#Cluster sampling in surveys
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
Cluster Sampling: Types, Advantages, Limitations, and Examples
Explore the various types, advantages, limitations, and real-world examples of cluster sampling in our informative blog. Learn how this sampling method can help researchers gather data efficiently and effectively for insightful analysis.
#Cluster sampling#Sampling techniques#Cluster sampling definition#Cluster sampling steps#Types of cluster sampling#Advantages of cluster sampling#Limitations of cluster sampling#Cluster sampling comparison#Cluster sampling examples#Cluster sampling applications#Cluster sampling process#Cluster sampling methodology#Cluster sampling in research#Cluster sampling in surveys#Cluster sampling in statistics#Cluster sampling design#Cluster sampling procedure#Cluster sampling considerations#Cluster sampling analysis#Cluster sampling benefits#Cluster sampling challenges#Cluster sampling vs other methods#Cluster sampling vs stratified sampling#Cluster sampling vs random sampling#Cluster sampling vs systematic sampling#Cluster sampling vs convenience sampling#Cluster sampling vs multistage sampling#Cluster sampling vs quota sampling#Cluster sampling vs snowball sampling#Cluster sampling steps explained
0 notes
Text
0 notes
Text

New SpaceTime out Friday
SpaceTime 20250516 Series 28 Episode 59
Possible Martian biosignatures continue to perplex scientists
Scientists are continuing to examine the fascinating possible detection of biosignatures on Cheyava Falls rock samples collected by NASA’s Mars Perseverance rover in the red planet’s Jezero Crater almost a year ago.






The odd family of stars desperate to leave home
Astronomers have discovered a strange cluster of over a thousand stars acting very strange – and no one knows why.



Artemis II Orion Moon Capsule delivered to NASA
The return of humans to the Moon is a step closer with the Orion capsule to be used for the manned Artemis II lunar mission officially handed over to NASA.





The Science Report
Warnings that parents using phones and tablets, around their kids may be affecting their kids health.
A man who injected himself with snake venom 856 times helps create an antivenom for all snake bites.
Claims that growing peas and potatoes could help; feed a city in times of global catastrophe.
Skeptics guide to Gestalt Therapy
SpaceTime covers the latest news in astronomy & space sciences.
The show is available every Monday, Wednesday and Friday through your favourite podcast download provider or from www.spacetimewithstuartgary.com
SpaceTime is also broadcast through the National Science Foundation on Science Zone Radio and on both i-heart Radio and Tune-In Radio.
SpaceTime daily news blog: http://spacetimewithstuartgary.tumblr.com/
SpaceTime facebook: www.facebook.com/spacetimewithstuartgary
SpaceTime Instagram @spacetimewithstuartgary
SpaceTime twitter feed @stuartgary
SpaceTime YouTube: @SpaceTimewithStuartGary
SpaceTime -- A brief history SpaceTime is Australia’s most popular and respected astronomy and space science news program – averaging over two million downloads every year. We’re also number five in the United States. The show reports on the latest stories and discoveries making news in astronomy, space flight, and science. SpaceTime features weekly interviews with leading Australian scientists about their research. The show began life in 1995 as ‘StarStuff’ on the Australian Broadcasting Corporation’s (ABC) NewsRadio network. Award winning investigative reporter Stuart Gary created the program during more than fifteen years as NewsRadio’s evening anchor and Science Editor. Gary’s always loved science. He was the dorky school kid who spent his weekends at the Australian Museum. He studied astronomy at university and was invited to undertake a PHD in astrophysics, but instead focused on a career in journalism and radio broadcasting. Gary’s radio career stretches back some 34 years including 26 at the ABC. His first gigs were spent as an announcer and music DJ in commercial radio, before becoming a journalist, and eventually joining ABC News and Current Affairs. He was part of the team that set up ABC NewsRadio and became one of its first on air presenters. When asked to put his science background to use, Gary developed StarStuff which he wrote, produced and hosted, consistently achieving 9 per cent of the national Australian radio audience based on the ABC’s Nielsen ratings survey figures for the five major Australian metro markets: Sydney, Melbourne, Brisbane, Adelaide, and Perth. That compares to the ABC’s overall radio listenership of just 5.6 per cent. The StarStuff podcast was published on line by ABC Science -- achieving over 1.3 million downloads annually. However, after some 20 years, the show finally wrapped up in December 2015 following ABC funding cuts, and a redirection of available finances to increase sports and horse racing coverage. Rather than continue with the ABC, Gary resigned so that he could keep the show going independently. StarStuff was rebranded as “SpaceTime”, with the first episode being broadcast in February 2016. Over the years, SpaceTime has grown, more than doubling its former ABC audience numbers and expanding to include new segments such as the Science Report -- which provides a wrap of general science news, weekly skeptical science features, special reports looking at the latest computer and technology news, and Skywatch – which provides a monthly guide to the night skies. The show is published three times weekly (every Monday, Wednesday and Friday) and available from the United States National Science Foundation on Science Zone Radio, and through both i-heart Radio and Tune-In Radio.
#science#space#astronomy#physics#news#nasa#astrophysics#esa#spacetimewithstuartgary#starstuff#spacetime#hubble space telescope#hubble#hubble telescope
14 notes
·
View notes
Text
POLL RESULTS JUST DROPPED!!
My hockeyblr experiences are largely catered to my own personal tastes -- mostly Leafs, a little Penguins and Stars, one or two who post about Stevie Y and Sergei Fedorov. These are obviously not the only teams out there.
This study was designed to survey as much of hockeyblr as it possibly could, gathering data on which teams people like and to what degrees. There were five questions and a free space -- my attempt to ask people to rank the teams they enjoyed in three levels, from religiously followed to casually affectionate, and an additional couple of questions on love for players versus team. I received over 500 responses. Here are the results.
Yeah, yeah, you all want to know: The most popular team is the Penguins, by a long shot, then the Leafs.
Because my sample size (n = 523) is actually fairly small compared to the number of NHL teams there are, I find definitive rankings tend to be difficult. It’s also worth noting that, as a mainly Leafs blog, my numbers are definitely going to be skewed a little in favour of the Leafs.
Your Guys
These are the teams closest to your heart: the ship you go down with, metaphorically or, depending on how married your old men are, literally. For me, I picked just the Leafs.
The average respondent had 1.9 teams in this category. The most popular, by far, was the Pittsburgh Penguins. Below is a table of teams, arranged roughly into tiers by the number of respondents. Each team has the number of respondents in brackets next to their three-letter code.
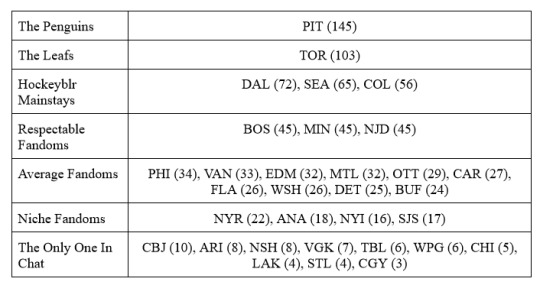
I allowed people to pick as many teams as they would like; the average person picked 1.9 teams, but here’s a distribution of how many teams they picked:
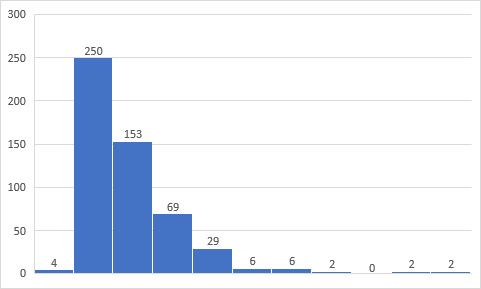
4 people picked 0 “your guys” teams, and 2 people picked seven, nine, or ten each teams. Just about half of people had one main team.
I then wondered: what teams were people most likely to only follow? That is, if you hold [x] team in the closest part of your heart, are you more or less likely to also hold any other teams? Almost exactly 25% of picks were solo; I wondered if there was any correlation at all.

Only a little bit! Of the samples large enough to actually consider (so: nothing in that cluster at the bottom left, who all received fewer than 10 picks total, and a few of whom -- CGY, CHI, NSH -- received zero solo pickers), the most devoted fans chose the Sharks, the Bruins, and the Leafs. The fans who liked the most other teams chose the Avs, the Kraken, the Canucks, Panthers, Sens, and Ducks.
Probably a next step would be to look for correlations: if people are a fan of one team, are they more likely to be fans of another? THAT BEING SAID that’s a lot of regressions. Maybe keep an eye on that for the future, but I don’t know!!
Objects of Enjoyment, and Generally Nice
These two were successive tiers meant to distinguish teams that people like from the ones in the category above. I admit I probably could have phrased the questions better; I received several comments saying that they’d watch any hockey when they wanted to put a game on. The dynamics between Your Guys versus Objects of Enjoyment versus Generally Nice would best be described as devoted fan of versus casual fan of versus favourable opinion towards.
As I said a few paragraphs back, people picked 1.9 “devoted fan” teams on average. Again on average, they picked 4.7 “casual fan” teams and 6.5 “favourable opinion” teams. Not all ratios are equal, though! Some teams had significantly more casual than devoted fans, and others still were much more liked generally than average.
I gave each team’s “devoted” count an index number of 1 and measured their casual and favourable count as a ratio against the index number. The teams assembled themselves into a few groups.
No Commitment

Arizona and Anaheim have decided to be soulbonded (Excel refuses to let them have different-coloured dots) and it took me three hundred million years to attempt to (and unsuccessfully) fix, so let’s ignore that. These teams all have a fairly high slope of interest -- a range of casual interest at about five times the pace of fervent interest, and good opinion at about ten times fervent interest. The Calgary Flames are an outlier on the entire graph, not just here.
Casual Interest
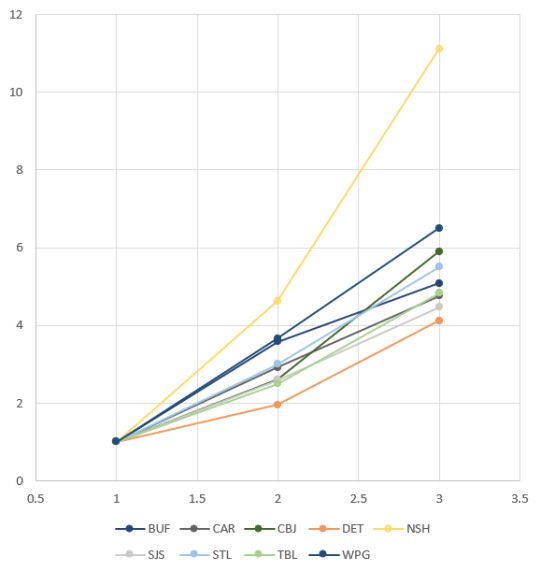
I gave up on trying to colour teams according to their real colours shortly after the Anaheim/Arizona debacle. Please employ the legend. Nashville is included on all five graphs for reference. These teams all have a casual interest factor of about 3, and a favourable opinion factor of around 5; the same ratio as the casual fans of the teams in the first category to their fervent fans.
Saturated Market
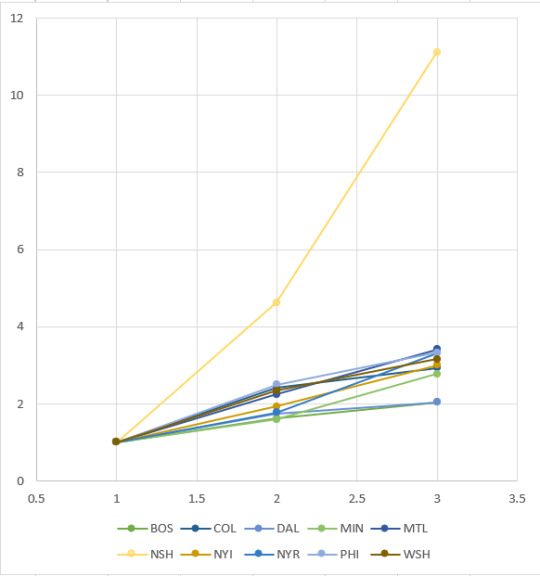
These teams have a much lower ratio of hardcore:casual:favourable fans, at about 1:2:3.
We Get It, Those Are Your Guys

Pittsburgh and Toronto; these teams have an almost equal ratio of all three categories.
...Whatever This Is
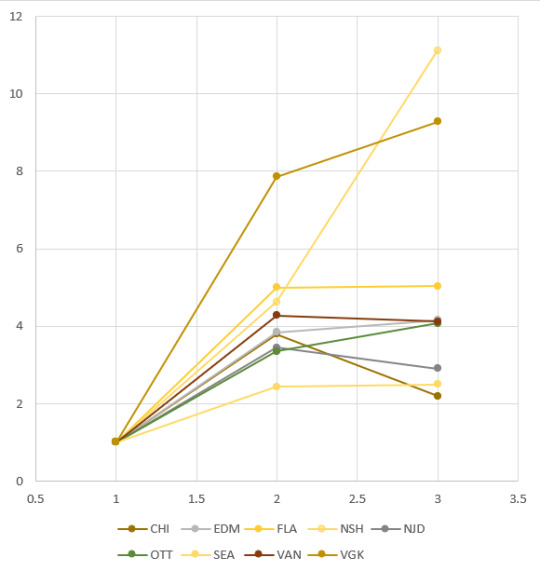
Every other category is defined by its ratios; this category is defined by its shape. While all teams have their rate of hardcore fandom set as 1, the other two tend to increase in a roughly linear form, without too much significant difference between the first interval and the second interval.
These teams, though (again, Nashville is for scale) don’t do that: they have a set increase between hardcore and casual, and a significantly smaller increase (or, in a couple cases, a decrease) between casual and favourable. This suggests perhaps some kind of divisiveness; if you’re not already in there, do you really want to get in further? Either that, or it’s something closer to what the Leafs and Penguins have: that is, a devotion. Like you’re in or you’re out.
Taking these values together
Because the casual:hardcore ratios are measured as indexes and not absolute values, they say nothing about the actual popularity of the team in question -- Calgary is one of the least popular, which is why I assume it’s so weirdly high up; small sample sizes lead to higher error values!
But we do have the absolute values, so we can measure them against each other.

If we consider the “In or Out” to be a category of its own while the other four are along more of a continuum, then we can absolutely see a correlation here -- larger fandoms tend to have more involved fanbases.
Players or Teams?
I also asked participants if their guys tended to be players or teams -- and if those they liked at a more casual level tended to be players or teams.
The results are… not particularly surprising.

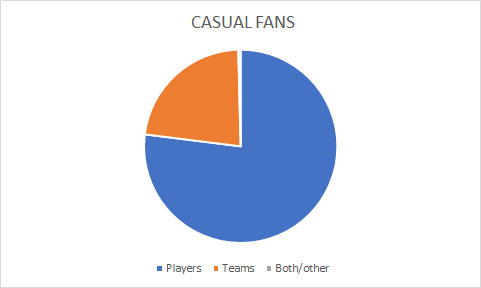
On a hardcore level, people tended to prefer teams, although the variability was pretty slight. On a casual level, individual players were much more popular.
I also wondered if people who chose more teams in the hardcore fan question tended to do that because they prefer players.
On average, people who picked players on their hardcore level chose 2.1 teams. People who picked teams chose 1.7 teams. That’s definitely a difference!
Fun Shtuff
I got way more write-in responses on the hardcore player/team question than on the casual question, including this:

Three separate people answered “Minnesota Wild” for their guys and chose no other teams on any level. Hell yes. (One person also did this for the Kings.)
It took about 300 responses before the first Flames fan (at the hardcore level.)
On all three levels, the Seattle Kraken are really popular -- they’re in the top five in each.
What's Next?
If I were to update this survey, I would probably include a question about where all of you are from -- some people (like me) follow their hometown team, while some people most certainly don't (shoutout to the one person from Edmonton who dislikes the Oilers) and others still don't have a hometown team (shoutout to my brasilian + european + etc mutuals and everyone else!!)
Feel free to shoot me an ask if you want me to do anything else with this data -- examine a specific team, give actual casual fan/etc counts and total aggregate rankings, anything else!
205 notes
·
View notes
Text




Yellow-breasted Chat (Icteria virens)
Chadron State Park - Fall '22 & '23
Would you believe my lifer YBCH was the first bird pictured here? In the Eastern US, Yellow-breasted Chat aren't rare, they just aren't common either. Typically migrants and very skulky, it can be hard to find one when they aren't singing their pretty head off. Once out West I had an easier time hearing them, especially since they like to cluster around water sources in the dry Southwest region.
Three different birds are pictured. All adult Yellow-breasted Chat have the same bright, lemon yellow chest they're named for, regardless of sex. The third bird pictured was a hatch-year, and still had some dingy juvenile plumage showing. The best way to tell these birds apart in hand is by the roof of their mouth! Males will be pitch-black, while females have a white-ish to pink mouth. Younger birds will be more dull, of course, but can still sometimes be sexed this way. In the field its best to get a good look at the mask and see if it is black (male) or dark gray (female)- or you could just wait until the male starts his long and loud chatter of a song.
All banding, marking, and sampling is being conducted under a federally authorized Bird Banding Permit issued by the U.S. Geological Survey's BBL. Permission to share images was granted by Bird Conservancy of the Rockies (BCR).
#yellow breasted chat#bird banding#(Not Warbler)#couldn't remember if I had posted these or not so I had to go scrounging
72 notes
·
View notes
Text
WHAT IS THE FARTHEST THING WE CAN SEE IN SPACE??
Blog#348
Saturday, November 11th, 2023
Welcome back,
Current observations suggest that the Universe is about 13.7 billion years old. We know that light takes time to travel, so that if we observe an object that is 13 billion light years away, then that light has been traveling towards us for 13 billion years. Essentially, we are seeing that object as it appeared 13 billion years ago.
With every year that passes, our newest technology enables us to see further and further back.

The image used for this stop on our journey is the Hubble Ultra Deep Field (UDF). The UDF is one of the deepest views of the visible universe to date; certainly it was the deepest when it was originally created in in 2003-2004. There are approximately 10,000 galaxies in this view, which is a sort of "core sample" of a very narrow patch of sky near the constellation Fornax. The smallest, reddest galaxies in the image, of which there are about 100, are among the most distant known objects!

The UDF looks back approximately 13 billion years (approximately between 400 and 800 million years after the Big Bang). Galaxies that existed in that time period would be very young and very different in structure and appearance than the grand spirals we see nearby today.
In December of 2012, astronomers announced a Hubble Space Telescope discovery of seven primitive galaxies located over 13 billion light years away from us.

The results are from survey of the same patch of sky known as the Ultra Deep Field (UDF). This survey, called UDF12, used Hubble's Wide Field Camera 3 to peer deeper into space in near-infrared light than any previous Hubble observation.
Why infrared? Because the Universe is expanding; therefore the farther back we look, the faster objects are moving away from us, which shifts their light towards the red. Redshift means that light that is emitted as ultraviolet or visible light is shifted more and more to redder wavelengths.

The extreme distance of these newly discovered galaxies means their light has been traveling to us for more than 13 billion years, from a time when the Universe was less than 4% of its current age.
Their discovery, which you can read more about in the NASA feature is exciting because it might give us an idea of how abundant galaxies were close to the era when astronomers think galaxies first started forming. (Phil Plait has a good column about this discovery too.)
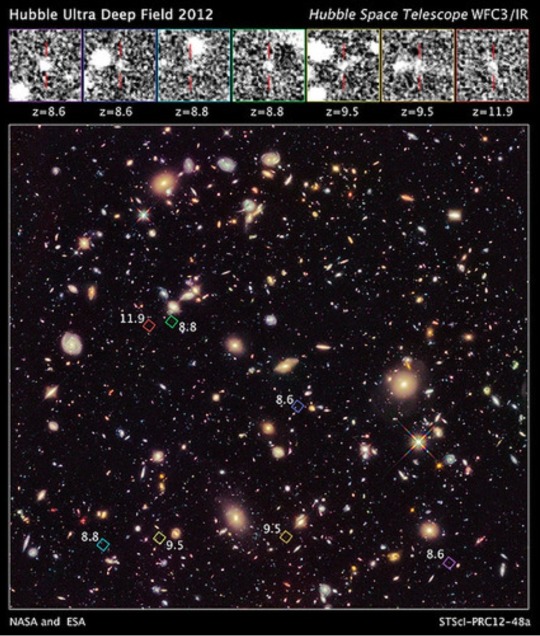
As of this writing it seems that one of the galaxies in this recent Hubble discovery may be a distance record breaker - it was observed 380 million years after the Big Bang, with a redshift of 11.9. This means the light from this galaxy (pictured below) left 13.3+ billion light years ago.

Just under a month ago, the current candidate was this object: a young galaxy called MACS0647-JD. It's only a tiny fraction of the size of our Milky Way - and was observed at 420 million years after the Big Bang, when the universe was 3 percent of its present age of 13.7 billion years. To spot this galaxy, astronomers used the powerful gravity from the massive galaxy cluster MACS J0647+7015 to magnify the light from the distant galaxy; this effect is called gravitational lensing

Originally published on imagine.gsfc.nasa.gov
COMING UP!!
(Wednesday, November 15th, 2023)
"WHERE DID WATER COME FROM ON EARTH??"
#astronomy#outer space#alternate universe#astrophysics#universe#spacecraft#white universe#space#parallel universe#astrophotography
89 notes
·
View notes
Text
"In the most comprehensive national study since the onset of the COVID-19 pandemic, a team of researchers that includes a Rutgers-organized consortium of pediatric sites has concluded that long COVID symptoms in children are tangible, pervasive, wide ranging and clinically distinct within specific age groups. Results of the study, funded by the National Institutes of Health (NIH), are published in the Journal of the American Medical Association. “We have convincing evidence that COVID-19 is not just a mild, benign illness for children,” said Lawrence C. Kleinman, a professor of pediatrics and population health expert at Rutgers Robert Wood Johnson Medical School (RWJMS) and the study’s third co-author. “There are children who are clearly disabled by long COVID for long periods of time.” In the early stages of the pandemic, a myth arose and was perpetuated suggesting that because children often developed only mild cases of COVID-19, the risks for young patients were not serious. But this conjecture dissipated amid a rash of data demonstrating that a few children infected with COVID-19 will get very sick and others will suffer an array of health complications long after initial exposure. Broadly defined, long COVID includes symptoms, signs, and conditions – such as aches, fatigue, memory loss and stomach pain – that develop, persist or relapse more than a month after a COVID-19 infection. Worldwide, an estimated 65 million people, including children, live with long COVID. Until recently, most research into COVID-19’s lingering effects focused on adults. To quantify long COVID’s impact on children and determine whether symptoms experienced by the youngest COVID-19 patients differ by age group and from adults, Kleinman and more than 140 researchers throughout the United States crunched data from NIH’s Researching COVID to Enhance Recovery (RECOVER) Initiative, a national effort to survey COVID-19’s long-term impact. As part of RECOVER, caregivers for 5,367 children (898 school-aged children and 4,469 adolescents) completed online surveys about their children’s health in time for this data analysis. Roughly 86 percent of the sample had previously been infected with COVID-19, while 14 percent – the control group – had not. The survey assessed 74 known and potential long COVID-19 symptoms across nine domains: eyes, ears, nose and throat; heart and lungs; gastrointestinal; dermatologic; musculoskeletal; neurologic; behavioral and psychological; menstrual; and general. By analyzing the responses, researchers found 45 percent of COVID-19 infected school-age children (ages 6 to 11) reported at least one prolonged symptom after initial recovery versus 33 percent of uninfected children. Thirty-nine percent of COVID-19 infected adolescents (ages 12 to 17) reported one prolonged symptom, compared with 27 percent of uninfected adolescents. These differences implicate the virus as a likely causal factor, rather than just having lived through the pandemic. Long COVID symptoms in children also were clustered in patterns distinct from adults and from each other. For instance, the most common symptom in adolescents was loss of smell and taste, followed by low energy, muscle aches and fatigue. For school-age children, memory and focus issues topped the list, followed by stomach pain, headaches and back or neck pain. Children experienced prolonged symptoms after COVID-19 infection “in almost every organ system, with the vast majority having multisystem involvement,” the authors wrote."
oh hey, remember a couple of years ago during the omicron wave when multisystem inflammatory syndrome was driving a lot of kids to go to the hospital?
29 notes
·
View notes
Note
There were a bunch of sea stacks west of Berk.
…Islands were typically formed out of volcanos erupting over and over. Now, Dart couldn’t quite make lava out of thin as a Heatblast. What they did have was a Gronckle one that could spew quite a bit of lava and the ability teleport several loads of stone via Omnitrix.
Dart.
Dart called Azmuth to debate on the merits of this, the cons of creating an entire new island for a species that tunnels everywhere. They already surveying the area’s underwater section allowing the Galvan present the facts straight. Whispering Deaths didn’t eat stone contrary to their classification. Thus, the dragons ought to know how to keep from sinking an island as long as they laid a wide enough base for it.
No major currents would be affected by adding onto a particularly close cluster of sea stacks. No sea dragons or land dragons roosted where they had chosen as an initial starting point. Besides, Worldshaker was going to be massive even as a hatchling if Dart’s own Screaming Death transformation was any indication.
They couldn’t wait any longer to figure this out.
—————————
It took them days.
A combined effort between Heatblast, Potbelly, and the surprisingly lava resistant Calderous.
Rock load after rock load to set a very wide island base for the Nemesis-Groundsplitter family. Adequately connected to the sea floor without any risks of the island “floating”. Dart mixed in plant matter and various ores to give the Whisperings Deaths something interesting to dig through. Some tree samplings were transplanted to the island, but Dart could only gently coax them to survive as Pipeline. Their only plant transformation lacked the natural connection Swampfire and Wildvine had.
Yet it was better than nothing after all.
Dart felt into a pattern of munching rocks as Potbelly, spewing lava and flying back to the rock pile to refuel. Over and over again.
The Omnitrix’s rough estimate showed the submerged base of the island as roughly two acres? None of the edges were perfectly circular or even so the calculation was very, very rough. The original sea stacks were incorporated into the center of the island. Several new stacks/cliffs were built up to make sure the island didn’t seem flat. Claymore helped the soil not feel as dead as pure stone.
Azmuth helped coach them through building a very rudimentary natural water pool that had various rock and plant materials to filter it. While not the most satisfying, the water pool was very roughly drinkable for the Deaths.
————————
Worldshaker and his siblings hatched onto the way to the new home island. He was bigger than his sibling by a lot, already almost half his mother’s size just by head size. His shortish tail left a lot to be desired while he lived up to his variant species name. The Screaming Death hatchling screamed the entire way there.
Dart ended up turning into Tone Depth just so they could ignore his wailing. Though, it was a little embarrassing not to realize the Dragon Riders ended up spotting them. Toothless’ Nemesis gave a cautionary growl—but otherwise the Vikings followed them all the way to the new island. Groundsplitter happily let her children tunnel into the ground to get their first taste of their instincts… Only Worldshaker stayed extremely close to his mother.
The Omnitrix would later play back the kids’ not so quiet cooing over the baby dragons. And Fishlegs blatant confusion over where in the world the Island came from.
—ROB’d Anon.
I don't think any natural island could handle so many large burrowers but an artificial one has better chances. Piranha Plants would have minor plant manipulation just not on the level of Swampfire and Wildvine. At least this introduction to the Screaming Death was way less destructive for Berk.

#sonicasura#sonicasura answers#asks#anonymous#ben 10#ben 10 series#ben ten#ben ten series#oc#original character#how to train your dragon#httyd
2 notes
·
View notes
Text
Optimizing Market Research: Sampling Strategies by Tehrihills Consulting

Introduction -
Sampling is a fundamental aspect of market research, allowing researchers to gain insights into a larger population without having to study each individual within it. At Tehrihills Consulting, we understand the critical role of sampling in facilitating accurate and actionable Market Data Analysis. Our approach integrates advanced techniques to ensure the representativeness and reliability of the data collected in global market research.
Imagine a scenario where a company aims to understand consumer preferences across different demographics for a new product launch. Conducting surveys or studies with the entire population would be impractical and costly. Instead, through strategic sampling, we can select representative samples from each demographic group and analyze their preferences, behaviors, and opinions. This approach not only streamlines the research process but also provides valuable insights that drive informed decision-making.
Sampling is not just about selecting a subset of the population; it's about strategically choosing the right sample to represent the entire population accurately. By leveraging advanced sampling techniques and cutting-edge research methodologies, Tehrihills Consulting ensures that our clients receive accurate, reliable, and actionable insights to fuel their business growth through global data collection and analysis.
Types of sampling: sampling methods -
1. Probability Sampling Methods: Researcher employ specific criteria to randomly select members from a population. Each member within the population has an equal chance of being chosen for inclusion in the sample, ensuring fairness and representativeness. This systematic approach allows Tehrihills Consulting to gather diverse insights from various segments of the target population, driving robust market research and data analysis outcomes.
Simple Random Sampling: Simple random sampling involves selecting elements from a population entirely at random, ensuring each member has an equal chance of being chosen. This method, akin to picking a name out of a hat, offers an unbiased approach to sample selection. For instance, in an organization of 300 employees, each individual has an equal opportunity of being selected for a sample, facilitating comprehensive insights for Tehrihills Consulting's global market research initiatives.
Systematic Sampling: Systematic sampling entails selecting elements at regular intervals from a population after an initial random selection. This method offers flexibility in sample selection intervals, allowing researchers to avoid unintentional clustering. For example, a researcher may choose every 10th individual from a population of 7000 to form a systematic sample, optimizing time and resources for data collection endeavors in global data collection and analysis
Stratified Sampling: Stratified sampling involves dividing a population into distinct groups based on predefined criteria and then selecting samples randomly from each group. This method enables researchers to obtain representative samples from diverse segments of the population. For instance, Tehrihills Consulting may stratify a population based on income levels to analyse consumer behaviours across various income brackets, thereby enhancing the efficacy of Market Data Analysis.
Cluster Sampling: Cluster sampling entails selecting entire groups or clusters from a population rather than individual units. These clusters, such as geographic regions or academic cohorts, are randomly chosen to represent the entire population. By organizing clusters based on demographic parameters, Tehrihills Consulting can derive actionable insights from diverse population segments, facilitating targeted marketing strategies and informed decision-making in global market research.
2. Non-Probability Sampling Methods: The researchers handpick sample participants according to the specific objectives of their research goals. Unlike probability-based approaches, this method lacks a rigid or predetermined selection process, resulting in varying opportunities for different elements of the population to be part of the sample. This flexible methodology enables Tehrihills Consulting to tailor sampling techniques to meet the unique requirements of each research project, ensuring comprehensive and targeted insights for our clients.
Convenience Sampling: Convenience sampling involves selecting samples based on their accessibility and proximity to the researcher. While convenient, this method may introduce bias due to its non-random nature. However, it serves as a pragmatic approach in situations with time and resource constraints, allowing Tehrihills Consulting to gather preliminary insights swiftly.
Quota Sampling: Quota sampling involves setting predetermined quotas for sample attributes, such as gender or age, to ensure representation across target demographics. While quota sampling facilitates demographic diversity in samples, Tehrihills Consulting acknowledges the potential for bias in sample selection and strives to mitigate it through rigorous research market research and data analysis methodologies.
Purposive Sampling: Purposive sampling entails selecting samples based on the researcher's judgment and expertise, focusing on specific characteristics relevant to the research objectives. While purposive sampling may not yield representative samples, it offers a quick and efficient means of obtaining insights tailored to client's market research solutions needs.
Snowball Sampling: Snowball sampling involves recruiting participants through referrals from existing sample members, cascading through interconnected networks like a snowball rolling downhill. This method proves invaluable in reaching elusive populations or addressing sensitive topics, ensuring Tehrihills Consulting's research initiatives encompass diverse perspectives.

Conclusion -
In conclusion, sampling methods serve as the bedrock of market research, enabling Tehrihills Consulting to gather comprehensive data for Global data collection and analysis and Market Data Analysis. By employing a diverse array of sampling techniques, we ensure the accuracy, reliability, and relevance of insights that drive our clients' success. Partner with Tehrihills Consulting for unparalleled market research solutions tailored to your business objectives.
Unlock the power of Market Data Analysis with Tehrihills Consulting – your trusted partner for Market Research and Data Analysis. Explore global data collection and analysis, Conjoint Data Analysis, Decipher survey programming, CATI Market Research & MaxDiff Analysis. Trust Tehrihills Consulting for accurate Global Market Research Analytics, and expert Data Validation. Partner with us for comprehensive market research solutions that leverage advanced Market Data Analysis techniques to propel your business forward.
#market research#survey programming#tehrihillsconsulting#decipher#forsta#survey#researchreports#marketresearch#surveyprogramming#marketresearchsolutions#datavalidation#MaxDiffanalysis#CATImarketresearch#dataanalysis#MarketInsights#customizedresearch#customerinsights
2 notes
·
View notes
Text
hiya guys, this is another post about how to avoid bias when polling on this account. in my last post i explained that this account uses cluster sampling, which (in theory) is the practice of sampling all of one category of people. in this case, that is the byler community.
but a major thing that can effect cluster sampling is another form of bias called non-response bias! it basically sounds exactly like what it is. this is when there is little to no response to your survey, so it's impossible to determine the results as accurate when you've only collected answers from a few people.
how do you avoid non-response bias? well, that's easy! by sharing the poll through links or reblogs you can help the poll reach more people/a wider audience & get more accurate results detailing how many people feel.
no pressure though, this is only if you're a nerd like me that cares about biases when sampling.
4 notes
·
View notes
Text
Stages of Statistics: Data Production
Data Production: Take sample data from the population, with sampling and study designs that avoid bias.
Display and Summarizing: Use appropriate displays and summaries of the sample data, according to variable types and roles.
Probability: Assume we know what's true for the population; how should random samples behave?
Statistical Inference: Assume we only know what's true about sampled values of a single variable or relationship; what can we infer about the larger population?

census: process of gathering information about the ENTIRE population.
Sample should be representative of the population.
Sampling design: obtain an unbiased sample.
Study design: carry out a properly designed study.
Bias: tendency of an estimate to deviate in one direction from a true value.
Selection bias occurs when the sample is non-representative of the larger population of interest. The best way to avoid selection bias is to utilize randomness.
Probability Sampling = sample chosen by chance
Simple Random Sample (SRS): Every individual in the population has an equal chance of being selected for the sample.
Random selection could look like... - drawing names out of a hat - table of random digits - computer generated (ex. https://www.random.org/)
Systematic Sample: Select subjects at a fixed interval determined by the total number of individuals and the sample size desired.
Example: You have 1000 subjects and would like a sample size of 100 subjects. Your interval would be 1000/100 = 10.
Stratified Random Sample: The population is divided into groups of similar individuals (strata). Select a separate proportional SRS from each stratum and combine to form the full sample.
Divide the population into non-overlapping strata.
Determine how many individuals to select from each strata (based on proportions).
Take SRS in each strata.
Combine SRS from each strata for sample.
Cluster Random Sample: Select small groups (clusters) at random from within the population and use all individuals in the selected clusters.
Divide the population into clusters.
Take an SRS of the clusters.
Include all individuals from each selected cluster in the sample.
Multi-Stage Samples: Uses stages to stratify or randomly sample increasingly more specific groups. Uses two or more sampling methods.
Suppose your company makes light bulbs and you'd like to test the effectiveness of the packaging. You don't have a complete list, so simple random sampling doesn't apply. Let's say that the bulbs come off the assembly line in boxes that contain 20 packages of four bulbs each.
One strategy would be to do the sample in two stages: 1) A quality control engineer removes every 200th box coming off the line. The plant produces 5,000 boxes daily. (This is an example of systematic sampling). 2) From each box, the engineer then samples three packages to inspect. (This is an example of cluster sampling).
Non-Probability Sampling & Problems
Convenience sample = Sampled individuals are found at a time or in a place that is handy for researchers.
Volunteer (self-selected) sample = Includes only individuals who have taken the initiative to participate, as opposed to being recruited by researchers.
Ex. most online surveys, product reviews, social media polls, asking audience members to raise their hands, "Rate Your Professor"
Haphazard sample = Selected without a scientific plan, according to the whim of whoever is drawing the sample.
Non-response = Occurs when individuals selected by researchers decline to be part of the sample.
Ex. If you ask 1000 managers about their workload, the busiest managers won't have time to answer and the least busy managers may not answer in fear of being downsized.
Example goal: A representative sample of undergraduate students from a particular university
SRS (Simple Random): A random number generator is used to select a certain number of students from the list of all those who attend the university.
Stratified Random: First divide all the students into schools – such as arts, sciences, engineering, and so on. Within each school, a random sample of students is taken dependent on the proportion of students in that school within the university.
Cluster: A random sample of classes is taken from all classes meeting at the university, and all students in each of the sampled classes are included in the sample.
Multi-Stage: First all the students are divided into schools. Within each school, a random sample of majors is selected. Within each major, a random sample of classes is selected. A t the last stage, either the entire cluster of students in each sampled class is included, or individual students are randomly sampled from each sampled class.
2 notes
·
View notes
Text
Astronomers discover striking evidence of 'unusual' stellar evolution
“Astronomers have found evidence that some stars boast unexpectedly strong surface magnetic fields, a discovery that challenges current models of how they evolve.
In stars like our sun, surface magnetism is linked to stellar spin, a process similar to the inner workings of a hand-cranked flashlight. Strong magnetic fields are seen in the hearts of magnetic sunspot regions, and cause a variety of space weather phenomena. Until now, low-mass stars—celestial bodies of lower mass than our sun that can rotate either very rapidly or relatively slowly—were thought to exhibit very low levels of magnetic activity, an assumption which has primed them as ideal host stars for potentially habitable planets.
In a new study, published today in The Astrophysical Journal Letters, researchers from The Ohio State University argue that a new internal mechanism called core-envelope decoupling—when the surface and core of the star start out spinning at the same rate, then drift apart—might be responsible for enhancing magnetic fields on cool stars, a process which could intensify their radiation for billions of years and impact the habitability of their nearby exoplanets.

The research was made possible due to a technique that Lyra Cao, lead author of the study and a graduate student in astronomy at Ohio State, and co-author Marc Pinsonneault, a professor of astronomy at Ohio State, developed earlier this year to make and characterize starspot and magnetic field measurements.
Although low-mass stars are the most common stars in the Milky Way and are often hosts to exoplanets, scientists know comparatively little about them, said Cao.
For decades, it was assumed that the physical processes of lower mass stars followed those of solar-type stars. Because stars gradually lose their angular momentum as they spin down, astronomers can use stellar spins as a device to understand the nature of a star's physical processes, and how they interact with their companions and their surroundings. However, there are times where the stellar rotation clock appears to stop in place, Cao said.
Using public data from the Sloan Digital Sky Survey to study a sample of 136 stars in M44, a star crib also known as Praesepe, or the Beehive cluster, the team found that the magnetic fields of the low-mass stars in the region appeared much stronger than current models could explain.”
continue article
#astronomy#cosmology#universe#space#evolution#magnetism#electromagnetism#magnetic fields#energy#spinning#oscillation#vortex#stars#planets#sun#rotation#counter rotation#scaling#science
2 notes
·
View notes
Text
The Rosette Nebula.
(Text of the web page above)
This composite image shows the Rosette star formation region, located about 5,000 light years from Earth. Data from the Chandra X-ray Observatory are colored red and outlined by a white line (roll your mouse over the image above). The X-rays reveal hundreds of young stars clustered in the center of the image and additional fainter clusters on either side. These clusters are labeled in the X-ray only image, where they are more obvious to the eye. Optical data from the Digitized Sky Survey and the Kitt Peak National Observatory (purple, orange, green and blue) show large areas of gas and dust, including giant pillars that remain behind after intense radiation from massive stars has eroded the more diffuse gas.
A recent Chandra study of the cluster on the right side of the image, named NGC 2237, provides the first probe of the low-mass stars in this satellite cluster. Previously only 36 young stars had been discovered in NGC 2237, but the Chandra work has increased this sample to about 160 stars. The presence of several X-ray emitting stars around the pillars and the detection of an outflow — commonly associated with very young stars — originating from a dark area of the optical image indicates that star formation is continuing in NGC 2237 (the outflow and some of the pillars are labeled in a close-up view). By combining these results with earlier studies, the scientists conclude that the central cluster formed first, followed by expansion of the nebula, which triggered the formation of the neighboring clusters, including NGC 2237.Image Credit: X-ray (NASA/CXC/SAO/J. Wang et al), Optical (DSS & NOAO/AURA/NSF/KPNO 0.9-m/T. Rector et al)
89K notes
·
View notes
Text

New SpaceTime out Monday
SpaceTime 20250203 Series 28 Episode 15
The building blocks of life discovered on the asteroid Bennu
Scientists have discovered the molecular building blocks of life in samples of the Asteroid Bennu brought back to Earth by NASA’s OSIRIS-REx spacecraft.



A new threat to planet Earth
Astronomers have detected a near Earth asteroid which could pose a threat to our planet.


New mission to investigate the moon mysterious domes
NASA is planning a new mission to study a cluster of strange dome like structures discovered on the Moon.







The Science Report
The CIA says COVID19 came from a lab in Wuhan China.

Study says Elderberry juice may be a potent tool for weight management.

Palaeontologists have discovered part of a feathered dinosaur tail preserved in a piece of amber.

Skeptics guide to UFO links with economic circumstances
SpaceTime -- A brief history
SpaceTime is Australia’s most popular and respected astronomy and space science news program – averaging over two million downloads every year. We’re also number five in the United States. The show reports on the latest stories and discoveries making news in astronomy, space flight, and science. SpaceTime features weekly interviews with leading Australian scientists about their research. The show began life in 1995 as ‘StarStuff’ on the Australian Broadcasting Corporation’s (ABC) NewsRadio network. Award winning investigative reporter Stuart Gary created the program during more than fifteen years as NewsRadio’s evening anchor and Science Editor. Gary’s always loved science. He studied astronomy at university and was invited to undertake a PHD in astrophysics, but instead focused on his career in journalism and radio broadcasting. Gary’s radio career stretches back some 34 years including 26 at the ABC. He worked as an announcer and music DJ in commercial radio, before becoming a journalist and eventually joining ABC News and Current Affairs. He was part of the team that set up ABC NewsRadio and became one of its first on air presenters. When asked to put his science background to use, Gary developed StarStuff which he wrote, produced and hosted, consistently achieving 9 per cent of the national Australian radio audience based on the ABC’s Nielsen ratings survey figures for the five major Australian metro markets: Sydney, Melbourne, Brisbane, Adelaide, and Perth. The StarStuff podcast was published on line by ABC Science -- achieving over 1.3 million downloads annually. However, after some 20 years, the show finally wrapped up in December 2015 following ABC funding cuts, and a redirection of available finances to increase sports and horse racing coverage. Rather than continue with the ABC, Gary resigned so that he could keep the show going independently. StarStuff was rebranded as “SpaceTime”, with the first episode being broadcast in February 2016. Over the years, SpaceTime has grown, more than doubling its former ABC audience numbers and expanding to include new segments such as the Science Report -- which provides a wrap of general science news, weekly skeptical science features, special reports looking at the latest computer and technology news, and Skywatch – which provides a monthly guide to the night skies. The show is published three times weekly (every Monday, Wednesday and Friday) and available from the United States National Science Foundation on Science Zone Radio, and through both i-heart Radio and Tune-In Radio.
SpaceTime covers the latest news in astronomy & space sciences.
The show is available every Monday, Wednesday and Friday through Apple Podcasts (itunes), Stitcher, Google Podcast, Pocketcasts, SoundCloud, Bitez.com, YouTube, your favourite podcast download provider, and from www.spacetimewithstuartgary.com
SpaceTime is also broadcast through the National Science Foundation on Science Zone Radio and on both i-heart Radio and Tune-In Radio.
SpaceTime daily news blog: http://spacetimewithstuartgary.tumblr.com/
SpaceTime facebook: www.facebook.com/spacetimewithstuartgary
SpaceTime Instagram @spacetimewithstuartgary
SpaceTime twitter feed @stuartgary
SpaceTime YouTube: @SpaceTimewithStuartGary
#science#space#astronomy#physics#news#nasa#astrophysics#esa#spacetimewithstuartgary#starstuff#spacetime#hubble telescope
11 notes
·
View notes
Text
Teknik Pengambilan Sampel Responden dalam Survei Kepuasan
Survei kepuasan pelanggan adalah alat penting dalam pengembangan strategi bisnis. Namun, untuk memperoleh hasil yang valid dan representatif, salah satu aspek terpenting yang perlu diperhatikan adalah teknik pengambilan sampel. Memilih responden yang tepat tidak hanya memengaruhi kualitas data, tetapi juga kredibilitas keputusan yang diambil berdasarkan survei tersebut. Di sinilah peran jasa sebar kuesioner terpercaya dan jasa survey kepuasan pelanggan sangat diperlukan.
Mengapa Teknik Pengambilan Sampel Sangat Penting?
Pengambilan sampel adalah proses memilih sejumlah individu dari populasi target untuk dijadikan responden dalam survei. Dalam konteks survei kepuasan pelanggan, populasi bisa berarti semua pelanggan yang pernah membeli atau menggunakan layanan dalam periode waktu tertentu. Jika sampel yang diambil tidak mewakili populasi, hasil survei akan menyesatkan.
Dengan menggunakan teknik pengambilan sampel yang tepat, Anda dapat:
Menghemat waktu dan biaya survei
Meningkatkan keakuratan hasil
Memastikan bahwa keputusan bisnis mencerminkan kebutuhan pelanggan yang sebenarnya
Karena alasan-alasan tersebut, banyak perusahaan kini memilih menggunakan jasa survey kepuasan pelanggan profesional untuk membantu dalam tahap ini.
Jenis-Jenis Teknik Pengambilan Sampel
Ada dua kategori utama dalam teknik pengambilan sampel: probabilitas dan non-probabilitas. Masing-masing memiliki kelebihan tergantung pada tujuan survei dan sumber daya yang tersedia.
1. Sampel Probabilitas
Dalam metode ini, setiap anggota populasi memiliki peluang yang sama untuk dipilih sebagai responden. Teknik ini ideal untuk menghasilkan data yang dapat digeneralisasi ke seluruh populasi.
Beberapa jenis teknik ini antara lain:
Simple Random Sampling: Responden dipilih secara acak dari seluruh populasi.
Stratified Sampling: Populasi dibagi menjadi beberapa subkelompok (misalnya berdasarkan usia, lokasi, atau jenis produk), lalu responden dipilih secara acak dari tiap subkelompok.
Cluster Sampling: Populasi dibagi menjadi klaster (misalnya cabang toko atau kota), kemudian beberapa klaster dipilih dan semua orang dalam klaster tersebut disurvei.
2. Sampel Non-Probabilitas
Metode ini tidak memberikan peluang yang sama bagi setiap individu dalam populasi untuk terpilih, tetapi tetap berguna untuk studi eksploratif atau saat keterbatasan sumber daya menjadi hambatan.
Contoh teknik ini:
Convenience Sampling: Mengambil responden dari kelompok yang mudah dijangkau, seperti pelanggan yang baru saja membeli produk.
Purposive Sampling: Memilih responden berdasarkan karakteristik tertentu yang relevan dengan tujuan survei.
Snowball Sampling: Responden awal diminta merekomendasikan orang lain untuk ikut serta dalam survei, cocok digunakan untuk pasar yang sempit atau sulit dijangkau.
Penyedia jasa sebar kuesioner terpercaya akan menyesuaikan teknik pengambilan sampel dengan kebutuhan dan tujuan bisnis Anda.
Peran Jasa Profesional dalam Pengambilan Sampel yang Efektif
Meskipun teknik-teknik di atas bisa dilakukan secara internal, kenyataannya banyak bisnis yang kurang memiliki keahlian dan alat untuk mengeksekusinya dengan akurat. Oleh karena itu, menggunakan jasa survey kepuasan pelanggan menjadi solusi yang efisien dan tepat sasaran.
Penyedia jasa yang berpengalaman akan:
Membantu mendefinisikan populasi target dengan akurat
Memilih teknik sampling terbaik sesuai anggaran dan tujuan
Menjamin distribusi kuesioner ke responden yang relevan
Menyediakan analisis data yang mendalam berdasarkan hasil responden terpilih
Kesimpulan
Pemilihan teknik pengambilan sampel responden yang tepat adalah fondasi dari survei kepuasan pelanggan yang sukses. Tanpa sampel yang representatif, hasil survei bisa menyesatkan dan merugikan bisnis. Oleh karena itu, penting untuk bekerja sama dengan jasa sebar kuesioner terpercaya yang memahami metodologi survei secara profesional.
0 notes
Text
Understanding Adolescent Health: Data Management Reflection
📌 1. Sample Description
The data I used for this analysis comes from the Add Health (The National Longitudinal Study of Adolescent to Adult Health) study, which surveyed a nationally representative sample of adolescents in grades 7–12 in the United States during the 1994–95 school year. The study population includes over 20,000 individual participants, capturing diverse backgrounds across schools, regions, and demographics.
The unit of analysis in this study is the individual adolescent, as each data record represents a unique person with their own characteristics.
For this assignment, I worked with a simplified subset of data from Wave I, focusing on variables relevant to my research question. My analytic sample includes approximately 2,500 adolescents who had complete and valid data on gender, age, and education level. This cleaned sample allowed for meaningful analysis while maintaining data quality and consistency.
2. Data Collection Procedures
The data used in this analysis comes from the Add Health study, a longitudinal, nationally representative survey of adolescents in the United States. The study design involved surveys and in-person interviews conducted over several waves. It combined self-reported questionnaires, interviewer-administered surveys, and parent reports, making it one of the most comprehensive health-related datasets for youth in the U.S.
The original purpose of the Add Health study was to understand how social environments and behaviors during adolescence affect health and social outcomes into adulthood. It was designed to explore the influence of family, school, peer groups, and neighborhoods on a wide range of outcomes, including education, mental health, substance use, and physical well-being.
Data were collected through several procedures:
Students completed in-school questionnaires during regular class hours.
A selected subsample participated in in-home interviews, which included sensitive questions using audio-computer-assisted self-interview (ACASI) techniques.
Parents or guardians also completed detailed questionnaires about household composition, health history, and socioeconomic background.
The initial wave of data (Wave I), which this analysis is based on, was collected in 1994–1995. This wave included over 90,000 students for the in-school survey and about 20,000 for the in-home interviews.
Data were collected across the United States, with schools sampled from urban, suburban, and rural regions in order to ensure national representation across geographic and demographic characteristics.
📋 2. Data Collection Procedures
Data for the Add Health study was collected using a multistage, stratified, school-based, cluster sampling design. Schools were selected to reflect the diversity of U.S. schools in terms of size, type (public/private), region, and urban/rural classification. Data collection occurred through:
In-school questionnaires filled out by students
In-home interviews conducted by trained interviewers
Parent questionnaires for additional background
The study gathered a wide range of data including social, behavioral, demographic, and health-related variables. All protocols followed ethical guidelines, and participants provided informed consent.
🧮 3. Measures and Data Management
My analysis focused on three main variables:
Gender: Originally coded numerically (1 = Male, 2 = Female), which I recoded to string labels (“Male” and “Female”) for clarity.
Age: Reported in years. I examined its distribution and created categories (e.g., 12–14, 15–17, 18+) to allow comparisons across adolescent stages.
Education Level: This variable included multiple detailed categories. I recoded them into broader levels such as "Middle School", "High School", and "Some College or More" to simplify the analysis.
Using Python and pandas, I performed the following data management steps:
Checked for and removed missing or invalid values
Recoded variables for interpretability
Generated frequency tables to examine distributions
Created a clean dataset for analysis
These steps allowed me to answer the following research question: "How do age and gender relate to educational attainment among adolescents?"
The organized dataset made it easier to identify trends and potential patterns related to demographic factors and education.
✅ Summary
This blog post outlines how I:
Identified and described my analytic sample
Summarized the Add Health study’s data collection methods
Cleaned and managed key variables to prepare for statistical analysis
Clear documentation of the data management process is critical for reproducibility and for helping others understand how raw survey data translates into meaningful insights.
0 notes