#PySpark training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text
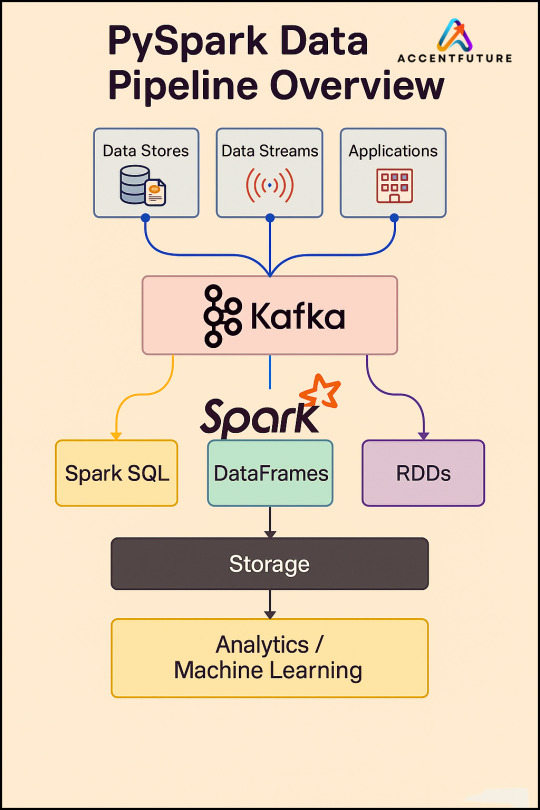
Pyspark Training
0 notes
Text
Master PySpark for High-Speed Data Processing Online!
youtube
0 notes
Text
Data engineer training and placement in Pune - JVM Institute
Kickstart your career with JVM Institute's top-notch Data Engineer Training in Pune. Expert-led courses, hands-on projects, and guaranteed placement support to transform your future!
#Best Data engineer training and placement in Pune#JVM institute in Pune#Data Engineering Classes Pune#Advanced Data Engineering Training Pune#Data engineer training and placement in Pune#Big Data courses in Pune#PySpark Courses in Pune
0 notes
Text
Python Training institute in Hyderabad
Best Python Training in Hyderabad by RS Trainings
Python is one of the most popular and versatile programming languages in the world, renowned for its simplicity, readability, and broad applicability across various domains like web development, data science, artificial intelligence, and more. If you're looking to learn Python or enhance your Python skills, RS Trainings offers the best Python training in Hyderabad, guided by industry IT experts. Recognized as the best place for better learning, RS Trainings is committed to delivering top-notch education that equips you with practical skills and knowledge.

Why Choose RS Trainings for Python?
1. Expert Instructors: Our Python training program is led by seasoned industry professionals who bring a wealth of experience and insights. They are adept at simplifying complex concepts and providing real-world examples to ensure you gain a deep understanding of Python.
2. Comprehensive Curriculum: The curriculum is meticulously designed to cover everything from the basics of Python to advanced topics. You'll learn about variables, data types, control structures, functions, modules, file handling, object-oriented programming, web development frameworks like Django and Flask, and data analysis libraries like Pandas and NumPy.
3. Hands-on Learning: We emphasize a practical approach to learning. Our training includes numerous hands-on exercises, coding assignments, and real-time projects that help you apply the concepts you learn in class, ensuring you gain practical experience.
4. Flexible Learning Options: RS Trainings offers both classroom and online training options to accommodate different learning preferences and schedules. Whether you are a working professional or a student, you can find a batch that fits your timetable.
5. Career Support: Beyond just training, we provide comprehensive career support, including resume building, interview preparation, and job placement assistance. Our aim is to help you smoothly transition into a successful career in Python programming.
Course Highlights:
Introduction to Python: Get an overview of Python and its applications, understanding why it is a preferred language for various domains.
Core Python Concepts: Dive into the core concepts, including variables, data types, control structures, loops, and functions.
Object-Oriented Programming: Learn about object-oriented programming in Python, covering classes, objects, inheritance, and polymorphism.
Web Development: Explore web development using popular frameworks like Django and Flask, and build your own web applications.
Data Analysis: Gain proficiency in data analysis using libraries like Pandas, NumPy, and Matplotlib.
Real-world Projects: Work on real-world projects that simulate industry scenarios, enhancing your practical skills and understanding.
Who Should Enroll?
Aspiring Programmers: Individuals looking to start a career in programming.
Software Developers: Developers wanting to add Python to their skill set.
Data Scientists and Analysts: Professionals aiming to leverage Python for data analysis and machine learning.
Web Developers: Web developers interested in using Python for backend development.
Students and Enthusiasts: Anyone with a passion for learning programming and Python.
Enroll Today!
Join RS Trainings, the best Python training institute in Hyderabad, and embark on a journey to master one of the most powerful programming languages. Our expert-led training, practical approach, and comprehensive support ensure you are well-prepared to excel in your career.
Visit our website or contact us to learn more about our Python training program, upcoming batches, and enrollment details. Elevate your programming skills with RS Trainings – the best place for better learning in Hyderabad!
#python training#python online training#python training in Hyderabad#python training institute in Hyderabad#python course online Hyderabad#pyspark course online
0 notes
Text
[Fabric] Dataflows Gen2 destino “archivos” - Opción 2
Continuamos con la problematica de una estructura lakehouse del estilo “medallón” (bronze, silver, gold) con Fabric, en la cual, la herramienta de integración de datos de mayor conectividad, Dataflow gen2, no permite la inserción en este apartado de nuestro sistema de archivos, sino que su destino es un spark catalog. ¿Cómo podemos utilizar la herramienta para armar un flujo limpio que tenga nuestros datos crudos en bronze?
Veamos una opción más pythonesca donde podamos realizar la integración de datos mediante dos contenidos de Fabric
Como repaso de la problemática, veamos un poco la comparativa de las características de las herramientas de integración de Data Factory dentro de Fabric (Feb 2024)
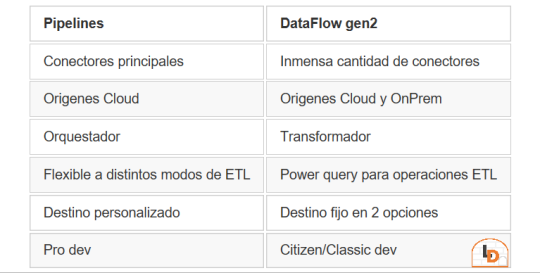
Si nuestro origen solo puede ser leído con Dataflows Gen2 y queremos iniciar nuestro proceso de datos en Raw o Bronze de Archivos de un Lakehouse, no podríamos dado el impedimento de delimitar el destino en la herramienta.
Para solucionarlo planteamos un punto medio de stage y un shortcut en un post anterior. Pueden leerlo para tener más cercanía y contexto con esa alternativa.
Ahora vamos a verlo de otro modo. El planteo bajo el cual llegamos a esta solución fue conociendo en más profundidad la herramienta. Conociendo que Dataflows Gen2 tiene la característica de generar por si mismo un StagingLakehouse, ¿por qué no usarlo?. Si no sabes de que hablo, podes leer todo sobre staging de lakehouse en este post.
Ejemplo práctico. Cree dos dataflows que lean datos con "Enable Staging" activado pero sin destino. Un dataflow tiene dos tablas (InternetSales y Producto) y otro tiene una tabla (Product). De esa forma pensaba aprovechar este stage automático sin necesidad de crear uno. Sin embargo, al conectarme me encontre con lo siguiente:
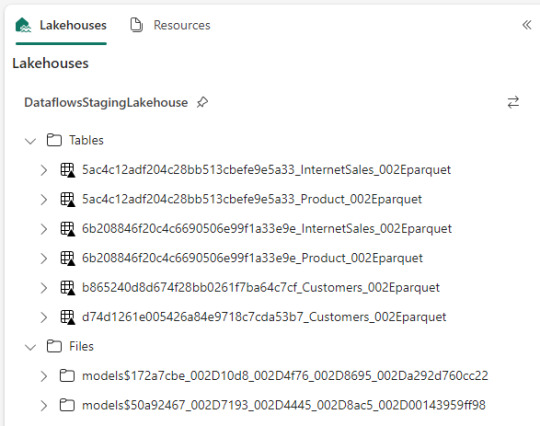
Dataflow gen2 por defecto genera snapshots de cada actualización. Los dataflows corrieron dos veces entonces hay 6 tablas. Por si fuera aún más dificil, ocurre que las tablas no tienen metadata. Sus columnas están expresadas como "column1, column2, column3,...". Si prestamos atención en "Files" tenemos dos models. Cada uno de ellos son jsons con toda la información de cada dataflow.
Muy buena información pero de shortcut difícilmente podríamos solucionarlo. Sin perder la curiosidad hablo con un Data Engineer para preguntarle más en detalle sobre la información que podemos encontrar de Tablas Delta, puesto que Fabric almacena Delta por defecto en "Tables". Ahi me compartió que podemos ver la última fecha de modificación con lo que podríamos conocer cual de esos snapshots es el más reciente para moverlo a Bronze o Raw con un Notebook. El desafío estaba. Leer la tabla delta más reciente, leer su metadata en los json de files y armar un spark dataframe para llevarlo a Bronze de nuestro lakehouse. Algo así:
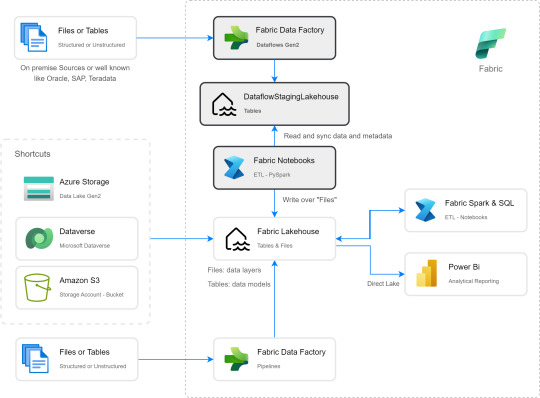
Si apreciamos las cajas con fondo gris, podremos ver el proceso. Primero tomar los datos con Dataflow Gen2 sin configurar destino asegurando tener "Enable Staging" activado. De esa forma llevamos los datos al punto intermedio. Luego construir un Notebook para leerlo, en mi caso el código está preparado para construir un Bronze de todas las tablas de un dataflow, es decir que sería un Notebook por cada Dataflow.
¿Qué encontraremos en el notebook?
Para no ir celda tras celda pegando imágenes, puede abrirlo de mi GitHub y seguir los pasos con el siguiente texto.
Trás importar las librerías haremos los siguientes pasos para conseguir nuestro objetivo.
1- Delimitar parámetros de Onelake origen y Onelake destino. Definir Dataflow a procesar.
Podemos tomar la dirección de los lake viendo las propiedades de carpetas cuando lo exploramos:

La dirección del dataflow esta delimitado en los archivos jsons dentro de la sección Files del StagingLakehouse. El parámetro sería más o menos así:
Files/models$50a92467_002D7193_002D4445_002D8ac5_002D00143959ff98/*.json
2- Armar una lista con nombre de los snapshots de tablas en Tables
3- Construimos una nueva lista con cada Tabla y su última fecha de modificación para conocer cual de los snapshots es el más reciente.
4- Creamos un pandas dataframe que tenga nombre de la tabla delta, el nombre semántico apropiado y la fecha de modificación
5- Buscamos la metadata (nombre de columnas) de cada Tabla puesto que, tal como mencioné antes, en sus logs delta no se encuentran.
6- Recorremos los nombre apropiados de tabla buscando su más reciente fecha para extraer el apropiado nombre del StagingLakehouse con su apropiada metadata y lo escribimos en destino.
Para más detalle cada línea de código esta documentada.
De esta forma llegaríamos a construir la arquitectura planteada arriba. Logramos así construir una integración de datos que nos permita conectarnos a orígenes SAP, Oracle, Teradata u otro onpremise que son clásicos y hoy Pipelines no puede, para continuar el flujo de llevarlos a Bronze/Raw de nuestra arquitectura medallón en un solo tramo. Dejamos así una arquitectura y paso del dato más limpio.
Por supuesto, esta solución tiene mucho potencial de mejora como por ejemplo no tener un notebook por dataflow, sino integrar de algún modo aún más la solución.
#dataflow#data integration#fabric#microsoft fabric#fabric tutorial#fabric tips#fabric training#data engineering#notebooks#python#pyspark#pandas
0 notes
Text
From Beginner to Pro: The Best PySpark Courses Online from ScholarNest Technologies

Are you ready to embark on a journey from a PySpark novice to a seasoned pro? Look no further! ScholarNest Technologies brings you a comprehensive array of PySpark courses designed to cater to every skill level. Let's delve into the key aspects that make these courses stand out:
1. What is PySpark?
Gain a fundamental understanding of PySpark, the powerful Python library for Apache Spark. Uncover the architecture and explore its diverse applications in the world of big data.
2. Learning PySpark by Example:
Experience is the best teacher! Our courses focus on hands-on examples, allowing you to apply your theoretical knowledge to real-world scenarios. Learn by doing and enhance your problem-solving skills.
3. PySpark Certification:
Elevate your career with our PySpark certification programs. Validate your expertise and showcase your proficiency in handling big data tasks using PySpark.
4. Structured Learning Paths:
Whether you're a beginner or seeking advanced concepts, our courses offer structured learning paths. Progress at your own pace, mastering each skill before moving on to the next level.
5. Specialization in Big Data Engineering:
Our certification course on big data engineering with PySpark provides in-depth insights into the intricacies of handling vast datasets. Acquire the skills needed for a successful career in big data.
6. Integration with Databricks:
Explore the integration of PySpark with Databricks, a cloud-based big data platform. Understand how these technologies synergize to provide scalable and efficient solutions.
7. Expert Instruction:
Learn from the best! Our courses are crafted by top-rated data science instructors, ensuring that you receive expert guidance throughout your learning journey.
8. Online Convenience:
Enroll in our online PySpark courses and access a wealth of knowledge from the comfort of your home. Flexible schedules and convenient online platforms make learning a breeze.
Whether you're a data science enthusiast, a budding analyst, or an experienced professional looking to upskill, ScholarNest's PySpark courses offer a pathway to success. Master the skills, earn certifications, and unlock new opportunities in the world of big data engineering!
#big data#data engineering#data engineering certification#data engineering course#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#pyspark certification course
1 note
·
View note
Text
PySpark SQL: Introduction & Basic Queries
Introduction
In today’s data-driven world, the volume and variety of data have exploded. Traditional tools often struggle to process and analyze massive datasets efficiently. That’s where Apache Spark comes into the picture — a lightning-fast, unified analytics engine for big data processing.
For Python developers, PySpark — the Python API for Apache Spark — offers an intuitive way to work with Spark. Among its powerful modules, PySpark SQL stands out. It enables you to query structured data using SQL syntax or DataFrame operations. This hybrid capability makes it easy to blend the power of Spark with the familiarity of SQL.
In this blog, we'll explore what PySpark SQL is, why it’s so useful, how to set it up, and cover the most essential SQL queries with examples — perfect for beginners diving into big data with Python.

Agenda
Here's what we'll cover:
What is PySpark SQL?
Why should you use PySpark SQL?
Installing and setting up PySpark
Basic SQL queries in PySpark
Best practices for working efficiently
Final thoughts
What is PySpark SQL?
PySpark SQL is a module of Apache Spark that enables querying structured data using SQL commands or a more programmatic DataFrame API. It offers:
Support for SQL-style queries on large datasets.
A seamless bridge between relational logic and Python.
Optimizations using the Catalyst query optimizer and Tungsten execution engine for efficient computation.
In simple terms, PySpark SQL lets you use SQL to analyze big data at scale — without needing traditional database systems.
Why Use PySpark SQL?
Here are a few compelling reasons to use PySpark SQL:
Scalability: It can handle terabytes of data spread across clusters.
Ease of use: Combines the simplicity of SQL with the flexibility of Python.
Performance: Optimized query execution ensures fast performance.
Interoperability: Works with various data sources — including Hive, JSON, Parquet, and CSV.
Integration: Supports seamless integration with DataFrames and MLlib for machine learning.
Whether you're building dashboards, ETL pipelines, or machine learning workflows — PySpark SQL is a reliable choice.
Setting Up PySpark
Let’s quickly set up a local PySpark environment.
1. Install PySpark:
pip install pyspark
2. Start a Spark session:
from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName("PySparkSQLExample") \ .getOrCreate()
3. Create a DataFrame:
data = [("Alice", 25), ("Bob", 30), ("Clara", 35)] columns = ["Name", "Age"] df = spark.createDataFrame(data, columns) df.show()
4. Create a temporary view to run SQL queries:
df.createOrReplaceTempView("people")
Now you're ready to run SQL queries directly!
Basic PySpark SQL Queries
Let’s look at the most commonly used SQL queries in PySpark.
1. SELECT Query
spark.sql("SELECT * FROM people").show()
Returns all rows from the people table.
2. WHERE Clause (Filtering Rows)
spark.sql("SELECT * FROM people WHERE Age > 30").show()
Filters rows where Age is greater than 30.
3. Adding a Derived Column
spark.sql("SELECT Name, Age, Age + 5 AS AgeInFiveYears FROM people").show()
Adds a new column AgeInFiveYears by adding 5 to the current age.
4. GROUP BY and Aggregation
Let’s update the data with multiple entries for each name:
data2 = [("Alice", 25), ("Bob", 30), ("Alice", 28), ("Bob", 35), ("Clara", 35)] df2 = spark.createDataFrame(data2, columns) df2.createOrReplaceTempView("people")
Now apply aggregation:
spark.sql(""" SELECT Name, COUNT(*) AS Count, AVG(Age) AS AvgAge FROM people GROUP BY Name """).show()
This groups records by Name and calculates the number of records and average age.
5. JOIN Between Two Tables
Let’s create another table:
jobs_data = [("Alice", "Engineer"), ("Bob", "Designer"), ("Clara", "Manager")] df_jobs = spark.createDataFrame(jobs_data, ["Name", "Job"]) df_jobs.createOrReplaceTempView("jobs")
Now perform an inner join:
spark.sql(""" SELECT p.Name, p.Age, j.Job FROM people p JOIN jobs j ON p.Name = j.Name """).show()
This joins the people and jobs tables on the Name column.
Tips for Working Efficiently with PySpark SQL
Use LIMIT for testing: Avoid loading millions of rows in development.
Cache wisely: Use .cache() when a DataFrame is reused multiple times.
Check performance: Use .explain() to view the query execution plan.
Mix APIs: Combine SQL queries and DataFrame methods for flexibility.
Conclusion
PySpark SQL makes big data analysis in Python much more accessible. By combining the readability of SQL with the power of Spark, it allows developers and analysts to process massive datasets using simple, familiar syntax.
This blog covered the foundational aspects: setting up PySpark, writing basic SQL queries, performing joins and aggregations, and a few best practices to optimize your workflow.
If you're just starting out, keep experimenting with different queries, and try loading real-world datasets in formats like CSV or JSON. Mastering PySpark SQL can unlock a whole new level of data engineering and analysis at scale.
PySpark Training by AccentFuture
At AccentFuture, we offer customizable online training programs designed to help you gain practical, job-ready skills in the most in-demand technologies. Our PySpark Online Training will teach you everything you need to know, with hands-on training and real-world projects to help you excel in your career.
What we offer:
Hands-on training with real-world projects and 100+ use cases
Live sessions led by industry professionals
Certification preparation and career guidance
🚀 Enroll Now: https://www.accentfuture.com/enquiry-form/
📞 Call Us: +91–9640001789
📧 Email Us: [email protected]
🌐 Visit Us: AccentFuture
1 note
·
View note
Text
PySpark Courses in Pune - JVM Institute
In today’s dynamic landscape, data reigns supreme, reshaping businesses across industries. Those embracing Data Engineering technologies are gaining a competitive edge by amalgamating raw data with advanced algorithms. Master PySpark with expert-led courses at JVM Institute in Pune. Learn big data processing, real-time analytics, and more. Join now to boost your career!
#Best Data engineer training and placement in Pune#JVM institute in Pune#Data Engineering Classes Pune#Advanced Data Engineering Training Pune#PySpark Courses in Pune#PySpark Courses in PCMC#Pune
0 notes
Text
Can I use Python for big data analysis?
Yes, Python is a powerful tool for big data analysis. Here’s how Python handles large-scale data analysis:

Libraries for Big Data:
Pandas:
While primarily designed for smaller datasets, Pandas can handle larger datasets efficiently when used with tools like Dask or by optimizing memory usage..
NumPy:
Provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays.
Dask:
A parallel computing library that extends Pandas and NumPy to larger datasets. It allows you to scale Python code from a single machine to a distributed cluster
Distributed Computing:
PySpark:
The Python API for Apache Spark, which is designed for large-scale data processing. PySpark can handle big data by distributing tasks across a cluster of machines, making it suitable for large datasets and complex computations.
Dask:
Also provides distributed computing capabilities, allowing you to perform parallel computations on large datasets across multiple cores or nodes.
Data Storage and Access:
HDF5:
A file format and set of tools for managing complex data. Python’s h5py library provides an interface to read and write HDF5 files, which are suitable for large datasets.
Databases:
Python can interface with various big data databases like Apache Cassandra, MongoDB, and SQL-based systems. Libraries such as SQLAlchemy facilitate connections to relational databases.
Data Visualization:
Matplotlib, Seaborn, and Plotly: These libraries allow you to create visualizations of large datasets, though for extremely large datasets, tools designed for distributed environments might be more appropriate.
Machine Learning:
Scikit-learn:
While not specifically designed for big data, Scikit-learn can be used with tools like Dask to handle larger datasets.
TensorFlow and PyTorch:
These frameworks support large-scale machine learning and can be integrated with big data processing tools for training and deploying models on large datasets.
Python’s ecosystem includes a variety of tools and libraries that make it well-suited for big data analysis, providing flexibility and scalability to handle large volumes of data.
Drop the message to learn more….!
2 notes
·
View notes
Text
[Fabric] Leer y escribir storage con Databricks
Muchos lanzamientos y herramientas dentro de una sola plataforma haciendo participar tanto usuarios técnicos (data engineers, data scientists o data analysts) como usuarios finales. Fabric trajo una unión de involucrados en un único espacio. Ahora bien, eso no significa que tengamos que usar todas pero todas pero todas las herramientas que nos presenta.
Si ya disponemos de un excelente proceso de limpieza, transformación o procesamiento de datos con el gran popular Databricks, podemos seguir usándolo.
En posts anteriores hemos hablado que Fabric nos viene a traer un alamacenamiento de lake de última generación con open data format. Esto significa que nos permite utilizar los más populares archivos de datos para almacenar y que su sistema de archivos trabaja con las convencionales estructuras open source. En otras palabras podemos conectarnos a nuestro storage desde herramientas que puedan leerlo. También hemos mostrado un poco de Fabric notebooks y como nos facilita la experiencia de desarrollo.
En este sencillo tip vamos a ver como leer y escribir, desde databricks, nuestro Fabric Lakehouse.
Para poder comunicarnos entre databricks y Fabric lo primero es crear un recurso AzureDatabricks Premium Tier. Lo segundo, asegurarnos de dos cosas en nuestro cluster:
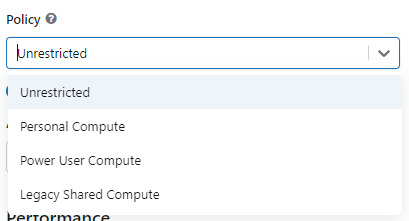
Utilizar un policy "unrestricted" o "power user compute"
2. Asegurarse que databricks podría pasar nuestras credenciales por spark. Eso podemos activarlo en las opciones avanzadas
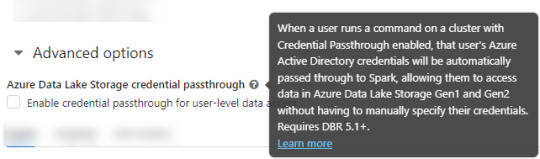
NOTA: No voy a entrar en más detalles de creación de cluster. El resto de las opciones de procesamiento les dejo que investiguen o estimo que ya conocen si están leyendo este post.
Ya creado nuestro cluster vamos a crear un notebook y comenzar a leer data en Fabric. Esto lo vamos a conseguir con el ABFS (Azure Bllob Fyle System) que es una dirección de formato abierto cuyo driver está incluido en Azure Databricks.
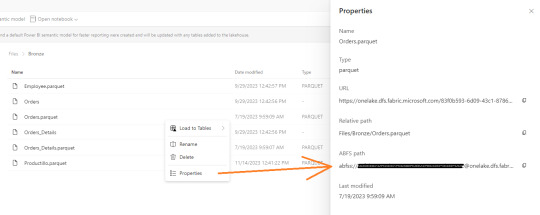
La dirección debe componerse de algo similar a la siguiente cadena:
oneLakePath = 'abfss://[email protected]/myLakehouse.lakehouse/Files/'
Conociendo dicha dirección ya podemos comenzar a trabajar como siempre. Veamos un simple notebook que para leer un archivo parquet en Lakehouse Fabric
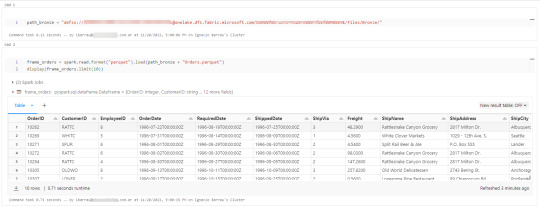
Gracias a la configuración del cluster, los procesos son tan simples como spark.read
Así de simple también será escribir.

Iniciando con una limpieza de columnas innecesarias y con un sencillo [frame].write ya tendremos la tabla en silver limpia.
Nos vamos a Fabric y podremos encontrarla en nuestro Lakehouse
Así concluye nuestro procesamiento de databricks en lakehouse de Fabric, pero no el artículo. Todavía no hablamos sobre el otro tipo de almacenamiento en el blog pero vamos a mencionar lo que pertine a ésta lectura.
Los Warehouses en Fabric también están constituidos con una estructura tradicional de lake de última generación. Su principal diferencia consiste en brindar una experiencia de usuario 100% basada en SQL como si estuvieramos trabajando en una base de datos. Sin embargo, por detras, podrémos encontrar delta como un spark catalog o metastore.
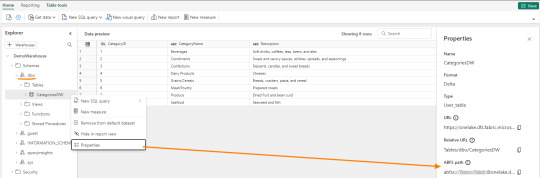
El path debería verse similar a esto:
path_dw = "abfss://[email protected]/WarehouseName.Datawarehouse/Tables/dbo/"
Teniendo en cuenta que Fabric busca tener contenido delta en su Spark Catalog de Lakehouse (tables) y en su Warehouse, vamos a leer como muestra el siguiente ejemplo
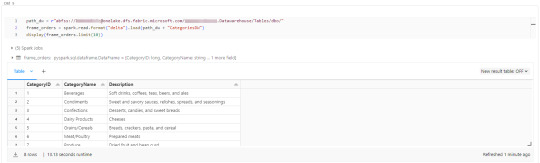
Ahora si concluye nuestro artículo mostrando como podemos utilizar Databricks para trabajar con los almacenamientos de Fabric.
#fabric#microsoftfabric#fabric cordoba#fabric jujuy#fabric argentina#fabric tips#fabric tutorial#fabric training#fabric databricks#databricks#azure databricks#pyspark
0 notes
Text
Hire AI Experts for Advanced Data Retrieval with Intelligent RAG Solutions
In today’s data-driven world, fast and accurate information retrieval is critical for business success. Retrieval-Augmented Generation (RAG) is an advanced AI approach that combines the strengths of retrieval-based search and generative models to produce highly relevant, context-aware responses.
At Prosperasoft, we help organizations harness the power of RAG to improve decision-making, drive engagement, and unlock deeper insights from their data.
Why Choose RAG for Your Business?
Traditional AI models often rely on static datasets, which can limit their relevance and accuracy. RAG bridges this gap by integrating real-time data retrieval with language generation capabilities. This means your AI system doesn’t just rely on pre-trained knowledge—it actively fetches the most current and relevant information before generating a response. The result? Faster query processing, improved accuracy, and significantly enhanced user experience.
At Prosperasoft, we deliver 85% faster query processing, 40% better data accuracy, and up to 5X higher user engagement through our custom-built RAG solutions. Whether you're a growing startup or a large enterprise, our intelligent systems are designed to scale and evolve with your data needs.
End-to-End RAG Expertise from Prosperasoft
Our team of offshore AI experts brings deep technical expertise and hands-on experience with cutting-edge tools like Amazon SageMaker, PySpark, LlamaIndex, Hugging Face, Langchain, and more. We specialize in:
Intelligent Data Retrieval Systems – Systems designed to fetch and prioritize the most relevant data in real time.
Real-Time Data Integration – Seamlessly pulling live data into your workflows for dynamic insights.
Advanced AI-Powered Responses – Combining large language models with retrieval techniques for context-rich answers.
Custom RAG Model Development – Tailoring every solution to your specific business objectives.
Enhanced Search Functionality – Boosting the relevance and precision of your internal and external search tools.
Model Optimization and Scalability – Ensuring performance, accuracy, and scalability across enterprise operations.
Empower Your Business with Smarter AI
Whether you need to optimize existing systems or build custom RAG models from the ground up, Prosperasoft provides a complete suite of services—from design and development to deployment and ongoing optimization. Our end-to-end RAG solution implementation ensures your AI infrastructure is built for long-term performance and real-world impact.
Ready to take your AI to the next level? Outsource RAG development to Prosperasoft and unlock intelligent, real-time data retrieval solutions that drive growth, efficiency, and smarter decision-making.
#Hire AI Experts#content generation#augmented AI#RAG technology#AI-powered content#content automation#hire#outsourcing
0 notes
Text
Transform Your Team into Data Engineering Pros with ScholarNest Technologies

In the fast-evolving landscape of data engineering, the ability to transform your team into proficient professionals is a strategic imperative. ScholarNest Technologies stands at the forefront of this transformation, offering comprehensive programs that equip individuals with the skills and certifications necessary to excel in the dynamic field of data engineering. Let's delve into the world of data engineering excellence and understand how ScholarNest is shaping the data engineers of tomorrow.
Empowering Through Education: The Essence of Data Engineering
Data engineering is the backbone of current data-driven enterprises. It involves the collection, processing, and storage of data in a way that facilitates effective analysis and insights. ScholarNest Technologies recognizes the pivotal role data engineering plays in today's technological landscape and has curated a range of courses and certifications to empower individuals in mastering this discipline.
Comprehensive Courses and Certifications: ScholarNest's Commitment to Excellence
1. Data Engineering Courses: ScholarNest offers comprehensive data engineering courses designed to provide a deep understanding of the principles, tools, and technologies essential for effective data processing. These courses cover a spectrum of topics, including data modeling, ETL (Extract, Transform, Load) processes, and database management.
2. Pyspark Mastery: Pyspark, a powerful data processing library for Python, is a key component of modern data engineering. ScholarNest's Pyspark courses, including options for beginners and full courses, ensure participants acquire proficiency in leveraging this tool for scalable and efficient data processing.
3. Databricks Learning: Databricks, with its unified analytics platform, is integral to modern data engineering workflows. ScholarNest provides specialized courses on Databricks learning, enabling individuals to harness the full potential of this platform for advanced analytics and data science.
4. Azure Databricks Training: Recognizing the industry shift towards cloud-based solutions, ScholarNest offers courses focused on Azure Databricks. This training equips participants with the skills to leverage Databricks in the Azure cloud environment, ensuring they are well-versed in cutting-edge technologies.
From Novice to Expert: ScholarNest's Approach to Learning
Whether you're a novice looking to learn the fundamentals or an experienced professional seeking advanced certifications, ScholarNest caters to diverse learning needs. Courses such as "Learn Databricks from Scratch" and "Machine Learning with Pyspark" provide a structured pathway for individuals at different stages of their data engineering journey.
Hands-On Learning and Certification: ScholarNest places a strong emphasis on hands-on learning. Courses include practical exercises, real-world projects, and assessments to ensure that participants not only grasp theoretical concepts but also gain practical proficiency. Additionally, certifications such as the Databricks Data Engineer Certification validate the skills acquired during the training.
The ScholarNest Advantage: Shaping Data Engineering Professionals
ScholarNest Technologies goes beyond traditional education paradigms, offering a transformative learning experience that prepares individuals for the challenges and opportunities in the world of data engineering. By providing access to the best Pyspark and Databricks courses online, ScholarNest is committed to fostering a community of skilled data engineering professionals who will drive innovation and excellence in the ever-evolving data landscape. Join ScholarNest on the journey to unlock the full potential of your team in the realm of data engineering.
#big data#big data consulting#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course
1 note
·
View note
Text
How to Read and Write Data in PySpark
The Python application programming interface known as PySpark serves as the front end for Apache Spark execution of big data operations. The most crucial skill required for PySpark work involves accessing and writing data from sources which include CSV, JSON and Parquet files.
In this blog, you’ll learn how to:
Initialize a Spark session
Read data from various formats
Write data to different formats
See expected outputs for each operation
Let’s dive in step-by-step.
Getting Started
Before reading or writing, start by initializing a SparkSession.
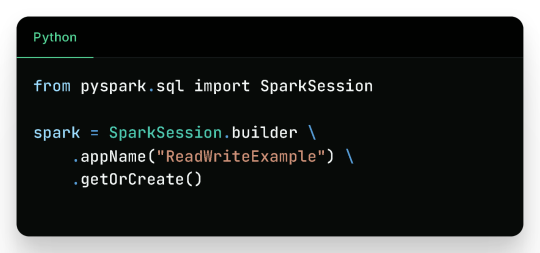
Reading Data in PySpark
1. Reading CSV Files
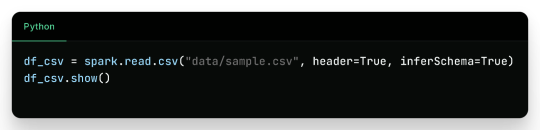
Sample CSV Data (sample.csv):

Output:

2. Reading JSON Files
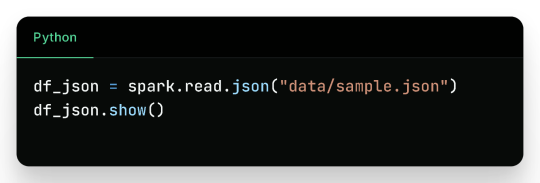
Sample JSON (sample.json):

Output:

3. Reading Parquet Files
Parquet is optimized for performance and often used in big data pipelines.

Assuming the parquet file has similar content:
Output:
4. Reading from a Database (JDBC)

Sample Table employees in MySQL:

Output:

Writing Data in PySpark
1. Writing to CSV
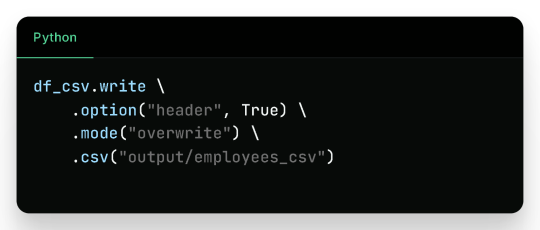
Output Files (folder output/employees_csv/):

Sample content:

2. Writing to JSON

Sample JSON output (employees_json/part-*.json):
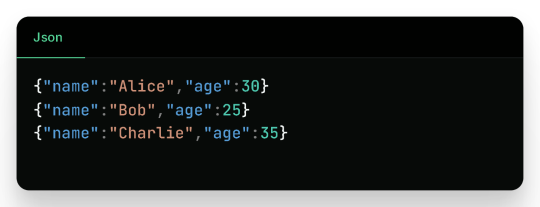
3. Writing to Parquet
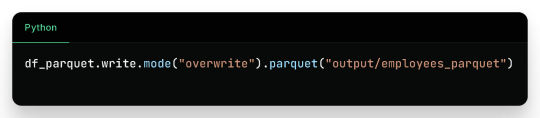
Output:
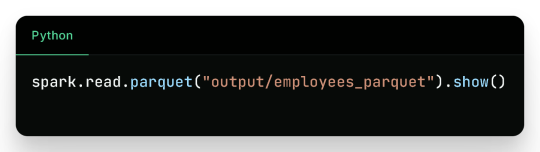
Binary Parquet files saved inside output/employees_parquet/
You can verify the contents by reading it again:
4. Writing to a Database
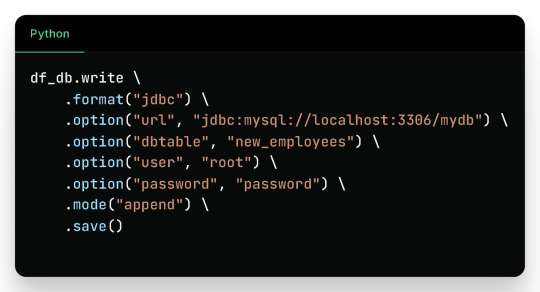
Check the new_employees table in your database — it should now include all the records.
Write Modes in PySpark
Mode
Description
overwrite
Overwrites existing data
append
Appends to existing data
ignore
Ignores if the output already exists
error
(default) Fails if data exists
Real-Life Use Case
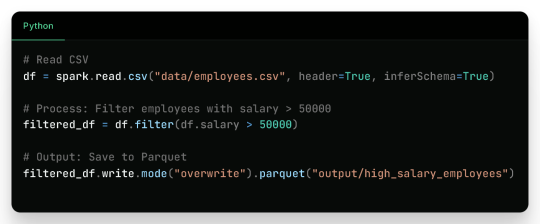
Filtered Output:
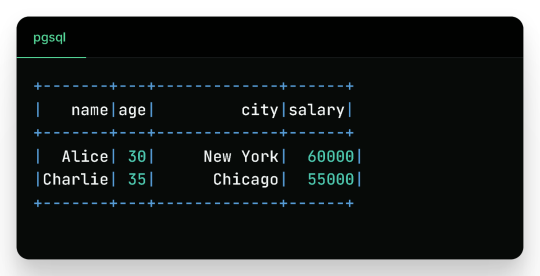
Wrap-Up
Reading and writing data in PySpark is efficient, scalable, and easy once you understand the syntax and options. This blog covered:
Reading from CSV, JSON, Parquet, and JDBC
Writing to CSV, JSON, Parquet, and back to Databases
Example outputs for every format
Best practices for production use
Keep experimenting and building real-world data pipelines — and you’ll be a PySpark pro in no time!
🚀Enroll Now: https://www.accentfuture.com/enquiry-form/
📞Call Us: +91-9640001789
📧Email Us: [email protected]
🌍Visit Us: AccentFuture
#apache pyspark training#best pyspark course#best pyspark training#pyspark course online#pyspark online classes#pyspark training#pyspark training online
0 notes
Text
Data Science Tutorial for 2025: Tools, Trends, and Techniques
Data science continues to be one of the most dynamic and high-impact fields in technology, with new tools and methodologies evolving rapidly. As we enter 2025, data science is more than just crunching numbers—it's about building intelligent systems, automating decision-making, and unlocking insights from complex data at scale.
Whether you're a beginner or a working professional looking to sharpen your skills, this tutorial will guide you through the essential tools, the latest trends, and the most effective techniques shaping data science in 2025.
What is Data Science?
At its core, data science is the interdisciplinary field that combines statistics, computer science, and domain expertise to extract meaningful insights from structured and unstructured data. It involves collecting data, cleaning and processing it, analyzing patterns, and building predictive or explanatory models.
Data scientists are problem-solvers, storytellers, and innovators. Their work influences business strategies, public policy, healthcare solutions, and even climate models.

Essential Tools for Data Science in 2025
The data science toolkit has matured significantly, with tools becoming more powerful, user-friendly, and integrated with AI. Here are the must-know tools for 2025:
1. Python 3.12+
Python remains the most widely used language in data science due to its simplicity and vast ecosystem. In 2025, the latest Python versions offer faster performance and better support for concurrency—making large-scale data operations smoother.
Popular Libraries:
Pandas: For data manipulation
NumPy: For numerical computing
Matplotlib / Seaborn / Plotly: For data visualization
Scikit-learn: For traditional machine learning
XGBoost / LightGBM: For gradient boosting models
2. JupyterLab
The evolution of the classic Jupyter Notebook, JupyterLab, is now the default environment for exploratory data analysis, allowing a modular, tabbed interface with support for terminals, text editors, and rich output.
3. Apache Spark with PySpark
Handling massive datasets? PySpark—Python’s interface to Apache Spark—is ideal for distributed data processing across clusters, now deeply integrated with cloud platforms like Databricks and Snowflake.
4. Cloud Platforms (AWS, Azure, Google Cloud)
In 2025, most data science workloads run on the cloud. Services like Amazon SageMaker, Azure Machine Learning, and Google Vertex AI simplify model training, deployment, and monitoring.
5. AutoML & No-Code Tools
Tools like DataRobot, Google AutoML, and H2O.ai now offer drag-and-drop model building and optimization. These are powerful for non-coders and help accelerate workflows for pros.
Top Data Science Trends in 2025
1. Generative AI for Data Science
With the rise of large language models (LLMs), generative AI now assists data scientists in code generation, data exploration, and feature engineering. Tools like OpenAI's ChatGPT for Code and GitHub Copilot help automate repetitive tasks.
2. Data-Centric AI
Rather than obsessing over model architecture, 2025’s best practices focus on improving the quality of data—through labeling, augmentation, and domain understanding. Clean data beats complex models.
3. MLOps Maturity
MLOps—machine learning operations—is no longer optional. In 2025, companies treat ML models like software, with versioning, monitoring, CI/CD pipelines, and reproducibility built-in from the start.
4. Explainable AI (XAI)
As AI impacts sensitive areas like finance and healthcare, transparency is crucial. Tools like SHAP, LIME, and InterpretML help data scientists explain model predictions to stakeholders and regulators.
5. Edge Data Science
With IoT devices and on-device AI becoming the norm, edge computing allows models to run in real-time on smartphones, sensors, and drones—opening new use cases from agriculture to autonomous vehicles.
Core Techniques Every Data Scientist Should Know in 2025
Whether you’re starting out or upskilling, mastering these foundational techniques is critical:
1. Data Wrangling
Before any analysis begins, data must be cleaned and reshaped. Techniques include:
Handling missing values
Normalization and standardization
Encoding categorical variables
Time series transformation
2. Exploratory Data Analysis (EDA)
EDA is about understanding your dataset through visualization and summary statistics. Use histograms, scatter plots, correlation heatmaps, and boxplots to uncover trends and outliers.
3. Machine Learning Basics
Classification (e.g., predicting if a customer will churn)
Regression (e.g., predicting house prices)
Clustering (e.g., customer segmentation)
Dimensionality Reduction (e.g., PCA, t-SNE for visualization)
4. Deep Learning (Optional but Useful)
If you're working with images, text, or audio, deep learning with TensorFlow, PyTorch, or Keras can be invaluable. Hugging Face’s transformers make it easier than ever to work with large models.
5. Model Evaluation
Learn how to assess model performance with:
Accuracy, Precision, Recall, F1 Score
ROC-AUC Curve
Cross-validation
Confusion Matrix
Final Thoughts
As we move deeper into 2025, data science tutorial continues to be an exciting blend of math, coding, and real-world impact. Whether you're analyzing customer behavior, improving healthcare diagnostics, or predicting financial markets, your toolkit and mindset will be your most valuable assets.
Start by learning the fundamentals, keep experimenting with new tools, and stay updated with emerging trends. The best data scientists aren’t just great with code—they’re lifelong learners who turn data into decisions.
0 notes