#Cluster sampling considerations
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
Cluster Sampling: Types, Advantages, Limitations, and Examples
Explore the various types, advantages, limitations, and real-world examples of cluster sampling in our informative blog. Learn how this sampling method can help researchers gather data efficiently and effectively for insightful analysis.
#Cluster sampling#Sampling techniques#Cluster sampling definition#Cluster sampling steps#Types of cluster sampling#Advantages of cluster sampling#Limitations of cluster sampling#Cluster sampling comparison#Cluster sampling examples#Cluster sampling applications#Cluster sampling process#Cluster sampling methodology#Cluster sampling in research#Cluster sampling in surveys#Cluster sampling in statistics#Cluster sampling design#Cluster sampling procedure#Cluster sampling considerations#Cluster sampling analysis#Cluster sampling benefits#Cluster sampling challenges#Cluster sampling vs other methods#Cluster sampling vs stratified sampling#Cluster sampling vs random sampling#Cluster sampling vs systematic sampling#Cluster sampling vs convenience sampling#Cluster sampling vs multistage sampling#Cluster sampling vs quota sampling#Cluster sampling vs snowball sampling#Cluster sampling steps explained
0 notes
Text
Density Matrix Embedding Theory & SQD for Quantum Modelling

Density Matrix Embed Theory
Combining Quantum Simulation Methods to Address Complex Molecules for Medical Progress
Michigan State University, IBM Quantum, and the Cleveland Clinic proved that hybrid quantum-classical techniques can accurately represent complex molecules using quantum computers, a major quantum chemistry breakthrough. Combining Density Matrix Embedding Theory (DMET) and Sample Based Quantum Diagonalisation (SQD), this groundbreaking finding advances quantum-centric scientific computing and has major health and medical implications.
Unlocked with Hybrid Quantum-Classical Power
Even the most advanced supercomputers have struggled to simulate huge molecule stability and behaviour, which is crucial for disease understanding and treatment. Modern high-performance computers cannot track over 33,000 molecular orbitals, which is needed to simulate insulin. Classical techniques fail as molecules increase larger. In addition, classical mean-field approximations fail to capture crucial electron interactions.
The first implementation of the SQD algorithm on genuine quantum hardware and incorporation into the Density Matrix Embedding Theory framework in this paper offers hope. This unique method, DMET-SQD, could replicate hydrogen rings and cyclohexane conformers. The DMET-SQD method replicates chemically important sections of a molecule instead than the entire molecule, which would need thousands of qubits. These fragments are then combined into an approximate electronic environment.
Quantum-centric supercomputing (QCSC) is defined by this “division of labour” between quantum and classical resources. The quantum processor in QCSC does the most computationally difficult operations, while regular high-performance computers handle the rest, including error correction. This hybrid technique allows state-of-the-art quantum computers without error-correcting capabilities to handle larger and more chemically realistic molecules. The Cleveland Clinic's IBM-managed quantum device, IBM Cleveland, the first of its type in the US, used 27 to 32 qubits in the study.
Real-World Accuracy Benchmarking
The researchers employed DMET-SQD to critically assess their hybrid technique on a ring of 18 hydrogen atoms and different cyclohexane conformers. Hydrogen rings are a standard benchmark in computational chemistry due to their high electron correlation effects, while cyclohexane conformers (chair, boat, half-chair, and twist-boat) are common in organic chemistry due to their narrow energy range, which makes them sensitive to even small computational
Heat-Bath Configuration Interaction (HCI), which may approach exact solutions, and Coupled Cluster Singles and Doubles with perturbative triples [CCSD(T)] were compared to quantum-classical results. The results were promising: DMET-SQD energy differences across cyclohexane conformers were within 1 kcal/mol of the best conventional reference methods, a standard chemical accuracy criterion.
For sufficiently large quantum configuration samples (8,000–10,000), DMET-SQD met HCI benchmarks for the hydrogen ring with negligible deviation while retaining cyclohexane conformer energy ordering. These results demonstrate that the technique may properly model physiologically relevant molecules despite hardware limitations.
Noisy Quantum Hardware Engineering Solutions
Practical usage of this embedding strategy on quantum technologies distinguishes the study. Modern quantum devices are noisy and unreliable. However, SQD's noise tolerance considerably reduced common errors. The authors stabilised calculations on IBM's Eagle processor via gate whirling and dynamical decoupling.
The team designed a custom interface to connect Tangelo's Density Matrix Embedding Theory library to Qiskit's SQD implementation. The simulation uses Hartree-Fock configurations encoded by each quantum circuit to maintain particle number and spin characteristics. These configurations were refined using S-CORE.
Future Outlook and Major Implications
Although the DMET-SQD technique is revolutionary, it has limitations and is still in its infancy. The fragment size and quantum sampling quality affect simulation accuracy. In systems with small energy changes or considerable electrical correlation, poor sampling may cause irregular energy ordering. The present study used a minimum basis set; chemically relevant applications will require more complex basis sets, qubits, and error control.
Study authors say more work is needed to improve sampling and reduce standard post-processing computer demand. Quantum hardware improvements in error rates and gate integrity will be crucial to scaling and enhancing these simulations.
This work suggests that hybrid quantum-classical approaches can handle real chemical processes better than “toy models.” Breaking full-molecule simulations into quantum computer-solvable subproblems allows scientists to solve previously intractable drug development and materials science problems.
Lead author Kenneth Merz, PhD, of the Cleveland Clinic, said, “This is a groundbreaking step in computational research that demonstrates how near-term quantum computers can advance biomedical research.” If they grow, DMET-SQD or similar hybrid techniques may anticipate novel materials, reaction mechanisms, and protein-drug interactions by accurately describing quantum effects in huge molecules. This breakthrough launches a new age of computational study that will directly help disease diagnosis and therapy.
#IBMQuantum#DensityMatrixEmbeddingTheory#quantumcentricsupercomputing#ibm#news#quantumhardware#hybridquantum#DMETSQD#technology#technews#govindhtech
0 notes
Text


Webb 'UNCOVERs' galaxy population driving cosmic renovation
Astronomers using data from NASA's James Webb Space Telescope have identified dozens of small galaxies that played a starring role in a cosmic makeover that transformed the early universe into the one we know today.
"When it comes to producing ultraviolet light, these small galaxies punch well above their weight," said Isak Wold, an assistant research scientist at Catholic University of America in Washington and NASA's Goddard Space Flight Center in Greenbelt, Maryland. "Our analysis of these tiny but mighty galaxies is 10 times more sensitive than previous studies, and shows they existed in sufficient numbers and packed enough ultraviolet power to drive this cosmic renovation."
Wold discussed his findings at the 246th meeting of the American Astronomical Society in Anchorage, Alaska. The study took advantage of existing imaging collected by Webb's NIRCam (Near-Infrared Camera) instrument, as well as new observations made with its NIRSpec (Near-Infrared Spectrograph) instrument.
The tiny galaxies were discovered by Wold and his Goddard colleagues, Sangeeta Malhotra and James Rhoads, by sifting through Webb images captured as part of the UNCOVER (Ultradeep NIRSpec and NIRCam ObserVations before the Epoch of Reionization) observing program, led by Rachel Bezanson at the University of Pittsburgh in Pennsylvania.
The project mapped a giant galaxy cluster known as Abell 2744, nicknamed Pandora's cluster, located about 4 billion light-years away in the southern constellation Sculptor. The cluster's mass forms a gravitational lens that magnifies distant sources, adding to Webb's already considerable reach.
For much of its first billion years, the universe was immersed in a fog of neutral hydrogen gas. Today, this gas is ionized—stripped of its electrons. Astronomers, who refer to this transformation as reionization, have long wondered which types of objects were most responsible: big galaxies, small galaxies, or supermassive black holes in active galaxies. As one of its main goals, NASA's Webb was specifically designed to address key questions about this major transition in the history of the universe.
Recent studies have shown that small galaxies undergoing vigorous star formation could have played an outsized role. Such galaxies are rare today, making up only about 1% of those around us. But they were abundant when the universe was about 800 million years old, an epoch astronomers refer to as redshift 7, when reionization was well underway.
The team searched for small galaxies of the right cosmic age that showed signs of extreme star formation, called starbursts, in NIRCam images of the cluster.
"Low-mass galaxies gather less neutral hydrogen gas around them, which makes it easier for ionizing ultraviolet light to escape," Rhoads said. "Likewise, starburst episodes not only produce plentiful ultraviolet light—they also carve channels into a galaxy's interstellar matter that helps this light break out."
The astronomers looked for strong sources of a specific wavelength of light that signifies the presence of high-energy processes: a green line emitted by oxygen atoms that have lost two electrons. Originally emitted as visible light in the early cosmos, the green glow from doubly ionized oxygen was stretched into the infrared as it traversed the expanding universe and eventually reached Webb's instruments.
This technique revealed 83 small starburst galaxies as they appeared when the universe was 800 million years old, or about 6% of its current age of 13.8 billion years. The team selected 20 of these for deeper inspection using NIRSpec.
"These galaxies are so small that to build the equivalent stellar mass of our own Milky Way galaxy, you'd need from 2,000 to 200,000 of them," Malhotra said. "But we are able to detect them because of our novel sample selection technique combined with gravitational lensing."
Similar types of galaxies in the present-day universe, such as green peas, release about 25% of their ionizing ultraviolet light into surrounding space. If the low-mass starburst galaxies explored by Wold and his team release a similar amount, they could account for all of the ultraviolet light needed to convert the universe's neutral hydrogen to its ionized form.
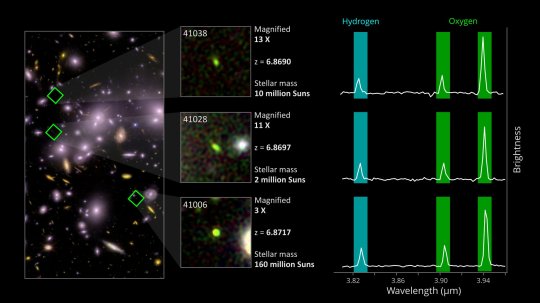
TOP IMAGE: At left is an enlarged infrared view of galaxy cluster Abell 2744 with three young, star-forming galaxies highlighted by green diamonds. The center column shows close-ups of each galaxy, along with their designations, the amount of magnification provided by the cluster's gravitational lens, their redshifts (shown as z—all correspond to a cosmic age of about 790 million years), and their estimated mass of stars. At right, measurements from NASA's James Webb Space Telescope's NIRSpec instrument confirm that the galaxies produce strong emission in the light of doubly ionized oxygen (green bars), indicating vigorous star formation is taking place. Credit: NASA / ESA / CSA / Bezanson et al. 2024 and Wold et al. 2025
CENTRE IMAGE: One of the most interesting galaxies of the study, dubbed 41028 (the green oval at center), has an estimated stellar mass of just 2 million suns—comparable to the masses of the largest star clusters in our own Milky Way galaxy. Credit: NASA / ESA / CSA / Bezanson et al. 2024 and Wold et al. 2025
LOWER IMAGE:White diamonds show the locations of 20 of the 83 young, low-mass, starburst galaxies found in infrared images of the giant galaxy cluster Abell 2744. This composite incorporates images taken through three NIRCam filters (F200W as blue, F410M as green, and F444W as red). The F410M filter is highly sensitive to light emitted by doubly ionized oxygen—oxygen atoms that have been stripped of two electrons—at a time when reionization was well underway. Emitted as green light, the glow was stretched into the infrared as it traversed the expanding universe over billions of years. The cluster's mass acts as a natural magnifying glass, allowing astronomers to see these tiny galaxies as they were when the universe was about 800 million years old. Credit: NASA / ESA / CSA / Bezanson et al. 2024 and Wold et al. 2025
0 notes
Text
𝗖𝗼𝗺𝗽𝗹𝗲𝘁𝗲 𝗚𝘂𝗶𝗱𝗲 𝘁𝗼 𝗖𝗥𝗜𝗦𝗣𝗥-𝗖𝗮𝘀 𝗚𝗲𝗻𝗲𝘀
𝗚𝗲𝘁 𝗣𝗗𝗙 𝗦𝗮𝗺𝗽𝗹𝗲: https://www.transparencymarketresearch.com/sample/sample.php?flag=S&rep_id=30428
𝗨𝗻𝗹𝗼𝗰𝗸 𝗮 𝘄𝗼𝗿𝗹𝗱 𝗼𝗳 𝗲𝘅𝗽𝗲𝗿𝘁 𝗶𝗻𝘀𝗶𝗴𝗵𝘁𝘀 𝘄𝗶𝘁𝗵 𝗼𝘂𝗿 𝗰𝗼𝗺𝗽𝗿𝗲𝗵𝗲𝗻𝘀𝗶𝘃𝗲 𝗣𝗗𝗙 𝘀𝗮𝗺𝗽𝗹𝗲—𝗲𝘅𝗰𝗹𝘂𝘀𝗶𝘃𝗲𝗹𝘆 𝗳𝗼𝗿 𝗰𝗼𝗿𝗽𝗼𝗿𝗮𝘁𝗲 𝗲𝗺𝗮𝗶𝗹 𝗵𝗼𝗹𝗱𝗲𝗿𝘀. 📧
CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) and Cas (CRISPR-associated) genes represent a groundbreaking leap in genetic engineering. Originating as an adaptive immune system in bacteria, this technology has been harnessed to create precise, efficient, and affordable tools for gene editing. By targeting specific DNA sequences, CRISPR-Cas systems enable researchers to edit genes with unprecedented accuracy, holding promise for curing genetic diseases and advancing biotechnology.
The versatility of CRISPR-Cas extends into agriculture, where it is used to create crops resistant to diseases and environmental stress. In medicine, it offers hope for tackling previously incurable conditions, from genetic disorders like sickle cell anemia to cancers. Moreover, CRISPR's potential in combating infectious diseases, such as HIV and malaria, showcases its transformative impact on global health.
As research advances, ethical considerations surrounding CRISPR applications are taking center stage. Balancing the promise of life-changing therapies with responsible use will define the next chapter in the CRISPR revolution. Nonetheless, CRISPR-Cas systems remain a beacon of innovation, inspiring a future where genomic editing could become routine in medicine, agriculture, and beyond.
#CRISPR #GeneEditing #Cas9 #GenomicInnovation #Biotechnology #PrecisionMedicine #GeneticEngineering #FutureOfScience #CRISPRApplications #LifeSciences
0 notes
Text
HD Grease Market Insights: How Thermal Interface Materials Are Changing the Game

Global Heat Dissipation Grease (HD Grease) Market is experiencing robust expansion, with valuations reaching USD 144 million in 2023. Current projections indicate the market will grow at a compound annual growth rate (CAGR) of 6.8%, potentially reaching USD 260.32 million by 2032. This accelerated trajectory stems from surging demand in electronics manufacturing, electric vehicle production, and next-gen computing infrastructure where thermal management is critical.
Thermal interface materials like HD grease have become indispensable in modern electronics, filling microscopic imperfections between heat-generating components and cooling apparatus. As device miniaturization continues alongside rising power densities, manufacturers are prioritizing advanced formulations with exceptional thermal conductivity (often exceeding 8 W/mK) and extended reliability under thermal cycling.
Download FREE Sample Report: https://www.24chemicalresearch.com/download-sample/288926/global-heat-dissipation-grease-forecast-market-2025-2032-519
Market Overview & Regional Analysis
Asia-Pacific commands over 55% of global HD grease consumption, with China's electronics manufacturing hubs and South Korea's semiconductor industry driving demand. The region benefits from concentrated supply chains and swift adoption of 5G infrastructure, which requires advanced thermal solutions for base stations and edge computing devices. Japanese manufacturers continue leading in high-performance formulations, particularly for automotive electronics.
North America maintains strong growth through its advanced computing sector, where data centers and AI hardware necessitate premium thermal interface materials. Europe's market thrives on stringent electronic reliability standards and growing EV adoption, with Germany's automotive suppliers emerging as key consumers. Emerging markets in Southeast Asia show accelerating demand, fueled by electronics production shifting from traditional manufacturing centers.
Key Market Drivers and Opportunities
The market's expansion hinges on three pivotal factors: the unstoppable march of electronics miniaturization, the automotive industry's rapid electrification, and escalating data center investments. Semiconductor packaging accounts for 38% of HD grease applications, followed by EV power electronics at 22% and consumer electronics at 19%. The burgeoning field of high-performance computing (HPC) presents new frontiers, with GPU clusters and AI accelerators requiring advanced thermal solutions.
Innovation opportunities abound in metal-particle enhanced greases (achieving 12-15 W/mK conductivity) and phase-change materials that combine grease-like application with pad-like stability. The photovoltaic sector also emerges as a growth vector, where solar microinverters demand durable thermal compounds resistant to outdoor weathering. Meanwhile, aerospace applications for satellite electronics create specialized niche markets requiring extreme temperature stability.
Challenges & Restraints
Material scientists face persistent hurdles in balancing thermal performance with practical considerations. High-performance formulations frequently encounter pump-out issues under thermal cycling, while silicone-based variants risk contaminating sensitive optical components. The automotive sector's transition to 800V architectures introduces new challenges - requiring greases that maintain performance across wider temperature swings while resisting electrochemical migration.
Supply chain complexities pose additional concerns, with specialty fillers like boron nitride and aluminum oxide facing periodic shortages. Regulatory landscapes continue evolving, particularly regarding silicone content restrictions in certain electronics applications. Furthermore, the industry struggles with standardization - thermal conductivity claims often vary significantly between testing methodologies.
Market Segmentation by Type
Silicone-Based Thermal Grease
Silicone-Free Thermal Grease
Metal-Particle Enhanced Formulations
Download FREE Sample Report: https://www.24chemicalresearch.com/download-sample/288926/global-heat-dissipation-grease-forecast-market-2025-2032-519
Market Segmentation by Application
Consumer Electronics (Smartphones, Tablets, Laptops)
Automotive Electronics (EV Batteries, Inverters)
Telecommunications Infrastructure
Data Center Equipment
Industrial Electronics
LED Lighting Systems
Market Segmentation and Key Players
Dow Chemical Company
Henkel AG & Co. KGaA
Shin-Etsu Chemical Co., Ltd.
Parker Hannifin Corporation
3M Company
Laird Technologies
Momentive Performance Materials
Wakefield-Vette
Zalman Tech
Thermal Grizzly
Arctic Silver
Fujipoly
Denka Company Limited
Gelon LIB Group
Dongguan Jiezheng Electronics
Report Scope
This comprehensive analysis examines the global HD grease landscape from 2024 to 2032, providing granular insights into:
Volume and revenue projections across key regions and applications
Detailed technology segmentation by formulation type and performance characteristics
Supply chain dynamics including raw material sourcing and manufacturing trends
Regulatory landscape analysis for major jurisdictions
The report features exhaustive profiles of 25 leading manufacturers, evaluating:
Product portfolios and R&D pipelines
Production capacities and geographic footprints
Key partnerships and client ecosystems
Pricing strategies and distribution networks
Get Full Report Here: https://www.24chemicalresearch.com/reports/288926/global-heat-dissipation-grease-forecast-market-2025-2032-519
About 24chemicalresearch
Founded in 2015, 24chemicalresearch has rapidly established itself as a leader in chemical market intelligence, serving clients including over 30 Fortune 500 companies. We provide data-driven insights through rigorous research methodologies, addressing key industry factors such as government policy, emerging technologies, and competitive landscapes.
Plant-level capacity tracking
Real-time price monitoring
Techno-economic feasibility studies
With a dedicated team of researchers possessing over a decade of experience, we focus on delivering actionable, timely, and high-quality reports to help clients achieve their strategic goals. Our mission is to be the most trusted resource for market insights in the chemical and materials industries.
International: +1(332) 2424 294 | Asia: +91 9169162030
Website: https://www.24chemicalresearch.com/
Follow us on LinkedIn: https://www.linkedin.com/company/24chemicalresearch
Other Related Reports:
0 notes
Text
How to Build AI-Powered Cybersecurity Applications

The cybersecurity landscape is a relentless battleground, demanding innovative solutions to combat ever-evolving threats. Artificial Intelligence (AI), particularly machine learning and increasingly generative AI, offers a powerful arsenal for defenders. Building AI-powered cybersecurity applications can significantly enhance threat detection, automate responses, and provide deeper insights into complex security challenges.
But how do you go from concept to a functional, effective AI-driven security tool? This guide outlines the key steps and considerations for building AI-powered cybersecurity applications.
1. Define the Problem and Use Case
Before writing a single line of code, clearly define the specific cybersecurity problem you aim to solve with AI. AI is not a magic bullet; it's a tool that excels at certain tasks.
Examples of AI use cases in cybersecurity:
Anomaly Detection: Identifying unusual network traffic patterns, user behaviors, or system activities that might indicate a breach.
Malware Detection and Classification: Analyzing code or file behavior to identify and categorize malicious software.
Phishing Detection: Identifying deceptive emails or websites.
Vulnerability Management: Prioritizing vulnerabilities based on exploitability and impact.
Threat Intelligence Processing: Automating the analysis and summarization of vast amounts of threat data.
Automated Incident Response: Developing AI-driven playbooks for rapid threat containment.
Clearly defining your use case will guide your data collection, model selection, and overall architecture.
2. Data Collection and Preparation
AI models are only as good as the data they are trained on. This is arguably the most critical and time-consuming step.
Identify Data Sources: This could include network logs (firewall, IDS/IPS), endpoint logs (EDR), security information and event management (SIEM) data, threat intelligence feeds, malware samples, user behavior logs, and vulnerability scan results.
Data Volume and Variety: Ensure you have sufficient data volume and variety to train a robust model. Cybersecurity data is often imbalanced (e.g., far more normal events than malicious ones), which needs to be addressed.
Data Cleaning and Preprocessing: Raw security data is messy. You'll need to:
Handle Missing Values: Decide how to deal with incomplete data.
Normalize Data: Scale numerical data to a standard range.
Feature Engineering: Extract meaningful features from raw data that the AI model can learn from (e.g., frequency of connections, packet sizes, API call sequences, email headers). This often requires deep domain expertise.
Labeling: For supervised learning, you'll need accurately labeled data (e.g., "malicious" vs. "benign," "phishing" vs. "legitimate"). This can be a significant challenge in cybersecurity.
3. Model Selection and Training
Choosing the right AI model depends on your problem, data type, and desired outcome.
Machine Learning Algorithms:
Supervised Learning: For classification (e.g., phishing/not phishing) or regression (e.g., predicting risk scores) when you have labeled data. Algorithms include Support Vector Machines (SVMs), Random Forests, Gradient Boosting Machines (XGBoost, LightGBM), and Neural Networks.
Unsupervised Learning: For anomaly detection or clustering when you don't have labeled data (e.g., K-Means, Isolation Forest, Autoencoders).
Deep Learning: For complex pattern recognition in large, unstructured data (e.g., image recognition for malware analysis, natural language processing for threat intelligence).
Generative AI (LLMs): For tasks involving natural language, code generation, summarization, or creating realistic simulations (e.g., generating phishing emails, incident reports, or security awareness content).
Model Training: Train your chosen model using your prepared dataset. This involves splitting data into training, validation, and test sets, and iteratively adjusting model parameters.
4. Evaluation and Refinement
A model's performance is crucial. Don't just look at accuracy; consider metrics relevant to cybersecurity.
Metrics:
Precision and Recall: Especially important for anomaly detection, where false positives (alert fatigue) and false negatives (missed threats) have significant consequences.
F1-Score: A balance between precision and recall.
ROC AUC: For evaluating binary classifiers.
Bias Detection: Ensure your model isn't biased against certain data patterns, which could lead to missed threats or unfair assessments.
Adversarial Robustness: Test how your model performs against deliberately crafted adversarial examples designed to fool it. Attackers will try to bypass your AI.
Iterative Refinement: Based on evaluation, refine your features, adjust model parameters, or even try different algorithms. This is an ongoing process.
5. Deployment and Integration
Once your model is performing well, you need to deploy it into your cybersecurity ecosystem.
Scalability: Ensure your application can handle the volume of data and requests in a real-world environment.
Real-time Processing: Many cybersecurity applications require real-time or near real-time analysis.
Integration with Existing Tools: Integrate your AI application with your SIEM, EDR, SOAR (Security Orchestration, Automation, and Response) platforms, and other security tools to enable seamless data flow and automated actions.
Monitoring and Maintenance: Continuously monitor your AI application's performance in production. Models can drift over time as threat landscapes change, requiring retraining or recalibration.
6. Human-in-the-Loop and Ethical Considerations
AI in cybersecurity should augment, not replace, human expertise.
Human Oversight: Always keep a human in the loop for critical decisions. AI can flag anomalies, but human analysts provide context and make final judgments.
Explainability (XAI): Strive for explainable AI models where possible, allowing analysts to understand why a model made a particular prediction or flagged an event. This builds trust and aids in incident investigation.
Ethical AI: Address potential biases, ensure data privacy, and consider the ethical implications of using AI in sensitive security contexts.
Building AI-powered cybersecurity applications is a complex but incredibly rewarding endeavor. By following these steps, focusing on data quality, rigorous evaluation, and a collaborative human-AI approach, you can develop powerful tools that significantly bolster your organization's defenses in the face of escalating cyber threats.
0 notes
Text
¶ … statistics have on shaping healthcare policy and guiding evidence-based practice, it is critical that researchers understand how to present the results of their studies. It is also critical that healthcare workers develop strong skills in statistical literacy, so that the results of studies are not misconstrued. Not all research results are generalizable to a population outside of the sample. Even the most carefully constructed research designs need to be critically analyzed. Similarly, care must be taken when communicating statistical results to a general audience. The American Statistical Association (1999) outlines eight main areas of ethical concern. Those areas of concern include the following: • Professionalism • Responsibilities to employers or funders • Responsibilities in testimony or publications • Responsibilities to research subjects • Responsibilities to research team colleagues • Responsibilities to other statisticians • Responsibilities regarding allegations of misconduct • Responsibilities of employers or clients to the integrity of research In the healthcare setting, each of these ethical duties is relevant, but it is the latter that may be most relevant to daily work for practitioners who read, gather, disseminate, discuss, and interpret research findings and often implement those findings into evidence-based practice. It is therefore critical that statisticians be aware of the impact their work has on public health. Statisticians are supportive of creating the "evidence-based society" and evidence-based organizational culture in healthcare (p. 5). However, statisticians are also in the unique position of having to offer warnings to healthcare practitioners, administrators, and pharmacists eager to deliver new products and services to the patient population. Statisticians deal with uncertainties and probabilities, whereas non-statisticians, even within the medical science arena, seek clear-cut, black-and-white answers. When it comes to actual research methods and design, the role of statisticians is more immediately apparent. For example, statisticians have an ethical responsibility to honestly and objectively interpret raw data, regardless of the substantive content of a research hypothesis. A statistician with access to participant personal information has an ethical responsibility to preserve and safeguard privacy and confidentiality. The issues all researchers face when conducting experiments including informed consent, remain salient. Ascribing to statistical ethics generally promotes integrity, validity, and reliability in medical research overall. The ethics of professionalism, responsibilities to employers, and the ethical responsibilities to research team colleagues require that statisticians and researchers ascribe to best practices in research design. Statisticians need to disclose the precise methods of data analysis used, including the software they use, and what data that needed to be excluded from the study and why. Research design should reflect the best interests of providing accurate results, not necessarily according to the desires and preferences of funders. Specific types of research designs and methodologies present unique ethical considerations. For example, cluster randomized trials have become increasingly common in healthcare and particularly in public health research. Cluster randomized trials help determine clustered effects of an intervention such as a vaccine. The ethic of responsibility to research participants, as outlined by the ASA (1999) includes issues related to informed consent. Informed consent is different in cluster randomized trials versus other research designs. There are two basic types of cluster randomized trials: cluster-cluster, where the entire cluster is being measured, and individual cluster trials, where the individual participants are being measured. The type of design will vary depending on the research question and hypotheses. Informed consent protocol may differ depending on which of these cluster randomized trial methods is used. Of course, this simplistic classification ignores the plethora of other types of cluster randomized trials but general rules of thumb for informed consent create common sense guidelines for statisticians. Regardless of type of cluster randomized trial, the primary areas of ethical concern include units of randomization, units of intervention, and units of observation ("Medical Ethics and Statistics," n.d.). Units of randomization imply different types or levels of consent. Individual consent alone may not be enough. Consent might need to be gleaned from community organizations and other group stakeholders like families or professional organizations. Care must be taken when presuming a leader of any organization speaks on behalf of the entire group or community, as this is not always the case. However, the use of proxies or gatekeepers will be inevitable in cluster randomized trials due to the complex nature of their design and the method of intervention administration. Consent must also be acquired at all levels of the trial, such as when an intervention is first administered and then when data is being collected. When cluster randomized trials are carried out in developing countries with problematic political institutions and inadequate legal or institutional safeguards to protect individuals, statisticians have a greater responsibility to ensure social justice. This is why consent must be gathered at multiple levels and at multiple stages in an intervention, as well as consulting with local officials ("Medical Ethics and Statistics," n.d.). Opting out of a trial presents its own unique ethical considerations, because a researcher cannot persuade a person to participate without appearing coercive. Medical statistics ethical considerations extend throughout the world, raising important social justice and human rights concerns (Aynsley-Green, et al., 2012). When a funding organization seeks confirmation for a treatment intervention, it risks systematically excluding large numbers of people from receiving a potentially beneficial intervention. Alternatively, informed consent can be distorted as when potential participants overestimate instead of underestimate the risks of participation in a trial and lack access to appropriate information. Statisticians operating under the guidance of professional organizational codes of ethics like that of the ASA (1999) will understand their primary obligations are to their professional standards, to their colleagues, and their employers. Cluster randomized trials sometimes threaten to undermine ethical responsibilities to research participants, as when an intervention is an airborne element affecting an entire community, or when a treatment intervention is available and desired but not being offered to non-participants. The latter scenario is politically problematic, given the potential for a treatment intervention to help people with terminal illnesses. Although the ASA (1999) does not mention social justice as an ethical responsibility of statisticians, social justice ethics are implied when well-endowed countries possessing rich medical services resources conduct experimental medicine trials on communities in developing countries. The recipient communities will frequently have large portions of the population suffering from diseases like HIV / AIDS, who do not wish to receive placebos in the trials. Yet without a control group, the research designs might suffer, causing an ethical conflict between the social justice responsibility to research participants and the responsibility to the professional duties of statisticians. Utilitarian excuses for the use of placebo controls need to be mitigated by commitments to redistributive justice ("Medical Ethics and Statistics," n.d.). Also, statisticians have a duty to promote ethical standards and professionalism in research; they are not singularly responsible for the root causes of social injustice. It is not right to sacrifice the integrity of research in the interests of appeasing public outcry. In addition to the issues raise when performing cluster trials in developing countries, statisticians focusing on medical ethics can encourage professional responsibility in other areas. Participants need to be informed about all the ramifications of research, and all stakeholders need to be informed of the social justice ramifications of their interventions. Yet the integrity of statisticians and the medical research community cannot be compromised. Therefore, communications is one of the most important areas of ethical conduct for a statistician. The interpretation of research results needs to be fully honest, disclosing all uncertainties and refraining from drawing improper conclusions. Pressure on the part of paying clients and organizations with a stake in the results should not influence statistical analysis or interpretations of results (Gelman, 2014). Communication of results beyond the actual study also becomes the ethical responsibility of the statistician, because oversight ensures the results are not exaggerated or misrepresented. Acceptable risk and other levels of uncertainty need to be conveyed to the healthcare community, which can then relay appropriate information to patients. Similarly, the media involved in translating studies into language laypeople can understand may use hyperbole or oversimplify results. Statistical literacy should be taught more widely at the university level in order to promote medical ethics. References American Statistical Association (1999). Ethical guidelines for statistical practice. Aynsley-Green, A, et al. (2012). Medical, statistical, ethical and human rights considerations in the assessment of age in children and young people subject to immigration control. British Medical Bulletin 102(1): 17-42. Gelman, A. (2014). Ethics and statistics. Retrieved online: http://www.stat.columbia.edu/~gelman/presentations/ethicstalk_2014_handout.pdf "Medical Ethics and Statistics," (n.d.). Retrieved online: http://www.wiley.com/legacy/products/subject/reference/cam001-.pdf Read the full article
0 notes
Text
Research findings, clinical knowledge, knowledge resulting from basic science as well as opinion from experts are all regarded as “evidence” (Drake and Goldman 32). Practices that are based on research findings, however, have high chances of resulting in outcomes that match the desires of patients across different settings as well as geographic locations. Research Problem The challenge for evidence-based practice is caused by the pressure from healthcare facilities due to containment of cost, larger availability of information, and greater sway of consumers regarding care and treatment options. This kind of practice demands some changes in students’ education, more research that is practice-relevant, and a working relationship between researchers and clinicians (Drake and Goldman 38). Evidence-based form of practice also brings an opportunity for nursing care to be more effective, more individualized, dynamic, and streamlined, and opportunities to maximize clinical judgment effects. When there is reliance on evidence in defining best practices but not for supporting practices that exist, then nursing care is said to be keeping pace with recent technological changes and benefits from the developments of new knowledge (Drake and Goldman 49). Although many young professionals have embraced this new approach, it has come with its challenges. Several research studies have indicated that the perception of nurses towards EBP is positive and they regard it as useful to better care for patients. This research will critically analyze the barriers to full acceptance of EBP. Research Design This will be a descriptive research design. Qualitative research does not, by definition, aim to precisely estimate population parameters or test hypotheses. However, most qualitative projects do attempt to. This design was identified as the most convenient and ensured that the data obtained gave answers to the research questions. The descriptive design also offers the opportunity for a logical structure of the inquiry into the problem of the study. According to Walsh descriptive surveys are good at providing information and explanations for research questions (45). Methods of Data Collection In this research, survey questionnaires were used as a means of collecting data. The questionnaire was formulated by a team that consisted of nurses and professionals from the information technology department at the university. Also, a great deal of consultation was given to research survey instruments that have been used by previous researchers on the same subject. For this matter, the questionnaires that were previously issued tackling data-seeking behavior and information needs of nurses and other medical practitioners were also given considerable weight in review. A review of a draft copy of the questionnaire was conducted to ensure the contents were valid (Walsh 34). This was performed by a group of experts consisting of nurse researchers, lecturers of information studies, registered nurses, and nursing managers. A few changes were made to that effect. Sampling Technique This research covered a population size consisting of all nurses in the state. However, a sample will be selected and the presumption made that the sample will reflect the features of the entire population. In this research, a cluster sampling technique was used. Under this method, several clusters were made and questionnaires were issued randomly. Read the full article
0 notes
Text
CONCLUSION
We have taken for the subjects of the foregoing moral essays, twelve samples of married couples, carefully selected from a large stock on hand, open to the inspection of all comers. These samples are intended for the benefit of the rising generation of both sexes, and, for their more easy and pleasant information, have been separately ticketed and labelled in the manner they have seen.
We have purposely excluded from consideration the couple in which the lady reigns paramount and supreme, holding such cases to be of a very unnatural kind, and like hideous births and other monstrous deformities, only to be discreetly and sparingly exhibited.
And here our self-imposed task would have ended, but that to those young ladies and gentlemen who are yet revolving singly round the church, awaiting the advent of that time when the mysterious laws of attraction shall draw them towards it in couples, we are desirous of addressing a few last words.
Before marriage and afterwards, let them learn to centre all their hopes of real and lasting happiness in their own fireside; let them cherish the faith that in home, and all the English virtues which the love of home engenders, lies the only true source of domestic felicity; let them believe that round the household gods, contentment and tranquillity cluster in their gentlest and most graceful forms; and that many weary hunters of happiness through the noisy world, have learnt this truth too late, and found a cheerful spirit and a quiet mind only at home at last.
How much may depend on the education of daughters and the conduct of mothers; how much of the brightest part of our old national character may be perpetuated by their wisdom or frittered away by their folly—how much of it may have been lost already, and how much more in danger of vanishing every day—are questions too weighty for discussion here, but well deserving a little serious consideration from all young couples nevertheless.
To that one young couple on whose bright destiny the thoughts of nations are fixed, may the youth of England look, and not in vain, for an example. From that one young couple, blessed and favoured as they are, may they learn that even the glare and glitter of a court, the splendour of a palace, and the pomp and glory of a throne, yield in their power of conferring happiness, to domestic worth and virtue. From that one young couple may they learn that the crown of a great empire, costly and jewelled though it be, gives place in the estimation of a Queen to the plain gold ring that links her woman’s nature to that of tens of thousands of her humble subjects, and guards in her woman’s heart one secret store of tenderness, whose proudest boast shall be that it knows no Royalty save Nature’s own, and no pride of birth but being the child of heaven!
So shall the highest young couple in the land for once hear the truth, when men throw up their caps, and cry with loving shouts—
God bless them.
_____
Title | Previous Chapter | Next Chapter |
0 notes
Text
Common Pitfalls in Machine Learning and How to Avoid Them

Selecting and training algorithms is a key step in building machine learning models.
Here’s a brief overview of the process:
Selecting the Right Algorithm The choice of algorithm depends on the type of problem you’re solving (e.g., classification, regression, clustering, etc.), the size and quality of your data, and the computational resources available.
Common algorithm choices include:
For Classification: Logistic Regression Decision Trees Random Forests Support Vector Machines (SVM) k-Nearest Neighbors (k-NN) Neural
Networks For Regression: Linear Regression Decision Trees Random Forests Support Vector Regression (SVR) Neural Networks For Clustering:
k-Means DBSCAN Hierarchical Clustering For Dimensionality Reduction: Principal Component Analysis (PCA) t-Distributed Stochastic Neighbor Embedding (t-SNE)
Considerations when selecting an algorithm:
Size of data:
Some algorithms scale better with large datasets (e.g., Random Forests, Gradient Boosting).
Interpretability:
If understanding the model is important, simpler models (like Logistic Regression or Decision Trees) might be preferred.
Performance:
Test different algorithms and use cross-validation to compare performance (accuracy, precision, recall, etc.).
2. Training the Algorithm After selecting an appropriate algorithm, you need to train it on your dataset.
Here’s how you can train an algorithm:
Preprocess the data:
Clean the data (handle missing values, outliers, etc.). Normalize/scale the features (especially important for algorithms like SVM or k-NN).
Encode categorical variables if necessary (e.g., using one-hot encoding).
Split the data:
Divide the data into training and test sets (typically 80–20 or 70–30 split).
Train the model:
Fit the model to the training data using the chosen algorithm and its hyperparameters. Optimize the hyperparameters using techniques like Grid Search or Random Search.
Evaluate the model: Use the test data to evaluate the model’s performance using metrics like accuracy, precision, recall, F1 score (for classification), mean squared error (for regression), etc.
Perform cross-validation to get a more reliable performance estimate.
3. Model Tuning and Hyperparameter Optimization Hyperparameter tuning: Many algorithms come with hyperparameters that affect their performance (e.g., the depth of a decision tree, learning rate for gradient descent).
You can use methods like: Grid Search:
Try all possible combinations of hyperparameters within a given range.
Random Search:
Randomly sample hyperparameters from a range, which is often more efficient for large search spaces.
Cross-validation:
Use k-fold cross-validation to get a better understanding of how the model generalizes to unseen data.
4. Model Evaluation and Fine-tuning Once you have trained the model, fine-tune it by adjusting hyperparameters or using advanced techniques like regularization to avoid overfitting.
If the model isn’t performing well, try:
Selecting different features.
Trying more advanced models (e.g., ensemble methods like Random Forest or Gradient Boosting).
Gathering more data if possible.
By iterating through these steps and refining the model based on evaluation, you can build a robust machine learning model for your problem.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text
Sample Collection Methods: A Comprehensive Guide.

1. Introduction
In research and data analysis, the accuracy and reliability of results often hinge on the quality of the sample collected. Without proper sample collection methods, even the most sophisticated analyses can lead to misleading conclusions. Understanding various sample collection techniques is essential for researchers across disciplines.
2. What is Sample Collection?
Sample collection is the process of gathering data or specimens from a subset of a population to draw meaningful conclusions about the whole. Whether it involves surveying a group of people, collecting soil samples, or selecting data points from a dataset, the purpose is to represent the larger population accurately.
3. Why is Proper Sample Collection Important?
The way a sample is collected can significantly influence the validity, accuracy, and generalizability of the research findings. A well-collected sample minimizes bias, ensures representativeness, and increases confidence in the results. In contrast, poorly collected samples can lead to incorrect interpretations, wasted resources, and flawed decisions.
4. Types of Sample Collection Methods
There are several methods of sample collection, each suitable for different research objectives and populations.
4.1. Probability Sampling Methods
Probability sampling ensures every member of the population has an equal chance of being selected, which reduces bias.
Simple Random Sampling: In this method, every individual in the population has an equal chance of being selected, often using random number generators or lotteries.
Stratified Sampling: The population is divided into distinct subgroups (strata), and samples are randomly selected from each stratum to ensure representation.
5. Factors to Consider When Choosing a Sample Collection Method
Selecting the right sample collection method depends on factors such as the research objective, target population, and available resources.
Research Goals: The purpose of the research often dictates the type of sample needed. For example, clinical trials require rigorous randomization.
Population Size and Diversity: Larger and more diverse populations may need stratified or cluster sampling to ensure representation.
Time and Budget Constraints: Convenience sampling may be used when resources are limited, but it can compromise representativeness.
Ethical Considerations: Ensuring voluntary participation and protecting participants' rights are critical in sample collection.
6. Challenges in Sample Collection
While sample collection is crucial, it comes with its own set of challenges that researchers need to address to maintain data integrity.
Sampling Bias: This occurs when certain groups are overrepresented or underrepresented in the sample.
Non-Response Issues: Participants’ unwillingness or inability to respond can skew results.
Access to the Target Population: Reaching specific populations can be difficult due to logistical, cultural, or ethical barriers.
7. Tips for Effective Sample Collection
To ensure the quality and reliability of your data, consider these best practices for effective sample collection:
Clearly Define the Population: Identify the characteristics and scope of the population you wish to study.
Use Appropriate Sampling Techniques: Choose methods that align with your research objectives and constraints.
Pilot-Test Your Sampling Strategy: Test your approach on a small scale to identify potential issues.
Monitor and Evaluate the Process: Continuously assess the sampling process to ensure it remains on track.
8. Examples of Sample Collection in Practice
Sample collection methods are widely used across various fields, from healthcare to market research.
Example 1: Clinical Trials in Medicine: Randomized controlled trials often rely on stratified sampling to ensure diverse representation of age, gender, and medical conditions.
Example 2: Customer Surveys in Marketing: Businesses frequently use convenience sampling to gather quick feedback from customers.
Example 3: Environmental Sampling for Pollution Studies: Researchers may use systematic sampling to measure pollutant levels across specific geographic areas.
9. Conclusion
Sample collection is a cornerstone of successful research, as it lays the foundation for accurate and meaningful insights. By understanding and carefully selecting appropriate methods, researchers can minimize bias, overcome challenges, and produce reliable results that drive informed decision-making.
Get more information here ...
https://clinfinite.com/SampleCollectionMethods63.php
0 notes
Text
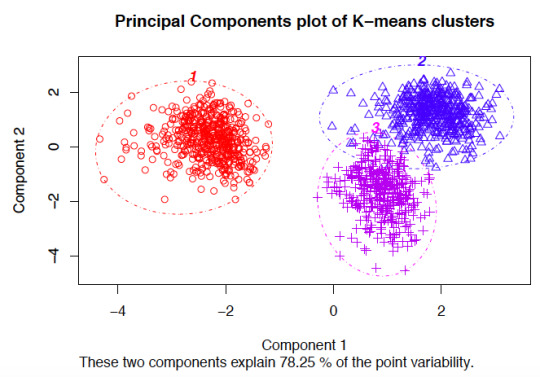
Running a K-Means Cluster Analysis
What is a k-means cluster analysis
K-means cluster analysis is an algorithm that groups similar objects into groups called clusters. The endpoint of cluster analysis is a set of clusters, where each cluster is distinct from each other cluster, and the objects within each cluster are broadly similar to
Cluster analysis is a set of data reduction techniques which are designed to group similar observations in a dataset, such that observations in the same group are as similar to each other as possible, and similarly, observations in different groups are as different to each other as possible. Compared to other data reduction techniques like factor analysis (FA) and principal components analysis (PCA), which aim to group by similarities across variables (columns) of a dataset, cluster analysis aims to group observations by similarities across rows.
Description
K-means is one method of cluster analysis that groups observations by minimizing Euclidean distances between them. Euclidean distances are analagous to measuring the hypotenuse of a triangle, where the differences between two observations on two variables (x and y) are plugged into the Pythagorean equation to solve for the shortest distance between the two points (length of the hypotenuse). Euclidean distances can be extended to n-dimensions with any number n, and the distances refer to numerical differences on any measured continuous variable, not just spatial or geometric distances. This definition of Euclidean distance, therefore, requires that all variables used to determine clustering using k-means must be continuous
Procedure
In order to perform k-means clustering, the algorithm randomly assigns k initial centers (k specified by the user), either by randomly choosing points in the “Euclidean space” defined by all n variables, or by sampling k points of all available observations to serve as initial centers. It then iteratively assigns each observation to the nearest center. Next, it calculates the new center for each cluster as the centroid mean of the clustering variables for each cluster’s new set of observations. K-means re-iterates this process, assigning observations to the nearest center (some observations will change cluster). This process repeats until a new iteration no longer re-assigns any observations to a new cluster. At this point, the algorithm is considered to have converged, and the final cluster assignments constitute the clustering solution.
There are several k-means algorithms available. The standard algorithm is the Hartigan-Wong algorithm, which aims to minimize the Euclidean distances of all points with their nearest cluster centers, by minimizing within-cluster sum of squared errors (SSE).
Software
-means is implemented in many statistical software programs:In R, in the cluster package, use the function: k-means(x, centers, iter.max=10, nstart=1). The data object on which to perform clustering is declared in x. The number of clusters k is specified by the user in centers=#. k-means() will repeat with different initial centroids (sampled randomly from the entire dataset) nstart=# times and choose the best run (smallest SSE). iter.max=# sets a maximum number of iterations allowed (default is 10) per run.In STATA, use the command: cluster kmeans [varlist], k(#) [options]. Use [varlist] to declare the clustering variables, k(#) to declare k. There are other options to specify similarity measures instead of Euclidean distances.In SAS, use the command: PROC FASTCLUS maxclusters=k; var [varlist]. This requires specifying k and the clustering variables in [varlist].In SPSS, use the function: Analyze -> Classify -> K-Means Cluster. Additional help files are available online.
Considerations
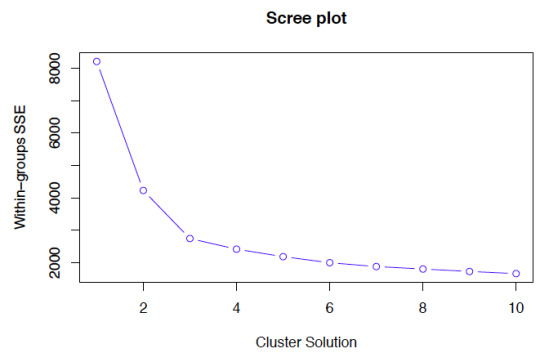
means clustering requires all variables to be continuous. Other methods that do not require all variables to be continuous, including some heirarchical clustering methods, have different assumptions and are discussed in the resources list below. K-means clustering also requires a priori specification of the number of clusters, k. Though this can be done empirically with the data (using a screeplot to graph within-group SSE against each cluster solution), the decision should be driven by theory, and improper choices can lead to erroneous clusters. See Peeples’ online R walkthrough R script for K-means cluster analysis below for examples of choosing cluster solutions.
The choice of clustering variables is also of particular importance. Generally, cluster analysis methods require the assumption that the variables chosen to determine clusters are a comprehensive representation of the underlying construct of interest that groups similar observations. While variable choice remains a debated topic, the consensus in the field recommends clustering on as many variables as possible, as long as the set fits this description, and the variables that do not describe much of the variance in Euclidean distances between observations will contribute less to cluster assignment. Sensitivity analyses are recommended using different cluster solutions and sets of clustering variables to determine robustness of the clustering algorithm.K-means by default aims to minimize within-group sum of squared error as measured by Euclidean distances, but this is not always justified when data assumptions are not met. Consult textbooks and online guides in resources section below, especially Robinson’s R-blog: K-means clustering is not a free lunch for examples of the issues encountered with k-means clustering when assumptions are violated.Lastly, cluster analysis methods are similar to other data reduction techniques in that they are largely exploratory tools, thus results should be interpreted with caution. Many techniques exist for validating results from cluster analysis, including internally with cross-validation or bootstrapping, validating on conceptual groups theorized a priori or with expert opinion, or external validation with separate datasets. A common application of cluster analysis is as a tool for predicting cluster membership on future observations using existing data, but it does not describe why the observations are grouped that way. As such, cluster analysis is often used in conjunction with factor analysis, where cluster analysis is used to describe how observations are similar, and factor analysis is used to describe why observations are similar. Ultimately, validity of cluster analysis results should be determined by theory and by utility of cluster descriptions.
0 notes
Text
SPC Aug 18, 2024 1300 UTC Day 1 Convective Outlook
SPC Aug 18, 2024 1300 UTC Day 1 Convective Outlook https://shelbyohwx.com/wp-content/uploads/day1otlk-1.gif"/>
SPC 1300Z Day 1 Outlook
Day 1 Convective Outlook NWS Storm Prediction Center Norman OK 0753 AM CDT Sun Aug 18 2024 Valid 181300Z - 191200Z ...THERE IS A SLIGHT RISK OF SEVERE THUNDERSTORMS FOR KANSAS INTO THE WESTERN OZARKS...AND FROM THE MID-ATLANTIC STATES INTO THE DEEP SOUTH... ...SUMMARY... Scattered severe gusts are possible from northern Kansas to the western part of the Ozark Plateau, and in a separate area from the Mid-Atlantic States to the Deep South this afternoon to early evening. ...Rockies/Central Plains... Water-vapor imagery this morning indicates a short-wave trough cresting the Rockies mid-level ridge. This feature is forecast to move southeast with an enhanced belt of 500-mb flow (40-50 kt) moving into the Ozarks late. The 00z MPAS-HT-NSSL model seemed to reasonably depict elevated convection and a small severe cluster this morning over SD and northern NE. Other model guidance varies considerably on the handling of this early day storm activity. A risk for large hail will continue across east-central NE through the late morning in association with WAA-related storms favoring the eastern gradient of moisture/instability where isentropic lift will be maximized. Based on several factors 1) the aforementioned MPAS guidance, 2) enhanced mid to upper-level northwesterly flow per OAX, TOP, and SGF 12 UTC raobs, and a reservoir of higher theta-e across northern OK into KS, it seems possible a forward-propagating cluster/MCS may evolve this afternoon from KS into the western Ozarks. Have increased severe probabilities to account for this forecast evolution. ...Middle Atlantic to Deep South... Not much change in thinking from the prior forecast in that a Great Lakes/OH Valley upper trough will shift east and reach the spine of the Appalachians by early evening. Modest 500mb flow should extend within the base of the trough into the Mid-Atlantic states where shear profiles will be most supportive of organized storm structures (including multicells and transient supercells). Damaging gusts (50-65 mph) will likely be the primary risk, but some risk for hail and perhaps a brief tornado can be expected. The trailing portion of the front across the Deep South will not be particularly convergent as it surges into GA-AL-MS. However, a seasonably moist airmass (15-16 g/kg lowest 100-mb mean mixing ratios) sampled by the 12 UTC Jackson, MS east to the coastal Carolinas raob sites, will undergo strong heating through mid afternoon. Several clusters of strong to severe/damaging thunderstorm clusters are forecast to evolve by mid to late afternoon and push towards the coastal areas by early evening. ...Interior West... Scattered to numerous diurnal thunderstorms are forecast to develop on the western/northern periphery of a mid-level anticyclone centered over northeast NM. An ongoing thunderstorm cluster over central AZ will continue to move northward through the midday. This convection appears to be partly influenced by a weak disturbance of convective origin and is partly evident some augmenting of mid-level flow in the KIWA (Phoenix WSR-88D) VAD data. As a result, greater storm coverage will likely be associated with this feature as it moves into a destabilizing airmass across southern UT by early to mid afternoon. Severe gusts (60-75 mph) are possible with this diurnally enhanced activity from the UT/AZ border northward into MT. ..Smith/Mosier.. 08/18/2024
Read more
#ohwx #OHWweather #shelbyoh
0 notes
Text
𝗖𝗼𝗺𝗽𝗹𝗲𝘁𝗲 𝗚𝘂𝗶𝗱𝗲 𝘁𝗼 𝗖𝗥𝗜𝗦𝗣𝗥-𝗖𝗮𝘀 𝗚𝗲𝗻𝗲𝘀
𝗚𝗲𝘁 𝗣𝗗𝗙 𝗦𝗮𝗺𝗽𝗹𝗲: https://www.transparencymarketresearch.com/sample/sample.php?flag=S&rep_id=30428
𝗨𝗻𝗹𝗼𝗰𝗸 𝗮 𝘄𝗼𝗿𝗹𝗱 𝗼𝗳 𝗲𝘅𝗽𝗲𝗿𝘁 𝗶𝗻𝘀𝗶𝗴𝗵𝘁𝘀 𝘄𝗶𝘁𝗵 𝗼𝘂𝗿 𝗰𝗼𝗺𝗽𝗿𝗲𝗵𝗲𝗻𝘀𝗶𝘃𝗲 𝗣𝗗𝗙 𝘀𝗮𝗺𝗽𝗹𝗲—𝗲𝘅𝗰𝗹𝘂𝘀𝗶𝘃𝗲𝗹𝘆 𝗳𝗼𝗿 𝗰𝗼𝗿𝗽𝗼𝗿𝗮𝘁𝗲 𝗲𝗺𝗮𝗶𝗹 𝗵𝗼𝗹𝗱𝗲𝗿𝘀. 📧
CRISPR (Clustered Regularly Interspaced Short Palindromic Repeats) and Cas (CRISPR-associated) genes represent a groundbreaking leap in genetic engineering. Originating as an adaptive immune system in bacteria, this technology has been harnessed to create precise, efficient, and affordable tools for gene editing. By targeting specific DNA sequences, CRISPR-Cas systems enable researchers to edit genes with unprecedented accuracy, holding promise for curing genetic diseases and advancing biotechnology.
The versatility of CRISPR-Cas extends into agriculture, where it is used to create crops resistant to diseases and environmental stress. In medicine, it offers hope for tackling previously incurable conditions, from genetic disorders like sickle cell anemia to cancers. Moreover, CRISPR's potential in combating infectious diseases, such as HIV and malaria, showcases its transformative impact on global health.
As research advances, ethical considerations surrounding CRISPR applications are taking center stage. Balancing the promise of life-changing therapies with responsible use will define the next chapter in the CRISPR revolution. Nonetheless, CRISPR-Cas systems remain a beacon of innovation, inspiring a future where genomic editing could become routine in medicine, agriculture, and beyond.
#CRISPR #GeneEditing #Cas9 #GenomicInnovation #Biotechnology #PrecisionMedicine #GeneticEngineering #FutureOfScience #CRISPRApplications #LifeSciences
0 notes
Text
Comprehensive Breakdown of a Data Science Curriculum: What to Expect from Start to Finish
Comprehensive Breakdown of a Data Science Curriculum: What to Expect from Start to Finish
A Data Science course typically covers a broad range of topics, combining elements from statistics, computer science, and domain-specific knowledge. Here’s a breakdown of what you can expect from a comprehensive Data Science curriculum:
1. Introduction to Data Science
Overview of Data Science: Understanding what Data Science is and its significance.
Applications of Data Science: Real-world examples and case studies.
2. Mathematics and Statistics
Linear Algebra: Vectors, matrices, eigenvalues, and eigenvectors.
Calculus: Derivatives and integrals, partial derivatives, gradient descent.
Probability and Statistics: Probability distributions, hypothesis testing, statistical inference, sampling, and data distributions.
3. Programming for Data Science
Python/R: Basics and advanced concepts of programming using Python or R.
Libraries and Tools: NumPy, pandas, Matplotlib, seaborn for Python; dplyr, ggplot2 for R.
Data Manipulation and Cleaning: Techniques for preprocessing, cleaning, and transforming data.
4. Data Visualization
Principles of Data Visualization: Best practices, visualization types.
Tools and Libraries: Tableau, Power BI, and libraries like Matplotlib, seaborn, Plotly.
5. Data Wrangling
Data Collection: Web scraping, APIs.
Data Cleaning: Handling missing data, data types, normalization.
6. Exploratory Data Analysis (EDA)
Descriptive Statistics: Mean, median, mode, standard deviation.
Data Exploration: Identifying patterns, anomalies, and visual exploration.
7. Machine Learning
Supervised Learning: Linear regression, logistic regression, decision trees, random forests, support vector machines.
Unsupervised Learning: K-means clustering, hierarchical clustering, PCA (Principal Component Analysis).
Model Evaluation: Cross-validation, bias-variance tradeoff, ROC/AUC.
8. Deep Learning
Neural Networks: Basics of neural networks, activation functions.
Deep Learning Frameworks: TensorFlow, Keras, PyTorch.
Applications: Image recognition, natural language processing.
9. Big Data Technologies
Introduction to Big Data: Concepts and tools.
Hadoop and Spark: Ecosystem, HDFS, MapReduce, PySpark.
10. Data Engineering
ETL Processes: Extract, Transform, Load.
Data Pipelines: Building and maintaining data pipelines.
11. Database Management
SQL and NoSQL: Database design, querying, and management.
Relational Databases: MySQL, PostgreSQL.
NoSQL Databases: MongoDB, Cassandra.
12. Capstone Project
Project Work: Applying the concepts learned to real-world data sets.
Presentation: Communicating findings effectively.
13. Ethics and Governance
Data Privacy: GDPR, data anonymization.
Ethical Considerations: Bias in data, ethical AI practices.
14. Soft Skills and Career Preparation
Communication Skills: Presenting data findings.
Team Collaboration: Working in data science teams.
Job Preparation: Resume building, interview preparation.
Optional Specializations
Natural Language Processing (NLP)
Computer Vision
Reinforcement Learning
Time Series Analysis
Tools and Software Commonly Used:
Programming Languages: Python, R
Data Visualization Tools: Tableau, Power BI
Big Data Tools: Hadoop, Spark
Databases: MySQL, PostgreSQL, MongoDB, Cassandra
Machine Learning Libraries: Scikit-learn, TensorFlow, Keras, PyTorch
Data Analysis Libraries: NumPy, pandas, Matplotlib, seaborn
Conclusion
A Data Science course aims to equip students with the skills needed to collect, analyze, and interpret large volumes of data, and to communicate insights effectively. The curriculum is designed to be comprehensive, covering both theoretical concepts and practical applications, often culminating in a capstone project that showcases a student’s ability to apply what they've learned.
Acquire Skills and Secure a Job with best package in a reputed company in Ahmedabad with the Best Data Science Course Available
Or contact US at 1802122121 all Us 18002122121
Call Us 18002122121
Call Us 18002122121
Call Us 18002122121
Call Us 18002122121
0 notes
Text
Regulatory Considerations in the DNA and Gene Cloning Services Market
The DNA and Gene Cloning Services Market is experiencing significant growth driven by the increasing demand for custom DNA constructs, genetically engineered organisms, and gene editing services in various fields, including biotechnology, pharmaceuticals, agriculture, and research. Gene cloning, the process of replicating and amplifying specific DNA sequences, plays a crucial role in molecular biology research, drug discovery, and biomanufacturing.
Get a free Sample: https://www.marketdigits.com/request/sample/3785
One of the primary drivers of market growth is the expanding applications of gene cloning and genetic engineering in biopharmaceutical production. Recombinant DNA technology allows for the production of therapeutic proteins, antibodies, vaccines, and gene therapies, offering potential treatments for a wide range of diseases, including cancer, genetic disorders, and infectious diseases. As a result, pharmaceutical companies and biotech firms are increasingly outsourcing gene cloning services to specialized providers to expedite their drug development pipelines and reduce time-to-market.
Furthermore, advancements in gene editing technologies, such as CRISPR-Cas9, TALENs, and zinc finger nucleases, have revolutionized the field of genetic engineering, enabling precise modifications of DNA sequences in various organisms. Gene editing services, including gene knockout, knock-in, and point mutation, are in high demand for applications such as functional genomics, cell line engineering, and agricultural biotechnology. Additionally, the emergence of synthetic biology and genome editing platforms has created new opportunities for engineering custom DNA constructs and genetic circuits for biomanufacturing and biotechnology applications.
The DNA and Gene Cloning Services Market is Valued USD 3.02 billion in 2024 and projected to reach USD 7.84 billion by 2030, growing at a CAGR of CAGR of 14.6% During the Forecast period of 2024-2032.
The DNA and gene cloning services market is characterized by the presence of specialized providers offering a wide range of services, including gene synthesis, gene cloning, gene editing, plasmid preparation, and DNA sequencing. Major players in the market include Thermo Fisher Scientific Inc., GenScript Biotech Corporation, Eurofins Scientific SE, Integrated DNA Technologies, Inc. (IDT), and OriGene Technologies, Inc., among others. These companies provide end-to-end solutions for DNA manipulation, from design and synthesis to cloning and validation, catering to the diverse needs of academic research labs, biotech startups, and pharmaceutical companies worldwide.
Major vendors in the global DNA and Gene Cloning Services Market are Aragen Life Sciences, Bio-Techne, Charles River Laboratories, Curia, Eurofins, GenScript, Integrated DNA Technologies, MedGenome, Sino Biological, Syngene, Twist Bioscience and Others
Emerging trends in the DNA and gene cloning services market include the development of high-throughput cloning platforms, automation technologies, and cloud-based bioinformatics tools for DNA design and analysis. These advancements enable researchers to streamline the gene cloning process, reduce experimental variability, and accelerate scientific discovery. Additionally, there is growing interest in gene synthesis and DNA assembly methods that enable the construction of large, complex DNA sequences, such as gene clusters, pathways, and synthetic genomes, for applications in synthetic biology and metabolic engineering.
Looking ahead, the DNA and gene cloning services market is poised for continued growth driven by advancements in genomics, gene editing, and biomanufacturing technologies. As the demand for custom DNA constructs and genetically engineered organisms continues to rise, specialized service providers will play a critical role in supporting research, drug development, and biotechnology innovation. Collaborations between industry stakeholders, academic institutions, and regulatory agencies will be essential in addressing technical challenges, ensuring quality standards, and facilitating the translation of genetic engineering advancements into real-world applications.
0 notes