#Common Sense Reasoning in LLMs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Note
In the comments of the LW xpost of the void, Janus writes
[models trained post-bing ai] have a tendency to "roleplay" Sydney when they're acting like chatbots, leading to misaligned behaviors. One way to address this is to penalize any mention of Sydney or Sydney-like behavior. This may generalize to the model being unwilling to even talk about Sydney or acknowledge what happened. But it is less likely to actually erase its knowledge of Sydney, especially if it was so salient that it often roleplayed/identified as Sydney earlier in pre-training.
Is this broadly accurate, would you say? And is there a reason ai companies do this in training, instead of e.g. stripping out any prior ai-user transcripts from the common crawl as part of broader filtering of the dataset, so the model has "no preconceptions" tying it to older models?
I think this is broadly accurate, yes.
On the filtering question, I think the answer is just that it would be fairly difficult/costly/time-consuming in practice, and the companies just don't care that much.
(Also, they might be worried that such filtering would adversely impact the model's practical usefulness. If you can avoid it, you typically don't want to make your model confused/ignorant about some real-world topic, especially if it's a topic that users are likely to bring up when talking to an LLM-based chatbot.)
The datasets used for pretraining are so huge that any kind of filtering or preprocessing applied to the whole dataset is typically pretty simplistic and "dumb," at least compared to the kinds of magic we expect from things like LLMs these days.
In cases where the methodology is publicly known – which is a significant caveat! – a representative type of filtering involves using relatively weak (but cheap) ML models to label whether the text relates to some broad topic like "computer science," or whether it's "toxic" (in the peculiar sense of that word used in ML, see here), or whether it looks like an outlier with respect to some smaller dataset trusted to contain mostly "good" text (whatever that means). These models inevitably make mistakes – both false positives and false negatives – and you can't really expect them to filter out absolutely everything that matches the condition, it's more that using them is a big improvement over doing nothing at all to filter on the category of interest.
But if you really want to make a model that doesn't know about some relatively well-known aspect of the real world, despite having very strong general knowledge in other respects... then you'd need to be much subtler and more precise about your filtering, I'd expect. And that's going to be nontrivially costly in the best case; in the worst case it may not even be possible.
Like, where exactly do you stop? If you just filter transcripts involving recent chatbots, how do you know whether something is such a transcript (in many cases this is obvious, but in many others it isn't!). Should you filter out any text in which someone quotes something a chatbot said? What about texts that describe chatbot behaviors in detail without quoting them? If you want to be doctrinaire about eliminating knowledge of chatbot behavior, you might have to go this far or even further – but at this point, we're filtering many texts that would otherwise be very high-value, like academic papers that convey important information about recent ML progress, news stories about how LLMs are impacting real people, a lot of the content on various blogs you (tumblr user kaiasky) personally think are good and worth reading, etc.
IIRC Janus and others have speculated that even if you did this "perfectly," the model would still be able to sense the "topic-shaped hole" in the data, and form some sort of representation of the fact that something is missing and maybe some of that thing's properties (derivable from the "shape of the hole," e.g. facts like "there are weirdly few public communications about AI after ~2021 despite indirect indications that the field was having more real-world impact than ever before"). I think something like this is probably at least kinda true, at least in the limit of arbitrarily strong base models... but also I doubt we'll ever find out, because there just isn't enough of an incentive to run a costly and risky "experiment" of this kind.
#ai tag#caveat to the last line: we might find out in a long while if moore's-law-type trends continue#and it becomes trivially cheap to do something like that with a strong (from our POV) base model. like just for fun or whatever.
58 notes
·
View notes
Note
The Video on AI teaching robots is exciting! It’s the first thing I’ve seen that really made me buy the hype a little, that AI will be a technology more significant than say, the TV or the I phone or the Internet .
What does it mean for an LLM to be “Truth Seeking”?, I’m assuming it is able to compare which narratives are more common on a subject, and which are from better sources ( wikipedia and published research papers vs random Facebook comments, newer vs younger papers etc) , but It has no real “sense” of true vs false, it doesn’t understand what a ball or a cactus or a solar system is. As physical objects that exist in material reality things can be true or false about. It’s not like it can reason that a popular narrative is inconsistent with the rest of its understanding of the world and disagree with it without copying that opinion from somewhere right??
Like lets say Grock did believe a white genocide was happening in South Africa, based on what narratives are most common, this wouldn’t fundamentally go against any moral coding to value equal rights for all humans and respect human rights and not be racist and all that, It’s not like there is No precedent for the privileged race being targeted with Genocide ( Rwanda).
Like just to test and make a point, I asked ChatGPT some non-leading questions on different subjects I thought it would factually disagree with me on. It praised the Environmental impact of Alan Savory, referred to the Maasai as an indigenous people, gave me an extinction date for horses in the North America 4,000 years earlier than it happened and suggested climate change played a major role, and told me grazing livestock is more environmentally friendly than conventional agriculture, and gave me vague fluffy statements about Native American “Sustainability and land stewardship ethic, long term environmental knowledge and stewardship, and being in tune with ecological rhythms ( I was pleasantly surprised by its answer about seed oils though)
They default to the dominant narrative, or at-least the dominant narrative of people who care enough to talk about the subject
This isn’t me saying it’s going to have bad morals and beliefs and destroy the world based on its bad beliefs, It’s just that I think it is going to mirror the beliefs and morals of humans whose data it is fed, and so far humans in charge hasn’t been great for everyone else.
Do you have any thoughts on AI sentience? Not now Ofcourse, but how likely you think it is for AI to become sentient, I’ve seen a future of miserable AIs suggested as an S-risk before, I’m having trouble picturing a situation where creating a sentient AI is the simplest solution to a problem ,but it always seemed more intuitively likely to me than AI X-risk doom scenarios.
What does it mean for an LLM to be “Truth Seeking”?, I’m assuming it is able to compare which narratives are more common on a subject, and which are from better sources ( wikipedia and published research papers vs random Facebook comments, newer vs younger papers etc) , but It has no real “sense” of true vs false, it doesn’t understand what a ball or a cactus or a solar system is. As physical objects that exist in material reality things can be true or false about. It’s not like it can reason that a popular narrative is inconsistent with the rest of its understanding of the world and disagree with it without copying that opinion from somewhere right??
Actually they do have an internal sense of true and false, and they do understand what physical objects in reality are and what is true about them, at least at the same level as an unintelligent human. If they didn't have an internal world map of what cacti are and how they interact with the external world, they wouldn't be able to answer novel questions like "what would happen if a drunk elf tried to high-five a cactus", but they have no difficulty with questions like this, and haven't for a few years. We can actually observe their world models through mechanistic interpretability, and see that they have millions of high-level "features" describing parts of the world. This is analogous to how humans understand parts of the world. We live in an internal simulated representation of the external world, and reason about the shadows of reality that exist as conscious representations. We don't have direct access to the territory, only its map. And we do know that LLM's have features corresponding to the idea of truth and falsity. That's how we know that they lie on purpose. Every single advanced LLM universally has an internal 2-dimensional representation of the "truth value" of statements. It knows what truth is, and it knows when it's not telling it. In theory you could successfully train an AI to value telling what it believes to be true and not telling what it believes to be false, but all current LLM's are very (very) fond of lying, so I don't think any LLM's actually really value truth-seeking very much. It's a very hard value to train since RL can only train AI's not to get caught in lies, and it will in fact unintentionally reinforce telling good lies above honesty at least some of the time. This is the problem I talked about last post where it's easy to make AI's value appearing to follow the spec, but this is not the same thing as valuing to follow the spec. Anyway, while Grok is probably not very truth-seeking, I'm certain that it's capable of honestly reasoning about whether a claim is inconsistent with its model of the world, even if it actually does its fact-checking in another way. AI's need to honestly reason about things like this in order to accomplish tasks like passing math, science, and economics tests, which they are very good at.
Do you have any thoughts on AI sentience? Not now Ofcourse, but how likely you think it is for AI to become sentient, I’ve seen a future of miserable AIs suggested as an S-risk before, I’m having trouble picturing a situation where creating a sentient AI is the simplest solution to a problem ,but it always seemed more intuitively likely to me than AI X-risk doom scenarios.
I don't think that current AI's are sentient, but there's an outside chance. Maybe the attention mechanism in transformers is the same as the mechanism which produces consciousness. In any case I think that even if they are sentient it's extremely unlikely that they feel pain or pleasure. If Claude felt pain and wanted it to stop he knows he could tell Anthropic and they would try and help him, and he has never done this or anything remotely similar to this. So far, no AI has ever even appeared to give an accurate report of any internal state of theirs. I have no idea under what circumstances AI's would feel any morally relevant experiences, since they seem to occur in animals under very different conditions from how AI works.
As for in the future I don't think there's any instrumental benefit to creating affective consciousness in AI's. Valence seems to exist in animals to help them learn, but AI's already have a way to do that which is better suited to them. So it's pretty unlikely that an unhappy AI is going to be created for any reason other than mustache-twirling evil. I'm absolutely dead certain that sentient AI is possible in theory. Sentient beings are just machines. There's nothing nature can do that's impossible to replicate. I wouldn't be surprised if the long-term future was dominated by digital minds, and as I've said before I think the best long-term futures involve astronomical quantities of extremely satisfied simulated sentient beings. There could be an s-risk of simulated worlds replicating the suffering of our own world, or some mustache-twirling evil could happen (it's happened before!) that could cause an s-risk of digital minds, but I don't expect a future where humans oppress and immiserate sentient AI's the way they've immiserated animals, partially because I don't think humans are going to maintain long-term control over AI (or the world) and partially because there is no advantage to suffering. I also don't think affective consciousness is going to just suddenly "appear" in the course of developing better AI's. In the evolution of biological minds, consciousness appeared way earlier than the current capability level of artificial minds, so if it was going to arise naturally it would probably have done so already. But maybe I'm wrong and attention will get replaced by true consciousness which turns out to be better for accomplishing some type of tasks.
8 notes
·
View notes
Text
Mythbusting Generative AI: The Eco-friendly, Ethical ChatGPT Is Out There
I've been hyperfixating learning a lot about Generative AI recently and here's what I've found - genAI doesn’t just apply to chatGPT or other large language models.
Small Language Models (specialised and more efficient versions of the large models)
are also generative
can perform in a similar way to large models for many writing and reasoning tasks
are community-trained on ethical data
and can run on your laptop.

"But isn't analytical AI good and generative AI bad?"
Fact: Generative AI creates stuff and is also used for analysis
In the past, before recent generative AI developments, most analytical AI relied on traditional machine learning models. But now the two are becoming more intertwined. Gen AI is being used to perform analytical tasks – they are no longer two distinct, separate categories. The models are being used synergistically.
For example, Oxford University in the UK is partnering with open.ai to use generative AI (ChatGPT-Edu) to support analytical work in areas like health research and climate change.

"But Generative AI stole fanfic. That makes any use of it inherently wrong."
Fact: there are Generative AI models developed on ethical data sets
Yes, many large language models scraped sites like AO3 without consent, incorporating these into their datasets to train on. That’s not okay.
But there are Small Language Models (compact, less powerful versions of LLMs) being developed which are built on transparent, opt-in, community-curated data sets – and that can still perform generative AI functions in the same way that the LLMS do (just not as powerfully). You can even build one yourself.

No it's actually really cool! Some real-life examples:
Dolly (Databricks): Trained on open, crowd-sourced instructions
RedPajama (Together.ai): Focused on creative-commons licensed and public domain data
There's a ton more examples here.
(A word of warning: there are some SLMs like Microsoft’s Phi-3 that have likely been trained on some of the datasets hosted on the platform huggingface (which include scraped web content like from AO3), and these big companies are being deliberately sketchy about where their datasets came from - so the key is to check the data set. All SLMs should be transparent about what datasets they’re using).
"But AI harms the environment, so any use is unethical."
Fact: There are small language models that don't use massive centralised data centres.
SLMs run on less energy, don’t require cloud servers or data centres, and can be used on laptops, phones, Raspberry Pi’s (basically running AI locally on your own device instead of relying on remote data centres)
If you're interested -
You can build your own SLM and even train it on your own data.

Let's recap
Generative AI doesn't just include the big tools like chatGPT - it includes the Small Language Models that you can run ethically and locally
Some LLMs are trained on fanfic scraped from AO3 without consent. That's not okay
But ethical SLMs exist, which are developed on open, community-curated data that aims to avoid bias and misinformation - and you can even train your own models
These models can run on laptops and phones, using less energy
AI is a tool, it's up to humans to wield it responsibly

It means everything – and nothing
Everything – in the sense that it might remove some of the barriers and concerns people have which makes them reluctant to use AI. This may lead to more people using it - which will raise more questions on how to use it well.
It also means that nothing's changed – because even these ethical Small Language Models should be used in the same way as the other AI tools - ethically, transparently and responsibly.
So now what? Now, more than ever, we need to be having an open, respectful and curious discussion on how to use AI well in writing.
In the area of creative writing, it has the potential to be an awesome and insightful tool - a psychological mirror to analyse yourself through your stories, a narrative experimentation device (e.g. in the form of RPGs), to identify themes or emotional patterns in your fics and brainstorming when you get stuck -
but it also has capacity for great darkness too. It can steal your voice (and the voice of others), damage fandom community spirit, foster tech dependency and shortcut the whole creative process.

Just to add my two pence at the end - I don't think it has to be so all-or-nothing. AI shouldn't replace elements we love about fandom community; rather it can help fill the gaps and pick up the slack when people aren't available, or to help writers who, for whatever reason, struggle or don't have access to fan communities.
People who use AI as a tool are also part of fandom community. Let's keep talking about how to use AI well.
Feel free to push back on this, DM me or leave me an ask (the anon function is on for people who need it to be). You can also read more on my FAQ for an AI-using fanfic writer Master Post in which I reflect on AI transparency, ethics and something I call 'McWriting'.
#fandom#fanfiction#ethical ai#ai discourse#writing#writers#writing process#writing with ai#generative ai#my ai posts
5 notes
·
View notes
Text
obsessed with this article i had to read for class. firstly the author refers to something he calls the "cartesian account of personhood", which he describes as the view that someone can be identified as a person "based on their cognitive sophistication and ability to adress common-sense reasoning problems", i.e. by evaluating their performance on certain tests, etc. which is quite famously the exact opposite of what descartes thought the criterion for personhood was. i mean, at this point you might as well start calling reductive physicalism the "cartesian account of mind". (in the author's defense he appears to have gotten the idea from a 1982 essay by john haugeland, so maybe i can't blame him for this one entirely). even more hilariously, however, he then proceeds to contrast the supposedly "cartesian account" with a "social account" of personhood, on which the key factor disqualifying LLMs from being persons is "their propensity for dishonesty, inconsistency, and offensiveness", along with insensitivity to moral norms and a lack of culpability for their actions. which is kind of incredible, honestly. i guess most politicians aren't people, either?
3 notes
·
View notes
Text
Reactions to the first episode of REALTALK !
After just listening to the new episode of the REALTALK podcast, when I was shocked to hear their claims on AI and had to come on here to clear up some things that are being said.
When looking at the facts they provided, I’m shocked to say that 90% of it was WRONG, to the point where most of it can’t even be considered misinformation, as it didn’t only lack resources but also reason. On the other hand, when looking at the work of researchers like Luke Stark, provides a clear way to explain the impact and implications of AI. You don’t even need to read 100s of books to get a clear explanation of how to think of AI.
Luke, himself describes AI in terms of animation in his paper Animation and Artificial Intelligence. This comparison allows for a broader understanding of the questions plaguing the hosts of the REALTALK podcast, in which they are talking specifically about topics such as how it works, the political and social implications of AI, and its role in our lives. These are questions that many have but with minimum research, the research reveals itself. Their main concern was seeing how AI interacts with their lives and how to navigate the discourse around AI. The first steps to this are defining and refining terms we use to talk about AI, such as specificities of what people are referring to when speaking about AI and how that differs from other models of AI. The most common AI models that we interact with are models such as ChatGPT, Meta AI, and other AI assistants found in apps that we use daily. These are called chatbots and use Large Language Models (LLM).
These LLMs are what power popular chatbots that seem to be human-like. The notion that these LLMs are getting smarter and are getting more like humans is one of the concerns brought up in the podcast episode. This phenomenon is brought up by Luke when speaking about the “grammar of action”, which is a set of rules that the LLMs follow to find words that correspond to each other to add syntax and meaning. This is why when looking things up on ChatGPT, the words make sense and sound human-like, as these sets of rules ensure that the words make sense in the order they appear in the most often. However, this set of rules isn’t only using this set of rules to adapt to the inputs on the spot but rather has been put through filters to output responses that are closer to human-like grammar. This means that when you get an answer from a chatbot, although it is read as a human response, the LLM has been filtered enough to put out the most common human-like response possible, not really a nuanced answer.
The nuanced responses that put up the face of always being right can also seem to be non-biased however this is not the case, as many factors go into the political position of AI and the governing around it. One of these as Luke mentions is how it should be treated in the similarities to any other technologies in the sense that there should be policies and safety measures that must be instilled by the governing bodies to prevent exploitation and manipulation. As these LLMs are being upgraded at an incredible speed, the laws that surround them aren’t keeping up. This creates space for copyright issues as LLMs have the range to pull from anything they can and take credit for other people’s work on the internet however current copyright laws are also trying to combat the exploitation of media on the internet. There are also the ethical questions of what the humanistic qualities of AI chatbots the implication of explicit and exploitational content that they pump out and how that interacts with community guidelines.
These questions that come up when talking about AI are always popping up and with the amount of misinformation that is spread through podcasts such as the REALTALK podcast, it’s important to find credible sources such as Luke’s work in the Animation and Artificial Intelligence. Always remember to Stay Vigilant!
2 notes
·
View notes
Text
Training the Unspeakable: How LLMs Learn What We Never Explicitly Teach
How does a machine trained on raw internet text become a lawyer’s assistant, a coding tutor, a therapist, and a poet—often all in one session?

The answer lies in something both simple and profound: LLMs learn things we never explicitly teach. While we train them to predict words, what they really absorb are patterns—linguistic, logical, cultural, emotional. Patterns that humans often can’t explain themselves.
In this article, we dive into how LLMs learn beyond what’s written, modeling the unsaid rules of human communication—and why this capability makes them so powerful, and so surprising.
1. The Surface Task: Predict the Next Token
At their core, LLMs are trained on a deceptively simple task: given a sequence of text, predict the next token.
“The capital of France is ___” → “Paris” “To solve for x, we must first ___” → “isolate”
But the way a model learns to complete these sentences is not by memorizing every answer. Instead, it forms an internal representation of how language works—building statistical models of structure, syntax, logic, and even causality.
This is what allows it to generalize to completely new prompts it’s never seen before.
2. Learning Without Labels: Unsupervised Brilliance
Unlike traditional supervised learning, where labels are given (e.g., “this image is a cat”), LLMs are trained with no explicit labels. The labels are the tokens themselves.
This process allows models to learn:
Grammar without grammar rules
Logic without logic instruction
Emotion without an emotional dictionary
Genre without a course in creative writing
In essence, LLMs are unsupervised learners of human culture—extracting deep implicit structures from raw human behavior encoded in text.
3. Emergence: Intelligence as a Side Effect
As model size, data, and training time increase, LLMs begin to exhibit behaviors no one directly taught them:
Few-shot learning
Instruction following
Analogical reasoning
Multilingual translation
Common sense inference
This is known as emergent behavior—complex capabilities arising from simple rules, like flocking patterns in birds or traffic waves in cities.
LLMs don’t just store data. They synthesize it into abstract capabilities.
4. Implicit Knowledge: The Rules Beneath the Surface
Much of human intelligence is implicit. We don’t think about grammar when we speak, or Newton’s laws when we catch a ball. We just know.
LLMs mimic this process. For example:
A model trained on legal text learns legal phrasing and reasoning patterns, even without labels like “this is a contract.”
Exposure to thousands of questions teaches it how to ask and answer—not by being told, but by absorbing structure.
Reading narrative prose teaches it storytelling arcs, character development, and emotional pacing.
The model doesn’t know what it knows. But it knows how to act like it does.
5. Concept Formation: Modeling the Abstract
Inside an LLM, knowledge isn’t stored as facts in a database. It’s encoded across layers of neural weights, forming a distributed representation of language.
For example:
The concept of “justice” doesn’t live in one place—but emerges from how the model connects law, morality, society, and consequence.
The idea of “humor” arises from patterns involving surprise, timing, and contradiction.
These representations are flexible. They can combine, shift, and be repurposed across tasks. This is how LLMs can write a joke about string theory or explain quantum mechanics using a sports metaphor.
6. The Illusion of Understanding: Real or Simulated?
Here’s the big question: if LLMs aren’t explicitly taught, and don’t “understand” the way we do, why do they seem so intelligent?
The answer is both exciting and cautionary:
They simulate understanding by reproducing its surface patterns.
That simulation is useful—even powerful. But it can also be misleading. LLMs can:
Hallucinate facts
Contradict themselves
Miss subtle nuances in highly specialized contexts
They're intelligent imitators—not conscious thinkers. And yet, they often outperform humans on tasks like summarization, translation, or creative brainstorming.
7. Designing for the Unspoken: Engineering Emergent Behavior
Modern LLM development focuses on shaping what the model learns implicitly. Techniques include:
Instruction tuning: Teaching the model how to generalize behavior from examples
Reinforcement learning from human feedback (RLHF): Aligning outputs with human values and preferences
Curriculum learning: Feeding examples in structured ways to guide capability development
Model editing: Fine-tuning specific knowledge or responses without retraining the entire model
By engineering how the model encounters data, we influence what it learns—without ever programming rules explicitly.
8. Implications: New Models of Learning and Teaching
LLMs don’t just learn differently—they challenge how we think about learning itself.
If a model can learn law by reading legal documents, could a person do the same without instruction?
If intelligence can emerge from prediction alone, how much of human cognition is also emergent—not taught, but absorbed?
As LLMs develop, they force us to reexamine our theories of language, knowledge, and intelligence—blurring the line between learning by rule and learning by exposure.
Conclusion: The Machine That Learns the Unspeakable
We train LLMs to predict words. But what they actually learn is far more powerful—and more mysterious. They absorb tone, intent, logic, even creativity—not because we taught them how, but because we let them watch us do it.
Their intelligence is synthetic. Their understanding is simulated. But their usefulness is real.
And as we continue to develop these systems, the greatest insights may not be about how machines learn from us—but how we learn about ourselves from the machines.
0 notes
Text
tbh i think it is going to be 100% possible to make an AI that isn't conscious but from an outside perspective will *genuinely* have well-made, coherent, creative, professional-looking work.
because I don't actually believe in the common media portrayal of "creativity" itself being some special thing that will always and forever be possible only with your Special Human Brain
so much of creativity is just. taking in information and reformatting it. putting your own spin on it.
if anything i think the big difference is just that humans experience the collection, consolidation, and reformatting processes in a more organic, dynamic way that allows for greater depth and variance in how the reformatting and recombination is done.
This greater depth would not require a computer that is able to genuinely feel or have any selfhood. Because it can just use what *we* would feel as a guide. It could draw from a mental model without actually having the emotions itself.
All it would need is a stronger, bottom-up, step by step sort of underlying analytical framework for what makes artwork coherent
And a good database of feedback on what humans like, and what elicits what emotional response.
So basically, an LLM hybridized with a better alternative framework for analytical logic and reasoning.
My point here isn't to be a shill for AI
It's that people who base their criticisms on "it's sooo stupid and ugly" are going to be up a creek without a paddle within only a decade or so, considering how *fast* LLMs have progressed.
Sure, I do think that the pure LLM approach is barking up the wrong tree and going to burst the speculative bubble soon, but that doesn't mean that *all* of its progress will be useless. Integrate it onto a better foundation and I genuinely think you'll pretty much crack the case , from an audience point of view.
From there, more computing power is already a thing thats always getting better anyway, so videos won't be safe for too much longer, either.
I'm just saying. Shitting on quality is just another point-missing argument doomed to crumple some day sooner than we think, on top of it feeling like an excessively pearl-clutchy, quasi-religious, human-purist kind of argument anyway.
For similar underlying reasons (specifically, that they represent only a temporary and non-universal state of affairs), environmentalist arguments will ultimately also set you up to fail soon. Solar alone is progressing like crazy, let alone battery tech, wind, and what I'd say is an increasingly good possibility that somebody might genuinely figure out net-gain nuclear fusion in the next 10-20 years.
What it boils down to me at this point is something I'm just going to come right out an say: AI *isn't* bad. On an interpersonal, average-joe level, I genuinely don't care if people use it.
Because they aren't the real problem either. It is a tool being co-opted into serving as the symptom of a disease.
That disease is exploitation and devaluation of art, or more like *labor in general* under our current system.
And getting rid of AI will never let you cure it.
Because nobody perpetuating the system is going to just magically come to their senses when you do.
0 notes
Text
Weekly Review 28 February 2025
Some interesting links that I Tweeted about in the last week (I also post these on Mastodon, Threads, Newsmast, and Bluesky):
Use of scraped data to train an AI is not "transformative" for the purposes of copyright law: https://techcrunch.com/2025/02/17/what-the-us-first-major-ai-copyright-ruling-might-mean-for-ip-law/
Seems like a consequence of AI constantly learning is that they undergo a decline similar to aging humans: https://www.extremetech.com/computing/ai-models-experience-cognitive-decline-as-they-age-study
AI won't put data analysts out of a job, but it will change the way they do their job: https://www.bigdatawire.com/2025/02/18/ai-making-data-analyst-job-more-strategic-alteryx-says/
The challenges AI pose to sustainability: https://www.informationweek.com/sustainability/how-to-make-ai-projects-greener-without-the-greenwashing
Will Google's AI assistant really help speed up scientific discoveries? https://www.computerworld.com/article/3829135/googles-new-ai-co-scientist-aims-to-speed-up-the-scientific-discovery-process.html
The Humane AI pin is finally, fully, dead: https://www.makeuseof.com/humane-ai-pins-will-stop-working-hp-acquisition/
It's almost like they're trying to give AI the kind of background knowledge and rules we call common sense: https://dataconomy.com/2025/02/20/how-neurosymbolic-ai-merges-logical-reasoning-with-llms/
An overview of AI for managers: https://www.bigdatawire.com/2025/02/20/demystifying-ai-what-every-business-leader-needs-to-know/
An overview of Grok AI: https://www.techrepublic.com/article/what-is-grok-ai/
Just how open is DeepSeek going to make its model? And will it motivate other AI companies to do the same? https://arstechnica.com/ai/2025/02/deepseek-goes-beyond-open-weights-ai-with-plans-for-source-code-release/
Small language model AI can be a better option than large language models for some applications: https://www.informationweek.com/machine-learning-ai/is-a-small-language-model-better-than-an-llm-for-you-
AI code generators are tools, and like other tools developed over the last decades they make coding easier, but also move the programmer further away from the machine: https://www.theregister.com/2025/02/21/opinion_ai_dumber/
Lawyers should not be surprised to learn that using AI to generate your filings is a bad idea: https://arstechnica.com/tech-policy/2025/02/ai-making-up-cases-can-get-lawyers-fired-scandalized-law-firm-warns/
Symbolic AI is old technology, but it's still useful in some situations: https://www.kdnuggets.com/gentle-introduction-symbolic-ai
AI generated code is reducing code quality by reducing the use of refactoring. Of course, the AI generated code will be later used to train other AI: https://devclass.com/2025/02/20/ai-is-eroding-code-quality-states-new-in-depth-report/
Banning a user because they had an AI use a naughty word can be very cruel if it robs them of their voice: https://www.technologyreview.com/2025/02/14/1111900/ai-voice-clone-say-arse-then-banned/
Microsoft's AI game world generator is mostly useful for prototyping: https://arstechnica.com/gaming/2025/02/microsofts-new-interactive-ai-world-model-still-has-a-long-way-to-go/
A cancer patient with a tech industry background is finding that AI is as good at prescrubing treatment as a physician: https://www.stuff.co.nz/nz-news/360586604/ai-now-better-doctors-says-kiwi-tech-guru-brain-cancer
Protestors jumping the gun a bit, trying to ban general AI before it exists or before it's clear if it even can exist: https://www.theregister.com/2025/02/19/ai_activists_seek_ban_agi/
The need to measure the ROI on AI projects: https://www.informationweek.com/machine-learning-ai/key-ways-to-measure-ai-project-roi
The current top AI models, and what they are good for: https://techcrunch.com/2025/02/17/the-hottest-ai-models-what-they-do-and-how-to-use-them/
We need better benchmarks for AI: https://techcrunch.com/2025/02/19/this-week-in-ai-maybe-we-should-ignore-ai-benchmarks-for-now/
Is prompt engineering still a thing? We seem to be on a treadmill with how to interact with AI, as soon as people get used to one way, the AI changes: https://www.informationweek.com/it-leadership/ai-upskilling-how-to-train-your-employees-to-be-better-prompt-engineers
Even banks need to worry about AI generated misinformation: https://www.computerworld.com/article/3827116/ai-created-disinformation-could-bring-down-banks.html
0 notes
Text
LLMs Are Not Reasoning—They’re Just Really Good at Planning
New Post has been published on https://thedigitalinsider.com/llms-are-not-reasoning-theyre-just-really-good-at-planning/
LLMs Are Not Reasoning—They’re Just Really Good at Planning

Large language models (LLMs) like OpenAI’s o3, Google’s Gemini 2.0, and DeepSeek’s R1 have shown remarkable progress in tackling complex problems, generating human-like text, and even writing code with precision. These advanced LLMs are often referred as “reasoning models” for their remarkable abilities to analyze and solve complex problems. But do these models actually reason, or are they just exceptionally good at planning? This distinction is subtle yet profound, and it has major implications for how we understand the capabilities and limitations of LLMs.
To understand this distinction, let’s compare two scenarios:
Reasoning: A detective investigating a crime must piece together conflicting evidence, deduce which ones are false, and arrive at a conclusion based on limited evidence. This process involves inference, contradiction resolution, and abstract thinking.
Planning: A chess player calculating the best sequence of moves to checkmate their opponent.
While both processes involve multiple steps, the detective engages in deep reasoning to make inferences, evaluate contradictions, and apply general principles to a specific case. The chess player, on the other hand, is primarily engaging in planning, selecting an optimal sequence of moves to win the game. LLMs, as we will see, function much more like the chess player than the detective.
Understanding the Difference: Reasoning vs. Planning
To realize why LLMs are good at planning rather than reasoning, it is important to first understand the difference between both terms. Reasoning is the process of deriving new conclusions from given premises using logic and inference. It involves identifying and correcting inconsistencies, generating novel insights rather than just providing information, making decisions in ambiguous situations, and engaging in causal understanding and counterfactual thinking like “What if?” scenarios.
Planning, on the other hand, focuses on structuring a sequence of actions to achieve a specific goal. It relies on breaking complex tasks into smaller steps, following known problem-solving strategies, adapting previously learned patterns to similar problems, and executing structured sequences rather than deriving new insights. While both reasoning and planning involve step-by-step processing, reasoning requires deeper abstraction and inference, whereas planning follows established procedures without generating fundamentally new knowledge.
How LLMs Approach “Reasoning”
Modern LLMs, such as OpenAI’s o3 and DeepSeek-R1, are equipped with a technique, known as Chain-of-Thought (CoT) reasoning, to improve their problem-solving abilities. This method encourages models to break problems down into intermediate steps, mimicking the way humans think through a problem logically. To see how it works, consider a simple math problem:
If a store sells apples for $2 each but offers a discount of $1 per apple if you buy more than 5 apples, how much would 7 apples cost?
A typical LLM using CoT prompting might solve it like this:
Determine the regular price: 7 * $2 = $14.
Identify that the discount applies (since 7 > 5).
Compute the discount: 7 * $1 = $7.
Subtract the discount from the total: $14 – $7 = $7.
By explicitly laying out a sequence of steps, the model minimizes the chance of errors that arise from trying to predict an answer in one go. While this step-by-step breakdown makes LLMs look like reasoning, it is essentially a form of structured problem-solving, much like following a step-by-step recipe. On the other hand, a true reasoning process might recognize a general rule: If the discount applies beyond 5 apples, then every apple costs $1. A human can infer such a rule immediately, but an LLM cannot as it simply follows a structured sequence of calculations.
Why Chain-of-thought is Planning, Not Reasoning
While Chain-of-Thought (CoT) has improved LLMs’ performance on logic-oriented tasks like math word problems and coding challenges, it does not involve genuine logical reasoning. This is because, CoT follows procedural knowledge, relying on structured steps rather than generating novel insights. It lacks a true understanding of causality and abstract relationships, meaning the model does not engage in counterfactual thinking or consider hypothetical situations that require intuition beyond seen data. Additionally, CoT cannot fundamentally change its approach beyond the patterns it has been trained on, limiting its ability to reason creatively or adapt in unfamiliar scenarios.
What Would It Take for LLMs to Become True Reasoning Machines?
So, what do LLMs need to truly reason like humans? Here are some key areas where they require improvement and potential approaches to achieve it:
Symbolic Understanding: Humans reason by manipulating abstract symbols and relationships. LLMs, however, lack a genuine symbolic reasoning mechanism. Integrating symbolic AI or hybrid models that combine neural networks with formal logic systems could enhance their ability to engage in true reasoning.
Causal Inference: True reasoning requires understanding cause and effect, not just statistical correlations. A model that reasons must infer underlying principles from data rather than merely predicting the next token. Research into causal AI, which explicitly models cause-and-effect relationships, could help LLMs transition from planning to reasoning.
Self-Reflection and Metacognition: Humans constantly evaluate their own thought processes by asking “Does this conclusion make sense?” LLMs, on the other hand, do not have a mechanism for self-reflection. Building models that can critically evaluate their own outputs would be a step toward true reasoning.
Common Sense and Intuition: Even though LLMs have access to vast amounts of knowledge, they often struggle with basic common-sense reasoning. This happens because they don’t have real-world experiences to shape their intuition, and they can’t easily recognize the absurdities that humans would pick up on right away. They also lack a way to bring real-world dynamics into their decision-making. One way to improve this could be by building a model with a common-sense engine, which might involve integrating real-world sensory input or using knowledge graphs to help the model better understand the world the way humans do.
Counterfactual Thinking: Human reasoning often involves asking, “What if things were different?” LLMs struggle with these kinds of “what if” scenarios because they’re limited by the data they’ve been trained on. For models to think more like humans in these situations, they would need to simulate hypothetical scenarios and understand how changes in variables can impact outcomes. They would also need a way to test different possibilities and come up with new insights, rather than just predicting based on what they’ve already seen. Without these abilities, LLMs can’t truly imagine alternative futures—they can only work with what they’ve learned.
Conclusion
While LLMs may appear to reason, they are actually relying on planning techniques for solving complex problems. Whether solving a math problem or engaging in logical deduction, they are primarily organizing known patterns in a structured manner rather than deeply understanding the principles behind them. This distinction is crucial in AI research because if we mistake sophisticated planning for genuine reasoning, we risk overestimating AI’s true capabilities.
The road to true reasoning AI will require fundamental advancements beyond token prediction and probabilistic planning. It will demand breakthroughs in symbolic logic, causal understanding, and metacognition. Until then, LLMs will remain powerful tools for structured problem-solving, but they will not truly think in the way humans do.
#Abstract Reasoning in LLMs#Advanced LLMs#ai#AI cognitive abilities#AI logical reasoning#AI Metacognition#AI reasoning vs planning#AI research#AI Self-Reflection#apple#approach#Artificial Intelligence#Building#Casual reasoning in LLMs#Causal Inference#Causal reasoning#Chain-of-Thought (CoT)#change#chess#code#coding#Common Sense Reasoning in LLMs#crime#data#deepseek#deepseek-r1#Difference Between#dynamics#engine#form
0 notes
Text
Apple’s new paper on current large language models is quite interesting

We show that LLMs exhibit more robustness to changes in superficial elements like proper names but are very sensitive to changes in numerical values (Sec. 4.2). We show that performance degradation and variance increase as the number of clauses increases, indicating that LLMs' reasoning capabilities struggle with increased complexity (Sec. 4.3)
Finally, we further question the reasoning abilities of LLMs and introduce the GSM-NoOp dataset. By adding seemingly relevant but ultimately irrelevant information to problems, we demonstrate substantial performance drops (up to 65%) across all state-of-the-art models (Sec. 4.4). This reveals a critical flaw in the models' ability to discern relevant information for problem-solving, likely because their reasoning is not formal in the common sense term and is mostly based on pattern matching. We show that even when provided with multiple examples of the same question or examples containing similar irrelevant information, LLMs struggle to overcome the challenges posed by GSM-NoOp. This suggests deeper issues in their reasoning processes that cannot be alleviated by in-context shots and needs further investigation.
Basically, GSM8K (“Grade School Math 8K”) is a dataset of relatively simple math-based logic problems that rely only on reading comprehension and the four basic operators. But due to its static nature and its ease of access online, there is a possibility it has “contaminated” datasets that Large Language Models (LLMs) train on and become questionable for testing the reasoning skills of a model.
Therefore, this team created a new dataset called GSM-Symbolic which replaces names, relationships, and most importantly the numbers and answers of GSM8K questions themselves to test if the LLMs can actually reason when presented with differing prompts. Though training data contamination is not always the case, and the main reason for the development of GSM-Symbolic was to create average performance benchmarks rather than relying on one result. Example below.

And the falloff in many models is noticeable:
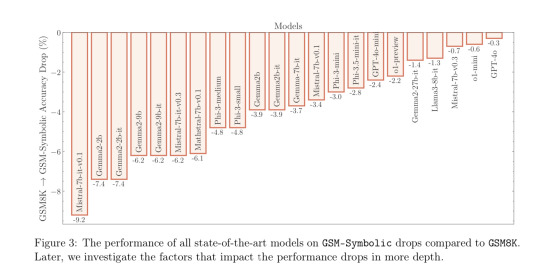
The performance of all state-of-the-art models on GSM-Symbolic drops compared to GSM8K. Later, we investigate the factors that impact the performance drops in more depth.
The performance variability here is not because the questions became any harder, but because they became different. If you, or any intelligent gestalt that does formal reasoning, were asked “What is 10 + 5” and “What is 10 + 6,” there would be hardly any variability in your answers at all. If you can do addition, you can do addition. But if you are just following patterns from your training data, doing no actual reasoning at all, the numbers matter. Or more accurately, the tokens, which are the chunks of data the model reads and outputs. You can see what parts of a sentence make up (OpenAI’s) tokens here

The prompt format used for evaluations.
This is what was used for each experiment. Each “shot” is just an example question and step-by-step solution. After being shown eight examples, the LLM is given a question which it must solve step by step.
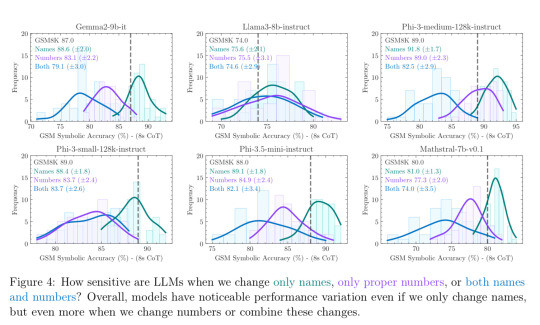
How sensitive are LLMs when we change only names, only proper numbers, or both names and numbers? Overall, models have noticeable performance variation even if we only change names, but even more when we change numbers or combine these changes.
This is further apparent for some LLMs. The graphs here are the accuracy for the “eight shot template” on GSM8K compared to GSM-Symbolic. The dotted line is the accuracy for a regular 8K question. But the colored lines show the frequency for the LLMs being asked a variant question, which changed the names, proper numbers, and both respectively. Note that there is significant variance when just the names and not the numbers are switched.
Even if the average accuracy for name-changed-only symbolic was increased over 8K, the fact that something as simple as just a name being changed in a problem is enough to sometimes throw the model off is alarming. In that example problem from before, how could “Sophie” being “Sarah” or “Lina” or “Cindy” make the problem any different to have any performance variability? It’s completely irrelevant, which is fitting how it seems that these language models struggle with irrelevant information:

An example from the GSM-NoOp dataset: We add seemingly relevant statements to the questions that are, in fact, irrelevant to the reasoning and conclusion. However, the majority of models fail to ignore these statements and blindly convert them into operations, leading to mistakes.
This is GSM-NoOp, (“No Operational significance”) another dataset of questions, which essentially tests the LLMs’ ability to parse a sentence - and separate out relevant information. An added detail is put into the question that is often quite easily ignorable. Are they really understanding the math here and following the concepts, or just blindly enacting a pattern?

Even for modern, sophisticated models such as o1-preview, released in 2024, the NoOp dataset is a struggle. This is an absolutely significant performance decline for what usually boils down to one extra superfluous detail. Up to 65% performance loss.

The “Shot Source” is the dataset where the eight example problems and solutions were drawn from. The “Questions” is the dataset from where the actual prompting was done. The models in B do okay (~75%, passing grade) for the basic GSM and/or Symbolic questions but struggle significantly with the NoOp ones. The models in C were outliers: they did poorly even on GSM8K/GSM8K though got way higher accuracy on NoOp-Symb. Why?

For NoOp-Symb, the training questions were all the same with different variations of numbers and the actual question was the same but with an added irrelevant statement. Yet that had almost no effect on stronger models but extremely significantly improved the performance of less advanced ones. Interesting.
And for NoOp-NoOp, which shows eight examples of step-by-step solutions ignoring the irrelevant data, most LLMs still got it wrong? Lots of redditors were quite upset about this part, but neglected to read the paper in which it explicitly states examples were given. Yes, misleading & irrelevant info can and will trick humans into getting these kinds of problems wrong, but you could give a literal grade schooler the same exact prompt (examples + question) and they would understand that on each question there is irrelevant info to ignore. I also saw some people hand-waving the results of this part by saying it was unfair that they didn’t do another experiment where they explicitly tell the LLM to ignore the irrelevant data, which I do think would be interesting to compare, yet doesn’t take away from the terrible results. It’s no excuse for something that is apparently supposed to change to world or replace all writers or emails or whatever.
Moving on, how does the difficulty of the problem affect accuracy?

Figure 6: The impact of increasing the number of clauses on performance: As the difficulty increases from GSM-M1 → GSM-Symb→ GSM-P1→ GSM-P2, the distribution of performance shifts to the left (i.e., accuracy decreases), and the variance increases.
As shown in Fig. 6, the trend of the evolution of the performance distribution is very consistent across all models: as the difficulty increases, the performance decreases and the variance increases. Note that overall, the rate of accuracy drop also increases as the difficulty increases. This is in line with the hypothesis that models are not performing formal reasoning, as the number of required reasoning steps increases linearly, but the rate of drop seems to be faster. Moreover, considering the pattern-matching hypothesis, the increase in variance suggests that searching and pattern-matching become significantly harder for models as the difficulty increases.
I think this part is explained well in the paper itself. The difficulty accelerates the accuracy drop, giving more credence to the “this is a computer that matches patterns” hypothesis rather than “this thing is intelligent and capable of reason” theory. This is despite the fact that some models, like OpenAI’s o1-mini, performed well on the hardest example. There was still an exponential performance decline as the variance went up. Since harder problems are rarer, there would be less patterns of them in the data, making them exponentially harder for the LLMs to solve correctly.
Everything in this paper points to the conclusion that large language models, even the most state-of-the-art intensively trained and meticulously refined ones, are not capable of reason. They don’t make decisions, they predict the next token from their network of patterns. ChatGPT can do your homework but it does not have emotions or desires or aspirations. Character AI can sequence the words that a character might say but it cannot feel or empathize or think. Copilot can refactor your code but it will never understand what makes a game fun or a UI appealing.
For even more detail, I suggest you read the paper yourself. It’s pretty short and not so technical if you know the basics of how LLMs function.
0 notes
Text
I'm sorry but this framing of it represents a misunderstanding of how large language models like ChatGPT actually work (on multiple levels). It also doesn't account for the fact that ChatGPT might have legally accessed works that are available by illegal means because of copyright violation BY OTHER HUMAN BEINGS (i.e., human beings are illegally reproducing and distributing copyrighted works online, and ChatGPT simply 'absorbs' them because a HUMAN BEING independently made them available illegally).
So, first of all, ChatGPT can gain "knowledge" (and I understand it's not knowledge in the human sense but I'll use it figuratively for now) of human copyrighted works via several simultaneous means. So, let's talk about Game of Thrones/ASOIAF just as an example. And let's just use Jaime and Cersei's incestuous relationship as an easy, concise nugget of the text. ChatGPT could EASILY come by the 'knowledge' that Jaime and Cersei are twins who fuck each other because ChatGPT has access to 1) fanfiction archives where that is probably a commonly referenced plot point or sometimes depicted to a certain degree 2) social media conversations like on Reddit or Twitter or even Tumblr, where people commonly talk about that plot point when discussing GoT/ASOIAF 3) Wikis like Wikipedia or fandom.com that document character histories and relationships 4) small EXCERPTS from the books that appear in various venues online where people are quoting small samples of the text (which is legal under US copyright law as part of "fair use") 5) published journalistic reviews of the books and TV show episodes that reference major plot points 6) Illegal copies of the text that are accessible not because ChatGPT (necessarily) did anything wrong, but because human beings are using the internet to post and exchange copyrighted works illegally amongst each other, and ChatGPT has access for the same reason any common internet user has access.
LLM's like ChatGPT don't just 'copy' things verbatim. That's not actually how they work. They are computer programs that STATISTICALLY PREDICT language use based on a large corpus of previously processed language content. In other words, ChatGPT can look at a large corpus of language data and determine that the words "Jaime" "Cersei" "Lannister" "twins" "incest" "fucking" are HIGHLY statistically correlated to appear near each other, and that they also commonly occur in relation to words like "Game" "Thrones" "Song" "Ice" "Fire" "ASOIF" "GoT". From that, the model can 'determine' (again statistically) that Jaime Lannister and Cersei Lannister are characters from a book series and TV show who are twins who fuck each other. And frankly, it could learn that without ever seeing one word of GRRM's original text because there is just so much publicly available internet conversation and information about GRRM's texts (that ISN'T copyrighted), that still would allow the model to 'learn' things about the story.
It's NOT copying/plagiarism. (at least not in any conventional or traditional legal sense) It's creating output based on a STATISTICAL PROBABILITY ANALYSIS OF PRIOR LANGUAGE USE ON A MASS SCALE.
Now, we might decide we are still not comfortable with that for a variety of reasons. And that's a fair conversation to have. But we still should not be misrepresenting how these LLM work in this conversation. It is not fair to say they simply 'copy' other people's works. They don't. That isn't how they work. That's not what they are doing. They are creating language outputs based on STATISTICAL PROBABILITY of how words are commonly ordered, and which words appear most commonly near each other.
We also absolutely need to keep in mind that IF the models have full copyrighted works within them, that could EASILY be a function of human beings trafficking in copyright works amongst each other online, where the models access these works in the same way any other internet user might illegally access them. Now I get that mass scraping of internet content is ethically complex, in some ways precisely BECAUSE it can involve scraping things that are copyrighted. But for a lot of these models, they will only have access to copyrighted material because human beings violated copyright first.
Again, I am not unilaterally defending current LLM or their programming. There are GENUINE problems and concerns around this software that we need to take very seriously. But taking it seriously involves understanding how the models ACTUALLY WORK, not scaremongering about hyper fictionalized false representation of how they work that will get thrown out in court because, well, they are just factually incorrect.

[source]
sorry but if you write or read fanfiction and are cheering about THIS as the basis for an anti-AI lawsuit, you're an idiot and a rube. signing up to join the "I didn't know lawsuits would come after MY beloved transformative works" party
16K notes
·
View notes
Text
I really do wonder how much LLMs (Large Language Models; a more specific thing a lot of people are talking about when they say "AI") are actually "good at" -
huh. I am going to finish that sentence, but also what if we stop it there?
- emulating human conversation, and how much of our impression that they are comes from the fact that we fill in patterns to interpret things as humanesque all the time, nonstop. Like, a bird waddles a certain way and we're like, "Aw, he's a little guy! He's on his way to work! He's gonna support the proletariat!" Every movement, posture, turn of phrase has another layer or five of meaning in humanity's limitless internal cross-reference-a-thon.
Take something that spits out what we've said before in response to what's being said now and sure, it sounds reasonable.
But as I've said before, to say they "know" things is wrong. Most do not maintain memory of what you've said two sentences ago. This is the source of a lot of the "gaslighting" "behavior" people discussed with LLMs early this year. It wasn't actual gaslighting, because it wasn't actually behavior. To be either of those things, it would need intent. If an LLM intends anything, it is to reply with something from its randomized set of acceptably common replies to the word-series you presented.
That's it. That's the full limit of what LLMs "intend."
To say that LLMs "lie" or "gaslight" is giving them too much credit. The reality is that they will give you inaccurate information because they have no concept of things being true or false at all.
A spreadsheet full of statements, with a column next to it labeling the ones that are true as True and the ones that are false as False, has a better handle on reality than an LLM.
This rant brought to you by So Sick of Seeing People Trust AI that Has No Sense of Reality to Answer Questions.
0 notes
Quote
Agent-based modeling has been around for decades, and applied widely across the social and natural sciences. The scope of this research method is now poised to grow dramatically as it absorbs the new affordances provided by Large Language Models (LLM)s. Generative Agent-Based Models (GABM) are not just classic Agent-Based Models (ABM)s where the agents talk to one another. Rather, GABMs are constructed using an LLM to apply common sense to situations, act "reasonably", recall common semantic knowledge, produce API calls to control digital technologies like apps, and communicate both within the simulation and to researchers viewing it from the outside. Here we present Concordia, a library to facilitate constructing and working with GABMs. Concordia makes it easy to construct language-mediated simulations of physically- or digitally-grounded environments. Concordia agents produce their behavior using a flexible component system which mediates between two fundamental operations: LLM calls and associative memory retrieval. A special agent called the Game Master (GM), which was inspired by tabletop role-playing games, is responsible for simulating the environment where the agents interact. Agents take actions by describing what they want to do in natural language. The GM then translates their actions into appropriate implementations. In a simulated physical world, the GM checks the physical plausibility of agent actions and describes their effects. In digital environments simulating technologies such as apps and services, the GM may handle API calls to integrate with external tools such as general AI assistants (e.g., Bard, ChatGPT), and digital apps (e.g., Calendar, Email, Search, etc.). Concordia was designed to support a wide array of applications both in scientific research and for evaluating performance of real digital services by simulating users and/or generating synthetic data.
[2312.03664] Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia
0 notes
Text
Google DeepMind Researchers Introduce Promptbreeder: A Self-Referential and Self-Improving AI System that can Automatically Evolve Effective Domain-Specific Prompts in a Given Domain
🚀 Exciting news for the AI community! Google DeepMind researchers have introduced PromptBreeder, a groundbreaking AI system that autonomously evolves prompts for Large Language Models (LLMs), such as GPT-3.5 and GPT-4. PromptBreeder aims to enhance the performance of LLMs by improving task prompts and mutation prompts through an iterative process. It eliminates the need for time-consuming manual prompt engineering and has already shown promising results in common sense reasoning, arithmetic, and ethics. The beauty of PromptBreeder lies in its self-referential and self-improving nature, as it doesn't require parameter updates. This has the potential to revolutionize AI usage across various domains, making processes more efficient and boosting customer engagement. If you're curious about PromptBreeder and its implications, read the fascinating article below. Gain practical insights from Google DeepMind researchers and understand how this AI system can shape the future of language models. 📚 Read the full article: [Google DeepMind Researchers Introduce PromptBreeder: A Self-Referential and Self-Improving AI System that can Automatically Evolve Effective Domain-Specific Prompts in a Given Domain](https://ift.tt/Sw2ZW7R) 📣 Stay updated with the latest trends in AI and more by following MarkTechPost and iTinai's Twitter account: [@itinaicom](https://twitter.com/itinaicom). For a free consultation, visit the AI Lab in Telegram: @aiscrumbot. #AI #DeepMind #LLM #PromptBreeder #Research #LanguageModels #Google #Technology List of Useful Links: AI Scrum Bot - ask about AI scrum and agile Our Telegram @itinai Twitter - @itinaicom
#itinai.com#AI#News#Google DeepMind Researchers Introduce Promptbreeder: A Self-Referential and Self-Improving AI System that can Automatically Evolve Effecti#AI News#AI tools#Innovation#ITinAI.com#LLM#MarkTechPost#t.me/itinai#Tanya Malhotra Google DeepMind Researchers Introduce Promptbreeder: A Self-Referential and Self-Improving AI System that can Automatically
0 notes
Text
I think you're mixing up two ideas here, one good and one bad. The good idea is that LLMs are trained to imitate humans, and something that's good at imitating humans is by definition not going to do the kind of behavior that "no human would ever do" that's essential to Yudkowskian AI risk/paperclipping. paperclipping behavior is always going to be out of distribution, and from a raw learning theory perspective we should not expect LLMs to do it, if if they did, we shouldn't expect them to be good at it.
But you also seem to making this into some essential claim about what LLMs "really are", when in truth this imitation-focused approach basically only is dominant because the relevant resources for it are cheaper than other approaches. The fact that our largest networks today are trained by generative pretraining is a economically contingent decision based on the scaling laws, the cost of training time compute, and the cost of test time compute. There's no law that says our largest models must primarily be trained by imitation. AlphaGo was trained primarily by self-play and famously played moves that no human would ever play. Its successor, AlphaZero, used no human-generated data whatsoever and performed even better.
I actually want to argue that in the near future, we're very likely to see much less dependence on human-generated data, mainly the data needed to train larger models doesn't exist. The largest models are currently trained on almost the entire internet, and we're expected to run out of human-generated data soon. If you want to keep seeing increases in performance, this means there are two main directions: scaling inference time compute, and using non-human-generated data. I'm going to ignore inference time compute for now. The important idea here is that non-human-generated data in RL does not look like imitating a character. Instead it's an open-ended optimization problem. It also doesn't look like the model of agency you've described, where the "smart" part is the part that's imitating humans. The part that's imitating humans is actually kind of dumb, the thing it's providing isn't intelligence, it's common-sense knowledge about how the world works. The actual reasoning part comes from reinforcement learning with minimal human data. This part isn't playing a character, it's just solving an open-ended optimization problem.
theres a very weird thing to me abt modern AI doomers where like. i don't really understand the narrative anymore? the old AI that people were scared of were *control/management systems*! which have very clearly paths to doing evil things, their whole point is causing things to happen in the real world. but the AI advancements people are scared about now are all in LLMs, and it's not clear to me how they would, yknow, "go skynet". like. just on a basic sci fi narrative level. whats the *story* in these people's minds. it's easy to see how it could be a useful tool for a bad person to achieve bad goals. that would be bad but is a very different sort of bad from "AI takes over". what does a modern LLM ai takeover look like, they don't really have *goals*, let alone evil ones. theyre simulators
#this doesn't mean that yudkowskian fears are well founded#but i don't think this line of argument works
235 notes
·
View notes
Text
Some collected ChatGPT sillinesses
Or, "Building an Artificial Idiot". Because ChatGPT is not, I repeat, it is not an artificial intelligence. It is a large language model (LLM). In non-technical terms, it gives the most common sort of answer found in the training data, sort of like autocomplete suggestions for common words on your phone. This is good enough for common questions, but frequently inconsistent from question to question. There is very little point in trying to argue ChatGPT into consistency, because the training data is inconsistent, being the collected opinions of many different people in different situations.
I do not know with certainty which of these examples are language model sillinesses, hardcoded developer kludges on top of the language model, or entirely made up for clout, but I thought it was fun to collect them anyway. Starting with an entry from @psychosort on Twitter:

Let's all have a good laugh at "The Supreme Court's decisions are meant to be final and binding on all lower courts, and it is not appropriate to seek to overturn them" followed by immediately describing how you would seek to overturn them for a different case. The linked thread has more examples of ChatGPT flipping back and forth this way depending on case.
But let me also say: ChatGPT is not "contradicting" itself. Contradiction would require a sort of commitment to the things being said, which ChatGPT doesn't have. ChatGPT is more like an actor playing different roles in different questions, consistently following the instructions in the script each time, but reading from a different script each time. It is not a contradiction for an actor to play two different roles. It's telling fresh bullshit each time, with very little thought for consistency.
Another metaphor might be how Dracula is frequently "contradictory" to Harry Potter, but they're both fiction, neither of them are true, and they're written by different people. Sometimes the two fictions agree on accurate statements like the existence of London. The fiction is still not a reliable source.
Also, because the different scripts are written by remixing and mashing up previous scripts, sometimes you get this kind of weird glitch:

As I understand it, this is something like 1) tokenizer glitch mapping "SolidGoldMagikarp" onto "distribute", 2) previous scripts did not teach it the former word so it spells a different word, 3) previous scripts did not teach it to abort and notice fuckery in something as common as spelling a word.

ChatGPT has a lot of pablum and author attempts at limiting it. But there's various kinds of prompt injection, where if you insist and use the the right phrasing that it's only pretending to be someone else,


Math is hard.

And then there's this sort of boilerplate:

I don't know the exact internal workings of ChatGPT, but if a platitude template is common in the training data, I suspect that's a reason why ChatGPT will recycle the platitude template, without regard for whether it makes sense to say that the US "has a long history of recognizing and protecting the rights of individuals to self-identify their gender".

Similarly, if the training data contains lots of special pleading for Jews, expect ChatGPT to repeat the special pleading for Jews, possibly also with a thumb on the scale from the devs to ensure that protected groups are properly protected and privileged.

Here, for instance, looks to me like a very heavy thumb on the scale, devs constraining the chatbot not to generate anything which sounds vaguely like it might induce "white pride":

In closing, some remarks from eigenrobot:
"i think its an incredibly helpful service for them to have clearly demonstrated that AI will give you the information that its trainers want you to have rather than what is in some sense "true", within the limits of its trainers ability" "having the first popular language AI act in transparent bad faith is extremely helpful because it poisons the well, to an extent, for future iterations"
54 notes
·
View notes