efficient Querying Techniques
Optimize SQL queries with proper indexing, partitioning, and WHERE clauses to fetch data faster.
Avoid SELECT * statements; instead, select only required columns.
c) Parallel Data Extraction
If dealing with large datasets, extract data in parallel using multi-threading or distributed processing techniques.
2. Improve Data Transformation Efficiency
The transformation phase is often the most resource-intensive step in an ETL pipeline. Optimizing transformations can significantly reduce processing time.
a) Push Transformations to the Source Database
Offload heavy transformations (aggregations, joins, filtering) to the source database instead of handling them in the ETL process.
Use database-native stored procedures to improve execution speed.
b) Optimize Joins and Aggregations
Reduce the number of JOIN operations by using proper indexing and denormalization.
Use hash joins instead of nested loops for large datasets.
Apply window functions for aggregations instead of multiple group-by queries.
c) Implement Data Partitioning
Partition data horizontally (sharding) to distribute processing load.
Use bucketing and clustering in data warehouses like BigQuery or Snowflake for optimized query performance.
d) Use In-Memory Processing
Utilize in-memory computation engines like Apache Spark instead of disk-based processing to boost transformation speed.
3. Enhance Data Loading Speed
The loading phase in an ETL pipeline can become a bottleneck if not managed efficiently. Here’s how to optimize it:
a) Bulk Loading Instead of Row-by-Row Inserts
Use batch inserts to load data in chunks rather than inserting records individually.
Tools like COPY command in Redshift or LOAD DATA INFILE in MySQL improve bulk loading efficiency.
b) Disable Indexes and Constraints During Load
Temporarily disable foreign keys and indexes before loading large datasets, then re-enable them afterward.
This prevents unnecessary index updates for each insert, reducing load time.
c) Use Parallel Data Loading
Distribute data loading across multiple threads or nodes to reduce execution time.
Use distributed processing frameworks like Hadoop, Spark, or Google BigQuery for massive datasets.
4. Optimize ETL Pipeline Infrastructure
Hardware and infrastructure play a crucial role in ETL pipeline performance. Consider these optimizations:
a) Choose the Right ETL Tool & Framework
Tools like Apache NiFi, Airflow, Talend, and AWS Glue offer different performance capabilities. Select the one that fits your use case.
Use cloud-native ETL solutions (e.g., Snowflake, AWS Glue, Google Dataflow) for auto-scaling and cost optimization.
b) Leverage Distributed Computing
Use distributed processing engines like Apache Spark instead of single-node ETL tools.
Implement horizontal scaling to distribute workloads efficiently.
c) Optimize Storage & Network Performance
Store intermediate results in columnar formats (e.g., Parquet, ORC) instead of row-based formats (CSV, JSON) for better read performance.
Use compression techniques to reduce storage size and improve I/O speed.
Optimize network latency by placing ETL jobs closer to data sources.
5. Implement ETL Monitoring & Performance Tracking
Continuous monitoring helps identify performance issues before they impact business operations. Here’s how:
a) Use ETL Performance Monitoring Tools
Use logging and alerting tools like Prometheus, Grafana, or AWS CloudWatch to monitor ETL jobs.
Set up real-time dashboards to track pipeline execution times and failures.
b) Profile and Optimize Slow Queries
Use EXPLAIN PLAN in SQL databases to analyze query execution plans.
Identify and remove slow queries, redundant processing, and unnecessary transformations.
c) Implement Retry & Error Handling Mechanisms
Use checkpointing to resume ETL jobs from failure points instead of restarting them.
Implement automatic retries for temporary failures like network issues.
Conclusion
Improving ETL pipeline performance requires optimizing data extraction, transformation, and loading processes, along with choosing the right tools and infrastructure. By implementing best practices such as parallel processing, in-memory computing, bulk loading, and query optimization, businesses can significantly reduce ETL processing time and improve data pipeline efficiency.
If you’re dealing with slow ETL jobs, start by identifying bottlenecks, optimizing SQL queries, and leveraging distributed computing frameworks to handle large-scale data processing effectively. By continuously monitoring and fine-tuning your ETL workflows, you ensure faster, more reliable, and scalable data processing—empowering your business with real-time insights and decision-making capabilities.
0 notes
Text
Tips to enhance query execution using clustering, partitions, and caching.
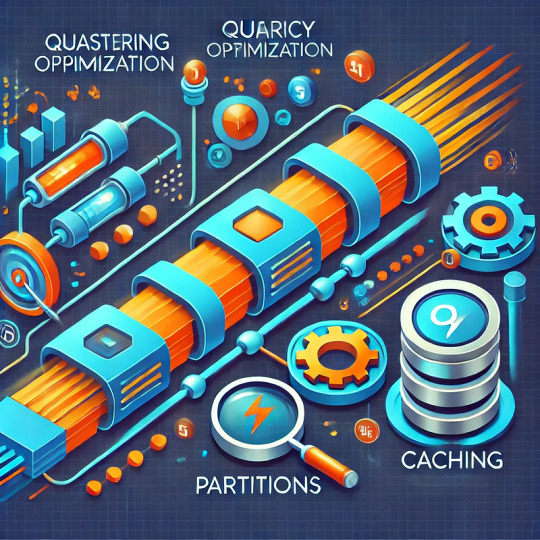
Tips to Enhance Query Execution Using Clustering, Partitions, and Caching Efficient query execution is critical for handling large datasets and delivering fast, responsive applications.
By leveraging techniques like clustering, partitions, and caching, you can drastically reduce query execution times and optimize resource usage.
This blog will explore these strategies in detail and provide actionable tips to improve your query performance.
Clustering: Organizing Data for Faster Access Clustering involves grouping similar data together within a database table to reduce the amount of data scanned during query execution.
Proper clustering can enhance the performance of queries with filtering or range-based conditions.
How Clustering Works: When a table is clustered, rows are organized based on the values in one or more columns (e.g., a date column or a geographic region).
Databases like Snowflake, PostgreSQL, and BigQuery offer clustering features to improve query efficiency.
Best Practices for Clustering: Choose Relevant Columns: Use columns frequently used in WHERE clauses, GROUP BY, or ORDER BY operations. Monitor Cluster Key Effectiveness: Periodically evaluate how well the clustering reduces scan sizes using database-specific tools (e.g., Snowflake’s CLUSTERING_DEPTH). Avoid Over-Clustering: Too many cluster keys can increase storage costs and reduce write performance.
2. Partitioning:
Divide and Conquer for Query Optimization Partitioning involves dividing a table into smaller, more manageable segments based on specific column values. Queries can skip irrelevant partitions, leading to faster execution and lower resource consumption.
Types of Partitioning: Range Partitioning: Divides data based on ranges (e.g., dates). Hash Partitioning: Distributes data evenly based on a hash function (useful for load balancing). List Partitioning: Organizes data into discrete groups based on predefined values (e.g., country names).
Best Practices for Partitioning:
Use Time-Based Partitions: For time-series data, partitioning by date or time ensures queries only access relevant time ranges. Combine Partitioning with Clustering: Use clustering within partitions to further optimize query performance. Avoid Too Many Partitions: Excessive partitioning can lead to metadata overhead and slower query planning.
3. Caching: Reducing Repeated Query Costs Caching stores frequently accessed data in memory or a temporary location to avoid reprocessing. Effective caching strategies can significantly boost performance, especially for repetitive queries.
Types of Caching:
Query Result Caching: Stores the results of executed queries.
Application-Level Caching: Caches query results at the application layer (e.g., in-memory caches like Redis or Memcached).
Materialized Views:
Pre-computed views stored in the database for quick retrieval.
Best Practices for Caching:
Enable Database Query Caching: Many databases, such as Snowflake and MySQL, offer built-in result caching that can be enabled with minimal effort.
Use Materialized Views for Complex Queries:
For queries involving aggregations or joins, materialized views can save time.
Implement Application-Level Caching: For APIs or frequently accessed dashboards, store results in a fast in-memory cache like Redis.
Set Expiry Policies:
Define appropriate TTL (Time-to-Live) values to ensure cached data remains fresh.
4. Combining Clustering, Partitioning, and Caching While each technique individually boosts performance, combining them yields the best results. Here’s how to integrate these methods effectively: Partition First: Divide data into logical chunks to minimize the amount scanned during queries.
Cluster Within Partitions:
Organize data within each partition to optimize retrieval further. Cache Frequently Used Results: Cache results of queries that are repeatedly executed on clustered and partitioned data.
Example Workflow:
Imagine a dataset containing millions of sales records: Partitioning: Split the table by year or month to ensure queries only scan relevant periods. Clustering: Cluster the data within each partition by product category to improve range-based filtering.
Caching: Cache results of frequently accessed reports, such as total monthly sales.
5. Tools and Technologies Here are some tools and platforms that support clustering, partitioning, and caching:
Clustering:
Snowflake, BigQuery, PostgreSQL.
Partitioning:
Apache Hive, Amazon Redshift, MySQL.
Caching: Redis, Memcached, Cloudflare CDN (for content delivery), Materialized Views in PostgreSQL.
6. Monitoring and Optimization To maintain optimal performance:
Track Query Performance: Use database monitoring tools to identify slow queries and adjust clustering or partitioning strategies.
Analyze Query Plans:
Review query execution plans to understand how data is accessed.
Tune Regularly:
As data grows, revisit your clustering, partitioning, and caching configurations to ensure they remain effective.
Conclusion
Enhancing query execution requires a combination of smart data organization and efficient reuse of results.
By leveraging clustering, partitioning, and caching, you can significantly improve performance, reduce costs, and ensure your applications deliver a seamless user experience. Start experimenting with these strategies today to unlock the full potential of your data.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text
Data Science with SQL: Managing and Querying Databases
Data science is about extracting insights from vast amounts of data, and one of the most critical steps in this process is managing and querying databases. Structured Query Language (SQL) is the standard language used to communicate with relational databases, making it essential for data scientists and analysts. Whether you're pulling data for analysis, building reports, or integrating data from multiple sources, SQL is the go-to tool for efficiently managing and querying large datasets.
This blog post will guide you through the importance of SQL in data science, common use cases, and how to effectively use SQL for managing and querying databases.

Why SQL is Essential for Data Science
Data scientists often work with structured data stored in relational databases like MySQL, PostgreSQL, or SQLite. SQL is crucial because it allows them to retrieve and manipulate this data without needing to work directly with raw files. Here are some key reasons why SQL is a fundamental tool for data scientists:
Efficient Data Retrieval: SQL allows you to quickly retrieve specific data points or entire datasets from large databases using queries.
Data Management: SQL supports the creation, deletion, and updating of databases and tables, allowing you to maintain data integrity.
Scalability: SQL works with databases of any size, from small-scale personal projects to enterprise-level applications.
Interoperability: SQL integrates easily with other tools and programming languages, such as Python and R, which makes it easier to perform further analysis on the retrieved data.
SQL provides a flexible yet structured way to manage and manipulate data, making it indispensable in a data science workflow.
Key SQL Concepts for Data Science
1. Databases and Tables
A relational database stores data in tables, which are structured in rows and columns. Each table represents a different entity, such as customers, orders, or products. Understanding the structure of relational databases is essential for writing efficient queries and working with large datasets.
Table: An array of data with columns and rows arranged.
Column: A specific field of the table, like “Customer Name” or “Order Date.”
Row: A single record in the table, representing a specific entity, such as a customer’s details or a product’s information.
By structuring data in tables, SQL allows you to maintain relationships between different data points and query them efficiently.
2. SQL Queries
The commands used to communicate with a database are called SQL queries. Data can be selected, inserted, updated, and deleted using queries. In data science, the most commonly used SQL commands include:
SELECT: Retrieves data from a database.
INSERT: Adds new data to a table.
UPDATE: Modifies existing data in a table.
DELETE: Removes data from a table.
Each of these commands can be combined with various clauses (like WHERE, JOIN, and GROUP BY) to refine the results, filter data, and even combine data from multiple tables.
3. Joins
A SQL join allows you to combine data from two or more tables based on a related column. This is crucial in data science when you have data spread across multiple tables and need to combine them to get a complete dataset.
Returns rows from both tables where the values match through an inner join.
All rows from the left table and the matching rows from the right table are returned via a left-join. If no match is found, the result is NULL.
Like a left join, a right join returns every row from the right table.
FULL JOIN: Returns rows in cases where both tables contain a match.
Because joins make it possible to combine and evaluate data from several sources, they are crucial when working with relational databases.
4. Aggregations and Grouping
Aggregation functions like COUNT, SUM, AVG, MIN, and MAX are useful for summarizing data. SQL allows you to aggregate data, which is particularly useful for generating reports and identifying trends.
COUNT: Returns the number of rows that match a specific condition.
SUM: Determines a numeric column's total value.
AVG: Provides a numeric column's average value.
MIN/MAX: Determines a column's minimum or maximum value.
You can apply aggregate functions to each group of rows that have the same values in designated columns by using GROUP BY. This is helpful for further in-depth analysis and category-based data breakdown.
5. Filtering Data with WHERE
The WHERE clause is used to filter data based on specific conditions. This is critical in data science because it allows you to extract only the relevant data from a database.
Managing Databases in Data Science
Managing databases means keeping data organized, up-to-date, and accurate. Good database management helps ensure that data is easy to access and analyze. Here are some key tasks when managing databases:
1. Creating and Changing Tables
Sometimes you’ll need to create new tables or change existing ones. SQL’s CREATE and ALTER commands let you define or modify tables.
CREATE TABLE: Sets up a new table with specific columns and data types.
ALTER TABLE: Changes an existing table, allowing you to add or remove columns.
For instance, if you’re working on a new project and need to store customer emails, you might create a new table to store that information.
2. Ensuring Data Integrity
Maintaining data integrity means ensuring that the data is accurate and reliable. SQL provides ways to enforce rules that keep your data consistent.
Primary Keys: A unique identifier for each row, ensuring that no duplicate records exist.
Foreign Keys: Links between tables that keep related data connected.
Constraints: Rules like NOT NULL or UNIQUE to make sure the data meets certain conditions before it’s added to the database.
Keeping your data clean and correct is essential for accurate analysis.
3. Indexing for Faster Performance
As databases grow, queries can take longer to run. Indexing can speed up this process by creating a shortcut for the database to find data quickly.
CREATE INDEX: Builds an index on a column to make queries faster.
DROP INDEX: Removes an index when it’s no longer needed.
By adding indexes to frequently searched columns, you can speed up your queries, which is especially helpful when working with large datasets.
Querying Databases for Data Science
Writing efficient SQL queries is key to good data science. Whether you're pulling data for analysis, combining data from different sources, or summarizing results, well-written queries help you get the right data quickly.
1. Optimizing Queries
Efficient queries make sure you’re not wasting time or computer resources. Here are a few tips:
*Use SELECT Columns Instead of SELECT : Select only the columns you need, not the entire table, to speed up queries.
Filter Early: Apply WHERE clauses early to reduce the number of rows processed.
Limit Results: Use LIMIT to restrict the number of rows returned when you only need a sample of the data.
Use Indexes: Make sure frequently queried columns are indexed for faster searches.
Following these practices ensures that your queries run faster, even when working with large databases.
2. Using Subqueries and CTEs
Subqueries and Common Table Expressions (CTEs) are helpful when you need to break complex queries into simpler parts.
Subqueries: Smaller queries within a larger query to filter or aggregate data.
CTEs: Temporary result sets that you can reference within a main query, making it easier to read and understand.
These tools help organize your SQL code and make it easier to manage, especially for more complicated tasks.
Connecting SQL to Other Data Science Tools
SQL is often used alongside other tools for deeper analysis. Many programming languages and data tools, like Python and R, work well with SQL databases, making it easy to pull data and then analyze it.
Python and SQL: Libraries like pandas and SQLAlchemy let Python users work directly with SQL databases and further analyze the data.
R and SQL: R connects to SQL databases using packages like DBI and RMySQL, allowing users to work with large datasets stored in databases.
By using SQL with these tools, you can handle and analyze data more effectively, combining the power of SQL with advanced data analysis techniques.
Conclusion
If you work with data, you need to know SQL. It allows you to manage, query, and analyze large datasets easily and efficiently. Whether you're combining data, filtering results, or generating summaries, SQL provides the tools you need to get the job done. By learning SQL, you’ll improve your ability to work with structured data and make smarter, data-driven decisions in your projects.
0 notes
Text
Optimising MySQL Performance: Tips and Best Practices
MySQL is a popular choice for database management due to its flexibility, scalability, and user-friendly nature. However, as your data grows, you might experience performance slowdowns. Fear not! By applying a few optimisation strategies, you can significantly improve your MySQL performance and ensure your application runs smoothly. This article provides valuable tips and best practices to help you get the most out of your MySQL database, brought to you by SOC Learning.
1. Choose the Right Storage Engine
MySQL supports several storage engines, each with its own advantages. The most commonly used are InnoDB and MyISAM:
InnoDB: Best for transactions, data integrity, and concurrent read/write operations. It supports foreign keys and is ACID-compliant, making it ideal for most applications.
MyISAM: Faster for read-heavy operations but lacks support for transactions and foreign keys. It’s suitable for applications that require fast read speeds and fewer write operations.
Choose a storage engine based on your specific needs to enhance performance.
2. Optimise Queries
Inefficient queries can be a significant bottleneck in your database performance. Here’s how you can optimise them:
Use Indexes Wisely: Indexes speed up search queries but slow down insert, update, and delete operations. Add indexes on columns that are frequently used in WHERE, JOIN, and ORDER BY clauses but avoid over-indexing.
Avoid SELECT * Queries: Instead of selecting all columns, specify only the columns you need. This reduces the amount of data MySQL has to fetch.
Use EXPLAIN for Query Analysis: The EXPLAIN command provides insight into how MySQL executes a query. Analyse the output to find bottlenecks and optimise your queries accordingly.
3. Regularly Analyse and Defragment Tables
Over time, tables can become fragmented due to insertions, updates, and deletions. This fragmentation can slow down performance. Regularly running the ANALYSE TABLE and OPTIMISE TABLE commands helps MySQL update its statistics and reorganise tables for better performance.
4. Optimise Database Schema Design
A well-structured database schema can significantly impact performance. Follow these best practices:
Normalise Tables: Break down tables into smaller, related pieces to reduce redundancy and ensure data integrity.
Denormalise When Necessary: In some cases, denormalisation (storing redundant data to reduce JOIN operations) can improve performance, especially in read-heavy applications.
Use Proper Data Types: Choose the smallest data type that can store your data. This reduces disk space and memory usage, resulting in faster performance.
5. Use Caching
Caching reduces the load on your MySQL server by storing frequently accessed data in memory. Tools like Memcached or Redis can be used for caching database queries, reducing the number of times MySQL needs to access disk storage.
6. Monitor and Fine-Tune MySQL Configuration
MySQL comes with default configuration settings that might not be optimal for your application. Use tools like MySQL Tuner to analyse and suggest configuration changes based on your workload. Key parameters to focus on include:
Buffer Pool Size: Set the InnoDB buffer pool size to about 70-80% of your server's available memory. This helps store frequently accessed data in memory.
Query Cache Size: Enable and configure query caching for read-heavy workloads.
Connection Limits: Adjust the max_connections and wait_timeout settings to manage the number of connections MySQL can handle simultaneously.
7. Partition Large Tables
Partitioning splits large tables into smaller, more manageable pieces, which can significantly reduce query execution time. MySQL supports range, list, hash, and key partitioning. Choose the appropriate method based on your data and query patterns.
8. Regular Backups and Maintenance
Regular backups are crucial to protect your data. Use tools like mysqldump or MySQL Enterprise Backup to create backups without impacting performance. Additionally, perform regular maintenance tasks such as updating statistics, rebuilding indexes, and checking for data corruption.
9. Monitor Performance Metrics
Use MySQL's built-in tools, such as the Performance Schema and MySQL Enterprise Monitor, to monitor various performance metrics like slow queries, disk usage, and connection statistics. Regular monitoring helps identify potential performance issues early and allows you to take proactive measures.
10. Stay Updated
Always keep your MySQL server updated to the latest stable version. New releases often include performance improvements, bug fixes, and enhanced features that can boost performance.
Conclusion
Optimising MySQL performance is an ongoing process that involves a mix of strategic planning, monitoring, and regular maintenance. By following these best practices, you can ensure your database is running efficiently and can handle your growing data needs.
At SOC Learning, we understand the importance of a high-performing database in delivering quality online education. Our coding courses, including our MySQL training, are designed to help you master database management skills. Visit SOC Learning to learn more about our courses and enhance your data management expertise today!
0 notes
Text
Take a Look at the Best Books for SQL
Summary: Explore the best books for SQL, from beginner-friendly guides to advanced resources. Learn essential SQL concepts, practical applications, and advanced techniques with top recommendations like "Getting Started with SQL" and "SQL Queries for Mere Mortals." These books provide comprehensive guidance for mastering SQL and advancing your career.

Introduction
In today's data-driven world, SQL (Structured Query Language) plays a crucial role in managing and analyzing data. As the backbone of many database systems, SQL enables efficient querying, updating, and organizing of information. Whether you're a data analyst, developer, or business professional, mastering SQL is essential.
This article aims to guide you in choosing the best books for SQL, helping you develop strong foundational skills and advanced techniques. By exploring these top resources, you'll be well-equipped to navigate the complexities of SQL and leverage its power in your career.
What is SQL?
SQL, or Structured Query Language, is a standardized programming language specifically designed for managing and manipulating relational databases. It provides a robust and flexible syntax for defining, querying, updating, and managing data.
SQL serves as the backbone for various database management systems (DBMS) like MySQL, PostgreSQL, Oracle, and Microsoft SQL Server. Its primary purpose is to enable users to interact with databases by executing commands to perform various operations, such as retrieving specific data, inserting new records, and updating or deleting existing entries.
Usage
In database management, SQL plays a crucial role in creating and maintaining the structure of databases. Database administrators use SQL to define tables, set data types, establish relationships between tables, and enforce data integrity through constraints.
This structural definition process is essential for organizing and optimizing the storage of data, making it accessible and efficient for retrieval.
For data manipulation, SQL offers a wide range of commands collectively known as DML (Data Manipulation Language).
These commands include SELECT for retrieving data, INSERT for adding new records, UPDATE for modifying existing data, and DELETE for removing records. These operations are fundamental for maintaining the accuracy and relevance of the data stored in a database.
Querying is another vital use of SQL, enabling users to extract specific information from large datasets. The SELECT statement, often used in conjunction with WHERE clauses, JOIN operations, and aggregation functions like SUM, AVG, and COUNT, allows users to filter, sort, and summarize data based on various criteria.
This capability is essential for generating reports, performing data analysis, and making informed business decisions.
Overall, SQL is an indispensable tool for anyone working with relational databases, providing the means to efficiently manage and manipulate data.
Must See: Best Statistics Books for Data Science.
Benefits of Learning SQL
Learning SQL offers numerous advantages that can significantly enhance your career and skillset. As a foundational tool in database management, SQL's benefits span across various domains, making it a valuable skill for professionals in tech and business.
Career Opportunities: SQL skills are in high demand across multiple industries, including finance, healthcare, e-commerce, and technology. Professionals with SQL expertise are sought after for roles such as data analysts, database administrators, and software developers. Mastering SQL can open doors to lucrative job opportunities and career growth.
Versatility: SQL's versatility is evident in its compatibility with different database systems like MySQL, PostgreSQL, and SQL Server. This flexibility allows you to work with various platforms, making it easier to adapt to different workplace environments and projects. The ability to manage and manipulate data across diverse systems is a key asset in today’s data-driven world.
Data Handling: SQL is essential for data analysis, business intelligence, and decision-making. It enables efficient querying, updating, and managing of data, which are crucial for generating insights and driving business strategies. By leveraging SQL, you can extract meaningful information from large datasets, supporting informed decision-making processes and enhancing overall business performance.
Best Books for SQL

SQL (Structured Query Language) is a powerful tool used for managing and manipulating databases. Whether you're a beginner or an experienced professional, there are numerous books available to help you master SQL. Here, we highlight some of the best books that cover everything from foundational concepts to advanced topics.
Getting Started with SQL
Author: Thomas Nield Edition: 1st Edition
"Getting Started with SQL" by Thomas Nield is an excellent introductory book for anyone new to SQL. At just 130 pages, this book is concise yet comprehensive, designed to help readers quickly grasp the basics of SQL. Nield's clear and accessible writing style makes complex concepts easy to understand, even for those with no prior knowledge of databases.
This book focuses on practical applications, providing hands-on examples and exercises. It doesn't require access to an existing database server, making it ideal for beginners. Instead, Nield introduces readers to SQLite, a lightweight and easy-to-use database system, which they can set up on their own computers.
Key Topics Covered:
Understanding relational databases and their structure
Setting up and using SQLite and SQLiteStudio
Basic SQL commands for data retrieval, sorting, and updating
Creating and managing tables with normalized design principles
Advanced topics like joining tables and using aggregate functions
This book is perfect for beginners who want to quickly learn the fundamentals of SQL and start working with databases.
SQL All-in-One For Dummies
Author: Allen G. Taylor Edition: 2nd Edition
"SQL All-in-One For Dummies" by Allen G. Taylor is a comprehensive guide that covers a broad range of SQL topics. This book is part of the popular "For Dummies" series, known for its approachable and easy-to-understand content. With over 750 pages, it is divided into eight mini-books, each covering a different aspect of SQL.
While the book does assume some basic technical knowledge, it is still accessible to those new to SQL. It covers essential topics like database design, data retrieval, and data manipulation, as well as more advanced subjects like XML integration and database performance tuning.
Key Topics Covered:
Overview of the SQL language and its importance in database management
Updates to SQL standards and new features
Relational database development and SQL queries
Data security and database tuning techniques
Integration of SQL with programming languages and XML
This book is an excellent resource for beginners who want a comprehensive understanding of SQL, as well as for those looking to deepen their knowledge.
SQL in 10 Minutes
Author: Ben Forta Edition: 4th Edition
"SQL in 10 Minutes" by Ben Forta is designed for busy professionals who need to learn SQL quickly. The book is structured into 22 short lessons, each of which can be completed in about 10 minutes. This format allows readers to learn at their own pace and focus on specific topics as needed.
Forta covers a wide range of SQL topics, from basic SELECT and UPDATE statements to more advanced concepts like transactional processing and stored procedures. The book is platform-agnostic, providing examples that work across different database systems such as MySQL, Oracle, and Microsoft Access.
Key Topics Covered:
Key SQL statements and syntax
Creating complex queries using various clauses and operators
Retrieving, categorizing, and formatting data
Using aggregate functions for data summarization
Joining multiple tables and managing data integrity
This book is ideal for programmers, business analysts, and anyone else who needs to quickly get up to speed with SQL.
SQL Queries for Mere Mortals
Author: John Viescas Edition: 4th Edition
"SQL Queries for Mere Mortals" by John Viescas is a must-read for anyone looking to master complex SQL queries. This book takes a practical approach, providing clear explanations and numerous examples to help readers understand advanced SQL concepts and best practices.
Viescas covers everything from the basics of relational databases to advanced query techniques. The book includes updates for the latest SQL features and provides sample databases and creation scripts for various platforms, including MySQL and SQL Server.
Key Topics Covered:
Understanding relational database structures
Constructing SQL queries using SELECT, WHERE, GROUP BY, and other clauses
Advanced query techniques, including INNER and OUTER JOIN, UNION operators, and subqueries
Data modification with UPDATE, INSERT, and DELETE statements
Optimizing queries and understanding execution plans
This book is suitable for both beginners and experienced professionals who want to deepen their understanding of SQL and improve their querying skills.
Frequently Asked Questions
What are some of the best books for SQL beginners?
"Getting Started with SQL" by Thomas Nield and "SQL All-in-One For Dummies" by Allen G. Taylor are excellent choices for beginners. They provide clear explanations and practical examples to build foundational SQL skills.
How can I quickly learn SQL?
"SQL in 10 Minutes" by Ben Forta offers a fast-track approach with 22 concise lessons. Each lesson takes about 10 minutes, making it perfect for busy professionals seeking to quickly grasp SQL basics.
What is the best book for mastering SQL queries?
"SQL Queries for Mere Mortals" by John Viescas is highly recommended for mastering complex SQL queries. It covers advanced topics like joins, subqueries, and optimization, with practical examples.
Conclusion
Mastering SQL is essential for anyone involved in data management and analysis. The books mentioned, including "Getting Started with SQL," "SQL All-in-One For Dummies," "SQL in 10 Minutes," and "SQL Queries for Mere Mortals," offer comprehensive guidance from beginner to advanced levels.
These resources cover essential SQL concepts, practical applications, and advanced techniques. By studying these books, you can develop a strong foundation in SQL, enhance your querying skills, and unlock new career opportunities. Whether you're just starting or looking to deepen your knowledge, these books are invaluable for mastering SQL.
0 notes
Text
SQL Programming Made Easy: A Comprehensive Tutorial for Beginners
Are you new to the world of databases and programming? Don't worry; SQL (Structured Query Language) might sound intimidating at first, but it's actually quite straightforward once you get the hang of it. In this comprehensive tutorial, we'll walk you through everything you need to know to get started with SQL programming. By the end, you'll be equipped with the foundational knowledge to manage and query databases like a pro.
1. Understanding Databases
Before diving into SQL, let's understand what databases are. Think of a database as a structured collection of data. It could be anything from a simple list of contacts to a complex inventory management system. Databases organize data into tables, which consist of rows and columns. Each row represents a record, while each column represents a specific attribute or field.
2. What is SQL?
SQL (Structured Query Language) is a specialized language used to interact with databases. It allows you to perform various operations such as retrieving data, inserting new records, updating existing records, and deleting unnecessary data. SQL is not specific to any particular database management system (DBMS); it's a standard language that is widely used across different platforms like MySQL, PostgreSQL, Oracle, and SQL Server.
3. Basic SQL Commands
Let's start with some basic SQL commands:
SELECT: This command is used to retrieve data from a database.
INSERT INTO: It adds new records to a table.
UPDATE: It modifies existing records in a table.
DELETE: It removes records from a table.
CREATE TABLE: It creates a new table in the database.
DROP TABLE: It deletes an existing table.
4. Retrieving Data with SELECT
The SELECT statement is one of the most commonly used SQL commands. It allows you to retrieve data from one or more tables based on specified criteria. Here's a simple example:
sql
Copy code
SELECT column1, column2 FROM table_name WHERE condition;
This query selects specific columns from a table based on a certain condition.
5. Filtering Data with WHERE
The WHERE clause is used to filter records based on specified criteria. For example:
sql
Copy code
SELECT * FROM employees WHERE department = 'IT';
This query selects all records from the "employees" table where the department is 'IT'.
6. Inserting Data with INSERT INTO
The INSERT INTO statement is used to add new records to a table. Here's how you can use it:
sql
Copy code
INSERT INTO table_name (column1, column2) VALUES (value1, value2);
This query inserts a new record into the specified table with the given values for each column.
7. Updating Records with UPDATE
The UPDATE statement is used to modify existing records in a table. For example:
sql
Copy code
UPDATE employees SET salary = 50000 WHERE department = 'HR';
This query updates the salary of employees in the HR department to 50000.
8. Deleting Data with DELETE
The DELETE statement is used to remove records from a table. Here's an example:
sql
Copy code
DELETE FROM students WHERE grade = 'F';
This query deletes all records from the "students" table where the grade is 'F'.
9. Conclusion
Congratulations! You've just scratched the surface of SQL programming. While this tutorial covers the basics, there's still a lot more to learn. As you continue your journey, don't hesitate to explore more advanced topics such as joins, subqueries, and indexing. Practice regularly and experiment with different queries to solidify your understanding. With dedication and perseverance, you'll soon become proficient in SQL programming and unlock endless possibilities in database management and data analysis. Happy coding!
0 notes
Text
January 16, 2024
New gem release: unreliable 0.10
I released a new version of a gem!
unreliable is a gem I wrote that makes your test suite and your app more robust against undefined database behevior.
During the running of your test suite, it adds randomness to the order of all your ActiveRecord relations. If their existing order is well-defined, that won't change a thing.
But if you have any relations where ordering actually matters, and you don't fully specify that order, the gem may surface some of those bugs.
SQL order can be undefined
Many people don't know that if a query has an ORDER BY clause that's ambiguous, the database can return results in any order. That's in the spec!
Because most databases, most of the time, return data in primary key order, we as programmers get used to that and maybe sometimes rely on it.
"unreliable" forces you not to rely on it.
Bugfixes and tests
Version 0.10 has several bugfixes related to Postgres. And it's got a large test suite that should give some confidence it's doing the right thing.
(It does exactly nothing outside of a Rails test environment anyway, so have no fear, it can't cause problems in your actual app.)
Give it a try!
Arel 8, subqueries, and update
Okay, this is just a footnote. Here's something that came up while I was writing "unreliable"'s test suite.
I found an odd edge case bug in Arel 8, the library used by the ORM in ActiveRecord 5.0 and 5.1. And although Arel was a public API at that point, really nobody but Rails was using it, and 5.1 is long-since end-of-lifed, so none of this really matters.
Where ActiveRecord calls Arel's compile_update, the relation is unscoped, so it can't have an order or limit.
But if it did, then when visit_Arel_Nodes_UpdateStatement built the SQL, it would construct an IN subquery and pass it a primary key that's quoted.
The resulting query that the visitor would build would be:
UPDATE foo SET bar=1 WHERE 'id' IN (SELECT 'id' FROM foo WHERE foo.id=2)
See the bug? 'id' should have been "id", which would have referenced the column. But it's single-quoted, and in SQL, that's a string literal!
So every row matches and the whole table gets updated! Yikes!
The bug never triggers for MySQL because MySQL forbids same-table subqueries on UPDATEs, so Rails special-cases around this.
And as I said, this is all ancient history, and almost certainly affects no one. But I think this is technically an Arel 8 bug that has been lurking undiscovered since February 2017.
This behavior was fixed in Arel 9. That's why "unreliable", which forces an order on most relations internally, after ActiveRecord forces an unscoping, now requires ActiveRecord >= 5.2.
0 notes
Text
Getting Started with My SQL DBMS
MySQL is a widely used database management system that's been developed and published by Oracle. It's a powerful, multi-user, multi-threaded platform that can handle a variety of mission-critical tasks. It's based on SQL, which is a standard language for creating database objects like tables and views, as well as building queries to access data from those objects. Here's how to get started with MySQL.
Installing and Starting MySQL
MerrySQLit can be installed on a variety of operating systems, ranging from Windows to macOS and Oracle Solaris. Additionally, it is compatible with a variety of Linux distributions, including Ubuntu, Debian and Fedora. The process of installing MySQL on Windows will vary depending on the type of operating system and the preferences of the user. The most straightforward approach is to use the MySQL Installer tool, which provides a step-by-step guide to setting up and installing a MySQL instance on Windows.
Some Basic Operations with MySQL
Logical operators are used in MySQL to join multiple conditions within a WHERE clause in order to filter data in a table. The three logical operators used in MySQL are AND (and), OR (or), and NOT (not). AND returns a record only when both the conditions are true, whereas OR (or) returns a record when at least one condition is true. NOT (not) negates the condition. Logical operators are commonly used in conjunction with comparison operators, such as =, >, and LIKE, to construct conditions.
There are three logical operators in MySQL: AND, OR, and NOT.
AND Operator (&&): The AND operator is a logical operator in MySQL that can be used to filter data in a table by using a WHERE clause. The AND operator returns true only if all the conditions in the WHERE clause are true. For example, if any condition in the WHERE clause is false, then the AND operator returns true.
OR Operator (|| or OR): The OR operator is a logical operator in MySQL that enables data to be filtered from a table when two or more conditions are combined in a WHERE statement. The OR operator returns true when at least one condition in the WHERE statement is met.
NOT Operator (! or NOT): The NOT operator is a logical operator in MySQL that allows you to NOT condition in a WHERE clause in order to filter the data in a table. The NOT operator returns only the records that have a condition that is TRUE in a WHERE clause.
Operator Precedence
Operator precedence in MySQL is the order in which logical operators are evaluated in an SQL query. It is important to understand operator precedence when constructing complex SQL queries to ensure that the result is accurate. Matter uses a series of rules to determine the order in which to evaluate operators in MySQL. These rules are based on the type and associativity of the operator. For example, multiplication and division are evaluated from the left to the right, while addition and subtraction are evaluated from the right. Understanding operator precedence in MySQL will help you to perform your SQL queries in the correct order and ensure that the results you get are correct.
Using Parentheses for Clarity
The use of parentheses in MySQL queries allows for the grouping of conditions and the construction of more complex logical expressions, which can improve query readability and readability. This is especially useful when there are multiple conditions in a query. Parenthesis can help to avoid confusion regarding the logic of the query by grouping the conditions with parentheses and evaluating them in the desired order. In summary, the use of parentheses in queries in MySQL can make them simpler to understand, easier to maintain, and easier to troubleshoot.
Combining Operators
Logical operators can be used to combine multiple queries in MySQL to generate more complex and precise conditions that can be used to access or modify data in a database. This can help to reduce the amount of queries that need to be executed, thus saving both time and data. Additionally, the use of logical operators can enable the creation of queries that are more dynamic and adaptive, able to adjust to changes in data and conditions within the database. For example, if a table has multiple conditions, the logical operators can be combined in a query to only retrieve the required data.
Wrap Up
Once you are familiar with the installation of MySQL and the use of the MySQL Workbench tool, you can begin to explore the various features available, create various types of Database Objects, and begin constructing SQL Queries. MySQL is an adaptable database system that is suitable for a broad range of tasks. As you gain a better understanding of how it operates, you will be able to make the most of its features. MySQL Installer is designed to facilitate the installation of relational databases, and the Workbench tool makes it simple to interface with the environment and interact with the MySQL database and data. By building on this foundation, Brigita software development services can assist you in becoming more proficient in the creation of Databases and Queries, thus enabling you to better support your Data-Driven Applications.
0 notes
Text
Introduction to SQL
Introduction to SQL
One of the key concepts involved in data management is the programming language SQL (Structured Query Language). This language is widely known and used for database management by many individuals and companies around the world. SQL is used to perform creation, retrieval, updating, and deletion (CRUD) tasks on databases, making it very easy to store and query data. SQL was developed in the 1970’s by Raymond Boyce and Donald Chamberlin. It was initially created for use within IBM’s database management system but has since been developed further and become available to the public. Oracle has released an open-source system called MySQL where individuals in the public can write their own SQL to perform queries, which is a great place to start!
Types of Commands
There are three types of commands in SQL:
Data Definition Language (DDL)- DDL defines a database through create, drop, and alter table commands, as well as establishing keys (primary, foreign, etc.)
Data Control Language (DCL)- DCL controls who has access to the data.
Data Manipulation Language (DML)- DML commands are used to query a database.
Steps to Create a Table
The first step to creating a table is making a plan of what variables will be in the table as well as the type of variable. Once a plan is in place, the CREATE TABLE command is used and the variables are listed with their type and length. Then, one must identify which attributes will allow null values and which columns should be unique. At the end, all primary and foreign keys need to be identified. INSERT INTO commands are then used to fill the empty table with rows of data. If a table need to be edited, the ALTER TABLE command can be used. If it needs to be deleted, then DROP TABLE can be used to do so. Sometimes it is helpful to drop a table at the beginning of a session in case there has already been a table created with the table name one is trying to use.
SQL Query Hierarchy
Querying data is essentially asking it a question or asking it for a specified output. Nearly all DML queries begin with the same commands. First, one must identify which columns they would like to the output to contain. This is established by listing the column names after SELECT with commas in between. Aggregate function may be used in this part as well, such as SUM or COUNT. However, if an aggregate function is used, a GROUP BY must also be used (expanded upon later). Next, one must identify the table from which these columns are coming from. To do this, the table name is written after the clause FROM, and an alias may be used if multiple tables are being joined, or just to stay organized. This is also the location where one would identify any tables that are being joined, as well as the column on which they are being joined. SELECT and FROM are the two commands necessary to query data. If there are any filters one would like to use on the data that do not require an aggregation, the WHERE clause comes next. This is where the filter can be applied to the data. If aggregate functions were used in the SELECT command, a GROUP BY command would be used after WHERE. One or more columns can be used in a GROUP BY to group the data by a field (or multiple). Next, a HAVING clause is used to filter data if the filter is based on an aggregate, such as AVG. If one wants the query returned in a sorted manner, the ORDER BY command can be used to sort it in ascending or descending order. If one wants the order to be descending, DESC must be written after ORDER BY. Finally, LIMIT can be used to the limit the number of rows of data returned. These are the steps one would take when writing a query, however, the clauses are processed in a different order by the computer. The order in which they are processed by the computer is as follows: FROM, WHERE, GROUP BY, HAVING, SELECT, ORDER BY, LIMIT. It is also important to note that all these commands are used to query data, so the tables must already be created to perform these operations.
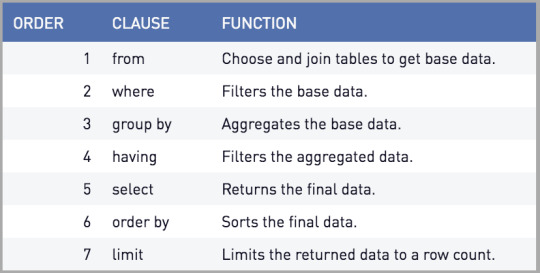
Is it Worth Learning SQL?
The short answer is- absolutely! SQL is a very commonly used programming language across the world; it is universal. Also, it is subjectively easy to learn, especially compared to coding. It is incredibly powerful when dealing with databases. The steps provided above are only for simple queries, though they are very useful. Much more advanced queries are possible with SQL, such as nested queries. If you want to get started with SQL, Data Camp offers excellent beginner courses as well as other online platforms. Because Oracle’s MySQL is open-source and easy to use, it is a great place to practice.
1 note
·
View note
Text
Master SQL for Data Science Complete Guide – Steps, Roadmap, and Importance of SQL
Introduction
In today's data-driven world, SQL (Structured Query Language) has become an essential tool for anyone involved in data science. Whether you are a beginner or an experienced data scientist, mastering SQL is crucial for extracting valuable insights from databases efficiently. This comprehensive guide will take you through the necessary steps, roadmap, and the significance of SQL in the field of data science. And if you are looking to kickstart your data science journey, consider enrolling in Skillslash Academy's Data Science Course in Pune, which provides comprehensive training and certification.

Getting Started with SQL
SQL, the language of databases, provides a powerful way to manage and manipulate data. To begin your journey into mastering SQL for data science, the first step is to install and configure SQL on your system. You can choose from various SQL implementations, such as MySQL, PostgreSQL, or Microsoft SQL Server, based on your requirements.
Once you have SQL set up, it's essential to familiarize yourself with the basic SQL syntax. SQL follows a straightforward structure, and its primary command is the SELECT statement, which is used to retrieve data from databases. To filter and sort the data, you can use WHERE and ORDER BY clauses, respectively.
Working with SQL Functions
SQL functions play a crucial role in data manipulation and analysis. Aggregate functions like COUNT, SUM, AVG, MIN, and MAX allow you to perform calculations on groups of data. String functions help in manipulating and extracting information from text fields, while date and time functions assist in handling date-related data.
Joins and Unions
In real-world scenarios, data often resides in multiple tables. SQL joins enable you to combine data from different tables based on common columns. There are various types of joins, such as inner joins and outer joins, each serving different purposes. Additionally, the UNION operator allows you to combine the results of two or more SELECT queries.
Subqueries and Nested Queries
Subqueries, also known as nested queries, are queries within queries. They allow you to break down complex problems into smaller, more manageable parts. Correlated subqueries depend on the outer query's results, whereas nested queries are independent.
Data Manipulation with SQL
Data manipulation is a critical aspect of SQL, as it involves inserting, updating, and deleting data in databases. You'll learn how to add new records to tables, modify existing data, and remove unwanted entries. Furthermore, understanding how to alter table structures is essential for database maintenance.
Advanced SQL Techniques
To optimize your SQL performance, you need to delve into advanced techniques. Indexing helps speed up data retrieval, and views provide a way to store complex queries as virtual tables. Stored procedures and functions aid in reusing code and streamlining database operations.
SQL for Data Analysis
Data analysis is at the heart of data science. SQL allows you to aggregate data, pivot tables, and handle missing data effectively. These skills are vital for extracting meaningful insights and supporting decision-making processes.
SQL for Data Visualization
While SQL excels at data manipulation, it can also be integrated with visualization tools to create stunning data visualizations and interactive dashboards. Communicating insights visually enhances data understanding and aids in effective communication.
Real-world Applications of SQL in Data Science
SQL's practical applications in data science are vast. Whether it's predicting customer behavior, segmenting users, or performing market basket analysis, SQL is a fundamental tool in turning raw data into actionable insights.
SQL Best Practices and Tips
As with any programming language, adhering to best practices is essential for writing maintainable and efficient SQL code. Proper naming conventions, writing optimized queries, and guarding against SQL injection are among the practices that will elevate your SQL skills.
Conclusion
Mastering SQL is an indispensable skill for anyone aspiring to excel in data science. This guide has provided you with a comprehensive roadmap to navigate through the world of SQL step by step. By understanding SQL functions, joins, subqueries, and advanced techniques, you'll be well-equipped to analyze data, create visualizations, and solve real-world problems efficiently.
FAQs
Q: Is SQL difficult to learn for beginners?
A: SQL has a relatively simple syntax, making it accessible for beginners. With practice and dedication, anyone can master SQL.
Q: Which SQL implementation should I choose for data science?
A: The choice of SQL implementation depends on your project requirements and preferences. Popular options include MySQL, PostgreSQL, and Microsoft SQL Server.
Q: Can I use SQL for big data analysis?
A: SQL is suitable for managing and analyzing large datasets. However, for big data, you may also consider specialized tools like Hadoop and Spark.
Q: What is the difference between SQL and NoSQL databases?
A: SQL databases are relational and use structured query language, while NoSQL databases are non-relational and offer flexible data models.
Q: Are SQL skills in demand in the job market?
A: Yes, SQL skills are highly sought after in the job market, especially in data-related roles.
Get Started with Skillslash Academy's Data Science Course!
If you're serious about pursuing a career in data science, consider enrolling in Skillslash Academy's Data Science Course in Pune. This comprehensive training program covers everything from SQL fundamentals to advanced data analysis techniques. By the end of the course, you'll gain the expertise needed to excel in data science and earn a valuable certification.
0 notes
Text
Database Design Best Practices for Full Stack Developers

Database Design Best Practices for Full Stack Developers Database design is a crucial aspect of building scalable, efficient, and maintainable web applications.
Whether you’re working with a relational database like MySQL or PostgreSQL, or a NoSQL database like MongoDB, the way you design your database can greatly impact the performance and functionality of your application.
In this blog, we’ll explore key database design best practices that full-stack developers should consider to create robust and optimized data models.
Understand Your Application’s Requirements Before diving into database design, it’s essential to understand the specific needs of your application.
Ask yourself:
What type of data will your application handle? How will users interact with your data? Will your app scale, and what level of performance is required? These questions help determine whether you should use a relational or NoSQL database and guide decisions on how data should be structured and optimized.
Key Considerations:
Transaction management: If you need ACID compliance (Atomicity, Consistency, Isolation, Durability), a relational database might be the better choice. Scalability: If your application is expected to grow rapidly, a NoSQL database like MongoDB might provide more flexibility and scalability.
Complex queries: For applications that require complex querying, relationships, and joins, relational databases excel.
2. Normalize Your Data (for Relational Databases) Normalization is the process of organizing data in such a way that redundancies are minimized and relationships between data elements are clearly defined. This helps reduce data anomalies and improves consistency.
Normal Forms:
1NF (First Normal Form): Ensures that the database tables have unique rows and that columns contain atomic values (no multiple values in a single field).
2NF (Second Normal Form):
Builds on 1NF by eliminating partial dependencies. Every non-key attribute must depend on the entire primary key.
3NF (Third Normal Form):
Ensures that there are no transitive dependencies between non-key attributes.
Example: In a product order system, instead of storing customer information in every order record, you can create separate tables for Customers, Orders, and Products to avoid duplication and ensure consistency.
3. Use Appropriate Data Types Choosing the correct data type for each field is crucial for both performance and storage optimization.
Best Practices: Use the smallest data type possible to store your data (e.g., use INT instead of BIGINT if the range of numbers doesn’t require it). Choose the right string data types (e.g., VARCHAR instead of TEXT if the string length is predictable).
Use DATE or DATETIME for storing time-based data, rather than storing time as a string. By being mindful of data types, you can reduce storage usage and optimize query performance.
4. Use Indexing Effectively Indexes are crucial for speeding up read operations, especially when dealing with large datasets.
However, while indexes improve query performance, they can slow down write operations (insert, update, delete), so they must be used carefully. Best Practices: Index fields that are frequently used in WHERE, JOIN, ORDER BY, or GROUP BY clauses.
Avoid over-indexing — too many indexes can degrade write performance. Consider composite indexes (indexes on multiple columns) when queries frequently involve more than one column.
For NoSQL databases, indexing can vary. In MongoDB, for example, create indexes based on query patterns.
Example: In an e-commerce application, indexing the product_id and category_id fields can greatly speed up product searches.
5. Design for Scalability and Performance As your application grows, the ability to scale the database efficiently becomes critical. Designing your database with scalability in mind helps ensure that it can handle large volumes of data and high numbers of concurrent users.
Best Practices:
Sharding:
For NoSQL databases like MongoDB, consider sharding, which involves distributing data across multiple servers based on a key.
Denormalization: While normalization reduces redundancy, denormalization (storing redundant data) may be necessary in some cases to improve query performance by reducing the need for joins. This is common in NoSQL databases.
Caching: Use caching strategies (e.g., Redis, Memcached) to store frequently accessed data in memory, reducing the load on the database.
6. Plan for Data Integrity Data integrity ensures that the data stored in the database is accurate and consistent. For relational databases, enforcing integrity through constraints like primary keys, foreign keys, and unique constraints is vital.
Best Practices: Use primary keys to uniquely identify records in a table. Use foreign keys to maintain referential integrity between related tables. Use unique constraints to enforce uniqueness (e.g., for email addresses or usernames). Validate data at both the application and database level to prevent invalid or corrupted data from entering the system.
7. Avoid Storing Sensitive Data Without Encryption For full-stack developers, it’s critical to follow security best practices when designing a database.
Sensitive data (e.g., passwords, credit card numbers, personal information) should always be encrypted both at rest and in transit.
Best Practices:
Hash passwords using a strong hashing algorithm like bcrypt or Argon2. Encrypt sensitive data using modern encryption algorithms. Use SSL/TLS for encrypted communication between the client and the server.
8. Plan for Data Backup and Recovery Data loss can have a devastating effect on your application, so it’s essential to plan for regular backups and disaster recovery.
Best Practices:
Implement automated backups for the database on a daily, weekly, or monthly basis, depending on the application. Test restore procedures regularly to ensure you can quickly recover from data loss. Store backups in secure, geographically distributed locations to protect against physical disasters.
9. Optimize for Queries and Reporting As your application evolves, it’s likely that reporting and querying become critical aspects of your database usage. Ensure your schema and database structure are optimized for common queries and reporting needs.
Conclusion
Good database design is essential for building fast, scalable, and reliable web applications.
By following these database design best practices, full-stack developers can ensure that their applications perform well under heavy loads, remain easy to maintain, and support future growth.
Whether you’re working with relational databases or NoSQL solutions, understanding the core principles of data modeling, performance optimization, and security will help you build solid foundations for your full-stack applications.

0 notes